REST efficiency by Mark Seemann
A fully RESTful API often looks inefficient from a client perspective, until you learn to change that perspective.
One of my readers, Filipe Ximenes, asks the following question of me:
"I read you post about avoiding hackable urls and found it very interesting. I'm currently studying about REST and I'm really interested on building true RESTful API's. One thing that is bothering me is how to access resources that are not in the API root. Eg: consider the following API flow:
"
root > users > user details > user messages"Now consider that one client wants to retrieve all the messages from a user. Does it need to "walk" the whole API (from it's root to "user messages")? This does not seem very efficient to me. Am I missing something? What would be a better solution for this?"
This is a common question which isn't particularly tied to avoiding hackable URLs, but simply to the hypermedia nature of a level 3 RESTful API.
The short answer is that it's probably not particularly inefficient. There are several reasons for that.
HTTP caching #
One of the great advantages of RESTful design is that instead of abstracting HTTP away, it very explicitly leverages the protocol. HTTP has bulit-in caching, so even if an API forces a client to walk the API as in the question above, it could conceivably result in only a single HTTP request:
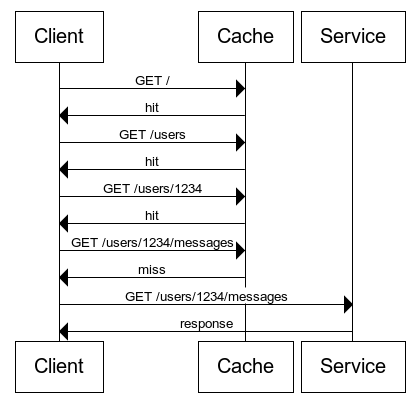
This cache could be anywhere between the client and the service. It could be a proxy server, a reverse proxy, or it could even be a local cache on the client machine; think of a Browser's local cache. It could be a combination of all of those caches. Conceivably, if a local cache is involved, a client could walk the API as described above with only a single (or even no) network request involved, because most of the potential requests would be cache hits.
This is one of the many beautiful aspects of REST. By leveraging the HTTP protocol, you can use the internet as your caching infrastructure. Even if you want a greater degree of control, you can use off-the-shelf software for your caching purposes.
Cool URLs #
As the RESTful Web Services Cookbook describes, URLs should be cool. This means that once you've given a URL to a client, you should honour requests for that URL in the future. This means that clients can 'bookmark' URLs if they like. That includes the final URL in the flow above.
Short-cut links #
Finally, an API can provide short-cut links to a client. Imagine, for example, that when you ask for a list of users, you get this:
<users xmlns:atom="http://www.w3.org/2005/Atom"> <user> <links> <atom:link rel="user-details" href="/users/1234" /> <atom:link rel="user-messages" href="/users/1234/messages" /> </links> <name>Foo</name> </user> <user> <links> <atom:link rel="user-details" href="/users/5678" /> <atom:link rel="user-messages" href="/users/5678/messages" /> </links> <name>Bar</name> </user> <user> <links> <atom:link rel="user-details" href="/users/9876" /> <atom:link rel="user-messages" href="/users/9876/messages" /> </links> <name>Baz</name> </user> </users>
As you can see in this example, a list of users can provide a short-cut to a user's messages, enabling a client to follow a more direct path:
root > users > user messages
The client would have to prioritize links of the relationship type user-messages over links of the user-details type.
Summary #
Efficiency is a common concern about HATEOAS systems, particularly because a client should always start at published URL. Often, the only published URL is the root URL, which forces the client to walk the rest of the API. This seems inefficient, but doesn't have to be because of all the other built-in mechanisms that work to effectively counter what at first looks like an inefficiency.
