ploeh blog danish software design
Asynchronous Injection
How to combine asynchronous programming with Dependency Injection without leaky abstractions.
C# has decent support for asynchronous programming, but it ultimately leads to leaky abstractions. This is often conspicuous when combined with Dependency Injection (DI). This leads to frequently asked questions around the combination of DI and asynchronous programming. This article outlines the problem and suggests an alternative.
The code base supporting this article is available on GitHub.
A synchronous example #
In this article, you'll see various stages of a small sample code base that pretends to implement the server-side behaviour of an on-line restaurant reservation system (my favourite example scenario). In the first stage, the code uses DI, but no asynchronous I/O.
At the boundary of the application, a Post method receives a Reservation object:
public class ReservationsController : ControllerBase { public ReservationsController(IMaîtreD maîtreD) { MaîtreD = maîtreD; } public IMaîtreD MaîtreD { get; } public IActionResult Post(Reservation reservation) { int? id = MaîtreD.TryAccept(reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); } }
The Reservation object is just a simple bundle of properties:
public class Reservation { public DateTimeOffset Date { get; set; } public string Email { get; set; } public string Name { get; set; } public int Quantity { get; set; } public bool IsAccepted { get; set; } }
In a production code base, I'd favour a separation of DTOs and domain objects with proper encapsulation, but in order to keep the code example simple, here the two roles are combined.
The Post method simply delegates most work to an injected IMaîtreD object, and translates the return value to an HTTP response.
The code example is overly simplistic, to the point where you may wonder what is the point of DI, since it seems that the Post method doesn't perform any work itself. A slightly more realistic example includes some input validation and mapping between layers.
The IMaîtreD implementation is this:
public class MaîtreD : IMaîtreD { public MaîtreD(int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; } public int Capacity { get; } public IReservationsRepository Repository { get; } public int? TryAccept(Reservation reservation) { var reservations = Repository.ReadReservations(reservation.Date); int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return Repository.Create(reservation); } }
The protocol for the TryAccept method is that it returns the reservation ID if it accepts the reservation. If the restaurant has too little remaining Capacity for the requested date, it instead returns null. Regular readers of this blog will know that I'm no fan of null, but this keeps the example realistic. I'm also no fan of state mutation, but the example does that as well, by setting IsAccepted to true.
Introducing asynchrony #
The above example is entirely synchronous, but perhaps you wish to introduce some asynchrony. For example, the IReservationsRepository implies synchrony:
public interface IReservationsRepository { Reservation[] ReadReservations(DateTimeOffset date); int Create(Reservation reservation); }
In reality, though, you know that the implementation of this interface queries and writes to a relational database. Perhaps making this communication asynchronous could improve application performance. It's worth a try, at least.
How do you make something asynchronous in C#? You change the return type of the methods in question. Therefore, you have to change the IReservationsRepository interface:
public interface IReservationsRepository { Task<Reservation[]> ReadReservations(DateTimeOffset date); Task<int> Create(Reservation reservation); }
The Repository methods now return Tasks. This is the first leaky abstraction. From the Dependency Inversion Principle it follows that
The"clients [...] own the abstract interfaces"
MaîtreD class is the client of the IReservationsRepository interface, which should be designed to support the needs of that class. MaîtreD doesn't need IReservationsRepository to be asynchronous.
The change of the interface has nothing to with what MaîtreD needs, but rather with a particular implementation of the IReservationsRepository interface. Because this implementation queries and writes to a relational database, this implementation detail leaks into the interface definition. It is, therefore, a leaky abstraction.
On a more practical level, accommodating the change is easily done. Just add async and await keywords in appropriate places:
public async Task<int?> TryAccept(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return await Repository.Create(reservation); }
In order to compile, however, you also have to fix the IMaîtreD interface:
public interface IMaîtreD { Task<int?> TryAccept(Reservation reservation); }
This is the second leaky abstraction, and it's worse than the first. Perhaps you could successfully argue that it was conceptually acceptable to model IReservationsRepository as asynchronous. After all, a Repository conceptually represents a data store, and these are generally out-of-process resources that require I/O.
The IMaîtreD interface, on the other hand, is a domain object. It models how business is done, not how data should be accessed. Why should business logic be asynchronous?
It's hardly news that async and await is infectious. Once you introduce Tasks, it's async all the way!
That doesn't mean that asynchrony isn't one big leaky abstraction. It is.
You've probably already realised what this means in the context of the little example. You must also patch the Post method:
public async Task<IActionResult> Post(Reservation reservation) { int? id = await MaîtreD.TryAccept(reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); }
Pragmatically, I'd be ready to accept the argument that this isn't a big deal. After all, you just replace all return values with Tasks, and add async and await keywords where they need to go. This hardly impacts the maintainability of a code base.
In C#, I'd be inclined to just acknowledge that, hey, there's a leaky abstraction. Moving on...
On the other hand, sometimes people imply that it has to be like this. That there is no other way.
Falsifiable claims like that often get my attention. Oh, really?!
Move impure interactions to the boundary of the system #
We can pretend that Task<T> forms a functor. It's also a monad. Monads are those incredibly useful programming abstractions that have been propagating from their origin in statically typed functional programming languages to more mainstream languages like C#.
In functional programming, impure interactions happen at the boundary of the system. Taking inspiration from functional programming, you can move the impure interactions to the boundary of the system.
In the interest of keeping the example simple, I'll only move the impure operations one level out: from MaîtreD to ReservationsController. The approach can be generalised, although you may have to look into how to handle pure interactions.
Where are the impure interactions in MaîtreD? They are in the two interactions with IReservationsRepository. The ReadReservations method is non-deterministic, because the same input value can return different results, depending on the state of the database when you call it. The Create method causes a side effect to happen, because it creates a row in the database. This is one way in which the state of the database could change, which makes ReadReservations non-deterministic. Additionally, Create also violates Command Query Separation (CQS) by returning the ID of the row it creates. This, again, is non-deterministic, because the same input value will produce a new return value every time the method is called. (Incidentally, you should design Create methods so that they don't violate CQS.)
Move reservations to a method argument #
The first refactoring is the easiest. Move the ReadReservations method call to the application boundary. In the above state of the code, the TryAccept method unconditionally calls Repository.ReadReservations to populate the reservations variable. Instead of doing this from within TryAccept, just pass reservations as a method argument:
public async Task<int?> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return await Repository.Create(reservation); }
This no longer compiles until you also change the IMaîtreD interface:
public interface IMaîtreD { Task<int?> TryAccept(Reservation[] reservations, Reservation reservation); }
You probably think that this is a much worse leaky abstraction than returning a Task. I'd be inclined to agree, but trust me: ultimately, this will matter not at all.
When you move an impure operation outwards, it means that when you remove it from one place, you must add it to another. In this case, you'll have to query the Repository from the ReservationsController, which also means that you need to add the Repository as a dependency there:
public class ReservationsController : ControllerBase { public ReservationsController( IMaîtreD maîtreD, IReservationsRepository repository) { MaîtreD = maîtreD; Repository = repository; } public IMaîtreD MaîtreD { get; } public IReservationsRepository Repository { get; } public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); int? id = await MaîtreD.TryAccept(reservations, reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); } }
This is a refactoring in the true sense of the word. It just reorganises the code without changing the overall behaviour of the system. Now the Post method has to query the Repository before it can delegate the business decision to MaîtreD.
Separate decision from effect #
As far as I can tell, the main reason to use DI is because some impure interactions are conditional. This is also the case for the TryAccept method. Only if there's sufficient remaining capacity does it call Repository.Create. If it detects that there's too little remaining capacity, it immediately returns null and doesn't call Repository.Create.
In object-oriented code, DI is the most common way to decouple decisions from effects. Imperative code reaches a decision and calls a method on an object based on that decision. The effect of calling the method can vary because of polymorphism.
In functional programming, you typically use a functor like Maybe or Either to separate decisions from effects. You can do the same here.
The protocol of the TryAccept method already communicates the decision reached by the method. An int value is the reservation ID; this implies that the reservation was accepted. On the other hand, null indicates that the reservation was declined.
You can use the same sort of protocol, but instead of returning a Nullable<int>, you can return a Maybe<Reservation>:
public async Task<Maybe<Reservation>> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); }
This completely decouples the decision from the effect. By returning Maybe<Reservation>, the TryAccept method communicates the decision it made, while leaving further processing entirely up to the caller.
In this case, the caller is the Post method, which can now compose the result of invoking TryAccept with Repository.Create:
public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = await MaîtreD.TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); }
Notice that the Post method never attempts to extract 'the value' from m. Instead, it injects the desired behaviour (Repository.Create) into the monad. The result of calling Select with an asynchronous lambda expression like that is a Maybe<Task<int>>, which is a awkward combination. You can fix that later.
The Match method is the catamorphism for Maybe. It looks exactly like the Match method on the Church-encoded Maybe. It handles both the case when m is empty, and the case when m is populated. In both cases, it returns a Task<IActionResult>.
Synchronous domain logic #
At this point, you have a compiler warning in your code:
Warning CS1998 This async method lacks 'await' operators and will run synchronously. Consider using the 'await' operator to await non-blocking API calls, or 'await Task.Run(...)' to do CPU-bound work on a background thread.Indeed, the current incarnation of
TryAccept is synchronous, so remove the async keyword and change the return type:
public Maybe<Reservation> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); }
This requires a minimal change to the Post method: it no longer has to await TryAccept:
public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = MaîtreD.TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); }
Apart from that, this version of Post is the same as the one above.
Notice that at this point, the domain logic (TryAccept) is no longer asynchronous. The leaky abstraction is gone.
Redundant abstraction #
The overall work is done, but there's some tidying up remaining. If you review the TryAccept method, you'll notice that it no longer uses the injected Repository. You might as well simplify the class by removing the dependency:
public class MaîtreD : IMaîtreD { public MaîtreD(int capacity) { Capacity = capacity; } public int Capacity { get; } public Maybe<Reservation> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); } }
The TryAccept method is now deterministic. The same input will always return the same input. This is not yet a pure function, because it still has a single side effect: it mutates the state of reservation by setting IsAccepted to true. You could, however, without too much trouble refactor Reservation to an immutable Value Object.
This would enable you to write the last part of the TryAccept method like this:
return reservation.Accept().ToMaybe();
In any case, the method is close enough to be pure that it's testable. The interactions of TryAccept and any client code (including unit tests) is completely controllable and observable by the client.
This means that there's no reason to Stub it out. You might as well just use the function directly in the Post method:
public class ReservationsController : ControllerBase { public ReservationsController( int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; } public int Capacity { get; } public IReservationsRepository Repository { get; } public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = new MaîtreD(Capacity).TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); } }
Notice that ReservationsController no longer has an IMaîtreD dependency.
All this time, whenever you make a change to the TryAccept method signature, you'd also have to fix the IMaîtreD interface to make the code compile. If you worried that all of these changes were leaky abstractions, you'll be happy to learn that in the end, it doesn't even matter. No code uses that interface, so you can delete it.
Grooming #
The MaîtreD class looks fine, but the Post method could use some grooming. I'm not going to tire you with all the small refactoring steps. You can follow them in the GitHub repository if you're interested. Eventually, you could arrive at an implementation like this:
public class ReservationsController : ControllerBase { public ReservationsController( int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; maîtreD = new MaîtreD(capacity); } public int Capacity { get; } public IReservationsRepository Repository { get; } private readonly MaîtreD maîtreD; public async Task<IActionResult> Post(Reservation reservation) { return await Repository.ReadReservations(reservation.Date) .Select(rs => maîtreD.TryAccept(rs, reservation)) .SelectMany(m => m.Traverse(Repository.Create)) .Match(InternalServerError("Table unavailable"), Ok); } }
Now the Post method is just a single, composed asynchronous pipeline. Is it a coincidence that this is possible?
This is no coincidence. This top-level method executes in the 'Task monad', and a monad is, by definition, composable. You can chain operations together, and they don't all have to be asynchronous. Specifically, maîtreD.TryAccept is a synchronous piece of business logic. It's unaware that it's being injected into an asynchronous context. This type of design would be completely run of the mill in F# with its asynchronous workflows.
Summary #
Dependency Injection frequently involves I/O-bound operations. Those typically get hidden behind interfaces so that they can be mocked or stubbed. You may want to access those I/O-bound resources asynchronously, but with C#'s support for asynchronous programming, you'll have to make your abstractions asynchronous.
When you make the leaf nodes in your call graph asynchronous, that design change ripples through the entire code base, forcing you to be async all the way. One result of this is that the domain model must also accommodate asynchrony, although this is rarely required by the logic it implements. These concessions to asynchrony are leaky abstractions.
Pragmatically, it's hardly a big problem. You can use the async and await keywords to deal with the asynchrony, and it's unlikely to, in itself, cause a problem with maintenance.
In functional programming, monads can address asynchrony without introducing sweeping leaky abstractions. Instead of making DI asynchronous, you can inject desired behaviour into an asynchronous context.
Behaviour Injection, not Dependency Injection.
How to get the value out of the monad
How do I get the value out of my monad? You don't. You inject the desired behaviour into the monad.
A frequently asked question about monads can be paraphrased as: How do I get the value out of my monad? This seems to particularly come up when the monad in question is Haskell's IO monad, from which you can't extract the value. This is by design, but then beginners are often stumped on how to write the code they have in mind.
You can encounter variations of the question, or at least the underlying conceptual misunderstanding, with other monads. This seems to be particularly prevalent when object-oriented or procedural programmers start working with Maybe or Either. People really want to extract 'the value' from those monads as well, despite the lack of guarantee that there will be a value.
So how do you extract the value from a monad?
The answer isn't use a comonad, although it could be, for a limited set of monads. Rather, the answer is mu.
Unit containers #
Before I attempt to address how to work with monads, I think it's worthwhile to speculate on what misleads people into thinking that it makes sense to even contemplate extracting 'the value' from a monad. After all, you rarely encounter the question: How do I get the value out of my collection?
Various collections form monads, but everyone intuitively understand that there isn't a single value in a collection. Collections could be empty, or contain many elements. Collections could easily be the most ordinary monad. Programmers deal with collections all the time.
Yet, I think that most programmers don't realise that collections form monads. The reason for this could be that mainstream languages rarely makes this relationship explicit. Even C# query syntax, which is nothing but monads in disguise, hides this fact.
What happens, I think, is that when programmers first come across monads, they often encounter one of a few unit containers.
What's a unit container? I admit that the word is one I made up, because I couldn't detect existing terminology on this topic. The idea, though, is that it's a functor guaranteed to contain exactly one value. Since functors are containers, I call such types unit containers. Examples include Identity, Lazy, and asynchronous functors.
You can extract 'the value' from most unit containers (with IO being the notable exception from the rule). Trivially, you can get the item contained in an Identity container:
> Identity<string> x = new Identity<string>("bar"); > x.Item "bar"
Likewise, you can extract the value from lazy and asynchronous values:
> Lazy<int> x = new Lazy<int>(() => 42); > x.Value 42 > Task<int> y = Task.Run(() => 1337); > await y 1337
My theory, then, is that some programmers are introduced to the concept of monads via lazy or asynchronous computations, and that this could establish incorrect mental models.
Semi-containers #
There's another category of monad that we could call semi-containers (again, I'm open to suggestions for a better name). These are data containers that contain either a single value, or no value. In this set of monads, we find Nullable<T>, Maybe, and Either.
Unfortunately, Maybe implementations often come with an API that enables you to ask a Maybe object if it's populated or empty, and a way to extract the value from the Maybe container. This misleads many programmers to write code like this:
Maybe<int> id = // ... if (id.HasItem) return new Customer(id.Item); else throw new DontKnowWhatToDoException();
Granted, in many cases, people do something more reasonable than throwing a useless exception. In a specific context, it may be clear what to do with an empty Maybe object, but there are problems with this Tester-Doer approach:
- It doesn't compose.
- There's no systematic technique to apply. You always need to handle empty objects in a context-specific way.
If you throw an exception when the object is empty, you'll likely have to deal with that exception further up in the call stack.
If you return a magic value (like returning -1 when a natural number is expected), you again force all callers to check for that magic number.
If you set a flag that indicates that an object was empty, again, you put the burden on callers to check for the flag.
This leads to defensive coding, which, at best, makes the code unreadable.
Behaviour Injection #
Interestingly, programmers rarely take a Tester-Doer approach to working with collections. Instead, they rely on APIs for collections and arrays.
In C#, LINQ has been around since 2007, and most programmers love it. It's common knowledge that you can use the Select method to, for example, convert an array of numbers to an array of strings:
> new[] { 42, 1337, 2112, 90125 }.Select(i => i.ToString())
string[4] { "42", "1337", "2112", "90125" }
You can do that with all functors, including Maybe:
Maybe<int> id = // ... Maybe<Customer> c = id.Select(x => new Customer(x));
A previous article offers a slightly more compelling example:
var viewModel = repository.Read(id).Select(r => r.ToViewModel());
Common to all the three above examples is that instead of trying to extract a value from the monad (which makes no sense in the array example), you inject the desired behaviour into the context of the data container. What that eventually brings about depends on the monad in question.
In the array example, the behaviour being injected is that of turning a number into a string. Since this behaviour is injected into a collection, it's applied to every element in the source array.
In the second example, the behaviour being injected is that of turning an integer into a Customer object. Since this behaviour is injected into a Maybe, it's only applied if the source object is populated.
In the third example, the behaviour being injected is that of turning a Reservation domain object into a View Model. Again, this only happens if the original Maybe object is populated.
Composability #
The marvellous quality of a monad is that it's composable. You could, for example, start by attempting to parse a string into a number:
string candidate = // Some string from application boundary Maybe<int> idm = TryParseInt(candidate);
This code could be defined in a part of your code base that deals with user input. Instead of trying to get 'the value' out of idm, you can pass the entire object to other parts of the code. The next step, defined in a different method, in a different class, perhaps even in a different library, then queries a database to read a Reservation object corresponding to that ID - if the ID is there, that is:
Maybe<Reservation> rm = idm.SelectMany(repository.Read);
The Read method on the repository has this signature:
public Maybe<Reservation> Read(int id)
The Read method returns a Maybe<Reservation> object because you could pass any int to the method, but there may not be a row in the database that corresponds to that number. Had you used Select on idm, the return type would have been Maybe<Maybe<Reservation>>. This is a typical example of a nested functor, so instead, you use SelectMany, which flattens the functor. You can do this because Maybe is a monad.
The result at this stage is a Maybe<Reservation> object. If all goes according to plan, it's populated with a Reservation object from the database. Two things could go wrong at this stage, though:
- The
candidatestring didn't represent a number. - The database didn't contain a row for the parsed ID.
idm is empty.
You can now pass rm to another part of the code base, which then performs this step:
Maybe<ReservationViewModel> vm = rm.Select(r => r.ToViewModel());
Functors and monads are composable (i.e. 'chainable'). This is a fundamental trait of functors; they're (endo)morphisms, which, by definition, are composable. In order to leverage that composability, though, you must retain the monad. If you extract 'the value' from the monad, composability is lost.
For that reason, you're not supposed to 'get the value out of the monad'. Instead, you inject the desired behaviour into the monad in question, so that it stays composable. In the above example, repository.Read and r.ToViewModel() are behaviors injected into the Maybe monad.
Summary #
When we learn something new, there's always a phase where we struggle to understand a new concept. Sometimes, we may, inadvertently, erect a tentative, but misleading mental model of a concept. It seems to me that this happens to many people while they're grappling with the concept of functors and monads.
One common mental wrong turn that many people seem to take is to try to 'get the value out of the monad'. This seems to be particularly common with IO in Haskell, where the issue is a frequently asked question.
I've also reviewed enough F# code to have noticed that people often take the imperative, Tester-Doer road to 'a option. That's the reason this article uses a majority of its space on various Maybe examples.
In a future article, I'll show a more complete and compelling example of behaviour injection.
Comments
Hi Mark, was very interested in your post as I do try and use Option Monads in my code, and I think I understand the point you are making about not thinking of an optional value as something that is composable. However, I recently had a couple of situations where I reluctantly had to check the value, would really appreciate any thoughts you may have?
The first example was where I have a UI and the user may specify a Latitude and a Longitude. The user may not yet have specified both values, so each is held as an Option
Having read your article, I realise I could change this to a Select statement on latitude, but that lambda would still need to check longitude.HasValue. Should I combine the two options somehow before doing a single Select?
The second example again relates to a UI where the user can enter values in a grid, or leave a row blank. I would like to calculate the mean, standard deviation and root mean square of the values, and normally all these functions would have the signature: double Mean(ICollection<double> values)
If I keep this then I need a function like
if(latitude.HasValue && longitude.HasValue)
Bearing = CalculateRhumbBearing(latitude.Value, longitude.Value, fixedLatitude, fixedLongitude).ToOptionMonad();
else
Bearing = OptionMonad<double>.None;
foreach(var item in values)
{
if(item.HasValue)
{
yield return item.Value;
}
}
Or some equivalent Where/Select combination. Can you advise me please, how you recommend transforming an IEnumerable<OptionMonad<X>> to an enumerable<X>? Or should I write a signature overload double Mean(ICollection<OptionMonad<double>> possibleValues) and ditto for SD and RMS?
Thanks, Sean
Sean, thank you for writing. The first example you give is quite common, and is easily addressed with using the applicative or monadic capabilities of Maybe. Often, in a language like C#, it's easiest to use monadic bind (in C# called SelectMany):
Bearing = latitude .SelectMany(lat => longitude .Select(lon => CalculateRhumbBearing(lat, lon, fixedLatitude, fixedLongitude)));
If you find code like that disagreeable, you can also write it with query syntax:
Bearing = from lat in latitude from lon in longitude select CalculateRhumbBearing(lat, lon, fixedLatitude, fixedLongitude);
Here, Bearing is a Maybe value. As you can see, in neither of the above alternatives is it necessary to check and extract the values. Bearing will be populated when both latitude and longitude are populated, and empty otherwise.
Regarding the other question, being able to filter out empty values from a collection is a standard operation in both F# and Haskell. In C#, you can write it like this:
public static IEnumerable<T> Choose<T>(this IEnumerable<IMaybe<T>> source) { return source.SelectMany(m => m.Match(new T[0], x => new[] { x })); }
This example is based on the Church-encoded Maybe, which is currently my favourite implementation. I decided to call the method Choose, as this is also the name it has in F#. In Haskell, this function is called catMaybes.
Hi Mark, did you ever think about publishing a Library containing all these types missing in .net Framework like Either? Or can you recommend an existing library?
Achim, thank you for writing. The thought has crossed my mind, but my position on this question seems to be changing.
Had you asked me one or two years ago, I'd have answered that I hadn't seriously considered doing that, and that I saw little reason to do so. There is, as far as I can tell, plenty of such libraries out there, although I can't recommend any in particular. This seems to be something that many people create as part of a learning exercise. It seems to be a rite of passage for many people, similarly to developing a Dependency Injection container, or an ORM.
Besides, a reusable library would mean another dependency that your code would have to take on.
These days, however, I'm beginning to reconsider my position. It seems that no such library is emerging as dominant, and some of the types involved (particularly Maybe) would really be useful.
Ideally, these types ought be in the .NET Base Class Library, but perhaps a second-best alternative would be to put them in a commonly-used shared library.
Hi Mark, thank you for the interesting article series.
Can you maybe provide guidance of how asynchronous operations can become part of a chain of operations? How would the 'functor flattening' be combined with the built Task/Task<T> types? Extending your example, how would you go about if we would like to enrich the reservation retrieved from repository with that day's special, which happens to be async:
Task<ReservationWithMenuSuggestion> EnrichWithSpecialOfTheDayAsync(Reservation reservation)
I tried with your Church encoded Maybe implementation, but I got stuck with the Task<T> wrapping/unwrapping/awaiting.
Ralph, thank you for writing. Please see if my new article Asynchronous Injection answers your question.
Hi Mark, I'm curious what do you think about this approach to monads - Maybe monad through async/await in C#
Dominik, thank you for writing. That's a clever article. As far as I can tell, the approach is similar to Nick Palladinos' Eff library. You can see how he rewrote one of my sample applications using it.
I've no personal experience with this approach, so I could easily be wrong in my assessment. Nick reports that he's had some success getting other people on board with such an approach, because the resulting user code looks like idiomatic C#. That is, I think, one compelling argument.
What I do find less appealing, however, is that, if I understand this correctly, the C# compiler enables you to mix, or interleave, disparate effects. As long as your method returns an awaitable object, you can await true asynchronous tasks, bind Maybe values, and conceivably invoke other effectful operations all in the same method - and you wouldn't be able to tell from the return type what to expect.
In my opinion, one of the most compelling benefits of modelling with universal abstractions is that they provide excellent encapsulation. You can use the type system to communicate the pre- and post-conditions of an operation.
If I see an operation that returns Maybe<User>, I expect that it may or may not return a User object. If I see a return type of Task<User>, I expect that I'm guaranteed to receive a User object, but that this'll happen asynchronously. Only if I see something like Task<Maybe<User>> do I expect the combination of those two effects.
My concern with making Maybe awaitable is that this enables one to return Maybe<User> from a method, but still make the implementation asynchronous (e.g. by querying a database for the user). That effect is now hidden, which in my view break encapsulation because you now have to go and read the implementation code in order to discover that this is taking place.
Mark, thanks for useful respond!
You are absolutely true that awaiting Maybe that have Task have side effects not visible to invoker. I agree that this is the smell I felt but you gave me the source of it.
Better abstractions revisited
How do you design better abstractions? A retrospective look on an old article for object-oriented programmers.
About a decade ago, I had already been doing test-driven development (TDD) and used Dependency Injection for many years, but I'd started to notice some patterns about software design. I'd noticed that interfaces aren't abstractions and that TDD isn't a design methodology. Sometimes, I'd arrive at interfaces that turned out to be good abstractions, but at other times, the interfaces I created seemed to serve no other purpose than enabling unit testing.
In 2010 I thought that I'd noticed some patterns for good abstractions, so I wrote an article called Towards better abstractions. I still consider it a decent attempt at communicating my findings, but I don't think that I succeeded. My thinking on the subject was still too immature, and I lacked a proper vocabulary.
While I had hoped that I would be able to elaborate on such observations, and perhaps turn them into heuristics, my efforts soon after petered out. I moved on to other things, and essentially gave up on this particular research programme. Years later, while trying to learn category theory, I suddenly realised that mathematical disciplines like category theory and abstract algebra could supply the vocabulary. After some further work, I started publishing a substantial and long-running article series called From design patterns to category theory. It goes beyond my initial attempt, but it finally enabled me to crystallise those older observations.
In this article, I'll revisit that old article, Towards better abstractions, and translate the vague terminology I used then, to the terminology presented in From design patterns to category theory.
The thrust of the old article is that if you can create a Composite or a Null Object from an interface, then it's likely to be a good abstraction. I still consider that a useful rule of thumb.
When can you create a Composite? When the abstraction gives rise to a monoid. When can you create a Null Object? When the abstraction gives rise to a monoid.
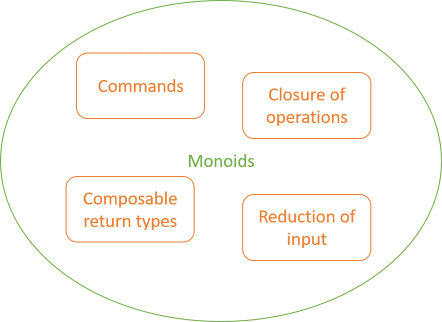
All the 'API shapes' I'd identified in Towards better abstractions form monoids.
Commands #
A Command seems to be universally identified by a method typically called Execute:
public void Execute()
From unit isomorphisms we know that methods with the void return type are isomorphic to (impure) functions that return unit, and that unit forms a monoid.
Furthermore, we know from function monoids that methods that return a monoid themselves form monoids. Therefore, Commands form monoids.
In early 2011 I'd already explicitly noticed that Commands are composable. Now I know the deeper reason for this: they're monoids.
Closure of operations #
In Domain-Driven Design, Eric Evans discusses the benefits of designing APIs that exhibit closure of operations. This means that a method returns the same type as all its input arguments. The simplest example is the one that I show in the old article:
public static T DoIt(T x)
That's just an endomorphism, which forms a monoid.
Another variation is a method that takes two arguments:
public static T DoIt(T x, T y)
This is a binary operation. While it's certainly a magma, in itself it's not guaranteed to be a monoid. In fact, Evans' colour-mixing example is only a magma, but not a monoid. You can, however, also view this as a special case of the reduction of input shape, below, where the 'extra' arguments just happen to have the same type as the return type. In that interpretation, such a method still forms a monoid, but it's not guaranteed to be meaningful. (Just like modulo 31 addition forms a monoid; it's hardly useful.)
The same sort of argument goes for methods with closure of operations, but more input arguments, like:
public static T DoIt(T x, T y, T z)
This sort of method is, however, rare, unless you're working in a stringly typed code base where methods look like this:
public static string DoIt(string x, string y, string z)
That's a different situation, though, because those strings should probably be turned into domain types that properly communicate their roles. Once you do that, you'll probably find that the method arguments have different types.
In any case, regardless of cardinality, you can view all methods with closure of operations as special cases of the reduction of input shape below.
Reduction of input #
This is the part of the original article where my struggles with vocabulary began in earnest. The situation is when you have a method that looks like this, perhaps as an interface method:
public interface IInputReducer<T1, T2, T3> { T1 DoIt(T1 x, T2 y, T3 z); }
In order to stay true to the terminology of my original article, I've named this reduction of input generic example IInputReducer. The reason I originally called it reduction of input is that such a method takes a set of input types as arguments, but only returns a value of a type that's a subset of the set of input types. Thus, the method looks like it's reducing the range of input types to a single one of those types.
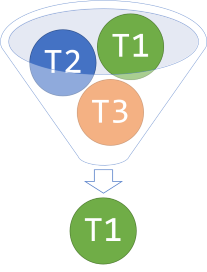
A realistic example could be a piece of HTTP middleware that defines an action filter as an interface that you can implement to intercept each HTTP request:
public interface IActionFilter { Task<HttpResponseMessage> ExecuteActionFilterAsync( HttpActionContext actionContext, CancellationToken cancellationToken, Task<HttpResponseMessage> continuation); }
This is a slightly modified version of an earlier version of the ASP.NET Web API. Notice that in this example, it's not the first argument's type that doubles as the return type, but rather the third and last argument. The reduction of input 'shape' can take an arbitrary number of arguments, and any of the argument types can double as a return type, regardless of position.
Returning to the generic IInputReducer example, you can easily make a Composite of it:
public class CompositeInputReducer<T1, T2, T3> : IInputReducer<T1, T2, T3> { private readonly IInputReducer<T1, T2, T3>[] reducers; public CompositeInputReducer(params IInputReducer<T1, T2, T3>[] reducers) { this.reducers = reducers; } public T1 DoIt(T1 x, T2 y, T3 z) { var acc = x; foreach (var reducer in reducers) acc = reducer.DoIt(acc, y, z); return acc; } }
Notice that you call DoIt on all the composed reducers. The arguments that aren't part of the return type, y and z, are passed to each call to DoIt unmodified, whereas the T1 value x is only used to initialise the accumulator acc. Each call to DoIt also returns a T1 object, so the acc value is updated to that object, so that you can use it as an input for the next iteration.
This is an imperative implementation, but as you'll see below, you can also implement the same behaviour in a functional manner.
For the sake of argument, pretend that you reorder the method arguments so that the method looks like this:
T1 DoIt(T3 z, T2 y, T1 x);
From Uncurry isomorphisms you know that a method like that is isomorphic to a function with the type 'T3 -> 'T2 -> 'T1 -> 'T1 (F# syntax). You can think of such a curried function as a function that returns a function that returns a function: 'T3 -> ('T2 -> ('T1 -> 'T1)). The rightmost function 'T1 -> 'T1 is clearly an endomorphism, and you already know that an endomorphism gives rise to a monoid. Finally, Function monoids informs us that a function that returns a monoid itself forms a monoid, so 'T2 -> ('T1 -> 'T1) forms a monoid. This argument applies recursively, because if that's a monoid, then 'T3 -> ('T2 -> ('T1 -> 'T1)) is also a monoid.
What does that look like in C#?
In the rest of this article, I'll revert the DoIt method signature to T1 DoIt(T1 x, T2 y, T3 z);. The monoid implementation looks much like the endomorphism code. Start with a binary operation:
public static IInputReducer<T1, T2, T3> Append<T1, T2, T3>( this IInputReducer<T1, T2, T3> r1, IInputReducer<T1, T2, T3> r2) { return new AppendedReducer<T1, T2, T3>(r1, r2); } private class AppendedReducer<T1, T2, T3> : IInputReducer<T1, T2, T3> { private readonly IInputReducer<T1, T2, T3> r1; private readonly IInputReducer<T1, T2, T3> r2; public AppendedReducer( IInputReducer<T1, T2, T3> r1, IInputReducer<T1, T2, T3> r2) { this.r1 = r1; this.r2 = r2; } public T1 DoIt(T1 x, T2 y, T3 z) { return r2.DoIt(r1.DoIt(x, y, z), y, z); } }
This is similar to the endomorphism Append implementation. When you combine two IInputReducer objects, you receive an AppendedReducer that implements DoIt by first calling DoIt on the first object, and then using the return value from that method call as the input for the second DoIt method call. Notice that y and z are just 'context' variables used for both reducers.
Just like the endomorphism, you can also implement the identity input reducer:
public class IdentityInputReducer<T1, T2, T3> : IInputReducer<T1, T2, T3> { public T1 DoIt(T1 x, T2 y, T3 z) { return x; } }
This simply returns x while ignoring y and z. The Append method is associative, and the IdentityInputReducer is both left and right identity for the operation, so this is a monoid. Since monoids accumulate, you can also implement an Accumulate extension method:
public static IInputReducer<T1, T2, T3> Accumulate<T1, T2, T3>( this IReadOnlyCollection<IInputReducer<T1, T2, T3>> reducers) { IInputReducer<T1, T2, T3> identity = new IdentityInputReducer<T1, T2, T3>(); return reducers.Aggregate(identity, (acc, reducer) => acc.Append(reducer)); }
This implementation follows the overall implementation pattern for accumulating monoidal values: start with the identity and combine pairwise. While I usually show this in a more imperative form, I've here used a proper functional implementation for the method.
The IInputReducer object returned from that Accumulate function has exactly the same behaviour as the CompositeInputReducer.
The reduction of input shape forms another monoid, and is therefore composable. The Null Object is the IdentityInputReducer<T1, T2, T3> class. If you set T1 = T2 = T3, you have the closure of operations 'shapes' discussed above; they're just special cases, so form at least this type of monoid.
Composable return types #
The original article finally discusses methods that in themselves don't look composable, but turn out to be so anyway, because their return types are composable. Without knowing it, I'd figured out that methods that return monoids are themselves monoids.
In 2010 I didn't have the vocabulary to put this into specific language, but that's all it says.
Summary #
In 2010 I apparently discovered an ad-hoc, informally specified, vaguely glimpsed, half-understood description of half of abstract algebra.
Riffs on Greenspun's tenth rule aside, things clicked for me once I started to investigate what category theory was about, and why it seemed so closely linked to Haskell. That's one of the reasons I started writing the From design patterns to category theory article series.
The patterns I thought that I could see in 2010 all form monoids, but there are many other universal abstractions from mathematics that apply to programming as well.
Some thoughts on anti-patterns
What's an anti-pattern? Are there rules to identify them, or is it just name-calling? Before I use the term, I try to apply some rules of thumb.
It takes time to write a book. Months, even years. It took me two years to write the first edition of Dependency Injection in .NET. The second edition of Dependency Injection in .NET is also the result of much work; not so much by me, but by my co-author Steven van Deursen.
When you write a book single-handedly, you can be as opinionated as you'd like. When you have a co-author, regardless of how much you think alike, there's bound to be some disagreements. Steven and I agreed about most of the changes we'd like to make to the second edition, but each of us had to yield or compromise a few times.
An interesting experience has been that on more than one occasion where I've reluctantly had to yield to Steven, over the time, I've come to appreciate his position. Two minds think better than one.
Ambient Context #
One of the changes that Steven wanted to make was that he wanted to change the status of the Ambient Context pattern to an anti-pattern. While I never use that pattern myself, I included it in the first edition in the spirit of the original Design Patterns book. The Gang of Four made it clear that the patterns they'd described weren't invented, but rather discovered:
The spirit, as I understand it, is to identify solutions that already exist, and catalogue them. When I wrote the first edition of my book, I tried to do that as well."We have included only designs that have been applied more than once in different systems."
I'd noticed what I eventually named the Ambient Context pattern several places in the .NET Base Class Library. Some of those APIs are still around today. Thread.CurrentPrincipal, CultureInfo.CurrentCulture, thread-local storage, HttpContext.Current, and so on.
None of these really have anything to do with Dependency Injection (DI), but people sometimes attempt to use them to solve problems similar to the problems that DI addresses. For that reason, and because the pattern was so prevalent, I included it in the book - as a pattern, not an anti-pattern.
Steven wanted to make it an anti-pattern, and I conceded. I wasn't sure I was ready to explicitly call it out as an anti-pattern, but I agreed to the change. I'm becoming increasingly happy that Steven talked me into it.
Pareto efficiency #
I've heard said of me that I'm one of those people who call everything I don't like an anti-pattern. I don't think that's true.
I think people's perception of me is skewed because even today, the most visited page (my greatest hit, if you will) is an article called Service Locator is an Anti-Pattern. (It concerns me a bit that an article from 2010 seems to be my crowning achievement. I hope I haven't peaked yet, but the numbers tell a different tale.)
While I've used the term anti-pattern in other connections, I prefer to be conservative with my use of the word. I tend to use it only when I feel confident that something is, indeed, an anti-pattern.
What's an anti-pattern? AntiPatterns defines it like this:
As definitions go, it's quite amphibolous. Is it the problem that generates negative consequences? Hardly. In the context, it's clear that it's the solution that causes problems. In any case, just because it's in a book doesn't necessarily make it right, but I find it a good start."An AntiPattern is a literary form that describes a commonly occurring solution to a problem that generates decidedly negative consequences."
I think that the phrase decidedly negative consequences is key. Most solutions come with some disadvantages, but in order for a 'solution' to be an anti-pattern, the disadvantages must clearly outweigh any advantages produced.
I usually look at it another way. If I can solve the problem in a different way that generates at least as many advantages, but fewer disadvantages, then the first 'solution' might be an anti-pattern. This way of viewing the problem may stem from my background in economics. In that perspective, an anti-pattern simply isn't Pareto optimal.
Falsifiability #
Another rule of thumb I employ to determine whether a solution could be an anti-pattern is Popper's concept of falsifiability. As a continuation of the Pareto efficiency perspective, an anti-pattern is a 'solution' that you can improve without any (significant) trade-offs.
That turns claims about anti-patterns into falsifiable statements, which I consider is the most intellectually honest way to go about claiming that things are bad.
Take, for example, the claim that Service Locator is an anti-pattern. In light of Pareto efficiency, that's a falsifiable claim. All you have to do to prove me wrong is to present a situation where Service Locator solves a problem, and I can't come up with a better solution.
I made the claim about Service Locator in 2010, and so far, no one has been able to present such a situation, even though several have tried. I'm fairly confident making that claim.
This way of looking at the term anti-pattern, however, makes me wary of declaiming solutions anti-patterns just because I don't like them. Could there be a counter-argument, some niche scenario, where the pattern actually couldn't be improved without trade-offs?
I didn't take it lightly when Steven suggested making Ambient Context an anti-pattern.
Preliminary status #
I've had some time to think about Ambient Context since I had the (civil) discussion with Steven. The more I think about it, the more I think that he's right; that Ambient Context really is an anti-pattern.
I never use that pattern myself, so it's clear to me that for all the situations that I typically encounter, there's always better solutions, with no significant trade-offs.
The question is: could there be some niche scenario that I'm not aware of, where Ambient Context is a bona fide good solution?
The more I think about this, the more I'm beginning to believe that there isn't. It remains to be seen, though. It remains to be falsified.
Summary #
I'm so happy that Steven van Deursen agreed to co-author the second edition of Dependency Injection in .NET with me. The few areas where we've disagreed, I've ultimately come around to agree with him. He's truly taken a good book and made it better.
One of the changes is that Ambient Context is now classified as an anti-pattern. Originally, I wasn't sure that this was the correct thing to do, but I've since changed my mind. I do think that Ambient Context belongs in the anti-patterns chapter.
I could be wrong, though. I was before.
Comments
Thanks for great input for discussion :P
Like with all other patterns and anti-patterns, I think there's a time and a place.
Simply looking at it in a one-dimensional manner, i.e. asking "does there exist a solution to this problem with the same advantages but less downsides?" must be qualified with "IN THIS TIME AND PLACE", in my opinion.
This way, the patterns/anti-patterns distinction does not make that much sense in a global perspective, because all patterns can be an anti-patterns in some situations, and vice versa.
For example, I like what Ambient Context does in Rebus: It provides a mechanism that enables user code to transparently enlist its bus operations in a unit of work, without requiring user code to pass that unit of work to each operation.
This is very handy, e.g. in OWIN-based applications, where the unit of work can be managed by an OWIN middleware that uses a
RebusTransactionScope,
this way enlisting all send/publish operations on the bus in that unit of work.
Had it not been possible to automatically pick up an ongoing ambient Rebus transaction context, one would probably need to pollute the interfaces of one's application with an ITransactionContext argument,
thus not handling the cross-cutting concern of managing the unit of work in a cross-cutting manner.
Mogens, thank you for writing. The reason I explicitly framed my treatment in a discourse related to Pareto efficiency is exactly because this view on optima is multi-dimensional. When considering whether a 'solution coordinate' is Pareto-optimal or not, the question is exactly whether or not it's possible to improve at least one dimension without exacerbating any other dimension. If you can make one dimension better without trade-offs, then you can make a Pareto improvement. If you can only make one dimension better at the cost of one or more other dimensions, then you already have a Pareto-optimal solution.
The theory of Pareto efficiency doesn't say anything about the number of dimensions. Usually, as in the linked Wikipedia article, the concept is illustrated in the plane, but conceptually, it applies to an arbitrary number of dimensions.
In the context of anti-patterns, those dimensions include time and place, as you say.
I consider something to be an anti-pattern if I can make a change that constitutes an improvement in at least one dimension, without trading off of any other dimensions. In other words, in this article, I'm very deliberately not looking at it in a one-dimensional manner.
As I wrote, I'm still not sure that Ambient Context is an anti-pattern (although I increasingly believe it to be). How can we even test that hypothesis when we can't really quantify software design?
On the other hand, if we leave the question about Ambient Context for a moment, I feel confident that Service Locator is an anti-pattern, even in what you call a global perspective. The reason I believe that is that I made that falsifiable claim in 2010, and here, almost nine years later, no-one has successfully produced a valid counter-example.
I don't have the same long history with the claim about Ambient Context, so I could be wrong. Perhaps you are, right now, proving me wrong. I can't tell, though, because I don't (yet) know enough about Rebus to be able to tell whether what you describe is Pareto-optimal.
The question isn't whether the current design is 'handy'. The question is whether it's possible to come up with a design that's 'globally' better; i.e. either has all the advantages of the current design, but fewer disadvantages; or has more advantages, and only the same disadvantages.
I may be able to suggest such an improvement if provided with some code examples, but in the end we may never agree whether one design is better than another. After all, since we can't quantify software design, a subjective judgement will always remain.
Mark,
Thanks for this thoughtful meta-analysis of what it means to be an anti-pattern and how we think about them. What are some considerations when designing a replacement for ambient context objects? What patterns have you found succesful in object-oriented code? I'm sure you'd mention Constructor Injection and CQRS with decorators.
How might one refactor ambient context out of a solution? Some say passing around an object, maybe some sort of continuation?
Drew, thank you for writing. Indeed, in object-oriented code, I'd typically replace Ambient Contexts with either injected dependencies or Decorators. I'm not sure I see how CQRS fits into this picture.
When refactoring away an Ambient Context, it's typically, before the refactoring, used like Context.DoSomething(). The first step is often to inject a dependency and make it available to the class as a property called Context. IIRC, the C# overload resolution system should then pick the instance property over the static class, so that Context.DoSomething() calls DoSomething on the injected Context property.
There may be some static member that also use the Ambient Context. If that's the case, you'll first have to make those static members instance members.
Once you've made those replacements everywhere, you should be able to delete the Ambient Context.
An Either functor
Either forms a normal functor. A placeholder article for object-oriented programmers.
This article is an instalment in an article series about functors. As another article explains, Either is a bifunctor. This makes it trivially a functor. As such, this article is mostly a place-holder to fit the spot in the functor table of contents, thereby indicating that Either is a functor.
Since Either is a bifunctor, it's actually not one, but two, functors. Many languages, C# included, are best equipped to deal with unambiguous functors. This is also true in Haskell, where Either l r is only a Functor over the right side. Likewise, in C#, you can make IEither<L, R> a functor by implementing Select:
public static IEither<L, R1> Select<L, R, R1>( this IEither<L, R> source, Func<R, R1> selector) { return source.SelectRight(selector); }
This method simply delegates all implementation to the SelectRight method; it's just SelectRight by another name. It obeys the functor laws, since these are just specializations of the bifunctor laws, and we know that Either is a proper bifunctor.
It would have been technically possible to instead implement a Select method by calling SelectLeft, but it seems generally more useful to enable syntactic sugar for mapping over 'happy path' scenarios. This enables you to write projections over operations that can fail.
Here's some C# Interactive examples that use the FindWinner helper method from the Church-encoded Either article. Imagine that you're collecting votes; you're trying to pick the highest-voted integer, but in reality, you're only interested in seeing if the number is positive or not. Since FindWinner returns IEither<VoteError, T>, and this type is a functor, you can project the right result, while any left result short-circuits the query. First, here's a successful query:
> from i in FindWinner(1, 2, -3, -1, 2, -1, -1) select i > 0 Right<VoteError, bool>(false)
This query succeeds, resulting in a Right object. The contained value is false because the winner of the vote is -1, which isn't a positive number.
On the other hand, the following query fails because of a tie.
> from i in FindWinner(1, 2, -3, -1, 2, -1) select i > 0 Left<VoteError, bool>(Tie)
Because the result is tied on -1, the return value is a Left object containing the VoteError value Tie.
Another source of error is an empty input collection:
> from i in FindWinner<int>() select i > 0 Left<VoteError, bool>(Empty)
This time, the Left object contains the Empty error value, since no winner can be found from an empty collection.
While the Select method doesn't implement any behaviour that SelectRight doesn't already afford, it enables you to use C# query syntax, as demonstrated by the above examples.
Next: A Tree functor.
Either bifunctor
Either forms a bifunctor. An article for object-oriented programmers.
This article is an instalment in an article series about bifunctors. As the overview article explains, essentially there's two practically useful bifunctors: pairs and Either. In the previous article, you saw how a pair (a two-tuple) forms a bifunctor. In this article, you'll see how Either also forms a bifunctor.
Mapping both dimensions #
In the previous article, you saw how, if you have maps over both dimensions, you can trivially implement SelectBoth (what Haskell calls bimap):
return source.SelectFirst(selector1).SelectSecond(selector2);
The relationship can, however, go both ways. If you implement SelectBoth, you can derive SelectFirst and SelectSecond from it. In this article, you'll see how to do that for Either.
Given the Church-encoded Either, the implementation of SelectBoth can be achieved in a single expression:
public static IEither<L1, R1> SelectBoth<L, L1, R, R1>( this IEither<L, R> source, Func<L, L1> selectLeft, Func<R, R1> selectRight) { return source.Match<IEither<L1, R1>>( onLeft: l => new Left<L1, R1>( selectLeft(l)), onRight: r => new Right<L1, R1>(selectRight(r))); }
Given that the input source is an IEither<L, R> object, there's isn't much you can do. That interface only defines a single member, Match, so that's the only method you can call. When you do that, you have to supply the two arguments onLeft and onRight.
The Match method is defined like this:
T Match<T>(Func<L, T> onLeft, Func<R, T> onRight)
Given the desired return type of SelectBoth, you know that T should be IEither<L1, R1>. This means, then, that for onLeft, you must supply a function of the type Func<L, IEither<L1, R1>>. Since a functor is a structure-preserving map, you should translate a left case to a left case, and a right case to a right case. This implies that the concrete return type that matches IEither<L1, R1> for the onLeft argument is Left<L1, R1>.
When you write the function with the type Func<L, IEither<L1, R1>> as a lambda expression, the input argument l has the type L. In order to create a new Left<L1, R1>, however, you need an L1 object. How do you produce an L1 object from an L object? You call selectLeft with l, because selectLeft is a function of the type Func<L, L1>.
You can apply the same line of reasoning to the onRight argument. Write a lambda expression that takes an R object r as input, call selectRight to turn that into an R1 object, and return it wrapped in a new Right<L1, R1> object.
This works as expected:
> new Left<string, int>("foo").SelectBoth(string.IsNullOrWhiteSpace, i => new DateTime(i)) Left<bool, DateTime>(false) > new Right<string, int>(1337).SelectBoth(string.IsNullOrWhiteSpace, i => new DateTime(i)) Right<bool, DateTime>([01.01.0001 00:00:00])
Notice that both of the above statements evaluated in C# Interactive use the same projections as input to SelectBoth. Clearly, though, because the inputs are first a Left value, and secondly a Right value, the outputs differ.
Mapping the left side #
When you have SelectBoth, you can trivially implement the translations for each dimension in isolation. In the previous article, I called these methods SelectFirst and SelectSecond. In this article, I've chosen to instead name them SelectLeft and SelectRight, but they still corresponds to Haskell's first and second Bifunctor functions.
public static IEither<L1, R> SelectLeft<L, L1, R>(this IEither<L, R> source, Func<L, L1> selector) { return source.SelectBoth(selector, r => r); }
The method body is literally a one-liner. Just call SelectBoth with selector as the projection for the left side, and the identity function as the projection for the right side. This ensures that if the actual value is a Right<L, R> object, nothing's going to happen. Only if the input is a Left<L, R> object will the projection run:
> new Left<string, int>("").SelectLeft(string.IsNullOrWhiteSpace) Left<bool, int>(true) > new Left<string, int>("bar").SelectLeft(string.IsNullOrWhiteSpace) Left<bool, int>(false) > new Right<string, int>(42).SelectLeft(string.IsNullOrWhiteSpace) Right<bool, int>(42)
In the above C# Interactive session, you can see how projecting three different objects using string.IsNullOrWhiteSpace works. When the Left object indeed does contain an empty string, the result is a Left value containing true. When the object contains "bar", however, it contains false. Furthermore, when the object is a Right value, the mapping has no effect.
Mapping the right side #
Similar to SelectLeft, you can also trivially implement SelectRight:
public static IEither<L, R1> SelectRight<L, R, R1>(this IEither<L, R> source, Func<R, R1> selector) { return source.SelectBoth(l => l, selector); }
This is another one-liner calling SelectBoth, with the difference that the identity function l => l is passed as the first argument, instead of as the last. This ensures that only Right values are mapped:
> new Left<string, int>("baz").SelectRight(i => new DateTime(i)) Left<string, DateTime>("baz") > new Right<string, int>(1_234_567_890).SelectRight(i => new DateTime(i)) Right<string, DateTime>([01.01.0001 00:02:03])
In the above examples, Right integers are projected into DateTime values, whereas Left strings stay strings.
Identity laws #
Either obeys all the bifunctor laws. While it's formal work to prove that this is the case, you can get an intuition for it via examples. Often, I use a property-based testing library like FsCheck or Hedgehog to demonstrate (not prove) that laws hold, but in this article, I'll keep it simple and only cover each law with a parametrised test.
private static T Id<T>(T x) => x; public static IEnumerable<object[]> BifunctorLawsData { get { yield return new[] { new Left<string, int>("foo") }; yield return new[] { new Left<string, int>("bar") }; yield return new[] { new Left<string, int>("baz") }; yield return new[] { new Right<string, int>( 42) }; yield return new[] { new Right<string, int>( 1337) }; yield return new[] { new Right<string, int>( 0) }; } } [Theory, MemberData(nameof(BifunctorLawsData))] public void SelectLeftObeysFirstFunctorLaw(IEither<string, int> e) { Assert.Equal(e, e.SelectLeft(Id)); }
This test uses xUnit.net's [Theory] feature to supply a small set of example input values. The input values are defined by the BifunctorLawsData property, since I'll reuse the same values for all the bifunctor law demonstration tests.
The tests also use the identity function implemented as a private function called Id, since C# doesn't come equipped with such a function in the Base Class Library.
For all the IEither<string, int> objects e, the test simply verifies that the original Either e is equal to the Either projected over the first axis with the Id function.
Likewise, the first functor law applies when translating over the second dimension:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectRightObeysFirstFunctorLaw(IEither<string, int> e) { Assert.Equal(e, e.SelectRight(Id)); }
This is the same test as the previous test, with the only exception that it calls SelectRight instead of SelectLeft.
Both SelectLeft and SelectRight are implemented by SelectBoth, so the real test is whether this method obeys the identity law:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothObeysIdentityLaw(IEither<string, int> e) { Assert.Equal(e, e.SelectBoth(Id, Id)); }
Projecting over both dimensions with the identity function does, indeed, return an object equal to the input object.
Consistency law #
In general, it shouldn't matter whether you map with SelectBoth or a combination of SelectLeft and SelectRight:
[Theory, MemberData(nameof(BifunctorLawsData))] public void ConsistencyLawHolds(IEither<string, int> e) { bool f(string s) => string.IsNullOrWhiteSpace(s); DateTime g(int i) => new DateTime(i); Assert.Equal(e.SelectBoth(f, g), e.SelectRight(g).SelectLeft(f)); Assert.Equal( e.SelectLeft(f).SelectRight(g), e.SelectRight(g).SelectLeft(f)); }
This example creates two local functions f and g. The first function, f, just delegates to string.IsNullOrWhiteSpace, although I want to stress that this is just an example. The law should hold for any two (pure) functions. The second function, g, creates a new DateTime object from an integer, using one of the DateTime constructor overloads.
The test then verifies that you get the same result from calling SelectBoth as when you call SelectLeft followed by SelectRight, or the other way around.
Composition laws #
The composition laws insist that you can compose functions, or translations, and that again, the choice to do one or the other doesn't matter. Along each of the axes, it's just the second functor law applied. This parametrised test demonstrates that the law holds for SelectLeft:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectLeft(IEither<string, int> e) { bool f(int x) => x % 2 == 0; int g(string s) => s.Length; Assert.Equal(e.SelectLeft(x => f(g(x))), e.SelectLeft(g).SelectLeft(f)); }
Here, f is the even function, whereas g is a local function that returns the length of a string. The second functor law states that mapping f(g(x)) in a single step is equivalent to first mapping over g and then map the result of that using f.
The same law applies if you fix the first dimension and translate over the second:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectRight(IEither<string, int> e) { char f(bool b) => b ? 'T' : 'F'; bool g(int i) => i % 2 == 0; Assert.Equal(e.SelectRight(x => f(g(x))), e.SelectRight(g).SelectRight(f)); }
Here, f is a local function that returns 'T' for true and 'F' for false, and g is a local function that, as you've seen before, determines whether a number is even. Again, the test demonstrates that the output is the same whether you map over an intermediary step, or whether you map using only a single step.
This generalises to the composition law for SelectBoth:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothCompositionLawHolds(IEither<string, int> e) { bool f(int x) => x % 2 == 0; int g(string s) => s.Length; char h(bool b) => b ? 'T' : 'F'; bool i(int x) => x % 2 == 0; Assert.Equal( e.SelectBoth(x => f(g(x)), y => h(i(y))), e.SelectBoth(g, i).SelectBoth(f, h)); }
Again, whether you translate in one or two steps shouldn't affect the outcome.
As all of these tests demonstrate, the bifunctor laws hold for Either. The tests only showcase six examples for either a string or an integer, but I hope it gives you an intuition how any Either object is a bifunctor. After all, the SelectLeft, SelectRight, and SelectBoth methods are all generic, and they behave the same for all generic type arguments.
Summary #
Either objects are bifunctors. You can translate the first and second dimension of an Either object independently of each other, and the bifunctor laws hold for any pure translation, no matter how you compose the projections.
As always, there can be performance differences between the various compositions, but the outputs will be the same regardless of composition.
A functor, and by extension, a bifunctor, is a structure-preserving map. This means that any projection preserves the structure of the underlying container. For Either objects, it means that left objects remain left objects, and right objects remain right objects, even if the contained values change. Either is characterised by containing exactly one value, but it can be either a left value or a right value. No matter how you translate it, it still contains only a single value - left or right.
The other common bifunctor, pair, is complementary. Not only does it also have two dimensions, but a pair always contains both values at once.
Next: Rose tree bifunctor.
Comments
I feel like the concepts of functor and bifunctor were used somewhat interchangeably in this post. Can we clarify this relationship?
To help us with this, consider type variance. The generic type Func<A> is covariant, but more specifically, it is covariant on A. That additional prepositional phrase is often omitted because it can be inferred. In contrast, the generic type Func<A, B> is both covariant and contravariant but (of course) not on the same type parameter. It is covariant in B and contravariant in A.
I feel like saying that a generic type with two type parameters is a (bi)functor also needs an additional prepositional phrase. Like, Either<L, R> is a bifunctor in L and R, so it is also a functor in L and a functor in R.
Does this seem like a clearer way to talk about a specific type being both a bifunctor and a fuctor?
Tyson, thank you for writing. I find no fault with what you wrote. Is it clearer? I don't know.
One thing that's surprised me throughout this endeavour is exactly what does or doesn't confuse readers. This, I can't predict.
A functor is, by its definition, assumed to be covariant. Contravariant functors also exist, but they're explicitly named contravariant functors to distinguish them from standard functors.
Ultimately, co- or contravariance of generic type arguments is (I think) insufficient to identify a type as a functor. Whether or not something is a functor is determined by whether or not it obeys the functor laws. Can we guarantee that all types with a covariant type argument will obey the functor laws?
I wasn't trying to discuss the relationship between functors and type variance. I just brought up type variance as an example in programming where I think adding additional prepositional phrases to statements can clarify things.
Tuple bifunctor
A Pair (a two-tuple) forms a bifunctor. An article for object-oriented programmers.
This article is an instalment in an article series about bifunctors. In the previous overview, you learned about the general concept of a bifunctor. In practice, there's two useful bifunctor instances: pairs (two-tuples) and Either. In this article, you'll see how a pair is a bifunctor, and in the next article, you'll see how Either fits the same abstraction.
Tuple as a functor #
You can treat a normal pair (two-tuple) as a functor by mapping one of the elements, while keeping the other generic type fixed. In Haskell, when you have types with multiple type arguments, you often 'fix' the types from the left, leaving the right-most type free to vary. Doing this for a pair, which in C# has the type Tuple<T, U>, this means that tuples are functors if we keep T fixed and enable translation of the second element from U1 to U2.
This is easy to implement with a standard Select extension method:
public static Tuple<T, U2> Select<T, U1, U2>( this Tuple<T, U1> source, Func<U1, U2> selector) { return Tuple.Create(source.Item1, selector(source.Item2)); }
You simply return a new tuple by carrying source.Item1 over without modification, while on the other hand calling selector with source.Item2. Here's a simple example, which also highlights that C# understands functors:
var t = Tuple.Create("foo", 42); var actual = from i in t select i % 2 == 0;
Here, actual is a Tuple<string, bool> with the values "foo" and true. Inside the query expression, i is an int, and the select expression returns a bool value indicating whether the number is even or odd. Notice that the string in the first element disappears inside the query expression. It's still there, but the code inside the query expression can't see "foo".
Mapping the first element #
There's no technical reason why the mapping has to be over the second element; it's just how Haskell does it by convention. There are other, more philosophical reasons for that convention, but in the end, they boil down to the ultimately arbitrary cultural choice of reading from left to right (in Western scripts).
You can translate the first element of a tuple as easily:
public static Tuple<T2, U> SelectFirst<T1, T2, U>( this Tuple<T1, U> source, Func<T1, T2> selector) { return Tuple.Create(selector(source.Item1), source.Item2); }
While, technically, you can call this method Select, this can confuse the C# compiler's overload resolution system - at least if you have a tuple of two identical types (e.g. Tuple<int, int> or Tuple<string, string>). In order to avoid that sort of confusion, I decided to give the method another name, and in keeping with how C# LINQ methods tend to get names, I thought SelectFirst sounded reasonable.
In Haskell, this function is called first, and is part of the Bifunctor type class:
Prelude Data.Bifunctor> first (even . length) ("foo", 42)
(False,42)
In C#, you can perform the same translation using the above SelectFirst extension method:
var t = Tuple.Create("foo", 42); var actual = t.SelectFirst(s => s.Length % 2 == 0);
This also returns a Tuple<bool, int> containing the values false and 42. Notice that in this case, the first element "foo" is translated into false (because its length is odd), while the second element 42 carries over unchanged.
Mapping the second element #
You've already seen how the above Select method maps over the second element of a pair. This means that you can already map over both dimensions of the bifunctor, but perhaps, for consistency's sake, you'd also like to add an explicit SelectSecond method. This is now trivial to implement, since it can delegate its work to Select:
public static Tuple<T, U2> SelectSecond<T, U1, U2>( this Tuple<T, U1> source, Func<U1, U2> selector) { return source.Select(selector); }
There's no separate implementation; the only thing this method does is to delegate work to the Select method. It's literally the Select method, just with another name.
Clearly, you could also have done it the other way around: implement SelectSecond and then call it from Select.
The SelectSecond method works as you'd expect:
var t = Tuple.Create("foo", 1337); var actual = t.SelectSecond(i => i % 2 == 0);
Again, actual is a tuple containing the values "foo" and false, because 1337 isn't even.
This fits with the Haskell implementation, where SelectSecond is called second:
Prelude Data.Bifunctor> second even ("foo", 1337)
("foo",False)
The result is still a pair where the first element is "foo" and the second element False, exactly like in the C# example.
Mapping both elements #
With SelectFirst and SelectSecond, you can trivially implement SelectBoth:
public static Tuple<T2, U2> SelectBoth<T1, T2, U1, U2>( this Tuple<T1, U1> source, Func<T1, T2> selector1, Func<U1, U2> selector2) { return source.SelectFirst(selector1).SelectSecond(selector2); }
This method takes two translations, selector1 and selector2, and first uses SelectFirst to project along the first axis, and then SelectSecond to map the second dimension.
This implementation creates an intermediary pair that callers never see, so this could theoretically be inefficient. In this article, however, I want to show you that it's possible to implement SelectBoth based on SelectFirst and SelectSecond. In the next article, you'll see how to do it the other way around.
Using SelectBoth is easy:
var t = Tuple.Create("foo", 42); var actual = t.SelectBoth(s => s.First(), i => i % 2 == 0);
This translation returns a pair where the first element is 'f' and the second element is true. This is because the first lambda expression s => s.First() returns the first element of the input string "foo", whereas the second lambda expression i => i % 2 == 0 determines that 42 is even.
In Haskell, SelectBoth is called bimap:
Prelude Data.Bifunctor> bimap head even ("foo", 42)
('f',True)
The return value is consistent with the C# example, since the input is also equivalent.
Identity laws #
Pairs obey all the bifunctor laws. While it's formal work to prove that this is the case, you can get an intuition for it via examples. Often, I use a property-based testing library like FsCheck or Hedgehog to demonstrate (not prove) that laws hold, but in this article, I'll keep it simple and only cover each law with a parametrised test.
private static T Id<T>(T x) => x; [Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SelectFirstObeysFirstFunctorLaw(string first, int second) { var t = Tuple.Create(first, second); Assert.Equal(t, t.SelectFirst(Id)); }
This test uses xUnit.net's [Theory] feature to supply a small set of example input values. It defines the identity function as a private function called Id, since C# doesn't come equipped with such a function in the Base Class Library.
The test simply creates a tuple with the input values and verifies that the original tuple t is equal to the tuple projected over the first axis with the Id function.
Likewise, the first functor law applies when translating over the second dimension:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SelectSecondObeysFirstFunctorLaw(string first, int second) { var t = Tuple.Create(first, second); Assert.Equal(t, t.SelectSecond(Id)); }
This is the same test as the previous test, with the only exception that it calls SelectSecond instead of SelectFirst.
Since SelectBoth in this example is implemented by composing SelectFirst and SelectSecond, you should expect it to obey the general identity law for bifunctors. It does, but it's always nice to see it with your own eyes:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SelectBothObeysIdentityLaw(string first, int second) { var t = Tuple.Create(first, second); Assert.Equal(t, t.SelectBoth(Id, Id)); }
Here you can see that projecting over both dimensions with the identity function returns the original tuple.
Consistency law #
In general, it shouldn't matter whether you map with SelectBoth or a combination of SelectFirst and SelectSecond:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] public void ConsistencyLawHolds(string first, int second) { Func<string, bool> f = string.IsNullOrWhiteSpace; Func<int, DateTime> g = i => new DateTime(i); var t = Tuple.Create(first, second); Assert.Equal( t.SelectBoth(f, g), t.SelectSecond(g).SelectFirst(f)); Assert.Equal( t.SelectFirst(f).SelectSecond(g), t.SelectSecond(g).SelectFirst(f)); }
This example creates two functions f and g. The first function, f, is just an alias for string.IsNullOrWhiteSpace, although I want to stress that it's just an example. The law should hold for any two (pure) functions. The second function, g, creates a new DateTime object from an integer, using one of the DateTime constructor overloads.
The test then verifies that you get the same result from calling SelectBoth as when you call SelectFirst followed by SelectSecond, or the other way around.
Composition laws #
The composition laws insist that you can compose functions, or translations, and that again, the choice to do one or the other doesn't matter. Along each of the axes, it's just the second functor law applied. You've already seen that SelectSecond is nothing but an alias for Select, so surely, the second functor law must hold for SelectSecond as well. This parametrised test demonstrates that it does:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SecondFunctorLawHoldsForSelectSecond(string first, int second) { Func<bool, char> f = b => b ? 'T' : 'F'; Func<int, bool> g = i => i % 2 == 0; var t = Tuple.Create(first, second); Assert.Equal( t.SelectSecond(x => f(g(x))), t.SelectSecond(g).SelectSecond(f)); }
Here, f is a function that returns 'T' for true and 'F' for false, and g is a function that, as you've seen before, determines whether a number is even. The second functor law states that mapping f(g(x)) in a single step is equivalent to first mapping over g and then map the result of that using f.
The same law applies if you fix the second dimension and translate over the first:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SecondFunctorLawHoldsForSelectFirst(string first, int second) { Func<int, bool> f = x => x % 2 == 0; Func<string, int> g = s => s.Length; var t = Tuple.Create(first, second); Assert.Equal( t.SelectFirst(x => f(g(x))), t.SelectFirst(g).SelectFirst(f)); }
Here, f is the even function, whereas g is a function that returns the length of a string. Again, the test demonstrates that the output is the same whether you map over an intermediary step, or whether you map using only a single step.
This generalises to the composition law for SelectBoth:
[Theory] [InlineData("foo", 42)] [InlineData("bar", 1337)] [InlineData("foobar", 0)] [InlineData("ploeh", 7)] [InlineData("fnaah", -6)] public void SelectBothCompositionLawHolds(string first, int second) { Func<int, bool> f = x => x % 2 == 0; Func<string, int> g = s => s.Length; Func<bool, char> h = b => b ? 'T' : 'F'; Func<int, bool> i = x => x % 2 == 0; var t = Tuple.Create(first, second); Assert.Equal( t.SelectBoth(x => f(g(x)), y => h(i(y))), t.SelectBoth(g, i).SelectBoth(f, h)); }
Again, whether you translate in one or two steps shouldn't affect the outcome.
As all of these tests demonstrate, the bifunctor laws hold for pairs. The tests only showcase 4-5 examples for a pair of string and integer, but I hope it gives you an intuition how any pair is a bifunctor. After all, the SelectFirst, SelectSecond, and SelectBoth methods are all generic, and they behave the same for all generic type arguments.
Summary #
Pairs (two-tuples) are bifunctors. You can translate the first and second element of a pair independently of each other, and the bifunctor laws hold for any pure translation, no matter how you compose the projections.
As always, there can be performance differences between the various compositions, but the outputs will be the same regardless of composition.
A functor, and by extension, a bifunctor, is a structure-preserving map. This means that any projection preserves the structure of the underlying container. In practice that means that for pairs, no matter how you translate a pair, it remains a pair. A pair is characterised by containing two values at once, and no matter how you translate it, it'll still contain two values.
The other common bifunctor, Either, is complementary. While it has two dimensions, it only contains one value, which is of either the one type or the other. It's still a bifunctor, though, because mappings preserve the structure of Either, too.
Next: Either bifunctor.
Bifunctors
Bifunctors are like functors, only they vary in two dimensions instead of one. An article for object-oriented programmers.
This article is a continuation of the article series about functors and about applicative functors. In this article, you'll learn about a generalisation called a bifunctor. The prefix bi typically indicates that there's two of something, and that's also the case here.
As you've already seen in the functor articles, a functor is a mappable container of generic values, like Foo<T>, where the type of the contained value(s) can be any generic type T. A bifunctor is just a container with two independent generic types, like Bar<T, U>. If you can map each of the types independently of the other, you may have a bifunctor.
The two most common bifunctors are tuples and Either.
Maps #
A normal functor is based on a structure-preserving map of the contents within a container. You can, for example, translate an IEnumerable<int> to an IEnumerable<string>, or a Maybe<DateTime> to a Maybe<bool>. The axis of variability is the generic type argument T. You can translate T1 to T2 inside a container, but the type of the container remains the same: you can translate Tree<T1> to Tree<T2>, but it remains a Tree<>.

A bifunctor involves a pair of maps, one for each generic type. You can map a Bar<string, int> to a Bar<bool, int>, or to a Bar<string, DateTime>, or even to a Bar<bool, DateTime>. Notice that the last example, mapping from Bar<string, int> to Bar<bool, DateTime> could be viewed as translating both axes simultaneously.
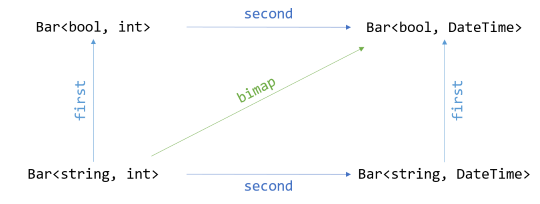
In Haskell, the two maps are called first and second, while the 'simultaneous' map is called bimap.
The first translation translates the first, or left-most, value in the container. You can use it to map Bar<string, int> to a Bar<bool, int>. In C#, we could decide to call the method SelectFirst, or SelectLeft, in order to align with the C# naming convention of calling the functor morphism Select.
Likewise, the second map translates the second, or right-most, value in the container. This is where you map Bar<string, int> to Bar<string, DateTime>. In C#, we could call the method SelectSecond, or SelectRight.
The bimap function maps both values in the container in one go. This corresponds to a translation from Bar<string, int> to Bar<bool, DateTime>. In C#, we could call the method SelectBoth. There's no established naming conventions for bifunctors in C# that I know of, so these names are just some that I made up.
You'll see examples of how to implement and use such functions in the next articles:
Other bifunctors exist, but the first two are the most common.Identity laws #
As is the case with functors, laws govern bifunctors. Some of the functor laws carry over, but are simply repeated over both axes, while other laws are generalisations of the functor laws. For example, the first functor law states that if you translate a container with the identity function, the result is the original input. This generalises to bifunctors as well:
bimap id id ≡ id
This just states that if you translate both axes using the endomorphic Identity, it's equivalent to applying the Identity.

Using C# syntax, you could express the law like this:
bf.SelectBoth(id, id) == bf;
Here, bf is some bifunctor, and id is the identity function. The point is that if you translate over both axes, but actually don't perform a real translation, nothing happens.
Likewise, if you consider a bifunctor a functor over two dimensions, the first functor law should hold for both:
first id ≡ id second id ≡ id
Both of those equalities only restate the first functor law for each dimension. If you map an axis with the identity function, nothing happens:
In C#, you can express both laws like this:
bf.SelectFirst(id) == bf; bf.SelectSecond(id) == bf;
When calling SelectFirst, you translate only the first axis while you keep the second axis constant. When calling SelectSecond it's the other way around: you translate only the second axis while keeping the first axis constant. In both cases, though, if you use the identity function for the translation, you effectively keep the mapped dimension constant as well. Therefore, one would expect the result to be the same as the input.
Consistency law #
As you'll see in the articles on tuple and Either bifunctors, you can derive bimap or SelectBoth from first/SelectFirst and second/SelectSecond, or the other way around. If, however, you decide to implement all three functions, they must act in a consistent manner. The name Consistency law, however, is entirely my own invention. If it has a more well-known name, I'm not aware of it.
In pseudo-Haskell syntax, you can express the law like this:
bimap f g ≡ first f . second g
This states that mapping (using the functions f and g) simultaneously should produce the same result as mapping using an intermediary step:
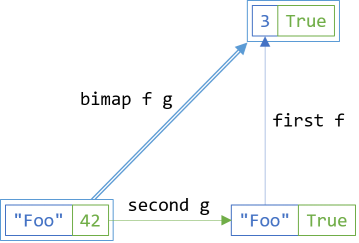
In C#, you could express it like this:
bf.SelectBoth(f, g) == bf.SelectSecond(g).SelectFirst(f);
You can project the input bifunctor bf using both f and g in a single step, or you can first translate the second dimension with g and then subsequently map that intermediary result along the first axis with f.
The above diagram ought to commute:
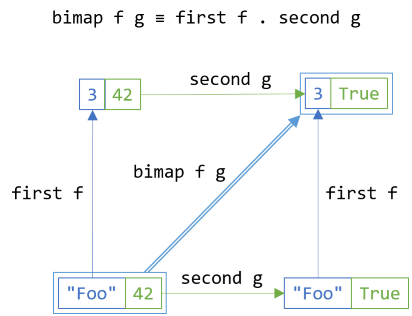
It shouldn't matter whether the intermediary step is applying f along the first axis or g along the second axis. In C#, we can write it like this:
bf.SelectFirst(f).SelectSecond(g) == bf.SelectSecond(g).SelectFirst(f);
On the left-hand side, you first translate the bifunctor bf along the first axis, using f, and then translate that intermediary result along the second axis, using g. On the right-hand side, you first project bf along the second axis, using g, and then map that intermediary result over the first dimension, using f.
Regardless of order of translation, the result should be the same.
Composition laws #
Similar to how the first functor law generalises to bifunctors, the second functor law generalises as well. For (mono)functors, the second functor law states that if you have two functions over the same dimension, it shouldn't matter whether you perform a projection in one, composed step, or in two steps with an intermediary result.
For bifunctors, you can generalise that law and state that you can project over both dimensions in one or two steps:
bimap (f . g) (h . i) ≡ bimap f h . bimap g i
If you have two functions, f and g, that compose, and two other functions, h and i, that also compose, you can translate in either one or two steps; the result should be the same.
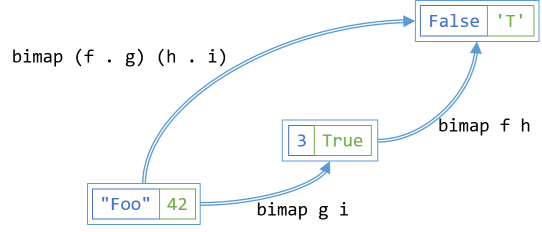
In C#, you can express the law like this:
bf.SelectBoth(x => f(g(x)), y => h(i(y))) == bf.SelectBoth(g, i).SelectBoth(f, h);
On the left-hand side, the first dimension is translated in one step. For each x contained in bf, the translation first invokes g(x), and then immediately calls f with the output of g(x). The second dimension also gets translated in one step. For each y contained in bf, the translation first invokes i(y), and then immediately calls h with the output of i(y).
On the right-hand side, you first translate bf along both axes using g and i. This produces an intermediary result that you can use as input for a second translation with f and h.
The translation on the left-hand side should produce the same output as the right-hand side.
Finally, if you keep one of the dimensions fixed, you essentially have a normal functor, and the second functor law should still hold. For example, if you hold the second dimension fixed, translating over the first dimension is equivalent to a normal functor projection, so the second functor law should hold:
first (f . g) ≡ first f . first g
If you replace first with fmap, you have the second functor law.
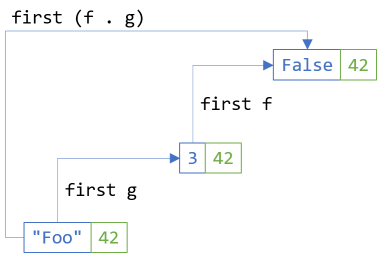
In C#, you can write it like this:
bf.SelectFirst(x => f(g(x))) == bf.SelectFirst(g).SelectFirst(f);
Likewise, you can keep the first dimension constant and apply the second functor law to projections along the second axis:
second (f . g) ≡ second f . second g
Again, if you replace second with fmap, you have the second functor law.
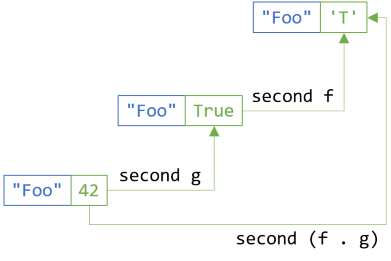
In C#, you express it like this:
bf.SelectSecond(x => f(g(x))) == bf.SelectSecond(g).SelectSecond(f);
The last two of these composition laws are specialisations of the general composition law, but where you fix either one or the other dimension.
Summary #
A bifunctor is a container that can be translated over two dimensions, instead of a (mono)functor, which is a container that can be translated over a single dimension. In reality, there isn't a multitude of different bifunctors. While others exist, tuples and Either are the two most common bifunctors. They share an abstraction, but are still fundamentally different. A tuple always contains values of both dimensions at the same time, whereas Either only contains one of the values.
Do trifunctors, quadfunctors, and so on, exist? Nothing prevents that, but they aren't particularly useful; in practice, you never run into them.
Next: Tuple bifunctor.
The Lazy applicative functor
Lazy computations form an applicative functor.
This article is an instalment in an article series about applicative functors. A previous article has described how lazy computations form a functor. In this article, you'll see that lazy computations also form an applicative functor.
Apply #
As you have previously seen, C# isn't the best fit for the concept of applicative functors. Nevertheless, you can write an Apply extension method following the applicative 'code template':
public static Lazy<TResult> Apply<TResult, T>( this Lazy<Func<T, TResult>> selector, Lazy<T> source) { return new Lazy<TResult>(() => selector.Value(source.Value)); }
The Apply method takes both a lazy selector and a lazy value called source. It applies the function to the value and returns the result, still as a lazy value. If you have a lazy function f and a lazy value x, you can use the method like this:
Lazy<Func<int, string>> f = // ... Lazy<int> x = // ... Lazy<string> y = f.Apply(x);
The utility of Apply, however, mostly tends to emerge when you need to chain multiple containers together; in this case, multiple lazy values. You can do that by adding as many overloads to Apply as you need:
public static Lazy<Func<T2, TResult>> Apply<T1, T2, TResult>( this Lazy<Func<T1, T2, TResult>> selector, Lazy<T1> source) { return new Lazy<Func<T2, TResult>>(() => y => selector.Value(source.Value, y)); }
This overload partially applies the input function. When selector is a function that takes two arguments, you can apply a single of those two arguments, and the result is a new function that closes over the value, but still waits for its second input argument. You can use it like this:
Lazy<Func<char, int, string>> f = // ... Lazy<char> c = // ... Lazy<int> i = // ... Lazy<string> s = f.Apply(c).Apply(i);
Notice that you can chain the various overloads of Apply. In the above example, you have a lazy function that takes a char and an int as input, and returns a string. It could, for instance, be a function that invokes the equivalent string constructor overload.
Calling f.Apply(c) uses the overload that takes a Lazy<Func<T1, T2, TResult>> as input. The return value is a Lazy<Func<int, string>>, which the first Apply overload then picks up, to return a Lazy<string>.
Usually, you may have one, two, or several lazy values, whereas your function itself isn't contained in a Lazy container. While you can use a helper method such as Lazy.FromValue to 'elevate' a 'normal' function to a lazy function value, it's often more convenient if you have another Apply overload like this:
public static Lazy<Func<T2, TResult>> Apply<T1, T2, TResult>( this Func<T1, T2, TResult> selector, Lazy<T1> source) { return new Lazy<Func<T2, TResult>>(() => y => selector(source.Value, y)); }
The only difference to the equivalent overload is that in this overload, selector isn't a Lazy value, while source still is. This simplifies usage:
Func<char, int, string> f = // ... Lazy<char> c = // ... Lazy<int> i = // ... Lazy<string> s = f.Apply(c).Apply(i);
Notice that in this variation of the example, f is no longer a Lazy<Func<...>>, but just a normal Func.
F# #
F#'s type inference is more powerful than C#'s, so you don't have to resort to various overloads to make things work. You could, for example, create a minimal Lazy module:
module Lazy = // ('a -> 'b) -> Lazy<'a> -> Lazy<'b> let map f (x : Lazy<'a>) = lazy f x.Value // Lazy<('a -> 'b)> -> Lazy<'a> -> Lazy<'b> let apply (x : Lazy<_>) (f : Lazy<_>) = lazy f.Value x.Value
In this code listing, I've repeated the map function shown in a previous article. It's not required for the implementation of apply, but you'll see it in use shortly, so I thought it was convenient to include it in the listing.
If you belong to the camp of F# programmers who think that F# should emulate Haskell, you can also introduce an operator:
let (<*>) f x = Lazy.apply x f
Notice that this <*> operator simply flips the arguments of Lazy.apply. If you introduce such an operator, be aware that the admonition from the overview article still applies. In Haskell, the <*> operator applies to any Applicative, which makes it truly general. In F#, once you define an operator like this, it applies specifically to a particular container type, which, in this case, is Lazy<'a>.
You can replicate the first of the above C# examples like this:
let f : Lazy<int -> string> = // ... let x : Lazy<int> = // ... let y : Lazy<string> = Lazy.apply x f
Alternatively, if you want to use the <*> operator, you can compute y like this:
let y : Lazy<string> = f <*> x
Chaining multiple lazy computations together also works:
let f : Lazy<char -> int -> string> = // ... let c : Lazy<char> = // ... let i : Lazy<int> = // ... let s = Lazy.apply c f |> Lazy.apply i
Again, you can compute s with the operator, if that's more to your liking:
let s : Lazy<string> = f <*> c <*> i
Finally, if your function isn't contained in a Lazy value, you can start out with Lazy.map:
let f : char -> int -> string = // ... let c : Lazy<char> = // ... let i : Lazy<int> = // ... let s : Lazy<string> = Lazy.map f c |> Lazy.apply i
This works without requiring additional overloads. Since F# natively supports partial function application, the first step in the pipeline, Lazy.map f c has the type Lazy<int -> string> because f is a function of the type char -> int -> string, but in the first step, Lazy.map f c only supplies c, which contains a char value.
Once more, if you prefer the infix operator, you can also compute s as:
let s : Lazy<string> = lazy f <*> c <*> i
While I find operator-based syntax attractive in Haskell code, I'm more hesitant about such syntax in F#.
Haskell #
As outlined in the previous article, Haskell is already lazily evaluated, so it makes little sense to introduce an explicit Lazy data container. While Haskell's built-in Identity isn't quite equivalent to .NET's Lazy<T> object, some similarities remain; most notably, the Identity functor is also applicative:
Prelude Data.Functor.Identity> :t f f :: a -> Int -> [a] Prelude Data.Functor.Identity> :t c c :: Identity Char Prelude Data.Functor.Identity> :t i i :: Num a => Identity a Prelude Data.Functor.Identity> :t f <$> c <*> i f <$> c <*> i :: Identity String
This little GHCi session simply illustrates that if you have a 'normal' function f and two Identity values c and i, you can compose them using the infix map operator <$>, followed by the infix apply operator <*>. This is equivalent to the F# expression Lazy.map f c |> Lazy.apply i.
Still, this makes little sense, since all Haskell expressions are already lazily evaluated.
Summary #
The Lazy functor is also an applicative functor. This can be used to combine multiple lazily computed values into a single lazily computed value.
Next: Applicative monoids.
Danish CPR numbers in F#
An example of domain-modelling in F#, including a fine example of using the option type as an applicative functor.
This article is an instalment in an article series about applicative functors, although the applicative functor example doesn't appear until towards the end. This article also serves the purpose of showing an example of Domain-Driven Design in F#.
Danish personal identification numbers #
As outlined in the previous article, in Denmark, everyone has a personal identification number, in Danish called CPR-nummer (CPR number).
CPR numbers have a simple format: DDMMYY-SSSS, where the first six digits indicate a person's birth date, and the last four digits are a sequence number. Some information, however, is also embedded in the sequence number. An example could be 010203-1234, which indicates a woman born February 1, 1903.
One way to model this in F# is with a single-case discriminated union:
type CprNumber = private CprNumber of (int * int * int * int) with override x.ToString () = let (CprNumber (day, month, year, sequenceNumber)) = x sprintf "%02d%02d%02d-%04d" day month year sequenceNumber
This is a common idiom in F#. In object-oriented design with e.g. C# or Java, you'd typically create a class and put guard clauses in its constructor. This would prevent a user from initialising an object with invalid data (such as 401500-1234). While you can create classes in F# as well, a single-case union with a private case constructor can achieve the same degree of encapsulation.
In this case, I decided to use a quadruple (4-tuple) as the internal representation, but this isn't visible to users. This gives me the option to refactor the internal representation, if I need to, without breaking existing clients.
Creating CPR number values #
Since the CprNumber case constructor is private, you can't just create new values like this:
let cpr = CprNumber (1, 1, 1, 1118)
If you're outside the Cpr module that defines the type, this doesn't compile. This is by design, but obviously you need a way to create values. For convenience, input values for day, month, and so on, are represented as ints, which can be zero, negative, or way too large for CPR numbers. There's no way to statically guarantee that you can create a value, so you'll have to settle for a tryCreate function; i.e. a function that returns Some CprNumber if the input is valid, or None if it isn't. In Haskell, this pattern is called a smart constructor.
There's a couple of rules to check. All integer values must fall in certain ranges. Days must be between 1 and 31, months must be between 1 and 12, and so on. One way to enable succinct checks like that is with an active pattern:
let private (|Between|_|) min max candidate = if min <= candidate && candidate <= max then Some candidate else None
Straightforward: return Some candidate if candidate is between min and max; otherwise, None. This enables you to pattern-match input integer values to particular ranges.
Perhaps you've already noticed that years are represented with only two digits. CPR is an old system (from 1968), and back then, bits were expensive. No reason to waste bits on recording the millennium or century in which people were born. It turns out, after all, that there's a way to at least partially figure out the century in which people were born. The first digit of the sequence number contains that information:
// int -> int -> int let private calculateFourDigitYear year sequenceNumber = let centuryDigit = sequenceNumber / 1000 // Integer division // Table from https://da.wikipedia.org/wiki/CPR-nummer match centuryDigit, year with | Between 0 3 _, _ -> 1900 | 4 , Between 0 36 _ -> 2000 | 4 , _ -> 1900 | Between 5 8 _, Between 0 57 _ -> 2000 | Between 5 8 _, _ -> 1800 | _ , Between 0 36 _ -> 2000 | _ -> 1900 + year
As the code comment informs the reader, there's a table that defines the century, based on the two-digit year and the first digit of the sequence number. Note that birth dates in the nineteenth century are possible. No Danes born before 1900 are alive any longer, but at the time the CPR system was introduced, one person in the system was born in 1863!
The calculateFourDigitYear function starts by pulling the first digit out of the sequence number. This is a four-digit number, so dividing by 1,000 produces the digit. I left a comment about integer division, because I often miss that detail when I read code.
The big pattern-match expression uses the Between active pattern, but it ignores the return value from the pattern. This explains the wild cards (_), I hope.
Although a pattern-match expression is often formatted over several lines of code, it's a single expression that produces a single value. Often, you see code where a let-binding binds a named value to a pattern-match expression. Another occasional idiom is to pipe a pattern-match expression to a function. In the calculateFourDigitYear function I use a language construct I've never seen anywhere else: the eight-lines pattern-match expression returns an int, which I simply add to year using the + operator.
Both calculateFourDigitYear and the Between active pattern are private functions. They're only there as support functions for the public API. You can now implement a tryCreate function:
// int -> int -> int -> int -> CprNumber option let tryCreate day month year sequenceNumber = match month, year, sequenceNumber with | Between 1 12 m, Between 0 99 y, Between 0 9999 s -> let fourDigitYear = calculateFourDigitYear y s if 1 <= day && day <= DateTime.DaysInMonth (fourDigitYear, m) then Some (CprNumber (day, m, y, s)) else None | _ -> None
The tryCreate function begins by pattern-matching a triple (3-tuple) using the Between active pattern. The month must always be between 1 and 12 (both included), the year must be between 0 and 99, and the sequenceNumber must always be between 0 and 9999 (in fact, I'm not completely sure if 0000 is valid).
Finding the appropriate range for the day is more intricate. Is 31 always valid? Clearly not, because there's no November 31, for example. Is 30 always valid? No, because there's never a February 30. Is 29 valid? This depends on whether or not the year is a leap year.
This reveals why you need calculateFourDigitYear. While you can use DateTime.DaysInMonth to figure out how many days a given month has, you need the year. Specifically, February 1900 had 28 days, while February 2000 had 29.
Ergo, if day, month, year, and sequenceNumber all fall within their appropriate ranges, tryCreate returns a Some CprNumber value; otherwise, it returns None.
Notice how this is different from an object-oriented constructor with guard clauses. If you try to create an object with invalid input, it'll throw an exception. If you try to create a CprNumber value, you'll receive a CprNumber option, and you, as the client developer, must handle both the Some and the None case. The compiler will enforce this.
> let gjern = Cpr.tryCreate 11 11 11 1118;; val gjern : Cpr.CprNumber option = Some 111111-1118 > gjern |> Option.map Cpr.born;; val it : DateTime option = Some 11.11.1911 00:00:00
As most F# developers know, F# gives you enough syntactic sugar to make this a joy rather than a chore... and the warm and fuzzy feeling of safety is priceless.
CPR data #
The above FSI session uses Cpr.born, which you haven't seen yet. With the tools available so far, it's trivial to implement; all the work is already done:
// CprNumber -> DateTime let born (CprNumber (day, month, year, sequenceNumber)) = DateTime (calculateFourDigitYear year sequenceNumber, month, day)
While the CprNumber case constructor is private, it's still available from inside of the module. The born function pattern-matches day, month, year, and sequenceNumber out of its input argument, and trivially delegates the hard work to calculateFourDigitYear.
Another piece of data you can deduce from a CPR number is the gender of the person:
// CprNumber -> bool let isFemale (CprNumber (_, _, _, sequenceNumber)) = sequenceNumber % 2 = 0 let isMale (CprNumber (_, _, _, sequenceNumber)) = sequenceNumber % 2 <> 0
The rule is that if the sequence number is even, then the person is female; otherwise, the person is male (and if you change sex, you get a new CPR number).
> gjern |> Option.map Cpr.isFemale;; val it : bool option = Some true
Since 1118 is even, this is a woman.
Parsing CPR strings #
CPR numbers are often passed around as text, so you'll need to be able to parse a string representation. As described in the previous article, you should follow Postel's law. Input could include extra white space, and the middle dash could be missing.
The .NET Base Class Library contains enough utility methods working on string values that this isn't going to be particularly difficult. It can, however, be awkward to interoperate with object-oriented APIs, so you'll often benefit from adding a few utility functions that give you curried functions instead of objects with methods. Here's one that adapts Int32.TryParse:
module private Int = // string -> int option let tryParse candidate = match candidate |> Int32.TryParse with | true, i -> Some i | _ -> None
Nothing much goes on here. While F# has pleasant syntax for handling out parameters, it can be inconvenient to have to pattern-match every time you'd like to try to parse an integer.
Here's another helper function:
module private String = // int -> int -> string -> string option let trySubstring startIndex length (s : string) = if s.Length < startIndex + length then None else Some (s.Substring (startIndex, length))
This one comes with two benefits: The first benefit is that it's curried, which enables partial application and piping. You'll see an example of this further down. The second benefit is that it handles at least one error condition in a type-safe manner. When trying to extract a sub-string from a string, the Substring method can throw an exception if the index or length arguments are out of range. This function checks whether it can extract the requested sub-string, and returns None if it can't.
I wouldn't be surprised if there are edge cases (for example involving negative integers) that trySubstring doesn't handle gracefully, but as you may have noticed, this is a function in a private module. I only need it to handle a particular use case, and it does that.
You can now add the tryParse function:
// string -> CprNumber option let tryParse (candidate : string ) = let (<*>) fo xo = fo |> Option.bind (fun f -> xo |> Option.map f) let canonicalized = candidate.Trim().Replace("-", "") let dayCandidate = canonicalized |> String.trySubstring 0 2 let monthCandidate = canonicalized |> String.trySubstring 2 2 let yearCandidate = canonicalized |> String.trySubstring 4 2 let sequenceNumberCandidate = canonicalized |> String.trySubstring 6 4 Some tryCreate <*> Option.bind Int.tryParse dayCandidate <*> Option.bind Int.tryParse monthCandidate <*> Option.bind Int.tryParse yearCandidate <*> Option.bind Int.tryParse sequenceNumberCandidate |> Option.bind id
The function starts by defining a private <*> operator. Readers of the applicative functor article series will recognise this as the 'apply' operator. The reason I added it as a private operator is that I don't need it anywhere else in the code base, and in F#, I'm always worried that if I add <*> at a more visible level, it could collide with other definitions of <*> - for example one for lists. This one particularly makes option an applicative functor.
The first step in parsing candidate is to remove surrounding white space and the interior dash.
The next step is to use String.trySubstring to pull out candidates for day, month, and so on. Each of these four are string option values.
All four of these must be Some values before we can even start to attempt to turn them into a CprNumber value. If only a single value is None, tryParse should return None as well.
You may want to re-read the article on the List applicative functor for a detailed explanation of how the <*> operator works. In tryParse, you have four option values, so you apply them all using four <*> operators. Since four values are being applied, you'll need a function that takes four curried input arguments of the appropriate types. In this case, all four are int option values, so for the first expression in the <*> chain, you'll need an option of a function that takes four int arguments.
Lo and behold! tryCreate takes four int arguments, so the only action you need to take is to make it an option by putting it in a Some case.
The only remaining hurdle is that tryCreate returns CprNumber option, and since you're already 'in' the option applicative functor, you now have a CprNumber option option. Fortunately, bind id is always the 'flattening' combo, so that's easily dealt with.
> let andreas = Cpr.tryParse " 0109636221";; val andreas : Cpr.CprNumber option = Some 010963-6221
Since you now have both a way to parse a string, and turn a CprNumber into a string, you can write the usual round-trip property:
[<Fact>] let ``CprNumber correctly round-trips`` () = Property.check <| property { let! expected = Gen.cprNumber let actual = expected |> string |> Cpr.tryParse Some expected =! actual }
This test uses Hedgehog, Unquote, and xUnit.net. The previous article demonstrates a way to test that Cpr.tryParse can handle mangled input.
Summary #
This article mostly exhibited various F# design techniques you can use to achieve an even better degree of encapsulation than you can easily get with object-oriented languages. Towards the end, you saw how using option as an applicative functor enables you to compose more complex optional values from smaller values. If just a single value is None, the entire expression becomes None, but if all values are Some values, the computation succeeds.
This article is an entry in the F# Advent Calendar in English 2018.
Next: The Lazy applicative functor.
Comments
Great post, a very good read! Interestingly enough we recently made an F# implementation for the swedish personal identification number. In fact v1.0.0 will be published any day now. Interesting to see how the problem with four-digit years are handled differently in Denmark and Sweden.
I really like the Between Active pattern of your solution, we did not really take as a generic approach, instead we modeled with types for Year, Month, Day, etc. But I find your solution to be very concise and clear. Also we worked with the Result type instead of Option to be able to provide the client with helpful error messages. For our Object Oriented friends we are also exposing a C#-friendly facade which adds a bit of boiler plate code.
Viktor, thank you for your kind words. The Result (or Either) type does, indeed, provide more information when things go wrong. This can be useful when client code needs to handle different error cases in different ways. Sometimes, it may also be useful, as you write, when you want to provide more helpful error messages.
Particularly when it comes to parsing or input validation, Either can be useful.
The main reason I chose to model with option in this article was that I wanted to demonstrate how to use the applicative nature of option, but I suppose I could have equally done so with Result.

Comments
Hi Mark,
aren't you loading more responsibilities on the
ReservationsController? Previously, it only had to delegate all the work toMaîtreDand return an appropriate result, now it additionally fetches reservations from the repository. You are also loading the handling of any errors the reservations repository might throw onto the controller, instead of handling them in theMaîtreDclass.You are also hard wiring a dependency on
MaîtreDinto theReservationsController; I thought one of the advantages of DI were to avoid newing up dependencies to concrete implementations outside of a centralized "builder class".Could you elaborate on these points? Thanks!
Ramon, thank you for writing. Am I loading more responsibilities on the Controller? Yes, I am. Too many? I don't think so.
To be fair, however, this example is unrealistically simplified (in order to make it easily understandable). There isn't much going on, overall, so one has to imagine that more things are happening than is actually the case. For instance, at the beginning of the example, so little is going on in the Controller that I think it'd be fair to ask why it's even necessary to distinguish between a Controller and a
MaîtreDclass.Usually, I'd say that the responsibility of a Controller object is to facilitate the translation of what goes on at the boundary of the application and what happens in the domain model. Using the terminology of the ports and adapters architecture, you could say that a Controller's responsibility is to serve as an Adapter between the technology-agnostic domain model and the technology-specific SDKs you'll need to bring into play to communicate with the 'real world'. Talking to databases fits that responsibility, I think.
The
MaîtreDclass didn't handle any database errors before, so I don't agree that I've moved that responsibility.When it comes to using a
MaîtreDobject from inside the Controller, I don't agree that I've 'hard-wired' it. It's not a dependency in the Dependency Injection sense; it's an implementation detail. Notice that it's aprivateclass field.Is it an 'advantage of DI' that you can "avoid newing up dependencies to concrete implementations outside of a centralized "builder class"?" How is that an advantage? Is that a goal?
In future articles, I'll discuss this sort of 'dependency elimination' in more details.
Mark, thanks for replying.
I assumed that some exception handling would be happening in the
MaitreDclass that would then migrate to theReservationsControllerand you left it out for the sake of simplicity. But granted, that can still happen inside the respository class.Let's imagine that for some reason, you want to write to the filesystem in addition to the database (eg. writing some reservation data like table number that can be printed and given to the customer). Following your reasoning, there would now be a reference to some
IReservationPrinterin the Controller. It suddenly has to hold references to all data exchange classes that it was previously unaware of, only caring about the resultMaîtreDwas returning.Maybe I didn't express myself properly: I thought Dependency Injection is a technique to resolve all implementation types at a single composition root. Of course this only applies to dependencies in the sense of DI, so where do you draw the line between implementation detail and dependency?
In any case I'm looking forward to reading more articles on this topic!
Ramon, in general when it comes to exception handling, you either handle exceptions at the source (i.e. in the Repository) or at the boundary of the application (which is typically done by frameworks already). I'm no fan of defensive coding.
Yes, but nowMaîtreDdoesn't have to do that. Is there anything inherently associated with business logic that stipulates that it handles data access?The following line of argument may be increasingly difficult to relate to as time moves forward, and business becomes increasingly digital, but there once was a time when business logic was paper-based. In paper-based organisations, data would flow through a business in the shape of paper; typically as forms. Data would arrive at the desk of a clerk or domain expert who would add more data or annotations to a form, and put it in his or her out-box for later collection.
My point is that I see nothing inherent in business logic to stipulate that business objects should be responsible for data retrieval or persistence. I recommend Domain Modeling Made Functional if you're interested in a comprehensive treatment of this way of looking at modelling business logic.
It is, and that still happens here. There are, however, fewer dependencies overall. I would argue that with the final design outlined here, the remaining dependency (IReservationsRepository) is also, architecturally, the only real dependency of the application. The initialIMaîtreDdependency is, in my opinion, an implementation detail. Exposing it as a dependency makes the code more brittle, and harder to refactor, but that's what I'm going to cover in future articles.Mark, I have to admit that I'm still not convinced (without having read the book you mentioned):
Expanding on your analogy, a clerk would maybe make a phone call or walk over to another desk if he needs more information regarding his current form (I know I do at my office). A maître d'hôtel would presumably open his book of reservations to check if he still has a table available and would write a new reservation in his book.
The
MaîtreDdoesn't need to know if the data it needs comes from the file system or a database or a web service (that's the responsibility of the repository class), all it cares about is that it needs some data. Currently, some other part of the system decides what dataMaîtreDhas to work with.Again, I didn't have a look at the reading recommendation yet. Maybe I should. ;)
I definitely agree with Mark that the business logic (in the final version of
MaîtreD.TryAccept) should be in a function that is pure and synchronous. However, I am also sympathetic to Ramon's argument.There are two UIs for the application that I am currently building at work. The primary interface is over HTTP and uses web controllers just like in Mark's example. The second interface is a CLI (that is only accessable to administrators with phsyical access to the server). Suppose my application was also an on-line restaurant reservation system and that a reservation could be made with both UIs.
Looking back at the final implementation of
ReservationsController.Post, the first three lines are independent ofControllerBaseand would also need to be executed when accessing the system though the CLI. My understanding is that Ramon's primary suggestion is to move these three lines intoMaîtreD.TryAccept. I am sympathetic to Ramon's argument in that I am in favor of extracting those three lines. However, I don't want them to be colocated with the final implimentatiion ofMaîtreD.TryAccept.In my mind, the single responsibility of
ReservationsController.Postis to translate the result of the reseravation request into the expected type of response. That would be just the fourth line in the final implementation of this method. In terms of naming, I like Ramon's suggestion that the first three lines ofReservationsController.Postbe moved toMaîtreD.TryAccept. But then I also want to move the final implementation ofMaîtreD.TryAcceptto a method on a different type. As we all know, naming is an impossible problem, so I don't have a good name for this new third type.What do you think Ramon? Have I understood your concerns and suggested something that you could get behind?
What about you Mark? You said that there was
Would two UIs be sufficient motivation in your eyes to justify distinguishing between a Controller and aMaîtreDclass?Tyson, thank you for joining the discussion. By adding a particular problem (more than one user interface) to be addressed, you make the discussion more specific. I think this helps to clarify some issues.
Ramon wrote:
That's okay; you don't have to be. I rarely write articles with the explicit intent of telling people that they must do something, or that they should never do something else. While it does happen, this article isn't such an article. If it helps you address a problem, then take what you find useful. If it doesn't, then ignore it.With Tyson's help, though, we can now discuss something more concrete. I think some of those observations identify a tender spot in my line of argument. In the initial version of
ReservationsController, the only responsibility of thePostmethod was to translate from and to HTTP. That's a distinct separation of responsibility, so clearly preferable.When I add the
Repositorydependency, I widen the scope of theReservationsController's responsibility, which now includes 'all IO'. This does blur the demarcation of responsibility, but often still works out well in practice, I find. Still, it depends on how much other stuff is going on related to IO. If you have too much IO going on, another separation of responsibilities is in order.I do find, however, that when implementing the same sort of software capability in different user interfaces, I need to specifically design for each user interface paradigm. A web-based user interface is quite different from a command-line interface, which is again different from a native application, or a voice-based interface, and so on. A web-based interface is, for example, stateless, whereas a native smart phone application would often be stateful. You can rarely reuse the 'user interface controller layer' for one type of application in a different type of application.
Even a command-line interface could be stateful by interactively asking a series of questions. That's such a different user interface paradigm that an object designed for one type of interaction is rarely reusable in another context.
What I do find is that fine-grained building blocks still compose. When
Indeed, but how do you model this in software? A program doesn't have the degree of ad-hoc flexibility that people have. It can't just arbitrarily decide to make a phone call if it doesn't have a 'phone' dependency. Even when using Dependency Injection, you'll have to add that dependency to a business object. You'll have to explicitly write code to give it that capability, and even so, an injected dependency doesn't magically imbue a business object with the capability to make 'ad-hoc phone calls'. A dependency comes with specific methods you can call in order to answer specific questions.TryAcceptis a pure function, it's always composable. This means that my chance of being able to reuse it becomes much higher than if it's an object injected with various dependencies.Once you're adding code that enables an object to ask specific questions, you might as well just answer those questions up-front and pass the answer as method arguments. That's what this article's refactoring does. It knows that the
That's a brilliant observation! This just once again demonstrates what Evans wrote in DDD, that insight about the domain arrive piecemeal. A maître d'hôtel clearly doesn't depend on any repository, but rather on the book of reservations. You can add that as a dependency, or pass it as a method argument. I'd lean toward doing the latter, because I'd tend to view a book as a piece of data.MaîtreDobject is going to ask about the existing reservations for the requested date, so it just passes that information as part of an 'execution context'.Ultimately, if we are to take the idea of inversion of control seriously, we should, well, invert control. When we inject dependencies, we let the object with those dependencies control its interactions with them. Granted, those interactions are now polymorphic, but control isn't inverted.
If you truly want to invert control, then load data, pass it to functions, and persist the return values. In that way, functions have no control of where data comes from, or what happens to it afterwards. This keeps a software design supple.
Hi Mark, Thanks for your post, I think it's very valuable.
In the past, I had a situation when I was a junior software developer and just started working on a small, internal web application (ASP.NET MVC) to support HR processes in our company. At the time, I was discovering blogs like yours, or fsharpforfunandprofit.com and was especially fond of the sandwich architecture. I was preparing to refactor one of the controllers just like your example in this post (Controller retrieving necessary data from the repository, passing it to the pure business logic, then wrapping the results in a request). Unfortunately, My more experienced colleague said that it's a "fat controller antipattern" and that the controller can have only one line of code - redirecting the request to the proper business logic method. I wanted to explain to him that he is wrong, but couldn't find proper arguments, or examples.
Now I have them. This post is great for this particular purpose.
I guess it comes down to the amount of responsibilities the controller should have.
Marek named the fat controller antipattern. I remember reading about some years ago and it stuck, that's why I usually model my controllers to delegate the request to a worker class, maybe map a return value to a transfer object and wrap it all in some
ActionResult. I can relate to the argument that all I/O should happen at the boundaries of the system, though I'm not seeing it on the controller's responsibility list, all the more so when I/O exceeds a simple database call.I think that is what I was aiming for. The third type that Tyson is looking a name for could then be some kind of thin Data Access Layer, serving as a façade to encapsulate all calls to I/O, that can be injected into the
MaîtreDclass.Isn't code flexibility usually modeled using conditionals? Assume we are a very important guest and our maître d'hôtel really wishes to make a reservation for us, but all tables are taken. He could decide to phone all currently known guests to ask for a confirmation, if some guest cannot make it, he could give the table to us.
Using the initial version of
TryAccept, it would lead to something like this:public async Task<int?> TryAccept(Reservation reservation) { if(await CheckTableAvailability(reservation)) { reservation.IsAccepted = true; return await Repository.Create(reservation); } else { return null; } } private async Task<bool> CheckTableAvailability(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); int reservedSeats = reservations.Sum(r => r.Quantity); if(Capacity < reservedSeats + reservation.Quantity) { foreach(var r in reservations) { if(!(await Telephone.AskConfirmation(r.Guest.PhoneNumber))) { //some guest cannot make it for his reservation return true; } } //all guests have confirmed their reservation - no table for us return false; } return true; }That is assuming that
MaîtreDhas a dependency on both the Repository and a Telephone. Not the best code I've ever written, but it serves its purpose. If the dependency onReservationis taken out of theMaîtreD, so could the dependency onTelephone. But then, you are deciding beforehand in the controller thatMaîtreDmight need to make a telephone call - that's business logic in the controller class and a weaker separation of concerns.And this is where I tend to disagree. The book of reservations in my eyes is owned and preciously guarded by the maître d'hôtel. Imagine some lowly garçon scribbling reservations in it. Unbelievable! Joking aside, the reservations in the book are pieces of data, no doubt about that - but I'd see the whole book as a resource owned by le maître and only him being able to request data from it. Of course, this depends on the model of the restaurant that I have in my mind, it might very well be different from yours - we didn't talk about a common model beforehand.
Apparently, I answered my own question when I moved the table availability check into its own private method. This way, a new dependency
TableAvailabilityCheckercan handle the availability check (complete with reservations book and phone calls), acting as a common data access layer.I have created a repository, where I tried to follow the steps outlined in this blog post with the new dependency. After all refactorings the controller looks like this:
public class ReservationsController : ControllerBase { private readonly MaitreD _maitreD; public ReservationsController(int capacity, IReservationsRepository repository, ITelephone telephone) { _maitreD = new MaitreD(capacity); Repository = repository; Telephone = telephone; } public IReservationsRepository Repository { get; } public ITelephone Telephone { get; } public async Task Post(Reservation reservation)
{
Reservation[] currentReservations = await Repository.ReadReservations(reservation.Date);
var confirmationCalls = currentReservations.Select(cr => Telephone.AskConfirmation(cr.Guest.PhoneNumber));
return _maitreD.CheckTableAvailability(currentReservations, reservation)
.Match(
some: r => new Maybe(r),
none: _maitreD.AskConfirmation(await Task.WhenAll(confirmationCalls), reservation)
)
.Match(
some: r => Ok(Repository.Create(_maitreD.Accept(r))),
none: new ContentResult { Content = "Table unavailable", StatusCode = StatusCodes.Status500InternalServerError } as ActionResult
);
}
}
During the refactorings, I was able to remove the
TableAvailabilityCheckeragain; I'm quite happy that the maître d'hôtel is checking the table availability and asking for the confirmations with the resources that are given to him. I'm not so happy with theTask.WhenAll()part, but I don't know how to make this more readable and at the same time make the calls only if we need them.All in all, I now think a bit differently about the controller responsibilities: Being at the boundary of the system, it is arguably the best place to make calls to external systems. If and how the information gathered from the outside is used however is still up to the business objects. Thanks, Mark, for the insight!
Thanks for writing this article. Doesn't testability suffer from turning the Maître d into an implementation detail of the ReservationsController? Now, we not only have to test for the controller's specific responsibilities but also for the behaviour that is implemented by the Maître d. Previously we could have provided an appropriate test double when instantiating the controller, knowing that the Maître d is tested and working. The resulting test classes would be more specific and focused. Is this a trade-off you made in favour of bringing the article's point across?
Max, thank you for writing. I don't think that testability suffers; on the contrary, I think that it improves. Once the
MaîtreDclass becomes deterministic, you no longer have to hide it behind a Test Double in order to be able to control its behaviour. You can control its behaviour simply by making sure that it receives the appropriate input arguments.The Facade Tests that cover
ReservationsControllerin the repository are, in my opinion, readable and maintainable.I've started a new article series about this topic, since I knew it'd come up. I hope that these articles will help illustrate my position.
Hi, Mark! Thank you for this blog post.
I really like the way of composing effectful and pure code the post explains. But here are some things I keep wondering about.
1) Is it correct that — given this approach — pure code cannot call back into impure code. When I say call back I mean it in a general way: maybe invoking a lambda passed as an argument to a function, maybe invoking a method on an injected dependency — basically the specific mechanics of calling back are irrelevant in this case.
2) In case point 1) is actually correct, have you ever had in your practice a task where the "ban" on callbacks was too limiting/impractical?
To give a more specific example of scenarios I have in mind, let's get back to
MaitreDfor a second. Let's imagine the amount of reservations data grew too big to load all at once. As a resultMaitreDneeds an instance ofReservationRepositoryso it can first run some business logic and based on the outcome read only a small specific subset of reservations from the repository.Or let's take a look at another imaginary scenario. Before confirming a reservation
MaitreDmust make a call to an external payment service to block a certain sum of money on the customer's card.These are only quick examples off the top of my head. Maybe dealing with them is easy, I would still be really grateful if you could give a couple of scenarios where you found it hard or impractical to do without "callbacks" and if and how you eventually manage to overcome the complications.
Mykola, thank you for writing. Yes, it's correct that a pure function can't call an impure function. This means, among other things, that you can't use Dependency Injection in functional programming.
Is that rule impractical? It depends on the programming language. In Haskell, that rule is enforced by the compiler. You can't break that rule, but the language is also designed in such a way that there's plenty of better ways to do things. In Haskell, that rule isn't impractical.
In a language like F#, that rule is no longer enforced, and there's also fewer built-in alternatives. The general solution to the problem is to use a free monad, but while it's possible to use free monads in F#, it's not as idiomatic, and there's a compelling argument to be made that going with partial application as Dependency Injection is more practical.
It's also possible to employ free monads in C#, but it's really non-idiomatic and hard to understand.
Haskell has some other general-purpose solutions (e.g. the so-called mtl style), but the only type of architecture I'm aware of that translates to F# or C# is free monads.
Does this mean that the ideas of this article is impractical for real software?
I don't think so. Let's consider your examples:
That's a frequently asked question, but in reality, I have a hard time imagining that. How much data is a reservation? It's a date (8 bytes), a quantity (in reality, a single byte is enough to keep track of that), as well as a name and an email address. Let's assume that an email address is, on average, shorter than 30 characters, and a name is shorter than 50 characters. We'll assume that we save both strings in UTF-8. Most characters are probably still just going to be 1 byte, but let's be generous and assume 2 bytes per character. That's 169 bytes per reservation, but let's be even more generous and say 200 bytes per reservation.What if we load 1,000 reservations? That's 200 kilobytes of memory. 10,000 reservations is 2 megabytes. That's about the size of an average web page. Is that too much data?
We routinely load web pages over the internet, and none but the Australians complain about the size.
My point is that I find it incredulous to claim that it'd be too much data if you need to load a couple of hundred of reservations in one go.
I can definitely imagine scenarios where you'd like to load reservations not only for the date in question, but also for surrounding dates. Even for a medium-sized restaurant, that's unlikely to be more than a few hundred, or perhaps a few thousand of reservations. That's not a lot of data. Most pictures on the WWW are bigger.
Just speculatively load extra data in one go. It's going to make your code much simpler, and is unlikely to affect performance if you're being smart about it. You can even consider to cache that data...
When it comes to your other question, I'll refer to a catch-phrase from the early days of large-scale web commerce (Pat Helland): take the money.
Don't make payment a blocking call. As soon as you have enough information to execute a purchase, kick it off as an asynchronous background job.
If a restaurant has that type of workflow that requires reservation of an amount on a credit card, you turn the business process into an asynchronous workflow. On the UI side, you make sure to reflect the current state of the system so that users don't try to reserve on dates that you already know are sold out. I show such a workflow in my functional architecture with F# Pluralsight course.
When a user makes a reservation, you take the reservation data and put it on a queue, and tell the user that you're working on it.
A background job receives the queued message and decides whether or not to accept the reservation. If it decides to accept it, it creates two other messages: one to reserve the money, and another a timeout.
Another background job receives the message to reserve the money on the credit card and attempts to do that. Once that's over, it reports success or failure by putting another message on a queue.
The reservation system receives the asynchronous message about the credit card and either commits or cancels the reservation. If it never gets such a message, the timeout message will eventually trigger a cancellation.
Each message handler can use the impure-pure-impure sandwich pattern, and in that way keep the business logic pure.
In my experience, you can often address issues like the ones you bring up by selecting an application architecture that best addresses those particular concerns. That'll make the implementation code simpler.
In fact, I'm often struggling to come up with an example scenario where something like a free monad would be necessary, because I always think to myself: Why would I do it that way? I'd just architect my application in this other way, and then the problem will go away by itself.
Hi Mark, I was just wondering - why is the controller asking its clients for a capacity, when it only uses it to imediately create a MaitreD? Should it not ask for the MaitreD in the first place, instead of sneakily conjuring it up in the constructor?
It feels like the controller owns the MaitreD, but the MaitreD represents pure and deterministic behaviour set up by its "capacity" dependency - and the capacity is only injected into the controller. So should it really be private?
Can't we just ask for the MaitreD, leave it public, forget about the "implementation detail" of a capacity, and be done with it?
Thanks!
votroto, thank you for writing. Injecting a concrete dependency is definitely an option. I'm currently working on a larger example code base that also has a
MaitreDclass, and in that code base I decided to inject that into the Controller instead of its constituent elements.It's a trade-off; I don't see one option as more correct than the other. In the present article, the
MaîtreDclass is so simple that it only has a single dependency:capacity. In this case, it's a toss-up. Either you injectcapacity, or you inject the entireMaîtreDclass. In both cases, you have a single dependency in addition to thatIReservationsRepositorydependency. In this situation, I chose to follow the principle of least knowledge. By injecting only thecapacity, theMaîtreDclass is an implementation detail not exposed to the rest of the world.In the larger example code base that I'm currently working on, the
MaitreDclass is more complex: it has several configuration values that determine its behaviour. If I wanted to keep theMaitreDclass an implementation detail, the Controller constructor would look like this:I don't think that this addresses any real concerns. If I ever decide to change the
MaitreDconstructor, I'd have to also change theReservationsControllerconstructor. Thus, whileReservationsControllermight not 'formally' depend onMaitreD, it still does so in practice. In that case I chose to injectMaitreDinstead:Don't read the above as an argument for one option over the other. I'm only trying to explain the deliberations I go through to arrive at a decision, one way or the other.