ploeh blog danish software design
Church encoding
Church encoding is a unified way to model data and functions. An introduction for object-oriented developers.
This article series is part of an even larger series of articles about the relationship between design patterns and category theory.
When asked why I like functional programming so much, I often emphasise the superior modelling ability that I get from algebraic data types. Particularly, languages like F# and Haskell have sum types in addition to the product types that most statically typed languages seem to have.
In short, a sum type gives you the ability to declare, as part of the type system, that a particular data type must be exactly one of a finite list of mutually exclusive options. This differs from common object-oriented sub-typing because class inheritance or interface implementation offers conceptually infinite extensibility. Sometimes, unconstrained extensibility is exactly what you need, but in other cases, the ability to define a closed set of cases can be an effective modelling tool. If you need an easy-to-read introduction to algebraic data types, I recommend Tomas Petricek's fine article Power of mathematics: Reasoning about functional types.
Interestingly, TypeScript has sum types, so they don't have to belong exclusively in the realm of functional programming. In this article series, you'll see an alternative way to represent sum types in C# using Church encoding.
Lambda calculus #
In the 1930s, several mathematicians were investigating the foundations of mathematics. One of them, Alonzo Church, developed lambda calculus as a universal model of computation. In a sense, you can think of lambda calculus as a sort of hypothetical programming language, although it was never designed to be a practical programming language. Even so, you can learn a lot from it.
In the untyped lambda calculus, the only primitive data type is a function. There are no primitive numbers, Boolean values, branching instructions, loops, or anything else you'd normally consider as parts of a programming language. Instead, there's only functions, written as lambda expressions:
λf.λx.f x
This looks opaque and mathematical, but most modern programmers should be familiar with lambda (λ) expressions. The above expression is an anonymous function that takes a single argument: f. The body of the function is the return value; here, another lambda expression: λx.f x. This lambda expression also takes a single argument: x.
In the untyped lambda calculus, everything is a function, so that includes f and x. The return value of the entire expression is f x, which means that the function f is applied to the value (in fact: function) x. The entire expression is therefore a higher-order function.
In C#, the corresponding lambda expression would be:
f => x => f(x)
This is a lambda expression that returns another lambda expression, which again returns the result of calling the function f with the value x.
In F#, it would be:
fun f -> fun x -> f x
and in Haskell, it would be:
\f -> \x -> f x
In both Haskell and F#, functions are already curried, so you can shorten that Haskell lambda expression to:
\f x -> f x
and the F# lambda expression to:
fun f x -> f x
This looks more like a function that takes two arguments, so alternatively, via uncurry isomorphisms, you can also write the C# representation like this:
(f, x) => f(x)
Those six lambda expressions, however, are statically typed, even though they're generic (or, as Haskellers would put it, parametric polymorphic). This means that they're not entirely equal to λf.λx.f x, but it should give you a sense of what a lambda expression is.
It turns out that using nothing but lambda expressions, one can express any computation; lambda calculus is Turing-complete.
Church encoding #
Since languages like C#, F#, Haskell, and others, include lambda expressions, you can reproduce as much of the lambda calculus as you'd like. In this article series, I'll mainly use it to show you how to represent sum types in C#. Later, you'll see how it relates to design patterns.
- Church-encoded Boolean values
- Church-encoded natural numbers
- Church-encoded Maybe
- Church-encoded Either
- Church-encoded payment types
- Church-encoded rose tree
These articles give you examples in C#. For Haskell examples, I found Travis Whitaker's article Scrap Your Constructors: Church Encoding Algebraic Types useful.
All C# code for these articles is available on GitHub.
Summary #
You can use lambda expressions to define all sorts of data types and computations. Because lambda calculus is a universal model of computation, you can learn about fundamental representations of computation. Particularly, lambda calculus offers a model of logical branching, which again teaches us how to model sum types.
Composite as a monoid - a business rules example
Composites are monoids. An example in C#, F#, and Haskell.
Towards the end of the first decade of the third millennium, I'd been writing object-oriented code for about ten years, and I'd started to notice some patterns in my code. I'd read Design Patterns 6-7 years earlier, but I noticed that I tended to use only a small subset of the patterns from the book - particularly Composite, Decorator, Chain of Responsibility, and a few others.
In particular, I noticed that modelling seemed to be easier, and the code better structured, when I could apply the Composite design pattern. It was also clear, however, that I couldn't always use the Composite pattern, so I started to speculate on what could be the distinguishing factors. In 2010, I made a first attempt at identifying when a Composite is possible, and when it isn't. Unfortunately, while it was a fine attempt (which I'll return to later), it didn't lead anywhere. Ultimately, I gave up on the subject and moved on to other things.
A revelation #
One of my interests in the next decade became functional programming. One day in late 2016 I came across this Code Review question by Scott Nimrod. It was an solution to the Business Rules kata, which, briefly told, is about implementing changing business rules in a sustainable manner.
In my answer to the question, I gave an outline (repeated below) of how I would address the problem in F#. As a comment to my answer, Scott wrote:
"Feels like the Decorator Pattern..."
I responded,
"Not really; it's the Composite pattern..."
A few days later, as I was doing something else, it suddenly dawned on me that not only was a few lines of F# code equivalent to the Composite design pattern, but those lines of code were also manifestations of fundamental abstractions from category theory. Originally, I thought Composite was a combination of applicative functors and monoids, but as I investigated, I discovered that Composites are simply monoids.
This article shows a concrete example of that discovery, starting with my original F# code, subsequently translating it to C# to demonstrate that it's a Composite, and concluding with a translation to Haskell in order to demonstrate that it all fits with the formalisation of Monoid there.
Original F# solution outline #
The kata is about modelling volatile business rules in a sustainable manner. Particularly, you must implement various business rules associated with payments for products and services. Making a rough outline of a model, I started by introducing some types in F#:
type Membership = Basic | Gold type Good = | PhysicalProduct of string | Book of string | Video of string | Membership of Membership | Upgrade type Command = | Slip of string * (Good list) | Activate of Membership | Upgrade | PayAgent
This basically states that there's a closed hierarchy of goods, and a closed hierarchy of business commands, as well as a Membership enumeration. A good can be a physical product with a name, a book with a name, a membership or upgrade, and so on. A command can be a packing slip, a membership activation, and so on.
Since I was only interested in a rough outline of a solution, I only sketched four business rules, all implemented as functions. The first creates a packing slip for certain goods:
// Good -> Command list let slipForShipping = function | PhysicalProduct name -> [Slip ("Shipping", [PhysicalProduct name])] | Book name -> [Slip ("Shipping", [Book name])] | Video name -> [Slip ("Shipping", [Video name])] | _ -> []
This function takes a Good value as input and returns a list of Command values as output. If the Good is a PhysicalProduct, Book, or Video, it returns a packing slip command; otherwise, it returns an empty list of commands.
The next business rule is a similar function:
// Good -> Command list let slipForRoyalty = function | Book name -> [Slip ("Royalty", [Book name])] | _ -> []
This business rule generates a royalty slip for any Book, but does nothing for any other Good.
The third business rule activates a membership:
// Good -> Command list let activate = function | Membership x -> [Activate x] | _ -> []
If the Good is a Membership, the activate function returns a list containing a single Activate command; otherwise, it returns an empty list.
Finally, the last rule upgrades a membership:
// Good -> Command list let upgrade = function | Good.Upgrade -> [Upgrade] | _ -> []
Similar to the previous functions, this one looks at the type of Good, and returns an Upgrade command when the input is an Upgrade good, and an empty list otherwise.
Notice that all four functions share the same type: Good -> Command list. I designed them like that on purpose, because this enables you to compose a list of business rules to a function that looks like a single rule:
// ('a -> 'b list) list -> 'a -> 'b list let handle rules good = List.collect (fun r -> r good) rules
This handle function takes a list of business rules (rules) and returns a new function with the type Good -> Command list (or, actually, a function with the type 'a -> 'b list - once again I've fallen into the trap of using too descriptive names). Notice that this is the same type as the individual rules.
You can now compose the four specific business rules:
// Good -> Command list let handleAll = handle [slipForShipping; slipForRoyalty; activate; upgrade]
This function also has the type Good -> Command list although it's a composition of four rules.
You can use it like this F# Interactive example:
> handleAll (Book "The Annotated Turing");;
val it : Command list =
[Slip ("Shipping",[Book "The Annotated Turing"]);
Slip ("Royalty",[Book "The Annotated Turing"])]
(Yes, I like The Annotated Turing - read my review on Goodreads.)
Notice that while each of the business rules produces only zero or one Command values, in this example handleAll returns two Command values.
This design, where a composition looks like the things it composes, sounds familiar.
Business rules in C# #
You can translate the above F# model to an object-oriented model in C#. Translating discriminated unions like Good and Command to C# always involves compromises. In order to keep the example as simple as possible, I decided to translate each of those to a marker interface, although I loathe that 'pattern':
public interface IGood { }
While the interface doesn't afford any behaviour, various classes can still implement it, like, for example, Book:
public class Book : IGood { public Book(string name) { Name = name; } public string Name { get; } }
Other IGood 'implementations' looks similar, and there's a comparable class hierarchy for ICommand, which is another marker interface.
The above F# code used a shared function type of Good -> Command list as a polymorphic type for a business rule. You can translate that to a C# interface:
public interface IRule { IReadOnlyCollection<ICommand> Handle(IGood good); }
The above slipForShipping function becomes a class that implements the IRule interface:
public class SlipForShippingRule : IRule { public IReadOnlyCollection<ICommand> Handle(IGood good) { if (good is PhysicalProduct || good is Book || good is Video) return new[] { new SlipCommand("Shipping", good) }; return new ICommand[0]; } }
Instead of pattern matching on a discriminated union, the Handle method examines the subtype of good and only returns a SlipCommand if the good is either a PhysicalProduct, a Book, or a Video.
The other implementations are similar, so I'm not going to show all of them, but here's one more:
public class ActivateRule : IRule { public IReadOnlyCollection<ICommand> Handle(IGood good) { var m = good as MembershipGood; if (m != null) return new[] { new ActivateCommand(m.Membership) }; return new ICommand[0]; } }
Since 'all' members of IRule return collections, which form monoids over concatenation, the interface itself gives rise to a monoid. This means that you can create a Composite:
public class CompositeRule : IRule { private readonly IRule[] rules; public CompositeRule(params IRule[] rules) { this.rules = rules; } public IReadOnlyCollection<ICommand> Handle(IGood good) { var commands = new List<ICommand>(); foreach (var rule in rules) commands.AddRange(rule.Handle(good)); return commands; } }
Notice how the implementation of Handle follows the template for monoid accumulation. It starts with the identity, which, for the collection concatenation monoid is the empty collection. It then loops through all the composed rules and updates the accumulator commands in each iteration. Here, I used AddRange, which mutates commands instead of returning a new value, but the result is the same. Finally, the method returns the accumulator.
You can now compose all the business rules and use the composition as though it was a single object:
var rule = new CompositeRule( new SlipForShippingRule(), new SlipForRoyaltyRule(), new ActivateRule(), new UpgradeRule()); var book = new Book("The Annotated Turing"); var commands = rule.Handle(book);
When the method returns, commands contains two SlipCommand objects - a packing slip, and a royalty slip.
Business rules in Haskell #
You can also port the F# code to Haskell, which is usually easy as long as the F# is written in a 'functional style'. Since Haskell has an explicit notion of monoids, you'll be able to see how the two above solutions are monoidal.
The data types are easy to translate to Haskell - you only have to adjust the syntax a bit:
data Membership = Basic | Gold deriving (Show, Eq, Enum, Bounded) data Good = PhysicalProduct String | Book String | Video String | Membership Membership | UpgradeGood deriving (Show, Eq) data Command = Slip String [Good] | Activate Membership | Upgrade | PayAgent deriving (Show, Eq)
The business rule functions are also easy to translate:
slipForShipping :: Good -> [Command] slipForShipping pp@(PhysicalProduct _) = [Slip "Shipping" [pp]] slipForShipping b@(Book _) = [Slip "Shipping" [b]] slipForShipping v@(Video _) = [Slip "Shipping" [v]] slipForShipping _ = [] slipForRoyalty :: Good -> [Command] slipForRoyalty b@(Book _) = [Slip "Royalty" [b]] slipForRoyalty _ = [] activate :: Good -> [Command] activate (Membership m) = [Activate m] activate _ = [] upgrade :: Good -> [Command] upgrade (UpgradeGood) = [Upgrade] upgrade _ = []
Notice that all four business rules share the same type: Good -> [Command]. This is conceptually the same type as in the F# code; instead of writing Command list, which is the F# syntax, the Haskell syntax for a list of Command values is [Command].
All those functions are monoids because their return types form a monoid, so in Haskell, you can compose them without further ado:
handleAll :: Good -> [Command] handleAll = mconcat [slipForShipping, slipForRoyalty, activate, upgrade]
mconcat is a built-in function that aggregates any list of monoidal values to a single value:
mconcat :: Monoid a => [a] -> a
Since all four functions are monoids, this just works out of the box. A Composite is just a monoid. Here's an example of using handleAll from GHCi:
*BusinessRules> handleAll $ Book "The Annotated Turing" [Slip "Shipping" [Book "The Annotated Turing"],Slip "Royalty" [Book "The Annotated Turing"]]
The result is as you'd come to expect.
Notice that not only don't you have to write a CompositeRule class, you don't even have to write a handle helper function. Haskell already understands monoids, so composition happens automatically.
If you prefer, you could even skip the handle function too:
*BusinessRules> mconcat [slipForShipping, slipForRoyalty, activate, upgrade] $ Book "Blindsight" [Slip "Shipping" [Book "Blindsight"],Slip "Royalty" [Book "Blindsight"]]
(Yes, you should also read Blindsight.)
It's not that composition as such is built into Haskell, but rather that the language is designed around a powerful ability to model abstractions, and one of the built-in abstractions just happens to be monoids. You could argue, however, that many of Haskell's fundamental abstractions are built from category theory, and one of the fundamental characteristics of a category is how morphisms compose.
Summary #
Composite are monoids. This article shows an example, starting with a solution in F#. You can translate the F# code to object-oriented C# and model the composition of business rules as a Composite. You can also translate the F# code 'the other way', to the strictly functional language Haskell, and thereby demonstrate that the solution is based on a monoid.
This article is a repost of a guest post on the NDC blog, reproduced here with kind permission.
Project Arbitraries with view patterns
Write expressive property-based test with QuickCheck and view patterns.
Recently, I was writing some QuickCheck-based tests of some business logic, and since the business logic in question involved a custom domain type called Reservation, I had to write an Arbitrary instance for it. Being a dutiful Haskell programmer, I wrapped it in a newtype in order to prevent warnings about orphaned instances:
newtype ArbReservation = ArbReservation { getReservation :: Reservation } deriving (Show, Eq) instance Arbitrary ArbReservation where arbitrary = do (d, e, n, Positive q, b) <- arbitrary return $ ArbReservation $ Reservation d e n q b
This is all fine as long as you just need one Reservation in a test, because in that case, you can simply pattern-match it out of ArbReservation:
testProperty "tryAccept reservation in the past" $ \ (Positive capacity) (ArbReservation reservation) -> let stub (IsReservationInFuture _ next) = next False stub (ReadReservations _ next) = next [] stub (Create _ next) = next 0 actual = iter stub $ runMaybeT $ tryAccept capacity reservation in isNothing actual
Here, reservation is a Reservation value because it was pattern-matched out of ArbReservation reservation. That's just like capacity is an Int, because it was pattern-matched out of Positive capacity.
Incidentally, in the spirit of the previous article, I'm here using in-lined properties implemented as lambda expressions. The lambda expressions use non-idiomatic formatting in order to make the tests more readable (and to prevent horizontal scrolling), but the gist of the matter is that the entire expression has the type Positive Int -> ArbReservation -> Bool. This is a Testable property because all the input types have Arbitrary instances.
Discommodity creeps in #
That's fine for that test case, but for the next, I needed not only a single Reservation value, but also a list of Reservation values. Again, with QuickCheck, you can't write a property with a type like Positive Int -> [Reservation] -> ArbReservation -> Bool, because there's no Arbitrary instance for [Reservation]. Instead, you'll need a property with the type Positive Int -> [ArbReservation] -> ArbReservation -> Bool.
One way to do that is to write the property like this:
testProperty "tryAccept reservation when capacity is insufficient" $ \ (Positive i) reservations (ArbReservation reservation) -> let stub (IsReservationInFuture _ next) = next True stub (ReadReservations _ next) = next $ getReservation <$> reservations stub (Create _ next) = next 0 reservedSeats = sum $ reservationQuantity <$> getReservation <$> reservations capacity = reservedSeats + reservationQuantity reservation - i actual = iter stub $ runMaybeT $ tryAccept capacity reservation in isNothing actual
Here, reservations has type [ArbReservation], so every time the test needs to operate on the values, it first has to pull the Reservation values out of it using getReservation <$> reservations. That seems unnecessarily verbose and repetitive, so it'd be nice if a better option was available.
View pattern #
Had I been writing F# code, I'd immediately be reaching for an active pattern, but this is Haskell. If there's one thing, though, I've learned about Haskell so far, it's that, if F# can do something, there's a very good chance Haskell can do it too - only, it may be called something else.
With a vague sense that I'd seen something similar in some Haskell code somewhere, I went looking, and about fifteen minutes later I'd found what I was looking for: a little language extension called view patterns. Just add the language extension to the top of the file where you want to use it:
{-# LANGUAGE ViewPatterns #-}
You can now change the property to pattern-match reservations out of a function call, so to speak:
testProperty "tryAccept reservation when capacity is insufficient" $ \ (Positive i) (fmap getReservation -> reservations) (ArbReservation reservation) -> let stub (IsReservationInFuture _ next) = next True stub (ReadReservations _ next) = next reservations stub (Create _ next) = next 0 reservedSeats = sum $ reservationQuantity <$> reservations capacity = reservedSeats + reservationQuantity reservation - i actual = iter stub $ runMaybeT $ tryAccept capacity reservation in isNothing actual
The function getReservation has the type ArbReservation -> Reservation, so fmap getReservation is a partially applied function with the type [ArbReservation] -> [Reservation]. In order to be able to call the overall lambda expression, the caller must supply an [ArbReservation] value to the view pattern, which means that the type of that argument must be [ArbReservation]. The view pattern then immediately unpacks the result of the function and gives you reservations, which is the return value of calling fmap getReservation with the input value(s). Thus, reservations has the type [Reservation].
The type of the entire property is now Positive Int -> [ArbReservation] -> ArbReservation -> Bool.
This removes some noise from the body of the property, so I find that this is a useful trick in this particular situation.
Summary #
You can use the view patterns GHC language extension when you need to write a function that takes an argument of a particular type, but you never care about the original input, but instead immediately wish to project it to a different value.
I haven't had much use for it before, but it seems to be useful in the context of QuickCheck properties.
Comments
I've seen folks wrap up the view pattern in a pattern synonym:
pattern ArbReservations :: [Reservation] -> [ArbReservation]
pattern ArbReservations rs <- (coerce -> rs) where ArbReservations rs = coerce rs
foo :: [ArbReservation] -> IO ()
foo (ArbReservations rs) = traverse print rs
(coerce is usually more efficient than fmap.)
OTOH I don't think orphan instances of Arbitrary are very harmful. It's unlikely that they'll get accidentally imported or overlap, because Arbitrary is purely used for testing. So in this specific case I'd probably just stick with an orphan instance and turn off the warning for that file.
Benjamin, thank you for the pattern synonyms tip; I'll have to try that next time.
Regarding orphaned instances, your point is something I've been considering myself, but I'm still at the point of my Haskell journey where I'm trying to understand the subtleties of the ecosystem, so I wasn't sure whether or not it'd be a good idea to allow orphaned Arbitrary instances.
When you suggest turning off the warning for a file, do you mean adding an {-# OPTIONS_GHC -fno-warn-orphans #-} pragma, or did you have some other method in mind?
Yep I meant OPTIONS_GHC.
Orphan instances are problematic because of the possibility that they'll be imported unintentionally or overlap with another orphan instance. If you import two modules which both define orphan instances for the same type then there's no way for GHC to know which one you meant when you attempt to use them. Since instances aren't named you can't even specify it manually, and the compiler can't check for this scenario ahead of time because of separate compilation. (Non-orphans are guaranteed unique by the fact that you can't import the parent type/class without importing the instance.)
In the case of Arbitrary these problems typically don't apply because the class is intended to be used for testing. Arbitrary instances are usually internal to your test project and not exported, so the potential for damage is small.
Benjamin, thank you for elaborating. That all makes sense to me.
Inlined HUnit test lists
An alternative way to organise tests lists with HUnit.
In the previous article you saw how to write parametrised test with HUnit. While the tests themselves were elegant and readable (in my opinion), the composition of test lists left something to be desired. This article offers a different way to organise test lists.
Duplication #
The main problem is one of duplication. Consider the main function for the test library, as defined in the previous article:
main = defaultMain $ hUnitTestToTests $ TestList [ "adjustToBusinessHours returns correct result" ~: adjustToBusinessHoursReturnsCorrectResult, "adjustToDutchBankDay returns correct result" ~: adjustToDutchBankDayReturnsCorrectResult, "Composed adjust returns correct result" ~: composedAdjustReturnsCorrectResult ]
It annoys me that I have a function with a (somewhat) descriptive name, like adjustToBusinessHoursReturnsCorrectResult, but then I also have to give the test a label - in this case "adjustToBusinessHours returns correct result". Not only is this duplication, but it also adds an extra maintenance overhead, because if I decide to rename the test, should I also rename the label?
Why do you even need the label? When you run the test, that label is printed during the test run, so that you can see what happens:
$ stack test --color never --ta "--plain"
ZonedTimeAdjustment-0.1.0.0: test (suite: ZonedTimeAdjustment-test, args: --plain)
:adjustToDutchBankDay returns correct result:
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
:adjustToBusinessHours returns correct result:
: [OK]
: [OK]
: [OK]
:Composed adjust returns correct result:
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
Test Cases Total
Passed 20 20
Failed 0 0
Total 20 20
I considered it redundant to give each test case in the parametrised tests their own labels, but I could have done that too, if I'd wanted to.
What happens if you remove the labels?
main = defaultMain $ hUnitTestToTests $ TestList $ adjustToBusinessHoursReturnsCorrectResult ++ adjustToDutchBankDayReturnsCorrectResult ++ composedAdjustReturnsCorrectResult
That compiles, but produces output like this:
$ stack test --color never --ta "--plain"
ZonedTimeAdjustment-0.1.0.0: test (suite: ZonedTimeAdjustment-test, args: --plain)
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
: [OK]
Test Cases Total
Passed 20 20
Failed 0 0
Total 20 20
If you don't care about the labels, then that's a fine solution. On the other hand, if you do care about the labels, then a different approach is warranted.
Inlined test lists #
Looking at an expression like "Composed adjust returns correct result" ~: composedAdjustReturnsCorrectResult, I find "Composed adjust returns correct result" more readable than composedAdjustReturnsCorrectResult, so if I want to reduce duplication, I want to go after a solution that names a test with a label, instead of a solution that names a test with a function name.
What is composedAdjustReturnsCorrectResult? It's just the name of a pure function (because its type is [Test]). Since it's referentially transparent, it means that in the test list in main, I can replace the function with its body! I can do this with all three functions, although, in order to keep things simplified, I'm only going to show you two of them:
main :: IO () main = defaultMain $ hUnitTestToTests $ TestList [ "adjustToBusinessHours returns correct result" ~: do (dt, expected) <- [ (zt (2017, 10, 2) (6, 59, 4) 0, zt (2017, 10, 2) (9, 0, 0) 0), (zt (2017, 10, 2) (9, 42, 41) 0, zt (2017, 10, 2) (9, 42, 41) 0), (zt (2017, 10, 2) (19, 1, 32) 0, zt (2017, 10, 3) (9, 0, 0) 0) ] let actual = adjustToBusinessHours dt return $ ZT expected ~=? ZT actual , "Composed adjust returns correct result" ~: do (dt, expected) <- [ (zt (2017, 1, 31) ( 7, 45, 55) 2 , zt (2017, 2, 28) ( 7, 0, 0) 0), (zt (2017, 2, 6) (10, 3, 2) 1 , zt (2017, 3, 6) ( 9, 3, 2) 0), (zt (2017, 2, 9) ( 4, 20, 0) 0 , zt (2017, 3, 9) ( 9, 0, 0) 0), (zt (2017, 2, 12) (16, 2, 11) 0 , zt (2017, 3, 10) (16, 2, 11) 0), (zt (2017, 3, 14) (13, 48, 29) (-1), zt (2017, 4, 13) (14, 48, 29) 0) ] let adjustments = reverse [adjustToNextMonth, adjustToBusinessHours, adjustToDutchBankDay, adjustToUtc] let adjust = appEndo $ mconcat $ Endo <$> adjustments let actual = adjust dt return $ ZT expected ~=? ZT actual ]
In order to keep the code listing to a reasonable length, I didn't include the third test "adjustToDutchBankDay returns correct result", but it works in exactly the same way.
This is a list with two values. You can see that the values are separated by a ,, just like list elements normally are. What's unusual, however, is that each element in the list is defined with a multi-line do block.
In C# and F#, I'm used to being able to just write new test functions, and they're automatically picked up by convention and executed by the test runner. I wouldn't be at all surprised if there was a mechanism using Template Haskell that enables something similar, but I find that there's something appealing about treating tests as first-class values all the way.
By inlining the tests, I can retain my F# and C# workflow. Just add a new test within the list, and it's automatically picked up by the main function. Not only that, but it's no longer possible to write a test that compiles, but is never executed by the test runner because it has the wrong type. This occasionally happens to me in F#, but with the technique outlined here, if I accidentally give the test the wrong type, it's not going to compile.
Conclusion #
Since HUnit tests are first-class values, you can define them inlined in test lists. For larger code bases, I'd assume that you'd want to spread your unit tests across multiple modules. In that case, I suppose that you could have each test module export a [Test] value. In the test library's main function, you'd need to manually concatenate all the exported test lists together, so a small maintenance burden remains. When you add a new test module, you'd have to add its exported tests to main.
I wouldn't be surprised, however, if a clever reader could point out to me how to avoid that as well.
Parametrised unit tests in Haskell
Here's a way to write parametrised unit tests in Haskell.
Sometimes you'd like to execute the same (unit) test for a number of test cases. The only thing that varies is the input values, and the expected outcome. The actual test code is the same for all test cases. Among object-oriented programmers, this is known as a parametrised test.
When I recently searched the web for how to do parametrised tests in Haskell, I could only find articles that talked about property-based testing, mostly with QuickCheck. I normally prefer property-based testing, but sometimes, I'd rather like to run a test with some deterministic test cases that are visible and readable in the code itself.
Here's one way I found that I could do that in Haskell.
Testing date and time adjustments in C# #
In an earlier article, I discussed how to model date and time adjustments as a monoid. The example code was written in C#, and I used a few tests to demonstrate that the composition of adjustments work as intended:
[Theory] [InlineData("2017-01-31T07:45:55+2", "2017-02-28T07:00:00Z")] [InlineData("2017-02-06T10:03:02+1", "2017-03-06T09:03:02Z")] [InlineData("2017-02-09T04:20:00Z" , "2017-03-09T09:00:00Z")] [InlineData("2017-02-12T16:02:11Z" , "2017-03-10T16:02:11Z")] [InlineData("2017-03-14T13:48:29-1", "2017-04-13T14:48:29Z")] public void AccumulatedAdjustReturnsCorrectResult( string dtS, string expectedS) { var dt = DateTimeOffset.Parse(dtS); var sut = DateTimeOffsetAdjustment.Accumulate( new NextMonthAdjustment(), new BusinessHoursAdjustment(), new DutchBankDayAdjustment(), new UtcAdjustment()); var actual = sut.Adjust(dt); Assert.Equal(DateTimeOffset.Parse(expectedS), actual); }
The above parametrised test uses xUnit.net (particularly its Theory feature) to execute the same test code for five test cases. Here's another example:
[Theory] [InlineData("2017-10-02T06:59:04Z", "2017-10-02T09:00:00Z")] [InlineData("2017-10-02T09:42:41Z", "2017-10-02T09:42:41Z")] [InlineData("2017-10-02T19:01:32Z", "2017-10-03T09:00:00Z")] public void AdjustReturnsCorrectResult(string dts, string expectedS) { var dt = DateTimeOffset.Parse(dts); var sut = new BusinessHoursAdjustment(); var actual = sut.Adjust(dt); Assert.Equal(DateTimeOffset.Parse(expectedS), actual); }
This one covers the three code paths through BusinessHoursAdjustment.Adjust.
These tests are similar, so they share some good and bad qualities.
On the positive side, I like how readable such tests are. The test code is only a few lines of code, and the test cases (input, and expected output) are in close proximity to the code. Unless you're on a phone with a small screen, you can easily see all of it at once.
For a problem like this, I felt that I preferred examples rather than using property-based testing. If the date and time is this, then the adjusted result should be that, and so on. When we read code, we tend to prefer examples. Good documentation often contains examples, and for those of us who consider tests documentation, including examples in tests should advance that cause.
On the negative side, tests like these still contain noise. Most of it relates to the problem that xUnit.net tests aren't first-class values. These tests actually ought to take a DateTimeOffset value as input, and compare it to another, expected DateTimeOffset value. Unfortunately, DateTimeOffset values aren't constants, so you can't use them in attributes, like the [InlineData] attribute.
There are other workarounds than the one I ultimately chose, but none that are as simple (that I'm aware of). Strings are constants, so you can put formatted date and time strings in the [InlineData] attributes, but the cost of doing this is two calls to DateTimeOffset.Parse. Perhaps this isn't a big price, you think, but it does make me wish for something prettier.
Comparing date and time #
In order to port the above tests to Haskell, I used Stack to create a new project with HUnit as the unit testing library.
The Haskell equivalent to DateTimeOffset is called ZonedTime. One problem with ZonedTime values is that you can't readily compare them; the type isn't an Eq instance. There are good reasons for that, but for the purposes of unit testing, I wanted to be able to compare them, so I defined this helper data type:
newtype ZonedTimeEq = ZT ZonedTime deriving (Show) instance Eq ZonedTimeEq where ZT (ZonedTime lt1 tz1) == ZT (ZonedTime lt2 tz2) = lt1 == lt2 && tz1 == tz2
This enables me to compare two ZonedTimeEq values, which are only considered equal if they represent the same date, the same time, and the same time zone.
Test Utility #
I also added a little function for creating ZonedTime values:
zt (y, mth, d) (h, m, s) tz = ZonedTime (LocalTime (fromGregorian y mth d) (TimeOfDay h m s)) (hoursToTimeZone tz)
The motivation is simply that, as you can tell, creating a ZonedTime value requires a verbose expression. Clearly, the ZonedTime API is flexible, but in order to define some test cases, I found it advantageous to trade readability for flexibility. The zt function enables me to compactly define some ZonedTime values for my test cases.
Testing business hours in Haskell #
In HUnit, a test is either a Test, a list of Test values, or an impure assertion. For a parametrised test, a [Test] sounded promising. At the beginning, I struggled with finding a readable way to express the tests. I wanted to be able to start with a list of test cases (inputs and expected outputs), and then fmap them to an executable test. At first, the readability goal seemed elusive, until I realised that I can also use do notation with lists (since they're monads):
adjustToBusinessHoursReturnsCorrectResult :: [Test] adjustToBusinessHoursReturnsCorrectResult = do (dt, expected) <- [ (zt (2017, 10, 2) (6, 59, 4) 0, zt (2017, 10, 2) (9, 0, 0) 0), (zt (2017, 10, 2) (9, 42, 41) 0, zt (2017, 10, 2) (9, 42, 41) 0), (zt (2017, 10, 2) (19, 1, 32) 0, zt (2017, 10, 3) (9, 0, 0) 0) ] let actual = adjustToBusinessHours dt return $ ZT expected ~=? ZT actual
This is the same test as the above C# test named AdjustReturnsCorrectResult, and it's about the same size as well. Since the test is written using do notation, you can take a list of test cases and operate on each test case at a time. Although the test creates a list of tuples, the <- arrow pulls each (ZonedTime, ZonedTime) tuple out of the list and binds it to (dt, expected).
This test literally consists of only three expressions, so according to my normal heuristic for test formatting, I don't even need white space to indicate the three phases of the AAA pattern. The first expression sets up the test case (dt, expected).
The next expression exercises the System Under Test - in this case the adjustToBusinessHours function. That's simply a function call.
The third expression verifies the result. It uses HUnit's ~=? operator to compare the expected and the actual values. Since ZonedTime isn't an Eq instance, both values are converted to ZonedTimeEq values. The ~=? operator returns a Test value, and since the entire test takes place inside a do block, you must return it. Since this particular do block takes place inside the list monad, the type of adjustToBusinessHoursReturnsCorrectResult is [Test]. I added the type annotation for the benefit of you, dear reader, but technically, it's not required.
Testing the composed function #
Translating the AccumulatedAdjustReturnsCorrectResult C# test to Haskell follows the same recipe:
composedAdjustReturnsCorrectResult :: [Test] composedAdjustReturnsCorrectResult = do (dt, expected) <- [ (zt (2017, 1, 31) ( 7, 45, 55) 2 , zt (2017, 2, 28) ( 7, 0, 0) 0), (zt (2017, 2, 6) (10, 3, 2) 1 , zt (2017, 3, 6) ( 9, 3, 2) 0), (zt (2017, 2, 9) ( 4, 20, 0) 0 , zt (2017, 3, 9) ( 9, 0, 0) 0), (zt (2017, 2, 12) (16, 2, 11) 0 , zt (2017, 3, 10) (16, 2, 11) 0), (zt (2017, 3, 14) (13, 48, 29) (-1), zt (2017, 4, 13) (14, 48, 29) 0) ] let adjustments = reverse [adjustToNextMonth, adjustToBusinessHours, adjustToDutchBankDay, adjustToUtc] let adjust = appEndo $ mconcat $ Endo <$> adjustments let actual = adjust dt return $ ZT expected ~=? ZT actual
The only notable difference is that this unit test consists of five expressions, so according to my formatting heuristic, I inserted some blank lines in order to make it easier to distinguish the three AAA phases from each other.
Running tests #
I also wrote a third test called adjustToDutchBankDayReturnsCorrectResult, but that one is so similar to the two you've already seen that I see no point showing it here. In order to run all three tests, I define the tests' main function as such:
main = defaultMain $ hUnitTestToTests $ TestList [ "adjustToBusinessHours returns correct result" ~: adjustToBusinessHoursReturnsCorrectResult, "adjustToDutchBankDay returns correct result" ~: adjustToDutchBankDayReturnsCorrectResult, "Composed adjust returns correct result" ~: composedAdjustReturnsCorrectResult ]
This uses defaultMain from test-framework, and hUnitTestToTests from test-framework-hunit.
I'm not happy about the duplication of text and test names, and the maintenance burden implied by having to explicitly add every test function to the test list. It's too easy to forget to add a test after you've written it. In the next article, I'll demonstrate an alternative way to compose the tests so that duplication is reduced.
Conclusion #
Since HUnit tests are first-class values, you can manipulate and compose them just like any other value. That includes passing them around in lists and binding them with do notation. Once you figure out how to write parametrised tests with HUnit, it's easy, readable, and elegant.
The overall configuration of the test runner, however, leaves a bit to be desired, so that's the topic for the next article.
Next: Inlined HUnit test lists.
Null Object as identity
When can you implement a Null Object? When the return types of your methods are monoids.
This article is part of a series of articles about design patterns and their category theory counterparts. In a previous article you learned how there's a strong relationship between the Composite design pattern and monoids. In this article you'll see that the Null Object pattern is essentially a special case of the Composite pattern.
I also think that there's a relationship between monoidal identity and the Null Object pattern similar to the relationship between Composite and monoids in general:
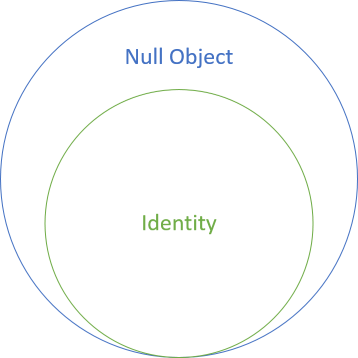
Once more, I don't claim that an isomorphism exists. You may be able to produce Null Object examples that aren't monoidal, but on the other hand, I believe that all identities are Null Objects.
Null Object #
While the Null Object design pattern isn't one of the patterns covered in Design Patterns, I consider it a structural pattern because Composite is a structural pattern, and Null Object is a special case of Composite.
Bobby Woolf's original text contains an example in Smalltalk, and while I'm no Smalltalk expert, I think a fair translation to C# would be an interface like this:
public interface IController { bool IsControlWanted(); bool IsControlActive(); void Startup(); }
The idea behind the Null Object pattern is to add an implementation that 'does nothing', which in the example would be this:
public class NullController : IController { public bool IsControlActive() { return false; } public bool IsControlWanted() { return false; } public void Startup() { } }
Woolf calls his implementation NoController, but I find it more intent-revealing to call it NullController. Both of the Boolean methods return false, and the Startup method literally does nothing.
Doing nothing #
What exactly does it mean to 'do nothing'? In the case of the Startup method, it's clear, because it's a bona fide no-op. This is possible for all methods without return values (i.e. methods that return void), but for all other methods, the compiler will insist on a return value.
For IsControlActive and IsControlWanted, Woolf solves this by returning false.
Is false always the correct 'do nothing' value for Booleans? And what should you return if a method returns an integer, a string, or a custom type? The original text is vague on that question:
"Exactly what "do nothing" means is subjective and depends on the sort of behavior the Client is expecting."Sometimes, you can't get any closer than that, but I think that often it's possible to be more specific.
Doing nothing as identity #
From unit isomorphisms you know that methods without return values are isomorphic to methods that return unit. You also know that unit is a monoid. What does unit and bool have in common? They both form monoids; bool, in fact, forms four different monoids, of which all and any are the best-known.
In my experience, you can implement the Null Object pattern by returning various 'do nothing' values, depending on their types:
- For
bool, return a constant value. Usually,falseis the appropriate 'do nothing' value, but it does depend on the semantics of the operation. - For
string, return"". - For collections, return an empty collection.
- For numbers, return a constant value, such as
0. - For
void, do nothing, which is equivalent to returning unit.
bool and int, more than one monoid exist, and the identity depends on which one you pick:
- The identity for the any monoid is
false. - The identity for
stringis"". - The identity for collections is the empty collection.
- The identity for the addition monoid is
0. - The identity for unit is unit.
foo.Op(Foo.Identity) == foo
In other words: the identity does nothing!
As a preliminary result, then, when all return values of your interface form monoids, you can create a Null Object.
Relationship with Composite #
In the previous article, you saw how the Composite design pattern was equivalent with the Haskell function mconcat:
mconcat :: Monoid a => [a] -> a
This function, however, seems more limited than it has to be. It says that if you have a linked list of monoidal values, you can reduce them to a single monoidal value. Is this only true for linked lists?
After all, in a language like C#, you'd typically express a Composite as a container of 'some collection' of objects, typically modelled by the IReadOnlyCollection<T> interface. There are several implementations of that interface, including lists, arrays, collections, and so on.
It seems as though we ought to be able to generalise mconcat, and, indeed, we can. The Data.Foldable module defines a function called fold:
fold :: (Monoid m, Foldable t) => t m -> m
Let me decipher that for you. It says that any monoid m contained in a 'foldable' container t can be reduced to a single value (still of the type m). You can read t m as 'a foldable container that contains monoids'. In C#, you could attempt to express it as IFoldable<TMonoid>.
In other words, the Composite design pattern is equivalent to fold. Here's how it relates to the Null Object pattern:
As a first step, consider methods like those defined by the above IController interface. In order to implement NullController, all of those methods ignore their (non-existent) input and return an identity value. In other words, we're looking for a Haskell function of the type Monoid m => a -> m; that is: a function that takes input of the type a and returns a monoidal value m.
You can do that using fold:
nullify :: Monoid m => a -> m nullify = fold (Identity $ const mempty)
Recall that the input to fold must be a Foldable container. The good old Identity type is, among other capabilities, Foldable. That takes care of the container. The value that we put into the container is a single function that ignores its input (const) and always returns the identity value (mempty). The result is a function that always returns the identity value.
This demonstrates that Null Object is a special case of Composite, because nullify is a special application of fold.
There's no reason to write nullify in such a complicated way, though. You can simplify it like this:
nullify :: Monoid m => a -> m nullify = const mempty
Once you recall, however, that functions are monoids if their return values are monoids, you can simplify it even further:
nullify :: Monoid m => a -> m nullify = mempty
The identity element for monoidal functions is exactly a function that ignores its input and returns mempty.
Controller identity #
Consider the IController interface. According to object isomorphisms, you can represent this interface as a tuple of three functions:
type Controller = (ControllerState -> Any, ControllerState -> Any, ControllerState -> ())
This is cheating a little, because the third tuple element (the one that corresponds to Startup) is pure, although I strongly suspect that the intent is that it should mutate the state of the Controller. Two alternatives are to change the function to either ControllerState -> ControllerState or ControllerState -> IO (), but I'm going to keep things simple. It doesn't change the conclusion.
Notice that I've used Any as the return type for the two first tuples. As I've previously covered, Booleans form monoids like any and all. Here, we need to use Any.
This tuple is a monoid because all three functions are monoids, and a tuple of monoids is itself a monoid. This means that you can easily create a Null Object using mempty:
λ> nullController = mempty :: Controller
The nullController is a triad of functions. You can access them by pattern-matching them, like this:
λ> (isControlWanted, isControlActive, startup) = nullController
Now you can try to call e.g. isControlWanted with various values in order to verify that it always returns false. In this example, I cheated and simply made ControllerState an alias for String:
λ> isControlWanted "foo"
Any {getAny = False}
λ> isControlWanted "bar"
Any {getAny = False}
You'll get similar behaviour from isControlActive, and startup always returns () (unit).
Relaxation #
As Woolf wrote in the original text, what 'do nothing' means is subjective. I think it's perfectly reasonable to say that monoidal identity fits the description of doing nothing, but you could probably encounter APIs where 'doing nothing' means something else.
As an example, consider avatars for online forums, such as Twitter. If you don't supply a picture when you create your profile, you get a default picture. One way to implement such a feature could be by having a 'null' avatar, which is used in place of a proper avatar. Such a default avatar object could (perhaps) be considered a Null Object, but wouldn't necessarily be monoidal. There may not even be a binary operation for avatars.
Thus, it's likely that you could encounter or create Null Objects that aren't monoids. That's the reason that I don't claim that a Null Object always is monoidal identity, although I do think that the reverse relationship holds: if it's identity, then it's a Null Object.
Summary #
Monoids are associative binary operations with identity. The identity is the value that 'does nothing' in that binary operation, like, for example, 0 doesn't 'do' anything under addition. Monoids, however, can be more complex than operations on primitive values. Functions, for example, can be monoids as well, as can tuples of functions.
The implication of that is that objects can be monoids as well. When you have a monoidal object, then its identity is the 'natural' Null Object.
The question was: when can you implement the Null Object pattern? The answer is that you can do that when all involved methods return monoids.
Next: Builder as a monoid.
Comments
All the examples of using Maybe I recall seeing always wrapped a data type that had a neutral element. So Maybe<int> would resolve to 0 or 1, while Maybe<string> to string.Empty. But what about data types that do not have a neutral element?
Suppose we have this DDD value object, NonEmptyString, written in C#. It has no public constructor and it is instantiated through a static factory method that returns a Maybe<NonEmptyString> containing an initialized NonEmptyString if the given input is not null or whitespace and None otherwise.
How do you treat the None case when calling the maybe.Match method? Since the neutral element for
string concatenation is string.empty, an invalid value for this value object, this type has no possibility of having a Null Object.
Can this situation be resolved in the functional way (without throwing an exception) or does it warrant throwing an exception?
Ciprian, thank you for writing. I'm not sure I understand what you man by Maybe wrapping a neutral element. I hope that's not how my introduction to Maybe comes across. Could you point to specific examples?
If NonEmptyString is, as the name implies, a string guaranteed to be non-empty, isn't it just a specialisation of NotEmptyCollection<T>? If so, indeed, there's no identity for NonEmptyString (but it does form a Semigroup).
Since it's a semigroup, though, you can lift it to a monoid my wrapping it in Maybe. If you do that, the identity of Maybe<NonEmptyString> would be nothing.
You are right, Mark. The NonEmptyString class is indeed a semigroup, thus has no neutral element.
This is not what confuses me, but what function to supply in the None case of a Maybe<SomeSemigroup> when calling the .Match method.
In the case of Maybe<SomeMonoid>, it's simple and intuitive, as you simply supply a function that returns the neutral element of that monoid.
But what about semigroups?
Here's a couple of generalized examples to better illustrate the question I'm having:
Maybe<SomeMonoid> firstMaybe = someService.GetSomeMonoid();
SomeMonoid value = firstMaybe.Match(Some: containedValue => containedValue, None: () => SomeMonoid.NeutralElement);
Maybe<SomeSemigroup> secondMaybe = someService.GetSomeSemigroup();
SomeSemigroup someSemigroup = secondMaybe.Match(Some: containedValue => containedValue, None: () => /*What to do here? Is it appropriate to throw an exception?*/);
I hope this time my question became clearer. I'm still in the process of wrapping my head around functional and category theory concepts, so my terminology may not be pinpoint accurate.
Ciprian, that's the problem with semigroups, isn't it? There's no single natural element to use in the absence of data.
Lifting a semigroup to a Maybe is one way to resolve that problem. Since Maybe is a functor, you can map the contents of the Maybe until you've mapped it into a value for which an identity exists.
In some cases, you can also fold a Maybe value by supplying a default value that makes sense in the specific context. A default value can be an appropriate fall-back value in a given context, even if it isn't a general identity.
I think I got it!
If you want to process that Maybe<SomeSemigroup> in a functional way, using the .Match(Some: ..., None: ...) method,
you actually have to transform the method using it from a mostly statement based one, to a mostly expression based one. You have to
pretend you don't know what's inside that Maybe for as long as possible, similar to using Lazy (or lazy evaluation in general).
In this fiddle I've played around and created both an imperative and functional query method for retrieving a book by title and author,
in order to prove myself that they can be made isomorphic. These two methods are GetBookFunctional and GetBookImperative.
However, I'm now trying to transform the GetBookImperativeWithoutElses into something functional using that .Match method, but I don't think it's possible.
The .Match method's signature is, practically speaking, equivalent to the if-else statement, whereas the GetBookImperativeWithoutElses method uses the if statement,
meaning the functional approach will be forced to treat the elses, whereas the imperative one won't.
Wow, so if you want to use this Maybe of semigroup and/or go fully functional, you really have to go deep down the functional rabbit hole.
Also, my guess is there is no guarantee that going from imperative to functional does not introduce more redundancy (like the elses in the second set of methods) into your system.
Am I right in these regards?
Ciprian, thank you for the link to the code. This explains why you're running into trouble. You absolutely can address the scenario that causes you trouble in a nice functional style, but once you start having the need to keep track of error data as well as happy-path data, Maybe is no longer the data structure you need.
Maybe enables you to model a case where data may or may not be available. It enables you distinguish something from nothing. On the other hand, in the absence of data, you have no information about the reason that data is missing.
In order to keep track of such information, you need Either, which models data that's either this or that.
I'll cover Either in future posts.
Hi Mark, your posts are very impressive. I started to learn category theory and try to use it to understand programming.
However, the idea of treating neutral elements as "do nothing" is not so helpful from my point of view. The neutral element is defined under a binary operation. But there is no clue that the return value of methods in the Null Object will be used in such a binary operation.
Also, this idea doens't give us a unique choice of "do nothing". Given a type, there could be more than one binary operations that makes the type a monoid. Why do we choose the neutral element under this binary operation instead of the other binary operation?
Edward, thank you for writing. If you don't find this useful, you are free to ignore it.
Personally, I find the Null Object pattern interesting, because it's a alternative to an if branch. Sometimes, in various programming contexts, you may run into situations where you need to do nothing on various special occasions. By employing the Null Object pattern, you may be able to avoid Shotgun Surgery by replacing scattered if checks with a Null Object.
This, however, begs the question: When is it possible to make a Null Object implementation of a polymorphic type?
This isn't always possible. For example, if the type has a method that returns a date and time, then which value do you return in order to 'do nothing'?
I can't easily answer that question, so a Null Object probably isn't possible with a design like that.
On the other hand, if the polymorphic type only defines monoidal operations, you know that a Null Object is possible.
In reality, to be honest, in API design, I'm more interested in the Composite pattern, but if I can make something a Composite, then the Null Object just comes along for the ride.
Thinking about monoids is, for me, mostly an analysis tool. It gives me guidance on what may be a good design. I don't presume to claim that in a language like C#, having bool og int as return types makes the monoidal operation unambiguous.
Haskell gets around that issue by wrapping the primitive types in distinguishable wrappers. Thus, neither Bool nor Int are Monoid instances, but Any, All, Sum, and Product are.
Endomorphic Composite as a monoid
A variation of the Composite design pattern uses endomorphic composition. That's still a monoid.
This article is part of a series of articles about design patterns and their category theory counterparts. In a previous article, you learned that the Composite design pattern is simply a monoid.
There is, however, a variation of the Composite design pattern where the return value from one step can be used as the input for the next step.
Endomorphic API #
Imagine that you have to implement some scheduling functionality. For example, you may need to schedule something to happen a month from now, but it should happen on a bank day, during business hours, and you want to know what the resulting date and time will be, expressed in UTC. I've previously covered the various objects for performing such steps. The common behaviour is this interface:
public interface IDateTimeOffsetAdjustment { DateTimeOffset Adjust(DateTimeOffset value); }
The Adjust method is an endomorphism; that is: the input type is the same as the return type, in this case DateTimeOffset. A previous article already established that that's a monoid.
Composite endomorphism #
If you have various implementations of IDateTimeOffsetAdjustment, you can make a Composite from them, like this:
public class CompositeDateTimeOffsetAdjustment : IDateTimeOffsetAdjustment { private readonly IReadOnlyCollection<IDateTimeOffsetAdjustment> adjustments; public CompositeDateTimeOffsetAdjustment( IReadOnlyCollection<IDateTimeOffsetAdjustment> adjustments) { if (adjustments == null) throw new ArgumentNullException(nameof(adjustments)); this.adjustments = adjustments; } public DateTimeOffset Adjust(DateTimeOffset value) { var acc = value; foreach (var adjustment in this.adjustments) acc = adjustment.Adjust(acc); return acc; } }
The Adjust method simply starts with the input value and loops over all the composed adjustments. For each adjustment it adjusts acc to produce a new acc value. This goes on until all adjustments have had a chance to adjust the value.
Notice that if adjustments is empty, the Adjust method simply returns the input value. In that degenerate case, the behaviour is similar to the identity function, which is the identity for the endomorphism monoid.
You can now compose the desired behaviour, as this parametrised xUnit.net test demonstrates:
[Theory] [InlineData("2017-01-31T07:45:55+2", "2017-02-28T07:00:00Z")] [InlineData("2017-02-06T10:03:02+1", "2017-03-06T09:03:02Z")] [InlineData("2017-02-09T04:20:00Z" , "2017-03-09T09:00:00Z")] [InlineData("2017-02-12T16:02:11Z" , "2017-03-10T16:02:11Z")] [InlineData("2017-03-14T13:48:29-1", "2017-04-13T14:48:29Z")] public void AdjustReturnsCorrectResult( string dtS, string expectedS) { var dt = DateTimeOffset.Parse(dtS); var sut = new CompositeDateTimeOffsetAdjustment( new NextMonthAdjustment(), new BusinessHoursAdjustment(), new DutchBankDayAdjustment(), new UtcAdjustment()); var actual = sut.Adjust(dt); Assert.Equal(DateTimeOffset.Parse(expectedS), actual); }
You can see the implementation for all four composed classes in the previous article. NextMonthAdjustment adjusts a date by a month into its future, BusinessHoursAdjustment adjusts a time to business hours, DutchBankDayAdjustment takes bank holidays and weekends into account in order to return a bank day, and UtcAdjustment convert a date and time to UTC.
Monoidal accumulation #
As you've learned in that previous article that I've already referred to, an endomorphism is a monoid. In this particular example, the binary operation in question is called Append. From another article, you know that monoids accumulate:
public static IDateTimeOffsetAdjustment Accumulate( IReadOnlyCollection<IDateTimeOffsetAdjustment> adjustments) { IDateTimeOffsetAdjustment acc = new IdentityDateTimeOffsetAdjustment(); foreach (var adjustment in adjustments) acc = Append(acc, adjustment); return acc; }
This implementation follows the template previously described:
- Initialize a variable
accwith the identity element. In this case, the identity is a class calledIdentityDateTimeOffsetAdjustment. - For each
adjustmentinadjustments,Appendtheadjustmenttoacc. - Return
acc.
mconcat. We'll get back to that in a moment, but first, here's another parametrised unit test that exercises the same test cases as the previous test, only against a composition created by Accumulate:
[Theory] [InlineData("2017-01-31T07:45:55+2", "2017-02-28T07:00:00Z")] [InlineData("2017-02-06T10:03:02+1", "2017-03-06T09:03:02Z")] [InlineData("2017-02-09T04:20:00Z" , "2017-03-09T09:00:00Z")] [InlineData("2017-02-12T16:02:11Z" , "2017-03-10T16:02:11Z")] [InlineData("2017-03-14T13:48:29-1", "2017-04-13T14:48:29Z")] public void AccumulatedAdjustReturnsCorrectResult( string dtS, string expectedS) { var dt = DateTimeOffset.Parse(dtS); var sut = DateTimeOffsetAdjustment.Accumulate( new NextMonthAdjustment(), new BusinessHoursAdjustment(), new DutchBankDayAdjustment(), new UtcAdjustment()); var actual = sut.Adjust(dt); Assert.Equal(DateTimeOffset.Parse(expectedS), actual); }
While the implementation is different, this monoidal composition has the same behaviour as the above CompositeDateTimeOffsetAdjustment class. This, again, emphasises that Composites are simply monoids.
Endo #
For comparison, this section demonstrates how to implement the above behaviour in Haskell. The code here passes the same test cases as those above. You can skip to the next section if you want to get to the conclusion.
Instead of classes that implement interfaces, in Haskell you can define functions with the type ZonedTime -> ZonedTime. You can compose such functions using the Endo newtype 'wrapper' that turns endomorphisms into monoids:
λ> adjustments = reverse [adjustToNextMonth, adjustToBusinessHours, adjustToDutchBankDay, adjustToUtc] λ> :type adjustments adjustments :: [ZonedTime -> ZonedTime] λ> adjust = appEndo $ mconcat $ Endo <$> adjustments λ> :type adjust adjust :: ZonedTime -> ZonedTime
In this example, I'm using GHCi (the Haskell REPL) to show the composition in two steps. The first step creates adjustments, which is a list of functions. In case you're wondering about the use of the reverse function, it turns out that mconcat composes from right to left, which I found counter-intuitive in this case. adjustToNextMonth should execute first, followed by adjustToBusinessHours, and so on. Defining the functions in the more intuitive left-to-right direction and then reversing it makes the code easier to understand, I hope.
(For the Haskell connoisseurs, you can also achieve the same result by composing Endo with the Dual monoid, instead of reversing the list of adjustments.)
The second step composes adjust from adjustments. It first maps adjustments to Endo values. While ZonedTime -> ZonedTime isn't a Monoid instances, Endo ZonedTime is. This means that you can reduce a list of Endo ZonedTime with mconcat. The result is a single Endo ZonedTime value, which you can then unwrap to a function using appEndo.
adjust is a function that you can call:
λ> dt 2017-01-31 07:45:55 +0200 λ> adjust dt 2017-02-28 07:00:00 +0000
In this example, I'd already prepared a ZonedTime value called dt. Calling adjust returns a new ZonedTime adjusted by all four composed functions.
Conclusion #
In general, you implement the Composite design pattern by calling all composed functions with the original input value, collecting the return value of each call. In the final step, you then reduce the collected return values to a single value that you return. This requires the return type to form a monoid, because otherwise, you can't reduce it.
In this article, however, you learned about an alternative implementation of the Composite design pattern. If the method that you compose has the same output type as its input, you can pass the output from one object as the input to the next object. In that case, you can escape the requirement that the return value is a monoid. That's the case with DateTimeOffset and ZonedTime: neither are monoids, because you can't add two dates and times together.
At first glance, then, it seems like a falsification of the original claim that Composites are monoids. As you've learned in this article, however, endomorphisms are monoids, so the claim still stands.
Next: Null Object as identity.
Coalescing Composite as a monoid
A variation of the Composite design pattern uses coalescing behaviour to return non-composable values. That's still a monoid.
This article is part of a series of articles about design patterns and their category theory counterparts. In a previous article, you learned that the Composite design pattern is simply a monoid.
Monoidal return types #
When all methods of an interface return monoids, you can create a Composite. This is fairly intuitive once you understand what a monoid is. Consider this example interface:
public interface ICustomerRepository { void Create(Customer customer); Customer Read(Guid id); void Update(Customer customer); void Delete(Guid id); }
While this interface is, in fact, not readily composable, most of the methods are. It's easy to compose the three void methods. Here's a composition of the Create method:
public void Create(Customer customer) { foreach (var repository in this.repositories) repository.Create(customer); }
In this case it's easy to compose multiple repositories, because void (or, rather, unit) forms a monoid. If you have methods that return numbers, you can add the numbers together (a monoid). If you have methods that return strings, you can concatenate the strings (a monoid). If you have methods that return Boolean values, you can or or and them together (more monoids).
What about the above Read method, though?
Picking the first Repository #
Why would you even want to compose two repositories? One scenario is where you have an old data store, and you want to move to a new data store. For a while, you wish to write to both data stores, but one of them stays the 'primary' data store, so this is the one from which you read.
Imagine that the old repository saves customer information as JSON files on disk. The new data store, on the other hand, saves customer data as JSON documents in Azure Blob Storage. You've already written two implementations of ICustomerRepository: FileCustomerRepository and AzureCustomerRepository. How do you compose them?
The three methods that return void are easy, as the above Create implementation demonstrates. The Read method, however, is more tricky.
One option is to only query the first repository, and return its return value:
public Customer Read(Guid id) { return this.repositories.First().Read(id); }
This works, but doesn't generalise. It works if you know that you have a non-empty collection of repositories, but if you want to adhere to the Liskov Substitution Principle, you should be able to handle the case where there's no repositories.
A Composite should be able to compose an arbitrary number of other objects. This includes a collection of no objects. The CompositeCustomerRepository class has this constructor:
private readonly IReadOnlyCollection<ICustomerRepository> repositories; public CompositeCustomerRepository( IReadOnlyCollection<ICustomerRepository> repositories) { if (repositories == null) throw new ArgumentNullException(nameof(repositories)); this.repositories = repositories; }
It uses standard Constructor Injection to inject an IReadOnlyCollection<ICustomerRepository>. Such a collection is finite, but can be empty.
Another problem with blindly returning the value from the first repository is that the return value may be empty.
In C#, people often use null to indicate a missing value, and while I find such practice unwise, I'll pursue this option for a bit.
A more robust Composite would return the first non-null value it gets:
public Customer Read(Guid id) { foreach (var repository in this.repositories) { var customer = repository.Read(id); if (customer != null) return customer; } return null; }
This implementation loops through all the injected repositories and calls Read on each until it gets a result that is not null. This will often be the first value, but doesn't have to be. If all repositories return null, then the Composite also returns null. To emphasise my position, I would never design C# code like this, but at least it's consistent.
If you've ever worked with relational databases, you may have had an opportunity to use the COALESCE function, which works in exactly the same way. This is the reason I call such an implementation a coalescing Composite.
The First monoid #
The T-SQL documentation for COALESCE describes the operation like this:
"Evaluates the arguments in order and returns the current value of the first expression that initially does not evaluate to NULL."
The Oracle documentation expresses it as:
"This may not be apparent, but that's a monoid.COALESCEreturns the first non-nullexprin the expression list."
Haskell's base library comes with a monoidal type called First, which is a
"Maybe monoid returning the leftmost non-Nothing value."Sounds familiar?
Here's how you can use it in GHCi:
λ> First (Just (Customer id1 "Joan")) <> First (Just (Customer id2 "Nigel"))
First {getFirst = Just (Customer {customerId = 1243, customerName = "Joan"})}
λ> First (Just (Customer id1 "Joan")) <> First Nothing
First {getFirst = Just (Customer {customerId = 1243, customerName = "Joan"})}
λ> First Nothing <> First (Just (Customer id2 "Nigel"))
First {getFirst = Just (Customer {customerId = 5cd5, customerName = "Nigel"})}
λ> First Nothing <> First Nothing
First {getFirst = Nothing}
(To be clear, the above examples uses First from Data.Monoid, not First from Data.Semigroup.)
The operator <> is an infix alias for mappend - Haskell's polymorphic binary operation.
As long as the left-most value is present, that's the return value, regardless of whether the right value is Just or Nothing. Only when the left value is Nothing is the right value returned. Notice that this value may also be Nothing, causing the entire expression to be Nothing.
That's exactly the same behaviour as the above implementation of the Read method.
First in C# #
It's easy to port Haskell's First type to C#:
public class First<T> { private readonly T item; private readonly bool hasItem; public First() { this.hasItem = false; } public First(T item) { if (item == null) throw new ArgumentNullException(nameof(item)); this.item = item; this.hasItem = true; } public First<T> FindFirst(First<T> other) { if (this.hasItem) return this; else return other; } }
Instead of nesting Maybe inside of First, as Haskell does, I simplified a bit and gave First<T> two constructor overloads: one that takes a value, and one that doesn't. The FindFirst method is the binary operation that corresponds to Haskell's <> or mappend.
This is only one of several alternative implementations of the first monoid.
In order to make First<T> a monoid, it must also have an identity, which is just an empty value:
public static First<T> Identity<T>() { return new First<T>(); }
This enables you to accumulate an arbitrary number of First<T> values to a single value:
public static First<T> Accumulate<T>(IReadOnlyList<First<T>> firsts) { var acc = Identity<T>(); foreach (var first in firsts) acc = acc.FindFirst(first); return acc; }
You start with the identity, which is also the return value if firsts is empty. If that's not the case, you loop through all firsts and update acc by calling FindFirst.
A composable Repository #
You can formalise such a design by changing the ICustomerRepository interface:
public interface ICustomerRepository { void Create(Customer customer); First<Customer> Read(Guid id); void Update(Customer customer); void Delete(Guid id); }
In this modified version, Read explicitly returns First<Customer>. The rest of the methods remain as before.
The reusable API of First makes it easy to implement a Composite version of Read:
public First<Customer> Read(Guid id) { var candidates = new List<First<Customer>>(); foreach (var repository in this.repositories) candidates.Add(repository.Read(id)); return First.Accumulate(candidates); }
You could argue that this seems to be wasteful, because it calls Read on all repositories. If the first Repository returns a value, all remaining queries are wasted. You can address that issue with lazy evaluation.
You can see (a recording of) a live demo of the example in this article in my Clean Coders video Composite as Universal Abstraction.
Summary #
While the typical Composite is implemented by directly aggregating the return values from the composed objects, variations exist. One variation picks the first non-empty value from a collection of candidates, reminiscent of the SQL COALESCE function. This is, however, still a monoid, so the overall conjecture that Composites are monoids still holds.
Another Composite variation exists, but that one turns out to be a monoid as well. Read on!
Comments
When all methods of an interface return monoids, you can create a Composite. This is fairly intuitive once you understand what a monoid is.
I've been struggling a bit with the terminology and I could use a bit of help.
I understand a Monoid<a> to be of type a -> a -> a. I further understand that it can be said that a "forms a monoid over" the specific a -> a -> a implementation. We can then say that an int forms two different monoids over addition and multiplication.
Is my understanding above accurate and if so wouldn't it be more accurate to say that you can create a composite from an interface only when all of its methods return values that form monoids? Saying that they have to return monoids (instead of values that form them) goes against my understanding that a monoid is a binary operation.
Thanks a lot for an amazing article series, and for this blog overall. Keep up the good work!
Nikola, thank you for writing. You're correct: it would be more correct to say that you can create a Composite from an interface when all of its methods return types that form monoids. Throughout this article series, I've been struggling to keep my language as correct and specific as possible, but I sometimes slip up.
This has come up before, so perhaps you'll find this answer helpful.
By the way, there's one exception to the rule that in order to be able to create a Composite, all methods must return types that form monoids. This is when the return type is the same as the input type. The resulting Composite is still a monoid, so the overall conclusion holds.
Maybe monoids
You can combine Maybe objects in several ways. An article for object-oriented programmers.
This article is part of a series about monoids. In short, a monoid is an associative binary operation with a neutral element (also known as identity).
You can combine Maybe objects in various ways, thereby turning them into monoids. There's at least two unconstrained monoids over Maybe values, as well as some constrained monoids. By constrained I mean that the monoid only exists for Maybe objects that contain certain values. You'll see such an example first.
Combining Maybes over semigroups #
If you have two Maybe objects, and they both (potentially) contain values that form a semigroup, you can combine the Maybe values as well. Here's a few examples.
public static Maybe<int> CombineMinimum(Maybe<int> x, Maybe<int> y) { if (x.HasItem && y.HasItem) return new Maybe<int>(Math.Min(x.Item, y.Item)); if (x.HasItem) return x; return y; }
In this first example, the semigroup operation in question is the minimum operation. Since C# doesn't enable you to write generic code over mathematical operations, the above method just gives you an example implemented for Maybe<int> values. If you also want to support e.g. Maybe<decimal> or Maybe<long>, you'll have to add overloads for those types.
If both x and y have values, you get the minimum of those, still wrapped in a Maybe container:
var x = new Maybe<int>(42); var y = new Maybe<int>(1337); var m = Maybe.CombineMinimum(x, y);
Here, m is a new Maybe<int>(42).
It's possible to combine any two Maybe objects as long as you have a way to combine the contained values in the case where both Maybe objects contain values. In other words, you need a binary operation, so the contained values must form a semigroup, like, for example, the minimum operation. Another example is maximum:
public static Maybe<decimal> CombineMaximum(Maybe<decimal> x, Maybe<decimal> y) { if (x.HasItem && y.HasItem) return new Maybe<decimal>(Math.Max(x.Item, y.Item)); if (x.HasItem) return x; return y; }
In order to vary the examples, I chose to implement this operation for decimal instead of int, but you can see that the implementation code follows the same template. When both x and y contains values, you invoke the binary operation. If, on the other hand, y is empty, then right identity still holds:
var x = new Maybe<decimal>(42); var y = new Maybe<decimal>(); var m = Maybe.CombineMaximum(x, y);
Since y in the above example is empty, the resulting object m is a new Maybe<decimal>(42).
You don't have to constrain yourself to semigroups exclusively. You can use a monoid as well, such as the sum monoid:
public static Maybe<long> CombineSum(Maybe<long> x, Maybe<long> y) { if (x.HasItem && y.HasItem) return new Maybe<long>(x.Item + y.Item); if (x.HasItem) return x; return y; }
Again, notice how most of this code is boilerplate code that follows the same template as above. In C#, unfortunately, you have to write out all the combinations of operations and contained types, but in Haskell, with its stronger type system, it all comes in the base library:
Prelude Data.Semigroup> Option (Just (Min 42)) <> Option (Just (Min 1337))
Option {getOption = Just (Min {getMin = 42})}
Prelude Data.Semigroup> Option (Just (Max 42)) <> mempty
Option {getOption = Just (Max {getMax = 42})}
Prelude Data.Semigroup> mempty <> Option (Just (Sum 1337))
Option {getOption = Just (Sum {getSum = 1337})}
That particular monoid over Maybe, however, does require as a minimum that the contained values form a semigroup. There are other monoids over Maybe that don't have any such constraints.
First #
As you can read in the introductory article about semigroups, there's two semigroup operations called first and last. Similarly, there's two operations by the same name defined over monoids. They behave a little differently, although they're related.
The first monoid operation returns the left-most non-empty value among candidates. You can view nothing as being a type-safe equivalent to null, in which case this monoid is equivalent to a null coalescing operator.
public static Maybe<T> First<T>(Maybe<T> x, Maybe<T> y) { if (x.HasItem) return x; return y; }
As long as x contains a value, First returns it. The contained values don't have to form monoids or semigroups, as this example demonstrates:
var x = new Maybe<Guid>(new Guid("03C2ECDBEF1D46039DE94A9994BA3C1E")); var y = new Maybe<Guid>(new Guid("A1B7BC82928F4DA892D72567548A8826")); var m = Maybe.First(x, y);
While I'm not aware of any reasonable way to combine GUIDs, you can still pick the left-most non-empty value. In the above example, m contains 03C2ECDBEF1D46039DE94A9994BA3C1E. If, on the other hand, the first value is empty, you get a different result:
var x = new Maybe<Guid>(); var y = new Maybe<Guid>(new Guid("2A2D19DE89D84EFD9E5BEE7C4ADAFD90")); var m = Maybe.First(x, y);
In this case, m contains 2A2D19DE89D84EFD9E5BEE7C4ADAFD90, even though it comes from y.
Notice that there's no guarantee that First returns a non-empty value. If both x and y are empty, then the result is also empty. The First operation is an associative binary operation, and the identity is the empty value (often called nothing or none). It's a monoid.
Last #
Since you can define a binary operation called First, it's obvious that you can also define one called Last:
public static Maybe<T> Last<T>(Maybe<T> x, Maybe<T> y) { if (y.HasItem) return y; return x; }
This operation returns the right-most non-empty value:
var x = new Maybe<Guid>(new Guid("1D9326CDA0B3484AB495DFD280F990A3")); var y = new Maybe<Guid>(new Guid("FFFC6CE263C7490EA0290017FE02D9D4")); var m = Maybe.Last(x, y);
In this example, m contains FFFC6CE263C7490EA0290017FE02D9D4, but while Last favours y, it'll still return x if y is empty. Notice that, like First, there's no guarantee that you'll receive a populated Maybe. If both x and y are empty, the result will be empty as well.
Like First, Last is an associative binary operation with nothing as the identity.
Generalisation #
The first examples you saw in this article (CombineMinimum, CombineMaximum, and so on), came with the constraint that the contained values form a semigroup. The First and Last operations, on the other hand, seem unconstrained. They work even on GUIDs, which notoriously can't be combined.
If you recall, though, first and last are both associative binary operations. They are, in fact, unconstrained semigroups. Recall the Last semigroup:
public static T Last<T>(T x, T y) { return y; }
This binary operation operates on any unconstrained type T, including Guid. It unconditionally returns y.
You could implement the Last monoid over Maybe using the same template as above, utilising the underlying semigroup:
public static Maybe<T> Last<T>(Maybe<T> x, Maybe<T> y) { if (x.HasItem && y.HasItem) return new Maybe<T>(Last(x.Item, y.Item)); if (x.HasItem) return x; return y; }
This implementation has exactly the same behaviour as the previous implementation of Last shown earlier. You can implement First in the same way.
That's exactly how Haskell works:
Prelude Data.Semigroup Data.UUID.Types> x =
sequence $ Last $ fromString "03C2ECDB-EF1D-4603-9DE9-4A9994BA3C1E"
Prelude Data.Semigroup Data.UUID.Types> x
Just (Last {getLast = 03c2ecdb-ef1d-4603-9de9-4a9994ba3c1e})
Prelude Data.Semigroup Data.UUID.Types> y =
sequence $ Last $ fromString "A1B7BC82-928F-4DA8-92D7-2567548A8826"
Prelude Data.Semigroup Data.UUID.Types> y
Just (Last {getLast = a1b7bc82-928f-4da8-92d7-2567548a8826})
Prelude Data.Semigroup Data.UUID.Types> Option x <> Option y
Option {getOption = Just (Last {getLast = a1b7bc82-928f-4da8-92d7-2567548a8826})}
Prelude Data.Semigroup Data.UUID.Types> Option x <> mempty
Option {getOption = Just (Last {getLast = 03c2ecdb-ef1d-4603-9de9-4a9994ba3c1e})}
The <> operator is the generic binary operation, and the way Haskell works, it changes behaviour depending on the type upon which it operates. Option is a wrapper around Maybe, and Last represents the last semigroup. When you stack UUID values inside of Option Last, you get the behaviour of selecting the right-most non-empty value.
In fact,
Any semigroup S may be turned into a monoid simply by adjoining an element e not in S and defining e • s = s = s • e for all s ∈ S.
That's just a mathematical way of saying that if you have a semigroup, you can add an extra value e and make e behave like the identity for the monoid you're creating. That extra value is nothing. The way Haskell's Data.Semigroup module models a monoid over Maybe instances aligns with the underlying mathematics.
Conclusion #
Just as there's more than one monoid over numbers, and more than one monoid over Boolean values, there's more than one monoid over Maybe values. The most useful one may be the one that elevates any semigroup to a monoid by adding nothing as the identity, but others exist. While, at first glance, the first and last monoids over Maybes look like operations in their own right, they're just applications of the general rule. They elevate the first and last semigroups to monoids by 'wrapping' them in Maybes, and using nothing as the identity.
Next: Lazy monoids.
The Maybe functor
An introduction to the Maybe functor for object-oriented programmers.
This article is an instalment in an article series about functors.
One of the simplest, and easiest to understand, functors is Maybe. It's also sometimes known as the Maybe monad, but this is not a monad tutorial; it's a functor tutorial. Maybe is many things; one of them is a functor. In F#, Maybe is called option.
Motivation #
Maybe enables you to model a value that may or may not be present. Object-oriented programmers typically have a hard time grasping the significance of Maybe, since it essentially does the same as null in mainstream object-oriented languages. There are differences, however. In languages like C# and Java, most things can be null, which can lead to much defensive coding. What happens more frequently, though, is that programmers forget to check for null, with run-time exceptions as the result.
A Maybe value, on the other hand, makes it explicit that a value may or may not be present. In statically typed languages, it also forces you to deal with the case where no data is present; if you don't, your code will not compile.
Finally, in a language like C#, null has no type, but a Maybe value always has a type.
If you appreciate the tenet that explicit is better than implicit, then you should favour Maybe over null.
Implementation #
If you've read the introduction, then you know that IEnumerable<T> is a functor. In many ways, Maybe is like IEnumerable<T>, but it's a particular type of collection that can only contain zero or one element(s). There are various ways in which you can implement Maybe in an object-oriented language like C#; here's one:
public sealed class Maybe<T> { internal bool HasItem { get; } internal T Item { get; } public Maybe() { this.HasItem = false; } public Maybe(T item) { if (item == null) throw new ArgumentNullException(nameof(item)); this.HasItem = true; this.Item = item; } public Maybe<TResult> Select<TResult>(Func<T, TResult> selector) { if (selector == null) throw new ArgumentNullException(nameof(selector)); if (this.HasItem) return new Maybe<TResult>(selector(this.Item)); else return new Maybe<TResult>(); } public T GetValueOrFallback(T fallbackValue) { if (fallbackValue == null) throw new ArgumentNullException(nameof(fallbackValue)); if (this.HasItem) return this.Item; else return fallbackValue; } public override bool Equals(object obj) { var other = obj as Maybe<T>; if (other == null) return false; return object.Equals(this.Item, other.Item); } public override int GetHashCode() { return this.HasItem ? this.Item.GetHashCode() : 0; } }
This is a generic class with two constructors. The parameterless constructor indicates the case where no value is present, whereas the other constructor overload indicates the case where exactly one value is available. Notice that a guard clause prevents you from accidentally passing null as a value.
The Select method has the correct signature for a functor. If a value is present, it uses the selector method argument to map item to a new value, and return a new Maybe<TResult> value. If no value is available, then a new empty Maybe<TResult> value is returned.
This class also override Equals. This isn't necessary in order for it to be a functor, but it makes it easier to compare two Maybe<T> values.
A common question about such generic containers is: how do you get the value out of the container?
The answer depends on the particular container, but in this example, I decided to enable that functionality with the GetValueOrFallback method. The only way to get the item out of a Maybe value is by supplying a fall-back value that can be used if no value is available. This is one way to guarantee that you, as a client developer, always remember to deal with the empty case.
Usage #
It's easy to use this Maybe class:
var source = new Maybe<int>(42);
This creates a new Maybe<int> object that contains the value 42. If you need to change the value inside the object, you can, for example, do this:
Maybe<string> dest = source.Select(x => x.ToString());
Since C# natively understands functors through its query syntax, you could also have written the above translation like this:
Maybe<string> dest = from x in source select x.ToString();
It's up to you and your collaborators whether you prefer one or the other of those alternatives. In both examples, though, dest is a new populated Maybe<string> object containing the string "42".
A more realistic example could be as part of a line-of-business application. Many enterprise developers are familiar with the Repository pattern. Imagine that you'd like to query a repository for a Reservation object. If one is found in the database, you'd like to convert it to a view model, so that you can display it.
var viewModel = repository.Read(id) .Select(r => r.ToViewModel()) .GetValueOrFallback(ReservationViewModel.Null);
The repository's Read method returns Maybe<Reservation>, indicating that it's possible that no object is returned. This will happen if you're querying the repository for an id that doesn't exist in the underlying database.
While you can translate the (potential) Reservation object to a view model (using the ToViewModel extension method), you'll have to supply a default view model to handle the case when the reservation wasn't found.
ReservationViewModel.Null is a static read-only class field implementing the Null Object pattern. Here, it's used for the fall-back value, in case no object was returned from the repository.
Notice that while you need a fall-back value at the end of your fluent interface pipeline, you don't need fall-back values for any intermediate steps. Specifically, you don't need a Null Object implementation for your domain model (Reservation). Furthermore, no defensive coding is required, because Maybe<T> guarantees that the object passed to selector is never null.
First functor law #
A Select method with the right signature isn't enough to be a functor. It must also obey the functor laws. Maybe obeys both laws, which you can demonstrate with a few examples. Here's some test cases for a populated Maybe:
[Theory] [InlineData("")] [InlineData("foo")] [InlineData("bar")] [InlineData("corge")] [InlineData("antidisestablishmentarianism")] public void PopulatedMaybeObeysFirstFunctorLaw(string value) { Func<string, string> id = x => x; var m = new Maybe<string>(value); Assert.Equal(m, m.Select(id)); }
This parametrised unit test uses xUnit.net to demonstrate that a populated Maybe value doesn't change when translated with the local id function, since id returns the input unchanged.
The first functor law holds for an empty Maybe as well:
[Fact] public void EmptyMaybeObeysFirstFunctorLaw() { Func<string, string> id = x => x; var m = new Maybe<string>(); Assert.Equal(m, m.Select(id)); }
When a Maybe starts empty, translating it with id doesn't change that it's empty. It's worth noting, however, that the original and the translated objects are considered equal because Maybe<T> overrides Equals. Even in the case of the empty Maybe, the value returned by Select(id) is a new object, with a memory address different from the original value.
Second functor law #
You can also demonstrate the second functor law with some examples, starting with some test cases for the populated case:
[Theory] [InlineData("", true)] [InlineData("foo", false)] [InlineData("bar", false)] [InlineData("corge", false)] [InlineData("antidisestablishmentarianism", true)] public void PopulatedMaybeObeysSecondFunctorLaw(string value, bool expected) { Func<string, int> g = s => s.Length; Func<int, bool> f = i => i % 2 == 0; var m = new Maybe<string>(value); Assert.Equal(m.Select(g).Select(f), m.Select(s => f(g(s)))); }
In this parametrised test, f and g are two local functions. g returns the length of a string (for example, the length of antidisestablishmentarianism is 28). f evaluates whether or not a number is even.
Whether you decide to first translate m with g, and then translate the return value with f, or you decide to translate the composition of those functions in a single Select method call, the result should be the same.
The second functor law holds for the empty case as well:
[Fact] public void EmptyMaybeObeysSecondFunctorLaw() { Func<string, int> g = s => s.Length; Func<int, bool> f = i => i % 2 == 0; var m = new Maybe<string>(); Assert.Equal(m.Select(g).Select(f), m.Select(s => f(g(s)))); }
Since m is empty, applying the translations doesn't change that fact - it only changes the type of the resulting object, which is an empty Maybe<bool>.
Haskell #
In Haskell, Maybe is built in. You can create a Maybe value containing an integer like this (the type annotations are optional):
source :: Maybe Int source = Just 42
Mapping source to a String can be done like this:
dest :: Maybe String dest = fmap show source
The function fmap corresponds to the above C# Select method.
It's also possible to use infix notation:
dest :: Maybe String dest = show <$> source
The <$> operator is an alias for fmap.
Whether you use fmap or <$>, the resulting dest value is Just "42".
If you want to create an empty Maybe value, you use the Nothing data constructor.
F# #
Maybe is also a built-in type in F#, but here it's called option instead of Maybe. You create an option containing an integer like this:
// int option let source = Some 42
While the case where a value is present was denoted with Just in Haskell, in F# it's called Some.
You can translate option values using the map function from the Option module:
// string option let dest = source |> Option.map string
Finally, if you want to create an empty option value, you can use the None case constructor.
Summary #
Together with a functor called Either, Maybe is one of the workhorses of statically typed functional programming. You aren't going to write much F# or Haskell before you run into it. In C# I've used variations of the above Maybe<T> class for years, with much success.
In this article, I only discussed Maybe in its role of being a functor, but it's so much more than that! It's also an applicative functor, a monad, and traversable (enumerable). Not all functors are that rich.
Next: An Either functor.
Comments
I think it's interesting to note that since C# 8.0 we don't require an extra generic type like Maybe<T> anymore in order to implement the maybe functor. Because C# 8.0 added nullable reference types, everything can be nullable now. By adding the right extension methods we can make T? a maybe functor and use its beautifully succinct syntax.
Due to the C#'s awkward dichotomy between value and reference types this involves some busy work, so I created a small nuget package for interested parties.
Robert, thank you for writing. That feature indeed seems like an improvement. I'm currently working in a code base with that feature enabled, and I definitely think that it's better than C# without it, but Maybe<T> it isn't. There's too many edge cases and backwards compatibility issues to make it as good.
Pragmatically, this is now what C# developers have to work with. Since it's now part of the language, it's likely that use of it will become more widespread than we could ever hope that Maybe<T> would be, so that's fine. On the other hand, Maybe<T> is now an impossible sell to C# developers.
Because of all the edge cases that the compiler could overlook, however, I don't see how this is ever going to be as good as a language without null references in the first place.

Comments
James