ploeh blog danish software design
Partial application is dependency injection
The equivalent of dependency injection in F# is partial function application, but it isn't functional.
This is the second article in a small article series called from dependency injection to dependency rejection.
People often ask me how to do dependency injection in F#. That's only natural, since I wrote Dependency Injection in .NET some years ago, and also since I've increasingly focused my energy on F# and other functional programming languages.
Over the years, I've seen other F# experts respond to that question, and often, the answer is that partial function application is the F# way to do dependency injection. For some years, I believed that as well. It turns out to be true in one sense, but incorrect in another. Partial application is equivalent to dependency injection. It's just not a functional solution to dealing with dependencies.
(To be as clear as I can be: I'm not claiming that partial application isn't functional. What I claim is that partial application used for dependency injection isn't functional.)
Attempted dependency injection using functions #
Returning to the example from the previous article, you could try to rewrite MaîtreD.TryAccept as a function:
// int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation // -> int option let tryAccept capacity readReservations createReservation reservation = let reservedSeats = readReservations reservation.Date |> List.sumBy (fun x -> x.Quantity) if reservedSeats + reservation.Quantity <= capacity then createReservation { reservation with IsAccepted = true } |> Some else None
You could imagine that this tryAccept function is part of a module called MaîtreD, just to keep the examples as equivalent as possible.
The function takes four arguments. The first is the capacity of the restaurant in question; a primitive integer. The next two arguments, readReservations and createReservation fill the role of the injected IReservationsRepository in the previous article. In the object-oriented example, the TryAccept method used two methods on the repository: ReadReservations and Create. Instead of using an interface, in the F# function, I make the function take two independent functions. They have (almost) the same types as their C# counterparts.
The first three arguments correspond to the injected dependencies in the previous MaîtreD class. The fourth argument is a Reservation value, which corresponds to the input to the previous TryAccept method.
Instead of returning a nullable integer, this F# version returns an int option.
The implementation is also equivalent to the C# example: Read the relevant reservations from the database using the readReservations function argument, and sum over their quantities. Based on the number of already reserved seats, decide whether or not to accept the reservation. If you can accept the reservation, set IsAccepted to true, call the createReservation function argument, and pipe the returned ID (integer) to Some. If you can't accept the reservation, then return None.
Notice that the first three arguments are 'dependencies', whereas the last argument is the 'actual input', if you will. This means that you can use partial function application to compose this function.
Application #
If you recall the definition of the previous IMaîtreD interface, the TryAccept method was defined like this (C# code snippet):
int? TryAccept(Reservation reservation);
You could attempt to define a similar function with the type Reservation -> int option. Normally, you'd want to do this closer to the boundary of the application, but the following example demonstrates how to 'inject' real database operations into the function.
Imagine that you have a DB module with these functions:
module DB = // string -> DateTimeOffset -> Reservation list let readReservations connectionString date = // .. // string -> Reservation -> int let createReservation connectionString reservation = // ..
The readReservations function takes a connection string and a date as arguments, and returns a list of reservations for that date. The createReservation function also takes a connection string, as well as a reservation. When invoked, it creates a new record for the reservation and returns the ID of the newly created row. (This sort of API violates CQS, so you should consider alternatives.)
If you partially apply these functions with a valid connection string, both have the type desired for their roles in tryAccept. This means that you can create a function from these elements:
// Reservation -> int option let tryAcceptComposition = let read = DB.readReservations connectionString let create = DB.createReservation connectionString tryAccept 10 read create
Notice how tryAccept itself is partially applied. Only the arguments corresponding to the C# dependencies are passed to it, so the return value is a function that 'waits' for the last argument: the reservation. As I've attempted to indicate by the code comment above the function, it has the desired type of Reservation -> int option.
Equivalence #
Partial application used like this is equivalent to dependency injection. To see how, consider the generated Intermediate Language (IL).
F# is a .NET language, so it compiles to IL. You can decompile that IL to C# to get a sense of what's going on. If you do that with the above tryAcceptComposition, you get something like this:
internal class tryAcceptComposition@17 : FSharpFunc<Reservation, FSharpOption<int>> { public int capacity; public FSharpFunc<Reservation, int> createReservation; public FSharpFunc<DateTimeOffset, FSharpList<Reservation>> readReservations; internal tryAcceptComposition@17( int capacity, FSharpFunc<DateTimeOffset, FSharpList<Reservation>> readReservations, FSharpFunc<Reservation, int> createReservation) { this.capacity = capacity; this.readReservations = readReservations; this.createReservation = createReservation; } public override FSharpOption<int> Invoke(Reservation reservation) { return MaîtreD.tryAccept<int>( this.capacity, this.readReservations, this.createReservation, reservation); } }
I've cleaned it up a bit, mostly by removing all attributes from the various elements. Notice how this is a class, with class fields, and a constructor that takes values for the fields and assigns them. It's constructor injection!
Partial application is dependency injection.
It compiles, works as expected, but is it functional?
Evaluation #
People sometimes ask me: How do I know whether my F# code is functional?
I sometimes wonder about that myself, but unfortunately, as nice a language as F# is, it doesn't offer much help in that regard. Its emphasis is on functional programming, but it allows mutation, object-oriented programming, and even procedural programming. It's a friendly and forgiving language. (This also makes it a great 'beginner' functional language, because you can learn functional concepts piecemeal.)
Haskell, on the other hand, is a strictly functional language. In Haskell, you can only write your code in the functional way.
Fortunately, F# and Haskell are similar enough that it's easy to port F# code to Haskell, as long as the F# code already is 'sufficiently functional'. In order to evaluate if my F# code is properly functional, I sometimes port it to Haskell. If I can get it to compile and run in Haskell, I take that as confirmation that my code is functional.
I've previously shown an example similar to this one, but I'll repeat the experiment here. Will porting tryAccept and tryAcceptComposition to Haskell work?
It's easy to port tryAccept:
tryAccept :: Int -> (ZonedTime -> [Reservation]) -> (Reservation -> Int) -> Reservation -> Maybe Int tryAccept capacity readReservations createReservation reservation = let reservedSeats = sum $ map quantity $ readReservations $ date reservation in if reservedSeats + quantity reservation <= capacity then Just $ createReservation $ reservation { isAccepted = True } else Nothing
Clearly, there are differences, but I'm sure that you can also see the similarities. The most important feature of this function is that it's pure. All Haskell functions are pure by default, unless explicitly declared to be impure, and that's not the case here. This function is pure, and so are both readReservations and createReservation.
The Haskell version of tryAccept compiles, but what about tryAcceptComposition?
Like the F# code, the experiment is to see if it's possible to 'inject' functions that actually operate against a database. Equivalent to the F# example, imagine that you have this DB module:
readReservations :: ConnectionString -> ZonedTime -> IO [Reservation] readReservations connectionString date = -- .. createReservation :: ConnectionString -> Reservation -> IO Int createReservation connectionString reservation = -- ..
Database operations are, by definition, impure, and Haskell admirably models that with the type system. Notice how both functions return IO values.
If you partially apply both functions with a valid connection string, the IO context remains. The type of DB.readReservations connectionString is ZonedTime -> IO [Reservation], and the type of DB.createReservation connectionString is Reservation -> IO Int. You can try to pass them to tryAccept, but the types don't match:
tryAcceptComposition :: Reservation -> IO (Maybe Int) tryAcceptComposition reservation = let read = DB.readReservations connectionString create = DB.createReservation connectionString in tryAccept 10 read create reservation
This doesn't compile.
It doesn't compile, because the database operations are impure, and tryAccept wants pure functions.
In short, partial application used for dependency injection isn't functional.
Summary #
Partial application in F# can be used to achieve a result equivalent to dependency injection. It compiles and works as expected, but it's not functional. The reason it's not functional is that (most) dependencies are, by their very nature, impure. They're either non-deterministic, have side-effects, or both, and that's often the underlying reason that they are factored into dependencies in the first place.
Pure functions, however, can't call impure functions. If they could, they would become impure themselves. This rule is enforced by Haskell, but not by F#.
When you inject impure operations into an F# function, that function becomes impure as well. Dependency injection makes everything impure, which explains why it isn't functional.
Functional programming solves the problem of decoupling (side) effects from program logic another way. That's the topic of the next article.
Next: Dependency rejection.
Dependency injection is passing an argument
Is dependency injection really just passing an argument? A brief review.
This is the first article in a small article series called from dependency injection to dependency rejection.
In a talk at the 2012 Northeast Scala Symposium, Rúnar Bjarnason casually remarked that dependency injection is "really just a pretentious way to say 'taking an argument'". Given that I've written a 500+ pages book about dependency injection, you might expect me to disagree with that. Yet, there's some truth to that statement, although it's not quite as simple as that.
In this article, I'll show you some simple examples and explain why, on the one hand, Rúnar Bjarnason is right, but also, on the other hand, why there's a bit more to it.
Restaurant reservation example #
Like the other articles in this series, the example scenario is on-line restaurant reservation. Imagine that you've been asked to develop an HTTP-based API that accepts JSON documents containing restaurant reservations. Furthermore, assume that you're using ASP.NET Web API with C# for the job, and that you're aspiring to use domain-driven design.
In order to handle the incoming POST request, you could write an action method like this:
public IHttpActionResult Post(ReservationRequestDto dto) { var validationMsg = validator.Validate(dto); if (validationMsg != "") return this.BadRequest(validationMsg); var r = mapper.Map(dto); var id = maîtreD.TryAccept(r); if (id == null) return this.StatusCode(HttpStatusCode.Forbidden); return this.Ok(); }
This method follows a simple and familiar path: validate input, map to a domain model, delegate to said model, examine posterior state, and return a result.
You may have noticed, though, that this method doesn't do all the work itself. It delegates some of the work to collaborators: validator, mapper, and maîtreD. Where do these collaborators come from?
They are dependencies. Could you make the Post method take them as arguments?
Unfortunately, you can't. The Post method constitutes part of the boundary of the HTTP API. ASP NET Web API routes and dispatches incoming HTTP requests by convention, and action methods must follow that convention. You can't just make the function take any argument you'd like, so you have to find another place to pass those dependencies to the object.
The second-best option (after the Post method itself) is via the constructor:
public ReservationsController( IValidator validator, IMapper mapper, IMaîtreD maîtreD) { this.validator = validator; this.mapper = mapper; this.maîtreD = maîtreD; }
This is the application of a design pattern called constructor injection. It captures the dependencies in class fields, making them available for members (like Post) of the class.
This turns out to be a regular pattern.
Turtles all the way down #
You could argue that the Post method is a special case, since it's part of the boundary of the system, and therefore must adhere to specific rules. On the other hand, these rule don't apply deeper in the implementation, so could you implement other objects by simply passing in dependencies as arguments?
Consider, as an example, the implementation of IMaîtreD.TryAccept:
public int? TryAccept(Reservation reservation) { var reservedSeats = reservationsRepository .ReadReservations(reservation.Date) .Sum(r => r.Quantity); if (reservedSeats + reservation.Quantity <= capacity) { reservation.IsAccepted = true; return reservationsRepository.Create(reservation); } return null; }
This method has another collaborator: reservationsRepository. It's another dependency. Where does it come from?
Could you make the TryAccept method take reservationsRepository as an argument?
Unfortunately, that's not possible either, because the method is defined by the IMaîtreD interface:
public interface IMaîtreD { int? TryAccept(Reservation reservation); }
You may recall that the above Post method is programmed against the IMaîtreD interface, and not the concrete class. It'd be a leaky abstraction to add IReservationsRepository as an argument to IMaîtreD.TryAccept, because not all implementations of the interface may need that dependency. Or perhaps another implementation has another dependency. Should we add that to the parameter list of IMaîtreD.TryAcceptas well?
Surely, that's not a tenable design principle. On the other hand, by using constructor injection, you can decouple implementation details from your abstractions:
public MaîtreD(int capacity, IReservationsRepository reservationsRepository) { this.capacity = capacity; this.reservationsRepository = reservationsRepository; }
This constructor not only takes an IReservationsRepository object, but also an integer that represents the capacity of the restaurant in question. This demonstrates that dependencies can also be primitive values.
Summary #
Dependency injection is, in a sense, only a specific way for objects to take arguments. Often, however, objects have roles defined by the interfaces they implement. Such objects may need collaborators that are not available via the APIs defined by these interfaces, so you'll have to supply dependencies via members that belong to the concrete class in question. Passing dependencies via a class' constructor is the best way to do that.
Comments
Hey Mark. You may want to update the article slightly to cover the use of the [FromServices] attribute, which allows you to inject any service into a controller action as method-level injection. The main article on it is this one.
I'm personally not a fan of using it, but it is an option that transforms standard injection into parameter-passing for controllers.
Juliano, thank you for writing. I wasn't aware of that particular capability, so thank you for bringing it to my attention.
My article attempts to explain a general software design problem, as well as a possible solution. While it uses ASP.NET as an example context, the main point is independent of any particular framework, or language, for that matter.
From dependency injection to dependency rejection
The problem typically solved by dependency injection in object-oriented programming is solved in a completely different way in functional programming.
Several years ago, I wrote a book called Dependency Injection in .NET, which was published in 2011. The book contains examples in C#, but since then I've increasingly become interested in functional programming to the extend that I now consider F# my primary language.
With that combination, it's no wonder that people often ask me how to do dependency injection in functional programming.
I've seen more than one answer, from other people, explaining how partial function application is equivalent to dependency injection. In a small series of articles, I'll explain both why this is true, but also why it's not functional. I'll conclude by showing a functional alternative to decoupling logic and (side) effects.

(Comic courtesy of John Muellerleile and Igal Tabachnik.)
There's another school of functional programmers who believe that dependency injection in functional programming involves a Free monad.
You can often make do with less, though.
In my experience, it's usually enough to refactor a unit to take only direct input and output, and then compose an impure/pure/impure 'sandwich'. You'll see an example later.
This article series contains the following parts:
- Dependency injection is passing an argument
- Partial application is dependency injection
- Dependency rejection
- Pure interactions
The scenario is to implement an HTTP-based API that can accept incoming JSON documents that represent restaurant reservations.
The fourth article on pure interactions is a gateway to another article series on free monads.
I should point out that nowhere in this article series do I reject dependency injection as a set of object-oriented patterns. In object-oriented programming, dependency injection is a well-known and comprehensively described way to achieve decoupling and testability. In the next article, you'll see a brief review of dependency injection in C#.
Decoupling application errors from domain models
How to prevent application-specific error cases from infecting your domain models.
Functional error-handling is often done with the Either monad. If all is good, the right case is returned, but if things go wrong, you'll want to return a value that indicates the error. In an application, you'll often need to be able to distinguish between different kinds of errors.
From application errors to HTTP responses #
When an application encounters an error, it should respond appropriately. A GUI-based application should inform the user about the error, a batch job should log it, and a REST API should return the appropriate HTTP status code.
Regular readers of this blog will know that I write many RESTful APIs in F#, using ASP.NET Web API. Since I like to write functional F#, but ASP.NET Web API is an object-oriented framework, I prefer to escape the object-oriented framework as soon as possible. (In general, it makes good architectural sense to write most of your code as framework-independent as possible.)
In my Test-Driven Development with F# Pluralsight course (a free, condensed version is also available), I demonstrate how to handle various error cases in a Controller class:
type ReservationsController (imp) = inherit ApiController () member this.Post (dtr : ReservationDtr) : IHttpActionResult = match imp dtr with | Failure (ValidationError msg) -> this.BadRequest msg :> _ | Failure CapacityExceeded -> this.StatusCode HttpStatusCode.Forbidden :> _ | Success () -> this.Ok () :> _
The injected imp function is a complete, composed, vertical feature implementation that performs both input validation, business logic, and data access. If input validation fails, it'll return Failure (ValidationError msg), and that value is translated to a 400 Bad Request response. Likewise, if the business logic returns Failure CapacityExceeded, the response becomes 403 Forbidden, and a success is returned as 200 OK.
Both ValidationError and CapacityExceeded are cases of an Error type. This is only a simple example, so these are the only cases defined by that type:
type Error = | ValidationError of string | CapacityExceeded
This seems reasonable, but there's a problem.
Error infection #
In F#, a function can't use a type unless that type is already defined. This is a problem because the Error type defined above mixes different concerns. If you seek to make illegal states unrepresentable, it follows that validation is not a concern in your domain model. Validation is still important at the boundary of an application, so you can't just ignore it. The ValidationError case relates to the application boundary, while CapacityExceeded relates to the domain model.
Still, when implementing your domain model, you may want to return a CapacityExceeded value from time to time:
// int -> int -> Reservation -> Result<Reservation,Error> let checkCapacity capacity reservedSeats reservation = if capacity < reservation.Quantity + reservedSeats then Failure CapacityExceeded else Success reservation
Notice how the return type of this function is Result<Reservation,Error>. In order to be able to implement your domain model, you've now pulled in the Error type, which also defines the ValidationError case. Your domain model is now polluted by an application boundary concern.
I think many developers would consider this trivial, but in my experience, failure to manage dependencies is the dominant reason for code rot. It makes the code less general, and less reusable, because it's now coupled to something that may not fit into a different context.
Particularly, the situation in the example looks like this:
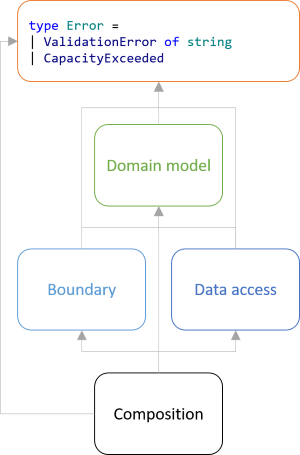
Boundary and data access modules depend on the domain model, as they should, but everything depends on the Error type. This is wrong. Modules or libraries should be able to define their own error types.
The Error type belongs in the Composition Root, but it's impossible to put it there because F# prevents circular dependencies (a treasured language feature).
Fortunately, the fix is straightforward.
Mapped Either values #
A domain model should be self-contained. As Robert C. Martin puts it in APPP:
Abstractions should not depend upon details. Details should depend upon abstractions.Your domain model is an abstraction of the real world (that's why it's called a model), and is the reason you're developing a piece of software in the first place. So start with the domain model:
type BookingError = CapacityExceeded // int -> int -> Reservation -> Result<Reservation,BookingError> let checkCapacity capacity reservedSeats reservation = if capacity < reservation.Quantity + reservedSeats then Failure CapacityExceeded else Success reservation
In this example, there's only a single type of domain error (CapacityExceeded), but that's mostly because this is an example. Real production code could define a domain error union with several cases. The crux of the matter is that BookingError isn't infected with irrelevant implementation details like validation error types.
You're still going to need an exhaustive discriminated union to model all possible error cases for your particular application, but that type belongs in the Composition Root. Accordingly, you also need a way to return validation errors in your validation module. Often, a string is all you need:
// ReservationDtr -> Result<Reservation,string> let validateReservation (dtr : ReservationDtr) = match dtr.Date |> DateTimeOffset.TryParse with | (true, date) -> Success { Reservation.Date = date Name = dtr.Name Email = dtr.Email Quantity = dtr.Quantity } | _ -> Failure "Invalid date."
The validateReservation function returns a Reservation value when validation succeeds, and a simple string with an error message if it fails.
You could, conceivably, return string values for errors from many different places in your code, so you're going to map them into an appropriate error case that makes sense in your application.
In this particular example, the Controller shown above should still look like this:
type Error = | ValidationError of string | DomainError type ReservationsController (imp) = inherit ApiController () member this.Post (dtr : ReservationDtr) : IHttpActionResult = match imp dtr with | Failure (ValidationError msg) -> this.BadRequest msg :> _ | Failure DomainError -> this.StatusCode HttpStatusCode.Forbidden :> _ | Success () -> this.Ok () :> _
Notice how similar this is to the initial example. The important difference, however, is that Error is defined in the same module that also implements ReservationsController. This is part of the composition of the specific application.
In order to make that work, you're going to need to map from one failure type to another. This is trivial to do with an extra function belonging to your Result (or Either) module:
// ('a -> 'b) -> Result<'c,'a> -> Result<'c,'b> let mapFailure f x = match x with | Success succ -> Success succ | Failure fail -> Failure (f fail)
This function takes any Result value and maps the failure case instead of the success case. It enables you to transform e.g. a BookingError into a DomainError:
let imp candidate = either { let! r = validateReservation candidate |> mapFailure ValidationError let i = SqlGateway.getReservedSeats connectionString r.Date let! r = checkCapacity 10 i r |> mapFailure (fun _ -> DomainError) return SqlGateway.saveReservation connectionString r }
This composition is a variation of the composition I've previously published. The only difference is that the error cases are now mapped into the application-specific Error type.
Conclusion #
Errors can occur in diverse places in your code base: when validating input, when making business decisions, when writing to, or reading from, databases, and so on.
When you use the Either monad for error handling, in a strongly typed language like F#, you'll need to define a discriminated union that models all the error cases you care about in the specific application. You can map module-specific error types into such a comprehensive error type using a function like mapFailure. In Haskell, it would be the first function of the Bifunctor typeclass, so this is a well-known function.
Comments
Mark,
Why is it a problem to use HttpStatusCode in the domain model. They appear to be a standard way of categorizing errors.
David, thank you for writing. The answer depends on your goals and definition of domain model.
I usually think of domain models in terms of separation of concerns. The purpose of a domain model is to model the business logic, and as Martin Fowler writes in PoEAA about the Domain Model pattern, "you'll want the minimum of coupling from the Domain Model to other layers in the system. You'll notice that a guiding force of many layering patterns is to keep as few dependencies as possible between the domain model and the other parts of the system."
In other words, you're separating the concern of implementing the business rules from the concerns of being able to save data in a database, render it on a screen, send emails, and so on. While also important, these are separate concerns, and I want to be able to vary those independently.
People often hear statements like that as though I want to reserve myself the right to replace my SQL Server database with Neo4J (more on that later, though!). That's actually not my main goal, but I find that if concerns are mixed, all change becomes harder. It becomes more difficult to change how data is saved in a database, and it becomes harder to change business rules.
The Dependency Inversion Principle tries to address such problems by advising that abstractions shouldn't depend on implementation details, but instead, implementation details should depend on abstractions.
This is where the goals come in. I find Robert C. Martin's definition of software architecture helpful. Paraphrased from memory, he defines a software architect's role as enabling change; not predicting change, but making sure that when change has to happen, it's as economical as possible.
As an architect, one of the heuristics I use is that I try to imagine how easily I can replace one component with another. It's not that I really believe that I may have to replace the SQL Server database with Neo4J, but thinking about how hard it would be gives me some insights about how to structure a software solution.
I also imagine what it'd be like to port an application to another environment. Can I port my web site's business rules to a batch job? Can I port my desktop client to a smart phone app? Again, it's not that I necessarily predict that I'll have to do this, but it tells me something about the degrees of freedom offered by the architecture.
If not explicitly addressed, the opposite of freedom tends to happen. In APPP, Robert C. Martin describes a number of design smells, one of them Immobility: "A design is immobile when it contains parts that could be useful in other systems, but the effort and risk involved with separating those parts from the original system are too great. This is an unfortunate, but very common occurrence."
Almost as side-effect, an immobile system is difficult to test. A unit test is a different environment than the intended environment. Well-architected systems are easy to unit test.
HTTP is a communications protocol. Its purpose is to enable exchange of information over networks. While it does that well, it's specifically concerned with that purpose. This includes HTTP status code.
If you use the heuristic of imagining that you'd have to move the heart of your application to a batch job, status codes like 301 Moved Permanently, 404 Not Found, or 405 Method Not Allowed make little sense.
Using HTTP status codes in a domain model couples the model to a particular environment, at least conceptually. It has little to do with the ubiquitous language that Eric Evans discusses in DDD.
From REST to algebraic data
Mapping RESTful HTTP requests to values of algebraic data types is easy.
In previous articles, you've seen how to easily model a simple domain model with algebraic data types, and how to use RESTful API design to surface such a model at the boundary of an application. In this article, you'll see how trivial it is to map incoming HTTP requests back to values of algebraic data types.
The advantage of REST is that you can make illegal states unrepresentable. Clients follow links, and while clients are supposed to treat links as opaque values, URLs still contain information your API can use.
Routing and dispatching #
Continuing where the previous article left off, clients can issue POST requests against a URL like https://example.com/credit-card. On the server, a well-known piece of code handles such requests. (In the example code base I've used so far, I've been using ASP.NET Web API, so the code that handles such a request is a Controller.) Since you know that URLs like that are always routed to that particular piece of code, you can create a new PaymentType value that specifically represents an individual payment with a credit card:
let paymentType = Individual { Name = "credit-card"; Action = "Pay" }
If, on the other hand, the client is using a provided link to POST a representation against the URL https://example.com/recurrent/start/credit-card, your server-side dispatcher will route the request to a different handler (Controller), in which case you can create a PaymentType value like this:
let paymentType = Parent { Name = "credit-card"; Action = "Pay" }
Finally, if the client has already created a parent payment and is now using the resulting link to create child payments, it may be POSTing to a URL like https://example.com/recurrent/42. Your server-side dispatcher will route that request to a third handler. Most web frameworks, including ASP.NET Web API, will be able to pull values out of URLs. In this case, you can configure it so that it pulls the value 42 out of the URL and binds it to a value called transactionKey. With this, again it's trivial to create a PaymentType value:
let paymentType = Child (transactionKey, { Name = "credit-card"; Action = "PayRecurrent" })
Notice that, despite containing different data, and being created three different places in the code base, they all have the same type: PaymentType. This means that you can pass these values to a common pay function, which handles the actual communication with the third-party payment service.
Code reuse #
Independent of the route the data arrived at, a central, reusable function named pay handles all such payments. This is still an impure boundary function that takes various other input apart from PaymentType. Without going into too much detail, it has a type like Config -> PaymentType -> Result<PaymentDtr,BoundaryFailure>. Don't worry if some of the details look obscure; the important point is that pay is a function that takes a PaymentType value as input. You can visualise the transition from HTTP requests to a function call like this:
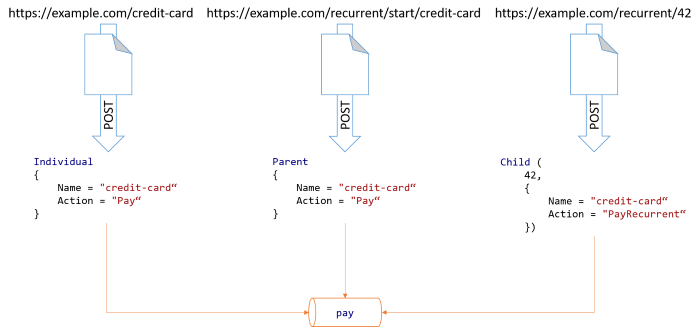
The pay function is composed from various smaller functions, some pure and some impure. Ultimately, it transforms all the input data to the format required by the third-party payment service, and forwards the transaction information. Inside that function you'll find the pattern match that you saw in my previous article.
Summary #
By making good use of routing and dispatching, you can easily map incoming HTTP requests to values of algebraic data types. This enables you to close the loop on exposing your domain model at the boundary of your system. Not only can clients request data from your API in terms of your model, but when clients send data to your API, you can translate that data back to your model.
Domain modelling with REST
Make illegal states unrepresentable by using hyperlinks as the engine of application state.
Every piece of software, whether it's a web service, smart phone app, batch job, or speech recognition system, interfaces with the world in some way. Sometimes, that interface is a user interface, sometimes it's a machine-readable interface; sometimes it involves rendering pixels on a screen, and sometimes it involves writing to files, selecting records from a database, sending emails, and so on.
Programmers often struggle with how to model these interactions. This is particularly difficult because at the boundaries, systems no longer adhere to popular programming paradigms. Previously, I've explained why, at the boundaries, applications aren't object-oriented. By the same type of argument, neither are they functional (as in 'functional programming').
If that's the case, why should you even bother with 'domain modelling'? Particularly, does it even matter that, with algebraic data types, you can make illegal states unrepresentable? If you need to compromise once you hit the boundary of your application, is it worth the effort?
It is, if you structure your application correctly. Proper (level 3) REST architecture gives you one way to structure applications in such a way that you can surface the constraints of your domain model to the interface layer. When done correctly, you can also make illegal states unrepresentable at the boundary.
A payment example #
In my previous article, I demonstrated how to use (static) types to model an on-line payment domain. To summarise, my task was to model three types of payments:
- Individual payments, which happen only once.
- Parent payments, which start a long-term payment relationship.
- Child payments, which are automated payments originally authorised by an initial parent payment.
"StartRecurrent" : "false" |
"StartRecurrent" : "true" |
|
|---|---|---|
"OriginalTransactionKey" : null |
Individual | Parent |
"OriginalTransactionKey" : "1234ABCD" |
Child | (Illegal) |
StartRecurrent to true. The other three combinations, on the other hand, are valid.
As I demonstrated in my previous article, you can easily model this with algebraic data types.
At the boundary, however, there are no static types, so how could you model something like that as a web service?
A RESTful solution #
A major advantage of REST is that it gives you a way to realise your domain model at the application boundary. It does require, though, that you design the API according to level 3 of the Richardson maturity model. In other words, it's not REST if you're merely tunnelling JSON (or XML) through HTTP. It's still not REST if you publish URL templates and expect clients to fill data into specific place-holders of those URLs.
It's REST if the only way a client can interact with your API is by following hyperlinks.
If you follow those design principles, however, it's easy to model the above payment domain as a RESTful API.
In the following, I will show examples in XML, but it could as well have been JSON. After all, a true REST API must support content negotiation. One of the reasons that I prefer XML is that I can use XPath to point out various nodes.
A client must begin at a pre-published 'home' resource, just like the home page of a web site. This resource presents affordances in the shape of hyperlinks. As recommended by the RESTful Web Services Cookbook, I always use ATOM links:
<home xmlns="http://example.com/payment" xmlns:atom="http://www.w3.org/2005/Atom"> <payment-methods> <payment-method> <links> <atom:link rel="example:pay-individual" href="https://example.com/gift-card" /> </links> <id>gift-card</id> </payment-method> <payment-method> <links> <atom:link rel="example:pay-individual" href="https://example.com/credit-card" /> <atom:link rel="example:pay-parent" href="https://example.com/recurrent/start/credit-card" /> </links> <id>credit-card</id> </payment-method> </payment-methods> </home>
A client receiving the above response is effectively presented with a choice. It can choose to pay with a gift card or credit card, and nothing else, however much it'd like to pay with, say, PayPal. For each of these payment methods, zero or more links are available.
Specifically, there are links to create both an individual or a parent payment with a credit card, but it's only possible to make an individual payment with a gift card. You can't set up a long-term, automated payment relationship with a gift card. (This may or may not make sense, depending on how you look at it, but it's fundamentally a business decision.)
Links are defined by relationship types, which are unique identifiers present in the rel attributes. You can think of them as equivalent to the human-readable text in an HTML a tag that suggests to a human user what to expect from clicking the link; only, rel attribute values are machine-readable and part of the contract between client and service.
Notice how the above XML representation only gives a client the option of making an individual or a parent payment with a credit card. A client can't make a child payment at this point. This follows the domain model, because you can't make a child payment without first having made a parent payment.
RESTful individual payments #
If a client wishes to make an individual payment, it follows the link identified by
/home/payment-methods/payment-method[id = 'credit-card']/links/atom:link[@rel = 'example:pay-individual']/@href
In the above XPath query, I've ignored the default document namespace in order to make the expression more readable. The query returns https://example.com/credit-card, and the client can now make an HTTP POST request against that URL with a JSON or XML document containing details about the payment (not shown here, because it's not important for this particular discussion).
RESTful parent payments #
If a client wishes to make a parent payment, the initial procedure is the same. First, it follows the link identified by
/home/payment-methods/payment-method[id = 'credit-card']/links/atom:link[@rel = 'example:pay-parent']/@href
The result of that XPath query is https://example.com/recurrent/start/credit-card, so the client can make an HTTP POST request against that URL with the payment details. Unlike the response for an individual payment, the response for a parent payment contains another link:
<payment xmlns="http://example.com/payment" xmlns:atom="http://www.w3.org/2005/Atom"> <links> <atom:link rel="example:pay-child" href="https://example.com/recurrent/42" /> <atom:link rel="example:payment-details" href="https://example.com/42" /> </links> <amount>13.37</amount> <currency>EUR</currency> <invoice>1234567890</invoice> </payment>
This response echoes the details of the payment: this is a payment of 13.37 EUR for invoice 1234567890. It also includes some links that a client can use to further interact with the payment:
- The
example:payment-detailslink can be used to query the API for details about the payment, for example its status. - The
example:pay-childlink can be used to make a child payment.
example:pay-child link is only returned if the previous payment was a parent payment. When a client makes an individual payment, this link isn't present in the response, but when the client makes a parent payment, it is.
Another design principle of REST is that cool URIs don't change; once the API has shown a URL like https://example.com/recurrent/42 to a client, it should honour that URL indefinitely. The upshot of that is that a client can save that URL for later use. If a client wants to, say, renew a subscription, it can make a new HTTP POST request to that URL a month later, and that's going to be a child payment. Clients don't have to hack the URL in order to figure out what the transaction key is; they can simply store the complete URL as is and use it later.
A network of options #
Using a design like the one sketched above, you can make illegal states unrepresentative. There's no way for a client to make a payment with StartRecurrent = true and a non-null transaction key; there's no link to that combination. Such an API uses hypermedia as the engine of application state.
It shouldn't be surprising that proper RESTful design works that way. After all, REST is essentially a distillate of the properties that make the World Wide Web work. On a human-readable web page, the user follows links to other pages, and a well-designed web site will only enable a link if the destination exists.
You can even draw a graph of the API I've sketched above:
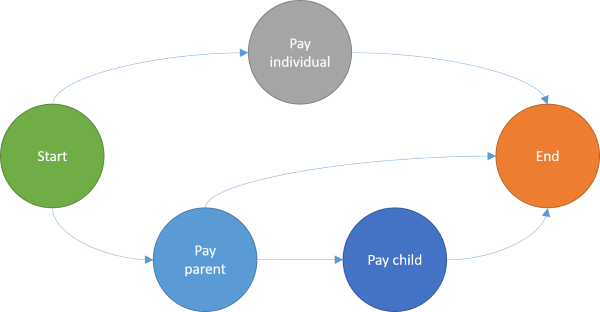
In this diagram, you can see that when you make an individual payment, that's all you can do. You can also see that the only way to make a child payment is by first making a parent payment. There's also a path from parent payments directly to the end node, because a client doesn't have to make a child payment just because it made a parent payment.
If you think that this looks like a finite state machine, then that's no coincidence. That's exactly what it is. You have states (the nodes) and paths between them. If a state is illegal, then don't add that node; only add nodes for legal states, then add links between the nodes that model legal transitions.
Incidentally, languages like F# excel at implementing finite state machines, so it's no wonder I like to implement RESTful APIs in F#.
Summary #
Truly RESTful design enables you to make illegal states unrepresentable by using hypermedia as the engine of application state. This gives you a powerful design tool to ensure that clients can only perform correct operations.
As I also wrote in my previous article, this, too, is no silver bullet. You can turn an API into a pit of success, but there are still many fault scenarios that you can't prevent.
If you were intrigued by this article, but are having trouble applying these design techniques to your own field, I'm available for hire for short or long-term engagements.
Easy domain modelling with types
Algebraic data types make domain modelling easy.
People often ask me if I think that F# is a good general-purpose language, and when I emphatically answer yes!, the natural next question is: why?
For years, I've been able to answer this question in the abstract, but I've been looking for a good concrete example with which I could illustrate the answer. I believe that I've now found such an example.
The abstract answer, by the way, is that F# has algebraic data types, which makes domain modelling much easier than in languages that don't have such types. Don't worry if the word 'algebraic' sounds scary, though. It's not at all difficult to understand, and I'll show you a simple example.
Payment types #
At the moment, I'm working on an integration project: I'm developing a RESTful API that serves as Facade in front of a third-party payment provider. The third-party provider exposes their own API and web-based GUI that enable our end users to pay for services using credit cards, PayPal, and so on. The API that I'm developing presents a simplified, RESTful API to other clients in our organisation.
The example you're going to see here is real code that I'm writing in order to implement the desired functionality.
The system must be able to handle several different types of payment:
- Sometimes, a user pays for a single thing, and that's the end of that transaction.
- Other times, however, a user engages into a long-term payment relationship. This could be, for example, a subscription, or an 'auto-fill' style of relationship. This is handled in two distinct phases:
- An initial payment (can sometimes be for a zero amount) that authorises the merchant to make further transactions.
- Subsequent payments, based off that initial payment. These payments can be automated, because they require no further user interaction than the initial authorisation.
You can indicate the type of payment when interacting with the payment service's JSON-based API, like this:
{
...
"StartRecurrent": "false"
...
}
Obviously, as the (illegal) ellipses suggests, there's much more data associated with a payment, but that's not important in this example. Since StartRecurrent is false, this is either an individual payment, or a child payment. If you want to start a long-term relationship, you must create a parent payment and set StartRecurrent to true.
Child payments, however, are a bit different, because you have to tell the payment service about the parent payment:
{
...
"OriginalTransactionKey": "1234ABCD",
"StartRecurrent": "false"
...
}
As you can see, when making a child payment, you supply the transaction ID for the parent payment. (This ID is given to you by the payment service when you initiate the parent payment.)
In this case, you're clearly not starting a new recurrent transaction.
There are two dimensions of variation in this example: StartRecurrent and OriginalTransactionKey. Let's put them in a table:
"StartRecurrent" : "false" |
"StartRecurrent" : "true" |
|
|---|---|---|
"OriginalTransactionKey" : null |
Individual | Parent |
"OriginalTransactionKey" : "1234ABCD" |
Child | (Illegal) |
OriginalTransactionKey and setting StartRecurrent to true is illegal, or, in best case, meaningless.
How would you model the rules laid out in the above table? In languages like C#, it's difficult, but in F# it's easy.
C# attempts #
Most C# developers would, I think, attempt to model a payment transaction with a class. If they aim for poka-yoke design, they might come up with a design like this:
public class PaymentType { public PaymentType(bool startRecurrent) { this.StartRecurrent = startRecurrent; } public PaymentType(string originalTransactionKey) { if (originalTransactionKey == null) throw new ArgumentNullException(nameof(originalTransactionKey)); this.StartRecurrent = false; this.OriginalTransactionKey = originalTransactionKey; } public bool StartRecurrent { private set; get; } public string OriginalTransactionKey { private set; get; } }
This goes a fair way towards making illegal states unrepresentable, but it doesn't communicate to a fellow programmer how it should be used.
Code that uses instances of this PaymentType class could attempt to read the OriginalTransactionKey, which, depending on the type of payment, could return null. That sort of design leads to defensive coding.
Other people might attempt to solve the problem by designing a class hierarchy:
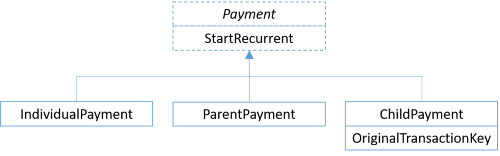
(A variation on this design is to define an IPayment interface, and three concrete classes that implement that interface.)
This design trades better protection of invariants for violations of the Liskov Substitution Principle. Clients will have to (attempt to) downcast to subtypes in order to access all relevant data (particularly OriginalTransactionKey).
For completeness sake, I can think of at least one other option with significantly different trade-offs: applying the Visitor design pattern. This is, however, quite a complex solution, and most people will find the disadvantages greater than the benefits.
Is it such a big deal, then? After all, it's only a single data value (OriginalTransactionKey) that may or may not be there. Surely, most programmers will be able to deal with that.
This may be true in this isolated case, but keep in mind that this is only a motivating example. In many other situations, the domain you're trying to model is much more intricate, with many more exceptions to general rules. The more dimensions you add, the more difficult it becomes to reason about the code.
F# model #
F#, on the other hand, makes dealing with such problems so simple that it's almost anticlimactic. The reason is that F#'s type system enables you to model alternatives of data, in addition to the combinations of data that C# (or Java) enables. Such alternatives are called discriminated unions.
In the code base I'm currently developing, I model the various payment types like this:
type PaymentService = { Name : string; Action : string } type PaymentType = | Individual of PaymentService | Parent of PaymentService | Child of originalTransactionKey : string * paymentService : PaymentService
Here, PaymentService is a record type with some data about the payment (e.g. which credit card to use).
Even if you're not used to reading F# code, you can see three alternatives outlined on each of the three lines of code that start with a vertical bar (|). The PaymentType type has exactly three 'subtypes' (they're called cases, though). The illegal state of a non-null OriginalTransactionKey combined with StartRecurrent value of true is not possible. It can't be compiled.
Not only that, but all clients given a PaymentType value must deal with all three cases (or the compiler will issue a warning). Here's one example where our code is creating the JSON document to send to the payment service:
let name, action, startRecurrent, transaction = match req.PaymentType with | Individual { Name = name; Action = action } -> name, action, false, None | Parent { Name = name; Action = action } -> name, action, true, None | Child (transactionKey, { Name = name; Action = action }) -> name, action, false, Some transactionKey
This code example also extracts name and action from the PaymentType value, but the relevant values to be aware of are startRecurrent and transaction.
- For an individual payment,
startRecurrentbecomesfalseandtransactionbecomesNone(meaning that the value is missing). - For a parent payment,
startRecurrentbecomestrueandtransactionbecomesNone. - For a child payment,
startRecurrentbecomesfalseandtransactionbecomesSome transactionKey.
transactionKey is only available when the payment is a child payment.
The values startRecurrent and transaction (as well as name and action) are then used to create a JSON document. I'm not showing that part of the code here, since there's actually a lot going on in the real code base, and it's not related to how to model the domain. Imagine that these values are passed to a constructor.
This is a real-world example that, I hope, demonstrates why I prefer F# over C# for domain modelling. The type system enables me to model alternatives as well as combinations of data, and thereby making illegal states unrepresentable - all in only a few lines of code.
Summary #
Classes, in languages like C# and Java, enable you to model combinations of data. The more fields or properties you add to a class, the more combinations are possible. This is often useful, but sometimes you need to be able to model alternatives, rather than combinations.
Some languages, like F#, Haskell, OCaml, Elm, Kotlin, and many others, have type systems that give you the power to model both combinations and alternatives. Such types systems are said to have algebraic data types, but while the word sounds 'mathy', such types make it much easier to model complex domains.
There are more reasons to love F# than only its algebraic data types, but this is the foremost reason I find it a better language for mainstream development work than C#.
If you want to see a more complex example of modelling with types, a good next step would be the first article in my Types + Properties = Software article series.
Finally, I should be careful that I don't oversell the idea of making illegal states unrepresentable. Algebraic data types give you an extra dimension in which you can model domains, but there are still rules that they can't enforce. As an example, you can't state that integers must only fall in a certain range (e.g. only positive integers allowed). There are other type systems, such as dependent types, that give you even more power to embed domain rules into types, but as far as I know, there are no type systems that can fully model all rules as types. You'll still have to write some code as well.
The article is an instalment in the 2016 F# Advent calendar.
Comments
Mark,
I must be missing something important but it seems to me that the only advantage of using F# in this case is that the match is enforced to be exhaustive by the compiler. And of course the syntax is also nicer than a bunch of if's. In all other respects, the solution is basically equivalent to the C# class hierarchy approach.
Am I mistaken?
Botond, thank you for writing. The major advantage is that enumeration of all possible cases is available at compile-time. One derived advantage of that is that the compiler can check whether a piece of code handles all cases. That's already, in my experience, a big deal. The sooner you can get feedback on your work, the better, and it doesn't get faster than compile-time feedback.
Another advantage of having all cases encoded in the type system is that it gives you better tool support. Imagine that you're looking at the return value of a function, and that this is the first time you're encountering that return type. If the return value is an abstract base class (or interface), you'll need to resort to either the documentation or reflection in order to figure out which subtypes exist. There can be arbitrarily many subtypes, and they can be scattered over arbitrarily many libraries (assemblies). Figuring out what to do with an abstract base class introduces a context switch that could have been avoided.
This is exactly another advantage offered by discriminated unions: when a function returns a discriminated union, you can immediately get tool support to figure out what to do with it, even if you've never encountered the type before.
The problem with examples such as the above is that I'm trying to explain how a language feature can help you with modelling complex domains, but if I try to present a really complex problem, no-one will have the patience to read the article. Instead, I have to come up with an example that's so simple that the reader doesn't give up, and hopefully still complex enough that the reader can imagine how it's a stand-in for a more complex problem.
When you look at the problem presented above, it's not that complex, so you can still keep a C# implementation in your head. As you add more variability to the problem, however, you can easily find yourself in a situation where the combinatorial explosion of possible values make it difficult to ensure that you've dealt with all edge cases. This is one of the main reasons that C# and Java code often throws run-time exceptions (particularly null-reference exceptions).
It did, in fact, turn out that the above example domain became more complex as I learned more about the entire range of problems I had to solve. When I described the problem above, I thought that all payments would have pre-selected payment methods. In other words, when a user is presented with a check-out page, he or she selects the payment method (PayPal, direct debit, and so on), and only then, when we know payment method, do we initiate the payment flow. It turns out, though, that in some cases, we should start the payment flow first, and then let the user pick the payment method from a list of options. It should be noted, however, that user-selection only makes sense for interactive payments, so a child payment can never be user-selectable (since it's automated).
It was trivial to extend the domain model with that new requirement:
type PaymentService = { Name : string; Action : string } type PaymentMethod = | PreSelected of PaymentService | UserSelectable of string list type TransactionKey = TransactionKey of string with override this.ToString () = match this with TransactionKey s -> s type PaymentType = | Individual of PaymentMethod | Parent of PaymentMethod | Child of TransactionKey * PaymentService
This effectively uses the static type system to state that both the Individual and Parent cases can be defined in one of two ways: PreSelected or UserSelectable, each of which, again, contains heterogeneous data (PaymentService versus string list). Child payments, on the other hand, can't be user-selectable, but must be defined by a PaymentService value, as well as a transaction key (at this point, I'd also created a single-case union for the transaction key, but that's a different topic; it's still a string).
Handling all the different combinations was equally easy, and the compiler guarantees that I've handled all possible combinations:
let services, selectables, startRecurrent, transaction = match req.PaymentType with | Individual (PreSelected ps) -> service ps, None, false, None | Individual (UserSelectable us) -> [||], us |> String.concat ", " |> Some, false, None | Parent (PreSelected ps) -> service ps, None, true, None | Parent (UserSelectable us) -> [||], us |> String.concat ", " |> Some, true, None | Child (TransactionKey transactionKey, ps) -> service ps, None, false, Some transactionKey
How would you handle this with a class hierarchy, and what would the consuming code look like?
When variable names are in the way
While Clean Code recommends using good variable names to communicate the intent of code, sometimes, variable names can be in the way.
Good guides to more readable code, like Clean Code, explain how explicitly introducing variables with descriptive names can make the code easier to understand. There's much literature on the subject, so I'm not going to reiterate it here. It's not the topic of this article.
In the majority of cases, introducing a well-named variable will make the code more readable. There are, however, no rules without exceptions. After all, one of the hardest tasks in programming is naming things. In this article, I'll show you an example of such an exception. While the example is slightly elaborate, it's a real-world example I recently ran into.
Escaping object-orientation #
Regular readers of this blog will know that I write many RESTful APIs in F#, but using ASP.NET Web API. Since I like to write functional F#, but ASP.NET Web API is an object-oriented framework, I prefer to escape the object-oriented framework as soon as possible. (In general, it makes good architectural sense to write most of your code as framework-independent as possible.)
ASP.NET Web API expects you handle HTTP requests using Controllers, so I use Constructor Injection to inject a function that will do all the actual work, and delegate each request to a function call. It often looks like this:
type PushController (imp) = inherit ApiController () member this.Post (portalId : string, req : PushRequestDtr) : IHttpActionResult = match imp req with | Success () -> this.Ok () :> _ | Failure (ValidationFailure msg) -> this.BadRequest msg :> _ | Failure (IntegrationFailure msg) -> this.InternalServerError (InvalidOperationException msg) :> _
This particular Controller only handles HTTP POST requests, and it does it by delegating to the injected imp function and translating the return value of that function call to various HTTP responses. This enables me to compose imp from F# functions, and thereby escape the object-oriented design of ASP.NET Web API. In other words, each Controller is an Adapter over a functional implementation.
For good measure, though, this Controller implementation ought to be unit tested.
A naive unit test attempt #
Each HTTP request is handled at the boundary of the system, and the boundary of the system is always impure - even in Haskell. This is particularly clear in the case of the above PushController, because it handles Success (). In success cases, the result is () (unit), which strongly implies a side effect. Thus, a unit test ought to care not only about what imp returns, but also the input to the function.
While you could write a unit test like the following, it'd be naive.
[<Property(QuietOnSuccess = true)>] let ``Post returns correct result on validation failure`` req (NonNull msg) = let imp _ = Result.fail (ValidationFailure msg) use sut = new PushController (imp) let actual = sut.Post req test <@ actual |> convertsTo<Results.BadRequestErrorMessageResult> |> Option.map (fun r -> r.Message) |> Option.exists ((=) msg) @>
This unit test uses FsCheck's integration for xUnit.net, and Unquote for assertions. Additionally, it uses a convertsTo function that I've previously described.
The imp function for PushController must have the type PushRequestDtr -> Result<unit, BoundaryFailure>. In the unit test, it uses a wild-card (_) for the input value, so its type is 'a -> Result<'b, BoundaryFailure>. That's a wider type, but it matches the required type, so the test compiles (and passes).
FsCheck populates the req argument to the test function itself. This value is passed to sut.Post. If you look at the definition of sut.Post, you may wonder what happened to the individual (and currently unused) portalId argument. The explanation is that the Post method can be viewed as a method with two parameters, but it can also be viewed as an impure function that takes a single argument of the type string * PushRequestDtr - a tuple. In other words, the test function's req argument is a tuple. The test is not only concise, but also robust against refactorings. If you change the signature of the Post method, odds are that the test will still compile. (This is one of the many benefits of type inference.)
The problem with the test is that it doesn't verify the data flow into imp, so this version of PushController also passes the test:
type PushController (imp) = inherit ApiController () member this.Post (portalId : string, req : PushRequestDtr) : IHttpActionResult = let minimalReq = { Transaction = { Invoice = ""; Status = { Code = { Code = 0 } } } } match imp minimalReq with | Success () -> this.Ok () :> _ | Failure (ValidationFailure msg) -> this.BadRequest msg :> _ | Failure (IntegrationFailure msg) -> this.InternalServerError (InvalidOperationException msg) :> _
As the name implies, the minimalReq value is the 'smallest' value I can create of the PushRequestDtr type. As you can see, this implementation ignores the req method argument and instead passes minimalReq to imp. This is clearly wrong, but it passes the unit test test.
Data flow testing #
Not only should you care about the output of imp, but you should also care about the input. This is because imp is inherently impure, so it'd be conceivable that the input values matter in some way.
As xUnit Test Patterns explains, automated tests should contain no branching, so I don't think it's a good idea to define a test-specific imp function using conditionals. Instead, we can use guard assertions to verify that the input is as expected:
[<Property(QuietOnSuccess = true)>] let ``Post returns correct result on validation failure`` req (NonNull msg) = let imp candidate = candidate =! snd req Result.fail (ValidationFailure msg) use sut = new PushController (imp) let actual = sut.Post req test <@ actual |> convertsTo<Results.BadRequestErrorMessageResult> |> Option.map (fun r -> r.Message) |> Option.exists ((=) msg) @>
The imp function is now implemented using Unquote's custom =! operator, which means that candidate must equal req. If not, Unquote will throw an exception, and thereby fail the test.
If candidate is equal to snd req, the =! operator does nothing, enabling the imp function to return the value Result.fail (ValidationFailure msg).
This version of the test verifies the entire data flow through imp: both input and output.
There is, however, a small disadvantage to writing the imp code this way. It isn't a big issue, but it annoys me.
Here's the heart of the matter: I had to come up with a name for the local PushRequestDtr value that the =! operator evaluates against snd req. I chose to call it candidate, which may seem reasonable, but that naming strategy doesn't scale.
In order to keep the introductory example simple, I chose a Controller method that doesn't (yet) use its portalId argument, but the code base contains other Controllers, for example this one:
type IdealController (imp) = inherit ApiController () member this.Post (portalId : string, req : IDealRequestDtr) : IHttpActionResult = match imp portalId req with | Success (resp : IDealResponseDtr) -> this.Ok resp :> _ | Failure (ValidationFailure msg) -> this.BadRequest msg :> _ | Failure (IntegrationFailure msg) -> this.InternalServerError (InvalidOperationException msg) :> _
This Controller's Post method passes both portalId and req to imp. In order to perform data flow verification of that implementation, the test has to look like this:
[<Property(QuietOnSuccess = true)>] let ``Post returns correct result on success`` portalId req resp = let imp pid candidate = pid =! portalId candidate =! req Result.succeed resp use sut = new IdealController (imp) let actual = sut.Post (portalId, req) test <@ actual |> convertsTo<Results.OkNegotiatedContentResult<IDealResponseDtr>> |> Option.map (fun r -> r.Content) |> Option.exists ((=) resp) @>
This is where I began to run out of good argument names. You need names for the portalId and req arguments of imp, but you can't use those names because they're already in use. You can't even shadow the names of the outer values, because the test-specific imp function has to close over those outer values in order to compare them to their expected values.
While I decided to call the local portal ID argument pid, it's hardly helpful. Explicit arguments have become a burden rather than a help to the reader. If only we could get rid of those explicit arguments.
Point free #
Functional programming offers a well-known alternative to explicit arguments, commonly known as point-free programming. Some people find point-free style unreadable, but sometimes it can make the code more readable. Could this be the case here?
If you look at the test-specific imp functions in both of the above examples with explicit arguments, you may notice that they follow a common pattern. First they invoke one or more guard assertions, and then they return a value. You can model this with a custom operator:
// 'Guard' composition. Returns the return value if ``assert`` doesn't throw. // ('a -> unit) -> 'b -> 'a -> 'b let (>>!) ``assert`` returnValue x = ``assert`` x returnValue
The first argument, ``assert``, is a function with the type 'a -> unit. This is the assertion function: it takes any value as input, and returns unit. The implication is that it'll throw an exception if the assertion fails.
After invoking the assertion, the function returns the returnValue argument.
The reason I designed it that way is that it's composable, which you'll see in a minute. The reason I named it >>! was that I wanted some kind of arrow, and I thought that the exclamation mark relates nicely to Unquote's use of exclamation marks.
This enables you to compose the first imp example (for PushController) in point-free style:
[<Property(QuietOnSuccess = true)>] let ``Post returns correct result on validation failure`` req (NonNull msg) = let imp = ((=!) (snd req)) >>! Result.fail (ValidationFailure msg) use sut = new PushController (imp) let actual = sut.Post req test <@ actual |> convertsTo<Results.BadRequestErrorMessageResult> |> Option.map (fun r -> r.Message) |> Option.exists ((=) msg) @>
At first glance, most people would be likely to consider this to be less readable than before, and clearly, that's a valid standpoint. On the other hand, once you get used to identify the >>! operator, this becomes a concise shorthand. A data-flow-verifying imp mock function is composed of an assertion on the left-hand side of >>!, and a return value on the right-hand side.
Most importantly, those hard-to-name arguments are gone.
Still, let's dissect the expression ((=!) (snd req)) >>! Result.fail (ValidationFailure msg).
The expression on the left-hand side of the >>! operator is the assertion. It uses Unquote's must equal =! operator as a function. (In F#, infix operators are functions, and you can use them as functions by surrounding them by brackets.) While you can write an assertion as candidate =! snd req using infix notation, you can also write the same expression as a function call: (=!) (snd req) candidate. Since this is a function, it can be partially applied: (=!) (snd req); the type of that expression is PushRequestDtr -> unit, which matches the required type 'a -> unit that >>! expects from its ``assert`` argument. That explains the left-hand side of the >>! operator.
The right-hand side is easier, because that's the return value of the composed function. In this case the value is Result.fail (ValidationFailure msg).
You already know that the type of >>! is ('a -> unit) -> 'b -> 'a -> 'b. Replacing the generic type arguments with the actual types in use, 'a is PushRequestDtr and 'b is Result<'a ,BoundaryFailure>, so the type of imp is PushRequestDtr -> Result<'a ,BoundaryFailure>. When you set 'a to unit, this fits the required type of PushRequestDtr -> Result<unit, BoundaryFailure>.
This works because in its current incarnation, the imp function for PushController only takes a single value as input. Will this also work for IdealController, which passes both portalId and req to its imp function?
Currying #
The imp function for IdealController has the type string -> IDealRequestDtr -> Result<IDealResponseDtr, BoundaryFailure>. Notice that it takes two arguments instead of one. Is it possible to compose an imp function with the >>! operator?
Consider the above example that exercises the success case for IdealController. What if, instead of writing
let imp pid candidate = pid =! portalId candidate =! req Result.succeed resp
you write the following?
let imp = ((=!) req) >>! Result.succeed resp
Unfortunately, that does work, because the type of that function is string * IDealRequestDtr -> Result<IDealResponseDtr, 'a>, and not string -> IDealRequestDtr -> Result<IDealResponseDtr, BoundaryFailure>, as it should be. It's almost there, but the input values are tupled, instead of curried.
You can easily correct that with a standard curry function:
let imp = ((=!) req) >>! Result.succeed resp |> Tuple2.curry
The Tuple2.curry function takes as input a function that has tupled arguments, and turns it into a curried function. Exactly what we need here!
The entire test is now:
[<Property(QuietOnSuccess = true)>] let ``Post returns correct result on success`` req resp = let imp = ((=!) req) >>! Result.succeed resp |> Tuple2.curry use sut = new IdealController (imp) let actual = sut.Post req test <@ actual |> convertsTo<Results.OkNegotiatedContentResult<IDealResponseDtr>> |> Option.map (fun r -> r.Content) |> Option.exists ((=) resp) @>
Whether or not you find this more readable than the previous example is, as always, subjective, but I like it because it's a succinct, composable way to address data flow verification. Once you get over the initial shock of partially applying Unquote's =! operator, as well as the cryptic-looking >>! operator, you may begin to realise that the same idiom is repeated throughout. In fact, it's more than an idiom. It's an implementation of a design pattern.
Mocks #
When talking about unit testing, I prefer the vocabulary of xUnit Test Patterns, because of its unrivalled consistent terminology. Using Gerard Meszaros' nomenclature, a Test Double with built-in verification of interaction is called a Mock.
Most people (including me) dislike Mocks because they tend to lead to brittle unit tests. They tend to, but sometimes you need them. Mocks are useful when you care about side-effects.
Functional programming emphasises pure functions, which, by definition, are free of side-effects. In pure functional programming, you don't need Mocks.
Since F# is a multi-paradigmatic language, you sometimes have to write code in a more object-oriented style. In the example you've seen here, I've shown you how to unit test that Controllers correctly work as Adapters over (impure) functions. Here, Mocks are useful, even if they have no place in the rest of the code base.
Being able to express a Mock with a couple of minimal functions is, in my opinion, preferable to adding a big dependency to a 'mocking library'.
Concluding remarks #
Sometimes, explicit values and arguments are in the way. By their presence, they force you to name them. Often, naming is good, because it compels you to make tacit knowledge explicit. In rare cases, though, the important detail isn't a value, or an argument, but instead an activity. An example of this is when verifying data flow. While the values are obviously present, the focus ought to be on the comparison. Thus, by making the local function arguments implicit, you can direct the reader's attention to the interaction - in this case, Unquote's =! must equal comparison.
In the introduction to this article, I told you that the code you've seen here is a real-life example. This is true.
I submitted my refactoring to point-free style as an internal pull request on the project I'm currently working. When I did that, I was genuinely in doubt about the readability improvement this would give, so I asked my reviewers for their opinions. I was genuinely ready to accept if they wanted to reject the pull request.
My reviewers disagreed internally, ultimately had a vote, and decided to reject the pull request. I don't blame them. We had a civil discussion about the pros and cons, and while they understood the advantages, they felt that the disadvantages weighed heavier.
In their context, I understand why they decided to decline the change, but that doesn't mean that I don't find this an interesting experiment. I expect to use something like this in the future in some contexts, while in other contexts, I'll stick with the more verbose (and harder to name) test-specific functions with explicit arguments.
Still, I like to solve problems using well-known compositions, which is the reason I prefer a composable, idiomatic approach over ad-hoc code.
If you'd like to learn more about unit testing and property-based testing in F# (and C#), you can watch some of my Pluralsight courses.
Decoupling decisions from effects
Functional programming emphasises pure functions, but sometimes decisions must be made based on impure data. The solution is to decouple decisions and effects.
Functional programmers love pure functions. Not only do they tend to be easy to reason about, they are also intrinsically testable. It'd be wonderful if we could build entire systems only from pure functions, but every functional programmer knows that the world is impure. Instead, we strive towards implementing as much of our code base as pure functions, so that an application is impure only at its boundaries.
The more you can do this, the more testable the system becomes. One rule of thumb about unit testing that I often use is that if a particular candidate for unit testing has a cyclomatic complexity of 1, it may be acceptable to skip unit testing it. Instead, we can consider such a unit a humble unit. If you can separate decisions from effects (which is what functional programmers often call impurities), you can often make the impure functions humble.
In other words: put all logic in pure functions that can be unit tested, and implement impure effects as humble functions that you don't need to unit test.
You want to see an example. So do I!
Example: conditional reading from file #
In a recent discussion, Jamie Cansdale asks how I'd design and unit test something like the following C# method if I could instead redesign it in F#.
public static string GetUpperText(string path) { if (!File.Exists(path)) return "DEFAULT"; var text = File.ReadAllText(path); return text.ToUpperInvariant(); }
Notice how this method contains two impure operations: File.Exists and File.ReadAllText. Decision logic seems interleaved with IO. How can decisions be separated from effects?
(For good measure I ought to point out that obviously, the above example is so simple that by itself, it almost doesn't warrant testing. Think of it as a stand-in for a more complex problem.)
With a statement-based language like C#, it can be difficult to see how to separate decision logic from effects without introducing interfaces, but with expression-based languages like F#, it becomes close to trivial. In this article, I'll show you three alternatives.
All three alternatives, however, make use of the same function for turning text into upper case:
// string -> string let getUpper (text : string) = text.ToUpperInvariant ()
Obviously, this function is so trivial that it's hardly worth testing, but remember to think about it as a stand-in for a more complex problem. It's a pure function, so it's easy to unit test:
[<Theory>] [<InlineData("foo", "FOO")>] [<InlineData("bar", "BAR")>] let ``getUpper returns correct value`` input expected = let actual = getUpper input expected =! actual
This test uses xUnit.net 2.1.0 and Unquote 3.1.2. The =! operator is a custom Unquote operator; you can read it as must equal; that is: expected must equal actual. It'll throw an exception if this isn't the case.
Custom unions #
Languages like F# come with algebraic data types, which means that in addition to complex structures, they also enable you to express types as alternatives. This means that you can represent a decision as one or more alternative pure values.
Although the examples you'll see later in this article are simpler, I think it'll be helpful to start with an ad hoc solution to the problem. Here, the decision is to either read from a file, or return a default value. You can express that using a custom discriminated union:
type Action = ReadFromFile of string | UseDefault of string
This type models two mutually exclusive cases: either you decide to read from the file identified by a file path (string), or your return a default value (also modelled as a string).
Using this Action type, you can write a pure function that makes the decision:
// string -> bool -> Action let decide path fileExists = if fileExists then ReadFromFile path else UseDefault "DEFAULT"
This function takes two arguments: path (a string) and fileExists (a bool). If fileExists is true, it returns the ReadFromFile case; otherwise, it returns the UseDefault case.
Notice how this function neither checks whether the file exists, nor does it attempt to read the contents of the file. It only makes a decision based on input, and returns information about this decision as output. This function is pure, so (as I've claimed numerous times) is easy to unit test:
[<Theory>] [<InlineData("ploeh.txt")>] [<InlineData("fnaah.txt")>] let ``decide returns correct result when file exists`` path = let actual = decide path true ReadFromFile path =! actual [<Theory>] [<InlineData("ploeh.txt")>] [<InlineData("fnaah.txt")>] let ``decide returns correct result when file doesn't exist`` path = let actual = decide path false UseDefault "DEFAULT" =! actual
One unit test function exercises the code path where the file exists, whereas the other test exercises the code path where it doesn't. Straightforward.
There's still some remaining work, because you need to somehow compose your pure functions with File.Exists and File.ReadAllText. You also need a way to extract the string value from the two cases of Action. One way to do that is to introduce another pure function:
// (string -> string) -> Action -> string let getValue f = function | ReadFromFile path -> f path | UseDefault value -> value
This is a function that returns the UseDefault data for that case, but invokes a function f in the ReadFromFile case. Again, since this function is pure it's easy to unit test it, but I'll leave that as an exercise.
You now have all the building blocks required to compose a function similar to the above GetUpperText C# method:
// string -> string let getUpperText path = path |> File.Exists |> decide path |> getValue (File.ReadAllText >> getUpper)
This implementation pipes path into File.Exists, which returns a Boolean value indicating whether the file exists. This Boolean value is then piped into decide path, which (as you may recall) returns an Action. That value is finally piped into getValue (File.ReadAllText >> getUpper). Recall that getValue will only invoke the function argument when the Action is ReadFromFile, so File.ReadAllText >> getUpper is only executed in this case.
Notice how decisions and effectful functions are interleaved. All the decision functions are covered by unit tests; only File.Exists and File.ReadAllText aren't covered, but I find it reasonable to treat these as humble functions.
Either #
Normally, decisions often involve a choice between two alternatives. In the above example, you saw how the alternatives were named ReadFromFile and UseDefault. Since a choice between two alternatives is so common, there's a well-known 'pattern' that gives you general-purpose tools to model decisions. This is known as the Either monad.
The F# core library doesn't (yet) come with an implementation of the Either monad, but it's easy to add. In this example, I'm using code from Scott Wlaschin's railway-oriented programming, although slightly modified, and including only the most essential building blocks for the example:
type Result<'TSuccess, 'TFailure> = | Success of 'TSuccess | Failure of 'TFailure module Result = // ('a -> Result<'b, 'c>) -> Result<'a, 'c> -> Result<'b, 'c> let bind f = function | Success succ -> f succ | Failure fail -> Failure fail // ('a -> 'b) -> Result<'a, 'c> -> Result<'b, 'c> let map f = function | Success succ -> Success (f succ) | Failure fail -> Failure fail // ('a -> bool) -> 'a -> Result<'a, 'a> let split f x = if f x then Success x else Failure x // ('a -> 'b) -> ('c -> 'b) -> Result<'a, 'c> -> 'b let either f g = function | Success succ -> f succ | Failure fail -> g fail
In fact, the bind and map functions aren't even required for this particular example, but I included them anyway, because otherwise, readers already familiar with the Either monad would wonder why they weren't there.
All these functions are generic and pure, so they are easy to unit test. I'm not going to show you the unit tests, however, as I consider the functions belonging to that Result module as reusable functions. This is a module that would ship as part of a well-tested library. In fact, it'll soon be added to the F# core library.
With the already tested getUpper function, you now have all the building blocks required to implement the desired functionality:
// string -> string let getUpperText path = path |> Result.split File.Exists |> Result.either (File.ReadAllText >> getUpper) (fun _ -> "DEFAULT")
This composition pipes path into Result.split, which uses File.Exists as a predicate to decide whether the path should be packaged into a Success or Failure case. The resulting Result<string, string> is then piped into Result.either, which invokes File.ReadAllText >> getUpper in the Success case, and the anonymous function in the Failure case.
Notice how, once again, the impure functions File.Exists and File.ReadAllText are used as humble functions, but interleaved with testable, pure functions that make all the decisions.
Maybe #
Sometimes, a decision isn't so much between two alternatives as it's a decision between something that may exist, but also may not. You can model this with the Maybe monad, which in F# comes in the form of the built-in option type.
In fact, so much is already built in (and tested by the F# development team) that you almost don't need to add anything yourself. The only function you could consider adding is this:
module Option = // 'a -> 'a option -> 'a let defaultIfNone def x = defaultArg x def
As you can see, this function simply swaps the arguments for the built-in defaultArg function. This is done to make it more pipe-friendly. This function will most likely be added in a future version of F#.
That's all you need:
// string -> string let getUpperText path = path |> Some |> Option.filter File.Exists |> Option.map (File.ReadAllText >> getUpper) |> Option.defaultIfNone "DEFAULT"
This composition starts with the path, puts it into a Some case, and pipes that option value into Option.filter File.Exists. This means that the Some case will only stay a Some value if the file exists; otherwise, it will be converted to a None value. Whatever the option value is, it's then piped into Option.map (File.ReadAllText >> getUpper). The composed function File.ReadAllText >> getUpper is only executed in the Some case, so if the file doesn't exist, the function will not attempt to read it. Finally, the option value is piped into Option.defaultIfNone, which returns the mapped value, or "DEFAULT" if the value was None.
Like in the two previous examples, the decision logic is implemented by pure functions, whereas the impure functions File.Exists and File.ReadAllText are handled as humble functions.
Summary #
Have you noticed a pattern in all the three examples? Decisions are separated from effects using discriminated unions (both the above Action, Result<'TSuccess, 'TFailure>, and the built-in option are discriminated unions). In my experience, as long as you need to decide between two alternatives, the Either or Maybe monads are often sufficient to decouple decision logic from effects. Often, I don't even need to write any tests, because I compose my functions from the known, well-tested functions that belong to the respective monads.
If your decision has to branch between three or more alternatives, you can consider a custom discriminated union. For this particular example, though, I think I prefer the third, Maybe-based composition, but closely followed by the Either-based composition.
In this article, you saw three examples of how to decouple decision from effects; and I didn't even show you the Free monad!
Comments
Mark,
I can't understand how can the getValue function be pure. While I agree that it's easy to test, it's still the higher order function and it's purity depends on the purity of function passed as the argument.
Even in Your example it takes File.ReadAllText >> getUpper which actually reaches to a file on the disk and I perceive it as reaching to an external shared state.
Is there something I misunderstood?
Grzegorz, thank you for writing. You make a good point, and in a sense you're correct. F# doesn't enforce purity, and this is both an advantage and a disadvantage. It's an advantage because it makes it easier for programmers migrating from C# to make a gradual transition to a more functional programming style. It's also an advantage exactly because it relies on the programmer's often-faulty reasoning to ensure that code is properly functional.
Functions in F# are only pure if they're implemented to be pure. For any given function type (signature) you can always create an impure function that fits the type. (If nothing else, you can always write "Hello, world!" to the console, before returning a value.)
The result of this is that few parts of F# are pure in the sense that you imply. Even List.map could be impure, if passed an impure function. In other words, higher-order functions in F# are only pure if composed of exclusively pure parts.
Clearly, this is in stark contrast to Haskell, where purity is enforced at the type level. In Haskell, a throw-away, poorly designed mini-API like the Action type and associated functions shown here wouldn't even compile. The Either and Maybe examples, on the other hand, would.
My assumption here is that function composition happens at the edge of the application - that is, in an impure (IO) context.
Untyped F# HTTP route defaults for ASP.NET Web API
In ASP.NET Web API, route defaults can be provided by a dictionary in F#.
When you define a route in ASP.NET Web API 2, you most likely use the MapHttpRoute overload where you have to supply default values for the route template:
public static IHttpRoute MapHttpRoute( this HttpRouteCollection routes, string name, string routeTemplate, object defaults)
The defaults arguments has the type object, but while the compiler will allow you to put any value here, the implicit intent is that in C#, you should pass an anonymous object with the route defaults. A standard route looks like this:
configuration.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", new { Controller = "Home", Id = RouteParameter.Optional });
Notice how the name of the properties (Controller and Id) (case-insensitively) match the place-holders in the route template ({controller} and {id}).
While it's not clear from the type of the argument that this is what you're supposed to do, once you've learned it, it's easy enough to do, and rarely causes problems in C#.
Flexibility #
You can debate the soundness of this API design, but as far as I can tell, it attempts to strike a balance between flexibility and syntax easy on the eyes. It does, for example, enable you to define a list of routes like this:
configuration.Routes.MapHttpRoute( "AvailabilityYear", "availability/{year}", new { Controller = "Availability" }); configuration.Routes.MapHttpRoute( "AvailabilityMonth", "availability/{year}/{month}", new { Controller = "Availability" }); configuration.Routes.MapHttpRoute( "AvailabilityDay", "availability/{year}/{month}/{day}", new { Controller = "Availability" }); configuration.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", new { Controller = "Home", Id = RouteParameter.Optional });
In this example, there are three alternative routes to an availability resource, keyed on either an entire year, a month, or a single date. Since the route templates (e.g. availability/{year}/{month}) don't specify an id place-holder, there's no reason to provide a default value for it. On the other hand, it would have been possible to define defaults for the custom place-holders year, month, or day, if you had so desired. In this example, however, there are no defaults for these place-holders, so if values aren't provided, none of the availability routes are matched, and the request falls through to the DefaultAPI route.
Since you can supply an anonymous object in C#, you can give it any property you'd like, and the code will still compile. There's no type safety involved, but using an anonymous object enables you to use a compact syntax.
Route defaults in F# #
The API design of the MapHttpRoute method seems forged with C# in mind. I don't know how it works in Visual Basic .NET, but in F# there are no anonymous objects. How do you supply route defaults, then?
As I described in my article on creating an F# Web API project, you can define a record type:
type HttpRouteDefaults = { Controller : string; Id : obj }
You can use it like this:
GlobalConfiguration.Configuration.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", { Controller = "Home"; Id = RouteParameter.Optional }) |> ignore
That works fine for DefaultAPI, but it's hardly flexible. You must supply both a Controller and a Id value. If you need to define routes like the availability routes above, you can't use this HttpRouteDefaults type, because you can't omit the Id value.
While defining another record type is only a one-liner, you're confronted with the problem of naming these types.
In C#, the use of anonymous objects is, despite appearances, an untyped approach. Could something similar be possible with F#?
It turns out that the MapHttpRoute also works if you pass it an IDictionary<string, object>, which is possible in F#:
config.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", dict [ ("Controller", box "Home") ("Id", box RouteParameter.Optional)]) |> ignore
While this looks more verbose than the previous alternative, it's more flexible. It's also stringly typed, which normally isn't an endorsement, but in this case is honest, because it's as strongly typed as the MapHttpRoute method. Explicit is better than implicit.
The complete route configuration corresponding to the above example would look like this:
config.Routes.MapHttpRoute( "AvailabilityYear", "availability/{year}", dict [("Controller", box "Availability")]) |> ignore config.Routes.MapHttpRoute( "AvailabilityMonth", "availability/{year}/{month}", dict [("Controller", box "Availability")]) |> ignore config.Routes.MapHttpRoute( "AvailabilityDay", "availability/{year}/{month}/{day}", dict [("Controller", box "Availability")]) |> ignore config.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", dict [ ("Controller", box "Home") ("Id", box RouteParameter.Optional)]) |> ignore
If you're interested in learning more about developing ASP.NET Web API services in F#, watch my Pluralsight course A Functional Architecture with F#.

Comments
A couple of questions: If you're porting your code from F# to Haskell and back into F#, why not just use Haskell in the first place?
Also, why would you want to mark a function as having side effects in the first place?
Thanks
Kurren, thank you for writing. Why not use Haskell in the first place? In some situations, if that's an option, I'd go for it. In most of my professional work, however, it's not. A bit of background is required, I think. I've spent most of my professional career working with Microsoft technologies. Most of my clients use .NET. The majority of my clients use C#, but some are interested in adopting functional programming. F# is a great bridge to functional programming, because it integrates so well with existing C# code.
Perhaps most importantly is that while these organisations learn F# as a new programming language, and a new paradigm, all other dimensions of software development remain the same. You can use familiar libraries and frameworks, you can use the same Continuous Integration and build tools as you've been used to, you can deploy like you always do, and you can operate and monitor your software like before.
If you start using Haskell, not only will developers have to learn an entire new ecosystem, but if you have a separate operations team, they would have be on board with that as well.
If you can't get the entire organisation to accept Haskell-based software, then F# is a great choice for a .NET shop. Developers will obviously know the difference, but the rest of the organisation can be oblivious to the choice of language.
When it comes to side-effects, that's one of the main motivations behind pure code in the first place. A major source of bugs is that often, programs have unintended side-effects. It's easy to introduce defects in a code base when side-effects are uncontrolled. That's the case for languages like C# and Java, and, unfortunately, F# as well. When you look at a method or function, there's no easy way to determine whether it has side-effects. In other words: all methods or functions could have side effects. (Also: all methods could return null.)
This slows you down when you work on an existing code base, because there's only one way to determine if side-effects or non-deterministic behaviour are part of the code you're about to call: you have to read it all.
On the other hand, if you can tell, just by looking at a function's type, whether or not it has side-effects, you can save yourself a lot of time. By definition, all the pure functions have no side-effect. You don't need to read the code in order to detect that.
In Haskell, this is guaranteed. In F#, you can design your system that way, but some discipline is required in order to uphold such a guarantee.