ploeh blog danish software design
Good times with F#
Some operations take time to perform, and you may want to capture that information. This post describes one way to do it.
Occasionally, you may find yourself in the situation where your software must make a decision based on how much time it has left. Is there time to handle one more message before shutting down? How much time did the last operation take? What was the time when it started?
It can be tempting to simply use DateTime.Now or DateTimeOffset.Now, but the problem is that it couples your code to the machine clock. It also tends to interleave timing logic with other logic, so that it becomes difficult to vary these independently. Incidentally, it also tends to make it difficult to unit test the time-dependent code.
Timed<'a> #
One alternative to DateTimeOffset.Now that I've recently found useful is to define a Timed<'a> generic type, like this:
type Timed<'a> = { Started : DateTimeOffset Stopped : DateTimeOffset Result : 'a } member this.Duration = this.Stopped - this.Started
A value of Timed<'a> not only carries with it the result of some computation, but also information about when it started and stopped. It also has a calculated property called Duration, which you can use to examine how long the operation took.
Untimed transformations #
Timed<'a> looks like a standard monadic type, and you can also implement standard Bind and Map functions for it:
module Untimed = let bind f x = let t = f x.Result { t with Started = x.Started } let map f x = { Started = x.Started; Stopped = x.Stopped; Result = f x.Result }
Notice, though, that these functions only transforms the Result (and, in the case of Bind, Stopped), but no actual time measurement is taking place; that's the reason I put both functions in a module called Untimed.
In the case of the Bind function, the time measurement is implicitly taking place when the f function is executed, because it returns a Timed<'b>. In the Map function, on the other hand, no time measurement takes place at all. The function simply maps Result from one value to another using the f function.
So far, I've found no use for the Bind function, and only occasional use for the Untimed.map function. What really matters, after all, is to measure time.
Timing functions #
Ultimately, Timed<'a> is only interesting if you measure the time computations take. Here are a few functions I've found useful to do that:
module Timed = let capture clock x = let now = clock() { Started = now; Stopped = now; Result = x } let map clock f x = let result = f x.Result let stopped = clock () { Started = x.Started; Stopped = stopped; Result = result }
Notice that both functions take a clock argument. This is a function with the signature unit -> DateTimeOffset, enabling the capture and map functions to get the time. As the name indicates, the capture function is used to capture a value and 'promote' it to a Timed<'a> value. This value can subsequently be used with the map function to measure the time it took to exectute the f function.
Clocks #
Using the computer's clock is easy:
let machineClock () = DateTimeOffset.Now
As you can tell, this function returns the value of DateTimeOffset.Now every time it's invoked.
You can also implement other clocks, e.g. for unit testing purposes. Here's one (not particularly Functional) way of doing it:
let qlock (q : System.Collections.Generic.Queue<DateTimeOffset>) () = q.Dequeue()
Obviously, since this clock is based on a Queue, I decided to call it qlock. Using that, you can define an easier-to-use function based on a sequence of DateTimeOffset values:
let seqlock (l : DateTimeOffset seq) = qlock (System.Collections.Generic.Queue<DateTimeOffset>(l))
Here's a fake clock that counts up all the days before Christmas in December (so obviously, I had to name it xlock):
let xlock = [1 .. 24] |> List.map (fun d -> DateTimeOffset(DateTime(2014, 12, d))) |> seqlock
The first time you execute xlock:
(xlock ()).ToString("d")
you get "01.12.2014", the next time you get "02.12.2014", the third time "03.12.2014", and so on.
Such fake clocks are mostly useful for testing, but you could also use them to perform simulations in accelerated time - or perhaps even move time backwards! (Last time I used it, WorldWide Telescope enabled you to look at the solar system in accelerated time. I don't know how that feature is implemented, but it sounds like a good case for a custom clock. The point of this digression is that depending on your application's need, being able to manipulate time may not be as exotic as it first sounds.)
Measuring the time of execution #
These are all the building blocks you need to measure the time it takes to perform an operation. There are various ways to do it, but given a clock of the type unit -> DateTimeOffset, you can close over the clock like this:
let time f x = x |> Timed.capture clock |> Timed.map clock f
The time function has the type ('a -> 'b) -> 'a -> Timed<'b>, so, if for example you have a function called readCustomerFromDb of the type int -> Customer option, you can time it like this:
let c = time readCustomerFromDb 42
This might give you a result like this:
{Started = 17.12.2014 11:24:38 +01:00;
Stopped = 17.12.2014 11:24:39 +01:00;
Result = Some {Id = 42; Name = "Foo";};}
As you can tell, the result of querying the database for customer 42 is the customer data, as well as information about when the operation started and stopped.
Concluding remarks #
The nice quality of Timed<'a> is that it decouples timing of operations from the result of those operations. This enables you to compose functions without explicitly having to consider how to measure their execution times.
It also helps with unit testing, because if you want to test what happens in a function if a previous function ran on a Sunday, or if it took more than three seconds to run, you can simply create a value of Timed<'a> that captures that information:
let c' = { Started = DateTimeOffset(DateTime(2014, 12, 14, 11, 43, 11)) Stopped = DateTimeOffset(DateTime(2014, 12, 14, 11, 43, 15)) Result = Some { Id = 1337; Name = "Ploeh" } }
This value can now be used in a unit test to verify the behaviour in that particular case.
In a future post, I will demonstrate how to compose more complex time-sensitive behaviour using Timed<'a> and the associated modules.
This post is number 17 in the 2014 F# Advent Calendar.
Update 2017-05-25: A more recent treatment, including a more realistic usage scenario, is available in the article Type Driven Development.
Name this operation
A type of operation seems to be repeatedly appearing in my code, but I can't figure out what to call it; can you help me?
Across various code bases that I work with, it seems like operations (methods or functions) like these keep appearing:
public IDictionary<string, string> Foo( IDictionary<string, string> bar, Baz baz)
In order to keep the example general, I've renamed the method to Foo, and the arguments to bar and baz; in this article throughout, I'll make heavy use of metasyntactic variables. The types involved aren't particularly important; in this example they are IDictionary<string, string> and Baz, but they could be anything. The crux of the matter is that the output type is the same as one of the inputs (in this case, IDictionary<string, string> is both input and output).
Another C# example could be:
public int Qux(int corge, string grault)
Notice that the types involved don't have to be interfaces or complex types. The only recurring motif seems to be that the type of one of the arguments is identical to the return type.
Although the return value shares its type with one of the input arguments, the implementation doesn't have to echo the value as output. In fact, this is often not the case.
At this point, there's also no implicit assumption that the operation is referentially transparent. Thus, we may have implementation where some database is queried. Another possibility is that the operation is a closure over additional values. Here's an F# example:
let sign calculateSignature issuer (expiry : DateTimeOffset) claims = claims |> List.append [ { Type = "signature"; Value = calculateSignature claims } { Type = "issuer"; Value = issuer } { Type = "expiry"; Value = expiry.ToString "o" }]
You could imagine that the purpose of this function is to sign a set of security claims, by calculating a signature and add this and other issuer claims to the input list of claims. The signature of this particular function is (Claim list -> string) -> string -> DateTimeOffset -> Claim list -> Claim list. However, the leftmost arguments aren't going to vary much, so it would make sense to partially apply the function. Imagine that you have a correctly implemented signature function called calculateHMacSha, and that the name of the issuer should be "Ploeh":
let sign' = sign calculateHMacSha "Ploeh"
The type of the sign' function is DateTimeOffset -> Claim list -> Claim list, which is equivalent to the above Foo and Qux methods.
The question is: What should we call such an operation?
Why care?
In its general form, such an operation would have the shape
public interface IGrault<T1, T2> { T1 Garply(T1 waldo, T2 fred); }
in C# syntax, or 'a -> 'b -> 'b type in F# syntax.
Why should you care about operations like these?
It turns out that they are rather composable. For instance, it's trivial to implement the Null Object pattern, because you can always simply return the matching argument. Often, it also makes sense to make Composites out of them, or chain them in various ways.
In Functional Programming, you may just do this by composing functions together (while not particularly considering the terminology of what you're doing), but in Object-Oriented languages like C#, we have to name the abstraction before we can use it (because we have to define the type).
If T2 or 'a is a predicate, the operation might be a filter, but as illustrated with the above sign' function, the operation may also enrich the input. In some cases, it may even replace the original input and return a completely different value (of the same type). Thus, such an operation could be a 'filter', an 'expansion', or a 'replacement'; those are quite vague properties, so any name for such operations are likely to be vague or broad as well.
My question to you is: what do we call this type of operation?
While I do have a short-list of candidate names, I encounter these constructs so often that I'd be surprised if such operations don't already have a conceptual name. If so, what is it? If not, what should we call them?
(I'd hoped that this type of operation was already a 'thing' in functional programming, so I asked on Twitter, but the context is often lost on Twitter, so therefore this blog post.)
The IsNullOrWhiteSpace trap
The IsNullOrWhiteSpace method may seem like a useful utility method, but poisons your design perspective.
The string.IsNullOrWhiteSpace method, together with its older sibling string.IsNullOrEmpty, may seem like useful utility methods. In reality, they aren't. In fact, they trick your mind into thinking that null is equivalent to white space, which it isn't.
Null isn't equivalent to anything; it's the absence of a value.
Various empty and white space strings ("", " ", etc), on the other hand, are values, although, perhaps, not particularly interesting values.
Example: search canonicalization #
Imagine that you have to write a simple search canonicalization algorithm for a music search service. The problem you're trying to solve is that when users search for music, the may use variations of upper and lower case letters, as well as type the artist name before the song title, or vice versa. In order to make your system as efficient as possible, you may want to cache popular search results, but it means that you'll need to transform each search term into a canonical form.
In order to keep things simple, let's assume that you only need to convert all letters to upper case, and order words alphabetically.
Here are five test cases, represented as a Parameterized Test:
[Theory] [InlineData("Seven Lions Polarized" , "LIONS POLARIZED SEVEN" )] [InlineData("seven lions polarized" , "LIONS POLARIZED SEVEN" )] [InlineData("Polarized seven lions" , "LIONS POLARIZED SEVEN" )] [InlineData("Au5 Crystal Mathematics", "AU5 CRYSTAL MATHEMATICS")] [InlineData("crystal mathematics au5", "AU5 CRYSTAL MATHEMATICS")] public void CanonicalizeReturnsCorrectResult( string searchTerm, string expected) { string actual = SearchTerm.Canonicalize(searchTerm); Assert.Equal(expected, actual); }
Here's one possible implementation that passes all five test cases:
public static string Canonicalize(string searchTerm) { return searchTerm .Split(new[] { ' ' }) .Select(x => x.ToUpper()) .OrderBy(x => x) .Aggregate((x, y) => x + " " + y); }
This implementation uses the space character to split the string into an array, then converts each sub-string to upper case letters, sorts the sub-strings in ascending order, and finally concatenates them all together to a single string, which is returned.
Continued example: making the implementation more robust #
The above implementation is quite naive, because it doesn't properly canonicalize if the user entered extra white space, such as in these extra test cases:
[InlineData("Seven Lions Polarized", "LIONS POLARIZED SEVEN")] [InlineData(" Seven Lions Polarized ", "LIONS POLARIZED SEVEN")]
Notice that these new test cases don't pass with the above implementation, because it doesn't properly remove all the white spaces. Here's a more robust implementation that passes all test cases:
public static string Canonicalize(string searchTerm) { return searchTerm .Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries) .Select(x => x.ToUpper()) .OrderBy(x => x) .Aggregate((x, y) => x + " " + y); }
Notice the addition of StringSplitOptions.RemoveEmptyEntries.
Testing for null #
If you consider the above implementation, does it have any other problems?
One, fairly obvious, problem is that if searchTerm is null, the method is going to throw a NullReferenceException, because you can't invoke the Split method on null.
Therefore, in order to protect the invariants of the method, you must test for null:
[Fact] public void CanonicalizeNullThrows() { Assert.Throws<ArgumentNullException>( () => SearchTerm.Canonicalize(null)); }
In this case, you've decided that null is simply invalid input, and I agree. Searching for null (the absence of a value) isn't meaningful; it must be a defect in the calling code.
Often, I see programmers implement their null checks like this:
public static string Canonicalize(string searchTerm) { if (string.IsNullOrWhiteSpace(searchTerm)) throw new ArgumentNullException("searchTerm"); return searchTerm .Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries) .Select(x => x.ToUpper()) .OrderBy(x => x) .Aggregate((x, y) => x + " " + y); }
Notice the use of IsNullOrWhiteSpace. While it passes all tests so far, it's wrong for a number of reasons.
Problems with IsNullOrWhiteSpace #
The first problem with this use of IsNullOrWhiteSpace is that it may give client programmers wrong messages. For example, if you pass the empty string ("") as searchTerm, you'll still get an ArgumentNullException. This is misleading, because it gives the wrong message: it states that searchTerm was null when it wasn't (it was "").
You may then argue that you could change the implementation to throw an ArgumentException.
if (string.IsNullOrWhiteSpace(searchTerm)) throw new ArgumentException("Empty or null.", "searchTerm");
This isn't incorrect per se, but not as explicit as it could have been. In other words, it's not as helpful to the client developer as it could have been. While it may not seem like a big deal in a single method like this, it's sloppy code like this that eventually wear client developers down; it's death by a thousand paper cuts.
Moreover, this implementation doesn't follow the Robustness Principle. Is there any rational reason to reject white space strings?
Actually, with a minor tweak, we can make the implementation work with white space as well. Consider these new test cases:
[InlineData("", "")] [InlineData(" ", "")] [InlineData(" ", "")]
These currently fail because of the use of IsNullOrWhiteSpace, but they ought to succeed.
The correct implementation of the Canonicalize method is this:
public static string Canonicalize(string searchTerm) { if (searchTerm == null) throw new ArgumentNullException("searchTerm"); return searchTerm .Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries) .Select(x => x.ToUpper()) .OrderBy(x => x) .Aggregate("", (x, y) => x + " " + y) .Trim(); }
First of all, the correct Guard Clause is to test only for null; null is the only invalid value. Second, the method uses another overload of the Aggregate method where an initial seed (in this case "") is used to initialize the Fold operation. Third, the final call to the Trim method ensures that there's no leading or trailing white space.
The IsNullOrWhiteSpace mental model #
The overall problem with IsNullOrWhiteSpace and IsNullOrEmpty is that they give you the impression that null is equivalent to white space strings. This is the wrong mental model: white space strings are proper string values that you can very often manipulate just as well as any other string.
If you insist on the mental model that white space strings are equivalent to null, you'll tend to put them in the same bucket of 'invalid' data. However, if you take a hard look at the preconditions for your classes, methods, or functions, you'll find that often, a white space string is going to be perfectly acceptable input. Why reject input you can understand? That will only make your code more difficult to use.
In testing terms, it's my experience that null rarely falls in the same Equivalence Class as white space strings. Therefore, it's wrong to implicitly treat them as if they do.
The IsNullOrWhiteSpace and IsNullOrEmpty methods imply that null and white space strings are equivalent, and this will often give you the wrong mental model of the boundary cases of your software. Be careful when using these methods.
Comments
I agree if this is used at code library, which will be used by other programmer. However when directly used at application level layer, it is common to use them, at least the IsNullOrEmpty one, and they are quite powerful. And I don't find any problem in using that.
"Dog" means "DOG" means "dog"
I'm pretty sure you are hating ("hate-ing") on the wrong statement in this code, and have taken the idea past the point of practicality.
if (string.IsNullOrWhiteSpace(searchTerm)) //this is not the part that is wrong (in this context*)
throw new ArgumentNullException("searchTerm"); //this is
Its wrong for two (or three) reasons...
- It is throwing an exception type that does not match the conditional statement that it comes from. The condition could be null or whitespace , but the exception is specific to null
- The message it tells the caller is misinforming the them about the problem
- * The lack of bracing is kind of wrong too - its so easy to avoid potential bugs and uninteded side effects by just adding braces. More on this later
That code should look more like this, where the ex and message match the conditional, and aligns with both how humans (even programmers) understand written language and one of your versions of the function (but with braces =D)
if (string.IsNullOrWhiteSpace(searchTerm))
{
throw new ArgumentException("A search term must be provided");
}
For most (if not all) human written languages, there is no semantic difference between words based on casing of letters. "Dog" means "DOG" means "dog". Likewise, for a function that accepts user input in order to arrange it for use in a search, there is no need to differentiate between values like null, "", " ", "\r\n\t", <GS>, and other unprintable whitespace characters. None of those inputs are acceptable except for very rare and specific use cases (not when the user is expected to provide some search criteria), so we only need to inform the caller correctly and not mislead them.
It is definitely useful to have null and empty be different values so that we can represent "not known" or "not set" for datum, but that does not apply in this case as the user has set the value by providing the function's argument. And I get what you are trying to say about robustness but in most cases the end result is the same for the user - they get no results. Catching the bad inputs earlier would save the resources needed to execute a futile search and would avoid wasting the user's time waiting on search results for data entry that was most likely a mistake.
RE: Bracing
If you object to the bracing being needed and do want to shorten the above further, use an extension method like this..
public static string NullIfWhiteSpace(this string value)
{
return string.IsNullOrWhiteSpace(value) ? null : value;
}
... then your function would could look like this...
public static string Canonicalize(string searchTerm)
{
_ = searchTerm.NullIfWhiteSpace() ?? throw new ArgumentException("A search term must be provided");
// etc...
This can be made into a Template (resharper) or snippet so you can have even less to type.
StingyJack, thank you for writing. You bring up more than one point. I'll try to address them in order.
You seem to infer from the example that the showcased Canonicalize function implements the search functionality. It doesn't. It canonicalises a search term. A question a library designer must consider is this: What is the contract of the Canonicalize function? What are the preconditions? What are the postconditions? Are there any invariants?
The point that I found most interesting about A Philosophy of Software Design was to favour generality over specialisation. As I also hint at in my review of that book, I think that I identified a connection with Postel's law that isn't explicitly mentioned there. The upshot, in any case, is that it's a good idea to make a function like Canonicalize as robust as possible.
When considering preconditions, then, what are the minimum requirements for it to be able to produce an output?
It turns out that it can, indeed, canonicalise whitespace strings. Since this is possible, it would artificially constrain the function to disallow that. This seems redundant.
When considering Postel's law, there's often a tension between allowing degenerate input and also allowing null input. It wouldn't be hard to handle a null searchTerm by also returning the empty string in that case. This would arguably be more robust, so why not do that?
That's never easy to decide, and someone might be able to convince me that this would, in fact, be more appropriate. On the other hand, one might ask: Is there a conceivable scenario where the search term is validly null?
In most code bases, I'd tend to consider null values as symptomatic of a bug in the calling code. If so, silently accepting null input might entail that defects go undetected. Thus, I tend to favour throwing exceptions on null input.
The bottom line is that there's a fundamental difference between null strings and whitespace strings, just like there's a fundamental difference between null integers and zero integers. It's often dangerous to conflate the two.
Regarding the bracing style, I'm well aware of the argument that omitting the braces can be dangerous. See e.g. the discussion on page 749 in Code Complete.
Impressed by such arguments, I used to insist on always including curly braces even for one-liners, until one day, someone (I believe it was Robert C. Martin) pointed out that these kinds of potential bugs are easily detected by unit tests. Since I routinely have test coverage of my code, I consider the extra braces redundant safety. If there was no cost to having them, I'd leave them, but in practice, they take up space.
Unit Testing methods with the same implementation
How do you comprehensibly unit test two methods that are supposed to have the same behaviour?
Occasionally, you may find yourself in situations where you need to have two (or more) public methods with the same behaviour. How do you properly cover them with unit tests?
The obvious answer is to copy and paste all the tests, but that leads to test duplication. People with a superficial knowledge of DAMP (Descriptive And Meaningful Phrases) would argue that test duplication isn't a problem, but it is, simply because it's more code that you need to maintain.
Another approach may be to simply ignore one of those methods, effectively not testing it, but if you're writing Wildlife Software, you have to have mechanisms in place that can protect you from introducing breaking changes.
This article outlines one approach you can use if your unit testing framework supports Parameterized Tests.
Example problem #
Recently, I was working on a class with a complex AppendAsync method:
public Task AppendAsync(T @event) { // Lots of stuff going on here... }
To incrementally define the behaviour of that AppendAsync method, I had used Test-Driven Development to implement it, ending with 13 test methods. None of those test methods were simple one-liners; they ranged from 3 to 18 statements, and averaged 8 statements per test.
After having fully implemented the AppendAsync method, I wanted to make the containing class implement IObserver<T>, with the OnNext method implemented like this:
public void OnNext(T value) { this.AppendAsync(value).Wait(); }
That was my plan, but how could I provide appropriate coverage with unit tests of that OnNext implementation, given that I didn't want to copy and paste those 13 test methods?
Parameterized Tests with varied behaviour #
In this code base, I was already using xUnit.net with its nice support for Parameterized Tests; in fact, I was using AutoFixture.Xunit with attribute-based test input, so my tests looked like this:
[Theory, AutoAtomData] public void AppendAsyncFirstEventWritesPageBeforeIndex( [Frozen(As = typeof(ITypeResolver))]TestEventTypeResolver dummyResolver, [Frozen(As = typeof(IContentSerializer))]XmlContentSerializer dummySerializer, [Frozen(As = typeof(IAtomEventStorage))]SpyAtomEventStore spyStore, AtomEventObserver<XmlAttributedTestEventX> sut, XmlAttributedTestEventX @event) { sut.AppendAsync(@event).Wait(); var feed = Assert.IsAssignableFrom<AtomFeed>( spyStore.ObservedArguments.Last()); Assert.Equal(sut.Id, feed.Id); }
This is the sort of test I needed to duplicate, but instead of calling sut.AppendAsync(@event).Wait(); I needed to call sut.OnNext(@event);. The only variation in the test should be in the exercise SUT phase of the test. How can you do that, while maintaining the terseness of using attributes for defining test cases? The problem with using attributes is that you can only supply primitive values as input.
First, I briefly experimented with applying the Template Method pattern, and while I got it working, I didn't like having to rely on inheritance. Instead, I devised this little, test-specific type hierarchy:
public interface IAtomEventWriter<T> { void WriteTo(AtomEventObserver<T> observer, T @event); } public enum AtomEventWriteUsage { AppendAsync = 0, OnNext } public class AppendAsyncAtomEventWriter<T> : IAtomEventWriter<T> { public void WriteTo(AtomEventObserver<T> observer, T @event) { observer.AppendAsync(@event).Wait(); } } public class OnNextAtomEventWriter<T> : IAtomEventWriter<T> { public void WriteTo(AtomEventObserver<T> observer, T @event) { observer.OnNext(@event); } } public class AtomEventWriterFactory<T> { public IAtomEventWriter<T> Create(AtomEventWriteUsage use) { switch (use) { case AtomEventWriteUsage.AppendAsync: return new AppendAsyncAtomEventWriter<T>(); case AtomEventWriteUsage.OnNext: return new OnNextAtomEventWriter<T>(); default: throw new ArgumentOutOfRangeException("Unexpected value."); } } }
This is test-specific code that I added to my unit tests, so there's no test-induced damage here. These types are defined in the unit test library, and are not available in the SUT library at all.
Notice that I defined an interface to abstract how to use the SUT for this particular test purpose. There are two small classes implementing that interface: one using AppendAsync, and one using OnNext. However, this small polymorphic type hierarchy can't be supplied from attributes, so I also added an enum, and a concrete factory to translate from the enum to the writer interface.
This test-specific type system enabled me to refactor my unit tests to something like this:
[Theory] [InlineAutoAtomData(AtomEventWriteUsage.AppendAsync)] [InlineAutoAtomData(AtomEventWriteUsage.OnNext)] public void WriteFirstEventWritesPageBeforeIndex( AtomEventWriteUsage usage, [Frozen(As = typeof(ITypeResolver))]TestEventTypeResolver dummyResolver, [Frozen(As = typeof(IContentSerializer))]XmlContentSerializer dummySerializer, [Frozen(As = typeof(IAtomEventStorage))]SpyAtomEventStore spyStore, AtomEventWriterFactory<XmlAttributedTestEventX> writerFactory, AtomEventObserver<XmlAttributedTestEventX> sut, XmlAttributedTestEventX @event) { writerFactory.Create(usage).WriteTo(sut, @event); var feed = Assert.IsAssignableFrom<AtomFeed>( spyStore.ObservedArguments.Last()); Assert.Equal(sut.Id, feed.Id); }
Notice that this is the same test case as before, but because of the two occurrences of the [InlineAutoAtomData] attribute, each test method is being executed twice: once with AppendAsync, and once with OnNext.
This gave me coverage, and protection against breaking changes of both methods, without making any test-induced damage.
The entire source code in this article is available here. The commit just before the refactoring is this one, and the commit with the completed refactoring is this one.
Comments
Ricardo, thank you for writing. xUnit.net's equivalent to [TestCaseSource] is to combine the [Theory] attribute with one of the built-in [PropertyData], [ClassData], etc. attributes. However, in this particular case, there's a couple of reasons that I didn't find those attractive:
- When supplying test data in this way, you can write any code you'd like, but you have to supply values for all the parameters for all the test cases. In the above example, I wanted to vary the System Under Test (SUT), while I didn't care about varying any of the other parameters. The above approach enabled my to do so in a fairly DRY manner.
- In general, I don't like using [PropertyData], [ClassData] (or NUnit's [TestCaseSource]) unless I truly have a set of reusable test cases. Having a member or type encapsulating a set of test cases implies that these test cases are reusable - but they rarely are.
That's an interesting take on test reuse. Exude also reminds me of F#'s Expecto. I'd be curious what you think of a few other reuse approaches.
First, I've found expecto's composable tests lists make reuse quite intuitive.
Second, some dev friends of mine have been contemplating test reuse.
The root idea sourced from a friend thinking about the fragile test problem. He concluded that tests should be decoupled from the system. Effectively, the test creates it's own anti-corruption layer which allows tests to stay clean even if the system is messy. This pushes tests to reflect requirements over implementations, which are much more stable. Initially skeptical, I've found significant value in the approach. Systems with role-based interfaces (e.g. ports and adapters) can write one core test suite verifying behaviors for all implementations of that interface.
I've been using this paradigm to map test reuse back to C#. The test list is a class with facts/theories and a constructor that takes the test list's anti-corruption abstraction as a constructor argument. Then I can make implementation-specific tests by inheriting the list and passing an implementation. The same could be done against a role interface instead of a test-specific abstraction if desired.
Taking it even further, I've been wondering if such tests could practically act as acceptance tests between teams as a lower cost alternative to gherkin.
That ended up long. Any depth of feedback would be appreciated.
Spencer, thank you for writing. Tests as first-class values are certainly much to be preferred. That's how I write parametrised tests in Haskell, because HUnit models tests as values. I'm aware that Expecto does the same.
I also agree with you that decoupling tests from implementation details is beneficial. People tend to think of this as only possible with Acceptance Tests or BDD-style tests, but I find that it's also possible in the small. In general, I've found property-based testing to be useful as a technique to add some distance between the test and the system under test.
The idea about using Acceptance Tests between teams sounds like a technique that Ian Robinson calls Consumer-Driven Contracts.
Thank you for your feedback. I'm glad you've also found value in tests as values and decoupling tests from implementations.
Consumer-Driven Contracts does seem to share a lot in common with my idea for using implementation-decoupled tests as acceptance tests. Ian's idea starts from thinking about the provider and how it can manage message compatibility with consumers. Mine started from the consumer and testing multiple implementations of a port abstraction. Then, realizing those tests could also be reused by external consumers (extension contributors, upstream teams).
I think the test-focused approach is able to partially mitigate a few of his concerns. First, the overall added work may be less because the tests already need to be defined for the consumer whether or not there is a complex externally-owned provider. Second, package systems have reached general adoption since his post and greatly improve coordination of shared code. Unit tests [can already be shared with a package manager](https://spencerfarley.com/2021/11/05/acceptance-test-logisitcs/), though there is definitely room for improvement.
I'm a smidge sad because I thought I'd had an original idea, but I'm very glad to discover another author to follow. Thanks for connecting me!
AtomEventStore
Announcing AtomEventStore: an open source, server-less .NET Event Store.
Grean has kindly open-sourced a library we've used internally for several projects: AtomEventStore. It's pretty nice, if I may say so.
It comes with quite a bit of documentation, and is also available on NuGet.
The original inspiration came from Yves Reynhout's article Your EventStream is a linked list.
Faking a continuously Polling Consumer with scheduled tasks
How to (almost) continuously poll a queue when you can only run a task at discrete intervals.
In a previous article, I described how you set up Azure Web Jobs to run only a single instance of a background process. However, the shortest time interval you can currently configure is to run a scheduled task every minute. If you want to use this trick to set up a Polling Consumer, it may seem limiting that you'll have to wait up to a minute before the scheduled task can pull new messages off the queue.
The problem #
The problem is this: a Web Job is a command-line executable you can schedule. The most frequent schedule you can set up is once per minute. Thus, once per minute, the executable can start and query a queue in order to see if there are new messages since it last looked.
If there are new messages, it can pull these messages off the queue and handle them one by one, until the queue is empty.
If there are no new messages, the executable exits. It will then be up to a minute before it will run again. This means that if a message arrives just after the executable exits, it will sit in the queue up to a minute before being handled.
At least, that's the naive implementation.
A more sophisticated approach #
Instead of exiting immediately, what if the executable was to wait for a small period, and then check again? This means that you'd be able to increase the polling frequency to run much faster than once per minute.
If the executable also keeps track of when it started, it can gracefully exit slightly before the minute is up, enabling the task scheduler to start a new process soon after.
Example: a recursive F# implementation #
You can implement the above strategy in any language. Here's an F# version. The example code below is the main 'loop' of the program, but a few things have been put into place before that. Most of these are configuration values pulled from the configuration system:
-
timeoutis a TimeSpan value that specifies for how long the executable should run before exiting. This value comes from the configuration system. Since the minimum schedule frequency for Azure Web Jobs is 1 minute, it makes sense to set this value to 1 minute. -
stopBeforeis essentiallyDateTimeOffset.Now + timeout. -
estimatedDurationis a TimeSpan containing your (conservative) estimate of how long time it takes to handle a single message. It's only used if there are no messages to be handled in the queue, as the algorithm then has no statistics about the average execution time for each message. This value comes from the configuration system. In a recent system, I just arbitrarily set it to 2 seconds. -
toleranceFactoris a decimal used as a multiplier in order to produce a margin for when the executable should exit, so that it can exit beforestopBefore, instead of idling for too long. This value comes from the configuration system. You'll have to experiment a bit with this value. When I originally deployed the code below, I had it set to 2, but it seems like the Azure team changed how Web Jobs are initialized, so currently I have it set to 5. -
idleTimeis a TimeSpan that controls how long the executable should sit idly waiting, if there are no messages in the queue. This value comes from the configuration system. In a recent system, I set it to 5 seconds, which means that you may experience up to 5 seconds delay from a message arrives on an empty queue, until it's picked up and handled. -
dequeueis the function that actually pulls a message off the queue. It has the signatureunit -> (unit -> unit) option. That looks pretty weird, but it means that it's a function that takes no input arguments. If there's a message in the queue, it returns a handler function, which is used to handle the message; otherwise, it returns None.
let rec handleUntilTimedOut (durations : TimeSpan list) = let avgDuration = match durations with | [] -> estimatedDuration | _ -> (durations |> List.sumBy (fun x -> x.Ticks)) / (int64 durations.Length) |> TimeSpan.FromTicks let margin = (decimal avgDuration.Ticks) * toleranceFactor |> int64 |> TimeSpan.FromTicks if DateTimeOffset.Now + margin < stopBefore then match dequeue() with | Some handle -> let before = DateTimeOffset.Now handle() let after = DateTimeOffset.Now let duration = after - before let newDurations = duration :: durations handleUntilTimedOut newDurations | _ -> if DateTimeOffset.Now + idleTime < stopBefore then Async.Sleep (int idleTime.TotalMilliseconds) |> Async.RunSynchronously handleUntilTimedOut durations handleUntilTimedOut []
As you can see, the first thing the handleUntilTimedOut function does is to attempt to calculate the average duration of handling a message. Calculating the average is easy enough if you have at least one observation, but if you have no observations at all, you can't calculate the average. This is the reason the algorithm needs the estimatedDuration to get started.
Based on the the average (or estimated) duration, the algorithm next calculates a safety margin. This margin is intended to give the executable a chance to exit in time: if it can see that it's getting too close to the timeout, it'll exit instead of attempting to handle another message, since handling another message may take so much time that it may push it over the timeout limit.
If it decides that, based on the margin, it still have time to handle a message, it'll attempt to dequeue a message.
If there's a message, it'll measure the time it takes to handle the message, and then append the measured duration to the list of already observed durations, and recursively call itself.
If there's no message in the queue, the algorithm will idle for the configured period, and then call itself recursively.
Finally, the handleUntilTimedOut [] expression kicks off the polling cycle with an empty list of observed durations.
Observations #
When appropriately configured, a typical Azure Web Job log sequence looks like this:
- 1 minute ago (55 seconds running time)
- 2 minutes ago (55 seconds running time)
- 3 minutes ago (56 seconds running time)
- 4 minutes ago (55 seconds running time)
- 5 minutes ago (56 seconds running time)
- 6 minutes ago (58 seconds running time)
- 7 minutes ago (55 seconds running time)
- 8 minutes ago (55 seconds running time)
- 9 minutes ago (58 seconds running time)
- 10 minutes ago (56 seconds running time)
Summary #
If you have a situation where you need to run a scheduled job (as opposed to a continuously running service or daemon), but you want it to behave like it was a continuously running service, you can make it wait until just before a new scheduled job is about to start, and then exit. This is an approach you can use anywhere you find yourself in that situation - not only on Azure.
Update 2015 August 11: See my article about Type Driven Development for an example of how to approach this problem in a well-designed, systematic, iterative fashion.
Comments
Indeed, this technique really shines when the task runs at discrete intervals and the actual job takes less time than each interval.
For example, if a job takes 20 seconds to complete, then inside a single task of 1 minute it's possible to run 2 jobs, using the technique described in this article. – This is very nice!
FWIW, this talk and this post seem to be related with the technique shown in this article.
OTOH, in the context of Windows Services, or similar, it's possible to run a task at even smaller intervals than 1 minute.
In this case, the trick is to measure how much time it takes to run the actual job. – Then, schedule the task to run in any period less than the measured time.
As an example, if a job takes 1 seconds to complete, schedule the task to run every 0.5 seconds on a background thread while blocking the foreground thread:
open System.Threading
open System.Threading.Tasks
module Scheduler =
let run job (period : TimeSpan) =
// Start
let cancellationTokenSource =
new CancellationTokenSource()
(new Task(fun () ->
let token = cancellationTokenSource.Token
while not token.IsCancellationRequested do
job()
token.WaitHandle.WaitOne period |> ignore)).Start()
// Loop
Console.WriteLine
"Scheduler running. Type \"quit\" or \"exit\" to stop."
let stop =
let line = Console.ReadLine().ToUpperInvariant()
line = "QUIT" || line = "EXIT"
while not stop do ()
// Stop
cancellationTokenSource.Cancel()
module Main =
let job () =
Console.Write "[."
Async.Sleep 1000 |> Async.RunSynchronously
Console.WriteLine ".] - OK"
Scheduler.run job (TimeSpan.FromSeconds 0.5)
Decommissioning Decoraptors
How to release objects from within a Decoraptor.
In my article about the Decoraptor design pattern, I deliberately ignored the question of decommissioning: what if the short-lived object created inside of the Decoraptor contains one or more disposable objects?
A Decoraptor creates instances of object graphs, and such object graphs may contain disposable objects. These disposable objects may be deeply buried inside of the object graph, and the root object itself may not implement IDisposable.
This is a know problem, and the solution is known as well: the object that composes the object graph is the only object with enough knowledge to dispose of any disposable objects within the object graph that it created, so an Abstract Factory should also be able to release objects again:
public interface IFactory<T> { T Create(); void Release(T item); }
This is similar to advice I've already given in conjunction with designing DI-Friendly frameworks.
Example: refactored Decoraptor #
With the new version of the IFactory<T> interface, you can refactor the Observeraptor class from the Decoraptor article:
public class Observeraptor<T> : IObserver<T> { private readonly IFactory<IObserver<T>> factory; public Observeraptor(IFactory<IObserver<T>> factory) { this.factory = factory; } public void OnCompleted() { var obs = this.factory.Create(); obs.OnCompleted(); this.factory.Release(obs); } public void OnError(Exception error) { var obs = this.factory.Create(); obs.OnError(error); this.factory.Release(obs); } public void OnNext(T value) { var obs = this.factory.Create(); obs.OnNext(value); this.factory.Release(obs); } }
As you can see, each method implementation now performs three steps:
- Use the factory to create an instance of IObserver<T>
- Delegate the method call to the new instance
- Release the short-lived instance
Some people prefer letting the factory return something that implements IDisposable, so that the Decoraptor can employ a using statement in order to manage the lifetime of the returned object. However, IObserver<T> itself doesn't derive from IDisposable, so if you want to do something like that, you'd need to invent some sort of Scope<T> class, which would implement IDisposable; that's another alternative.
Example: refactored factory #
Refactoring the Decoraptor itself to take decommissioning into account is fairly easy, but you also need to implement the Release method on any factory implementations. Furthermore, the factory should be thread-safe, because often, the entire point of introducing a Decoraptor in the first place is to deal with Services that aren't thread-safe.
Implementing a thread-safe Composer isn't too difficult, but certainly increases the complexity of it:
public class SqlMeterFactory : IFactory<IObserver<MeterRecord>> { private readonly ConcurrentDictionary<IObserver<MeterRecord>, MeteringContext> observers; public SqlMeterFactory() { this.observers = new ConcurrentDictionary<IObserver<MeterRecord>, MeteringContext>(); } public IObserver<MeterRecord> Create() { var ctx = new MeteringContext(); var obs = new SqlMeter(ctx); this.observers[obs] = ctx; return obs; } public void Release(IObserver<MeterRecord> item) { MeteringContext ctx; if (this.observers.TryRemove(item, out ctx)) ctx.Dispose(); } }
Fortunately, instead of having to handle the complexity of a thread-safe implementation, you can delegate that part to a ConcurrentDictionary.
Disposable graphs #
The astute reader may have been wondering about this: shouldn't SqlMeter implement IDisposable? And if so, wouldn't it be easier to simply dispose of it directly, instead of having to deal with a dictionary of root objects as keys, and disposable objects as values?
The short answer is that, in this particular example, this would indeed have been a more correct, as well as a simpler, solution. Consider the SqlMeter class:
public class SqlMeter : IObserver<MeterRecord> { private readonly MeteringContext ctx; public SqlMeter(MeteringContext ctx) { this.ctx = ctx; } public void OnNext(MeterRecord value) { this.ctx.Records.Add(value); this.ctx.SaveChanges(); } public void OnCompleted() { } public void OnError(Exception error) { } }
Since SqlMeter has a class field of the type MeteringContext, and MeteringContext, via deriving from DbContext, is a disposable object, SqlMeter itself also ought to implement IDisposable.
Yes, indeed, it should, and the only reason I didn't do that was for the sake of the example. If SqlMeter had implemented IDisposable, you'd be tempted to implement SqlMeterFactory.Release by simply attempting to downcast the incoming item from IObserver<MeterRecord> to IDisposable, and then, if the cast succeeds, invoke its Dispose method.
However, the only reason we know that SqlMeter ought to implement IDisposable is because it has a concrete dependency. Concrete types can implement IDisposable, but interfaces should not, since IDisposable is an implementation detail. (I do realize that some interfaces defined by the .NET Base Class Library derives from IDisposable, but I consider those Leaky Abstractions. As Nicholas Blumhardt put it: "an interface [...] generally shouldn't be disposable. There's no way for the one defining an interface to foresee all possible implementations of it - you can always come up with a disposable implementation of practically any interface.")
The point of this discussion is that as soon as a class has an abstract dependency (as opposed to a concrete dependency), the class may or may not be relying on something that is disposable. That's not enough to warrant the class itself to implement the IDisposable interface. For this reason, when an Abstract Factory creates an object graph, the root object of that graph should rarely implement IDisposable, and that's the reason it's not enough to attempt a downcast.
This was the reason that I intentionally didn't implement IDisposable on SqlMeter, even though I should have: to demonstrate how a Release method should deal with object graphs where the disposable objects are deeply buried as leaf nodes in the graph. A Release method may not always be able to traverse the graph, so this is the reason that the factory must also have the decommissioning responsibility: only the Composer knows what it composed, so only it knows how to safely dismantle the graph again.
Summary #
Throwing IDisposable into the mix always makes things much more complicated, so if you can, try to implement your classes in such a way that they aren't disposable. This is often possible, but if you can't avoid it, you must add a Release method to your Abstract Factory and handle the additional complexity of decommissioning object graphs.
Some (but not all!) DI Containers already do this, so that may be one reason to use a DI Container.
Decoraptor
A Dependency Injection design pattern
This article describes a Dependency Injection design pattern called Decoraptor. It can be used as a solution to the problem:
How can you address lifetime mismatches without introducing a Leaky Abstraction?
By adding a combination of a Decorator and Adapter between the Client and its Service.
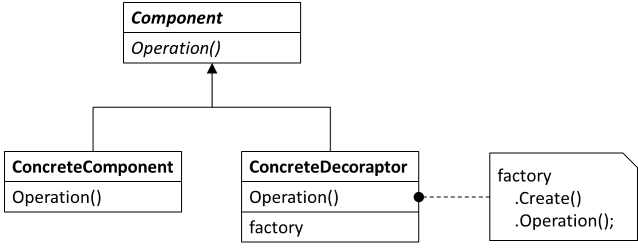
Sometimes, when a Client wishes to talk to a Service (Component in the figure; in practice often an interface), the Client may have a long lifetime, whereas, because of technical constraints in the implementation, the Service must only have a short lifetime. If not addressed, this may lead to a Captive Dependency: the long-lived Client holds onto the Service for too long.
One solution to this is a Decoraptor - a combination of a Decorator and an Adapter. A Decoraptor is a long-lived object that adapts an Abstract Factory, and uses the factory to create a short-lived instance of the interface that it, itself, implements.
How it works #
A Decoraptor is an Adapter that looks almost like a Decorator. It implements an interface (Component in the above figure) by adapting an Abstract Factory. The factory creates other instances of the implemented interface, so the Decoraptor implements each operation defined by the interface by
- Invoking the factory to create a new instance of the same interface
- Delegating the operation to the new instance
While not strictly a Decorator, a Decoraptor is closely related because it ultimately delegates all implementation to another implementation of the interface it, itself, implements. The only purpose of a Decoraptor is to match two otherwise incompatible lifetimes.
When to use it #
While a Decoraptor is a fairly simple piece of infrastructure code, it still adds complexity to a code base, so it should only be used if necessary. The simplest solution to the Captive Dependency problem is to align the Client's lifetime to the Service's lifetime; in other words, make the Client's lifetime as short as the Service's lifetime. This doesn't require a Decoraptor: it only requires you to compose the Client/Service object graph every time you want to create a new instance of the Service.
Another alternative to a Decoraptor is to consider whether it's possible to refactor the Service so that it can have a longer lifetime. Often, the reason why a Service should have a short life span is because it isn't thread-safe. Sometimes, making a Service thread-safe isn't that difficult; in such cases, this may be a better solution (but sometimes, making something thread-safe is extremely difficult, in which case Decoraptor may be a much simpler solution).
Still, there may be cases where creating a new Client every time you want to use it isn't desirable, or even possible. The most common concern is often performance, although in my experience, that's rarely a real problem. More substantial is a concern that sometimes, due to technical constraints, it isn't possible to make the Client shorter-lived. In these cases, a Decoraptor is a good solution.
A Decoraptor is a better alternative to injecting an Abstract Factory directly into the Client, because doing that is a Leaky Abstraction. The Client is programming against an interface, and, according to the Dependency Inversion Principle,
Therefore, it would be a Leaky Abstraction if the Client were to define the interface based on the requirements of a particular implementation of that interface. A Decoraptor is a better alternative, because it enables the Client to define the interface it needs, and the Service to implement the interface as it can, and the Decoraptor's single responsibility is to make those two ends meet."clients [...] own the abstract interfaces"
- Agile Principles, Patterns, and Practices, chapter 11
Implementation details #
Let the Client define the interface it needs, without taking lifetime issues into consideration. Implement the interface in a separate class, again disregarding specific lifetime issues.
Define an Abstract Factory that creates new instances of the interface required by the Client. Create a new class that implements the interface, but takes the factory as a dependency. This is the Decoraptor. In the Decoraptor, implement each method by invoking the factory to create the short-lived instance of the interface, and delegate the method implementation to that instance.
Create a class that implements the Abstract Factory by creating new instances of the short-lived Service.
Inject the factory into the Decoraptor, and inject the Decoraptor into the long-lived Client. The Decoraptor has the same lifetime as the Client, but each Service instance only exists for the duration of a single method call.
Motivating example #
When using Passive Attributes with ASP.NET Web API, the Filter containing all the behaviour must be added to the overall collection of Filters:
var filter = new MeteringFilter(observer); config.Filters.Add(filter);
Due to the way ASP.NET Web API works, this configuration happens during Application_Start, so there's only going to be a single instance of MeteringFilter around. In other work, the MeteringFilter is a long-lived Client; it effectively has Singleton lifetime scope.
MeteringFilter depends on IObserver<MeterRecord> (See the article about Passive Attributes for the full code of MeteringFilter). The observer injected into the MeteringFilter object will have the same lifetime as the MeteringFilter object. The Filter will be used from concurrent threads, and while MeteringFilter itself is thread-safe (it has immutable state), the injected observer may not be.
To be more concrete, this question was recently posted on Stack Overflow:
"The filter I'm implementing has a dependency on a repository, which itself has a dependency on a custom DbContext. [...] I'm not sure how to implement this, while taking advantage of the DI container's lifetime management capabilities (so that a new DbContext will be used per request)."It sounds like the DbContext in question is probably an Entity Framework DbContext, which makes sense: last time I looked, DbContext wasn't thread-safe. Imagine that the IObserver<MeterRecord> implementation looks like this:
public class SqlMeter : IObserver<MeterRecord> { private readonly MeteringContext ctx; public SqlMeter(MeteringContext ctx) { this.ctx = ctx; } public void OnNext(MeterRecord value) { this.ctx.Records.Add(value); this.ctx.SaveChanges(); } public void OnCompleted() { } public void OnError(Exception error) { } }
The SqlMeter class here takes the place of the Service in the more abstract language used above. In the Stack Overflow question, it sounds like there's a Repository between the Client and the DbContext, but I think this example captures the essence of the problem.
This is exactly the issue outlined above. Due to technical constraints, the MeteringFilter must be a Singleton, while (again due to technical constraints) each Observer must be either Transient or scoped to each request.
Refactoring notes #
In order to resolve a problem like the example above, you can introduce a Decoraptor, which sits between the Client (MeteringFilter) and the Service (SqlMeter). The Decoraptor relies on an Abstract Factory to create new instances of SqlMeter:
public interface IFactory<T> { T Create(); }
In this case, the Abstract Factory is a generic interface, but it could also be a non-generic interface that only creates instances of IObserver<MeterRecord>. Some people prefer delegates instead, so would use e.g. Func<IObserver<MeterRecord>>. You could also define an Abstract Base Class instead of an interface, if that's more to your liking.
This particular example also disregards decommissioning concerns. Effectively, the Abstract Factory will create instances of SqlMeter, but since these instances simply go out of scope, the contained MeteringContext isn't being disposed of in a deterministic manner. In a future article, I will remedy this situation.
Example: generic Decoraptor for Observers #
In order to resolve the lifetime mismatch between MeteringFilter and SqlMeter you can introduce a generic Decoraptor:
public class Observeraptor<T> : IObserver<T> { private readonly IFactory<IObserver<T>> factory; public Observeraptor(IFactory<IObserver<T>> factory) { this.factory = factory; } public void OnCompleted() { this.factory.Create().OnCompleted(); } public void OnError(Exception error) { this.factory.Create().OnError(error); } public void OnNext(T value) { this.factory.Create().OnNext(value); } }
Notice that Observeraptor<T> can adapt any IObserver<T> because it depends on the generic IFactory<IObserver<T>> interface. In each method defined by IObserver<T>, it first uses the factory to create an instance of a short-lived IObserver<T>, and then delegates the implementation to that object.
Since MeteringFilter depends on IObserver<MeterRecord>, you also need an implementation of IFactory<IObserver<MeterRecord>> in order to compose the MeteringFilter object graph:
public class SqlMeterFactory : IFactory<IObserver<MeterRecord>> { public IObserver<MeterRecord> Create() { return new SqlMeter(new MeteringContext()); } }
This implementation simply creates a new instance of SqlMeter and MeteringContext every time the Create method is invoked; hardly surprising, I should hope.
You now have all building blocks to correctly compose MeteringFilter in Application_Start:
var factory = new SqlMeterFactory(); var observer = new Observeraptor<MeterRecord>(factory); var filter = new MeteringFilter(observer); config.Filters.Add(filter);
Because SqlMeterFactory creates new instances of SqlMeter every time MeteringFilter invokes IObserver<MeterRecord>.OnNext, the lifetime requirements of the DbContext are satisfied. Moreover, MeteringFilter only depends on IObserver<MeterRecord>, so is perfectly shielded from that implementation detail, so no Leaky Abstraction was introduced.
Known examples #
Questions related to the issue of lifetime mismatches are regularly being asked on Stack Overflow, and I've had a bit of success recommending Decoraptor as a solution, although at that time, I had yet to come up with the name:
- Dependency Injection - new instance required in several of a classes methods
- IOC DI Multi-Threaded Lifecycle Scoping in Background Tasks
Comments
Hi Mark! I'm implementing a global filter in ASP.NET WebApi 2, which depends on a service that in turn requires access to the current request's HttpContext. Would a decoraptor-like pattern around HttpContext.Current be appropriate for this or is that asking for trouble with regards to thread-safety or other potential gotchas? Thank you!
I put together this Gist to show what I'm after.
Tony, thank you for writing. I always managed to stay away from HttpContext.Current. I don't like the Ambient Context design, and I don't trust that I can reason about how it actually works with concurrent requests. If you're writing a filter, can't you get what you need from the HttpActionContext that's passed as an argument to IActionFilter.ExecuteActionFilterAsync?
I don't know exactly what it is that you need from HttpContext, and I'm also not sure that I'm looking at the correct version of documentation for ASP.NET Web API, so I could be missing the point here.
Mark, thanks for the quick reply. The service in question is meant to be responsible for plucking
off certain properties out of the Request and mapping them to a context object used in downstream processing of
OnActionExecutionAsync. It is meant to be an extension point for users of the filter. Anyway, I was striving to make HttpContextBase an explicit constructor
dependency of the service. Needless to say, I couldn't do what you're proposing in the
composition root.
However, instead of constructor injection, I suppose I could float the context from the filter's
ActionExecutingContext.HttpContext, into an instance method of the service like
_myService.MapRequestInfo(ActionExecutingContext.HttpContext). This appears to be what ASP.NET Core does for custom middleware components: https://docs.microsoft.com/en-us/aspnet/core/fundamentals/http-context?view=aspnetcore-3.1#use-httpcontext-from-middleware.
Would you favor this approach or do you think there might be a design smell going on?
Tony, it sounds like you're designing a model for middleware. It's not clear to me why you're doing this; filters are already middleware.
As I wrote, I'm in the dark. It's been years since I worked with ASP.NET Web API 2, and I'm not even sure that I'm looking at the right API documentation. Unless I'm looking at the wrong version of the API, though, doesn't ExecuteActionFilterAsync provide the objects you need? For example, you can get the request object from actionContext.Request.
Mark, thanks for your input.
Yes, you are correct about having access to the request via actionContext.Request (though the Headers
property doesn't seem mockable for unit testing) -- I'm multi-targeting
netcore and netfx and mistakenly pasted the code for the wrong framework in my previous comment. Sorry for the
confusion.
I guess it *is* kind of like middleware for my filter, where each middleware contributes data that the filter aggregates as a dictionary and sends off to a SaaS service as the context for evaluating a feature flag. The thing is, this is for an abstraction over the vendor's SDK and developers who use this abstraction need the flexibility to add whatever KVPs are necessary for the evaluation of any given feature flag being introduced. The idea is, if a developer is implementing toggle point code for a new feature flag that requires some contextual info, they can create and register a new service/"middleware" that provides that contextual info. I added an example class to the Gist for clarity.
Also, the flag context might not ALWAYS be derived from the HTTP request alone; it could come from configuration info or some other source I suppose. Hopefully, that sheds more light on the subject.
Tony, it's still not quite clear to me what you're trying to do (e.g. what's MyCustomFilter?), but if you truly have a class that depends on HttpContextBase, I think that you're supposed to use HttpContextWrapper.
Agreed. HttpContextWrapper is in the decoraptor's factory method. :)
Apologies. I renamed MyCustomFilter to FeatureGateFilter -- it's inspired by Microsoft.FeatureManagement but I'm using the passive attributes pattern so this is the guy who does the work of locating [FeatureGate] attributes, calling the feature context providers, and finally talking to the SaaS service (passing the accumulated context along for evaluation).
In any case, I get your point about avoiding HttpContext. I may look to pass the Request into the GetContext method (method injection?) instead of constructor injection for that reason, though some of the context providers may not use it.
Tony, what I meant with HttpContextWrapper was that it already represents the abstraction you need (HttpContextBase). Why would you need a Decoraptor around it?
Oh, the answer is because HttpContextWrapper doesn't behave reliably with a singleton lifetime and it can't be
anything else
(even when registered with a transient lifetime in a DI container) because it always gets promoted to a singleton due to
the object
graph being added to the global filters collection. Unlike ASP.NET Core, which supports type activation of filters via
FilterCollection.Add<TFilterType>() and friends, it seems ASP.NET MVC 5 filters can only be added by instance, effectively making the entire dependency graph singleton, as you pointed out in the "Motivating Example" section above.
For thoroughness, what I meant by "doesn't behave reliably" is that each property access, httpContextWrapper.Request for example, yields a new object instance (which seems promising), but its nested property values, say httpContextWrapper.Request.Headers, are referentially equal to the instances of their initial evaluation. Therefore, I also observed that httpContextWrapper.Request.Path is always "/" assuming the initial request was for the root, regardless of the actual URLs associated with successive requests. (At least these were my obversations. 🤷.) So that's how I landed here on decoraptor.
Tony, if a Decoraptor around HttpContextBase addresses your problem, then by all means go for it 🙂
CQS versus server generated IDs
How can you both follow Command Query Separation and assign unique IDs to Entities when you save them? This post examines some options.
In my Encapsulation and SOLID Pluralsight course, I explain why Command Query Separation (CQS) is an important component of Encapsulation. When first exposed to CQS, many people start to look for edge cases, so a common question is something like this:
What would you do if you had a service that saves to a database and returns the ID (which is set by the database)? The Save operation is a Command, but if it returns void, how do I get the ID?This is actually an exercise I've given participants when I've given the course as a workshop, so before you read my proposed solutions, consider taking a moment to see if you can come up with a solution yourself.
Typical, CQS-violating design #
The problem is that in many code bases, you occasionally need to save a brand-new Entity to persistent storage. Since the object is an Entity (as defined in Domain-Driven Design), it must have a unique ID. If your system is a concurrent system, you can't just pick a number and expect it to be unique... or can you?
Instead, many programmers rely on their underlying database to add a unique ID to the Entity when it saves it, and then return the ID to the client. Accordingly, they introduce designs like this:
public interface IRepository<T> { int Create(T item); // other members }
The problem with this design, obviously, is that it violates CQS. The Create method ought to be a Command, but it returns a value. From the perspective of Encapsulation, this is problematic, because if we look only at the method signature, we could be tricked into believing that since it returns a value, the Create method is a Query, and therefore has no side-effects - which it clearly has. That makes it difficult to reason about the code.
It's also a leaky abstraction, because most developers or architects implicitly rely on a database implementation to provide the ID. What if an implementation doesn't have the ability to come up with a unique ID? This sounds like a Liskov Substitution Principle violation just waiting to happen!
The easiest solution #
When I wrote "you can't just pick a number and expect it to be unique", I almost gave away the easiest solution to this problem:
public interface IRepository<T> { void Create(Guid id, T item); // other members }
Just change the ID from an integer to a GUID (or UUID, if you prefer). This does enable clients to come up with a unique ID for the Entity - after all, that's the whole point of GUIDs.
Notice how, in this alternative design, the Create method returns void, making it a proper Command. From an encapsulation perspective, this is important because it enables you to immediately identify that this is a method with side-effects - just by looking at the method signature.
But wait: what if you do need the ID to be an integer? That's not a problem; there's also a solution for that.
A solution with integer IDs #
You may not like the easy solution above, but it is a good solution that fits in a wide variety in situations. Still, there can be valid reasons that using a GUID isn't an acceptable solution:
- Some databases (e.g. SQL Server) don't particularly like if you use GUIDs as table keys. You can, but integer keys often perform better, and they are also shorter.
- Sometimes, the Entity ID isn't only for internal use. Once, I worked on a customer support ticket system, and my suggestion of using a GUID as an ID wasn't met with enthusiasm. When a customer calls on the phone about an existing support case, it isn't reasonable to ask him or her to read an entire GUID aloud; it's simply too error-prone.
Here's my modified solution:
public interface IRepository<T> { void Create(Guid id, T item); int GetHumanReadableId(Guid id); // other members }
Notice that the Create method is the same as before. The client must still supply a GUID for the Entity, and that GUID may or may not be the 'real' ID of the Entity. However, in addition to the GUID, the system also associates a (human-readable) integer ID with the Entity. Which one is the 'real' ID isn't particularly important; the important part is that there's another method you can use to get the integer ID associated with the GUID: the GetHumanReadableId method.
The Create method is a Command, which is only proper, because creating (or saving) the Entity mutates the state of the system. The GetHumanReadableId method, on the other hand, is a Query: you can call it as many times as you like: it doesn't change the state of the system.
If you want to store your Entities in a database, you can still do that. When you save the Entity, you save it with the GUID, but you can also let the database engine assign an integer ID; it might even be a monotonically increasing ID (1, 2, 3, 4, etc.). At the same time, you could have a secondary index on the GUID.
When a client invokes the GetHumanReadableId method, the database can use the secondary index on the GUID to quickly find the Entity and return its integer ID.
Performance #
"But," you're likely to say, "I don't like that! It's bad for performance!"
Perhaps. My first impulse is to quote Donald Knuth at you, but in the end, I may have to yield that my proposed design may result in two out-of-process calls instead of one. Still, I never promised that my solution wouldn't involve a trade-off. Most software design decisions involve trade-offs, and so does this one. You gain better encapsulation for potentially worse performance.
Still, the performance drawback may not involve problems as such. First, while having to make two round trips to the database may perform worse than a single one, it may still be fast enough. Second, even if you need to know the (human-readable) integer ID, you may not need to know it when you create it. Sometimes you can get away with saving the Entity in one action, and then you may only need to know what the ID is seconds or minutes later. In this case, separating reads and writes may actually turn out to be an advantage.
Must all code be designed like this? #
Even if you disregard your concerns about performance, you may find this design overly complex, and more difficult to use. Do I really recommend that all code should be designed like that?
No, I don't recommend that all code should be designed according to the CQS principle. As Martin Fowler points out, in Object-Oriented Software Construction, Bertrand Meyer explains how to design an API for a Stack with CQS. It involves a Pop Command, and a Top Query: in order to use it, you would first have to invoke the Top Query to get the item on the top of the stack, and then subsequently invoke the Pop Command to modify the state of the stack.
One of the problems with such a design is that it isn't thread-safe. It's also more unwieldy to use than e.g. the standard Stack<T>.Pop method.
My point with all of this isn't to dictate to you that you should always follow CQS. The point is that you can always come up with a design that does.
In my career, I've met many programmers who write a poorly designed class or interface, and then put a little apology on top of it:
public interface IRepository<T> { // CQS is impossible here, because we need the ID int Create(T item); // other members }
Many times, we don't know of a better way to do things, but it doesn't mean that such a way doesn't exist; we just haven't learned about it yet. In this article, I've shown you how to solve a seemingly impossible design challenge with CQS.
Knowing that even a design problem such as this can be solved with CQS should put you in a better position to make an informed decision. You may still decide to violate CQS and define a Create method that returns an integer, but if you've done that, it's because you've weighed the alternatives; not because you thought it impossible.
Summary #
It's possible to apply CQS to most problems. As always, there are trade-offs involved, but knowing how to apply CQS, even if, at first glance, it seems impossible, is an important design skill.
Personally, I tend to adhere closely to CQS when I do Object-Oriented Design, but I also, occasionally, decide to break that principle. When I do, I do so realising that I'm making a trade-off, and I don't do it lightly.
Comments
POST /api/users
This should return the Location of the created url. Would you suggest, the location be the status of the create user command.
GET /api/users/createtoken/abc123
UI Developers do not like this pattern. It creates extra work for them.
(Bear in mind I'm pretty ignorant when it comes to CQRS but I figured that it would get around not being able to return anything directly from a command)
But then again I suppose you'd still need the GetHumanReadableId method for later on...
Tony, thank you for writing. What you suggest is one way to model it. Essentially, if a client starts with:
POST /api/users
One option for a response is, as you suggest, something like:
HTTP/1.1 202 Accepted Location: /api/status/1234
A client can poll on that URL to get the status of the task. When the resource is ready, it will include a link to the user resource that was finally created. This is essentially a workflow just like the RESTbucks example in REST in Practice. You'll also see an example of this approach in my Pluralsight course on Functional Architecture, and yes, this makes it more complicated to implement the client. One example is the publicly available sample client code for that course.
While it puts an extra burden on the client developer, it's a very robust implementation because it's based on asynchronous workflows, which not only makes it horizontally scalable, but also makes it much easier to implement robust occasionally connected clients.
However, this isn't the only RESTful option. Here's an alternative. The request is the same as before:
POST /api/users
But now, the response is instead:
HTTP/1.1 201 Created
Location: /api/users/8765
{ "name" : "Mark Seemann" }
Notice that this immediately creates the resource, as well as returns a representation of it in the response (consider the JSON in the example a placeholder). This should be easier on the poor UI Developers :)
In any case, this discussion is entirely orthogonal to CQS, because at the boundaries, applications aren't Object-Oriented - thus, CQS doesn't apply to REST API design. Both POST, PUT, and DELETE verbs imply the intention to modify a resource's state, yet the HTTP specification describes how such requests should return proper responses. These verbs violate CQS because they both involve state mutation and returning a response.
Steve, thank you for writing. Yes, raising an event from a Command is definitely valid, since a Command is all about side-effects, and an event is also a side effect. The corollary of this is that you can't raise events from Queries if you want to adhere to CQS. In my Pluralsight course on encapsulation, I briefly touch on this subject in the Encapsulation module (module 2), in the clip called Queries, at 1:52.
(BTW, in this article, and the course as well, I'm discussing CQS (Command Query Separation), not CQRS (Command Query Responsibility Segregation). Although these ideas are related, it's important to realise that they aren't synonymous. CQS dates back to the 1980s, while CQRS is a more recent invention, from the 2000s - the earliest dated publication that's easy to find is from 2010, but it discusses CQRS as though people already know what it is, so the idea must be a bit older than that.)
Mark, thank you for this post and sorry for my late response, but I've got some questions about it.
First of all, I would not have designed the repository the way you showed at the beginning of your post - instead I would have opted for something like this:
public interface IRepository<T> { T CreateEntity(); void AttachEntity(T entity); }
The CreateEntity method behaves like a factory in that it creates a new instance of the specified entity without an ID assigned (the entity is also not attached to the repository). The AttachEntity method takes an existing entity and assigns a valid ID to it. After a call to this method, the client can get the new ID by using the corresponding get method on the entity. This way the repository acts like a service facade as it provides creational, querying and persistance services to the client for a single type of entities.
What do you think about this? From my point of view, the AttachEntity method is clearly a command, but what about the CreateEntity method? I would say it is a query because it does not change the state of the underlying repository when it is called - but is this really the case? If not, could we say that factories always violate CQS? What about a CreateEntity implementation that attaches the newly created entity to the repository?
Kenny, thank you for writing. FWIW, I wouldn't have designed a Repository like I show in the beginning of the article either, but I've seen lots of Repositories designed like that.
Your proposed solution looks like it respects CQS as well, so that's another alternative to my suggested solutions. Based on your suggested method signatures, at least, CreateEntity looks like a Query. If a factory only creates a new object and returns it, it doesn't change the observable state of the system (no class fields mutated, no files were written to disk, no bytes were sent over the network, etc.).
If, on the other hand, the CreateEntity method also attaches the newly created entity to the repository, then it would violate CQS, because that would change the observable state of the system.
Your design isn't too far from the one I suggest in this very article - I just don't include the CreateEntity method in my interface definition, because I consider the creation of an Entity (in memory) to be a separate concern from being able to persist it.
Then, if you omit the CreateEntity method, you'll see that your AttachEntity method plays the same role is my Create method; the only difference is that I keep the ID separate from the Entity, while you have the ID as a writable property on the Entity. Instead of invoking a separate Query (GetHumanReadableId) to figure out what the server-generated ID is, you invoke a Query attached to the Entity (its ID property).
The reason I didn't chose this design is because it messes with the invariants of the Entity. If you consider an Entity as defined in Domain-Driven Design, an Entity is an object that has a long-lasting identity. This is most often implemented by giving the Entity an Id property; I do that too, but make sure that the id is mandatory by requiring clients to supply it through the constructor. As I explain in my Pluralsight course about encapsulation, a very important part about encapsulation is to make sure that it's impossible (or at least difficult) to put an object into an invalid state. If you allow an Entity to be put into a state where it has no ID, I would consider that an invalid state.
Thank you for your comprehensive answer, Mark. I also like the idea of injecting the ID of an entity directly into its constructor - but I haven't actually applied this 'pattern' in my projects yet. Although it's a bit off-topic, I have to ask: the ID injection would result in something like this:
public abstract class Entity<T> { private readonly T _id; protected Entity(T id) { _id = id; } public T ID { get { return _id; } } public override int GetHashCode() { return _id.GetHashCode(); } public override bool Equals(object other) { var otherEntity = other as Entity; if (otherEntity == null) return false; return _id == otherEntity._id; } }
I know it is not perfect, so please think about it as a template.
Anyway, I prefer this design but often this results in unnecessarily complicated code, e.g. when the user is able to create an entity object temporarily in a dialog and he or she can choose whether to add it or discard of it at the end of the dialog. In this case I would use a DTO / View Model etc. that only exists because I cannot assign a valid ID to an entity yet.
Do you have a pattern that circumvents this problem? E.g. clone an existing entity with an temporary / invalid ID and assign a valid one to it (which I would find very reasonable)?
Kenny, thank you for writing. Yes, you could model it like that Entity<T> class, although there are various different concerns mixed here. Whether or not you want to override Equals and GetHashCode is independent of the discussion about protecting invariants. This may already be clear to you, but I just wanted to get that out of the way.
The best answer to your question, then, is to make it simpler, if at all possible. The first question you should ask yourself is: can the ID really be any type? Can you have an Entity<object>? Entity<Random>? Entity<UriBuilder>? That seems strange to me, and probably not what you had in mind.
The simplest solution to the problem you pose is simply to settle on GUIDs as IDs. That would make an Entity look like this:
public class Foo
{
private readonly Guid id;
public Foo(Guid id)
{
if (id == Guid.Empty)
throw new ArgumentException("Empty GUIDs not allowed.", "id");
this.id = id;
}
public Guid Id
{
get { return this.id; }
}
// other members go here...
}
Obviously, this makes the simplification that the ID is a GUID, which makes it easy to create a 'temporary' instance if you need to do that. You'll also note that it protects its invariants by guarding against the empty GUID.
(Although not particularly relevant for this discussion, you'll also notice that I made this a concrete class. In general, I favour composition over inheritance, and I see no reason to introduce an abstract base class only in order to take and expose an ID - such code is unlikely to change much. There's no behaviour here because I also don't override Equals or GetHashCode, because I've come to realise that doing so with the implementation you suggest is counter-productive... but that, again, is another discussion.)
Then what if you can't use a GUID. Well, you could still resort to the solution that I outline above, and still use a GUID, and then have another Query that can give you an integer that corresponds to the GUID.
However, ultimately, this isn't how I tend to architect my systems these days. As Greg Young has pointed out in a white paper draft (sadly) no longer available on the internet, you can't really expect to make Distributed Domain-Driven Design work with the 'classic' n-layer architecture. However, once you separate reads and writes (AKA CQRS) you no longer have the sort of problem you ask about, because your write model should be modelling commands and events, instead of Entities. FWIW, in my Functional Architecture with F# Pluralsight course, I also touch on some of those concepts.
It's a great topic. There's another approach used for this problem in some ORMs, particularly in NHibernate: Hi/Lo algorithm.
It is possible to preload a batch of IDs and distribute them among new objects. I've written a blog post about it: link
In the proposed solution that uses both integer IDs and Guids, would you expect child tables to use GUIDs as foreign keys also?
If the aggregate is passed in its entirety into a stored procedure, then scope_identity() can come into play. When a merge/replication scenario is not of concern, then you would be able to make use of integer IDs everywhere internally.
Irfan, thank you for writing. To the degree you choose to use GUIDs as described in this article, it's in order to obey the CQS principle. Thus, it's entirely a concern of the client(s). How you relate tables inside of a relational database is an implementation detail.
If by 'aggregate' you mean an Aggregate Root as described in DDD, then the root is the root of a tree. Translated to typical relational database design, it'd be a row in a table. By definition, any children of such a root don't have individual identity, so I don't see how it'd make sense to associate a GUID with the children; you'd never query them individually, because if you do, then the Aggregate Root is no longer an Aggregate Root.
How you associate the children with the root is an implementation detail. Again, in typical, normalised database design, you'd typically find children via foreign key relationship. Since this is an implementation detail, you can use any key type you'd like for that purpose; most likely, that'll be some sort of integer.
Hi Mark. I noticed in a comment to one of Kenny's questions you said you would not design a repository the way it was originally designed in this example. How would you design a repository layer? I've always found this type of repository design to not quite feel right but see it all over the place.
Thanks,
Ben
Ben, thank you for writing. To be clear, the Repository pattern is one of the most misunderstood and misrepresented design patterns that I can think of. It was originally described in Martin Fowler's book Patterns of Enterprise Application Architecture, but if you look up the pattern description there, it has nothing to do with how people normally use it. It's a prime example of design patterns being ambiguous and open not only to interpretation, but to semantic shift.
Regardless of the interpretation, I don't use the Repository design pattern. Following the Dependency Inversion Principle, "clients […] own the abstract interfaces" (APPP, chapter 11), so if I need to, say, read some data from a database, I define a data reader interface in the client library. Following other SOLID principles as well, I'd typically end up with most interfaces having only a single member. These days, though, if I do Dependency Injection at all, I mostly use partial application of higher-order functions.
Mark, when you get to choose the database design, do most of your tables include both a (supplied) Guid ID and a (database-generated) int ID?
Tyson, thank you for writing. There are a couple of options.
You could just use a GUID as the table key. DBAs typically dislike that option because, if you use that as the table's clustered index, it'll force the database to physically rearrange the table every time you insert a row (since GUIDs aren't, in general, increasing). Notice, however, that this argument is entirely concerned with performance. Using a GUID as a table key has no impact on database design in general. It is, after all, just an integer.
Thus, if the table in question is likely to remain small (i.e. have few rows) and with only the occasional insert, I see no reason to have the standard INT IDENTITY column.
For busier tables, you can have both columns. For example, the code base I'm currently working with defines its Reservations table like this:
CREATE TABLE [dbo].[Reservations] ( [Id] INT NOT NULL IDENTITY, [At] DATETIME2 (7) NOT NULL, [Name] NVARCHAR (50) NOT NULL, [Email] NVARCHAR (50) NOT NULL, [Quantity] INT NOT NULL, [PublicId] UNIQUEIDENTIFIER NOT NULL UNIQUE, [RestaurantId] INT NOT NULL PRIMARY KEY CLUSTERED ([Id] ASC) )
The Id column exclusively exists to keep the database happy. The code that interacts with the database never uses it; it uses PublicId.
To be honest, I used to have a decent grasp on database design, SQL Server, and related performance considerations, but it's about a decade back. I'm sure you could produce some cases where such a design would be detrimental, but on the other hand, I believe that the majority of code out there isn't even near the extremes where you need to compromise on the design.
Hello, Mark! Thank you for the encyclopedia of knowledge and experience you have shared and continue to share with us through this blog and your books!
I've recently read Domain Modeling Made Functional by Scott Wlaschin and am currently reading your new book, Code That Fits in Your Head. I've taken quite a liking to the idea that not just entities, but also events should be modeled within a domain. In addition to common events such as queries/commands, any expected error or success cases can also be wrapped in a type. This manner of extensive typing seems to help improve the "What you see is all there is" factor when learning/understanding a code base. Given that we have some expected events that occur when interacting with a database through commands and queries, it might make sense to encapsulate that domain model in the return types of these methods.
The query portion is straightforward. As you've discussed in your book, we can use Maybe<T> to indicate a successful or unsuccessful query. We might also be so crazy as to use an Either<T, TException> to propagate some exception message/data to be logged/returned at the bread-end of our impure/pure workflow.
Would it violate CQS to do the same for commands? We're doing a side effect on the database, no question. We're also probably returning some data that is relevant to the incoming command parameter within the resulting message from either the IOSuccess or IOFailure. A pattern I've been using for a web API project is something similar to the following:
public sealed record IOSuccess(string Value); public abstract record Failure(string Value); public sealed record ValidationFailure(string Value) : Failure(Value); public sealed record IOFailure(string Value) : Failure(Value); public sealed record GetBalloonQuery(BalloonId Id); public sealed record UpdateBalloonCommand(Balloon Balloon); public sealed record PopBalloonCommand(BalloonId Id, IPointyObject Needle); public interface IBalloonRepository { Task<Either<IReadOnlyCollection<Balloon>, IOFailure>> GetBalloonsAsync(); Task<Either<Balloon, IOFailure>> GetBalloonAsync(GetBalloonQuery query); Task<Either<IOSuccess, IOFailure>> UpdateBalloonAsync(UpdateBalloonCommand command); Task<Either<IOSuccess, IOFailure>> DeleteBalloonAsync(PopBalloonCommand command); }
I think this fits quite well with the idea that we can XXX out the name of the method and the types will tell the full story, no question at all. I also like that this seems to follow from Domain Driven Design, where we are being super explicit about the domain event because of the specificity of the object parameters we're sending down the wire.
Does this idea hold any merit when looking to design APIs that follow the CQS philosophy? Where might you direct a greenhorn developer to learn more about this topic?
Zach, thank you for writing.
As I write above, it's up to you if you want to follow CQS. If you do, however, you have to play by the rules, and the rules are that Commands don't return data.
We may have to make some concessions to the language in which we work. In C#, for example, we have to accept that Task (without a generic type argument) is 'asynchronous void', even though it looks like a return value.
If you want to be explicit about errors, then yes, there's always a risk that a state mutation may fail. Being explicit about that, too, might compel you to model a Command as having a return type like Task<Either<MyError, Unit>> (customarily, for Either values, errors go to the left, contrary to the isomorphic Result, where they go to the right). I don't, however, design side-effecting actions like that in C#.
Even so, in none of these variations does a Command return data in the happy-path scenario.
The API you suggest violate the rule that Commands mustn't return data. You are, of course, free to design APIs as you like, but CQS it isn't. As a counterexample, UpdateBalloonAsync returns an IOSuccess in the happy-path scenario, and that value again contains a string.
If you removed the string Value from IOSuccess it'd be isomorphic to unit. Transitively, then, the return type of UpdateBalloonAsync would be isomorphic to Task<Either<IOFailure, Unit>> (again, errors go to the left, because 'success is right'). If you allow Commands to throw exceptions, that again would be isomorphic to Task, with the implied understanding that the Command may throw an exception.
Where would I direct someone who want to learn more about the topic?
That's not that easy to answer. As Bertrand Meyer writes:
"Side-effect-producing functions, which have been elevated by some languages (C seems to be the most extreme example) to the status of an institution, conflict with the classical notion of function in mathematics."
As far as I can tell, that 'institution' continues with most mainstream languages like C#, Java, JavaScript, etcetera. This implies that you're unlikely to find strong treatment of the topic of CQS in 'traditional' object-oriented material.
As the above quote also implies by its use of the word function, you'll find that this distinction between pure functions and impure actions is more prevalent and explicit in functional programming.
Why DRY?
Code duplication is often harmful - except when it isn't. Learn how to think about the trade-offs involved.
Good programmers know that code duplication should be avoided. There's a cost associated with duplicated code, so we have catchphrases like Don't Repeat Yourself (DRY) in order to remind ourselves that code duplication is evil.
It seems to me that some programmers see themselves as Terminators: out to eliminate all code duplication with extreme prejudice; sometimes, perhaps, without even considering the trade-offs involved. Every time you remove duplicated code, you add a level of indirection, and as you've probably heard before, all problems in computer science can be solved by another level of indirection, except for the problem of too many levels of indirection.
Removing code duplication is important, but it tends to add a cognitive overhead. Therefore, it's important to understand why code duplication is harmful - or rather: when it's harmful.
Rates of change #
Imagine that you copy a piece of code and paste it into ten other code bases, and then never touch that piece of code again. Is that harmful?
Probably not.
Here's one of my favourite examples. When protecting the invariants of objects, I always add Guard Clauses against nulls:
if (subject == null) throw new ArgumentNullException("subject");
In fact, I have a Visual Studio code snippet for this; I've been using this code snippet for years, which means that I have code like this Guard Clause duplicated all over my code bases. Most likely, there are thousands of examples of such Guard Clauses on my hard drive, with the only variation being the name of the parameter. I don't mind, because, in my experience, these two lines of code never change.
Yet many programmers see that as a violation of DRY, so instead, they introduce something like this:
Guard.AgainstNull(subject, "subject");
The end result of this is that you've slightly increased the cognitive overhead, but what have you gained? As far as I can tell: nothing. The code still has the same number of Guard Clauses. Instead of idiomatic if statements, they are now method calls, but it's hardly DRY when you have to repeat those calls to Guard.AgainstNull all over the place. You'd still be repeating yourself.
The point here is that DRY is a catchphrase, but shouldn't be an excuse for avoiding thinking explicitly about any given problem.
If the duplicated code is likely to change a lot, the cost of duplication is likely to be high, because you'll have to spend time making the same change in lots of different places - and if you forget one, you'll be introducing bugs in the system. If the duplicated code is unlikely to change, perhaps the cost is low. As with all other risk management, you conceptually multiply the risk of the adverse event happening with the cost of the damage associated with that event. If the product is low, don't bother addressing the risk.
The Rule of Three #
It's not a new observation that unconditional elimination of duplicated code can be harmful. The Rule of Three exists for this reason:
- Write a piece of code.
- Write the same piece of code again. Resist the urge to generalise.
- Write the same piece of code again. Now you are allowed to consider generalising it.
Another reason is that even if the duplication is 'real' (and not coincidental), you may not have enough examples to enable you to make the correct refactoring. Often, even duplicated code comes with small variations:
- The logic is the same, but a string value differs.
- The logic is almost the same, but one duplicate performs an extra small step.
- The logic looks similar, but operates on two different types of object.
- etc.
If you refactor too prematurely, you may perform the wrong refactoring. Often, people introduce helper methods, and then when they realize that the axis of variability was not what they expected, they add more and more parameters to the helper method, and more and more complexity to its implementation. This leads to ripple effects. Ripple effects lead to thrashing. Thrashing leads to poor maintainability. Poor maintainability leads to low productivity.
This is, in my experience, the most important reason to follow the Rule of Three: wait, until you have more facts available to you. You don't have to take the rule literally either. You can wait until you have four, five, or six examples of the duplication, if the rate of change is low.
The parallel to statistics #
If you've ever taken a course in statistics, you would have learned that the less data you have, the less confidence you can have in any sort of analysis. Conversely, the more samples you have, the more confidence can you have if you are trying to find or verify some sort of correlation.
The same holds true for code duplication, I believe. The more samples you have of duplicated code, the better you understand what is truly duplicated, and what varies. The better you understand the axes of variability, the better a refactoring you can perform in order to get rid of the duplication.
Summary #
Code duplication is costly - but only if the code changes. The cost of code duplication, thus, is C*p, where C is the cost incurred, when you need to change the code, and p is the probability that you'll need to change the code. In my experience, for example, the Null Guard Clause in this article has a cost of duplication of 0, because the probability that I'll need to change it is 0.
There's a cost associated with removing duplication - particularly if you make the wrong refactoring. Thus, depending on the values of C and p, you may be better off allowing a bit of duplication, instead of trying to eradicate it as soon as you see it.
You may not be able to quantify C and p (I'm not), but you should be able to estimate whether these values are small or large. This should help you decide if you need to eliminate the duplication right away, or if you'd be better off waiting to see what happens.
Comments
I would add one more aspect to this article: Experience.
The more experience you gain the more likely you will perceive parts of your code which could possibly benefit from a generalization; but not yet because it would be premature.
I try to keep these places in mind and try to simplify the potential later refactoring. When your code meets the rule of three, you’re able to adopt your preparations to efficiently refactor your code. This leads to better code even if the code isn't repeated for the third time.
Needless to say that experience is always crucial but I like to show people, who are new to programing, which decisions are based on experience and which are based on easy to follow guidelines like the rule of three.
Markus, thank you for writing. Yes, I agree that experience is always helpful.
Wonderful article but I'd like to say that I prefer sticking to the Zero one infinity rule instead of the Rule Of Three
That way I do overcome my laziness of searching for duplicates and extracting them to a procedure. Also it does help to keep code DRY without insanity to use it only on 2 or more lines of code. If it's a non-ternary oneliner I'm ok with that. If it's 2 lines of code I may consider making a procedure out of it and 3 lines and more are extracted every time I need to repeat them.
I generally agree with the points raised here, but I'd like to point out another component to the example used of argument validation. I realize this post is fairly old now, so I'm not entirely sure if you'd agree or not considering new development since then.
While it is fair to say that argument validation is simple enough not to warrant some sort of encapsulation like the Guard class, this can quickly change once you add other factors into the mix, like number of arguments, and project-specific style rules. Take this sample code as an example:
if (subject1 == null) { throw new ArgumentNullException("subject1"); } if (subject2 == null) { throw new ArgumentNullException("subject2"); } if (subject3 == null) { throw new ArgumentNullException("subject3"); } if (subject4 == null) { throw new ArgumentNullException("subject4"); } if (subject5 == null) { throw new ArgumentNullException("subject5"); }
This uses "standard" StyleCop rules with 5 parameters (probably the very limit of what is acceptable before having to refactor the code). Every block has the explicit scope added, and a line break after the scope terminator, as per style guidelines. This can get incredibly verbose and distract from the main logic of the method, which in cases like this, can become smaller than the argument validation code itself! Now, compare that to a more modern approach using discards:
_ = subject1 ?? throw new ArgumentNullException("subject1"); _ = subject2 ?? throw new ArgumentNullException("subject2"); _ = subject3 ?? throw new ArgumentNullException("subject3"); _ = subject4 ?? throw new ArgumentNullException("subject4"); _ = subject5 ?? throw new ArgumentNullException("subject5");
Or even better, using C#6 expression name deduction and the new, native guard method:
ArgumentNullException.ThrowIfNull(subject1); ArgumentNullException.ThrowIfNull(subject2); ArgumentNullException.ThrowIfNull(subject3); ArgumentNullException.ThrowIfNull(subject4); ArgumentNullException.ThrowIfNull(subject5);
Now, even that can be improved upon, and C# is moving in the direction of making contract checks like this even easier.
I only wanted to make the point that, in this particular example, there are other benefits to the refactor besides just DRY, and those can be quite important as well since we read code much more than we write it: any gains in clarity and conciseness can net substantial productivity improvements.
Juliano, thank you for writing. I agree that the first example is too verbose, but when addressing it, I'd start from the position that it's just a symptom. The underlying problem, here, is that the style guide is counterproductive. For the same reason, I don't write null guards that way.
I'm not sure that the following was your intent, so please excuse me as I take this topic in the direction of one of my pet peeves. In general, I think that 'we' have a tendency towards action bias. Instead of taking a step back and consider whether a problem even ought to be a problem, we often launch directly into producing a solution.
In the spirit of five whys, we may first find that the underlying explanation of the problem is the style guide.
Asking one more time, we may begin to consider the need for null guards altogether. Why do we need them? Because objects may be null. Is there a way to avoid that? In modern C#, you can turn on the nullable reference types feature. Other languages like Haskell famously have no nulls.
I realise that this line of inquiry is unproductive when you have existing C# code bases.
Your point, however, remains valid. It's perfectly fine to extract a helper method when the motivation is to make the code more readable. And while my book Code That Fits in Your Head is an attempt to instrumentalise readability to some extend, a subjective component will always linger.
I don't agree that the style guide is counter productive per se. There are fair justifications for prefering the explicit braces and the blank lines in the StyleCop documentation. They might not be the easiest in the eyes in this particular scenario, but we have to take into consideration the ease of enforcement in the entire project of a particular style. If you deviate from the style only in certain scenarios, it becomes much harder to manage on a big team. Applying the single rule everywhere is much easier. I do understand however that this is fairly subjective, so I won't pursue the argument here.
Now, regarding nullable reference types, I'd just like to point out that one cannot only rely on that feature for argument validation. As you are aware, that's an optional feature, that might not be enabled on consumer code. If you are writing a reusable library for example, and you rely solely on Nullable Reference Types as your argument validation strategy, this will still cause runtime exceptions if a consumer that does not have NRTs enabled calls you passing null, and this would be a very bad developer experience for them as the stack trace will be potentially very cryptic. For that reason, it is a best practice to keep the runtime checks in place even when using nullable reference types.
Juliano, thank you for writing. I'm sure that there are reasons for that style guide. I admit that I haven't read them (you didn't link to them), but I can think of some arguments myself. Unless you're interested in that particular discussion, I'll leave it at that. Ultimately, this blog post is about DRY in general, and not particularly about Guard Clauses.
I'm aware of the limitations of nullable reference types. This once again highlights the difference between developing and maintaining a reusable library versus a complete application.
Understanding the forces that apply in a particular context is, I believe, a key to making good decisions.
I love the call out of risk * probability. I use threat matrixes to guide decisions all the time.

I'd also like to elaborate that duplication is determined not just by similar code, but by similar forces that change the code. If code looks similar, but changes for different reasons, then centralizing will cause tension between the different cases.
Using the example above, guard clauses are unlikely to change together. Most likely, the programmmer changes a parameter and just the single guard clause is effected. Since the clauses don't change for the same reason, the effect of duplication is very low.
Different forces might effect all guard clauses and justify centralizing. For example, if a system wanted to change its global null handling strategy at debug-time versus production.
However, I often see semantically separate code struggling to share an implementation. I think header interfaces and conforming container-like library wrappers are companion smells of this scenario. For example, I frequently see multiple flows trying to wrap email notifications behind some generic email notification abstraction. The parent flow is still coupled to the idea of email, the two notifications still change separately, and there's an extra poor abstraction between us and sending emails.

Comments
Hey Mark,
In a mathematical sense, I would say that this operation is an accumulation: you take a (complex or simple) value and according to the second parameter (and possible other contextual information), this value is transformed, which could mean that either subvalues are changed on the (mutable) target or a new value (which is probably immutable) is created from the given information. This whole process could imply that information is added or stripped from the first parameter.
What I found interesting is that there is always exactly one other parameter (not two or more), and it feels like the information from two is incorporated into parameter one.
Thus I would call this operation a Junction or Consolidation because information of parameter 2 is joined with parameter 1.
Kenny, thank you for your suggestions. Others have pointed out the similarities with accumulation, so that looks like the most popular candidate. Junction and Consolidation are new to me, but I've added both to my list.
When it comes to the second argument, I decided to present the problem with only a second argument in order to keep it simple. You could also have variations with two or three arguments, but since you can rephrase any parameter list to a Parameter Object, it's not particularly important.
Dear Mark,
I choose Junction over accumulation because it is a word that (almost) everybody is familiar with: a junction of rivers. When two or more rivers meet, they form a new river or the tributary rivers flow into the main river. I think this natural phenomenon is a reasonable metaphor for the operation your describing in your post.
Accumulation in contrast is specific to mathematics and IMHO I don't think everybody would understand the concept immediately (especially when lacking academic math education). Thus I think the name Junction can be grasped more easily - especially if you think of other OOP patterns like Factory, Command, Memento or Decorator: the pattern name provides a metaphor to a thing or phenomena (almost) everybody knows, which make them easy to learn and remember.
It was never my intention to imply that I necessarily considered Accumulation the best option, but it has been mentioned independently multiple times.
At first, I didn't make the connection to river junctions, but now that you've explained the metaphor, I really like it. It's like a tributary joining a major river. The Danube is still the Danube after the Inn has joined it. Thank you.
Sorry, I didn't want to sound like a teacher :-)
Not sure if you came to a conclusion here. Here are some relevant terms I've witnessed other places.
I'm curious, did you experiment with this pattern in a language without partial application? It seems like shepherding operations into the shared type would be verbose.
Spencer, thank you for writing. You're certainly reaching back into the past!
Identifying a name for this kind of API was something that I struggled with at least as far back as 2010, where, for lack of better terms at the time I labelled them Closure of Operations and Reduction of Input. As I learned much later, these are essentially endomorphisms.
I've learned a lot from your content! I decided to start at the beginning to experience your evolution of thought over time. I love how deeply you think and your clear explanations of complex ideas. Thank you for sharing your experience!
Endomorphism makes sense. I got too focused on my notion of piping and forgot the key highlighted value was closure.