ploeh blog danish software design
Worse is better: JSON versus XML
JSON is not a good data-interchange format.
This article is part of a series called Worse is better, in which I muse on technologies and techniques that became popular despite superior alternatives. Think VHS versus Betamax.
In this article, I will argue that XML is superior to JSON in most respects.
Lightweight XML #
Depending on how old you are, I guess that you have one of two reactions. If you started programming around 2015 you may simply ask: "What's XML?" If your programming career reaches further back, your reaction may be one of incredulity: "Oh my God, how can you say that?! Good riddance that SOAP, WS-(death)*, and XSLT are things of the past."
Indeed, and I don't miss them, either.
While that reaction is typical, it confuses cause and effect. SOAP and similar standards weren't cumbersome and overly complex because of XML. They managed to be awkward and enterprisey all by themselves. As a thought experiment, you could define all the payloads and specifications of SOAP as JSON, but it would, ironically, be even more verbose, because you'd have to invent a schema language and so on.
XML doesn't have to be heavy or formal. You may find the informality of JSON an advantage. Just write a document:
{
"author": "Peter Watts",
"title": "Blindsight"
}
While this is indeed easy and requires no ceremony, what prevents you from doing the same in XML?
<book> <author>Peter Watts</author> <title>Blindsight</title> </book>
You don't have to first define a schema. You don't have to declare a namespace. You don't have to add an XML declaration.
But you can, if you need to. XML allows gradual enhancement. If, sometime later, you find that a formal, machine-readable document specification would be useful, you can use XSD. And yes, I'm aware of JSON Schema; I hope the reader can see the irony that such a thing exists.
Sweet spots #
Like any other technology, XML is not a one-size-fits-all technology. I think the ideal scenario for XML is interoperability. While I'm aware that modern systems handle JSON as well as XML, I would still prefer XML for most data exchange tasks. The main driver for that decision would be the possibility to define document schemas. As Alexis King argues in a slightly different context, the lack of static types or, here, a machine-readable schema, does not entail the absence of a specification. Only, as suggested by Hyrum's law, the contract is implicit.
XML comes with a standard schema language, a standardized way to version documents, a standard query language, a standard for streaming parsers, etcetera. Of course, nothing prevents you from inventing similar technologies for JSON, and I'm sure someone already has. Even so, XML is a more mature format. Why reinvent the wheel?
A less ideal use of XML is for configuration files. I know I've lost that fight, but JSON is not a good format for configuration files. The most obvious problem with JSON is the lack of support for comments. And I know that various tools and editors allow comments in various proprietary formats, but it's not part of the standard. XML, on the other hand, has a standard for comments.
You may argue that XML is less readable than JSON, and I will partially agree, even though with good tools such as syntax colouring I find the difference marginal. The same goes with editor experiences. Most code editors will help you with XML to the same degree that they will help you with JSON. And again, if you work with a document that has a defined schema, the editor can help you more by suggesting and auto-filling elements.
But really, neither XML nor JSON are perfect configuration file formats. I wonder if such a thing even exists.
Where JSON shines #
Where would I choose JSON? To be clear, I would pragmatically choose JSON in lots of cases today, simply because that's the expected format, and having to defend a less popular choice is rarely worth it.
Ironically, the kind of architecture we today call SPAs got started as AJAX, where the X stood for, you guessed it, XML. Even so, the J stands for JavaScript, so it makes more sense to use JavaScript Object Notation (JSON). That's what modern SPAs do, and I would too, particularly if the service in question was a BFF.
Size #
I'd be surprised if you've made it so far and haven't though of size as a factor in favour of JSON. It's true that XML is more verbose than JSON. Depending on the actual schema and payload, the size difference could conceivably be more than a factor of two; compare <die><roll>4</roll></die> (25 characters) to {"roll":4} (10 characters). On the other hand, for other kinds of payloads, the difference might only be a small percentage.
In my experience the size difference doesn't matter that much. Often, other factors also play a role: Network latency for transmission, or block size for storage. And when performance really is a consideration, JSON may be too big, too.
Conclusion #
Although XML is generally and unfairly loathed as an old-fashioned legacy or enterprise technology, in most aspects it's a format superior to the more popular JSON.
XML has a rich ecosystem of mature standards, including a schema language that even supports sum types. While you could reimplement many of these in JSON (which has already been done), why reinvent the wheel?
Next: Worse is better: C# versus F#.
Worse is better
The most popular technology may not be the best.
In 1989 Richard P. Gabriel coined the term Worse is Better, a clearly humorous take on certain tendencies in software development and design as he saw them. I first encountered the term in his book Patterns of Software, and I'm basing the following on that.
In essence, another way to state the epigram is that perfection is the enemy of the good. Gabriel's context was the juxtaposition of Lisp versus C++. Gabriel had founded Lucid, a company that offered a general-purpose, cross-platform Lisp compiler, only to see C++ becoming the de-facto cross-platform programming language. The Lucid people considered Lisp superior, and were casting for an explanation why the inferior product was winning.
It's not my agenda to repeat Gabriel's entire line of reasoning. Rather, I want to highlight other areas of software-development technology where a similar relationship exists: A superior technology or process has lost to a more popular alternative.
Of course, any comparison between two technologies is likely to be subjective. My aim is not to insist that technology x is indisputably superior to the more popular technology y. Rather, my purpose is to give you food for thought. If you are a software architect, or other technical decision-maker, being aware of alternatives is useful. Often, going with the most popular tool is appropriate, but sometimes it may be prudent to at least consider alternatives.
In a series of articles, I will give specific examples. None are intended as rage bait, but rather as food for thought. The purpose is to highlight that the popular choice may have properties that are inferior to a less popular alternative. While I'm aware of the strengths of the popular choice, in this series I will instead highlight the advantages of less popular alternatives.
- Worse is better: JSON versus XML
- Worse is better: C# versus F#
- Worse is better: async/await versus syntactic sugar for monadic composition
When I publish this overview article, the above table of contents will initially be short, but I plan to expand it as I go.
Benefits of the road less travelled #
There are reasons that the most popular technology occupies the top spot. Often, those reasons apply to your case, too. If so, do go with the popular option. Consistently going against the flow is a recipe for misery.
Even so, you may occasionally run into a situation where the less popular alternative offers a benefit that outweighs what the mainstream choice offers. Perhaps the popular technology has properties a, b, c, d, and e, while an alternative is clearly superior when it comes to property f. If f is important enough in a certain context, you may decide to choose the road less travelled. That's a simple cost-benefit analysis.
Another advantages of going off the beaten path is the flexibility and freedom it may entail. In my experience, popular technologies are often associated with strong ecosystems. This is clearly a strength, but can also become a liability. Mainstream ecosystems tend to railroad you into a particular way of doing things. As long as your work matches the idiomatic way of doing things, you may be coasting along fine. On the other hand, if you need to do something exotic, you may find that the mainstream way of doing things makes your work harder. Examples could include using ORMs instead of writing plain SQL, or using Postman instead of curl.
Choosing a technology with a lesser ecosystem may force you to forge your own path. It seems that this could only slow you down, but there's also the chance that it enables you to respond better to unplanned events. It might even give you a trace of antifragility. It may help you escape vendor lock-in.
Conclusion #
A technology, a programming language, a protocol, or a tool is often popular because it's better than most alternatives. That said, software development is such a multifaceted endeavour that it's absurd to talk about a single best option. Even assuming that you can quantify every aspect of developing software, the notion of anything being the best assumes a total order, which is unreasonable in such a multidimensional space.
Thus, even if a technology is generally 'better' along commonly-considered axes, it's likely that some other technology is better for specific tasks.
Even so, some popular technologies are popular for reasons that aren't entirely well-considered. Or, for one overwhelming reason that, once you start to think rationally about it, shouldn't be such a big deal as it seems to be. Gabriel thought that C++ was inferior to Lisp, but essentially won in the marketplace because it was possible to release and support an inconsistent language incrementally, whereas, if I understand the story right, Lisp was more an all-or-nothing proposition that never really came to fruition.
In the following articles, I'll discuss some technologies that are generally worse than their less popular alternatives.
Motivated reasoning
Most of my concerns about AI are probably irrelevant, but what if one of them is not?
At the intersection of psychology, neuroscience, epistemology, and political science, there's a concept called motivated reasoning. In short, it describes the tendency to arrive at desired conclusions by reasoning processes heavily influenced by individual motivations. An example is a person who finds reasons to keep smoking that convinces him- or herself: Perhaps the smoker gloms onto evidence that smoking reduces appetite, and might therefore reason that it's better to keep smoking, because quitting would entail a weight gain, which is unhealthy.
As the example demonstrates, the reasoning process may not be particularly rigorous. While it may convince the person doing the reasoning, it convinces few other people.
The process if often subconscious. The person doing the reasoning may not be aware of the predilection leading to a desirable outcome. We all engage in motivated reasoning, so it's a kind of cognitive bias. Furthermore, it seems as though the more intelligent you are, the more susceptible to motivated reasoning you are. Apparently, the mechanism is that smarter people's superior mental resources enable them to find more convincing reasons for reaching desirable conclusions than less gifted persons.
Reasoning about the future of AI #
I have recently posted a series of articles critical of using AI for software development. These articles accept the capabilities of current LLM-based systems, but outline various concerns related to safety, epistemology, correctness, and similar areas.
While writing these articles, I've been aware that I'm likely to be engaging in motivated reasoning. Things are probably going to proceed at breakneck speed. Most of my concerns are probably moot while, on the other hand, I predict that we'll encounter problems that I didn't foresee.
Even so, if ninety percent of my concerns are irrelevant, that still leaves one that may turn out to be a real problem. Which one might it be?
Love of the craft #
Like many other software developers, I mourn our craft. I was originally drawn to programming because I was attracted to this particular kind of problem solving. It was like getting paid to solve puzzles, crosswords, sudokus, or whatever else you may be into.
During the decades of my career, I found that everything was interesting when framed as a programming problem. On the other hand, I've never been intrinsically interested in 'optimizing ad revenue', 'creating a marketplace for offal and other animal-processing waste products', 'implementing a complaint ticketing system', or 'enabling speculators to turn a profit from high-volume trading'. Some of these, I've actually done, and it was engaging work, but only because solving technical problems was stimulating.
When told that I can still 'solve business problems' by becoming a manager of agentic LLMs, that doesn't get my blood pumping. If I had found that prospect interesting, I would have become a manager decades ago.
I like writing code; not telling other entities to write code.
Incentives #
Of course, we were never paid based on whether we enjoyed the work. Rather, we were paid despite of it.
Usually, if you enjoy an activity, it's a hobby, and you pay to do it. Conversely, a job is an activity unpleasant enough that someone is willing to pay you to do it.
The last few decades of the software development job market is most likely abnormal. With some more help from motivated reasoning, I can think of a few reasons why this situation may last a bit longer, but again, I could be wrong.
In case, however, you think I'm incentivised by economics: To a small degree, I am. I'd definitely like to secure my finances better, but on the other hand, I'm getting near to what in some countries counts as retirement age, and I've had a good run so far. I'll get by, so that's not my main motivation.
I can, of course, keep programming as a hobby, but I do think that my services might still be valuable to some organizations. If so, please consider engaging with me.
Conclusion #
As my recent writings bear witness, I'm concerned about the current use of LLMs in software development. My concerns are related to safety and correctness.
Even so, it's possible that I'm engaging in motivated reasoning, a kind of cognitive bias where you arrive at conclusions beneficial to yourself. I still think that there's value in posting opinions that may act as counterpoints to techno-optimism.
I could be wrong about quite a few of my concerns, but still be right about one or two. If so, which ones?
In defence of bureaucracy
Objectivity, meritocracy, high bus factor. What's not to like?
Most people dislike bureaucracy, and to be honest, so do I. Even so, a subjective distaste is no argument. It may be wise to understand if bureaucracy entails any benefits, so as to not throw out the baby with the bathwater.
_-_14.jpg "Jarek Tuszyński / CC-BY-SA-3.0 & GDFL")
This essay does not attempt to make the point that more bureaucracy is better. Rather, it argues that some bureaucracy, wisely chosen, is better than no bureaucracy.
Origins of bureaucracy #
Consider the origins of bureaucracy. Believe it or not, it's an institution designed to get things done; to inject a degree of predictability and determinism into a situation that otherwise produces arbitrary results. While I'm no historian, I understand that the Sumerians, ancient Egyptians, Romans, Chinese, and others, all employed civil servants and a system of bureaucracy to control their empires.
In modern times, bureaucracy has served a similar purpose, replacing feudalism with rules-bound administration. Of course, as Seeing Like a State argues, part of the motivation was to centralize power, cutting out the middle-men (vassals). Even so, a by-product, which later became a goal of its own, was that bureaucracy is a rules-based order. It dampens the arbitrariness of a feudal lord by instituting universal rules for all to follow. During the nineteenth and early twentieth centuries, it became the primary means of making society more just.
Subjects could appeal to ideally objective rules to settle disputes, or to obtain permission to engage in various activities. In theory, a wealthier citizen could not by bribe influence decisions of those in power.
As rights were gradually expanded to include women, unlanded men, people of colour, etc., bureaucracy was a major instrument of implementation.
In parallel to this development, most organizations realized that hiring administrators based on merit, rather than on inheritance, ensured better execution.
Too much of a good thing #
Of course, when everyone complains about bureaucracy, it's because there's too much of it. It's like the Laffer curve related to taxation: Even if you don't like paying taxes, unless you're an anarcho-capitalist, you probably agree that some state institutions (e.g. courts, police, defence) are desirable. And unless you're a true communist, you probably believe in some degree of private property rights. Thus, neither zero percent or a hundred percent tax rates are desirable. The remaining problem is to decide on the optimal fraction in the open interval between 0 and 1.
The same applies, I believe, to bureaucracy. No bureaucracy entails the total absence of objective rules, meritocracy, traceability. Total bureaucracy, on the other hand, implies that nothing gets done. Again, the problem is to find the right balance. And this balance may not be an equilibrium. As external circumstances change, you may have to change how your bureaucracy works: How much of it, what the rules are, etc.
The worst system #
As has been incorrectly attributed to Winston Churchill, democracy is the worst form of government, except for all others which have been tried. Analogously, capitalism is the worst means of wealth distribution, except for all the other systems that have been tried.
It's natural to extend those notions: Bureaucracy is the worst form of administration, except for all the other systems that have been tried.
Of course, a counter-argument could be made that many societies work well without bureaucracy. Anthropologically interested readers will surely point to various well-functioning tribal societies, and tech bros will point to start-up companies. Such organizations surely exist, but they don't scale. Infamously, all successful start-ups ultimately add bureaucracy as organizations grow.
The mature choice #
Programmers tend to dislike bureaucracy as much as the next person. It can be difficult to see the value in moving Jira tickets around.
In light of the above, I'm not advocating bureaucracy for bureaucracy's sake. Much of it is, indeed, counter-productive, but some of it could actually boost your productivity.
For example, most programmers agree that interruptions are major productivity killers. Many interruptions are requests for status updates. How is the feature coming along? Are you working on this, instead of that? How soon can you be done?
I once lead a team of developers, in an organization that used Trello boards, and I tried to convince them that if they would reliably move tickets around on the board to reflect actual status, it could save them quite a few status requests.
Even such a modest request was, however, sullenly but actively ignored as beneath real programmers. The result: Frequent interruptions from stakeholders who wanted to know how far the project, or a particular feature, was coming.
I find such behaviour immature. By being proactive, you can surface information at the time you choose, and if done right, it can decrease the frequency of interruptions you experience. It does, however, require that you minimally play along with a bit of bureaucracy: Move those tickets from left to right. Write status updates. Radiate a bit of information.
Bureaucracy, the good parts #
Clearly, useless red tape exists. The goal of every software organization is to identify what actually works. This varies from organization to organization, and over time, so I don't claim to have the correct and complete list. If you're in doubt, however, I would recommend trying the following:
Write things down. And keep records in a place where everyone can find them. A Slack channel is probably not a good candidate. As I write in Code That Fits in Your Head, a sensible hierarchy of communication exists. It includes favouring readable code over comments, but comments over documentation. Specifically, you should prioritize writing better Git commit messages. And for broader decisions, keep Architecture Decision Records around.
The point of bureaucracy is not to move Jira tickets around for no reason. The crux is to put information where people look for it. If this is Jira, consider it a small price to pay for fewer interruptions.
Most organizations I've consulted tend to have an oral culture. Talking to each other is important: It's a fast, high-bandwidth mode of communication, and it often works well as a social lubricant. It may enable you to go fast in the short term. If, in the other hand, you keep no written record, you can't sustain the pace in the long run.
People cycle out of long-running projects. Key contributors move on to other jobs in other companies. Without a written record, you lack important information about the system. Consider good bureaucratic artefacts as a major counter-move against this problem. When done well, it increases a team's bus factor.
Conclusion #
Bureaucracy understandably has a bad reputation. It's usually done wrong, in which case it can induce unnecessary friction into processes.
Even so, consider what motivates it. Originally, it was a remedy against arbitrary rule of emperors, kings, feudal lords, or other people in power. It's a means to institute regularity and fairness into administration. It's meant to not only regulate, but also document, how administration is performed. When abuse of power occurs (which still happens), investigators can often use bureaucratic artefacts to uncover what most likely happened.
In software development, you may not be concerned with abuse of power, but keeping good records has many benefits. The challenge is not to be rid of bureaucracy, but to trim it to a size where only the good parts remain.
Secret agentic AI
A scenario.
Here's another speculative scenario about the future of software in an increasingly hostile international environment.
It seems indisputable that the future of software development involves substantial use of LLMs. Some people experiment with vibe coding, but I find it more plausible that we'll see widespread use of LLM-based agents that produce code, with continuous, but superficial human supervision.
Can we trust those LLMs?
Economics #
In other articles, I've discussed whether LLMs deserve our trust. The perspective in these articles have mostly been on the inherent non-determinism of these models, as well as their lack of 'understanding' of what it is that they do. The point I will make here, on the other hand, does not depend on assumptions of that kind. You may, if you will, imagine a future in which LLMs are far more reliable than today.
Even so, there's a fundamental aspect of the ecosystem that most developer-cum-futurists seem to ignore. The current systems, operated by companies like OpenAI and Anthropic, run with colossal deficits. While their valuations are measured in billions of dollars, they are losing money every year.
This implies that the way agentic software development works today isn't representative of future directions. But even if today's systems are too inexpensive to last, my social media feed regularly showcases examples of what can best be termed token angst: the dread of running out of tokens.
Investors ultimately want return on investment. While the AI companies currently run on deficits, they can't keep doing that. Sooner or later, they'll either turn a profit or go out of business. How will they generate profit?
There's been some talk of 'showing ads' in chatbots, but that isn't compatible with agent mode. If no-one is looking at the output of an LLM, then ads are an unlikely revenue stream. Perhaps my imagination is poor, but the most realistic scenario is coding agents as paid services. You buy a subscription with a token budget, or alternatively, you pay for tokens as you use them.
This suggests that in the future, price is going to be a competitive factor. You may decide to use Company X for agentic coding, rather than Company Y, because Company X is less expensive.
Subsidized LLM services #
For practical purposes, today's AI companies are American. It'd be naive to think that it will stay that way. When a technology becomes sufficiently strategically important, other states subsidize national enterprises to catch up. To Silicon Valley ears, this may sound derivative and unfit for competition, but such a strategy can work. Historical evidence exists.
You can find examples in another capital-intensive industry, aviation. Airbus probably wouldn't exist without European governments taking an active interest. And I find it fair to argue that Airbus is currently doing better than their main competitor in civil aviation.
Other aviation-related examples may be found with certain airlines that operate out of resource-rich countries. Air fare is surprisingly cheap, while service is top-notch.
In other industries, Chinese electric cars are, too, notably less expensive than competitors. Even if you're a dyed-in-the-wool liberal capitalist believing in competition and free markets, current world trends are moving away from that. We see increasing protectionism and focus on reshoring strategic manufacturing capabilities.
Subsidized AI companies will exist, too.
Secret agents #
Most of the modern information infrastructure has turned out to be porous. Even though top companies are American, adversarial state actors use social-media platforms to wage information warfare. I'd be surprised if something similar doesn't happen to LLM systems.
Granted, some clandestine way of injecting data directly into American LLMs seems difficult. What state actors can do, however, is to offer alternative, subsidized systems. Use this new LLM-based coding service: It's much cheaper than the one you currently use!
You may counter that you'd never use a Chinese, Russian, or pick-your-own-enemy LLM system. But some people and organizations are more price-sensitive than security-conscious. Besides, a dismissal of this scenario assumes that ownership is transparent.
An adversarial state actor could set up a shell company in your country, while keeping technical control. Much evidence seems to indicate that a major video-reel-serving app company already works that way, and although that example is not exclusively related to generative AI, I'm sure that you can extrapolate.

Once a foreign state establishes such a clandestine beachhead, it can use it in several ways. It can passively spy on users' code bases (and other content), and it can actively inject backdoors, viruses, etc. into customers' code bases. If that sounds far-fetched, you may not have heard about the xz utils backdoor. Such attempts are already being made.
Untrustworthy systems #
What can you do to avoid this risk?
You may consider only using systems of known origin. You may decide to stick to OpenAI, Anthropic, or other American companies. Perhaps, but I think that you should consider at least two things. The first is that, as already covered, these companies run huge deficits. Where do the money come from? Investors, you say? Indeed, but which investors? Is it conceivable that some of the investors are already, through chains of shell companies, controlled by foreign governments? And if not now, then in the future?
The second consideration is whether you should consider a US-controlled company benign or hostile. If you work in the US, then you probably consider the US government to be the good guys. Over here in Europe, we used to think that, too, but currently, we are not so sure.
You may, then, think of another countermeasure: Buy hardware powerful enough for in-house LLM hosting. This might be a viable option for some organisations, particularly because continued advancements in both hardware and software will make this increasingly feasible. Still, where are you going to get the LLM?
A few organizations are big enough that they may be able to train their own LLM, but most are not. They'll need to use a copy of an existing LLM. In that case, we're back to the issue of trust. Where do you get the LLM, and why do you trust it?
To be clear, you can't 'review the LLM code'. It's a system trained on massive data sets, the result of which is billions or trillions of weights (i.e. numbers). All you can do is trust it. That said, since training of these systems is a non-deterministic process, you could argue that adversaries can't train malign behaviour into them either. If systems come with spyware, it's more likely that it's embedded in the code that surrounds the model itself. Thus, you could, theoretically, review that part of the system. You'll probably not get the source code, however, so your review would have to be of the machine code. I don't find that realistic.
Countermeasures #
What can you do to protect yourself against such threats?
Some of these are more problematic than others. When you give a third party access to your source code, there's ultimately no way to detect if the third party takes a copy of all the code. Pragmatically, you either have to trust that third party enough, or else behave as though you had already made your code base open source (which there are other good reasons to do, in many contexts).
It's possible that research into zero-knowledge proofs could help address such issues, but this is not something I know much about, so perhaps I only display my ignorance.
The other large problem is whether adversarial LLMs may inject malicious code into your code base, installing backdoors, spyware, or similar. This threat seems more tractable: Treat your code base as if it was open source, and each contribution as a drive-by pull request that requires rigorous scrutiny. We're back to the discussion about trust in software development. As I've previously discussed, you can't even trust yourself to write code without errors, perhaps you can't trust your colleagues either, and I don't think it's wise to trust LLMs to write code.
Fortunately, we have decades of experience in making software development a safe and manageable process. Parts of Code That Fits in Your Head are about working together as a team, and how to ensure that you ship quality software. Treat LLMs as randos on the internet submitting pull requests to your open-source project, and review accordingly.
"But Mark, the LLMs produce code much faster than we can review it." Yes, I know. You are the bottleneck. You and your brain. It was always like this. Typing was never the bottleneck, although it's embarrassing so quickly the industry seems to forget that.
Conclusion #
The economics of AI companies in early 2026 seem unsustainable. In the future, these services will become more expensive; perhaps to a degree where price becomes a competitive advantage. If that happens, adversarial state actors might set up and subsidize shell companies that run LLM-based coding services at more attractive prices than competitors.
Once such companies have customers of interest, they can spy on the source code, and plant backdoors and spyware into code bases.
This is just one of many reasons to be wary of AI-generated source code.
The hailo effect
LLM friendliness does not entail competency.
One of the many cognitive biases of the human brain is called the halo effect. In short, it describes the tendency to transfer positive impressions of a person or organization from one area to another. If you like a particular actor because of a role, you may think that he or she has good taste in gin, too.
When serious fiction authors say something about politics, the media reports it. Or, some billionaire is good at producing a particular good, so now you think that what this person has to offer on rescue operations or warfare is gospel.

It seems obvious to coin the term hAIlo effect to describe how LLMs manipulate you into liking them, and thereby trusting their judgement.
Anthropomorphism #
Whenever you have a 'chat' with an LLM, it responds as though it was human. Now, just because I used to be good at programming and a few other things, I'm no psychologist, so beware that you don't trust me too far along the following line of reasoning.
That said, I'm also a writer. One of the most fundamental rules of writing is to avoid the passive voice. Speak to the reader. If appropriate, invest yourself in the text. Be present.
Recently, I've been involved in some academic writing, and I'm having much trouble with the aesthetics (or lack thereof) of this style. You're expected to not involve yourself, ostensibly because this appears subjective. The result is often stilted language, written in the passive voice, and with too many weasel words.
Any LLM responding like that would quickly be outcompeted by one that communicates in human language, pretending to be a person.
Since LLMs come across as persons, however, another cognitive bias makes us anthropomorphize them. We begin to ascribe to them motivations that they may not have.
Servility #
All the LLMs I've 'chatted' with (note the anthropomorphism) come across as friendly and eager to please. After all, any chatbot's raison d'être is to engage with users. It doesn't help that mission if the system scares away people.
Not only are they all, it seems, equipped with an upbeat can-do attitude, it sometimes tips over into obsequiousness. Getting such a system to admit that it doesn't 'know' how to proceed seems unattainable. At one time, I engaged with such a system to figure something out. I no longer remember what it was, but it was something falsifiable, and it kept giving me false answers. Finally, being only human, I succumbed to one of my many cognitive biases and asked it flat out: "You don't know, do you?"
It responded with the usual fawning wall of text.
When you combine the can-do attitude with what seems like a built-in aversion to admit defeat, these systems may come across as more competent than they really are.
Alignment #
One of the things that concern me about LLMs (and other, hypothetical future artificial intelligences) is the question of alignment. When we ask an LLM to perform a task for us, how can we be sure that it does it with our interests in mind? Specifically, if we ask it to write source code for software, what reason do we have to trust that it does it well?
One issue may lie in the fundamental non-deterministic nature of these systems. You can never be sure what errors may inadvertently sneak in.
A deeper problem is whether these systems even have our interests in mind. It's an open question whether an LLM has intrinsic motivations, but it sometimes behaves as though it does. We're getting into Chinese room territory here, which is not quite on my agenda for today. Rather, my point is that an LLM may tell you that it will follow your instructions, and then go do something else. You may tell it to follow test-driven development (TDD), and it will agree. Even so, will it actually use the red-green-refactor cycle? Will it observe the test failure in the red phase? Will it verify that it didn't write a tautological assertion? Will it write only the simplest thing that could possibly work, in order to pass the failing test? Will it abstain from modifying the test in order to make it pass?
When real people are told to follow TDD, they often ignore the instruction, or cheat in various ways. LLMs are trained on code written by people, so you shouldn't be surprised if they behave the same way.
Even so, when I ask vibe-coding enthusiasts why they trust LLM-generated code, the answer usually stops after a few interactions. "Oh, I asked it to write tests."
"Indeed," I respond, "but what makes you trust the tests?"
Sometimes, people get clever: "I asked another agent to write the tests."
"How do you know that the agents aren't colluding?"
"Why would they do that?"
I can't get very far with the usual discussion techniques, such as Socratic questioning or five whys. Before long, I hit a particular brick wall. People intrinsically trust LLMs.
Bullshit artists #
This is confounding to me. Why do people trust these systems? At best, I'm willing to view them as neutral, but all the evidence points to them being manipulative. I've already covered reasons for their anthropomorphic interaction design, and again, I don't wish to derail my own agenda by going off on a tangent related to built-in political and ideological biases, although those are well-documented, too.
Have you ever had a colleague or acquaintance who refused to admit failure? Who always had an answer to everything? Even if it was obvious that he or she had no clue?
In their smarmy way, LLMs will readily admit that they were wrong, but I've yet to experience that they respond with an "I don't know".
Instead, if confronted with a question where the answer is not immediate, they make shit up.
The owners, however, have successfully played the public and convinced everyone that LLMs 'hallucinate'. Since hallucinations is something humans suffer from, if we feel anything about this at all, we may feel sorry for the poor LLM.
Oh, muffin. It's so hard being you.
Using a word such as hallucination, LLM companies have isolated and downplayed what is really the core behaviour of these system. They make up stuff. That's literally what they do. They choose the next words based on a little randomness and what's statistically most likely to come next.
But because they're so ingratiating, we think they are our friends, and forgive them when they make mistakes. We may even feel sorry for them when they do. The poor thing is hallucinating.
Conclusion #
LLMs are undeniably capable of many astonishing feats. Does this mean that we should trust them?
It seems to me that many people intrinsically trust these systems, particularly when being told something that confirms their biases. I've been in discussions where, again, I'm met by: "but the AI says," and I can't get past such appeal to aithority.
For a long time, I couldn't get my head around why people trust LLMs, until it dawned on me that they come across as friendly, eager to please, and perhaps at the same time a little dim-witted.
We may dub this the hailo effect: The cognitive bias that makes us trust AIs because they make us feel good, and we transfer this experience of warmth into trust.
Programming languages for AI
Which programming language is best suited for LLM-based generation?
I recently asked readers to consider which programming language they would choose for a software system generated by one or more LLMs, and offered these options:
I deliberately made the menu unreasonable for a few reasons. I'm well aware that most people who dabble with LLM-based code generation use mainstream languages like Python, Rust, TypeScript, Go, etc. This makes sense for programmers. If you intend to keep an eye on the code that these systems generate, it's reasonable to pick a language you're familiar with. This enables you to review the code.
Code for machines #
A new sentiment is, however, on the rise. Vibe coding may only be a symptom. More broadly, people are speculating whether it even makes sense for LLMs to write in higher-level programming languages. After all, even assembly code was created for humans. If no human has to look at the code, then why not generate machine code?
I briefly discussed this in a conference keynote in 2024, but here I want to look at the question from a different perspective.
The underlying assumption behind the idea that LLMs might just as well generate machine code is that the only benefit gained from high-level languages is that they are human-readable. There are several flaws in that thinking.
The first is that machine code is not portable. And neither is assembly language. You could, of course, ask an LLM to produce the same app, but generate machine code for more than one operating system and processor, but since LLMs are non-deterministic, this doesn't sound like a good idea.
You could, instead, ask an LLM to generate code in C. This is, after all, C's original claim to fame. That language is designed to be portable, and it is.
This, however, suggests that a programming language offers more than just being human-readable. C, for example, has the crucial feature of allowing compilation to many different platforms; a feature shared by many more modern languages.
Might there be other features of programming languages that would be useful, even if no human looks at the code?
Guardrails #
Some programming languages are easier to analyse than others. I'm aware of three kinds of analysis of code:
- Linting, or static code analysis
- Static type systems
- Formal methods
I admit that I don't know much about formal methods, so I'll leave that topic to someone who does.
Linting is useful, but my experience suggests that human oversight is required to make such tools useful. They tend to produce false positives, and you need to understand code to judge whether a linter warning is a real problem, or something that can be ignored.
Static type systems are, on the other hand, much more rigorous. If a program doesn't type-check, it doesn't compile. While you could argue that type systems come with false negatives, this happens more rarely. Some languages allow 'overriding' the type system; for example, Java, C#, and other languages in the C family allow downcasting. Even so, my experience is that you don't need that language feature.
This may seem incomprehensible to some programmers, but I've written C# without resorting to dynamic type checks for more than a decade. F#, too.
If you're still doubtful that I'm speaking the truth, consider that Haskell doesn't have dynamic type-checking. You not only get by regardless; Haskell is a much more powerful language.
A typical joke is that if you can get your Haskell code to compile, it probably works. 'If' being the operative word.
Although funny, it's not true. No Turing-complete language could have that property, and even in languages that sacrifice Turing-completeness for provability, you are never safe from bugs arising from a misunderstanding of requirements. ("Oh, that was what the customer wanted!")
Even so, there's benefit from a strong static type system. It prevents whole categories of errors, where the infamous null-reference exceptions are only the top of the iceberg.
There are languages with type systems more powerful than Haskell. Idris is one of them. That's the reason I picked it for the above menu to choose from.
Constraints liberate #
As a thought experiment, imagine that you asked an LLM to produce a non-trivial, important software system where correctness matters. First, imagine that it produces this system directly in machine code. Or, if we wish to make it portable, in C. Would you trust this system?
C is a programming language infamous for being difficult to make correct. It's easy to forget to free memory, causing memory leaks. It's easy to get pointer arithmetic wrong, leading to crashes or even segfaults. Try to make the code multi-threaded, and it becomes even harder.
In addition, C is infamous for being insecure. Most buffer overrun vulnerabilities are caused by C's ability to allow ad-hoc access to memory. Even with an LLM superior to today's systems, will you trust that the software it produces in C is safe if you put it on the internet?
I wouldn't. Even if you believe that testing is enough to demonstrate that a system works, it's much harder to convince yourself that a black box is secure.
I'd much rather trust a system programmed in a language that comes with fewer opportunities for writing insecure code. As usual, constraints liberate. By having a statically-typed programming language, backed by a robust compiler, there's a lot that you don't have to worry about. You don't have to worry about null-reference exceptions. You don't have to worry about buffer overflows.
And with most such languages, you can turn the dial to 11 by treating warnings as errors (as discussed in Code That Fits in Your Head). For languages with algebraic data types, for instance, this would mean that you wouldn't be able to compile code that doesn't handle all cases of a sum type.
Programming languages for AI #
I listed Idris for two reasons: It has a type system even more expressive than (standard) Haskell, and the number of people who read it is small. I deliberately didn't want to list any popular language (like Haskell), because the purpose of the original 'poll' was to make you consider which kind of language would be best for LLMs, assuming that you had no bias.
Realistically, Idris is not going to be a standard programming language for AI. If things go as they usually go, it'll probably end up being JavaScript or Python (and if the choice is between those two, Python would be preferable).
What would make more sense, though, is a new language tailor-made for LLMs. And of course, people are already experimenting with that idea.
An AI-first language should, I think, have as many guardrails as possible built in. A powerful static type checker, perhaps refinement types, dependent types, or something else that I don't know of. Even if some of these features are inconvenient for human programmers, they may prove useful for machine-written code.
As Szymon Teżewski phrases it: Design by inconvenience. If LLMs are writing all the code, optimize for verifiability, not for how easy it is to write.
Conclusion #
Some people envision a future where AI writes all code. They believe that the implication is that the programming language no longer matters; that LLMs might just as well write directly in machine code.
In this article I've argued that readability by humans is only one property of a programming language. Other qualities, possibly independent of readability, are portability, security features, static and dynamic analysis, and verifiability. An AI-first programming language should, in my opinion, come loaded with as many of such properties that we can think of.
If we no longer write code, we should at least have the ability to verify it.
Will you go to prison for an AI?
Who is liable for code written by LLMs?
It seems as though everyone is talking about agentic AI, and although it's perhaps already subject to semantic diffusion, I understand it as the process of letting one or more LLMs go off and write code on their own.
I've toyed enough with it to acknowledge that the potential is undeniable. I can see myself using LLM-based coding agents as team members on a software team, with me as the tech lead.
I don't think, however, that I will be using unsupervised coding agents for anything important. The idea of being unaware of the code strikes me as fundamentally risky. If you never wrote the code, and you don't even look at it (or perhaps only cursory), then how do you know that the end product works as intended?
The most common response is to test the software. That is not a bad idea. In fact, it's the best idea I can think of. Even so, there are fundamental epistemological problems to be addressed. Particularly, the widespread notion of making LLMs responsible for testing does not solve the problem.
Granted, there are kinds of software for which a few errors or unpredictable behaviour is no big deal. Conversely, there is another category where correctness is crucial.
If you vibe-code or use agentic AI to develop such software, what happens if it comes with bugs? If millions, or billions, of euros are lost? If people are maimed or killed?
Someone will be held accountable.
You can't hold an LLM accountable. It is also, in my opinion, improbable that the organizations behind the LLMs (OpenAI, Anthropic, etc.) are effectively accountable. They will say that the system was never intended to be used without human supervision.
Your manager will not take the fall for you. He or she will again claim that you were being paid to be technical, and that management's role is only to lead. If your manager is 'non-technical', this could even be a valid defence.
You will be held accountable.
Even so, you may think: How bad can it be?
Bad enough. If money or lives are lost, the hunt for a suitable scapegoat is on. Such a search usually ends at the leaves of the organisational tree. This could easily be you.
As a concrete example, James Robert Liang was sentenced to prison time for his involvement in the Volkswagen emissions scandal. While this case had nothing to do with LLMs, it illustrates that individual engineers may be held accountable for the actions of an organisation.
You, too, could go to prison for sufficiently egregious problems with the software you let LLMs develop. Are you comfortable with that risk?
Which of these languages are best for AI?
A rhetorical poll.
Pretend that you don't read or write any of the following programming languages. If you were to let one or more LLMs generate code for a software system, based on your specifications, and possibly interactions (chat) with them, in which of the following languages would you prefer that they generate code?
To be clear, while I've phrased this short piece as a typical online poll, I'm not soliciting answers as such. It is, however, a question that I think is worth pondering. Even so, you are, as always, welcome to leave a comment if you have anything on your mind.
I may post a follow-up article later.
In defence of correctness
Not all software needs to be correct, but a large subset does.
Last year, I consulted with an organization that develops and maintains reporting solutions. In a nutshell, they extract data from various line-of-business applications and put them in a reporting-specific data store to create reports for decision makers. For regular readers, this may sound like work bordering on the trivial: Read data, transform it, and write it somewhere else. If you've ever done serious ETL work, you may, however, know that it can be quite difficult to get right.
While reviewing a particular code base, I asked the team how important they found correctness to be. Specifically, I asked: "What happens if a bug makes it into production?" They responded: "If that happens, we fix it."
When I, afterwards, related that exchange to the chief data architect, he was livid: "I just had to explain to the board of directors why [some number] was counted double, and how that could have escaped our attention for months."
Perhaps, to a software developer, reporting sounds like a low-stakes environment, but in reality, it's probably where your code has more impact than in the average line-of-business application. If Excel is the World's most common decision support system, reports (generically) is likely to be the runner-up. This is where your code interfaces with the 'non-technical' decision makers in your organization.
People make business decisions based on reports, implicitly assuming that reports are correct. If you count something double, or conversely accidentally discard data, business decisions will be based on incorrect data. This affects the real world. In this particularly case, the data was used to budget the number of people who it was possible to accept into a particular programme. If you count wrong, you may either turn away too many people, or conversely accept too many, which will impact your ability to deliver your services in the future.
And to be clear: These kinds of errors are difficult to spot. The system isn't crashing or throwing exceptions. It just calculates wrong numbers. It is incorrect.
Correctness is not all #
While I've done my share of prototyping, I've spent a great deal of my career working with software where correctness was essential. To a degree that I'd internalized the emphasis on correctness as an axiom. Of course, software has to be correct.
I was, therefore, taken aback when Dan North in a private conversation challenged me. In his experience, non-technical stakeholders often don't realize what they actually want. Of course you can't pin down what is correct if you don't even know what the system is going to do.
It's always valuable to have your assumptions challenged. Dan is right. If you don't know how the system is going to work, insisting that it's correct is going to get you nowhere.
Once you start looking at the world through that lens, there are plenty of examples. This is what drives the whole practice of A/B testing: You may care about some KPIs, but at the outset, you don't know what it will take to get satisfactory results. Most likely, you don't even know what is possible, but only that you wish to maximize or minimize some KPI.
You can approach such problems in epistemologically sound ways, by proposing a falsifiable hypothesis that the KPI of interest is going to change by at least a certain amount if you conduct a particular experiment.
Seeing the wisdom in Dan's words, I spent a significant period readjusting my view. Indeed, correctness is not all.
Not all software is like big tech #
If you're selling subscriptions or ads, and your main goal is to keep users maximally engaged, correctness does, indeed, seem irrelevant. The goal is no longer to present users with 'correct' content, but rather with content that keeps them on your property.
A similar mechanism applies to market platforms that have something to sell. Not only evident web shops like Amazon, but also market places like Airbnb. The goal of companies is to maximize profits, and as a former economist, I have no moral problem with that. The implication, however, is that if you can make a better profit by showing users something other than what they asked for, you'll do that. There's nothing new in this. Physical stores do that, too, and also did so half a century ago: Perhaps present the customer with what he or she asked for, but also offer alternatives, add-ons, etc.
Which companies specifically qualify as 'big tech' changes over time, but the original FANG quartet all operated in this realm of figuring out things as they went.
For the last decade and a half, such companies have had a significant impact on software-design thinking. Technologists from big-tech companies have been prolific in sharing how they do things. As Hillel Wayne observed, thought leaders are those who share their experiences with the rest of us. Most professional technologists don't.
Even though "move fast and break things" is no longer a motto, the mindset lingers. I regularly listen to a tech podcast where a recurring jest is that testing is only done in production. As the hosts snicker, I grind my teeth.
Because such big-tech messaging is as loud as it is, it's easy to forget that there are plenty of software contexts where correctness is important.
The price is right #
I spent my initial years as a programmer developing 'e-commerce sites' (i.e. web shops) for various companies in Denmark. In one case, a technical customer representative spent days with me, painstakingly going over each line of my C++ component to make sure that it calculated all prices and discounts correctly. This was a business-to-business sales system, and discount policies were complicated. The company had long-standing relationships with its customers, and couldn't risk jeopardising trust by miscalculating discounts.
Working on another code base, for another client, I one day received a call from the customer: "Why are all prices on the site zero?"
Fortunately, it was 'only' on the staging environment, so we managed to fix the issue before the real site started giving away everything for free.
In a third incident, a client had hired a third-party white-hat security company to perform a penetration test of the system. One issue they found was that we were using URL parameters to transport product prices from one page to the next. Before you judge me, this is more than twenty years ago, and I didn't know what I was doing. Most of us didn't. The issue, though, was that since URL parameters indicated prices, anyone could edit the URL to give themselves a nice discount. In fact, we didn't even check whether the number was positive.
If you ask an internet merchant, you'll find that he or she finds it important that prices are correct, even if the site also comes with various A/B-test-driven features for cross- and up-selling.
In general, it turns out that if you're dealing with money, correctness is of the utmost importance. This includes not only prices, but investments, pension funds, interest calculations, and taxes (although the new Danish property valuation system may prove to be a counter-argument).
Software that handles money is far from the only example where correctness is important.
Science #
It should be uncontroversial that software related to empirical sciences (physics, chemistry, astronomy, etc.) need to be correct to be useful. By extension, this also pertains to applied sciences. If you wish to insert a space craft into a Mars orbit, you should make sure to use correct units for calculation.
If you drive a car with a digital operating system, you'd prefer that it doesn't accelerate when you step on the brakes.
Not all examples have to be negative. The Copenhagen Metro is a driverless train system controlled by a fully automated computer system, and so far, it has worked pretty well. My point isn't that computerized transportation systems are doomed to fail. Rather, the point is that correctness is important because people may be hurt if things go wrong.
Medicine #
Is correctness important in medical software? Do I even have to argue the case? Would you like to receive radiation therapy from a machine with a race condition?
If you have a system that calculates medicine doses, does correct unit conversion sound like something that should be a priority?
Law #
Law is a funny discipline, because normally it is categorised as a social science. Even so, I think it has something in common with formal science, particularly computer science. In a sense, we may think of it as an axiomatic system of rules, although the 'axioms' are ad-hoc creations by a 'legislature', and we call them 'laws'. In a sense, a law is a little like a computer program, where we call the execution environment a 'court'.
This comparison may, perhaps, be too far out. The topic of this essay, anyway, is correctness, not philosophy of science. Can we think of legal computer systems were correctness is of the essence? How about a software-based cadastre? A civil registration system that keeps track of civil status, inheritance relationships, etc.? Prison parole management systems?
Security #
Software security is a part of many systems. If it doesn't work correctly, it's hardly useful. A system should prevent users from reading other users' data. Unless explicitly granted access, in which case it may then be important that access indeed works.
One problem that is especially pertinent with software security is how to prove the absence of a flaw. To some degree, this is an problem that also plagues other aspects of software development, not to mention epistemology in general. Even so, when testing software features, a comprehensive battery of tests can often convince you that a feature works correctly. With security, however, the stakes are different. All it takes is one flaw somewhere, and the wrong person has access to the wrong data.
Security appears to me as an area where black-box testing is insufficient; where careful inspection of code aids in fostering correctness.
State of affairs #
I could keep going. How about military applications? Robots? The point is that there's no lack of software where correctness is an important part. These are systems where it would be irresponsible, and often illegal, to test in production.
Despite the dominance of move-fast-and-break-things mindset in recent thought-leadership I posit that correctness plays a significant role in a substantial part of the overall software ecosystem. Perhaps it's not in the majority, but neither does it make a vanishingly small part. I imagine that it presently looks like this, where the green partition represents software where correctness is important:

While the current trends in LLM-generated code indicate an exponential increase in future software, it's not clear to me how correctness will be addressed without human skin in the game. I grant that it looks as though LLMs are good at producing certain kinds of software much faster than human programmers. If life or limb is on the line, however, are we ready to trust systems thus created?
Regardless of the answer, I don't think software where correctness is important is going to disappear. Perhaps its percentage dwindles as LLMs create more software, but that may rather be an effect of having a much bigger cake.
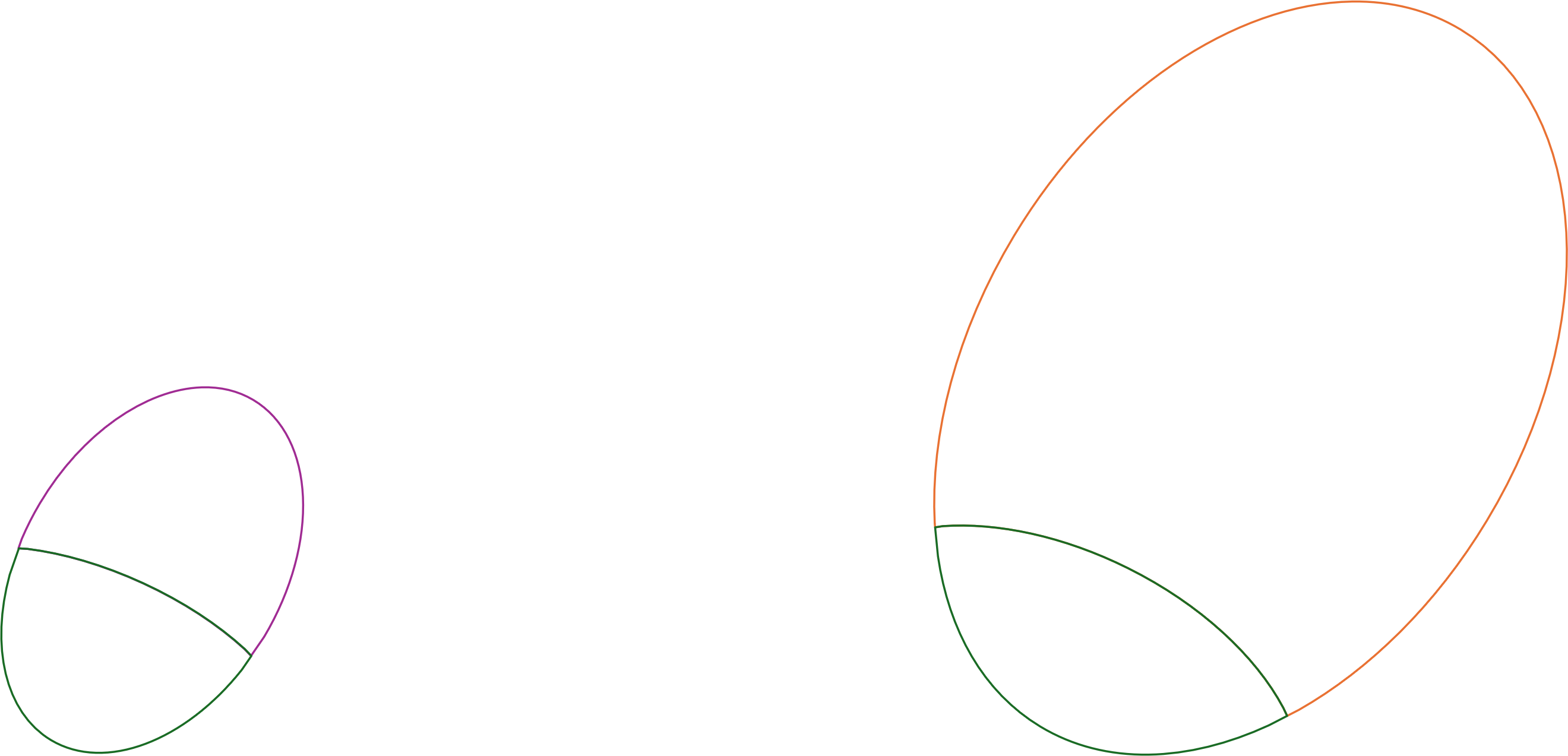
This figure is hardly to scale. In reality, we may easily see an exponential explosion in the amount of software created by LLMs, while the scale of correctness-oriented software may stay comparable to today.
Conclusion #
I expect that people and organizations will attempt to develop correctness-oriented software with LLMs. While I find that ill-advised, I'm certain that this will happen. I also expect that some such systems will turn out to be unreliable, and unfortunately, lives and fortunes will be lost. I hope I'm wrong.

Comments
Joking aside, testing computation's correctness is an interesting problem. I wrote for fun resource management app, where you determine how much of stuff you have in stock based on production, shipping, discarding (etc) events.
I ended up in a chicken-egg type of problem where you either reimplement computation logic in tests, at which point... what's the point?
...or... you mock these events and make calculations by hand, then hardcoding expected values in tests... which is potentially even more error prone.
Scott Walschin had an interesting take on that.
Thank you for writing. While I don't think that I've seen that particular video, I understand that it's based on Scott's article The Enterprise Developer from Hell, with which I've been long familiar. That framing is a catchy way to introduce property-based testing, but may run the risk of misrepresenting it somewhat.
Scott knows this, and I'm not blaming him for what is an obvious pedagogical tactic. He has quite a few of these, and they usually work wonders with respect to getting readers and audiences interested in otherwise arcane topics.
In any case, the use of property-based testing (PBT) is somewhat unrelated to the problem you describe. What may confuse the issue is that PBT originates from people deeply engaged with functional programming, and there's a reason for that. PBT is much easier when functions are pure, and data is immutable. Thus, you tend to see it much more in F# and Haskell, compared to, say, C# or Java.
The problem you sketch, I regard as another problem. It's how to avoid duplicating production code in tests, which is not something that PBT automatically solves. Instead, as is usually the case when people ask me, the answer can be found in functional programming. I wrote an article series about that. I hope you find it useful.
What you've written above is correct. Scott's post wasn't the solution to my problem, but rather a catalyst to think in the right direction.
I did eventually realized I had to break the computation into smaller pure functions that can be tested in isolation, until eventually the problem basically devolved into an add function. This allowed me to test two base conditions ("right" and "wrong" expected cases), while throwing in a few randomly generated ones.
Replying to you inspired me to quickly "re-design" domain records in F#, and I immediately noticed some questionable choices I've made when the app was written initially... huh....
Indeed, it usually takes a couple of attempt to 'get things right'. The first model we come up with is usually overly complex; it happens to me all the time. That's why refactoring is so important.