Less is more: language features by Mark Seemann
Many languages have redundant features; progress in language design includes removing those features.
(This post is also available in Japanese.)
There are many programming languages, and new ones are being introduced all the time. Are these languages better than previous languages? Obviously, that's impossible to answer, since there's no clear measurement of what constitutes a 'better' programming language.
Still, if you look at a historical trend, it looks as though one way to make a better language is to identify a redundant language feature, and design a new language that doesn't have that feature.
"perfection is attained not when there is nothing more to add, but when there is nothing more to remove." - Antoine de Saint Exupéry
In this article, you'll see various examples of language features that have already proven to be redundant, and other features where we are seeing strong indications that they are redundant.
Limitless ways to shoot yourself in the foot. #
When the first computers were created, programs had to be written in machine code or assembly language. In machine code, you can express everything the CPU can do, because the machine code is written it terms of a CPU's instruction set. While it's possible to write correct programs in machine code, you can also write a lot of incorrect programs, including programs that crash horribly, or perhaps even destroy the machine on which they are running.
You're most likely used to writing code in a higher-level language, but even so, if you share my experience with this, you'll agree that it takes a lot of trial and error to get things right. For every correct program, there are many incorrect variations. The set of incorrect programs is much bigger than the set of correct programs.
With machine code, you have limitless ways to create incorrect programs. Yes: you can express everything the CPU can execute, but most of it will be incorrect. Thus, the set of valid programs is a small subset of the set of all possible instructions.
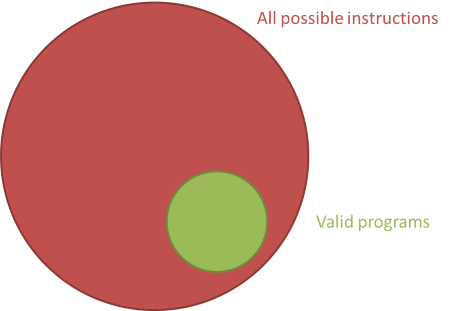
Early computer programmers quickly discovered that writing in machine code was extremely error-prone, and the code was also as unreadable as it could be. One way to address this problem was to introduce assembly language, but it didn't solve the underlying problems: most assembly languages were just 'human-readable' one-to-one mappings over machine code, so you still have unlimited ways to express incorrect programs.
High-level languages #
After having suffered with machine code and assembly language for some time, programmers figured out how to express programs in high-level languages. The first programming languages aren't in much use today, but a good example of a 'low-level' high-level language still in use today is C.
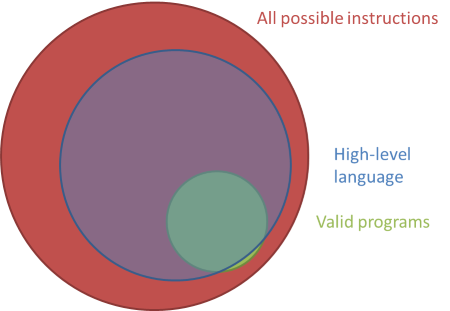
In C, you can express almost all valid programs. There are still tons of ways to write incorrect programs that will crash the program (or the computer), but since the language is an abstraction over machine code, there are instructions you can't express. Most of these are invalid instruction sequences anyway, so it's for the better.
Notice what happened: moving from machine code to a high-level programming language removes a feature of the language. In machine code, you can express anything; in a high-level language, there are things you can't express. You're okay with that, because the options that were taken away from you were bad for you.
GOTO #
In 1968, Edsger Dijkstra published his (in)famous paper Go To Statement Considered Harmful. In it, he argued that the GOTO statement was an bad idea, and that programs would be 'better' without the GOTO statement. This sparked a decade-long controversy, but these days we've come to understand that Dijkstra was right. Some of the most popular languages in use today (e.g. Java and JavaScript) don't have GOTO at all.

Since GOTO has turned out to be an entirely redundant language feature, a language without it doesn't limit your ability to express valid programs, but it does limit your ability to express invalid programs.
Do you notice a pattern?
Take something away, and make an improvement.
There's nothing new about this; Robert C. Martin told us that years ago.
You can't just arbitrarily take away anything, because that may constrain you in such a way that there are valid programs you can no longer write:

You have to take away the right features.
Exceptions #
Today, everyone seems to agree that errors should be handled via some sort of exception mechanisms; at least, everyone can agree that error codes are not the way to go (and I agree). We need something richer than error codes, and something that balances usefulness with robustness.
The problem with exceptions is that this mechanism is really only GOTO statements in disguise - and we've already learned that GOTO is considered harmful.
A better approach is to use a sum type to indicate either success or failure in a composable form.
Pointers #
As Robert C. Martin also pointed out, in older languages, including C and C++, you can manipulate pointers, but as soon as you introduce polymorphism, you no longer need 'raw' pointers. Java doesn't have pointers; JavaScript doesn't do pointers; C# does allow you to use pointers, but I've personally never needed them outside of interop with the Windows API.
As these languages have demonstrated, you don't need access to pointers in order to be able to pass values by reference. Pointers can be abstracted away.
Numbers #
Most strongly typed languages give you an opportunity to choose between various different number types: bytes, 16-bit integers, 32-bit integers, 32-bit unsigned integers, single precision floating point numbers, etc. That made sense in the 1950s, but is rarely important these days; we waste time worrying about the micro-optimization it is to pick the right number type, while we lose sight of the bigger picture. As Douglas Crockford explains, in JavaScript there's only a single number type, which is a great idea - just too bad it's the wrong single number type.
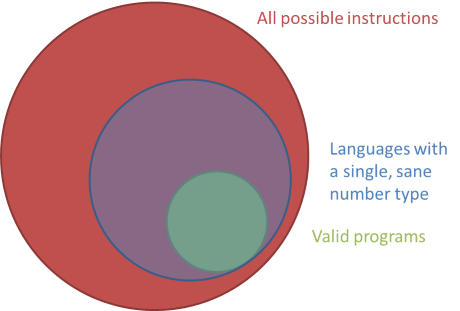
With the modern computer resources we have today, a programming language that would restrict you to a single, sane number type would be superior to the mess we have today.
Null pointers #
Nulls are one of the most misunderstood language constructs. There's nothing wrong with the concept of a value that may or may not be present. Many great programming languages have this concept. In Haskell, it's called Maybe; in F#, it's called option; in T-SQL it's called null. What's common in all these languages is that it's an opt-in language feature: you can declare a value as being 'nullable', but by default, it isn't (nullable).
However, due to Tony Hoare's self-admitted billion-dollar mistake, mainstream languages have null pointers: C, C++, Java, C#. The problem isn't the concept of 'null', but rather that everything can be null, which makes it impossible to distinguish between the cases where null is an appropriate and expected value, from the cases where null is a defect.
Design a language without null pointers, and you take away the ability to produce null pointer exceptions.
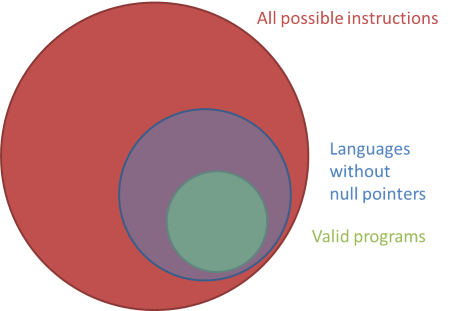
If Tony Hoare is correct that null pointers cost billions of dollars in the last few decades, getting rid of that source of defects can save you lots of money. From Turing-complete languages like T-SQL, Haskell, and F# we know that you can express all valid programs without null pointers, while a huge source of defects is removed.
Mutation #
A central concept in Procedural, Imperative, and Object-Oriented languages is that you can change the value of a variable while executing your program. That's the reason it's called a variable. This seems intuitive, since a CPU contains registers, and what you actually do when you execute a program is that you move values in and out of those registers. It's also intuitive because the purpose of most programs is to change the state of the world: Store a record in a database. Send an email. Repaint the screen. Print a document. Etc.
However, it turns out that mutation is also a large source of defects in software, because it makes it much harder to reason about code. Consider a line of C# code like this:
var r = this.mapper.Map(rendition);
When the Map method returns, has rendition been modified? Well, if you follow Command Query Separation, it shouldn't, but the only way you can be sure is to review the implementation of the Map method. What if that method exhibits the same problem, by calling into other methods that could mutate the state of the application? There's nothing in C# (or Java, or JavaScript, etc.) that prevents this from happening.
In a complicated program with a big call stack, it's impossible to reason about the code, because everything could mutate, and once you have tens or hundreds of variables in play, you can no longer keep track of them. Did the isDirty flag change? Where? What about the customerStatus?
Imagine taking away the ability to mutate state:

Most languages don't completely take away this ability, but as Haskell (a Turing complete language) demonstrates, it's possible to write any program without implicit state mutation.
At this point, many people might object that Haskell is too difficult and unintuitive, but to me, that kind of argumentation is reminiscent of the resistance to removing GOTO. If you are used to relying on GOTO, you have to learn alternative ways to model the same behaviour without GOTO. Likewise, if you are used to relying on state mutation, you have to learn alternative ways to model the same behaviour without state mutation.
Reference Equality #
In Object-Oriented languages like C# and Java, the default equality comparison is Reference Equality. If two variables point to the same memory address, the variables are considered equal. If two variables have all identical constituent values, but point to two different memory addresses, they are considered different. That's not intuitive, and many software defects are caused by this.
What if you take away Reference Equality from a language?

What if all data structures instead had Structural Equality?
This one I'm not entirely sure about, but in my experience, I almost never need Reference Equality. For Basic Correctness you never need it, but I wonder if you may need the occasional reference comparison in order to implement some performance optimizations... Still, it wouldn't hurt to switch the defaults so that Structural Equality was the default, and there was a special function you could invoke to compare two variables for Reference Equality.
Inheritance #
Even in 2015, inheritance is everywhere, although it's more than 20 years ago the Gang of Four taught us to favor object composition over class inheritance. It turns out that there's nothing you can do with inheritance that you can't also do with composition with interfaces. The converse doesn't hold in languages with single inheritance: there are things you can do with interfaces (such as implement more than one), that you can't do with inheritance. Composition is a superset of inheritance.
This isn't just theory: in my experience, I've been able to avoid inheritance in the way I've designed my code for many years. Once you get the hang of it, it's not even difficult.
Interfaces #
Many strongly typed languages (for example Java and C#) have interfaces, which is a mechanism to implement polymorphism. In this way, you can bundle various operations together as methods on an interface. However, one of the consequences of SOLID is that you should favour Role Interfaces over Header Interfaces, and as I've previously explained, the logical conclusion is that all interfaces should only have a single member.
When interfaces only have a single member, the interface declaration itself tends to mostly be in the way - the only thing that matters is the operation. In C#, you could just use a delegate instead, and even Java has lambdas now.
There's nothing new about this. Functional languages have used functions as the basic compositional unit for years.
In my experience, you can model everything with single-member interfaces, which also implies that you can model everything with functions. Again, this isn't really surprising, since functional languages like Haskell are Turing complete too.
It's possible to get by without interfaces. In fact, Robert C. Martin finds them harmful.
Reflection #
If you've ever done any sort of meta-programming in .NET or Java, you probably know what Reflection is. It's a set of APIs and language or platform features that enable you to inspect, query, manipulate, or emit code.
Meta-programming is an indispensable tool, so I'd be sorry to lose it. However, Reflection isn't the only way to enable meta-programming. Some languages are homoiconic, which means that a program in such languages is structured as data, which itself can be queried and manipulated like any other data. Such languages don't need Reflection as a feature, because meta-programming is baked into the language, so to speak.
In other words: Reflection is a language feature aimed at the goal of meta-programming. If meta-programming can be achieved via homoiconicity instead, it would imply that Reflection is a redundant feature.
Cyclic Dependencies #
While it may be true that null pointers are the biggest single source of software defects, in my experience the greatest single source of unmaintainable code is coupling. One of the most problematic types of coupling is cyclic dependencies. In languages like C# and Java, cyclic dependencies are almost impossible to avoid.
Here's one of my own mistakes that I only discovered because I started to look for it: in the otherwise nice and maintainable AtomEventStore, there's an interface called IXmlWritable:
public interface IXmlWritable { void WriteTo(XmlWriter xmlWriter, IContentSerializer serializer); }
As you can tell, the WriteTo method takes an IContentSerializer argument.
public interface IContentSerializer { void Serialize(XmlWriter xmlWriter, object value); XmlAtomContent Deserialize(XmlReader xmlReader); }
Notice that the Deserialize method returns an XmlAtomContent value. How is XmlAtomContent defined? Like this:
public class XmlAtomContent : IXmlWritable
Notice that it implements IXmlWritable. Oh, dear!
Although I'm constantly on the lookout for these kinds of things, that one slipped right past me.
In F# (and, I believe, OCaml), on the other hand, this wouldn't even have compiled!
While F# has a way to introduce small cycles within a module using the and and rec keywords, there are no accidental cycles. You have to explicitly use those keywords to enable limited cycles - and there's no way to define cycles that span modules or libraries.
What an excellent protection against tightly coupled code! Take away the ability to (inadvertently) introduce Cyclic Dependencies, and get a better language!

This has even been shown to work in the wild: Scott Wlaschin examined C# and F# projects for cycles, and found that F# projects have fewer and smaller cycles than C# projects. This analysis was later enhanced and corroborated by Evelina Gabasova.
Summary #
What I've tried to illustrate in this article is that there are many ways in which you could make a better language by taking away a particular feature from an existing language. Take away a redundant feature, and you'll still have a Turing complete language that can do (close to) anything, but with fewer options for shooting yourself in the foot.
Perhaps the ultimate programming language is a language without:
- GOTO
- Exceptions
- Pointers
- Lots of specialized number types
- Null pointers
- Mutation
- Reference equality
- Inheritance
- Interfaces
- Reflection
- Cyclic dependencies
Have I identified all possible redundant features? Most likely not, so here's a great opportunity for language designers to define an even better language, by finding something new to take away!
Update September 14 2015: This article sparked a .NET Rocks! episode with even more discussion about this topic.

Comments
The idea that Javascript is a superset of "valid programs", but that C is not, could do with more explanation.
My background is in server code (Haskell/Java/Python/Javascript/Rust), web code (Javascript) and embedded code (Rust/C) (with some ARM assembly for when Rust/C can't produce the needed program unaided). This makes the idea that I could express programs in Javascript, which I couldn't in C, very interesting.
I think that Rust is going to be very important in embedded development, in a few years.
P.S. I hope I have commented in the correct way.
Chris, thank you for writing. Where in this article do I claim that there are programs you could express in JavaScript, but not in C?
Thanks for the post Mark. Some great points; I like especially the idea of disallowing cyclic dependencies. That'd be awesome on a legacy Java project I'm working on now!
Having working in Scala and a little Haskell, I can say I love the Maybe type. One thing I have trouble visualising still is Exceptions. I think I need to find some more examples on doing without exceptions in real applications.
I guess there's somewhat of a middle ground between having the "safest" language, vs the most performant language. In a lot of cases you don't need awesome performance so the safest language is the better one... but in some you do. You occasionally need control over how your bits are packed.
Let's hope for the future!
Lachlan, thank you for writing. When it comes to working without exceptions, the point is to replace them with something stronger. Scott Wlashin's post and presentation about Railway Oriented Programming is a great place to start. You can see another example in my No Mocks presentation, and in one of my up-coming Pluralsight courses.
When it comes to the balance between safe and performant, there will always be room for languages that sacrifice safety for speed, but in my experience, this shouldn't be a common concern. As soon as you're doing any sort of significant I/O, the cost of that tends to be so much higher than any potential imperfections in pure CPU processing.
Apart from that, I don't see why, in principle, a safe language couldn't also be performant. These two traits don't seem to me to be intrinsically mutually exclusive.
As one of less-is-more advocates, I feel your article makes sense instinctively. However, one thing keeps bugging me:How do you define "valid programs"?
I think I know what you try to mean with it, but once we try to be more specific, validity can only be defined in terms of a certain framework of semantics. If we have such a framework, then we can derive a programming language from it, which would be a language that only accepts valid programs and reject others. Problem solved.
In reality we don't have such a framework. We don't know what is a valid program precisely. There are programs that doesn't seem to make sense, and there are programs that are obviously useful, but there are huge gray area inbetween. It's actually a moving target---the context, the environment, the user, and other outside factors will greatly affect what's valid or not. But the fact that we don't know what valid programs shakes the ground of this whole discussion, doesn't it? Or it can end up tautology---"valid programs are defined in terms of this language, so this language fit the best to cover the valid programs."
Shiro Kawai, thank you for writing. In this article, I deliberately left the definition of validity vague. Why do we write software? If we exclude Katas and the like (which we do for training), software is ultimately written in order to solve problems; in order to be used. A valid program is a program that's useful.
This doesn't change the discussion, which is pragmatic. From experience, we know that we don't need GOTO; from experience, we know that we don't need pointers; from experience, we know that we don't need null pointers; from experience, we know that we don't need inheritance; etc.
Hi, thanks for the reply. I believe I get your intent. What I wanted was to point out a danger of this kind of argument. Because when you write software to solve problems, you need to articulate the problem, and the way you frame the problem is inevitably influenced by the frame of your language of choice. In other words, when you think you tighten the circle of the language features, it's not necessarily that you get it close to supposed set of "valid programs", but you may just as well start ignoring useful programs outside of your langauge circle and you don't even realize that. You just think "ok, there may be some programs that falls outside but it's not that important." How do you verify that the excluded gray area isn't that important?
(I wrote "you", but actually this is something I constanly try to remind myself, since I tend to be dragged toward feature-minimalism. I love Scheme.)
For example, you talk single-member inheritance and you brought up Haskell, but you didn't mention type classes. Isn't type classe sort of interface, in a sense that it defines a protocol consists of multiple functions? Do you say it's actually redundant? Or will you dismiss programs that can be expressed well using type classes "unimportant"?
Another controversial (and probably obscure) feature is change-class in CL. This one is such a beast that it's difficult to cope with many modern features (obviously it invalidates strict typecheckers). However, in the context where the feature is needed, I don't know if there's a replacement. If you get rid of it, you just have to give up the kind of software that require the feature. That's a reasonable trade-off, but what you do is that you cut off a part of "valid programs" in order to tighten the circle.
There's no solid circle of valid programs, and as you tighten the circle of the language, you actually shape the circle of valid programs that suit to the circle of language you draw. That's not necessarily a bad thing, but the language designers need to be aware of it, that's what I wanted to say.
It's a good point that a language shapes how you approach problems. In this discussion, I assume that all languages (both existing and hypothetical) are Turing complete, but even under that assumption, there will be problems that are difficult, or perhaps even impossible, to address in a particular language.
The question is whether that isn't true for all languages?
In a sense, the most 'powerful' languages are all the dialects of machine code. By definition, they should be able to express everything a particular CPU can do, so by corollary, they should be the most complete languages available. Despite being complete, these dialects don't have inheritance, exceptions, Reflection, interfaces, or a lot of other things. Such features are features that have been added to some languages. Logically, I don't see how 'removing' such a feature constrains one's ability to express 'all valid programs'.
To be fair, that argument of mine doesn't apply to all the language features I've described. For example, CPU instruction sets most certainly allow immutability.
What I was aiming at with my article was never a formal discussion about how a hypothetical language would, or wouldn't, be able to express 'all valid programs'. The purpose was more to point out that decades of experience should by now have taught the overall programmer community that there are many language features that we can do without.
As I pointed out, you can't arbitrarily remove features. Some features are extremely important within a particular language, while it may be irrelevant in another language. While I don't know much about Type Classes, it seems to be an example of this: it's very important in Haskell, but doesn't exist at all in C# or F#.
This is also the reason why I don't think we'll ever have a single, perfect programming language. In the future, we'll also have many different languages, and they'll be good at different types of problems.
Just as it is today, it'll be important to know more than a single programming language, because, exactly as you wrote, a problem may 'fall outside' a given language, but then, if you know another language, you may realise that you can use it to solve that particular problem.