ploeh blog danish software design
The Maybe applicative functor
An introduction to the Maybe applicative functor for object-oriented programmers.
This article is an instalment in an article series about applicative functors. Previously, in a related series, you got an introduction to Maybe as a functor. Not all functors are applicative, but some are, and Maybe is one of them (like list).
In this article, you'll see how to make a C# Maybe class applicative. While I'm going to start with F# and Haskell, you can skip to the C# section if you'd like.
F# #
A few years ago, I did the Roman numerals kata in F#. This is an exercise where you have to convert between normal base 10 integers and Roman numerals. Conversions can fail in both directions, because Roman numerals don't support negative numbers, zero, or numbers greater than 3,999, and Roman numerals represented as strings could be malformed.
Some Roman numbers are written in a subtractive style, e.g. "IV" means subtract 1 (I) from 5 (V). It's easy enough to subtract two numbers, but because parsing isn't guaranteed to succeed, I didn't have two numbers; I had two number options (recall that in F#, Maybe is called option).
How do you subtract one int option from another int option?
Both of these values could be Some, or they could be None. What should happen in each case? With Maybe, only four combinations are possible, so you can put them in a table:
Some x |
None |
|
|---|---|---|
Some y |
Some (x - y) |
None |
None |
None |
None |
Some cases should you return a Some case with the result of the subtraction; in all other cases, you should return None.
You can do this with regular pattern matching, but it's hardly the most elegant solution:
// int option let difference = match minuend, subtrahend with | Some m, Some s -> Some (m - s) | _ -> None
You could attempt to solve this with a specialised helper function like this:
module Option = // ('a -> 'b -> 'c) -> 'a option -> 'b option -> 'c option let map2 f xo yo = match xo, yo with | Some x, Some y -> Some (f x y) | _ -> None
which you could use like this:
let difference = Option.map2 (-) minuend subtrahend
It doesn't, however, generalise well... What if you need to operate on three option values, instead of two? Or four? Should you add map3 and map4 functions as well?
Making option an applicative functor addresses that problem. Here's one possible implementation of <*>:
// ('a -> 'b) option -> 'a option -> 'b option let (<*>) fo xo = match fo, xo with | Some f, Some x -> Some (f x) | _ -> None
This enables you two write the subtraction like this:
let difference = Some (-) <*> minuend <*> subtrahend
For a detailed explanation on how that works, see the previous explanation for lists; it works the same way for Maybe as it does for List.
In the end, however, I didn't think that this was the most readable code, so in the Roman numeral exercise, I chose to use a computation expression instead.
Haskell #
In Haskell, Maybe is already Applicative as part of the language. Without further ado, you can simply write:
difference = pure (-) <*> minuend <*> subtrahend
As is the case with the F# code, I don't consider this the most readable way to express the subtraction of two integers. In F#, I ultimately decided to use a computation expression. In Haskell, that's equivalent to using do notation:
difference :: Maybe Integer difference = do m <- minuend s <- subtrahend return $ m - s
While more verbose, I think it's clearer that one number is being subtracted from another number.
This works for Maybe because not only is Maybe Applicative, it's also a Monad. It's its monadness that enables the do notation. Not all applicative functors are monads, but Maybe is.
C# #
In a previous article you saw how to implement the Maybe functor in C#. You can extend it so that it also becomes an applicative functor:
public static Maybe<TResult> Apply<T, TResult>( this Maybe<Func<T, TResult>> selector, Maybe<T> source) { if (selector.HasItem && source.HasItem) return new Maybe<TResult>(selector.Item(source.Item)); else return new Maybe<TResult>(); } public static Maybe<Func<T2, TResult>> Apply<T1, T2, TResult>( this Maybe<Func<T1, T2, TResult>> selector, Maybe<T1> source) { if (selector.HasItem && source.HasItem) { Func<T2, TResult> g = x => selector.Item(source.Item, x); return new Maybe<Func<T2, TResult>>(g); } else return new Maybe<Func<T2, TResult>>(); }
As was the case for making sequences applicative in C#, you need overloads of the Apply method, because C#'s type inference is inadequate for this task.
If you have two Maybe<int> values, minuend and subtrahend, you can now perform the subtraction:
Func<int, int, int> subtract = (x, y) => x - y; Maybe<int> difference = subtract.ToMaybe().Apply(minuend).Apply(subtrahend);
Like in F# and Haskell, applicative style is hardly the most readable way to express subtraction. It'd be nice if you could write it like Haskell's do notation. You can, but to do that, you must make Maybe a monad, and this isn't a monad tutorial. Mike Hadlow has a good monad tutorial for C# developers, the gist of which is that you must implement SelectMany in order to turn your generic type into a monad. For now, I'll leave this as an exercise for you, but if you add an appropriate SelectMany method, you'd be able to write the subtraction like this:
Maybe<int> difference = from m in minuend from s in subtrahend select m - s;
Again, I think this is more readable, but it does require that the type in question is a monad, and not all applicative functors are (but Maybe is).
Summary #
This article demonstrates that lists or sequences aren't the only applicative functors. Maybe is also an applicative functor, but more exist. The next article will give you another example.
Next: Applicative validation.
Applicative combinations of functions
Applicative lists and sequences enable you to create combinations of functions as well as values.
This article is an instalment in an article series about applicative functors. In the previous article, you saw how you can use applicative lists and sequences to generate combinations of values; specifically, the example demonstrated how to generate various password character combinations.
People often create passwords by using a common word as basis, and then turn characters into upper- or lower case. Someone feeling particularly tech-savvy may replace certain characters with digits, in an imitation of 1337. While this isn't secure, let's look at how to create various combinations of transformations using applicative lists and sequences.
List of functions #
In the previous article, I mentioned that there was a feature of applicative lists that I had, so far, deliberately ignored.
If you consider an example like this:
let passwordCombinations = [sprintf "%s%s%s%s%s%s"] <*> ["P"; "p"] <*> ["a"; "4"] <*> ["ssw"] <*> ["o"; "0"] <*> ["rd"] <*> [""; "!"]
you may have already noticed that while the left side of the <*> operator is a list of functions, it contains only a single function. What happens if you supply more than a single function?
You get a combination of each function and each list element.
Assume that you have three functions to convert characters:
module Char = // char -> char let toUpper c = System.Char.ToUpperInvariant c // char -> char let toLower c = System.Char.ToLowerInvariant c // Not even trying to be complete: // char -> char let to1337 = function | 'a' | 'A' -> '4' | 'b' -> '6' | 'E' -> '3' | 'H' -> '#' | 'i' -> '!' | 'l' -> '1' | 'o' | 'O' -> '0' | 't' -> '+' | c -> c
All three are functions that convert one char value to another, although many values could pass through without being modified. Since they all have the same type, you can create a list of them:
> List.map String.map [Char.toUpper; Char.toLower; Char.to1337] <*> ["Hello"; "World"];; val it : string list = ["HELLO"; "WORLD"; "hello"; "world"; "#e110"; "W0r1d"]
There's a bit to unpack there. Recall that all three functions in the Char module have the same type: char -> char. Making a list of them gives you a (char -> char) list, but you really need a (string -> string) list. Fortunately, the built-in String.map function takes a char -> char function and uses it to map each char values in a string. Thus, List.map String.map [Char.toUpper; Char.toLower; Char.to1337] gives you a (string -> string) list.
When you apply (<*>) that list of functions with a list of string values, you get all possible combinations of each function used with each string. Both "Hello" and "World" are converted to upper case, lower case, and 1337.
Combinations of functions #
Perhaps you're happy with the above combinations, but can we do better? As an example, you'll notice that to1337 only converts an upper-case 'E' to '3', but ignores a lower-case 'e'. What if you also want the combination where 'e' is first converted to upper case, and then to 1337? You'd like that, but you still want to retain the combinations where each of these transformations are applied without the other.
Fear not; functions are values, so you can combine them as well!
In the previous article, did you notice how you could model the presence or absence of a particular value? Specifically, the last character in the potential password could be '!', but '!' could also be omitted.
Consider, again, the expression for all password combinations:
let passwordCombinations = [sprintf "%s%s%s%s%s%s"] <*> ["P"; "p"] <*> ["a"; "4"] <*> ["ssw"] <*> ["o"; "0"] <*> ["rd"] <*> [""; "!"]
Notice that the last list contains two options: "!" and the empty string (""). You can read about this in another article series, but character strings are monoids, and one of the characteristics of monoids is that they have an identity element - a 'neutral' element, if you will. For strings, it's ""; you can append or prepend the empty string as much as you'd like, but it's not going to change the other string.
If you have a set of functions of the type 'a -> 'a, then the built-in function id is the identity element. You can compose any 'a -> 'a function with id, and it's not going to change the other function.
Since functions are values, then, you can create combinations of functions:
// (char -> char) list let maps = [fun f g h -> f >> g >> h] <*> [Char.toUpper; id] <*> [Char.toLower; id] <*> [Char.to1337; id]
Here, maps is a list of functions, but it's not only three functions as in the above example. It's eight functions:
> List.length maps;; val it : int = 8
The above applicative composition of maps combines three lists of functions. Each list presents two alternatives: a function (e.g. Char.toUpper), and id. In other words, a choice between doing something, and doing nothing. The lambda expression fun f g h -> f >> g >> h takes three (curried) arguments, and returns the composition of calling f, then passing the result of that to g, and again passing the result of that to h. f is either Char.toUpper or id, g is either Char.toLower or id, and h is either Char.to1337 or id. That's eight possible combinations.
Combine eight functions with two string values, and you get sixteen alternatives back:
> List.map String.map maps <*> ["Hello"; "World"];; val it : string list = ["he110"; "w0r1d"; "hello"; "world"; "#3LL0"; "W0RLD"; "HELLO"; "WORLD"; "he110"; "w0r1d"; "hello"; "world"; "#e110"; "W0r1d"; "Hello"; "World"]
Notice, for example, how one of the suggested alternatives is "#3LL0". Previously, there was no translation from 'e' to '3', but now there is, via Char.toUpper >> id >> Char.to1337.
Some of the combinations are redundant. For example, "hello" is generated twice, by Char.toUpper >> Char.toLower >> id and id >> Char.toLower >> id, respectively. You can reduce the output with List.distinct:
> List.map String.map maps <*> ["Hello"; "World"] |> List.distinct;; val it : string list = ["he110"; "w0r1d"; "hello"; "world"; "#3LL0"; "W0RLD"; "HELLO"; "WORLD"; "#e110"; "W0r1d"; "Hello"; "World"]
You can write equivalent code in Haskell, but it's so similar to the F# code that there's no reason to show it.
Translation to C# #
Using the Apply extension methods from the previous article, you can translate the above code to C#.
While you can use the .NET Base Class Library's Char.ToUpperInvariant and Char.ToLowerInvariant methods as is, you'll need to supply a to1337 function. You can write it as a named static method, but you can also write it as a delegate:
Func<char, char> to1337 = c => { switch (c) { case 'A': case 'a': return '4'; case 'b': return '6'; case 'E': return '3'; case 'H': return '#'; case 'i': return '!'; case 'l': return '1'; case 'o': case 'O': return '0'; case 't': return '+'; default: return c; } };
You're also going to need an id function:
Func<char, char> id = c => c;
In order to compose three functions to one, you can write something like this:
Func<Func<char, char>, Func<char, char>, Func<char, char>, Func<char, char>> compose3 = (f, g, h) => x => h(g(f(x)));
That's going to be a contender for some of the most obscure C# code I've written in a while. By the double use of =>, you can tell that it's a delegate that returns a delegate. That's not even the worst part: check out the type of the thing! In reality, nothing happens here that doesn't also happen in the above F# code, but it's an example of the superiority of Hindley–Milner type inference: in F#, you don't have to explicitly type out the type.
With a function to compose three other functions, you can now apply the three alternative functions:
IEnumerable<Func<char, char>> maps = new[] { compose3 } .Apply(new[] { Char.ToUpperInvariant, id }) .Apply(new[] { Char.ToLowerInvariant, id }) .Apply(new[] { to1337, id });
Now you have a sequence of functions that translate char values to char values. What you really need, though, is a sequence of functions that translate string values to string values.
The F# core library defines the built-in String.map function, but as far as I can tell, there's no equivalent method in the .NET Base Class Library. Therefore, you must implement it yourself:
Func<Func<char, char>, Func<string, string>> stringMap = f => (string s) => new string(s.Select(f).ToArray());
This is a function that takes a Func<char, char> as input and returns a Func<string, string>. Again, the type declaration isn't the prettiest.
You can now apply maps to some string values, using the Apply extension method:
IEnumerable<string> hellos = maps.Select(stringMap).Apply(new[] { "Hello", "World" });
This produces exactly the same output as the above F# example, even in the same order.
Applicative functors are elegant in F# and Haskell, but awkward in a language like C# - mostly because of its inferior type inference engine.
Summary #
Previous articles demonstrated how applicative lists can be used to compose several lists into a list that contains all possible combinations. In this article you saw how this also extends to combinations of functions.
The last three articles (including the present) focus on lists as applicative functors, but lists aren't the only type of applicative functor. In the next articles, you'll encounter some other applicative functors.
An applicative password list
How to use the applicative functor capabilities of lists to create a password list, with examples that object-oriented programmers can understand.
This article is an instalment in an article series about applicative functors. In the previous article, you saw how to use Haskell and F# lists as applicative functors to generate combinations of values. In this article, you'll see a similar example, but this time, there will also be a C# example.
Guess the password variation #
Years ago, I worked in an organisation that (among other things) produced much demo software. Often, the demo software would include a demonstration of the security features of a product, which meant that, as a user evaluating the software, you had to log in with a user name and password. In order to keep things simple, the password was usually Passw0rd!, or some variation thereof.
(Keep in mind that this was demoware. Password strength wasn't a concern. We explicitly wanted the password to be easy to guess, so that users evaluating the software had a chance to test how log in worked. This was long before social login and the like.)
We had more than one package of demoware, and over the years, variations of the standard password had snuck in. Sometimes it'd be all lower-case; sometimes it'd use 4 instead of a, and so on. As the years went on, the number of possible permutations grew.
Recently, I had a similar problem, but for security reasons, I don't want to divulge what it was. Let's just pretend that I had to guess one of those old demo passwords.
There weren't that many possible variations, but just enough that I couldn't keep them systematically in my head.
- The first letter could be upper or lower case.
- The second letter could be a or 4.
- The o could be replaced with a zero (0).
- The password could end with an exclamation mark (!), but it might also be omitted.
> let (<*>) fs l = fs |> List.collect (fun f -> l |> List.map f);;
val ( <*> ) : fs:('a -> 'b) list -> l:'a list -> 'b list
> [sprintf "%s%s%s%s%s%s"]
<*> ["P"; "p"] <*> ["a"; "4"] <*> ["ssw"] <*> ["o"; "0"] <*> ["rd"] <*> [""; "!"];;
val it : string list =
["Password"; "Password!"; "Passw0rd"; "Passw0rd!"; "P4ssword"; "P4ssword!";
"P4ssw0rd"; "P4ssw0rd!"; "password"; "password!"; "passw0rd"; "passw0rd!";
"p4ssword"; "p4ssword!"; "p4ssw0rd"; "p4ssw0rd!"]
This produces a list of all the possible password combinations according to the above rules. Since there weren't that many, I could start trying each from the start, until I found the correct variation.
The first list contains a single function. Due to the way sprintf works, sprintf "%s%s%s%s%s%s" is a function that takes six (curried) string arguments, and returns a string. The number 6 is no coincidence, because you'll notice that the <*> operator is used six times.
There's no reason to repeat the exegesis from the previous article, but briefly:
sprintf "%s%s%s%s%s%s"has the typestring -> string -> string -> string -> string -> string -> string.[sprintf "%s%s%s%s%s%s"]has the type(string -> string -> string -> string -> string -> string -> string) list.[sprintf "%s%s%s%s%s%s"] <*> ["P"; "p"]has the type(string -> string -> string -> string -> string -> string) list.[sprintf "%s%s%s%s%s%s"] <*> ["P"; "p"] <*> ["a"; "4"]has the type(string -> string -> string -> string -> string) list.- ...and so on.
<*>, an argument is removed from the resulting function contained in the returned list. When you've applied six lists with the <*> operator, the return value is no longer a list of functions, but a list of values.
Clearly, then, that's no coincidence. I deliberately shaped the initial function to take six arguments, so that it would match the six segments I wanted to model.
Perhaps the most interesting quality of applicative functors is that you can compose an arbitrary number of objects, as long as you have a function to match the number of arguments.
Haskell #
This time I started with F#, but in Haskell, <*> is a built-in operator, so obviously this also works there:
passwordCombinations :: [String] passwordCombinations = [printf "%s%s%s%s%s%s"] <*> ["P", "p"] <*> ["a", "4"] <*> ["ssw"] <*> ["o", "0"] <*> ["rd"] <*> ["", "!"]
The output is the same as the above F# code.
C# #
While you can translate the concept of lists as an applicative functor to C#, this is where you start testing the limits of the language; or perhaps I've simply forgotten too much C# to do it full justice.
Instead of making linked lists an applicative functor, let's consider a type closer to the spirit of the C# language: IEnumerable<T>. The following code attempts to turn IEnumerable<T> into an applicative functor.
Consider the above F# implementation of <*> (explained in the previous article). It uses List.collect to flatten what would otherwise had been a list of lists. List.collect has the type ('a -> 'b list) -> 'a list -> 'b list. The corresponding method for IEnumerable<T> already exists in the .NET Base Class Library; it's called SelectMany. (Incidentally, this is also the monadic bind function, but this is still not a monad tutorial.)
For an applicative functor, we need a method that takes a sequence of functions, and a sequence of values, and produces a sequence of return values. You can translate the above F# function to this C# extension method:
public static IEnumerable<TResult> Apply<T, TResult>( this IEnumerable<Func<T, TResult>> selectors, IEnumerable<T> source) { return selectors.SelectMany(source.Select); }
That's a single line of code! That's not so bad. What's the problem?
So far there's no problem. You can, for example, write code like this:
Func<string, int> sl = s => s.Length; var lengths = new[] { sl }.Apply(new[] { "foo", "bar", "baz" });
This will return a sequence of the numbers 3, 3, 3. That seems, however, like quite a convoluted way of getting the lengths of some strings. A normal Select method would have sufficed.
Is it possible to repeat the above password enumeration in C#? In order to do that, you need a function that takes six string arguments and returns a string:
Func<string, string, string, string, string, string, string> concat = (x, y, z, æ, ø, å) => x + y + z + æ + ø + å;
With programmers' penchant to start with the variable name x, and continue with y and z, most people will have a problem with six variables - but not us Danes! Fortunately, we've officially added three extra letters to our alphabet for this very purpose! So with that small problem out of the way, you can now attempt to reproduce the above F# code:
var combinations = new[] { concat } .Apply(new[] { "P", "p" }) .Apply(new[] { "a", "4" }) .Apply(new[] { "ssw" }) .Apply(new[] { "o", "0" }) .Apply(new[] { "rd" }) .Apply(new[] { "", "!" });
That looks promising, but there's one problem: it doesn't compile.
The problem is that concat is a function that takes six arguments, and the above Apply method expects selectors to be functions that take exactly one argument.
Alas, while it's not pretty, you can attempt to address the problem with an overload:
public static IEnumerable<Func<T2, T3, T4, T5, T6, TResult>> Apply<T1, T2, T3, T4, T5, T6, TResult>( this IEnumerable<Func<T1, T2, T3, T4, T5, T6, TResult>> selectors, IEnumerable<T1> source) { return selectors.SelectMany(f => source.Select(x => { Func<T2, T3, T4, T5, T6, TResult> g = (y, z, æ, ø, å) => f(x, y, z, æ, ø, å); return g; })); }
This overload of Apply takes selectors of arity six, and return a sequence of functions with arity five.
Does it work now, then?
Unfortunately, it still doesn't compile, because new[] { concat }.Apply(new[] { "P", "p" }) has the type IEnumerable<Func<string, string, string, string, string, string>>, and no overload of Apply exists that supports selectors with arity five.
You'll have to add such an overload as well:
public static IEnumerable<Func<T2, T3, T4, T5, TResult>> Apply<T1, T2, T3, T4, T5, TResult>( this IEnumerable<Func<T1, T2, T3, T4, T5, TResult>> selectors, IEnumerable<T1> source) { return selectors.SelectMany(f => source.Select(x => { Func<T2, T3, T4, T5, TResult> g = (y, z, æ, ø) => f(x, y, z, æ, ø); return g; })); }
You can probably see where this is going. This overload returns a sequence of functions with arity four, so you'll have to add an Apply overload for such functions as well, plus for functions with arity three and two. Once you've done that, the above fluent chain of Apply method calls work, and you get a sequence containing all the password variations.
> new[] { concat } . .Apply(new[] { "P", "p" }) . .Apply(new[] { "a", "4" }) . .Apply(new[] { "ssw" }) . .Apply(new[] { "o", "0" }) . .Apply(new[] { "rd" }) . .Apply(new[] { "", "!" }) string[16] { "Password", "Password!", "Passw0rd", "Passw0rd!", "P4ssword", "P4ssword!", "P4ssw0rd", "P4ssw0rd!", "password", "password!", "passw0rd", "passw0rd!", "p4ssword", "p4ssword!", "p4ssw0rd", "p4ssw0rd!" }
In F# and Haskell, the compiler automatically figures out the return type of each application, due to a combination of currying and Hindley–Milner type inference. Perhaps I've allowed my C# skills to atrophy, but I don't think there's an easy resolution to this problem in C#.
Obviously, you can always write a reusable library with Apply overloads that support up to some absurd arity. Once those methods are written, they're unlikely to change. Still, it seems to me that we're pushing the envelope.
Summary #
In this article, you saw how to turn C# sequences into an applicative functor. While possible, there are some bumps in the road.
There's still an aspect of using lists and sequences as applicative functors that I've been deliberately ignoring so far. The next article covers that. After that, we'll take a break from lists and look at some other applicative functors.
Comments
In F# and Haskell, the compiler automatically figures out the return type of each application, due to a combination of currying and Hindley–Milner type inference. Perhaps I've allowed my C# skills to atrophy, but I don't think there's an easy resolution to this problem in C#.
I think the difference is that all functions in F# and Haskell are automatically curried, but nothing is automatically curreid in C#. If you explicitly curry concat, then the code complies and works as expected. Here is one way to achieve that.
var combinations = new[] { LanguageExt.Prelude.curry(concat) } .Apply(new[] { "P", "p" }) .Apply(new[] { "a", "4" }) .Apply(new[] { "ssw" }) .Apply(new[] { "o", "0" }) .Apply(new[] { "rd" }) .Apply(new[] { "", "!" });
In this example, I curried concat using curry from the NuGet package LanguageExt. It is a base class library for functional programming in C#.
So you don't need many overloads of your Apply for varrying numbers of type parameters. You just need many overloads of curry.
Tyson, thank you for writing. Yes, you're right that it's the lack of default currying that makes this sort of style less than ideal in C#. This seems to be clearly demonstrated by your example.
Full deck
An introduction to applicative functors in Haskell, with a translation to F#.
This article is an instalment in an article series about applicative functors. While (non-applicative) functors can be translated to an object-oriented language like C# in a straightforward manner, applicative functors are more entrenched in functional languages like Haskell. This article introduces the concept with a motivating example in Haskell, and also shows a translation to F#. In the next article, you'll also see how to implement an applicative functor in C#.
Deck of cards in Haskell #
Imagine that you want to model a card game. In order to do so, you start by defining data types for suits, faces, and cards:
data Suit = Diamonds | Hearts | Clubs | Spades deriving (Show, Eq, Enum, Bounded) data Face = Two | Three | Four | Five | Six | Seven | Eight | Nine | Ten | Jack | Queen | King | Ace deriving (Show, Eq, Enum, Bounded) data Card = Card { face :: Face, suit :: Suit } deriving (Show, Eq)
Since both Suit and Face are instances of the Enum and Bounded typeclasses, you can easily enumerate them:
allFaces :: [Face] allFaces = [minBound .. maxBound] allSuits :: [Suit] allSuits = [minBound .. maxBound]
For example, allSuits enumerates all four Suit values:
λ> allSuits [Diamonds,Hearts,Clubs,Spades]
Notice, by the way, how the code for allFaces and allSuits is identical. The behaviour, however, is different, because the types are different.
While you can enumerate suits and faces, how do you create a full deck of cards?
A full deck of cards should contain one card of every possible combination of suit and face. Here's one way to do it, taking advantage of lists being applicative functors:
fullDeck :: [Card] fullDeck = pure Card <*> allFaces <*> allSuits
This will give you all the possible cards. Here are the first six:
λ> forM_ (take 6 fullDeck) print
Card {face = Two, suit = Diamonds}
Card {face = Two, suit = Hearts}
Card {face = Two, suit = Clubs}
Card {face = Two, suit = Spades}
Card {face = Three, suit = Diamonds}
Card {face = Three, suit = Hearts}
How does it work? Let's break it down, starting from left:
λ> :type Card Card :: Face -> Suit -> Card λ> :type pure Card pure Card :: Applicative f => f (Face -> Suit -> Card) λ> :type pure Card <*> allFaces pure Card <*> allFaces :: [Suit -> Card] λ> :type pure Card <*> allFaces <*> allSuits pure Card <*> allFaces <*> allSuits :: [Card]
From the top, Card is a function that takes a Face value and a Suit value and returns a Card value. Object-oriented programmers can think of it as a constructor.
Next, pure Card is the Card function, elevated to an applicative functor. At this point, the compiler hasn't decided which particular applicative functor it is; it could be any applicative functor. Specifically, it turns out to be the list type ([]), which means that pure Card has the type [Face -> Suit -> Card]. That is: it's a list of functions, but a list of only a single function. At this point, however, this is still premature. The type doesn't materialise until we apply the second expression.
The type of allFaces is clearly [Face]. Since the <*> operator has the type Applicative f => f (a -> b) -> f a -> f b, the expression on the left must be the same functor as the expression on the right. The list type ([]) is an applicative functor, and because allFaces is a list, then pure Card must also be a list, in the expression pure Card <*> allFaces. In other words, in the definition of <*>, you can substitute f with [], and a with Face. The interim result is [Face -> b] -> [Face] -> [b]. What is b, then?
You already know that pure Card has the type [Face -> Suit -> Card], so b must be Suit -> Card. That's the reason that pure Card <*> allFaces has the type [Suit -> Card]. It's a list of functions. This means that you can use <*> a second time, this time with allSuits, which has the type [Suit].
Using the same line of reasoning as before, you can substitute Suit for a in the type of <*>, and you get [Suit -> b] -> [Suit] -> [b]. What is b now? From the previous step, you know that the expression on the left has the type [Suit -> Card], so b must be Card. That's why the entire expression has the type [Card].
Deck of cards in F# #
You can translate the above Haskell code to F#. The first step is to make F# lists applicative. F# also supports custom operators, so you can add a function called <*>:
// ('a -> 'b) list -> 'a list -> 'b list let (<*>) fs l = fs |> List.collect (fun f -> l |> List.map f)
This implementation iterates over all the functions in fs; for each function, it maps the list l with that function. Had you done that with a normal List.map, this would have returned a list of lists, but by using List.collect, you flatten the list.
It's worth noting that this isn't the only way you could have implemented <*>, but this is the implementation that behaves like the Haskell function. An alternative implementation could have been this:
// ('a -> 'b) list -> 'a list -> 'b list let (<*>) fs = List.collect (fun x -> fs |> List.map (fun f -> f x))
This variation has the same type as the first example, and still returns all combinations, but the order is different. In the following of this article, as well as in subsequent articles, I'll use the first version.
Here's the playing cards example translated to F#:
type Suit = Diamonds | Hearts | Clubs | Spades type Face = | Two | Three | Four | Five | Six | Seven | Eight | Nine | Ten | Jack | Queen | King | Ace type Card = { Face: Face; Suit : Suit } // Face list let allFaces = [ Two; Three; Four; Five; Six; Seven; Eight; Nine; Ten; Jack; Queen; King; Ace] // Suit list let allSuits = [Diamonds; Hearts; Clubs; Spades] // Card list let fullDeck = [fun f s -> { Face = f; Suit = s }] <*> allFaces <*> allSuits
The F# code is slightly more verbose than the Haskell code, because you have to repeat all the cases for Suit and Face. You can't enumerate them automatically, like you can in Haskell.
It didn't make much sense to me to attempt to define a pure function, so instead I simply inserted a single lambda expression in a list, using the normal square-bracket syntax. F# doesn't have constructors for record types, so you have to pass a lambda expression, whereas in Haskell, you could simply use the Card function.
The result is the same, though:
> fullDeck |> List.take 6 |> List.iter (printfn "%A");;
{Face = Two; Suit = Diamonds;}
{Face = Two; Suit = Hearts;}
{Face = Two; Suit = Clubs;}
{Face = Two; Suit = Spades;}
{Face = Three; Suit = Diamonds;}
{Face = Three; Suit = Hearts;}
While the mechanics of applicative functors translate well to F#, it leaves you with at least one problem. If you add the above operator <*>, you've now 'used up' that operator for lists. While you can define an operator of the same name for e.g. option, you'd have to put them in separate modules or namespaces in order to prevent them from colliding. This also means that you can't easily use them together.
For that reason, I wouldn't consider this the most idiomatic way to create a full deck of cards in F#. Normally, I'd do this instead:
// Card list let fullDeck = [ for suit in allSuits do for face in allFaces do yield { Face = face; Suit = suit } ]
This alternative syntax takes advantage of F#'s 'extended list comprehension' syntax. FWIW, you could have done something similar in Haskell:
fullDeck :: [Card] fullDeck = [Card f s | f <- allFaces, s <- allSuits]
List comprehension, however, is (as the name implies) specific to lists, whereas an applicative functor is a more general concept.
Summary #
This article introduced you to lists as an applicative functor, using the motivating example of having to populate a full deck of cards with all possible combinations of suits and faces.
The next article in the series shows another list example. The F# and Haskell code will be similar to the code in the present article, but the next article will also include a translation to C#.
Next: An applicative password list.
Applicative functors
An applicative functor is a useful abstraction. While typically associated with functional programming, applicative functors can be conjured into existence in C# as well.
This article series is part of a larger series of articles about functors, applicatives, and other mappable containers.
In a former article series, you learned about functors, and how they also exist in object-oriented design. Perhaps the utility of this still eludes you, although, if you've ever had experience with LINQ in C#, you should realise that the abstraction is invaluable. Functors are abundant; applicative functors not quite so much. On the other hand, applicative functors enable you to do more.
I find it helpful to think of applicative functors as an abstraction that enable you to express combinations of things.
In the functor article series, I mostly focused on the mechanics of implementation. In this article series, I think that you'll find it helpful to slightly change the perspective. In these articles, I'll show you various motivating examples of how applicative functors are useful.
- Full deck
- An applicative password list
- Applicative combinations of functions
- The Maybe applicative functor
- Applicative validation
- The Test Data Generator applicative functor
- Danish CPR numbers in F#
- The Lazy applicative functor
- Applicative monoids
A Haskell perspective #
A normal functor maps objects in an 'elevated world' (like C#'s IEnumerable<T> or IObservable<T>) using a function in the 'normal world'. As a variation, an applicative functor maps objects in an 'elevated world' using functions from the same 'elevated world'.
In Haskell, an applicative functor is defined like this:
class Functor f => Applicative f where pure :: a -> f a (<*>) :: f (a -> b) -> f a -> f b
This is a simplification; there's more to the Applicative typeclass than this, but this should highlight the essence. What it says is that an applicative functor must already be a Functor. It could be any sort of Functor, like [] (linked list), Maybe, Either, and so on. Since Functor is an abstraction, it's called f.
The definition furthermore says that in order for a functor to be applicative, two functions must exist: pure and <*> ('apply').
pure is easy to understand. It simply 'elevates' a 'normal' value to a functor value. For example, you can elevate the number 42 to a list value by putting it in a list with a single element: [42]. Or you can elevate "foo" to Maybe by containing it in the Just case: Just "foo". That is, literally, what pure does for [] (list) and Maybe.
The <*> operator applies an 'elevated' function to an 'elevated' value. When f is [], this literally means that you have a list of functions that you have to apply to a list of values. Perhaps you can already see what I meant by combinations of things.
This sounds abstract, but follow the above list of links in order to see several examples.
An F# perspective #
Applicative functors aren't explicitly modelled in F#, but they're easy enough to add if you need them. F# doesn't have typeclasses, so implementing applicative functors tend to be more on a case-by-case basis.
If you need list to be applicative, pure should have the type 'a -> 'a list, and <*> should have the type ('a -> 'b) list -> 'a list -> 'b list. At this point, you already run into the problem that pure is a reserved keyword in F#, so you'll have to find another name, or simply ignore that function.
If you need option to be applicative, <*> should have the type ('a -> 'b) option -> 'a option -> 'b option. Now you run into your second problem, because which function is <*>? The one for list, or the one for option? It can't be both, so you'll have to resort to all sorts of hygiene to prevent these two versions of the same operator from clashing. This somewhat limits its usefulness.
Again, refer to the above list of linked articles for concrete examples.
A C# perspective #
Applicative functors push the limits of what you can express in C#, but the equivalent to <*> would be a method with this signature:
public static Functor<TResult> Apply<T, TResult>( this Functor<Func<T, TResult>> selector, Functor<T> source)
Here, the class Functor<T> is a place-holder for a proper functor class. A concrete example could be for IEnumerable<T>:
public static IEnumerable<TResult> Apply<T, TResult>( this IEnumerable<Func<T, TResult>> selectors, IEnumerable<T> source)
As you can see, here you somehow have to figure out how to combine a sequence of functions with a sequence of values.
In some of the examples in the above list of linked articles, you'll see how this will stretch the capability of C#.
Summary #
This article only attempts to provide an overview of applicative functors, while examples are given in linked articles. I find it helpful to think of applicative functors as an abstraction that enables you to model arbitrary combinations of objects. This is a core feature in Haskell, occasionally useful in F#, and somewhat alien to C#.
Next: Full deck.
Asynchronous functors
Asynchronous computations form functors. An article for object-oriented programmers.
This article is an instalment in an article series about functors. The previous article covered the Lazy functor. In this article, you'll learn about closely related functors: .NET Tasks and F# asynchronous workflows.
A word of warning is in order. .NET Tasks aren't referentially transparent, whereas F# asynchronous computations are. You could argue, then, that .NET Tasks aren't proper functors, but you mostly observe the difference when you perform impure operations. As a general observation, when impure operations are allowed, the conclusions of this overall article series are precarious. We can't radically change how the .NET languages work, so we'll have to soldier on, pretending that impure operations are delegated to other parts of our system. Under this undue assumption, we can pretend that Task<T> forms a functor.
Task functor #
You can write an idiomatic Select extension method for Task<T> like this:
public async static Task<TResult> Select<T, TResult>( this Task<T> source, Func<T, TResult> selector) { var x = await source; return selector(x); }
With this extension method in scope, you can compose asynchronous computations like this:
Task<int> x = // ... Task<string> y = x.Select(i => i.ToString());
Or, if you prefer query syntax:
Task<int> x = // ... Task<string> y = from i in x select i.ToString();
In both cases, you start with a Task<int> which you map into a Task<string>. Perhaps you've noticed that these two examples closely resemble the equivalent Lazy functor examples. The resemblance isn't coincidental. The same abstraction is in use in both places. This is the functor abstraction. That's what this article series is all about, after all.
The difference between the Task functor and the Lazy functor is that lazy computations don't run until forced. Tasks, on the other hand, typically start running in the background when created. Thus, when you finally await the value, you may actually not have to wait for it. This does, however, depend on how you created the initial task.
First functor law for Task #
The Select method obeys the first functor law. As usual in this article series, actually proving that this is the case belongs to the realm of computer science. Instead of proving that the law holds, you can use property-based testing to demonstrate that it does. The following example shows a single property written with FsCheck 2.11.0 and xUnit.net 2.4.0.
[Property(QuietOnSuccess = true)] public void TaskObeysFirstFunctorLaw(int i) { var left = Task.FromResult(i); var right = Task.FromResult(i).Select(x => x); Assert.Equal(left.Result, right.Result); }
This property accesses the Result property of the Tasks involved. This is typically not the preferred way to pull the value of Tasks, but I decided to do it like this since FsCheck 2.4.0 doesn't support asynchronous properties.
Even though you may feel that a property-based test gives you more confidence than a few hard-coded examples, such a test is nothing but a demonstration of the first functor law. It's no proof, and it only demonstrates that the law holds for Task<int>, not that it holds for Task<string>, Task<Product>, etcetera.
Second functor law for Task #
As is the case with the first functor law, you can also use a property to demonstrate that the second functor law holds:
[Property(QuietOnSuccess = true)] public void TaskObeysSecondFunctorLaw( Func<string, byte> f, Func<int, string> g, int i) { var left = Task.FromResult(i).Select(g).Select(f); var right = Task.FromResult(i).Select(x => f(g(x))); Assert.Equal(left.Result, right.Result); }
Again the same admonitions apply: that property is no proof. It does show, however, that given two functions, f and g, it doesn't matter if you map a Task in one or two steps. The output is the same in both cases.
Async functor #
F# had asynchronous workflows long before C#, so it uses a slightly different model, supported by separate types. Instead of Task<T>, F# relies on a generic type called Async<'T>. It's still a functor, since you can trivially implement a map function for it:
module Async = // 'a -> Async<'a> let fromValue x = async { return x } // ('a -> 'b) -> Async<'a> -> Async<'b> let map f x = async { let! x' = x return f x' }
The map function uses the async computation expression to access the value being computed asynchronously. You can use a let! binding to await the value computed in x, and then use the function f to translate that value. The return keyword turns the result into a new Async value.
With the map function, you can write code like this:
let (x : Async<int>) = // ... let (y : Async<string>) = x |> Async.map string
Once you've composed an asynchronous workflow to your liking, you can run it to compute the value in which you're interested:
> Async.RunSynchronously y;; val it : string = "42"
This is the main difference between F# asynchronous workflows and .NET Tasks. You have to explicitly run an asynchronous workflows, whereas Tasks are usually, implicitly, already running in the background.
First functor law for Async #
The Async.map function obeys the first functor law. Like above, you can use FsCheck to demonstrate how that works:
[<Property(QuietOnSuccess = true)>] let ``Async obeys first functor law`` (i : int) = let left = Async.fromValue i let right = Async.fromValue i |> Async.map id Async.RunSynchronously left =! Async.RunSynchronously right
In addition to FsCheck and xUnit.net, this property also uses Unquote 4.0.0 for the assertion. The =! operator is an assertion that the left-hand side must equal the right-hand side. If it doesn't, then the operator throws a descriptive exception.
Second functor law for Async #
As is the case with the first functor law, you can also use a property to demonstrate that the second functor law holds:
[<Property(QuietOnSuccess = true)>] let ``Async obeys second functor law`` (f : string -> byte) g (i : int) = let left = Async.fromValue i |> Async.map g |> Async.map f let right = Async.fromValue i |> Async.map (g >> f) Async.RunSynchronously left =! Async.RunSynchronously right
As usual, the second functor law states that given two arbitrary (but pure) functions f and g, it doesn't matter if you map an asynchronous workflow in one or two steps. There could be a difference in performance, but the functor laws don't concern themselves with the time dimension.
Both of the above properties use the Async.fromValue helper function to create Async values. Perhaps you consider it cheating that it immediately produces a value, but you can add a delay if you want to pretend that actual asynchronous computation takes place. It'll make the tests run slower, but otherwise will not affect the outcome.
Task and Async isomorphism #
The reason I've covered both Task<T> and Async<'a> in the same article is that they're equivalent. You can translate a Task to an asynchronous workflow, or the other way around.
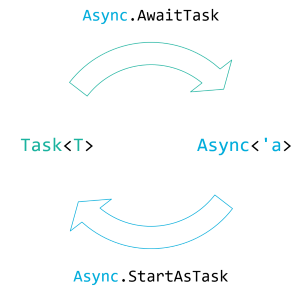
There's performance implications of going back and forth between Task<T> and Async<'a>, but there's no loss of information. You can, therefore, consider these to representations of asynchronous computations isomorphic.
Summary #
Whether you do asynchronous programming with Task<T> or Async<'a>, asynchronous computations form functors. This enables you to piecemeal compose asynchronous workflows.
Next: The Const functor.
Comments
As a general observation, when impure operations are allowed, the conclusions of this overall article series are precarious. We can't radically change how the .NET languages work, so we'll have to soldier on, pretending that impure operations are delegated to other parts of our system. Under this undue assumption, we can pretend that Task<T> forms a functor.
I am with you. I also want to be pragmatic here and treat Task<T> as a functor. It is definitely better than the alternative.
At the same time, I want to know what prevents Task<T> from actually being a functor so that I can compensate when needed.
A word of warning is in order. .NET Tasks aren't referentially transparent, whereas F# asynchronous computations are. You could argue, then, that .NET Tasks aren't proper functors, but you mostly observe the difference when you perform impure operations.
Can you elaborate about this? Why is Task<T> not referentially transparent? Why is the situation worse with impure operations? What issue remains when restricting to pure functions? Is this related to how the stack trace is closely related to how many times await appears in the code?
Tyson, thank you for writing. That .NET tasks aren't referentially transparent is a result of memoisation, as Diogo Castro pointed out to me.
The coming article about Task asynchronous programming as an IO surrogate will also discuss this topic.
Ha! So funny. It is the same caching behavior that I pointed out in this comment. I wish I had known about Diogo's comment. I could have just linked there.
You could argue, then, that .NET Tasks aren't proper functors, but you mostly observe the difference when you perform impure operations.
I am still not completely following though. Are you saying that this caching behavior prevents .NET Tasks from satisfying one of the functor laws? If so, is it the identity law or the composition law? If it is the composition law, what are the two functions that demonstate the failure? Even when allowing impure functions, I can't think of an example. However, I will keep thinking about this and comment again if I find an example.
Tyson, I am, in general trying to avoid claiming that any of this applies in the presence of impurity. Take something as trivial as Select(i => new Random().Next(i)), for Task or any other 'functor'. It's not even going to evaluate to the same outcome between two runs.
I think I understand your hesitation now regarding impurity. I also think I can argue that the existence of impure functions in C# does not prevent Task<T> from being a functor.
Before I give that argument and we consider if it works, I want to make sure there isn't a simpler issue only involving pure functions the prevents Task<T> from being a functor.
You could argue, then, that .NET Tasks aren't proper functors, but you mostly observe the difference when you perform impure operations.
Your use of "mostly" makes me think that you believe there is a counterexample only involving pure functions that shows Task<T> is not a functor. Do I correctly understanding what you meant by that sentence? If so, can you share that counterexample? If not, can you elaborate so that I can better understand what you meant.
Tyson, I wrote this article two years ago. I can't recall if I had anything specific in mind, or if it was just a throwaway phrase. Even if I had a specific counter-example in mind, I might have been wrong, just like the consensus is about Fermat's last theorem.
If you can produce an example, however, you'd prove me right 😀
Typing is not a programming bottleneck
Some developers seem to think that typing is a major bottleneck while programming. It's not.
I sometimes give programming advice to people. They approach me with a software design problem, and, to the best of my ability, I suggest a remedy. Despite my best intentions, my suggestions sometimes meet resistance. One common reaction is that my suggestion isn't idiomatic, but recently, another type of criticism seems to be on the rise.
The code that I suggest is too verbose. It involves too much typing.
I'll use this article to reflect on that criticism.
The purpose of code #
Before we get into the details of the issue, I'd like to start with the big picture. What's the purpose of code?
I've discussed this extensively in my Clean Coders video on Humane Code. In short, the purpose of source code is to communicate the workings of a piece of software to the next programmer who comes along. This could easily include your future self.
Perhaps you disagree with that proposition. Perhaps you think that the purpose of source code is to produce working software. It's that, too, but that's not its only purpose. If that was the only purpose, you might as well write the software in machine code.
Why do we have high-level programming languages like C#, Java, JavaScript, Ruby, Python, F#, Visual Basic, Haskell, heck - even C++?
As far as I can tell, it's because programmers are all human, and humans have limited cognitive capacity. We can't keep track of hundreds, or thousands, of global variables, or the states of dozens of complex resources. We need tools that help us structure and understand complex systems so that they're broken down into (more) manageable chunks. High-level languages help us do that.
The purpose of source code is to be understood. You read source code much more that you write. I'm not aware of any scientific studies, but I think most programmers will agree that over the lifetime of a code base, any line of code will be read orders of magnitude more often that it's edited.
Typing speed #
How many lines of code do you produce during a productive working day?
To be honest, I can't even answer that question myself. I've never measured it, since I consider it to be irrelevant. The Mythical Man-Month gives the number as 10, but let's be generous and pretend it's ten times that. This clearly depends on lots of factors, such as the language in which you're writing, the state of the code base, and so on. You'd tend to write more lines in a pristine greenfield code base, whereas you'll write fewer lines of code in a complicated legacy code base.
How many characters is a line of code? Let's say it's 80 characters, because that's the maximum width code ought to have. I realise that many people write wider lines, but on the other hand, most developers (fortunately) use indentation, so as a counter-weight, code often has some blank space to the left as well. This is all back-of-the-envelope calculations anyway.
When I worked in a Microsoft product group, we typically planned that a productive, 'full' day of coding was five hours. Even on productive days, the rest was used in meetings, administration, breaks, and so on.
If you write code for five hours, and produce 100 lines of code, at 80 characters per line, that's 8,000 characters. Your IDE is likely to help you with statement completion and such, but for the sake of argument, let's pretend that you have to type it all in.
8,000 characters in five hours is 1,600 characters per hour, or 27 characters per minute.
I'm not a particularly fast typist, but I can type ten times faster than that.
Typing isn't a bottleneck.
Is more code worse? #
I tend to get drawn into these discussions from time to time, but good programming has little to do with how fast you can produce lines of code.
To be clear, I entirely accept that statement completion, refactoring support, and such are, in general, benign features. While I spend most of my programming time thinking and reading, I also tend to write code in bursts. The average count of lines per hour may not be great, but that's because averages smooth out the hills and the valleys of my activity.
Still, increasingly frequent objection to some of my suggestions is that what I suggest implies 'too much' code. Recently, for example, I had to defend the merits of the Fluent Builder pattern that I suggest in my DI-Friendly Library article.
As another example, consider two alternatives for modelling a restaurant reservation. First, here's a terse option:
public class Reservation { public DateTimeOffset Date { get; set; } public string Email { get; set; } public string Name { get; set; } public int Quantity { get; set; } public bool IsAccepted { get; set; } }
Here's a longer alternative:
public sealed class Reservation { public Reservation( DateTimeOffset date, string name, string email, int quantity) : this(date, name, email, quantity, false) { } private Reservation( DateTimeOffset date, string name, string email, int quantity, bool isAccepted) { Date = date; Name = name; Email = email; Quantity = quantity; IsAccepted = isAccepted; } public DateTimeOffset Date { get; } public string Name { get; } public string Email { get; } public int Quantity { get; } public bool IsAccepted { get; } public Reservation WithDate(DateTimeOffset newDate) { return new Reservation(newDate, Name, Email, Quantity, IsAccepted); } public Reservation WithName(string newName) { return new Reservation(Date, newName, Email, Quantity, IsAccepted); } public Reservation WithEmail(string newEmail) { return new Reservation(Date, Name, newEmail, Quantity, IsAccepted); } public Reservation WithQuantity(int newQuantity) { return new Reservation(Date, Name, Email, newQuantity, IsAccepted); } public Reservation Accept() { return new Reservation(Date, Name, Email, Quantity, true); } public override bool Equals(object obj) { if (!(obj is Reservation other)) return false; return Equals(Date, other.Date) && Equals(Name, other.Name) && Equals(Email, other.Email) && Equals(Quantity, other.Quantity) && Equals(IsAccepted, other.IsAccepted); } public override int GetHashCode() { return Date.GetHashCode() ^ Name.GetHashCode() ^ Email.GetHashCode() ^ Quantity.GetHashCode() ^ IsAccepted.GetHashCode(); } }
Which alternative is better? The short version is eight lines of code, including the curly brackets. The longer version is 78 lines of code. That's ten times as much.
I prefer the longer version. While it takes longer to type, it comes with several benefits. The main benefit is that because it's immutable, it can have structural equality. This makes it trivial to compare objects, which, for example, is something you do all the time in unit test assertions. Another benefit is that such Value Objects make better domain models. The above Reservation Value Object only shows the slightest sign of emerging domain logic in the Accept method, but once you start modelling like this, such objects seem to attract more domain behaviour.
Maintenance burden #
Perhaps you're now convinced that typing speed may not be the bottleneck, but you still feel that you don't like the verbose Reservation alternative. More code could be an increased maintenance burden.
Consider those With[...] methods, such as WithName, WithQuantity, and so on. Once you make objects immutable, such copy-and-update methods become indispensable. They enable you to change a single property of an object, while keeping all other values intact:
> var r = new Reservation(DateTimeOffset.Now, "Foo", "foo@example.com", 3); > r.WithQuantity(4) Reservation { Date=[11.09.2018 19:19:29 +02:00], Email="foo@example.com", IsAccepted=false, Name="Foo", Quantity=4 }
While convenient, such methods can increase the maintenance burden. If you realise that you need to change the name of one of the properties, you'll have to remember to also change the name of the copy-and-update method. For example, if you change Quantity to NumberOfGuests, you'll have to also remember to rename WithQuantity to WithNumberOfGuests.
I'm not sure that I'm ready to concede that this is a prohibitive strain on the sustainability of a code base, but I do grant that it's a nuisance. This is one of the many reasons that I prefer to use programming languages better equipped for such domain modelling. In F#, for example, a record type similar to the above immutable Reservation class would be a one-liner:
type Reservation =
{ Date : DateTimeOffset; Name : string; Email : string; Quantity : int; IsAccepted : bool }
Such a declarative approach to types produces an immutable record with the same capabilities as the 78 lines of C# code.
That's a different story, though. There's little correlation between the size of code, and how 'good' it is. Sometimes, less code is better; sometimes, more code is better.
Summary #
I'll dispense with the usual Edsger Dijkstra and Bill Gates quotes on lines of code. The point that lines of code is a useless metric in software development has been made already. My point is a corollary. Apparently, it has to be explicitly stated: Programmer productivity has nothing to do with typing speed.
Unless you're disabled in some way, you can type fast enough to be a productive programmer. Typing isn't a programming bottleneck.
Comments
Watch a bad typist code. (It's easier with coding-heavy tutorial videos). It usually go as: type four or five characters, backspace, make a correction, type another six characters, backspace, make another fix, type a few more character, etc.
They rarely get more than 10 keystrokes out before have to stop and go back. This reeks havoc with your cognitive flow, and makes it much harder to get into the "groove" of coding. Once you can type fluidly, you can concetrate on the code itself, rather than the mechanics of entering it.
Moreover, in many cases, too much verbosity might only lead to more defects (unless you're a strong advocate of TDD et similia)
That said, one thing that I really liked about your article is the version of the Builder pattern you've implemented in the Reservation class. I love immutability in my classes and I often use the Builder pattern implemented as a inner class, just to be able to access the private cTor.
One thing that I don't like with your approach is that in case you have a bit parameter list in your cTor (as you do in the example), the consumers are forced to create a "dummy" instance and then call the WithXXX() methods on it when possible. I guess it could be solved adding a static readonly Empty property on the Reservation class that can be used as a starting point.
Anyways thank you for sharing this!
James, thank you for writing. I agree that being able to type out your thoughts as fast as possible lowers the barrier between your brain and whatever medium you're working in. I had something similar in mind when I wrote
"I also tend to write code in bursts. The average count of lines per hour may not be great, but that's because averages smooth out the hills and the valleys of my activity."I do, however, have mounting concerns about what you call the groove of coding. Flow state is generally characterised by a lack of reflection that I have often found to be counter-productive. These days, when programming, I deliberately use the Pomodoro technique - not to motivate me to code, but to force me to take breaks. Uncountable are the times I've had an important realisation about my work as soon as I'm away from the keyboard. These insights never seem to come to me when I'm in flow.
Perhaps you're now convinced that typing speed may not be the bottleneck, but you still feel that you don't like the verbose
Reservationalternative. More code could be an increased maintenance burden. Consider thoseWith[...]methods, such asWithName,WithQuantity, and so on. Once you make objects immutable, such copy-and-update methods become indispensable.
You could create a more generic With method that would enable modifying any property. Here is an alternative design of the Reservation class including such a method. It is untested, so it might not work properly in every case.
public sealed class Reservation
{
public Reservation(
DateTimeOffset date,
string name,
string email,
int quantity) :
this(date, name, email, quantity, false)
{
}
private Reservation(
DateTimeOffset date,
string name,
string email,
int quantity,
bool isAccepted)
{
Date = date;
Name = name;
Email = email;
Quantity = quantity;
IsAccepted = isAccepted;
}
private Reservation()
{
}
public DateTimeOffset Date { get; private set; }
public string Name { get; private set; }
public string Email { get; private set; }
public int Quantity { get; private set; }
public bool IsAccepted { get; private set; }
public Reservation With(string propertyName, object value)
{
if (propertyName == null)
{
throw new ArgumentNullException(nameof(propertyName));
}
var property = typeof(Reservation).GetProperty(propertyName);
if (property == null)
{
throw new ArgumentException($"Property ${propertyName} does not exist.");
}
if (!IsAssignable(property, value))
{
throw new ArgumentException($"Value ${value} is not assignable to property ${propertyName}");
}
var result = new Reservation();
foreach (var prop in typeof(Reservation).GetProperties())
{
prop.SetValue(result, prop.Name == propertyName ? value : prop.GetValue(this));
}
return result;
}
public Reservation Accept()
{
return new Reservation(Date, Name, Email, Quantity, true);
}
public override bool Equals(object obj)
{
if (!(obj is Reservation other))
return false;
return Equals(Date, other.Date)
&& Equals(Name, other.Name)
&& Equals(Email, other.Email)
&& Equals(Quantity, other.Quantity)
&& Equals(IsAccepted, other.IsAccepted);
}
public override int GetHashCode()
{
return
Date.GetHashCode() ^
Name.GetHashCode() ^
Email.GetHashCode() ^
Quantity.GetHashCode() ^
IsAccepted.GetHashCode();
}
private static bool IsAssignable(PropertyInfo property, object value)
{
if (value == null && property.PropertyType.IsValueType &&
Nullable.GetUnderlyingType(property.PropertyType) == null)
{
return false;
}
return value == null || property.PropertyType.IsAssignableFrom(value.GetType());
}
}
Of course this design is not type-safe and we are throwing exceptions whenever the types of property and value don't match. Property names can be passed using nameof which will provide compile-time feedback. I believe it would be possible to write a code analyzer that would help calling the With method by raising compilation errors whenever the types don't match. The With method could be even designed as an extension method on object and distributed in a Nuget package with the anayler alongside it.
The Lazy functor
Lazy evaluation forms a functor. An article for object-oriented programmers.
This article is an instalment in an article series about functors. Previous articles have covered Maybe, rose trees, and other functors. This article provides another example.
Most programming languages are eagerly evaluated. Sometimes, however, you'd like to defer execution of an expensive operation. On .NET, you can use Lazy<T> to achieve that goal. This generic type, like so many others, forms a functor.
Functor #
You can implement an idiomatic Select extension method for Lazy<T> like this:
public static Lazy<TResult> Select<T, TResult>( this Lazy<T> source, Func<T, TResult> selector) { return new Lazy<TResult>(() => selector(source.Value)); }
This would, for example, enable you to write code like this:
Lazy<int> x = // ... Lazy<string> y = x.Select(i => i.ToString());
Or, using query syntax:
Lazy<int> x = // ... Lazy<string> y = from i in x select i.ToString();
You can add more steps to such a pipeline of lazy computation until you finally decide to force evaluation with the Value property.
Notice that while the Select method looks like it might force evaluation as well, by accessing the Value property, this happens inside a new lazily evaluated lambda expression. Thus, all steps in a Lazy pipeline are deferred until evaluation is forced.
First functor law #
The Select method obeys the first functor law. As usual in this article series, actually proving that this is the case belongs in the realm of computer science. Instead of proving that the law holds, you can demonstrate that it does using property-based testing. The following example shows a single property written with FsCheck 2.11.0 and xUnit.net 2.4.0.
[Property(QuietOnSuccess = true)] public void LazyObeysFirstFunctorLaw(int i) { var left = Lazy.FromValue(i); var right = Lazy.FromValue(i).Select(x => x); Assert.Equal(left.Value, right.Value); }
Even though you may feel that a property-based test gives you more confidence than a few hard-coded examples, such a test is nothing but a demonstration of the first functor law. It's no proof, and it only demonstrates that the law holds for Lazy<int>, not that it holds for Lazy<string>, Lazy<Address>, etcetera.
Both this property and the next uses this little static helper method:
public static Lazy<T> FromValue<T>(T value) { return new Lazy<T>(() => value); }
This helper method is only a convenience. You can put in a delay if you want to pretend that actual lazy evaluation takes place. It'll make the tests run slower, but otherwise will not affect the outcome.
Second functor law #
As is the case with the first functor law, you can also use a property to demonstrate that the second functor law holds:
[Property(QuietOnSuccess = true)] public void LazyObeysSecondFunctorLaw( Func<string, byte> f, Func<int, string> g, int i) { var left = Lazy.FromValue(i).Select(g).Select(f); var right = Lazy.FromValue(i).Select(x => f(g(x))); Assert.Equal(left.Value, right.Value); }
Again the same admonitions apply: that property is no proof. It does show, however, that given two functions, f and g, it doesn't matter if you map a Lazy computation in one or two steps. The output is the same in both cases.
F# #
F# has built-in language support for lazy evaluations, but surprisingly doesn't supply a map function. You can, however, easily implement such a function yourself:
module Lazy = // ('a -> 'b) -> Lazy<'a> -> Lazy<'b> let map f (x : Lazy<'a>) = lazy f x.Value
This enables you to write code like this:
let (x : Lazy<int>) = // ... let (y : Lazy<string>) = x |> Lazy.map string
The F# language feature is based on the same Lazy<T> class that you can use from C# (and Visual Basic .NET), so the behaviour is the same as described above. The functor laws hold for the Lazy.map function just like it holds for the above Select method.
Haskell #
Unlinke C#, F#, and most other programming languages, Haskell is lazily evaluated. All values, whether scalar or complex, are lazy by default. For that reason, there's no explicit Lazy type in Haskell.
Haskell values are, in themselves, not functors, but you can put any value into the Identity functor. Since all values are already lazy, you could view Identity as Haskell's Lazy functor.
The equivalence is only partial, however. .NET Lazy objects are small state machines. Before you've forced evaluation, they carry around the expression to be evaluated. Once you've evaluated the value once, Lazy objects effectively replace the lazy expression with its result. Thus, the next time you access the Value property, you immediately receive the result.
Haskell's lazily evaluated values are different. Since they're immutable, they don't 'change state' like that. On the other hand, sometimes the Haskell compiler can identify optimisations that it can apply to make lazily evaluated values more efficient. In other cases, you may have to apply more explicit memoisation.
Summary #
In languages with eager evaluation (which is most of them), you can model deferred execution as a functor. This enables you to compose lazily evaluated expressions piecemeal.
Next: Asynchronous functors.
The Identity functor
The Identity functor is a data container that doesn't do anything. It's a functor nonetheless. An article for object-oriented programmers.
This article is an instalment in an article series about functors. In previous articles, you've learned about useful functors such as Maybe. In this article, you'll learn about a (practically) useless functor called Identity. You can skip this article if you want.
If Identity is useless, then why bother?
The inutility of Identity doesn't mean that it doesn't exist. The Identity functor exists, whether it's useful or not. You can ignore it, but it still exists. In C# or F# I've never had any use for it (although I've described it before), while it turns out to be occasionally useful in Haskell, where it's built-in. The value of Identity is language-dependent.
You may still derive value from this article. My motivation for writing it is to add another example to the set of functor examples presented in this article series. By presenting a varied selection of functors, it's my hope that you, from examples, gain insight.
Identity objects #
You can implement Identity as a C# class:
public sealed class Identity<T> { public Identity(T item) { Item = item; } public T Item { get; } public Identity<TResult> Select<TResult>(Func<T, TResult> selector) { return new Identity<TResult>(selector(Item)); } public override bool Equals(object obj) { if (!(obj is Identity<T> other)) return false; return Equals(Item, other.Item); } public override int GetHashCode() { return Item?.GetHashCode() ?? 0; } }
This class is just a wrapper around any object of the generic type T. The value could even be null if T is a reference type.
Since Identity<T> exposes the Select instance method, you can translate wrapped values, as this C# Interactive example demonstrates:
> new Identity<string>("foo").Select(s => s.Length) Identity<int> { Item=3 }
You can also, if you prefer, use query syntax:
> from i in new Identity<int>(2) select 'f' + new String('o', i) Identity<string> { Item="foo" }
You can also unwrap the value:
> Identity<string> x = new Identity<string>("bar"); > x.Item "bar"
Admittedly, this isn't the most exciting or useful class you could ever write. It is, however, a functor.
First functor law #
The Select method obeys the first functor law. As usual in this article series, actually proving that this is the case belongs in the realm of computer science. I would guess, however, that in this particular case, the proof would be manageable. Instead of proving this, though, you can demonstrate that the law holds using property-based testing. The following example shows a single property written with FsCheck 2.11.0 and xUnit.net 2.4.0.
[Property(QuietOnSuccess = true)] public void IdentityObeysFirstFunctorLaw(int i) { var left = new Identity<int>(i); var right = new Identity<int>(i).Select(x => x); Assert.Equal(left, right); }
Even though you may feel that a property-based test gives you more confidence than a few hard-coded examples, such a test is nothing but a demonstration of the first functor law. It's no proof, and it only demonstrates that the law holds for Identity<int>, not that it holds for Identity<string>, Identity<Customer>, etcetera.
Second functor law #
As is the case with the first functor law, you can also use a property to demonstrate that the second functor law holds:
[Property(QuietOnSuccess = true)] public void IdentityObeysSecondFunctorLaw( Func<string, byte> f, Func<int, string> g, int i) { var left = new Identity<int>(i).Select(g).Select(f); var right = new Identity<int>(i).Select(x => f(g(x))); Assert.Equal(left, right); }
Again the same admonitions apply: that property is no proof. It does show, however, that given two functions, f and g, it doesn't matter if you map an Identity object in one or two steps. The output is the same in both cases.
F# #
While the Identity functor is built into the Haskell standard library, there's no Identity functor in F#. While it can be occasionally useful in Haskell, Identity is useless in F#, like it is in C#. Again, that doesn't imply that you can't define it. You can:
type Identity<'a> = Identity of 'a module Identity = // Identity<'a> -> 'a let get (Identity x) = x // ('a -> 'b) -> Identity<'a> -> Identity<'b> let map f (Identity x) = Identity (f x)
With this type, you can wrap, map, and unwrap values to your heart's content:
> Identity "foo" |> Identity.map Seq.length;;
val it : Identity<int> = Identity 3
> Identity 2 |> Identity.map (fun i -> "f" + String ('o', i));;
val it : Identity>string> = Identity "foo"
> let x = Identity "bar";;
val x : Identity<string> = Identity "bar"
> Identity.get x;;
val it : string = "bar"
There's not much point to this, apart from demonstrating that it's possible.
Summary #
The Identity functor exists, and you can implement it in C# and F#, although I don't see any use for it. Haskell has a type system that can express abstractions such as Functor in the type system itself. In that language, then, you can define functions that return any type of functor (e.g. Maybe, Tree, and so on). If you need a plain vanilla version of such a function, you can make it return Identity.
The point of this article was only to identify the existence of the Identity functor, and to perhaps illustrate that the concept of a functor encompasses various data structures and behaviours.
Next: The Lazy functor.
On Constructor Over-injection
Constructor Over-injection is a code smell, not an anti-pattern.
Sometimes, people struggle with how to deal with the Constructor Over-injection code smell. Often, you can address it by refactoring to Facade Services. This is possible when constructor arguments fall in two or more natural clusters. Sometimes, however, that isn't possible.
Cross-cutting concerns #
Before we get to the heart of this post, I want to get something out of the way. Sometimes constructors have too many arguments because they request various services that represent cross-cutting concerns:
public Foo( IBar bar, IBaz baz, IQux qux, IAuthorizationManager authorizationManager, ILog log, ICache cache, ICircuitBreaker breaker)
This Foo class has seven dependencies passed via the constructor. Three of those (bar, baz, and qux) are regular dependencies. The other four are various incarnations of cross-cutting concerns: logging, caching, authorization, stability. As I describe in my book, cross-cutting concerns are better addressed with Decorators or the Chain of Responsibility pattern. Thus, such a Foo constructor ought really to take just three arguments:
public Foo( IBar bar, IBaz baz, IQux qux)
Making cross-cutting concerns 'disappear' like that could decrease the number of constructor arguments to an acceptable level, thereby effectively dealing with the Constructor Over-injection smell. Sometimes, however, that's not the issue.
No natural clusters #
Occasionally, a class has many dependencies, and the dependencies form no natural clusters:
public Ploeh( IBar bar, IBaz baz, IQux qux, IQuux quux, IQuuz quuz, ICorge corge, IGrault grault, IGarply garply, IWaldo waldo, IFred fred, IPlugh plugh, IXyzzy xyzzy, IThud thud) { Bar = bar; Baz = baz; Qux = qux; Quux = quux; Quuz = quuz; Corge = corge; Grault = grault; Garply = garply; Waldo = waldo; Fred = fred; Plugh = plugh; Xyzzy = xyzzy; Thud = thud; }
This seems to be an obvious case of the Constructor Over-injection code smell. If you can't refactor to Facade Services, then what other options do you have?
Introducing a Parameter Object isn't likely to help #
Some people, when they run into this type of situation, attempt to resolve it by introducing a Parameter Object. In its simplest form, the Parameter Object is just a collection of properties that client code can access. In other cases, the Parameter Object is a Facade over a DI Container. Sometimes, the Parameter Object is defined as an interface with read-only properties.
One way to use such a Parameter Object could be like this:
public Ploeh(DependencyCatalog catalog) { Bar = catalog.Bar; Baz = catalog.Baz; Qux = catalog.Qux; Quux = catalog.Quux; Quuz = catalog.Quuz; Corge = catalog.Corge; Grault = catalog.Grault; Garply = catalog.Garply; Waldo = catalog.Waldo; Fred = catalog.Fred; Plugh = catalog.Plugh; Xyzzy = catalog.Xyzzy; Thud = catalog.Thud; }
Alternatively, some people just store a reference to the Parameter Object and then access the read-only properties on an as-needed basis.
None of those alternatives are likely to help. One problem is that such a DependencyCatalog will be likely to violate the Interface Segregation Principle, unless you take great care to make a 'dependency catalogue' per class. For instance, you'd be tempted to add Wibble, Wobble, and Wubble properties to the above DependencyCatalog class, because some other Fnaah class needs those dependencies in addition to Bar, Fred, and Waldo.
Deodorant #
Fundamentally, Constructor Over-injection is a code smell. This means that it's an indication that something is not right; that there's an area of code that bears investigation. Code smells aren't problems in themselves, but rather symptoms.
Constructor Over-injection tends to be a symptom that a class is doing too much: that it's violating the Single Responsibility Principle. Reducing thirteen constructor arguments to a single Parameter Object doesn't address the underlying problem. It only applies deodorant to the smell.
Address, if you can, the underlying problem, and the symptom is likely to disappear as well.
Guidance, not law #
This is only guidance. There could be cases where it's genuinely valid to have dozens of dependencies. I'm being deliberately vague, because I don't wish to go into an elaborate example. Usually, there's more than one way to solve a particular problem, and occasionally, it's possible that collecting many services in a single class would be appropriate. (This sounds like a case for the Composite design pattern, but let's assume that there could be cases where that's not possible.)
This is similar to using cyclomatic complexity as a guide. Every now and then, a big, flat switch statement is just the best and most maintainable solution to a problem, even when it has a cyclomatic complexity of 37...
Likewise, there could be cases where it's genuinely not a problem with dozens of constructor arguments.
Summary #
Constructor Over-injection is a code smell, not an anti-pattern. It's a good idea to be aware of the smell, and address it when you discover it. You should, however, deal with the problem instead of applying deodorant to the smell. The underlying problem is usually that the class with the many dependencies has too many responsibilities. Address that problem, and the smell is likely to evaporate as well.
Comments
Hi Mark, I have question about “Parameter Object” approach you mentioned. In my previous project we was using this approach heavily. I know disadvantages you described and honestly I was against this approach but after some time I saw some advantages I want to discuss.
We have a lot of services that was reading data from some external databases, do some basic validation and fixing and than save to other database – so it was most integration code. Every of our services had bootstrapper attached by attribute that was describing dependencies. Each have only one parameter with so called “catalog” that was façade over DI with read only properties (sometimes even in tree structure to make it simpler to use like Catalog.Repositories.Server.SomeRepository). We have some base class for common dependencies like logging, common infrastructure services etc (we also use interceptor for cross cutting concerns but sometimes we have to log something explicitly).
In unit tests we used same bootstrapper that service was using with repositories changed to mocks. Advantage that I’m seeing is that when using lot of unit tests and service like this when we are maintain the code when something is changing in service we don’t had to touch any unit test – it is similar to using parameter object in general even outside the scope of constructor – when using single complex object as input parameter there is also no problem when on 100 unit test break after we change add some method parameter. It is service locator antipattern but only in one place – other code is not using DI.
Sometimes when I’m thinking about anti pattern approach in general I have a feeling similar to you when you was explaining other approach to async injection “you cannot do that” – “Oh, really”? Maybe pattern police will hunt me but is this really so bad?
Dominik, thank you for writing. To be clear: there's no pattern police. Design patterns is (or was) an attempt to establish a vocabulary that can act as short-cuts for long, elaborate chains of arguments. The same goes for anti-patterns.
Most experienced programmers over time discover that certain ways of doing things yield more benefits than disadvantages (patterns) or yield more disadvantages than benefits (anti-patterns). Instead of having to explain the possible consequences every time we run into such situations, we can reach for a generalised description and refer to it by names such as Composite, Decorator, Service Locator, etc.
The same goes for more basic design principles such as the SOLID principles. If you find yourself writing code such as Catalog.Repositories.Server.SomeRepository, you're already in territory where the Law of Demeter (or the Occasionally Useful Suggestion of Demeter) applies. The Law of Demeter is less than a law and more like a code smell. If you find yourself 'dotting into' a deep object graph like that, you should stop and consider how that's going to impact long-term maintainability.
Either an object doesn't need everything that a service catalogue exposes, in which case it'd be at odds with the Interface Segregation Principle, or it does need all of those services, in which case the class in question most likely violates the Single Responsibility Principle.
You can address the first of these concerns by injecting only the services that a class needs. If you're concerned about the impact on unit tests of changing dependencies, consider using an Auto-mocking Container.
You can address the second of the above concerns by refactoring to Facade Services.
Mark, thanks for detailed answer (as always).
In matter of catalog approach it was always smelly for me and honestly I was against using it but sometimes I had no good arguments to get rid of it. Automocking container is very promising for me – as matter of fact I saw this approach when analyzing one of your github samples and for start it looked like magic when xunit+autofixture+automoq was used and I have to admit it was love at first sight and I will absolutely deep dive into this topic.
When talking about pattern police I was some kind of joking. I understand the source and meaning of the patterns and it is very good that we have them but sometimes they are problematic. Many times some question / discussion on places like stuckoverflow is broken by some “police man” that is saying that “your approach is antipattern”. Even if this maybe is true it sometimes kills some new approaches because people are real believers and they believe in patterns as if they were some religion and they will be fight for it instead of discuss and assume that maybe it is not always true or maybe this case is not really antipattern.
Other thing is that people forgot after some time what is the real purpose / source of the pattern – the just use it automatically. My favorite anecdote/joke illustrate this
- Mom why you are cutting edges of the cake
- Becouse we should do this
- But why
- Becoue we have to
- But why
- Becouse… my mom did this
- Grandma why you are cutting edges of the cake
- Becouse… my mom did this
- Great grandma why you are cutting edges of the cake
- Becouse I have small stove

Comments
I think we agreed that the issue is not C#'s weak type inference but its lack of default function currying? My guess is that you wrote this quoted part of this article before my comment on your previous article.
Tyson, thank you for writing.
Yes, June 27, 2017, in fact...You're correct that this particular issue is related to the uncurried nature of C# methods.
I do, however, maintain that C#'s type inference capabilities are weaker than F#'s or Haskell's. To be clear, I view this as the result of priorities. I don't think that the people who designed and wrote the C# compiler are less skilled than the designers of F# or Haskell. The C# compiler has to solve many other problems, such as for example overload resolution, which is a language feature in direct opposition to currying. The C# compiler is excellent at overload resolution, a task with which the F# compiler sometimes struggle (and is not even a language feature in Haskell).
Your comment is, however, a reminder that I should consider how I phrase such notions in the future. Thank you for pointing that out. As I'm publishing and get feedback, I constantly learn new things. I'm always grateful when someone like you take the time to educate me.
I'll see if I can improve in the future. I do, however, still have a backlog of articles I wrote months, or even more than a year, ago, so it's possible that more errors escape my attention when I proof read them before publication. If that happens, I'll appreciate more corrections.
Thank you very much for your kind reply. I agree with everything you said.
I will expand my comment a bit to give a clearer picture of my understanding.
First, very little is "needed"; most things are merely sufficient. In particular, we don't need to overload your
Applymethod to achieve your goal. As I mentioned before, it sufficies to have a singleApplymethod and instead create overloads of a function calledcurrythat explicitly curries a given function. Furthermore, I think there is a sense in which this latter approach to overcome the lack of default currying is somehow minimal or most abstract or most general.Second, compared to languages like F# or Haskell, type inference is definitely weaker in C#. This issue was also present (in a subtle way) in your previous article, but I decided to largely ignore it in order to keep my comment more focused. In your previous article, you expliciltly defined the local variable
In particular, you explicitly told the C# compiler that the type of all of these six variable isconcatlike thisstring. That part was necessary; the type inference in C# is not strong enough to innfer (possibily in some use ofconcat) that the types could bestring.Suppose instead of defining
Again, I think there is a sense in which this explicit way to specify non-inferable types is somehow minimal or most abstract or most general.concatas a local variable (withFunc<string, string, string, string, string, string, string>as its type) you had defined it as a member method on a class. Then its type in C# is some kind "method group". The method group of a method essentially corresponds to the set of methods containing itself and its overloads. Then in order to passconcatintocurry, there needs to be a type conversion (or cast) from its method group toFunc<string, string, string, string, string, string, string>. This is also something that the C# system cannot do, and so Language Ext has overloads of a function calledfunto do this explicitly. Using it on our hypothetical member functionconcatwould look likeMy impression is that there is some low hanging fruit here for strengthing the type inference of the C# compiler. If a method group correpsonds to a singleton set (and that method has no
reforoutarguments), then I would think it would be straight forward to consider an implicit cast from the method group to the correspondingFuncorActiondelegate.