ploeh blog danish software design
Dependency Injection in ASP.NET Web API with Castle Windsor
This post describes how to compose Controllers with Castle Windsor in the ASP.NET Web API
In my previous post I described how to use Dependency Injection (DI) in the ASP.NET Web API using Poor Man's DI. It explained the basic building blocks, including the relevant extensibility points in the Web API. Poor Man's DI can be an easy way to get started with DI and may be sufficient for a small code base, but for larger code bases you may want to adopt a more convention-based approach. Some DI Containers provide excellent support for Convention over Configuration. One of these is Castle Windsor.
Composition Root #
Instead of the PoorMansCompositionRoot from the example in the previous post, you can create an implementation of IHttpControllerActivator that acts as an Adapter over Castle Windsor:
public class WindsorCompositionRoot : IHttpControllerActivator { private readonly IWindsorContainer container; public WindsorCompositionRoot(IWindsorContainer container) { this.container = container; } public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { var controller = (IHttpController)this.container.Resolve(controllerType); request.RegisterForDispose( new Release( () => this.container.Release(controller))); return controller; } private class Release : IDisposable { private readonly Action release; public Release(Action release) { this.release = release; } public void Dispose() { this.release(); } } }
That's pretty much all there is to it, but there are a few points of interest here. First of all, the class implements IHttpControllerActivator just like the previous PoorMansCompositionRoot. That's the extensibility point you need to implement in order to create Controller instances. However, instead of hard-coding knowledge of concrete Controller classes into the Create method, you delegate creation of the instance to an injected IWindsorContainer instance. However, before returning the IHttpController instance created by calling container.Resolve, you register that object graph for disposal.
With Castle Windsor decommissioning is done by invoking the Release method on IWindsorContainer. The input into the Release method is the object graph originally created by IWindsorContainer.Resolve. That's the rule from the Register Resolve Release pattern: What you Resolve you must also Release. This ensures that if the Resolve method created a disposable instance (even deep in the object graph), the Release method signals to the container that it can now safely dispose of it. You can read more about this subject in my book.
The RegisterForDispose method takes as a parameter an IDisposable instance, and not a Release method, so you must wrap the call to the Release method in an IDisposable implementation. That's the little private Release class in the code example. It adapts an Action delegate into a class which implements IDisposable, invoking the code block when Dispose is invoked. The code block you pass into the constructor of the Release class is a closure around the outer variables this.container and controller so when the Dispose method is called, the container releases the controller (and the entire object graph beneath it).
Configuring the container #
With the WindsorCompositionRoot class in place, all that's left is to set it all up in Global.asax. Since IWindsorContainer itself implements IDisposable, you should create and configure the container in the application's constructor so that you can dispose it when the application exits:
private readonly IWindsorContainer container; public WebApiApplication() { this.container = new WindsorContainer().Install(new DependencyConventions()); } public override void Dispose() { this.container.Dispose(); base.Dispose(); }
Notice that you can configure the container with the Install method directly in the constructor. That's the Register phase of the Register Resolve Release pattern.
In Application_Start you tell the ASP.NET Web API about your WindsorCompositionRoot instead of PoorMansCompositionRoot from the previous example:
GlobalConfiguration.Configuration.Services.Replace( typeof(IHttpControllerActivator), new WindsorCompositionRoot(this.container));
Notice that the container instance field is passed into the constructor of WindsorCompositionRoot, so that it can use the container instance to Resolve Controller instances.
Summary #
Setting up DI in the ASP.NET Web API with a DI Container is easy, and it would work very similarly with other containers (not just Castle Windsor), although the Release mechanisms tend to be a bit different from container to container. You'll need to create an Adapter from IHttpControllerActivator to your container of choice and set it all up in the Global.asax.
Dependency Injection and Lifetime Management with ASP.NET Web API
This post describes how to properly use Dependency Injection in the ASP.NET Web API, including proper Lifetime Management.
The ASP.NET Web API supports Dependency Injection (DI), but the appropriate way to make it work is not the way it's documented by Microsoft. Even though the final version of IDependencyResolver includes the notion of an IDependencyScope, and thus seemingly supports decommissioning (the release of IDisposable dependencies), it's not very useful.
The problem with IDependencyResolver #
The main problem with IDependencyResolver is that it's essentially a Service Locator. There are many problems with the Service Locator anti-pattern, but most of them I've already described elsewhere on this blog (and in my book). One disadvantage of Service Locator that I haven't yet written so much about is that within each call to GetService there's no context at all. This is a general problem with the Service Locator anti-pattern, not just with IDependencyResolver. Glenn Block originally pointed this out to me. The problem is that in an implementation, all you're given is a Type instance and asked to return an object, but you're not informed about the context. You don't know how deep in a dependency graph you are, and if you're being asked to provide an instance of the same service multiple times, you don't know whether it's within the same HTTP request, or whether it's for multiple concurrent HTTP requests.
In the ASP.NET Web API this issue is exacerbated by another design decision that the team made. Contrary to the IDependencyResolver design, I find this other decision highly appropriate. It's how context is modeled. In previous incarnations of web frameworks from Microsoft, we've had such abominations as HttpContext.Current, HttpContextBase and HttpContextWrapper. If you've ever tried to work with these interfaces, and particularly if you've tried to do TDD against any of these types, you know just how painful they are. That they are built around the Singleton pattern certainly doesn't help.
The ASP.NET Web API does it differently, and that's very fortunate. Everything you need to know about the context is accessible through the HttpRequestMessage class. While you could argue that it's a bit of a God Object, it's certainly a step in the right direction because at least it's a class you can instantiate within a unit test. No more nasty Singletons.
This is good, but from the perspective of DI this makes IDependencyResolver close to useless. Imagine a situation where a dependency deep in the dependency graph need to know something about the context. What was the request URL? What was the base address (host name etc.) requested? How can you share dependency instances within a single request? To answer such questions, you must know about the context, and IDependencyResolver doesn't provide this information. In short, IDependencyResolver isn't the right hook to compose dependency graphs. Fortunately, the ASP.NET Web API has a better extensibility point for this purpose.
Composition within context #
Because HttpRequestMessage provides the context you may need to compose dependency graphs, the best extensibility point is the extensibility point which provides an HttpRequestMessage every time a graph should be composed. This extensibility point is the IHttpControllerActivator interface:
public interface IHttpControllerActivator { IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType); }
As you can see, each time the Web API framework invokes this method, it will provide an HttpRequestMessage instance. This seems to be the best place to compose the dependency graph for each request.
Example: Poor Man's DI #
As an example, consider a Controller with this constructor signature:
public RootController(IStatusQuery statusQuery)
If this is the only Controller in your project, you can compose its dependency graph with a custom IHttpControllerActivator. This is easy to do:
public class PoorMansCompositionRoot : IHttpControllerActivator { public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { if (controllerType == typeof(RootController)) return new RootController( new StatusQuery()); return null; } }
The Create implementation contains a check on the supplied controllerType parameter, creating a RootController instance if the requested Controller type is RootController. It simply creates the (very shallow) dependency graph by injecting a new StatusQuery instance into a new RootController instance. If the requested Controller type is anything else than RootController, the method returns null. It seems to be a convention in the Web API that if you can't supply an instance, you should return null. (This isn't a design I'm fond of, but this time I'm only on the supplying side, and I can only pity the developers on the receiving side (the ASP.NET team) that they'll have to write all those null checks.)
Some readers may think that it would be better to use a DI Container here, and that's certainly possible. In a future post I'll provide an example on how to do that.
The new PoorMansCompositionRoot class must be registered with the Web API framework before it will work. This is done with a single line in Application_Start in Global.asax.cs:
GlobalConfiguration.Configuration.Services.Replace( typeof(IHttpControllerActivator), new PoorMansCompositionRoot());
This replaces the default implementation that the framework provides with the PoorMansCompositionRoot instance.
Decommissioning #
Implementing IHttpControllerActivator.Create takes care of composing object graphs, but what about decommissioning? What if you have dependencies (deep within the dependency graph) implementing the IDisposable interface? These must be disposed of after the request has ended (unless they are Singletons) - if not, you will have a resource leak at hand. However, there seems to be no Release hook in IHttpControllerActivator. On the other hand, there's a Release hook in IDependencyResolver, so is IDependencyResolver, after all, the right extensibility point? Must you trade off context for decommissioning, or can you have both?
Fortunately you can have both, because there's a RegisterForDispose extension method hanging off HttpRequestMessage. It enables you to register all appropriate disposable instances for disposal after the request has completed.
Example: disposing of a disposable dependency #
Imagine that, instead of the StatusQuery class from the previous example, you need to use a disposable implementation of IStatusQuery. Each instance must be disposed of after each request completes. In order to accomplish this goal, you can modify the PoorMansCompositionRoot implementation to this:
public class PoorMansCompositionRoot : IHttpControllerActivator { public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { if (controllerType == typeof(RootController)) { var disposableQuery = new DisposableStatusQuery(); request.RegisterForDispose(disposableQuery); return new RootController(disposableQuery); } return null; } }
Notice that the disposableQuery instance is passed to the RegisterForDispose method before it's injected into the RootController instance and the entire graph is returned from the method. After the request completes, DisposableStatusQuery.Dispose will be called.
If you have a dependency which implements IDisposable, but should be shared across all requests, obviously you shouldn't register it for disposal. Such Singletons you can keep around and dispose of properly when the application exits gracefull (if that ever happens).
Summary #
Proper DI and Lifetime Management with the ASP.NET Web API is easy once you know how to do it. It only requires a few lines of code.
Stay away from the IDependencyResolver interface, which is close to useless. Instead, implement IHttpControllerActivator and use the RegisterForDispose method for decommissioning.
In a future post I will demonstrate how to use a DI Container instead of Poor Man's DI.
Comments
You have one implementation of IFoo, namely Foo, and for efficiency reasons, or perhaps because Foo is a Mediator, you'd like to share the same instance of Foo between Service1 and Service2. However, Foo isn't thread-safe, so you can only share the Foo instance within a single request. For each request, you want to use a single instance of Foo.
This is the Per Graph lifestyle pattern (p. 259 in my book).
That's not possible with IDependencyResolver, but it is with IHttpControllerActivator.
First of all I would like to mention that I just read your book and I enjoyed it very much.
Straight to the point with good simple examples and metaphors.
What I have noticed thought, from your book and from this blog post, is that you give handing IDisposable object a great deal of attention.
I have written a lightweight service container over at Github (https://github.com/seesharper/LightInject/wiki/Getting-started) that tries to do the "right thing" with a minimal effort.
Then I started to read about handling disposable services in your book and realized that this is actually quite a complicated thing to deal with.
It also seems to be unclear how a service container actually should do this. The various container implementations has pretty much its own take on the disposable challenge where as Spring.Net for instance, does not seem to go very far on this topic. Yet it is one of the most popular DI frameworks out there.
The question then remains, is automatic handling of disposable objects a necessity for any container or is a feature?
If it is absolutely necessary, how complex does it need to be. I would rather not implement a whole ref-count system on top of the CLR :)
Regards
Bernhard Richter
StructureMap, for example, has no decommissioning capability, and when you ask Jeremy Miller, it's by design. The reason for this is that if you don't have any disposable dependencies at all, it's just an overhead keeping track of all the instances created by the container. Garbage collection will ensure that resources are properly reclaimed.
Containers that do keep track of the instances they created will leak unless you explicitly remember to Release what you Resolve. By that argument, Jeremy Miller considers StructureMap's design safer because in the majority case there will be no leaks. IMO, the downside of that is that if you have disposable dependencies, they will leak and there's nothing you can do about.
On the other hand, with a container like Castle Windsor, it's important to Release what you Resolve, or you might have leaks. The advantage, however, is that you're guaranteed that everything can be properly disposed of.
Thus, in the end, no matter the strategy, it all boils down to that the developers using the container must exercise discipline. However, they are two different kinds of discipline: Either never use disposable dependencies or always Release what you Resolve.
Great article, thanks a lot! Loved your book as well :)
I just have a little observation that returning null in the Create method causes a 404. Instead we could do the following to call the default implementation for other controllers:
return new DefaultHttpControllerActivator().Create(request, controllerDescriptor, controllerType);
How would you handle db calls that need to be made to validate objects in say
[CustomValidationAttribute()] tagswhere you need the objects used to validate again in the actual web api action method?
In general, I don't like attributes with behaviour, but prefer passive attributes. Still, that just moves the implementation to the Filter's ExecuteActionFilterAsync method, so that doesn't really address your question.
If you need access to the actual objects created from the incoming request, you probably could pull it out of the HttpActionContext passed into ExecuteActionFilterAsync, but why bother? You can access the object from the Controller.
A Filter attribute in ASP.NET Web API, to be useful, represents a Cross-Cutting Concern, such as security, logging, metering, caching, etc. Cross-Cutting Concerns are cross-cutting exactly because they are independent of the actual values or objects in use. This isn't the case for validation, which tends to be specific to particular types, so these are most likely better addressed by a Controller, or a Service invoked by the Controller, rather than by a custom attribute.
Once you're in the Controller, if you need access to a database, you can inject a data access object (commonly referred to as a Repository) into the Controller.
Concrete Dependencies
Concrete classes can also be used as dependencies
Usually, when we think about Dependency Injection (DI), we tend to consider that only polymorphic types (interfaces or (abstract) base classes) can act as dependencies. However, in a previous blog post I described how primitives can be used as dependencies. A primitive is about as far removed from polymorphism as it can be, but there's a middle ground too. Sometimes 'normal' concrete classes with non-virtual members can be used as dependencies with to great effect.
While the Liskov Substitution Principle is voided by injecting a concrete type, there can be other good reasons to occasionaly do something like this. Consider how many times you've written an extension method to perform some recurring task. Sometimes it turns out that an extension method isn't the best way to encapsulate a common algorithm. It might start out simple enough, but then you realize that you need to provide the extension method with a control parameter in order to 'configure' it. This causes you to add more arguments to the extension method, or to add more overloads. Soon, you have something like the Object Mother (anti-)pattern on your hand.
A concrete class can sometimes be a better way to encapsulate common algorithms in a way where the behavior can be tweaked or changed in one go. Sometimes the boundary can become blurred. In the previous post I examined constructor arguments such as strings and integers, but what about an Uri instance? It might act as a base URI for creating absolute links from within a Controller. An Uri instance isn't really a primitive, although it basically just encapsulates something which is a string. It's an excellent example of the Value Object pattern, providing a rich API for manipulating and querying URIs.
It can be more complex that that. Consider Hyprlinkr as an example. What it does is to produce URI links to other Controllers in an ASP.NET Web API service in a strongly typed way. It's not really a polymorphic dependency as such, although it does implement an interface. It's more like a reusable component which produces a determinstic result without side-effects. In Functional Programming terminology, it's comparable to a pure function. For a number of reasons, this is a prime candidate for a concrete dependency.
Before I get to that, I want to show you what I mean when I talk about locally scoped methods, including extension methods and such. Then I want to talk about using the RouteLinker class (the main class in Hyprlinkr) as a classic polymorphic dependency, and why that doesn't really work either. Finally, I want to talk about why the best option is to treat RouteLinker as a concrete dependency.
RouteLinker as a local variable #
While Hyprlinkr was always designed with DI in mind, you actually don't have to use DI to use it. From within an ApiController class, you can just create an instance like this:
var linker = new RouteLinker(this.Request);
With this locally scoped variable you can start creating links to other resources:
Href = linker.GetUri<NoDIController>(r => r.Get(id)).ToString()
That seems easy, so why make it hard than that? Well, it's easy as long as you have only a single, default route in your web service. As soon as you add more routes, you'll need to help Hyprlinkr a bit by providing a custom IRouteDispatcher. That goes as the second argument in a constructor overload:
var linker = new RouteLinker(this.Request, ??);
The question is: how do you create an instance of the desired IRouteDispatcher? You could do it inline every time you want to create an instance of RouteLinker:
var linker = new RouteLinker(this.Request, new MyCustomRouteDispatcher());
However, that's starting to look less than DRY. This is where many people might consider creating an extension method which creates a RouteLinker instance from an HttpRequestMessage instance. Now what if you need to supply a configuration value to the custom route dispatcher? Should you pull it from app.config straight from within your extension method? Then what if you need to be able to vary that configuration value from a unit test? This could lead toward an unmaintainable mess quickly. Perhaps it would be better injecting the dependency after all...
IResourceLinker as a polymorphic dependency #
The RouteLinker class actually implements an interface (IResourceLinker) so would it be worthwhile to inject it as a polymorphic interface? This is possible, but actually leads to more trouble. The problem is that due to its signature, it's damn hard to unit test. The interface looks like this:
public interface IResourceLinker { Uri GetUri<T>(Expression<Action<T>> method); }
That may at first glance look innocuous, but is actually quite poisonous. The first issue is that it's impossible to define proper setups when using dynamic mocks. This is because of the Expression parameter. The problem is that while the following Moq setup compiles, it can never work:
linkerStub
.Setup(x => x.GetUri<ArtistController>(c => c.Get(artistId)))
.Returns(uri);
The problem is that the expression passed into the Setup method isn't the same as the expression used in the SUT. It may look like the same expression, but it's not. Most of the expression tree actually is the same, but the problem is the leaf of the tree. The leaf of the expression tree is the reference to the artistId variable. This is a test variable, while in the SUT it's a variable which is internal to the SUT. While the values of both variables are expected to be the same, the variables themselves aren't.
It might be possible to write a custom equality comparer that picks expression trees apart in order to compare the values of leaf nodes, but that could become messy very quickly.
The only option seems to define Setups like this:
linkerStub .Setup(x => x.GetUri(It.IsAny<Expression<Action<ArtistController>>>())) .Returns(uri);
That sort of defies the purpose of a dynamic Test Double...
That's not the only problem with the IResourceLinker interface. The other problem is the return type. Since Uri doesn't have a default constructor, it's necessary to tell Moq what to return when the GetUri method is called. While the default behavior of Moq is to return null if no matching Setups were found, I never allow null in my code, so I always change Moq's behavior to return something proper instead. However, this has the disadvantage that if there's no matching Setup when the SUT attempts to invoke the GetUri method, Moq will throw an exception because there's no default constructor for Uri and it doesn't know what else to return.
This leads to Fixture Setup code like this:
linkerStub .Setup(x => x.GetUri(It.IsAny<Expression<Action<ArtistController>>>())) .Returns(uri); linkerStub .Setup(x => x.GetUri(It.IsAny<Expression<Action<ArtistAlbumsController>>>())) .Returns(uri); linkerStub .Setup(x => x.GetUri(It.IsAny<Expression<Action<ArtistTracksController>>>())) .Returns(uri); linkerStub .Setup(x => x.GetUri(It.IsAny<Expression<Action<SimilarArtistsController>>>())) .Returns(uri);
...and that's just to prevent the unit test from crashing. Each and every unit test that hits the same method must have this Setup because the SUT method internally invokes the GetUri method four times with four different parameters. This is pure noise and isn't even part of the test case itself. The tests become very brittle.
If only there was a better way...
RouteLinker as a concrete dependency #
What would happen if you inject the concrete RouteLinker class into other classes? This might look like this:
private readonly RouteLinker linker; public HomeController( RouteLinker linker) { this.linker = linker; }
Creating links from within the Controller is similar to before:
Href = this.linker.GetUri<HomeController>(r => r.GetHome()).ToString(),
What about unit testing? Well, since the GetUri method is strictly deterministic, given the same input, it will always produce the same output. Thus, from a unit test, you only have to ask the instance of RouteLinker injected into the SUT what it would return if invoked with a specific input. Then you can compare this expected output with the actual output.
[Theory, AutoUserData] public void GetHomeReturnsResultWithCorrectSelfLink( [Frozen]RouteLinker linker, HomeController sut) { var actual = sut.GetHome(); var expected = new AtomLinkModel { Href = linker.GetUri<HomeController>(r => r.GetHome()).ToString(), Rel = "self" }.AsSource().OfLikeness<AtomLinkModel>(); Assert.True(actual.Links.Any(expected.Equals)); }
In this test, you Freeze the RouteLinker instance, which means that the linker variable is the same instance as the RouteLinker injected into the SUT. Next, you ask that RouteLinker instance what it would produce when invoked in a particular way, and since AtomLinkModel doesn't override Equals, you produce a Likeness from the AtomLinkModel and verify that the actual collection of links contains the expected link.
That's much more precise than those horribly forgiving It.IsAny constraints. The other advantage is also that you don't have to care about Setups of methods you don't care about in a particular test case. The SUT can invoke the GetUri method as many times as it wants, with as many different arguments as it likes, and the test is never going to break because of that. Since the real implementation is injected, it always works without further Setup.
Granted, strictly speaking these aren't unit tests any longer, but rather Facade Tests.
This technique works because the GetUri method is deterministic and has no side-effects. Thus, it's very similar to Function Composition in Functional languages.
The order of AutoFixture Customizations matter
This post answers a FAQ about ordering of AutoFixture Customizations
With AutoFixture you can encapsulate common Customizations using the Customize method and the ICustomization interface. However, customizations may 'compete' for the same requests in the sense that more than one customization is able to handle a request.
As an example, consider a request for something as basic as IEnumerable<T>. By default, AutoFixture can't create instances of IEnumerable<T>, but more than one customization can.
As previously described the MultipleCustomization handles requests for sequences just fine:
var fixture = new Fixture().Customize(new MultipleCustomization()); var seq = fixture.CreateAnonymous<IEnumerable<int>>();
However, the AutoMoqCustomization can also (sort of) create sequences:
var fixture = new Fixture().Customize(new AutoMoqCustomization()); var seq = fixture.CreateAnonymous<IEnumerable<int>>();
However, in this case, the implementation of IEnumerable<int> is a dynamic proxy, so it's not much of a sequence after all.
Mocking IEnumerable<T> #
Here I need to make a little digression on why that is, because this seems to confuse a lot of people. Consider what a dynamic mock object is: it's a dynamic proxy which implements an interface (or abstract base class). It doesn't have a lot of implemented behavior. Dynamic mocks do what we tell them through their configuration APIs (such as the Setup methods for Moq). If we don't tell them what to do, they must fall back on some sort of default implementation. When the AutoMoqCustomization is used, it sets Mock<T>.DefaultValue to DefaultValue.Mock, which means that the default behavior is to return a new dynamic proxy for reference types.
Here's how an unconfigured dymamic proxy of IEnumerable<T> will behave: the interface only has two (very similar) methods:
public interface IEnumerable<out T> : IEnumerable { IEnumerator<T> GetEnumerator(); }
Via IEnumerable the interface also defines the non-generic GetEnumerator method, but it's so similar to the generic GetEnumerator method that the following discussion applies for both.
When you iterate over IEnumerable<T> using foreach, or when you use LINQ, the first thing that happens is that the GetEnumerator method is called. An unconfigured dynamic mock will respond by returning another dynamic proxy implementing IEnumerator<T>. This interface directly and indirectly defines these methods:
T Current { get; }
object IEnumerator.Current { get; }
bool MoveNext();
void Reset();
void Dispose();
Iterating over a sequence will typically start by invoking the MoveNext method. Since the dynamic proxy is unconfigured, it has to fall back to default behavior. For booleans the default value is false, so the return value of a call to MoveNext would be false. This means that there are no more elements in the sequence. Iteration stops even before it begins. In effect, such an implementation would look like an empty sequence.
OK, back to AutoFixture.
Ordering Customizations #
Frequently I receive questions like this:
"Creating lists with AutoFixture seems inconsistent. When MultipleCustomization comes before AutoMoqCustomization, lists are popuplated, but the other way around they are empty. Is this a bug?"
No, this is by design. By now, you can probably figure out why.
Still, lets look at the symptoms. Both of these tests pass:
[Fact] public void OnlyMultipleResolvingSequence() { var fixture = new Fixture().Customize(new MultipleCustomization()); var seq = fixture.CreateAnonymous<IEnumerable<int>>(); Assert.NotEmpty(seq); } [Fact] public void OnlyAutoMoqResolvingSequence() { var fixture = new Fixture().Customize(new AutoMoqCustomization()); var seq = fixture.CreateAnonymous<IEnumerable<int>>(); Assert.Empty(seq); }
Notice that in the first test, the sequence is not empty, whereas in the second test, the sequence is empty. This is because the MultipleCustomization produces a 'proper' sequence, while the AutoMoqCustomization produces a dynamic proxy of IEnumerable<int> as described above. At this point, this should hardly be surprising.
The same obvervations can be made when both Customizations are in use:
[Fact] public void WrongOrderResolvingSequence() { var fixture = new Fixture().Customize( new CompositeCustomization( new AutoMoqCustomization(), new MultipleCustomization())); var seq = fixture.CreateAnonymous<IEnumerable<int>>(); Assert.Empty(seq); } [Fact] public void CorrectOrderResolvingSequnce() { var fixture = new Fixture().Customize( new CompositeCustomization( new MultipleCustomization(), new AutoMoqCustomization())); var seq = fixture.CreateAnonymous<IEnumerable<int>>(); Assert.NotEmpty(seq); }
Both of these tests also pass. In the first test the sequence is empty, and in the second it contains elements. This is because the first Customization 'wins'.
In general, a Customization may potentially be able to handle a lot of requests. For instance, the AutoMoqCustomization can handle all requests for interfaces and abstract base classes. Thus, multiple Customizations may be able to handle a request, so AutoFixture needs a conflict resolution strategy. That strategy is simply that the first Customization which can handle a request gets to do that, and the other Customizations are never invoked. You can use this feature to put specific Customizations in front of more catch-all Customizations. That's essentially what happens when you put MultipleCustomization in front of AutoMoqCustomization.
FizzBuzz kata in F#: stage 2
In my previous post I walked you through stage 1 of the FizzBuzz kata. In this post I'll walk you through stage 2 of the kata, where new requirements are introduced (see the kata itself for details). This makes the implementation much more complex.
Unit test #
In order to meet the new requirements, I first modified and expanded my existing test cases:
[<Theory>] [<InlineData(1, "1")>] [<InlineData(2, "2")>] [<InlineData(3, "Fizz")>] [<InlineData(4, "4")>] [<InlineData(5, "Buzz")>] [<InlineData(6, "Fizz")>] [<InlineData(7, "7")>] [<InlineData(8, "8")>] [<InlineData(9, "Fizz")>] [<InlineData(10, "Buzz")>] [<InlineData(11, "11")>] [<InlineData(12, "Fizz")>] [<InlineData(13, "Fizz")>] [<InlineData(14, "14")>] [<InlineData(15, "FizzBuzz")>] [<InlineData(16, "16")>] [<InlineData(17, "17")>] [<InlineData(18, "Fizz")>] [<InlineData(19, "19")>] [<InlineData(20, "Buzz")>] [<InlineData(30, "FizzBuzz")>] [<InlineData(31, "Fizz")>] [<InlineData(32, "Fizz")>] [<InlineData(33, "Fizz")>] [<InlineData(34, "Fizz")>] [<InlineData(35, "FizzBuzz")>] [<InlineData(36, "Fizz")>] [<InlineData(37, "Fizz")>] [<InlineData(38, "Fizz")>] [<InlineData(39, "Fizz")>] [<InlineData(50, "Buzz")>] [<InlineData(51, "FizzBuzz")>] [<InlineData(52, "Buzz")>] [<InlineData(53, "FizzBuzz")>] [<InlineData(54, "FizzBuzz")>] [<InlineData(55, "Buzz")>] [<InlineData(56, "Buzz")>] [<InlineData(57, "FizzBuzz")>] [<InlineData(58, "Buzz")>] [<InlineData(59, "Buzz")>] let FizzBuzzReturnsCorrectResult number expected = number |> FizzBuzz |> should equal expected
This is the same test code as before, only with new or modified test data.
Implementation #
Compared with the stage 1 implementation, my implementation to meet the new requirements is much more complex. First, I'll post the entire code listing and then walk you through the details:
let FizzBuzz number = let arithmeticFizzBuzz number = seq { if number % 3 = 0 then yield "Fizz" if number % 5 = 0 then yield "Buzz" } let digitalFizzBuzz digit = seq { if digit = 3 then yield "Fizz" if digit = 5 then yield "Buzz" } let rec digitize number = seq { yield number % 10 let aTenth = number / 10 if aTenth >= 1 then yield! digitize aTenth } let arithmeticFizzBuzzes = number |> arithmeticFizzBuzz let digitalFizzBuzzes = number |> digitize |> Seq.collect digitalFizzBuzz let fizzOrBuzz = arithmeticFizzBuzzes |> Seq.append digitalFizzBuzzes |> Seq.distinct |> Seq.toArray |> Array.sort |> Array.rev |> String.Concat if fizzOrBuzz = "" then number.ToString() else fizzOrBuzz
First of all, you may wonder where the original implementation went. According to the requirements, the function must still 'Fizz' or 'Buzz' when a number is divisible by 3 or 5. This is handled by the nested arithmeticFizzBuzz function:
let arithmeticFizzBuzz number = seq { if number % 3 = 0 then yield "Fizz" if number % 5 = 0 then yield "Buzz" }
The seq symbol specifies a sequence expression, which means that everything within the curly brackets is expected to produce parts of a sequence. It works a bit like the yield keyword in C#.
Due to F#'s strong type inference, the type of the function is int -> seq<string>, which means that it takes an integer as input and returns a sequence of strings. In C# an equivalent signature would be IEnumerable<string> arithmeticFizzBuzz(int number). This function produces a sequence of strings depending on the input.
- 1 produces an empty sequence.
- 2 produces an empty sequence.
- 3 produces a sequence containing the single string "Fizz".
- 4 produces an empty seqence.
- 5 produces a sequence containing the single string "Buzz".
- 6 produces a sequence containing the single string "Fizz".
- 15 produces a sequence containing the strings "Fizz" and "Buzz" (in that order).
That doesn't quite sound like the original requirements, but the trick will be to concatenate the strings. Thus, an empty sequence will be "", "Fizz" will be "Fizz", "Buzz" will be "Buzz", but "Fizz" and "Buzz" will become "FizzBuzz".
The digitalFizzBuzz function works in much the same way, but expects only a single digit.
let digitalFizzBuzz digit = seq { if digit = 3 then yield "Fizz" if digit = 5 then yield "Buzz" }
- 1 produces an empty sequence.
- 2 produces an empty sequence.
- 3 produces a sequence containing the single string "Fizz".
- 4 produces an empty seqence.
- 5 produces a sequence containing the single string "Buzz".
- 6 produces an empty sequence.
In order to be able to apply the new rule of Fizzing and Buzzing if a digit is 3 or 5, it's necessary to split a number into digits. This is done by the recursive digitize function:
let rec digitize number = seq { yield number % 10 let aTenth = number / 10 if aTenth >= 1 then yield! digitize aTenth }
This function works recursively by first yielding the rest of a division by 10, and then calling itself recursively with a tenth of the original number. Since the number is an integer, the division simply still produces an integer. The function produces a sequence of digits, but in a sort of backwards way.
- 1 produces a sequence containing 1.
- 2 produces a sequence containing 2.
- 12 produces a sequence containing 2 followed by 1.
- 23 produces a sequence containing 3 followed by 2.
- 148 produces 8, 4, 1.
This provides all the building blocks. To get the arithmetic (original) FizzBuzzes, the number is piped into the arithmeticFizzBuzz function:
let arithmeticFizzBuzzes = number |> arithmeticFizzBuzz
In order to get the digital (new) FizzBuzzes, the number is first piped into the digitize function, and the resulting sequence of digits is then piped to the digitalFizzBuzz function by way of the Seq.collection function.
let digitalFizzBuzzes = number
|> digitize
|> Seq.collect digitalFizzBuzz
The Seq.collect function is a built-in function that takes a sequence of elements (in this case a sequence of digits) and for each element calls a method that produces a sequence of elements, and then concatenates all the produced sequences. As an example, consider the number 53.
Calling digitize with the number 53 produces the sequence { 3; 5 }. Calling digitalFizzBuzz with 3 produces the sequence { "Fizz" } and calling digitalFizzBuzz with 5 produces { "Buzz" }. Seq.collect concatenates these two sequences to produce the single sequence { "Fizz"; "Buzz" }.
Now we have two sequences of "Fizz" or "Buzz" strings - one produced by the old, arithmetic function, and one produced by the new, digital function. These two sequences can now be merged and ordered with the purpose of producing a single string:
let fizzOrBuzz = arithmeticFizzBuzzes
|> Seq.append digitalFizzBuzzes
|> Seq.distinct
|> Seq.toArray
|> Array.sort
|> Array.rev
|> String.Concat
First, the Seq.append function simply concatenates the two sequences into a single sequence. This could potentially result in a sequence like this: { "Fizz"; "Buzz"; "Fizz" }. The Seq.distinct function gets rid of the duplicates, but the ordering may be wrong - the sequence may look like this: { "Buzz"; "Fizz" }. This can be fixed by sorting the sequence, but sorting alphabetically would always put "Buzz" before "Fizz" so it's also necessary to reverse the sequence. There's no function in the Seq module which can reverse a sequence, so first the Seq.toArray function is used to convert the sequence to an array. After sorting and reversing the array, the result is one of four arrays: [], [ "Fizz" ], [ "Buzz" ], or [ "Fizz"; "Buzz" ]. The last step is to concatenate these string arrays to a single string using the String.Concat BCL method.
If there were no Fizzes or Buzzes, the string will be empty, in which case the number is converted to a string and returned; otherwise, the fizzOrBuzz string is returned.
if fizzOrBuzz = "" then number.ToString() else fizzOrBuzz
To print the FizzBuzz list for numbers from 1 to 100 the same solution as before can be used.
What I like about Functional Programming is that data just flows through the function. There's not state and no mutation - only operations on sequences of data.
FizzBuzz kata in F#: stage 1
In previous posts I've walked through the Bank OCR kata in F#. In this post, I will do the same for the first stage of the very simple FizzBuzz kata. This is a very simple kata, so if you already know F#, there will be nothing new to see here. On the other hand, if you've yet to be exposed to F#, this is a good place to start - I'll attempt to walk you through the code assuming that you don't know F# yet.
Unit test #
Since I developed the solution using Test-Driven Development, I started by writing a single Parameterized Test:
[<Theory>] [<InlineData(1, "1")>] [<InlineData(2, "2")>] [<InlineData(3, "Fizz")>] [<InlineData(4, "4")>] [<InlineData(5, "Buzz")>] [<InlineData(6, "Fizz")>] [<InlineData(7, "7")>] [<InlineData(8, "8")>] [<InlineData(9, "Fizz")>] [<InlineData(10, "Buzz")>] [<InlineData(11, "11")>] [<InlineData(12, "Fizz")>] [<InlineData(13, "13")>] [<InlineData(14, "14")>] [<InlineData(15, "FizzBuzz")>] [<InlineData(16, "16")>] [<InlineData(17, "17")>] [<InlineData(18, "Fizz")>] [<InlineData(19, "19")>] [<InlineData(20, "Buzz")>] let FizzBuzzReturnsCorrectResult number expected = number |> FizzBuzz |> should equal expected
This test uses xUnit.net data theories to provide a set of test data in the form of an integer as input and an expected string.
The number input variable is piped to the FizzBuzz function, using F#'s pipe operator |>. This is just another way of writing
FizzBuzz number
The pipe operator simply takes the data being piped and uses it as the last input parameter to the function being piped. In this case, the number integer variable is the data being piped, so it's used as the last input parameter to the FizzBuzz function, which only takes a single paramter.
The result of invoking the FizzBuzz function is a string. This result is again piped to the should method, which is defined by the FsUnit module. The should method is an assertion function that takes three input parameters. The first two parameters are supplied as part of the function invokation as equal expected, but since the pipe operator is being used, the third and final parameter value is the result of invoking the FizzBuzz function.
In all, the test states that when the FizzBuzz function is called with number, the result should be equal to the expected string.
Implementation #
The FizzBuzz implementation is really simple:
let FizzBuzz number = match number with | i when i % 3 = 0 && i % 5 = 0 -> "FizzBuzz" | i when i % 3 = 0 -> "Fizz" | i when i % 5 = 0 -> "Buzz" | _ -> number.ToString()
All it does is to use pattern matching against the number input argument. In all cases except the last one, the value of number is matched against any number, but with a condition. The first condition is that the number should be divible by both 3 and 5. If this is the case, the result to the right of the -> operator is returned from the function ("FizzBuzz").
The last line of the match block uses an underscore as the match pattern. This is a catch-all pattern that's being triggered if none of the other patterns are matched. In this case, the number input argument is converted to a string and returned.
Printing all lines #
The kata requires me to print the output for all numbers from 1 to 100. The astute reader may have noticed that the FizzBuzz function doesn't do that - it only converts a single integer to a string. However, printing all numbers fizzed and buzzed is easy:
[1..100]
|> List.map FizzBuzz
|> List.reduce (sprintf "%s\r\n%s")
The first line defines a list of numbers from 1 to 100. The next line pipes this list of integers into the List.map function, which applies the FizzBuzz function to each integer. The output of this function call is another list of strings ["1"; "2"; "Fizz"; "4"; "Buzz"; etc.]. This list of strings is piped into the List.reduce function, which in this case uses the sprintf function to concatenate the strings and add a line break after each element, so that it formats correctly.
The List.reduce function applies a function to pairwise elements in a list in order to produce a new element of the same type. Consider the beginning of the list of strings ["1"; "2"; "Fizz"; "4"; "Buzz"; etc.]. The List.reduce function starts with "1" and "2" and applies a function in order to produce a new string from those two strings. That function is the sprintf function, which is similar to the more well-known String.Format method in the BCL. In this case, the template is to take the two strings and insert a line break between them. Thus, when applied to "1" and "2", the result is
1
2
(notice the line break). Now, the List.reduce function takes that string and the next string in the list ("Fizz") and applies the funtion again, giving this result:
1 2 Fizz
It now takes this string and the next value ("4") and applies the sprintf function once more, etc. This is how the final list is being printed.
In a future post I'll walk you through stage 2 of the kata.
Comments
Hyprlinkr
This post serves as an announcement that my latest open source project Hyprlinkr is available. It's a very sharply focused helper library for the ASP.NET Web API, enabling you to create type-safe hyperlinks between resources in a RESTful API.
It's basically a reusable package of the RouteLinker class I previously presented as a spike. The original idea wasn't mine, but José F. Romaniello's - I just took the idea and created a project out of it.
The library is mostly useful if you build level 3 RESTful APIs with the ASP.NET Web API.
It's available as a NuGet package.
Apart from that, I'll refer you to the project site for more information.
Comments
The one thing I am struggling to reconcile, you must have some insight on, is the addition of the link properties to the model.
I am thinking that hyperlinks should be a responsibility of the serializer and not the model...
At the time I wrote that article i was trying different syntax to create a DSL to express a workflow, like the coffee workflow in "Rest on practice".
i think this is an step forward
thanks
Primitive Dependencies
Primitives are also dependencies
There are tons of examples of how Dependency Injection (DI) can be used to decouple clients and services. When the subject is DI, the focus tends to be heavily on the Liskov Substitution Principle (LSP), so most people think about dependencies as polymorphic types (interfaces or abstract base classes). Primitive types like strings and integers tend to be ignored or discouraged. It doesn't help that most DI Containers need extra help to deal with such values.
Primitives are dependencies, too. It doesn't really matter whether or not they are polymorphic. In the end, a dependency is something that the client depends on - hence the name. It doesn't really matter whether the dependency is an interface, a class or a primitive type. In most object-oriented languages, everything is an object - even integers and booleans (although boxing occurs).
There are several ways to inject dependencies into clients. My book describes a set of patterns including Constructor Injection and Property Injection. It's important to keep in mind that ultimately, the reason why Constructor Injection should be your preferred DI pattern has nothing to do with polymorphism. It has to do with protecting the invariants of the class.
Therefore, if the class in question requires a primitive value in order to work, that is a dependency too. Primitive constructor arguments can be mixed with polymorphic arguments. There's really no difference.
Example: a chart reader #
Imagine that you're building a service which provides Top 40 music chart data. There's a ChartController which relies on an IChartReader:
public class ChartController { private readonly IChartReader chartReader; public ChartController(IChartReader chartReader) { if (chartReader == null) throw new ArgumentNullException("chartReader"); this.chartReader = chartReader; } // ... }
One implementation of IChartReader is based on a database, so it requires a connection string (a primitive). It also requires a configuration value which establishes the size of the chart:
public class DbChartReader : IChartReader { private readonly int top; private readonly string chartConnectionString; public DbChartReader(int top, string chartConnectionString) { if (top <= 0) throw new ArgumentOutOfRangeException( "top", "Only positive numbers allowed."); if (chartConnectionString == null) throw new ArgumentNullException("chartConnectionString"); this.top = top; this.chartConnectionString = chartConnectionString; } // ... }
When top has the value 40, the chart is a Top 40 chart; when the value is 10 it's a Top 10 chart; etc.
Unit testing #
Obviously, a class like DbChartReader is easy to wire up in a unit test:
[Fact] public void UnitTestingExample() { var sut = new DbChartReader( top: 10, chartConnectionString: "localhost;foo;bar"); // Act goes here... // Assert goes here... }
Hard-coded composition #
When it's time to bootstrap a complete application, one of the advantages of treating primitives as dependencies is that you have many options for how and where you define those values. At the beginning of an application's lifetime, the best option is often to hard-code some or all of the values. This is as easy to do with primitive dependencies as with polymorphic dependencies:
var controller = new ChartController( new DbChartReader( top: 40, chartConnectionString: "foo"));
This code is part of the application's Composition Root.
Configuration-based composition #
If the time ever comes to move the arms of the the Configuration Complexity Clock towards using the configuration system, that's easy to do too:
var topString = ConfigurationManager.AppSettings["top"]; var top = int.Parse(topString); var chartConnectionString = ConfigurationManager .ConnectionStrings["chart"].ConnectionString; var controller = new ChartController( new DbChartReader( top, chartConnectionString));
This is still part of the Composition Root.
Wiring a DI Container with primitives #
Most DI Containers need a little help with primitives. You can configure components with primitives, but you often need to be quite explicit about it. Here's an example of configuring Castle Windsor:
container.Register(Component .For<ChartController>()); container.Register(Component .For<IChartReader>() .ImplementedBy<DbChartReader>() .DependsOn( Dependency.OnAppSettingsValue("top"), Dependency.OnValue<string>( ConfigurationManager.ConnectionStrings["chart"] .ConnectionString)));
This configures the ChartController type exactly like the previous example, but it's actually more complicated now, and you even lost the feedback from the compiler. That's not good, but you can do better.
Conventions for primitives #
A DI Container like Castle Windsor enables you define your own conventions. How about these conventions?
- If a dependency is a string and it ends with "ConnectionString", the part of the name before "ConnectionString" is the name of an entry in the app.config's connectionStrings element.
- If a dependency is a primitive (e.g. an integer) the name of the constructor argument is the key to the appSettings entry.
That would be really nice because it means that you can keep on evolving you application by adding code, and it just works. Need a connection string to the 'artist database'? Just add a constructor argument called "artistConnectionString" and a corresponding artist connection string in your app.config.
Here's how those conventions could be configured with Castle Windsor:
container.Register(Classes .FromAssemblyInDirectory(new AssemblyFilter(".") .FilterByName(an => an.Name.StartsWith("Ploeh"))) .Pick() .WithServiceAllInterfaces()); container.Kernel.Resolver.AddSubResolver( new ConnectionStringConventions()); container.Kernel.Resolver.AddSubResolver( new AppSettingsConvention());
The Register call scans all appropriate assemblies in the application's root and registers all components according to the interfaces they implement, while the two sub-resolvers each implement one of the conventions described above.
public class ConnectionStringConventions : ISubDependencyResolver { public bool CanResolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return dependency.TargetType == typeof(string) && dependency.DependencyKey.EndsWith("ConnectionString"); } public object Resolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { var name = dependency.DependencyKey.Replace("ConnectionString", ""); return ConfigurationManager.ConnectionStrings[name].ConnectionString; } }
The CanResolve method ensures that the Resolve method is only invoked for string dependencies with names ending with "ConnectionString". If that's the case, the connection string is simply read from the app.config file according to the name.
public class AppSettingsConvention : ISubDependencyResolver { public bool CanResolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return dependency.TargetType == typeof(int); // or bool, Guid, etc. } public object Resolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { var appSettingsKey = dependency.DependencyKey; var s = ConfigurationManager.AppSettings[appSettingsKey]; return Convert.ChangeType(s, dependency.TargetType); } }
This other convention can be used to trigger on primitive dependencies. Since this is a bit of demo code, it only triggers on integers, but I'm sure you'll be able to figure out how to make it trigger on other types as well.
Using convention-based techniques like these can turn a DI Container into a very powerful piece of infrastructure. It just sit there, and it just works, and rarely do you have to touch it. As long as all developers follow the conventions, things just work.
Comments
Basically, Unity has very little in terms of Fluent APIs, convention over configuration, etc. but what it does have is a very open architecture. This means it's almost always possible to write a bit of Reflection code to configure Unity by convention.
FWIW, there's a chapter in my book about Unity and its extensibility mechanisms, but to be fair, it doesn't cover exactly this scenario.
It appears it is possible, and that someone has created an extension for convention:
http://aspiringcraftsman.com/2009/06/13/convention-based-registration-extension/
Facade Test
This post proposes the term Facade Test for an automated test which is more than a unit test, but not quite an integration test.
There are several definitions of what a unit test is, but the one that I personally prefer goes something like this:
A unit test is an automated test that tests a unit in isolation.
This is still a rather loose definition. What's a unit? What's does isolation mean? The answers to these questions seem to be a bit fluffy, but I think it's safe to say that a unit isn't bigger than a class. It's not a library (or 'assembly' in .NET terms). It's not all types in a namespace. In my opinion, a unit is a method... and a bit more. In OO, a method is coupled to it's defining class, which is the reason why I think of a unit as a bit more than a method.
If that's a unit, then isolation means that you should be able to test the unit without using or relying on any other moving pieces of production code.
Often, unit testing means that you have to decouple objects in order to achieve isolation. There's a few ways to do that, but Dependency Injection is a very common approach. That often leads to heavy use of dynamic mocks and too many interfaces that exist exclusively to support unit testing.
Sometimes, a good alternative is to write automated tests that exercise a larger group of classes. When all the collaborating classes are deterministic and implemented within the same library, this can be an effective approach. Krzysztof Koźmic describes that
Another example is AutoFixture, which has hundreds of automated tests against the Fixture class.
We need a name for tests like these. While we could call them Integration Tests, this label would lump them together with tests that exercise several libraries at once.
To distinguish such tests from Unit Tests on the one side, and Integration Tests on the other side, I suggest the name Facade Test
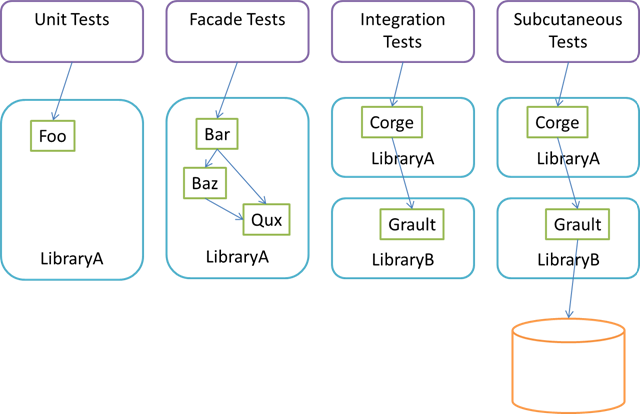
The reason why I suggest the term Facade Test is that such automated tests tend to mostly target a small subset of classes that act as Facades over many other classes in a library.
Comments
Unit test: usually just one class but occasionally a couple of closely related classes, constructed and executed directly from the test code. Runs fast and no contact with the outside world.
Database or Comms test: testing in isolation that a single class that interacts with something externally works. e.g. a class that accesses the database actually accesses the database, a class that contacts a remote server actual contacts a remote server (probably a special one we wrote for testing purposes).
Scenario test: multiple classes, but with all external dependencies replaced with test doubles (e.g. no database access, no SOAP calls, no HTTP requests). Object graph is constructed via the same mechanism as the real object graph. So in some sense this tests the DI configuration. This is a form of integration test, but everything runs in memory so they are quick. Most of our tests are at this level.
Acceptance test: full application running and tested with Selenium.
And then there is manual testing.
"Let's drive this through Facade Tests" now means something else than "Let's drive this through Unit Tests".
Test-specific Equality versus Domain Equality
As a reaction to my two previous blog posts, Joe Miller asks on Twitter:
That's a fair question which I'd like to answer here.
You should definitely strive towards having domain objects with strong equality semantics. Many things (including unit testing) becomes easier when domain objects override Equals in a meaningful manner. By all means should you prefer that over any Resemblance or Likeness craziness.
What is meaningful equality for a domain object? Personally, I find the guidance provided by Domain-Driven Design indispensable:
- If the domain object is an Entity, two objects are equal if their IDs are equal. No other properties should be compared.
- If the domain object is a Value Object, two object are equal if (all) their encapsulated data is equal.
- If the domain object is a Service, by default I'd say that the default reference equality is often the most correct (i.e. don't override Equals).
Now consider the very common case of mapping layers, or the slightly related scenario of an Anti-corruption Layer. In such cases, the code translates Entities to and from other representations. How do we unit test such mapping code?
If we were to rely on the domain object's built-in equality, we would only be testing that the identity of the Entity is as expected, but not whether or not the mapping code properly maps all the other data. In such cases we need Test-specific Equality, and that's exactly what Resemblances and Likenesses provide.
In the previous example, this is exactly what happens. The SUT produces a new instance of the RequestReservationCommand:
[HttpPost] public ViewResult Post(BookingViewModel model) { this.channel.Send(model.MakeReservation()); return this.View("Receipt", model); }
The MakeReservation method is implemented like this:
public RequestReservationCommand MakeReservation() { return new RequestReservationCommand( this.Date, this.Email, this.Name, this.Quantity); }
Notice that nowhere does the code specify the identity of the RequestReservationCommand instance. This is done by the RequestReservationCommand constructor itself, because it's a domain rule that (unless deserialized) each command has a unique ID.
Thus, from the unit test, you have absolutely no chance of knowing what the ID will be (it's a GUID). You could argue back and forth on whether the RequestReservationCommand class is an Entity or a Value Object, but in both cases, Domain Equality would involve comparing IDs, and those will never match. Therefore, the correct Test-specific Equality is to compare the values without the Id property.
Comments
From a behavioral point of view, we don't really care about the value of the ID (the Guid). From other tests we know that a new instance of a command will always have a unique ID. It's part of the command's invariants. Thus, we know that the ID is going to be unique, so having to configure an Ambient Context is only going to add noise to a unit test.

Comments
I am getting an error -
The type or namespace name 'DependencyConventions' could not be found (are you missing a using directive or an assembly reference?)
I added Castle windsor via Nuget in VS 2012 Web Express.
What's the problem?
Thanks,
Mahesh.
Not even remotely related to Web API, but I was wondering if a blog post about CQRS and DI in general was in the pipeline. Last time I posted I hadn't read your book, now that I have, I'm finding myself reading your blog posts like a book and I can't wait for the next. Great book by the way, can't recommend it enough, unless you're on some sort of diet.
Luis
Does the above implementation also resolve normal MVC4 website controllers? If so is there any extra setup required in the Global.asax file? Prior to MVC4 I was using the ControllerFactory method described in your book but is this still the best way?
How about using Windsor/above technique for injecting dependencies into MVC 4 attributes? I am using customized Authorize and ExceptionFilter attributes and so far I have not found a nice, easy and clean way to inject dependencies into them?
A better approach is to use global filters with behaviour, and use only passive attributes.
Autofac has the concept of LifetimeScopes. Using these, the code looks like the following:
public IHttpController Create(HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType)
{
var scope = _container.BeginLifetimeScope();
var controller = (IHttpController)scope.Resolve(controllerType);
request.RegisterForDispose(scope);
return controller;
}
If you want to register dependencies that are different for every request (like Hyprlinkr's RouteLinker), you can do this when beginning the lifetime scope:
public IHttpController Create(HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType)
{
var scope = _container.BeginLifetimeScope(x => RegisterRequestDependantResources(x, request));
var controller = (IHttpController)scope.Resolve(controllerType);
request.RegisterForDispose(scope);
return controller;
}
private static void RegisterRequestDependantResources(ContainerBuilder containerBuilder, HttpRequestMessage request)
{
containerBuilder.RegisterInstance(new RouteLinker(request));
containerBuilder.RegisterInstance(new ResourceLinkVerifier(request.GetConfiguration()));
}
Sorry for the formatting, I have no idea how to format code here.
Nice article.
As I understand WebApiApplication can be instantiated several times and disposed several times as well. This page(http://msdn.microsoft.com/en-gb/library/ms178473.aspx) says "The Application_Start and Application_End methods are special methods that do not represent HttpApplication events. ASP.NET calls them once for the lifetime of the application domain, not for each HttpApplication instance."
So as I understand your approach we can get into a situation using disposed context.
What do you think about this?
Anyway your example is very useful for me.
As there are multiple instances of HttpApplication per application
(If I put a breakpoint in the constructor it gets hit multiple times)
As you can see by these articles, there is not a single instance of HttpApplication, but multiple
http://lowleveldesign.wordpress.com/2011/07/20/global-asax-in-asp-net/
http://msdn.microsoft.com/en-us/library/a0xez8f2(v=vs.71).aspx
wouldn't it be more appropriate to go in Application_Start?
I've been studying this article and some of your answers like this one to StackOverflow questions pertaining to DI. It seems that the established community efforts to integrate popular IoC containers such as Ninject are, at their core,implementations of IDependencyResolver, rather than IHttpControllerActivator.
Are these popular community efforts missing the 'access to context' trait of your solution, or are they simply accomplishing it another way? Are there any established projects, open-source or otherwise, that do what you propose, or is this still an untapped 'pull request' opportunity for projects like the Ninject MVC, etc?
Jeff, thank you for writing. You are indeed correct that one of the many problems with the Service Locator anti-pattern (and therefore also IDependencyResolver) is that the overall context is hidden. Glenn Block originally pointed that particular problem out to me.
This is also the case with IDependencyResolver, because when GetService(Type) or GetServices(Type) is invoked, the only information the composition engine knows, is the requested type. Thus, resolving something that requires access to the HttpRequestMessage or one of its properties, is impossible with IDependencyResolver, but perfectly possible with IHttpControllerActivator.
So, yes, I would definitely say that any DI Container that provides 'ASP.NET Web API integration' by implementing IDependencyResolver is missing out. In any case, these days I rarely use a DI Container, so I don't consider it a big deal - and if I need to use a DI Container, I just need to add those few lines of code listed above in this blog post.
Can't figure out, how is it better to organize my solution.
There are, for example, three projects Cars.API, Cars.Core, and Cars.Data. API contains web-interface, Core contains all the abstractions, and Data communicates with DB. Data and API should depend on Core according to Dependency inversion principle. At this point everything seems to be clear, but then we implement our Composition Root in the API project, which makes it dependent on the Data project containing implementations of abstractions that are stored in Core project. Is it violation of Dependency inversion principle?
P.S. thank you for your book and the articles you write.
Dmitry, thank you for writing. Does this or this help?
In the Configuring the Container section, you are placing the Install inside the constructor. Whenever the application starts up or executes a request, the constructor seems to be called multiple times. In turn, the container will be created multiple times throughout its life time. Is that the point? Or should the container be moved into the Application_Start? Although the constructor is called multiple times, application start seems to be called once. The dispose doesnt seem to be called till the end as well. Is there something earlier in the lifecycle that would cause a need for the Register to be done in the constructor?
I very much enjoy your book and your blog btw. great source of solid information!
Andrew, thank you for writing. In general, I don't recall that this has ever been an issue, but see previous threads in the comments for this post. The question's come up before.
I do, however, admit that I've never formally studied the question like I did with WCF, so it's possible that I'm wrong on this particular issue. Also, details of the framework could have changed in the five years that's gone by since I wrote the article.