ploeh blog danish software design
Reader as a profunctor
Any function gives rise to a profunctor. An article for object-oriented programmers.
This article is an instalment in a short article series about profunctors. It assumes that you've read the introduction.
Previous articles in the overall article series on functors and similar abstractions discussed Reader as both a covariant functor, as well as a contravariant functor. As the profunctor introduction intimated, if you combine the properties of both co- and contravariance, you'll have a profunctor.
There's a wide selection of well-known functors and a smaller selection of contravariant functors. Of all those that I've covered so far, only one appears in both lists: Reader.
Reader #
Consider, again, this IReader interface:
public interface IReader<R, A> { A Run(R environment); }
When discussing IReader as a covariant functor, we'd fix R and let A vary. When discussing the same interface as a contravariant functor, we'd fix A and let R vary. If you allow both to vary freely, you have a profunctor.
As the profunctor overview article asserted, you can implement ContraMap and Select with DiMap, or you can implement DiMap with ContraMap and Select. Since previous articles have supplied both Select and ContraMap for IReader, it's a natural opportunity to see how to implement DiMap:
public static IReader<R1, A1> DiMap<R, R1, A, A1>( this IReader<R, A> reader, Func<R1, R> contraSelector, Func<A, A1> coSelector) { return reader.ContraMap(contraSelector).Select(coSelector); }
You simply pass contraSelector to ContraMap and coSelector to Select, while chaining the two method calls. You can also flip the order in which you call these two functions - as long as they are both pure functions, it'll make no difference. You'll shortly see an example of flipping the order.
First, though, an example of using DiMap. Imagine that you have this IReader implementation:
public sealed class TotalSecondsReader : IReader<TimeSpan, double> { public double Run(TimeSpan environment) { return environment.TotalSeconds; } }
This class converts a TimeSpan value into the total number of seconds represented by that duration. You can project this Reader in both directions using DiMap:
[Fact] public void ReaderDiMapExample() { IReader<TimeSpan, double> reader = new TotalSecondsReader(); IReader<DateTime, bool> projection = reader.DiMap((DateTime dt) => dt.TimeOfDay, d => d % 2 == 0); Assert.True(projection.Run(new DateTime(3271, 12, 11, 2, 3, 4))); }
This example maps the Reader from TimeSpan to DateTime by mapping in the opposite direction: The lambda expression (DateTime dt) => dt.TimeOfDay returns the time of day of a given DateTime. This value is a TimeSpan value representing the time passed since midnight on that date.
The example also checks whether or not a double value is an even number.
When the resulting projection is executed, the expected result is true because the input date and time is first converted to a time of day (02:03:04) by the contraSelector. Then TotalSecondsReader converts that duration to the total number of seconds: 2 * 60 * 60 + 3 * 60 + 4 = 7,384. Finally, 7,384 is an even number, so the output is true.
Raw functions #
As already explained in the previous Reader articles, the IReader interface is mostly a teaching device. In a language where you can treat functions as values, you don't need the interface. In C#, for example, the standard function delegates suffice. You can implement DiMap directly on Func<A, B>:
public static Func<R1, A1> DiMap<R, R1, A, A1>( this Func<R, A> func, Func<R1, R> contraSelector, Func<A, A1> coSelector) { return func.Select(coSelector).ContraMap(contraSelector); }
As promised, I've here flipped the order of methods in the chain, so that the implementation first calls Select and then ContraMap. This is entirely arbitrary, and I only did it to demonstrate that the order doesn't matter.
Here's another usage example:
[Fact] public void AreaOfDate() { Func<Version, int> func = v => v.Major + v.Minor * v.Build; Func<DateTime, double> projection = func.DiMap( (DateTime dt) => new Version(dt.Year, dt.Month, dt.Day), i => i * i * Math.PI); Assert.Equal( expected: 16662407.390443427686297314140028, actual: projection(new DateTime(1991, 12, 26))); }
This example starts with a nonsensical function that calculates a number from a Version value. Using DiMap the example then transforms func into a function that produces a Version from a DateTime and also calculates the area of a circle with the radius i.
Clearly, this isn't a useful piece of code - it only demonstrates how DiMap works.
Identity law #
As stated in the profunctor introduction, I don't intend to make much of the profunctor laws, since they are only reiterations of the (covariant) functor and contravariant functor laws. Still, an example (not a proof) of the profunctor identity law may be in order:
[Fact] public void ProfunctorIdentityLaw() { Func<Guid, int> byteRange = g => g.ToByteArray().Max() - g.ToByteArray().Min(); T id<T>(T x) => x; Func<Guid, int> projected = byteRange.DiMap<Guid, Guid, int, int>(id, id); var guid = Guid.NewGuid(); Assert.Equal(byteRange(guid), projected(guid)); }
This example uses another silly function. Given any Guid, the byteRange function calculates the difference between the largest and smallest byte in the value. Projecting this function with the identity function id along both axes should yield a function with the same behaviour. The assertion phase generates an arbitrary Guid and verifies that both byteRange and projected produce the same resulting value.
Haskell #
As usual, I've adopted many of the concepts and ideas from Haskell. The notion of a profunctor is so exotic that, unlike the Contravariant type class, it's not (to my knowledge) part of the base library. Not that I've ever felt the need to import it, but if I did, I would probably use Data.Profunctor. This module defines a Profunctor type class, of which a normal function (->) is an instance. The type class defines the dimap function.
We can replicate the above AreaOfDate example using the Profunctor type class, and the types and functions in the time library.
First, I'll implement func like this:
func :: Num a => (a, a, a) -> a func (maj, min, bld) = maj + min * bld
Instead of using a Version type (which I'm not sure exists in the 'standard' Haskell libraries) this function just uses a triple (three-tuple).
The projection is a bit more involved:
projection :: Day -> Double projection = dimap ((\(maj, min, bld) -> (fromInteger maj, min, bld)) . toGregorian) (\i -> toEnum (i * i) * pi) func
It basically does the same as the AreaOfDate, but the lambda expressions look more scary because of all the brackets and conversions. Haskell isn't always more succinct than C#.
> projection $ fromGregorian 1991 12 26 1.6662407390443427e7
Notice that GHCi returns the result in scientific notation, so while the decimal separator seems to be oddly placed, the result is the same as in the C# example.
Conclusion #
The Reader functor is not only a (covariant) functor and a contravariant functor. Since it's both, it's also a profunctor. And so what?
This knowledge doesn't seem immediately applicable, but shines an interesting light on the fabric of code. If you squint hard enough, most programming constructs look like functions, and functions are profunctors. I don't intent to go so far as to claim that 'everything is a profunctor', but the Reader profunctor is ubiquitous.
I'll return to this insight in a future article.
Next: Invariant functors.
Profunctors
Functors that are both co- and contravariant. An article for C# programmers.
This article series is part of a larger series of articles about functors, applicatives, and other mappable containers. Particularly, you've seen examples of both functors and contravariant functors.
What happens if you, so to speak, combine those two?
Mapping in both directions #
A profunctor is like a bifunctor, except that it's contravariant in one of its arguments (and covariant in the other). Usually, you'd list the contravariant argument first, and the covariant argument second. By that convention, a hypothetical Profunctor<A, B> would be contravariant in A and covariant in B.
In order to support such mapping, you could give the class a DiMap method:
public sealed class Profunctor<A, B> { public Profunctor<A1, B1> DiMap<A1, B1>(Func<A1, A> contraSelector, Func<B, B1> coSelector) // ...
Contrary to (covariant) functors, where C# will light up some extra compiler features if you name the mapping method Select, there's no extra language support for profunctors. Thus, you can call the method whatever you like, but here I've chosen the name DiMap just because that's what the Haskell Profunctors package calls the corresponding function.
Notice that in order to map the contravariant type argument A to A1, you must supply a selector that moves in the contrary direction: from A1 to A. Mapping the covariant type argument B to B1, on the other hand, goes in the same direction: from B to B1.
An example might look like this:
Profunctor<TimeSpan, double> profunctor = CreateAProfunctor(); Profunctor<string, bool> projection = profunctor.DiMap<string, bool>(TimeSpan.Parse, d => d % 1 == 0);
This example starts with a profunctor where the contravariant type is TimeSpan and the covariant type is double. Using DiMap you can map it to a Profunctor<string, bool>. In order to map the profunctor value's TimeSpan to the projection value's string, the method call supplies TimeSpan.Parse: a (partial) function that maps string to TimeSpan.
The second argument maps the profunctor value's double to the projection value's bool by checking if d is an integer. The lambda expression d => d % 1 == 0 implements a function from double to bool. That is, the profunctor covaries with that function.
Covariant mapping #
Given DiMap you can implement the standard Select method for functors.
public Profunctor<A, B1> Select<B1>(Func<B, B1> selector) { return DiMap<A, B1>(x => x, selector); }
Equivalently to bifunctors, when you have a function that maps both dimensions, you can map one dimension by using the identity function for the dimension you don't need to map. Here I've used the lambda expression x => x as the identity function.
You can use this Select method with standard method-call syntax:
Profunctor<DateTime, string> profunctor = CreateAProfunctor(); Profunctor<DateTime, int> projection = profunctor.Select(s => s.Length);
or with query syntax:
Profunctor<DateTime, TimeSpan> profunctor = CreateAProfunctor(); Profunctor<DateTime, int> projection = from ts in profunctor select ts.Minutes;
All profunctors are also covariant functors.
Contravariant mapping #
Likewise, given DiMap you can implement a ContraMap method:
public Profunctor<A1, B> ContraMap<A1>(Func<A1, A> selector) { return DiMap<A1, B>(selector, x => x); }
Using ContraMap is only possible with normal method-call syntax, since C# has no special understanding of contravariant functors:
Profunctor<long, DateTime> profunctor = CreateAProfunctor(); Profunctor<string, DateTime> projection = profunctor.ContraMap<string>(long.Parse);
All profunctors are also contravariant functors.
While you can implement Select and ContraMap from DiMap, it's also possible to go the other way. If you have Select and ContraMap you can implement DiMap.
Laws #
In the overall article series, I've focused on the laws that govern various universal abstractions. In this article, I'm going to treat this topic lightly, since it'd mostly be a reiteration of the laws that govern co- and contravariant functors.
The only law I'll highlight is the profunctor identity law, which intuitively is a generalisation of the identity laws for co- and contravariant functors. If you map a profunctor in both dimensions, but use the identity function in both directions, nothing should change:
Profunctor<Guid, string> profunctor = CreateAProfunctor(); Profunctor<Guid, string> projection = profunctor.DiMap((Guid g) => g, s => s);
Here I've used two lambda expressions to implement the identity function. While they're two different lambda expressions, they both 'implement' the general identity function. If you aren't convinced, we can demonstrate the idea like this instead:
T id<T>(T x) => x; Profunctor<Guid, string> profunctor = CreateAProfunctor(); Profunctor<Guid, string> projection = profunctor.DiMap<Guid, string>(id, id);
This alternative representation defines a local function called id. Since it's generic, you can use it as both arguments to DiMap.
The point of the identity law is that in both cases, projection should be equal to profunctor.
Usefulness #
Are profunctors useful in everyday programming? So far, I've found no particular use for them. This mirrors my experience with contravariant functors, which I also find little use for. Why should we care, then?
It turns out that, while we rarely work explicitly with profunctors, they're everywhere. Normal functions are profunctors.
In addition to normal functions (which are both covariant and contravariant) other profunctors exist. At the time that I'm writing this article, I've no particular plans to add articles about any other profunctors, but if I do, I'll add them to the above list. Examples include Kleisli arrows and profunctor optics.
The reason I find it worthwhile to learn about profunctors is that this way of looking at well-behaved functions shines an interesting light on the fabric of computation, so to speak. In a future article, I'll expand on that topic.
Conclusion #
A profunctor is a functor that is covariant in one dimension and contravariant in another dimension. While various exotic examples exist, the only example that you'd tend to encounter in mainstream programming is the Reader profunctor, also known simply as functions.
Next: Reader as a profunctor.
Functor variance compared to C#'s notion of variance
A note on C# co- and contravariance, and how it relates to functors.
This article is an instalment in an article series about contravariant functors. It assumes that you've read the introduction, and a few of the examples.
If you know your way around C# you may know that the language has its own notion of co- and contravariance. Perhaps you're wondering how it fits with contravariant functors.
Quite well, fortunately.
Assignment compatibility #
For the C# perspective on co- and contravariance, the official documentation is already quite good. It starts with this example of assignment compatibility:
// Assignment compatibility. string str = "test"; // An object of a more derived type is assigned to an object of a less derived type. object obj = str;
This kind of assignment is always possible, because a string is also already an object. An upcast within the inheritance hierarchy is always possible, so C# automatically allows it.
F#, on the other hand, doesn't. If you try to do something similar in F#, it doesn't compile:
let str = "test" let obj : obj = str // Doesn't compile
The compiler error is:
This expression was expected to have type 'obj' but here has type 'string'
You have to explicitly use the upcast operator:
let str = "test" let obj = str :> obj
When you do that, the explicit type declaration of the value is redundant, so I removed it.
In this example, you can think of :> as a function from string to obj: string -> obj. In C#, the equivalent function would be Func<string, object>.
These functions always exist for types that are properly related to each other, upcast-wise. You can think of it as a generic function 'a -> 'b (or Func<A, B>), with the proviso that A must be 'upcastable' to B:

In my head, I'd usually think about this as A being a subtype of B, but unless I explain what I mean by subtyping, it usually confuses people. I consider anything that can 'act as' something else a subtype. So string is a subtype of object, but I also consider TimeSpan a subtype of IComparable, because that cast is also always possible:
TimeSpan twoMinutes = TimeSpan.FromMinutes(2); IComparable comp = twoMinutes;
Once again, F# is only happy if you explicitly use the :> operator:
let twoMinutes = TimeSpan.FromMinutes 2. let comp = twoMinutes :> IComparable
All this is surely old hat to any .NET developer with a few months of programming under his or her belt. All the same, I want to drive home one last point (that you already know): Automatic upcast conversions are transitive. Consider a class like HttpStyleUriParser, which is part of a small inheritance hierarchy: object -> UriParser -> HttpStyleUriParser (sic, that's how the documentation denotes the inheritance hierarchy; be careful about the arrow direction!). You can upcast an HttpStyleUriParser to both UriParser and object:
HttpStyleUriParser httParser = new HttpStyleUriParser(); UriParser parser = httParser; object op = httParser;
Again, the same is true in F#, but you have to explicitly use the :> operator.
To recapitulate: C# has a built-in automatic conversion that upcasts. It's also built into F#, but here as an operator that you explicitly have to use. It's like an automatic function from subtype to supertype.
Covariance #
The C# documentation continues with an example of covariance:
// Covariance. IEnumerable<string> strings = new List<string>(); // An object that is instantiated with a more derived type argument // is assigned to an object instantiated with a less derived type argument. // Assignment compatibility is preserved. IEnumerable<object> objects = strings;
Since IEnumerable<T> forms a (covariant) functor you can lift a function Func<A, B> to a function from IEnumerable<A> to IEnumerable<B>. Consider the above example that goes from IEnumerable<string> to IEnumerable<object>. Let's modify the diagram from the functor article:
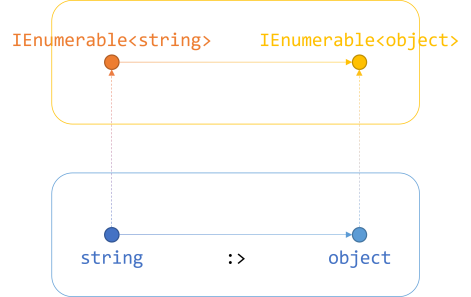
Since the C# compiler already knows that an automatic function (:>) exists that converts string to object, it can automatically convert IEnumerable<string> to IEnumerable<object>. You don't have to call Select to do this. The compiler does it for you.
How does it do that?
It looks for a little annotation on the generic type argument. For covariant types, the relevant keyword is out. And, as expected, the T in IEnumerable<T> is annotated with out:
public interface IEnumerable<out T>
The same is true for Func<T, TResult>, which is both covariant and contravariant:
public delegate TResult Func<in T, out TResult>(T arg);
The in keyword denotes contravariance, but we'll get to that shortly.
The reason that covariance is annotated with the out keyword is that covariant type arguments usually sit in the return-type position. The rule is actually a little more nuanced than that, but I'll again refer you to Sandy Maguire's excellent book Thinking with Types if you're interested in the details.
Contravariance #
So far, so good. What about contravariance? The C# documentation continues its example:
// Contravariance. // Assume that the following method is in the class: // static void SetObject(object o) { } Action<object> actObject = SetObject; // An object that is instantiated with a less derived type argument // is assigned to an object instantiated with a more derived type argument. // Assignment compatibility is reversed. Action<string> actString = actObject;
The Action<T> delegate gives rise to a contravariant functor. The T is also annotated with the in keyword, since the type argument sits in the input position:
public delegate void Action<in T>(T obj)
Again, let's modify the diagram from the article about contravariant functors:
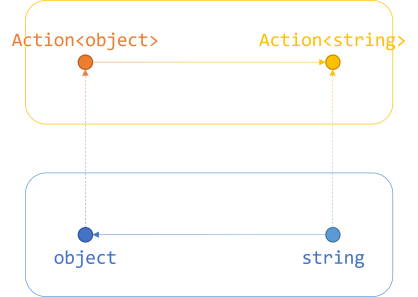
Again, since the C# compiler already knows that an automatic function exists that converts string to object, it can automatically convert Action<object> to Action<string>. You don't have to call Contramap to do this. The compiler does it for you.
It knows that Action<T> is contravariant because it's annotated with the in keyword. Thus, it allows contravariant assignment.
It all checks out.
Conclusion #
The C# compiler understands co- and contravariance, but while it automatically supports it, it only deals with automatic conversion from subtype to supertype. Thus, for those kinds of conversions, you don't need a Select or ContraMap method.
The functor notion of co- and contravariance is a generalisation of how the C# compiler works. Instead of relying on automatic conversions, the Select and ContraMap methods enable you to supply arbitrary conversion functions.
Readability verification
How do you know whether the code you wrote is readable?
In a recent Twitter thread about pair and mob programming, Dan North observes:
"That’s the tricky problem I was referring to. If you think you can write code that other humans can understand, without collaborating or calibrating with other humans, assuming that an after-the-fact check will always be affirmative, then you are a better programmer than me."
I neither think that I'm a better programmer than Dan nor that, without collaboration, I can write code that other humans can understand. That's why I'd like someone else to review my code. Not write it together with me, but read it after I've written it.
Advantages of pair and ensemble programming #
Pair programming and ensemble (AKA mob) programming is an efficient way to develop software. It works for lots of people. I'm not insisting otherwise.
By working together, you can pool skills. Imagine working on a feature for a typical web application. This involves user interface, business logic, data access, and possibly other things as well. Few people are experts in all those areas. Personally, I'm comfortable around business logic and data access, but know little about web front-end development. It's great to have someone else's expertise to draw on.
By working together in real time, you avoid hand-offs. If I had to help implementing a feature in an asynchronous manner, I'd typically implement domain logic and data access in a REST API, then tell a front-end expert that the API is ready. This way of working introduces wait times into the process, and may also cause rework if it turns out that the way I designed the API doesn't meet the requirements of the front end.
Real-time collaboration addresses some of these concerns. It also improves code ownership. In Code That Fits in Your Head, I quote Birgitta Böckeler and Nina Siessegger:
"Consistent pairing makes sure that every line of code was touched or seen by at least 2 people. This increases the chances that anyone on the team feels comfortable changing the code almost anywhere. It also makes the codebase more consistent than it would be with single coders only.
"Pair programming alone does not guarantee you achieve collective code ownership. You need to make sure that you also rotate people through different pairs and areas of the code, to prevent knowledge silos."
With mob programming, you take many of these advantages to the next level. If you include a domain expert in the group, you can learn about what the organisation actually needs as you're developing a feature. If you include specialised testers, they may see edge cases or error modes you didn't think of. If you include UX experts, you'll have a chance to develop software that users can actually figure out how to use.
There are lots of benefits to be had from pair and ensemble programming. In Code That Fits in Your Head I recommend that you try it. I've recommended it to my customers. I've had good experiences with it myself:
"I’ve used [mob programming] with great success as a programming coach. In one engagement, I spent two to three days a week with a few other programmers, helping them apply test-driven development practices to their production code bases. After a few months of that, I went on vacation. Meanwhile those programmers kept going with test-driven development. Mob programming is great for knowledge transfer."
I don't, however, think that it's a one-size-fits-all solution.
The curse of knowledge #
While outlining the advantages of pair and ensemble programming, I didn't mention readability. I don't see how those ways of working address the problem of writing readable code.
I've reviewed code written by pairs, and it was neither more nor less readable than code written by a single programmer. I think that there's an easy-to-understand reason for this. It relates to the curse of knowledge:
"In 1990, Elizabeth Newton earned a Ph.D. in psychology at Stanford by studying a simple game in which she assigned people to one of two roles: “tappers” or “listeners.” Tappers received a list of twenty-five well-known songs, such as “Happy Birthday to You” and “The Star-Spangled Banner.” Each tapper was asked to pick a song and tap out the rhythm to a listener (by knocking on a table). The listener’s job was to guess the song, based on the rhythm being tapped. (By the way, this experiment is fun to try at home if there’s a good “listener” candidate nearby.)
"The listener’s job in this game is quite difficult. Over the course of Newton’s experiment, 120 songs were tapped out. Listeners guessed only 2.5 percent of the songs: 3 out of 120.
"But here’s what made the result worthy of a dissertation in psychology. Before the listeners guessed the name of the song, Newton asked the tappers to predict the odds that the listeners would guess correctly. They predicted that the odds were 50 percent.
"The tappers got their message across 1 time in 40, but they thought they were getting their message across 1 time in 2. Why?
"When a tapper taps, she is hearing the song in her head. Go ahead and try it for yourself—tap out “The Star-Spangled Banner.” It’s impossible to avoid hearing the tune in your head. Meanwhile, the listeners can’t hear that tune—all they can hear is a bunch of disconnected taps, like a kind of bizarre Morse Code.
"In the experiment, tappers are flabbergasted at how hard the listeners seem to be working to pick up the tune. Isn’t the song obvious? The tappers’ expressions, when a listener guesses “Happy Birthday to You” for “The Star-Spangled Banner,” are priceless: How could you be so stupid?
"It’s hard to be a tapper. The problem is that tappers have been given knowledge (the song title) that makes it impossible for them to imagine what it’s like to lack that knowledge. When they’re tapping, they can’t imagine what it’s like for the listeners to hear isolated taps rather than a song. This is the Curse of Knowledge. Once we know something, we find it hard to imagine what it was like not to know it. Our knowledge has “cursed” us. And it becomes difficult for us to share our knowledge with others, because we can’t readily re-create our listeners’ state of mind.
"The tapper/listener experiment is reenacted every day across the world. The tappers and listeners are CEOs and frontline employees, teachers and students, politicians and voters, marketers and customers, writers and readers. All of these groups rely on ongoing communication, but, like the tappers and listeners, they suffer from enormous information imbalances. When a CEO discusses “unlocking shareholder value,” there is a tune playing in her head that the employees can’t hear."
When you're writing code, you're a tapper. As you're writing the code, you know why you are writing it the way you do, you know what you've already tried that didn't work, the informal requirements that someone told you about over the water cooler, etc.
Why should pair or ensemble programming change that?
"One of the roles of a PR is to verify that someone who didn't write the new code can understand it.
"The constant communication of pair programming can result in code only that pair understands. Does a book with two authors not need an editor?"
So, how do you verify that code is readable?
Readability #
I often forget to remind the reader that discussions like this one, about software productivity, mostly rely on anecdotal evidence. There's little scientific evidence about these topics. The ensuing discussions tend to rely on subjectivity, and so, ultimately, does this one.
In Code That Fits in Your Head, I suggest heuristics for writing readable code, but ultimately, the only reliable test of readability that I can think of is simple:
Ask someone else to read the code.
That's what a code review ought to do. Anyone who took part in writing the code is a tapper. After I've written code, I'm a tapper. I'm in no position to evaluate whether the code I just wrote is readable.
You need a listener (or, here: a reader) to evaluate whether or not sufficient information came across.
I agree with Dan North that I need other humans to collaborate and calibrate. I just disagree that people who write code are in a position to evaluate whether the code is readable (and thereby can sustain the business in the long run).
Rejection #
What happens, then, if I submit a pull request that the reviewer finds unreadable?
The reviewer should either suggest improvements or decline the pull request.
I can tell from Dan's tweet that he's harbouring a common misconception about the pull request review process:
"assuming that an after-the-fact check will always be affirmative"
No, I don't assume that my pull requests always pass muster. That's also the reason that pull requests should be small. They should be small enough that you can afford to have them rejected.
I'm currently helping one of my clients with some code. I add some code and send an agile pull request.
Several times in the last month, my pull requests have remained unmerged. In none of the cases, actually, have the reviewer outright rejected the pull request. He just started asking questions, then we had a short debate over GitHub, and then I came to the conclusion that I should close the pull request myself.
No drama, just feedback.
Conclusion #
How do you verify that code is readable?
I can't think of anything better than asking someone else to read the code.
Obviously, we shouldn't ask random strangers about readability. We should ask team members to review code. One implication of collective code ownership is that when a team member accepts a pull request, he or she is also taking on the shared responsibility of maintaining that code. As I write in Code That Fits in Your Head, a fundamental criterion for evaluating a pull request is: Will I be okay maintaining this?
Serendipity-driven development
How much does providence drive thought leadership?
I regularly listen to podcasts. Many podcast episodes are structured around an interview with a guest. A common interview technique (and icebreaker, I suppose) is to ask the guest how he or she became a voice in the field that's the topic for the episode. Surprisingly often, the answer is that it's basically a happy coincidence. He or she was young, had no specific plans, but tried a few things until eventually becoming enamoured with a particular topic.
That's not just technology podcasts. I also listen to interviews with scientists and artists on a variety of topics.
A few people are driven from an early age to study something specific. Most, it seems, are not. I'm no exception. I had a false start as an economist, but was so extremely fortunate that the 1990's were such a boom decade of IT that you could get a job in the field if you could spell HTML.
It seems to me that it's a common (Western) experience for a young person to start adult life without much of a plan, but an unrealised responsiveness to certain stimuli. As a young person, you may have a general notion of your own inclinations, so you seek out certain activities and avoid others. Still, you may not really know yourself.
I didn't know myself at 18. After gymnasium (~ high school) in 1989 my best friend started at computer science at the University of Copenhagen. I had no experience with computers and thought it sounded incredibly dry. I wanted to be a rock star or a comic book artist in the French-Belgian style.
In order to get an education, though, I started at economics at the University of Copenhagen. Talk about a dry subject.
Well, at least I learned game theory, n-dimensional topology, optimal control theory, chaos theory, and some other branches of mathematics, so perhaps the years weren't entirely wasted...
Computers weren't on my radar, but I soon realised that it'd be practical to buy a PC in order to write my thesis.
So, I bought one and soon found the computer much more interesting than economics.
You may not realise that you'll love something until you try it.
Thought leadership #
I recently wrote an article about the cognitive dissonance I felt when interacting with many of my heroes. The ensuing Twitter discussion was enlightening.
Many of my heroes balk at being called heroes or thought leaders, but I agree with Hillel Wayne:
"That's why, incidentally, "thought leaders" have so much weight in our industry. We like to make fun of them, but fact of the matter is that the Thought Leaders are the ones actually trying to communicate their techniques.
"(That's why I want to unironically be a Thought Leader)"
I've been called a though leader a few times already, and like Hillel Wayne, I gratefully accept the label.
There's little scientific evidence about what works in software development, and most innovation happens behind closed doors. Thought leaders are those that observe and share the innovation with the rest of the world.
I follow though leaders on Twitter, listen to podcasts on which they are guests, and read books.
I learned a lot from the discussion related to my article about feeling stuck. I feel that I better understand why opposing views exist. Much has to do with context and nuance, two important factors easily lost on Twitter.
I also think that personal experience plays a big role. Thought leaders share anecdotal evidence. As is also the case in science and business, we tend to share our successes.
What feels like a success is what resonates with us.
It's like the serendipity when you're young and finally encounter something that feels compatible with you. Should we call it serendipity-driven development?
A couple of examples may be in order.
Pair programming #
While I now have an increased awareness of what motivates other thought leaders, I still often disagree. It wouldn't be unnatural if our personal experiences with particular practices influence our positions.

One such example is pair programming. In an interview (sorry, can't remember which) Robert C. Martin told how he found test-driven development dumb until either Kent Beck or Ward Cunningham paired with him to show him the light. Recently, Brian Marick shared a similar experience:
"When I first heard of XP, I thought pair programming was the *second* stupidest idea I'd ever heard. The stupidest was everyone working in the same team room (*not* an "open office"). But..."
This seems to be a common experience with pair programming. Most people dislike it until they have actually tried it.
Well, I've tried both pair programming and ensemble (AKA mob) programming, and I don't like it.
That's all: It's my preference - not any sort of objective truth. What little scientific evidence we can find in our field does seem to indicate that pair programming is efficient. In my book Code That Fits in Your Head I've put aside my dislike to instead endorse pair and ensemble programming as something you should consider.
There's enough evidence (anecdotal and otherwise) that it works well for many people, so give it a try.
I also use it myself. While I find it exhausting, I find ensemble programming incredibly well-suited to knowledge transfer. I've used it to great success when teaching development organisations new ways of doing things.
Even with the nicest people in the room, however, the process drains me. One reason is probably that I've a strong introvert side to my personality.
Another perspective to consider is the role you assume.
A common theme when people share stories of how they saw the light of pair programming is that they learned it from luminaries. If Kent Beck or Ward Cunningham personally tutors you, it's easy to see how it could feel like a revelation.
On the other hand, survivorship bias could be at work. Perhaps Kent Beck showed pair programming and test-driven development to many people who never caught the bug, and thus never discussed it in public.
In my own experience, I mostly taught myself test-driven development long before I tried pair programming, and I'd heard about pair programming long before I tried it. When I did try it, I wasn't the person being taught. I was in the role of the teacher.
Teaching is both a satisfying and exhausting activity. I do consider myself a teacher of sorts, but I prefer to write. Whenever I've taught a workshop, given a lecture, or consulted, I'm always left happy but exhausted. It's really hard work.
So is pair programming, in my experience. Efficient, most likely, but hard work. I can't muster much enthusiasm about it.
REST #
Another topic about which I regularly disagree with others is REST. Just try to find some of my articles tagged REST and read the comments.
For the record, the crowd who disagrees with me is a completely different set of people than those with whom I disagree about pair programming and other agile practices.
The people who disagree with me about REST may be right, and I could be wrong. My views on REST are strongly influenced by early experience. Do be aware of the pattern.
In early 2012 a client asked for my help designing a stable API. The customer didn't ask me to design a REST API - in fact, I think he had a SOAP API in mind, but he was open to other options. One requirement was clear, though: The API had to be exceptionally stable and backwards compatible. There was a reason for this.
My customer's business was to provide a consumer-grade online service. They were currently talking to a hardware producer who'd include support for the service in consumer hardware. Imagine thousands (perhaps millions) of devices sitting in people's homes, using the online service via the API we were about to design.
Even if the hardware producer were to enable firmware upgrades of the devices, there'd be no way we could roll out new versions of client software in a controlled way. This meant that backwards compatibility was a top priority.
I'd recently learned enough about REST to see the opportunity, so I suggested it as a principle for designing APIs that could evolve without breaking backwards compatibility.
The resulting REST API was a success, and I worked with that client for many years on other projects.
This experience clearly shaped my view on REST. To me, the major benefit of REST is the ability to design evolvable APIs without breaking changes. It does work best, however, if you design level 3 REST APIs.
People use HTTP APIs for all sorts of other reasons. Perhaps the driving factor isn't evolvability, but rather interoperability. Perhaps they're developing backends for frontends or APIs strictly for internal use in an organisation. In some scenarios you can easier schedule updates of clients to coincide with updates to the API, in which case backwards compatibility is less of a concern.
Another concern about API design is who's empowered by your design. It seems fair to say that a level 2 REST API is an easier sell. To many client developers, that's all they've ever encountered - they've never seen a level 3 REST API.
I readily admit that a level 3 REST API puts an additional up-front burden on client developers. Such a design is a long game. If the API is active for many years, such investments are likely to pay off, while it may not be worthwhile in the short term. It could even hurt initial adoption, so it's not a one-size-fits-all architectural choice.
In the context of thought leadership, however, my point is that I acknowledge that my view on REST, too, is flavoured by initial personal success.
Conclusion #
I think it's natural to latch on to certain practices via serendipity, You go through life without being aware of a thing that turns out to be highly compatible with your preferences in a given context. Until you one day do encounter it, and it changes your life.
I consider this only human. It's certainly happened to me multiple times, and I'd be surprised if it doesn't happen to others.
Perhaps the people extolling the virtues of pair programming had great initial experiences that they've managed to carry forward. For me, the experience has been another.
Likewise, I had an initial positive experience with REST that surely influenced my position on its virtues. Other people could have had a negative experience, and naturally protest against my ideas. There's nothing wrong with that.
"Only a crisis - actual or perceived - produces real change. When that crisis occurs, the actions that are taken depend on the ideas that are lying around. That, I believe, is our basic function: to develop alternatives to existing policies, to keep them alive and available until the politically impossible becomes the politically inevitable"
Thought leadership strikes me as similar to Friedman's ideas on policy alternatives. I don't see my role as an enforcer of ideas. I write in order to keep certain ideas alive, in the hope that one day, someone picks them up and uses them.
Reader as a contravariant functor
Any function gives rise to a contravariant functor. An article for object-oriented programmers.
This article is an instalment in an article series about contravariant functors. It assumes that you've read the introduction. In the first example article, you saw how the Command Handler pattern gives rise to a contravariant functor. The next article gave another example based on predicates.
In the overview article I also mentioned that equivalence and comparison form contravariant functors. Each can be described with an interface, or just function syntax. Let's put them in a table to compare them:
| Name | C# method signature | C# delegate(s) | Haskell type(s) |
|---|---|---|---|
| Command Handler | void Execute(TCommand command); |
Action<TCommand> |
a -> ()a -> IO () |
| Specification | bool IsSatisfiedBy(T candidate); |
Predicate<T>Func<T, bool> |
a -> Bool |
| Equivalence | bool Equals(T x, T y); |
Func<T, T, bool> |
a -> a -> Bool |
| Comparison | int Compare(T x, T y); |
Func<T, T, int> |
a -> a -> Ordering |
In some cases, there's more than one possible representation. For example, in C# Predicate is isomorphic to Func<T, bool>. When it comes to the Haskell representation of a Command Handler, the 'direct' translation of Action<T> is a -> (). In (Safe) Haskell, however, a function with that type is always a no-op. More realistically, a 'handler' function would have the type a -> IO () in order to allow side effects to happen.
Do you notice a pattern?
Input variance #
There's a pattern emerging from the above table. Notice that in all the examples, the function types are generic (AKA parametrically polymorphic) in their input types.
This turns out to be part of a general rule. The actual rule is a little more complicated than that. I'll recommend Sandy Maguire's excellent book Thinking with Types if you're interested in the details.
For first-order functions, you can pick and fix any type as the return type and let the input type(s) vary: that function will give rise to a contravariant functor.
In the above table, various handlers fix void (which is isomorphic to unit (()) as the output type and let the input type vary. Both Specification and Equivalence fix bool as the output type, and Comparison fix int (or, in Haskell, the more sane type Ordering), and allow the input type to vary.
You can pick any other type. If you fix it as the output type for a function and let the input vary, you have the basis for a contravariant functor.
Reader #
Consider this IReader interface:
public interface IReader<R, A> { A Run(R environment); }
If you fix the environment type R and let the output type A vary, you have a (covariant) functor. If, on the other hand, you fix the output type A and allow the input type R to vary, you can have yourself a contravariant functor:
public static IReader<R1, A> ContraMap<R, R1, A>( this IReader<R, A> reader, Func<R1, R> selector) { return new FuncReader<R1, A>(r => reader.Run(selector(r))); }
As an example, you may have this (rather unwarranted) interface implementation:
public sealed class MinutesReader : IReader<int, TimeSpan> { public TimeSpan Run(int environment) { return TimeSpan.FromMinutes(environment); } }
You can fix the output type to TimeSpan and let the input type vary using the ContraMap functions:
[Fact] public void WrappedContravariantExample() { IReader<int, TimeSpan> r = new MinutesReader(); IReader<string, TimeSpan> projected = r.ContraMap((string s) => int.Parse(s)); Assert.Equal(new TimeSpan(0, 21, 0), projected.Run("21")); }
When you Run the projected reader with the input string "21", the ContraMap function first calls the selector, which (in this case) parses "21" to the integer 21. It then calls Run on the 'original' reader with the value 21. Since the 'original' reader is a MinutesReader, the output is a TimeSpan value that represents 21 minutes.
Raw functions #
As was also the case when I introduced the Reader (covariant) functor, the IReader interface is just a teaching device. You don't need the interface in order to turn first-order functions into contravariant functors. It works on raw functions too:
public static Func<R1, A> ContraMap<R, R1, A>(this Func<R, A> func, Func<R1, R> selector) { return r => func(selector(r)); }
In the following I'm going to dispense with the IReader interface and instead work with raw functions.
Identity law #
A ContraMap method with the right signature isn't enough to be a contravariant functor. It must also obey the contravariant functor laws. As usual, it's proper computer-science work to actually prove this, but you can write some tests to demonstrate the identity law for functions. In this article, you'll see parametrised tests written with xUnit.net. First, the identity law:
[Theory] [InlineData(42)] [InlineData(1337)] [InlineData(2112)] [InlineData(90125)] public void ContravariantIdentityLaw(int input) { Func<int, string> f = i => i.ToString(); Func<int, string> actual = f.ContraMap((int i) => i); Assert.Equal(f(input), actual(input)); }
Here I'm using the (int i) => i lambda expression as the identity function. As usual, you can't easily compare functions for equality, so you'll have to call them to verify that they produce the same output, which they do.
Composition law #
Like the above example, you can also write a parametrised test that demonstrates that ContraMap obeys the composition law for contravariant functors:
[Theory] [InlineData(4.2)] [InlineData(13.37)] [InlineData(21.12)] [InlineData(901.25)] public void ContravariantCompositionLaw(double input) { Func<string, int> h = s => s.Length; Func<double, TimeSpan> f = i => TimeSpan.FromSeconds(i); Func<TimeSpan, string> g = ts => ts.ToString(); Assert.Equal( h.ContraMap((double d) => g(f(d)))(input), h.ContraMap(g).ContraMap(f)(input)); }
This test defines two local functions, f and g. Once more, you can't directly compare methods for equality, so instead you have to invoke both compositions to verify that they return the same int value.
They do.
Isomorphisms #
Now that we understand that any first-order function is contravariant, we can see that the previous examples of predicates, handlers, comparisons, and equivalences are really just special cases of the Reader contravariant functor.
For example, Predicate<T> is trivially isomorphic to Func<T, bool>. Still, it might be worthwhile to flesh out how other translations might work:
public static ISpecification<T> AsSpecification<T>(this Predicate<T> predicate) { return new DelegateSpecificationAdapter<T>(predicate); } public static ISpecification<T> AsSpecification<T>(this Func<T, bool> predicate) { return new DelegateSpecificationAdapter<T>(predicate); } private class DelegateSpecificationAdapter<T> : ISpecification<T> { private readonly Predicate<T> predicate; public DelegateSpecificationAdapter(Predicate<T> predicate) { this.predicate = predicate; } public DelegateSpecificationAdapter(Func<T, bool> predicate) : this((Predicate<T>)(x => predicate(x))) { } public bool IsSatisfiedBy(T candidate) { return predicate(candidate); } } public static Predicate<T> AsPredicate<T>(this ISpecification<T> specification) { return candidate => specification.IsSatisfiedBy(candidate); } public static Func<T, bool> AsFunc<T>(this ISpecification<T> specification) { return candidate => specification.IsSatisfiedBy(candidate); }
Above are conversions between ISpecification<T> on the one hand, and Predicate<T> and Func<T, bool> on the other. Not shown are the conversions between Predicate<T> and Func<T, bool>, since they are already built into C#.
Most saliently in this context is that it's possible to convert both ISpecification<T> and Predicate<T> to Func<T, bool>, and Func<T, bool> to ISpecification<T> or Predicate<T> without any loss of information. Specifications and predicates are isomorphic to an open constructed Func - that is, a Reader.
I'll leave the other isomorphisms as exercises, with the following hints:
- You can only convert an
ICommandHandler<T>to aFuncif you introduce aUnitvalue, but you could also try to useAction<T>. - For Equivalence, you'll need to translate the two input arguments to a single object or value.
- The same goes for Comparison.
All the contravariant functor examples shown so far in this article series are isomorphic to the Reader contravariant functor.
Particularly, this also explains why it was possible to make IEqualityComparer.GetHashCode contravariant.
Haskell #
The Haskell base package comes with a Contravariant type class and various instances.
In order to replicate the above MinutesReader example, we can start by implementing a function with equivalent behaviour:
Prelude Data.Functor.Contravariant Data.Time> minutes m = secondsToDiffTime (60 * m) Prelude Data.Functor.Contravariant Data.Time> :t minutes minutes :: Integer -> DiffTime
As GHCi reports, the minutes function has the type Integer -> DiffTime (DiffTime corresponds to .NET's TimeSpan).
The above C# example contramaps a MinutesReader with a function that parses a string to an int. In Haskell, we can use the built-in read function to equivalent effect.
Here's where Haskell gets a little odd. In order to fit the Contravariant type class, we need to flip the type arguments of a function. A normal function is usually written as having the type a -> b, but we can also write it as the type (->) a b. With this notation, minutes has the type (->) Integer DiffTime.
In order to make minutes a contravariant instance, we need to fix DiffTime and let the input vary. What we'd like to have is something like this: (->) a DiffTime. Alas, that's not how you define a legal type class instance in Haskell. We have to flip the types around so that we can partially apply the type. The built-in newtype Op does that:
Prelude Data.Functor.Contravariant Data.Time> :t Op minutes Op minutes :: Op DiffTime Integer
Since the general, partially applied type Op a is a Contravariant instance, it follows that the specific type Op DiffTime is. This means that we can contramap Op minutes with read:
Prelude Data.Functor.Contravariant Data.Time> :t contramap read (Op minutes) contramap read (Op minutes) :: Op DiffTime String
Notice that this maps an Op DiffTime Integer to an Op DiffTime String.
How do you use it?
You can retrieve the function wrapped in Op with the getOp function:
Prelude Data.Functor.Contravariant Data.Time> :t getOp (contramap read (Op minutes)) getOp (contramap read (Op minutes)) :: String -> DiffTime
As you can tell, this expression indicates a String -> DiffTime function. This means that if you call it with a string representation of an integer, you should get a DiffTime value back:
Prelude Data.Functor.Contravariant Data.Time> getOp (contramap read (Op minutes)) "21" 1260s
As usual, this is way too complicated to be immediately useful, but it once again demonstrates that contravariant functors are ubiquitous.
Conclusion #
Normal first-order functions give rise to contravariant functors. With sufficiently tinted glasses, most programming constructs look like functions. To me, at least, this indicates that a contravariant functor is a fundamental abstraction in programming.
This result looks quite abstract, but future articles will build on it to arrive at a (to me) fascinating conclusion. Until then, though...
The Equivalence contravariant functor
An introduction to the Equivalence contravariant functor for object-oriented programmers.
This article is an instalment in an article series about contravariant functors. It assumes that you've read the introduction. In previous articles, you saw examples of the Command Handler and Specification contravariant functors. This article presents another example.
In a recent article I described how I experimented with removing the id property from a JSON representation in a REST API. I also mentioned that doing that made one test fail. In this article you'll see the failing test and how the Equivalence contravariant functor can improve the situation.
Baseline #
Before I made the change, the test in question looked like this:
[Theory] [InlineData(1049, 19, 00, "juliad@example.net", "Julia Domna", 5)] [InlineData(1130, 18, 15, "x@example.com", "Xenia Ng", 9)] [InlineData( 956, 16, 55, "kite@example.edu", null, 2)] [InlineData( 433, 17, 30, "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); var db = new FakeDatabase(); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), db); var dto = new ReservationDto { Id = "B50DF5B1-F484-4D99-88F9-1915087AF568", At = at.ToString("O"), Email = email, Name = name, Quantity = quantity }; await sut.Post(dto); var expected = new Reservation( Guid.Parse(dto.Id), at, new Email(email), new Name(name ?? ""), quantity); Assert.Contains(expected, db.Grandfather); }
You can find this test in the code base that accompanies my book Code That Fits in Your Head, although I've slightly simplified the initialisation of expected since I froze the code for the manuscript. I've already discussed this particular test in the articles Branching tests, Waiting to happen, and Parametrised test primitive obsession code smell. It's the gift that keeps giving.
It's a state-based integration test that verifies the state of the FakeDatabase after 'posting' a reservation to 'the REST API'. I'm using quotes because the test doesn't really perform an HTTP POST request (it's not a self-hosted integration test). Rather, it directly calls the Post method on the sut. In the assertion phase, it uses Back Door Manipulation (as xUnit Test Patterns terms it) to verify the state of the Fake db.
If you're wondering about the Grandfather property, it represents the original restaurant that was grandfathered in when I expanded the REST API to a multi-tenant service.
Notice, particularly, the use of dto.Id when defining the expected reservation.
Brittle assertion #
When I made the Id property internal, this test no longer compiled. I had to delete the assignment of Id, which also meant that I couldn't use a deterministic Guid to define the expected value. While I could create an arbitrary Guid, that would never pass the test, since the Post method also generates a new Guid.
In order to get to green as quickly as possible, I rewrote the assertion:
Assert.Contains( db.Grandfather, r => DateTime.Parse(dto.At, CultureInfo.InvariantCulture) == r.At && new Email(dto.Email) == r.Email && new Name(dto.Name ?? "") == r.Name && dto.Quantity == r.Quantity);
This passed the test so that I could move on. It may even be the simplest thing that could possibly work, but it's brittle and noisy.
It's brittle because it explicitly considers the four properties At, Email, Name, and Quantity of the Reservation class. What happens if you add a new property to Reservation? What happens if you have similar assertions scattered over the code base?
This is one reason that DRY also applies to unit tests. You want to have as few places as possible that you have to edit when making changes. Otherwise, the risk increases that you forget one or more.
Not only is the assertion brittle - it's also noisy, because it's hard to read. There's parsing, null coalescing and object initialisation going on in those four lines of Boolean operations. Perhaps it'd be better to extract a well-named helper method, but while I'm often in favour of doing that, I'm also a little concerned that too many ad-hoc helper methods obscure something essential. After all:
"Abstraction is the elimination of the irrelevant and the amplification of the essential"
The hardest part of abstraction is striking the right balance. Does a well-named helper method effectively communicate the essentials while eliminating only the irrelevant. While I favour good names over bad names, I'm also aware that good names are skin-deep. If I can draw on a universal abstraction rather than coming up with an ad-hoc name, I prefer doing that.
Which universal abstraction might be useful in this situation?
Relaxed comparison #
The baseline version of the test relied on the structural equality of the Reservation class:
public override bool Equals(object? obj) { return obj is Reservation reservation && Id.Equals(reservation.Id) && At == reservation.At && EqualityComparer<Email>.Default.Equals(Email, reservation.Email) && EqualityComparer<Name>.Default.Equals(Name, reservation.Name) && Quantity == reservation.Quantity; }
This implementation was auto-generated by a Visual Studio Quick Action. From C# 9, I could also have made Reservation a record, in which case the compiler would be taking care of implementing Equals.
The Reservation class already defines the canonical way to compare two reservations for equality. Why can't we use that?
The PostValidReservationWhenDatabaseIsEmpty test can no longer use the Reservation class' structural equality because it doesn't know what the Id is going to be.
One way to address this problem is to inject a hypothetical IGuidGenerator dependency into ReservationsController. I consider this a valid alternative, since the Controller already takes an IClock dependency. I might be inclined towards such a course of action for other reasons, but here I wanted to explore other options.
Can we somehow reuse the Equals implementation of Reservation, but relax its behaviour so that it doesn't consider the Id?
This would be what Ted Neward called negative variability - the ability to subtract from an existing feature. As he implied in 2010, normal programming languages don't have that capability. That strikes me as true in 2021 as well.
The best we can hope for, then, is to put the required custom comparison somewhere central, so that at least it's not scattered across the entire code base. Since the test uses xUnit.net, a class that implements IEqualityComparer<Reservation> sounds like just the right solution.
This is definitely doable, but it's odd having to define a custom equality comparer for a class that already has structural equality. In the context of the PostValidReservationWhenDatabaseIsEmpty test, we understand the reason, but for a future team member who may encounter the class out of context, it might be confusing.
Are there other options?
Reuse #
It turns out that, by lucky accident, the code base already contains an equality comparer that almost fits:
internal sealed class ReservationDtoComparer : IEqualityComparer<ReservationDto> { public bool Equals(ReservationDto? x, ReservationDto? y) { var datesAreEqual = Equals(x?.At, y?.At); if (!datesAreEqual && DateTime.TryParse(x?.At, out var xDate) && DateTime.TryParse(y?.At, out var yDate)) datesAreEqual = Equals(xDate, yDate); return datesAreEqual && Equals(x?.Email, y?.Email) && Equals(x?.Name, y?.Name) && Equals(x?.Quantity, y?.Quantity); } public int GetHashCode(ReservationDto obj) { var dateHash = obj.At?.GetHashCode(StringComparison.InvariantCulture); if (DateTime.TryParse(obj.At, out var dt)) dateHash = dt.GetHashCode(); return HashCode.Combine(dateHash, obj.Email, obj.Name, obj.Quantity); } }
This class already compares two reservations' dates, emails, names, and quantities, while ignoring any IDs. Just what we need?
There's only one problem. ReservationDtoComparer compares ReservationDto objects - not Reservation objects.
Would it be possible to somehow, on the spot, without writing a new class, transform ReservationDtoComparer to an IEqualityComparer<Reservation>?
Well, yes it is.
Contravariant functor #
We can contramap an IEqualityComparer<ReservationDto> to a IEqualityComparer<Reservation> because equivalence gives rise to a contravariant functor.
In order to enable contravariant mapping, you must add a ContraMap method:
public static class Equivalance { public static IEqualityComparer<T1> ContraMap<T, T1>( this IEqualityComparer<T> source, Func<T1, T> selector) where T : notnull { return new ContraMapComparer<T, T1>(source, selector); } private sealed class ContraMapComparer<T, T1> : IEqualityComparer<T1> where T : notnull { private readonly IEqualityComparer<T> source; private readonly Func<T1, T> selector; public ContraMapComparer(IEqualityComparer<T> source, Func<T1, T> selector) { this.source = source; this.selector = selector; } public bool Equals([AllowNull] T1 x, [AllowNull] T1 y) { if (x is null && y is null) return true; if (x is null || y is null) return false; return source.Equals(selector(x), selector(y)); } public int GetHashCode(T1 obj) { return source.GetHashCode(selector(obj)); } } }
Since the IEqualityComparer<T> interface defines two methods, the selector must contramap the behaviour of both Equals and GetHashCode. Fortunately, that's possible.
Notice that, as explained in the overview article, in order to map from an IEqualityComparer<T> to an IEqualityComparer<T1>, the selector has to go the other way: from T1 to T. How this is possible will become more apparent with an example, which will follow later in the article.
Identity law #
A ContraMap method with the right signature isn't enough to be a contravariant functor. It must also obey the contravariant functor laws. As usual, it's proper computer-science work to actually prove this, but you can write some tests to demonstrate the identity law for the IEqualityComparer<T> interface. In this article, you'll see parametrised tests written with xUnit.net. First, the identity law:
[Theory] [InlineData("18:30", 1, "18:30", 1)] [InlineData("18:30", 2, "18:30", 2)] [InlineData("19:00", 1, "19:00", 1)] [InlineData("18:30", 1, "19:00", 1)] [InlineData("18:30", 2, "18:30", 1)] public void IdentityLaw(string time1, int size1, string time2, int size2) { var sut = new TimeDtoComparer(); T id<T>(T x) => x; IEqualityComparer<TimeDto>? actual = sut.ContraMap<TimeDto, TimeDto>(id); var dto1 = new TimeDto { Time = time1, MaximumPartySize = size1 }; var dto2 = new TimeDto { Time = time2, MaximumPartySize = size2 }; Assert.Equal(sut.Equals(dto1, dto2), actual.Equals(dto1, dto2)); Assert.Equal(sut.GetHashCode(dto1), actual.GetHashCode(dto1)); }
In order to observe that the two comparers have identical behaviours, the test must invoke both the Equals and the GetHashCode methods on both sut and actual to assert that the two different objects produce the same output.
All test cases pass.
Composition law #
Like the above example, you can also write a parametrised test that demonstrates that ContraMap obeys the composition law for contravariant functors:
[Theory] [InlineData(" 7:45", "18:13")] [InlineData("18:13", "18:13")] [InlineData("22" , "22" )] [InlineData("22:32", "22" )] [InlineData( "9" , "9" )] [InlineData( "9" , "8" )] public void CompositionLaw(string time1, string time2) { IEqualityComparer<TimeDto> sut = new TimeDtoComparer(); Func<string, (string, int)> f = s => (s, s.Length); Func<(string s, int i), TimeDto> g = t => new TimeDto { Time = t.s, MaximumPartySize = t.i }; IEqualityComparer<string>? projection1 = sut.ContraMap((string s) => g(f(s))); IEqualityComparer<string>? projection2 = sut.ContraMap(g).ContraMap(f); Assert.Equal( projection1.Equals(time1, time2), projection2.Equals(time1, time2)); Assert.Equal( projection1.GetHashCode(time1), projection2.GetHashCode(time1)); }
This test defines two local functions, f and g. Once more, you can't directly compare methods for equality, so instead you have to call both Equals and GetHashCode on projection1 and projection2 to verify that they return the same values.
They do.
Relaxed assertion #
The code base already contains a function that converts Reservation values to ReservationDto objects:
public static ReservationDto ToDto(this Reservation reservation) { if (reservation is null) throw new ArgumentNullException(nameof(reservation)); return new ReservationDto { Id = reservation.Id.ToString("N"), At = reservation.At.ToIso8601DateTimeString(), Email = reservation.Email.ToString(), Name = reservation.Name.ToString(), Quantity = reservation.Quantity }; }
Given that it's possible to map from Reservation to ReservationDto, it's also possible to map equality comparers in the contrary direction: from IEqualityComparer<ReservationDto> to IEqualityComparer<Reservation>. That's just what the PostValidReservationWhenDatabaseIsEmpty test needs!
Most of the test stays the same, but you can now write the assertion as:
var expected = new Reservation( Guid.NewGuid(), at, new Email(email), new Name(name ?? ""), quantity); Assert.Contains( expected, db.Grandfather, new ReservationDtoComparer().ContraMap((Reservation r) => r.ToDto()));
Instead of using the too-strict equality comparison of Reservation, the assertion now takes advantage of the relaxed, test-specific comparison of ReservationDto objects.
What's not to like?
To be truthful, this probably isn't a trick I'll perform often. I think it's fair to consider contravariant functors an advanced programming concept. On a team, I'd be concerned that colleagues wouldn't understand what's going on here.
The purpose of this article series isn't to advocate for this style of programming. It's to show some realistic examples of contravariant functors.
Even in Haskell, where contravariant functors are en explicit part of the base package, I can't recall having availed myself of this functionality.
Equivalence in Haskell #
The Haskell Data.Functor.Contravariant module defines a Contravariant type class and some instances to go with it. One of these is a newtype called Equivalence, which is just a wrapper around a -> a -> Bool.
In Haskell, equality is normally defined by the Eq type class. You can trivially 'promote' any Eq instance to an Equivalence instance using the defaultEquivalence value.
To illustrate how this works in Haskell, you can reproduce the two reservation types:
data Reservation = Reservation { reservationID :: UUID, reservationAt :: LocalTime, reservationEmail :: String, reservationName :: String, reservationQuantity :: Int } deriving (Eq, Show) data ReservationJson = ReservationJson { jsonAt :: String, jsonEmail :: String, jsonName :: String, jsonQuantity :: Double } deriving (Eq, Show, Read, Generic)
The ReservationJson type doesn't have an ID, whereas Reservation does. Still, you can easily convert from Reservation to ReservationJson:
reservationToJson :: Reservation -> ReservationJson reservationToJson (Reservation _ at email name q) = ReservationJson (show at) email name (fromIntegral q)
Now imagine that you have two reservations that differ only on reservationID:
reservation1 :: Reservation reservation1 = Reservation (fromWords 3822151499 288494060 2147588346 2611157519) (LocalTime (fromGregorian 2021 11 11) (TimeOfDay 12 30 0)) "just.inhale@example.net" "Justin Hale" 2 reservation2 :: Reservation reservation2 = Reservation (fromWords 1263859666 288625132 2147588346 2611157519) (LocalTime (fromGregorian 2021 11 11) (TimeOfDay 12 30 0)) "just.inhale@example.net" "Justin Hale" 2
If you compare these two values using the standard equality operator, they're (not surprisingly) not the same:
> reservation1 == reservation2 False
Attempting to compare them using the default Equivalence value doesn't help, either:
> (getEquivalence $ defaultEquivalence) reservation1 reservation2 False
But if you promote the comparison to Equivalence and then contramap it with reservationToJson, they do look the same:
> (getEquivalence $ contramap reservationToJson $ defaultEquivalence) reservation1 reservation2 True
This Haskell example is equivalent in spirit to the above C# assertion.
Notice that Equivalence is only a wrapper around any function of the type a -> a -> Bool. This corresponds to the IEqualityComparer interface's Equals method. On the other hand, Equivalence has no counterpart to GetHashCode - that's a .NETism.
When using Haskell as inspiration for identifying universal abstractions, it's not entirely clear how Equivalence is similar to IEqualityComparer<T>. While a -> a -> Bool is isomorphic to its Equals method, and thus gives rise to a contravariant functor, what about the GetHashCode method?
As this article has demonstrated, it turned out that it's possible to also contramap the GetHashCode method, but was that just a fortunate accident, or is there something more fundamental going on?
Conclusion #
Equivalence relations give rise to a contravariant functor. In this article, you saw how this property can be used to relax assertions in unit tests.
Strictly speaking, an equivalence relation is exclusively a function that compares two values to return a Boolean value. No GetHashCode method is required. That's a .NET-specific implementation detail that, unfortunately, has been allowed to leak into the object base class. It's not part of the concept of an equivalence relation, but still, it's possible to form a contravariant functor from IEqualityComparer<T>. Is this just a happy coincidence, or could there be something more fundamental going on?
Read on.
Keep IDs internal with REST
Instead of relying on entity IDs, use hypermedia to identify resources.
Whenever I've helped teams design HTTP APIs, sooner or later one request comes up - typically from client developers: Please add the entity ID to the representation.
In this article I'll show an alternative, but first: the normal state of affairs.
Business as usual #
It's such a common requirement that, despite admonitions not to expose IDs, I did it myself in the code base that accompanies my book Code That Fits in Your Head. This code base is a level 3 REST API, and still, I'd included the ID in the JSON representation of a reservation:
{
"id": "bf4e84130dac451b9c94049da8ea8c17",
"at": "2021-12-08T20:30:00.0000000",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
At least the ID is a GUID, so I'm not exposing internal database IDs.
After having written the book, the id property kept nagging me, and I wondered if it'd be possible to get rid of it. After all, in a true REST API, clients aren't supposed to construct URLs from templates. They're supposed to follow links. So why do you need the ID?
Following links #
Early on in the system's lifetime, I began signing all URLs to prevent clients from retro-engineering URLs. This also meant that most of my self-hosted integration tests were already following links:
[Theory] [InlineData(867, 19, 10, "adur@example.net", "Adrienne Ursa", 2)] [InlineData(901, 18, 55, "emol@example.gov", "Emma Olsen", 5)] public async Task ReadSuccessfulReservation( int days, int hours, int minutes, string email, string name, int quantity) { using var api = new LegacyApi(); var at = DateTime.Today.AddDays(days).At(hours, minutes) .ToIso8601DateTimeString(); var expected = Create.ReservationDto(at, email, name, quantity); var postResp = await api.PostReservation(expected); Uri address = FindReservationAddress(postResp); var getResp = await api.CreateClient().GetAsync(address); getResp.EnsureSuccessStatusCode(); var actual = await getResp.ParseJsonContent<ReservationDto>(); Assert.Equal(expected, actual, new ReservationDtoComparer()); AssertUrlFormatIsIdiomatic(address); }
This parametrised test uses xUnit.net 2.4.1 to first post a new reservation to the system, and then following the link provided in the response's Location header to verify that this resource contains a representation compatible with the reservation that was posted.
A corresponding plaintext HTTP session would start like this:
POST /restaurants/90125/reservations?sig=aco7VV%2Bh5sA3RBtrN8zI8Y9kLKGC60Gm3SioZGosXVE%3D HTTP/1.1
Content-Type: application/json
{
"at": "2021-12-08 20:30",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
HTTP/1.1 201 Created
Content-Type: application/json; charset=utf-8
Location: example.com/restaurants/90125/reservations/bf4e84130dac451b9c94049da8ea8c17?sig=ZVM%2[...]
{
"id": "bf4e84130dac451b9c94049da8ea8c17",
"at": "2021-12-08T20:30:00.0000000",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
That's the first request and response. Clients can now examine the response's headers to find the Location header. That URL is the actual, external ID of the resource, not the id property in the JSON representation.
The client can save that URL and request it whenever it needs the reservation:
GET /restaurants/90125/reservations/bf4e84130dac451b9c94049da8ea8c17?sig=ZVM%2[...] HTTP/1.1
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"id": "bf4e84130dac451b9c94049da8ea8c17",
"at": "2021-12-08T20:30:00.0000000",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
The actual, intended use of the API doesn't rely on the id property, neither do the tests.
Based on this consistent design principle, I had reason to hope that I'd be able to remove the id property.
Breaking change #
My motivation for making this change was to educate myself. I wanted to see if it would be possible to design a REST API that doesn't expose IDs in their JSON (or XML) representations. Usually I'm having trouble doing this in practice because when I'm consulting, I'm typically present to help the organisation with test-driven development and how to organise their code. It's always hard to learn new ways of doing things, and I don't wish to overwhelm my clients with too many changes all at once.
So I usually let them do level 2 APIs because that's what they're comfortable with. With that style of HTTP API design, it's hard to avoid id fields.
This wasn't a constraint for the book's code, so I'd gone full REST on that API, and I'm happy that I did. By habit, though, I'd exposed the id property in JSON, and I now wanted to perform an experiment: Could I remove the field?
A word of warning: You can't just remove a JSON property from a production API. That would constitute a breaking change, and even though clients aren't supposed to use the id, Hyrum's law says that someone somewhere probably already is.
This is just an experiment that I carried out on a separate Git branch, for my own edification.
Leaning on the compiler #
As outlined, I had relatively strong faith in my test suite, so I decided to modify the Data Transfer Object (DTO) in question. Before the change, it looked like this:
public sealed class ReservationDto { public LinkDto[]? Links { get; set; } public string? Id { get; set; } public string? At { get; set; } public string? Email { get; set; } public string? Name { get; set; } public int Quantity { get; set; } }
At first, I simply tried to delete the Id property, but while it turned out to be not too bad in general, it did break one feature: The ability of the LinksFilter to generate links to reservations. Instead, I changed the Id property to be internal:
public sealed class ReservationDto { public LinkDto[]? Links { get; set; } internal string? Id { get; set; } public string? At { get; set; } public string? Email { get; set; } public string? Name { get; set; } public int Quantity { get; set; } }
This enables the LinksFilter and other internal code to still access the Id property, while the unit tests no longer could. As expected, this change caused some compiler errors. That was expected, and my plan was to lean on the compiler, as Michael Feathers describes in Working Effectively with Legacy Code.
As I had hoped, relatively few things broke, and they were fixed in 5-10 minutes. Once everything compiled, I ran the tests. Only a single test failed, and this was a unit test that used some Back Door Manipulation, as xUnit Test Patterns terms it. I'll return to that test in a future article.
None of my self-hosted integration tests failed.
ID-free interaction #
Since clients are supposed to follow links, they can still do so. For example, a maître d'hôtel might request the day's schedule:
GET /restaurants/90125/schedule/2021/12/8?sig=82fosBYsE9zSKkA4Biy5t%2BFMxl71XiLlFKaI2E[...] HTTP/1.1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyZXN0YXVyYW50IjpbIjEiLCIyMTEyIiwi[...]
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"name": "The Vatican Cellar",
"year": 2021,
"month": 12,
"day": 8,
"days": [
{
"date": "2021-12-08",
"entries": [
{
"time": "20:30:00",
"reservations": [
{
"links": [
{
"rel": "urn:reservation",
"href": "http://example.com/restaurants/90125/reservations/bf4e84130dac4[...]"
}
],
"at": "2021-12-08T20:30:00.0000000",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
]
}
]
}
]
}
I've edited the response quite heavily by removing other links, and so on.
Clients that wish to navigate to Snow Moe Beal's reservation must locate its urn:reservation link and use the corresponding href value. This is an opaque URL that clients can use to make requests:
GET /restaurants/90125/reservations/bf4e84130dac451b9c94049da8ea8c17?sig=vxkBT1g1GHRmx[...] HTTP/1.1
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"at": "2021-12-08T20:30:00.0000000",
"email": "snomob@example.com",
"name": "Snow Moe Beal",
"quantity": 1
}
In none of these interactions do clients rely on the id property - which is also gone now. It's gone because the Id property on the C# DTO is internal, which means that it's not being rendered.
Mission accomplished.
Conclusion #
It always grates on me when I have to add an id property to a representation in an HTTP API. It's often necessary when working with a level 2 API, but with a proper hypermedia-driven REST API, it may not be necessary.
At least, the experiment I performed with the code base from my book Code That Fits in Your Head indicates that this may be so.
Comments
It seems to me that this approach will cause problems if 3rd parties need to integrate with your API in a way where they themselves need to store references to entities in your system. For example, they may expose your entities to their users with additional data in their systems/integrations. Sure, it is possible for them to use the URI as a primary key (if you guarantee a sensible max URI length; another can of worms), but if you internally use INT or UNIQUEIDENTIFIER as your primary key, I would not want to force them to use VARCHAR(whatever) as primary key.
Therefore, in all our APIs, we document in the API specification that the IDs, though required by JSON:API (which we follow) to be passed as string values for consistency, can be safely assumed to be integers (or GUIDs, if relevant). We even document that they are 32-bit ints, so any clients know they can safely use INT fields instead of BIGINT.
JSON:API requires all entities to have a single ID. For obvious reasons, IDs should be stable. Therefore, for entities that represent an association between two other entities and do not have a separate, persisted ID, we have a need to have API IDs that contain information about the associated entities. To combat Hyrum's law, we typically concatenate the associated IDs using a known delimiter and encode the resulting string using a non-standard, URL-friendly encoding (i.e., not Base64, which may contain non-URL-friendly characters and is often obvious). This way, the IDs appear opaque to API clients. Of course, the format of these IDs are not documented in our API specifications, as they are not intended to be stored. Instead, the actual association is documented and the related entities retrievable (of course, since this information inherent to the entity's very nature), and the associated IDs may be used by clients in a multi-column primary key, just like we do.
All of the above assumes that the integrating clients use a SQL database or similar. Let's face it; many do. If you have (or may hve in the future) a single client that do this, you have to take the above into account.
Christer, thank you for writing. I think that one of the problems with discussions about REST APIs, or just HTTP APIs in general, is that people use them for all sorts of things. At one extreme, you have Backends For Frontends, where, if you aren't writing the API with the single client in mind, you're doing something wrong. At the other extreme, you have APIs that may have uncountable and unknown clients. When I write about REST, I mostly have the latter kind in mind.
When designing APIs for many unknown clients, it makes little sense to take 'special needs' into account. Different clients may present mutually exclusive requirements.
Clients that need to 'bookmark' REST resources in a database can do that by defining two columns: one an ordinary primary key column on which the table defines its clustered index, and another column for the link value itself, with a UNIQUE constraint. Something like this (in T-SQL dialect):
CREATE TABLE [dbo].[Foo] ( [Id] INT NOT NULL IDENTITY PRIMARY KEY CLUSTERED, [Address] NVARCHAR (850) NOT NULL UNIQUE NONCLUSTERED, -- Other columns go here... );
Client code can look up an API resource on internal key, or on address, as required.
Your URLs include a signature, which changes if you need to switch signing keys. Furthermore, the base URL for your API may change. The entities are still the same; the restaurant previously at old.domain/restaurants/1?sig=abc is the same as the restaurant now at new.domain/restaurants/1?sig=123. With your proposed bookmark-based solution, the API clients would effectively lose the associations in their system.
Also, indexing a very long varchar column probably works fine for tables that are fairly small and not overly busy. But for large and/or busy tables containing entities that are created every second of every day (say, passages through gates at hundreds of large construction sites, which is one of the domains I work with), I think that the performance would suffer unreasonably. (Admittedly, I have of course not measured this; this is just speculation, and anyway not my main point.)
You say you write APIs with arbitrary clients in mind. I do, too. That is one of the reasons I design my APIs at REST level 2 instead of 3. (JSON:API does offer some possibility of just "following links" if the client wishes to do that, though it is does not allow for APIs that are fully level 3/HATEOAS.) Having stable IDs with well-known formats and being able to construct URLs seems pragmatically like a good solution that keeps client developers happy. I do not have decades of experience, but I have never encountered clients who have been unhappy with my decision to go for level 2 instead of level 3. (I imagine I would have encountered some resistance in the opposite case, though that is pure speculation on my part.) Furthermore, I have never encountered the need for breaking changes that would be non-breaking by level 3 standards.
You say it makes little sense to take "special needs" into account. Idealistically, I agree. Pragmatically, 1) SQL databases are so ubiquitous and have been for such a long time that making life better for those developers by including an ID with a guaranteed format seems like a fair decision, and 2) our APIs (and many others, I assume) are created not just for 3rd party integration but also for one or more 1st party front-ends, which naturally tends to receive some preferential treatment (e.g. features and designs that probably aren't useful to other clients).
Christer, thank you for writing. It's possible that I'm going about this the wrong way. I only report on what's been working for me, but that said, while I do have decades of general programming experience, I don't have decades of REST experience. I designed my first REST API in 2012.
Additionally, just because one style of API design works well, that doesn't rule out that other types of design also work.
Finally, this particular article is an experiment. I've never done something like this in the wild, so it's possible that it does have unforeseen issues.
A couple of answers to your various points, though:
I don't foresee having to change signing keys, but if that happens, it'd be a breaking change to remove support for old keys. One might have to, instead, retire old signing keys in the same way one can retire old service versions. Even if a key gets 'compromised', it's not an immediate issue. It only means that any client that possesses the leaked key can construct URLs directly by retro-engineering implied URL templates. This would still be undocumented and unsupported use of the API, which means that ultimately, it'd be against the client developers' own self-interest in doing that.
Signing the URLs isn't a security measure; it's more like a nudge.
"our APIs (and many others, I assume) are created not just for 3rd party integration but also for one or more 1st party front-ends, which naturally tends to receive some preferential treatment"
I've written APIs like that as well, and if there's one thing I've learned from doing that is that if I'm ever again put in charge of such an API, I'll strongly resist giving preferential treatment to any clients. If a particular client needs a particular feature, the client team can develop and maintain a Backend for Frontend, which bases its own implementation on the general-purpose API.
My experience with supporting particular clients is that client needs evolve much faster than APIs. This makes sense. Someone wants to do A/B testing on the client's user interface. Depending on the outcome of such a test, at least one of the supporting features will now be obsolete. I'm not much inclined having to support such features in an API where backwards compatibility is critical.
But again, these things are never clear-cut. Much depends on the overall goals of the organisation - and these may also change over time. I'm not claiming that my way is best - only that it's possible.
Unit testing private helper methods
Evolving a private helper method, guided by tests.
A frequently asked question about unit testing and test-driven development (TDD) is how to test private helper methods. I've already attempted to answer that question: through the public API, but a recent comment to a Stack Overflow question made me realise that I've failed to supply a code example.
Show, don't tell.
In this article I'll show a code example that outlines how a private helper method can evolve under TDD.
Threshold #
The code example in this article comes from my book Code That Fits in Your Head. When you buy the book, you get not only the finished code examples, but the entire Git repository, with detailed commit messages.
A central part of the code base is a method that decides whether or not to accept a reservation attempt. It's essentially a solution to the Maître d' kata. I wrote most of the book's code with TDD, and after commit fa12fd69c158168178f3a75bcd900e5caa7e7dec I decided that I ought to refactor the implementation. As I wrote in the commit message:
Filter later reservations based on date The line count of the willAccept method has now risen to 28. Cyclomatic complexity is still at 7. It's ripe for refactoring.
I think, by the way, that I made a small mistake. As far as I can tell, the WillAccept line count in this commit is 26 - not 28:
public bool WillAccept( IEnumerable<Reservation> existingReservations, Reservation candidate) { if (existingReservations is null) throw new ArgumentNullException(nameof(existingReservations)); if (candidate is null) throw new ArgumentNullException(nameof(candidate)); var relevantReservations = existingReservations .Where(r => candidate.At.Date == r.At.Date); List<Table> availableTables = Tables.ToList(); foreach (var r in relevantReservations) { var table = availableTables.Find(t => r.Quantity <= t.Seats); if (table is { }) { availableTables.Remove(table); if (table.IsCommunal) availableTables.Add(table.Reserve(r.Quantity)); } } return availableTables.Any(t => candidate.Quantity <= t.Seats); }
Still, I knew that it wasn't done - that I'd be adding more tests that would increase both the size and complexity of the method. It was brushing against more than one threshold. I decided that it was time for a prophylactic refactoring.
Notice that the red-green-refactor checklist explicitly states that refactoring is part of the process. It doesn't, however, mandate that refactoring must be done in the same commit as the green phase. Here, I did red-green-commit-refactor-commit.
While I decided to refactor, I also knew that I still had some way to go before WillAccept would be complete. With the code still in flux, I didn't want to couple tests to a new method, so I chose to extract a private helper method.
Helper method #
After the refactoring, the code looked like this:
public bool WillAccept( IEnumerable<Reservation> existingReservations, Reservation candidate) { if (existingReservations is null) throw new ArgumentNullException(nameof(existingReservations)); if (candidate is null) throw new ArgumentNullException(nameof(candidate)); var relevantReservations = existingReservations .Where(r => candidate.At.Date == r.At.Date); var availableTables = Allocate(relevantReservations); return availableTables.Any(t => candidate.Quantity <= t.Seats); } private IEnumerable<Table> Allocate( IEnumerable<Reservation> reservations) { List<Table> availableTables = Tables.ToList(); foreach (var r in reservations) { var table = availableTables.Find(t => r.Quantity <= t.Seats); if (table is { }) { availableTables.Remove(table); if (table.IsCommunal) availableTables.Add(table.Reserve(r.Quantity)); } } return availableTables; }
I committed the change, and wrote in the commit message:
Extract helper method from WillAccept This quite improves the complexity of the method, which is now 4, and at 18 lines of code. The new helper method also has a cyclomatic complexity of 4, and 17 lines of code. A remaining issue with the WillAccept method is that the code operates on different levels of abstraction. The call to Allocate represents an abstraction, while the filter on date is as low-level as it can get.
As you can tell, I was well aware that there were remaining issues with the code.
Since the new Allocate helper method is private, unit tests can't reach it directly. It's still covered by tests, though, just as that code block was before I extracted it.
More tests #
I wasn't done with the WillAccept method, and after a bout of other refactorings, I added more test cases covering it.
While the method ultimately grew to exhibit moderately complex behaviour, I had only two test methods covering it: one (not shown) for the rejection case, and another for the accept (true) case:
[Theory, ClassData(typeof(AcceptTestCases))] public void Accept( TimeSpan seatingDuration, IEnumerable<Table> tables, IEnumerable<Reservation> reservations) { var sut = new MaitreD(seatingDuration, tables); var r = Some.Reservation.WithQuantity(11); var actual = sut.WillAccept(reservations, r); Assert.True(actual); }
I based the example code on the impureim sandwich architecture, which meant that domain logic (including the WillAccept method) is all pure functions. The nice thing about pure functions is that they're easy to unit test.
The Accept test method uses an object data source (see the article Parametrised test primitive obsession code smell for another example of the motivation behind using objects for test parametrisation), so adding more test cases were simply a matter of adding them to the data source:
Add(TimeSpan.FromHours(6), new[] { Table.Communal(11) }, new[] { Some.Reservation.WithQuantity(11).TheDayAfter() }); Add(TimeSpan.FromHours(2.5), new[] { Table.Standard(12) }, new[] { Some.Reservation.WithQuantity(11).AddDate( TimeSpan.FromHours(-2.5)) }); Add(TimeSpan.FromHours(1), new[] { Table.Standard(14) }, new[] { Some.Reservation.WithQuantity(9).AddDate( TimeSpan.FromHours(1)) });
The bottom two test cases are new additions. In that way, by adding new test cases, I could keep evolving WillAccept and its various private helper methods (of which I added more). While no tests directly exercise the private helper methods, the unit tests still transitively exercise the private parts of the code base.
Since I followed TDD, no private helper methods sprang into existence untested. I didn't have to jump through hoops in order to be able to unit test private helper methods. Rather, the private helper methods were a natural by-product of the red-green-refactor process - particularly, the refactor phase.
Conclusion #
Following TDD doesn't preclude the creation of private helper methods. In fact, private helper methods can (and should?) emerge during the refactoring phase of the red-green-refactoring cycle.
For long-time practitioners of TDD, there's nothing new in this, but people new to TDD are still learning. This question keeps coming up, so I hope that this example is useful.
The Specification contravariant functor
An introduction for object-oriented programmers to the Specification contravariant functor.
This article is an instalment in an article series about contravariant functors. It assumes that you've read the introduction. In the previous article, you saw an example of a contravariant functor based on the Command Handler pattern. This article gives another example.
Domain-Driven Design discusses the benefits of the Specification pattern. In its generic incarnation this pattern gives rise to a contravariant functor.
Interface #
DDD introduces the pattern with a non-generic InvoiceSpecification interface. The book also shows other examples, and it quickly becomes clear that with generics, you can generalise the pattern to this interface:
public interface ISpecification<T> { bool IsSatisfiedBy(T candidate); }
Given such an interface, you can implement standard reusable Boolean logic such as and, or, and not. (Exercise: consider how implementations of and and or correspond to well-known monoids. Do the implementations look like Composites? Is that a coincidence?)
The ISpecification<T> interface is really just a glorified predicate. These days the Specification pattern may seem somewhat exotic in languages with first-class functions. C#, for example, defines both a specialised Predicate delegate, as well as the more general Func<T, bool> delegate. Since you can pass those around as objects, that's often good enough, and you don't need an ISpecification interface.
Still, for the sake of argument, in this article I'll start with the Specification pattern and demonstrate how that gives rise to a contravariant functor.
Natural number specification #
Consider the AdjustInventoryService class from the previous article. I'll repeat the 'original' Execute method here:
public void Execute(AdjustInventory command) { var productInventory = this.repository.GetByIdOrNull(command.ProductId) ?? new ProductInventory(command.ProductId); int quantityAdjustment = command.Quantity * (command.Decrease ? -1 : 1); productInventory = productInventory.AdjustQuantity(quantityAdjustment); if (productInventory.Quantity < 0) throw new InvalidOperationException("Can't decrease below 0."); this.repository.Save(productInventory); }
Notice the Guard Clause:
if (productInventory.Quantity < 0)
Image that we'd like to introduce some flexibility here. It's admittedly a silly example, but just come along for the edification. Imagine that we'd like to use an injected ISpecification<ProductInventory> instead:
if (!specification.IsSatisfiedBy(productInventory))
That doesn't sound too difficult, but what if you only have an ISpecification implementation like the following?
public sealed class NaturalNumber : ISpecification<int> { public readonly static ISpecification<int> Specification = new NaturalNumber(); private NaturalNumber() { } public bool IsSatisfiedBy(int candidate) { return 0 <= candidate; } }
That's essentially what you need, but alas, it only implements ISpecification<int>, not ISpecification<ProductInventory>. Do you really have to write a new Adapter just to implement the right interface?
No, you don't.
Contravariant functor #
Fortunately, an interface like ISpecification<T> gives rise to a contravariant functor. This will enable you to compose an ISpecification<ProductInventory> object from the NaturalNumber specification.
In order to enable contravariant mapping, you must add a ContraMap method:
public static ISpecification<T1> ContraMap<T, T1>( this ISpecification<T> source, Func<T1, T> selector) { return new ContraSpecification<T, T1>(source, selector); } private class ContraSpecification<T, T1> : ISpecification<T1> { private readonly ISpecification<T> source; private readonly Func<T1, T> selector; public ContraSpecification(ISpecification<T> source, Func<T1, T> selector) { this.source = source; this.selector = selector; } public bool IsSatisfiedBy(T1 candidate) { return source.IsSatisfiedBy(selector(candidate)); } }
Notice that, as explained in the overview article, in order to map from an ISpecification<T> to an ISpecification<T1>, the selector has to go the other way: from T1 to T. How this is possible will become more apparent with an example, which will follow later in the article.
Identity law #
A ContraMap method with the right signature isn't enough to be a contravariant functor. It must also obey the contravariant functor laws. As usual, it's proper computer-science work to actually prove this, but you can write some tests to demonstrate the identity law for the ISpecification<T> interface. In this article, you'll see parametrised tests written with xUnit.net. First, the identity law:
[Theory] [InlineData(-102)] [InlineData( -3)] [InlineData( -1)] [InlineData( 0)] [InlineData( 1)] [InlineData( 32)] [InlineData( 283)] public void IdentityLaw(int input) { T id<T>(T x) => x; ISpecification<int> projection = NaturalNumber.Specification.ContraMap<int, int>(id); Assert.Equal( NaturalNumber.Specification.IsSatisfiedBy(input), projection.IsSatisfiedBy(input)); }
In order to observe that the two Specifications have identical behaviours, the test has to invoke IsSatisfiedBy on both of them to verify that the return values are the same.
All test cases pass.
Composition law #
Like the above example, you can also write a parametrised test that demonstrates that ContraMap obeys the composition law for contravariant functors:
[Theory] [InlineData( "0:05")] [InlineData( "1:20")] [InlineData( "0:12:10")] [InlineData( "1:00:12")] [InlineData("1.13:14:34")] public void CompositionLaw(string input) { Func<string, TimeSpan> f = TimeSpan.Parse; Func<TimeSpan, int> g = ts => (int)ts.TotalMinutes; Assert.Equal( NaturalNumber.Specification.ContraMap((string s) => g(f(s))).IsSatisfiedBy(input), NaturalNumber.Specification.ContraMap(g).ContraMap(f).IsSatisfiedBy(input)); }
This test defines two local functions, f and g. Once more, you can't directly compare methods for equality, so instead you have to call IsSatisfiedBy on both compositions to verify that they return the same Boolean value.
They do.
Product inventory specification #
You can now produce the desired ISpecification<ProductInventory> from the NaturalNumber Specification without having to add a new class:
ISpecification<ProductInventory> specification = NaturalNumber.Specification.ContraMap((ProductInventory inv) => inv.Quantity);
Granted, it is, once more, a silly example, but the purpose of this article isn't to convince you that this is better (it probably isn't). The purpose of the article is to show an example of a contravariant functor, and how it can be used.
Predicates #
For good measure, any predicate forms a contravariant functor. You don't need the ISpecification interface. Here are ContraMap overloads for Predicate<T> and Func<T, bool>:
public static Predicate<T1> ContraMap<T, T1>(this Predicate<T> predicate, Func<T1, T> selector) { return x => predicate(selector(x)); } public static Func<T1, bool> ContraMap<T, T1>(this Func<T, bool> predicate, Func<T1, T> selector) { return x => predicate(selector(x)); }
Notice that the lambda expressions are identical in both implementations.
Conclusion #
Like Command Handlers and Event Handlers, generic predicates give rise to a contravariant functor. This includes both the Specification pattern, Predicate<T>, and Func<T, bool>.
Are you noticing a pattern?

Comments
I have not found the concept of a profunctor useful in everyday programming, but I have found one very big use for them.
I am the maintainer of Elmish.WPF. This project makes it easy to create a WPF application in the style of the Model-View-Update / MVU / Elm Architecture. In a traditional WPF application, data goes between a view model and WPF via properties on that view model. Elmish.WPF makes that relationship a first-class concept via the type
Binding<'model, 'msg>. This type is a profunctor; contravariant in'modeland covariant in'msg. The individual mapping functions areBinding.mapModelandBinding.mapMsgrespectively.This type was not always a profunctor. Recall that a profunctor is not really just a type but a type along with its mapping functions (or a single combined function). In versions 1, 2, and 3 of Elmish.WPF, this type is not a profunctor due to the missing mapping function(s). I added the mapping functions in version 4 (currently a prelease) that makes
Binding<'model, 'msg>(along with those functions) a profunctor. This abstraction has made it possible to significantly improve both the internal implementation as well as the public API.As you stated, a single function
a -> bis a profunctor; contravariant inaand covariant inb. I think of this as the canonical profunctor, or maybe "the original" profunctor. I think it is interesting to compare each profunctor to this one. In the case ofBinding<'model, 'msg>, is implemented by two functions: one from the (view) model to WPF with type'model -> objthat we could calltoWpfand one from WPF with typeobj -> 'msgthat we could callfromWpf. Of course, composing these two functions results in a single function that is a profunctor in exactly the way we expect.Now here is something that I don't understand. In addition to
Binding.mapModelandBinding.mapMsg, I have discovered another function with useful behavior in the functionBinding.mapMsgWithModel. Recall that a functiona -> bis not just profunctor in (contravariant)aand (covariant)b, but it is also a monad inb(withafixed). The composed functiontoWpf >> fromWpfis such a monad andBinding.mapMsgWithModelis its "bind" function. The leads one to think thatBinding<'model, 'msg>could be a monad in'msg(with'modelfixed). My intuition is that this is not the case, but maybe I am wrong.Tyson, it's great to learn that there are other examples of useful profunctors in the wild. It might be useful to add it to a 'catalogue' of profunctor examples, if someone ever compiles such a list - but perhaps it's a little to specific for a general-purpose catalogue...
After much digging around in the source code you linked, I managed to locate the definition of Binding<'model, 'msg>, which, however, turns out to be too complex for me to do a full analysis on a Saturday morning.
One of the cases, however, the TwoWayData<'model, 'msg> type looks much like a lens - another profunctor example.
Might
Binding<'model, 'msg>also form a monad?One simple test I've found useful for answering such a question is to consider whether a lawful
joinfunction exists. In Haskell, thejoinfunction has the typeMonad m => m (m a) -> m a. The intuitive interpretation is that if you can 'flatten' a nested functor, then that functor is also a monad.So the question is: Can you reasonably write a function with the type
Binding<'model, Binding<'model, 'msg>> -> Binding<'model, 'msg>?If you can write a lawful implementation of this
joinfunction, theBinding<'model, 'msg>forms a monad.Thank you for linking to the deinition of
Binding<'model, 'msg>. I should have done that. Yes, theTwoWayData<'model, 'msg>case is probably the simplest. Good job finding it. I have thought about implementing such ajoinfunction, but it doesn't seem possible to me.