ploeh blog danish software design
Argument Name Role Hint
This article describes how object roles can by indicated by argument or variable names.
In my overview article on Role Hints I described how making object roles explicit can help making code more object-oriented. One way code can convey information about the role played by an object is by proper naming of variables and method arguments. In many ways, this is the converse view of a Type Name Role Hint.
To reiterate, the Design Guidelines for Developing Class Libraries provides this rule:
Consider using names based on a parameter's meaning rather than names based on the parameter's type.
As described in the post about Type Name Role Hints, this rule makes sense when the argument type is too generic to provide enough information about role played by an object.
Example: unit test variables #
Previously I've described how explicitly naming unit test variables after their roles clearly communicates to the Test Reader the purpose of each variable.
[Fact] public void GetUserNameFromProperSimpleWebTokenReturnsCorrectResult() { // Fixture setup var sut = new SimpleWebTokenUserNameProjection(); var request = new HttpRequestMessage(); request.Headers.Authorization = new AuthenticationHeaderValue( "Bearer", new SimpleWebToken(new Claim("userName", "foo")).ToString()); // Exercise system var actual = sut.GetUserName(request); // Verify outcome Assert.Equal("foo", actual); // Teardown }
Currently I prefer these well-known variable names in unit tests:
- sut
- expected
- actual
Further variables can be named on a case-by-case basis, like the request variable in the above example.
Example: Selecting next Wizard Page #
Consider a Wizard in a rich client, implemented using the MVVM pattern. A Wizard can be modeled as a 'Graph of Responsibility'. A simple example may look like this:
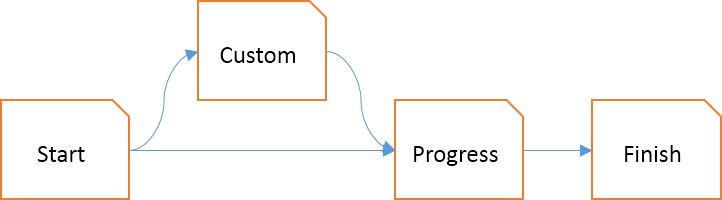
This is a rather primitive Wizard where the start page asks you whether you want to proceed in a 'default' or 'custom' way:
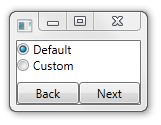
If you select Default and press Next, the Wizard will immediately proceed to the Progress step. If you select Custom, the Wizard will first show you the Custom step, where you can tweak your experience. Subsequently, when you press Next, the Progess step is shown.
Imagine that each Wizard page must implement the IWizardPage interface:
public interface IWizardPage : INotifyPropertyChanged { IWizardPage Next { get; } IWizardPage Previous { get; } }
The Start page's View Model must wait for the user's selection and then serve the correct Next page. Using the DIP, the StartWizardPageViewModel doesn't need to know about the concrete 'custom' and 'progress' steps:
private readonly IWizardPage customPage; private readonly IWizardPage progressPage; private bool isCustomChecked; public StartWizardPageViewModel( IWizardPage progressPage, IWizardPage customPage) { this.progressPage = progressPage; this.customPage = customPage; } public IWizardPage Next { get { if (this.isCustomChecked) return this.customPage; return this.progressPage; } }
Notice that the StartWizardPageViewModel depends on two different IWizardPage objects. In such a case, the interface name is insufficient to communicate the role of each dependency. Instead, the argument names progressPage and customPage are used to convey the role of each object. The role of the customPage is more specific than just being a Wizard page - it's the 'custom' page.
Example: Message Router #
While you may not be building Wizard-based user interfaces with MVVM, I chose the previous example because the problem domain (that of modeling a Wizard UI) is something most of us can relate to. Another set of examples is much more general-purpose in nature, but may feel more abstract.
Due to the multicore problem, asynchronous messaging architectures are becoming increasingly common - just consider the growing popularity of CQRS. In a Pipes and Filters architecture, Message Routers are central. Many variations of Message Routers presented in Enterprise Integration Patterns provide examples in C# where the alternative outbound channels are identified with Role Hints such as outQueue1, outQueue2, etc. See e.g. pages 83, 233, 246, etc. Due to copyright reasons, I'm not going to repeat them here, but here's a generic Message Router that does much the same:
public class ConditionalRouter<T> { private readonly IMessageSpecification<T> specification; private readonly IChannel<T> firstChannel; private readonly IChannel<T> secondChannel; public ConditionalRouter( IMessageSpecification<T> specification, IChannel<T> firstChannel, IChannel<T> secondChannel) { this.specification = specification; this.firstChannel = firstChannel; this.secondChannel = secondChannel; } public void Handle(T message) { if (this.specification.IsSatisfiedBy(message)) this.firstChannel.Send(message); else this.secondChannel.Send(message); } }
Once again, notice how the ConditionalRouter selects between the two roles of firstChannel and secondChannel based on the outcome of the Specification. The constructor argument names carry (slightly) more information about the role of each channel than the interface name.
Summary #
Parameter or variable names can be used to convey information about the role played by an object. This is especially helpful when the type of the object is very general (such as string, DateTime, int, etc.), but can also be used to select among alternative objects of the same type even when the type is specific enough to adhere to the Single Responsibility and Interface Segregation principles.
Type Name Role Hints
This article describes how object roles can by indicated by type names.
In my overview article on Role Hints I described how making object roles explicit can help making code more object-oriented. When first hearing about the concept of object roles, a typical reaction is: How is that different from the class name? Doesn't the class name communicate the purpose of the class?
Sometimes it does, so this is a fair question. However, there are certainly other situations where this isn't the case at all.
Consider many primitive types: do the names int (or Int32), bool (or Boolean), Guid, DateTime, Version, string, etc. communicate anything about the roles played by instances?
In most cases, such type names provide poor hints about the roles played by the instances. Most developers already implicitly know this, and the Design Guidelines for Developing Class Libraries also provides this rule:
Consider using names based on a parameter's meaning rather than names based on the parameter's type.
Most of us can probably agree that code like this would be hard to use correctly:
public static bool TryCreate(Uri u1, Uri u2, out Uri u3)
Which values should you use for u1? Which value for u2?
Fortunately, the actual signature follows the Design Guidelines:
public static bool TryCreate(Uri baseUri, Uri relativeUri, out Uri result)
This is much better because the argument names communicate the roles the various Uri parameters play relative to each other. With the object roles provided by descriptive parameter names, the method signature is often all the documentation required to understand the proper intended use of the method.
The Design Guidelines' rules sound almost universal. Are there cases when the name of a type is more informative than the argument or variable name?
Example: Uri.IsBaseOf #
To stay with the Uri class for a little while longer, consider the IsBaseOf method:
public bool IsBaseOf(Uri uri)
This method accepts any Uri instance as input parameter. The uri argument doesn't play any other role than being an Uri instance, so there's no reason that an API designer should go out of his or her way to come up with some artificial 'role' name for the parameter. In this example, the name of the type is sufficient information about the role played by the instance - or you could say that in this context the class itself and the role it plays conflates into the same name.
Example: MVC instances #
If you've ever worked with ASP.NET MVC or ASP.NET Web API you may have noticed that rarely do you refer to Model, View or Controller instances with variables. Often, you just return a new model directly from the relevant Action Method:
public ViewResult Get() { var now = DateTime.Now; var currentMonth = new Month(now.Year, now.Month); return this.View(this.reader.Query(currentMonth)); }
In this example, notice how the model is implicitly created with a call to the reader's Query method. (However, you get a hint about the intermediary variables' roles from their names.) If we ever assign a model instance to a local variable before returning it with a call to the View method, we often tend to simply name that variable model.
Furthermore, in ASP.NET MVC, do you ever create instances of Controllers or Views (except in unit tests)? Instances of Controllers and Views are created by the framework. Basically, the role each Controller and View plays is embodied in their class names - HomeController, BookingController, BasketController, BookingViewModel, etc.
Example: Command Handler #
Consider a 'standard' CQRS implementation with a single Command Handler for each Command message type in the system. The Command Handler interface might be defined like this:
public interface ICommandHandler<T> { void Execute(T command); }
At this point, the type argument T could be literally any type, so the argument name command conveys the role of the object better than the type. However, once you look at a concrete implementation, the method signature materializes into something like this:
public void Execute(RequestReservationCommand command)
In the concrete case, the type name (RequestReservationCommand) carries more information about the role than the argument name (command).
Example: Dependency Injection #
With basic Dependency Injection, a common Role Hint is the type itself.
public BasketController( IBasketService basketService, CurrencyProvider currencyProvider) { if (basketService == null) throw new ArgumentNullException("basketService"); if (currencyProvider == null) throw new ArgumentNullException("currencyProvider"); this.basketService = basketService; this.currencyProvider = currencyProvider; }
From the point of view of the BasketController, the type names of the IBasketService interface and the CurrencyProvider abstract base class carry all required information about the role played by these dependencies. You can tell this because the argument names simply echo the type names. In the complete system, there could conceivably be more than one implementation of IBasketService, but in the context of the BasketController, some IBasketService instance is all that is required.
Summary #
The more generic a type is, the less information about role does the type name itself carry. Primitives and Value Objects such as integers, strings, Guids, Uris, etc. can be used in so many ways that you should strongly consider proper naming of arguments and variables to convey information about the role played by an object. This is what the Framework Design Guidelines suggest. However, as types become increasingly specific, their names carry more information about their roles. For very specific classes, the class name itself may carry all appropriate information about the object's intended role. As a rule of thumb, expect such classes to also adhere to the Single Responsibility Principle.
Role Hints
This article provides an overview of different ways to hint at the role an object is playing.
One of the interesting points in Lean Architecture is that many so-called object-oriented languages aren't really object-oriented, but rather class-oriented. This is as true for C# as for Java. The code artifacts are classes (or interfaces, etc.); not objects.
When asked to distinguish, most of us understand that objects are instances of classes, but since the languages are centered around classes, we sometimes forget this distinction and treat objects and classes as one and the same. When this happens, we run into some of the problems that Udi Dahan describes in his excellent talk Making Roles Explicit. The solution is proposed in the same talk: make roles explicit.
So, what's a role? you might ask. A role is the purpose of an object instance in a given context. (That sounds a bit like the (otherwise rather confusingly described) concept of DCI.) An object can play more than one role during its lifetime, or a class can be instantiated in one of the roles it can play. Some objects can play only a single role.
There are several ways to hint at the role played by an object:
- Type Name. Use the name of the type (such as the class name) to hint at the role played by instances of the class. This seems to be mostly relevant for objects that can play only a single role.
- Argument Name. Use the name of an argument (or variable) to hint at the role played by an instance.
- Metadata. Use data about code (such as attributes or marker interfaces) to hint at the role played by instances of the class.
- Role Interfaces. A class can implement several Role Interfaces; clients can treat instances as the roles they require.
- Partial Type Name. Use part of the type name to hint at a role played by objects. This can be used to enable Convention over Configuration.
Making the role of an object explicit can tip the balance in favor of true object-orientation instead of class-orientation. It will likely make your code easier to read, understand and maintain.
Zookeepers must become Rangers
For want of a nail the shoe was lost... This post explains why Zookeeper developers must become Ranger developers to escape the vicious cycle of impossible deadlines and low-quality code.
In a previous article I wrote about Ranger and Zookeper developers. The current article is going to make no sense to you if you haven't read the previous, but in brief, Rangers explicitly deal with versioning and forwards and backwards compatibility (henceforth called temporal compatibility) in order to produce workable code.
While reading the previous article, you may have thought that you'd rather like to be a Ranger than a Zookeeper, simply because it sounds cooler. Well, I didn't pick those names by accident :) You don't want to be a Zookeeper developer.
Zookeepers may be under the impression that, since they (or their organization) control the entire installation base of their code, they don't need to deal with the versioning aspect of software design. This is an illusion. It may seem like a little thing, but, through a chain reaction, the lack of versioning leads to impossible deadlines, slipping code quality, death marches and many unpleasant aspects of our otherwise wonderful vocation.
In order to escape the vicious cycle of low-quality-code, death marches, and firefighting, Zookeepers need to explicitly deal with versioning of the software they produce, essentially turning themselves into Rangers.
In the following, I will make two assumptions about the type of software I discuss here:
- It's impossible to predict all future feature requirements.
- Applications don't exist in a vacuum. They depend on other applications, and other applications depend on them.
For the vast majority of Zoo Software, I believe these tenets to be true.
In order to understand why versioning is so important (even for Zoo Software) it's important to first understand why Zookeepers consistently disregard it.
We don't need no steenking design guidelines #
It's sometimes a bit surprising to me that (.NET) programmers are resistant to good design. There's this tome of knowledge originally published as the Framework Design Guidelines and later published online on MSDN as the Design Guidelines for Developing Class Libraries. Even if you don't care to read through it all, tools such as Visual Studio Code Analysis and FxCop (which is free) encapsulate many of those guidelines and helps identify when your code diverges.
In my experience, Zookeeper resistance against the Framework Design Guidelines is perfectly examplified by the 'rules' related to selecting between classes and interfaces:
- Do favor defining classes over interfaces.
- Do use abstract (MustInherit in Visual Basic) classes instead of interfaces to decouple the contract from implementations.
(For the record, I think this is horrible advice, but that's a discussion for another day.)
The problem with a guideline like this is that most Zookeepers react to such advice by thinking: "This isn't relevant for the kind of code I write. I control the entire install base of my code, so it's not a problem for me to introduce a breaking change. That entire knowledge base of design guidelines is targeted at another type of developers. I need not care about it."
Zookeepers fail to address versioning and temporal compatibility because they (incorrectly) assume that they can always schedule deployments of services and clients together in such a way that breaking changes never actually break anything. That may work as long as systems are monolithic and exist in a vacuum, but as soon as you start integrating systems, this disregard for versioning leads straight to hell.
Example: an internal music catalog service #
Now that you understand why Zookeepers tend to ignore versioning it's time to understand where that attitude leads. This is best done with an example.
Imagine a team tasked with building a music catalog service for internal use. In the first release of the service a track looks like this:
<track> <name>Recovery</name> <artist>Curve</artist> <album>Come Clean</album> <length>288</length> </track>
This is obviously a naïve attempt, and a bit of planning could probably have prevented the following nasty particular surprise. However, this is just an illustrative example, and I'm sure you've found yourself in a situation where a new requirement took you entirely by surprise - no matter how much you tried to predict the future.
After the team has released the first version of the music catalog service, it turns out that some tracks may be the result of collaborations, and thus have multiple artists. The track may also appear in multiple albums (such as compilations or greatest hits collections), or on no album at all. Thus, version 2 of a track will have to look like this:
<track> <name>Under Pressure</name> <artists> <artist>David Bowie</artist> <artist>Queen</artist> </artists> <albums> <album>Hot Space</album> <album>Greatest Hits</album> <album>The Singles: 1969-1993</album> </albums> <length>242</length> </track>
This is obviously a breaking change, but since the team works in an organization where the entire installation base is under control, they work with the Enterprise Architecture team to schedule a release of this breaking change with all their clients.
However, the service was made to support other systems, so this change must be coordinated with all the known clients. It turns out that three systems depend on the music catalog service.
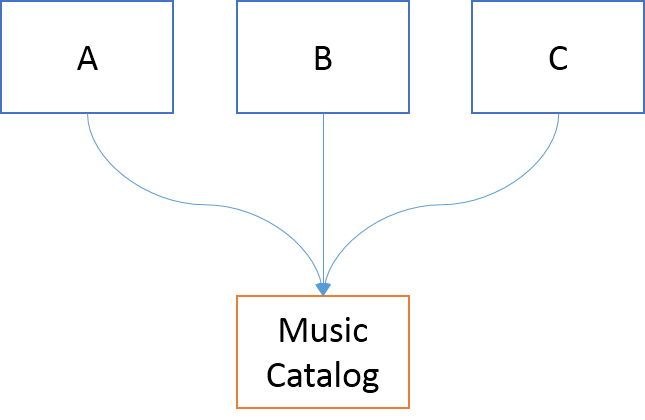
Each of these systems are being worked on by separate teams, each with individual deadlines. These teams are not planning to deploy new versions of their applications all on the same day. Their immediate schedules are already set, and they aren't aligned.
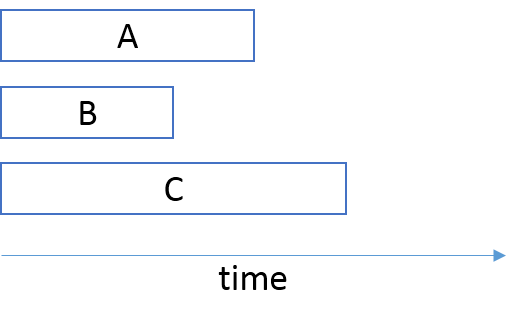
The Architecture team must negotiate future iterations with teams A, B, and C to line them up so that the music catalog team can release their new version on the same day.
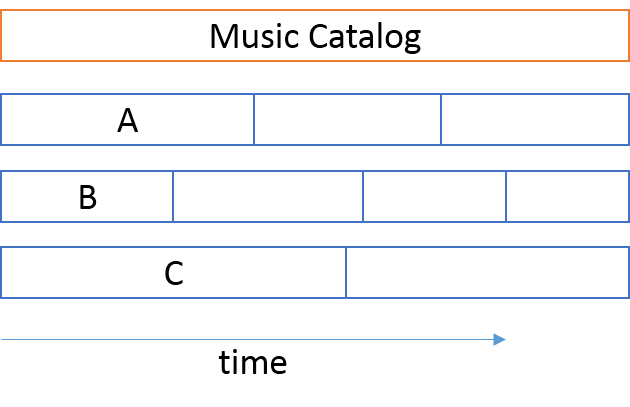
This alignment may be months into the future - perhaps a significant fraction of a year. The music catalog team can't sit still while they wait for this date to arrive, so they work on other new features, most likely introducing other breaking changes along the way.
Meanwhile, team A goes through three iterations. In the first two iterations, they know that they are going to deploy into a production environment with version 1 of the music catalog, so they are going to need a testing environment that looks like that. For the third iteration, they know that they are going to deploy into a production environment with version 2 of the music catalog, so they are going to have to change their testing environment to reflect that fact.
Team B goes through four iterations that don't align with those of Team A. When Team A updates their testing environment to music catalog version 2, Team B is still working on an iteration where they must test against version 1. Thus, they must have their own testing environment. They can't share the testing environment with Team A.
The same is true for Team C: it needs its own private testing environment. Notice that this is a testing environment that not only involves configuration and maintenance of the team's own application, but also of its dependency, the music catalog service. In order to provide realistic data for performance testing, each testing environment must also be maintained with representative sample data, and may have to run on production-like hardware, in production-like network topologies. Add software licences to the mix, and you may start to realize that such a testing environment is expensive.
So far, the analysis has been unrealistically simplified. It turns out that the A, B, and C applications have other dependencies besides the music catalog service.
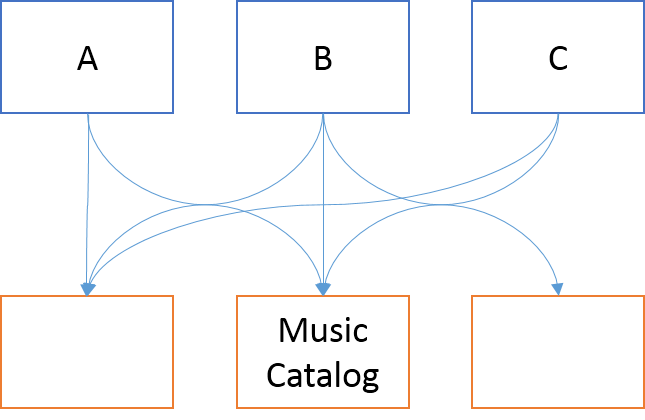
Each of these dependencies are also moving, producing new features. Some of those new features also involve breaking changes. Once again, the Enterprise Architecture team must negotiate a coordinated deployment date to make sure nothing breaks. However, the organization have more applications than A, B, and C. Application D, for instance, doesn't depend on the music catalog service, but it shares a dependency with application A. Thus, Team D must take part in the coordination effort, making sure that they deploy their new version on the same day as everyone else. Meanwhile, they'll need yet another one of those expensive testing environments.
I'm not making this up. I've had clients (financial institutions) that had hundreds of testing environments and big, coordinated deployments. Their applications didn't have two or three dependencies, but dozens of dependencies each - often on mainframe-based systems (very expensive).
The rot of Big Bang Releases #
All this leads to Big Bang Releases. Once or twice each year, all Zoo Sofware is simultaneously deployed according to a meticulously laid plan. This date becomes an unnegotiatable deadline. No team can miss the deadline, because dozens of other teams directly or indirectly depend on each other.
What happens when a Big Bang deadline grows nearer? What if you aren't ready to release? What if you just discovered a catastrophic bug?
This is what happens:
- Teams work nights and weekends to meet deadlines. Members burn out, or get divorced, or decide to quit. More work is left for remaining team members. A vicious circle indeed.
- Software is deployed with known bugs. Often, it's simply not possible to address all bugs in time, because they are discovered too late.
- The team enters survival mode, building up technical debt. Unit tests are ignored. Dirty hacks are made. Code rots. In the end, the team deploys a version of the software where they don't really know what works and what doesn't work. This makes it harder to work on the next version, because the lack of test coverage means that they don't even know if they'll be introducing breaking changes. At the absence of knowledge it's better to assume the worst. Another vicious cycle is created.
Remember: each team must deploy at the Big Bang Release, no matter how bad the quality is. It's not even possible to elect to skip a release all together, because the other teams have built their new versions with the assumption that your application's breaking changes will be deployed. In a Big Bang Release, there are only two options: Deploy everything, or deploy nothing. Deciding to deploy nothing may threaten the entire company's existence, so that decision is rarely made.
Do you think I'm exaggerating? I have seen this happen more than once. In fact, I also strongly suspect that this sort of situation recently unfolded itself within a big international ISV - at least, the symptoms are all here, for all to see :)
All this because Zookeepers don't deal with temporal compatibility.
Call to action #
Zookeepers must stop being Zookeepers and become Rangers. There's no excuse to not deal explicitly with versioning. You can't just introduce a breaking change in your code. The cost is often much larger than you think. The repercussions can be immense. Sometimes there's no way around breaking changes, but deal with them in tried-and-true ways. Introduce your new API side-by-side with the old API and deprecate the old API. Give clients a chance to move to the new API at their own pace. Monitor usage of your API to figure out when it's safe to completely remove the deprecated API. There are many well-described ways to deal with versioning and temporal compatibility. This is not an article about how to evolve an API, but rather a call to action: explicitly address versioning, or face the consequences!
Looser coupling can help. What I've described here is simply a form of tight temporal coupling. Still, even with loosely coupled, asynchronous, messaging-based architectures, messages must still be explicitly versioned to avoid problems.
Once an orginazation has moved entirely to a loosely coupled, explicitly versioned architecture where each team can use Continuous Delivery, they may find that they don't need that Enterprise Achitecture team at all :)
Rangers and Zookeepers
This article discusses software that runs in the wild, versus software running in potentially controllable environments.
There are many perspectives on software development. One particular perspective that has always interested me is the distinction between software running 'in the wild' versus software running in potentially controllable environments (such as corporate networks, including DMZs). Whether it's one or the other has a substantial impact on how you write, release and maintain software.
Historical perspective #
Software 'in the wild' is simply software where you don't know, or can't control, the install base. In the good old days (a few years ago) that typically meant software produced by ISVs such as Microsoft, Oracle, SAS, SAP, Autodesk, Adobe etc. The software produced by such organizations were/are often purchased by license and deployed by enterprise operations organizations. Even for ISVs targeting end-users directly (such as personal tax software, single player games, etc.), the software was/is typically installed by the individual user, and the ISV had/has zero control of the deployment environment or schedule.
The opposite of ISV Software has until recently been Enterprise Software. The problem with this term is that it has become almost derogatory, but I don't think that's entirely fair, because the forces working on this kind of software are very different from those working on ISV software. In this category I count specialized software made for specialized, internal purposes. It can be developed by in-house developers or a hired team, but the main characteristic is that the software is deployed in a potentially controllable environment (I originally wrote 'controlled environment,' but one reviewer interpreted this to indicate only software explicitly managed by process and tools such as Chef or Puppet). Even if there are several deployment environments such as testing, staging and production, and even if we are talking about Client/Server architectures with desktop clients deployed to enterprise desktops, an operations team should be able to keep track of all installations and schedule updates (if any). Often the original developers can work with operations to troubleshoot problems directly on the installed machine (or at least get logs).
Note that I'm not counting software such as SAP, Microsoft Dynamics or Oracle as Enterprise Software, despite the fact that such software is used by enterprises. Enterprise software is software developed by the enterprise itself, for its own purposes.
Enterprise Software can be a small system that sits in a corner of a corporate network, used by two employees every last weekday of the month. It can also be a massively scalable system build for a special occasion, such as the official site for a big sports tournament like the FIFA World Cup or the Summer Olympics.
Current perspective #
The historical distinction of ISV versus Enterprise Development makes less and less sense today. First of all, with the shift of emphasis towards SaaS, traditional ISVs are moving into an area that looks a lot like Enterprise Development. With SaaS, vendors suddenly find themselves in a situation where they control the entire installation base (at least on the service side). Some of them are now figuring out that this enables them to iterate faster than before. Apparently even such an Enterprisey-sounding service as the Team Foundation Service is now deploying new features several times a year. Expect that cadence to increase.
On the other hand, the rising popularity of Open Source Software (OSS) suddenly puts a lot of OSS developers in the old position of ISV developers. OSS tends to run in the wild, and the developers have no control of the installation base or upgrade schedules.
Oh, and do I even have to say 'Apps'?
Thus, we need a better terminology. Developing, supporting and managing software in 'the wild' sounds a lot like the duties of a Ranger: you can put overall plans into motion to nudge the environment in a certain direction, and sometimes you encounter a particular specimen with which you can interact, but essentially you'll have to understand complex environmental dynamics and plan for the long term.
If traditional ISV developers, as well as OSS programmers, are Rangers, then Enterprise and SaaS developers must be Zookeepers. They deal with a controlled environment, can keep an accurate tally, and execute detailed project plans at pre-planned schedules.
OK, I admit that it sounds cooler to be a Ranger than a Zookeeper, but the metaphor makes sense to me :)
As a corrollary, we can talk about Wildlife Software versus Zoo Software.
Forces #
The forces working on Wildlife Software versus Zoo Software are very different:
| Advantages | Disadvantages | |
|---|---|---|
| Wildlife Software | Since you can't control the installation base, you have to make the software robust, well-tested, secure, easy (enough) to install, and documented. It should be well-instrumented and possible to troubleshoot without being the original developer. Once you release a version into the wild, it must be able to stand on its own, or it will die. This is a rather Darwinian environment, but the advantage is that the software that survives tends to have some attributes we often associate with high 'quality'. | Traditionally, producing software with all these 'quality' attributes has been an expensive and slow endeavor. It also leads to conservatism, because every change must be carefully considered. Once released into the wild, a feature or behavior of a piece of software can't be changed (in that version). To wit: Microsoft has traditionally shipped new versions of Windows, Office, Visual Studio, the BCL etc. years apart. The BCL is peppered with sealed or internal classes, much to the chagrin of programmers everywhere. |
| Zoo Software | The Product Owners of Zoo Software will expect their programmers to be able to iterate much faster, since the installation base is much smaller and well-known. There are fewer environment permutations to consider - e.g. you may know up front that the software should only have to be able to run on Windows Server 2008 R2 with a SQL Server 2008 R2 database. The entire deployment environment is also well-known, so there are many assumptions you can trust to hold. This indicates that you should be able to produce software in an 'agile' manner. Because the Zoo is a much less dangerous place, the software can be less robust (at least along some axes), which again indicates that it can be produced by a smaller team than corresponding Wildlife Software. This again helps keeping down cost. | There are certain quality shortcuts that can be safely made with Zoo Software - e.g. never testing the software on Windows XP if you know it's never going to run on that OS. However, once a team under deadline pressure starts to make warranted shortcuts, it may begin making unwarranted shortcuts as well. Thus, we often experience Zoo Software that is poorly tested, is extremely difficult to deploy, is poorly documented and hard to operate. This, I believe, is why Enterprise Development today has such a negative ring to it. |
Now that former ISVs are moving into Zoo Software via SaaS, it's going to be interesting to see what happens in this space.
Conclusion #
Don't jump to conclusions about the advantages of either approach. This article is meant to be descriptive, first and foremost. This means that I'm describing the characteristics of Wildlife and Zoo Software as I most commonly encounter those types of software. I'm fully aware of initiatives such as DevOps, so I'm not saying that software has to be like I describe it - I'm just describing what I'm currently observing.
Comments
It's an interesting dynamic that while ISVs is moving into creating what can be thought of as Zoo Software due to the SaaS environment the fact that the client in a SaaS environment most often is browser-based means that they remain in Ranger-role on the client-side since the myriad of different browsers and browser-versions makes the new client-world as wild if not even wilder than a traditional desktop application environment.
Encapsulation of properties
This post explains why Information Hiding isn't entirely the same thing as Encapsulation.
Despite being an old concept, Encapsulation is one of the most misunderstood principles of object-oriented programming. Particularly for C# and Visual Basic.NET developers, this concept is confusing because those languages have properties. Other languages, including F#, have properties too, but it would be far from me to suggest that F# programmers are confused :)
(As an aside, even in languages without formal properties, such as e.g. Java, you often see property-like constructs. In Java, for example, a pair of a getter and a setter method is sometimes informally referred to as a property. In the end, that's also how .NET properties are implemented. Thus, the present article can also be applied to Java and other 'property-less' languages.)
In my experience, the two most important aspects of encapsulation are Protection of Invariants and Information Hiding. Earlier, I have had much to say about Protection of Invariants, including the invariants of properties. In this post, I will instead focus on Information Hiding.
With all that confusion (which I will get back to), you would think that Information Hiding is really hard to grasp. It's not - it's really simple, but I think that the name erects an effective psychological barrier to understanding. If instead we were to call it Implementation Hiding, I think most people would immediately grasp what it's all about.
However, since Information Hiding has this misleading name, it becomes really difficult to understand what it means. Does it mean that all information in an object should be hidden from clients? How can we reconcile such a viewpoint with the fundamental concept that object-orientation is about data and behavior? Some people take the misunderstanding so far that they begin to evangelize against properties as a design principle. Granted, too heavy a reliance on properties leads to violations of the Law of Demeter as well as Feature Envy, but without properties, how can a client ever know the state of a system?
Direct field access isn't the solution, as this discloses data to an even larger degree than properties. Still, in the lack of better guidance, the question of Encapsulation often degenerates to the choice between fields and properties. Perhaps the most widely known and accepted .NET design guideline is that data should be exposed via properties. This again leads to the redundant 'Automatic Property' language feature.
Tell me again: how is this
public string Name { get; set; }
better than this?
public string Name;
The Design Guidelines for Developing Class Libraries isn't wrong. It's just important to understand why properties are preferred over fields, and it has only partially to do with Encapsulation. The real purpose of this guideline is to enable versioning of types. In other words: it's about backwards compatibility.
An example demonstrating how properties enable code to evolve while maintaining backwards compatibility is in order. This example also demonstrates Implementation Hiding.
Example: a tennis game #
The Tennis kata is one of my favorite TDD katas. Previously, I posted my own, very specific take on it, but I've also, when teaching, asked groups to do it as an exercise. Often participants arrive at a solution not too far removed from this example:
public class Game { private int player1Score; private int player2Score; public void PointTo(Player player) { if (player == Player.One) if (this.player1Score >= 30) this.player1Score += 10; else this.player1Score += 15; else if (this.player2Score >= 30) this.player2Score += 10; else this.player2Score += 15; } public string Score { get { if (this.player1Score == this.player2Score && this.player1Score >= 40) return "Deuce"; if (this.player1Score > 40 && this.player1Score == this.player2Score + 10) return "AdvantagePlayerOne"; if (this.player2Score > 40 && this.player2Score == this.player1Score + 10) return "AdvantagePlayerTwo"; if (this.player1Score > 40 && this.player1Score >= this.player2Score + 20) return "GamePlayerOne"; if (this.player2Score > 40) return "GamePlayerTwo"; var score1Word = ToWord(this.player1Score); var score2Word = ToWord(this.player2Score); if (score1Word == score2Word) return score1Word + "All"; return score1Word + score2Word; } } private string ToWord(int score) { switch (score) { case 0: return "Love"; case 15: return "Fifteen"; case 30: return "Thirty"; case 40: return "Forty"; default: throw new ArgumentException( "Unexpected score value.", "score"); } } }
Granted: there's a lot more going on here than just a single property, but I wanted to provide an example of enough complexity to demonstrate why Information Hiding is an important design principle. First of all, this Game class tips its hat to that other principle of Encapsulation by protecting its invariants. Notice that while the Score property is public, it's read-only. It wouldn't make much sense if the Game class allowed an external caller to assign a value to the property.
When it comes to Information Hiding the Game class hides the implementation details by exposing a single Score property, but internally storing the state as two integers. It doesn't hide the state of the game, which is readily available via the Score property.
The benefit of hiding the data and exposing the state as a property is that it enables you to vary the implementation independently from the public API. As a simple example, you may realize that you don't really need to keep the score in terms of 0, 15, 30, 40, etc. Actually, the scoring rules of a tennis game are very simple: in order to win, a player must win at least four points with at least two more points than the opponent. Once you realize this, you may decide to change the implementation to this:
public class Game { private int player1Score; private int player2Score; public void PointTo(Player player) { if (player == Player.One) this.player1Score += 1; else this.player2Score += 1; } public string Score { get { if (this.player1Score == this.player2Score && this.player1Score >= 3) return "Deuce"; if (this.player1Score > 3 && this.player1Score == this.player2Score + 1) return "AdvantagePlayerOne"; if (this.player2Score > 3 && this.player2Score == this.player1Score + 1) return "AdvantagePlayerTwo"; if (this.player1Score > 3 && this.player1Score >= this.player2Score + 2) return "GamePlayerOne"; if (this.player2Score > 3) return "GamePlayerTwo"; var score1Word = ToWord(this.player1Score); var score2Word = ToWord(this.player2Score); if (score1Word == score2Word) return score1Word + "All"; return score1Word + score2Word; } } private string ToWord(int score) { switch (score) { case 0: return "Love"; case 1: return "Fifteen"; case 2: return "Thirty"; case 3: return "Forty"; default: throw new ArgumentException( "Unexpected score value.", "score"); } } }
This is a true Refactoring because it modifies (actually simplifies) the internal implementation without changing the external API one bit. Good thing those integer fields were never publicly exposed.
The tennis game scoring system is actually a finite state machine and from Design Patterns we know that this can be effectively implemented using the State pattern. Thus, a further refactoring could be to implement the Game class with a set of private or internal state classes. However, I will leave this as an exercise to the reader :)
The progress towards the final score often seems to be an important aspect in sports reporting, so another possible future development of the Game class might be to enable it to not only report on its current state (as the Score property does), but also report on how it arrived at that state. This might prompt you to store the sequence of points as they were scored, and calculate past and current state based on the history of points. This would cause you to change the internal storage from two integers to a sequence of points scored.
In both the above refactoring cases, you would be able to make the desired changes to the Game class because the implementation details are hidden.
Conclusion #
Information Hiding isn't Data Hiding. Implementation Hiding would be a much better word. Properties expose data about the object while hiding the implementation details. This enables you to vary the implementation and the public API independently. Thus, the important benefit from Information Hiding is that it enables you to evolve your API in a backwards compatible fashion. It doesn't mean that you shouldn't expose any data at all, but since properties are just as much members of a class' public API as its methods, you must exercise the same care when designing properties as when designing methods.
Update (2012.12.02): A reader correctly pointed out to me that there was a bug in the Game class. This bug has now been corrected.
Comments
http://www.itmweb.com/essay550.htm
In his conclusion he makes the following uncommon distinction: "Abstraction, information hiding, and encapsulation are very different, but highly-related, concepts. One could argue that abstraction is a technique that helps us identify which specific information should be visible, and which information should be hidden. Encapsulation is then the technique for packaging the information in such a way as to hide what should be hidden, and make visible what is intended to be visible."
Within a theoretical discussion, I agree with his conclusion that "a stronger argument can be made for keeping the concepts, and thus the terms, distinct". A key thing to keep in mind here according to this definition encapsulating something doesn't necessarily mean it is hidden.
When you refer to "encapsulation" you seem to refer to e.g. Rumbaugh's definition: "Encapsulation (also information hiding) consists of separating the external aspects of an object which are accessible to other objects, from the internal implementation details of the object, which are hidden from other objects." who ironically doesn't seem to make a distinction between information hiding and encapsulation, highlighting the problem even more. This also corresponds to the first listed definition on the wikipedia article on encapsulation you link to, but not the second.
1. A language mechanism for restricting access to some of the object's components.
2. A language construct that facilitates the bundling of data with the methods (or other functions) operating on that data.
When hiding information we almost always (always?) encapsulate something, which is probably why many see them as the same thing.
In a practical setting where we are just quickly trying to convey ideas things get even more problematic. When I refer to "encapsulation" I usually refer to information hiding, because that is generally my intention when encapsulating something. Interpreting it the other way around where encapsulation is seen solely as an OOP principle where state is placed within the context of a class with restricted access is more problematic when no distinction is made with information hiding. The many other ways in which information can be hidden are neglected.
Keeping this warning in mind on the ambiguous definitions of encapsulation and information hiding, I wonder how you feel about my blog posts where I discuss information hiding beyond the scope of the class. To me this is a useful thing to do, for all the same reasons as information hiding in general is a good thing to do.
In "Improved encapsulation using lambdas" I discuss how a piece of reusable code can be encapsulated within the scope of one function by using lambdas.
http://whathecode.wordpress.com/2011/06/05/improved-encapsulation-using-lambdas/
In "Beyond private accessibility" I discuss how variables used only within one function could potentially be hidden from other functions in a class.
http://whathecode.wordpress.com/2011/06/13/beyond-private-accessibility/
I'm glad I subscribed to this blog, you seem to talk about a lot of topics I'm truly interested in. :)
The main purpose of this post is to drive a big stake through the notion that properties = Encapsulation.
The lambda trick you describe is an additional way to scope a method - another is to realize that interfaces can also be used for scoping.
While I agree 100% with the intent of that statement, I just wanted to warn you that according to some definitions, a property encapsulates a backing field, a getter, and a setter. Whether or not that getter and setter hide anything or are protected, is assumed by some to be an entirely different concept, namely information hiding.
However using the 'mainstream' OOP definition of encapsulation you are absolutely right that a property with a public getter and setter (without any implementation logic inside) doesn't encapsulate anything as no access restrictions are imposed.
And as per my cause, neither does moving something to the scope of the class with access restrictions provide the best possible information hiding in OOP. You are only hiding complexity from fellow programmers who will consume the class, but not for those who have to maintain it (or extend from it in the case of protected members).
You are probably right his example can be further encapsulated, but if you are taking the effort of encapsulating something I would at least try to make it reusable instead of making a specific 'PlayerScore' class.
A score is basically a range of values which is a construct which is missing from C# and Java, but e.g. Ruby has. From experience I can tell you implementing it yourself is truly useful as you start seeing opportunities to use it everywhere: https://github.com/Whathecode/Framework-Class-Library-Extension/blob/master/Whathecode.System/Arithmetic/Range/Interval.cs
Probably I would create a generic or abstract 'Score' class which is composed of a range and possibly some additional logic (Reset(), events, ...)
As to moving the logic of the game (the score comparison) to the 'PlayerScore' class, I don't think I entirely agree. This is the concern of the 'Game' class and not the 'Score'. When separating these concerns one could use the 'Score' class in different types of games as well.
However I feel that it's just not a very good fit in C# compared to functional languages like F# or Clojure where functions are truely first class and defining a function inside another function is fully supported with the same syntax as regular functions. What I really would like if C# simply would let you define functions inside functions with the usual syntax.
Regarding performance I don't know how C# does it but I imagine it's similar to the F# inner function performance hit is negligible: http://stackoverflow.com/questions/7920234/what-are-the-performance-side-effects-of-defining-functions-inside-a-recursive-f
Maybe it's better to encapsulate the private func as a public func in a nested private (static?) class and then have the inner function as a private function of that class.
AppSettings convention for Castle Windsor
This post describes a generalized convention for Castle Windsor that handles AppSettings primitives.
In my previous post I explained how Convention over Configuration is the preferred way to use a DI Container. Some readers asked to see some actual convention implementations (although I actually linked to them in the post). In fact, I've previously showcased some simple conventions expressed with Castle Windsor's API.. In this post I'm going to show you another convention, which is completely reusable. Feel free to copy and paste :)
Most conventions are really easy to implement. Actually, sometimes it takes more effort to express the specification than it actually takes to implement it.
This convention deals with Primitive Dependencies. In my original post on the topic I included an AppSettingsConvention class as part of the code listing, but that implementation was hard-coded to only deal with integers. This narrow convention can be generalized:
The AppSettingsConvention should map AppSettings .config values into Primitive Dependencies.
- If a class has a dependency, the name of the dependency is assumed to be the name of the constructor argument (or property, for that matter). If, for example, the name of a constructor argument is top, this is the name of the dependency.
- If there's an appSettings key with the same name in the .config, and if there's a known conversion from string to the type of the dependency, the .config value is converted and used.
Example requirement: int top #
Consider this constructor:
public DbChartReader(int top, string chartConnectionString)
In this case the convention should look after an AppSettings key named top as well as check whether there's a known conversion from string to int (there is). Imagine that the .config file contains this XML fragment:
<appSettings> <add key="top" value="40" /> </appSettings>
The convention should read "40" from the .config file and convert it to an integer and inject 40 into a DbChartReader instance.
Example requirement: Uri catalogTrackBaseUri #
Consider this constructor:
public CatalogApiTrackLinkFactory(Uri catalogTrackBaseUri)
In this case the convention should look after an AppSettings key named catalogTrackBaseUri and check if there's a known conversion from string to Uri. Imagine that the .config file contains this XML fragment:
<appSettings> <add key="catalogTrackBaseUri" value="http://www.ploeh.dk/foo/img/"/> <add key="foo" value="bar"/> <add key="baz" value="42"/> </appSettings>
The convention should read "http://www.ploeh.dk/foo/img/" from the .config file and convert it to a Uri instance.
Implementation #
By now it should be clear what the conventions should do. With Castle Windsor this is easily done by implementing an ISubDependencyResolver. Each method is a one-liner:
public class AppSettingsConvention : ISubDependencyResolver { public bool CanResolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return ConfigurationManager.AppSettings.AllKeys .Contains(dependency.DependencyKey) && TypeDescriptor .GetConverter(dependency.TargetType) .CanConvertFrom(typeof(string)); } public object Resolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return TypeDescriptor .GetConverter(dependency.TargetType) .ConvertFrom( ConfigurationManager.AppSettings[dependency.DependencyKey]); } }
The ISubDependencyResolver interface is an example of the Tester-Doer pattern. Only if the CanResolve method returns true is the Resolve method invoked.
The CanResolve method performs two checks:
- Is there an AppSettings key in the configuration which is equal to the name of the dependency?
- Is there a known conversion from string to the type of the dependency?
The Resolve method simply reads the .config value and converts it to the appropriate type and returns it.
Adding the convention to an IWindsorContainer instance is easy:
container.Kernel.Resolver.AddSubResolver( new AppSettingsConvention());
Summary #
The AppSettingsConvention is a completely reusable convention for Castle Windsor. With it, Primitive Dependencies are automatically wired the appropriate .config values if they are defined.
Comments
- it would handle all the type conversion for you
- the approach, since the dependency is set up as part of the ComponentModel is statically analysable, whereas ISDR works dynamically so your components that depend on values from config file would show up as "Potentially misconfigured components".
When to use a DI Container
This post explains why a DI Container is useful with Convention over Configuration while Poor Man's DI might be a better fit for a more explicit Composition Root.
Note (2018-07-18): Since I wrote this article, I've retired the term Poor Man's DI in favour of Pure DI.
It seems to me that lately there's been a backlash against DI Containers among alpha geeks. Many of the software leaders that I myself learn from seem to dismiss the entire concept of a DI Container, claiming that it's too complex, too 'magical', that it isn't a good architectural pattern, or that the derived value doesn't warrant the 'cost' (most, if not all, DI Containers are open source, so they are free in a monetary sense, but there's always a cost in learning curve etc.).
This must have caused Krzysztof Koźmic to write a nice article about what sort of problem a DI Container solves. I agree with the article, but want to provide a different perspective here.
In short, it makes sense to me to illustrate the tradeoffs of Poor Man's DI versus DI Containers in a diagram like this:
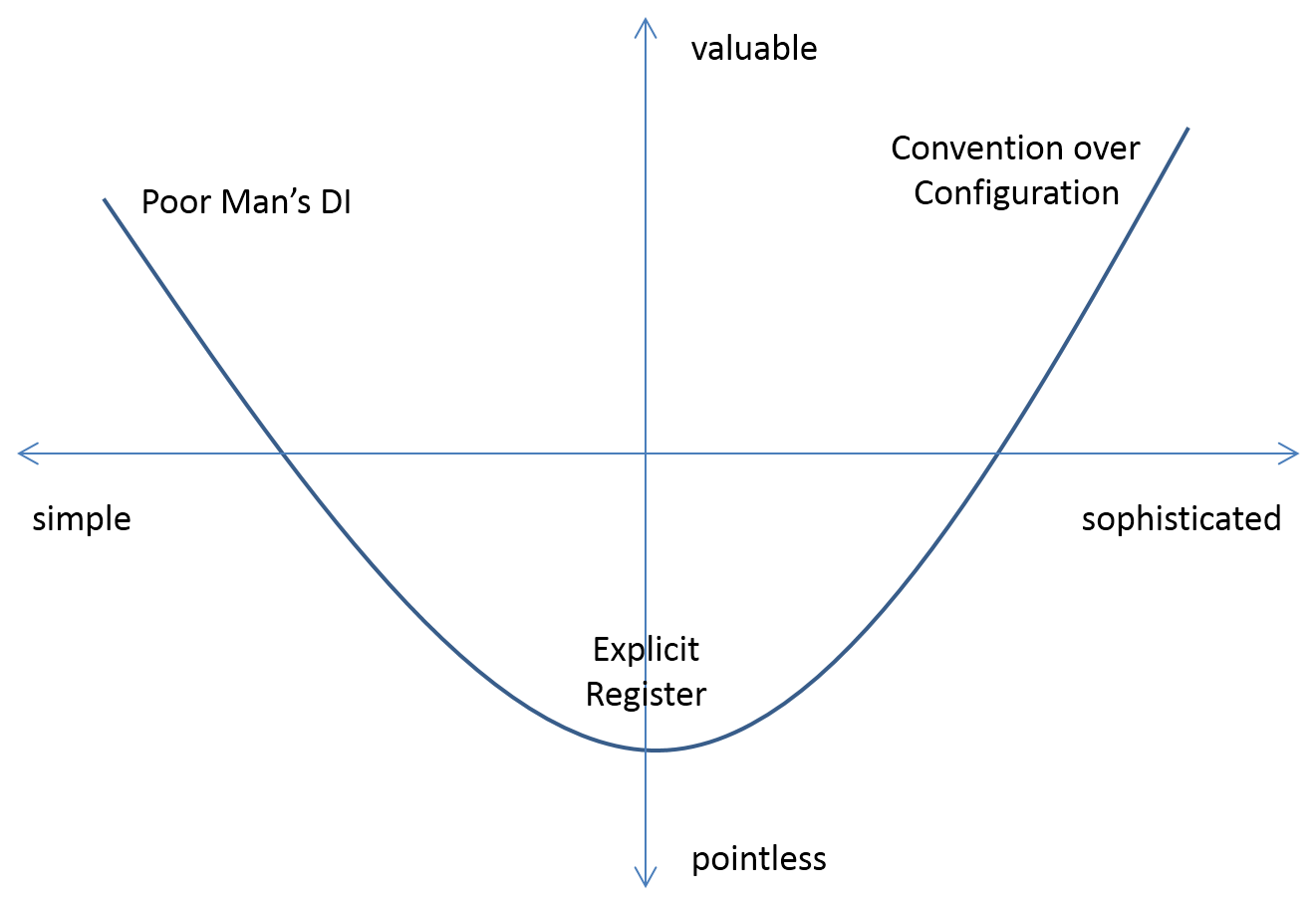
The point of the diagram is that Poor Man's DI can be valuable because it's simple, while a DI Container can be either valuable or pointless depending on how it's used. However, when used in a sufficiently sophisticated way I consider a DI Container to offer the best value/cost ratio. When people criticize DI Containers as being pointless I suspect that what really happened was that they gave up before they were out of the Trough of Disillusionment. Had they continued to learn, they might have arrived at a new Plateau of Productivity.
| DI style | Advantages | Disadvantages |
|---|---|---|
| Poor Man's DI |
|
|
| Explicit Register |
|
|
| Convention over Configuration |
|
|
There are other, less important advantages and disadvantages of each approach, but here I'm focusing on three main axes that I consider important:
- How easy is it to understand and learn?
- How soon will you get feedback if something is not right?
- How easy is it to maintain?
The major advantage of Poor Man's DI is that it's easy to learn. You don't have to learn the API of any DI Container (Unity, Autofac, Ninject, StructureMap, Castle Windsor, etc.) and while individual classes still use DI, once you find the Composition Root it'll be evident what's going on and how object graphs are constructed. No 'magic' is involved.
The second big advantage of Poor Man's DI is often overlooked: it's strongly typed. This is an advantage because it provides the fastest feedback about correctness that you can get. However, strong typing cuts both ways because it also means that every time you refactor a constructor, you will break the Composition Root. If you are sharing a library (Domain Model, Utility, Data Access component, etc.) between more than one application (unit of deployment), you may have more than one Composition Root to maintain. How much of a burden this is depends on how often you refactor constructors, but I've seen projects where this happens several times each day (keep in mind that constructor are implementation details).
If you use a DI Container, but explicitly Register each and every component using the container's API, you lose the rapid feedback from strong typing. On the other hand, the maintenance burden is also likely to drop because of Auto-wiring. Still, you'll need to register each new class or interface when you introduce them, and you (and your team) still has to learn the specific API of that container. In my opinion, you lose more advantages than you gain.
Ultimately, if you can wield a DI Container in a sufficiently sophisticated way, you can use it to define a set of conventions. These conventions define a rule set that your code should adhere to, and as long as you stick to those rules, things just work. The container drops to the background, and you rarely need to touch it. Yes, this is hard to learn, and is still weakly typed, but if done right, it enables you to focus on code that adds value instead of infrastructure. An additional advantage is that it creates a positive feedback mechanism forcing a team to produce code that is consistent with the conventions.
Example: Poor Man's DI #
The following example is part of my Booking sample application. It shows the state of the Ploeh.Samples.Booking.Daemon.Program class as it looks in the git tag total-complexity (git commit ID 64b7b670fff9560d8947dd133ae54779d867a451).
var queueDirectory = new DirectoryInfo(@"..\..\..\BookingWebUI\Queue").CreateIfAbsent(); var singleSourceOfTruthDirectory = new DirectoryInfo(@"..\..\..\BookingWebUI\SSoT").CreateIfAbsent(); var viewStoreDirectory = new DirectoryInfo(@"..\..\..\BookingWebUI\ViewStore").CreateIfAbsent(); var extension = "txt"; var fileDateStore = new FileDateStore( singleSourceOfTruthDirectory, extension); var quickenings = new IQuickening[] { new RequestReservationCommand.Quickening(), new ReservationAcceptedEvent.Quickening(), new ReservationRejectedEvent.Quickening(), new CapacityReservedEvent.Quickening(), new SoldOutEvent.Quickening() }; var disposable = new CompositeDisposable(); var messageDispatcher = new Subject<object>(); disposable.Add( messageDispatcher.Subscribe( new Dispatcher<RequestReservationCommand>( new CapacityGate( new JsonCapacityRepository( fileDateStore, fileDateStore, quickenings), new JsonChannel<ReservationAcceptedEvent>( new FileQueueWriter<ReservationAcceptedEvent>( queueDirectory, extension)), new JsonChannel<ReservationRejectedEvent>( new FileQueueWriter<ReservationRejectedEvent>( queueDirectory, extension)), new JsonChannel<SoldOutEvent>( new FileQueueWriter<SoldOutEvent>( queueDirectory, extension)))))); disposable.Add( messageDispatcher.Subscribe( new Dispatcher<SoldOutEvent>( new MonthViewUpdater( new FileMonthViewStore( viewStoreDirectory, extension))))); var q = new QueueConsumer( new FileQueue( queueDirectory, extension), new JsonStreamObserver( quickenings, messageDispatcher)); RunUntilStopped(q);
Yes, that's a lot of code. I deliberately chose a non-trivial example to highlight just how much stuff there might be. You don't have to read and understand all of this code to appreciate that it might require a bit of maintenance. It's a big object graph, with some shared subgraphs, and since it uses the new keyword to create all the objects, every time you change a constructor signature, you'll need to update this code, because it's not going to compile until you do.
Still, there's no 'magical' tool (read: DI Container) involved, so it's pretty easy to understand what's going on here. As Dan North put it once I saw him endorse this technique: 'new' is the new 'new' :) Once you see how Explicit Register looks, you may appreciate why.
Example: Explicit Register #
The following example performs exactly the same work as the previous example, but now in a state (git tag: controllers-by-convention; commit ID: 13fc576b729cdddd5ec53f1db907ec0a7d00836b) where it's being wired by Castle Windsor. The name of this class is DaemonWindsorInstaller, and all components are explictly registered. Hang on to something.
container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\Queue").CreateIfAbsent()) .Named("queueDirectory")); container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\SSoT").CreateIfAbsent()) .Named("ssotDirectory")); container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\ViewStore").CreateIfAbsent()) .Named("viewStoreDirectory")); container.Register(Component .For<IQueue>() .ImplementedBy<FileQueue>() .DependsOn( Dependency.OnComponent("directory", "queueDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IStoreWriter<DateTime>, IStoreReader<DateTime>>() .ImplementedBy<FileDateStore>() .DependsOn( Dependency.OnComponent("directory", "ssotDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IStoreWriter<ReservationAcceptedEvent>>() .ImplementedBy<FileQueueWriter<ReservationAcceptedEvent>>() .DependsOn( Dependency.OnComponent("directory", "queueDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IStoreWriter<ReservationRejectedEvent>>() .ImplementedBy<FileQueueWriter<ReservationRejectedEvent>>() .DependsOn( Dependency.OnComponent("directory", "queueDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IStoreWriter<SoldOutEvent>>() .ImplementedBy<FileQueueWriter<SoldOutEvent>>() .DependsOn( Dependency.OnComponent("directory", "queueDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IChannel<ReservationAcceptedEvent>>() .ImplementedBy<JsonChannel<ReservationAcceptedEvent>>()); container.Register(Component .For<IChannel<ReservationRejectedEvent>>() .ImplementedBy<JsonChannel<ReservationRejectedEvent>>()); container.Register(Component .For<IChannel<SoldOutEvent>>() .ImplementedBy<JsonChannel<SoldOutEvent>>()); container.Register(Component .For<ICapacityRepository>() .ImplementedBy<JsonCapacityRepository>()); container.Register(Component .For<IConsumer<RequestReservationCommand>>() .ImplementedBy<CapacityGate>()); container.Register(Component .For<IConsumer<SoldOutEvent>>() .ImplementedBy<MonthViewUpdater>()); container.Register(Component .For<Dispatcher<RequestReservationCommand>>()); container.Register(Component .For<Dispatcher<SoldOutEvent>>()); container.Register(Component .For<IObserver<Stream>>() .ImplementedBy<JsonStreamObserver>()); container.Register(Component .For<IObserver<DateTime>>() .ImplementedBy<FileMonthViewStore>() .DependsOn( Dependency.OnComponent("directory", "viewStoreDirectory"), Dependency.OnValue("extension", "txt"))); container.Register(Component .For<IObserver<object>>() .UsingFactoryMethod(k => { var messageDispatcher = new Subject<object>(); messageDispatcher.Subscribe(k.Resolve<Dispatcher<RequestReservationCommand>>()); messageDispatcher.Subscribe(k.Resolve<Dispatcher<SoldOutEvent>>()); return messageDispatcher; })); container.Register(Component .For<IQuickening>() .ImplementedBy<RequestReservationCommand.Quickening>()); container.Register(Component .For<IQuickening>() .ImplementedBy<ReservationAcceptedEvent.Quickening>()); container.Register(Component .For<IQuickening>() .ImplementedBy<ReservationRejectedEvent.Quickening>()); container.Register(Component .For<IQuickening>() .ImplementedBy<CapacityReservedEvent.Quickening>()); container.Register(Component .For<IQuickening>() .ImplementedBy<SoldOutEvent.Quickening>()); container.Register(Component .For<QueueConsumer>()); container.Kernel.Resolver.AddSubResolver(new CollectionResolver(container.Kernel));
This is actually more verbose than before - almost double the size of the Poor Man's DI example. To add spite to injury, this is no longer strongly typed in the sense that you'll no longer get any compiler errors if you change something, but a change to your classes can easily lead to a runtime exception, since something may not be correctly configured.
This example uses the Registration API of Castle Windsor, but imagine the horror if you were to use XML configuration instead.
Other DI Containers have similar Registration APIs (apart from those that only support XML), so this problem isn't isolated to Castle Windsor only. It's inherent in the Explicit Register style.
I can't claim to be an expert in Java, but all I've ever heard and seen of DI Containers in Java (Spring, Guice, Pico), they don't seem to have Registration APIs much more sophisticated than that. In fact, many of them still seem to be heavily focused on XML Registration. If that's the case, it's no wonder many software thought leaders (like Dan North with his 'new' is the new 'new' line) dismiss DI Containers as being essentially pointless. If there weren't a more sophisticated option, I would tend to agree.
Example: Convention over Configuration #
This is still the same example as before, but now in a state (git tag: services-by-convention-in-daemon; git commit ID: 0a7e6f246cacdbefc8f6933fc84b024774d02038) where almost the entire configuration is done by convention.
container.AddFacility<ConsumerConvention>(); container.Register(Component .For<IObserver<object>>() .ImplementedBy<CompositeObserver<object>>()); container.Register(Classes .FromAssemblyInDirectory(new AssemblyFilter(".").FilterByName(an => an.Name.StartsWith("Ploeh.Samples.Booking"))) .Where(t => !(t.IsGenericType && t.GetGenericTypeDefinition() == typeof(Dispatcher<>))) .WithServiceAllInterfaces()); container.Kernel.Resolver.AddSubResolver(new ExtensionConvention()); container.Kernel.Resolver.AddSubResolver(new DirectoryConvention(container.Kernel)); container.Kernel.Resolver.AddSubResolver(new CollectionResolver(container.Kernel)); #region Manual configuration that requires maintenance container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\Queue").CreateIfAbsent()) .Named("queueDirectory")); container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\SSoT").CreateIfAbsent()) .Named("ssotDirectory")); container.Register(Component .For<DirectoryInfo>() .UsingFactoryMethod(() => new DirectoryInfo(@"..\..\..\BookingWebUI\ViewStore").CreateIfAbsent()) .Named("viewStoreDirectory")); #endregion
It's pretty clear that this is a lot less verbose - and then I even left three explicit Register statements as a deliberate decision. Just because you decide to use Convention over Configuration doesn't mean that you have to stick to this principle 100 %.
Compared to the previous example, this requires a lot less maintenance. While you are working with this code base, most of the time you can concentrate on adding new functionality to the software, and the conventions are just going to pick up your changes and new classes and interfaces. Personally, this is where I find the best tradeoff between the value provided by a DI Container versus the cost of figuring out how to implement the conventions. You should also keep in mind that once you've learned to use a particular DI Container like this, the cost goes down.
Summary #
Using a DI Container to compose object graphs by convention presents an unparalled opportunity to push infrastructure code to the background. However, if you're not prepared to go all the way, Poor Man's DI may actually be a better option. Don't use a DI Container just to use one. Understand the value and cost associated with it, and always keep in mind that Poor Man's DI is a valid alternative.
Comments
Testing usually seems to be the pressure release for not using an IoC container in a static language. Even if it's just a matter of not writing the tests for the overridden constructor, testing is usually thrown out. And in a world without tests, Poor Man's DI (or not DI at all) is often the "simpler" solution. Less lines of code, "it just works," etc etc. There are lots of options when you only look at the implementation without concern about how one is to provide automated verification against regressions.
If using TDD or even just "testing," an IoC container is always the simpler solution. Unless, of course -- if you just switch to a language or framework that lets you do both. *cough* ruby *cough* python *cough* dynamic languages *cough*
Just to add another perspective:
I created some extension methods in one of my core libraries that registers everything that ends with Service, Factory, Provider etc. Additionally, I created some extension methods for special areas like NHibernate or AutoMapping.
With these extension methods and a project that adheres to these conventions, my composition roots are very short and need virtually no maintenance.
I have successfully used this approach in several mid to big sized projects. It just works, I wouldn't want to work without a DI container anymore as it would cost so much more time.
1.) A constructor with no arguments. Dependencies are initialized in the constructor. This constructor can be used to instantiate the object like "myThing = new MyThing();" This is not using DI at all.
2.) A constructor with arguments for each dependency. Dependencies are passed in. This constructor is used for testing, since it actually uses DI.
This "Poor Man's DI" is a concept because it's a cheap way to get DI into a class that may not have originally been written to support DI. In a way, it seems to give devs the best of both worlds. Users can still instantiate the class simply, but users can also test it. It sounds fine, but it has some issues because the class is still bound to its dependencies and because the implementation uses different code than the tests.
Looking deeper at your example, I see that's not what your "Poor Man's DI" example is. Your way is fully testable, but I don't think its deserving of the extra "Poor Man's DI" moniker because it's just hand-rolled class instantiation. Or to put it another way: If your code is an example of "Poor Man's DI," then wouldn't any DI that wasn't handled through an IoC container? You are just creating objects with code -- nothing special. (or wrong, either)
If that's what "Poor Man's DI" means, there should probably be a new phrase to identify the practice that I've seen the phrase tied to -- as it's a "special" and unique practice. (Take that however you will. :) )
Now that I think about it,the concept of "Poor Man's DI" and "Bastard Injection" seem to refer to different things. Given your definition, Poor Man's DI basically seems to mean that I don't use an IoC container. It's a concept defining the method in which the object is created. But Bastard Injection refers to what I think would be the more common use of "Poor Man's DI," the practice of creating two constructors. It's a concept defining the method in which the class itself is written. I guess, then, it's possible for me to use Bastard Injection with Poor Man's DI, so long as I don't call the default constructor?
As one more side note: I really don't like the name "Bastard Injection" due to the coarse language. I know it's an anti-pattern, but "bastard" is a word I'd never ever accept from myself or other developers in a professional setting, especially with a client. I just asked my wife, an public elementary school teacher and librarian, and she said that word would not be accepted in her class or at any school she's been at. I don't think it's helpful to give PG13-level words to programming concepts. :)
How do considerations of lifetime management factor in? I may want Singleton here, Transient there, etc. That would seem to favor Explicit Register.
There's also the option of integration-testing the Composition Root to provide some type-checking.
When it comes to lifetime management, there are answers on more than one level.
On the pragmatic level, I've often found that in reality, most of my graphs tend to need to be Transient (or Per Graph) because some commonly used leaf node must be Transient (or Per Graph) for whatever reason. Once that happens, if most (say: more than 75%) of all objects are already Transient, does it really matter if a few more are also Transient? Yes, it could have been more efficient, but if you profile your app, you're most likely to discover that your bottleneck is somewhere else entirely.
On a more explicit level, it would be possible to define a convention that picks up a hint about the desired lifetime from the type itself. You could for example call a service "ThreadSafeFoo" to hint that Singleton would be appropriate - or perhaps you could adorn it with a [ThreadSafe] attribute...
Testing the container itself I don't find particularly useful, but a set of smoke tests of the entire app can be helpful.
I may be wrong, but reading your post I understand that the goal of a DI Container is to compose object graphs. This is undoubtedly true. Yet I think that this is just one of DI Containers' goals, and possibly not even the main one.
I'm sure you already know the amazing post An Autofac Lifetime Primer by Nicholas Blumhardt. It is about AutoFac, but it covers principles that are common to all the CI Containers.
Reading Nicholas post what I get is that a CI Container is a tool whose main goal is to manage resources lifetimes. Nicholas defines a resource as "anything with acquisition and release phases in its lifecycle". IoC Containers "provide a good solution to the resource management problem" and "to do this, they need to take ownership of the disposable components that they create". In other words, not only do DI Containers compose object graphs, but they also take care of the lifecycle of objects they created. Nicholas post is very detailed in explaining how and why a DI Container must track resources and guarantee that their disposal is properly managed.
This is an excerpt I find particurarly significant:
"[...] you need to find a strategy to ensure resources are disposed when they’re no longer required. The most widely-attempted one is based around the idea that whatever object acquires the resource should also release it. I pejoratively call it “ad-hoc” because it doesn’t work consistently. Eventually you’ll come up against one (and likely more) of the following issues:
Sharing: When multiple independent components share a resource, it is very hard to figure out when none of them requires it any more. Either a third party will have to know about all of the potential users of the resource, or the users will have to collaborate. Either way, things get hard fast.
Cascading Changes: Let’s say we have three components – A uses B which uses C. If no resources are involved, then no thought needs to be given to how resource ownership or release works. But, if the application changes so that C must now own a disposable resource, then both A and B will probably have to change to signal appropriately (via disposal) when that resource is no longer needed. The more components involved, the nastier this one is to unravel."
CI Containers solve these problems.
Poor Man (or Pure) CI solves the compose phase only. But the CI should also take care of resource disposal, or it would not provide any Unit of Work and possibly lead to memory leaks or NullPointerExceptions at runtime. What a basic Por Man implementation provides is just an Instance Per Dependency Scope (every request gets a new instance). With few modificatios, it could provide a Single Instance Scope (that is, a Singleton). But you might agree that managing nested scopes, shared dependencies, instances per web request and a proper disposal management with a Poor Man CI is all but a simple task.
So, I'm not sure the distinction between Poor Man and DI Containers is only a matter of Convention over Configuration. I got to the conclusion that the main goal of a DI Container is lifecycle management, much more than object graph composition.
What do you think?
Arialdo, thank you for writing.
Like you, I used to think that lifetime management was an strong motivation to use a DI Container; there's an entire chapter about lifetime management in my book.
There may be cases where that's true, but these days I prefer the the explicit lifetime matching I get from Pure DI.
While you can make lifetime management quite complicated, I prefer to keep it simple, so in practice, I only use the Singleton and Transient lifetime styles. Additionally, I prefer to design my components so that they aren't disposable. If I must use a disposable third-party object, my next priority would be to use a Decoraptor, and add decommissioning support if necessary. Only if none of that is possible will I begin to look at disposal from the Composition Root.
Usually, when you only use Singleton and Transient, manual disposal from the Composition Root is easy. There's no practical reason to dispose of the Singletons, so you only need to dispose of the Transient objects. How you do that varies from framework to framework, but in ASP.NET Web API, for example, it's easy.
Dependency Injection in ASP.NET Web API with Castle Windsor
This post describes how to compose Controllers with Castle Windsor in the ASP.NET Web API
In my previous post I described how to use Dependency Injection (DI) in the ASP.NET Web API using Poor Man's DI. It explained the basic building blocks, including the relevant extensibility points in the Web API. Poor Man's DI can be an easy way to get started with DI and may be sufficient for a small code base, but for larger code bases you may want to adopt a more convention-based approach. Some DI Containers provide excellent support for Convention over Configuration. One of these is Castle Windsor.
Composition Root #
Instead of the PoorMansCompositionRoot from the example in the previous post, you can create an implementation of IHttpControllerActivator that acts as an Adapter over Castle Windsor:
public class WindsorCompositionRoot : IHttpControllerActivator { private readonly IWindsorContainer container; public WindsorCompositionRoot(IWindsorContainer container) { this.container = container; } public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { var controller = (IHttpController)this.container.Resolve(controllerType); request.RegisterForDispose( new Release( () => this.container.Release(controller))); return controller; } private class Release : IDisposable { private readonly Action release; public Release(Action release) { this.release = release; } public void Dispose() { this.release(); } } }
That's pretty much all there is to it, but there are a few points of interest here. First of all, the class implements IHttpControllerActivator just like the previous PoorMansCompositionRoot. That's the extensibility point you need to implement in order to create Controller instances. However, instead of hard-coding knowledge of concrete Controller classes into the Create method, you delegate creation of the instance to an injected IWindsorContainer instance. However, before returning the IHttpController instance created by calling container.Resolve, you register that object graph for disposal.
With Castle Windsor decommissioning is done by invoking the Release method on IWindsorContainer. The input into the Release method is the object graph originally created by IWindsorContainer.Resolve. That's the rule from the Register Resolve Release pattern: What you Resolve you must also Release. This ensures that if the Resolve method created a disposable instance (even deep in the object graph), the Release method signals to the container that it can now safely dispose of it. You can read more about this subject in my book.
The RegisterForDispose method takes as a parameter an IDisposable instance, and not a Release method, so you must wrap the call to the Release method in an IDisposable implementation. That's the little private Release class in the code example. It adapts an Action delegate into a class which implements IDisposable, invoking the code block when Dispose is invoked. The code block you pass into the constructor of the Release class is a closure around the outer variables this.container and controller so when the Dispose method is called, the container releases the controller (and the entire object graph beneath it).
Configuring the container #
With the WindsorCompositionRoot class in place, all that's left is to set it all up in Global.asax. Since IWindsorContainer itself implements IDisposable, you should create and configure the container in the application's constructor so that you can dispose it when the application exits:
private readonly IWindsorContainer container; public WebApiApplication() { this.container = new WindsorContainer().Install(new DependencyConventions()); } public override void Dispose() { this.container.Dispose(); base.Dispose(); }
Notice that you can configure the container with the Install method directly in the constructor. That's the Register phase of the Register Resolve Release pattern.
In Application_Start you tell the ASP.NET Web API about your WindsorCompositionRoot instead of PoorMansCompositionRoot from the previous example:
GlobalConfiguration.Configuration.Services.Replace( typeof(IHttpControllerActivator), new WindsorCompositionRoot(this.container));
Notice that the container instance field is passed into the constructor of WindsorCompositionRoot, so that it can use the container instance to Resolve Controller instances.
Summary #
Setting up DI in the ASP.NET Web API with a DI Container is easy, and it would work very similarly with other containers (not just Castle Windsor), although the Release mechanisms tend to be a bit different from container to container. You'll need to create an Adapter from IHttpControllerActivator to your container of choice and set it all up in the Global.asax.
Comments
I am getting an error -
The type or namespace name 'DependencyConventions' could not be found (are you missing a using directive or an assembly reference?)
I added Castle windsor via Nuget in VS 2012 Web Express.
What's the problem?
Thanks,
Mahesh.
Not even remotely related to Web API, but I was wondering if a blog post about CQRS and DI in general was in the pipeline. Last time I posted I hadn't read your book, now that I have, I'm finding myself reading your blog posts like a book and I can't wait for the next. Great book by the way, can't recommend it enough, unless you're on some sort of diet.
Luis
Does the above implementation also resolve normal MVC4 website controllers? If so is there any extra setup required in the Global.asax file? Prior to MVC4 I was using the ControllerFactory method described in your book but is this still the best way?
How about using Windsor/above technique for injecting dependencies into MVC 4 attributes? I am using customized Authorize and ExceptionFilter attributes and so far I have not found a nice, easy and clean way to inject dependencies into them?
A better approach is to use global filters with behaviour, and use only passive attributes.
Autofac has the concept of LifetimeScopes. Using these, the code looks like the following:
public IHttpController Create(HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType)
{
var scope = _container.BeginLifetimeScope();
var controller = (IHttpController)scope.Resolve(controllerType);
request.RegisterForDispose(scope);
return controller;
}
If you want to register dependencies that are different for every request (like Hyprlinkr's RouteLinker), you can do this when beginning the lifetime scope:
public IHttpController Create(HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType)
{
var scope = _container.BeginLifetimeScope(x => RegisterRequestDependantResources(x, request));
var controller = (IHttpController)scope.Resolve(controllerType);
request.RegisterForDispose(scope);
return controller;
}
private static void RegisterRequestDependantResources(ContainerBuilder containerBuilder, HttpRequestMessage request)
{
containerBuilder.RegisterInstance(new RouteLinker(request));
containerBuilder.RegisterInstance(new ResourceLinkVerifier(request.GetConfiguration()));
}
Sorry for the formatting, I have no idea how to format code here.
Nice article.
As I understand WebApiApplication can be instantiated several times and disposed several times as well. This page(http://msdn.microsoft.com/en-gb/library/ms178473.aspx) says "The Application_Start and Application_End methods are special methods that do not represent HttpApplication events. ASP.NET calls them once for the lifetime of the application domain, not for each HttpApplication instance."
So as I understand your approach we can get into a situation using disposed context.
What do you think about this?
Anyway your example is very useful for me.
As there are multiple instances of HttpApplication per application
(If I put a breakpoint in the constructor it gets hit multiple times)
As you can see by these articles, there is not a single instance of HttpApplication, but multiple
http://lowleveldesign.wordpress.com/2011/07/20/global-asax-in-asp-net/
http://msdn.microsoft.com/en-us/library/a0xez8f2(v=vs.71).aspx
wouldn't it be more appropriate to go in Application_Start?
I've been studying this article and some of your answers like this one to StackOverflow questions pertaining to DI. It seems that the established community efforts to integrate popular IoC containers such as Ninject are, at their core,implementations of IDependencyResolver, rather than IHttpControllerActivator.
Are these popular community efforts missing the 'access to context' trait of your solution, or are they simply accomplishing it another way? Are there any established projects, open-source or otherwise, that do what you propose, or is this still an untapped 'pull request' opportunity for projects like the Ninject MVC, etc?
Jeff, thank you for writing. You are indeed correct that one of the many problems with the Service Locator anti-pattern (and therefore also IDependencyResolver) is that the overall context is hidden. Glenn Block originally pointed that particular problem out to me.
This is also the case with IDependencyResolver, because when GetService(Type) or GetServices(Type) is invoked, the only information the composition engine knows, is the requested type. Thus, resolving something that requires access to the HttpRequestMessage or one of its properties, is impossible with IDependencyResolver, but perfectly possible with IHttpControllerActivator.
So, yes, I would definitely say that any DI Container that provides 'ASP.NET Web API integration' by implementing IDependencyResolver is missing out. In any case, these days I rarely use a DI Container, so I don't consider it a big deal - and if I need to use a DI Container, I just need to add those few lines of code listed above in this blog post.
Can't figure out, how is it better to organize my solution.
There are, for example, three projects Cars.API, Cars.Core, and Cars.Data. API contains web-interface, Core contains all the abstractions, and Data communicates with DB. Data and API should depend on Core according to Dependency inversion principle. At this point everything seems to be clear, but then we implement our Composition Root in the API project, which makes it dependent on the Data project containing implementations of abstractions that are stored in Core project. Is it violation of Dependency inversion principle?
P.S. thank you for your book and the articles you write.
In the Configuring the Container section, you are placing the Install inside the constructor. Whenever the application starts up or executes a request, the constructor seems to be called multiple times. In turn, the container will be created multiple times throughout its life time. Is that the point? Or should the container be moved into the Application_Start? Although the constructor is called multiple times, application start seems to be called once. The dispose doesnt seem to be called till the end as well. Is there something earlier in the lifecycle that would cause a need for the Register to be done in the constructor?
I very much enjoy your book and your blog btw. great source of solid information!
Andrew, thank you for writing. In general, I don't recall that this has ever been an issue, but see previous threads in the comments for this post. The question's come up before.
I do, however, admit that I've never formally studied the question like I did with WCF, so it's possible that I'm wrong on this particular issue. Also, details of the framework could have changed in the five years that's gone by since I wrote the article.
Dependency Injection and Lifetime Management with ASP.NET Web API
This post describes how to properly use Dependency Injection in the ASP.NET Web API, including proper Lifetime Management.
The ASP.NET Web API supports Dependency Injection (DI), but the appropriate way to make it work is not the way it's documented by Microsoft. Even though the final version of IDependencyResolver includes the notion of an IDependencyScope, and thus seemingly supports decommissioning (the release of IDisposable dependencies), it's not very useful.
The problem with IDependencyResolver #
The main problem with IDependencyResolver is that it's essentially a Service Locator. There are many problems with the Service Locator anti-pattern, but most of them I've already described elsewhere on this blog (and in my book). One disadvantage of Service Locator that I haven't yet written so much about is that within each call to GetService there's no context at all. This is a general problem with the Service Locator anti-pattern, not just with IDependencyResolver. Glenn Block originally pointed this out to me. The problem is that in an implementation, all you're given is a Type instance and asked to return an object, but you're not informed about the context. You don't know how deep in a dependency graph you are, and if you're being asked to provide an instance of the same service multiple times, you don't know whether it's within the same HTTP request, or whether it's for multiple concurrent HTTP requests.
In the ASP.NET Web API this issue is exacerbated by another design decision that the team made. Contrary to the IDependencyResolver design, I find this other decision highly appropriate. It's how context is modeled. In previous incarnations of web frameworks from Microsoft, we've had such abominations as HttpContext.Current, HttpContextBase and HttpContextWrapper. If you've ever tried to work with these interfaces, and particularly if you've tried to do TDD against any of these types, you know just how painful they are. That they are built around the Singleton pattern certainly doesn't help.
The ASP.NET Web API does it differently, and that's very fortunate. Everything you need to know about the context is accessible through the HttpRequestMessage class. While you could argue that it's a bit of a God Object, it's certainly a step in the right direction because at least it's a class you can instantiate within a unit test. No more nasty Singletons.
This is good, but from the perspective of DI this makes IDependencyResolver close to useless. Imagine a situation where a dependency deep in the dependency graph need to know something about the context. What was the request URL? What was the base address (host name etc.) requested? How can you share dependency instances within a single request? To answer such questions, you must know about the context, and IDependencyResolver doesn't provide this information. In short, IDependencyResolver isn't the right hook to compose dependency graphs. Fortunately, the ASP.NET Web API has a better extensibility point for this purpose.
Composition within context #
Because HttpRequestMessage provides the context you may need to compose dependency graphs, the best extensibility point is the extensibility point which provides an HttpRequestMessage every time a graph should be composed. This extensibility point is the IHttpControllerActivator interface:
public interface IHttpControllerActivator { IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType); }
As you can see, each time the Web API framework invokes this method, it will provide an HttpRequestMessage instance. This seems to be the best place to compose the dependency graph for each request.
Example: Poor Man's DI #
As an example, consider a Controller with this constructor signature:
public RootController(IStatusQuery statusQuery)
If this is the only Controller in your project, you can compose its dependency graph with a custom IHttpControllerActivator. This is easy to do:
public class PoorMansCompositionRoot : IHttpControllerActivator { public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { if (controllerType == typeof(RootController)) return new RootController( new StatusQuery()); return null; } }
The Create implementation contains a check on the supplied controllerType parameter, creating a RootController instance if the requested Controller type is RootController. It simply creates the (very shallow) dependency graph by injecting a new StatusQuery instance into a new RootController instance. If the requested Controller type is anything else than RootController, the method returns null. It seems to be a convention in the Web API that if you can't supply an instance, you should return null. (This isn't a design I'm fond of, but this time I'm only on the supplying side, and I can only pity the developers on the receiving side (the ASP.NET team) that they'll have to write all those null checks.)
Some readers may think that it would be better to use a DI Container here, and that's certainly possible. In a future post I'll provide an example on how to do that.
The new PoorMansCompositionRoot class must be registered with the Web API framework before it will work. This is done with a single line in Application_Start in Global.asax.cs:
GlobalConfiguration.Configuration.Services.Replace( typeof(IHttpControllerActivator), new PoorMansCompositionRoot());
This replaces the default implementation that the framework provides with the PoorMansCompositionRoot instance.
Decommissioning #
Implementing IHttpControllerActivator.Create takes care of composing object graphs, but what about decommissioning? What if you have dependencies (deep within the dependency graph) implementing the IDisposable interface? These must be disposed of after the request has ended (unless they are Singletons) - if not, you will have a resource leak at hand. However, there seems to be no Release hook in IHttpControllerActivator. On the other hand, there's a Release hook in IDependencyResolver, so is IDependencyResolver, after all, the right extensibility point? Must you trade off context for decommissioning, or can you have both?
Fortunately you can have both, because there's a RegisterForDispose extension method hanging off HttpRequestMessage. It enables you to register all appropriate disposable instances for disposal after the request has completed.
Example: disposing of a disposable dependency #
Imagine that, instead of the StatusQuery class from the previous example, you need to use a disposable implementation of IStatusQuery. Each instance must be disposed of after each request completes. In order to accomplish this goal, you can modify the PoorMansCompositionRoot implementation to this:
public class PoorMansCompositionRoot : IHttpControllerActivator { public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { if (controllerType == typeof(RootController)) { var disposableQuery = new DisposableStatusQuery(); request.RegisterForDispose(disposableQuery); return new RootController(disposableQuery); } return null; } }
Notice that the disposableQuery instance is passed to the RegisterForDispose method before it's injected into the RootController instance and the entire graph is returned from the method. After the request completes, DisposableStatusQuery.Dispose will be called.
If you have a dependency which implements IDisposable, but should be shared across all requests, obviously you shouldn't register it for disposal. Such Singletons you can keep around and dispose of properly when the application exits gracefull (if that ever happens).
Summary #
Proper DI and Lifetime Management with the ASP.NET Web API is easy once you know how to do it. It only requires a few lines of code.
Stay away from the IDependencyResolver interface, which is close to useless. Instead, implement IHttpControllerActivator and use the RegisterForDispose method for decommissioning.
In a future post I will demonstrate how to use a DI Container instead of Poor Man's DI.
Comments
You have one implementation of IFoo, namely Foo, and for efficiency reasons, or perhaps because Foo is a Mediator, you'd like to share the same instance of Foo between Service1 and Service2. However, Foo isn't thread-safe, so you can only share the Foo instance within a single request. For each request, you want to use a single instance of Foo.
This is the Per Graph lifestyle pattern (p. 259 in my book).
That's not possible with IDependencyResolver, but it is with IHttpControllerActivator.
First of all I would like to mention that I just read your book and I enjoyed it very much.
Straight to the point with good simple examples and metaphors.
What I have noticed thought, from your book and from this blog post, is that you give handing IDisposable object a great deal of attention.
I have written a lightweight service container over at Github (https://github.com/seesharper/LightInject/wiki/Getting-started) that tries to do the "right thing" with a minimal effort.
Then I started to read about handling disposable services in your book and realized that this is actually quite a complicated thing to deal with.
It also seems to be unclear how a service container actually should do this. The various container implementations has pretty much its own take on the disposable challenge where as Spring.Net for instance, does not seem to go very far on this topic. Yet it is one of the most popular DI frameworks out there.
The question then remains, is automatic handling of disposable objects a necessity for any container or is a feature?
If it is absolutely necessary, how complex does it need to be. I would rather not implement a whole ref-count system on top of the CLR :)
Regards
Bernhard Richter
StructureMap, for example, has no decommissioning capability, and when you ask Jeremy Miller, it's by design. The reason for this is that if you don't have any disposable dependencies at all, it's just an overhead keeping track of all the instances created by the container. Garbage collection will ensure that resources are properly reclaimed.
Containers that do keep track of the instances they created will leak unless you explicitly remember to Release what you Resolve. By that argument, Jeremy Miller considers StructureMap's design safer because in the majority case there will be no leaks. IMO, the downside of that is that if you have disposable dependencies, they will leak and there's nothing you can do about.
On the other hand, with a container like Castle Windsor, it's important to Release what you Resolve, or you might have leaks. The advantage, however, is that you're guaranteed that everything can be properly disposed of.
Thus, in the end, no matter the strategy, it all boils down to that the developers using the container must exercise discipline. However, they are two different kinds of discipline: Either never use disposable dependencies or always Release what you Resolve.
Great article, thanks a lot! Loved your book as well :)
I just have a little observation that returning null in the Create method causes a 404. Instead we could do the following to call the default implementation for other controllers:
return new DefaultHttpControllerActivator().Create(request, controllerDescriptor, controllerType);
How would you handle db calls that need to be made to validate objects in say
[CustomValidationAttribute()] tagswhere you need the objects used to validate again in the actual web api action method?
In general, I don't like attributes with behaviour, but prefer passive attributes. Still, that just moves the implementation to the Filter's ExecuteActionFilterAsync method, so that doesn't really address your question.
If you need access to the actual objects created from the incoming request, you probably could pull it out of the HttpActionContext passed into ExecuteActionFilterAsync, but why bother? You can access the object from the Controller.
A Filter attribute in ASP.NET Web API, to be useful, represents a Cross-Cutting Concern, such as security, logging, metering, caching, etc. Cross-Cutting Concerns are cross-cutting exactly because they are independent of the actual values or objects in use. This isn't the case for validation, which tends to be specific to particular types, so these are most likely better addressed by a Controller, or a Service invoked by the Controller, rather than by a custom attribute.
Once you're in the Controller, if you need access to a database, you can inject a data access object (commonly referred to as a Repository) into the Controller.

Comments
Thanks for sharing,
Jason
In such a case, one had to change an acceptance test if a service could not deal with legacy clients. A developer who does this or a manager who commands this, acts unprofessional.
A team that calls itself agile and does not use the tools and techniques necessary for agile development, is just a bunch of cowboy coders, but neither "Zookeepers" nor "Rangers".
The point of the article (IMO) is that developers need to learn a new tool that you haven't listed - namely good internal version handling (and to start thinking of internal collaborators in the same way as external).
A tricky thing for an organisation is to decide when make the move from (easy-to-write) temporally coupled code to discrete services (with increased versioning and infrastructure overheads). Most places with this problem have started off small, grow quickly by bolting bits onto the existing architecture, and by the time someone switched on enough to start changing the organisation takes charge, it is too late to make the switch easily. TBH most places I've worked where this is the root cause of the problems, the Enterprise Architect team can't see the wood for the trees.
However, the other Markus is spot on. The message of this article isn't that you should use TDD, Continuous Integration, etc. Lot's of people have already said that before me. The message is that even if you are an 'internal' developer, you must think explicitly about versioning and backwards compatibility.