ploeh blog danish software design
Picture archivist in F#
A comprehensive code example showing how to implement a functional architecture in F#.
This article shows how to implement the picture archivist architecture described in a previous article. In short, the task is to move some image files to directories based on their date-taken metadata. The architectural idea is to load a directory structure from disk into an in-memory tree, manipulate that tree, and use the resulting tree to perform the desired actions:
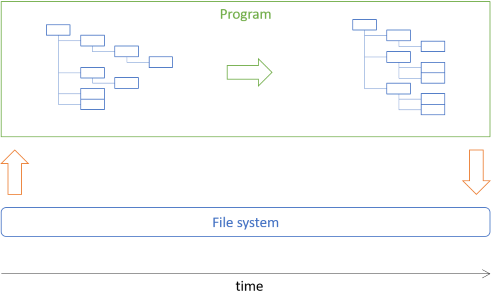
Much of the program will manipulate the tree data, which is immutable.
The previous article showed how to implement the picture archivist architecture in Haskell. In this article, you'll see how to do it in F#. This is essentially a port of the Haskell code.
Tree #
You can start by defining a rose tree:
type Tree<'a, 'b> = Node of 'a * Tree<'a, 'b> list | Leaf of 'b
If you wanted to, you could put all the Tree code in a reusable library, because none of it is coupled to a particular application, such as moving pictures. You could also write a comprehensive test suite for the following functions, but in this article, I'll skip that.
Notice that this sort of tree explicitly distinguishes between internal and leaf nodes. This is necessary because you'll need to keep track of the directory names (the internal nodes), while at the same time you'll want to enrich the leaves with additional data - data that you can't meaningfully add to the internal nodes. You'll see this later in the article.
While I typically tend to define F# types outside of modules (so that you don't have to, say, prefix the type name with the module name - Tree.Tree is so awkward), the rest of the tree code goes into a module, including two helper functions:
module Tree = // 'b -> Tree<'a,'b> let leaf = Leaf // 'a -> Tree<'a,'b> list -> Tree<'a,'b> let node x xs = Node (x, xs)
The leaf function doesn't add much value, but the node function offers a curried alternative to the Node case constructor. That's occasionally useful.
The rest of the code related to trees is also defined in the Tree module, but I'm going to present it formatted as free-standing functions. If you're confused about the layout of the code, the entire code base is available on GitHub.
The rose tree catamorphism is this cata function:
// ('a -> 'c list -> 'c) -> ('b -> 'c) -> Tree<'a,'b> -> 'c let rec cata fd ff = function | Leaf x -> ff x | Node (x, xs) -> xs |> List.map (cata fd ff) |> fd x
In the corresponding Haskell implementation of this architecture, I called this function foldTree, so why not retain that name? The short answer is that the naming conventions differ between Haskell and F#, and while I favour learning from Haskell, I still want my F# code to be as idiomatic as possible.
While I don't enforce that client code must use the Tree module name to access the functions within, I prefer to name the functions so that they make sense when used with qualified access. Having to write Tree.foldTree seems redundant. A more idiomatic name would be fold, so that you could write Tree.fold. The problem with that name, though, is that fold usually implies a list-biased fold (corresponding to foldl in Haskell), and I'll actually need that name for that particular purpose later.
So, cata it is.
In this article, tree functionality is (with one exception) directly or transitively implemented with cata.
Filtering trees #
It'll be useful to be able to filter the contents of a tree. For example, the picture archivist program will only move image files with valid metadata. This means that it'll need to filter out all files that aren't image files, as well as image files without valid metadata.
It turns out that it'll be useful to supply a function that throws away None values from a tree of option leaves. This is similar to List.choose, so I call it Tree.choose:
// ('a -> 'b option) -> Tree<'c,'a> -> Tree<'c,'b> option let choose f = cata (fun x -> List.choose id >> node x >> Some) (f >> Option.map Leaf)
You may find the type of the function surprising. Why does it return a Tree option, instead of simply a Tree?
While List.choose simply returns a list, it can do this because lists can be empty. This Tree type, on the other hand, can't be empty. If the purpose of Tree.choose is to throw away all None values, then how do you return a tree from Leaf None?
You can't return a Leaf because you have no value to put in the leaf. Similarly, you can't return a Node because, again, you have no value to put in the node.
In order to handle this edge case, then, you'll have to return None:
> let l : Tree<string, int option> = Leaf None;; val l : Tree<string,int option> = Leaf None > Tree.choose id l;; val it : Tree<string,int> option = None
If you have anything other than a None leaf, though, you'll get a proper tree, but wrapped in an option:
> Tree.node "Foo" [Leaf (Some 42); Leaf None; Leaf (Some 2112)] |> Tree.choose id;;
val it : Tree<string,int> option = Some (Node ("Foo",[Leaf 42; Leaf 2112]))
While the resulting tree is wrapped in a Some case, the leaves contain unwrapped values.
Bifunctor, functor, and folds #
Through its type class language feature, Haskell has formal definitions of functors, bifunctors, and other types of folds (list-biased catamorphisms). F# doesn't have a similar degree of formalism, which means that while you can still implement the corresponding functionality, you'll have to rely on conventions to make the functions recognisable.
It's straighforward to start with the bifunctor functionality:
// ('a -> 'b) -> ('c -> 'd) -> Tree<'a,'c> -> Tree<'b,'d> let bimap f g = cata (f >> node) (g >> leaf)
This is, apart from the syntax differences, the same implementation as in Haskell. Based on bimap, you can also trivially implement mapNode and mapLeaf functions if you'd like, but you're not going to need those for the code in this article. You do need, however, a function that we could consider an alias of a hypothetical mapLeaf function:
// ('b -> 'c) -> Tree<'a,'b> -> Tree<'a,'c> let map f = bimap id f
This makes Tree a functor.
It'll also be useful to reduce a tree to a potentially more compact value, so you can add some specialised folds:
// ('c -> 'a -> 'c) -> ('c -> 'b -> 'c) -> 'c -> Tree<'a,'b> -> 'c let bifold f g z t = let flip f x y = f y x cata (fun x xs -> flip f x >> List.fold (>>) id xs) (flip g) t z // ('a -> 'c -> 'c) -> ('b -> 'c -> 'c) -> Tree<'a,'b> -> 'c -> 'c let bifoldBack f g t z = cata (fun x xs -> List.foldBack (<<) xs id >> f x) g t z
In an attempt to emulate the F# naming conventions, I named the functions as I did. There are similar functions in the List and Option modules, for instance. If you're comparing the F# code with the Haskell code in the previous article, Tree.bifold corresponds to bifoldl, and Tree.bifoldBack corresponds to bifoldr.
These enable you to implement folds over leaves only:
// ('c -> 'b -> 'c) -> 'c -> Tree<'a,'b> -> 'c let fold f = bifold (fun x _ -> x) f // ('b -> 'c -> 'c) -> Tree<'a,'b> -> 'c -> 'c let foldBack f = bifoldBack (fun _ x -> x) f
These, again, enable you to implement another function that'll turn out to be useful in this article:
// ('b -> unit) -> Tree<'a,'b> -> unit let iter f = fold (fun () x -> f x) ()
The picture archivist program isn't going to explicitly need all of these, but transitively, it will.
Moving pictures #
So far, all the code shown here could be in a general-purpose reusable library, since it contains no functionality specifically related to image files. The rest of the code in this article, however, will be specific to the program. I'll put the domain model code in another module that I call Archive. Later in the article, we'll look at how to load a tree from the file system, but for now, we'll just pretend that we have such a tree.
The major logic of the program is to create a destination tree based on a source tree. The leaves of the tree will have to carry some extra information apart from a file path, so you can introduce a specific type to capture that information:
type PhotoFile = { File : FileInfo; TakenOn : DateTime }
A PhotoFile not only contains the file path for an image file, but also the date the photo was taken. This date can be extracted from the file's metadata, but that's an impure operation, so we'll delegate that work to the start of the program. We'll return to that later.
Given a source tree of PhotoFile leaves, though, the program must produce a destination tree of files:
// string -> Tree<'a,PhotoFile> -> Tree<string,FileInfo> let moveTo destination t = let dirNameOf (dt : DateTime) = sprintf "%d-%02d" dt.Year dt.Month let groupByDir pf m = let key = dirNameOf pf.TakenOn let dir = Map.tryFind key m |> Option.defaultValue [] Map.add key (pf.File :: dir) m let addDir name files dirs = Tree.node name (List.map Leaf files) :: dirs let m = Tree.foldBack groupByDir t Map.empty Map.foldBack addDir m [] |> Tree.node destination
This moveTo function looks, perhaps, overwhelming, but it's composed of three conceptual steps:
- Create a map of destination folders (
m). - Create a list of branches from the map (
Map.foldBack addDir m []). - Create a tree from the list (
Tree.node destination).
moveTo function starts by folding the input data into a map m. The map is keyed by the directory name, which is formatted by the dirNameOf function. This function takes a DateTime as input and formats it to a YYYY-MM format. For example, December 20, 2018 becomes "2018-12".
The entire mapping step groups the PhotoFile values into a map of the type Map<string,FileInfo list>. All the image files taken in April 2014 are added to the list with the "2014-04" key, all the image files taken in July 2011 are added to the list with the "2011-07" key, and so on.
In the next step, the moveTo function converts the map to a list of trees. This will be the branches (or sub-directories) of the destination directory. Because of the desired structure of the destination tree, this is a list of shallow branches. Each node contains only leaves.

The only remaining step is to add that list of branches to a destination node. This is done by piping (|>) the list of sub-directories into Tree.node destination.
Since this is a pure function, it's easy to unit test. Just create some test cases and call the function. First, the test cases.
In this code base, I'm using xUnit.net 2.4.1, so I'll first create a set of test cases as a test-specific class:
type MoveToDestinationTestData () as this = inherit TheoryData<Tree<string, PhotoFile>, string, Tree<string, string>> () let photoLeaf name (y, mth, d, h, m, s) = Leaf { File = FileInfo name; TakenOn = DateTime (y, mth, d, h, m, s) } do this.Add ( photoLeaf "1" (2018, 11, 9, 11, 47, 17), "D", Node ( "D", [Node ("2018-11", [Leaf "1"])])) do this.Add ( Node ("S", [photoLeaf "4" (1972, 6, 6, 16, 15, 0)]), "D", Node ("D", [Node ("1972-06", [Leaf "4"])])) do this.Add ( Node ("S", [ photoLeaf "L" (2002, 10, 12, 17, 16, 15); photoLeaf "J" (2007, 4, 21, 17, 18, 19)]), "D", Node ("D", [ Node ("2002-10", [Leaf "L"]); Node ("2007-04", [Leaf "J"])])) do this.Add ( Node ("1", [ photoLeaf "a" (2010, 1, 12, 17, 16, 15); photoLeaf "b" (2010, 3, 12, 17, 16, 15); photoLeaf "c" (2010, 1, 21, 17, 18, 19)]), "2", Node ("2", [ Node ("2010-01", [Leaf "a"; Leaf "c"]); Node ("2010-03", [Leaf "b"])])) do this.Add ( Node ("foo", [ Node ("bar", [ photoLeaf "a" (2010, 1, 12, 17, 16, 15); photoLeaf "b" (2010, 3, 12, 17, 16, 15); photoLeaf "c" (2010, 1, 21, 17, 18, 19)]); Node ("baz", [ photoLeaf "d" (2010, 3, 1, 2, 3, 4); photoLeaf "e" (2011, 3, 4, 3, 2, 1)])]), "qux", Node ("qux", [ Node ("2010-01", [Leaf "a"; Leaf "c"]); Node ("2010-03", [Leaf "b"; Leaf "d"]); Node ("2011-03", [Leaf "e"])]))
That looks like a lot of code, but is really just a list of test cases. Each test case is a triple of a source tree, a destination directory name, and an expected result (another tree).
The test itself, on the other hand, is compact:
[<Theory; ClassData(typeof<MoveToDestinationTestData>)>] let ``Move to destination`` source destination expected = let actual = Archive.moveTo destination source expected =! Tree.map string actual
The =! operator comes from Unquote and means something like must equal. It's an assertion that will throw an exception if expected isn't equal to Tree.map string actual.
The reason that the assertion maps actual to a tree of strings is that actual is a Tree<string,FileInfo>, but FileInfo doesn't have structural equality. So either I had to implement a test-specific equality comparer for FileInfo (and for Tree<string,FileInfo>), or map the tree to something with proper equality, such as a string. I chose the latter.
Calculating moves #
One pure step remains. The result of calling the moveTo function is a tree with the desired structure. In order to actually move the files, though, for each file you'll need to keep track of both the source path and the destination path. To make that explicit, you can define a type for that purpose:
type Move = { Source : FileInfo; Destination : FileInfo }
A Move is simply a data structure. Contrast this with typical object-oriented design, where it would be a (possibly polymorphic) method on an object. In functional programming, you'll regularly model intent with a data structure. As long as intents remain data, you can easily manipulate them, and once you're done with that, you can run an interpreter over your data structure to perform the work you want accomplished.
The unit test cases for the moveTo function suggest that file names are local file names like "L", "J", "a", and so on. That was only to make the tests as compact as possible, since the function actually doesn't manipulate the specific FileInfo objects.
In reality, the file names will most likely be longer, and they could also contain the full path, instead of the local path: "C:\foo\bar\a.jpg".
If you call moveTo with a tree where each leaf has a fully qualified path, the output tree will have the desired structure of the destination tree, but the leaves will still contain the full path to each source file. That means that you can calculate a Move for each file:
// Tree<string,FileInfo> -> Tree<string,Move> let calculateMoves = let replaceDirectory (f : FileInfo) d = FileInfo (Path.Combine (d, f.Name)) let rec imp path = function | Leaf x -> Leaf { Source = x; Destination = replaceDirectory x path } | Node (x, xs) -> let newNPath = Path.Combine (path, x) Tree.node newNPath (List.map (imp newNPath) xs) imp ""
This function takes as input a Tree<string,FileInfo>, which is compatible with the output of moveTo. It returns a Tree<string,Move>, i.e. a tree where the leaves are Move values.
Earlier, I wrote that you can implement desired Tree functionality with the cata function, but that was a simplification. If you can implement the functionality of calculateMoves with cata, I don't know how. You can, however, implement it using explicit pattern matching and simple recursion.
The imp function builds up a file path as it recursively negotiates the tree. All Leaf nodes are converted to a Move value using the leaf node's current FileInfo value as the Source, and the path to figure out the desired Destination.
This code is still easy to unit test. First, test cases:
type CalculateMovesTestData () as this = inherit TheoryData<Tree<string, FileInfo>, Tree<string, (string * string)>> () do this.Add (Leaf (FileInfo "1"), Leaf ("1", "1")) do this.Add ( Node ("a", [Leaf (FileInfo "1")]), Node ("a", [Leaf ("1", Path.Combine ("a", "1"))])) do this.Add ( Node ("a", [Leaf (FileInfo "1"); Leaf (FileInfo "2")]), Node ("a", [ Leaf ("1", Path.Combine ("a", "1")); Leaf ("2", Path.Combine ("a", "2"))])) do this.Add ( Node ("a", [ Node ("b", [ Leaf (FileInfo "1"); Leaf (FileInfo "2")]); Node ("c", [ Leaf (FileInfo "3")])]), Node ("a", [ Node (Path.Combine ("a", "b"), [ Leaf ("1", Path.Combine ("a", "b", "1")); Leaf ("2", Path.Combine ("a", "b", "2"))]); Node (Path.Combine ("a", "c"), [ Leaf ("3", Path.Combine ("a", "c", "3"))])]))
The test cases in this parametrised test are tuples of an input tree and the expected tree. For each test case, the test calls the Archive.calculateMoves function with tree and asserts that the actual tree is equal to the expected tree:
[<Theory; ClassData(typeof<CalculateMovesTestData>)>] let ``Calculate moves`` tree expected = let actual = Archive.calculateMoves tree expected =! Tree.map (fun m -> (m.Source.ToString (), m.Destination.ToString ())) actual
Again, the test maps FileInfo objects to strings to support easy comparison.
That's all the pure code you need in order to implement the desired functionality. Now you only need to write some code that loads a tree from disk, and imprints a destination tree to disk, as well as the code that composes it all.
Loading a tree from disk #
The remaining code in this article is impure. You could put it in dedicated modules, but for this program, you're only going to need three functions and a bit of composition code, so you could also just put it all in the Program module. That's what I did.
To load a tree from disk, you'll need a root directory, under which you load the entire tree. Given a directory path, you read a tree using a recursive function like this:
// string -> Tree<string,string> let rec readTree path = if File.Exists path then Leaf path else let dirsAndFiles = Directory.EnumerateFileSystemEntries path let branches = Seq.map readTree dirsAndFiles |> Seq.toList Node (path, branches)
This recursive function starts by checking whether the path is a file that exists. If it does, the path is a file, so it creates a new Leaf with that path.
If path isn't a file, it's a directory. In that case, use Directory.EnumerateFileSystemEntries to enumerate all the directories and files in that directory, and map all those directory entries recursively. That produces all the branches for the current node. Finally, return a new Node with the path and the branches.
Loading metadata #
The readTree function only produces a tree with string leaves, while the program requires a tree with PhotoFile leaves. You'll need to read the Exif metadata from each file and enrich the tree with the date-taken data.
In this code base, I've written a little Photo module to extract the desired metadata from an image file. I'm not going to list all the code here; if you're interested, the code is available on GitHub. The Photo module enables you to write an impure operation like this:
// FileInfo -> PhotoFile option let readPhoto file = Photo.extractDateTaken file |> Option.map (fun dateTaken -> { File = file; TakenOn = dateTaken })
This operation can fail for various reasons:
- The file may not exist.
- The file exists, but has no metadata.
- The file has metadata, but no date-taken metadata.
- The date-taken metadata string is malformed.
Tree<string,string> with readPhoto, you'll get a Tree<string,PhotoFile option>. That's when you'll need Tree.choose. You'll see this soon.
Writing a tree to disk #
The above calculateMoves function creates a Tree<string,Move>. The final piece of impure code you'll need to write is an operation that traverses such a tree and executes each Move.
// Tree<'a,Move> -> unit let writeTree t = let copy m = Directory.CreateDirectory m.Destination.DirectoryName |> ignore m.Source.CopyTo m.Destination.FullName |> ignore printfn "Copied to %s" m.Destination.FullName let compareFiles m = let sourceStream = File.ReadAllBytes m.Source.FullName let destinationStream = File.ReadAllBytes m.Destination.FullName sourceStream = destinationStream let move m = copy m if compareFiles m then m.Source.Delete () Tree.iter move t
The writeTree function traverses the input tree, and for each Move, it first copies the file, then it verifies that the copy was successful, and finally, if that's the case, it deletes the source file.
Composition #
You can now compose an impure-pure-impure sandwich from all the Lego pieces:
// string -> string -> unit let movePhotos source destination = let sourceTree = readTree source |> Tree.map FileInfo let photoTree = Tree.choose readPhoto sourceTree let destinationTree = Option.map (Archive.moveTo destination >> Archive.calculateMoves) photoTree Option.iter writeTree destinationTree
First, you load the sourceTree using the readTree operation. This returns a Tree<string,string>, so map the leaves to FileInfo objects. You then load the image metatadata by traversing sourceTree with Tree.choose readPhoto. Each call to readPhoto produces a PhotoFile option, so this is where you want to use Tree.choose to throw all the None values away.
Those two lines of code constitute the initial impure step of the sandwich (yes: mixed metaphors, I know).
The pure part of the sandwich is the composition of the pure functions moveTo and calculateMoves. Since photoTree is a Tree<string,PhotoFile> option, you'll need to perform that transformation inside of Option.map. The resulting destinationTree is a Tree<string,Move> option.
The final, impure step of the sandwich, then, is to apply all the moves with writeTree.
Execution #
The movePhotos operation takes source and destination arguments. You could hypothetically call it from a rich client or a background process, but here I'll just call if from a command-line program. The main operation will have to parse the input arguments and call movePhotos:
[<EntryPoint>] let main argv = match argv with | [|source; destination|] -> movePhotos source destination | _ -> printfn "Please provide source and destination directories as arguments." 0 // return an integer exit code
You could write more sophisticated parsing of the program arguments, but that's not the topic of this article, so I only wrote the bare minimum required to get the program working.
You can now compile and run the program:
$ ./ArchivePictures "C:\Users\mark\Desktop\Test" "C:\Users\mark\Desktop\Test-Out" Copied to C:\Users\mark\Desktop\Test-Out\2003-04\2003-04-29 15.11.50.jpg Copied to C:\Users\mark\Desktop\Test-Out\2011-07\2011-07-10 13.09.36.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-04\2014-04-18 14.05.02.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-04\2014-04-17 17.11.40.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-05\2014-05-23 16.07.20.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-06\2014-06-21 16.48.40.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-06\2014-06-30 15.44.52.jpg Copied to C:\Users\mark\Desktop\Test-Out\2016-05\2016-05-01 09.25.23.jpg Copied to C:\Users\mark\Desktop\Test-Out\2017-08\2017-08-22 19.53.28.jpg
This does indeed produce the expected destination directory structure.
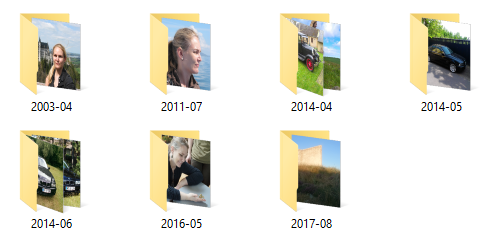
It's always nice when something turns out to work in practice, as well as in theory.
Summary #
Functional software architecture involves separating pure from impure code so that no pure functions invoke impure operations. Often, you can achieve that with what I call the impure-pure-impure sandwich architecture. In this example, you saw how to model the file system as a tree. This enables you to separate the impure file interactions from the pure program logic.
Picture archivist in Haskell
A comprehensive code example showing how to implement a functional architecture in Haskell.
This article shows how to implement the picture archivist architecture described in the previous article. In short, the task is to move some image files to directories based on their date-taken metadata. The architectural idea is to load a directory structure from disk into an in-memory tree, manipulate that tree, and use the resulting tree to perform the desired actions:
Much of the program will manipulate the tree data, which is immutable.
Tree #
You can start by defining a rose tree:
data Tree a b = Node a [Tree a b] | Leaf b deriving (Eq, Show, Read)
If you wanted to, you could put all the Tree code in a reusable library, because none of it is coupled to a particular application, such as moving pictures. You could also write a comprehensive test suite for the following functions, but in this article, I'll skip that.
Notice that this sort of tree explicitly distinguishes between internal and leaf nodes. This is necessary because you'll need to keep track of the directory names (the internal nodes), while at the same time you'll want to enrich the leaves with additional data - data that you can't meaningfully add to the internal nodes. You'll see this later in the article.
The rose tree catamorphism is this foldTree function:
foldTree :: (a -> [c] -> c) -> (b -> c) -> Tree a b -> c foldTree _ fl (Leaf x) = fl x foldTree fn fl (Node x xs) = fn x $ foldTree fn fl <$> xs
Sometimes I name the catamorphism cata, sometimes something like tree, but using a library like Data.Tree as another source of inspiration, in this article I chose to name it foldTree.
In this article, tree functionality is (with one exception) directly or transitively implemented with foldTree.
Filtering trees #
It'll be useful to be able to filter the contents of a tree. For example, the picture archivist program will only move image files with valid metadata. This means that it'll need to filter out all files that aren't image files, as well as image files without valid metadata.
It turns out that it'll be useful to supply a function that throws away Nothing values from a tree of Maybe leaves. This is similar to the catMaybes function from Data.Maybe, so I call it catMaybeTree:
catMaybeTree :: Tree a (Maybe b) -> Maybe (Tree a b) catMaybeTree = foldTree (\x -> Just . Node x . catMaybes) (fmap Leaf)
You may find the type of the function surprising. Why does it return a Maybe Tree, instead of simply a Tree? And if you accept the type as given, isn't this simply the sequence function?
While catMaybes simply returns a list, it can do this because lists can be empty. This Tree type, on the other hand, can't be empty. If the purpose of catMaybeTree is to throw away all Nothing values, then how do you return a tree from Leaf Nothing?
You can't return a Leaf because you have no value to put in the leaf. Similarly, you can't return a Node because, again, you have no value to put in the node.
In order to handle this edge case, then, you'll have to return Nothing:
Prelude Tree> catMaybeTree $ Leaf Nothing Nothing
Isn't this the same as sequence, then? It's not, because sequence short-circuits all data, as this list example shows:
Prelude> sequence [Just 42, Nothing, Just 2112] Nothing
Contrast this with the behaviour of catMaybes:
Prelude Data.Maybe> catMaybes [Just 42, Nothing, Just 2112] [42,2112]
You've yet to see the Traversable instance for Tree, but it behaves in the same way:
Prelude Tree> sequence $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)] Nothing
The catMaybeTree function, on the other hand, returns a filtered tree:
Prelude Tree> catMaybeTree $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)] Just (Node "Foo" [Leaf 42,Leaf 2112])
While the resulting tree is wrapped in a Just case, the leaves contain unwrapped values.
Instances #
The article about the rose tree catamorphism already covered how to add instances of Bifunctor, Bifoldable, and Bitraversable, so I'll give this only cursory treatment. Refer to that article for a more detailed treatment. The code that accompanies that article also has QuickCheck properties that verify the various laws associated with those instances. Here, I'll just list the instances without further comment:
instance Bifunctor Tree where bimap f s = foldTree (Node . f) (Leaf . s) instance Bifoldable Tree where bifoldMap f = foldTree (\x xs -> f x <> mconcat xs) instance Bitraversable Tree where bitraverse f s = foldTree (\x xs -> Node <$> f x <*> sequenceA xs) (fmap Leaf . s) instance Functor (Tree a) where fmap = second instance Foldable (Tree a) where foldMap = bifoldMap mempty instance Traversable (Tree a) where sequenceA = bisequenceA . first pure
The picture archivist program isn't going to explicitly need all of these, but transitively, it will.
Moving pictures #
So far, all the code shown here could be in a general-purpose reusable library, since it contains no functionality specifically related to image files. The rest of the code in this article, however, will be specific to the program. I'll put the domain model code in another module and import some functionality:
module Archive where import Data.Time import Text.Printf import System.FilePath import qualified Data.Map.Strict as Map import Tree
Notice that Tree is one of the imported modules.
Later, we'll look at how to load a tree from the file system, but for now, we'll just pretend that we have such a tree.
The major logic of the program is to create a destination tree based on a source tree. The leaves of the tree will have to carry some extra information apart from a file path, so you can introduce a specific type to capture that information:
data PhotoFile = PhotoFile { photoFileName :: FilePath, takenOn :: LocalTime } deriving (Eq, Show, Read)
A PhotoFile not only contains the file path for an image file, but also the date the photo was taken. This date can be extracted from the file's metadata, but that's an impure operation, so we'll delegate that work to the start of the program. We'll return to that later.
Given a source tree of PhotoFile leaves, though, the program must produce a destination tree of files:
moveTo :: (Foldable t, Ord a, PrintfType a) => a -> t PhotoFile -> Tree a FilePath moveTo destination = Node destination . Map.foldrWithKey addDir [] . foldr groupByDir Map.empty where dirNameOf (LocalTime d _) = let (y, m, _) = toGregorian d in printf "%d-%02d" y m groupByDir (PhotoFile fileName t) = Map.insertWith (++) (dirNameOf t) [fileName] addDir name files dirs = Node name (Leaf <$> files) : dirs
This moveTo function looks, perhaps, overwhelming, but it's composed of only three steps:
- Create a map of destination folders (
foldr groupByDir Map.empty). - Create a list of branches from the map (
Map.foldrWithKey addDir []). - Create a tree from the list (
Node destination).
. operator, you'll have to read the composition from right to left.
Notice that this function works with any Foldable data container, so it'd work with lists and other data structures besides trees.
The moveTo function starts by folding the input data into a map. The map is keyed by the directory name, which is formatted by the dirNameOf function. This function takes a LocalTime as input and formats it to a YYYY-MM format. For example, December 20, 2018 becomes "2018-12".
The entire mapping step groups the PhotoFile values into a map of the type Map a [FilePath]. All the image files taken in April 2014 are added to the list with the "2014-04" key, all the image files taken in July 2011 are added to the list with the "2011-07" key, and so on.
In the next step, the moveTo function converts the map to a list of trees. This will be the branches (or sub-directories) of the destination directory. Because of the desired structure of the destination tree, this is a list of shallow branches. Each node contains only leaves.
The only remaining step is to add that list of branches to a destination node.
Since this is a pure function, it's easy to unit test. Just create some input values and call the function:
"Move to destination" ~: do (source, destination, expected) <- [ ( Leaf $ PhotoFile "1" $ lt 2018 11 9 11 47 17 , "D" , Node "D" [Node "2018-11" [Leaf "1"]]) , ( Node "S" [ Leaf $ PhotoFile "4" $ lt 1972 6 6 16 15 00] , "D" , Node "D" [Node "1972-06" [Leaf "4"]]) , ( Node "S" [ Leaf $ PhotoFile "L" $ lt 2002 10 12 17 16 15, Leaf $ PhotoFile "J" $ lt 2007 4 21 17 18 19] , "D" , Node "D" [Node "2002-10" [Leaf "L"], Node "2007-04" [Leaf "J"]]) , ( Node "1" [ Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15, Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15, Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19] , "2" , Node "2" [ Node "2010-01" [Leaf "a", Leaf "c"], Node "2010-03" [Leaf "b"]]) , ( Node "foo" [ Node "bar" [ Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15, Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15, Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19], Node "baz" [ Leaf $ PhotoFile "d" $ lt 2010 3 1 2 3 4, Leaf $ PhotoFile "e" $ lt 2011 3 4 3 2 1 ]] , "qux" , Node "qux" [ Node "2010-01" [Leaf "a", Leaf "c"], Node "2010-03" [Leaf "b", Leaf "d"], Node "2011-03" [Leaf "e"]]) ] let actual = moveTo destination source return $ expected ~=? actual
This is an inlined parametrised HUnit test. While it looks like a big unit test, it still follows my test formatting heuristic. There's only three expressions, but the arrange expression is big because it creates a list of test cases.
Each test case is a triple of a source tree, a destination directory name, and an expected result. In order to make the test data code more compact, it utilises this test-specific helper function:
lt y mth d h m s = LocalTime (fromGregorian y mth d) (TimeOfDay h m s)
For each test case, the test calls the moveTo function with the destination directory name and the source tree. It then asserts that the expected value is equal to the actual value.
Calculating moves #
One pure step remains. The result of calling the moveTo function is a tree with the desired structure. In order to actually move the files, though, for each file you'll need to keep track of both the source path and the destination path. To make that explicit, you can define a type for that purpose:
data Move = Move { sourcePath :: FilePath, destinationPath :: FilePath } deriving (Eq, Show, Read)
A Move is simply a data structure. Contrast this with typical object-oriented design, where it would be a (possibly polymorphic) method on an object. In functional programming, you'll regularly model intent with a data structure. As long as intents remain data, you can easily manipulate them, and once you're done with that, you can run an interpreter over your data structure to perform the work you want accomplished.
The unit test cases for the moveTo function suggest that file names are local file names like "L", "J", "a", and so on. That was only to make the tests as compact as possible, since the function actually doesn't manipulate the specific FilePath values.
In reality, the file names will most likely be longer, and they could also contain the full path, instead of the local path: "C:\foo\bar\a.jpg".
If you call moveTo with a tree where each leaf has a fully qualified path, the output tree will have the desired structure of the destination tree, but the leaves will still contain the full path to each source file. That means that you can calculate a Move for each file:
calculateMoves :: Tree FilePath FilePath -> Tree FilePath Move calculateMoves = imp "" where imp path (Leaf x) = Leaf $ Move x $ replaceDirectory x path imp path (Node x xs) = Node (path </> x) $ imp (path </> x) <$> xs
This function takes as input a Tree FilePath FilePath, which is compatible with the output of moveTo. It returns a Tree FilePath Move, i.e. a tree where the leaves are Move values.
To be fair, returning a tree is overkill. A [Move] (list of moves) would have been just as useful, but in this article, I'm trying to describe how to write code with a functional architecture. In the overview article, I explained how you can model a file system using a rose tree, and in order to emphasise that point, I'll stick with that model a little while longer.
Earlier, I wrote that you can implement desired Tree functionality with the foldTree function, but that was a simplification. If you can implement the functionality of calculateMoves with foldTree, I don't know how. You can, however, implement it using explicit pattern matching and simple recursion.
The imp function builds up a file path (using the </> path combinator) as it recursively negotiates the tree. All Leaf nodes are converted to a Move value using the leaf node's current FilePath value as the sourcePath, and the path to figure out the desired destinationPath.
This code is still easy to unit test:
"Calculate moves" ~: do (tree, expected) <- [ (Leaf "1", Leaf $ Move "1" "1"), (Node "a" [Leaf "1"], Node "a" [Leaf $ Move "1" $ "a" </> "1"]), (Node "a" [Leaf "1", Leaf "2"], Node "a" [ Leaf $ Move "1" $ "a" </> "1", Leaf $ Move "2" $ "a" </> "2"]), (Node "a" [Node "b" [Leaf "1", Leaf "2"], Node "c" [Leaf "3"]], Node "a" [ Node ("a" </> "b") [ Leaf $ Move "1" $ "a" </> "b" </> "1", Leaf $ Move "2" $ "a" </> "b" </> "2"], Node ("a" </> "c") [ Leaf $ Move "3" $ "a" </> "c" </> "3"]]) ] let actual = calculateMoves tree return $ expected ~=? actual
The test cases in this parametrised test are tuples of an input tree and the expected tree. For each test case, the test calls the calculateMoves function with tree and asserts that the actual tree is equal to the expected tree.
That's all the pure code you need in order to implement the desired functionality. Now you only need to write some code that loads a tree from disk, and imprints a destination tree to disk, as well as the code that composes it all.
Loading a tree from disk #
The remaining code in this article is impure. You could put it in dedicated modules, but for this program, you're only going to need three functions and a bit of composition code, so you could also just put it all in the Main module. That's what I did.
To load a tree from disk, you'll need a root directory, under which you load the entire tree. Given a directory path, you read a tree using a recursive function like this:
readTree :: FilePath -> IO (Tree FilePath FilePath) readTree path = do isFile <- doesFileExist path if isFile then return $ Leaf path else do dirsAndfiles <- listDirectory path let paths = fmap (path </>) dirsAndfiles branches <- traverse readTree paths return $ Node path branches
This recursive function starts by checking whether the path is a file or a directory. If it's a file, it creates a new Leaf with that FilePath.
If path isn't a file, it's a directory. In that case, use listDirectory to enumerate all the directories and files in that directory. These are only local names, so prefix them with path to create full paths, then traverse all those directory entries recursively. That produces all the branches for the current node. Finally, return a new Node with the path and the branches.
Loading metadata #
The readTree function only produces a tree with FilePath leaves, while the program requires a tree with PhotoFile leaves. You'll need to read the Exif metadata from each file and enrich the tree with the date-taken data.
In this code base, I've used the hsexif library for this. That enables you to write an impure operation like this:
readPhoto :: FilePath -> IO (Maybe PhotoFile) readPhoto path = do exifData <- parseFileExif path let dateTaken = either (const Nothing) Just exifData >>= getDateTimeOriginal return $ PhotoFile path <$> dateTaken
This operation can fail for various reasons:
- The file may not exist.
- The file exists, but has no metadata.
- The file has metadata, but no date-taken metadata.
- The date-taken metadata string is malformed.
readPhoto converts the Either value returned by parseFileExif to Maybe and binds the result with getDateTimeOriginal.
When you traverse a Tree FilePath FilePath with readPhoto, you'll get a Tree FilePath (Maybe PhotoFile). That's when you'll need catMaybeTree. You'll see this soon.
Writing a tree to disk #
The above calculateMoves function creates a Tree FilePath Move. The final piece of impure code you'll need to write is an operation that traverses such a tree and executes each Move.
applyMoves :: Foldable t => t Move -> IO () applyMoves = traverse_ move where move m = copy m >> compareFiles m >>= deleteSource copy (Move s d) = do createDirectoryIfMissing True $ takeDirectory d copyFileWithMetadata s d putStrLn $ "Copied to " ++ show d compareFiles m@(Move s d) = do sourceBytes <- B.readFile s destinationBytes <- B.readFile d return $ if sourceBytes == destinationBytes then Just m else Nothing deleteSource Nothing = return () deleteSource (Just (Move s _)) = removeFile s
As I wrote above, a tree of Move values is, to be honest, overkill. Any Foldable container will do, as the applyMoves operation demonstrates. It traverses the data structure, and for each Move, it first copies the file, then it verifies that the copy was successful, and finally, if that's the case, it deletes the source file.
All of the operations invoked by these three steps are defined in various libraries part of the base GHC installation. You're welcome to peruse the source code repository if you're interested in the details.
Composition #
You can now compose an impure-pure-impure sandwich from all the Lego pieces:
movePhotos :: FilePath -> FilePath -> IO () movePhotos source destination = fmap fold $ runMaybeT $ do sourceTree <- lift $ readTree source photoTree <- MaybeT $ catMaybeTree <$> traverse readPhoto sourceTree let destinationTree = calculateMoves $ moveTo destination photoTree lift $ applyMoves destinationTree
First, you load the sourceTree using the readTree operation. This is a Tree FilePath FilePath value, because the code is written in do notation, and the context is MaybeT IO (). You then load the image metatadata by traversing sourceTree with readPhoto. This produces a Tree FilePath (Maybe PhotoFile) that you then filter with catMaybeTree. Again, because of do notation and monad transformer shenanigans, photoTree is a Tree FilePath PhotoFile value.
Those two lines of code is the initial impure step of the sandwich (yes: mixed metaphors, I know).
The pure part of the sandwich is the composition of the pure functions moveTo and calculateMoves. The result is a Tree FilePath Move value.
The final, impure step of the sandwich, then, is to applyMoves.
Execution #
The movePhotos operation takes source and destination arguments. You could hypothetically call it from a rich client or a background process, but here I'll just call if from a command-line program. The main operation will have to parse the input arguments and call movePhotos:
main :: IO () main = do args <- getArgs case args of [source, destination] -> movePhotos source destination _ -> putStrLn "Please provide source and destination directories as arguments."
You could write more sophisticated parsing of the program arguments, but that's not the topic of this article, so I only wrote the bare minimum required to get the program working.
You can now compile and run the program:
$ ./archpics "C:\Users\mark\Desktop\Test" "C:\Users\mark\Desktop\Test-Out" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2003-04\\2003-04-29 15.11.50.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2011-07\\2011-07-10 13.09.36.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-17 17.11.40.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-18 14.05.02.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-05\\2014-05-23 16.07.20.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-30 15.44.52.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-21 16.48.40.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2016-05\\2016-05-01 09.25.23.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2017-08\\2017-08-22 19.53.28.jpg"
This does indeed produce the expected destination directory structure.
It's always nice when something turns out to work in practice, as well as in theory.
Summary #
Functional software architecture involves separating pure from impure code so that no pure functions invoke impure operations. Often, you can achieve that with what I call the impure-pure-impure sandwich architecture. In this example, you saw how to model the file system as a tree. This enables you to separate the impure file interactions from the pure program logic.
The Haskell type system enforces the functional interaction law, which implies that the architecture is, indeed, properly functional. Other languages, like F#, don't enforce the law via the compiler, but that doesn't prevent you doing functional programming. Now that we've verified that the architecture is, indeed, functional, we can port it to F#.
Next: Picture archivist in F#.
Comments
This seems a fair architecture.
However, at first glance it does not seem very memory efficient, because everything might be loaded in RAM, and that poses a strict limit.
But then, I remember that Haskell does lazy evaluation, so is it the case here? Are path and the tree lazily loaded and processed?
In "traditional" architectures, IO would be scattered inside the program, and as each file might be read one at a time, and handled. This sandwich of purity with impure buns forces not to do that.
Jiehong, thank you for writing. It's true that Haskell is lazily evaluated, but some strictness rules apply to IO, so it's not so simple.
Just running a quick experiment with the code base shown here, when I try to move thousands of files, the program sits and thinks for quite some time before it starts to output progress. This indicates to me that it does, indeed, load at least the structure of the tree into memory before it starts moving the files. Once it does that, though, it looks like it runs at constant memory.
There's an interplay of laziness and IO in Haskell that I still don't sufficiently master. When I publish the port to F#, however, it should be clear that you could replace all the nodes of the tree with explicitly lazy values. I'd be surprised if something like that isn't possible in Haskell as well, but here I'll solicit help from readers more well-versed in these matters than I am.
I really like your posts and I'm really liking this series. But I struggle with Haskell syntax, specially the difference between the operators $, <$>, <>, <*>. Is there a cheat sheet explaining these operators?
André, thank you for writing. I've written about why I think that terse operators make the code overall more readable, but that's obviously not an explanation of any of those operators.
I'm not aware of any cheat sheets for Haskell, although a Google search seems to indicate that many exist. I'm not sure that a cheat sheet will help much if one doesn't know Haskell, and if one does know Haskell, one is likely to also know those operators.
$ is a sort of delimiter that often saves you from having to nest other function calls in brackets.
<$> is just an infix alias for fmap. In C#, that corresponds to the Select method.
<> is a generalised associative binary operation as defined by Data.Semigroup or Data.Monoid. You can read more about monoids and semigroups here on the blog.
<*> is part of the Applicative type class. It's hard to translate to other languages, but when I make the attempt, I usually call it Apply.
Naming newtypes for QuickCheck Arbitraries
A simple naming scheme for newtypes to add Arbitrary instances.
Naming is one of those recurring difficult problems in software development. How do you come up with good names?
I'm not aware of any general heuristic for that, but sometimes, in specific contexts, a naming scheme presents itself. Here's one.
Orphan instances #
When you write QuickCheck properties that involve your own custom types, you'll have to add Arbitrary instances for those types. As an example, here's a restaurant reservation record type:
data Reservation = Reservation { reservationId :: UUID , reservationDate :: LocalTime , reservationName :: String , reservationEmail :: String , reservationQuantity :: Int } deriving (Eq, Show, Read, Generic)
You can easily add an Arbitrary instance to such a type:
instance Arbitrary Reservation where arbitrary = liftM5 Reservation arbitrary arbitrary arbitrary arbitrary arbitrary
The type itself is part of your domain model, while the Arbitrary instance only belongs to your test code. You shouldn't add the Arbitrary instance to the domain model, but that means that you'll have to define the instance apart from the type definition. That, however, is an orphan instance, and the compiler will complain:
test\ReservationAPISpec.hs:31:1: warning: [-Worphans] Orphan instance: instance Arbitrary Reservation To avoid this move the instance declaration to the module of the class or of the type, or wrap the type with a newtype and declare the instance on the new type. | 31 | instance Arbitrary Reservation where | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^...
Technically, this isn't a difficult problem to solve. The warning even suggests remedies. Moving the instance to the module that declares the type is, however, inappropriate, since test-specific instances don't belong in the domain model. Wrapping the type in a newtype is more appropriate, but what should you call the type?
Suppress the warning #
I had trouble coming up with good names for such newtype wrappers, so at first I decided to just suppress that particular compiler warning. I simply added the -fno-warn-orphans flag exclusively to my test code.
That solved the immediate problem, but I felt a little dirty. It's okay, though, because you're not supposed to reuse test libraries anyway, so the usual problems with orphan instances don't apply.
After having worked a little like this, however, it dawned on me that I needed more than one Arbitrary instance, and a naming scheme presented itself.
Naming scheme #
For some of the properties I wrote, I needed a valid Reservation value. In this case, valid means that the reservationQuantity is a positive number, and that the reservationDate is in the future. It seemed natural to signify these constraints with a newtype:
newtype ValidReservation = ValidReservation Reservation deriving (Eq, Show) instance Arbitrary ValidReservation where arbitrary = do rid <- arbitrary d <- (\dt -> addLocalTime (getPositive dt) now2019) <$> arbitrary n <- arbitrary e <- arbitrary (Positive q) <- arbitrary return $ ValidReservation $ Reservation rid d n e q
The newtype is, naturally, called ValidReservation and can, for example, be used like this:
it "responds with 200 after reservation is added" $ WQC.property $ \ (ValidReservation r) -> do _ <- postJSON "/reservations" $ encode r let actual = get $ "/reservations/" <> toASCIIBytes (reservationId r) actual `shouldRespondWith` 200
For the few properties where any Reservation goes, a name for a newtype now also suggests itself:
newtype AnyReservation = AnyReservation Reservation deriving (Eq, Show) instance Arbitrary AnyReservation where arbitrary = AnyReservation <$> liftM5 Reservation arbitrary arbitrary arbitrary arbitrary arbitrary
The only use I've had for that particular instance so far, though, is to ensure that any Reservation correctly serialises to, and deserialises from, JSON:
it "round-trips" $ property $ \(AnyReservation r) -> do let json = encode r let actual = decode json actual `shouldBe` Just r
With those two newtype wrappers, I no longer have any orphan instances.
Summary #
A simple naming scheme for newtype wrappers for QuickCheck Arbitrary instances, then, is:
- If the instance is truly unbounded, prefix the wrapper name with Any
- If the instance only produces valid values, prefix the wrapper name with Valid
Functional file system
How do you model file systems in a functional manner, so that unit testing is enabled? An overview.
One of the many reasons that I like functional programming is that it's intrinsically testable. In object-oriented programming, you often have to jump through hoops to enable testing. This is also the case whenever you need to interact with the computer's file system. Just try to search the web for file system interface, or mock file system. I'm not going to give you any links, because I think such questions are XY problems. I don't think that the most common suggestions are proper solutions.
In functional programming, anyway, Dependency Injection isn't functional, because it makes everything impure. How, then, do you model the file system in such a way that it's pure, decoupled from the logic you'd like to add on top of it, and still has enough fidelity that you can perform most tasks?
You model the file system as a tree, or a forest.
File systems are hierarchies #
It should come as no surprise that file systems are hierarchies, or trees. Each logical drive is the root of a tree. Files are leaves, and directories are internal nodes. Does that sound familiar? That sounds like a rose tree.
Rose trees are immutable data structures. It doesn't get much more functional than that. Why not use a rose tree (or a forest) to model the file system?
What about interaction with the actual file system? Usually, when you encounter object-oriented attempts at decoupling an abstraction from the actual file system, you'll find polymorphic operations such as WriteAllText, GetFileSystemEntries, CreateDirectory, and so on. These would be the (mockable) methods that you have to implement, usually as Humble Objects.
If you, instead of a set of interfaces, model the file system as a forest, interacting with the actual file system is not even part of the abstraction. That's a typical shift of perspective from object-oriented design to functional programming.
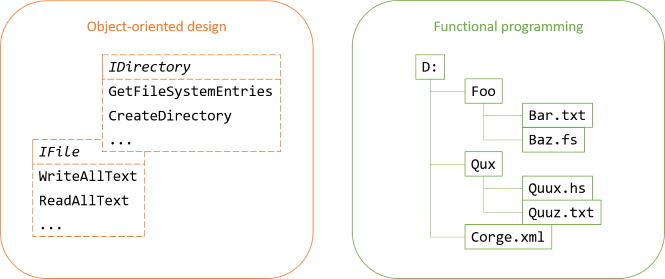
In object-oriented design, you typically attempt to model data with behaviour. Sometimes that fits the underlying reality well, but in this case it doesn't. While you have file and directory objects with behaviour, the actual structure of a file system is implicit. It's hidden in the interactions between the objects.
By modelling the file system as a tree, you explicitly use the structure of the data. How you load a tree into program memory, or how you imprint a tree unto the file system isn't part of the abstraction. When it comes to input and output, you're free to do what you want.
Once you have a model of a directory structure in memory, you can manipulate it to your heart's content. Since rose trees are functors, you know that all transformations are structure-preserving. That means that you don't even need to write tests for those parts of your application.
You'll appreciate an example, I'm sure.
Picture archivist example #
As an example, I'll attempt to answer an old Code Review question. I already gave an answer in 2015, but I'm not so happy with it today as I was back then. The question is great, though, because it explicitly demonstrates how people have a hard time escaping the notion that abstraction is only available via interfaces or abstract base classes. In 2015, I had long since figured out that delegates (and thus functions) are anonymous interfaces, but I still hadn't figured out how to separate pure from impure behaviour.
The question's scenario is how to implement a small program that can inspect a collection of image files, extract the date-taken metadata from each file, and move the files to a new directory structure based on that information.
For example, you could have files organised in various directories according to motive.

You soon realise, however, that that archiving strategy is untenable, because what do you do if there's more than one type of motive in a picture? Instead, you decide to organise the files according to month and year.
Clearly, there's some input and output involved in this application, but there's also some logic that you'd like to unit test. You need to parse the metadata, figure out where to move each image file, filter out files that are not images, and so on.
Object-oriented picture archivist #
If you were to implement such a picture archivist program with an object-oriented design, you may use Dependency Injection so that you can 'mock' the file system during unit testing. A typical program might then work like this at run time:
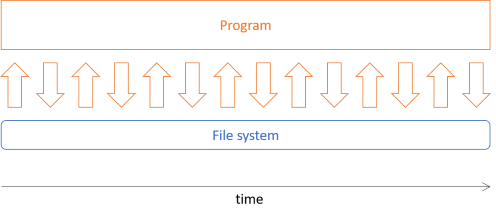
The program has fine-grained, busy interaction with the file system (through a polymorphic interface). It'll typically read one file, load its metadata, decide where to put the file, and copy it there. Then it'll move on to the next file, although it might also do this in parallel. Throughout the program execution, there's input and output going on, which makes it difficult to isolate the pure from the impure code.
Even if you write a program like that in F#, it's hardly a functional architecture.
Such an architecture is, in theory, testable, but my experience is that if you attempt to reproduce such busy, fine-grained interaction with mocks and stubs, you're likely to end up with brittle tests.
Functional picture archivist #
In functional programming, you'll have to reject the notion of dependencies. Instead, you can often resort to the simple architecture I call an impure-pure-impure sandwich; here, specifically:
- Load data from disk (impure)
- Transform the data (pure)
- Write data to disk (impure)
When the program starts, it loads data from disk into a tree. It then manipulates the in-memory model of the files in question, and once it's done, it traverses the entire tree and applies the changes.
This gives you a much clearer separation between the pure and impure parts of the code base. The pure part is bigger, and easier to unit test.
Example code #
This article gave you an overview of the functional architecture. In the next two articles, you'll see how to do this in practice. First, I'll implement the above architecture in Haskell, so that we know that if it works there, the architecture does, indeed, respect the functional interaction law.
Based on the Haskell implementation, you'll then see a port to F#.
These two articles share the same architecture. You can read both, or one of them, as you like. The source code is available on GitHub.Summary #
One of the hardest problems in transitioning from object-oriented programming to functional programming is that the design approach is so different. Many well-understood design patterns and principles don't translate easily. Dependency Injection is one of those. Often, you'll have to flip the model on its head, so to speak, before you can take it on in a functional manner.
While most object-oriented programmers would say that object-oriented design involves focusing on 'the nouns', in practice, it often revolves around interactions and behaviour. Sometimes, that's appropriate, but often, it's not.
Functional programming, in contrast, tends to take a more data-oriented perspective. Load some data, manipulate it, and publish it. If you can come up with an appropriate data structure for the data, you're probably on your way to implementing a functional architecture.
Next: Picture archivist in Haskell.
A rose tree functor
Rose trees form normal functors. A place-holder article for object-oriented programmers.
This article is an instalment in an article series about functors. As another article explains, a rose tree is a bifunctor. This makes it trivially a functor. As such, this article is mostly a place-holder to fit the spot in the functor table of contents, thereby indicating that rose trees are functors.
Since a rose tree is a bifunctor, it's actually not one, but two, functors. Many languages, C# included, are best equipped to deal with unambiguous functors. This is also true in Haskell, where you'd usally define the Functor instance over a bifunctor's right, or second, side. Likewise, in C#, you can make IRoseTree<N, L> a functor by implementing Select:
public static IRoseTree<N, L1> Select<N, L, L1>( this IRoseTree<N, L> source, Func<L, L1> selector) { return source.SelectLeaf(selector); }
This method simply delegates all implementation to the SelectLeaf method; it's just SelectLeaf by another name. It obeys the functor laws, since these are just specializations of the bifunctor laws, and we know that a rose tree is a proper bifunctor.
It would have been technically possible to instead implement a Select method by calling SelectNode, but it seems marginally more useful to enable syntactic sugar for mapping over the leaves.
Menu example #
As an example, imagine that you're defining part of a menu bar for an old-fashioned desktop application. Perhaps you're even loading the structure of the menu from a text file. Doing so, you could create a simple tree that represents the edit menu:
IRoseTree<string, string> editMenuTemplate = RoseTree.Node("Edit", RoseTree.Node("Find and Replace", new RoseLeaf<string, string>("Find"), new RoseLeaf<string, string>("Replace")), RoseTree.Node("Case", new RoseLeaf<string, string>("Upper"), new RoseLeaf<string, string>("Lower")), new RoseLeaf<string, string>("Cut"), new RoseLeaf<string, string>("Copy"), new RoseLeaf<string, string>("Paste"));
At this point, you have an IRoseTree<string, string>, so you might as well have used a 'normal' tree instead of a rose tree. The above template, however, is only a first step, because you have this Command class:
public class Command { public Command(string name) { Name = name; } public string Name { get; } public virtual void Execute() { } }
Apart from this base class, you also have classes that derive from it: FindCommand, ReplaceCommand, and so on. These classes override the Execute method by implenting find, replace, etc. functionality. Imagine that you also have a store or dictionary of these derived objects. This enables you to transform the template tree into a useful user menu:
IRoseTree<string, Command> editMenu = from name in editMenuTemplate select commandStore.Lookup(name);
Notice how this transforms only the leaves, using the command store's Lookup method. This example uses C# query syntax, because this is what the Select method enables, but you could also have written the translation by just calling the Select method.
The internal nodes in a menu have no behavious, so it makes little sense to attempt to turn them into Command objects as well. They're only there to provide structure to the menu. With a 'normal' tree, you wouldn't have been able to enrich only the leaves, while leaving the internal nodes untouched, but with a rose tree you can.
The above example uses the Select method (via query syntax) to translate the nodes, thereby providing a demonstration of how to use the rose tree as the functor it is.
Summary #
The Select doesn't implement any behaviour not already provided by SelectLeaf, but it enables C# query syntax. The C# compiler understands functors, but not bifunctors, so when you have a bifunctor, you might as well light up that language feature as well by adding a Select method.
Next: A Visitor functor.
Rose tree bifunctor
A rose tree forms a bifunctor. An article for object-oriented developers.
This article is an instalment in an article series about bifunctors. While the overview article explains that there's essentially two practically useful bifunctors, here's a third one. rose trees.
Mapping both dimensions #
Like in the previous article on the Either bifunctor, I'll start by implementing the simultaneous two-dimensional translation SelectBoth:
public static IRoseTree<N1, L1> SelectBoth<N, N1, L, L1>( this IRoseTree<N, L> source, Func<N, N1> selectNode, Func<L, L1> selectLeaf) { return source.Cata( node: (n, branches) => new RoseNode<N1, L1>(selectNode(n), branches), leaf: l => (IRoseTree<N1, L1>)new RoseLeaf<N1, L1>(selectLeaf(l))); }
This article uses the previously shown Church-encoded rose tree and its catamorphism Cata.
In the leaf case, the l argument received by the lambda expression is an object of the type L, since the source tree is an IRoseTree<N, L> object; i.e. a tree with leaves of the type L and nodes of the type N. The selectLeaf argument is a function that converts an L object to an L1 object. Since l is an L object, you can call selectLeaf with it to produce an L1 object. You can use this resulting object to create a new RoseLeaf<N1, L1>. Keep in mind that while the RoseLeaf class requires two type arguments, it never requires an object of its N type argument, which means that you can create an object with any node type argument, including N1, even if you don't have an object of that type.
In the node case, the lambda expression receives two objects: n and branches. The n object has the type N, while the branches object has the type IEnumerable<IRoseTree<N1, L1>>. In other words, the branches have already been translated to the desired result type. That's how the catamorphism works. This means that you only have to figure out how to translate the N object n to an N1 object. The selectNode function argument can do that, so you can then create a new RoseNode<N1, L1> and return it.
This works as expected:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree RoseNode<string, int>("foo", IRoseTree<string, int>[2] { 42, 1337 }) > tree.SelectBoth(s => s.Length, i => i.ToString()) RoseNode<int, string>(3, IRoseTree<int, string>[2] { "42", "1337" })
This C# Interactive example shows how to convert a tree with internal string nodes and integer leaves to a tree of internal integer nodes and string leaves. The strings are converted to strings by counting their Length, while the integers are turned into strings using the standard ToString method available on all objects.
Mapping nodes #
When you have SelectBoth, you can trivially implement the translations for each dimension in isolation. For tuple bifunctors, I called these methods SelectFirst and SelectSecond, while for Either bifunctors, I chose to name them SelectLeft and SelectRight. Continuing the trend of naming the translations after what they translate, instead of their positions, I'll name the corresponding methods here SelectNode and SelectLeaf. In Haskell, the functions associated with Data.Bifunctor are always called first and second, but I see no reason to preserve such abstract naming in C#. In Haskell, these functions are part of the Bifunctor type class; the abstract names serve an actual purpose. This isn't the case in C#, so there's no reason to retain the abstract names. You might as well use names that communicate intent, which is what I've tried to do here.
If you want to map only the internal nodes, you can implement a SelectNode method based on SelectBoth:
public static IRoseTree<N1, L> SelectNode<N, N1, L>( this IRoseTree<N, L> source, Func<N, N1> selector) { return source.SelectBoth(selector, l => l); }
This simply uses the l => l lambda expression as an ad-hoc identity function, while passing selector as the selectNode argument to the SelectBoth method.
You can use this to map the above tree to a tree made entirely of numbers:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree.SelectNode(s => s.Length) RoseNode<int, int>(3, IRoseTree<int, int>[2] { 42, 1337 })
Such a tree is, incidentally, isomorphic to a 'normal' tree. It might be a good exercise, if you need one, to demonstrate the isormorphism by writing functions that convert a Tree<T> into an IRoseTree<T, T>, and vice versa.
Mapping leaves #
Similar to SelectNode, you can also trivially implement SelectLeaf:
public static IRoseTree<N, L1> SelectLeaf<N, L, L1>( this IRoseTree<N, L> source, Func<L, L1> selector) { return source.SelectBoth(n => n, selector); }
This is another one-liner calling SelectBoth, with the difference that the identity function n => n is passed as the first argument, instead of as the last. This ensures that only RoseLeaf values are mapped:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree.SelectLeaf(i => i % 2 == 0) RoseNode<string, bool>("foo", IRoseTree<string, bool>[2] { true, false })
In the above C# Interactive session, the leaves are mapped to Boolean values, indicating whether they're even or odd.
Identity laws #
Rose trees obey all the bifunctor laws. While it's formal work to prove that this is the case, you can get an intuition for it via examples. Often, I use a property-based testing library like FsCheck or Hedgehog to demonstrate (not prove) that laws hold, but in this article, I'll keep it simple and only cover each law with a parametrised test.
private static T Id<T>(T x) => x; public static IEnumerable<object[]> BifunctorLawsData { get { yield return new[] { new RoseLeaf<int, string>("") }; yield return new[] { new RoseLeaf<int, string>("foo") }; yield return new[] { RoseTree.Node<int, string>(42) }; yield return new[] { RoseTree.Node(42, new RoseLeaf<int, string>("bar")) }; yield return new[] { exampleTree }; } } [Theory, MemberData(nameof(BifunctorLawsData))] public void SelectNodeObeysFirstFunctorLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectNode(Id)); }
This test uses xUnit.net's [Theory] feature to supply a small set of example input values. The input values are defined by the BifunctorLawsData property, since I'll reuse the same values for all the bifunctor law demonstration tests. The exampleTree object is the tree shown in Church-encoded rose tree.
The tests also use the identity function implemented as a private function called Id, since C# doesn't come equipped with such a function in the Base Class Library.
For all the IRoseTree<int, string> objects t, the test simply verifies that the original tree t is equal to the tree projected over the first axis with the Id function.
Likewise, the first functor law applies when translating over the second dimension:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectLeafObeysFirstFunctorLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectLeaf(Id)); }
This is the same test as the previous test, with the only exception that it calls SelectLeaf instead of SelectNode.
Both SelectNode and SelectLeaf are implemented by SelectBoth, so the real test is whether this method obeys the identity law:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothObeysIdentityLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectBoth(Id, Id)); }
Projecting over both dimensions with the identity function does, indeed, return an object equal to the input object.
Consistency law #
In general, it shouldn't matter whether you map with SelectBoth or a combination of SelectNode and SelectLeaf:
[Theory, MemberData(nameof(BifunctorLawsData))] public void ConsistencyLawHolds(IRoseTree<int, string> t) { DateTime f(int i) => new DateTime(i); bool g(string s) => string.IsNullOrWhiteSpace(s); Assert.Equal(t.SelectBoth(f, g), t.SelectLeaf(g).SelectNode(f)); Assert.Equal( t.SelectNode(f).SelectLeaf(g), t.SelectLeaf(g).SelectNode(f)); }
This example creates two local functions f and g. The first function, f, creates a new DateTime object from an integer, using one of the DateTime constructor overloads. The second function, g, just delegates to string.IsNullOrWhiteSpace, although I want to stress that this is just an example. The law should hold for any two (pure) functions.
The test then verifies that you get the same result from calling SelectBoth as when you call SelectNode followed by SelectLeaf, or the other way around.
Composition laws #
The composition laws insist that you can compose functions, or translations, and that again, the choice to do one or the other doesn't matter. Along each of the axes, it's just the second functor law applied. This parametrised test demonstrates that the law holds for SelectNode:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectNode(IRoseTree<int, string> t) { char f(bool b) => b ? 'T' : 'F'; bool g(int i) => i % 2 == 0; Assert.Equal( t.SelectNode(x => f(g(x))), t.SelectNode(g).SelectNode(f)); }
Here, f is a local function that returns the the character 'T' for true, and 'F' for false; g is the even function. The second functor law states that mapping f(g(x)) in a single step is equivalent to first mapping over g and then map the result of that using f.
The same law applies if you fix the first dimension and translate over the second:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectLeaf(IRoseTree<int, string> t) { bool f(int x) => x % 2 == 0; int g(string s) => s.Length; Assert.Equal( t.SelectLeaf(x => f(g(x))), t.SelectLeaf(g).SelectLeaf(f)); }
Here, f is the even function, whereas g is a local function that returns the length of a string. Again, the test demonstrates that the output is the same whether you map over an intermediary step, or whether you map using only a single step.
This generalises to the composition law for SelectBoth:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothCompositionLawHolds(IRoseTree<int, string> t) { char f(bool b) => b ? 'T' : 'F'; bool g(int x) => x % 2 == 0; bool h(int x) => x % 2 == 0; int i(string s) => s.Length; Assert.Equal( t.SelectBoth(x => f(g(x)), y => h(i(y))), t.SelectBoth(g, i).SelectBoth(f, h)); }
Again, whether you translate in one or two steps shouldn't affect the outcome.
As all of these tests demonstrate, the bifunctor laws hold for rose trees. The tests only showcase five examples, but I hope it gives you an intuition how any rose tree is a bifunctor. After all, the SelectNode, SelectLeaf, and SelectBoth methods are all generic, and they behave the same for all generic type arguments.
Summary #
Rose trees are bifunctors. You can translate the node and leaf dimension of a rose tree independently of each other, and the bifunctor laws hold for any pure translation, no matter how you compose the projections.
As always, there can be performance differences between the various compositions, but the outputs will be the same regardless of composition.
A functor, and by extension, a bifunctor, is a structure-preserving map. This means that any projection preserves the structure of the underlying container. For rose trees this means that the shape of the tree remains the same. The number of leaves remain the same, as does the number of internal nodes.
Next: Contravariant functors.
Rose tree catamorphism
The catamorphism for a tree with different types of nodes and leaves is made up from two functions.
This article is part of an article series about catamorphisms. A catamorphism is a universal abstraction that describes how to digest a data structure into a potentially more compact value.
This article presents the catamorphism for a rose tree, as well as how to identify it. The beginning of this article presents the catamorphism in C#, with examples. The rest of the article describes how to deduce the catamorphism. This part of the article presents my work in Haskell. Readers not comfortable with Haskell can just read the first part, and consider the rest of the article as an optional appendix.
A rose tree is a general-purpose data structure where each node in a tree has an associated value. Each node can have an arbitrary number of branches, including none. The distinguishing feature from a rose tree and just any tree is that internal nodes can hold values of a different type than leaf values.
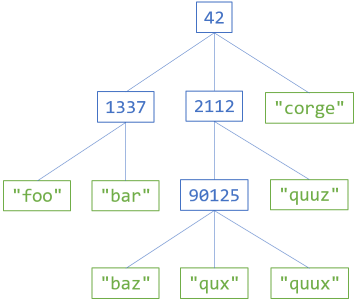
The diagram shows an example of a tree of internal integers and leaf strings. All internal nodes contain integer values, and all leaves contain strings. Each node can have an arbitrary number of branches.
C# catamorphism #
As a C# representation of a rose tree, I'll use the Church-encoded rose tree I've previously described. The catamorphism is this extension method:
public static TResult Cata<N, L, TResult>( this IRoseTree<N, L> tree, Func<N, IEnumerable<TResult>, TResult> node, Func<L, TResult> leaf) { return tree.Match( node: (n, branches) => node(n, branches.Select(t => t.Cata(node, leaf))), leaf: leaf); }
Like most of the other catamorphisms shown in this article series, this one consists of two functions. One that handles the leaf case, and one that handles the partially reduced node case. Compare it with the tree catamorphism: notice that the rose tree catamorphism's node function is identical to the the tree catamorphism. The leaf function, however, is new.
In previous articles, you've seen other examples of catamorphisms for Church-encoded types. The most common pattern has been that the Church encoding (the Match method) was also the catamorphism, with the Peano catamorphism being the only exception so far. When it comes to the Peano catamorphism, however, I'm not entirely confident that the difference between Church encoding and catamorphism is real, or whether it's just an artefact of the way I originally designed the Church encoding.
When it comes to the present rose tree, however, notice that the catamorphisms is distinctly different from the Church encoding. That's the reason I called the method Cata instead of Match.
The method simply delegates the leaf handler to Match, while it adds behaviour to the node case. It works the same way as for the 'normal' tree catamorphism.
Examples #
You can use Cata to implement most other behaviour you'd like IRoseTree<N, L> to have. In a future article, you'll see how to turn the rose tree into a bifunctor and functor, so here, we'll look at some other, more ad hoc, examples. As is also the case for the 'normal' tree, you can calculate the sum of all nodes, if you can associate a number with each node.
Consider the example tree in the above diagram. You can create it as an IRoseTree<int, string> object like this:
IRoseTree<int, string> exampleTree = RoseTree.Node(42, RoseTree.Node(1337, new RoseLeaf<int, string>("foo"), new RoseLeaf<int, string>("bar")), RoseTree.Node(2112, RoseTree.Node(90125, new RoseLeaf<int, string>("baz"), new RoseLeaf<int, string>("qux"), new RoseLeaf<int, string>("quux")), new RoseLeaf<int, string>("quuz")), new RoseLeaf<int, string>("corge"));
If you want to calculate a sum for a tree like that, you can use the integers for the internal nodes, and perhaps the length of the strings of the leaves. That hardly makes much sense, but is technically possible:
> exampleTree.Cata((x, xs) => x + xs.Sum(), x => x.Length) 93641
Perhaps slightly more useful is to count the number of leaves:
> exampleTree.Cata((_, xs) => xs.Sum(), _ => 1) 7
A leaf node has, by definition, exactly one leaf node, so the leaf lambda expression always returns 1. In the node case, xs contains the partially summed leaf node count, so just Sum those together while ignoring the value of the internal node.
You can also measure the maximum depth of the tree:
> exampleTree.Cata((_, xs) => 1 + xs.Max(), _ => 0) 3
Consistent with the example for 'normal' trees, you can arbitrarily decide that the depth of a leaf node is 0, so again, the leaf lambda expression just returns a constant value. The node lambda expression takes the Max of the partially reduced xs and adds 1, since an internal node represents another level of depth in a tree.
Rose tree F-Algebra #
As in the previous article, I'll use Fix and cata as explained in Bartosz Milewski's excellent article on F-Algebras.
As always, start with the underlying endofunctor:
data RoseTreeF a b c = NodeF { nodeValue :: a, nodes :: ListFix c } | LeafF { leafValue :: b } deriving (Show, Eq, Read) instance Functor (RoseTreeF a b) where fmap f (NodeF x ns) = NodeF x $ fmap f ns fmap _ (LeafF x) = LeafF x
Instead of using Haskell's standard list ([]) for the nodes, I've used ListFix from the article on list catamorphism. This should, hopefully, demonstrate how you can build on already established definitions derived from first principles.
As usual, I've called the 'data' types a and b, and the carrier type c (for carrier). The Functor instance as usual translates the carrier type; the fmap function has the type (c -> c1) -> RoseTreeF a b c -> RoseTreeF a b c1.
As was the case when deducing the recent catamorphisms, Haskell isn't too happy about defining instances for a type like Fix (RoseTreeF a b). To address that problem, you can introduce a newtype wrapper:
newtype RoseTreeFix a b = RoseTreeFix { unRoseTreeFix :: Fix (RoseTreeF a b) } deriving (Show, Eq, Read)
You can define Bifunctor, Bifoldable, Bitraversable, etc. instances for this type without resorting to any funky GHC extensions. Keep in mind that ultimately, the purpose of all this code is just to figure out what the catamorphism looks like. This code isn't intended for actual use.
A pair of helper functions make it easier to define RoseTreeFix values:
roseLeafF :: b -> RoseTreeFix a b roseLeafF = RoseTreeFix . Fix . LeafF roseNodeF :: a -> ListFix (RoseTreeFix a b) -> RoseTreeFix a b roseNodeF x = RoseTreeFix . Fix . NodeF x . fmap unRoseTreeFix
roseLeafF creates a leaf node:
Prelude Fix List RoseTree> roseLeafF "ploeh"
RoseTreeFix {unRoseTreeFix = Fix (LeafF "ploeh")}
roseNodeF is a helper function to create internal nodes:
Prelude Fix List RoseTree> roseNodeF 6 (consF (roseLeafF 0) nilF)
RoseTreeFix {unRoseTreeFix = Fix (NodeF 6 (ListFix (Fix (ConsF (Fix (LeafF 0)) (Fix NilF)))))}
Even with helper functions, construction of RoseTreeFix values is cumbersome, but keep in mind that the code shown here isn't meant to be used in practice. The goal is only to deduce catamorphisms from more basic universal abstractions, and you now have all you need to do that.
Haskell catamorphism #
At this point, you have two out of three elements of an F-Algebra. You have an endofunctor (RoseTreeF a b), and an object c, but you still need to find a morphism RoseTreeF a b c -> c. Notice that the algebra you have to find is the function that reduces the functor to its carrier type c, not any of the 'data types' a or b. This takes some time to get used to, but that's how catamorphisms work. This doesn't mean, however, that you get to ignore a or b, as you'll see.
As in the previous articles, start by writing a function that will become the catamorphism, based on cata:
roseTreeF = cata alg . unRoseTreeFix where alg (NodeF x ns) = undefined alg (LeafF x) = undefined
While this compiles, with its undefined implementations, it obviously doesn't do anything useful. I find, however, that it helps me think. How can you return a value of the type c from the LeafF case? You could pass a function argument to the roseTreeF function and use it with x:
roseTreeF fl = cata alg . unRoseTreeFix where alg (NodeF x ns) = undefined alg (LeafF x) = fl x
While you could, technically, pass an argument of the type c to roseTreeF and then return that value from the LeafF case, that would mean that you would ignore the x value. This would be incorrect, so instead, make the argument a function and call it with x. Likewise, you can deal with the NodeF case in the same way:
roseTreeF :: (a -> ListFix c -> c) -> (b -> c) -> RoseTreeFix a b -> c roseTreeF fn fl = cata alg . unRoseTreeFix where alg (NodeF x ns) = fn x ns alg (LeafF x) = fl x
This works. Since cata has the type Functor f => (f a -> a) -> Fix f -> a, that means that alg has the type f a -> a. In the case of RoseTreeF, the compiler infers that the alg function has the type RoseTreeF a b c -> c, which is just what you need!
You can now see what the carrier type c is for. It's the type that the algebra extracts, and thus the type that the catamorphism returns.
This, then, is the catamorphism for a rose tree. As has been the most common pattern so far, it's a pair, made from two functions. It's still not the only possible catamorphism, since you could trivially flip the arguments to roseTreeF, or the arguments to fn.
I've chosen the representation shown here because it's similar to the catamorphism I've shown for a 'normal' tree, just with the added function for leaves.
Basis #
You can implement most other useful functionality with roseTreeF. Here's the Bifunctor instance:
instance Bifunctor RoseTreeFix where bimap f s = roseTreeF (roseNodeF . f) (roseLeafF . s)
Notice how naturally the catamorphism implements bimap.
From that instance, the Functor instance trivially follows:
instance Functor (RoseTreeFix a) where fmap = second
You could probably also add Applicative and Monad instances, but I find those hard to grasp, so I'm going to skip them in favour of Bifoldable:
instance Bifoldable RoseTreeFix where bifoldMap f = roseTreeF (\x xs -> f x <> fold xs)
The Bifoldable instance enables you to trivially implement the Foldable instance:
instance Foldable (RoseTreeFix a) where foldMap = bifoldMap mempty
You may find the presence of mempty puzzling, since bifoldMap takes two functions as arguments. Is mempty a function?
Yes, mempty can be a function. Here, it is. There's a Monoid instance for any function a -> m, where m is a Monoid instance, and mempty is the identity for that monoid. That's the instance in use here.
Just as RoseTreeFix is Bifoldable, it's also Bitraversable:
instance Bitraversable RoseTreeFix where bitraverse f s = roseTreeF (\x xs -> roseNodeF <$> f x <*> sequenceA xs) (fmap roseLeafF . s)
You can comfortably implement the Traversable instance based on the Bitraversable instance:
instance Traversable (RoseTreeFix a) where sequenceA = bisequenceA . first pure
That rose trees are Traversable turns out to be useful, as a future article will show.
Relationships #
As was the case for 'normal' trees, the catamorphism for rose trees is more powerful than the fold. There are operations that you can express with the Foldable instance, but other operations that you can't. Consider the tree shown in the diagram at the beginning of the article. This is also the tree that the above C# examples use. In Haskell, using RoseTreeFix, you can define that tree like this:
exampleTree = roseNodeF 42 ( consF ( roseNodeF 1337 ( consF (roseLeafF "foo") $ consF (roseLeafF "bar") nilF)) $ consF ( roseNodeF 2112 ( consF ( roseNodeF 90125 ( consF (roseLeafF "baz") $ consF (roseLeafF "qux") $ consF (roseLeafF "quux") nilF)) $ consF (roseLeafF "quuz") nilF)) $ consF ( roseLeafF "corge") nilF)
You can trivially calculate the sum of string lengths of all leaves, using only the Foldable instance:
Prelude RoseTree> sum $ length <$> exampleTree 25
You can also fairly easily calculate a sum of all nodes, using the length of the strings as in the above C# example, but that requires the Bifoldable instance:
Prelude Data.Bifoldable Data.Semigroup RoseTree> bifoldMap Sum (Sum . length) exampleTree
Sum {getSum = 93641}
Fortunately, we get the same result as above.
Counting leaves, or measuring the depth of a tree, on the other hand, is impossible with the Foldable instance, but interestingly, it turns out that counting leaves is possible with the Bifoldable instance:
countLeaves :: (Bifoldable p, Num n) => p a b -> n countLeaves = getSum . bifoldMap (const $ Sum 0) (const $ Sum 1)
This works well with the example tree:
Prelude RoseTree> countLeaves exampleTree 7
Notice, however, that countLeaves works for any Bifoldable instance. Does that mean that you can 'count the leaves' of a tuple? Yes, it does:
Prelude RoseTree> countLeaves ("foo", "bar")
1
Prelude RoseTree> countLeaves (1, 42)
1
Or what about EitherFix:
Prelude RoseTree Either> countLeaves $ leftF "foo" 0 Prelude RoseTree Either> countLeaves $ rightF "bar" 1
Notice that 'counting the leaves' of tuples always returns 1, while 'counting the leaves' of Either always returns 0 for Left values, and 1 for Right values. This is because countLeaves considers the left, or first, data type to represent internal nodes, and the right, or second, data type to indicate leaves.
You can further follow that train of thought to realise that you can convert both tuples and EitherFix values to small rose trees:
fromTuple :: (a, b) -> RoseTreeFix a b fromTuple (x, y) = roseNodeF x (consF (roseLeafF y) nilF) fromEitherFix :: EitherFix a b -> RoseTreeFix a b fromEitherFix = eitherF (`roseNodeF` nilF) roseLeafF
The fromTuple function creates a small rose tree with one internal node and one leaf. The label of the internal node is the first value of the tuple, and the label of the leaf is the second value. Here's an example:
Prelude RoseTree> fromTuple ("foo", 42)
RoseTreeFix {unRoseTreeFix = Fix (NodeF "foo" (ListFix (Fix (ConsF (Fix (LeafF 42)) (Fix NilF)))))}
The fromEitherFix function turns a left value into an internal node with no leaves, and a right value into a leaf. Here are some examples:
Prelude RoseTree Either> fromEitherFix $ leftF "foo"
RoseTreeFix {unRoseTreeFix = Fix (NodeF "foo" (ListFix (Fix NilF)))}
Prelude RoseTree Either> fromEitherFix $ rightF 42
RoseTreeFix {unRoseTreeFix = Fix (LeafF 42)}
While counting leaves can be implemented using Bifoldable, that's not the case for measuring the depths of trees (I think; leave a comment if you know of a way to do this with one of the instances shown here). You can, however, measure tree depth with the catamorphism:
treeDepth :: RoseTreeFix a b -> Integer treeDepth = roseTreeF (\_ xs -> 1 + maximum xs) (const 0)
The implementation is similar to the implementation for 'normal' trees. I've arbitrarily decided that leaves have a depth of zero, so the function that handles leaves always returns 0. The function that handles internal nodes receives xs as a partially reduced list of depths below the node in question. Take the maximum of those and add 1, since each internal node has a depth of one.
Prelude RoseTree> treeDepth exampleTree 3
This, hopefully, illustrates that the catamorphism is more capable, and that the fold is just a (list-biased) specialisation.
Summary #
The catamorphism for rose trees is a pair of functions. One function transforms internal nodes with their partially reduced branches, while the other function transforms leaves.
For a realistic example of using a rose tree in a real program, see Picture archivist in Haskell.
This article series has so far covered progressively more complex data structures. The first examples (Boolean catamorphism and Peano catamorphism) were neither functors, applicatives, nor monads. All subsequent examples, on the other hand, are all of these, and more. The next example presents a functor that's neither applicative nor monad, yet still foldable. Obviously, what functionality it offers is still based on a catamorphism.
Comments
Each node can have an arbitrary number of branches, including none.
Because of this sentence, in the picture of an example after the containing paragraph, I expected to see a(n) (internal) node with no branches.
You can also measure the maximum depth of the tree:
> exampleTree.Cata((_, xs) => 1 + xs.Max(), _ => 0) 3
Max will throw an exception when given an internal node with no children. What value do you want to return in that case?
Tyson, thank you for writing. You're right that my implementation doesn't properly handle the empty edge case. That's also the case for Haskell's maximum function. I find it annoying that it's a partial function.
One can handle that edge case by assigning an arbitrary depth to an empty node, just as is the case for leaf nodes. If leaf nodes get assigned a depth of 0, wouldn't it be natural to also give empty internal nodes a depth of 0?
Yes, very natural. In particular, such a definition would be consistent with the corresponding definition for Tree<>. More specifically, we want the behaviors to be the same when the two type parameters in IRoseTree<,> are the same (and the function passed in for leaf is the same as the one passed in for node after fixing the second argument to Enumberable.Empty<TResult>()>).
I think the smallest change to get the depth to be 0 for an internal node with no children is to replace Max with a slight variant that returns -1 when there are no children. I don't think this is readable though. It is quite the magic number. But it is just the codification of the thought process that lead to it.
Each (internal) node can have an arbitrary number of branches, including none.
...
...an internal node represents another level of depth in a tree.
It is because of such edge cases that Jeremy Gibbons in his PhD thesis Algebras for Tree Algorithms says (on page 44) that the internal nodes of his rose tree must include at least one child.
Meertens allows his lists of children to be empty, so permitting parents with no children; to avoid this rather strange concept we use non-empty lists.
I think Jeremy has me convinced. One could say that this heterogenous rose tree was obtained from the homogeneous variant by adding a type for the leaves. The homogeneous variant denoted leaves via an empty list of children. It makes sense then to remove the empty list approach for making a leaf when adding the typed approach. So, I think the best fix then would be to modify your definition of RoseNode<,> in your first rose tree article to be the same as Jeremy's (by requiring that IEnumerable<> of children is non-empty). This change would also better match your example pictures of a rose tree, which do not include an internal node without children.
Yes, it'd definitely be an option to change the definition of an internal node to a NonEmptyCollection.
My underlying motivation for defining the type like I've done in these articles, however, was to provide the underlying abstraction for a functional file system. In order to model a file system, empty nodes should be possible, because they correspond to empty directories.
Church-encoded rose tree
A rose tree is a tree with leaf nodes of one type, and internal nodes of another.
This article is part of a series of articles about Church encoding. In the previous articles, you've seen how to implement a Maybe container, and how to implement an Either container. Through these examples, you've learned how to model sum types without explicit language support. In this article, you'll see how to model a rose tree.
A rose tree is a general-purpose data structure where each node in a tree has an associated value. Each node can have an arbitrary number of branches, including none. The distinguishing feature from a rose tree and just any tree is that internal nodes can hold values of a different type than leaf values.
The diagram shows an example of a tree of internal integers and leaf strings. All internal nodes contain integer values, and all leaves contain strings. Each node can have an arbitrary number of branches.
Contract #
In C#, you can represent the fundamental structure of a rose tree with a Church encoding, starting with an interface:
public interface IRoseTree<N, L> { TResult Match<TResult>( Func<N, IEnumerable<IRoseTree<N, L>>, TResult> node, Func<L, TResult> leaf); }
The structure of a rose tree includes two mutually exclusive cases: internal nodes and leaf nodes. Since there's two cases, the Match method takes two arguments, one for each case.
The interface is generic, with two type arguments: N (for Node) and L (for leaf). Any consumer of an IRoseTree<N, L> object must supply two functions when calling the Match method: a function that turns a node into a TResult value, and a function that turns a leaf into a TResult value.
Both cases must have a corresponding implementation.
Leaves #
The leaf implementation is the simplest:
public sealed class RoseLeaf<N, L> : IRoseTree<N, L> { private readonly L value; public RoseLeaf(L value) { this.value = value; } public TResult Match<TResult>( Func<N, IEnumerable<IRoseTree<N, L>>, TResult> node, Func<L, TResult> leaf) { return leaf(value); } public override bool Equals(object obj) { if (!(obj is RoseLeaf<N, L> other)) return false; return Equals(value, other.value); } public override int GetHashCode() { return value.GetHashCode(); } }
The RoseLeaf class is an Adapter over a value of the generic type L. As is always the case with Church encoding, it implements the Match method by unconditionally calling one of the arguments, in this case the leaf function, with its adapted value.
While it doesn't have to do this, it also overrides Equals and GetHashCode. This is an immutable class, so it's a great candidate to be a Value Object. Making it a Value Object makes it easier to compare expected and actual values in unit tests, among other benefits.
Nodes #
The node implementation is slightly more complex:
public sealed class RoseNode<N, L> : IRoseTree<N, L> { private readonly N value; private readonly IEnumerable<IRoseTree<N, L>> branches; public RoseNode(N value, IEnumerable<IRoseTree<N, L>> branches) { this.value = value; this.branches = branches; } public TResult Match<TResult>( Func<N, IEnumerable<IRoseTree<N, L>>, TResult> node, Func<L, TResult> leaf) { return node(value, branches); } public override bool Equals(object obj) { if (!(obj is RoseNode<N, L> other)) return false; return Equals(value, other.value) && Enumerable.SequenceEqual(branches, other.branches); } public override int GetHashCode() { return value.GetHashCode() ^ branches.GetHashCode(); } }
A node contains both a value (of the type N) and a collection of sub-trees, or branches. The class implements the Match method by unconditionally calling the node function argument with its constituent values.
Again, it overrides Equals and GetHashCode for the same reasons as RoseLeaf. This isn't required to implement Church encoding, but makes comparison and unit testing easier.
Usage #
You can use the RoseLeaf and RoseNode constructors to create new trees, but it sometimes helps to have a static helper method to create values. It turns out that there's little value in a helper method for leaves, but for nodes, it's marginally useful:
public static IRoseTree<N, L> Node<N, L>(N value, params IRoseTree<N, L>[] branches) { return new RoseNode<N, L>(value, branches); }
This enables you to create tree objects, like this:
IRoseTree<string, int> tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337));
That's a single node with the label "foo" and two leaves with the values 42 and 1337, respectively. You can create the tree shown in the above diagram like this:
IRoseTree<int, string> exampleTree = RoseTree.Node(42, RoseTree.Node(1337, new RoseLeaf<int, string>("foo"), new RoseLeaf<int, string>("bar")), RoseTree.Node(2112, RoseTree.Node(90125, new RoseLeaf<int, string>("baz"), new RoseLeaf<int, string>("qux"), new RoseLeaf<int, string>("quux")), new RoseLeaf<int, string>("quuz")), new RoseLeaf<int, string>("corge"));
You can add various extension methods to implement useful functionality. In later articles, you'll see some more compelling examples, so here, I'm only going to show a few basic examples. One of the simplest features you can add is a method that will tell you if an IRoseTree<N, L> object is a node or a leaf:
public static IChurchBoolean IsLeaf<N, L>(this IRoseTree<N, L> source) { return source.Match<IChurchBoolean>( node: (_, __) => new ChurchFalse(), leaf: _ => new ChurchTrue()); } public static IChurchBoolean IsNode<N, L>(this IRoseTree<N, L> source) { return new ChurchNot(source.IsLeaf()); }
Since this article is part of the overall article series on Church encoding, and the purpose of that article series is also to show how basic language features can be created from Church encodings, these two methods return Church-encoded Boolean values instead of the built-in bool type. I'm sure you can imagine how you could change the type to bool if you'd like.
You can use these methods like this:
> IRoseTree<Guid, double> tree = new RoseLeaf<Guid, double>(-3.2); > tree.IsLeaf() ChurchTrue { } > tree.IsNode() ChurchNot(ChurchTrue) > IRoseTree<long, string> tree = RoseTree.Node<long, string>(42); > tree.IsLeaf() ChurchFalse { } > tree.IsNode() ChurchNot(ChurchFalse)
In a future article, you'll see some more compelling examples.
Terminology #
It's not entirely clear what to call a tree like the one shown here. The Wikipedia entry doesn't state one way or the other whether internal node types ought to be distinguishable from leaf node types, but there are indications that this could be the case. At least, it seems that the term isn't well-defined, so I took the liberty to retcon the name rose tree to the data structure shown here.
In the paper that introduces the rose tree term, Meertens writes:
While the concept is foreign in C#, you can trivially introduce a unit data type:"We consider trees whose internal nodes may fork into an arbitrary (natural) number of sub-trees. (If such a node has zero descendants, we still consider it internal.) Each external node carries a data item. No further information is stored in the tree; in particular, internal nodes are unlabelled."
public class Unit { public readonly static Unit Instance = new Unit(); private Unit() { } }
This enables you to create a rose tree according to Meertens' definition:
IRoseTree<Unit, int> meertensTree = RoseTree.Node(Unit.Instance, RoseTree.Node(Unit.Instance, RoseTree.Node(Unit.Instance, new RoseLeaf<Unit, int>(2112)), new RoseLeaf<Unit, int>(42), new RoseLeaf<Unit, int>(1337), new RoseLeaf<Unit, int>(90125)), RoseTree.Node(Unit.Instance, new RoseLeaf<Unit, int>(1984)), new RoseLeaf<Unit, int>(666));
Visually, you could draw it like this:
Thus, the tree structure shown here seems to be a generalisation of Meertens' original definition.
I'm not a mathematician, so I may have misunderstood some things. If you have a better name than rose tree for the data structure shown here, please leave a comment.
Yeats #
Now that we're on the topic of rose tree as a term, you may, as a bonus, enjoy a similarly-titled poem:
As far as I can tell, though, Yeats' metaphor is dissimilar to Meertens'.THE ROSE TREE
"O words are lightly spoken"
Said Pearse to Connolly,
"Maybe a breath of politic words
Has withered our Rose Tree;
Or maybe but a wind that blows
Across the bitter sea.""It needs to be but watered,"
James Connolly replied,
"To make the green come out again
And spread on every side,
And shake the blossom from the bud
To be the garden's pride."
"But where can we draw water"
Said Pearse to Connolly,
"When all the wells are parched away?
O plain as plain can be
There's nothing but our own red blood
Can make a right Rose Tree."
Summary #
You may occasionally find use for a tree that distinguishes between internal and leaf nodes. You can model such a tree with a Church encoding, as shown in this article.
Next: Catamorphisms.
Comments
If you have a better name than rose tree for the data structure shown here, please leave a comment.
I would consider using heterogeneous rose tree.
In your linked Twitter thread, Keith Battocchi shared a link to the thesis of Jeremy Gibbons (which is titled Algebras for Tree Algorithms). In his thesis, he defines rose tree as you have and then derives from that (on page 45) the special cases that he calls unlabelled rose tree, leaf-labeled rose tree, branch-labeled rose tree, and homogeneous rose tree.
The advantage of Jeremy's approach is that the name of each special case is formed from the named of the general case by adding an adjective. The disadvantage is the ambiguity that comes from being inconsistent with the definition of rose tree compared to both previous works and current usage (as shown by your numerous links).
The goal of naming is communication, and the name rose tree risks miscommunication, which is worse than no communication at all. Miscommunication would result by (for example) calling this heterogeneous rose tree a rose tree and someone that knows the rose tree definition in Haskell skims over your definition thinking that they already know it. However, I think you did a good job with this article and made that unlikely.
The advantage of heterogeneous rose tree is that the name is not overloaded and heterogeneous clearly indicates the intended variant. If a reader has heard of a rose tree, then they probably know there are several variants and can infer the correct one from this additional adjective.
In the end though, I think using the name rose tree as you did was a good choice. Your have now written several articles involving rose trees and they all use the same variant. Since you always use the same variant, it would be a bit verbose to always include an additional adjective to specify the variant.
The only thing I would have considered changing is the first mention of rose tree in this article. It is common in academic writing to start with the general definition and then give shorter alternatives for brevity. This is one way it could have been written in this article.
A heterogeneous rose tree is a tree with leaf nodes of one type, and internal nodes of another.
This article is part of a series of articles about Church encoding. In the previous articles, you've seen how to implement a Maybe container, and how to implement an Either container. Through these examples, you've learned how to model sum types without explicit language support. In this article, you'll see how to model a heterogeneous rose tree.
A heterogeneous rose tree is a general-purpose data structure where each node in a tree has an associated value. Each node can have an arbitrary number of branches, including none. The distinguishing feature from a heterogeneous rose tree and just any tree is that internal nodes can hold values of a different type than leaf values. For brevity, we will omit heterogeneous and simply call this data structure a rose tree.
Tyson, thank you for writing. I agree that specificity is desirable. I haven't read the Gibbons paper, so I'll have to reflect on your summary. If I understand you correctly, a type like IRoseTree shown in this article constitutes the general case. In Haskell, I simply named it Tree a b, which is probably too general, but may help to illustrate the following point.
As far as I remember, C# doesn't have type aliases, so Haskell makes the point more succinct. If I understand you correctly, then, you could define a heterogeneous rose tree as:
type HeterogeneousRoseTree = Tree
Furthermore, I suppose that a leaf-labeled rose tree is this:
type LeafLabeledRoseTree b = Tree () b
Would the following be a branch-labeled rose tree?
type BranchLabeledRoseTree a = Tree a ()
And this is, I suppose, a homogeneous rose tree:
type HomogeneousRoseTree a = Tree a a
I can't imagine what an unlabelled rose tree is, unless it's this:
type UnlabelledRoseTree = Tree () ()
I don't see how that'd be of much use, but I suppose that's just my lack of imagination.
Chain of Responsibility as catamorphisms
The Chain of Responsibility design pattern can be viewed as a list fold over the First monoid, followed by a Maybe fold.
This article is part of a series of articles about specific design patterns and their category theory counterparts. In it, you'll see how the Chain of Responsibility design pattern is equivalent to a succession of catamorphisms. First, you apply the First Maybe monoid over the list catamorphism, and then you conclude the reduction with the Maybe catamorphism.
Pattern #
The Chain of Responsibility design pattern gives you a way to model cascading conditionals with an object structure. It's a chain (or linked list) of objects that all implement the same interface (or base class). Each object (apart from the the last) has a reference to the next object in the list.
A client (some other code) calls a method on the first object in the list. If that object can handle the request, it does so, and the interaction ends there. If the method returns a value, the object returns the value.
If the first object determines that it can't handle the method call, it calls the next object in the chain. It only knows the next object as the interface, so the only way it can delegate the call is by calling the same method as the first one. In the above diagram, Imp1 can't handle the method call, so it calls the same method on Imp2, which also can't handle the request and delegates responsibility to Imp3. In the diagram, Imp3 can handle the method call, so it does so and returns a result that propagates back up the chain. In that particular example, Imp4 never gets involved.
You'll see an example below.
One of the advantages of the pattern is that you can rearrange the chain to change its behaviour. You can even do this at run time, if you'd like, since all objects implement the same interface.
User icon example #
Consider an online system that maintains user profiles for users. A user is modelled with the User class:
public User(int id, string name, string email, bool useGravatar, bool useIdenticon)
While I only show the signature of the class' constructor, it should be enough to give you an idea. If you need more details, the entire example code base is available on GitHub.
Apart from an id, a name and email address, a user also has two flags. One flag tracks whether the user wishes to use his or her Gravatar, while another flag tracks if the user would like to use an Identicon. Obviously, both flags could be true, in which case the current business rule states that the Gravatar should take precedence.
If none of the flags are set, users might still have a picture associated with their profile. This could be a picture that they've uploaded to the system, and is being tracked by a database.
If no user icon can be found or generated, ultimately the system should use a fallback, default icon:
![]()
To summarise, the current rules are:
- Use Gravatar if flag is set.
- Use Identicon if flag is set.
- Use uploaded picture if available.
- Use default icon.
To request an icon, a client can use the IIconReader interface:
public interface IIconReader { Icon ReadIcon(User user); }
The Icon class is just a Value Object wrapper around a URL. The idea is that such a URL can be used in an img tag to show the icon. Again, the full source code is available on GitHub if you'd like to investigate the details.
The various rules for icon retrieval can be implemented using this interface.
Gravatar reader #
Although you don't have to implement the classes in the order in which you are going to compose them, it seems natural to do so, starting with the Gravatar implementation.
public class GravatarReader : IIconReader { private readonly IIconReader next; public GravatarReader(IIconReader next) { this.next = next; } public Icon ReadIcon(User user) { if (user.UseGravatar) return new Icon(new Gravatar(user.Email).Url); return next.ReadIcon(user); } }
The GravatarReader class both implements the IIconReader interface, but also decorates another object of the same polymorphic type. If user.UseGravatar is true, it generates the appropriate Gravatar URL based on the user's Email address; otherwise, it delegates the work to the next object in the Chain of Responsibility.
The Gravatar class contains the implementation details to generate the Gravatar Url. Again, please refer to the GitHub repository if you're interested in the details.
Identicon reader #
When you compose the chain, according to the above business logic, the next type of icon you should attempt to generate is an Identicon. It's natural to implement the Identicon reader next, then:
public class IdenticonReader : IIconReader { private readonly IIconReader next; public IdenticonReader(IIconReader next) { this.next = next; } public Icon ReadIcon(User user) { if (user.UseIdenticon) return new Icon(new Uri(baseUrl, HashUser(user))); return next.ReadIcon(user); } // Implementation details go here... }
Again, I'm omitting implementation details in order to focus on the Chain of Responsibility design pattern. If user.UseIdenticon is true, the IdenticonReader generates the appropriate Identicon and returns the URL for it; otherwise, it delegates the work to the next object in the chain.
Database icon reader #
The DBIconReader class attempts to find an icon ID in a database. If it succeeds, it creates a URL corresponding to that ID. The assumption is that that resource exists; either it's a file on disk, or it's an image resource generated on the spot based on binary data stored in the database.
public class DBIconReader : IIconReader { private readonly IUserRepository repository; private readonly IIconReader next; public DBIconReader(IUserRepository repository, IIconReader next) { this.repository = repository; this.next = next; } public Icon ReadIcon(User user) { if (!repository.TryReadIconId(user.Id, out string iconId)) return next.ReadIcon(user); var parameters = new Dictionary<string, string> { { "iconId", iconId } }; return new Icon(urlTemplate.BindByName(baseUrl, parameters)); } private readonly Uri baseUrl = new Uri("https://example.com"); private readonly UriTemplate urlTemplate = new UriTemplate("users/{iconId}/icon"); }
This class demonstrates some variations in the way you can implement the Chain of Responsibility design pattern. The above GravatarReader and IdenticonReader classes both follow the same implementation pattern of checking a condition, and then performing work if the condition is true. The delegation to the next object in the chain happens, in those two classes, outside of the if statement.
The DBIconReader class, on the other hand, reverses the structure of the code. It uses a Guard Clause to detect whether to exit early, which is done by delegating work to the next object in the chain.
If TryReadIconId returns true, however, the ReadIcon method proceeds to create the appropriate icon URL.
Another variation on the Chain of Responsibility design pattern demonstrated by the DBIconReader class is that it takes a second dependency, apart from next. The repository is the usual misapplication of the Repository design pattern that everyone think they use correctly. Here, it's used in the common sense to provide access to a database. The main point, though, is that you can add as many other dependencies to a link in the chain as you'd like. All links, apart from the last, however, must have a reference to the next link in the chain.
Default icon reader #
Like linked lists, a Chain of Responsibility has to ultimately terminate. You can use the following DefaultIconReader for that.
public class DefaultIconReader : IIconReader { public Icon ReadIcon(User user) { return Icon.Default; } }
This class unconditionally returns the Default icon. Notice that it doesn't have any next object it delegates to. This terminates the chain. If no previous implementation of the IIconReader has returned an Icon for the user, this one does.
Chain composition #
With four implementations of IIconReader, you can now compose the Chain of Responsibility:
IIconReader reader = new GravatarReader( new IdenticonReader( new DBIconReader(repo, new DefaultIconReader())));
The first link in the chain is a GravatarReader object that contains an IdenticonReader object as its next link, and so on. Referring back to the source code of GravatarReader, notice that its next dependency is declared as an IIconReader. Since the IdenticonReader class implements that interface, you can compose the chain like this, but if you later decide to change the order of the objects, you can do so simply by changing the composition. You could remove objects altogether, or add new classes, and you could even do this at run time, if required.
The DBIconReader class requires an extra IUserRepository dependency, here simply an existing object called repo.
The DefaultIconReader takes no other dependencies, so this effectively terminates the chain. If you try to pass another IIconReader to its constructor, the code doesn't compile.
Haskell proof of concept #
When evaluating whether a design is a functional architecture, I often port the relevant parts to Haskell. You can do the same with the above example, and put it in a form where it's clearer that the Chain of Responsibility pattern is equivalent to two well-known catamorphisms.
Readers not comfortable with Haskell can skip the next few sections. The object-oriented example continues below.
User and Icon types are defined by types equivalent to above. There's no explicit interface, however. Creation of Gravatars and Identicons are both pure functions with the type User -> Maybe Icon. Here's the Gravatar function, but the Identicon function looks similar:
gravatarUrl :: String -> String gravatarUrl email = "https://www.gravatar.com/avatar/" ++ show (hashString email :: MD5Digest) getGravatar :: User -> Maybe Icon getGravatar u = if useGravatar u then Just $ Icon $ gravatarUrl $ userEmail u else Nothing
Reading an icon ID from a database, however, is an impure operation, so the function to do this has the type User -> IO (Maybe Icon).
Lazy I/O in Haskell #
Notice that the database icon-querying function has the return type IO (Maybe Icon). In the introduction you read that the Chain of Responsibility design pattern is a sequence of catamorphisms - the first one over a list of First values. While First is, in itself, a Semigroup instance, it gives rise to a Monoid instance when combined with Maybe. Thus, to showcase the abstractions being used, you could create a list of Maybe (First Icon) values. This forms a Monoid, so is easy to fold.
The problem with that, however, is that IO is strict under evaluation, so while it works, it's no longer lazy. You can combine IO (Maybe (First Icon)) values, but it leads to too much I/O activity.
You can solve this problem with a newtype wrapper:
newtype FirstIO a = FirstIO (MaybeT IO a) deriving (Functor, Applicative, Monad, Alternative) firstIO :: IO (Maybe a) -> FirstIO a firstIO = FirstIO . MaybeT getFirstIO :: FirstIO a -> IO (Maybe a) getFirstIO (FirstIO (MaybeT x)) = x instance Semigroup (FirstIO a) where (<>) = (<|>) instance Monoid (FirstIO a) where mempty = empty
This uses the GeneralizedNewtypeDeriving GHC extension to automatically make FirstIO Functor, Applicative, Monad, and Alternative. It also uses the Alternative instance to implement Semigroup and Monoid. You may recall from the documentation that Alternative is already a "monoid on applicative functors."
Alignment #
You now have three functions with different types: two pure functions with the type User -> Maybe Icon and one impure database-bound function with the type User -> IO (Maybe Icon). In order to have a common abstraction, you should align them so that all types match. At first glance, User -> IO (Maybe (First Icon)) seems like a type that fits all implementations, but that causes too much I/O to take place, so instead, use User -> FirstIO Icon. Here's how to lift the pure getGravatar function:
getGravatarIO :: User -> FirstIO Icon getGravatarIO = firstIO . return . getGravatar
You can lift the other functions in similar fashion, to produce getGravatarIO, getIdenticonIO, and getDBIconIO, all with the mutual type User -> FirstIO Icon.
Haskell composition #
The goal of the Haskell proof of concept is to compose a function that can provide an Icon for any User - just like the above C# composition that uses Chain of Responsibility. There's, however, no way around impurity, because one of the steps involve a database, so the aim is a composition with the type User -> IO Icon.
While a more compact composition is possible, I'll show it in a way that makes the catamorphisms explicit:
getIcon :: User -> IO Icon getIcon u = do let lazyIcons = fmap (\f -> f u) [getGravatarIO, getIdenticonIO, getDBIconIO] m <- getFirstIO $ fold lazyIcons return $ fromMaybe defaultIcon m
The getIcon function starts with a list of all three functions. For each of them, it calls the function with the User value u. This may seem inefficient and redundant, because all three function calls may not be required, but since the return values are FirstIO values, all three function calls are lazily evaluated - even under IO. The result, lazyIcons, is a [FirstIO Icon] value; i.e. a lazily evaluated list of lazily evaluated values.
This first step is just to put the potential values in a form that's recognisable. You can now fold the lazyIcons to a single FirstIO Icon value, and then use getFirstIO to unwrap it. Due to do notation, m is a Maybe Icon value.
This is the first catamorphism. Granted, the generalisation that fold offers is not really required, since lazyIcons is a list; mconcat would have worked just as well. I did, however, choose to use fold (from Data.Foldable) to emphasise the point. While the fold function itself isn't the catamorphism for lists, we know that it's derived from the list catamorphism.
The final step is to utilise the Maybe catamorphism to reduce the Maybe Icon value to an Icon value. Again, the getIcon function doesn't use the Maybe catamorphism directly, but rather the derived fromMaybe function. The Maybe catamorphism is the maybe function, but you can trivially implement fromMaybe with maybe.
For golfers, it's certainly possible to write this function in a more compact manner. Here's a point-free version:
getIcon :: User -> IO Icon getIcon = fmap (fromMaybe defaultIcon) . getFirstIO . fold [getGravatarIO, getIdenticonIO, getDBIconIO]
This alternative version utilises that a -> m is a Monoid instance when m is a Monoid instance. That's the reason that you can fold a list of functions. The more explicit version above doesn't do that, but the behaviour is the same in both cases.
That's all the Haskell code we need to discern the universal abstractions involved in the Chain of Responsibility design pattern. We can now return to the C# code example.
Chains as lists #
The Chain of Responsibility design pattern is often illustrated like above, in a staircase-like diagram. There's, however, no inherent requirement to do so. You could also flatten the diagram:

This looks a lot like a linked list.
The difference is, however, that the terminator of a linked list is usually empty. Here, however, you have two types of objects. All objects apart from the rightmost object represent a potential. Each object may, or may not, handle the method call and produce an outcome; if an object can't handle the method call, it'll delegate to the next object in the chain.
The rightmost object, however, is different. This object can't delegate any further, but must handle the method call. In the icon reader example, this is the DefaultIconReader class.
Once you start to see most of the list as a list of potential values, you may realise that you'll be able to collapse into it a single potential value. This is possible because a list of values where you pick the first non-empty value forms a monoid. This is sometimes called the First monoid.
In other words, you can reduce, or fold, all of the list, except the rightmost value, to a single potential value:
When you do that, however, you're left with a single potential value. The result of folding most of the list is that you get the leftmost non-empty value in the list. There's no guarantee, however, that that value is non-empty. If all the values in the list are empty, the result is also empty. This means that you somehow need to combine a potential value with a value that's guaranteed to be present: the terminator.
You can do that wither another fold:
This second fold isn't a list fold, but rather a Maybe fold.
Maybe #
The First monoid is a monoid over Maybe, so add a Maybe class to the code base. In Haskell, the catamorphism for Maybe is called maybe, but that's not a good method name in object-oriented design. Another option is some variation of fold, but in C#, this functionality tends to be called Aggregate, at least for IEnumerable<T>, so I'll reuse that terminology:
public TResult Aggregate<TResult>(TResult @default, Func<T, TResult> func) { if (func == null) throw new ArgumentNullException(nameof(func)); return hasItem ? func(item) : @default; }
You can implement another, more list-like Aggregate overload from this one, but for this article, you don't need it.
From TryReadIconId to Maybe #
In the above code examples, DBIconReader depends on IUserRepository, which defined this method:
bool TryReadIconId(int userId, out string iconId);
From Tester-Doer isomorphisms we know, however, that such a design is isomorphic to returning a Maybe value, and since that's more composable, do that:
Maybe<string> ReadIconId(int userId);
This requires you to refactor the DBIconReader implementation of the ReadIcon method:
public Icon ReadIcon(User user) { Maybe<string> mid = repository.ReadIconId(user.Id); Lazy<Icon> lazyResult = mid.Aggregate( @default: new Lazy<Icon>(() => next.ReadIcon(user)), func: id => new Lazy<Icon>(() => CreateIcon(id))); return lazyResult.Value; }
A few things are worth a mention. Notice that the above Aggregate method (the Maybe catamorphism) requires you to supply a @default value (to be used if the Maybe object is empty). In the Chain of Responsibility design pattern, however, the fallback value is produced by calling the next object in the chain. If you do this unconditionally, however, you perform too much work. You're only supposed to call next if the current object can't handle the method call.
The solution is to aggregate the mid object to a Lazy<Icon> and then return its Value. The @default value is now a lazy computation that calls next only if its Value is read. When mid is populated, on the other hand, the lazy computation calls the private CreateIcon method when Value is accessed. The private CreateIcon method contains the same logic as before the refactoring.
This change of DBIconReader isn't strictly necessary in order to change the overall Chain of Responsibility to a pair of catamorphisms, but serves, I think, as a nice introduction to the use of the Maybe catamorphism.
Optional icon readers #
Previously, the IIconReader interface required each implementation to return an Icon object:
public interface IIconReader { Icon ReadIcon(User user); }
When you have an object like GravatarReader that may or may not return an Icon, this requirement leads toward the Chain of Responsibility design pattern. You can, however, shift the responsibility of what to do next by changing the interface:
public interface IIconReader { Maybe<Icon> ReadIcon(User user); }
An implementation like GravatarReader becomes simpler:
public class GravatarReader : IIconReader { public Maybe<Icon> ReadIcon(User user) { if (user.UseGravatar) return new Maybe<Icon>(new Icon(new Gravatar(user.Email).Url)); return new Maybe<Icon>(); } }
No longer do you have to pass in a next dependency. Instead, you just return an empty Maybe<Icon> if you can't handle the method call. The same change applies to the IdenticonReader class.
Since Maybe is a functor, and the DBIconReader already works on a Maybe<string> value, its implementation is greatly simplified:
public Maybe<Icon> ReadIcon(User user) { return repository.ReadIconId(user.Id).Select(CreateIcon); }
Since ReadIconId returns a Maybe<string>, you can simply use Select to transform the icon ID to an Icon object if the Maybe is populated.
Coalescing Composite #
As an intermediate step, you can compose the various readers using a Coalescing Composite:
public class CompositeIconReader : IIconReader { private readonly IIconReader[] iconReaders; public CompositeIconReader(params IIconReader[] iconReaders) { this.iconReaders = iconReaders; } public Maybe<Icon> ReadIcon(User user) { foreach (var iconReader in iconReaders) { var mIcon = iconReader.ReadIcon(user); if (IsPopulated(mIcon)) return mIcon; } return new Maybe<Icon>(); } private static bool IsPopulated<T>(Maybe<T> m) { return m.Aggregate(false, _ => true); } }
I prefer a more explicit design over this one, so this is just an intermediate step. This IIconReader implementation composes an array of other IIconReader objects and queries each in order to return the first populated Maybe value it finds. If it doesn't find any populated value, it returns an empty Maybe object.
You can now compose your IIconReader objects into a Composite:
IIconReader reader = new CompositeIconReader( new GravatarReader(), new IdenticonReader(), new DBIconReader(repo));
While this gives you a single object on which you can call ReadIcon, the return value of that method is still a Maybe<Icon> object. You still need to reduce the Maybe<Icon> object to an Icon object. You can do this with a Maybe helper method:
public T GetValueOrDefault(T @default) { return Aggregate(@default, x => x); }
Given a User object named user, you can now use the composition and the GetValueOrDefault method to get an Icon object:
Icon icon = reader.ReadIcon(user).GetValueOrDefault(Icon.Default);
First you use the composed reader to produce a Maybe<Icon> object, and then you use the GetValueOrDefault method to reduce the Maybe<Icon> object to an Icon object.
The latter of these two steps, GetValueOrDefault, is already based on the Maybe catamorphism, but the first step is still too implicit to clearly show the nature of what's actually going on. The next step is to refactor the Coalescing Composite to a list of monoidal values.
First #
While not strictly necessary, you can introduce a First<T> wrapper:
public sealed class First<T> { public First(T item) { if (item == null) throw new ArgumentNullException(nameof(item)); Item = item; } public T Item { get; } public override bool Equals(object obj) { if (!(obj is First<T> other)) return false; return Equals(Item, other.Item); } public override int GetHashCode() { return Item.GetHashCode(); } }
In this particular example, the First<T> class adds no new capabilities, so it's technically redundant. You could add to it methods to combine two First<T> objects into one (since First forms a semigroup), and perhaps a method or two to accumulate multiple values, but in this article, none of those are required.
While the class as shown above doesn't add any behaviour, I like that it signals intent, so I'll use it in that role.
Lazy I/O in C# #
Like in the above Haskell code, you'll need to be able to combine two First<T> objects in a lazy fashion, in such a way that if the first object is populated, the I/O associated with producing the second value never happens. In Haskell I addressed that concern with a newtype that, among other abstractions, is a monoid. You can do the same in C# with an extension method:
public static Lazy<Maybe<First<T>>> FindFirst<T>( this Lazy<Maybe<First<T>>> m, Lazy<Maybe<First<T>>> other) { if (m.Value.IsPopulated()) return m; return other; } private static bool IsPopulated<T>(this Maybe<T> m) { return m.Aggregate(false, _ => true); }
The FindFirst method returns the first (leftmost) non-empty object of two options. It's a lazy version of the First monoid, and that's still a monoid. It's truly lazy because it never accesses the Value property on other. While it has to force evaluation of the first lazy computation, m, it doesn't have to evaluate other. Thus, whenever m is populated, other can remain non-evaluated.
Since monoids accumulate, you can also write an extension method to implement that functionality:
public static Lazy<Maybe<First<T>>> FindFirst<T>(this IEnumerable<Lazy<Maybe<First<T>>>> source) { var identity = new Lazy<Maybe<First<T>>>(() => new Maybe<First<T>>()); return source.Aggregate(identity, (acc, x) => acc.FindFirst(x)); }
This overload just uses the earlier FindFirst extension method to fold an arbitrary number of lazy First<T> objects into one. Notice that Aggregate is the C# name for the list catamorphisms.
You can now compose the desired functionality using the basic building blocks of monoids, functors, and catamorphisms.
Composition from universal abstractions #
The goal is still a function that takes a User object as input and produces an Icon object as output. While you could compose that functionality directly in-line where you need it, I think it may be helpful to package the composition in a Facade object.
public class IconReaderFacade { private readonly IReadOnlyCollection<IIconReader> readers; public IconReaderFacade(IUserRepository repository) { readers = new IIconReader[] { new GravatarReader(), new IdenticonReader(), new DBIconReader(repository) }; } public Icon ReadIcon(User user) { IEnumerable<Lazy<Maybe<First<Icon>>>> lazyIcons = readers .Select(r => new Lazy<Maybe<First<Icon>>>(() => r.ReadIcon(user).Select(i => new First<Icon>(i)))); Lazy<Maybe<First<Icon>>> m = lazyIcons.FindFirst(); return m.Value.Aggregate(Icon.Default, fi => fi.Item); } }
When you initialise an IconReaderFacade object, it creates an array of the desired readers. Whenever ReadIcon is invoked, it first transforms all those readers to a sequence of potential icons. All the values in the sequence are lazily evaluated, so in this step, nothing actually happens, even though it looks as though all readers' ReadIcon method gets called. The Select method is a structure-preserving map, so all readers are still potential producers of Icon objects.
You now have an IEnumerable<Lazy<Maybe<First<Icon>>>>, which must be a good candidate for the prize for the most nested generic .NET type of 2019. It fits, though, the input type for the above FindFirst overload, so you can call that. The result is a single potential value m. That's the list catamorphism applied.
Finally, you force evaluation of the lazy computation and apply the Maybe catamorphism (Aggregate). The @default value is Icon.Default, which gets returned if m turns out to be empty. When m is populated, you pull the Item out of the First object. In either case, you now have an Icon object to return.
This composition has exactly the same behaviour as the initial Chain of Responsibility implementation, but is now composed from universal abstractions.
Summary #
The Chain of Responsibility design pattern describes a flexible way to implement conditional logic. Instead of relying on keywords like if or switch, you can compose the conditional logic from polymorphic objects. This gives you several advantages. One is that you get better separations of concerns, which will tend to make it easier to refactor the code. Another is that it's possible to change the behaviour at run time, by moving the objects around.
You can achieve a similar design, with equivalent advantages, by composing polymorphically similar functions in a list, map the functions to a list of potential values, and then use the list catamorphism to reduce many potential values to one. Finally, you apply the Maybe catamorphism to produce a value, even if the potential value is empty.
Tester-Doer isomorphisms
The Tester-Doer pattern is equivalent to the Try-Parse idiom; both are equivalent to Maybe.
This article is part of a series of articles about software design isomorphisms. An isomorphism is when a bi-directional lossless translation exists between two representations. Such translations exist between the Tester-Doer pattern and the Try-Parse idiom. Both can also be translated into operations that return Maybe.
Given an implementation that uses one of those three idioms or abstractions, you can translate your design into one of the other options. This doesn't imply that each is of equal value. When it comes to composability, Maybe is superior to the two other alternatives, and Tester-Doer isn't thread-safe.
Tester-Doer #
The first time I explicitly encountered the Tester-Doer pattern was in the Framework Design Guidelines, which is from where I've taken the name. The pattern is, however, older. The idea that you can query an object about whether a given operation would be possible, and then you only perform it if the answer is affirmative, is almost a leitmotif in Object-Oriented Software Construction. Bertrand Meyer often uses linked lists and stacks as examples, but I'll instead use the example that Krzysztof Cwalina and Brad Abrams use:
ICollection<int> numbers = // ... if (!numbers.IsReadOnly) numbers.Add(1);
The idea with the Tester-Doer pattern is that you test whether an intended operation is legal, and only perform it if the answer is affirmative. In the example, you only add to the numbers collection if IsReadOnly is false. Here, IsReadOnly is the Tester, and Add is the Doer.
As Jeffrey Richter points out in the book, this is a dangerous pattern:
"The potential problem occurs when you have multiple threads accessing the object at the same time. For example, one thread could execute the test method, which reports that all is OK, and before the doer method executes, another thread could change the object, causing the doer to fail."In other words, the pattern isn't thread-safe. While multi-threaded programming was always supported in .NET, this was less of a concern when the guidelines were first published (2006) than it is today. The guidelines were in internal use in Microsoft years before they were published, and there wasn't many multi-core processors in use back then.
Another problem with the Tester-Doer pattern is with discoverability. If you're looking for a way to add an element to a collection, you'd usually consider your search over once you find the Add method. Even if you wonder Is this operation safe? Can I always add an element to a collection? you might consider looking for a CanAdd method, but not an IsReadOnly property. Most people don't even ask the question in the first place, though.
From Tester-Doer to Try-Parse #
You could refactor such a Tester-Doer API to a single method, which is both thread-safe and discoverable. One option is a variation of the Try-Parse idiom (discussed in detail below). Using it could look like this:
ICollection<int> numbers = // ... bool wasAdded = numbers.TryAdd(1);
In this special case, you may not need the wasAdded variable, because the original Add operation never returned a value. If, on the other hand, you do care whether or not the element was added to the collection, you'd have to figure out what to do in the case where the return value is true and false, respectively.
Compared to the more idiomatic example of the Try-Parse idiom below, you may have noticed that the TryAdd method shown here takes no out parameter. This is because the original Add method returns void; there's nothing to return. From unit isomorphisms, however, we know that unit is isomorphic to void, so we could, more explicitly, have defined a TryAdd method with this signature:
public bool TryAdd(T item, out Unit unit)
There's no point in doing this, however, apart from demonstrating that the isomorphism holds.
From Tester-Doer to Maybe #
You can also refactor the add-to-collection example to return a Maybe value, although in this degenerate case, it makes little sense. If you automate the refactoring process, you'd arrive at an API like this:
public Maybe<Unit> TryAdd(T item)
Using it would look like this:
ICollection<int> numbers = // ... Maybe<Unit> m = numbers.TryAdd(1);
The contract is consistent with what Maybe implies: You'd get an empty Maybe<Unit> object if the add operation 'failed', and a populated Maybe<Unit> object if the add operation succeeded. Even in the populated case, though, the value contained in the Maybe object would be unit, which carries no further information than its existence.
To be clear, this isn't close to a proper functional design because all the interesting action happens as a side effect. Does the design have to be functional? No, it clearly isn't in this case, but Maybe is a concept that originated in functional programming, so you could be misled to believe that I'm trying to pass this particular design off as functional. It's not.
A functional version of this API could look like this:
public Maybe<ICollection<T>> TryAdd(T item)
An implementation wouldn't mutate the object itself, but rather return a new collection with the added item, in case that was possible. This is, however, always possible, because you can always concatenate item to the front of the collection. In other words, this particular line of inquiry is increasingly veering into the territory of the absurd. This isn't, however, a counter-example of my proposition that the isomorphism exists; it's just a result of the initial example being degenerate.
Try-Parse #
Another idiom described in the Framework Design Guidelines is the Try-Parse idiom. This seems to be a coding idiom more specific to the .NET framework, which is the reason I call it an idiom instead of a pattern. (Perhaps it is, after all, a pattern... I'm sure many of my readers are better informed about how problems like these are solved in other languages, and can enlighten me.)
A better name might be Try-Do, since the idiom doesn't have to be constrained to parsing. The example that Cwalina and Abrams supply, however, relates to parsing a string into a DateTime value. Such an API is already available in the base class library. Using it looks like this:
bool couldParse = DateTime.TryParse(candidate, out DateTime dateTime);
Since DateTime is a value type, the out parameter will never be null, even if parsing fails. You can, however, examine the return value couldParse to determine whether the candidate could be parsed.
In the running commentary in the book, Jeffrey Richter likes this much better:
"I like this guideline a lot. It solves the race-condition problem and the performance problem."I agree that it's better than Tester-Doer, but that doesn't mean that you can't refactor such a design to that pattern.
From Try-Parse to Tester-Doer #
While I see no compelling reason to design parsing attempts with the Tester-Doer pattern, it's possible. You could create an API that enables interaction like this:
DateTime dateTime = default(DateTime); bool canParse = DateTimeEnvy.CanParse(candidate); if (canParse) dateTime = DateTime.Parse(candidate);
You'd need to add a new CanParse method with this signature:
public static bool CanParse(string candidate)
In this particular example, you don't have to add a Parse method, because it already exists in the base class library, but in other examples, you'd have to add such a method as well.
This example doesn't suffer from issues with thread safety, since strings are immutable, but in general, that problem is always a concern with the Tester-Doer anti-pattern. Discoverability still suffers in this example.
From Try-Parse to Maybe #
While the Try-Parse idiom is thread-safe, it isn't composable. Every time you run into an API modelled over this template, you have to stop what you're doing and check the return value. Did the operation succeed? Was should the code do if it didn't?
Maybe, on the other hand, is composable, so is a much better way to model problems such as parsing. Typically, methods or functions that return Maybe values are still prefixed with Try, but there's no longer any out parameter. A Maybe-based TryParse function could look like this:
public static Maybe<DateTime> TryParse(string candidate)
You could use it like this:
Maybe<DateTime> m = DateTimeEnvy.TryParse(candidate);
If the candidate was successfully parsed, you get a populated Maybe<DateTime>; if the string was invalid, you get an empty Maybe<DateTime>.
A Maybe object composes much better with other computations. Contrary to the Try-Parse idiom, you don't have to stop and examine a Boolean return value. You don't even have to deal with empty cases at the point where you parse. Instead, you can defer the decision about what to do in case of failure until a later time, where it may be more obvious what to do in that case.
Maybe #
In my Encapsulation and SOLID Pluralsight course, you get a walk-through of all three options for dealing with an operation that could potentially fail. Like in this article, the course starts with Tester-Doer, progresses over Try-Parse, and arrives at a Maybe-based implementation. In that course, the example involves reading a (previously stored) message from a text file. The final API looks like this:
public Maybe<string> Read(int id)
The protocol implied by such a signature is that you supply an ID, and if a message with that ID exists on disc, you receive a populated Maybe<string>; otherwise, an empty object. This is not only composable, but also thread-safe. For anyone who understands the universal abstraction of Maybe, it's clear that this is an operation that could fail. Ultimately, client code will have to deal with empty Maybe values, but this doesn't have to happen immediately. Such a decision can be deferred until a proper context exists for that purpose.
From Maybe to Tester-Doer #
Since Tester-Doer is the least useful of the patterns discussed in this article, it makes little sense to refactor a Maybe-based API to a Tester-Doer implementation. Nonetheless, it's still possible. The API could look like this:
public bool Exists(int id) public string Read(int id)
Not only is this design not thread-safe, but it's another example of poor discoverability. While the doer is called Read, the tester isn't called CanRead, but rather Exists. If the class has other members, these could be listed interleaved between Exists and Read. It wouldn't be obvious that these two members were designed to be used together.
Again, the intended usage is code like this:
string message; if (fileStore.Exists(49)) message = fileStore.Read(49);
This is still problematic, because you need to decide what to do in the else case as well, although you don't see that case here.
The point is, still, that you can translate from one representation to another without loss of information; not that you should.
From Maybe to Try-Parse #
Of the three representations discussed in this article, I firmly believe that a Maybe-based API is superior. Unfortunately, the .NET base class library doesn't (yet) come with a built-in Maybe object, so if you're developing an API as part of a reusable library, you have two options:
- Export the library's
Maybe<T>type together with the methods that return it. - Use Try-Parse for interoperability reasons.
FileStore example from my Pluralsight course, this would imply not a TryParse method, but a TryRead method:
public bool TryRead(int id, out string message)
This would enable you to expose the method in a reusable library. Client code could interact with it like this:
string message; if (!fileStore.TryRead(50, out message)) message = "";
This has all the problems associated with the Try-Parse idiom already discussed in this article, but it does, at least, have a basic use case.
Isomorphism with Either #
At this point, I hope that you find it reasonable to believe that the three representations, Tester-Doer, Try-Parse, and Maybe, are isomorphic. You can translate between any of these representations to any other of these without loss of information. This also means that you can translate back again.
While I've only argued with a series of examples, it's my experience that these three representations are truly isomorphic. You can always translate any of these representations into another. Mostly, though, I translate into Maybe. If you disagree with my proposition, all you have to do is to provide a counter-example.
There's a fourth isomorphism that's already well-known, and that's between Maybe and Either. Specifically, Maybe<T> is isomorphic to Either<Unit, T>. In Haskell, this is easily demonstrated with this set of functions:
toMaybe :: Either () a -> Maybe a toMaybe (Left ()) = Nothing toMaybe (Right x) = Just x fromMaybe :: Maybe a -> Either () a fromMaybe Nothing = Left () fromMaybe (Just x) = Right x
Translated to C#, using the Church-encoded Maybe together with the Church-encoded Either, these two functions could look like the following, starting with the conversion from Maybe to Either:
// On Maybe: public static IEither<Unit, T> ToEither<T>(this IMaybe<T> source) { return source.Match<IEither<Unit, T>>( nothing: new Left<Unit, T>(Unit.Value), just: x => new Right<Unit, T>(x)); }
Likewise, the conversion from Either to Maybe:
// On Either: public static IMaybe<T> ToMaybe<T>(this IEither<Unit, T> source) { return source.Match<IMaybe<T>>( onLeft: _ => new Nothing<T>(), onRight: x => new Just<T>(x)); }
You can convert back and forth to your heart's content, as this parametrised xUnit.net 2.3.1 test shows:
[Theory] [InlineData(42)] [InlineData(1337)] [InlineData(2112)] [InlineData(90125)] public void IsomorphicWithPopulatedMaybe(int i) { var expected = new Right<Unit, int>(i); var actual = expected.ToMaybe().ToEither(); Assert.Equal(expected, actual); }
I decided to exclude IEither<Unit, T> from the overall theme of this article in order to better contrast three alternatives that may not otherwise look equivalent. That IEither<Unit, T> is isomorphic to IMaybe<T> is a well-known result. Besides, I think that both of these two representations already inhabit the same conceptual space. Either and Maybe are both well-known in statically typed functional programming.
Summary #
The Tester-Doer pattern is a decades-old design pattern that attempts to model how to perform operations that can potentially fail, without relying on exceptions for flow control. It predates mainstream multi-core processors by decades, which can explain why it even exists as a pattern in the first place. At the time people arrived at the pattern, thread-safety wasn't a big concern.
The Try-Parse idiom is a thread-safe alternative to the Tester-Doer pattern. It combines the two tester and doer methods into a single method with an out parameter. While thread-safe, it's not composable.
Maybe offers the best of both worlds. It's both thread-safe and composable. It's also as discoverable as any Try-Parse method.
These three alternatives are all, however, isomorphic. This means that you can refactor any of the three designs into one of the other designs, without loss of information. It also means that you can implement Adapters between particular implementations, should you so desire. You see this frequently in F# code, where functions that return 'a option adapt Try-Parse methods from the .NET base class library.
While all three designs are equivalent in the sense that you can translate one into another, it doesn't imply that they're equally useful. Maybe is the superior design, and Tester-Doer clearly inferior.
Next: Builder isomorphisms.

Comments
I find that last statement slightly ambiguous. I prefer to say...
...which is more precise.
I was very confused by these names at first. They suggest that the most important difference between them is the use of
List.foldandList.foldBackin their respective implementations. However, for bothbifoldandbifoldBack, the behavior does not depend at all on the choice betweenList.foldandList.foldBack(as long asidandxsare given in the correct order). Instead, the difference betweenbifoldandbifoldBackis completely determined by (the minor choice to useflipinbifoldand) whether the function composition operator is to the right (as inbifold) or to the left (as inbifoldBack). This is slightly easier to see whenbifoldBackis implemented ascata (fun x xs -> f x << List.foldBack (<<) xs id) g t z. The reason that the choice betweenList.foldandList.foldBackdoesn't matter is because both function composition operators are associative (and because the seed value is the identity element for both functions).The idea of a catamorphism is still very new to me. Instead of directly aggregating the parts of a tree into a single value like
bifoldandbifoldBack(viacata), I have historically exposed a minimal set of needed tree traversal orderings and then follow such a call withSeq.foldorSeq.foldBack. I thinkbifolddoes a preorder traversal andbifoldBackdoes a reverse preorder traversal. So, after all that, I now understand the names.I don't know how to implement
calculateMovesviacataeither. Nonetheless, there is still a domain-independent abstraction waiting to be extracted.Think of the
scanfunction that exists in F# in theSeqandListmodules. We can implement a similar function for your rose tree. I did so in this commit. NowcalculateMovesis trivial, it still passes your domain-specific tests, andscancan be subjected to domain-independent unit tests.Now the question is...can
scanbe implemented bycata? Or maybe...cancatabe implemented byscan? I don't know the answer to either of these questions. Alternatively, we can ask...doesscancorrespond to some concept in category theory? I don't know that either. You are way ahead of me in your understanding of category theory, but I am doing my best to catch up.Tyson, thank you for writing. That's a neat refactoring. I spent a couple of hours with it yesterday to see if I could implement your
scanfunction withcata, but like you, it eludes me. It doesn't look like it's possible, although I'd love to be proven wrong.I'm not aware of any theoretical foundations for
scan, but there's so many things I don't know...I originally came across the concept of F-Algebras and catamorphisms when I read Bartosz Milewski's article. I've later discovered that the recursion-schemes package was there all along. Not only does it define
cata, but it also includes much other functionality that I still haven't absorbed. Perhaps there might be a clue there...One tree functionality that this article didn't use is the
applyfunction of an applicative functor. Of courseapplycan be implemented in terms ofbind. Doing so here would yield an implementation ofapplythat transitively depends oncata.Is there a way (perhaps an ellegant way) to directly implement
applyviacata? I am asking because I have a monad withapplyimplemented in terms ofbind, but I would like an implementation with better behavior.Tyson, thank you for writing. Yes, you can implement the Applicative instance directly from the catamorphism.
Tyson, FWIW I figured out how to implement calculateMoves directly with the catamorphism.