Is Layering Worth the Mapping? by Mark Seemann
For years, layered application architecture has been a de-facto standard for loosely coupled architectures, but the question is: does the layering really provide benefit?
In theory, layering is a way to decouple concerns so that UI concerns or data access technologies don't pollute the domain model. However, this style of architecture seems to come at a pretty steep price: there's a lot of mapping going on between the layers. Is it really worth the price, or is it OK to define data structures that cut across the various layers?
The short answer is that if you cut across the layers, it's no longer a layered application. However, the price of layering may still be too high.
In this post I'll examine the problem and the proposed solution and demonstrate why none of them are particularly good. In the end, I'll provide a pointer going forward.
Proper Layering #
To understand the problem with layering, I'll describe a fairly simple example. Assume that you are building a music service and you've been asked to render a top 10 list for the day. It would have to look something like this in a web page:

As part of rendering the list, you must color the Movement values accordingly using CSS.
A properly layered architecture would look something like this:
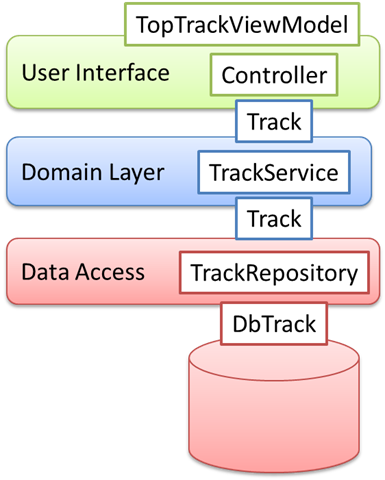
Each layer defines some services and some data-carrying classes (Entities, if you want to stick with the Domain-Driven Design terminology). The Track class is defined by the Domain layer, while the TopTrackViewModel class is defined in the User Interface layer, and so on. If you are wondering about why Track is used to communicate both up and down, this is because the Domain layer should be the most decoupled layer, so the other layers exist to serve it. In fact, this is just a vertical representation of the Ports and Adapters architecture, with the Domain Model sitting in the center.
This architecture is very decoupled, but comes at the cost of much mapping and seemingly redundant repetition. To demonstrate why that is, I'm going to show you some of the code. This is an ASP.NET MVC application, so the Controller is an obvious place to start:
public ViewResult Index() { var date = DateTime.Now.Date; var topTracks = this.trackService.GetTopFor(date); return this.View(topTracks); }
This doesn't look so bad. It asks an ITrackService for the top tracks for the day and returns a list of TopTrackViewModel instances. This is the implementation of the track service:
public IEnumerable<TopTrackViewModel> GetTopFor( DateTime date) { var today = DateTime.Now.Date; var yesterDay = today - TimeSpan.FromDays(1); var todaysTracks = this.repository.GetTopFor(today).ToList(); var yesterdaysTracks = this.repository.GetTopFor(yesterDay).ToList(); var length = todaysTracks.Count; var positions = Enumerable.Range(1, length); return from tt in todaysTracks.Zip( positions, (t, p) => new { Position = p, Track = t }) let yp = (from yt in yesterdaysTracks.Zip( positions, (t, p) => new { Position = p, Track = t }) where yt.Track.Id == tt.Track.Id select yt.Position) .DefaultIfEmpty(-1) .Single() let cssClass = GetCssClass(tt.Position, yp) select new TopTrackViewModel { Position = tt.Position, Name = tt.Track.Name, Artist = tt.Track.Artist, CssClass = cssClass }; } private static string GetCssClass( int todaysPosition, int yesterdaysPosition) { if (yesterdaysPosition < 0) return "new"; if (todaysPosition < yesterdaysPosition) return "up"; if (todaysPosition == yesterdaysPosition) return "same"; return "down"; }
While that looks fairly complex, there's really not a lot of mapping going on. Most of the work is spent getting the top 10 track for today and yesterday. For each position on today's top 10, the query finds the position of the same track on yesterday's top 10 and creates a TopTrackViewModel instance accordingly.
Here's the only mapping code involved:
select new TopTrackViewModel { Position = tt.Position, Name = tt.Track.Name, Artist = tt.Track.Artist, CssClass = cssClass };
This maps from a Track (a Domain class) to a TopTrackViewModel (a UI class).
This is the relevant implementation of the repository:
public IEnumerable<Track> GetTopFor(DateTime date) { var dbTracks = this.GetTopTracks(date); foreach (var dbTrack in dbTracks) { yield return new Track( dbTrack.Id, dbTrack.Name, dbTrack.Artist); } }
You may be wondering about the translation from DbTrack to Track. In this case you can assume that the DbTrack class is a class representation of a database table, modeled along the lines of your favorite ORM. The Track class, on the other hand, is a proper object-oriented class which protects its invariants:
public class Track { private readonly int id; private string name; private string artist; public Track(int id, string name, string artist) { if (name == null) throw new ArgumentNullException("name"); if (artist == null) throw new ArgumentNullException("artist"); this.id = id; this.name = name; this.artist = artist; } public int Id { get { return this.id; } } public string Name { get { return this.name; } set { if (value == null) throw new ArgumentNullException("value"); this.name = value; } } public string Artist { get { return this.artist; } set { if (value == null) throw new ArgumentNullException("value"); this.artist = value; } } }
No ORM I've encountered so far has been able to properly address such invariants - particularly the non-default constructor seems to be a showstopper. This is the reason a separate DbTrack class is required, even for ORMs with so-called POCO support.
In summary, that's a lot of mapping. What would be involved if a new field is required in the top 10 table? Imagine that you are being asked to provide the release label as an extra column.
- A Label column must be added to the database schema and the DbTrack class.
- A Label property must be added to the Track class.
- The mapping from DbTrack to Track must be updated.
- A Label property must be added to the TopTrackViewModel class.
- The mapping from Track to TopTrackViewModel must be updated.
- The UI must be updated.
That's a lot of work in order to add a single data element, and this is even a read-only scenario! Is it really worth it?
Cross-Cutting Entities #
Is strict separation between layers really so important? What would happen if Entities were allowed to travel across all layers? Would that really be so bad?
Such an architecture is often drawn like this:

Now, a single Track class is allowed to travel from layer to layer in order to avoid mapping. The controller code hasn't really changed, although the model returned to the View is no longer a sequence of TopTrackViewModel, but simply a sequence of Track instances:
public ViewResult Index() { var date = DateTime.Now.Date; var topTracks = this.trackService.GetTopFor(date); return this.View(topTracks);}
The GetTopFor method also looks familiar:
public IEnumerable<Track> GetTopFor(DateTime date) { var today = DateTime.Now.Date; var yesterDay = today - TimeSpan.FromDays(1); var todaysTracks = this.repository.GetTopFor(today).ToList(); var yesterdaysTracks = this.repository.GetTopFor(yesterDay).ToList(); var length = todaysTracks.Count; var positions = Enumerable.Range(1, length); return from tt in todaysTracks.Zip( positions, (t, p) => new { Position = p, Track = t }) let yp = (from yt in yesterdaysTracks.Zip( positions, (t, p) => new { Position = p, Track = t }) where yt.Track.Id == tt.Track.Id select yt.Position) .DefaultIfEmpty(-1) .Single() let cssClass = GetCssClass(tt.Position, yp) select Enrich( tt.Track, tt.Position, cssClass); } private static string GetCssClass( int todaysPosition, int yesterdaysPosition) { if (yesterdaysPosition < 0) return "new"; if (todaysPosition < yesterdaysPosition) return "up"; if (todaysPosition == yesterdaysPosition) return "same"; return "down"; } private static Track Enrich( Track track, int position, string cssClass) { track.Position = position; track.CssClass = cssClass; return track; }
Whether or not much has been gained is likely to be a subjective assessment. While mapping is no longer taking place, it's still necessary to assign a CSS Class and Position to the track before handing it off to the View. This is the responsibility of the new Enrich method:
private static Track Enrich( Track track, int position, string cssClass) { track.Position = position; track.CssClass = cssClass; return track; }
If not much is gained at the UI layer, perhaps the data access layer has become simpler? This is, indeed, the case:
public IEnumerable<Track> GetTopFor(DateTime date) { return this.GetTopTracks(date); }
If, hypothetically, you were asked to add a label to the top 10 table it would be much simpler:
- A Label column must be added to the database schema and the Track class.
- The UI must be updated.
This looks good. Are there any disadvantages? Yes, certainly. Consider the Track class:
public class Track { public int Id { get; set; } public string Name { get; set; } public string Artist { get; set; } public int Position { get; set; } public string CssClass { get; set; } }
It also looks simpler than before, but this is actually not particularly beneficial, as it doesn't protect its invariants. In order to play nice with the ORM of your choice, it must have a default constructor. It also has automatic properties. However, most insidiously, it also somehow gained the Position and CssClass properties.
What does the Position property imply outside of the context of a top 10 list? A position in relation to what?
Even worse, why do we have a property called CssClass? CSS is a very web-specific technology so why is this property available to the Data Access and Domain layers? How does this fit if you are ever asked to build a native desktop app based on the Domain Model? Or a REST API? Or a batch job?
When Entities are allowed to travel along layers, the layers basically collapse. UI concerns and data access concerns will inevitably be mixed up. You may think you have layers, but you don't.
Is that such a bad thing, though?
Perhaps not, but I think it's worth pointing out:
The choice is whether or not you want to build a layered application. If you want layering, the separation must be strict. If it isn't, it's not a layered application.
There may be great benefits to be gained from allowing Entities to travel from database to user interface. Much mapping cost goes away, but you must realize that then you're no longer building a layered application - now you're building a web application (or whichever other type of app you're initially building).
Further Thoughts #
It's a common question: how hard is it to add a new field to the user interface?
The underlying assumption is that the field must somehow originate from a corresponding database column. If this is the case, mapping seems to be in the way.
However, if this is the major concern about the application you're currently building, it's a strong indication that you are building a CRUD application. If that's the case, you probably don't need a Domain Model at all. Go ahead and let your ORM POCO classes travel up and down the stack, but don't bother creating layers: you'll be building a monolithic application no matter how hard you try not to.
In the end it looks as though none of the options outlined in this article are particularly good. Strict layering leads to too much mapping, and no mapping leads to monolithic applications. Personally, I've certainly written quite a lot of strictly layered applications, and while the separation of concerns was good, I was never happy with the mapping overhead.
At the heart of the problem is the CRUDy nature of many applications. In such applications, complex object graphs are traveling up and down the stack. The trick is to avoid complex object graphs.
Move less data around and things are likely to become simpler. This is one of the many interesting promises of CQRS, and particularly it's asymmetric approach to data.
To be honest, I wish I had fully realized this when I started writing my book, but when I finally realized what I'd implicitly felt for long, it was too late to change direction. Rest assured that nothing in the book is fundamentally flawed. The patterns etc. still hold, but the examples could have been cleaner if the sample applications had taken a CQRS-like direction instead of strict layering.

Comments
- Domain layer with rich objects and protected variations
- Commands and Command handlers (write only) acting on the domain entities
- Mapping domain layer using NHibernate (I thought at first to start by creating a different data model because of the constraints of orm on the domain, but i managed to get rid of most of them - like having a default but private constructor, and mapping private fields instead of public properties ...)
- Read model which consist of view models.
- Red model mapping layer which uses the orm to map view models to database directly (thus i got rid of mapping between view models and domains - but introduced a mapping between view models and database).
- Query objects to query the read model.
at the end of application i came to almost the same conclusion of not being happy with the mappings.
- I have to map domain model to database.
- I have to map between view models (read model) and database.
- I have to map between view models and commands.
- I have to map between commands and domain model.
- Having many fine grained commands is good in terms of defining strict behaviors and ubiquitous language but at the cost of maintainability, now when i introduce a new field most probably will have to modify a database field, domain model, view model, two data mappings for domain model and view model, 1 or more command and command handlers, and UI !
So taking the practice of CQRS for me enriched the domain a little, simplified the operations and separated it from querying, but complicated the implementation and maintenance of the application.
So I am still searching for a better approach to gain the rich domain model behavior and simplifying maintenance and eliminate mappings.
I too have felt pain of a lot of useless mapping a lot times. But even for CRUD applications where the business rules do not change much, I still almost always take the pain and do the mapping because I have a deep sitting fear of monolthic apps and code rot. If I give my entities lots of different concerns (UI, persistence, domainlogic etc.), isn't this kind of code smell the culture medium for more code smell and code rot? When evolving my application and I am faced with a quirk in my code, I often only have two choices: Add a new quirk or remove the original quirk. It kind of seems that in the long run a rotten monolithic app that his hard to maintain and extend becomes almost inevitable if I give up SoC the way you described.
Did I understand you correctly that you'd say it's OK to soften SoC a bit and let the entity travel across all layers for *some* apps? If yes, what kind of apps? Do you share my fear of inevitable code rot? How do you deal with this?
I use either convention based NH mappings which make me almost forget it's there, or MemoryImage to reconstruct my object model (the boilerplate is reduced by wrapping my objects with proxies that intercept method calls and record them as a json Event Source). In both cases I can use a helper library which wraps my objects with proxies that help protect invariants.
My web UI is built using a framework along the lines of the Naked Object a pattern*, which can be customised using ViewModels and custom views, and which enforces good REST design. This framework turns objects into pages and methods into ajax forms.
I built all this stuff after getting frustrated with the problems you mention above, inspired in part by all the time I spent at Uni trying to make games (in which an in memory domain model is rendered to the screen by a disconnected rendering engine, and input collected via a separate mechanism and applied to that model).
The long of the short of it is that I can add a field to the screen in seconds, and add a new feature in minutes. There are some trade offs, but it's great to feel like I am just writing an object model and leaving the rest to my frameworks.
*not Naked Objects MVC, a DIY library thats not ready for the public yet.
http://en.wikipedia.org/wiki/Naked_objects
https://github.com/mcintyre321/NhCodeFirst my mappings lib (but Fluent NH is probably fine)
http://martinfowler.com/bliki/MemoryImage.html
https://github.com/mcintyre321/Harden my invariant helper library
The only thing I'm saying is that it's better to build a monolithic application when you know and understand that this is what you are doing, than it is to be building a monolithic application while under the illusion that you are building a decoupled application.
If there's a point in there, it's that static languages (without designers) generally don't lend well to RAD, and if RAD is what you need, you have many popular options that aren't C#.
Also, I have two problems with some of the sample code you wrote. Specifically, the Enrich method. First, a method signature such as:
T Method(T obj, ...);
Implies to consumers that the method is pure. Because this isn't the case, consumers will incorrectly use this method without the intention of modifying the original object. Second, if it is true that your ViewModels are POCOs consisting of your mapped properties AND a list of computed properties, perhaps you should instead use inheritance. This implementation is certainly SOLID:
(sorry for the formatting)
class Track
{
/* Mapped Properties */
public Track()
{
}
protected Track(Track rhs)
{
Prop1 = rhs.Prop1;
Prop2 = rhs.Prop2;
Prop3 = rhs.Prop3;
}
}
class TrackWebViewModel : Track
{
public string ClssClass { get; private set; }
public TrackWebViewModel(Track track, string cssClass) : this(track)
{
CssClass = cssClass;
}
}
let cssClass = GetCssClass(tt.Position, yp) select Enrich(tt.Track, tt.Position, cssClass)
Simply becomes
select new TrackWebViewModel(tt.Track, tt.Position, cssClass)
While your suggested, inheritance-based solution seems cleaner, please note that it also introduces a mapping (in the copy constructor). Once you start doing this, there's almost always a composition-based solution which is at least as good as the inheritance-based solution.
As far as the copy-ctor, yes, that is a mapping, but when you add a field, you just have to modify a file you're already modifying. This is a bit nicer than having to update mapping code halfway across your application. But you're right, composting a Track into a specific view model would be a nicer approach with fewer modifications required to add more view models and avoiding additional mapping.
Though, I still am a bit concerned about the architecture as a whole. I understand in this post you were thinking out loud about a possible way to reduce complexity in certain types of applications, yet I'm wondering if you had considered using a platform designed for applications like this instead of using C#. Rails is quite handy when you need CRUD.
thanks for the blog posts and DI book, which I'm currently reading over the weekend. I guess the scenario you're describing here is more or less commonplace, and as the team I'm working on are constantly bringing this subject up on the whiteboard, I thought I'd share a few thoughts on the mapping part. Letting the Track entity you're mentioning cross all layers is probably not a good idea.
I agree that one should program to interfaces. Thus, any entity (be it an entity created via LINQ to SQL, EF, any other ORM/DAL or business object) should be modeled and exposed via an interface (or hierarchy thereof) from repositories or the like. With that in mind, here's what I think of mapping between entities. Popular ORM/DALs provide support for partial entities, external mapping files, POCOs, model-first etc.
Take this simple example:
// simplified pattern (deliberately not guarding args, and more)
interface IPageEntity { string Name { get; }}
class PageEntity : IPageEntity {}
class Page : IPage
{
private IPageEntity entity;
private IStrategy strategy;
public Page(IPageEntity entity, IStrategy strategy)
{
this.entity = entity;
this.strategy = strategy;
}
public string Name
{
get { return this.entity.Name; }
set { this.strategy.CopyOnWrite(ref this.entity).Name = value; }
}
}
One of the benefits from using an ORM/DAL is that queries are strongly typed and results are projected to strongly typed entities (concrete or anonymous). They are prime candidates for embedding inside of business objects (BO) (as DTOs), as long as they implement the required interface for injected in the constructor. This is much more flexible (and clean) rather than taking a series of arguments, each corresponding to a property on the original entity. Instead of having the BO keeping private members mapped to the constructor args, and subsequently mapping public properties and methods to said members, you simply map to the entity injected in the BO.
The benefit is much greater performance (less copying of args), a consistent design pattern and a layer of indirection in your BO that allows you to capture any potential changes to your entity (such as using the copy-on-write pattern that creates an exact copy of the entity, releasing it from a potential shared cache you've created by decorating the repository, from which the entity originally was retrieved).
Again, in my example one of the goals were to make use of shared (cached) entities for high performance, while making sure that there are no side effects from changing a business object (seeing this from client code perspective).
Code following the above pattern is just as testable as the code in your example (one could argue it's even easier to write tests, and maintenance is vastly reduced). Whenever I see BO constructors taking huge amounts of args I cry blood.
In my experience, this allows a strictly layered application to thrive without the mapping overhead.
Your thoughts?
What do you propose in cases when you have a client server application with request/response over WCF and the domain model living on the server? Is there a better way than for example mapping from NH entities to DataContracts and from DataContracts to ViewModels?
Thnaks for the post!
"... asks an ITrackService for the top tracks for the day and returns a list of TopTrackViewModel instances..."
The diagram really makes it look like the TrackService returns Track objects to the Controller and the Controller maps them into TopTrackViewModel objects. If that is the case... how would you communicate the Position and CssClass properties that the Domain Layer has computed between the two layers?
Also, I noticed that ITrackService.GetTopFor(DateTime date) never uses the input parameter... should it really be more like ITrackService.GetTopForToday() instead?
Awesome blog! Is there an email address I can contact you in private?
If the service layer exists in order to decouple the service from the client, you must translate from the internal model to a service API. However, if this is the case, keep in mind that at the service boundary, you are no longer dealing with objects at all, so translation or mapping is conceptually very important. If you have .NET on both sides it's easy to lose sight of this, but imagine that either service or client is implemented in COBOL and you may begin to understand the importance of translation.
So as always, it's a question of evaluating the advantages and disadvantages of each alternative in the concrete situation. There's no one correct answer.
Personally, I'm beginning to consider ORMs the right solution to the wrong problem. A relational database is rarely the correct data store for a LoB application or your typical web site.
Pardon me if I've gotten this wrong, because I'm approaching your post as an actionscript developer who is entirely self-taught. I don't know C#, but I like to read posts on good design from whatever language.
How I might resolve this problem is to create a TrackDisplayModel Class that wraps the Track Class and provides the "enriched" methods of the position and cssClass. In AS, we have something called a Proxy Class that allows us to "repeat" methods on an inner object without writing a lot of code, so you could pass through the properties of the Track by making TrackDisplayModel extend Proxy. By doing this, I'd give up code completion and type safety, so I might not find that long term small cost worth the occasional larger cost of adding a field in more conventional ways.
Does C# have a Class that is like Proxy that could be used in this way?
No matter how you'd achieve such things, I'm not to happy about doing this, as most of the variability axes we get from a multi-paradigmatic language such as C# is additive - it means that while it's fairly easy to add new capabilities to objects, it's actually rather hard to remove capabilities.
When we map from e.g. a domain model to a UI model, we should consider that we must be able to do both: add as well as subtract behavior. There may be members in our domain model we don't want the UI model to use.
Also, when the application enables the user to write as well as read data, we must be able to map both ways, so this is another reason why we must be able to add as well as remove members when traversing layers.
I'm not saying that a dynamic approach isn't viable - in fact, I find it attractive in various scenarios. I'm just saying that simply exposing a lower-level API to upper layers by adding more members to it seems to me to go against the spirit of the Single Responsibility Principle. It would just be tight coupling on the semantic level.
You might also want to refer to my answer to Amy immediately above. The data structures the UI requires may be entirely different from the Domain Model, which again could be different from the data access model. The UI will often be an aggregate of data from many different data sources.
In fact, I'd consider it a code smell if you could get by with the same data structure in all layers. If one can do that, one is most likely building a CRUD application, in which case a monolithic RAD application might actually be a better architectural choice.
You've mentioned in your blogs (here and elsewhere) and on stackoverflow simliar sentiments to your last comment:
<blockquote>
I'd consider it a code smell if you could get by with the same data structure in all layers. If one can do that, one is most likely building a CRUD application, in which case a monolithic RAD application might actually be a better architectural choice.
</blockquote>
Most line of business (LoB) apps consist of CRUD operations. As such, when does an LoB app cross the line from being strictly "CRUDy" and jumps into the realm where where layering (or using CQRS) is preferable? Could you expand on your definition of building a CRUD application?
What I think would be the correct thing, on the other hand, would be to make a conscious decision as a team on which way to go. If the team agrees that the project is most likely a CRUD application, then it can save itself the trouble of having all those layers. However, it's very important to stress to non-technical team members and stake holders (project managers etc.) that there's a trade-off here: We've decided to go with RAD development. This will enables us to go fast as long as our assumption about a minimum of business logic holds true. On the other hand, if that assumption fails, we'll be going very slowly. Put it in writing and make sure those people understand this.
You can also put it another way: creating a correctly layered application is slow, but relatively safe. Assuming that you know what you're doing with layering (lots of people don't), developing a layered application removes much of that risk. Such an architecture is going to be able to handle a lot of the changes you'll throw at it, but it'll be slow going.
HTH
If youre 'referring to the case where there is actually a domain to model, then CQRS (the concept) is easily the answer. However, even in such app you'd have some parts which are CRUD. I simply like to use the appropriate tool for the job. For complex Aggregate Roots, Event Sourcing simplifies storage a lot. For 'dumb' objects, directly CRUD stuff. Of course, everything is done via a repository.
Now, for complex domain I'd also use a message driven architecture so I'd have Domain events with handlers which will generate any read model required. I won't really have a mapping problem as event sourcing will solve it for complex objects while for simple objects at most I'll automap or use the domain entities directly .
Nice blog!
All the mapping stems from querying/reading the domain model. I have come to the conclusion that this is what leads to all kinds of problems such as:
- lazy loading
- mapping
- fetching strategies
The domain model has state but should *do* stuff. As you stated, the domain needs highly cohesive aggregates to get the object graph a short as possible. I do not use an ORM (I do my own mapping) so I do not have ORM specific classes.
So I am 100% with you on the CQRS. There are different levels to doing CQRS and I think many folks shy away from it because they think there is only the all-or-nothing asynchronous messaging way to get to CQRS. Yet there are various approaches depending on the need, e.g.:-
All within the same transaction scope with no messaging (100% consistent):
- store read data in same table (so different columns) <-- probably the most typical option in this scenario
- store read data in separate table in the same database
- store read data in another table in another database
Using eventual consistency via messaging / service bus (such as Shuttle - http://shuttle.codeplex.com/ | MassTransit | NServiceBus):
- store read data in same table (so different columns)
- store read data in separate table in the same database
- store read data in another table in another database <-- probably the most typical option in this scenario
Using C# I would return the data from my query layer as a DataRow or DataTable and in the case of something more complex a DTO.
Regards,
Eben