Using NuGet with autonomous repositories by Mark Seemann
NuGet is a great tool if used correctly. Here's one way to do it.
In my recent post about NuGet, I described why the Package Restore feature is insidious. As expected, this provoked some readers, who didn't like my recommendation of adding NuGet packages to source control. That's understandable; the problem with a rant like my previous post is that while it tells you what not to do, it's not particularly constructive. While I told you to store NuGet packages in your source control system, I didn't describe patterns for doing it effectively. My impression was that it's trivial to do this, but based on the reactions I got, I realize that this may not be the case. Could it be that some readers react strongly because they don't know what else to do (than to use NuGet Package Restore)? In this post, I'll describe a way to use and organize NuGet packages that have worked well for me in several organizations.
Publish/Subscribe #
In Grean we use NuGet in a sort of Publish/Subscribe style. This is a style I've also used in other organizations, to great effect. It's easy: create reusable components as autonomous libraries, and publish them as NuGet packages. If you don't feel like sharing your internal building blocks with the rest of the world, you can use a custom, internal package repository, or you can use MyGet (that's what we do in Grean).
A reusable component may be some package you've created for internal use. Something that packages the way you authenticate, log, instrument, render, etc. in your organization.
Every time you have a new version of one of your components (let's call it C1), you publish the NuGet package.
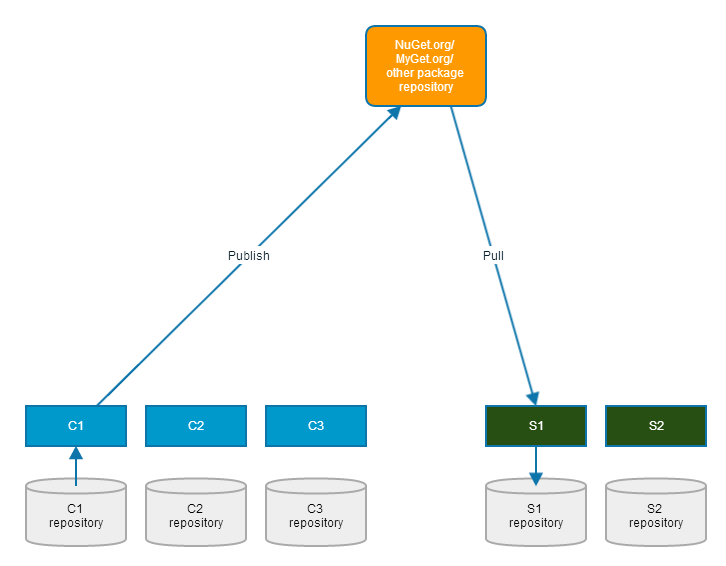
Just like other Publish/Subscribe systems, the only other party that you rely on at this moment is the queue/bus/broker - in this case the package repository, like NuGet.org or MyGet.org. No other systems need to be available to do this.
You do this for every reusable component you want to publish. Each is independent of other components.
Pull based on need #
In addition to reusable components, you probably also build systems; that is, applications that actually do something. You probably build those systems on top of reusable components - yours, and other publicly available NuGet packages. Let's call one such system S1.
Whenever you need a NuGet package (C1), you add it to the Visual Studio project where you need it, and then you commit your changes to that system's source control. It effectively means checking in the NuGet package, including all the binaries, to source control. However, the S1 repository is not the same repository as the C1 repository. Both are autonomous systems.
The only system you need to be available when you add the NuGet package C1 is the NuGet package source (NuGet.org, MyGet.org, etc.). The only system you need to be available to commit the changes to S1 is your source control system, and if you use a Distributed Version Control System (DVCS), it's always going to be available.
Pretty trivial so far.
"This isn't pub/sub," you'll most likely say. That's right, not in the traditional sense. Still, if you adopt the pattern language of Enterprise Integration Patterns, you can think of yourself (and your colleagues) as a Polling Consumer.
"But," I suppose you'll say, "I'm not polling the repository and pulling down every package ever published."
True, but you could, and if you did, you'd most likely be filtering away most package updates, because they don't apply to your system. That corresponds to applying a Message Filter.
This last part is important, so let me rephrase it:
Just because your system uses a particular NuGet package, it doesn't mean that you have to install every single version ever published.
It seems to me that at least some of the resistance to adding packages to your repository is based on something like that. As Urs Enzler writes:
[Putting packages in source control is] "not an option if your repo grows > 100GB per month due to monthly updates of BIG nuget packages"While I'm not at all in possession of all the facts regarding Urs Enzler's specific problems, it just got me thinking: do you really need to update your local packages every time a new package is published? You shouldn't have to, I think.
As an example, consider my own open source project AutoFixture, which keeps a fairly high release cadence. It's released according to the principles of Continuous Delivery, so every time there's a new feature or fix, we release a new NuGet package. In 2013, we released 47 versions of the AutoFixture NuGet package, including one major release. That's almost a release every week, but while I use AutoFixture in many other projects, I don't try to keep up with it. I just install AutoFixture when I start a new project, and then I mostly update the package if I need one of the new features or bug fixes. Occasionally, I also update packages in order to not fall too much behind.
As a publicly visible case, consider Hyprlinkr, which uses AutoFixture as one of its dependencies. While going though Hyprlinkr's NuGet packages recently, I discovered that the Hyprlinkr code base was using AutoFixture 2.12.0 - an 18 months old version! I simply hadn't needed to update the package during that time. AutoFixture follows Semantic Versioning, and we go to great lengths to ensure that we don't break existing functionality (unless we do a major release).
Use the NuGet packages you need, commit them to source control, and update them as necessary. For all well-designed packages, you should be able to skip versions without ill effects. This enables you to treat the code bases for each system (S1, S2, etc.) as autonomous systems. Everything you need in order to work with that code base is right there in the source code repository.
Stable Dependency Principle #
What if you need to keep up-to-date with a package that rapidly evolves? From Urs Enzler's tweet, I get the impression that this is the case not only for Urs, but for other people too. Imagine that the creator of such a package frequently publishes new versions, and that you have to keep up to date. If that's the case, it must imply that the package isn't stable, because otherwise, you'd be able to skip updates.
Let me repeat that:
If you depend on a NuGet package, and you have to stay up-to-date, it implies that the package is unstable.
If this is the case, you have an entirely other problem on your hand. It has nothing to do with NuGet Package Restore, or whether you're keeping packages in source control or not. It means that you're violating the Stable Dependencies Principle (SDP). If you feel pain in that situation, that's expected, but the solution isn't Package Restore, but a better dependency hierarchy.
If you can invert the dependency, you can solve the problem. If you can't invert the dependency, you'd probably benefit from an Anti-corruption Layer. There are plenty of better solution that address the root cause of your problems. NuGet Package Restore, on the other hand, is only symptomatic relief.

Comments
Can you elaborate a bit on not breaking existing functionality in newer versions (as long as they have one major version)? What tools are you using to achieve that? I read your post on Semantic Versioning from couple months ago. I manage OSS project and it has quite a big public API - each release I try hard to think of anything I or other contributors might have broken. Are you saying that you relay strictly on programmer deep knowledge of the project when deciding on a new version number? Also, do you build AutoFixture or any other .NET project of yours for Linux/Mono?
For AutoFixture, as well as other OSS projects I maintain, we rely almost exclusively on unit tests, keeping in mind that trustworthy tests are append-only. AutoFixture has some 4000+ unit tests, so if none of those break, I feel confident that a release doesn't contain breaking changes.
For my other OSS projects, the story is the same, although the numbers differ.
- Albedo has 354 tests.
- ZeroToNine has 200 tests.
- Hyprlinkr has 88 tests.
These are much smaller projects than AutoFixture, but since they were all built with TDD, they have excellent code coverage.Currently, I don't build any of these .NET projects for Mono, as I've never had the need.
So you verify behaviour didn't change with a help of automated tests and a good test coverage. What I had in mind is some technique to verify not only the desired behaviour is in place, but also a public API (method signatures, class constructors, set of public types). I should probably clarify that in one of my projects public API is not fully covered by unit-tests. Most critical parts of it are covered, but not all of it. Let's say that upcoming release contains bugfixes as well as new features. I also decided that couple of public API methods are obsolete and deleted them. That makes a breaking change. Let's say I had a lot on my mind and I forgot about the fact that I made those changes. Some time goes by, I'd like to push a new version with all these changes to NuGet, but I'd like to double-check that the public API is still in place compared to the last release. Are there some tools that help with that, may be the ones you use? Or do you rely fully on the tests and your process in that regard? My approach to releases and versioning is a LOT more error prone than yours, clearly, that's the part of my projects that I'd like to improve.
The only technique I rely on apart from automated tests is code reviews. When I write code myself, I always keep in mind if I'm breaking anything. When I receive Pull Requests (PR), I always review them with an eye towards breaking changes. Basically, if a PR changes an existing test, I review it very closely. Obviously, any change that involves renaming of types or members, or that changes public method signatures, are out of the question.
While I'm not aware of any other technique than discipline that will protect against breaking changes, you could always try to check out the tests you have against a previous version, and see if they all pass against the new version. If they don't, you have a breaking change.
You can also make a diff of everything that's happened since your last release, and then meticulously look through all types and members to see if anything was renamed, or method signatures changed. This will also tell you if you have breaking changes.
However, in the end, if you find no breaking changes using these approaches, it's still not a guarantee that you have no breaking changes, because you may have changed the behaviour of some methods. Since you don't have full test coverage, it's hard to tell.
What you could try to do, is to have Pex create a full test suite for your latest released version. This test suite will give you a full snapshot of the behaviour of that release. You could then try to run that test suite on your release candidate to see if anything changed. I haven't tried this myself, and I presume that there's still a fair bit of work involved, but perhaps it's worth a try.