Domain modelling with REST by Mark Seemann
Make illegal states unrepresentable by using hyperlinks as the engine of application state.
Every piece of software, whether it's a web service, smart phone app, batch job, or speech recognition system, interfaces with the world in some way. Sometimes, that interface is a user interface, sometimes it's a machine-readable interface; sometimes it involves rendering pixels on a screen, and sometimes it involves writing to files, selecting records from a database, sending emails, and so on.
Programmers often struggle with how to model these interactions. This is particularly difficult because at the boundaries, systems no longer adhere to popular programming paradigms. Previously, I've explained why, at the boundaries, applications aren't object-oriented. By the same type of argument, neither are they functional (as in 'functional programming').
If that's the case, why should you even bother with 'domain modelling'? Particularly, does it even matter that, with algebraic data types, you can make illegal states unrepresentable? If you need to compromise once you hit the boundary of your application, is it worth the effort?
It is, if you structure your application correctly. Proper (level 3) REST architecture gives you one way to structure applications in such a way that you can surface the constraints of your domain model to the interface layer. When done correctly, you can also make illegal states unrepresentable at the boundary.
A payment example #
In my previous article, I demonstrated how to use (static) types to model an on-line payment domain. To summarise, my task was to model three types of payments:
- Individual payments, which happen only once.
- Parent payments, which start a long-term payment relationship.
- Child payments, which are automated payments originally authorised by an initial parent payment.
"StartRecurrent" : "false" |
"StartRecurrent" : "true" |
|
|---|---|---|
"OriginalTransactionKey" : null |
Individual | Parent |
"OriginalTransactionKey" : "1234ABCD" |
Child | (Illegal) |
StartRecurrent to true. The other three combinations, on the other hand, are valid.
As I demonstrated in my previous article, you can easily model this with algebraic data types.
At the boundary, however, there are no static types, so how could you model something like that as a web service?
A RESTful solution #
A major advantage of REST is that it gives you a way to realise your domain model at the application boundary. It does require, though, that you design the API according to level 3 of the Richardson maturity model. In other words, it's not REST if you're merely tunnelling JSON (or XML) through HTTP. It's still not REST if you publish URL templates and expect clients to fill data into specific place-holders of those URLs.
It's REST if the only way a client can interact with your API is by following hyperlinks.
If you follow those design principles, however, it's easy to model the above payment domain as a RESTful API.
In the following, I will show examples in XML, but it could as well have been JSON. After all, a true REST API must support content negotiation. One of the reasons that I prefer XML is that I can use XPath to point out various nodes.
A client must begin at a pre-published 'home' resource, just like the home page of a web site. This resource presents affordances in the shape of hyperlinks. As recommended by the RESTful Web Services Cookbook, I always use ATOM links:
<home xmlns="http://example.com/payment" xmlns:atom="http://www.w3.org/2005/Atom"> <payment-methods> <payment-method> <links> <atom:link rel="example:pay-individual" href="https://example.com/gift-card" /> </links> <id>gift-card</id> </payment-method> <payment-method> <links> <atom:link rel="example:pay-individual" href="https://example.com/credit-card" /> <atom:link rel="example:pay-parent" href="https://example.com/recurrent/start/credit-card" /> </links> <id>credit-card</id> </payment-method> </payment-methods> </home>
A client receiving the above response is effectively presented with a choice. It can choose to pay with a gift card or credit card, and nothing else, however much it'd like to pay with, say, PayPal. For each of these payment methods, zero or more links are available.
Specifically, there are links to create both an individual or a parent payment with a credit card, but it's only possible to make an individual payment with a gift card. You can't set up a long-term, automated payment relationship with a gift card. (This may or may not make sense, depending on how you look at it, but it's fundamentally a business decision.)
Links are defined by relationship types, which are unique identifiers present in the rel attributes. You can think of them as equivalent to the human-readable text in an HTML a tag that suggests to a human user what to expect from clicking the link; only, rel attribute values are machine-readable and part of the contract between client and service.
Notice how the above XML representation only gives a client the option of making an individual or a parent payment with a credit card. A client can't make a child payment at this point. This follows the domain model, because you can't make a child payment without first having made a parent payment.
RESTful individual payments #
If a client wishes to make an individual payment, it follows the link identified by
/home/payment-methods/payment-method[id = 'credit-card']/links/atom:link[@rel = 'example:pay-individual']/@href
In the above XPath query, I've ignored the default document namespace in order to make the expression more readable. The query returns https://example.com/credit-card, and the client can now make an HTTP POST request against that URL with a JSON or XML document containing details about the payment (not shown here, because it's not important for this particular discussion).
RESTful parent payments #
If a client wishes to make a parent payment, the initial procedure is the same. First, it follows the link identified by
/home/payment-methods/payment-method[id = 'credit-card']/links/atom:link[@rel = 'example:pay-parent']/@href
The result of that XPath query is https://example.com/recurrent/start/credit-card, so the client can make an HTTP POST request against that URL with the payment details. Unlike the response for an individual payment, the response for a parent payment contains another link:
<payment xmlns="http://example.com/payment" xmlns:atom="http://www.w3.org/2005/Atom"> <links> <atom:link rel="example:pay-child" href="https://example.com/recurrent/42" /> <atom:link rel="example:payment-details" href="https://example.com/42" /> </links> <amount>13.37</amount> <currency>EUR</currency> <invoice>1234567890</invoice> </payment>
This response echoes the details of the payment: this is a payment of 13.37 EUR for invoice 1234567890. It also includes some links that a client can use to further interact with the payment:
- The
example:payment-detailslink can be used to query the API for details about the payment, for example its status. - The
example:pay-childlink can be used to make a child payment.
example:pay-child link is only returned if the previous payment was a parent payment. When a client makes an individual payment, this link isn't present in the response, but when the client makes a parent payment, it is.
Another design principle of REST is that cool URIs don't change; once the API has shown a URL like https://example.com/recurrent/42 to a client, it should honour that URL indefinitely. The upshot of that is that a client can save that URL for later use. If a client wants to, say, renew a subscription, it can make a new HTTP POST request to that URL a month later, and that's going to be a child payment. Clients don't have to hack the URL in order to figure out what the transaction key is; they can simply store the complete URL as is and use it later.
A network of options #
Using a design like the one sketched above, you can make illegal states unrepresentative. There's no way for a client to make a payment with StartRecurrent = true and a non-null transaction key; there's no link to that combination. Such an API uses hypermedia as the engine of application state.
It shouldn't be surprising that proper RESTful design works that way. After all, REST is essentially a distillate of the properties that make the World Wide Web work. On a human-readable web page, the user follows links to other pages, and a well-designed web site will only enable a link if the destination exists.
You can even draw a graph of the API I've sketched above:
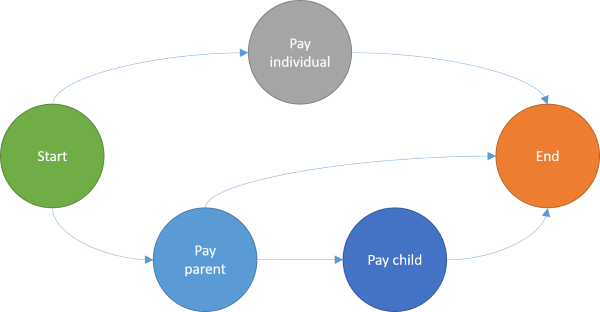
In this diagram, you can see that when you make an individual payment, that's all you can do. You can also see that the only way to make a child payment is by first making a parent payment. There's also a path from parent payments directly to the end node, because a client doesn't have to make a child payment just because it made a parent payment.
If you think that this looks like a finite state machine, then that's no coincidence. That's exactly what it is. You have states (the nodes) and paths between them. If a state is illegal, then don't add that node; only add nodes for legal states, then add links between the nodes that model legal transitions.
Incidentally, languages like F# excel at implementing finite state machines, so it's no wonder I like to implement RESTful APIs in F#.
Summary #
Truly RESTful design enables you to make illegal states unrepresentable by using hypermedia as the engine of application state. This gives you a powerful design tool to ensure that clients can only perform correct operations.
As I also wrote in my previous article, this, too, is no silver bullet. You can turn an API into a pit of success, but there are still many fault scenarios that you can't prevent.
If you were intrigued by this article, but are having trouble applying these design techniques to your own field, I'm available for hire for short or long-term engagements.
