What to test and not to test by Mark Seemann
Should you unit test everything? Hardly surprising, the answer is that It Depends™. This article outlines some of the circumstances you might consider.
Some years ago, I, somewhat to my own surprise, found myself on the wrong side of a controversy about whether one should test trivial code. The context was a discussion about Test-Driven Development (TDD), and for reasons that I still stand behind today, I argued that you should test all code, including trivial code, such as property getters.
Most of the 'TDD community' reacted quite negatively to that article, some in not-so-nice ways. Some people reacted, I believe, based on their dislike of the conclusion, without responding to my arguments. Others, however, gave reasoned rebuttals. When people like Derick Bailey and Mark Rendle disagree with me, in a reasoned matter, even, I consider that a good reason to revisit my thinking.
Could I have been wrong? That certainly wouldn't be the first time, but even re-reading the article today, I find my logic sound. Yet, I've substantially nuanced my position since then.
It took me some time to understand how I could disagree so radically with people I respect. It didn't take me five years, though, but while I've been at peace with the apparent conflict for years, I've never written a coherent description of my current understanding of this problem space. This article is my attempt to remedy that omission.
Context matters #
Whenever you consult an expert about how to address a problem, you'll invariably get the answer that it depends. I'd suggest that if you don't get that answer, the person is probably not an expert, after all. A useful expert will also be able to tell you on what 'it' depends.
In an abstract sense, what 'it' depends on is the context.
I wrote my original piece from a particular context. Part of that context is explicitly present in the article, but another part is entirely implicit. People read the article from within their own contexts, which in many cases turned out to be incongruent with mine. No wonder people disagreed.
Watching the wildlife #
My context at that time was that I had some success with AutoFixture, an open source library, which is what I consider wildlife software. Once you've released a version of the software, you have no control of where it's installed, or how it's used.
This means that backwards compatibility becomes important. If I broke something, I would inconvenience the users of my software. Making sure that compatibility didn't break became one of my highest priorities. I used unit tests for regression tests, and I did, indeed, test the entire public API of AutoFixture, to make sure that no breaking changes were introduced.
That was my implicit context. Read in that light, my dogmatic insistence on testing everything hopefully makes a little more sense.
Does that mean that my conclusion transfers to other circumstances? No, of course it doesn't. If you're developing and maintaining zoo software, breaking changes are of less concern. From that perspective, my article could easily look like the creation of an unhinged mind.
The purpose of tests #
In order to figure out what to test, and what not to test, you should ask yourself the question: what's the purpose of testing?
At first glance, that may seem like an inane question, but there's actually more than one purpose of a unit test. When doing TDD, the purpose of a test is to provide feedback about the API you're developing. A unit test is the first client of the production API. If a test is difficult to write, the production API is difficult to use. More on TDD later, though.
You may say that another purpose of automated tests is that they prevent errors. That's not the case, though. Automated tests prevent regressions.
If you wrote the correct test, your test suite may also help to prevent errors, but a unit test is only as good as the programmer who wrote it. You could have made a mistake when you wrote the test. Or perhaps you misunderstood the specification of what you were trying to implement. Why do you even trust tests?
The cost of regressions #
Why do you want to prevent regressions? Because they're costly?
Based on the little risk management I know about, you operate with two dimensions of risk: the impact of an event, should it occur, and the probability that the event occurs.
Should we all be worried that an asteroid will hit the Earth and wipe out most life? The impact of such an event is truly catastrophic, yet the probability is diminishingly small, so the risk is insignificant. The risk of going for a drive in a car is much higher.
How do you reduce risk? You either decrease the probability that the adverse event will happen, or you reduce the impact of it, should it happen.
Steve Freeman once wrote a nice article about the distinction between fail-safe software, and software that could safely fail. Unfortunately, that article seems to have disappeared from the internet. The point, however, was that with unit tests, we attempt to make our software fail-safe. The unit tests act as a gate that prevents bad versions of the software from being released. That's not a bad strategy for managing risk, but only half of the strategies available.
For example, Continuous Delivery describes how you can use Canary Releases and automated rollbacks to reduce the impact of errors. That's what Steve Freeman called safe fail.
I apologise for this detour around risk management, but I think that it's important that you make an explicit decision about automated testing. You can use unit tests to prevent regressions. What's the impact of an error in production, though?
This depends on the type of software you're developing. When considering alternatives, I often envision the various options as inhabiting a continuum:

For some types of software, an error 'in production' could be fatal. This would be the case for guidance software for Voyager 1, 2, other guidance software, software for medical devices, and so on. If you deploy a defect to Voyager 2, you've probably lost the craft for ever.
(I'd be surprised if the Voyager guidance software is actually covered by unit tests, but I'd expect that other quality assurance checks are in place. For comparison, the space shuttle software development process has been appraised at CMMI level 5.)
On the other side of the continuum, as a software developer, you probably write small ad-hoc development tools for your own use. For example, a few years ago I did a lot of REST API development, and many of the APIs I worked with required OAuth authentication. I wrote a little command-line program that I could use to log on to an internal system and exchange that to a token. I don't think that I wrote any tests for that program. If there were problems with it, I'd just open the source code and fix the problem. Errors were cheap in that situation.
Most software probably falls somewhere in the middle of those extremes. The cost of errors in wildlife software is probably higher than it is for zoo software, but most software can get by with less coverage than everything.
Cyclomatic complexity #
How do you know that your software works? You test it. If you want to automate your testing efforts, you write unit tests... but a unit test suite is software. How do you know that your tests work? Is it going to be turtles all the way down?
I think that we can trust tests for other reasons, but one of them is that each test case exercises a deterministic path through a unit that supports many paths of execution.
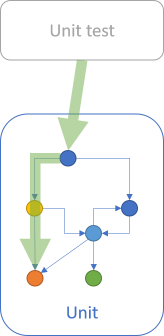
In other words, each unit test is an example of a singular execution path. Tests, then, should have a cyclomatic complexity of 1. In other words, you write (test) code with a cyclomatic complexity of 1 in order to test code with a higher cyclomatic complexity.
Should you test code that has a cyclomatic complexity of 1?
What would be the point of that? Why would you write a unit test with a cyclomatic complexity of 1 to test a piece of code with a cyclomatic complexity of 1? Wouldn't you just be adding more code?
From the perspective of trusting the code, there's no reason to trust such a test more than the code that it exercises. In that light, I think it makes sense to not write that test.
To be clear, there could be other reasons to test code with a cyclomatic complexity of 1. One reason, that I pointed out in my original article, is that you don't know if the simple piece of code will stay simple. Another reason is to prevent regressions. A common metaphor for unit testing is double-entry bookkeeping. If you write the unit test in a different way than the implementation, the two views on that behaviour may keep each other in check. You could do that with triangulation using parametrised tests, or perhaps with property-based testing.
I tend to use a heuristic where the farther to the left I am on the above continuum, the more I'm inclined to skip testing of simple functionality. Code with a cyclomatic complexity of 1 falls into that bucket.
TDD #
Let's return our attention to TDD. The previous paragraphs have mostly discussed automated tests as a way to prevent regressions. TDD gives us an entirely different motivation for writing tests: the tests provide feedback on the design of our production code.
Viewed like this, the tests themselves are only artefacts of the TDD process. It's usually a good idea to keep them around after the standard red-green-refactor cycle, because they serve double-duty as regression tests.
Should you test-drive everything? If you're inexperienced with TDD, you get the best exercise by test-driving as much as possible. This still doesn't have to mean that you must write a an explicit test case for each class member. That's what both Mark Rendle and Derick Bailey pointed out. It's often enough if the tests somehow exercise those members.
Revisiting my old article, my mistake was that I conflated TDD with regression testing. My motivation for writing an explicit test case for each member, no matter how trivial, was to preserve backwards compatibility. It really had nothing to do with TDD.
When in doubt #
Despite all other rules of thumb I've so far listed, I'll suggest a few exceptions.
Even if a piece of code theoretically has a cyclomatic complexity of 1, if you're in doubt of how it works, then write a test.
If you have a defect in production, then reproduce that defect with one or more tests, even if the code in question is 'trivial'. Obviously, it wasn't trivial after all, if it caused a bug in production.
Pragmatism #
When you're learning something new, you're typically struggling with even the most basic concepts. That's just how learning works. In that phase of learning, it often pays to follow explicit rules. A way to think about this is the Dreyfus model of skill acquisition. Once you gain some experience, you can start deviating from the rules. We could call this pragmatism.
I often discuss TDD with people who plead for pragmatism. Those people have typically practised TDD for years, if not decades. So have I, and, believe it or not, I'm often quite pragmatic when I practice TDD 'for real'. This is, however, a prerogative of experience.
You can only be pragmatic if you know how to be dogmatic.I use the concept of dogmatism as an antonym to pragmatism. I view pragmatism in programming as the choice of practical solutions over theoretical principles. It's a choice, which means that you must be aware of alternatives.
If you don't know the (principled) alternative, there's no choice.
When you're learning something new, you're still not aware of how to do things according to principle. That's natural. I find myself in that situation all the time. If you keep at it, though, eventually you'll have gained enough experience that you can make actual choices.
This applies to TDD as well. When you're still learning TDD, stick to the principles, particularly when it's inconvenient. Once you've done TDD for a few years, you've earned the right to be pragmatic.
Conclusion #
Which parts of your code base should you (unit) test? It Depends™.
It depends on why you are unit testing, and on the cost of defects in production, and probably many other things I didn't think of.
What's the purpose of tests? Are you using TDD to get feedback on your API design ideas? Or is the main purpose of tests to prevent regressions? Your answers to such questions should guide your decisions on how much to test.
Recently, I've mostly been writing about topics related to computer science, such as the relationships between various branches of mathematics to computation. In such realms, laws apply, and answers tend to be either right or wrong. A piece like this article is different.
This is fundamentally a deeply subjective essay. It's based on my experience with writing automated tests in various circumstances since 2003. I've tried to be as explicit about my context as possible, but I've most likely failed to identify one or more implicit assumptions or biases. I do, therefore, encourage comments.
I wrote this commentary because people keep asking me about how much to test, and when. I suppose it's because they wish to learn from me, and I'm happy to share what I know, to the best of my ability. I have much to learn myself, though, so read this only as the partial, flawed, personal answer that it is.
