Zone of Ceremony by Mark Seemann
Static typing doesn't have to involve much ceremony.
I seem to get involved in long and passionate debates about static versus dynamic typing on a regular basis. I find myself clearly on the side of static typing, but this article isn't about the virtues of static versus dynamic typing. The purpose is to correct a common misconception about statically typed languages.
Ceremony #
People who favour dynamically typed languages over statically typed languages often emphasise that they find the lack of ceremony productive. That seems reasonable; only, it's a false dichotomy.
"Ceremony is what you have to do before you get to do what you really want to do."
Dynamically typed languages do seem to be light on ceremony, but you can't infer from that that statically typed languages have to require lots of ceremony. Unfortunately, all mainstream statically typed languages belong to the same family, and they do involve ceremony. I think that people extrapolate from what they know; they falsely conclude that all statically typed languages must come with the overhead of ceremony.
It looks to me more as though there's an unfortunate Zone of Ceremony:
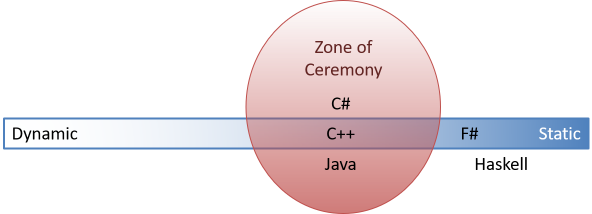
Such a diagram can never be anything but a simplification, but I hope that it's illuminating. C++, Java, and C# are all languages that involve ceremony. To the right of them are what we could term the trans-ceremonial languages. These include F# and Haskell.
In the following, I'll show some code examples in various languages. I'll discuss ceremony according to the above definition. The discussion focuses on the amount of preparatory work one has to do, such as creating a new file, declaring a new class, and declaring types. The discussion is not about the implementation code. For that reason, I've removed colouring from the implementation code, and emphasised the code that I consider ceremonial.
Low ceremony of JavaScript #
Imagine that you're given a list of numbers, as well as a quantity. The quantity is a number to be consumed. You must remove elements from the left until you've consumed at least that quantity. Then return the rest of the list.
> consume ([1,2,3], 1); [ 2, 3 ] > consume ([1,2,3], 2); [ 3 ] > consume ([1,2,3], 3); [ 3 ] > consume ([1,2,3], 4); []
The first example consumes only the leading 1, while both the second and the third example consumes both 1 and 2 because the sum of those values is 3, and the requested quantity is 2 and 3, respectively. The fourth example consumes all elements because the requested quantity is 4, and you need both 1, 2, and 3 before the sum is large enough. You have to pick strictly from the left, so you can't decide to just take the elements 1 and 3.
If you're wondering why such a function would be useful, here's my motivating example.
In JavaScript, you could implement the consume function like this:
var consume = function (source, quantity) { if (!source) { return []; } var accumulator = 0; var result = []; for (var i = 0; i < source.length; i++) { var x = source[i]; if (quantity <= accumulator) result.push(x); accumulator += x; } return result; }
I'm a terrible JavaScript programmer, so I'm sure that it could have been done more elegantly, but as far as I can tell, it gets the job done. I wrote some tests, and I have 17 passing test cases. The point isn't about how you write the function, but how much ceremony is required. In JavaScript you don't need to declare any types. Just name the function and its arguments, and you're ready to write code.
High ceremony of C# #
Contrast the JavaScript example with C#. The same function in C# would look like this:
public static class Enumerable { public static IEnumerable<int> Consume( this IEnumerable<int> source, int quantity) { if (source is null) yield break; var accumulator = 0; foreach (var i in source) { if (quantity <= accumulator) yield return i; accumulator += i; } } }
Here you have to declare the type of each method argument, as well as the return type of the method. You also have to put the method in a class. This may not seem like much overhead, but if you later need to change the types, editing is required. This can affect downstream callers, so simple type changes ripple through code bases.
It gets worse, though. The above Consume method only handles int values. What if you need to call the method with long arrays?
You'd have to add an overload:
public static IEnumerable<long> Consume( this IEnumerable<long> source, long quantity) { if (source is null) yield break; var accumulator = 0L; foreach (var i in source) { if (quantity <= accumulator) yield return i; accumulator += i; } }
Do you need support for short? Add an overload. decimal? Add an overload. byte? Add an overload.
No wonder people used to dynamic languages find this awkward.
Low ceremony of F# #
You can write the same functionality in F#:
let inline consume quantity = let go (acc, xs) x = if quantity <= acc then (acc, Seq.append xs (Seq.singleton x)) else (acc + x, xs) Seq.fold go (LanguagePrimitives.GenericZero, Seq.empty) >> snd
There's no type declaration in sight, but nonetheless the function is statically typed. It has this somewhat complicated type:
quantity: ^a -> (seq< ^b> -> seq< ^b>)
when ( ^a or ^b) : (static member ( + ) : ^a * ^b -> ^a) and
^a : (static member get_Zero : -> ^a) and ^a : comparison
While this looks arcane, it means that it support sequences of any type that comes with a zero value and supports addition and comparison. You can call it with both 32-bit integers, decimals, and so on:
> consume 2 [1;2;3];; val it : seq<int> = seq [3] > consume 2m [1m;2m;3m];; val it : seq<decimal> = seq [3M]
Static typing still means that you can't just call it with any type of value. An expression like consume "foo" [true;false;true] will not compile.
You can explicitly declare types in F# (like you can in C#), but my experience is that if you don't, type changes tend to just propagate throughout your code base. Change a type of a function, and upstream callers generally just 'figure it out'. If you think of functions calling other functions as a graph, you often only have to adjust leaf nodes even when you change the type of something deep in your code base.
Low ceremony of Haskell #
Likewise, you can write the function in Haskell:
consume quantity = reverse . snd . foldl go (0, []) where go (acc, ys) x = if quantity <= acc then (acc, x:ys) else (acc + x, ys)
Again, you don't have to explicitly declare any types. The compiler figures them out. You can ask GHCi about the function's type, and it'll tell you:
> :t consume consume :: (Foldable t, Ord a, Num a) => a -> t a -> [a]
It's more compact than the inferred F# type, but the idea is the same. It'll compile for any Foldable container t and any type a that belongs to the classes of types called Ord and Num. Num supports addition and Ord supports comparison.
There's little ceremony involved with the types in Haskell or F#, yet both languages are statically typed. In fact, their type systems are more powerful than C#'s or Java's. They can express relationships between types that those languages can't.
Summary #
In debates about static versus dynamic typing, contributors often generalise from their experience with C++, Java, or C#. They dislike the amount of ceremony required in these languages, but falsely believe that it means that you can't have static types without ceremony.
The statically typed mainstream languages seem to occupy a Zone of Ceremony.
Static typing without ceremony is possible, as evidenced by languages like F# and Haskell. You could call such languages trans-ceremonial languages. They offer the best of both worlds: compile-time checking and little ceremony.

Comments
In your initial
intC# example, I think your point is that method arguments and the return type require manifest typing. Then for your example aboutlong(and comments aboutshort,decimal, andbyte), I think your point is that C#'s type system is primarily nominal. You then contrast those C# examples with F# and Haskell examples that utilize inferred and structural aspects of their type systems.I also sometimes get involved in debates about static versus dynamic typing and find myself on the side of static typing. Furthermore, I also typically hear arguments against manifest and nominal typing instead of against static typing. In theory, I agree with those arguments; I also prefer type systems that are inferred and structural instead of those that are manifest and nominal.
I see the tradeoff as being among the users of the programming language, those responsible for writing and maintaining the compiler/interpreter, and what can be said about the correctness of the code. (In the rest of this paragraph, all statements about things being simple or complex are meant to be relative. I will also exaggerate for the sake of simplifying my statements.) For a dynamic language, the interpreter and coding are simple but there are no guarantees about correctness. For a static, manifest, and nominal language, the compiler is somewhere between simple and complex, the coding is complex, but at least there are some guarantees about correctness. For a static, inferred, structural language, the compiler is complex, coding is simple, and there are some guarantees about correctness.
Contrasting a dynamic language with one that is static, inferred, and structural, I see the tradeoff as being directly between the the compiler/interpreter writers and what can be said about the correctness of the code while the experience of those writing code in the language is mostly unchanged. I think that is your point being made by contrasting the JavaScript example (a dynamic language) with the F# and Haskell examples (that demonstrate the static, inferred, and structural behavior of their type systems).
While we are on the topic, I would like to say something that I think is controversial about duck typing. I think duck typing is "just" a dynamic type system that is also structural. This contradicts the lead of its Wikipedia article (linked above) as well as the subsection about structural type systems. They both imply that nominal vs structural typing is a spectrum that only exists for static languages. I disagree; I think dynamic languages can also exist on that spectrum. It is just that most dynamic languages are also structural. In contrast, I think that the manifest vs inferred spectrum exists for static languages but not for dynamic languages.
Nonetheless, that subsection makes a great observation. For structural languages, the difference between static and dynamic languages is not just some guarantees about correctness. Dynamic languages check for type correctness at the last possible moment. (That is saying more than saying that the type check happens at runtime.) For example, consider a function with dead code that "doesn't type". If the type system were static, then this function cannot be executed, but if the type system were dynamic, then it could be executed. More practically, suppose the function is a simple
if-elsestatement with code in theelsebranch that "doesn't type" and that the corresponding Boolean expression always evaluates totrue. If the type system were static, then this function cannot be executed, but if the type system were dynamic, then it could be executed.In my experience, the typical solution of a functional programmer would be to strengthen the input types so that the
elsebranch can be proved by the compiler to be dead code and then delete the dead code. This approach makes this one function simpler, and I generally am in favor of this. However, there is a sense in which we can't always repeat this for the calling function. Otherwise, we would end up with a program that is provably correct, which is impossible for a Turning-complete language. Instead, I think the practical solution is to (at some appropriate level) short-circuit the computation when given input that is not known to be good and either do nothing or report back to the user that the input wasn't accepted.Using mostly both C# and TypeScript, two statically typed languages, I’ve experienced how it’s terser in TypeScript, essentially thanks to its type inference and its structural typing. I like the notion of “Ceremony” you gave to describe this and the fact that it’s not correlated to the kind of typing, dynamic or static 👍
Still, TypeScript is more verbose than F#, as we can see with the following code translation from F# to TypeScript using object literal instead of tuple for the better support of the former:
// const consume = (source: number[], quantity: number): number[] const consume = (source: number[], quantity: number) => source.reduce(({ acc, xs }, x) => quantity <= acc ? { acc, xs: xs.concat(x) } : { acc: acc + x, xs }, { acc: 0, xs: [] as number[] } ).xs;Checks:
As we can see, the code is a little more verbose than in JavaScript but still terser than in C#. The returned type is inferred as
number[]but theas number[]is a pity, necessary because the inferred type of the empty array[]isany[].consumeis not generic: TypeScript/JavaScript as only one primitive for numbers:number. It works for common scenarios but their no simple way to make it work withBigInt, for instance using the union typenumber | bigint. The more pragmatic option would be to copy-paste, replacingnumberwithbigintand0with0n.