Curb code rot with thresholds by Mark Seemann
Code bases deteriorate unless you actively prevent it. Institute some limits that encourage developers to clean up.
From time to time I manage to draw the ire of people, with articles such as The 80/24 rule or Put cyclomatic complexity to good use. I can understand why. These articles suggest specific constraints to which people should consider consenting. Don't write code wider than 80 characters. Don't write code with a cyclomatic complexity higher than 7.
It makes people uncomfortable.
Sophistication #
I hope that regular readers understand that I'm a more sophisticated thinker than some of my texts may suggest. I deliberately simplify my points.
I do this to make the text more readable. I also aspire to present sufficient arguments, and enough context, that a charitable reader will understand that everything I write should be taken as food for thought rather than gospel.
Consider a sentence like the above: I deliberately simplify my points. That sentence, in itself, is an example of deliberate simplification. In reality, I don't always simplify my points. Perhaps sometimes I simplify, but it's not deliberate. I could have written: I often deliberately simplify some of my points. Notice the extra hedge words. Imagine an entire text written like that. It would be less readable.
I could hedge my words when I write articles, but I don't. I believe that a text that states its points as clearly as possible is easier to understand for any careful reader. I also believe that hedging my language will not prevent casual readers from misunderstanding what I had in mind.
Archetypes #
Why do I suggest hard limits on line width, cyclomatic complexity, and so on?
In light of the above, realise that the limits I offer are suggestions. A number like 80 characters isn't a hard limit. It's a representation of an idea; a token. The same is true for the magic number seven, plus or minus two. That too, represents an idea - the idea that human short-term memory is limited, and that this impacts our ability to read and understand code.
The number seven serves as an archetype. It's a proxy for a more complex idea. It's a simplification that, hopefully, makes it easier to follow the plot.
Each method should have a maximum cyclomatic complexity of seven. That's easier to understand than each method should have a maximum cyclomatic complexity small enough that it fits within the cognitive limits of the human brain's short-term memory.
I've noticed that a subset of the developer population is quite literal-minded. If I declare: don't write code wider than 80 characters they're happy if they agree, and infuriated if they don't.
If you've been paying attention, you now understand that this isn't about the number 80, or 24, or 7. It's about instituting useful quantitative guidance. The actual number is less important.
I have reasons to prefer those specific values. I've already motivated them in previous articles. I'm not, though, obdurately attached to those particular numbers. I'd rather work with a team that has agreed to a 120-character maximum width than with a team that follows no policy.
How code rots #
No-one deliberately decides to write legacy code. Code bases gradually deteriorate.
Here's another deliberate simplification: code gradually becomes more complicated because each change seems small, and no-one pays attention to the overall quality. It doesn't happen overnight, but one day you realise that you've developed a legacy code base. When that happens, it's too late to do anything about it.
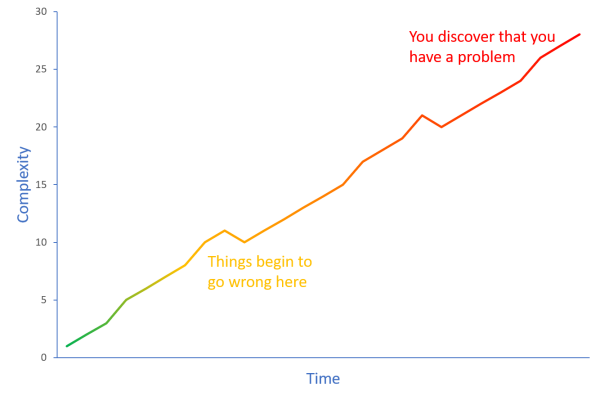
At the beginning, a method has low complexity, but as you fix defects and add features, the complexity increases. If you don't pay attention to cyclomatic complexity, you pass 7 without noticing it. You pass 10 without noticing it. You pass 15 and 20 without noticing it.
One day you discover that you have a problem - not because you finally look at a metric, but because the code has now become so complicated that everyone notices. Alas, now it's too late to do anything about it.
Code rot sets in a little at a time; it works like boiling the proverbial frog.
Thresholds #
Agreeing on a threshold can help curb code rot. Institute a rule and monitor a metric. For example, you could agree to keep an eye on cyclomatic complexity. If it exceeds 7, you reject the change.
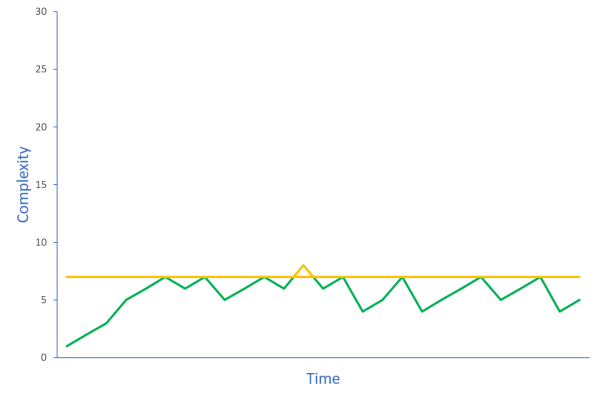
Such rules work because they can be used to counteract gradual decay. It's not the specific value 7 that contributes to better code quality; it's the automatic activation of a rule based on a threshold. If you decide that the threshold should be 10 instead, that'll also make a difference.
Notice that the above diagram suggests that exceeding the threshold is still possible. Rules are in the way if you must rigidly obey them. Situations arise where breaking a rule is the best response. Once you've responded to the situation, however, find a way to bring the offending code back in line. Once a threshold is exceeded, you don't get any further warnings, and there's a risk that that particular code will gradually decay.
What you measure is what you get #
You could automate the process. Imagine running cyclomatic complexity analysis as part of a Continuous Integration build and rejecting changes that exceed a threshold. This is, in a way, a deliberate attempt to hack the management effect where you get what you measure. With emphasis on a metric like cyclomatic complexity, developers will pay attention to it.
Be aware, however, of Goodhart's law and the law of unintended consequences. Just as code coverage is a useless target measure, you have to be careful when you institute hard rules.
I've had success with introducing threshold rules because they increase awareness. It can help a technical leader shift emphasis to the qualities that he or she wishes to improve. Once the team's mindset has changed, the rule itself becomes redundant.
I'm reminded of the Dreyfus model of skill acquisition. Rules make great training wheels. Once you become proficient, the rules are no longer required. They may even be in your way. When that happens, get rid of them.
Conclusion #
Code deteriorates gradually, when you aren't looking. Instituting rules that make you pay attention can combat code rot. Using thresholds to activate your attention can be an effective countermeasure. The specific value of the threshold is less important.
In this article, I've mostly used cyclomatic complexity as an example of a metric where a threshold could be useful. Another example is line width; don't exceed 80 characters. Or line height: methods shouldn't exceed 24 lines of code. Those are examples. If you agree that keeping an eye on a metric would be useful, but you disagree with the threshold I suggest, pick a value that suits you better.
It's not the specific threshold value that improves your code; paying attention does.

Comments
In F#, it's not uncommon to have inner functions (local functions defined inside other functions). How would you calculate the cyclomatic complexity of a function that contains inner functions?
To be specific, I'm actually wondering about how to count the number of activated objects in a function, which you talk about in your book, Code That Fits in Your Head. I have been wanting to ask you this for some time, but haven't been able to find a good article to comment on. I think this is the closest I can get.
In terms of activated objects: Would you count all activated objects in all sub-functions as counting towards the top-level function? Or would you count the inner functions separately, and have calls to the inner function contribute only "one point" to the top-level functions? I think the latter makes most sense, but I'm not sure. I base my reasoning on the fact that an inner function, being a closure, is similar to a class with fields and a single method (closures are a poor man's objects and vice versa). Another way to view it is that you could refactor by extracting the function and adding any necessary parameters.
PS, this is not just theoretical. I am toying with a linter for F# and want "number of activated objects" as one of the rules.
Christer, thank you for writing. For the purposes of calculating cyclomatic complexity of inner functions, aren't they equivalent to (private) helper methods?
If so, they don't count towards the cyclomatic complexity of the containing function.
As for the other question, I don't count functions as activated objects, but I do count the values they return. When the function is referentially transparent, however, they're equal. I do talk more about this in my talk Fractal Architecture, of which you can find several recordings on the internet; here's one.
The book also discusses this, and that part is also freely available here on the blog.
The short answer is that it's essential that you can prevent 'inner' objects from leaking out from method calls. Per definition, functions that are referentially transparent do have that property. For methods that aren't referentially transparent, encapsulation may still achieve the same effect, if done right. Usually, however, it isn't.
Mark, thank you for the response. What you say about cyclomatic complexity makes sense, especially given your previous writings on the subject. I am still a bit fuzzy on how to count activated objects, though.
If a function returns a tuple of which one item is ignored, would that ignored object count as an activated object? (Does the fact that a tuple could technically be considered as a single object with
.Item1and.Item2properties change the answer?) And what about piping? Eta reduction?An example would be handy right about now, so what would you say are the activated object counts of the following functionally identical functions, and why?
let f (a, b) = let c, _ = getCD (a, b) in clet f (a, b) = (a, b) |> getCD |> fstlet f = getCD >> fstlet f = getCDFstNote the "trick" of number 3: By removing the explicit parameter, it is now impossible to tell just from looking at the code how many tupled items
faccepts, if any. And in number 4, even the knowledge that an intermediate function in the composition returns a tuple of 2 values is removed.Additionally: I assume that returning a value counts as "activating" an object? So
let f x = xhas 1 activated object? What about the functionally identicallet f = id? Would that be 1 or 0?I guess what I'm after is a more fully developed concept of "the number of activated objects" of a function/method, to the point where a useful linter rule could be implemented based on it; something similar to your previous writings on how method calls do not increase the cyclomatic complexity, which was a very useful clarification that I have seen you repeat several times. I have given the matter some thought myself, but as you can see, I haven't been able to come up with good answer.
It seems that I should have been more explicit about the terminology related to the adjective activated. I was inspired by the notion of object activation described in Thinking Fast and Slow. The idea is that certain pieces of information move to the forefront in the mind, and that these 'objects' impact decision-making. Kahneman labels such information as activated when it impacts the decision process.
The heuristic I had in mind was to port that idea to an (informal) readability analysis. Given that the human short-time memory is quite limited, I find it useful to count the mental load of a given piece of code.
The point, then, is not to count all objects or values in scope, but rather those that are required to understand what a piece of code does. For example, if you look at an instance method on a class, the class could have four class fields, but if only one of those fields are used in the method, only that one is activated - even though the other three are also in scope.
With that in mind, let's try to look at your four examples.
a,b, andc: 3 objects.aandb: 2 objects.getCDas an object.Note that I've employed qualifying words. The point of the analysis is to highlight objects that might stress our short-term memory. It's not an exact science, and I never intended it to be. Rather, I see it as a possible springboard for having a discussion about relative readability of code. A team can use the heuristic to compare alternatives.
With your examples in mind, you'd be likely to run into programmers who find the first two examples more readable than the third. It's certainly more 'detailed', so, in a sense, it's easier to understand what's going on. That works as long as you only have a few values in play, but cognitively, it doesn't scale.
I do tend to prefer eta reductions and point-free notation exactly because they tend to reduce the number of activated objects, but these techniques certainly also raise the abstraction level. On the other hand, once someone understands something like function composition (
>>) or point-free notation, they can now leverage long-term memory for that, instead of having to rely on limited short-term memory in order to understand a piece of code. By moving more information to long-term memory, we can reduce the load on short-term memory, thereby freeing it up for other information.Perhaps that's a bit of a digression, but I always intended the notion of object activation to be a heuristic rather than an algorithm.
Mark, thank you for the excellent clarification. It gave me one of those "a-ha" moments that accompanies a sudden jump in understanding. In hindsight, of course this is about the cognitive load of a piece of code, and of course that will be different for different people, based for example on which abstractions they are used to.
In terms of the code examples, I think we both agree that
let f = a >> brequires less mental load thanlet f = a >> b >> c >> d >> e. In other words, I would argue that functions in a composition do contribute to cognitive load. This may however also depend on the actual functions that are composed.In any case, I am now less certain than before that a simple linter rule (i.e., an algorithm) can capture cognitive load in a way that is generally useful. I will have to think about this some more.