Epistemology of software by Mark Seemann
How do you know that your code works?
In 2023 I gave a conference keynote titled Epistemology of software, a recording of which is available on YouTube. In it, I try to answer the question: How do we know that software works?
The keynote was for a mixed audience with some technical, but also a big contingent of non-technical, software people, so I took a long detour around general epistemology, and particularly the philosophy of science as it pertains to empirical science. Towards the end of the presentation, I returned to the epistemology of software in particular. While I recommend that you watch the recording for a broader perspective, I want to reiterate the points about software development here. Personally, I like prose better than video when it comes to succinctly present and preserve ideas.
How do we know anything? #
In philosophy of science it's long been an established truth that we can't know anything with certainty. We can only edge asymptotically closer to what we believe is the 'truth'. The most effective method for that is the 'scientific method', which grossly simplified is an iterative process of forming hypotheses, making predictions, performing experiments, and corroborating or falsifying predictions. When experiments don't quite turn out as predicted, you may adjust your hypothesis accordingly.
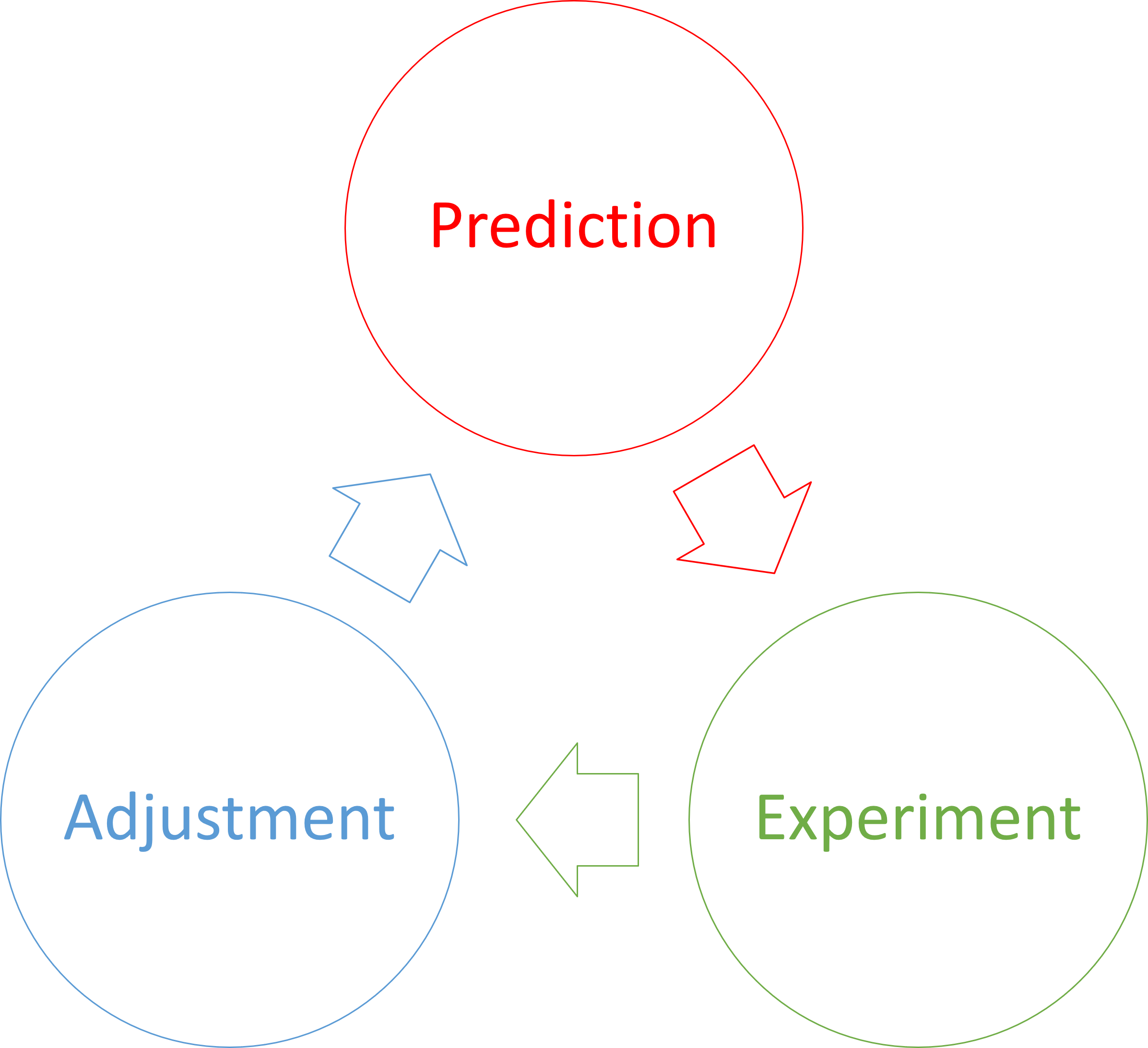
An example, however, may still be useful to set the stage. Consider Galilei's idea of dropping a small and a big ball from the Leaning Tower of Pisa. The prediction is that two objects of different mass will hit the ground simultaneously, if dropped from the same height simultaneously. This experiment have been carried out multiple times, even in vacuum chambers.
Even so, thousands of experiments do not constitute proof that two objects fall with the same acceleration. The experiments only make it exceedingly likely that this is so.
What happens if you apply scientific thinking to software development?
Empirical epistemology of software #
Put yourself in the shoes of a non-coding product owner. He or she needs an application to solve a particular problem. How does he or she know when that goal has been reached?
Ultimately, he or she can only do what any scientist can do: Form hypotheses, make predictions, and perform experiments. Sometimes product owners assign these jobs to other people, but so do scientists.
Testing can be ad-hoc or planned, automated or manual, thorough or cursory, but it's really the only way a product owner can determine whether or not the software works.
When I started as a software developer, testing was often the purview of a dedicated testing department. The test manager would oversee the production of a test plan, which was a written document that manual testers were supposed to follow. Even so, this, too, is an empirical approach to software verification. Each test essentially implies a hypothesis: If we perform these steps, the application will behave in this particular, observable manner.
For an application designed for human interaction, letting a real human tester interact with it may be the most realistic test scenario, but human testers are slow. They also tend to make mistakes. The twentieth time they run through the same test scenario, they are likely to overlook details.
If you want to perform faster, and more reliable, tests, you may wish to automated the tests. You could, for example, write code that executes a test plan. This, however, raises another problem: If tests are also code, how do we know that the tests contain no bugs?
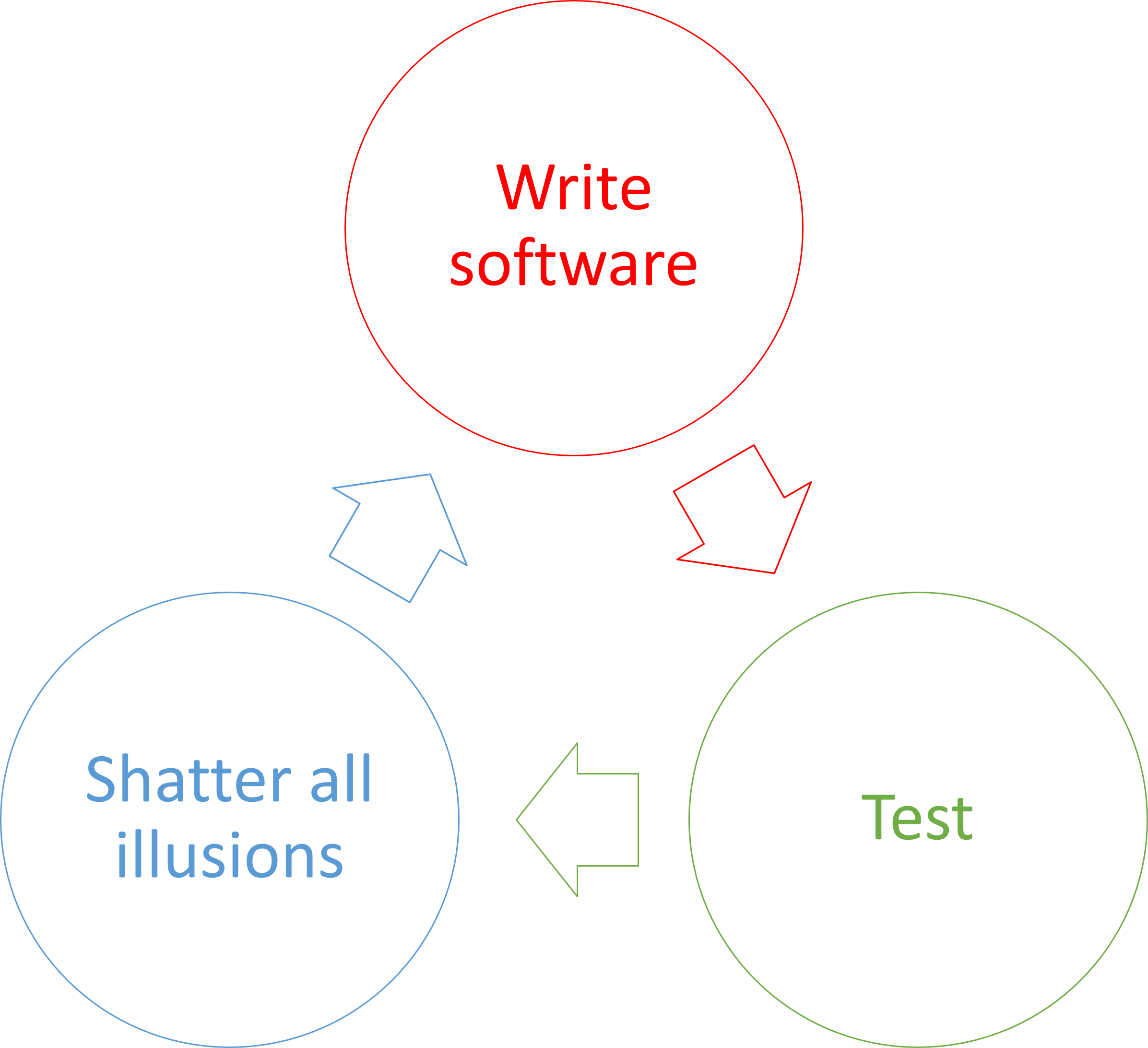
The scientific method of software #
How about using the the scientific method? Even more specifically, proceed by making incremental falsifiable predictions about the code you write.
For instance, write a single automated test without accompanying production code:
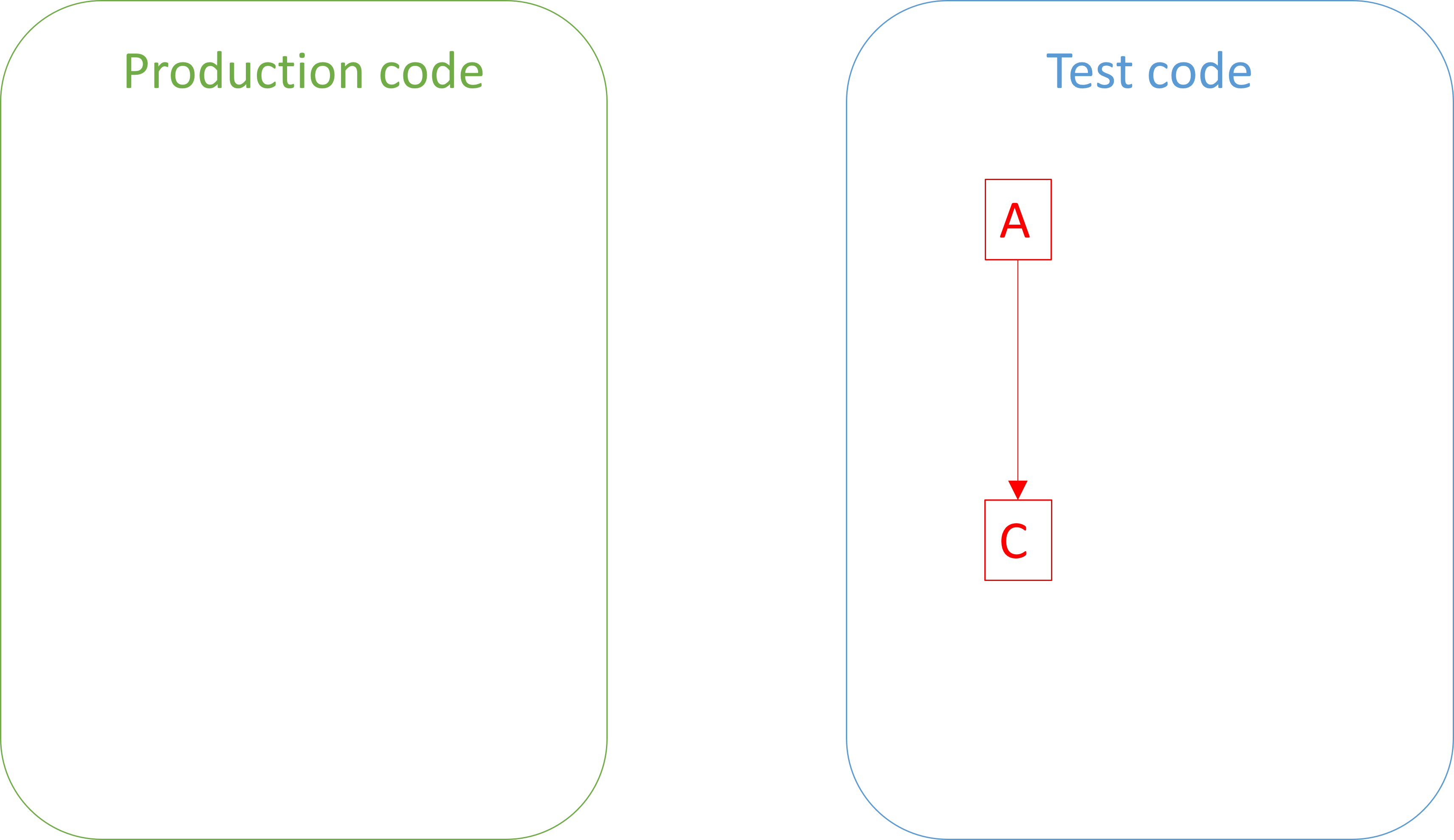
Before you run the test code, you make a prediction based on the implicit hypothesis formulated by the red-green-refactor checklist: If this test runs, it will fail.
This is a falsifiable prediction. While you expect the test to fail, it may succeed if, for example, you've inadvertently written a tautological assertion. In other words, if your prediction is falsified, you know that the test code is somehow wrong. On the other hand, if the test fails (as predicted), you've failed to falsify your prediction. As empirical science goes, this is the best you can hope for. It doesn't prove that the test is correct, but corroborates the hypothesis that it is.
The next step in the red-green-refactor cycle is to write just enough code to pass the test. You do that, and before rerunning the test implicitly formulate the opposite hypothesis: If this test runs, it will succeed.
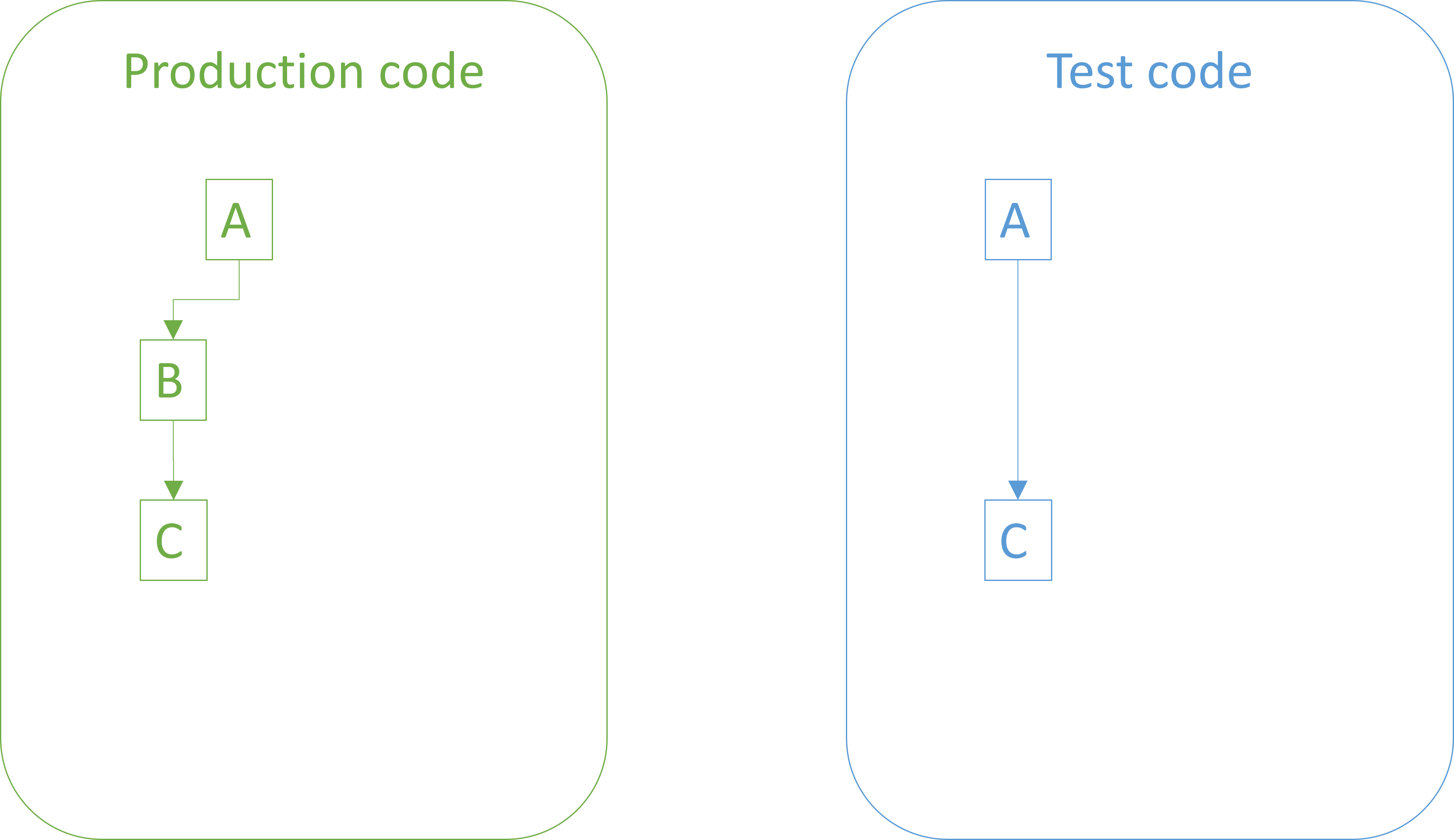
This, again, is a falsifiable prediction. If, despite expectations, the test fails, you know that something is wrong. Most likely, it's the implementation that you just wrote, but it could also be the test which, after all, is somehow defective. Or perhaps a circuit in your computer was struck by a cosmic ray. On the other hand, if the test passes, you've failed to falsify your prediction, which is the best you can hope for.
You now write a second test, which comes with the implicit falsifiable prediction: If I run all tests, the new test will fail.
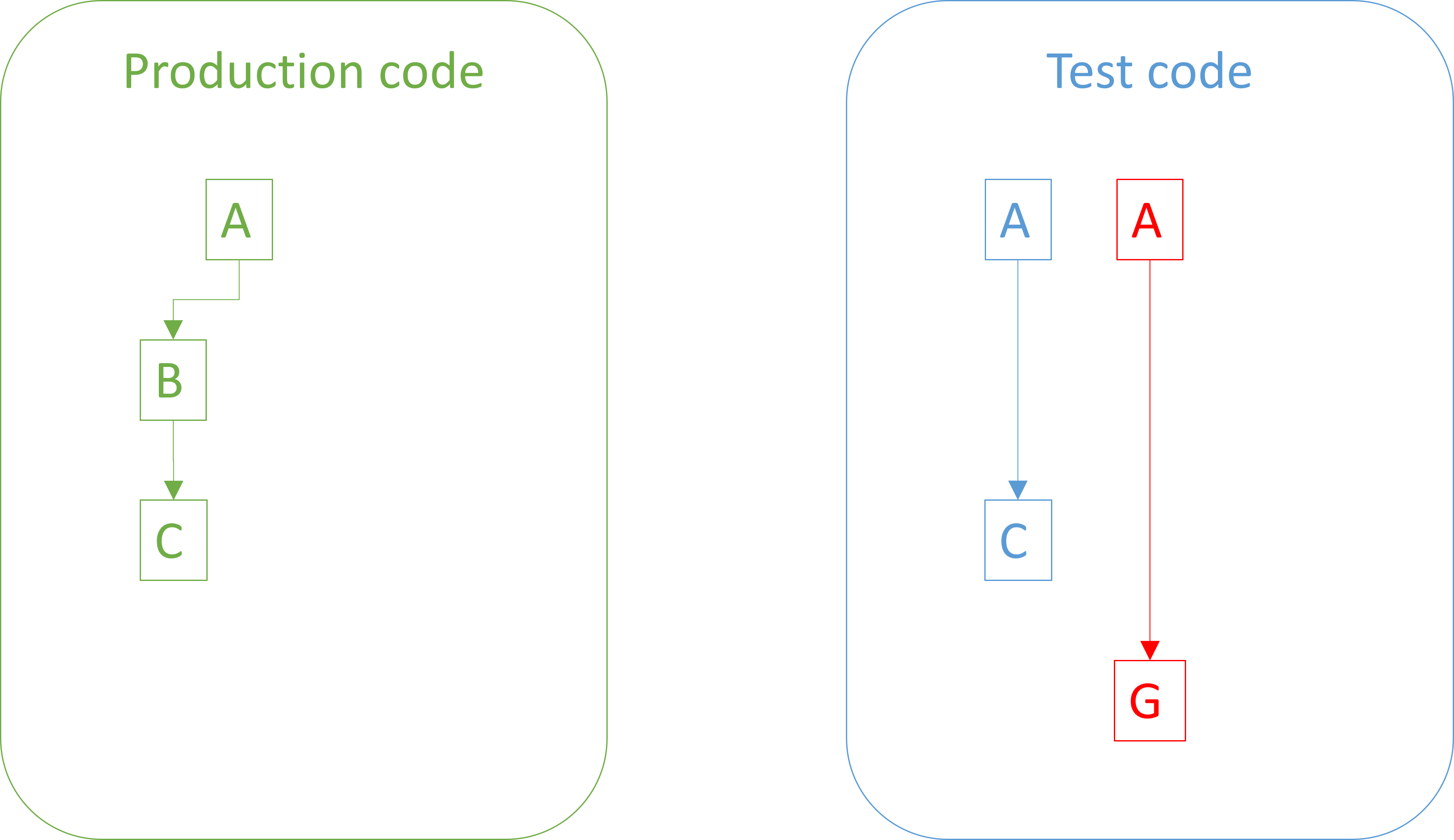
The process repeats. A succeeding test falsifies the prediction, while a failing test only corroborates the hypothesis.
Again, implement just enough code for the hypothesis that if you run all tests, they will pass.
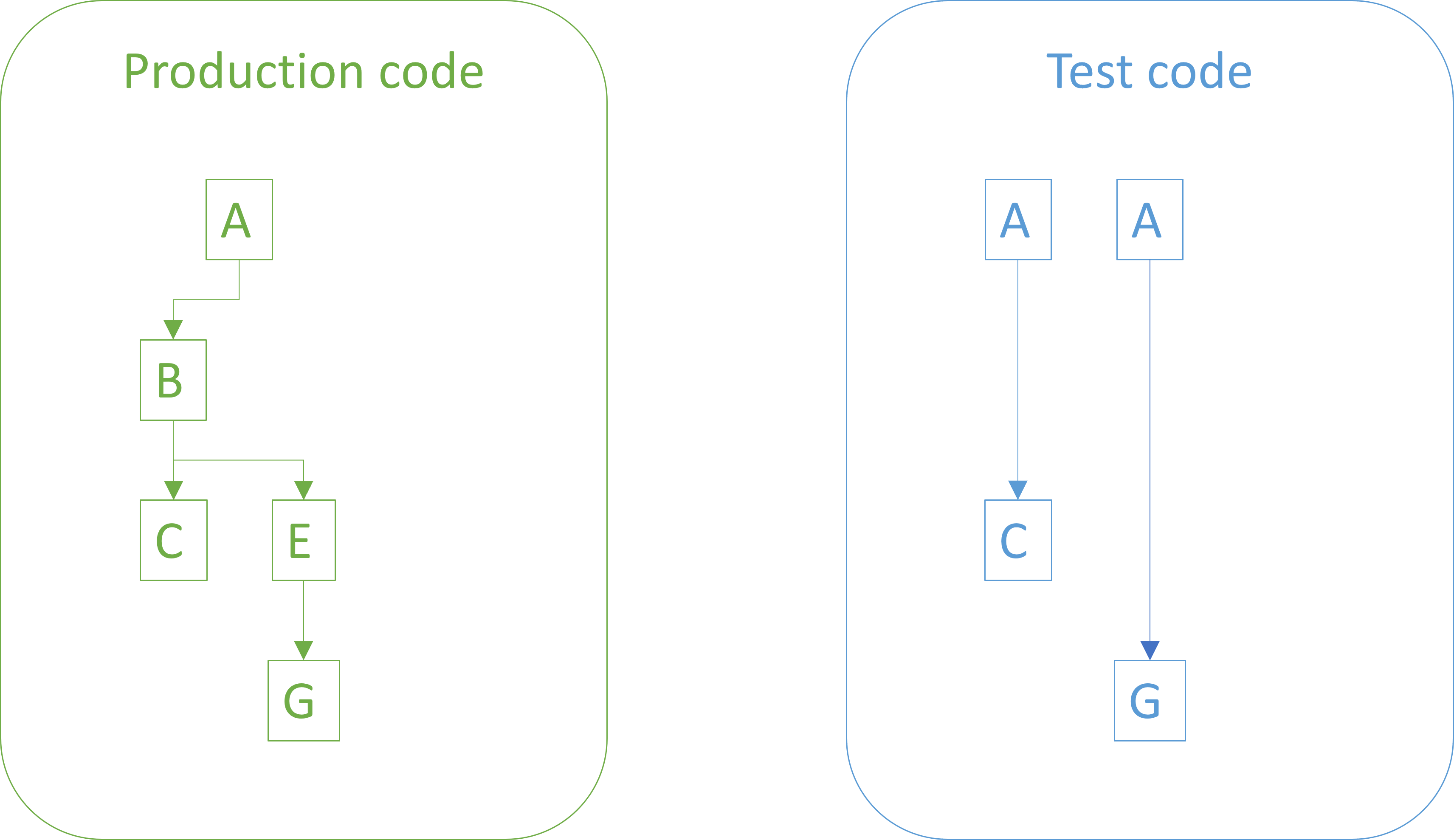
If this hypothesis, too, is corroborated (i.e. you failed to falsify it), you move on until you believe that you're done.
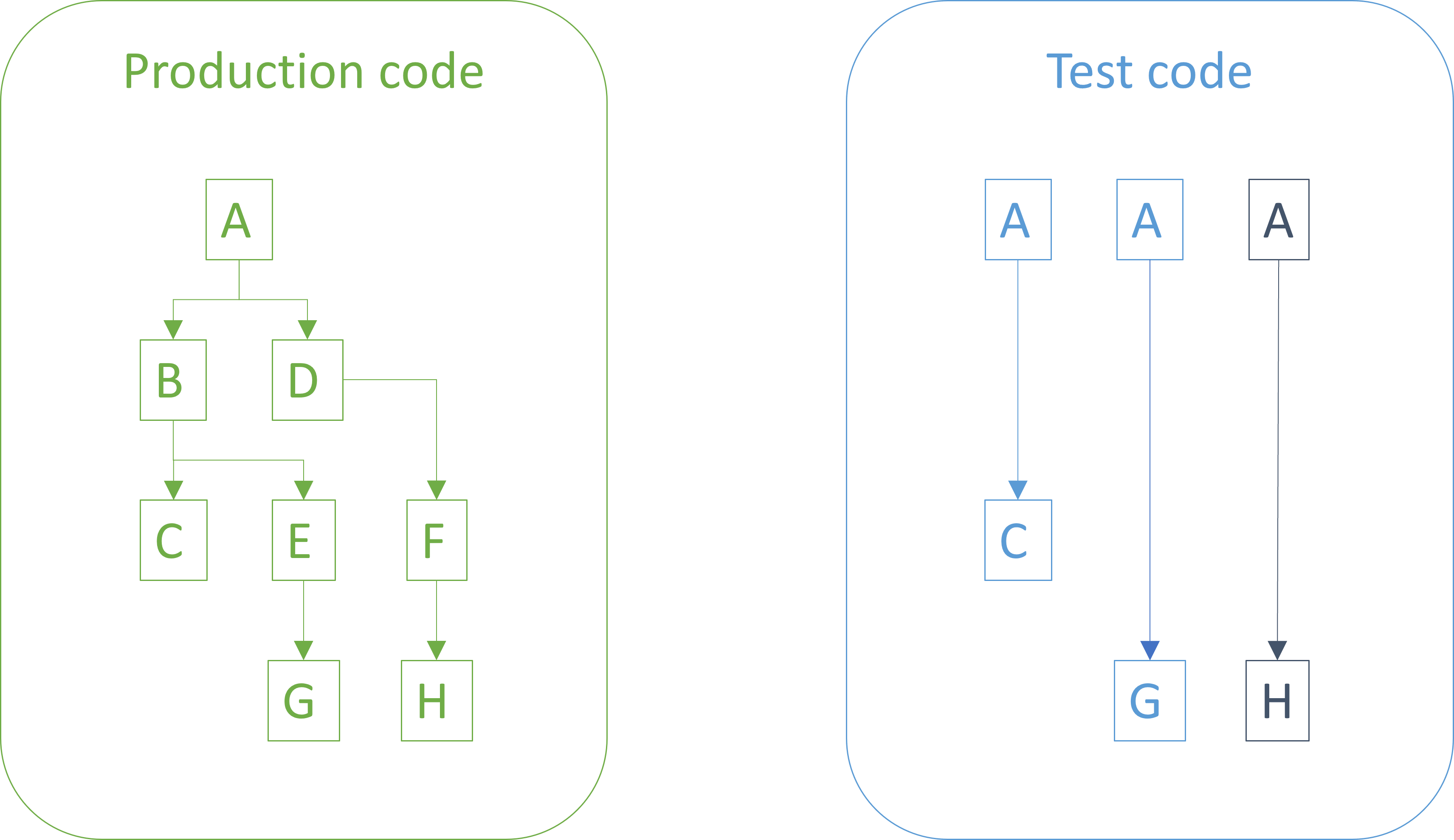
As this process proceeds, you corroborate two related hypotheses: That the test code is correct, and that the production code is. None of these hypotheses are ever proven, but as you add tests that are first red, then green, and then stay green, you increase confidence that the entire code complex works as intended.
If you don't write the test first, you don't get to perform the first experiment: That you predict the new test to fail. If you don't do that, you collect no empirical evidence that the tests work as hypothesized. In other words, you'd lose half of the scientific evidence you otherwise could have gathered.
TDD is the scientific method #
Let me spell this out: Test-driven development (TDD) is an example of the scientific method. Watching a new test fail is an important part of the process. Without it, you have no empirical reason to believe that the tests are correct.
While you may read the test code, that only puts you on the same scientific footing as the ancient Greeks' introspective philosophy: The four humours, extramission, the elements, etc. By reading test code, or even writing it, you may believe that you understand what the code does, but reading it without running it gives you no empirical way to verify whether that belief is correct.
Consider: How many times have you written code that you believed was correct, but turned out contained errors?
If you write the test after the system under test (SUT), you can run the test to see it pass, but consider what you can only falsify in that case: If the test passes, you've learned little. It may be that the test exercises the SUT, but it may also be that you've written a tautological assertion. It may also be that you've faithfully captured a bug in the production code, and now preserved in for eternity as something that looks like a regression test. Or perhaps the test doesn't even cover the code path that you believe it covers.
Conversely, if such a test (that you believe to be correct) fails, you're also in the dark. Was the test wrong, after all? Or does the SUT have a defect?
This is the reason that the process for writing Characterization Tests includes a step where you
"Write an assertion that you know will fail."
I prefer a variation where I write what I believe is the correct assertion, but then temporarily sabotage the SUT to fail the assertion. The important part is to see the test fail, because the failure to falsify a strong prediction is important empirical evidence.
Conclusion #
How do we know that the software we develop works as intended? The answer lies in the much larger question: How do we know anything?
Scientific thinking effectively answers this by 'the scientific method': Form a hypothesis, make falsifiable predictions, perform experiments, adjust, repeat.
We can subject software to the same rigorous regimen that scientists do: Hypothesize that the software works in certain ways under given conditions, predict observable behaviour, test, record outcomes, fix defects, repeat.
Test-driven development closely follows that process, so is a highly scientific methodology for developing software. It should be noted that science is hard, and so is TDD. Still, if you care that your software behaves as it's supposed to, it's one of the most rigorous and effective processes I'm aware of.
