TDD as induction by Mark Seemann
A metaphor.
In the mid 2010s I was working with a Danish software development organisation, effectively acting as a lead developer. Because of a shortage of salaried employees, we needed to hire freelancers, and after I had exhausted my local network, I turned to international contacts. One (excellent) addition to the team was Mike Hadlow, who worked out of England.
On his first day, we had him clone the repository and run the tests. About five minutes later, we received a message from him (paraphrasing from memory): "Guys, I have three failing tests. Is this expected?"
No, we didn't expect that. The team had used test-driven development (TDD) for the code. It had hundreds of tests, all of them deterministic. Or so we thought.
It didn't take long to figure out that three tests failed on Mike's computer because it, naturally, was configured with the UK English locale, whereas so far, everyone had been running with the Danish locale. In Danish, like many other languages, comma is the decimal separator and period the thousands separator. As readers of this article will know, in English, it's the other way around.
The three tests failed because they expected Danish formatting rules to be in effect.
I don't remember the specifics, but once we had identified the root cause, fixing it was easy. Be more explicit in the arrange phase, or be less explicit in the assertion phase.
The lesson was that even tests written with TDD make implicit assumptions about the environment.
Horizontal scaling #
A decade earlier, a colleague taught me that the most difficult scale-out was going from one to two. This was in the early noughties, and the challenge of the day was scaling out servers. Already back then, we were running into the problem of stagnating CPU clock speed improvements. For decades, computers had become faster each year, so if you had performance issues, often you could wait a year or two and buy a faster machine.
In the early 2000s, this stopped being the rule, and chip manufacturers instead started to add more processors to a single chip. This solved some problems, but not all. Another attempt to address performance problems was to scale out instead of up. Instead of buying a faster, more expensive computer, you'd buy another computer like the one you already had, and somehow distribute the workload. If you could make that work, that made better economic sense than buying more expensive equipment only to decommission the old machine.
The problem, however, was that at the time, most software was designed with the implicit assumption that it would run on one machine only. Not client software, perhaps, but certainly database servers, and often application servers, too. Going from one to two machines was not a trivial undertaking.
On the other hand, once you had done the hard work of enabling, say, a web site to run on two servers, it would typically be trivial to make it run on three, or four.
Two as many #
The notion that the most difficult scale-out is going from one to two made such a deep impression that it's been with me ever since. It seems to generalise to other fields, too. That going from the singular to the plural is where you find most barriers. Once you've enabled having two of something, then the actual number seems to be of lesser importance.
It took me a long time to come to terms with the notion that the number two is only a 'representation' for any plural number. One reason, I think, is that my thinking may have been tainted by an innocuous phrase that my mother often uttered: "En, to, mange" or, in English, one, two, many.
As any 'real' software tester will tell you, it's actually nought, one, many. It took me many years of test-driven development (TDD) to finally accept that when testing for plurality, it was often good enough to test with collections of two values. In my early TDD years, I would often insist on adding a test case for the 'three' case, but over the years I learned that this extra step didn't enable me to move forward. In the parlance of the transformation priority premise, adding such a test case lead to no transformation.
Once I, grudgingly, accepted that two is many, I started noticing other patterns and connections.
TDD and inductive reasoning #
Much has already been said about TDD, particularly example-driven development, as a sort of inductive reasoning. You start with one example, and implement the simplest thing that could possibly work. You add another example, and the System Under Test becomes slightly more sophisticated. After enough iterations, you have a working solution.
This looks like inductive reasoning, in that you are generalising from the specific to the general.
Such an analogy calls for criticism, because inductive reasoning in general suffers from fundamental epistemological problems. How do we know that we can safely generalise from finite examples?
We can, because TDD is not a process of uncovering some natural law. The problem of induction, typically, is that in natural science, researchers attempt to uncover underlying relationships; cause and effect. Their area of study, however, is the result of natural processes. Or, if a researcher studies economics, perhaps a result of complex social interactions. In scientific settings, the object of study is not man-made, and you can't ask anyone for the correct answer.
With TDD, the situation is different. You can consult the source code. In fact, if TDD is done right and you made no mistakes, the System Under Test (SUT) should be the generalisation of all the examples.
Of course, to err is human, so you could have made mistakes, but with TDD we are on much more solid ground than is usually the case in epistemology.
This seems to suggest that TDD has more in common with formal science than with natural or social science.
Tests as statements #
Consider a test following the Arrange Act Assert pattern. As the last step indicates, a test is an assertion. It's a claim that if things are arranged just so, and a particular action is taken, posterior state will have certain verifiable properties. We might consider such a construction a formal statement. Formal, in the sense that it's expressed in a formal (programming) language, and a statement because its truth value is either true (i.e. passed) or false (i.e. either failed, crashed, or hanging).
Excluding property-based testing from the discussion, a test is still an example. We shouldn't infer a system's general behaviour from a single example, but when viewed collectively, we may, as discussed above, engage in inductive reasoning. For the rest of this article, however, that is not what I have in mind. Rather, I want to talk about an independent kind of generalisation; a different dimension, if you will.
So far, I have discussed how we may infer a system's behaviour from examples. The more examples you provide, the more you trust the induction.
In the rest of this article, I will discuss how replicating a test to multiple environments tend to demonstrate increased adaptability. In this light, a single test is a statement about one single example, but the statement is now assumed to be universal. It should hold in all circumstances described by it.
What does that mean?
Tests are the first clients #
As I wrote a long time ago, in an otherwise too confrontational article, unit tests are the first clients of the SUT's APIs. Only once tests pass do you put the SUT to use in its intended context. The function/class/module/component that you test-drove now becomes part of the overall solution. The View Model correctly helps render the user interface. The Domain Model makes the right decision. A security component correctly rejects unauthorised users.
When you integrate a test-driven unit in a larger system, any test (even a manual test) of that system is a secondary test. Often, you simply verify that the composition of smaller elements work as intended. Occasionally, an integration test reveals that the unit doesn't work in the new context.
This is expected. It's the reason integration testing is important.
When unit tests succeed, but integration tests fail, the reason is usually that the unit tests are too parochial. Integration test failures reveal that the unit has to handle situations that you hadn't thought of. Sometimes, the problem is that input is more varied than you initially thought. Other times, like the above story about Danish and UK locales, it turns out that the test made implicit assumptions that ought to be explicit.
While this error-discovery process is normal, in my experience, once you've addressed bugs that only manifest in a new context, additional contexts tend to unearth few new problems. You find most defects in the first context, which is the automated test environment. You find a few more test once you move the code to a new execution context. After that, however, error discovery tends to dry out.
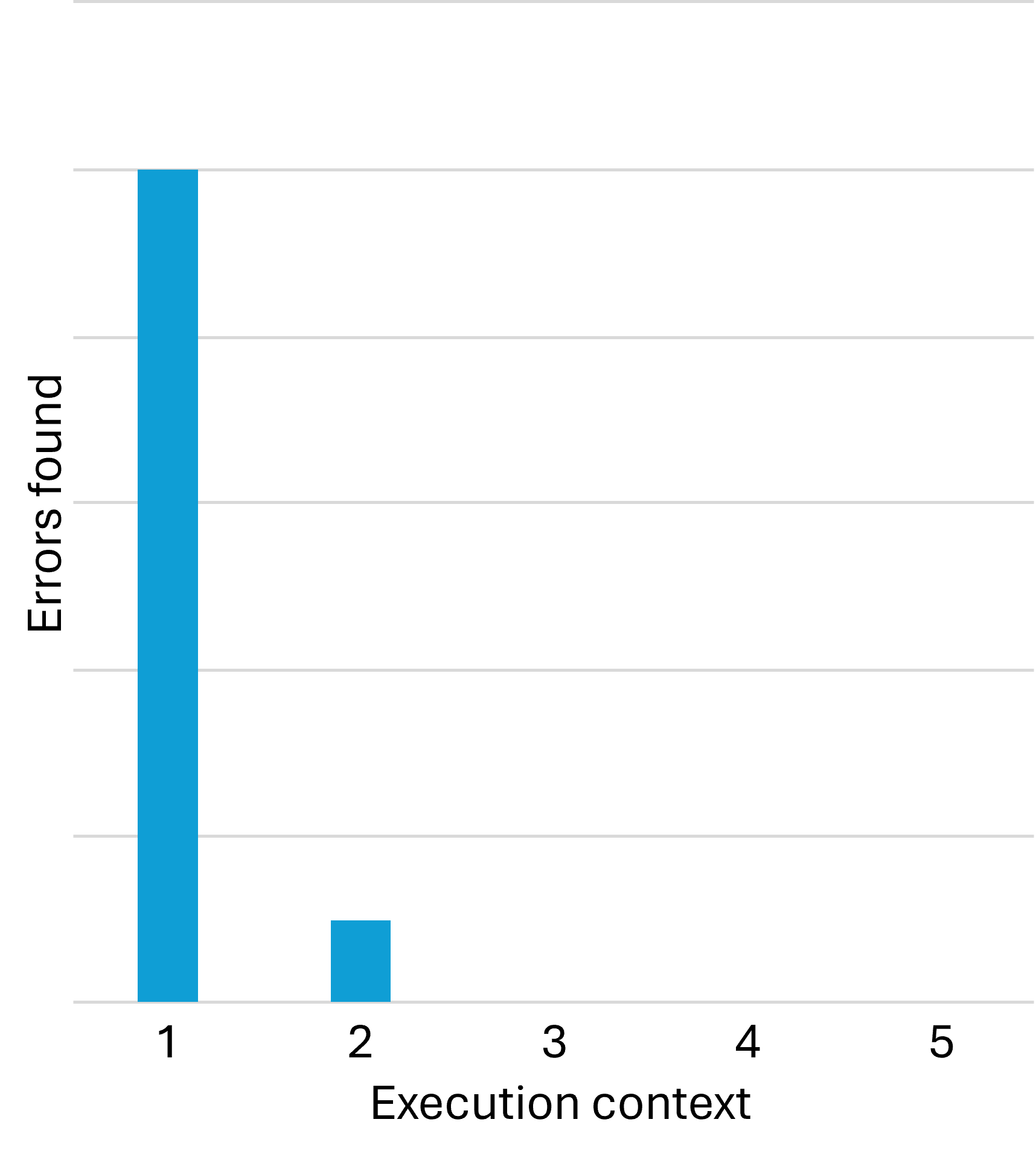
In my desire to make a point, I'm deliberately simplifying things. It is not, however, my intention to mislead anyone. In reality, you do sometimes find new errors in the third or fourth context. Some errors, as everyone knows, only manifest in production, and only in certain mysterious circumstances. In other words, the above chart is deceptive in the sense that it seems to claim that the third, fourth, etc. contexts reveal no additional bugs. This is not the case.
That said, in my experience the relationship is clearly non-linear, and for a long time, I wondered about that.
Mathematical induction #
Although the following is, at best, an imperfect metaphor, this reminds me of mathematical induction. You start with the statement that a particular example (implemented as a test) works in a single environment (typically a developer machine). Call this statement P(1).

Already when you synchronise your code with coworkers' code, the example or use case now executes on multiple other machines; P(2), P(3), etc.

As the initial anecdote about locale-dependent tests shows, you may already find a problem here. In many cases, however, the development machines are sufficiently identical that any single test is effectively running in the same context. In this sense, you may still be establishing that the first statement, P(1), holds.
If so, you may discover problems in execution contexts that differ from developer machines to a larger degree.
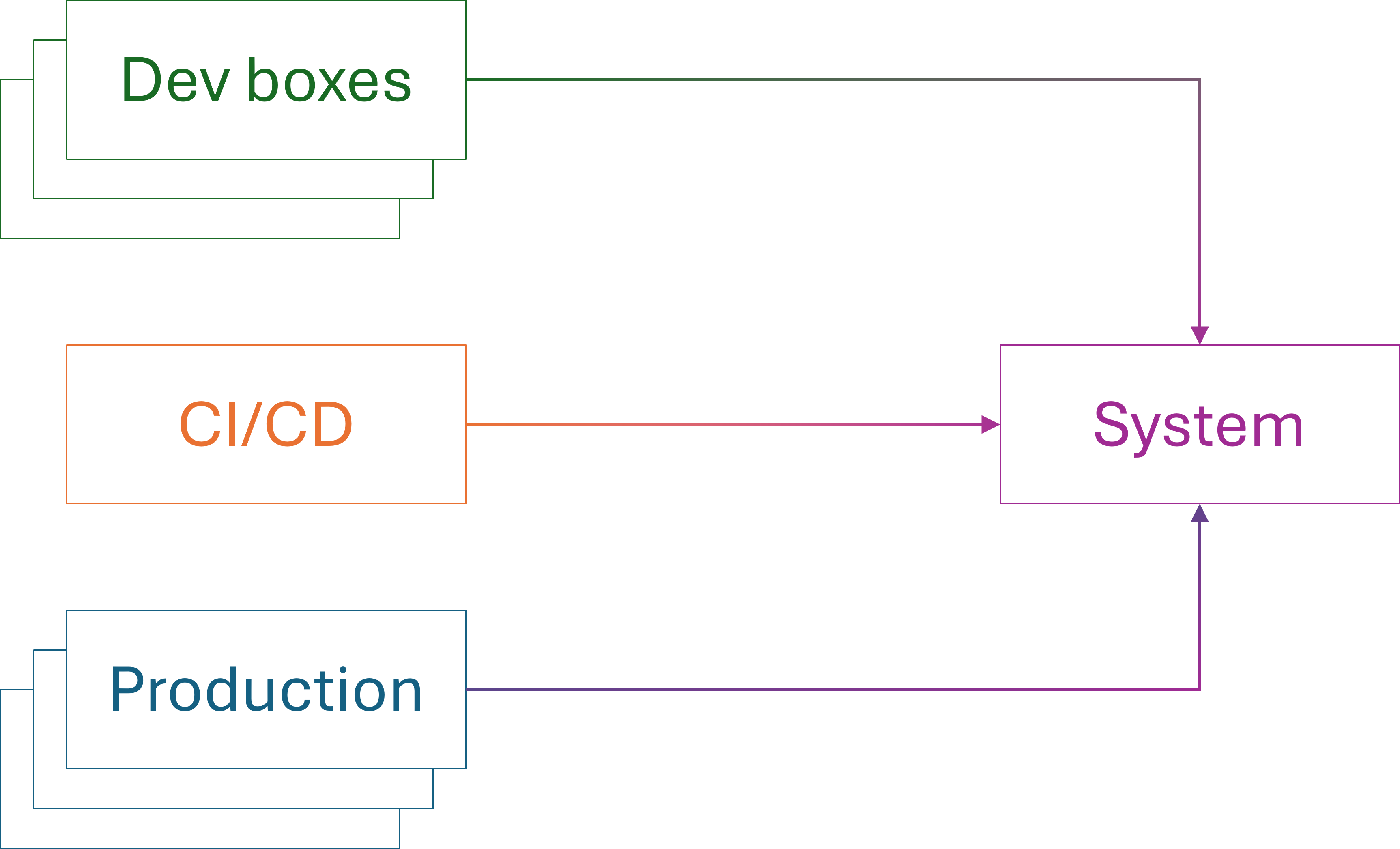
Sometimes with mathematical induction, you need to establish more than a single base case. You may, for example, first prove P(1) and P(2). The induction step then assumes P(n-2) and P(n-1) in order to prove P(n).
Although the metaphor is flawed in more than one way, the non-linear relationship between environments and defect discovery reminds me of this kind of induction. Experience indicates that if an example works in the first and second context, it typically works in new contexts.
Implicit assumptions #
This induction-like relationship sometimes falls apart, as the opening anecdote illustrates. Sometimes, as the anecdote example shows, the problem is not with the implementation, but with the test. In mathematics, it may turn out that a proof makes implicit assumptions, and that it doesn't hold as universally as first believed. An example is that Euler believed that the characteristics of all polyhedra was constant, but failed to take non-convex shapes into account.
In the same way, tests may inadvertently assume that some property is universal. Later, you may discover that such an assumption, for example about locale, is not as universal as you thought.
This explains why my DIPPP coauthor Steven van Deursen correctly insisted that Ambient Context should be classified as an anti-pattern. Otherwise, it's too easy to forget essential pre-conditions, and thus make it easier to introduce bugs that only appear in certain contexts.
This is one of many reasons I prefer Haskell over most other programming languages. Haskell APIs don't make implicit assumptions about execution context. Or, rather, they have deterministic behaviour according to 'standards' which are often English; e.g. a decimal number like 12.3 always renders as "12.3", and never as "12,3", as it would in German, Danish, etc.
Even so, as Conal Elliot complains, some APIs are not as deterministic as one might hope.
The bottom line is that when writing tests, one has to carefully and explicitly state all relevant assumptions as part of the test.
Conclusion #
As imperfect a metaphor as it is, I find comfort in comparing defect discovery using automated tests with induction. After decades of test-driven development, I've wondered if there's a deeper reason that if test-driven code works on one machine, it tends to work on most machines, and that the relationship seems to be distinctly non-linear.
An automated test, if it properly describes all relevant context, is effectively a statement that a particular example always behaves the same. We may, then, choose to believe that if it works in one context, and we've seen it work in one additional, arbitrary context, it seems likely that it will work in most other contexts.
