Yes silver bullet by Mark Seemann
Since Fred Brooks published his essay, I believe that we, contrary to his prediction, have witnessed several silver bullets.
I've been rereading Fred Brooks's 1986 essay No Silver Bullet because I've become increasingly concerned that people seem to draw the wrong conclusions from it. Semantic diffusion seems to have set in. These days, when people state something along the lines that there's no silver bullet in software development, I often get the impression that they mean that there's no panacea.
Indeed; I agree. There's no miracle cure that will magically make all problems in software development go away. That's not what the essay states, however. It is, fortunately, more subtle than that.
No silver bullet reread #
It's a great essay. It's not my intent to dispute the central argument of the essay, but I think that Brooks made one particular assumption that I disagree with. That doesn't make me smarter in any way. He wrote the essay in 1986. I'm writing this in 2019, with the benefit of the experience of all the years in-between. Hindsight is 20-20, so anyone could make the observations that I do here.
Before we get to that, though, a brief summary of the essence of the essay is in order. In short, the conclusion is this:
The beginning of the essay is a brilliant analysis of the reasons why software development is inherently difficult. If you read this together with Jack Reeves What Is Software Design? (available various places on the internet, or as an appendix in APPP), you'll probably agree that there's an inherent complexity to software development that no invention is likely to dispel."There is no single development, in either technology or management technique, which by itself promises even one order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity."
Ostensibly in the tradition of Aristotle, Brooks distinguishes between essential and accidental complexity. This distinction is central to his argument, so it's worth discussing for a minute.
Software development problems are complex, i.e. made up of many interacting sub-problems. Some of that complexity is accidental. This doesn't imply randomness or sloppiness, but only that the complexity isn't inherent to the problem; that it's only the result of our (human) failure to achieve perfection.
If you imagine that you could whittle away all the accidental complexity, you'd ultimately reach a point where, in the words of Saint Exupéry, there is nothing more to remove. What's left is the essential complexity.
Brooks' conjecture is that a typical software development project comes with both essential and accidental complexity. In his 1995 reflections "No Silver Bullet" Refired (available in The Mythical Man-Month), he clarifies what he already implied in 1986:
This I fundamentally disagree with, but more on that later. It makes sense to me to graphically represent the argument like this:"It is my opinion, and that is all, that the accidental or representational part of the work is now down to about half or less of the total."
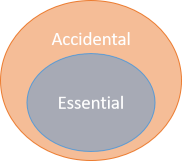
The way that I think of Brooks' argument is that any software project contains some essential and some accidental complexity. For a given project, the size of the essential complexity is fixed.
Brooks believes that less than half of the overall complexity is accidental:
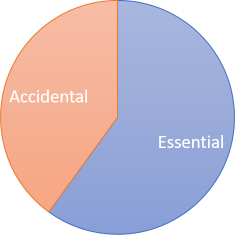
While a pie chart better illustrates the supposed ratio between the two types of complexity, I prefer to view Brooks' arguments as the first diagram, above. In that visualisation, the essential complexity is a core of fixed size, while accidental complexity is something you can work at removing. If you keep improving your process and technology, you may, conceptually, be able to remove (almost) all of it.

Brooks' point, with which I agree, is that if the essential complexity is inherent, then you can't reduce the size of it. The only way to decrease the overall complexity is to reduce the accidental complexity.
If you agree with the assessment that less than half of the overall complexity in modern software development is accidental, then it follows that no dramatic improvements are available. Even if you remove all accidental complexity, you've only reduced overall complexity by, say, forty percent.
Accidental complexity abounds #
I find Brooks' arguments compelling. I do not, however, accept the premise that there's only little accidental complexity left. Instead of the above diagrams, I believe that the situation looks more like this (not to scale):

I think that most of the complexity in software development is accidental. I'm not sure about today, but I believe that I have compelling evidence that this was the case in 1986, so I don't see why it shouldn't still be the case.
To be clear, this is all anecdotal, since I don't believe that software development is quantifiable. In the essay, Brooks explicitly talks about the invisibility of software. Software is pure thought stuff; you can't measure it. I discuss this in my Humane Code video, but I also recommend that you read The Leprechauns of Software Engineering if you have any illusions that we, as an industry, have any reliable measurements of productivity.
Brooks predicts that, within the decade (from 1986 to 1996), there would be no single development that would increase productivity with an order of magnitude, i.e. by a factor of at least ten. Ironically, when he wrote "No Silver Bullet" Refired in 1995, at least two such developments were already in motion.
We can't blame Brooks for not identifying those developments, because in 1995, their impact was not yet apparent. Again, hindsight is 20-20.
Neither of these two developments are purely technological, although technology plays a role. Notice, though, that Brooks' prediction included technology or management technique. It's in the interaction between technology and the humane that the orders-of-magnitude developments emerged.
World Wide Web #
I have a dirty little secret. In the beginning of my programming career, I became quite the expert on a programming framework called Microsoft Commerce Server. In fact, I co-authored a chapter of Professional Commerce Server 2000 Programming, and in 2003 I received an MVP award as an acknowledgement of my work in the Commerce Server community (such as it were; it was mostly on Usenet).
The Commerce Server framework was a black box. This was long before Microsoft embraced open source, and while there was a bit of official documentation, it was superficial; it was mostly of the getting-started kind.
Over several years, I managed to figure out how the framework really worked, and thus, how one could extend it. This was a painstaking process. Since it was a black box, I couldn't just go and read the code to figure out how it worked. The framework was written in C++ and Visual Basic, so there wasn't even IL code to decompile.
I had one window into the framework. It relied on SQL Server, and I could attach the profiler tool to spy on its interaction with the database. Painstakingly, over several years, I managed to wrest the framework's secrets from it.
I wasted much time doing detective work like that.
In general, programming in the late nineties and early two-thousands was less productive, not because the languages or tools were orders-of-magnitude worse than today, but because when you hit a snag, you were in trouble.
These days, if you run into a problem beyond your abilities, you can ask for help on the World Wide Web. Usually, you'll find an existing answer on Stack Overflow, and you'll be able to proceed without too much delay.
Compared to twenty years ago, I believe that the World Wide Web has increased my productivity more than ten-fold. While it also existed in 1995, there wasn't much content. It's not the technology itself that provides the productivity increase, but rather the synergy of technology and human knowledge.
I think that Brooks vastly underestimated how much time one can waste when one is stuck. That's a sort of accidental complexity, although in the development process rather than in the technology itself.
Automated testing #
In the late nineties, I was developing web sites (with Commerce Server). When I wanted to run my code to see if it worked, I'd launch the web site on my laptop, log in, click around and enter data until I was convinced that the functionality was working as it should. Most of the time, however, it wasn't, so I'd change a bit of the code, and go through the same process again.
I think that's a common way to 'test' software; at least, it was back then.
While you could get good at going through these motions quickly, verifying a single, or a handful of related functionalities, could easily take at least a couple of seconds, and usually more like half a minute.
If you had dozens, or even hundreds, of different scenarios to address, you obviously wouldn't run through them all every time you changed the code. At the very best, you'd click your way through three of four usage scenarios that you thought were relevant to the change you'd made. Other functionality, earlier declared done, you just considered to be unaffected.
Needless to say, regressions were regular occurrences.
In 2003 I discovered test-driven development, and through that, automated testing. While you can't directly compare unit tests with whole usage scenarios, I think it's fair to compare something like automated integration tests or user-scenario tests (whatever you want to call them) with manually clicking through an application.
Even an integration test, if written properly, can verify a scenario at least ten times faster than you can do it by hand. A more realistic estimate is probably hundred times faster, or more.
Granted, you have to write the automated test as well, and I know that it's not always trivial. Still, once you have an automated test suite in place, you can run it all the time.
I never ran through all usage scenarios when I manually 'tested' my software. With automated tests, I do. This saves me from most regressions.
This improvement is, in my opinion, a no-brainer. It's easily a factor ten improvement. All the time wasted manually 'testing' the software, plus the time wasted fixing regressions, can be put to better use.
At the time Brooks was writing his own retrospective (in 1995), Kent Beck was beginning to talk to other people about test-driven development. As is a common theme in this article, hindsight is 20-20.
Honourable mentions #
There's been other improvements in software development since 1986. I considered including several other improvements as bona fide orders-of-magnitude improvements, but I think that's probably going too far. Each of the following developments have, however, offered significant improvements:
- Git. It's surprising how much more productive Git can make you. While it's somewhat better than centralised source control systems at the functionality also available with those other systems, the productivity increase comes from all the new, unanticipated workflows it enables. Before I started using DVCS, I'd have lots of code that was commented out, so that I could experiment with various alternatives. With Git, I just create a new branch, or stash my changes, and experiment with abandon. While it's probably not a ten-fold increase in productivity, I believe it's the simplest technology change you can make to dramatically increase your productivity.
- Garbage collection. Since I've admitted that I worked with Microsoft Commerce Server, I've probably lost all credibility with my reader already, but let's see if I can win back a little. While Commerce Server programming involved VBScript programming, it also often involved COM programming, and I did quite a bit of that in C++. Having to make sure that you've cleaned up all memory after use is a bother. Garbage collection just makes this work go away. It's hardly a ten-fold improvement in productivity, but I do find it significant.
- Agile software development. The methodology of decreasing the feedback time between implementation and deployment has made me much more productive. I'm not interested in peddling any particular methodology like Scrum as much as just the general concept of getting rapid feedback. Particularly if you combine continuous delivery with Git, you have a powerful combination. Brooks already talked about incremental software development, and had some hopes attached to this as well. My personal experience can only agree with his sentiment. Again, probably not in itself a ten-fold increase in productivity, but enough that I wouldn't want to work on a project where rapid feedback and incremental development wasn't valued.
Personally, I'm inclined to believe another order-of-magnitude improvement is right at our feet.
Statically typed functional programming #
This section is conjecture on my part. The improvements I've so far covered are already realised (at least for those who choose to take advantage of them). The improvement I'll cover here is more speculative.
I believe that statically typed functional programming offers another order-of-magnitude improvement over existing software development. Twenty years ago, I believed that object-oriented programming was a good idea. I now believe that I was wrong about that, so it's possible that in another twenty years, I'll also believe that I was wrong about functional programming. Take the following for what it is.
When I carefully reread No Silver Bullet, I got the distinct impression that Brooks considered low-level details of programming part of its essential complexity:
It's unreasonable to blame anyone writing in 1986, or 1995 for that matter, to think that"Much of the complexity in a software construct is, however, not due to conformity to the external world but rather to the implementation itself - its data structures, its algorithms, its connectivity."
for loops, variables, program state, and such other programming stables were anything but essential parts of the complexity of developing software.
Someone, unfortunately I forget who, once made the point that all mainstream programming languages are layers of abstractions of how a CPU works. Assembly language is basically just mnemonics on top of a CPU instruction set, then C can be thought of as an abstraction over assembly language, C++ as the next step in abstraction, Java and C# as sort of abstractions of C++, and so on. The origin of the design is the physical CPU. You could say that these languages are designed in a bottom-up fashion.
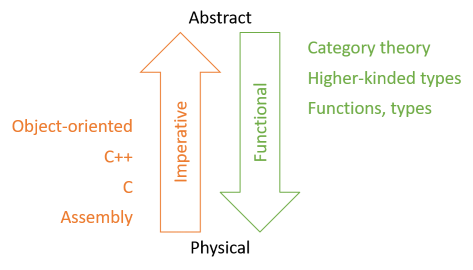
Some functional languages (perhaps most famously Haskell, but also APL, and, possibly, Lisp) are designed in a much more top-down fashion. You start with mathematical abstractions like category theory and then figure out how to crystallise the theory into a programming language, and then again, via more layers of abstractions, how to turn the abstract language into machine code.
The more you learn about the pure functional alternative to programming, the more you begin to see mutable program state, variables, for loops, and similar language constructs merely as artefacts of the underlying model. Brooks, I think, thought of these as part of the essential complexity of programming. I don't think that that's the case. You can get by just fine with other abstractions instead.
Besides, Brooks writes, under the heading of Complexity:
When he writes functions, I don't think that he means functions in the Haskell sense. I think that he means operations, procedures, or methods."From the complexity comes the difficulty of enumerating, much less understanding, all the possible states of the program, and from that comes the unreliability. From the complexity of the functions comes the difficulty of invoking those functions, which makes programs hard to use."
Indeed, when you look at a C# method signature like the following, it's hard to enumerate, understand, or remember, all that it does:
int? TryAccept(Reservation reservation);
If this is a high-level function, many things could happen when you call that method. It could change the state of a database. It could send an email. It could mutate a variable. Not only that, but the behaviour could depend on non-deterministic factors, such as the date, time of day, or just raw randomness. Finally, how should you handle the return value? What does it mean if the return value is null? What if it's not? Is 0 a valid value? Are negative numbers valid? Are they different from positive values?
It is, indeed, difficult to enumerate all the possible states of such a function.
Consider, instead, a Haskell function with a type like this:
tryAccept :: Int -> Reservation -> MaybeT ReservationsProgram Int
What happens if you invoke this function? It returns a value. Does it send any emails? Does it mutate any state? No, it can't, because the static type informs us that this is a pure function. If any programmer, anywhere inside of the function, or the functions it calls, or functions they call, etc. tried to do something impure, it wouldn't have compiled.
Can we enumerate the states of the program? Certainly. We just have to figure out what ReservationsProgram is. After following a few types, we find this statically typed enumeration:
data ReservationsInstruction next = IsReservationInFuture Reservation (Bool -> next) | ReadReservations UTCTime ([Reservation] -> next) | Create Reservation (Int -> next) deriving Functor
Essentially, there's three 'actions' that this type enables. The tryAccept function returns the ReservationsProgram inside of a MaybeT container, so there's a fourth option that something short-circuits along the way.
You don't even have to keep track of this yourself. The compiler keeps you honest. Whenever you invoke the tryAccept function, the compiler will insist that you write code that can handle all possible outcomes. If you turn on the right compiler flags, the code is not going to compile if you don't.
(Both code examples are taken from the same repository.)
Haskellers jokingly declare that if Haskell code compiles, it works. While humorous, there's a kernel of truth in that. An advanced type system can carry much information about the behaviour of a program. Some people, particularly programmers who come from a dynamically typed background, find Haskell's type system rigid. That's not an unreasonable criticism, but often, in dynamically typed languages, you have to write many automated tests to ensure that your program behaves as desired, and that it correctly handles various edge cases. A type system like Haskell's, on the other hand, embeds those rules in types instead of in tests.
While you should still write automated tests for Haskell programs, fewer are needed. How many fewer? Compared to C-based languages, a factor ten isn't an unreasonable guess.
After a few false starts, in 2014 I finally decided that F# would be my default choice of language on .NET. The reason for that decision was that I felt so much more productive in F# compared to C#. While F#'s type system doesn't embed information about pure versus impure functions, it does support sum types, which is what enables the sort of compile-time enumeration that Brooks discusses.
F# is still my .NET language of choice, but I find that I mostly 'think in' Haskell these days. My conjecture is that a sufficiently advanced type system (like Haskell's) could easily represent another order-of-magnitude improvement over mainstream imperative languages.
Improvements for those who want them #
The essay No Silver Bullet is a perspicacious work. I think more people should read at least the first part, where Brooks explains why software development is hard. I find that analysis brilliant, and I agree: software development presupposes essential complexity. It's inherently hard.
There's no reason to make it harder than it has to be, though.
More than once, I've discussed productivity improvements with people, only to be met with the dismissal that 'there's no silver bullet'.
Granted, there's no magical solution that will solve all problems with software development, but that doesn't mean that improvements can't be had.
Consider the improvements I've argued for here. Everyone now uses the World Wide Web and sites like Stack Overflow for research; that particular improvement is firmly embedded in all organisations. On the other hand, I still regularly talk to organisations that don't routinely use automated testing.
People still use centralised version control (like TFS or SVN). If there was ever a low-hanging fruit, changing to Git is one. Git is free, and there's plenty of tools you can use to migrate your version history to it. There's also plenty of training and help to be had. Yes, it'll require a small investment to make the change, but the productivity increase is significant.
So it is with technology improvements. Automated testing is available, but not ubiquitous. Git is free, but still organisations stick to suboptimal version control. Haskell and F# are mature languages, yet programmers still program in C# or Java."The future is already here — it's just not very evenly distributed."
Summary #
The essay No Silver Bullet was written in 1986, but seems to me to be increasingly misunderstood. When people today talk about it at all, it's mostly as an excuse to stay where they are. "There's no silver bullets," they'll say.
The essay, however, doesn't argue that no improvements can be had. It only argues that no more order-of-magnitude improvements can be had.
In the present essay I argue that, since Brooks wrote No Silver Bullet, more than one such improvement happened. Once the World Wide Web truly began furnishing information at your fingertips, you could be more productive because you wouldn't be stuck for days or weeks. Automated testing reduces the work that manual testers used to perform, as well as limiting regressions.
If you accept my argument, that order-of-magnitude improvements appeared after 1986, this implies that Brooks' premise was wrong. In that case, there's no reason to believe that we've seen the last significant improvement to software development.
I think that more such improvements await us. I suggest that statically typed functional programming offers such an advance, but if history teaches us anything, it seems that breakthroughs tend to be unpredictable.

Comments
As always I enjoy reading your blog, even though I don't understand half of it most of the time. Or is that most of it half of the time? Allow me to put a few observations forward.
First I should confess, that I have actually not read the whole of Brook's essay. When I initially tried I got about half way through; it sounds like I should make another go at it. That of course will not stop me from commenting on the above.
Brook talks about complexity. To me designing and implementing a software system is not complex. Quantum physics is complex. Flying an airplane is difficult. Software development may be difficult depending on the task at hand (and unfortunately the qualifications of the team), but I would argue that it at most falls into the same category as flying an airplane.
I would properly also state, that there are no silver bullets. But like you I feel that people understand it incorrectly and there is definetely no reason for making things harder than they are. I think the examples of technology that helps are excellent and exactly describe that things do move forward.
That being said, it does not take away the creativity of the right decomposition, the responsibility for getting the use cases right, and especially the liability for getting it wrong. Sadly especially the last of overlooked. People should be reminded of where the phrase 'live under the bridge' comes from.
To end my ramblins, I would also look a little into the future. As you know I am somewhat sceptial about machine learning and AI. However, looking at the recent break throughs and use cases in these areas, I would not be surprised of a future where software development is done by 'an AI' assemblying pre-defined 'entities' to create the software we need. Like an F16 cannot be flown without a computer, future software cannot be created by a human.
Karsten, thank you for writing. I'm not inclined to agree that software development falls into the same category of complexity as flying a plane. It seems to me to be orders of magnitudes more complex.
Just look at error rates.
Would you ever board an air plane if flying had error rates similar to those observed in software development? Would you fly even if only one percent of all flights ended with plane crash?
In reality, flying is extremely safe. Would you claim that software development is as safe, predictable, and manageable as flying?
I see no evidence of that.
Are pilots significantly more capable human beings than software developers, or does something else explain the discrepancy in failure rates?
Hi Mark. The fact that error rates are higher in software development is more a statement to the bad state our industry is in and has been for a milinium or more.
Why do we except that we produce crappy systems or in your words software that is not safe, predictable, and manageble? The list of excuses is very long and the list of results is very short. We as an industry are simply doing it wrong, but most people prefers hand waving and marketing than simple and plausible heuristic.
To use your analogy about planes I could ask if you would fly with a place that had (only) been unit tested? Properly not as it is never the unit that fails, but always the integration. Should be test all integrations then? Yes, why not?
The used of planes or pilots (or whatever) may have been bad. My point was, that I do not see software development as complex.
Karsten, if we, as an industry, are doing it wrong, then why are we doing that?
And what should we be doing instead?