Confidence from Facade Tests by Mark Seemann
Recycling an old neologism of mine, I try to illustrate a point about the epistemology of testing function composition.
This article continues the introduction of a series on the epistemology of interaction testing. In the first article, I attempted to explain how to test the composition of functions. Despite my best efforts, I felt that that article somehow fell short of its potential. Particularly, I felt that I ought to have been able to provide some illustrations.
After publishing the first article, I finally found a way to illustrate what I'd been trying to communicate. That's this article. Better late than never.
Previously, on epistemology of interaction testing #
A brief summary of the previous article may be in order. The question this article series tries to address is how to unit test composition of functions - particularly pure functions.
Consider the illustration from the previous article, repeated here for your convenience:
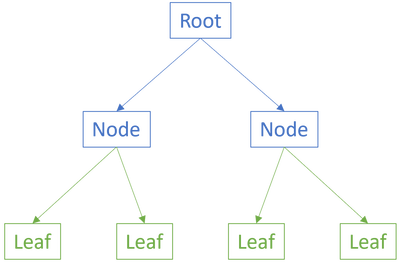
When the leaves are pure functions they are intrinsically testable. That's not the hard part, but how do we test the internal nodes or the root?
While most people would reach for Stubs and Spies, those kinds of Test Doubles tend to break encapsulation.
What are the alternatives?
An alternative I find useful is to test groups of functions composed together. Particularly when they are pure functions, you have no problem with non-deterministic behaviour. On the other hand, this approach seems to run afoul of the problem with combinatorial explosion of integration testing so eloquently explained by J.B. Rainsberger.
What I suggest, however, isn't quite integration testing.
Neologism #
If it isn't integration testing, then what is it? What do we call it?
I'm going to resurrect and recycle an old term of mine: Facade Tests. Ten years ago I had a more narrow view of a term like 'unit test' than I do today, but the overall idea seems apt in this new context. A Facade Test is a test that exercises a Facade.
These days, I don't find it productive to distinguish narrowly between different kinds of tests. At least not to the the degree that I wish to fight over terminology. On the other hand, occasionally it's useful to have a name for a thing, in order to be able to differentiate it from some other thing.
The term Facade Tests is my attempt at a neologism. I hope it helps.
Code coverage as a proxy for confidence #
The question I'm trying to address is how to test functions that compose other functions - the internal nodes or the root in the above graph. As I tried to explain in the previous article, you need to build confidence that various parts of the composition work. How do you gain confidence in the leaves?
One way is to test each leaf individually.
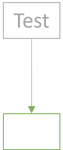
The first test or two may exercise a tiny slice of the System Under Test (SUT):
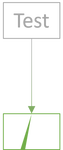
The next few tests may exercise another part of the SUT:
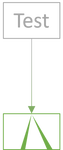
Keep adding more tests:
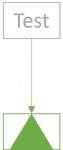
Stop when you have good confidence that the SUT works as intended:
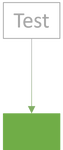
If you're now thinking of code coverage, I can't blame you. To be clear, I haven't changed my position about code coverage. Code coverage is a useless target measure. On the other hand, there's no harm in having a high degree of code coverage. It still might give you confidence that the SUT works as intended.
You may think of the amount of green in the above diagrams as a proxy for confidence. The more green, the more confident you are in the SUT.
None of the arguments here hinge on code coverage per se. What matters is confidence.
Facade testing confidence #
With all the leaves covered, you can move on to the internal nodes. This is the actual problem that I'm trying to address. We would like to test an internal node, but it has dependencies. Fortunately, the context of this article is that the dependencies are pure functions, so we don't have a problem with non-deterministic behaviour. No need for Test Doubles.
It's really simple, then. Just test the internal node until you're confident that it works:
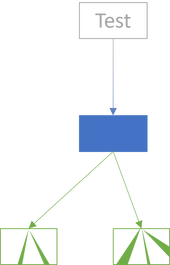
The goal is to build confidence in the internal node, the new SUT. While it has dependencies, covering those with tests is no longer the goal. This is the key difference between Facade Testing and Integration Testing. You're not trying to cover all combinations of code paths in the integrated set of components. You're still just trying to test the new SUT.
Whether or not these tests exercise the leaves is irrelevant. The leaves are already covered by other tests. What 'coverage' you get of the leaves is incidental.
Once you've built confidence in internal nodes, you can repeat the process with the root node:
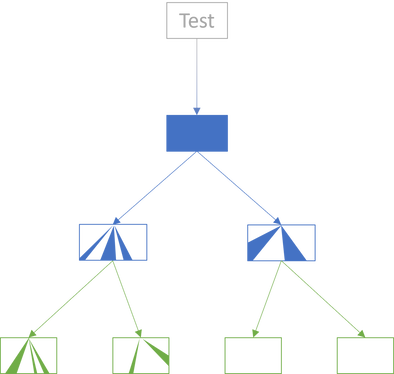
The test covers enough of the root node to give you confidence in it. Some of the dependencies are also partially exercised by the tests, but this is still secondary. The way I've drawn the diagram, the left internal node is exercised in such a way that its dependencies (the leaves) are partially exercised. The test apparently also exercises the right internal node, but none of that activity makes it interact with the leaves.
These aren't integration tests, so they avoid the problem of combinatorial explosion.
Conclusion #
This article was an attempt to illustrate the prose in the previous article. You can unit test functions that compose other functions by first unit testing the leaf functions and then the compositions. While these tests exercise an 'integration' of components, the purpose is not to test the integration. Thus, they aren't integration tests. They're facade tests.
Next: An abstract example of refactoring from interaction-based to property-based testing.

Comments
I really appreciate that you are writing about testing compositions of pure functions. As an F# dev who tries to adhere to the impureim sandwich (which, indeed, you helped me with before), this is something I have also been struggling with, and failing to find good answers to.
But following your suggestion, aren’t we testing implementation details?
Using the terminology in this article, I often have a root function that is public, which composes and delegates work to private helper functions. Compared to having all the logic directly in the root function, the code is, unsurprisingly, easier to read and maintain this way. However, all the private helper functions (internal nodes and leaves) as well as the particularities of how the root and the internal nodes compose their “children”, are very much just implementation details of the root function.
I occasionally need to change such code in a way that does not change the public API (at least not significantly enough to cause excessive test maintenance), but which significantly restructures the internal helpers. If I were to test as suggested in this article, I would have many broken tests on my hands. These would be tests of the internal nodes and leaves (which may not exist at all after the refactor, having been replaced with completely different functions) as well as tests of how the root node composes the other functions (which, presumably, would still pass but may not actually test anything useful anymore).
In short, testing in the way suggested here would act as a force to avoid refactoring, which seems counter-productive.
One would also need to use
InternalsVisibleToor similar in order to test those helpers. I’m not very concerned about that on its own (though I’d like to keep the helpersprivate), but it always smells of testing implementation details, which, as I argue, is what I think we’re doing. (One could alternatively make the helpers public – they’re pure, after all, so presumably no harm done – but that would expose a public API that no-one should actually use, and doesn’t avoid the main problem anyway.)As a motivating example from my world, consider a system for sending email notifications. The root function accepts a list of notifications that should be sent, together with any auxiliary data (names and other data from all users referenced by the notifications; translated strings; any environment-specific data such as base URLs for links; etc.), and returns the email HTML (or at least a structure that maps trivially to HTML). In doing this, the code has to group notifications in several levels, sort them in various ways, merge similar consecutive notifications in non-trivial ways, hide notifications that the user has not asked to receive (but which must still be passed to the root function since they are needed for other logic), and so on. All in all, I have almost 600 lines of pure code that does this. (In addition, I have 150 lines that fetches everything from the DB and creates necessary lookup maps of auxiliary data to pass to the root function. I consider this code “too boring to fail”.)
The pure part of the code was recently significantly revamped. Had I had tests for private/internal helpers, the refactor would likely have been much more painful.
I expect there is no perfect way to make the code both testable and easy to refactor. But I am still eager to hear your thoughts on my concern: Following your suggestion, aren’t we testing implementation details?
Christer, thank you for writing. The short answer is: yes.
Isn't this a separate problem, though? If you're using Stubs and Spies to test interaction, and other tests to verify your implementations, then isn't that a similar problem?
I'm going to graze this topic in the future article in this series tentatively titled Refactoring pure function composition without breaking existing tests, but I should probably write another article more specifically about this topic...
Christer (and everyone who may be interested), I've long been wanting to expand on my previous answer, and I finally found the time to write an article that discusses the implementation-detail question.
Apart from that I also want to remind readers that the article Refactoring pure function composition without breaking existing tests has been available since May 1st, 2023. It shows one example of using the Strangler pattern to refactor pure Facade Tests without breaking them.
This doesn't imply that one should irresponsibly make every pure function public. These days, I make things internal by default, but make them public if I think they'd be good seams. Particularly when following test-driven development, it's possible to unit test private helpers via a
publicAPI. This does, indeed, have the benefit that you're free to refactor those helpers without impacting test code.The point of this article series isn't that you should make pure functions public and test interactions with property-based testing. The point is that if you already have pure functions and you wish to test how they interact, then property-based testing is a good way to achieve that goal.
If, on the other hand, you have a pure function for composing emails, and you can keep all helper functions
private, still cover it enough to be confident that it works, and do that by only exercising a singlepublicroot function (mail-slot testing) then that's preferable. That's what I would aim for as well.