Test-driving the pyramid's top by Mark Seemann
Some thoughts on TDD related to integration and systems testing.
My recent article Works on most machines elicited some responses. Upon reflection, it seems that most of the responses relate to the top of the Test Pyramid.
While I don't have an one-shot solution that addresses all concerns, I hope that nonetheless I can suggest some ideas and hopefully inspire a reader or two. That's all. I intend nothing of the following to be prescriptive. I describe my own professional experience: What has worked for me. Perhaps it could also work for you. Use the ideas if they inspire you. Ignore them if you find them impractical.
The Test Pyramid #
The Test Pyramid is often depicted like this:
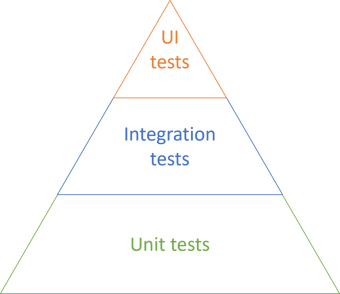
This seems to indicate that while the majority of tests should be unit tests, you should also have a substantial number of integration tests, and quite a few UI tests.
Perhaps the following is obvious, but the Test Pyramid is an idea; it's a way to communicate a concept in a compelling way. What one should take away from it, I think, is only this: The number of tests in each category should form a total order, where the unit test category is the maximum. In other words, you should have more unit tests than you have tests in the next category, and so on.
No-one says that you can only have three levels, or that they have to have the same height. Finally, the above figure isn't even a pyramid, but rather a triangle.
I sometimes think of the Test Pyramid like this:
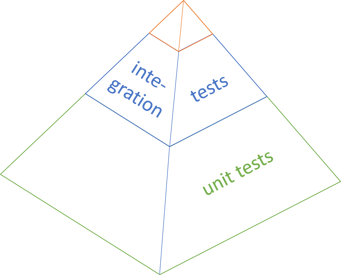
To be honest, it's not so much whether or not the pyramid is shown in perspective, but rather that the unit test base is significantly more voluminous than the other levels, and that the top is quite small.
Levels #
In order to keep the above discussion as recognisable as possible, I've used the labels unit tests, integration tests, and UI tests. It's easy to get caught up in a discussion about how these terms are defined. Exactly what is a unit test? How does it differ from an integration test?
There's no universally accepted definition of a unit test, so it tends to be counter-productive to spend too much time debating the finer points of what to call the tests in each layer.
Instead, I find the following criteria useful:
- In-process tests
- Tests that involve more than one process
- Tests that can only be performed in production
I'll describe each in a little more detail. Along the way, I'll address some of the reactions to Works on most machines.
In-process tests #
The in-process category corresponds roughly to the Test Pyramid's unit test level. It includes 'traditional' unit tests such as tests of stand-alone functions or methods on objects, but also Facade Tests. The latter may involve multiple modules or objects, perhaps even from multiple libraries. Many people may call them integration tests because they integrate more than one module.
As long as an automated test runs in a single process, in memory, it tends to be fast and leave no persistent state behind. This is almost exclusively the kind of test I tend to test-drive. I often follow an outside-in TDD process, an example of which is shown in my book Code That Fits in Your Head.
Consider an example from the source code that accompanies the book:
[Fact] public async Task ReserveTableAtTheVaticanCellar() { using var api = new SelfHostedApi(); var client = api.CreateClient(); var timeOfDayLaterThanLastSeatingAtTheOtherRestaurants = TimeSpan.FromHours(21.5); var at = DateTime.Today.AddDays(433).Add( timeOfDayLaterThanLastSeatingAtTheOtherRestaurants); var dto = Some.Reservation.WithDate(at).ToDto(); var response = await client.PostReservation("The Vatican Cellar", dto); response.EnsureSuccessStatusCode(); }
I think of a test like this as an automated acceptance test. It uses an internal test-specific domain-specific language (test utilities) to exercise the REST service's API. It uses ASP.NET self-hosting to run both the service and the HTTP client in the same process.
Even though this may, at first glance, look like an integration test, it's an artefact of test-driven development. Since it does cut across both HTTP layer and domain model, some readers may think of it as an integration test. It uses a stateful in-memory data store, so it doesn't involve more than a single process.
Tests that span processes #
There are aspects of software that you can't easily drive with tests. I'll return to some really gnarly examples in the third category, but in between, we find concerns that are hard, but still possible to test. The reason that they are hard is often because they involve more than one process.
The most common example is data access. Many software systems save or retrieve data. With test-driven development, you're supposed to let the tests inform your API design decisions in such a way that everything that involves difficult, error-prone code is factored out of the data access layer, and into another part of the code that can be tested in process. This development technique ought to drain the hard-to-test components of logic, leaving behind a Humble Object.
One reaction to Works on most machines concerns exactly that idea:
"As a developer, you need to test HumbleObject's behavior."
It's almost tautologically part of the definition of a Humble Object that you're not supposed to test it. Still, realistically, ladeak has a point.
When I wrote the example code to Code That Fits in Your Head, I applied the Humble Object pattern to the data access component. For a good while, I had a SqlReservationsRepository class that was so simple, so drained of logic, that it couldn't possibly fail.
Until, of course, the inevitable happened: There was a bug in the SqlReservationsRepository code. Not to make a long story out of it, but even with a really low cyclomatic complexity, I'd accidentally swapped two database columns when reading from a table.
Whenever possible, when I discover a bug, I first write an automated test that exposes that bug, and only then do I fix the problem. This is congruent with my lean bias. If a defect can occur once, it can occur again in the future, so it's better to have a regression test.
The problem with this bug is that it was in a Humble Object. So, ladeak is right. Sooner or later, you'll have to test the Humble Object, too.
That's when I had to bite the bullet and add a test library that tests against the database.
One such test looks like this:
[Theory] [InlineData(Grandfather.Id, "2022-06-29 12:00", "e@example.gov", "Enigma", 1)] [InlineData(Grandfather.Id, "2022-07-27 11:40", "c@example.com", "Carlie", 2)] [InlineData(2, "2021-09-03 14:32", "bon@example.edu", "Jovi", 4)] public async Task CreateAndReadRoundTrip( int restaurantId, string at, string email, string name, int quantity) { var expected = new Reservation( Guid.NewGuid(), DateTime.Parse(at, CultureInfo.InvariantCulture), new Email(email), new Name(name), quantity); var connectionString = ConnectionStrings.Reservations; var sut = new SqlReservationsRepository(connectionString); await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual); }
The entire test runs in a special context where a database is automatically created before the test runs, and torn down once the test has completed.
"When building such behavior, you can test against a shared instance of the service in your dev team or run that service on your dev machine in a container."
Yes, those are two options. A third, in the spirit of GOOS, is to strongly favour technologies that support automation. Believe it or not, you can automate SQL Server. You don't need a Docker container for it. That's what I did in the above test.
I can see how a Docker container with an external dependency can be useful too, so I'm not trying to dismiss that technology. The point is, however, that simpler alternatives may exist. I, and others, did test-driven development for more than a decade before Docker existed.
Tests that can only be performed in production #
The last category of tests are those that you can only perform on a production system. What might be examples of that?
I've run into a few over the years. One such test is what I call a Smoke Test: Metaphorically speaking, turn it on and see if it develops smoke. These kinds of tests are good at catching configuration errors. Does the web server have the right connection string to the database? A test can verify whether that's the case, but it makes no sense to run such a test on a development machine, or against a test system, or a staging environment. You want to verify that the production system is correctly configured. Only a test against the production system can do that.
For every configuration value, you may want to consider a Smoke Test.
There are other kinds of tests you can only perform in production. Sometimes, it's not technical concerns, but rather legal or financial constraints, that dictate circumstances.
A few years ago I worked with a software organisation that, among other things, integrated with the Danish personal identification number system (CPR). Things may have changed since, but back then, an organisation had to have a legal agreement with CPR before being granted access to its integration services. It's an old system (originally from 1968) with a proprietary data integration protocol.
We test-drove a parser of the data format, but that still left behind a Humble Object that would actually perform the data transfers. How do we test that Humble Object?
Back then, at least, there was no test system for the CPR service, and it was illegal to query the live system unless you had a business reason. And software testing did not constitute a legal reason.
The only legal option was to make the Humble Object as simple and foolproof as possible, and then observe how it worked in actual production situations. Containers wouldn't help in such a situation.
It's possible to write automated tests against production systems, but unless you're careful, they're difficult to write and maintain. At least, go easy on the assertions, since you can't assume much about the run-time data and behaviour of a live system. Smoke tests are mostly just 'pings', so can be written to be fairly maintenance-free, but you shouldn't need many of them.
Other kinds of tests against production are likely to be fragile, so it pays to minimise their number. That's the top of the pyramid.
User interfaces #
I no longer develop user interfaces, so take the following with a pinch of salt.
The 'original' Test Pyramid that I've depicted above has UI tests at the pyramid's top. That doesn't necessarily match the categories I've outlined here; don't assume parity.
A UI test may or may not involve more than one process, but they are often difficult to maintain for other reasons. Perhaps this is where the pyramid metaphor starts to break down. All models are wrong, but some are useful.
Back when I still programmed user interfaces, I'd usually test-drive them via a subcutaneous API, and rely on some variation of MVC to keep the rendered controls in sync. Still, once in a while, you need to verify that the user interface looks as it's supposed to. Often, the best tool for that job is the good old Mark I Eyeball.
This still means that you need to run the application from time to time.
"Docker is also very useful for enabling others to run your software on their machines. Recently, we've been exploring some apps that consisted of ~4 services (web servers) and a database. All of them written in different technologies (PHP, Java, C#). You don't have to setup environment variables. You don't need to have relevant SDKs to build projects etc. Just run docker command, and spin them instantly on your PC."
That sounds like a reasonable use case. I've never found myself in such circumstances, but I can imagine the utility that containers offer in a situation like that. Here's how I envision the scenario:
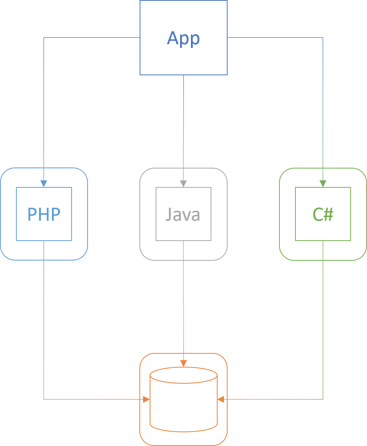
The boxes with rounded corners symbolise containers.
Again, my original goal with the previous article wasn't to convince you that container technologies are unequivocally bad. Rather, it was to suggest that test-driven development (TDD) solves many of the problems that people seem to think can only be solved with containers. Since TDD has many other beneficial side effects, it's worth considering instead of mindlessly reaching for containers, which may represent only a local maximum.
How could TDD address qfilip's concern?
When I test-drive software, I favour real dependencies, and I favour Fake objects over Mocks and Stubs. Were I to return to user-interface programming today, I'd define its external dependencies as one or more interfaces, and implement a Fake Object for each.
Not only will this enable me to simulate the external dependencies with the Fakes. If I implement the Fakes as part of the production code, I'd even be able to spin up the system, using the Fakes instead of the real system.

A Fake is an implementation that 'almost works'. A common example is an in-memory collection instead of a database. It's neither persistent nor thread-safe, but it's internally consistent. What you add, you can retrieve, until you delete it again. For the purposes of starting the app in order to verify that the user interface looks correct, that should be good enough.
Another related example is NServiceBus, which comes with a file transport that is clearly labeled as not for production use. While it's called the Learning Transport, it's also useful for exploratory testing on a development machine. While this example clearly makes use of an external resource (the file system), it illustrates how a Fake implementation can alleviate the need for a container.
Uses for containers #
Ultimately, it's still useful to be able to stand up an entire system, as qfilip suggests, and if containers is a good way to do that, it doesn't bother me. At the risk of sounding like a broken record, I never intended to say that containers are useless.
When I worked as a Software Development Engineer in Microsoft, I had two computers: A laptop and a rather beefy tower PC. I've always done all programming on laptops, so I repurposed the tower as a virtual server with all my system's components on separate virtual machines (VM). The database in one VM, the application server in another, and so on. I no longer remember what all the components were, but I seem to recall that I had four VMs running on that one box.
While I didn't use it much, I found it valuable to occasionally verify that all components could talk to each other on a realistic network topology. This was in 2008, and Docker wasn't around then, but I could imagine it would have made that task easier.
I don't dispute that Docker and Kubernetes are useful, but the job of a software architect is to carefully identify the technologies on which a system should be based. The more technology dependencies you take on, the more rigid the design.
After a few decades of programming, my experience is that as a programmer and architect, I can find better alternatives than depending on container technologies. If testers and IT operators find containers useful to do their jobs, then that's fine by me. Since my code works on most machines, it works in containers, too.
Truly Humble Objects #
One last response, and I'll wrap this up.
"As a developer, you need to test HumbleObject's behavior. What if a DatabaseConnection or a TCP conn to a message queue is down?"
How should such situations be handled? There may always be special cases, but in general, I can think of two reactions:
- Log the error
- Retry the operation
Assuming that the Humble Object is a polymorphic type (i.e. inherits a base class or implements an interface), you should be able to extract each of these behaviours to general-purpose components.
In order to log errors, you can either use a Decorator or a global exception handler. Most frameworks provide a way to catch (otherwise) unhandled exceptions, exactly for this purpose, so you don't have to add such functionality to a Humble Object.
Retry logic can also be delegated to a third-party component. For .NET I'd start looking at Polly, but I'd be surprised if other platforms don't have similar libraries that implement the stability patterns from Release It.
Something more specialised, like a fail-over mechanism, sounds like a good reason to wheel out the Chain of Responsibility pattern.
All of these can be tested independently of any Humble Object.
Conclusion #
In a recent article I reflected on my experience with TDD and speculated that a side effect of that process is code flexible enough to work on most machines. Thus, I've never encountered the need for a containers.
Readers responded with comments that struck me as mostly related to the upper levels of the Test Pyramid. In this article, I've attempted to address some of those concerns. I still get by without containers.
