Continuous delivery without a CI server by Mark Seemann
An illustrative example.
More than a decade ago, I worked on a small project. It was a small single-page application (SPA) with a REST API backend, deployed to Azure. As far as I recall, the REST API used blob storage, so all in all it wasn't a complex system.
We were two developers, and although we wanted to do continuous delivery (CD), we didn't have much development infrastructure. This was a little startup, and back then, there weren't a lot of free build services available. We were using GitHub, but it was before it had any free services to compile your code and run tests.
Given those constraints, we figured out a simple way to do CD, even though we didn't have a continuous integration (CI) server.
I'll tell you how we did this.
Shining an extraordinary light on the mundane #
The reason I'm relating this little story isn't to convince you that you, too, should do it that way. Rather, it's a didactic device. By doing something extreme, we can sometimes learn about the ordinary.
You can only be pragmatic if you know how to be dogmatic.
From what I hear and read, it seems that there's a lot of organizations that believe that they're doing CI (or perhaps even CD) because they have a CI server. What the following tale will hopefully highlight is that, while build servers are useful, they aren't a requirement for CI or CD.
Distributed CD #
Dramatis personae: My colleague and me. Scene: One small SPA project with a REST API and blob storage, to be deployed to Azure. Code base in GitHub. Two laptops. Remote work.
One of us (let's say me) would start on implementing a feature, or fixing a bug. I'd use test-driven development (TDD) to get feedback on API ideas, as well as to accumulate a suite of regression tests. After a few hours of effective work, I'd send a pull request to my colleague.
Since we were only two people on the team, the responsibility was clear. It was the other person's job to review the pull request. It was also clear that the longer the reviewer dawdled, the less efficient the process would be. For that reason, we'd typically have agile pull requests with a good turnaround time.
While we were taking advantage of GitHub as a central coordination hub for pull requests, Git itself is famously distributed. Thus, we wondered whether it'd be possible to make the CD process distributed as well.
Yes, apart from GitHub, what we did was already distributed.
A little more automation #
Since we were both doing TDD, we already had automated tests. Due to the simple setup of the system, we'd already automated more than 80% of our process. It wasn't much of a stretch to automate whatever else needed automation. Such as deployment.
We agreed on a few simple rules:
- Every part of our process should be automated.
- Reviewing a pull request included running all tests.
When people review pull requests, they often just go to GitHub and look around before issuing an LGTM.
But, you do realize that this is Git, right? You can pull down the proposed changes and run them.
What if you're already in the middle of something, working on the same code base? Stash your changes and pull down the code.
The consequence of this process was that every time a pull request was accepted, we already knew that it passed all automated tests on two physical machines. We actually didn't need a server to run the tests a third time.
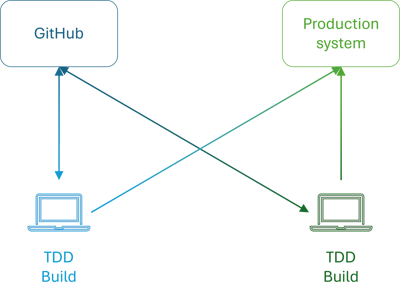
After a merge, the final part of the development process mandated that the original author should deploy to production. We had Bash script that did that.
Simplicity #
This process came with some built-in advantages. First of all, it was simple. There wasn't a lot of moving parts, so there weren't many steps that could break.
Have you ever had the pleasure of troubleshooting a build? The code works on your machine, but not on the build server.
It sometimes turns out that there's a configuration mismatch with the compiler or test tools. Thus, the problem with the build server doesn't mean that you prevented a dangerous defect from being deployed to production. No, the code just didn't compile on the build server, but would actually have run fine on the production system.
It's much easier troubleshooting issues on your own machine than on some remote server.
I've also seen build servers that were set up to run tests, but along the way, something had failed and the tests didn't run. And no-one was looking at logs or warning emails from the build system because that system would already be sending hundreds of warnings a day.
By agreeing to manually(!) run the automated tests as part of the review process, we were sure that they were exercised.
Finally, by keeping the process simple, we could focus on what mattered: Delivering value to our customer. We didn't have to waste time learning how a proprietary build system worked.
Does it scale? #
I know what you're going to say: This may have worked because the overall requirements were so simple. This will never work in a 'real' development organization, with a 'real' code base.
I understand. I never claimed that it would.
The point of this story is to highlight what CI and CD is. It's a way of working where you continuously integrate your code with everyone else's code, and where you continuously deploy changes to production.
In reality, having a dedicated build system for that can be useful. These days, such systems tend to be services that integrate with GitHub or other sites, rather than an actual server that you have to care for. Even so, having such a system doesn't mean that your organization makes use of CI or CD.
(Oh, and for the mathematically inclined: In this context continuous doesn't mean actually continuous. It just means arbitrarily often.)
Conclusion #
CI and CD are processes that describe how we work with code, and how we work together.
Continuous integration means that you often integrate your code with everyone else's code. How often? More than once a day.
Continuous deployment means that you often deploy code changes to production. How often? Every time new code is integrated.
A build system can be convenient to help along such processes, but it's strictly speaking not required.
