Favour flat code file folders by Mark Seemann
How code files are organised is hardly related to sustainability of code bases.
My recent article Folders versus namespaces prompted some reactions. A few kind people shared how they organise code bases, both on Twitter and in the comments. Most reactions, however, carry the (subliminal?) subtext that organising code in file folders is how things are done.
I'd like to challenge that notion.
As is usually my habit, I mostly do this to make you think. I don't insist that I'm universally right in all contexts, and that everyone else are wrong. I only write to suggest that alternatives exist.
The previous article wasn't a recommendation; it's was only an exploration of an idea. As I describe in Code That Fits in Your Head, I recommend flat folder structures. Put most code files in the same directory.
Finding files #
People usually dislike that advice. How can I find anything?!
Let's start with a counter-question: How can you find anything if you have a deep file hierarchy? Usually, if you've organised code files in subfolders of subfolders of folders, you typically start with a collapsed view of the tree.
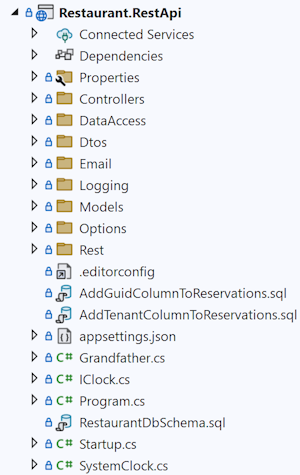
Those of my readers who know a little about search algorithms will point out that a search tree is an efficient data structure for locating content. The assumption, however, is that you already know (or can easily construct) the path you should follow.
In a view like the above, most files are hidden in one of the collapsed folders. If you want to find, say, the Iso8601.cs file, where do you look for it? Which path through the tree do you take?
Unfair!, you protest. You don't know what the Iso8601.cs file does. Let me enlighten you: That file contains functions that render dates and times in ISO 8601 formats. These are used to transmit dates and times between systems in a platform-neutral way.
So where do you look for it?
It's probably not in the Controllers or DataAccess directories. Could it be in the Dtos folder? Rest? Models?
Unless your first guess is correct, you'll have to open more than one folder before you find what you're looking for. If each of these folders have subfolders of their own, that only exacerbates the problem.
If you're curious, some programmer (me) decided to put the Iso8601.cs file in the Dtos directory, and perhaps you already guessed that. That's not the point, though. The point is this: 'Organising' code files in folders is only efficient if you can unerringly predict the correct path through the tree. You'll have to get it right the first time, every time. If you don't, it's not the most efficient way.
Most modern code editors come with features that help you locate files. In Visual Studio, for example, you just hit Ctrl+, and type a bit of the file name: iso:
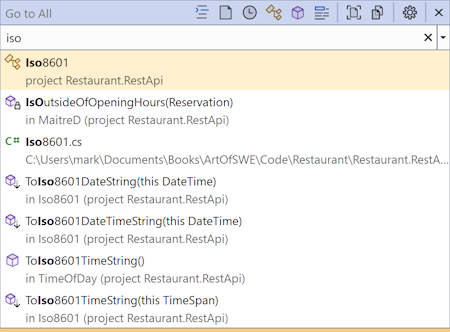
Then hit Enter to open the file. In Visual Studio Code, the corresponding keyboard shortcut is Ctrl+p, and I'd be highly surprised if other editors didn't have a similar feature.
To conclude, so far: Organising files in a folder hierarchy is at best on par with your editor's built-in search feature, but is likely to be less productive.
Navigating a code base #
What if you don't quite know the name of the file you're looking for? In such cases, the file system is even less helpful.
I've seen people work like this:
- Look at some code. Identify another code item they'd like to view. (Examples may include: Looking at a unit test and wanting to see the SUT, or looking at a class and wanting to see the base class.)
- Move focus to the editor's folder view (in Visual Studio called the Solution Explorer).
- Scroll to find the file in question.
- Double-click said file.
Regardless of how the files are organised, you could, instead, go to definition (F12 with my Visual Studio keyboard layout) in a single action. Granted, how well this works varies with editor and language. Still, even when editor support is less optimal (e.g. a code base with a mix of F# and C#, or a Haskell code base), I can often find things faster with a search (Ctrl+Shift+f) than via the file system.
A modern editor has efficient tools that can help you find what you're looking for. Looking through the file system is often the least efficient way to find the code you're looking for.
Large code bases #
Do I recommend that you dump thousands of code files in a single directory, then?
Hardly, but a question like that presupposes that code bases have thousands of code files. Or more, even. And I've seen such code bases.
Likewise, it's a common complaint that Visual Studio is slow when opening solutions with hundreds of projects. And the day Microsoft fixes that problem, people are going to complain that it's slow when opening a solution with thousands of projects.
Again, there's an underlying assumption: That a 'real' code base must be so big.
Consider alternatives: Could you decompose the code base into multiple smaller code bases? Could you extract subsystems of the code base and package them as reusable packages? Yes, you can do all those things.
Usually, I'd pull code bases apart long before they hit a thousand files. Extract modules, libraries, utilities, etc. and put them in separate code bases. Use existing package managers to distribute these smaller pieces of code. Keep the code bases small, and you don't need to organise the files.
Maintenance #
But, if all files are mixed together in a single folder, how do we keep the code maintainable?
Once more, implicit (but false) assumptions underlie such questions. The assumption is that 'neatly' organising files in hierarchies somehow makes the code easier to maintain. Really, though, it's more akin to a teenager who 'cleans' his room by sweeping everything off the floor only to throw it into his cupboard. It does enable hoovering the floor, but it doesn't make it easier to find anything. The benefit is mostly superficial.
Still, consider a tree.
This may not be the way you're used to see files and folders rendered, but this diagram emphases the tree structure and makes what happens next starker.
The way that most languages work, putting code files in folders makes little difference to the compiler. If the classes in my Controllers folder need some classes from the Dtos folder, you just use them. You may need to import the corresponding namespace, but modern editors make that a breeze.
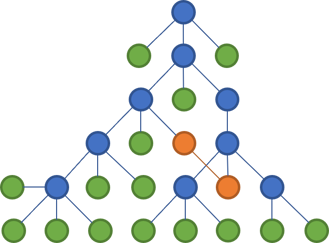
In the above tree, the two files who now communicate are coloured orange. Notice that they span across two main branches of the tree.
Thus, even though the files are organised in a tree, it has no impact on the maintainability of the code base. Code can reference other code in other parts of the tree. You can easily create cycles in a language like C#, and organising files in trees makes no difference.
Most languages, however, enforce that library dependencies form a directed acyclic graph (i.e. if the data access library references the domain model, the domain model can't reference the data access library). The C# (and most other languages) compiler enforces what Robert C. Martin calls the Acyclic Dependencies Principle. Preventing cycles prevents spaghetti code, which is key to a maintainable code base.
(Ironically, one of the more controversial features of F# is actually one of its greatest strengths: It doesn't allow cycles.)
Tidiness #
Even so, I do understand the lure of organising code files in an elaborate hierarchy. It looks so neat.
Previously, I've touched on the related topic of consistency, and while I'm a bit of a neat freak myself, I have to realise that tidiness seems to be largely unrelated to the sustainability of a code base.
As another example in this category, I've seen more than one code base with consistently beautiful documentation. Every method was adorned with formal XML documentation with every input parameter as well as output described.
Every new phase in a method was delineated with another neat comment, nicely adorned with a 'comment frame' and aligned with other comments.
It was glorious.
Alas, that documentation sat on top of 750-line methods with a cyclomatic complexity above 50. The methods were so long that developers had to introduce artificial variable scopes to avoid naming collisions.
The reason I was invited to look at that code in the first place was that the organisation had trouble with maintainability, and they asked me to help.
It was neat, yet unmaintainable.
This discussion about tidiness may seem like a digression, but I think it's important to make the implicit explicit. If I'm not much mistaken, preference for order is a major reason that so many developers want to organise code files into hierarchies.
Organising principles #
What other motivations for file hierarchies could there be? How about the directory structure as an organising principle?
The two most common organising principles are those that I experimented with in the previous article:
- By technical role (Controller, View Model, DTO, etc.)
- By feature
A technical leader might hope that, by presenting a directory structure to team members, it imparts an organising principle on the code to be.
It may even do so, but is that actually a benefit?
It might subtly discourage developers from introducing code that doesn't fit into the predefined structure. If you organise code by technical role, developers might put most code in Controllers, producing mostly procedural Transaction Scripts. If you organise by feature, this might encourage duplication because developers don't have a natural place to put general-purpose code.
You can put truly shared code in the root folder, the counter-argument might be. This is true, but:
- This seems to be implicitly discouraged by the folder structure. After all, the hierarchy is there for a reason, right? Thus, any file you place in the root seems to suggest a failure of organisation.
- On the other hand, if you flaunt that not-so-subtle hint and put many code files in the root, what advantage does the hierarchy furnish?
In Information Distribution Aspects of Design Methodology David Parnas writes about documentation standards:
"standards tend to force system structure into a standard mold. A standard [..] makes some assumptions about the system. [...] If those assumptions are violated, the [...] organization fits poorly and the vocabulary must be stretched or misused."
(The above quote is on the surface about documentation standards, and I've deliberately butchered it a bit (clearly marked) to make it easier to spot the more general mechanism.)
In the same paper, Parnas describes the danger of making hard-to-change decisions too early. Applied to directory structure, the lesson is that you should postpone designing a file hierarchy until you know more about the problem. Start with a flat directory structure and add folders later, if at all.
Beyond files? #
My claim is that you don't need much in way of directory hierarchy. From this doesn't follow, however, that we may never leverage such options. Even though I left most of the example code for Code That Fits in Your Head in a single folder, I did add a specialised folder as an anti-corruption layer. Folders do have their uses.
"Why not take it to the extreme and place most code in a single file? If we navigate by "namespace view" and search, do we need all those files?"
Following a thought to its extreme end can shed light on a topic. Why not, indeed, put all code in a single file?
Curious thought, but possibly not new. I've never programmed in SmallTalk, but as I understand it, the language came with tooling that was both IDE and execution environment. Programmers would write source code in the editor, but although the code was persisted to disk, it may not have been as text files.
Even if I completely misunderstand how SmallTalk worked, it's not inconceivable that you could have a development environment based directly on a database. Not that I think that this sounds like a good idea, but it sounds technically possible.
Whether we do it one way or another seems mostly to be a question of tooling. What problems would you have if you wrote an entire C# (Java, Python, F#, or similar) code base as a single file? It becomes more difficult to look at two or more parts of the code base at the same time. Still, Visual Studio can actually give you split windows of the same file, but I don't know how it scales if you need multiple views over the same huge file.
Conclusion #
I recommend flat directory structures for code files. Put most code files in the root of a library or app. Of course, if your system is composed from multiple libraries (dependencies), each library has its own directory.
Subfolders aren't prohibited, only generally discouraged. Legitimate reasons to create subfolders may emerge as the code base evolves.
My misgivings about code file directory hierarchies mostly stem from the impact they have on developers' minds. This may manifest as magical thinking or cargo-cult programming: Erect elaborate directory structures to keep out the evil spirits of spaghetti code.
It doesn't work that way.

Comments
"A development environment based directly on a database" reminds me immediately of An oral history of Bank Python. To quote that post:
My chaotic idea is that by Conway's Law, the organizing principle should be by owners of code, and change of owner should force a renaming across the repo, notifying all users of the change.
Yufan Lou, thank you for sharing that article. Interesting read; I can't say that I'm that surprised.