When is an implementation detail an implementation detail? by Mark Seemann
On the tension between encapsulation and testability.
This article is part of a series called Epistemology of interaction testing. A previous article in the series elicited this question:
"following your suggestion, aren’t we testing implementation details?"
This frequently-asked question reminds me of an old joke. I think that I first heard it in the eighties, a time when phones had rotary dials, everyone smoked, you'd receive mail through your apartment door's letter slot, and unemployment was high. It goes like this:
A painter gets a helper from the unemployment office. A few days later the lady from the office calls the painter and apologizes deeply for the mistake.
"What mistake?"
"I'm so sorry, instead of a painter we sent you a gynaecologist. Please just let him go, we'll send you a..."
"Let him go? Are you nuts, he's my best worker! At the last job, they forgot to leave us the keys, and the guy painted the whole room through the letter slot!"
I always think of this joke when the topic is testability. Should you test everything through a system's public API, or do you choose to expose some internal APIs in order to make the code more testable?
Letter slots #
Consider the simplest kind of program you could write: Hello world. If you didn't consider automated testing, then an idiomatic C# implementation might look like this:
internal class Program { private static void Main(string[] args) { Console.WriteLine("Hello, World!"); } }
(Yes, I know that with modern C# you can write such a program using a single top-level statement, but I'm writing for a broader audience, and only use C# as an example language.)
How do we test a program like that? Of course, no-one seriously suggests that we really need to test something that simple, but what if we make it a little more complex? What if we make it possible to supply a name as a command-line argument? What if we want to internationalise the program? What if we want to add a help feature? What if we want to add a feature so that we can send a hello to another recipient, on another machine? When does the behaviour become sufficiently complex to warrant automated testing, and how do we achieve that goal?
For now, I wish to focus on how to achieve the goal of testing software. For the sake of argument, then, assume that we want to test the above hello world program.
As given, we can run the program and verify that it prints Hello, World! to the console. This is easy to do as a manual test, but harder if you want to automate it.
You could write a test framework that automatically starts a new operating-system process (the program) and waits until it exits. This framework should be able to handle processes that exit with success and failure status codes, as well as processes that hang, or never start, or keep restarting... Such a framework also requires a way to capture the standard output stream in order to verify that the expected text is written to it.
I'm sure such frameworks exist for various operating systems and programming languages. There is, however, a simpler solution if you can live with the trade-off: You could open the API of your source code a bit:
public class Program { public static void Main(string[] args) { Console.WriteLine("Hello, World!"); } }
While I haven't changed the structure or the layout of the source code, I've made both class and method public. This means that I can now write a normal C# unit test that calls Program.Main.
I still need a way to observe the behaviour of the program, but there are known ways of redirecting the Console output in .NET (and I'd be surprised if that wasn't the case on other platforms and programming languages).
As we add more and more features to the command-line program, we may be able to keep testing by calling Program.Main and asserting against the redirected Console. As the complexity of the program grows, however, this starts to look like painting a room through the letter slot.
Adding new APIs #
Real programs are usually more than just a command-line utility. They may be smartphone apps that react to user input or network events, or web services that respond to HTTP requests, or complex asynchronous systems that react to, and send messages over durable queues. Even good old batch jobs are likely to pull data from files in order to write to a database, or the other way around. Thus, the interface to the rest of the world is likely larger than just a single Main method.
Smartphone apps or message-based systems have event handlers. Web sites or services have classes, methods, or functions that handle incoming HTTP requests. These are essentially event handlers, too. This increases the size of the 'test surface': There are more than a single method you can invoke in order to exercise the system.
Even so, a real program will soon grow to a size where testing entirely through the real-world-facing API becomes reminiscent of painting through a letter slot. J.B. Rainsberger explains that one major problem is the combinatorial explosion of required test cases.
Another problem is that the system may produce side effects that you care about. As a basic example, consider a system that, as part of its operation, sends emails. When testing this system, you want to verify that under certain circumstances, the system sends certain emails. How do you do that?
If the system has absolutely no concessions to testability, I can think of two options:
- You contact the person to whom the system sends the email, and ask him or her to verify receipt of the email. You do that every time you test.
- You deploy the System Under Test in an environment with an SMTP gateway that redirects all email to another address.
Clearly the first option is unrealistic. The second option is a little better, but you still have to open an email inbox and look for the expected message. Doing so programmatically is, again, technically possible, and I'm sure that there are POP3 or IMAP assertion libraries out there. Still, this seems complicated, error-prone, and slow.
What could we do instead? I would usually introduce a polymorphic interface such as IPostOffice as a way to substitute the real SmtpPostOffice with a Test Double.
Notice what happens in these cases: We introduce (or make public) new APIs in order to facilitate automated testing.
Application-boundary API and internal APIs #
It's helpful to distinguish between the real-world-facing API and everything else. In this diagram, I've indicated the public-facing API as a thin green slice facing upwards (assuming that external stimulus - button clicks, HTTP requests, etc. - arrives from above).
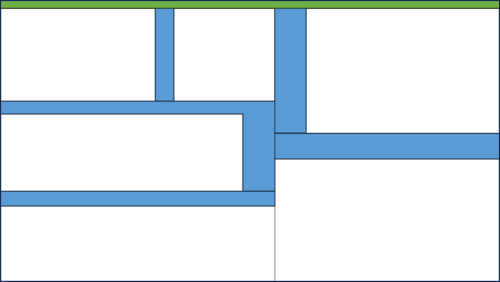
The real-world-facing API is the code that must be present for the software to work. It could be a button-click handler or an ASP.NET action method:
[HttpPost("restaurants/{restaurantId}/reservations")] public async Task<ActionResult> Post(int restaurantId, ReservationDto dto)
Of course, if you're using another web framework or another programming language, the details differ, but the application has to have code that handles an HTTP POST request on matching addresses. Or a button click, or a message that arrives on a message bus. You get the point.
These APIs are fairly fixed. If you change them, you change the externally observable behaviour of the system. Such changes are likely breaking changes.
Based on which framework and programming language you're using, the shape of these APIs will be given. Like I did with the above Main method, you can make it public and use it for testing.
A software system of even middling complexity will usually also be decomposed into smaller components. In the figure, I've indicated such subdivisions as boxes with gray outlines. Each of these may present an API to other parts of the system. I've indicated these APIs with light blue.
The total size of internal APIs is likely to be larger than the public-facing API. On the other hand, you can (theoretically) change these internal interfaces without breaking the observable behaviour of the system. This is called refactoring.
These internal APIs will often have public access modifiers. That doesn't make them real-world-facing. Be careful not to confuse programming-language access modifiers with architectural concerns. Objects or their members can have public access modifiers even if the object plays an exclusively internal role. At the boundaries, applications aren't object-oriented. And neither are they functional.
Likewise, as the original Main method example shows, public APIs may be implemented with a private access modifier.
Why do such internal APIs exist? Is it only to support automated testing?
Decomposition #
If we introduce new code, such as the above IPostOffice interface, in order to facilitate testing, we have to be careful that it doesn't lead to test-induced design damage. The idea that one might introduce an API exclusively to support automated testing rubs some people the wrong way.
On the other hand, we do introduce (or make public) APIs for other reasons, too. One common reason is that we want to decompose an application's source code so that parallel development is possible. One person (or team) works on one part, and other people work on other parts. If those parts need to communicate, we need to agree on a contract.
Such a contract exists for purely internal reasons. End users don't care, and never know of it. You can change it without impacting users, but you may need to coordinate with other teams.
What remains, though, is that we do decompose systems into internal parts, and we've done this since before Parnas wrote On the Criteria to Be Used in Decomposing Systems into Modules.
Successful test-driven development introduces seams where they ought to be in any case.
Testing implementation details #
An internal seam is an implementation detail. Even so, when designed with care, it can serve multiple purposes. It enables teams to develop in parallel, and it enables automated testing.
Consider the example from a previous article in this series. I'll repeat one of the tests here:
[Theory] [AutoData] public void HappyPath(string state, string code, (string, bool, Uri) knownState, string response) { _repository.Add(state, knownState); _stateValidator .Setup(validator => validator.Validate(code, knownState)) .Returns(true); _renderer .Setup(renderer => renderer.Success(knownState)) .Returns(response); _target .Complete(state, code) .Should().Be(response); }
This test exercises a happy-path case by manipulating IStateValidator and IRenderer Test Doubles. It's a common approach to testability, and what dhh would label test-induced design damage. While I'm sympathetic to that position, that's not my point. My point is that I consider IStateValidator and IRenderer internal APIs. End users (who probably don't even know what C# is) don't care about these interfaces.
Tests like these test against implementation details.
This need not be a problem. If you've designed good, stable seams then these tests can serve you for a long time. Testing against implementation details become a problem if those details change. Since it's hard to predict how things change in the future, it behoves us to decouple tests from implementation details as much as possible.
The alternative, however, is mail-slot testing, which comes with its own set of problems. Thus, judicious introduction of seams is helpful, even if it couples tests to implementation details.
Actually, in the question I quoted above, Christer van der Meeren asked whether my proposed alternative isn't testing implementation details. And, yes, that style of testing also relies on implementation details for testing. It's just a different way to design seams. Instead of designing seams around polymorphic objects, we design them around pure functions and immutable data.
There are, I think, advantages to functional programming, but when it comes to relying on implementation details, it's only on par with object-oriented design. Not worse, not better, but the same.
Conclusion #
Every API in use carries a cost. You need to keep the API stable so that users can use it tomorrow like they did yesterday. This can make it difficult to evolve or improve an API, because you risk introducing a breaking change.
There are APIs that a system must have. Software exists to be used, and whether that entails a user clicking on a button or another computer system sending a message to your system, your code must handle such stimulus. This is your real-world-facing contract, and you need to be careful to keep it consistent. The smaller that surface area is, the simpler that task is.
The same line of reasoning applies to internal APIs. While end users aren't impacted by changes in internal seams, other code is. If you change an implementation detail, this could cost maintenance work somewhere else. (Modern IDEs can handle some changes like that automatically, such as method renames. In those cases, the cost of change is low.) Therefore, it pays to minimise the internal seams as much as possible. One way to do this is by decoupling to delete code.
Still, some internal APIs are warranted. They help you decompose a large system into smaller subparts. While there's a potential maintenance cost with every internal API, there's also the advantage of working with smaller, independent units of code. Often, the benefits are larger than the cost.
When done well, such internal seams are useful testing APIs as well. They're still implementation details, though.
