Validation and business rules by Mark Seemann
A definition of validation as distinguished from business rules.
This article suggests a definition of validation in software development. A definition, not the definition. It presents how I currently distinguish between validation and business rules. I find the distinction useful, although perhaps it's a case of reversed causality. The following definition of validation is useful because, if defined like that, it's a solved problem.
My definition is this:
Validation is a pure function that decides whether data is acceptable.
I've used the word acceptable because it suggests a link to Postel's law. When validating, you may want to allow for some flexibility in input, even if, strictly speaking, it's not entirely on spec.
That's not, however, the key ingredient in my definition. The key is that validation should be a pure function.
While this may sound like an arbitrary requirement, there's a method to my madness.
Business rules #
Before I explain the benefits of the above definition, I think it'll be useful to outline typical problems that developers face. My thesis in Code That Fits in Your Head is that understanding limits of human cognition is a major factor in making a code base sustainable. This again explains why encapsulation is such an important idea. You want to confine knowledge in small containers that fit in your head. Information shouldn't leak out of these containers, because that would require you to keep track of too much stuff when you try to understand other code.
When discussing encapsulation, I emphasise contract over information hiding. A contract, in the spirit of Object-Oriented Software Construction, is a set of preconditions, invariants, and postconditions. Preconditions are particularly relevant to the topic of validation, but I've often experienced that some developers struggle to identify where validation ends and business rules begin.
Consider an online restaurant reservation system as an example. We'd like to implement a feature that enables users to make reservations. In order to meet that end, we decide to introduce a Reservation class. What are the preconditions for creating a valid instance of such a class?
When I go through such an exercise, people quickly identify requirement such as these:
- The reservation should have a date and time.
- The reservation should contain the number of guests.
- The reservation should contain the name or email (or other data) about the person making the reservation.
A common suggestion is that the restaurant should also be able to accommodate the reservation; that is, it shouldn't be fully booked, it should have an available table at the desired time of an appropriate size, etc.
That, however, isn't a precondition for creating a valid Reservation object. That's a business rule.
Preconditions are self-contained #
How do you distinguish between a precondition and a business rule? And what does that have to do with input validation?
Notice that in the above examples, the three preconditions I've listed are self-contained. They are statements about the object or value's constituent parts. On the other hand, the requirement that the restaurant should be able to accommodate the reservation deals with a wider context: The table layout of the restaurant, prior reservations, opening and closing times, and other business rules as well.
Validation is, as Alexis King points out, a parsing problem. You receive less-structured data (CSV, JSON, XML, etc.) and attempt to project it to a more-structured format (C# objects, F# records, Clojure maps, etc.). This succeeds when the input satisfies the preconditions, and fails otherwise.
Why can't we add more preconditions than required? Consider Postel's law. An operation (and that includes object constructors) should be liberal in what it accepts. While you have to draw the line somewhere (you can't really work with a reservation if the date is missing), an object shouldn't require more than it needs.
In general we observe that the fewer pre-conditions, the easier it is to create an object (or equivalent functional data structure). As a counter-example, this explains why Active Record is antithetical to unit testing. One precondition is that there's a database available, and while not impossible to automate in tests, it's quite the hassle. It's easier to work with POJOs in tests. And unit tests, being the first clients of an API, tell you how easy it is to use that API.
Contracts with third parties #
If validation is fundamentally parsing, it seems reasonable that operations should be pure functions. After all, a parser operates on unchanging (less-structured) data. A programming-language parser takes contents of text files as input. There's little need for more input than that, and the output is expected to be deterministic. Not surprisingly, Haskell is well-suited for writing parsers.
You don't, however, have to buy the argument that validation is essentially parsing, so consider another perspective.
Validation is a data transformation step you perform to deal with input. Data comes from a source external to your system. It can be a user filling in a form, another program making an HTTP request, or a batch job that receives files over FTP.
Even if you don't have a formal agreement with any third party, Hyrum's law implies that a contract does exist. It behoves you to pay attention to that, and make it as explicit as possible.
Such a contract should be stable. Third parties should be able to rely on deterministic behaviour. If they supply data one day, and you accept it, you can't reject the same data the next days on grounds that it was malformed. At best, you may be contravariant in input as time passes; in other words, you may accept things tomorrow that you didn't accept today, but you may not reject tomorrow what you accepted today.
Likewise, you can't have validation rules that erratically accept data one minute, reject the same data the next minute, only to accept it later. This implies that validation must, at least, be deterministic: The same input should always produce the same output.
That's half of the way to referential transparency. Do you need side effects in your validation logic? Hardly, so you might as well implement it as pure functions.
Putting the cart before the horse #
You may still think that my definition smells of a solution in search of a problem. Yes, pure functions are convenient, but does it naturally follow that validation should be implemented as pure functions? Isn't this a case of poor retconning?
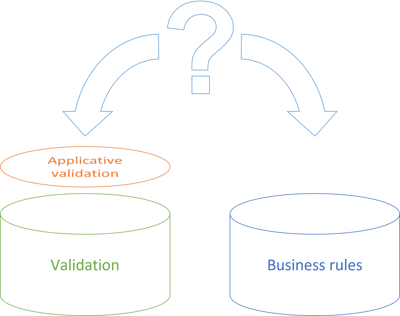
When faced with the question: What is validation, and what are business rules? it's almost as though I've conveniently sized the Validation sorting bucket so that it perfectly aligns with applicative validation. Then, the Business rules bucket fits whatever is left. (In the figure, the two buckets are of equal size, which hardly reflects reality. I estimate that the Business rules bucket is much larger, but had I tried to illustrate that, too, in the figure, it would have looked akilter.)
This is suspiciously convenient, but consider this: My experience is that this perspective on validation works well. To a great degree, this is because I consider validation a solved problem. It's productive to be able to take a chunk of a larger problem and put it aside: We know how to deal with this. There are no risks there.
Definitions do, I believe, rarely spring fully formed from some Platonic ideal. Rather, people observe what works and eventually extract a condensed description and call it a definition. That's what I've attempted to do here.
Business rules change #
Let's return to the perspective of validation as a technical contract between your system and a third party. While that contract should be as stable as possible, business rules change.
Consider the online restaurant reservation example. Imagine that you're the third-party programmer, and that you've developed a client that can make reservations on behalf of users. When a user wants to make a reservation, there's always a risk that it's not possible. Your client should be able to handle that scenario.
Now the restaurant becomes so popular that it decides to change a rule. Earlier, you could make reservations for one, three, or five people, even though the restaurant only has tables for two, four, or six people. Based on its new-found popularity, the restaurant decides that it only accepts reservations for entire tables. Unless it's on the same day and they still have a free table.
This changes the behaviour of the system, but not the contract. A reservation for three is still valid, but will be declined because of the new rule.
"Things that change at the same rate belong together. Things that change at different rates belong apart."
Business rules change at different rates than preconditions, so it makes sense to decouple those concerns.
Conclusion #
Since validation is a solved problem, it's useful to be able to identify what is validation, and what is something else. As long as an 'input rule' is self-contained (or parametrisable), deterministic, and has no side-effects, you can model it with applicative validation.
Equally useful is it to be able to spot when applicative validation isn't a good fit. While I'm sure that someone has published a ValidationT monad transformer for Haskell, I'm not sure I would recommend going that route. In other words, if some business operation involves impure actions, it's not going to fit the mold of applicative validation.
This doesn't mean that you can't implement business rules with pure functions. You can, but in my experience, abstractions other than applicative validation are more useful in those cases.
