Decomposing CTFiYH's sample code base by Mark Seemann
An experience report.
In my book Code That Fits in Your Head (CTFiYH) I write in the last chapter:
If you've looked at the book's sample code base, you may have noticed that it looks disconcertingly monolithic. If you consider the full code base that includes the integration tests, as [the following figure] illustrates, there are all of three packages[...]. Of those, only one is production code.
[Figure caption:] The packages that make up the sample code base. With only a single production package, it reeks of a monolith.
Later, after discussing dependency cycles, I conclude:
I've been writing F# and Haskell for enough years that I naturally follow the beneficial rules that they enforce. I'm confident that the sample code is nicely decoupled, even though it's packaged as a monolith. But unless you have a similar experience, I recommend that you separate your code base into multiple packages.
Usually, you can't write something that cocksure without it backfiring, but I was really, really confident that this was the case. Still, it's always nagged me, because I believe that I should walk the walk rather than talk the talk. And I do admit that this was one of the few claims in the book that I actually didn't have code to back up.
So I decided to spend part of a weekend to verify that what I wrote was true. You won't believe what happened next.
Decomposition #
Reader, I was right all along.
I stopped my experiment when my package graph looked like this:
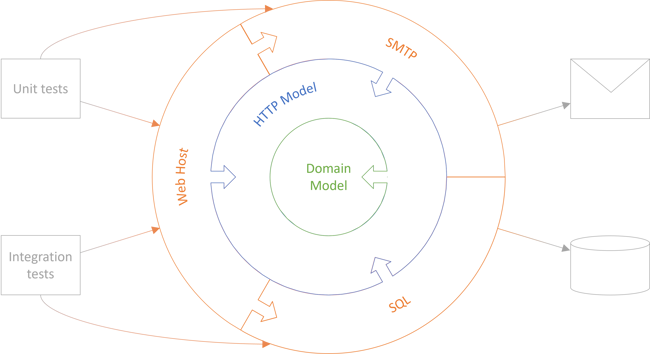
Does that look familiar? It should; it's a poster example of Ports and Adapters, or, if you will, Clean Architecture. Notice how all dependencies point inward, following the Dependency Inversion Principle.
The Domain Model has no dependencies, while the HTTP Model (Application Layer) only depends on the Domain Model. The outer layer contains the ports and adapters, as well as the Composition Root. The Web Host is a small web project that composes everything else. In order to do that, it must reference everything else, either directly (SMTP, SQL, HTTP Model) or transitively (Domain Model).
The Adapters, on the other hand, depend on the HTTP Model and (not shown) the SDKs that they adapt. The SqlReservationsRepository class, for example, is implemented in the SQL library, adapting the System.Data.SqlClient SDK to look like an IReservationsRepository, which is defined in the HTTP Model.
The SMTP library is similar. It contains a concrete implementation called SmtpPostOffice that adapts the System.Net.Mail API to look like an IPostOffice object. Once again, the IPostOffice interface is defined in the HTTP Model.
The above figure is not to scale. In reality, the outer ring is quite thin. The SQL library contains only SqlReservationsRepository and some supporting text files with SQL DDL definitions. The SMTP library contains only the SmtpPostOffice class. And the Web Host contains Program, Startup, and a few configuration file DTOs (options, in ASP.NET parlance).
Application layer #
The majority of code, at least if I use a rough proxy measure like number of files, is in the HTTP Model. I often think of this as the application layer, because it's all the logic that's specific to to the application, in contrast to the Domain Model, which ought to contain code that can be used in a variety of application contexts (REST API, web site, batch job, etc.).
In this particular, case the application is a REST API, and it turns out that while the Domain Model isn't trivial, more goes on making sure that the REST API behaves correctly: That it returns correctly formatted data, that it validates input, that it detects attempts at tampering with URLs, that it redirects legacy URLs, etc.
This layer also contains the interfaces for the application's real dependencies: IReservationsRepository, IPostOffice, IRestaurantDatabase, and IClock. This explains why the SQL and SMTP packages need to reference the HTTP Model.
If you have bought the book, you have access to its example code base, and while it's a Git repository, this particular experiment isn't included. After all, I just made it, two years after finishing the book. Thus, if you want to compare with the code that comes with the book, here's a list of all the files I moved to the HTTP Model package:
- AccessControlList.cs
- CalendarController.cs
- CalendarDto.cs
- Day.cs
- DayDto.cs
- DtoConversions.cs
- EmailingReservationsRepository.cs
- Grandfather.cs
- HomeController.cs
- HomeDto.cs
- Hypertext.cs
- IClock.cs
- InMemoryRestaurantDatabase.cs
- IPeriod.cs
- IPeriodVisitor.cs
- IPostOffice.cs
- IReservationsRepository.cs
- IRestaurantDatabase.cs
- Iso8601.cs
- LinkDto.cs
- LinksFilter.cs
- LoggingClock.cs
- LoggingPostOffice.cs
- LoggingReservationsRepository.cs
- Month.cs
- NullPostOffice.cs
- Period.cs
- ReservationDto.cs
- ReservationsController.cs
- ReservationsRepository.cs
- RestaurantDto.cs
- RestaurantsController.cs
- ScheduleController.cs
- SigningUrlHelper.cs
- SigningUrlHelperFactory.cs
- SystemClock.cs
- TimeDto.cs
- UrlBuilder.cs
- UrlIntegrityFilter.cs
- Year.cs
As you can see, this package contains the Controllers, the DTOs, the interfaces, and some REST- and HTTP-specific code such as SigningUrlHelper, UrlIntegrityFilter, LinksFilter, security, ISO 8601 formatters, etc.
Domain Model #
The Domain Model is small, but not insignificant. Perhaps the most striking quality of it is that (with a single, inconsequential exception) it contains no interfaces. There are no polymorphic types that model application dependencies such as databases, web services, messaging systems, or the system clock. Those are all the purview of the application layer.
As the book describes, the architecture is functional core, imperative shell, and since dependencies make everything impure, you can't have those in your functional core. While, with a language like C#, you can never be sure that a function truly is pure, I believe that the entire Domain Model is referentially transparent.
For those readers who have the book's sample code base, here's a list of the files I moved to the Domain Model:
- Email.cs
- ITableVisitor.cs
- MaitreD.cs
- Name.cs
- Reservation.cs
- ReservationsVisitor.cs
- Restaurant.cs
- Seating.cs
- Table.cs
- TimeOfDay.cs
- TimeSlot.cs
If the entire Domain Model consists of immutable values and pure functions, and if impure dependencies make everything impure, what's the ITableVisitor interface doing there?
This interface doesn't model any external application dependency, but rather represents a sum type with the Visitor pattern. The interface looks like this:
public interface ITableVisitor<T> { T VisitStandard(int seats, Reservation? reservation); T VisitCommunal(int seats, IReadOnlyCollection<Reservation> reservations); }
Restaurant tables are modelled this way because the Domain Model distinguishes between two fundamentally different kinds of tables: Normal restaurant tables, and communal or shared tables. In F# or Haskell such a sum type would be a one-liner, but in C# you need to use either the Visitor pattern or a Church encoding. For the book, I chose the Visitor pattern in order to keep the code base as object-oriented as possible.
Circular dependencies #
In the book I wrote:
The passive prevention of cycles [that comes from separate packages] is worth the extra complexity. Unless team members have extensive experience with a language that prevents cycles, I recommend this style of architecture.
Such languages do exist, though. F# famously prevents cycles. In it, you can't use a piece of code unless it's already defined above. Newcomers to the language see this as a terrible flaw, but it's actually one of its best features.
Haskell takes a different approach, but ultimately, its explicit treatment of side effects at the type level steers you towards a ports-and-adapters-style architecture. Your code simply doesn't compile otherwise!
I've been writing F# and Haskell for enough years that I naturally follow the beneficial rules that they enforce. I'm confident that the sample code is nicely decoupled, even though it's packaged as a monolith. But unless you have a similar experience, I recommend that you separate your code base into multiple packages.
As so far demonstrated in this article, I'm now sufficiently conditioned to be aware of side effects and non-determinism that I know to avoid them and push them to be boundaries of the application. Even so, it turns out that it's insidiously easy to introduce small cycles when the language doesn't stop you.
This wasn't much of a problem in the Domain Model, but one small example may still illustrate how easy it is to let your guard down. In the Domain Model, I'd added a class called TimeOfDay (since this code base predates TimeOnly), but without thinking much of it, I'd added this method:
public string ToIso8601TimeString() { return durationSinceMidnight.ToIso8601TimeString(); }
While this doesn't look like much, formatting a time value as an ISO 8601 value isn't a Domain concern. It's an application boundary concern, so belongs in the HTTP Model. And sure enough, once I moved the file that contained the ISO 8601 conversions to the HTTP Model, the TimeOfDay class no longer compiled.
In this case, the fix was easy. I removed the method from the TimeOfDay class, but added an extension method to the other ISO 8601 conversions:
public static string ToIso8601TimeString(this TimeOfDay timeOfDay) { return ((TimeSpan)timeOfDay).ToIso8601TimeString(); }
While I had little trouble moving the files to the Domain Model one-by-one, once I started moving files to the HTTP Model, it turned out that this part of the code base contained more coupling.
Since I had made many classes and interfaces internal by default, once I started moving types to the HTTP Model, I was faced with either making them public, or move them en block. Ultimately, I decided to move eighteen files that were transitively linked to each other in one go. I could have moved them in smaller chunks, but that would have made the internal types invisible to the code that (temporarily) stayed behind. I decided to move them all at once. After all, while I prefer to move in small, controlled steps, even moving eighteen files isn't that big an operation.
In the end, I still had to make LinksFilter, UrlIntegrityFilter, SigningUrlHelperFactory, and AccessControlList.FromUser public, because I needed to reference them from the Web Host.
Test dependencies #
You may have noticed that in the above diagram, it doesn't look as though I separated the two test packages into more packages, and that is, indeed, the case. I've recently described how I think about distinguishing kinds of tests, and I don't really care too much whether an automated test exercises only a single function, or a whole bundle of objects. What I do care about is whether a test is simple or complex, fast or slow. That kind of thing.
The package labelled "Integration tests" on the diagram is really a small test library that exercises some SQL Server-specific behaviour. Some of the tests in it verify that certain race conditions don't occur. They do that by keep trying to make the race condition occur, until they time out. Since the timeout is 30 seconds per test, this test suite is slow. That's the reason it's a separate library, even though it contains only eight tests. The book contains more details.
The "Unit tests" package contains the bulk of the tests: 176 tests, some of which are FsCheck properties that each run a hundred test cases.
Some tests are self-hosted integration tests that rely on the Web Host, and some of them are more 'traditional' unit tests. Dependencies are transitive, so I drew an arrow from the "Unit tests" package to the Web Host. Some unit tests exercise objects in the HTTP Model, and some exercise the Domain Model.
You may have another question: If the Integration tests reference the SQL package, then why not the SMTP package? Why is it okay that the unit tests reference the SMTP package?
Again, I want to reiterate that the reason I distinguished between these two test packages were related to execution speed rather than architecture. The few SMTP tests are fast enough, so there's no reason to keep them in a separate package.
In fact, the SMTP tests don't exercise that the SmtpPostOffice can send email. Rather, I treat that class as a Humble Object. The few tests that I do have only verify that the system can parse configuration settings:
[Theory] [InlineData("m.example.net", 587, "grault", "garply", "g@example.org")] [InlineData("n.example.net", 465, "corge", "waldo", "c@example.org")] public void ToPostOfficeReturnsSmtpOffice( string host, int port, string userName, string password, string from) { var sut = Create.SmtpOptions(host, port, userName, password, from); var db = new InMemoryRestaurantDatabase(); var actual = sut.ToPostOffice(db); var expected = new SmtpPostOffice(host, port, userName, password, from, db); Assert.Equal(expected, actual); }
Notice, by the way, the use of structural equality on a service. Consider doing that more often.
In any case, the separation of automated tests into two packages may not be the final iteration. It's worked well so far, in this context, but it's possible that had things been different, I would have chosen to have more test packages.
Conclusion #
In the book, I made a bold claim: Although I had developed the example code as a monolith, I asserted that I'd been so careful that I could easily tease it apart into multiple packages should I chose to do so.
This sounded so much like hubris that I was trepidatious writing it. I wrote it anyway, because, while I hadn't tried, I was convinced that I was right.
Still, it nagged me ever since. What if, after all, I was wrong? I've been wrong before.
So I decided to finally make the experiment, and to my relief it turned out that I'd been right.
Don't try this at home, kids.
