Domain Model first by Mark Seemann
Persistence concerns second.
A few weeks ago, I published an article with the title Do ORMs reduce the need for mapping? Not surprisingly, this elicited more than one reaction. In this article, I'll respond to a particular kind of reaction.
First, however, I'd like to reiterate the message of the previous article, which is almost revealed by the title: Do object-relational mappers (ORMs) reduce the need for mapping? To which the article answers a tentative no.
Do pay attention to the question. It doesn't ask whether ORMs are bad in general, or in all cases. It mainly analyses whether the use of ORMs reduces the need to write code that maps between different representations of data: From database to objects, from objects to Data Transfer Objects (DTOs), etc.
Granted, the article looks at a wider context, which I think is only a responsible thing to do. This could lead some readers to extrapolate from the article's specific focus to draw a wider conclusion.
Encapsulation-first #
Most of the systems I work with aren't CRUD systems, but rather systems where correctness is important. As an example, one of my clients does security-heavy digital infrastructure. Earlier in my career, I helped write web shops when these kinds of systems were new. Let me tell you: System owners were quite concerned that prices were correct, and that orders were taken and handled without error.
In my book Code That Fits in Your Head I've tried to capture the essence of those kinds of system with the accompanying sample code, which pretends to be an online restaurant reservation system. While this may sound like a trivial CRUD system, the business logic isn't entirely straightforward.
The point I was making in the previous article is that I consider encapsulation to be more important than 'easy' persistence. I don't mind writing a bit of mapping code, since typing isn't a programming bottleneck anyway.
When prioritising encapsulation you should be able to make use of any design pattern, run-time assertion, as well as static type systems (if you're working in such a language) to guard correctness. You should be able to compose objects, define Value Objects, wrap single values to avoid primitive obsession, make constructors private, leverage polymorphism and effectively use any trick your language, idiom, and platform has on offer. If you want to use Church encoding or the Visitor pattern to represent a sum type, you should be able to do that.
When writing these kinds of systems, I start with the Domain Model without any thought of how to persist or retrieve data.
In my experience, once the Domain Model starts to congeal, the persistence question tends to answer itself. There's usually one or two obvious ways to store and read data.
Usually, a relational database isn't the most obvious choice.
Persistence ignorance #
Write the best API you can to solve the problem, and then figure out how to store data. This is the allegedly elusive ideal of persistence ignorance, which turns out to be easier than rumour has it, once you cast a wider net than relational databases.
It seems to me, though, that more than one person who has commented on my previous article have a hard time considering alternatives. And granted, I've consulted with clients who knew how to operate a particular database system, but nothing else, and who didn't want to consider adopting another technology. I do understand that such constraints are real, too. Thus, if you need to compromise for reasons such as these, you aren't doing anything wrong. You may still, however, try to get the best out of the situation.
One client of mine, for example, didn't want to operate anything else than SQL Server, which they already know. For an asynchronous message-based system, then, we chose NServiceBus and configured it to use SQL Server as a persistent queue.
Several comments still seem to assume that persistence must look in a particular way.
"So having a Order, OrderLine, Person, Address and City, all the rows needed to be loaded in advance, mapped to objects and references set to create the object graph to be able to, say, display shipping costs based on person's address."
I don't wish to single out Vlad, but this is both the first comment, and it captures the essence of other comments well. I imagine that what he has in mind is something like this:
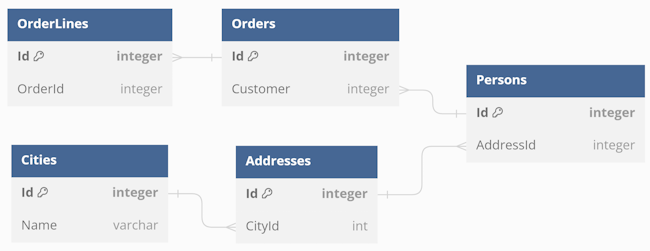
I've probably simplified things a bit too much. In a more realistic model, each person may have a collection of addresses, instead of just one. If so, it only strengthens Vlad's point, because that would imply even more tables to read.
The unstated assumption, however, is that a fully normalised relational data model is the correct way to store such data.
It's not. As I already mentioned, I spent the first four years of my programming career developing web shops. Orders were an integral part of that work.
An order is a document. You don't want the customer's address to be updatable after the fact. With a normalised relational model, if you change the customer's address row in the future, it's going to look as though the order went to that address instead of the address it actually went to.
This also explains why the order lines should not point to the actually product entries in the product catalogue. Trust me, I almost shipped such a system once, when I was young and inexperienced.
You should, at the very least, denormalise the database model. To a degree, this has already happened here, since the implied order has order lines, that, I hope, are copies of the relevant product data, rather than linked to the product catalogue.
Such insights, however, suggest that other storage mechanisms may be more appropriate.
Putting that aside for a moment, though, how would a persistence-ignorant Domain Model look?
I'd probably start with something like this:
var order = new Order( new Person("Olive", "Hoyle", new Address("Green Street 15", new City("Oakville"), "90125")), new OrderLine(123, 1), new OrderLine(456, 3), new OrderLine(789, 2));
(As the ZIP code implies, I'm more of a Yes fan, but still can't help but relish writing new Order in code.)
With code like this, many a DDD'er would start talking about Aggregate Roots, but that is, frankly, a concept that never made much sense to me. Rather, the above order is a tree composed of immutable data structures.
It trivially serializes to e.g. JSON:
{
"customer": {
"firstName": "Olive",
"lastName": "Hoyle",
"address": {
"street": "Green Street 15",
"city": { "name": "Oakville" },
"zipCode": "90125"
}
},
"orderLines": [
{
"sku": 123,
"quantity": 1
},
{
"sku": 456,
"quantity": 3
},
{
"sku": 789,
"quantity": 2
}
]
}
All of this strongly suggests that this kind of data would be much easier to store and retrieve with a document database instead of a relational database.
While that's just one example, it strikes me as a common theme when discussing persistence. For most online transaction processing systems, relational database aren't necessarily the best fit.
The cart before the horse #
Another comment also starts with the premise that a data model is fundamentally relational. This one purports to model the relationship between sheikhs, their wives, and supercars. While I understand that the example is supposed to be tongue-in-cheek, the comment launches straight into problems with how to read and persist such data without relying on an ORM.
Again, I don't intend to point fingers at anyone, but on the other hand, I can't suggest alternatives when a problem is presented like that.
The whole point of developing a Domain Model first is to find a good way to represent the business problem in a way that encourages correctness and ease of use.
If you present me with a relational model without describing the business goals you're trying to achieve, I don't have much to work with.
It may be that your business problem is truly relational, in which case an ORM probably is a good solution. I wrote as much in the previous article.
In many cases, however, it looks to me as though programmers start with a relational model, only to proceed to complain that it's difficult to work with in object-oriented (or functional) code.
If you, on the other hand, start with the business problem and figure out how to model it in code, the best way to store the data may suggest itself. Document databases are often a good fit, as are event stores. I've never had need for a graph database, but perhaps that would be a better fit for the sheikh domain suggested by qfilip.
Reporting #
While I no longer feel that relational databases are particularly well-suited for online transaction processing, they are really good at one thing: Ad-hoc querying. Because it's such a rich and mature type of technology, and because SQL is a powerful language, you can slice and dice data in multiple ways.
This makes relational databases useful for reporting and other kinds of data extraction tasks.
You may have business stakeholders who insist on a relational database for that particular reason. It may even be a good reason.
If, however, the sole purpose of having a relational database is to support reporting, you may consider setting it up as a secondary system. Keep your online transactional data in another system, but regularly synchronize it to a relational database. If the only purpose of the relational database is to support reporting, you can treat it as a read-only system. This makes synchronization manageable. In general, you should avoid two-way synchronization if at all possible, but one-way synchronization is usually less of a problem.
Isn't that going to be more work, or more expensive?
That question, again, has no single answer. Of course setting up and maintaining two systems is more work at the outset. On the other hand, there's a perpetual cost to be paid if you come up with the wrong architecture. If development is slow, and you have many bugs in production, or similar problems, the cause could be that you've chosen the wrong architecture and you're now fighting a losing battle.
On the other hand, if you relegate relational databases exclusively to a reporting role, chances are that there's a lot of off-the-shelf software that can support your business users. Perhaps you can even hire a paratechnical power user to take care of that part of the system, freeing you to focus on the 'actual' system.
All of this is only meant as inspiration. If you don't want to, or can't, do it that way, then this article doesn't help you.
Conclusion #
When discussing databases, and particularly ORMs, some people approach the topic with the unspoken assumption that a relational database is the only option for storing data. Many programmers are so skilled in relational data design that they naturally use those skills when thinking new problems over.
Sometimes problems are just relational in nature, and that's fine. More often than not, however, that's not the case.
Try to model a business problem without concern for storage and see where that leads you. Test-driven development is often a great technique for such a task. Then, once you have a good API, consider how to store the data. The Domain Model that you develop in that way may naturally suggest a good way to store and retrieve the data.

Comments
Heh, that's fair criticism, not finger pointing. I wanted to give a better example here, but I gave up halfway through writing it. You raised some good points. I'll have to rethink my approach on domain modeling further, before asking any meaningful questions.
Years of working with EF-Core in a specific way got me... indoctrinated. Not all things are bad ofcourse, but I have missed the bigger picture in some areas, as far as I can tell.
Thanks for dedicating so many articles to the subject.