ploeh blog danish software design
A Functional architecture with F#
My new Pluralsight course, A Functional Architecture with F#, is now available.
Whenever I've talked to object-oriented developers about F#, a common reaction has been that it looks enticing, but that they don't see how they'd be able to build a 'normal' application with it. F# has gained a reputation for being a 'niche' language, good for scientific computation and financial calculations, but not useful for mainstream applications.
Not only is F# a Turing-complete, general purpose programming language, but it has many advantages to offer compared to, say, C#. That said, though, building a 'normal' application with F# will only make sense if you know how to work with the language, and define an architecture that takes advantage of all it has to offer. Therefore, I thought that it would be valuable to show one possible way to do this, through a comprehensive example.
This was the motivation behind my new Pluralsight course A Functional Architecture with F#, which is now available! In it, you'll see extensive code demos of a web application written entirely in F# (and a bit of GUI in JavaScript, but the course only shows the F# code).
If you don't already have a Pluralsight account, you can get a free trial of up to 200 minutes.
REST efficiency
A fully RESTful API often looks inefficient from a client perspective, until you learn to change that perspective.
One of my readers, Filipe Ximenes, asks the following question of me:
"I read you post about avoiding hackable urls and found it very interesting. I'm currently studying about REST and I'm really interested on building true RESTful API's. One thing that is bothering me is how to access resources that are not in the API root. Eg: consider the following API flow:
"
root > users > user details > user messages"Now consider that one client wants to retrieve all the messages from a user. Does it need to "walk" the whole API (from it's root to "user messages")? This does not seem very efficient to me. Am I missing something? What would be a better solution for this?"
This is a common question which isn't particularly tied to avoiding hackable URLs, but simply to the hypermedia nature of a level 3 RESTful API.
The short answer is that it's probably not particularly inefficient. There are several reasons for that.
HTTP caching #
One of the great advantages of RESTful design is that instead of abstracting HTTP away, it very explicitly leverages the protocol. HTTP has bulit-in caching, so even if an API forces a client to walk the API as in the question above, it could conceivably result in only a single HTTP request:
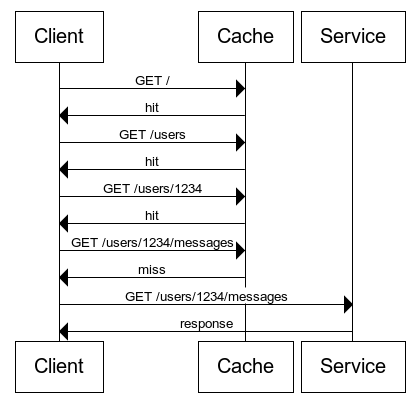
This cache could be anywhere between the client and the service. It could be a proxy server, a reverse proxy, or it could even be a local cache on the client machine; think of a Browser's local cache. It could be a combination of all of those caches. Conceivably, if a local cache is involved, a client could walk the API as described above with only a single (or even no) network request involved, because most of the potential requests would be cache hits.
This is one of the many beautiful aspects of REST. By leveraging the HTTP protocol, you can use the internet as your caching infrastructure. Even if you want a greater degree of control, you can use off-the-shelf software for your caching purposes.
Cool URLs #
As the RESTful Web Services Cookbook describes, URLs should be cool. This means that once you've given a URL to a client, you should honour requests for that URL in the future. This means that clients can 'bookmark' URLs if they like. That includes the final URL in the flow above.
Short-cut links #
Finally, an API can provide short-cut links to a client. Imagine, for example, that when you ask for a list of users, you get this:
<users xmlns:atom="http://www.w3.org/2005/Atom"> <user> <links> <atom:link rel="user-details" href="/users/1234" /> <atom:link rel="user-messages" href="/users/1234/messages" /> </links> <name>Foo</name> </user> <user> <links> <atom:link rel="user-details" href="/users/5678" /> <atom:link rel="user-messages" href="/users/5678/messages" /> </links> <name>Bar</name> </user> <user> <links> <atom:link rel="user-details" href="/users/9876" /> <atom:link rel="user-messages" href="/users/9876/messages" /> </links> <name>Baz</name> </user> </users>
As you can see in this example, a list of users can provide a short-cut to a user's messages, enabling a client to follow a more direct path:
root > users > user messages
The client would have to prioritize links of the relationship type user-messages over links of the user-details type.
Summary #
Efficiency is a common concern about HATEOAS systems, particularly because a client should always start at published URL. Often, the only published URL is the root URL, which forces the client to walk the rest of the API. This seems inefficient, but doesn't have to be because of all the other built-in mechanisms that work to effectively counter what at first looks like an inefficiency.
Hyprlinkr 1.0.0
Hyprlinkr 1.0.0 is released.
According to the definition of Semantic Versioning, Hyprlinkr has been in pre-release in more than a year. With the release of ASP.NET Web API 2, I thought it was a good occasion to look at a proper release version.
I've tested Hyprlinkr against Web API 2, and apart from some required assembly redirects, it passes all tests against Web API 2 as well as Web API 1. Being able to support both Web API 1 and 2 is important, I think, because not everyone will be able to migrate to Web API 2 right away.
Since Hyprlinkr is finally out of pre-release mode, it also means that no breaking changes will be introduced before Hyprlinkr 2, which isn't even on the drawing board yet. Since this constitutes a contract, I also trimmed down the API a bit before releasing Hyprlinkr 1.0.0, but all the essential methods are still available.
ZeroToNine
Introducing ZeroToNine, a tool for maintaining .NET Assembly versions across multiple files.
When working with Semantic Versioning in my .NET projects, I prefer to explicitly update the version information in all relevant AssemblyInfo files. However, doing that by hand is quite tedious when you have many AssemblyInfo files, so instead, I rely on an automated tool.
For years, I used a PowerShell script, but recently, I decided to start over and write a 'real' tool, deployable via NuGet. It's called ZeroToNine, is free, and open source. Using it looks like this:
Zero29 -i minorThis increments the minor version in all AssemblyInfo files in all subdirectories beneath your present working directory.
This is great, because it enables me to do a complete pull of a pull request, build it and run all tests, assign a new version, and push it, without ever leaving the command-line. Since I already do all my Git work in Git Bash, modifying the AssemblyVersion files was the last step I needed to make available from the command line. The main logic is implemented in a library, so if you don't like command-line tools, but would like to build another tool based on ZeroToNine, you can do that too.
It's available via NuGet, and is written in F#.
Comments
Can you clarify where one would install this when adding the NuGet package to a solution of several projects?
Your documentation says that it will update AssemblyInfo files in all subdirectories beneath the present working directory, but I thought that NuGet packages are applied at a project level, not at a solution level. So, wouldn't this mean that I would be running your tool from one of the many project directories, in which only that project's AssemblyInfo file would be affected?
I'm sure I'm not grasping something simple, but I'm anxious to incorporate this into my workflow!
NuGet packages can contain executable tools as well as, or instead of, libraries. These executables can be found in the package's tools folder. This is what the Zero29 package does. It's not associated with any particular Visual Studio project.
As an example, using Zero29 from the root of the Albedo folder, you can do this:
$ Src/packages/Zero29.0.4.0/tools/Zero29.exe -l
There are other NuGet packages that work in the same way; e.g. NuGet.CommandLine and xunit.runners.
The ZeroToNine NuGet package, on the other hand, is a 'normal' library, so installs as a reference to a particular Visual Studio project.
Semantic Versioning with Continuous Deployment
When you use Semantic Versioning with Continuous Deployment, version numbers must be checked into source control systems by programmers.
If you aren't already using Semantic Versioning, you should. It makes it much easier to figure out how to version your releases. Even if you're 'just' building software for your internal organization, or a single customer, you should still care about versioning of the software you release. Instead of an ad-hoc versioning scheme, Semantic Versioning offers a set of easy-to-understand rules about when to increment which version number.
In short, you
- increment the patch version (e.g. from 2.3.4 to 2.3.5) when you only release bug fixes and the like
- increment the minor version (e.g. from 1.3.2 to 1.4.0) when you add new features
- increment the major version (e.g. from 3.2.9 to 4.0.0) when you introduce breaking changes
Continuous Deployment #
While Semantic Versioning is great, it requires a bit of consideration when combined with Continuous Deployment. Every time you deploy a new version, you should increment the version number.
Continuous Delivery and Continuous Deployment rely on automation. A code check-in triggers an automated build, which is subsequently processed by a Deployment Pipeline, and potentially released to end-users. Each released (or releasable) build should have a unique version.
Traditionally, Build Servers have had the responsibility of incrementing version numbers - typically by incrementing a build number, like this:
- 3.7.11.942
- 3.7.12.958
- 3.7.13.959
- 3.7.14.979
- 3.7.15.987
Unfortunately, this versioning scheme is wrong if you combine Semantic Versioning with Continuous Deployment. Even if you throw away the fourth build number, you're left with a sequence like this:
- 3.7.11 (bug fix)
- 3.7.12 (partial new feature, hidden behind a Feature Toggle.)
- 3.7.13 (performance improvement)
- 3.7.14 (completed feature initiated in 3.7.12)
- 3.7.15 (breaking changes in public API)
Semantic Versioning might look like this:
- 3.7.11 (bug fix)
- 3.7.12 (partial new feature, hidden behind a Feature Toggle.)
- 3.7.13 (performance improvement)
- 3.8.0 (completed feature initiated in 3.7.12)
- 4.0.0 (breaking changes in public API)
Versioning is a programmer decision #
With Continuous Deployment, every time you integrate code (check in, merge, rebase, whatever), you produce a version of the software that will be deployed. This means that every time you integrate, something or somebody should assign a new version to the software.
The rules of Semantic Versioning require explicit decisions to be made. Only the development team understands what a particular commit contains. Is it a fix? Is it a new feature? Is it a breaking change? A Build Server doesn't know how to answer these questions, but you do.
A few years ago, I changed the delivery scheme for my open source project AutoFixture to use Semantic Versioning with Continuous Deployment. When I did that, I realised that I could no longer rely on a Build Server for controlling the version. Instead, I would have to explicitly control the versioning as part of the commit process.
Because AutoFixture is a .NET project, I decided to use the version assignment mechanism already present in the framework: The [AssemblyVersion] and [AssemblyFileVersion] attributes that you typically put in AssemblyInfo files.
The version control system used for AutoFixture is Git, so it works like this in practice:
- A programmer adds one or more commits to a branch.
- The programmer sends a pull request.
- I pull down the commits from the pull request.
- I increment all the version attributes in all the AssemblyInfo files, and commit that change.
- I push the commits to master.
- The Build Server picks up the new commits, and the Deployment Pipeline kicks in.
After more than two years of experience with this way of controlling software versions, I'm consistently using this approach for all my open source software, as well as the internal software we create in Grean.
Summary #
If you want to use Continuous Deployment (or Delivery) with Semantic Versioning, the assignment of a new version number is a programmer decision. Only a human understands when a commit constitutes a bug fix, a new feature, or a breaking change. The new version number must be committed to the version control system, so that whomever or whatever compiles and/or releases the software will always use the same version number for the same version of the source code.
The version number is kept in the source control system, together with the source code. It's not the realm of a Build Server.
Comments
Augi, it's true that you can create other approaches in order to attempt to address the issue, but the bottom line remains that a human being must make the decision about how to increment the version number. As you suggest, you can put information guiding that decision outside the source code itself, but then you'd be introducing another movable part that can break. If you do something like you suggest, you'll still need to add some machine-readable metadata to the linked issue ID. To add spite to injury, this also makes it more difficult to reproduce what the Build Server does on your local machine - particularly if you're attempting to build while offline.
While it sounds like it would be possible, what do you gain by doing something like that?
Mark, I also have a Visual Studio solution or two with multiple AssemblyInfo.cs files (although not as many as you) and wish to use a common version number for each contained project. I came up with the following approach, which doesn't require any automation. It only uses the Visual Studio/MSBuild <Link /> functionality. The key is simply to use the Add As Link functionality for common attributes.
Simply put, I split out the common information (Version info and company/copyright/trademark info) from projects' AssemblyInfo.cs files into another file called SolutionAssemblyInfo.cs. I place that file at the root of the solution (outside of any project folders). Then, for each project, remove the version information from the AssemblyInfo.cs file and use the 'Add As Link' function in the 'Add Existing Item' function in Visual Studio to link to the SolutionAssemblyInfo.cs file. With that, you have only one place to update the version information: the SolutionAssemblyInfo.cs file. Any change to that version information will be included in each project.
That might be enough information to get you going, but if not, I'll expand and outline the specific process. The basic idea is to look at the AssemblyInfo.cs file as having two sets of metadata:
- Metadata specific to the project itself:
- Metadata that really should be shared amongst all projects in the solution. Specifically:
- [AssemblyVersion]
- [AssemblyFileVersion]
- [AssemblyInformationalVersion] (Although, depending on your needs, you may choose to leave this attribute in the project-specifics AssemblyInfo.cs)
- [AssemblyCompany]
- [AssemblyCopyright]
- [AssemblyTrademark]
You can separate the shared metadata into a common AssemblyInfo.cs file. Then, by linking to that common file in each project (as opposed to including), you won't need to update 28 files; you'll only need to update the common one.
Assume I have the following AssemblyInfo.cs file for one of my projects:
// AssemblyInfo.cs
using System.Reflection;
using System.Runtime.InteropServices;
[assembly: AssemblyTitle("SampleProject")]
[assembly: AssemblyDescription("")]
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyCompany("Company Name")]
[assembly: AssemblyProduct("SampleProject")]
[assembly: AssemblyCopyright("Copyright (c) Company Name 2013")]
[assembly: AssemblyTrademark("")]
[assembly: AssemblyCulture("")]
[assembly: ComVisible(false)]
[assembly: Guid("7ae5f3ab-e519-4c44-bb65-489305fc36b0")]
[assembly: AssemblyVersion("1.0.0.0")]
[assembly: AssemblyFileVersion("1.0.0.0")]
// AssemblyInfo.cs
using System.Reflection;
using System.Runtime.InteropServices;
[assembly: AssemblyTitle("SampleProject")]
[assembly: AssemblyDescription("")]
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyProduct("SampleProject")]
[assembly: AssemblyCulture("")]
[assembly: ComVisible(false)]
[assembly: Guid("7ae5f3ab-e519-4c44-bb65-489305fc36b0")]
// SolutionAssemblyInfo.cs
using System.Reflection;
[assembly: AssemblyCompany("Company Name")]
[assembly: AssemblyCopyright("Copyright (c) Company Name 2013")]
[assembly: AssemblyTrademark("")]
[assembly: AssemblyVersion("1.0.0.0")]
[assembly: AssemblyFileVersion("1.0.0.0")]
// Depending on your needs, AssemblyInformationalVersion as well?
The SolutionAssemblyInfo.cs goes in the root of your solution and should initially not be included in any projects. Then, for each project:
- Remove all attributes that went into SolutionAssemblyInfo.cs
- Right-click the project and "Add..., Existing Item..."
- Navigate to the SolutionAssemblyInfo.cs file
- Instead of clicking the "Add" button, click the little drop-down on it and select "Add As Link"
- If you want the new linked SolutionAssemblyInfo.cs file to show up under the Properties folder (like the AssesmblyInfo.cs file), just drag it from the project root into the Properties folder. Unfortunately, you can't simply add the link to the Properties folder directly (at least not in VS 2012).
That's it. Now, you will be able to access this SolutionAssemblyInfo.cs file from any of your projects and any changes you make to that file will persist into the linked file, being shared with all projects.
The downside to this, as opposed to an automation solution, is that you need to repeat this process (starting with "Remove all attributes...") for all new projects you add. However, in my opinion, that's a small, one-time-per-project price to pay. With the above, you let the established tool work for you with built-in features.
Chris, thank you for your comment. That may actually be a good way to do it, too. While I did know about the add as link feature of Visual Studio, I've had bad experiences with it in the past. This may actually be a Pavlovian reaction on my part, because I must admit that I can no longer remember what those bad experiences were :$
I had been thinking about this a bit myself and I believe an easy solution to this is to just make use of a modified branching structure in the same/similar setup as the versioning. So you'd have your major/minor/build branches and your build server could increment numbers differently depending on which branch you update which would fully take care of the automation side of things for you. This would be rather trivial to setup and maintain but fulfill your requirements set out in the post.
Of course you would have to be quite disciplined as to which branch you commit your code to but I don't see that being too much of an overhead, you usually know when you're going to be patching/creating new featuresd or introducing breaking changes before you start working. Worst case make use of git stash save/pop to move work between branches.
Could call this semantic branching?
Could call this semantic branching?
You might be interested in the GitFlowVersion project, which leverages some of the concepts you mention.
Laurence, Marijn, thank you for your comments. As cool as Git is (currently, I'm not aware of anything better), I don't like coupling a process unnecessarily to a particular tool. What if, some day, something better than Git arrives?
Additionally, I agree with Martin Fowler, Jez Humble, and others, that branching is essentially evil, so I don't think it's a good idea building an entire versioning scheme around branches.
As an alternative, I've introduced ZeroToNine, a command-line tool (and library) that works independently of any version control system.
you'd be introducing another movable part that can break...
...sounds like it would be possible, what do you gain by doing something like that?
Humans are/have moving parts that can break too ;). In large organisations there are often as many differences of opinion as there are people. One developer's "breaking change" or "feature" is another's "improvement" or "bugfix". Human decision making also introduces arbitrarily variable logic. Software projects rotate developers in and out all the time. Will they all apply consistent logic to their versioning decisions?
Developers can make a decision about releases without incrementing a number in a file. They can for example click on a "Push to NuGet" or "Release to GitHub" button (which is a human, developer decision). It's then trivial for a CI server to calculate or increment a PATCH number based on the last NuGet or GitHub Push/Release. A MINOR version can be easily determined by linking to an issue tracker with issues that are linked to milestones. A MAJOR version is probably simplest when a human increments it, but I see no reason why it couldn't also be triggered by monitoring changes or breakages to existing unit tests (for example). Considering the clarity of the semver MAJOR.MINOR.PATCH definitions, I think an algorithm determining the version number is more consistent than a human decision. For example (in pseudo-code):
while (a release request is in progress)
if (app has previously been 'released' to some repository AND has subsequently changed in any way)
increment PATCH...
unless (all issues and features in next milestone have been marked closed, subsequent to last release)
increment MINOR and reset PATCH to zero...
unless (unit tests that predate release have changed OR dependent application unit tests are failing OR some other determination of breaking change)
increment MAJOR and reset MINOR and PATCH to zero...
Rob, thank you for writing. If I could have defined a trustworthy automated system to figure out semantic versioning, I would have done it. Is your proposed algorithm sufficiently robust?
- How does the algorithm determine if all issues and features in the 'next milestone' have been marked closed? What if your issue tracking system is off-line?
- Considering that the context here is Continuous Delivery, would one really have to create and maintain a 'milestone' for every update?
- When an 'issue' is resolved, how does the algorithm know if it was a new feature, or a bug fix?
- How does the algorithm determine if a unit test has changed in a breaking fashion? A unit test could have been refactored simply to make it easier to read, without actually changing the behaviour of the system.
- How does the algorithm determine if a failing test was due to a breaking change, or that the actual reason was a badly written test?
What about versioning based on the branch names. I mean, what if we name a branch regarding to what it is suposed to do at the end. For instance, naming branches as feature-xxx, major-xxx, patch-xxx. Where I want to go is to automate the semantic versioning everytime a pull/merge request is accepted. So then the CI/CD tool, through a shell for instance, can just look at the last commit comment which is usually 'Merge branch xxx into master' (where xxx can be feature-yyy, major-yyy, patch-yyy) and increment the version acording to the branch merged. If it's a feature it increases the digit in the middle and resets the last one. On the other hand it it's a patch it only increases the last digit. Would it work? I mean the assignment of the new version is still a programmer decision which is done when they branch from master.
Gus, thank you for writing. I think your suggestion could work as well, although I haven't tried it.
The advantage of your suggestion is that it's more declarative. You address the question of what should happen (major, minor, patch), instead of how it should happen (which number). That's usually a good thing.
The disadvantage is that you push the burden of this to a central build step (on a build server, I presume), so it introduces more moving parts into the process, as well as a single point of failure.
Fortunately, the evaluation of advantages versus disadvantages can be a personal (or team) decision, so one can choose the option one likes best. It's always good to have options to choose from in the first place, so thank you for sharing!
Mark, I feel a bit outdated responding to a post that has a 4th birthday coming up. I completely agree with Semantic versioning, even for cloud application deployments which my team is working with at this moment. I am intrigued to how your workflow is working.
In our current workflow, we are forcing a version and changelog to be associated with a Pull Request. Thus, the developer is incrementing this as part of the PR and our auditor pipeline is ensuring that the version/changelog is updated. The team of course still have to ensure this version is correct, ie are you sure this is a micro change, look like a new feature to me or looks to me like you broke API compatibility and this is a major increment. The issue we are starting to hit with this early model is our team is growing and we are facing constant merge conflicts with our version file and Changelog (its a ruby on rails project thus we use a config.yml for the version which is read in at runtime by our app and displayed properly as a link on the apps's page back to our Changelog version)
It appears in your workflow that you have hooks set up so that these are initiated by the person merging the code such these files are only changed post-merge and commited then. If this is elaborated on in one of your books, let me know and my team could take a "work" break to go do some reading. I appreciate your time on the matter.
Jonathan, thank you for writing, and don't worry about the age of the post. It only pleases me that apparently I've managed to produce something durable enough to be of interest four years later.
In the interest of full disclosure, the busiest code base on which I've ever used this technique is AutoFixture, and to be clear, I've handed off the reigns of that project. I've worked on bigger and more busy code bases than that, but these were internal enterprise code bases that didn't use Semantic Versioning.
Based on my experience with AutoFixture, I'd still use the process I used back then. It went something like this:
- If a code review resulted in my decision to accept a pull request, I'd pull it down on my laptop.
- Once on my laptop, I'd run the entire build locally. While I do realise that GitHub has a merge button, I regarded this as an extra verification step. While we had CI servers running, I think it never hurts to verify that it also builds on a developer's machine. Otherwise, you'd just have a problem the next time someone pulls master.
- If the build passed, I'd merge the branch locally.
- I'd then run a single Zero29 command to update all version information in all appropriate files.
- This single command would modify a set of text files, which I'd then check in. If you look at the AutoFixture commit history, you'll see lots of those check-ins.
- Once checked in, I'd tag the commit with the version. Often I'd use a cryptic bash command that I no longer remember to first read the current version with Zero29, then pipe that number to some other utility that could produce the appropriate tag, and then pipe that to
git tag. The point is: that could be an automated step as well. - Then I'd build the release binaries. That would be one other command.
- Penultimately, I'd publish the release by pushing all binaries to NuGet.org. That would be one other bash command.
- Finally, I'd push master and the new tag to GitHub.
I'm sure you could even write a server-side script with a Web UI that could do this, if you wanted to, but I've always preferred doing a local build as part of the verification process.
I don't think I've written much more about this, rather than the announcement post for ZeroToNine, as well as the documentation for it.
Layers, Onions, Ports, Adapters: it's all the same
If you apply the Dependency Inversion Principle to Layered Architecture, you end up with Ports and Adapters.
One of my readers, Giorgio Sala, asks me:
In his book "Implementing DDD" mr Vernon talks a lot about the Ports and Adapter architecture as a next level step of the Layered architecture. I would like to know your thinking about it.
The short answer is that this is more or less the architecture I describe in my book, although in the book, I never explicitly call it out by that name.
Layered architecture #
In my book, I describe the common pitfalls of a typical layered architecture. For example, in chapter 2, I analyse a typical approach to layered architecture; it's an example of what not to do. Paraphrased from the book's figure 2.13, the erroneous implementation creates this dependency graph:
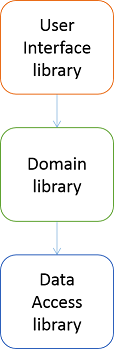
The arrows show the direction of dependencies; i.e. the User Interface library depends on the Domain library, which in turn depends on the Data Access library. This violates the Dependency Inversion Principle (DIP), because the Domain library depends on the Data Access library, and the DIP says that:
Abstractions should not depend upon details. Details should depend upon abstractions.
Later in chapter 2, and throughout the rest of my book, I demonstrate how to invert the dependencies. Paraphrased, figure 2.12 looks like this:
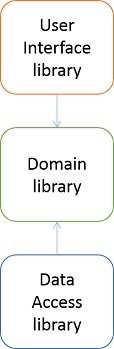
This is almost the same figure as the previous, but notice that the direction of dependency has changed, so that the Data Access library now depends on the Domain library, instead of the other way around. This is the DIP applied: the details (UI, Data Access) depend on the abstractions (the Domain Model).
Onion layers #
The example from chapter 2 in my book is obviously simplified, with only three libraries involved. Imagine a generalized architecture following the DIP:
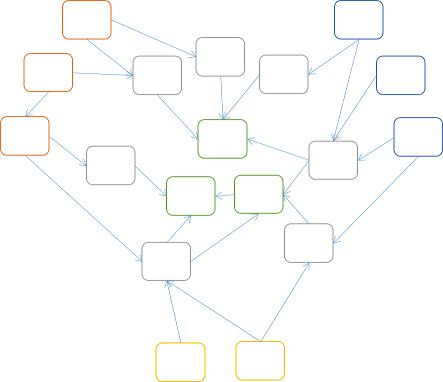
While there are many more libraries, notice that all dependencies still point inwards. If you're still thinking in terms of layers, you can draw concentric layers around the boxes:
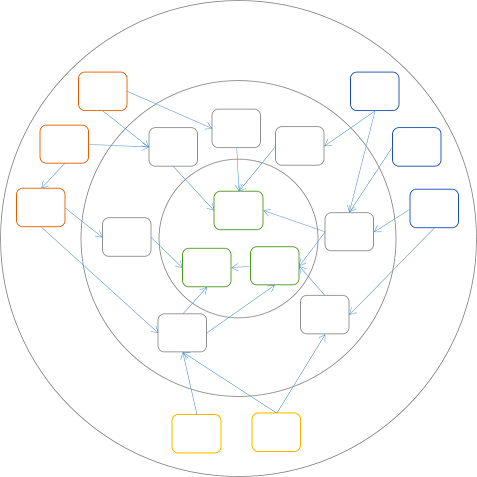
These concentric layers resemble the layers of an onion, so it's not surprising that Jeffrey Palermo calls this type of architecture for Onion Architecture.
The DIP still applies, so dependencies can only go in one direction. However, it would seem that I've put the UI components (the orange boxes) and the Data Access components (the blue boxes) in the same layer. (Additionally, I've added some yellow boxes that might symbolise unit tests.) This may seem unfamiliar, but actually makes sense, because the components in the outer layer are all at the boundaries of the application. Some boundaries (such as UI, RESTful APIs, message systems, etc.) face outward (to the internet, extranets, etc.), while other boundaries (e.g. databases, file systems, dependent web services, etc.) face inward (to the OS, database servers, etc.).
As the diagram implies, components can depend on other components within the same layer, but does that mean that UI components can talk directly to Data Access components?
Hexagonal architecture #
While traditional Layered Architecture is no longer the latest fad, it doesn't mean that all of its principles are wrong. It's still not a good idea to allow UI components to depend directly on the Data Access layer; it would couple such components together, and you might accidentally bypass important business logic.
You have probably noticed that I've grouped the orange, yellow, and blue boxes into separate clusters. This is because I still want to apply the old rule that UI components must not depend on Data Access components, and vice versa. Therefore, I introduce bulkheads between these groups:
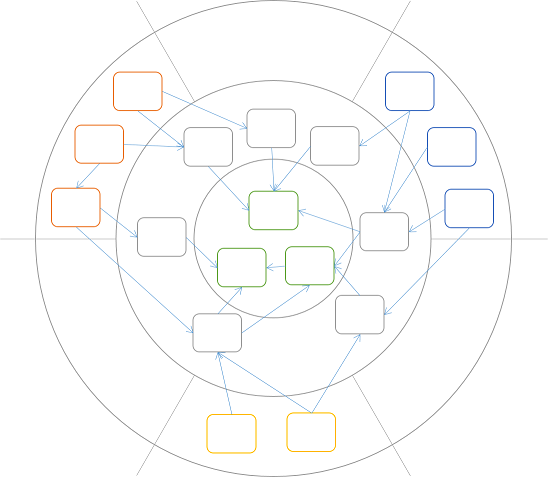
Although it may seem a bit accidental that I end up with exactly six sections (three of them empty), it does nicely introduce Alistair Cockburn's closely related concept of Hexagonal Architecture:
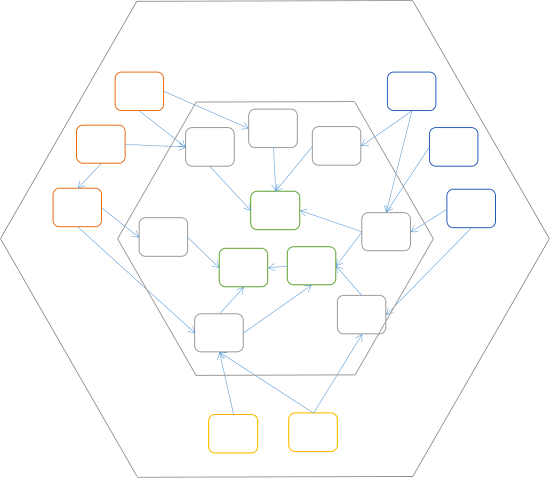
You may feel that I cheated a bit in order to make my diagram hexagonal, but that's okay, because there's really nothing inherently hexagonal about Hexagonal Architecture; it's not a particularly descriptive name. Instead, I prefer the alternative name Ports and Adapters.
Ports and Adapters #
The only thing still bothering me with the above diagram is that the dependency hierarchy is too deep (at least conceptually). When the diagram consisted of concentric circles, it had three (onion) layers. The hexagonal dependency graph above still has those intermediary (grey) components, but as I've previously attempted to explain, the flatter the dependency hierarchy, the better.
The last step, then, is to flatten the dependency hierarchy of the inner hexagon:
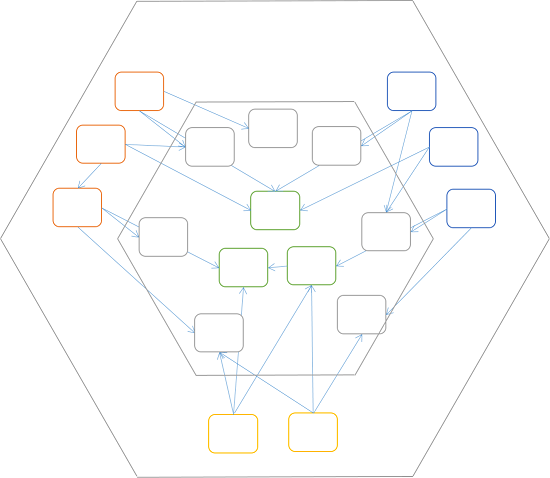
The components in the inner hexagon have few or no dependencies on each other, while components in the outer hexagon act as Adapters between the inner components, and the application boundaries: its ports.
Summary #
In my book, I never explicitly named the architecture I describe, but essentially, it is the Ports and Adapters architecture. There are other possible application architectures than the variations described here, and some of them still work well with Dependency Injection, but the main architectural emphasis in Dependency Injection in .NET is Ports and Adapters, because I judged it to be the least foreign for the majority of the book's readers.
The reason I never explicitly called attention to Ports and Adapters or Onion Architecture in my book is that I only became aware of these pattern names as I wrote the book. At that time, I didn't feel confident that what I did matched those patterns, but the more I've learned, the more I've become convinced that this was what I'd been doing all along. This just confirms that Ports and Adapters is a bona fide pattern, because one of the attributes of patterns is that they materialize independently in different environments, and are then subsequently discovered as patterns.
Not going to NDC London after all
Unfortunately, I've had to cancel my speaking engagement at NDC London 2013.
Ever since I was accepted as a speaker at NDC London 2013, I've really looked forward to it. Unfortunately, due to serious illness in my family, I've decided to cancel my appearance at the conference. This has been a difficult decision to make, but now that I've made it, I can feel that it's the right decision, even though it pains me.
I hope to be able to return to NDC another time, both in Oslo and in London.
If you visit my Lanyrd profile, you will see that while I have removed myself from NDC London, I'm still scheduled to speak at the Warm Crocodile Developer Conference in January 2014. I still hope to be able to attend and speak here. Not only is it realistic to hope that my family situation is better in January, but because the conference is in my home town, it also means that it puts less of a strain on my family. This may change, though...
Albedo
Albedo is a .NET library targeted at making Reflection programming more consistent, using a common set of abstractions and utilities.
For the last five weeks, Nikos Baxevanis, Adam Chester, and I have been working on a new, small Open Source project: Albedo.
It's a .NET library targeted at making Reflection programming more consistent, using a common set of abstractions and utilities. The project site may actually contain more details than you'd care to read, but here's a small code sample to either whet your appetite, or scare you away:
PropertyInfo pi = from v in new Properties<Version>() select v.Minor; var version = new Version(2, 7); var visitor = new ValueCollectingVisitor(version); var actual = new PropertyInfoElement(pi).Accept(visitor); Assert.Equal(version.Minor, actual.Value.OfType<int>().First());
Albedo is available via NuGet.
Mocks for Commands, Stubs for Queries
When unit testing, use Mocks for Commands, and Stubs for Queries.
A few years ago, I helped an organization adopt Test-Driven Development. One question that kept coming up was when to use Stubs, and when to use Mocks. (First, you need to understand the conceptual difference between Mocks and Stubs, so go read xUnit Test Patterns, and then resume reading this blog post once you're done. If you need a shorter introduction, you can read my MSDN Magazine article on the subject.)
After having answered the question on when to use what, a couple of times, I arrived at this simple rule, based on the language of Command Query Separation (CQS):
- Use Mocks for Commands
- Use Stubs for Queries
This discovery made me really happy, and I planned to blog about it. Then, soon after, I saw the exact same advice in GOOS (ch. 24, p. 278):
Allow Queries; Expect CommandsThat verified that I was on the right track, but on the other hand, since the rule was already described, I didn't see the value of restating what was already public knowledge.
A couple of years later, it's clear to me that this rule may be public knowledge, but is certainly isn't common knowledge. This is, without comparison, the most common mistake I see people make, when I review unit tests. Thus, although it has already been said in GOOS, I'll repeat it here.
Use Mocks for Commands; Stubs for QueriesThrough an example, you'll learn why Mocks for Queries are dangerous, and how a technique I call Data Flow Verification can help.
(Anti-)Example: Mocking Queries #
In this example, you'll see how easily things can go wrong when you use Mocks for Queries. Assume that you want to test SomeController, that uses an IUserRepository:
public interface IUserRepository { User Read(int userId); void Create(int userId); }
In the first test, you want to verify that when you invoke SomeController.GetUser, it returns the user from the injected Repository, so you write this unit test:
[Fact] public void GetUserReturnsCorrectResult() { var expected = new User(); var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(It.IsAny<int>())).Returns(expected); var sut = new SomeController(td.Object); var actual = sut.GetUser(1234); Assert.Equal(expected, actual); }
This test uses Moq, but it could have used another dynamic mock library as well, or even hand-written Test Doubles.
The most remarkable characteristic of this test is the unconditional return of a value from the Test Double, as implemented by the use of It.IsAny<int>(). Why you'd do this is a small mystery to me, but I see it time and again when I review unit tests. This is the source of many problems.
Using a technique called Devil's Advocate, when reviewing, I usually tell the author that I can make the test pass with this (obviously degenerate) implementation:
public User GetUser(int userId) { return this.userRepository.Read(0); }
In my experience, this will most likely prompt you to add another test:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserCallsRepositoryWithCorrectValue(int userId) { var td = new Mock<IUserRepository>(); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(r => r.Read(userId)); }
Jolly good attempt, sport! Regrettably, it doesn't protect you against my Devil's Advocate technique; I can implement the GetUser method like this:
public User GetUser(int userId) { this.userRepository.Read(userId); return this.userRepository.Read(0); }
This is so obviously wrong that you'd be likely to argue that no-one in their right mind would do something like that. While I agree, the fact that this (obviously incorrect) implementation passes all unit tests should inform you about the quality of your unit tests.
Strict Mocks are not the solution #
The problem is that the second test method (GetUserCallsRepositoryWithCorrectValue) attempts to use a Mock to verify a Query. This is wrong, as indicated by GOOS.
In desperation, some people attempt to resolve their conundrum by tightening the constraints of the Mock. This road leads towards Strict Mocks, and there lies madness. Soon, you'll learn the reason for this.
First, you may attempt to constrain the number of times the Read method can be invoked:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserCallsRepositoryWithCorrectValue(int userId) { var td = new Mock<IUserRepository>(); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(r => r.Read(userId), Times.Once()); }
Notice the addition of the Times.Once() clause in the last line. This instructs Moq that Read(userId) can only be invoked once, and that an exception should be thrown if it's called more than once. Surprisingly, the Devil's Advocate implementation still passes all tests:
public User GetUser(int userId) { this.userRepository.Read(userId); return this.userRepository.Read(0); }
While this may seem surprising, the reason it passes is that the assertion only states that Read(userId) should be invoked exactly once; it doesn't state anything about Read(0), as long as userId isn't 0.
Second, you attempt to resolve that problem by stating that no matter the input, the Read method must be invoked exactly once:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserCallsRepositoryWithCorrectValue(int userId) { var td = new Mock<IUserRepository>(); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(r => r.Read(It.IsAny<int>()), Times.Once()); }
Notice that the input constraint is loosened to It.IsAny<int>(); combined with Times.Once(), it should ensure that the Read method is invoked exactly once. It does, but the devil is still mocking you (pun intended):
public User GetUser(int userId) { return this.userRepository.Read(0); }
This is the first degenerate implementation I added, so now you're back where you began: it passes all tests. The new test case (that uses a Mock against a Query) has added no value at all.
Third, in utter desperation, you turn to Strict Mocks:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserCallsRepositoryWithCorrectValue(int userId) { var td = new Mock<IUserRepository>(MockBehavior.Strict); td.Setup(r => r.Read(userId)).Returns(new User()); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(); }
Notice the use of MockBehavior.Strict in the Mock constructor, as well as the explicit Setup in the Fixture Setup phase.
Finally, this reigns in the devil; I have no other recourse than to implement the Read method correctly:
public User GetUser(int userId) { return this.userRepository.Read(userId); }
If the Devil's Advocate technique indicates that a faulty implementation implies a bad test suite, then a correct implementation must indicate a good test suite, right?
Not quite, because the use of a Strict Mock makes your tests much less maintainable. You should already know this, but I'll show you an example.
Assume that you have a rule that if the User returned by the Read method has an ID of 0, it means that the user doesn't exist, and should be created. (There are various problems with this design, most notably that it violates CQS, but that's another story...)
In order to verify that a non-existing User is created during reading, you add this unit test:
[Fact] public void UserIsSavedIfItDoesNotExist() { var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(1234)).Returns(new User { Id = 0 }); var sut = new SomeController(td.Object); sut.GetUser(1234); td.Verify(r => r.Create(1234)); }
This is a fine test that verifies a Command (Create) with a Mock. This implementation passes the test:
public User GetUser(int userId) { var u = this.userRepository.Read(userId); if (u.Id == 0) this.userRepository.Create(1234); return u; }
Alas! Although this implementation passes the new test, it breaks an existing test! Can you guess which one? Yes: the test that verifies a Query with a Strict Mock. It breaks because it explicitly states that the only method call allowed on the Repository is the Read method.
You can resolve the problem by editing the test:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserCallsRepositoryWithCorrectValue(int userId) { var td = new Mock<IUserRepository>(MockBehavior.Strict); td.Setup(r => r.Read(userId)).Returns(new User { Id = userId }); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(); }
Notice that userId was added to the returned User in the Setup for the Strict Mock.
Having to edit existing tests is a genuine unit test smell. Not only does it add an unproductive overhead (imagine that many tests break instead of a single one), but it also decreases the trustworthiness of your test suite.
Data Flow Verification #
The solution is really simple: use a conditional Stub to verify the data flow through the SUT. Here's the single test you need to arrive at a correct implementation:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserReturnsCorrectValue(int userId) { var expected = new User(); var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(userId)).Returns(expected); var sut = new SomeController(td.Object); var actual = sut.GetUser(userId); Assert.Equal(expected, actual); }
Even when I attempt to use the Devil's Advocate technique, there's no way I can provide a faulty implementation. The method must invoke Read(userId), because otherwise it can't return expected. If it invokes the Read method with any other value, it may get a User instance, but not expected.
The Data Flow Verification test uses a (conditional) Stub to verify a Query. The distinction may seem subtle, but it's important. The Stub doesn't require that Read(userId) is invoked, but is configured in such a way that if (and only if) Read(userId) is invoked, it'll return expected.
With the Stub verifying the Query (GetUserReturnsCorrectValue), and the other test that uses a Mock to verify a Command (UserIsSavedIfItDoesNotExist), the final implementation is:
public User GetUser(int userId) { var u = this.userRepository.Read(userId); if (u.Id == 0) this.userRepository.Create(1234); return u; }
These two tests correctly specify the behaviour of the system in a terse and maintainable way.
Conclusion #
Data Flow Verification is remarkably simple, so I'm continually taken aback that people seem to go out of their way to avoid it. Use it to verify Queries with Stubs, and keep the Mocks with the Commands.
P.S. 2023-08-14. See the article Replacing Mock and Stub with a Fake for a decade-later follow-up to this post.Comments
Hi Mark, I wonder if the statement "Use Queries with Stubs" intentionally leaves out Fakes, or is it just a simplified view on the topic, and the statement should actually be "Use Queries with Stubs or Fakes"?
Marcin, thank you for writing. The beginning of this article starts by establishing that it uses the pattern language from xUnit Test Patterns. In that language, a Fake is not the same as a Stub.
Depending on the interface, a Fake may implement methods that are both Commands and Queries, so when you use a Fake, you'll be using it for both. The article An example of state-based testing in C# shows an example of that.
These days I rarely use Stubs and Mocks, instead favouring state-based testing.
Replace overloading with Discriminated Unions
In F#, Discriminated Unions provide a good alternative to overloading.
When you're learning a new programming language, you may experience these phases:
- [language x] is the coolest thing ever :D
- [language x] sucks, because it can't do [xyz], like [language y], which I know really well :(
- Now I finally understand that in [language x] I don't need [xyz], because it has different idioms o_O
From C#, I'm used to method overloading as a design technique to provide an API with easy-to-learn default methods, and more complicated, but more flexible, methods - all in the same family of methods. Alas, in F#, function overloading isn't possible. (Well, method overloading is still possible, because you can create .NET classes in F#, but if you're creating a module with free-standing functions, you can't have two functions with the same name, but different parameters.)
This really bothered me until I realized that F# has other language constructs that enable you to approach that problem differently. Discriminated Unions is one such language construct.
Multiple related functions #
Recently, I was working with a little module that enabled me to list a range of dates. As an example, I wanted to be able to list all dates in a given year, or all dates in a given month.
My first attempt looked like this:
module Dates = let InitInfinite (date : DateTime) = date |> Seq.unfold (fun d -> Some(d, d.AddDays 1.0)) let InYear year = DateTime(year, 1, 1) |> InitInfinite |> Seq.takeWhile (fun d -> d.Year = year) let InMonth year month = DateTime(year, month, 1) |> InitInfinite |> Seq.takeWhile (fun d -> d.Month = month)
These functions did what I wanted them to do, but I found the names awkward. The InYear and InMonth functions are closely related, so I would have liked to call them both In, as I would have been able to do in C#. That would have enabled me to write code such as:
let actual = Dates.In year
and
let actual = Dates.In year month
where year and month are integer values. Alas, that's not possible, so instead I had to settle for the slightly more clumsy InYear:
let actual = Dates.InYear year
and InMonth:
let actual = Dates.InMonth year month
That is, until I realized that I could model this better with a Discriminated Union.
One function #
After a day or so, I had one of those small revelations described in Domain-Driven Design: implicitly, I was working with a concept of a period. Time to make the implicit concept explicit:
type Period = | Year of int | Month of int * int module Dates = let InitInfinite (date : DateTime) = date |> Seq.unfold (fun d -> Some(d, d.AddDays 1.0)) let private InYear year = DateTime(year, 1, 1) |> InitInfinite |> Seq.takeWhile (fun d -> d.Year = year) let private InMonth year month = DateTime(year, month, 1) |> InitInfinite |> Seq.takeWhile (fun d -> d.Month = month) let In period = match period with | Year(y) -> InYear y | Month(y, m) -> InMonth y m
Notice that I defined a Period Discriminated Union outside the module, because it enables me to write client code like:
let actual = Dates.In(Year(year))
and
let actual = Dates.In(Month(year, month))
This syntax requires slightly more characters than the previous alternative, but is (subjectively) more elegant.
If you prefer, you can refactor the In function to:
let In = function | Year(y) -> InYear y | Month(y, m) -> InMonth y m
You may have noticed that this implementation still relies on the two private functions InYear and InMonth, but it's easy to refactor the In function to a single function:
let In period = let generate dt predicate = dt |> InitInfinite |> Seq.takeWhile predicate match period with | Year(y) -> generate (DateTime(y, 1, 1)) (fun d -> d.Year = y) | Month(y, m) -> generate (DateTime(y, m, 1)) (fun d -> d.Month = m)
As you can see, the introduction of a Period Discriminated Union enabled me to express the API in a way that closely resembles what I originally envisioned.
A richer API #
Once I made the change to a Discriminated Union, I discovered that I could make my API richer. Soon, I had this Dates module:
type Period = | Year of int | Month of int * int | Day of int * int * int module Dates = let InitInfinite (date : DateTime) = date |> Seq.unfold (fun d -> Some(d, d.AddDays 1.0)) let In period = let generate dt predicate = dt |> InitInfinite |> Seq.takeWhile predicate match period with | Year(y) -> generate (DateTime(y, 1, 1)) (fun d -> d.Year = y) | Month(y, m) -> generate (DateTime(y, m, 1)) (fun d -> d.Month = m) | Day(y, m, d) -> DateTime(y, m, d) |> Seq.singleton let BoundariesIn period = let getBoundaries firstTick (forward : DateTime -> DateTime) = let lastTick = forward(firstTick).AddTicks -1L (firstTick, lastTick) match period with | Year(y) -> getBoundaries (DateTime(y, 1, 1)) (fun d -> d.AddYears 1) | Month(y, m) -> getBoundaries (DateTime(y, m, 1)) (fun d -> d.AddMonths 1) | Day(y, m, d) -> getBoundaries (DateTime(y, m, d)) (fun d -> d.AddDays 1.0)
Notice that I added a Day case. Originally, I didn't think it would be valuable, as Dates.In(Day(year, month, day)) seemed like quite a convoluted way of saying DateTime(year, month, day). However, it turned out that the In abstraction was valuable, also with a single day - simply because it's an abstraction.
Additionally, I then discovered the utility of a function called BoundariesIn, which gives me the boundaries of a Period - that is, the very first and last tick of the Period.
Summary #
It's easy to become frustrated while learning a new programming language. In F#, I was annoyed by the lack of function overloading, until I realized that a single function taking a Discriminated Union might actually be a richer idiom.

Comments
What about a desktop applications written entirely in F#? When you create a desktop applciation in F#, what do you use to create the GUI?
I am currently writting my first application in F# and need to decide what we will use to create the GUI. There seems to be many ways this could be done.
There are probably many more that I missed as well.
Among these, Elmish.WPF stands out to me. Their page commnicates a strong ethos, which I find both enticing and convincing. The core idea seems to be the Elm Architecture, which I have also seen expressed as the MVU architecture, where MVU stands for Model, View, Update.
Have you come across that architecture before? I am very interested to hear your opinion about it.
P.S. Also worth mentioning is Fabulous, which uses Xamarin.Forms, so this seems like a good choice for mobile app development.
Tyson, thank you for writing. I haven't done any desktop application development in ten years, so I don't think I'm qualified to make recommendations.
Do your web applications include GUIs? If so, what UI framework(s) do you like to use there (such as Angular, React, Elm, etc.)?
P.S. I have been investigating Elmish.WPF and love what I have found. The Elm / MVU / Model, View, Update architecture seems to be a specific (or the ultimate?) applicaiton of the functional programming prinicple of pushing impure behavior to the boundry of the applicaiton.
Tyson, seriously, I think that the last time I wrote any GUI code was with Angular some time back in 2014, after which I walked away in disgust. Since then, I've mostly written REST APIs, with the occasional daemon and console application thrown in here and there.
Many of the REST APIs I've helped develop are consumed by apps with GUIs, but someone else developed those, and I wasn't involved.