ploeh blog danish software design
Configuring Azure Web Jobs
It's easy to configure Azure Web Jobs written in .NET.
Azure Web Jobs is a nice feature for Azure Web Sites, because it enables you to bundle a background worker, scheduled batch job, etc. together with your Web Site. It turns out that this feature works pretty well, but it's not particularly well-documented, so I wanted to share a few nice features I've discovered while using them.
You can write a Web Job as a simple Command Line executable, but if you can supply command-line arguments to it, I have yet to discover how to do that. A good alternative is an app.config file with configuration settings, but it can be a hassle to deal with various configuration settings across different deployment environments. There's a simple solution to that.
CloudConfigurationManager #
If you use CloudConfigurationManager.GetSetting, configuration settings are read using various fallback mechanisms. The CloudConfigurationManager class is poorly documented, and I couldn't find documentation for the current version, but one documentation page about a deprecated version sums it up well enough:
"The GetSetting method reads the configuration setting value from the appropriate configuration store. If the application is running as a .NET Web application, the GetSetting method will return the setting value from the Web.config or app.config file. If the application is running in Windows Azure Cloud Service or in a Windows Azure Website, the GetSetting will return the setting value from the ServiceConfiguration.cscfg."That is probably still true, but I've found that it actually does more than that. As far as I can tell, it attempts to read configuration settings in this prioritized order:
- Try to find the configuration value in the Web Site's online configuration (see below).
- Try to find the configuration value in the .cscfg file.
- Try to find the configuration value in the app.config file or web.config file.
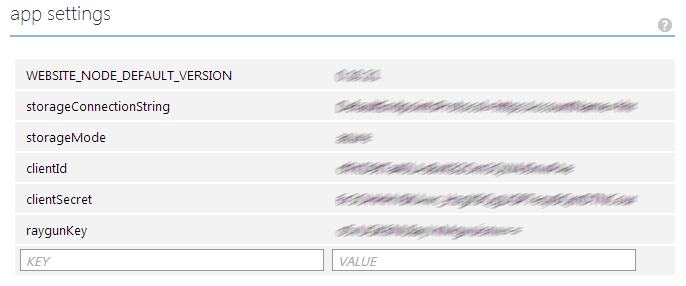
(It's possible that, under the hood, this UI actually maintains an auto-generated .cscfg file, in which case the first two bullet points above turn out to be one and the same.)
This is a really nice feature, because it means that you can push your deployments directly from your source control system (I use Git), and leave your configuration files empty in source control:
<appSettings> <add key="timeout" value="0:01:00" /> <add key="estimatedDuration" value="0:00:02" /> <add key="toleranceFactor" value="2" /> <add key="idleTime" value="0:00:05" /> <add key="storageMode" value="files" /> <add key="storageConnectionString" value="" /> <add key="raygunKey" value="" /> </appSettings>
Instead of having to figure out how to manage or merge those super-secret keys in the build system, you can simply shortcut the whole issue by not involving those keys in your build system; they're only stored in Azure - where you can't avoid having them anyway, because your system needs them in order to work.
Usage #
It's easy to use CloudConfigurationManager: instead of getting your configuration values with ConfigurationManager.AppSettings, you use CloudConfigurationManager.GetSetting:
let clientId = CloudConfigurationManager.GetSetting "clientId"
The CloudConfigurationManager class isn't part of the .NET Base Class Library, but you can easily add it from NuGet; it's called Microsoft.WindowsAzure.ConfigurationManager. The Azure SDK isn't required - it's just a stand-alone library with no dependencies, so I happily add it to my Composition Root when I know I'm going to deploy to an Azure Web Site.
Web Jobs #
Although I haven't found any documentation to that effect yet, a .NET console application running as an Azure Web Job will pick up configuration settings in the way described above. On other words, it shares configuration values with the web site that it's part of. That's darn useful.
Service Locator violates SOLID
Yet another reason to avoid the Service Locator anti-pattern is that it violates the principles of Object-Oriented Design.
Years ago, I wrote an article about Service Locator. Regular readers of this blog may already know that I consider Service Locator an anti-pattern. That hasn't changed, but I recently realized that there's another way to explain why Service Locator is the inverse of good Object-Oriented Design (OOD). My original article didn't include that perspective at all, so perhaps this is a clearer way of explaining it.
In this article, I'll assume that you're familiar with the SOLID principles (also known as the Principles of OOD), and that you accept them as generally correct. It's not because I wish to argue by an appeal to authority, but rather because threre's already a large body of work that explains why these principles are beneficial to software design.
In short, Service Locator violates SOLID because it violates the Interface Segregation Principle (ISP). That's because a Service Locator effectively has infinitely many members.
Service Locator deconstructed #
In order to understand why a Service Locator has infinitely many members, you'll need to understand what a Service Locator is. Often, it's a class or interface with various members, but it all boils down to a single member:
T Create<T>();
Sometimes the method takes one or more parameters, but that doesn't change the conclusion, so I'm leaving out those input parameters to keep things simple.
A common variation is the untyped, non-generic variation:
object Create(Type type);
Since my overall argument relies on the generic version, first I'll need to show you why those two methods are equivalent. If you imagine that all you have is the non-generic version, you can easily write a generic extension method for it:
public static class ServiceLocatorEnvy { public static T Create<T>(this IServiceLocator serviceLocator) { return (T)serviceLocator.Create(typeof(T)); } }
As you can see, this extension method has exactly the same signature as the generic version; you can always create a generic Service Locator based on a non-generic Service Locator. Thus, while my main argument (coming up next) is based on a generic Service Locator, it also applies to non-generic Service Locators.
Infinite methods #
From a client's perspective, there's no limit to how many variations of the Create method it can invoke:
var foo = serviceLocator.Create<IFoo>(); var bar = serviceLocator.Create<IBar>(); var baz = serviceLocator.Create<IBaz>(); // etc.
Again, from the client's perspective, that's equivalent to multiple method definitions like:
IFoo CreateFoo(); IBar CreateBar(); IBaz CreateBaz(); // etc.
However, the client can keep coming up with new types to request, so effectively, the number of Create methods is infinite!
Relation to the Interface Segregation Principle #
By now, you understand that a Service Locator is an interface or class with effectively an infinite number of methods. That violates the ISP, which states:
Clients should not be forced to depend on methods they do not use.However, since a Service Locator exposes an infinite number of methods, any client using it is forced to depend on infinitely many methods it doesn't use.
Quod Erat Demonstrandum #
The Service Locator anti-pattern violates the ISP, and thus it also violates SOLID as a whole. SOLID is also known as the Principles of OOD. Therefore, Service Locator is bad Objected-Oriented Design.
Update 2015-10-26: The fundamental problem with Service Locator is that it violates encapsulation.
Comments
Nelson, thank you for writing. First, it's important to realize that this overall argument applies to methods with 'free' generic type parameters; that is, a method where the type in itself isn't generic, but the method is. One example of the difference I mean is that a generic Abstract Factory is benign, whereas a Server Locator isn't.
Second, that still leaves the case where you may have a generic parameter that determines the return type of the method. The LINQ Select method is an example of such a method. These tend not to be problematic, but I had some trouble explaining why that is until James Jensen explained it to me.
Dear Mark,
I totally agree with your advise on Service Locator being an anti-pattern, specifically if it is used within the core logic. However, I don't think that your argumentation in this post is correct. I think that you apply Object-Oriented Programming Principles to Metaprogramming, which should not be done, but I'm not quite sure if my argument is completely reasonable.
All .NET DI Containers that I know of use the Reflection API to solve the problem of dynamically composing an object graph. The very essence of this API is it's ability to inspect and call members of any .NET type, even the ones that the code was not compiled against. Thus you do not use Strong Object-Oriented Typing any longer, but access the members of a e.g. a class indirectly using a model that relies on the Type class and its associated types. And this is the gist of it: code is treated as data, this is Metaprogramming, as we all know.
Without these capabilities, DI containers wouldn't be able to do their job because they couldn't e.g. analyze the arguments of a class's constructor to further
instantiate other objects needed. Thus we can say that DI containers are just an abstraction over the Metaprogramming API of .NET.
And of course, these containers offer an API that is shaped by their Metaprogramming foundation. This can be seen in your post: although you discuss the
generic variation T Create<T>(), this is just syntactic sugar for the actual important method: object Create(Type type).
Metaprogramming in C# is totally resolved at runtime, and therefore one shouldn't apply the Interface Segregation Principle to APIs that are formed by it. These are designed to help you improve the Object-Oriented APIs which particularly incorporate Static Typing enforced by the compiler. A DI container does not have an unlimited number of Create methods, it has a single one and it receives a Type argument - the generic version just creates the Type object for you. And the parameter has to be as "weak" as Type, because we cannot use Static Typing - this technically allows the client to pass in types that the container is not configured for, but you cannot prevent this using the compiler because of the dynamic nature of the Reflection API.
What is your opinion on that?
Kenny, thank you for writing. The point that this post is making is mainly that Service Locator violates the Interface Segregation Principle (ISP). The appropriate perspective on ISP (and LSP and DIP as well) is from a client. The client of a Service Locator effectively sees an API with infinitely many methods. That's where the damage is done.
How the Service Locator is implemented isn't important to ISP, LSP, or DIP. (The SRP and OCP, on the other hand, relate to implementations.) You may notice that this article doesn't use the word container a single time.
Dear Mark,
I get the point that you are talking from the client's perspective - but even so, a client programming against a Service Locator should be aware that it is programming against an abstraction of a Metaprogramming API (and not an Object-Oriented API). If you think about the call to the Create method, then you basically say "Give me an object graph with the specified type as the object graph root" as a client - how do you implement this with the possibilities that OOP provides? You can't model this with classes, interfaces, and the means of Procedural and Structural Programming that are integrated in OOP - because these techniques do not allow you to treat code as data.
And again, your argument is based on the generic version of the Create method, but that shouldn't be the
point of focus. It is the non-generic version object Create (Type type) which clearly indicates
that it is a Metaprogramming API because of the Type parameter and the object return type -
Type is the entry point to .NET
Reflection and object is the only type the Service Locator can guarantee as the object graph is dynamically resolved
at runtime - no Strong Typing involved. The existence of the generic Create variation is merely justified
because software developers are lazy - they don't want to manually downcast the returned object to the type they
actually need. Well, one could argue that this comforts the Single Point of Truth / Don't repeat yourself
principles, too, as all information to create the object graph and to downcast the root object are derived
from the generic type argument, but that doesn't change the fact that Service Locator is a Metaprogramming API.
And that's why I solely used the term DI container throughout my previous comment, because Service Locator is just the part of the API of a DI container that is concerned with resolving object graphs (and the Metainformation to create these object graphs was registered beforehand). Sure, you can implement Service Locators as a hard-wired registry of Singleton objects (or even Factories that create objects on the fly) to circumvent the use of the Reflection API (although one probably had to use some sort of Type ID in this case, maybe in form of a string or GUID). But honestly, these are half-baked solutions that do not solve the problem in a reusable way. A reusable Service Locator must treat code as data, especially if you want additional features like lifetime management.
Another point: take for example the MembershipProvider class - this polymorphic abstraction is truly a violation of the Interface Segregation Principle because it offers way too many members that a client probably won't need. But notice that each of these members has a different meaning, which is not the case with the Create methods of the Service Locator. The generic Create method is just another abstraction over the non-generic version to simplify the access to the Service Locator.
Long story short: Service Locator is a Metaprogramming API, the SOLID principles target Object-Oriented APIs, thus the latter shouldn't be used to assess the former. There's is no real way to hide the fact that clients need to be aware that they are calling a Metaprogramming API if they directly reference a Service Locator (which shouldn't be done in core logic).
Kenny, thank you for writing. While I don't agree with everything you wrote, your arguments are well made, and I have no problems following them. If we disagree, I think we disagree about semantics, because the way I read your comment, I think it eventually leads you to the same conclusions that I have arrived at.
Ultimately, you also state that Service Locator isn't an Object-Oriented Design, and in that, I entirely agree. The SOLID principles are also known as the principles of Object-Oriented Design, so when I'm stating that I think that Service Locator violates SOLID, my more general point is that Service Locator isn't Object-Oriented because it violates a fundamental principle of OOD. You seem to have arrived at the same conclusion, although via a different route. I always like when that happens, because it confirms that the conclusion may be true.
To be honest, though, I don't consider the arguments I put forth in the present article as my strongest ever. Sometimes, I write articles on topics that I've thought about for years, but I also often write articles that are half-baked ideas; I put these articles out in order to start a discussion, so I appreciate your comments.
I'm much happier with the article that argues that Service Locator violates Encapsulation.
AutoFixture conventions with Albedo
You can use Albedo with AutoFixture to build custom conventions.
In a question to one of my previous posts, Jeff Soper asks about using custom, string-based conventions for AutoFixture:
"I always wince when testing for the ParameterType.Name value [...] It seems like it makes a test that would use this implementation very brittle."Jeff's concern is that when you're explicitly looking for a parameter (or property or field) with a particular name (like "currencyCode"), the unit test suite may become brittle, because if you change the parameter name, the string may retain the old name, and the Customization no longer works.
Jeff goes on to say:
"This makes me think that I shouldn't need to be doing this, and that a design refactoring of my SUT would be a better option."His concerns can be addressed on several different levels, but in this post, I'll show you how you can leverage Albedo to address some of them.
If you often find yourself in a situation where you're writing an AutoFixture Customization based on string matching of parameters, properties or fields, you should ask yourself if you're targeting one specific class, or if you're writing a convention? If you often target individual specific classes, you probably need to rethink your strategy, but you can easily run into situations where you need to introduce true conventions in your code base. This can be beneficial, because it'll make your code more consistent.
Here's an example from the code base in which I'm currently working. It's a REST service written in F#. To model the JSON going in and out, I've defined some Data Transfer Records, and some of them contain dates. However, JSON doesn't deal particularly well with dates, so they're treated as strings. Here's a JSON representation of a comment:
{
"author": {
"id": "1234",
"name": "Mark Seemann",
"email": "1234@ploeh.dk"
},
"createdDate": "2014-04-30T18:14:08.1051775+00:00",
"text": "Is this a comment?"
}
The record is defined like this:
type CommentRendition = { Author : PersonRendition CreatedDate : string Text : string }
This is a problem for AutoFixture, because it sees CreatedDate as a string, and populates it with an anonymous string. However, much of the code base expects the CreatedDate to be a proper date and time value, which can be parsed into a DateTimeOffset value. This would cause many tests to fail if I didn't change the behaviour.
Instead of explicitly targeting the CreatedDate property on the CommentRendition record, I defined a conventions: any parameter, field, or property that ends with "date" and has the type string, should be populated with a valid string representation of a date and time.
This is easy to write as a one-off Customization, but then it turned out that I needed an almost similar Customization for IDs: any parameter, field, or property that ends with "id" and has the type string, should be populated with a valid GUID string formatted in a certain way.
Because ParameterInfo, PropertyInfo, and FieldInfo share little polymorphic behaviour, it's time to pull out Albedo, which was created for situations like this. Here's a reusable convention which can check any parameter, proeprty, or field for a given name suffix:
type TextEndsWithConvention(value, found) = inherit ReflectionVisitor<bool>() let proceed x = TextEndsWithConvention (value, x || found) :> IReflectionVisitor<bool> let isMatch t (name : string) = t = typeof<string> && name.EndsWith(value, StringComparison.OrdinalIgnoreCase) override this.Value = found override this.Visit (pie : ParameterInfoElement) = let pi = pie.ParameterInfo isMatch pi.ParameterType pi.Name |> proceed override this.Visit (pie : PropertyInfoElement) = let pi = pie.PropertyInfo isMatch pi.PropertyType pi.Name |> proceed override this.Visit (fie : FieldInfoElement) = let fi = fie.FieldInfo isMatch fi.FieldType fi.Name |> proceed static member Matches value request = let refraction = CompositeReflectionElementRefraction<obj>( [| ParameterInfoElementRefraction<obj>() :> IReflectionElementRefraction<obj> PropertyInfoElementRefraction<obj>() :> IReflectionElementRefraction<obj> FieldInfoElementRefraction<obj>() :> IReflectionElementRefraction<obj> |]) let r = refraction.Refract [request] r.Accept(TextEndsWithConvention(value, false)).Value
It simply aggregates a boolean value (found), based on the name and type of various properties, fields, and parameters that comes its way. If there's a match, found will be true; otherwise, it'll be false.
The date convention is now trivial:
type DateStringCustomization() = let builder = { new ISpecimenBuilder with member this.Create(request, context) = if request |> TextEndsWithConvention.Matches "date" then box ((context.Resolve typeof<DateTimeOffset>).ToString()) else NoSpecimen request |> box } interface ICustomization with member this.Customize fixture = fixture.Customizations.Add builder
The ID convention is very similar:
type IdStringCustomization() = let builder = { new ISpecimenBuilder with member this.Create(request, context) = if request |> TextEndsWithConvention.Matches "id" then box ((context.Resolve typeof<Guid> :?> Guid).ToString "N") else NoSpecimen request |> box } interface ICustomization with member this.Customize fixture = fixture.Customizations.Add builder
With these conventions in place in my entire test suite, I can simply follow them and get correct values. What happens if I refactor one of my fields so that they no longer have the correct suffix? That's likely to break my tests, but that's a good thing, because it alerts me that I deviated from the conventions, and (inadvertently, I should hope) made the production code less consistent.
Single Writer Web Jobs on Azure
How to ensure a Single Writer in load-balanced Azure deployments
In my Functional Architecture with F# Pluralsight course, I describe how using the Actor model (F# Agents) can make a concurrent system much simpler to implement, because the Agent can ensure that the system only has a Single Writer. Having a Single Writer eliminates much complexity, because while the writer decides what to write (if at all), nothing changes. Multiple readers can still read data, but as long as the Single Writer can keep up with input, this is a much simpler way to deal with concurrency than the alternatives.
However, the problem is that while F# Agents work well on a single machine, they don't (currently) scale. This is particularly notable on Azure, because in order get the guaranteed SLA, you'll need to deploy your application to two or more nodes. If you have an F# Agent running on both nodes, obviously you no longer have a Single Writer, and everything just becomes much more difficult. If only there was a way to ensure a Single Writer in a distributed environment...
Fortunately, it looks like the (in-preview) Azure feature Web Jobs (inadvertently) solves this major problem for us. Web Jobs come in three flavours:
- On demand
- Continuously running
- Scheduled
That turns out not to be a particularly useful option as well, because
"If your website runs on more than one instance, a continuously running task will run on all of your instances."On the other hand
"On demand and scheduled tasks run on a single instance selected for load balancing by Microsoft Azure."It sounds like Scheduled Web Jobs is just what we need!
There's just one concern that we need to address: what happens if a Scheduled Web Job is taking too long running, in such a way that it hasn't completed when it's time to start it again. For example, what if you run a Scheduled Web Job every minute, but it sometimes takes 90 seconds to complete? If a new process starts executing while the first one is running, you would no longer have a Single Writer.
Reading the documentation, I couldn't find any information about how Azure handles this scenario, so I decided to perform some tests.
The Qaiain email micro-service proved to be a fine tool for the experiment. I slightly modified the code to wait for 90 seconds before exiting:
[<EntryPoint>] let main argv = match queue |> AzureQ.dequeue with | Some(msg) -> msg.AsString |> Mail.deserializeMailData |> send queue.DeleteMessage msg | _ -> () Async.Sleep 90000 |> Async.RunSynchronously match queue |> AzureQ.dequeue with | Some(msg) -> msg.AsString |> Mail.deserializeMailData |> send queue.DeleteMessage msg | _ -> () 0 // return an integer exit code
In addition to that, I also changed how the subject of the email that I would receive would look, in order to capture the process ID of the running application, as well as the time it sent the email:
smtpMsg.Subject <-
sprintf
"Process ID: %i, Time: %O"
(Process.GetCurrentProcess().Id)
DateTimeOffset.Now
My hypothesis was that if Scheduled Web Jobs are well-behaved, a new job wouldn't start if an existing job was already running. Here are the results:
| Time | Process |
|---|---|
| 17:31:39 | 37936 |
| 17:33:10 | 37936 |
| 17:33:43 | 50572 |
| 17:35:14 | 50572 |
| 17:35:44 | 47632 |
| 17:37:15 | 47632 |
| 17:37:46 | 14260 |
| 17:39:17 | 14260 |
| 17:39:50 | 38464 |
| 17:41:21 | 38464 |
| 17:41:51 | 46052 |
| 17:43:22 | 46052 |
| 17:43:54 | 52488 |
| 17:45:25 | 52488 |
| 17:45:56 | 46816 |
| 17:47:27 | 46816 |
| 17:47:58 | 30244 |
| 17:49:29 | 30244 |
| 17:50:00 | 30564 |
| 17:51:31 | 30564 |
This looks great, but it's easier to see if I visualize it:
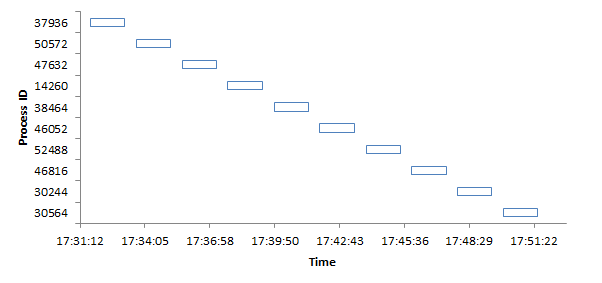
As you can see, processes do not overlap in time. This is a highly desirable result, because it seems to guarantee that we can have a Single Writer running in a distributed, load-balanced system.
Azure Web Jobs are currently in preview, so let's hope the Azure team preserve this functionality in the final version. If you care about this, please let the team know.
Composed assertions with Unquote
With F# and Unquote, you can write customized, composable assertions.
Yesterday, I wrote this unit test:
[<Theory; UnitTestConventions>] let PostReturnsCorrectResult (sut : TasksController) (task : TaskRendition) = let result : IHttpActionResult = sut.Post task verify <@ result :? Results.StatusCodeResult @> verify <@ HttpStatusCode.Accepted = (result :?> Results.StatusCodeResult).StatusCode @>
For the record, here's the SUT:
type TasksController() = inherit ApiController() member this.Post(task : TaskRendition) = this.StatusCode HttpStatusCode.Accepted :> IHttpActionResult
There's not much to look at yet, because at that time, I was just getting started, and as always, I was using Test-Driven Development. The TasksController class is an ASP.NET Web API 2 Controller. In this incarnation, it merely accepts an HTTP POST, ignores the input, and returns 202 (Accepted).
The unit test uses AutoFixture.Xunit to create an instance of the SUT and a DTO record, but that's not important in this context. It also uses Unquote for assertions, although I've aliased the test function to verify. Although Unquote is an extremely versatile assertion module, I wasn't happy with the assertions I wrote.
What's the problem? #
The problem is the duplication of logic. First, it verifies that result is, indeed, an instance of StatusCodeResult. Second, if that's the case, it casts result to StatusCodeResult in order to access its concrete StatusCode property; it feels like I'm almost doing the same thing twice.
You may say that this isn't a big deal in a test like this, but in my experience, this is a smell. The example looks innocuous, but soon, I'll find myself writing slightly more complicated assertions, where I need to type check and cast more than once. This can rapidly lead to Assertion Roulette.
The xUnit.net approach #
For a minute there, I caught myself missing xUnit.net's Assert.IsAssignableFrom<T> method, because it returns a value of type T if the conversion is possible. That would have enabled me to write something like:
let scr = Assert.IsAssignableFrom<Results.StatusCodeResult> result
Assert.Equal(HttpStatusCode.Accepted, scr.StatusCode)
It seems a little nicer, although in my experience, this quickly turns to spaghetti, too. Still, I found myself wondering if I could do something similar with Unquote.
A design digression #
At this point, you are welcome to pull GOOS at me and quote: listen to your tests! If the tests are difficult to write, you should reconsider your design; I agree, but I can't change the API of ASP.NET Web API. In Web API 1, my preferred return type for Controller actions were HttpResponseMessage, but it was actually a bit inconvenient to work with in unit tests. Web API 2 introduces various IHttpActionResult implementations that are easier to unit test. Perhaps this could be better, but it seems like a step in the right direction.
In any case, I can't change the API, so coming up with a better way to express the above assertion is warranted.
Composed assertions #
To overcome this little obstacle, I wrote this function:
let convertsTo<'a> candidate = match box candidate with | :? 'a as converted -> Some converted | _ -> None
(You have to love a language that let's you write match box! There's also a hint of such nice over Some converted...)
The convertsTo function takes any object as input, and returns an Option containing the converted value, if the conversion is possible; otherwise, it returns None. In other words, the signature of the convertsTo function is obj -> 'a option.
This enables me to write the following Unquote assertion:
[<Theory; UnitTestConventions>] let PostReturnsCorrectResult (sut : TasksController) (task : TaskRendition) = let result : IHttpActionResult = sut.Post task verify <@ result |> convertsTo<Results.StatusCodeResult> |> Option.map (fun x -> x.StatusCode) |> Option.exists ((=) HttpStatusCode.Accepted) @>
While this looks more verbose than my two original assertions, this approach is more composable.
The really beautiful part of this is that Unquote can still tell me what goes wrong, if the test doesn't pass. As an example, if I change the SUT to:
type TasksController() = inherit ApiController() member this.Post(task : TaskRendition) = this.Ok() :> IHttpActionResult
The assertion message is:
System.Web.Http.Results.OkResult |> Dsl.convertsTo |> Option.map (fun x -> x.StatusCode) |> Option.exists ((=) Accepted) None |> Option.map (fun x -> x.StatusCode) |> Option.exists ((=) Accepted) None |> Option.exists ((=) Accepted) false
Notice how, in a series of reductions, Unquote breaks down for me exactly what went wrong. The top line is my original expression. The next line shows me the result of evaluating System.Web.Http.Results.OkResult |> Dsl.convertsTo; the result is None. Already at this point, it should be quite evident what the problem is, but in the next line again, it shows the result of evaluating None |> Option.map (fun x -> x.StatusCode); again, the result is None. Finally, it shows the result of evaluating None |> Option.exists ((=) Accepted), which is false.
Here's another example. Assume that I change the SUT to this:
type TasksController() = inherit ApiController() member this.Post(task : TaskRendition) = this.StatusCode HttpStatusCode.OK :> IHttpActionResult
In this example, instead of returning the wrong implementation of IHttpActionResult, the SUT does return a StatusCodeResult instance, but with the wrong status code. Unquote is still very helpful:
System.Web.Http.Results.StatusCodeResult |> Dsl.convertsTo |> Option.map (fun x -> x.StatusCode) |> Option.exists ((=) Accepted) Some System.Web.Http.Results.StatusCodeResult |> Option.map (fun x -> x.StatusCode) |> Option.exists ((=) Accepted) Some OK |> Option.exists ((=) Accepted) false
Notice that it still uses a series of reductions to show how it arrives at its conclusion. Again, the first line is the original expression. The next line shows the result of evaluating System.Web.Http.Results.StatusCodeResult |> Dsl.convertsTo, which is Some System.Web.Http.Results.StatusCodeResult. So far so good; this is as required. The third line shows the result of evaluating Some System.Web.Http.Results.StatusCodeResult |> Option.map (fun x -> x.StatusCode), which is Some OK. Still good. Finally, it shows the result of evaluating Some OK |> Option.exists ((=) Accepted), which is false. The value in the option was HttpStatusCode.OK, but should have been HttpStatusCode.Accepted.
Summary #
Unquote is a delight to work with. As the project site explains, it's not an API or a DSL. It just evaluates and reports on the expressions you write. If you already know F#, you already know how to use Unquote, and you can write your assertion expressions as expressive and complex as you want.
Exude
Announcing Exude, an extension to xUnit.net providing test cases as first-class, programmatic citizens.
Sometimes, when writing Parameterized Tests with xUnit.net, you need to provide parameters that don't lend themselves easily to be defined as constants in [InlineData] attributes.
In Grean, we've let ourselves inspire by Mauricio Scheffer's blog post First-class tests in MbUnit, but ported the concept to xUnit.net and released it as open source.
It's called Exude and is available on GitHub and on NuGet.
Here's a small example:
[FirstClassTests] public static IEnumerable<ITestCase> YieldFirstClassTests() { yield return new TestCase(_ => Assert.Equal(1, 1)); yield return new TestCase(_ => Assert.Equal(2, 2)); yield return new TestCase(_ => Assert.Equal(3, 3)); }
More examples and information is available on the project site.
Arbitrary Version instances with FsCheck
This post explains how to configure FsCheck to create arbitrary Version values.
When I unit test generic classes or methods, I often like to use Version as one of the type arguments. The Version class is a great test type because
- it's readily available, as it's defined in the System namespace in mscorlib
- it overrides Equals so that it's easy to compare two values
- it's a complex class, because it composes four integers, so it's a good complement to String, Int32, Object, Guid, and other primitive types
Recently, I've been picking up FsCheck to do Property-Based Testing, but out of the box it doesn't know how to create arbitrary Version instances.
It turns out that you can easily and elegantly tell FsCheck how to create arbitrary Version instances, but since I haven't seen it documented, I thought I'd share my solution:
type Generators = static member Version() = Arb.generate<byte> |> Gen.map int |> Gen.four |> Gen.map (fun (ma, mi, bu, re) -> Version(ma, mi, bu, re)) |> Arb.fromGen
As the FsCheck documentation explains, you can create custom Generator by defining a static class that exposes members that return Arbitrary<'a> - in this case Arbitrary<Version>.
If you'd like me to walk you through what happens here, read on, and I'll break it down for you.
First, Arb.generate<byte> is a Generator of Byte values. While FsCheck doesn't know how to create arbitrary Version values, it does know how to create arbitrary values of various primitive types, such as Byte, Int32, String, and so on. The Version constructors expect components as Int32 values, so why did I select Byte values instead? Because Version doesn't accept negative numbers, and if I had kicked off my Generator with Arb.generate<int>, it would have created all sorts of integers, including negative values. While it's possible to filter or modify the Generator, I thought it was easier to simply kick off the Generator with Byte values, because they are never negative.
Second, Gen.map int converts the initial Gen<byte> to Gen<int> by invoking F#'s built-in int conversion function.
Third, Gen.four is a built-in FsCheck Generator Combinator that converts a Generator into a Generator of four-element tuples; in this case it converts Get<int> to Gen<int * int * int * int>: a Generator of a four-integer tuple.
Fourth, Gen.map (fun (ma, mi, bu, re) -> Version(ma, mi, bu, re)) converts Gen<int * int * int * int> to Gen<Version> by another application of Gen.map. The function supplied to Gen.map takes the four-element tuple of integers and invokes the Version constructor with the major, minor, build, and revision integer values.
Finally, Arb.fromGen converts Gen<Version> to Arbitrary<Version>, which is what the member must return.
To register the Generators custom class with FsCheck, I'm currently doing this:
do Arb.register<Generators>() |> ignore
You can see this entire code in context here.
SOLID: the next step is Functional
If you take the SOLID principles to their extremes, you arrive at something that makes Functional Programming look quite attractive.
You may have seen this one before, but bear with me :)
The venerable master Qc Na was walking with his student, Anton. Hoping to prompt the master into a discussion, Anton said "Master, I have heard that objects are a very good thing - is this true?" Qc Na looked pityingly at his student and replied, "Foolish pupil - objects are merely a poor man's closures."
Chastised, Anton took his leave from his master and returned to his cell, intent on studying closures. He carefully read the entire "Lambda: The Ultimate..." series of papers and its cousins, and implemented a small Scheme interpreter with a closure-based object system. He learned much, and looked forward to informing his master of his progress.
On his next walk with Qc Na, Anton attempted to impress his master by saying "Master, I have diligently studied the matter, and now understand that objects are truly a poor man's closures." Qc Na responded by hitting Anton with his stick, saying "When will you learn? Closures are a poor man's object." At that moment, Anton became enlightened.
While this is a lovely parable, it's not a new observation that objects and closures seem closely related, and there has been much discussion back and forth about this already. Still, in light of a recent question and answer about how to move from Object-Oriented Composition to Functional Composition, I'd still like to explain how, in my experience, the SOLID principles lead to a style of design that makes Functional Programming quite attractive.
A SOLID road map #
In a previous article, I've described how application of the Single Responsibility Principle (SRP) leads to many small classes. Furthermore, if you rigorously apply the Interface Segregation Principle (ISP), you'll understand that you should favour Role Interfaces over Header Interfaces.
If you keep driving your design towards smaller and smaller interfaces, you'll eventually arrive at the ultimate Role Interface: an interface with a single method. This happens to me a lot. Here's an example:
public interface IMessageQuery { string Read(int id); }
If you apply the SRP and ISP like that, you're likely to evolve a code base with many fine-grained classes that each have a single method. That has happened to me more than once; AutoFixture is an example of a big and complex code base that looks like that, but my other publicly available code bases tend to have the same tendency. In general, this works well; the most consistent problem is that it tends to be a bit verbose.
Objects as data with behaviour #
One way to characterise objects is that they are data with behaviour; that's a good description. In practice, when you have many fine-grained classes with a single method, you may have classes like this:
public class FileStore : IMessageQuery { private readonly DirectoryInfo workingDirectory; public FileStore(DirectoryInfo workingDirectory) { this.workingDirectory = workingDirectory; } public string Read(int id) { var path = Path.Combine( this.workingDirectory.FullName, id + ".txt"); return File.ReadAllText(path); } }
This FileStore class is a simple example of data with behaviour.
- The behaviour is the Read method, which figures out a file path for a given ID and returns the contents of the file.
-
The data (also sometimes known as the state) is the
workingDirectoryfield.
The workingDirectory field is a Concrete Dependency, but it could also have been a primitive value or an interface or abstract base class. In the last case, we would often call the pattern Constructor Injection.
Obviously, the data could be multiple values, instead of a single value.
The FileStore example class implements the IMessageQuery interface, so it's a very representative example of what happens when you take the SRP and ISP to their logical conclusions. It's a fine class, although a little verbose.
When designing like this, not only do you have to come up with a name for the interface itself, but also for the method, and for each concrete class you create to implement the interface. Naming is difficult, and in such cases, you have to name the same concept twice or more. This often leads to interfaces named IFooer with a method called Foo, IBarer with a method called Bar, etc. You get the picture. This is a smell (that also seems vaguely reminiscent of the Reused Abstractions Principle). There must be a better way.
Hold that thought.
Functions as pure behaviour #
As the introductory parable suggests, perhaps Functional Programming offers an alternative. Before you learn about Closures, though, you'll need to understand Functions. In Functional Programming, a Function is often defined as a Pure Function - that is: a deterministic operation without side-effects.
Since C# has some Functional language support, I'll first show you the FileStore.Read method as a Pure Function in C#:
Func<DirectoryInfo, int, string> read = (workingDirectory, id) => { var path = Path.Combine(workingDirectory.FullName, id + ".txt"); return File.ReadAllText(path); };
This Function does the same as the FileStore.Read method, but it has no data. You must pass in the working directory as a function argument just like the ID. This doesn't seem equivalent to an object.
Closures as behaviour with data #
A Closure is an important concept in Functional Programming. In C# it looks like this:
var workingDirectory = new DirectoryInfo(Environment.CurrentDirectory); Func<int, string> read = id => { var path = Path.Combine(workingDirectory.FullName, id + ".txt"); return File.ReadAllText(path); };
This is called a Closure because the Function closes over the Outer Variable workingDirectory. Effectively, the function captures the value of the Outer Variable.
What does that compile to?
Obviously, the above C# code compiles to IL, but if you reverse-engineer the IL back to C#, this is what it looks like:
[CompilerGenerated] private sealed class <>c__DisplayClass3 { public DirectoryInfo workingDirectory; public string <UseClosure>b__2(int id) { return File.ReadAllText( Path.Combine(this.workingDirectory.FullName, id + ".txt")); } }
It's a class with a field and a method! Granted, the names look somewhat strange, and the field is a public, mutable field, but it's essentially identical to the FileStore class!
Closures are behaviour with data, whereas objects are data with behaviour. Hopefully, the opening parable makes sense to you now. This is an example of one of Erik Meijer's favourite design concepts called duality.
Partial Function Application #
Another way to close over data is called Partial Function Application, but the result is more or less the same. Given the original pure function:
Func<DirectoryInfo, int, string> read = (workingDirectory, id) => { var path = Path.Combine(workingDirectory.FullName, id + ".txt"); return File.ReadAllText(path); };
you can create a new Function from the first Function by only invoking it with some of the arguments:
var wd = new DirectoryInfo(Environment.CurrentDirectory); Func<int, string> r = id => read(wd, id);
The r function also closes over the wd variable, and the compiled IL is very similar to before.
Just use F#, then! #
If SOLID leads you to many fine-grained classes with a single method, C# starts to be in the way. A class like the above FileStore class is proper Object-Oriented Code, but is quite verbose; the Closures and Partially Applied Functions compile, but are hardly idiomatic C# code.
On the other hand, in F#, the above Closure is simply written as:
let workingDirectory = DirectoryInfo(Environment.CurrentDirectory) let read id = let path = Path.Combine(workingDirectory.FullName, id.ToString() + ".txt") File.ReadAllText(path)
The read value is a Function with the signature 'a -> string, which means that it takes a value of the generic type 'a (in C#, it would typically have been named T) and returns a string. This is just a more general version of the IMessageQuery.Read method. When 'a is int, it's the same signature, but in F#, I only had to bother naming the Function itself. Functions are anonymous interfaces, so these are also equivalent.
Likewise, if you have a Pure Function like this:
let read (workingDirectory : DirectoryInfo) id = let path = Path.Combine(workingDirectory.FullName, id.ToString() + ".txt") File.ReadAllText(path)
the Partially Applied Function is written like this:
let wd = DirectoryInfo(Environment.CurrentDirectory) let r = read wd
The r Function is another Function that takes an ID as input, and returns a string, but notice how much less ceremony is involved.
Summary #
SOLID, particularly the SRP and ISP, leads you towards code bases with many fine-grained classes with a single method. Such objects represent data with behaviour, but can also be modelled as behaviour with data: Closures. When that happens repeatedly, it's time to make the switch to a Functional Programming Language like F#.
Comments
It's surprising to me that we've not moved more to the functional paradigm as an industry, when so many pieces of evidence point to it working more effectively than OO.
It feels like people can't seem to break away from those curly braces, which is perhaps why Scala is doing so well on the JVM.
public class MyService
{
...
public MyService(IMessageQuery messageQuery)
{...}
}
How would you do this with a closure? Your function no longer has a type that we can use (it's just int -> string). Surely your service doesn't look like this?
type MyService (messageQuery: int -> string) = ...How would you register the types for injection in this example?
Richard, thank you for writing. You ask "Surely your service doesn't look like this? type MyService (messageQuery: int -> string) = ..."
Probably not. Why even have a class? A client consuming the closure would just take it as a function argument:
let myClient f =
let message = f 42
// Do something else interesting...
// Return a result...
Here, f is a function with the int -> string signature, and myClient is another function. Just as you can keep on composing classes using the Composite, Decorator, and Adapter patterns, you can keep on composing functions with other functions by taking functions as function arguments.
At the top level of your application, you may have to implement a class to fit into a framework. For an example of integrating with the ASP.NET Web API, see my A Functional Architecture with F# Pluralsight course.
When it comes to integrating with a DI Container, I tend to not care about that these days. I prefer composing the application with Poor Man's DI, and that works beautifully with F#.
Excellent post!
Under "Partial Function Application", you state "Given the original pure function" - the file I/O would appear to make that impure. Similarly under "Just use F#, then!" with "Likewise, if you have a Pure Function like this".
Bill, you are correct! I may have gotten a little carried away at that point. The method is side-effect-free, and deterministic (unless someone comes by and changes the file), but it does depend on state on disk. Thank you for pointing that out; I stand corrected. Hopefully, that mistake of mine doesn't detract from the overall message.
Hey Mark, obviously switching to F# is not always that easy. I currently have a very similar situation like the one you describe in this post. I refactored the code to using partial application and a functional programming style with C# which works fine. You are saying that the two approaches are actually more or less the same thing which I can see. I am wondering now what the benefit is from refactoring to a functional style with partial application? Does it make sense to do that using C#? The dependencies that I inject are repositories with DB access. So I don't get the true benefits of FP because of the state of the DB. Is it still reasonable to switch to the FP approach? Personally I just like the style and I think it is a littel bit cleaner to have no constructors and private fields. Any thoughts on that? Thanks, Leif.
Leif, thank you for writing. Is there value in adopting a functional style in C#? Yes, I think so, but not (in my opinion) from closures or partial function application. While it's possible to do this in C#, the syntax is awkward compared to F#. It also goes somewhat against the grain of C#.
The main benefit from FP is immutable state, which makes it much easier to reason about the code and the state of the application. Once you understand how to model a problem around immutable data, even C# code becomes much easier to reason about, so I definitely think it makes sense to adopt patterns for working with immutable data in C#.
For years, I've written C# code like that. Not only is it possible, but I strongly prefer it over more 'normal' C# with mutable state. Still, there's a lot of boilerplate code you have to write in C#, such as constructors and read-only property pairs, copy-and-update methods, structural equality, etc. After having done that for a couple of years, I got tired of writing all that boilerplate code, when I get it for free in F#.
Like you, I still have a large body of C# code that I have to maintain, so while I choose F# for most new development, I write 'functional C#' in my C# code bases. Even if there are small pockets of mutable state here and there (like you describe), I still think it makes sense to keep as much as possible immutable.
Using NuGet with autonomous repositories
NuGet is a great tool if used correctly. Here's one way to do it.
In my recent post about NuGet, I described why the Package Restore feature is insidious. As expected, this provoked some readers, who didn't like my recommendation of adding NuGet packages to source control. That's understandable; the problem with a rant like my previous post is that while it tells you what not to do, it's not particularly constructive. While I told you to store NuGet packages in your source control system, I didn't describe patterns for doing it effectively. My impression was that it's trivial to do this, but based on the reactions I got, I realize that this may not be the case. Could it be that some readers react strongly because they don't know what else to do (than to use NuGet Package Restore)? In this post, I'll describe a way to use and organize NuGet packages that have worked well for me in several organizations.
Publish/Subscribe #
In Grean we use NuGet in a sort of Publish/Subscribe style. This is a style I've also used in other organizations, to great effect. It's easy: create reusable components as autonomous libraries, and publish them as NuGet packages. If you don't feel like sharing your internal building blocks with the rest of the world, you can use a custom, internal package repository, or you can use MyGet (that's what we do in Grean).
A reusable component may be some package you've created for internal use. Something that packages the way you authenticate, log, instrument, render, etc. in your organization.
Every time you have a new version of one of your components (let's call it C1), you publish the NuGet package.
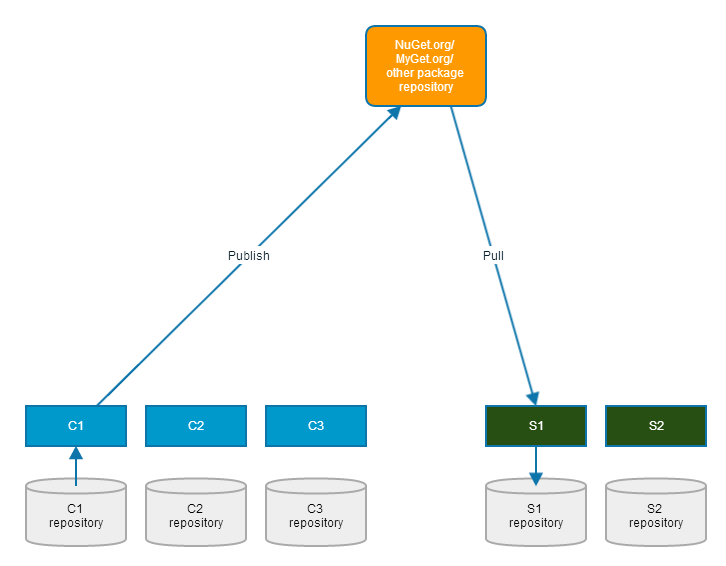
Just like other Publish/Subscribe systems, the only other party that you rely on at this moment is the queue/bus/broker - in this case the package repository, like NuGet.org or MyGet.org. No other systems need to be available to do this.
You do this for every reusable component you want to publish. Each is independent of other components.
Pull based on need #
In addition to reusable components, you probably also build systems; that is, applications that actually do something. You probably build those systems on top of reusable components - yours, and other publicly available NuGet packages. Let's call one such system S1.
Whenever you need a NuGet package (C1), you add it to the Visual Studio project where you need it, and then you commit your changes to that system's source control. It effectively means checking in the NuGet package, including all the binaries, to source control. However, the S1 repository is not the same repository as the C1 repository. Both are autonomous systems.
The only system you need to be available when you add the NuGet package C1 is the NuGet package source (NuGet.org, MyGet.org, etc.). The only system you need to be available to commit the changes to S1 is your source control system, and if you use a Distributed Version Control System (DVCS), it's always going to be available.
Pretty trivial so far.
"This isn't pub/sub," you'll most likely say. That's right, not in the traditional sense. Still, if you adopt the pattern language of Enterprise Integration Patterns, you can think of yourself (and your colleagues) as a Polling Consumer.
"But," I suppose you'll say, "I'm not polling the repository and pulling down every package ever published."
True, but you could, and if you did, you'd most likely be filtering away most package updates, because they don't apply to your system. That corresponds to applying a Message Filter.
This last part is important, so let me rephrase it:
Just because your system uses a particular NuGet package, it doesn't mean that you have to install every single version ever published.
It seems to me that at least some of the resistance to adding packages to your repository is based on something like that. As Urs Enzler writes:
[Putting packages in source control is] "not an option if your repo grows > 100GB per month due to monthly updates of BIG nuget packages"While I'm not at all in possession of all the facts regarding Urs Enzler's specific problems, it just got me thinking: do you really need to update your local packages every time a new package is published? You shouldn't have to, I think.
As an example, consider my own open source project AutoFixture, which keeps a fairly high release cadence. It's released according to the principles of Continuous Delivery, so every time there's a new feature or fix, we release a new NuGet package. In 2013, we released 47 versions of the AutoFixture NuGet package, including one major release. That's almost a release every week, but while I use AutoFixture in many other projects, I don't try to keep up with it. I just install AutoFixture when I start a new project, and then I mostly update the package if I need one of the new features or bug fixes. Occasionally, I also update packages in order to not fall too much behind.
As a publicly visible case, consider Hyprlinkr, which uses AutoFixture as one of its dependencies. While going though Hyprlinkr's NuGet packages recently, I discovered that the Hyprlinkr code base was using AutoFixture 2.12.0 - an 18 months old version! I simply hadn't needed to update the package during that time. AutoFixture follows Semantic Versioning, and we go to great lengths to ensure that we don't break existing functionality (unless we do a major release).
Use the NuGet packages you need, commit them to source control, and update them as necessary. For all well-designed packages, you should be able to skip versions without ill effects. This enables you to treat the code bases for each system (S1, S2, etc.) as autonomous systems. Everything you need in order to work with that code base is right there in the source code repository.
Stable Dependency Principle #
What if you need to keep up-to-date with a package that rapidly evolves? From Urs Enzler's tweet, I get the impression that this is the case not only for Urs, but for other people too. Imagine that the creator of such a package frequently publishes new versions, and that you have to keep up to date. If that's the case, it must imply that the package isn't stable, because otherwise, you'd be able to skip updates.
Let me repeat that:
If you depend on a NuGet package, and you have to stay up-to-date, it implies that the package is unstable.
If this is the case, you have an entirely other problem on your hand. It has nothing to do with NuGet Package Restore, or whether you're keeping packages in source control or not. It means that you're violating the Stable Dependencies Principle (SDP). If you feel pain in that situation, that's expected, but the solution isn't Package Restore, but a better dependency hierarchy.
If you can invert the dependency, you can solve the problem. If you can't invert the dependency, you'd probably benefit from an Anti-corruption Layer. There are plenty of better solution that address the root cause of your problems. NuGet Package Restore, on the other hand, is only symptomatic relief.
Comments
Can you elaborate a bit on not breaking existing functionality in newer versions (as long as they have one major version)? What tools are you using to achieve that? I read your post on Semantic Versioning from couple months ago. I manage OSS project and it has quite a big public API - each release I try hard to think of anything I or other contributors might have broken. Are you saying that you relay strictly on programmer deep knowledge of the project when deciding on a new version number? Also, do you build AutoFixture or any other .NET project of yours for Linux/Mono?
For AutoFixture, as well as other OSS projects I maintain, we rely almost exclusively on unit tests, keeping in mind that trustworthy tests are append-only. AutoFixture has some 4000+ unit tests, so if none of those break, I feel confident that a release doesn't contain breaking changes.
For my other OSS projects, the story is the same, although the numbers differ.
- Albedo has 354 tests.
- ZeroToNine has 200 tests.
- Hyprlinkr has 88 tests.
Currently, I don't build any of these .NET projects for Mono, as I've never had the need.
So you verify behaviour didn't change with a help of automated tests and a good test coverage. What I had in mind is some technique to verify not only the desired behaviour is in place, but also a public API (method signatures, class constructors, set of public types). I should probably clarify that in one of my projects public API is not fully covered by unit-tests. Most critical parts of it are covered, but not all of it. Let's say that upcoming release contains bugfixes as well as new features. I also decided that couple of public API methods are obsolete and deleted them. That makes a breaking change. Let's say I had a lot on my mind and I forgot about the fact that I made those changes. Some time goes by, I'd like to push a new version with all these changes to NuGet, but I'd like to double-check that the public API is still in place compared to the last release. Are there some tools that help with that, may be the ones you use? Or do you rely fully on the tests and your process in that regard? My approach to releases and versioning is a LOT more error prone than yours, clearly, that's the part of my projects that I'd like to improve.
The only technique I rely on apart from automated tests is code reviews. When I write code myself, I always keep in mind if I'm breaking anything. When I receive Pull Requests (PR), I always review them with an eye towards breaking changes. Basically, if a PR changes an existing test, I review it very closely. Obviously, any change that involves renaming of types or members, or that changes public method signatures, are out of the question.
While I'm not aware of any other technique than discipline that will protect against breaking changes, you could always try to check out the tests you have against a previous version, and see if they all pass against the new version. If they don't, you have a breaking change.
You can also make a diff of everything that's happened since your last release, and then meticulously look through all types and members to see if anything was renamed, or method signatures changed. This will also tell you if you have breaking changes.
However, in the end, if you find no breaking changes using these approaches, it's still not a guarantee that you have no breaking changes, because you may have changed the behaviour of some methods. Since you don't have full test coverage, it's hard to tell.
What you could try to do, is to have Pex create a full test suite for your latest released version. This test suite will give you a full snapshot of the behaviour of that release. You could then try to run that test suite on your release candidate to see if anything changed. I haven't tried this myself, and I presume that there's still a fair bit of work involved, but perhaps it's worth a try.
How to use FSharp.Core 4.3.0 when all you have is 4.3.1
If you only have F# 3.1 installed on a machine, but need to use a compiled application that requires F# 3.0, here's what you can do.
This post uses a particular application, Zero29, as an example in order to explain a problem and one possible solution. However, the post isn't about Zero29, but rather about a particular F# DLL hell.
Currently, I'm repaving one of my machines, which is always a good idea to do regularly, because it's a great remedy against works on my machine syndrome. This machine doesn't yet have a lot of software, but it does have Visual Studio 2013 and F# 3.1.
Working with a code base, I wanted to use Zero29 to incement the version number of the code, so first I executed:
$ packages/Zero29.0.4.1/tools/Zero29 -l
which promptly produced this error message:
Unhandled Exception: System.IO.FileNotFoundException: Could not load file or assembly 'FSharp.Core, Version=4.3.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a' or one of its dependencies. The system cannot find the file specified. at Ploeh.ZeroToNine.Program.main(String[] argv)
On one level, this makes sense, because Zero29 0.4.1 was compiled against F# 3.0 (which corresponds to FSharp.Core 4.3.0.0).
On another level, this is surprising, since I do have F# 3.1 (FSharp.Core 4.3.1.0) on my machine. Until the error message appeared, I had lived with the naïve assumption that when you install F# 3.1, it would automatically add redirects from FSharp.Core 4.3.0.0 to 4.3.1.0, or perhaps make sure that FSharp.Core 4.3.0.0 was also available. Apparently, I've become too used to Semantic Versioning, which is definitely not the versioning scheme used for F#.
Here's one way to address the issue.
Although Zero29 is my own (and contributors') creation, I didn't want to recompile it just to deal with this issue; it should also be usable for people with F# 3.0 on their machines.
Even though it's a compiled program, you can still add an application configuration file to it, so I created an XML file called Zero29.exe.config, placed it alongside Zero29.exe, and added this content:
<?xml version="1.0" encoding="utf-8"?> <configuration> <runtime> <assemblyBinding xmlns="urn:schemas-microsoft-com:asm.v1"> <dependentAssembly> <assemblyIdentity name="FSharp.Core" publicKeyToken="b03f5f7f11d50a3a" culture="neutral"/> <bindingRedirect oldVersion="4.3.0.0" newVersion="4.3.1.0"/> </dependentAssembly> </assemblyBinding> </runtime> </configuration>
This solved the problem, although I now have the derived problem that this new file isn't part of the Zero29 NuGet package, and I don't know if it's going to ruin my colleagues' ability to use Zero29 if I check it into source control...
Another option may be to add the redirect to machine.config, instead of an application-specific redirect, but I have no desire to manipulate my machine.config files if I can avoid it, so I didn't try that.

Comments
Howard, thank you for writing. You should always keep your secrets out of source control. In some projects, I've used web.config transforms for that purpose. Leave your checked-in
.configfiles empty, and have local (not checked-in).configfiles on development machines, production servers, and so on.As far as I know, on most other platforms, people simply use environment variables instead of configuration files. To me, that sounds like a simple solution to the problem.