ploeh blog danish software design
Herding Code podcast
I'm on Herding Code.
At the Danish Developer Conference 2013 I had the pleasure of meeting Jon Galloway, who interviewed me for a Herding Code podcast. In this interview, we talk about AutoFixture, testing (or not testing) trivial code, as well as lots of the unit testing topics I also cover in my Pluralsight course on Advanced Unit Testing.
REST lesson learned: Avoid 204 responses
Avoid 204 responses if you're building a HATEOAS application.
This is a lesson about REST API design that I learned while building non-trivial REST APIs. In order to be as supportive of the client as possible, a REST API should not return 204 (No Content) responses.
From the service's perspective, a 204 (No Content) response may be a perfectly valid response to a POST, PUT or DELETE request. Particularly, for a DELETE request it seems very appropriate, because what else can you say?
However, from the perspective of a proper HATEOAS-aware client, a 204 response is problematic because there are no links to follow. When hypermedia acts as the engine of application state, when there are no links, there's no state. In other words, a 204 response throws away all application state.
If a client encounters a 204 response, it can either give up, go to the entry point of the API, or go back to the previous resource it visited. Neither option is particularly good.
Giving up is not a good option if there's still work to do. Essentially, this is equivalent to a crashing client.
Going to the entry point of the API may allow the client to move on, doing what it was doing, but state may still be lost.
Going back (the equivalent of using your browser's back button) may be the best option, but has a couple of problems: First, if the client just did a DELETE, the previous resource in the history may now be gone (it was just deleted). The client would have to go back twice to arrive at a proper resource. Second, while your browser has built-in history, a programmatic HTTP client probably hasn't. You could add that feature to your client, but it would require more work. Once more, it would require the client to maintain state, which means that you'd be moving state from hypermedia to the client. It's just not a HATEOAS-compliant approach.
A good REST API should make it easy to be a client. While this is only a variation of Postel's law, I also like to think of this in terms or courtesy. The service has a lot of information available to it, so it might as well be courteous and help the client by sharing appropriate pieces of information.
Instead of a 204 (No Content) response, tell the client what it can do now.
Responding to POST requests #
An HTTP POST request often represents some sort of Command - that is: an intent to produce side effects. If the service handles the request synchronously, it should return the result of invoking the Command.
A common POST action is to create a new resource. At the very least, the REST API should return a 201 (Created) with a proper Location header. That's all described in detail in the RESTful Web Services Cookbook.
Even if the API decides to handle the request asynchronously, it can provide one or more links. Actually, the specification of 202 (Accepted) says that the "entity returned with this response SHOULD include an indication of the request's current status and [...] a pointer to a status monitor". That sounds like a link to me.
Responding to PUT requests #
An HTTP PUT request is often intended to update the state of a particular resource. Instead of returning 204 (No Content), the API should be courteous and return the new state of the resource. You may think that this is redundant because the client just transferred the state of the resource to the service, so why pay transmission costs to get the resource back from the service?
Even if a client PUTs the entire state of a resource to the API, the API may still have information about the resource not available to the client. The most universal example is probably the resource's ETag. If the client wishes to do further processing on the resource, it's likely going to need the ETag value sooner or later.
The representation of the resource may also include optional or denormalized data that the client may not have. If that data is optional, the client can make a PUT without it, but it might want that data to display to a user, so it would have to read the latest state of the resource regardless.
Responding to DELETE requests #
A DELETE request represents the intent to delete a resource. Thus, if the service successfully handles a DELETE request, what else can it do than returning a 204 (No Content)? After all, the resource has just been removed.
A resource is often a member of a collection, or otherwise 'owned' by a container. As an example, http://foo.ploeh.dk/api/tags/rock represents a "rock" tag, but another way of looking at it is that the /rock resource is contained within the tags container (which is itself a resource). This should be familiar to Atom Pub users.
Imagine that you want to delete the http://foo.ploeh.dk/api/tags/rock resource. In order to accomplish that goal, you issue a DELETE request against it. If all your client gets back is a 204 (No Content), it's just lost its context. Where does it go from there? Unless you keep state on the client, you don't know where you came from.
Instead of returning 204 (No Content), the API should be helpful and suggest places to go. In this example I think one obvious link to provide is to http://foo.ploeh.dk/api/tags - the container from which the client just deleted a resource. Perhaps the client wishes to delete more resources, so that would be a helpful link.
Responding to GET requests #
Returning 204 (No Content) as a response to a GET request is a bit weird, but probably not completely unheard of. Such a resource would represent a flag or semaphore, where the existence of the resource (as opposed to a 404 (Not Found)) signifies something. However, consider being helpful to the client and at least provide a link it can use to move on.
Summary #
Technically, responding with 204 (No Content) is perfectly valid, but if a REST API does that, its clients lose their current context. A service should be helpful and inform clients where they can go from the current resource. This will make client development easier, and only puts a small burden on the service.
REST lesson learned: Avoid user-supplied data in URI segments
Be careful with user-supplied data in URI segments.
This is a lesson about design of REST APIs that I learned the hard way: if you built service URIs from dynamic data, be careful with the data you allow in URI segments.
Some HTTP frameworks (e.g. the ASP.NET Web API) let you define URI templates or routes that handle incoming requests - e.g.
routeTemplate: "api/{controller}/{id}"
which means that a request to http://foo.ploeh.dk/api/fnaah/sgryt would map the value "fnaah" to controller, and the value "sgryt" to id.
If you are building a level 2 or less service, you may even publish your URI templates to consumers. If you are building a level 3 RESTful API, you may not be publishing your URI templates, but you can still use them internally.
Avoid user-supplied data in URI segments #
Be careful with the source of data you allow to populate URI segments of your URI template. At one point, I was involved with designing a REST API that (among other things) included a 'tag cloud' feature. If you wanted to see the contents of a specific tag, you could navigate to it.
Tags were all user-defined strings, and they had no internal ID, so our first attempt was to simply treat the value of the tag as the ID. That seemed reasonable, because we wanted the tag resource to list all the resources with that particular tag value. Thus, we modeled the URI template for tag resources like the above route template.
That worked well for a URL like http://foo.ploeh.dk/api/tags/rock because it would simply match the value "rock" to the id variable, and we could then list all resources tagged with "rock".
However, some user had defined a tag with the value of "sticky & sweet" (notice the ampersand character), which meant that when you wanted to see all resources with this link, you would have to navigate to http://foo.ploeh.dk/api/tags/sticky & sweet. However, that sort of URL is considered dangerous, and IIS will (by default) refuse to handle it.
Can you get around this by URL encoding the value? No, it's part of the request path, not part of any query string, so that's not going to work. The issue isn't that the URL is invalid, but that the server considers it to be dangerous. Even if you URL encode it, the server will decode it before handling it, and that would you leave you at square one.
You can either change the URI template so that the URL instead becomes http://foo.ploeh.dk/api/tags?id=sticky%20%26%20sweet. This URL encodes the query string (the part of the URL that comes after the ?), but gives you an ugly URL.
Another alternative is to be very strict about input validation, and only allow users to create values that are safe when used as URI segments. However, that's putting an unreasonable technical limitation on an application feature. If a user wants to tag a resource with "sticky & sweet", the service should allow it.
In the end, we used a third alternative: we assigned an internal ID to all tags and mapped back and forth so that the URL for the "sticky & sweet" tag became http://foo.ploeh.dk/api/tags/1234. Yes: that makes it impossible to guess the URL, but we were building a level 3 RESTful API, so clients are expected to follow links - not guess the URL.
REST lessons learned
This post provides an overview of some lessons I learned while bulding non-trivial REST APIs.
Last year I spent a good deal of the year designing and implementing a handful of non-trivial REST APIs for a customer of mine. During that process, I learned some small lessons about the design of RESTful systems that I haven't seen described elsewhere, and I want to share these lessons with you.
In order to learn the concepts and philosphy behind REST, I think that REST in Practice is a great resource (pun intended), but when it comes to practical guidance, I find the RESTful Web Services Cookbook invaluable. It's full of useful and concrete tips and tricks for building RESTful APIs, but I don't remember reading about the following lessons, that I had to learn the hard way.
There's so much hype and misrepresentation about REST that I have to point out that when I'm talking about REST, I mean full-on, level 3 REST, with resources, verbs, hypermedia controls and the works.
Each of these lessons deserves a small article of its own, but here's an overview:
- Avoid user-supplied data in URI segments
- Avoid 204 responses
- Avoid hackable URLs
- Consider a home link on all resources
- Consider a self link on all resources
- Consider including identity in URLs
I hope you find these tips useful.
How to change the Generate Property Stub refactoring code snippet in Visual Studio 2012
This post describes how to change the code template for the 'Generate Property Stub' refactoring in Visual Studio 2012.
This is mostly a quick note for my own benefit (since I just spent half an hour chasing this down), but I'm posting it here on the blog, in case someone else might find it useful. Here's how to change the code snippet for the "Generate Property Stub" smart tag in Visual Studio 2012:
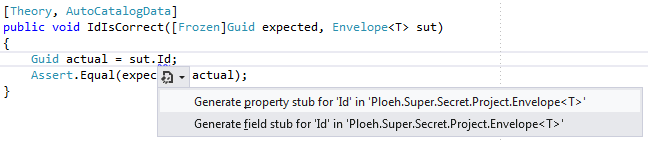
The template for this code is defined in
C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC#\Snippets\1033 \Refactoring\GenerateProperty - Auto Property.snippet
You can open this file and hand-edit it, but contrary to previous versions of Visual Studio, it seems that you have to restart Visual Studio before the change takes effect.
If you do this, be sure that you know what you're doing; you'd be mucking around with the internals of your Visual Studio installation.
Advanced Unit Testing Pluralsight course
Service announcement: my new Pluralsight course Advanced Unit Testing is now available. Read more in Pluralsight's announcement, or go straight to the course.
If you don't already have a Pluralsight account, you can get a free trial of up to 200 minutes.
FizzBuzz kata in Clojure
This post describes my first experience with doing the FizzBuzz kata in Clojure.
After having looked at Clojure for some time, I finally had a bit of time to play with it, so I decided to do the FizzBuzz kata in Clojure.
Single fizzbuzz function #
Clojure has a built-in testing framework, so I wrote a Parameterized Test for a single fizzbuzz function. Using TDD, I added test cases a little at a time, attempting to follow the Transformation Priority Premise, but the end result is this:
(ns fizzbuzz.core-test
(:use clojure.test
fizzbuzz.core))
(deftest fizzbuzz-test
(are [expected i] (= expected (fizzbuzz i))
"1" 1
"2" 2
"Fizz" 3
"4" 4
"Buzz" 5
"Fizz" 6
"7" 7
"8" 8
"Fizz" 9
"Buzz" 10
"11" 11
"Fizz" 12
"13" 13
"14" 14
"FizzBuzz" 15
"FizzBuzz" 30))
Clojure syntax is somewhat backwards from what I'm normally used to, but the are macro expands into a collection of tests that each evaluate whether the result of invoking the fizzbuzz function with i is equal to expected.
Through a series of transformations of the SUT, I ended up with this implementation of the fizzbuzz function:
(ns fizzbuzz.core)
(defn fizzbuzz [i]
(cond
(= 0 (mod i 15)) "FizzBuzz"
(= 0 (mod i 3)) "Fizz"
(= 0 (mod i 5)) "Buzz"
:else (str i)))
This defines a function called fizzbuzz taking a single argument i. The cond macro evaluates each test and returns the expression associated with the first test that evauluates to true. The first test checks if i is divisible with 15 and returns "FizzBuzz" if this is the case; the next test checks if i is divisible with 3 and returns "Fizz" if this is true, and so on.
Printing a range of fizzbuzz values #
The task defined by the kata is to print all FizzBuzz values from 1 to 100, so the above function is't the final solution. The next step I took was to write a test that defines a version of the fizzbuzz function taking two parameters:
(def acceptance-expected "1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz 16 17 Fizz 19 Buzz Fizz 22 23 Fizz Buzz 26 Fizz 28 29 FizzBuzz 31 32 Fizz 34 Buzz Fizz 37 38 Fizz Buzz 41 Fizz 43 44 FizzBuzz 46 47 Fizz 49 Buzz Fizz 52 53 Fizz Buzz 56 Fizz 58 59 FizzBuzz 61 62 Fizz 64 Buzz Fizz 67 68 Fizz Buzz 71 Fizz 73 74 FizzBuzz 76 77 Fizz 79 Buzz Fizz 82 83 Fizz Buzz 86 Fizz 88 89 FizzBuzz 91 92 Fizz 94 Buzz Fizz 97 98 Fizz Buzz") (deftest acceptance-test (is (= acceptance-expected (fizzbuzz 1 101))))
I decided to define the acceptance-expected value outside of the test case itself, as I thought that made the test a bit more readable. The test case is defined by the is macro and states that the expected value is acceptance-expected and the actual value is the result of invoking the fizzbuzz function with two arguments: 1 as the (inclusive) start value, and 101 as the (exclusive) end value. The above code listing of fizzbuzz only accept one argument, but the new test case requires two arguments, so I added an overload to the function:
(defn fizzbuzz
([i]
(cond
(= 0 (mod i 15)) "FizzBuzz"
(= 0 (mod i 3)) "Fizz"
(= 0 (mod i 5)) "Buzz"
:else (str i)))
([start end]
(apply str
(interpose "\n"
(map fizzbuzz (range start end))))))
The previous implementation is still there, now contained within the overload taking a single argument i, but now there's also a new overload taking two arguments: start and end.
This overload generates a sequence of integers from start to end using the range function. It then maps that sequence of integers into a sequence of strings by mapping each integer to a string with the fizzbuzz function. That gives you a sequence of strings such as ("1" "2" "Fizz" "4" "Buzz").
In order to print all the FizzBuzz strings, I need to interpose a newline character between each string, which produces a new sequence of strings such as ("1" "\n" "2" "\n" "Fizz" "\n" "4" "\n" "Buzz"). To concatenate all these strings, I apply the str function to the sequence.
Printing FizzBuzz values from 1 to 100 #
The requirements of the kata is to print all FizzBuzz values from 1 to 100, and the code already does this. However, I interpret the kata as requiring a single function that takes no parameters, so I added an acceptance test case:
(deftest acceptance-test (is (= acceptance-expected (fizzbuzz 1 101))) (is (= acceptance-expected (fizzbuzz))))
Notice the second test case in the last line of code that invokes the fizzbuzz function without any parameters. It's easily resolved by adding a third overload:
(defn fizzbuzz
([]
(fizzbuzz 1 101))
([i]
(cond
(= 0 (mod i 15)) "FizzBuzz"
(= 0 (mod i 3)) "Fizz"
(= 0 (mod i 5)) "Buzz"
:else (str i)))
([start end]
(apply str
(interpose "\n"
(map fizzbuzz (range start end))))))
As you can see, the first overload takes no parameters and simply invokes the previously desribed overload with the start and end arguments.
FWIW, this entire solution is structurally similar to my implementation of FizzBuzz in F#.
Ploeh blog syndication feed addresses
Service announcement about syndication feed addresses for ploeh blog.
Now that Google Reader is closing down and a lot of my readers may want to migrate their ploeh blog subscription to another service, I think it's the right time for a quick post about ploeh blog's syndication feed addresses.
When I migrated my blog to Jekyll I made it a priority to ensure a certain level of backwards compatibility. The permalinks for the old posts are still served, although they are now redirects. For that reason, I also left the old syndication feed addresses in place. Specifically, I left this old RSS feed address in place: /SyndicationService.asmx/GetRss. This feed address sort of works, but has issues.
There are several problems with the 'legacy' feed address:
- Due to the way Jekyll works, the address actually points to an index.html file. Since a Jekyll-powered site is a static site, I don't control the server, and thus I can't manipulate the HTTP headers for individual resources. HTML files are served with the "text/html" Content-Type, which doesn't fit the XML content. Some clients seem to dislike this.
- Google Reader has created some 'ghost' entries based on the feed. I wonder if it has anything to do with the faulty Content-Type.
- Other users have reported that their clients (e.g. Outlook) don't like the feed. Again, I suspect it's because of the faulty Content-Type. While I think those clients should follow Postel's law, they apparently don't.
- The address looks very implementation-specific.
However, ploeh blog has new, 'proper' syndication feed addresses, so if you're already in the process of migrating your subscriptions away from Google Reader, please take a moment to update your subscription. That 'legacy' RSS address may not stick around forever.
The proper syndication feed addresses for ploeh blog are:
Both serve responses with the "text/xml" Content-Type.How to automatically populate properties with AutoMoq
This post explains how to automatically populate properties when using AutoFixture.AutoMoq.
In a previous blog post I described how to configure AutoFixture.AutoMoq to set up all mock instances to have 'normal' property behavior. This enables you to assign and retrieve values from properties defined by interfaces, but still doesn't fill those properties with values.
Apparently, people want to do that, so here's how to do it with the AutoMoq glue library.
This solution builds upon the PropertiesPostprocessor described in my previous blog post. All you have to do is define a different Customization for AutoFixture so that, instead of using the AutoMoqPropertiesCustomization described in the previous post, you'll need a variation:
public class AutoPopulatedMoqPropertiesCustomization : ICustomization { public void Customize(IFixture fixture) { fixture.Customizations.Add( new PropertiesPostprocessor( new MockPostprocessor( new MethodInvoker( new MockConstructorQuery())))); fixture.ResidueCollectors.Add( new Postprocessor( new MockRelay(), new AutoPropertiesCommand( new PropertiesOnlySpecification()))); } private class PropertiesOnlySpecification : IRequestSpecification { public bool IsSatisfiedBy(object request) { return request is PropertyInfo; } } }
The PropertiesPostprocessor assigned to the Fixture's Customizations has the same configuration as shown in AutoMoqPropertiesCustomization, but the object graph passed to the Fixture's ResidueCollectors is different. It's still a MockRelay, but now decorated with a Postprocessor instance, configured with an AutoPropertiesCommand instance, which is the class in AutoFixture responsible for implementing the AutoProperties feature.
The only thing special about this configuration is that you need to pass a PropertiesOnlySpecification to the AutoPropertiesCommand instance. This is because, by default, AutoPropertiesCommand attempts to fill both properties and fields of a generated instance (we call that a specimen), but it turns out that when you ask Moq to generate an instance of an interface, the generated type has a lot of public fields that you don't want to mess with. The PropertiesOnlySpecification class filters the population algorithm so that it only attempts to populate public properties.
This test passes:
[Fact] public void AutoPopulatedProperties() { var fixture = new Fixture().Customize( new AutoPopulatedMoqPropertiesCustomization()); var h = fixture.Create<IHasProperties>(); Assert.NotEqual(default(string), h.Text); Assert.NotEqual(default(int), h.Number); }
With the described AutoPopulatedMoqPropertiesCustomization, AutoFixture will populate all writable properties on interfaces generated by Moq. I still don't think this is a good idea, which is why it isn't the default behavior for AutoFixture, but as you can tell, it's not too hard to do.
How to configure AutoMoq to set up all properties
This post explains how to configure AutoFixture.AutoMoq to setup all interface properties to behave like normal properties.
From time to time, people want the AutoFixture.AutoMoq Auto-Mocking Container to set up all mock instances to have 'normal' property behavior.
By default, Moq doesn't implement any members of an interface. You have to explicitly configure the desired behavior using the Setup methods. This is also true for properties (which are really only special methods).
Consider, as an example, this interface:
public interface IHasProperties { string Text { get; set; } int Number { get; set; } }
Personally, I think such an interface design is a design smell, but that's not the issue here.
Moq behavior #
The issue is that by default, Moq behaves like this:
[Fact] public void DefaultMoqDoesNotSetupProperties() { var h = new Mock<IHasProperties>().Object; h.Text = "foo"; h.Number = 42; Assert.Equal(default(string), h.Text); Assert.Equal(default(int), h.Number); }
As you can infer from this test, the IHasProperties instance completely ignores any attempt at assigning values to the properties. When you attempt to read the property values, Moq returns the default value for the property type - often null.
You can configure each property individually, but you can also configure the Mock instance to implement all properties as thought they are normal, well-behaved properties:
[Fact] public void ManualSetupProperties() { var td = new Mock<IHasProperties>(); td.SetupAllProperties(); var h = td.Object; h.Text = "foo"; h.Number = 42; Assert.Equal("foo", h.Text); Assert.Equal(42, h.Number); }
Notice the use of the SetupAllProperties method. So far, this is all about Moq, and really has nothing to do with AutoFixture.
AutoFixture.AutoMoq and interface property behavior #
Adhering to the Principle of least surprise, the AutoFixture.AutoMoq glue library doesn't change this behavior:
[Fact] public void DefaultAutoMoqDoesNotSetupProperties() { var fixture = new Fixture().Customize(new AutoMoqCustomization()); var h = fixture.Create<IHasProperties>(); h.Text = "foo"; h.Number = 42; Assert.Equal(default(string), h.Text); Assert.Equal(default(int), h.Number); }
However, it's easy to change the behavior in an ad hoc manner:
[Fact] public void ManualSetupPropertiesOnAutoMoq() { var fixture = new Fixture().Customize(new AutoMoqCustomization()); var h = fixture.Create<IHasProperties>(); Mock.Get(h).SetupAllProperties(); h.Text = "foo"; h.Number = 42; Assert.Equal("foo", h.Text); Assert.Equal(42, h.Number); }
As you can see, you can use the static Mock.Get method to get the underlying Mock<IHasProperties> and explicitly invoke the SetupAllProperties method.
If you prefer AutoFixture to automate this for you, it's fairly easy to do. First, you'll need to write an ISpecimenBuilder that hooks into the Mock creation process and invokes the SetupAllProperties method:
public class PropertiesPostprocessor : ISpecimenBuilder { private readonly ISpecimenBuilder builder; public PropertiesPostprocessor(ISpecimenBuilder builder) { this.builder = builder; } public object Create(object request, ISpecimenContext context) { dynamic s = this.builder.Create(request, context); if (s is NoSpecimen) return s; s.SetupAllProperties(); return s; } }
This class must decorate another ISpecimenBuilder, whose responsibility it is to create Mock<T> instances. The example code shown here is only a proof of concept, so it only does the bare minimum of defensive coding, assuming that if the object returned from the decorated ISpecimenBuilder is not a NoSpecimen, then it must be a Mock instance. In that case, it invokes SetupAllProperties on it.
You'll need to compose this PropertiesPostprocessor class together with all the other building blocks of the AutoMoq glue library. Currently, there's no specific hook into AutoMoqCustomization that enables you to do that, but if you decompose AutoMoqCustomization, you'll realize how easy it is to replicate the behavior while adding your new PropertiesPostprocessor class:
public class AutoMoqPropertiesCustomization : ICustomization { public void Customize(IFixture fixture) { fixture.Customizations.Add( new PropertiesPostprocessor( new MockPostprocessor( new MethodInvoker( new MockConstructorQuery())))); fixture.ResidueCollectors.Add(new MockRelay()); } }
The only difference from the AutoMoqCustomization implementation is the addition of PropertiesPostprocessor decorating MockPostprocessor.
This test now passes:
[Fact] public void AutoSetupProperties() { var fixture = new Fixture().Customize( new AutoMoqPropertiesCustomization()); var h = fixture.Create<IHasProperties>(); h.Text = "foo"; h.Number = 42; Assert.Equal("foo", h.Text); Assert.Equal(42, h.Number); }
As you can see, the Mock object created by AutoFixture now implements properties as normal, well-behaved properties.

Comments
Xander, thank you for writing. If you read this article carefully, you may notice that it's not an exegesis of the HTTP specification, but a guideline to writing pleasant and useful RESTful services.
The bottom line is that if you're a client developer trying to follow links, 204 responses are annoying, which isn't the same as to say that they're invalid (they're not).
Could the service put links in the headers? Perhaps it could, but then it'd be forcing the client developer to do more work (by looking after links in two places).
Forcing client developers to do more work scales poorly (in terms of effort, not performance). A service developer needs to do a particular piece of work once, after which it's available to all client developers (even if there are hundreds of clients).
If a service doesn't provide a consistent API, every client developer has to duplicate the work the service developer could have done once. Every time that happens, you risk introducing bugs (on the client side). The end result is a more brittle system.
In the end, this has nothing to do with HTTP, but with Postel's law.
Mark, I understand why you might say that about link headers, but not all media types are hypermedia (image/png, audio/mp4, video/ogg to name a few) whereas all HTTP header sections are. Given that, wouldn't it be wise for a client to always maintain awareness of protocol-level linking and, when a media type offers links, maintain awareness of that as well?
Since you mentioned client/server development, it's worth considering that once a given domain (be it 'people', 'autos', 'nutrition', etc.) has become cemented with standard media types and link relations, there would probably be a community effort to develop client and server libraries and applications for varying languages and platforms so that each development team doesn't have to write and test their own implementations from scratch (see: HTML browsers and frameworks.)
It makes sense that the 'World Wide Web' has become standard and RESTful; everyone is interested in the domain of general-purpose knowledge and entertainment. Unfortunately I think it will still be a while before we see many other, more specific domains become standardized to that same degree.
Derek, thank you for writing. It's a good point that some media types like images, audio, etc. don't have a natural place to put meta-data like links. Conceivably, that might even include vendor-specific media types where, for some reason or other, links don't fit.
In such cases, I think that links in headers sounds preferable to no links at all. In the presence of such media types, my argument against links in headers no longer holds.
Once more, we've learned that no advice is independent of context. In the context of a RESTful API where such media types may occur, clients would have to be aware that links can appear in headers as well as in the body of any document. In such APIs, 204 responses may be perfectly fine. Here, the extra work of looking two places (both in the body, and in headers) is warranted.
In contexts of APIs where such media types don't occur, clients have no particular reason to expect links in headers. In this case, I still maintain that 204 responses put an unwarranted burden on client developers.
So far, I've only been involved with APIs without such special media types, so my initial advice was obviously coloured by my experience. Thus, I appreciate the alternative perspective.