ploeh blog danish software design
Primitive Dependencies
Primitives are also dependencies
There are tons of examples of how Dependency Injection (DI) can be used to decouple clients and services. When the subject is DI, the focus tends to be heavily on the Liskov Substitution Principle (LSP), so most people think about dependencies as polymorphic types (interfaces or abstract base classes). Primitive types like strings and integers tend to be ignored or discouraged. It doesn't help that most DI Containers need extra help to deal with such values.
Primitives are dependencies, too. It doesn't really matter whether or not they are polymorphic. In the end, a dependency is something that the client depends on - hence the name. It doesn't really matter whether the dependency is an interface, a class or a primitive type. In most object-oriented languages, everything is an object - even integers and booleans (although boxing occurs).
There are several ways to inject dependencies into clients. My book describes a set of patterns including Constructor Injection and Property Injection. It's important to keep in mind that ultimately, the reason why Constructor Injection should be your preferred DI pattern has nothing to do with polymorphism. It has to do with protecting the invariants of the class.
Therefore, if the class in question requires a primitive value in order to work, that is a dependency too. Primitive constructor arguments can be mixed with polymorphic arguments. There's really no difference.
Example: a chart reader #
Imagine that you're building a service which provides Top 40 music chart data. There's a ChartController which relies on an IChartReader:
public class ChartController { private readonly IChartReader chartReader; public ChartController(IChartReader chartReader) { if (chartReader == null) throw new ArgumentNullException("chartReader"); this.chartReader = chartReader; } // ... }
One implementation of IChartReader is based on a database, so it requires a connection string (a primitive). It also requires a configuration value which establishes the size of the chart:
public class DbChartReader : IChartReader { private readonly int top; private readonly string chartConnectionString; public DbChartReader(int top, string chartConnectionString) { if (top <= 0) throw new ArgumentOutOfRangeException( "top", "Only positive numbers allowed."); if (chartConnectionString == null) throw new ArgumentNullException("chartConnectionString"); this.top = top; this.chartConnectionString = chartConnectionString; } // ... }
When top has the value 40, the chart is a Top 40 chart; when the value is 10 it's a Top 10 chart; etc.
Unit testing #
Obviously, a class like DbChartReader is easy to wire up in a unit test:
[Fact] public void UnitTestingExample() { var sut = new DbChartReader( top: 10, chartConnectionString: "localhost;foo;bar"); // Act goes here... // Assert goes here... }
Hard-coded composition #
When it's time to bootstrap a complete application, one of the advantages of treating primitives as dependencies is that you have many options for how and where you define those values. At the beginning of an application's lifetime, the best option is often to hard-code some or all of the values. This is as easy to do with primitive dependencies as with polymorphic dependencies:
var controller = new ChartController( new DbChartReader( top: 40, chartConnectionString: "foo"));
This code is part of the application's Composition Root.
Configuration-based composition #
If the time ever comes to move the arms of the the Configuration Complexity Clock towards using the configuration system, that's easy to do too:
var topString = ConfigurationManager.AppSettings["top"]; var top = int.Parse(topString); var chartConnectionString = ConfigurationManager .ConnectionStrings["chart"].ConnectionString; var controller = new ChartController( new DbChartReader( top, chartConnectionString));
This is still part of the Composition Root.
Wiring a DI Container with primitives #
Most DI Containers need a little help with primitives. You can configure components with primitives, but you often need to be quite explicit about it. Here's an example of configuring Castle Windsor:
container.Register(Component .For<ChartController>()); container.Register(Component .For<IChartReader>() .ImplementedBy<DbChartReader>() .DependsOn( Dependency.OnAppSettingsValue("top"), Dependency.OnValue<string>( ConfigurationManager.ConnectionStrings["chart"] .ConnectionString)));
This configures the ChartController type exactly like the previous example, but it's actually more complicated now, and you even lost the feedback from the compiler. That's not good, but you can do better.
Conventions for primitives #
A DI Container like Castle Windsor enables you define your own conventions. How about these conventions?
- If a dependency is a string and it ends with "ConnectionString", the part of the name before "ConnectionString" is the name of an entry in the app.config's connectionStrings element.
- If a dependency is a primitive (e.g. an integer) the name of the constructor argument is the key to the appSettings entry.
That would be really nice because it means that you can keep on evolving you application by adding code, and it just works. Need a connection string to the 'artist database'? Just add a constructor argument called "artistConnectionString" and a corresponding artist connection string in your app.config.
Here's how those conventions could be configured with Castle Windsor:
container.Register(Classes .FromAssemblyInDirectory(new AssemblyFilter(".") .FilterByName(an => an.Name.StartsWith("Ploeh"))) .Pick() .WithServiceAllInterfaces()); container.Kernel.Resolver.AddSubResolver( new ConnectionStringConventions()); container.Kernel.Resolver.AddSubResolver( new AppSettingsConvention());
The Register call scans all appropriate assemblies in the application's root and registers all components according to the interfaces they implement, while the two sub-resolvers each implement one of the conventions described above.
public class ConnectionStringConventions : ISubDependencyResolver { public bool CanResolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return dependency.TargetType == typeof(string) && dependency.DependencyKey.EndsWith("ConnectionString"); } public object Resolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { var name = dependency.DependencyKey.Replace("ConnectionString", ""); return ConfigurationManager.ConnectionStrings[name].ConnectionString; } }
The CanResolve method ensures that the Resolve method is only invoked for string dependencies with names ending with "ConnectionString". If that's the case, the connection string is simply read from the app.config file according to the name.
public class AppSettingsConvention : ISubDependencyResolver { public bool CanResolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { return dependency.TargetType == typeof(int); // or bool, Guid, etc. } public object Resolve( CreationContext context, ISubDependencyResolver contextHandlerResolver, ComponentModel model, DependencyModel dependency) { var appSettingsKey = dependency.DependencyKey; var s = ConfigurationManager.AppSettings[appSettingsKey]; return Convert.ChangeType(s, dependency.TargetType); } }
This other convention can be used to trigger on primitive dependencies. Since this is a bit of demo code, it only triggers on integers, but I'm sure you'll be able to figure out how to make it trigger on other types as well.
Using convention-based techniques like these can turn a DI Container into a very powerful piece of infrastructure. It just sit there, and it just works, and rarely do you have to touch it. As long as all developers follow the conventions, things just work.
Facade Test
This post proposes the term Facade Test for an automated test which is more than a unit test, but not quite an integration test.
There are several definitions of what a unit test is, but the one that I personally prefer goes something like this:
A unit test is an automated test that tests a unit in isolation.
This is still a rather loose definition. What's a unit? What's does isolation mean? The answers to these questions seem to be a bit fluffy, but I think it's safe to say that a unit isn't bigger than a class. It's not a library (or 'assembly' in .NET terms). It's not all types in a namespace. In my opinion, a unit is a method... and a bit more. In OO, a method is coupled to it's defining class, which is the reason why I think of a unit as a bit more than a method.
If that's a unit, then isolation means that you should be able to test the unit without using or relying on any other moving pieces of production code.
Often, unit testing means that you have to decouple objects in order to achieve isolation. There's a few ways to do that, but Dependency Injection is a very common approach. That often leads to heavy use of dynamic mocks and too many interfaces that exist exclusively to support unit testing.
Sometimes, a good alternative is to write automated tests that exercise a larger group of classes. When all the collaborating classes are deterministic and implemented within the same library, this can be an effective approach. Krzysztof Koźmic describes that
Another example is AutoFixture, which has hundreds of automated tests against the Fixture class.
We need a name for tests like these. While we could call them Integration Tests, this label would lump them together with tests that exercise several libraries at once.
To distinguish such tests from Unit Tests on the one side, and Integration Tests on the other side, I suggest the name Facade Test
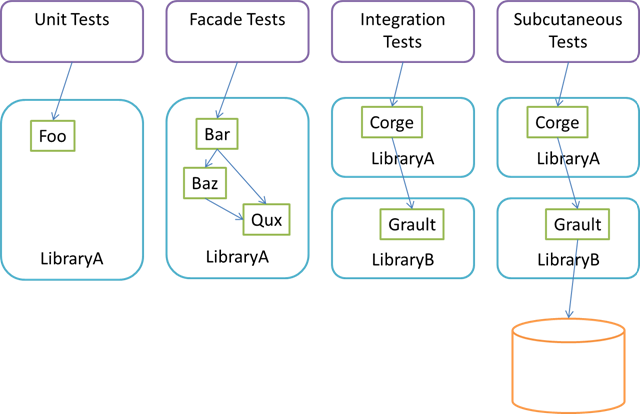
The reason why I suggest the term Facade Test is that such automated tests tend to mostly target a small subset of classes that act as Facades over many other classes in a library.
Comments
Unit test: usually just one class but occasionally a couple of closely related classes, constructed and executed directly from the test code. Runs fast and no contact with the outside world.
Database or Comms test: testing in isolation that a single class that interacts with something externally works. e.g. a class that accesses the database actually accesses the database, a class that contacts a remote server actual contacts a remote server (probably a special one we wrote for testing purposes).
Scenario test: multiple classes, but with all external dependencies replaced with test doubles (e.g. no database access, no SOAP calls, no HTTP requests). Object graph is constructed via the same mechanism as the real object graph. So in some sense this tests the DI configuration. This is a form of integration test, but everything runs in memory so they are quick. Most of our tests are at this level.
Acceptance test: full application running and tested with Selenium.
And then there is manual testing.
"Let's drive this through Facade Tests" now means something else than "Let's drive this through Unit Tests".
Test-specific Equality versus Domain Equality
As a reaction to my two previous blog posts, Joe Miller asks on Twitter:
That's a fair question which I'd like to answer here.
You should definitely strive towards having domain objects with strong equality semantics. Many things (including unit testing) becomes easier when domain objects override Equals in a meaningful manner. By all means should you prefer that over any Resemblance or Likeness craziness.
What is meaningful equality for a domain object? Personally, I find the guidance provided by Domain-Driven Design indispensable:
- If the domain object is an Entity, two objects are equal if their IDs are equal. No other properties should be compared.
- If the domain object is a Value Object, two object are equal if (all) their encapsulated data is equal.
- If the domain object is a Service, by default I'd say that the default reference equality is often the most correct (i.e. don't override Equals).
Now consider the very common case of mapping layers, or the slightly related scenario of an Anti-corruption Layer. In such cases, the code translates Entities to and from other representations. How do we unit test such mapping code?
If we were to rely on the domain object's built-in equality, we would only be testing that the identity of the Entity is as expected, but not whether or not the mapping code properly maps all the other data. In such cases we need Test-specific Equality, and that's exactly what Resemblances and Likenesses provide.
In the previous example, this is exactly what happens. The SUT produces a new instance of the RequestReservationCommand:
[HttpPost] public ViewResult Post(BookingViewModel model) { this.channel.Send(model.MakeReservation()); return this.View("Receipt", model); }
The MakeReservation method is implemented like this:
public RequestReservationCommand MakeReservation() { return new RequestReservationCommand( this.Date, this.Email, this.Name, this.Quantity); }
Notice that nowhere does the code specify the identity of the RequestReservationCommand instance. This is done by the RequestReservationCommand constructor itself, because it's a domain rule that (unless deserialized) each command has a unique ID.
Thus, from the unit test, you have absolutely no chance of knowing what the ID will be (it's a GUID). You could argue back and forth on whether the RequestReservationCommand class is an Entity or a Value Object, but in both cases, Domain Equality would involve comparing IDs, and those will never match. Therefore, the correct Test-specific Equality is to compare the values without the Id property.
Comments
From a behavioral point of view, we don't really care about the value of the ID (the Guid). From other tests we know that a new instance of a command will always have a unique ID. It's part of the command's invariants. Thus, we know that the ID is going to be unique, so having to configure an Ambient Context is only going to add noise to a unit test.
Resemblance and Likeness
In a previous post I described the Resemblance idiom. In this post I present a class that can be used to automate the process of creating a Resemblance.
The Resemblance idiom enables you to write readable unit tests, but the disadvantage is that you will have to write (and maintain) quite a few test-specific Resemblance classes. If you're a Coding Neat Freak like me, you'll also have to override GetHashCode in every Resemblance, just because you're overriding Equals. If you're still looking for ways to torment yourself, you'll realize that the typical Resemblance implementation of Equals contains branching logic, so ideally, it should be unit tested too. (Yes, I do occasionally unit test my unit testing helper classes. AutoFixture, which is essentially one big unit test helper, is currently covered by some three thousand tests.)
In that light, wouldn't it be nice if you were able to automate the process of defining Resemblance classes? With the Likeness class, you can. Likeness is currently bundled with AutoFixture, so you get it if you install the AutoFixture NuGet package or if you download the AutoFixture zip file from its CodePlex site. The Likeness class can be found in an assembly named Ploeh.SemanticComparison. In the future, I plan on packaging this as a separate NuGet package, but currently, it's included with AutoFixture.
Likeness #
Before I show you how to turn a Likeness into a Resemblance, I think a very short introduction to Likeness is in order. A couple of years ago I introduced Likeness on my blog, but I think a re-introduction is in order. In the context of the unit test from the previous blog post, instead of manually writing a test like this:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<RequestReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = model.MakeReservation(); channelMock.Verify(c => c.Send(It.Is<RequestReservationCommand>(cmd => cmd.Date == expected.Date && cmd.Email == expected.Email && cmd.Name == expected.Name && cmd.Quantity == expected.Quantity))); }
Likeness will do it for you, using Reflection to match properties according to name and type. By default, Likeness compares all properties of the destination instance. This will not work in this test, because the RequestReservationCommand also includes an Id property which is a Guid which is never going to be the same across different instances:
public MakeReservationCommand( DateTime date, string email, string name, int quantity) { this.date = date; this.email = email; this.name = name; this.quantity = quantity; this.id = Guid.NewGuid(); }
Notice that the above test exludes the Id property. It's not very clear that this is going on, so a Test Reader may think that this is an accidental omission. With Likeness, this becomes explicit:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<MakeReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = model.MakeReservation() .AsSource().OfLikeness<MakeReservationCommand>() .Without(d => d.Id); channelMock.Verify(c => c.Send(It.Is<MakeReservationCommand>(x => expected.Equals(x)))); }
Notice how the Without method explicitly states that the Id property should be excluded from the comparison. By convention, all other properties on the target type (MakeReservationCommand, which in this case is the same as the source type) must be equal to each other.
The AsSource().OfLikeness extension method chain creates an instance of Likeness<MakeReservationCommand, MakeReservationCommand>, which isn't the same as an instance of MakeReservationCommand. Thus, you are still forced to use the slightly awkward It.Is syntax to express what equality means:
channelMock.Verify(c => c.Send(It.Is<MakeReservationCommand>(x => expected.Equals(x))));
If a Likeness could be used as a Resemblance, the test would be more readable.
Likeness as Resemblance #
The definition of the Likeness class is this:
public class Likeness<TSource, TDestination> : IEquatable<TDestination>
While it implements IEquatable<TDestination> it isn't a TDestination. That's the reason for the It.Is syntax above.
Thanks to awesome work by Nikos Baxevanis, a Likeness instance can create a dynamic proxy of TDestination, as long as TDestination is non-sealed and doesn't seal the Equals method. The method is called CreateProxy:
public TDestination CreateProxy();
This effectively turns the Likeness into a Resemblance by dynamically emitting a derived class that overrides Equals in the way that the Likeness instance (re)defines equality. With that, you can rewrite the unit test so that it's both readable and maintainable:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<RequestReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = model.MakeReservation() .AsSource().OfLikeness<RequestReservationCommand>() .Without(d => d.Id) .CreateProxy(); channelMock.Verify(c => c.Send(expected)); }
The only difference in the definition of the expected variable is the additional call to CreateProxy. This changes the type of expected so that it's no longer Likeness<MakeReservationCommand, MakeReservationCommand>, but rather MakeReservationCommand (actually, a dynamically created sub-type of MakeReservationCommand). This enables you to write a readable assertion:
channelMock.Verify(c => c.Send(expected));
This is exactly the same assertion as the assertion used with the Resemblance idiom described in the previous post. Thus, Likeness has now been turned into a Resemblance, and you no longer have to manually create and maintain concrete Resemblance classes.
Comments
Once again, you guys have done it. I've used foo.AsSource().OfLikeness() before, but the CreateProxy trick solved the exact problem I was having.
I'm continually impressed with the power you've packed into this relatively small tool (AutoFixture).
The Resemblance idiom
In this post I describe a unit testing trick which can be used to make assertions more readable.
Many TDD or unit testing experts (e.g. Roy Osherove) give the advice that a unit test should only contain a single assertion. This is a pretty good piece of advice, but sometimes a single assertion is best interpreted as a single logical assertion.
When it comes to state-based testing, you can often write a Custom Assertion to encapsulate multiple assertions into a single logical assertion. For interaction-based testing (i.e. using mock objects) this can be a bit harder.
In order to write readable unit tests with single assertions, I sometimes use an idiom that I'll describe here. Since I've never seen it described anywhere else, I can't reasonably call it a design pattern, so I'll stick with the less universal term idiom - I call it the Resemblance idiom. In short, it introduces a test-specific override of an object's equality method.
Motivating example #
Assume that you're TDD'ing this method:
[HttpPost] public ViewResult Post(BookingViewModel model) { this.channel.Send(model.MakeReservation()); return this.View("Receipt", model); }
Obviously, when TDD'ing, the method isn't going to have any implementation before the test has been written, but for educational purposes, in this case I'm showing you the implementation before the test - I still wrote the tests first. This is the implementation you'd like to arrive at - particularly this line of code:
this.channel.Send(model.MakeReservation());
The challenge here is that the MakeReservation method returns an instance of RequestReservationCommand, which is a data-carrying class (some would call it a DTO) that doesn't override Equals. One option is to override Equals, but that would lead to Equality Pollution, since the equality semantics of RequestReservationCommand isn't going to match what you need in order to write the test.
Using Moq, your first take might look something like this:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<RequestReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = model.MakeReservation(); channelMock.Verify(c => c.Send(It.Is<RequestReservationCommand>(cmd => cmd.Date == expected.Date && cmd.Email == expected.Email && cmd.Name == expected.Name && cmd.Quantity == expected.Quantity))); }
This works, but is awkward. First of all, I'd prefer a more readable test than this. Secondly, what happens if, in the future, someone adds a new property to the RequestReservationCommand class? If you have a lot of tests like this one, should they all be updated to include the new property in the comparison?
Attempted fix #
The first fix you might attempt involves extracting the comparison to a helper method like this one:
private static bool Equals(RequestReservationCommand expected, RequestReservationCommand actual) { return actual.Date == expected.Date && actual.Email == expected.Email && actual.Name == expected.Name && actual.Quantity == expected.Quantity; }
This is better because at least it gives you a central method where you can manage which properties should be included in the comparison, but from a test invocation perspective it's still a bit unwieldy:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<RequestReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = model.MakeReservation(); channelMock.Verify(c => c.Send(It.Is<RequestReservationCommand>(cmd => Equals(expected, cmd)))); }
You're still stuck with the It.Is noise and a lambda expression. Being a static helper method, it's also not very object-oriented. Perhaps you don't care about that, but by not being object-oriented, it's also not very composable. This can come back to bite you if you want to compare complex object graphs, because it's dificult to compose static methods. There's a another way which provides a better alternative.
Resemblance #
The trick is to recall that ultimately, most unit testing is about determining whether the actual outcome is equal to the expected outcome. Since the Equals method is virtual, you can simply create a test-specific child class that overrides the Equals method. This is what I call a Resemblance.
private class RequestReservationCommandResemblance : RequestReservationCommand { public RequestReservationCommandResemblance(RequestReservationCommand source) : base(source.Date, source.Email, source.Name, source.Quantity) { } public override bool Equals(object obj) { var other = obj as RequestReservationCommand; if (other != null) return object.Equals(this.Date, other.Date) && object.Equals(this.Email, other.Email) && object.Equals(this.Name, other.Name) && object.Equals(this.Quantity, other.Quantity); return base.Equals(obj); } public override int GetHashCode() { return this.Date.GetHashCode() ^ this.Email.GetHashCode() ^ this.Name.GetHashCode() ^ this.Quantity.GetHashCode(); } }
Notice that the RequestReservationCommandResemblance class derives from RequestReservationCommand in order to override Equals (and GetHashCode for good measure). This looks a bit more complicated than the previous attempt at a fix, but it's much more object-oriented and composable, and most importantly: the test is much easier to read because almost all the noise can be removed:
[Theory, AutoWebData] public void PostSendsOnChannel( [Frozen]Mock<IChannel<RequestReservationCommand>> channelMock, BookingController sut, BookingViewModel model) { sut.Post(model); var expected = new RequestReservationCommandResemblance(model.MakeReservation()); channelMock.Verify(c => c.Send(expected)); }
Notice in particular how you're now able to state exactly what you care about, instead of how you care about it:
channelMock.Verify(c => c.Send(expected));
You may still feel that the overhead of creating a new test-specific class just for this purpose doesn't quite justify the increased readability and composability, but stay tuned - I have more tricks to show you.
Comments
"One situation we want to avoid, however, is when we can’t diagnose a test
failure that has happened. The last thing we should have to do is crack open the
debugger and step through the tested code to find the point of disagreement.", GOOS
In GOOS they are better off because they use Hamcrest, and their mocking library understands Hamcrest matchers. That's not the situation in .NET (yet).
The only way around this that I can think of is to call the Verify method four times - one for each property above. IMO that would be sacrificing either readability or maintainability to optimize for a failure scenario which should only occur rarely. I prefer to optimize for readability instead. YMMV.
Or something like
IEqualityComparer[RequestReservationCommand] CreateRequestReservationCommandComparer()
{
return CreateComparer[RequestReservationCommand](
c => c.Date, c => c.Email, c => c.Name, c => c.Quantity
);
}
Although I'm not sure how composable that would be.
BTW, I can't seem to post any comment containing the less than sign, it says:
An error has been encountered while processing the page. We have logged the error condition and are working to correct the problem. We apologize for any inconvenience.
(and yes: the comment engine here is really crappy - sorry about that)
Do you have a solution for that?
When it comes to direct assertions, like Assert.Equal, I'd love it if we had something like Hamcrest Matchers in .NET (actually, there is a .NET port, but last time I looked, it seemed abandonded). The next best thing is often a custom IEqualityComparer, but that doesn't necessarily solve the pretty print error reporting need.
Sometimes, it's nice to have both, so one can implement a custom IEqualityComparer and then use that class to also implement a Resemblance.
FWIW, the Likeness class described in the next blog post is built that way. It also includes a ShouldEqual method as a very concrete way of providing more readable error reporting...
I used the approach with an implementation of IEqualityComparer
Bank OCR kata in F#: user stories 3 and 4
In previous posts, I've walked through the first two user stories of the Bank OCR kata in F#. In this post I'll walk through my implementation of user stories 3 and 4.
The reason I'm collecting both user stories in a single blog post is that the requirements of user story 4 represent a change from user story 3, and since I didn't use a DVCS for this kata, I no longer have my implementation for user story 3.
The core unit test #
As with the previous user stories, I started by writing a Parameterized Test:
[<Theory>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| ||_ _| | _||_| ||_| _|", "123456789")>] [<InlineData(" _ _ _ _ _ _ _ _ _||_||_ |_||_| _||_||_ |_ _| | _||_||_||_ |_||_| _|", "345882865")>] [<InlineData(" _ _ _ _ _ _ _||_||_ |_||_| _||_| ||_| _| | _||_||_||_ |_| | |", "345882814")>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| ||_ _| | _||_| ||_||_|", "123456789")>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| | _| _| | _||_| ||_||_|", "133456788 AMB ['133456188', '193456788']")>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_|| | | _| _| | _||_| ||_||_|", "133456780 ERR")>] [<InlineData(" _ _ _ _ _ _ _||_||_ |_||_| _||_| ||_| _|| | _||_||_||_ |_| | |", "345882814")>] [<InlineData(" _ _ _ _ _ _ |_||_ | || | _| _ _||_ |_||_| | ||_| |_| _||_|", "86110??36 ILL")>] [<InlineData(" _ _ _ _ _ _ _||_||_ |_||_| _||_| ||_| _| | _|| |_| |_| | |", "345?8?814 ILL")>] [<InlineData(" | | | | | | | | | | | | | | | | | |", "711111111")>] [<InlineData(" _ _ _ _ _ _ _ _ _ | | | | | | | | | | | | | | | | | |", "777777177")>] [<InlineData(" _ _ _ _ _ _ _ _ _ _|| || || || || || || || | |_ |_||_||_||_||_||_||_||_|", "200800000")>] [<InlineData(" _ _ _ _ _ _ _ _ _ _| _| _| _| _| _| _| _| _| _| _| _| _| _| _| _| _| _|", "333393333")>] [<InlineData(" _ _ _ _ _ _ _ _ _ |_||_||_||_||_||_||_||_||_| |_||_||_||_||_||_||_||_||_|", "888888888 AMB ['888886888', '888888880', '888888988']")>] [<InlineData(" _ _ _ _ _ _ _ _ _ |_ |_ |_ |_ |_ |_ |_ |_ |_ _| _| _| _| _| _| _| _| _|", "555555555 AMB ['559555555', '555655555']")>] [<InlineData(" _ _ _ _ _ _ _ _ _ |_ |_ |_ |_ |_ |_ |_ |_ |_ |_||_||_||_||_||_||_||_||_|\r\n", "666666666 AMB ['686666666', '666566666']")>] [<InlineData(" _ _ _ _ _ _ _ _ _ |_||_||_||_||_||_||_||_||_| _| _| _| _| _| _| _| _| _|", "999999999 AMB ['993999999', '999959999', '899999999']")>] [<InlineData(" _ _ _ _ _ _ _ |_||_|| || ||_ | | ||_ | _||_||_||_| | | | _|", "490067715 AMB ['490067115', '490867715', '490067719']")>] [<InlineData(" _ _ _ _ _ _ _ _| _| _||_||_ |_ ||_||_| ||_ _| | _||_| ||_| _|", "123456789")>] [<InlineData(" _ _ _ _ _ _ _ | || || || || || || ||_ | |_||_||_||_||_||_||_| _| |", "000000051")>] [<InlineData(" _ _ _ _ _ _ _ |_||_|| ||_||_ | | | _ | _||_||_||_| | | | _|", "490867715")>] let ParseToPrintoutReturnsCorrectResult entry expected = entry |> ParseToPrintout |> should equal expected
Once again the test utilizes xUnit.net's data theories feature to decouple the test code from the test data, as well as FsUnit for the assertion DSL.
The test is really simple: it's 85 lines of data and three lines of code which state that the result of piping the entry argument to the ParseToPrintout function should be equal to the expected argument.
Implementation #
The implementation may seem more daunting. At first, I'll post the function in its entirety, and afterwards I'll break it down and walk you through it.
let ParseToPrintout entry = let toPrintable opt = match opt with | Some(d) -> d.ToString() | None -> "?" let formatEntry s = s |> ParseToDigits |> Seq.map toPrintable |> String.Concat let isLegible potentialDigits = potentialDigits |> Seq.forall Option.isSome let isValidAndLegible s = let potentialDigits = s |> ParseToDigits (potentialDigits |> isLegible) && (potentialDigits |> skipNones |> IsValid) if entry |> isValidAndLegible then entry |> formatEntry else let getCandidates chars = let withAlternatives c = seq { match c with | ' ' -> yield! [ '|'; '_' ] | '|' | '_' -> yield ' ' | _ -> yield! [] } chars |> Seq.mapi (fun i _ -> chars |> ReplaceAt i withAlternatives) |> Seq.concat let validCandidates = entry.ToCharArray() |> getCandidates |> Seq.map ToString |> Seq.filter isValidAndLegible |> Seq.toList let formatAlternatives alternatives = alternatives |> Seq.map formatEntry |> Seq.map (sprintf "'%s'") |> Seq.reduce (sprintf "%s, %s") match validCandidates with | [head] -> head |> formatEntry | [] -> if entry |> ParseToDigits |> isLegible then entry |> formatEntry |> sprintf "%s ERR" else entry |> formatEntry |> sprintf "%s ILL" | _ -> validCandidates |> formatAlternatives |> sprintf "%s AMB [%s]" (formatEntry entry)
The first thing to notice is that the ParseToPrintout function is composed of quite a few helper functions. A thing that I currently don't like so much about F# is that it's necessary to define a function before it can be used, so all the helper functions must appear before the function that defines the general flow.
It's possible to move the helper functions to other modules so that they don't clutter the implementation, but most of the functions defined here seem to me to be a very specialized part of the overall implementation. In this particular code base, I've been working under the assumption that it would be best to define a function in as narrow a scope as possible, but looking at the result, I don't think that was the right decision. In the future, I think I'll move more helper functions to a separate module.
Valid and legible #
As a start, skim past the helper functions. The actual program flow of the function starts here:
if entry |> isValidAndLegible then entry |> formatEntry
That part of the if/then branch should be fairly easy to understand. If the entry is valid (according to the checksum function from user story 2) and legible, the result is formatted and returned.
The isValidAndLegible function determines whether the entry is... well... valid and legible. The first thing it does is to pipe the string into the ParseToDigits function, which, you'll recall, returns a sequence of integer options.
To figure out whether those potential digits are legible it invokes the isLegible function, which I'll return to shortly.
In order to figure out whether the potential digits are valid, it invokes the IsValid method from user story 2. However, in order to do so, it needs to convert the sequence of integer options to a sequence of integers. It does that by invoking the skipNones helper method, that I defined in a helper module:
let skipNones sequence = Seq.collect Option.toArray sequence
This function takes a sequence of options and returns a sequence of values by skipping all the Nones. It does that by turning each option into an array of 0 or 1 elements and then concatenate all these arrays together to form a new sequence.
This array is piped into the IsValid function, which will only return true if there are exactly nine digits and the checksum is OK.
The isLegible function is simpler because all it needs to do is to verify that all the options are Somes (instead of Nones).
Formatting the entry #
The formatEntry function pipes the entry into the ParseToDigits function, which returns a sequence of integer options. Each option is mapped into a string, replacing each None with a "?".
Finally, the sequence of strings is concatenated into a single string by piping it to the built-in String.Concat method.
Finding candidates #
While formatting the entry is fairly easy if it's valid and legible, it suddenly becomes much harder to attempt to find other candidates if the entry seems invalid. What needs to be done in this case is to iterate through each and every character of the entry and try to replace just a single character at a time to see if it produces a better entry.
According to user story 4, a blank space could be either a vertical pipe or and underscore, while an underscore and a pipe might instead be a blank space. This relationship can be formalized by the withAlternatives function:
let withAlternatives c = seq { match c with | ' ' -> yield! [ '|'; '_' ] | '|' | '_' -> yield ' ' | _ -> yield! [] }
This function takes as input a single character and returns a sequence of characters. If the input is ' ', the output is a list containing '|' and '_'. On the other hand, if the input is either '|' or '_', the output is a sequence with the single element ' '. For all other characters (such as line breaks), the output is an empty sequence, indicating that no replacement should be attempted.
This defines the alternatives which can be fed into the ReplaceAt helper function:
let ReplaceAt index produceReplacements sequence = sequence |> Seq.nth index |> produceReplacements |> Seq.map (fun x -> sequence |> ReplaceElementAt index x)
In this case, the ReplaceAt function takes as input a sequence of characters (the entry string) and a function providing alternatives (withAlternatives) and produces a sequence of sequence of characters where only a single character has been replaced according to the alternatives.
If that sounds difficult, perhaps these unit tests explain the behavior better:
[<Fact>] let ProduceAllReplacementsAtReturnsCorrectResult1() = let actual = ReplaceAt 0 (fun c -> [ 'I'; 'i' ]) "123" actual |> Seq.map ToString |> should equalSequence [ "I23"; "i23" ] [<Fact>] let ProduceAllReplacementsAtReturnsCorrectResult2() = let actual = ReplaceAt 1 (fun c -> [ 'V' ]) "153" actual |> Seq.map ToString |> should equalSequence [ "1V3" ]
The first unit tests replaces the first (zero-indexed) character in the input string "123" with two alternatives, 'I' and 'i', producing the output sequence of "I23" and "i23".
The second test replaces the second (zero-indexed) character in the input string "153" with the single alternative 'V' to produce the output "1V3".
The ReplaceAt function does this by first using the Seq.nth function to pick the nth character out of the sequence, and then pipe that character into the function that produces the alternatives. This produces a sequence of replacement characters, e.g. '|' and '_' as explained above.
This sequence of replacement characters is then used to produce a sequence of strings where the element at the index is replaced with each of the replacement characters. In order to do that, the original input is piped into the ReplaceElementAt helper function:
let ReplaceElementAt index element sequence = let beforeIndex = sequence |> Seq.take index let atIndex = element |> Seq.singleton let afterIndex = sequence |> Seq.skip (index + 1) afterIndex |> Seq.append atIndex |> Seq.append beforeIndex
This function takes a sequence of elements (e.g. a string) and returns another sequence (e.g. another string) by replacing the element at the specified index with the supplied element.
All these helper functions can be combined to produce a sequence of candidate strings:
chars |> Seq.mapi (fun i _ -> chars |> ReplaceAt i withAlternatives) |> Seq.concat
Of these candidates, a lot will be invalid, but filtering them to find only the valid candidates is fairly easy:
let validCandidates =
entry.ToCharArray()
|> getCandidates
|> Seq.map ToString
|> Seq.filter isValidAndLegible
|> Seq.toList
This final list of candidates is a list instead of a sequence because it enables me to use list pattern matching to deal with the cases of a single, none, or multiple valid alternatives:
match validCandidates with | [head] -> head |> formatEntry | [] -> if entry |> ParseToDigits |> isLegible then entry |> formatEntry |> sprintf "%s ERR" else entry |> formatEntry |> sprintf "%s ILL" | _ -> validCandidates |> formatAlternatives |> sprintf "%s AMB [%s]" (formatEntry entry)
If there's only a single valid alternative, the [head] match is triggered and the decomposed head variable is simply piped to the formatEntry function.
If there's no valid alternative, the [] match is triggered, and the final formatting is then based on whether or not the entry is legible or not.
Finally, if there are multiple candidates, each is formatted and appended as ambiguous alternatives to the original (invalid) input.
In case you'd like to take an even closer look at the code, I've attached the entire solution as a zip file: KataBankOCR.zip (299.62 KB)
Comments
Soon, I'll write a small blog post on one way in which SOLID relates to Functional Programming.
I second 'Real World Functional Programming: With Examples in F# and C#', it's a really great book!
One very minor change to one of your helper-functions could be to use the backward pipe operator when combining the sequences in ReplaceElementAt, that way one doesn't need to have the somewhat confusing reverse append-order. Or simply use seq { } and you won't need the atIndex. See following gist for alternatives:
https://gist.github.com/3049158
Thanks for the alternatives for the ReplaceElementAt function. I was never happy with the readability of my implementation. I like the seq { } alternative best, so I've updated my own source code :)
Bank OCR kata in F#: user story 2
Following up on my initial post about the Bank OCR kata, this post walks through the code required to implement user story 2, which is about calculating a checksum.
The code I previously described already contains a function called ParseToDigits which returns a sequence of digits, so it seems reasonable to express the validation function as based on a sequence of digits as input.
The core unit test #
To ensure that the behavior of the new IsValid function would be correct, I wrote this Parameterized Test:
[<Theory>] [<InlineData(1, 2, 3, 4, 5, 6, 7, 8, 9, true)>] [<InlineData(3, 4, 5, 8, 8, 2, 8, 6, 5, true)>] [<InlineData(3, 4, 5, 8, 8, 2, 8, 1, 4, true)>] [<InlineData(7, 1, 5, 8, 8, 2, 8, 6, 4, true)>] [<InlineData(7, 4, 5, 8, 8, 2, 8, 6, 5, false)>] [<InlineData(7, 4, 5, 8, 8, 2, 8, 6, 9, false)>] [<InlineData(7, 4, 5, 8, 8, 2, 8, 6, 8, false)>] [<InlineData(1, 2, 3, 4, 5, 6, 7, 8, 8, false)>] [<InlineData(1, 3, 3, 4, 5, 6, 7, 8, 8, false)>] [<InlineData(1, 3, 3, 4, 5, 6, 7, 8, 0, false)>] let IsValidReturnsCorrectResult d9 d8 d7 d6 d5 d4 d3 d2 d1 expected = seq { yield! [d9; d8; d7; d6; d5; d4; d3; d2; d1] } |> IsValid |> should equal expected
As was the case for the previous tests, this test utilizes xUnit.net's data theories feature to succinctly express a parameterized test, as well as FsUnit for the assertion DSL.
Once again I'd like to point out how the use of pipes enables me to very compactly follow the Arrange Act Assert (AAA) test pattern.
Implementation #
The IsValid function is very simple:
let IsValid digits = match digits |> Seq.toArray with | [| d9; d8; d7; d6; d5; d4; d3; d2; d1 |] -> (d1 + 2 * d2 + 3 * d3 + 4 * d4 + 5 * d5 + 6 * d6 + 7 * d7 + 8 * d8 + 9 * d9) % 11 = 0 | _ -> false
The input sequence is converted to an array by piping it into the Seq.toArray function. The resulting array is then matched against an expected shape.
If the array contains exactly 9 elements, each element is decomposed into a named variable (d9, d8, etc.) and passed to the correct checksum formula. The formula only returns true if the calculated result is zero; otherwise it returns false.
If the input doesn't match the expected pattern, the return value is false. The following tests prove this:
[<Fact>] let IsValidOfTooShortSequenceReturnsFalse() = seq { yield! [3; 4; 5; 8; 8; 2; 8; 6] } |> IsValid |> should equal false [<Fact>] let IsValidOfTooLongSequenceReturnsFalse() = seq { yield! [3; 4; 5; 8; 8; 2; 8; 6; 5; 7] } |> IsValid |> should equal false
In a future post I will walk you through user stories 3 and 4.
Comments
Because of F# powerful type inference, that's what the function ends up doing anyway, but with TDD, it's the test that specifies the shape of the API, not the other way around.
However, I could also have written [d9; d8; d7; d6; d5; d4; d3; d2; d1] |> List.toSeq... There's no particular reason why I chose a sequence expression over that...
Bank OCR kata in F#: user story 1
In case my previous post left readers in doubt about whether or not I like Functional Programming (FP), this post should make it clear that I (also) love FP.
A couple of years ago I had the pleasure of performing a technical review of Real World Functional Programming, which caused me to significantly shift my C# coding style towards a more functional style.
Now I want to take the next step, so I've started doing katas in F#. In a series of blog posts, I'll share my experiences with learning F# as I go along. I'm sure that the F# gods will wince from my code, but that's OK - if any of my readers find this educational, my goal will be met.
In this post I'll start out with the first use case of the Bank OCR kata.
The core unit test #
The first thing I wanted to do was write a couple of tests to demonstrate that I could parse the input. This Parameterized Test uses xUnit.net data theories and FsUnit for the assertion:
[<Theory>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| ||_ _| | _||_| ||_| _|", 123456789)>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| ||_ _| | _||_| ||_||_|", 123456788)>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_||_| | _| _| | _||_| ||_||_|", 133456788)>] [<InlineData(" _ _ _ _ _ _ _ | _| _||_||_ |_ ||_|| | | _| _| | _||_| ||_||_|", 133456780)>] let ParseToNumberReturnsCorrectResult entry expected = entry |> ParseToNumber |> should equal expected
One of the many nice features of F# is that it's possible to break string literals over multiple lines, so instead of having one wide, unreadable string with "\r\n" instead of line breaks, I could write the test cases directly in the test source code and keep them legible.
In the test function body itself, I pipe the entry function argument into the ParseToNumber function using the pipeline operator |>, so
entry |> ParseToNumber
is equivalent to writing
ParseToNumber entry
However, by piping the input into the SUT and the result further on to the assertion, I achieve a very dense test method where it's fairly clear that it follows the Arrange Act Assert (AAA) pattern.
The assertion is expressed using FsUnit's F# adapter over xUnit.net. It should be clear that it states that the result (piped from the ParseToNumber function) should be equal to the expected function argument.
Implementation #
Here's the body of the ParseToNumber function:
let ParseToNumber entry = entry |> ParseToDigits |> Seq.map Option.get |> Seq.reduce (fun x y -> x * 10 + y)
If you're used to read and write C# you may be wondering about the compactness of it all. Where are all the type declarations?
F# is a strongly typed language, but it has very sophisticated type inferencing capabilities, so the compiler is able to infer that the signature is string - > int, which (in this case) is read as a function which takes a string as input and returns an integer. The equivalent C# notation would be public int ParseToNumber(string entry).
How does the F# compiler know this?
The entry parameter is easy to infer because the function body invokes the ParseToDigits function, which takes a string as input. Therefore, entry must be a string as well.
The output type is a little harder to understand, but basically it boils down to something like this: the ParseToDigits function returns a sequence (basically, an IEnumerable<T>) of integer options. The Seq.map function converts this to a sequence of integers, and the Seq.fold function aggregates that sequence into a single integer.
Don't worry if you didn't understand all that yet - I'll walk you through the body of the function now.
The entry argument is piped into the ParseToDigits function, which returns a sequence of integer options. An option is a type that either has, or doesn't have, a value, so the next step is to unwrap all the values. This is done by piping the option sequence into the Seq.map function, which is equivalent to the LINQ Select method. The Option.get method simply unwraps a single option. It will throw an exception if the value is None, but in this implementation, this is the desired behavior.
The last thing to do is to aggregate the sequence of integers into a single number. The Seq.reduce method aggregates the sequence according to a given accumulator function.
In F#, an inline code block is written with the fun keyword, but it's entirely equivalent to a C# code block, which would look like this:
(x, y) => x * 10 + y
This function basically interprets the sequence of integers as a stream of digits, so in order to arrive at the correct digital representation of the number, each accumulated result is multiplied by ten and added to the new digit.
Obviously, all the real parsing takes place in the ParseToDigits function:
let ParseToDigits (entry : string) = let toIntOption ocrDigit = match ocrDigit |> Seq.toArray with | [| (' ', '|', '|'); ('_', ' ', '_'); (' ', '|', '|') |] -> Some 0 | [| (' ', ' ', ' '); (' ', ' ', ' '); (' ', '|', '|') |] -> Some 1 | [| (' ', ' ', '|'); ('_', '_', '_'); (' ', '|', ' ') |] -> Some 2 | [| (' ', ' ', ' '); ('_', '_', '_'); (' ', '|', '|') |] -> Some 3 | [| (' ', '|', ' '); (' ', '_', ' '); (' ', '|', '|') |] -> Some 4 | [| (' ', '|', ' '); ('_', '_', '_'); (' ', ' ', '|') |] -> Some 5 | [| (' ', '|', '|'); ('_', '_', '_'); (' ', ' ', '|') |] -> Some 6 | [| (' ', ' ', ' '); ('_', ' ', ' '); (' ', '|', '|') |] -> Some 7 | [| (' ', '|', '|'); ('_', '_', '_'); (' ', '|', '|') |] -> Some 8 | [| (' ', '|', ' '); ('_', '_', '_'); (' ', '|', '|') |] -> Some 9 | _ -> None let lines = entry.Split([| "\r\n" |], StringSplitOptions.RemoveEmptyEntries) Seq.zip3 lines.[0] lines.[1] lines.[2] |> chunk 3 |> Seq.map toIntOption
That may look scary, but is actually not that bad.
The function contains the nested function toIntOption which is local to the scope of ParseToDigits. One of the things I don't like that much about F# is that you have to declare and implement the details before the general flow, so you almost have to read the code backwards if you want the overview before diving into all the details.
The first thing the ParseToDigit function does is to split the input into three lines according to the specification of the kata. It uses the standard .NET String.Split method to do that.
Next, it zips each of these three lines with each other. When you zip something, you take the first element of each sequence and create a tuple out of those three elements; then the second element of each sequence, and so forth. The result is a sequence of tuples, where each tuple represents a vertical slice down a digit.
As an example, let's look at the digit 0:
_ | | |_|
The first vertical slice contains the characters ' ', '|' and '|' so that results in the tuple (' ', '|', '|'). The next vertical slice corresponds to the tuple ('_', ' ', '_') and the third (' ', '|', '|').
With me so far? OK, good.
The Seq.zip3 function produces a sequence of such tuples, but since the kata states that each digit is exactly three characters wide, it's necessary to divide that stream of tuples into chunks of three. In order to do that, I pipe the zipped sequence to the chunk function.
Seq.zip3 lines.[0] lines.[1] lines.[2] |> chunk 3
I'll post the chunk function further down, but the result is a sequence of sequence of chars which can then be mapped with the toIntOption function.
Now that I've explained how those tuples look, the toIntOption shouldn't be too hard to understand. Each ocrDigit argument is expected to be a sequence of three tuples, so after creating an array from the sequence, the function uses pattern matching to match each tuple array to an option value.
It simply matches an array of the tuples (' ', '|', '|'); ('_', ' ', '_'); (' ', '|', '|') to the number 0 (as explained above), and so on.
If there's no match, it returns the option value None, instead of Some.
Hang on, I'm almost done. The last part of the puzzle is the chunk function:
let rec chunk size sequence = let skipOrEmpty size s = if s |> Seq.truncate size |> Seq.length >= size then s |> Seq.skip size else Seq.empty seq { yield sequence |> Seq.truncate size let next = sequence |> skipOrEmpty size if not (Seq.isEmpty next) then yield! chunk size next }
Just like the ParseToDigits function, the chunk function uses a nested function to do some of its work.
First of all you may notice that the function declaration uses the rec keyword, which means that this is a recursive function. FP is all about recursion, so this is just something you'll have to get used to.
The main part of the function consists of a sequence expression, denoted by the seq keyword.
First the function returns the first n elements from the sequence, in order to return the first chunk. Next, it skips that chuck and if the sequence isn't empty it recursively calls itself with the rest of the sequence.
The skipOrEmpty function is just a little helper function to work around the behavior of the Seq.skip function, which throws an exception if you ask it to skip some elements of a sequence which doesn't contain that many elements.
That's it. The code is actually quite compact, but I just took a long time explaining it all in some detail.
In a future post I'll walk through the other use cases of the Bank OCR kata.
Comments
Yeah, in a small example like this it doesn't really matter and readability is more important. But I think things like this should be mentioned, so that people are not surprised if they try to use the function in different contexts.
Design patterns across paradigms
This blog post makes the banal observation that design patterns tend to be intimately coupled to the paradigm in which they belong.
It seems as though lately it has become hip to dismiss design patterns as a bit of a crutch to overcome limitations in Object-Oriented Design (OOD). One example originates from The Joy of Clojure:
"In this section, we'll attempt to dissuade you from viewing Clojure features as design patterns [...] and instead as an inherent nameless quality.
"[...]the patterns described [in Design Patterns] are aimed at patching deficiencies in popular object-oriented programming languages. This practical view of design patterns isn't directly relevant to Clojure, because in many ways the patterns are ever-present and are first-class citizens of the language itself." (page 303)
From what little I've understood about Clojure, that seems like a reasonable assertion.
Another example is a tweet by Neal Swinnerton:
and Stefan Tilkov elaborates:
"@ploeh @sw1nn @ptrelford many OO DPs only exist to replace missing FP features in the first place"
First of all: I completely agree. In fact, I find these statements rather uncontroversial. The only reason I'm writing this is because I see this sentiment popping up more and more (but perhaps I'm just suffering from the Baader-Meinhof phenomenon).
Patterns for OOD #
Many 'traditional' design patterns describe how to solve problems which are complex when working with object-oriented languages. A lot of those problems are inherent in the object-oriented paradigm.
Other paradigms may provide inherent solutions to those problems. As an example, Functional Programming (FP) includes the central concept of Function Composition. Functions can be composed according to signature. In OOD terminology you can say that the signature of a function defines its type.
Most of the classic design patterns are based upon the idea of programming to an interface instead of a concrete class. In OOD, it's necessary to point this out as a piece of explicit advice because the default in OOD is to program against a concrete class.
That's not the case in FP because functions can be composed as long as their signatures are compatible. Loose coupling is, so to speak, baked into the paradigm.
Thus, it's true that many of the OOD patterns are irrelevant in an FP context. That doesn't mean that FP doesn't need patterns.
Patterns for FP #
So if FP (or Clojure, for that matter) inherently address many of the shortcomings of OOD that give rise to patterns, does it mean that design patterns are redundant in FP?
Hardly. This is reminiscent of the situation of a couple of years ago when Ruby on Rails developers were pointing fingers at everyone else because they had superior productivity, but now when they are being tasked with maintaining complex system, they are learning the hard way that Active Record is an anti-pattern. Duh.
FP has shortcomings as well, and patterns will emerge to address them. While FP has been around for a long time, it hasn't been as heavily used (and thus subjected to analysis) as OOD, so the patterns may not yet have been formulated yet, but if FP gains traction (and I believe it will), patterns will emerge. However, they will be different patterns.
Once we have an extensive body of patterns for FP, we'll be able to state the equivalent of the introductory assertion:
Most of the established FP patterns address shortcomings of FP. Using the FloopyDoopy paradigm makes most of them redundant.
What would be shortcomings of FP? I don't know them all, but here's a couple of suggestions:
Mutability #
Apart from calculation-intensive software, most software is actually all about mutating state: Take an order. Save to the database. Write a file. Send an email. Render a view. Print a document. Write to the console. Send a message...
In FP they've come up with this clever concept of monads to 'work around' the problem of mutating state. Yes, monads are very clever, but if they feel foreign in OOD it's because they're not required. Mutation is an inherent part of the OOD paradigm, and it very intuitively maps to the 'real world', where mutation happens all the time. Monads are cool, but not particularly intuitive.
FP practitioners may not realize this, but a monad is a design pattern invented to address a shortcoming in 'pure' functional languages.
Discoverability #
As Phil Trelford kindly pointed out at GOTO Copenhagen 2012, OOD is often characterized by 'dot-driven development.' What does that mean?
It means that given a variable, we can often just enter ".", and our IDE is going to give us a list of methods we can call on the object:

Since behavior is contained by each type, we can use patterns such as Fluent Interface to make it easy to learn a new API. While we can laugh at the term 'dot-driven development' it's hard to deny that it makes it very easy to learn.
The API itself carries the information about how to use it, and what is possible. That's very Clean Code. Out-of-band documentation isn't required.
I wouldn't even know how to address this shortcoming in FP, but I'm sure patterns will evolve.
Different paradigms require different patterns #
All of this boils down to a totally banal observation:
Most patterns address shortcomings specific to a paradigm
Saying that most of the OOD patterns are redundant in FP is like saying that you don't need oven mittens to pour a glass of water.
There might be a slight overlap, but I'd expect most patterns to be tightly coupled to the paradigm in which they were originally stated.
There might be a few patterns that are generally applicable.
The bottom line is that FP isn't inherently better just because many of the OOD design patterns are redundant. Neither is OOD inherently better. They are different. That's all.
Comments
Reg. mutatable state:
"Mutation is an inherent part of the OOD paradigm, and it very intuitively maps to the 'real world', where mutation happens all the time."
As Rich Hickley also told us at Goto Copenhagen, above statement may not be entirely true. Current state changes, but that does not mean that previous state ceases to exist. Also, as software devs we are not necessarily interested in representing the real world, but rather a view of the world that suits our business domain. So the question becomes: does the OOD notion of mutable state suit our business domain, or is the FP model, where everything is an immutable value in time, a better fit?
While we are programmers, we are still human, and unless you get involved in pretty advanced theoretical physics, a practical and very precise world view is that objects change state over time.
Alson, I see dot-driven development even more production in functional programming, or at least what I do as FP in C#. Function composition is nicely enhanced using static extensions over Func, Action and Task. I used this in one of my posts on comparing performance of object instantiation methods.
http://c2.com/cgi/wiki?AreDesignPatternsMissingLanguageFeatures
discussed the necessity of Pattern in FP.
The notion that pattern are not required in FP seems to be around for some time,
PaulGraham said "Peter Norvig found that 16 of the 23 patterns in Design Patterns were 'invisible or simpler' in Lisp." http://www.norvig.com/design-patterns/
- Trying to combine OOD and pure FP is pointless and misses the point. Less is more.
- Design patterns are analogous to cooking recipes.
- Monads are not a "design pattern invented to address a shortcoming in 'pure' functional languages".
I came late to comment, but again I'm here due to an exchange of tweets with the author. I've pointed out a S.O. question titled SOLID for functional programming with a totally misleading answer (in my opinion, it's clear).
In that case the answer lacks technical correctness, but in this post Mark Seemann points out a concept that is difficult to contradict.
Patterns are abstraction that provides concrete solutions (pardon the pun) to identifiable problems
that present themselves in different shapes.
Tha fact that when we talk of patterns we talk of them in relation to OO languages, it just a contingency.
I've to completely agree with the author; functional languages need patterns too and as more these become popular as more functional patterns will arise.
TDD test suites should run in 10 seconds or less
Most guidance about Test-Driven Development (TDD) will tell you that unit tests should be fast. Examples of such guidance can be found in FIRST and xUnit Test Patterns. Rarely does it tell you how fast unit tests should be.
10 seconds for a unit test suite. Max.
Here's why.
When you follow the Red/Green/Refactor process, ideally you'd be running your unit test suite at least three times for each iteration:
- Red. Run the test suite.
- Green. Run the test suite.
- Refactor. Run the test suite.
Each time you run the unit test suite, you're essentially blocked. You have to wait until the test run has completed until you get the result.
During that wait time, it's important to keep focus. If the test run takes too long, your mind starts to wonder, and you'll suffer from context switching when you have to resume work.
When does your mind start to wonder? After about 10 seconds. That number just keeps popping up when the topic turns to focused attention. Obviously it's not a hard limit. Obviously there are individual and contextual variations. Still, it seems as though a 10 second short-term attention span is more or less hard-wired into the human brain.
Thus, a unit test suite used for TDD should run in less than 10 seconds. If it's slower, you'll be less productive because you'll constantly lose focus.
Implications #
The test suite you work with when you do TDD should execute in less than 10 seconds on your machine. If you have hundreds of tests, each test should be faster than 100 milliseconds. If you have thousands, each test should be faster than 10 milliseconds. You get the picture.
That test suite doesn't need to be the same as is running on your CI server. It could be a subset of tests. That's OK. The TDD suite may just be part of your Test Pyramid.
Selective test runs #
Many people work around the Slow Tests anti-pattern by only running one test at a time, or perhaps one test class. In my experience, this is not an optimal solution because it slows you down. Instead of just going
- Red
- Run
- Green
- Run
- Refactor
- Run
you'd need to go
- Red
- Specifically instruct your Test Runner to run only the test you just wrote
- Green
- Decide which subset of tests may have been affected by the new test. This obviously involves the new test, but may include more tests.
- Run the tests you just selected
- Refactor
- Decide which subset of tests to run now
- Run the tests you just selected
Obviously, that introduces friction into your process. Personally, I much prefer to have a fast test suite that I can run all the time at a key press.
Still, there are tools available that promises to do this analysis for you. One of them are Mighty Moose, with which I've had varying degrees of success. Another similar approach is NCrunch.
References? #
For a long time I've been wanting to write this article, but I've always felt held back by a lack of citations I could exhibit. While the Wikipedia link does provide a bit of information, it's not that convincing in itself (and it also cites the time span as 8 seconds).
However, that 10 second number just keeps popping up in all sorts of contexts, not all of them having anything to do with software development, so I decided to run with it. However, if some of my readers can provide me with better references, I'd be delighted.
Or perhaps I'm just suffering from confirmation bias...
Comments
Some of that can be alleviated with a DVCS, but rapid feedback just makes things a lot easier.
>> Mighty Moose, with which I've had varying degrees of success. Another similar approach is NCrunch.
I tried both the tools in a real VS solution (contained about 180 projects, 20 of them are test ones). Mighty Moose was continuously throwing exceptions and I didn't manage to get it work at all. NCrunch could not compile some of projects (it uses Mono compiler) but works with some success with the remained ones. Yes, feedback is rather fast (2-5 secs instead of 10-20 using ReSharper test runner), but it unstable and I've returned to ReSharper back.
TDD cannot be used for large applications.
I was doing some research myself. From what I understand, the Wikipedia article you link to talks mainly about attention span in the context of someone doing a certain task and being disturbed. However, while we wait for our unit tests to finish, we're not doing anything. This is more similar to waiting for a website to download and render.
The studies on "tolerable waiting time" are all over the map, but even old ones talk about 2 seconds. This paper mentions several studies, two of them from pre-internet days (scroll down to the graphics for a comparison table). This would mean that, ideally, we would need our tests to run in not 10 but 2 seconds! I say ideally, because this seams unrealistic to me at this moment (especially in projects where even compilation takes longer than 2 seconds). Maybe in the future, who knows.
Peter, thank you for writing. I recall reading about the 10 second rule some months before I wrote the article, but that, when writing the article, I had trouble finding public reference material. Thank you for making the effort of researching this and sharing your findings. I don't dispute what you wrote, but here are some further thoughts on the topic:
If the time limit really is two seconds, that's cause for some concern. I agree with you that it might be difficult to achieve that level of response time for a moderately-sized test suite. This does, however, heavily depend on various factors, the least of which isn't the language and platform.
For instance, when working with a 'warm' C# code base, compilation time can be fast enough that you might actually be able to compile and run hundreds of tests within two seconds. On the other hand, just compiling a moderately-sized Haskell code base takes longer than two seconds on my machine (but then, once Haskell compiles, you don't need a lot of tests to verify that it works correctly).
When working in interpreted languages, like SmallTalk (where TDD was originally rediscovered), Ruby, or JavaScript, there's no compilation step, so tests start running immediately. Being interpreted, the test code may run slower than compiled code, but my limited experience with JavaScript is that it can still be fast enough.

Comments
Basically, Unity has very little in terms of Fluent APIs, convention over configuration, etc. but what it does have is a very open architecture. This means it's almost always possible to write a bit of Reflection code to configure Unity by convention.
FWIW, there's a chapter in my book about Unity and its extensibility mechanisms, but to be fair, it doesn't cover exactly this scenario.
It appears it is possible, and that someone has created an extension for convention:
http://aspiringcraftsman.com/2009/06/13/convention-based-registration-extension/