Should interfaces be asynchronous? by Mark Seemann
Async and await are notorious for being contagious. Must all interfaces be Task-based, just in case?
I recently came across this question on Mastodon:
"To async or not to async?
"How would you define a library interface for a service that probably will be implemented with an in memory procedure - let's say returning a mapped value to a key you registered programmatically - and a user of your API might want to implement a decorator that needs a 'long running task' - for example you want to log a msg into your db or load additional mapping from a file?
"Would you define the interface to return a Task<string> or just a string?"
While seemingly a simple question, it's both fundamental and turns out to have deeper implications than you may at first realize.
Interpretation #
Before I proceed, I'll make my interpretation of the question more concrete. This is just how I interpret the question, so doesn't necessarily reflect the original poster's views.
The post itself doesn't explicitly mention a particular language, and since several languages now have async and await features, the question may be of more general interest that a question constrained to a single language. On the other hand, in order to have something concrete to discuss, it'll be useful with some real code examples. From perusing the discussion surrounding the original post, I get the impression that the language in question may be C#. That suits me well, since it's one of the languages with which I'm most familiar, and is also a language where programmers of other C-based languages should still be able to follow along.
My interpretation of the implementation, then, is this:
public sealed class NameMap { private readonly Dictionary<Guid, string> knownIds = new() { { new Guid("4778CA3D-FB1B-4665-AAC1-6649CEFA4F05"), "Bob" }, { new Guid("8D3B9093-7D43-4DD2-B317-DCEE4C72D845"), "Alice" } }; public string GetName(Guid guid) { return knownIds.TryGetValue(guid, out var name) ? name : "Trudy"; } }
Nothing fancy, but, as Fandermill writes in a follow-up post:
"Used examples that first came into mind, but it could be anything really."
The point, as I understand it, is that the intended implementation doesn't require asynchrony. A Decorator, on the other hand, may.
Should we, then, declare an interface like the following?
public interface INameMap { Task<string> GetName(Guid guid); }
If we do, the NameMap class can't automatically implement that interface because the return types of the two GetName methods don't match. What are the options?
Conform #
While the following may not be the 'best' answer, let's get the obvious solution out of the way first. Let the implementation conform to the interface:
public sealed class NameMap : INameMap { private readonly Dictionary<Guid, string> knownIds = new() { { new Guid("4778CA3D-FB1B-4665-AAC1-6649CEFA4F05"), "Bob" }, { new Guid("8D3B9093-7D43-4DD2-B317-DCEE4C72D845"), "Alice" } }; public Task<string> GetName(Guid guid) { return Task.FromResult( knownIds.TryGetValue(guid, out var name) ? name : "Trudy"); } }
This variation of the NameMap class conforms to the interface by making the GetName method look asynchronous.
We may even keep the synchronous implementation around as a public method if some client code might need it:
public sealed class NameMap : INameMap { private readonly Dictionary<Guid, string> knownIds = new() { { new Guid("4778CA3D-FB1B-4665-AAC1-6649CEFA4F05"), "Bob" }, { new Guid("8D3B9093-7D43-4DD2-B317-DCEE4C72D845"), "Alice" } }; public Task<string> GetName(Guid guid) { return Task.FromResult(GetNameSync(guid)); } public string GetNameSync(Guid guid) { return knownIds.TryGetValue(guid, out var name) ? name : "Trudy"; } }
Since C# doesn't support return-type-based overloading, we need to distinguish these two methods by giving them different names. In C# it might be more idiomatic to name the asynchronous method GetNameAsync and the synchronous method just GetName, but for reasons that would be too much of a digression now, I've never much liked that naming convention. In any case, I'm not going to go in this direction for much longer, so it hardly matters how we name these two methods.
Kinds of interfaces #
Another digression is, however, quite important. Before we can look at some more code, I'm afraid that we have to perform a bit of practical ontology, as it were. It starts with the question: Why do we even need interfaces?
I should also make clear, as a digression within a digression, that by 'interface' in this context, I'm really interested in any kind of mechanism that enables you to achieve polymorphism. In languages like C# or Java, we may in fact avail ourselves of the interface keyword, as in the above INameMap example, but we may equally well use a base class or perhaps just what C# calls a delegate. In other languages, we may use function or action types, or even function pointers.
Regardless of specific language constructs, there are, as far as I can tell, two kinds of interfaces:
- Interfaces that enable variability or extensibility in behaviour.
- Interfaces that mostly or exclusively exist to support automated testing.
While there may be some overlap between these two kinds, in my experience, the intersection between the two tends to be surprisingly small. Interfaces tend to mostly belong to one of those two categories.
Strategies and higher-order functions #
In design-patterns parlance, examples of the first kind are Builder, State, Chain of Responsibility, Template Method, and perhaps most starkly represented by the Strategy pattern. A Strategy is an encapsulated piece of behaviour that you pass around as a single 'thing' (an object).
And granted, you could also use a Strategy to access a database or make a web-service call, but that's not how the pattern was originally described. We'll return to that use case in the next section.
Rather, the first kind of interface exists to enable extensibility or variability in algorithms. Typical examples (from Design Patterns) include page layout, user interface component rendering, building a maze, finding the most appropriate help topic for a given application context, and so on. If we wish to relate this kind of interface to the SOLID principles, it mostly exists to support the Open-closed principle.
A good heuristics for identifying such interfaces is to consider the Reused Abstractions Principle (Jason Gorman, 2010, I'd link to it, but the page has fallen off the internet. Use your favourite web archive to read it.). If your code base contains multiple production-ready implementations of the same interface, you're reusing the interface, most likely to vary the behaviour of a general-purpose data structure.
And before the functional-programming (FP) crowd becomes too smug: FP uses this kind of interface all the time. In the FP jargon, however, we rather talk about higher-order functions and the interfaces we use to modify behaviour are typically modelled as functions and passed as lambda expressions. So when you write Cata((_, xs) => xs.Sum(), _ => 1) (as one does), you might as well just have passed a Visitor implementation to an Accept method.
This hints at a more quantifiable distinction: If the interface models something that's intended to be a pure function, it'd typically be part of a higher-order API in FP, while we in object-oriented design (once again) lack the terminology to distinguish these interfaces from the other kind.
These days, in C# I mostly use these kinds of interfaces for the Visitor pattern.
Seams #
The other kind of interface exists to afford automated testing. In Working Effectively with Legacy Code, Michael Feathers calls such interfaces Seams. Modern object-oriented code bases often use Dependency Injection (DI) to control which Strategies are in use in a given context. The production system may use an object that communicates with a relational database, while an automated test environment might replace that with a Test Double.
Yes, I wrote Strategies. As I suggested above, a Strategy is really a replaceable object in its purest form. When you use DI you may call all those interfaces IUserRepository, ICommandHandler, IEmailGateway, and so on, but they're really all Strategies.
Contrary to the first kind of interface, you typically only find a single production implementation of each of these interfaces. If you find more that one, the rest are usually Decorators (one that logs, one that caches, one that works as a Circuit Breaker, etc.). All other implementations will be defined in the test code as dynamic mocks or Fakes.
Code bases that rely heavily on DI in order to support testing rub many people the wrong way. In 2014 David Heinemeier Hansson published a serious criticism of such test-induced damage. For the record, I agree with the criticism, but not with the conclusion. While I still practice test-driven development, I only define interfaces for true architectural dependencies. So, yes, my code bases may have an IReservationsRepository or IEmailGateway, but no ICommandHandler or IUserManager.
The bottom line, though, is that some interfaces exist to support testing. If there's a better way to make inherently non-deterministic systems behave deterministically in a test context, I've yet to discover it.
(As an aside, it's worth looking into tests that adopt non-deterministic behaviour as a driving principle, or at least an unavoidable state of affairs. Property-based testing is one such approach, but I also found the article When I'm done, I don't clean up by Arialdo Martini interesting. You may also want to refer to my article Waiting to happen for a discussion of how to make tests independent of system time.)
Where to define interfaces #
The reason the above distinction is important is that it fundamentally determines where interfaces should be defined. In short, the first kind of interface is part of an object model's API, and should be defined together with that API. The second kind, on the other hand, is part of a particular application's architecture, and should be defined by the client code that talks to the interface.
As an example of the first kind, consider this recent example, where the IPriorityEditor<T> interface is part of the PriorityCollection<T> API. You must ship the interface together with the class, because the Edit method takes an interface implementation as an argument. It's how client code interacts with the API.
Another example is this Table class that comes with an ITableVisitor<T> interface. In both cases, we'd expect interface implementations to be deterministic. These interfaces don't exist to support automated testing, but rather to afford a flexible programming model.
For the sake of argument, imagine that you package such APIs in reusable libraries that you publish via a package manager. In that case, it's obvious that the interface is as much part of the package as the class.
Contrast this with the other kind of interface, as described in the article Decomposing CTFiYH's sample code base or showcased in the article An example of state-based testing in C#. In the latter example, the interfaces IUserReader and IUserRepository are not part of any pre-packaged library. Rather, they are defined by the application code to support application-specific needs.
This may be even more evident if you contemplate the diagram in Decomposing CTFiYH's sample code base. Interfaces like IPostOffice and IReservationsRepository only exist to support the application. Following the Dependency Inversion Principle
"clients [...] own the abstract interfaces"
In these code bases, only the Controllers (or rather the tests that exercise them) need these interfaces, so the Controllers get to define them.
Should it be asynchronous, then? #
Okay, so should INameMap.GetName return string or Task<string>, then?
Hopefully, at this point, it should be clear that the answer depends on what kind of interface it is.
If it's the first kind, the return type should support the requirements of the API. If the object model doesn't need the return type to be asynchronous, it shouldn't be.
If it's the second kind of interface, the application code decides what it needs, and defines the interface accordingly.
In neither case, however, is it the concrete class' responsibility to second-guess what client code might need.
But client code may need the method to be asynchronous. What's the harm of returning Task<string>, just in case?
The problem, as you may well be aware, is that the asynchronous programming model is contagious. Once you've made an API asynchronous, you can't easily make it synchronous, whereas if you have a synchronous API, you can easily make it asynchronous. This follows from Postel's law, in this case: Be conservative with what you send.
Library API #
Imagine, for the sake of argument, that the NameMap class is defined in a reusable library, wrapped in a package and imported into your code base via a package manager (NuGet, Maven, pip, NPM, Hackage, RubyGems, etc.).
Clearly it shouldn't implement any interface in order to 'support unit testing', since such interfaces should be defined by application code.
It could implement one or more 'extensibility' interfaces, if such interfaces are part of the wider API offered by the library. In the case of the NameMap class, we don't really know if that's the case. To complete this part of the argument, then, I'd just leave it as shown in the first code example, shown above. It doesn't need to implement any interface, and GetName can just return string.
Domain Model #
What if, instead of an external library, the NameMap class is part of an application's Domain Model?
In that case, you could define application-level interfaces as part of the Domain Model. In fact, most people do. Even so, I'd recommend that you don't, at least if you're aiming for a Functional Core, Imperative Shell architecture, a functional architecture, or even a Ports and Adapters or, if you will, Clean Architecture. The interfaces that exist only to support testing are application concerns, so keep them out of the Domain Model and instead define them in the Application Model.
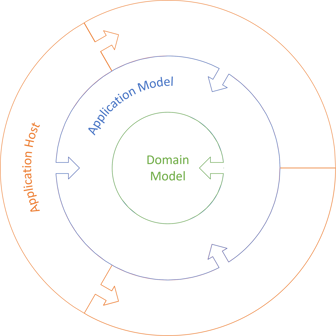
You don't have to follow my advice. If you want to define interfaces in the Domain Model, I can't stop you. But what if, as I recommend, you define application-specific interfaces in the Application Model? If you do that, your NameMap Domain Model can't implement your INameMap interface, because the dependencies point the other way, and most languages will not allow circular dependencies.
In that case, what do you do if, as the original toot suggested, you need to Decorate the GetName method with some asynchronous behaviour?
You can always introduce an Adapter:
public sealed class NameMapAdapter : INameMap { private readonly NameMap imp; public NameMapAdapter(NameMap imp) { this.imp = imp; } public Task<string> GetName(Guid guid) { return Task.FromResult(imp.GetName(guid)); } }
Now any NameMap object can look like an INameMap. This is exactly the kind of problem that the Adapter pattern addresses.
But, you say, that's too much trouble! I don't want to have to maintain two classes that are almost identical.
I understand the concern, and it may even be appropriate. Maybe you're right. As usual, I don't really intend this article to be prescriptive. Rather, I'm offering ideas for your consideration, and you can choose to adopt them or ignore them as it best fits your context.
When it comes to whether or not an Adapter is an unwarranted extra complication, I'll return to that topic later in this article.
Application Model #
The final architectural option is when the concrete NameMap class is part of the Application Model, where you'd also define the application-specific INameMap interface. In that case, we must assume that the NameMap class implements some application-specific concern. If you want it to implement an interface so that you can wrap it in a Decorator, then do that. This means that the GetName method must conform to the interface, and if that means that it must be asynchronous, then so be it.
As Kent Beck wrote in a Facebook article that used to be accessible without a Facebook account (but isn't any longer):
"Things that change at the same rate belong together. Things that change at different rates belong apart."
If the concrete NameMap class and the INameMap interface are both part of the application model, it's not unreasonable to guess that they may change together. (Do be mindful of Shotgun Surgery, though. If you expect the interface and the concrete class to frequently change, then perhaps another design might be more appropriate.)
Easier Adapters #
Before concluding this article, let's revisit the topic of introducing an Adapter for the sole purpose of 'architectural purity'. Should you really go to such lengths only to 'do it right'? You decide, but
You can only be pragmatic if you know how to be dogmatic.
I'm presenting a dogmatic solution for your consideration, so that you know what it might look like. Would I follow my own 'dogmatic' advice? Yes, I usually do, but then, I wouldn't log the return value of a pure function, so I wouldn't introduce an interface for that purpose, at least. To be fair to Fandermill, he or she also wrote: "or load additional mapping from a file", which could be an appropriate motivation for introducing an interface. I'd probably go with an Adapter in that case.
Whether or not an Adapter is an unwarranted complication depends, however, on language specifics. In high-ceremony languages like C#, Java, or C++, adding an Adapter involves at least one new file, and dozens of lines of code.
Consider, on the other hand, a low-ceremony language like Haskell. The corresponding getName function might close over a statically defined map and have the type getName :: UUID -> String.
How do you adapt such a pure function to an API that returns IO (which is roughly comparable to task-based programming)? Trivially:
getNameM :: Monad m => UUID -> m String getNameM = return . getName
For didactic purposes I have here shown the 'Adapter' as an explicit function, but in idiomatic Haskell I'd consider this below the Fairbairn threshold; I'd usually just inline the composition return . getName if I needed to adapt the getName function to the Kleisli category.
You can do the same in F#, where the composition would be getName >> Task.FromResult. F# compositions usually go in the (for Westerners) intuitive left-to-right directions, whereas Haskell compositions follow the mathematical right-to-left convention.
The point, however, is that there's nothing conceptually complicated about an Adapter. Unfortunately, however, some languages require substantial ceremony to implement them.
Conclusion #
Should an API return a Task-based (asynchronous) value 'just in case'? In general: No.
You can't predict all possible use cases, so don't make an API more complicated than it has to be. If you need to implement an application-specific interface, use the Adapter design pattern.
A possible exception to this rule is if the entire API (the concrete implementation and the interface) only exists to support a specific application. If the interface and its concrete implementation are both part of the Application Model, you may as well skip the Adapter step and consider the concrete implementation as its own Adapter.
