Three data architectures for the server by Mark Seemann
A comparison, for educational purposes.
Use the right tool for the job. How often have you encountered that phrase when discussing software architecture?
There's nothing wrong with the sentiment per se, but it's almost devoid of meaning. It doesn't pass the 'not test'. Try to negate it and imagine if anyone would seriously hold that belief: Don't use the right tool for the job, said no-one ever.
Even so, the underlying idea is that there are better and worse ways to solve problems. In software architecture too. It follows that you should choose the better solution.
How to do that requires skill and experience. When planning a good software architecture, an important consideration is how it'll handle future requirements. This seems to indicate that an architect should be able to predict the future in order to pick the best architecture. Which is, in general, not possible. Predicting the future is not the topic of this article.
There is, however, a more practical issue related to the notion of using the right tool for the job. One that we can address.
Choice #
In order to choose the better solution, you need to be aware of alternatives. You can't choose if there's nothing to choose from. This seems obvious, but a flowchart may drive home the point in an even stronger fashion.

On the other hand, if you have options, you're now in a position to choose.
In order to make a decision, you must be able to identify alternatives. This is hardly earth-shattering, but perhaps a bit abstract. To make it concrete, in this article, I'll look at a particular example.
Default data architecture #
Many applications need some sort of persistent storage. Particularly when it comes to (relational) database-based systems, I've seen more than one organization defaulting to a single data architecture: A presentation layer with View Models, a business logic layer with Domain Models, and a data access layer with ORM objects. A few decades ago, you'd typically see that model illustrated with horizontal layers. This is no longer en vogue. Today, most organizations that I consult with will tell me that they've decided on Ports and Adapters. Even so, if you do it right, it's the same architecture.
Reusing a diagram from a recent article, we may draw it like this:
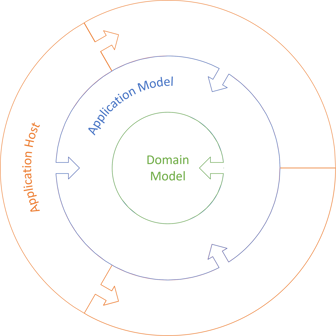
The architect or senior developer who made that decision is obviously aware of some of the lore in the industry. He or she can often name that data architecture as either Ports and Adapters, Hexagonal Architecture, Clean Architecture, or, more rarely, Onion Architecture.
I still get the impression that this way of arranging code was chosen by default, without much deliberation. I see it so often that it strikes me as a 'default architecture'. Are architects aware of alternatives? Can they compare the benefits and drawbacks of each alternative?
Three alternatives #
As an example, I'll explore three alternative data architectures, one of them being Ports and Adapters. My goal with this is only to raise awareness. Since I rarely (if ever) see my customers use anything other than Ports and Adapters, I think some readers may benefit from seeing some alternatives.
I'll show three ways to organize data with code, but that doesn't imply that these are the only three options. At the very least, some hybrid combinations are also possible. It's also possible that a fourth or fifth alternative exists, and I'm just not aware of it.
In three articles, you'll see each data architecture explored in more detail.
- Using Ports and Adapters to persist restaurant table configurations
- Using a Shared Data Model to persist restaurant table configurations
- Using only a Domain Model to persist restaurant table configurations
As the titles suggest, all three examples will attempt to address the same problem: How to persist restaurant table configuration for a restaurant. The scenario is the same as already outlined in the article Serialization with and without Reflection, and the example code base also attempts to follow the external data format of those articles.
Data formats #
In JSON, a table may be represented like this:
{
"singleTable": {
"capacity": 16,
"minimalReservation": 10
}
}
Or like this:
{ "communalTable": { "capacity": 10 } }
But I'll also explore what happens if you need to support multiple external formats, such as XML. Generally speaking, a given XML specification may lean towards favouring a verbose style based on elements, or a terser style based on attributes. An example of the former could be:
<communal-table> <capacity>12</capacity> </communal-table>
or
<single-table> <capacity>4</capacity> <minimal-reservation>3</minimal-reservation> </single-table>
while examples of the latter style include
<communal-table capacity="12" />
and
<single-table capacity="4" minimal-reservation="3" />
As it turns out, only one of the three data architectures is flexible enough to fully address such requirements.
Comparisons #
A REST API is the kind of application where data representation flexibility is most likely to be an issue. Thus, that only one of the three alternative architectures is able to exhibit enough expressive power in that dimension doesn't disqualify the other two. Each come with their own benefits and drawbacks.
| Ports and Adapters | Shared Data Model | Domain Model only | |
| Advantages |
|
|
|
| Disadvantages |
|
|
|
I'll discuss each alternative's benefits and drawbacks in their individual articles.
An important point of all this is that none of these articles are meant to be prescriptive. While I do have favourites, my biases are shaped by the kind of work I typically do. In other contexts, another alternative may prevail.
Example code #
As usual, example code is in C#. Of the three languages in which I'm most proficient (the other two being F# and Haskell), this is the most easily digestible for a larger audience.
All three alternatives are written with ASP.NET 8.0, and it's unavoidable that there will be some framework-specific details. In Code That Fits in Your Head, I made it an explicit point that while the examples in the book are in C#, the book (and the code in it) should be understandable by developers who normally use Java, C++, TypeScript, or similar C-based languages.
The book is, for that reason, light on .NET-specific details. Instead, I published an article that collects all the interesting .NET things I ran into while writing the book.
Not so here. The three articles cover enough ASP.NET particulars that readers who don't care about that framework are encouraged to skim-read.
I've developed the three examples as three branches of the same Git repository. The code is available upon request against a small support donation of 10 USD (or more). If you're one of my regular supporters, you have my gratitude and can get the code without further donation. Send me an email in both cases.
Conclusion #
There's more than one way to organize a code base to deal with data. Depending on context, one may be a better choice than another. Thus, it pays to be aware of alternatives.
In the remaining articles in this series, you'll see three examples of how to deal with persistent data from a database. In order to establish a baseline, the first covers the well-known Ports and Adapters architecture.
Next: Using Ports and Adapters to persist restaurant table configurations.
