Using a Shared Data Model to persist restaurant table configurations by Mark Seemann
A data architecture example in C# and ASP.NET.
This is part of a small article series on data architectures. In this, the second instalment, you'll see a common attempt at addressing the mapping issue that I mentioned in the previous article. As the introductory article explains, the example code shows how to create a new restaurant table configuration, or how to display an existing resource. The sample code base is an ASP.NET 8.0 REST API.
Keep in mind that while the sample code does store data in a relational database, the term table in this article mainly refers to physical tables, rather than database tables.
The idea in this data architecture is to use a single, shared data model for each business object in the service. This is in contrast to the Ports and Adapters architecture, where you typically have a Data Transfer Object (DTO) for (JSON or XML) serialization, another class for the Domain Model, and a third to support an object-relational mapper.
An architecture diagram may attempt to illustrate the idea like this:
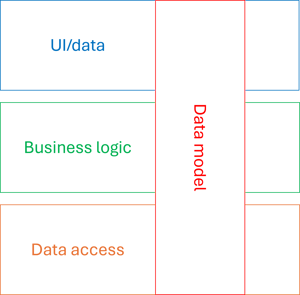
While ostensibly keeping alive the idea of application layers, data models are allowed to cross layers to be used both for database persistence, business logic, and in the presentation layer.
Data model #
Since the goal is to use a single class to model all application concerns, it means that we also need to use it for database persistence. The most commonly used ORM in .NET is Entity Framework, so I'll use that for the example. It's not something that I normally do, so it's possible that I could have done it better than what follows.
Still, assume that the database schema defines the Tables table like this:
CREATE TABLE [dbo].[Tables] ( [Id] INT NOT NULL IDENTITY PRIMARY KEY, [PublicId] UNIQUEIDENTIFIER NOT NULL UNIQUE, [Capacity] INT NOT NULL, [MinimalReservation] INT NULL )
I used a scaffolding tool to generate Entity Framework code from the database schema and then modified what it had created. This is the result:
public partial class Table { [JsonIgnore] public int Id { get; set; } [JsonIgnore] public Guid PublicId { get; set; } public string Type => MinimalReservation.HasValue ? "single" : "communal"; public int Capacity { get; set; } public int? MinimalReservation { get; set; } }
Notice that I added [JsonIgnore] attributes to two of the properties, since I didn't want to serialize them to JSON. I also added the calculated property Type to include a discriminator in the JSON documents.
HTTP interaction #
A client can create a new table with a POST HTTP request:
POST /tables HTTP/1.1
content-type: application/json
{"type":"communal","capacity":12}
Notice that the JSON document doesn't follow the desired schema described in the introduction article. It can't, because the data architecture is bound to the shared Table class. Or at least, if it's possible to attain the desired format with a single class and only some strategically placed attributes, I'm not aware of it. As the article Using only a Domain Model to persist restaurant table configurations will show, it is possible to attain that goal with the appropriate middleware, but I consider doing that to be an example of the third architecture, so not something I will cover in this article.
The service will respond to the above request like this:
HTTP/1.1 201 Created Location: https://example.com/Tables/777779466d2549d69f7e30b6c35bde3c
Clients can later use the address indicated by the Location header to retrieve a representation of the resource:
GET /Tables/777779466d2549d69f7e30b6c35bde3c HTTP/1.1 accept: application/json
Which elicits this response:
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{"type":"communal","capacity":12}
The JSON format still doesn't conform to the desired format because the Controller in question deals exclusively with the shared Table data model.
Boundary #
At the boundary of the application, Controllers handle HTTP requests with action methods (an ASP.NET term). The framework matches requests by a combination of naming conventions and attributes. The Post action method handles incoming POST requests.
[HttpPost] public async Task<IActionResult> Post(Table table) { var id = Guid.NewGuid(); await repository.Create(id, table).ConfigureAwait(false); return new CreatedAtActionResult( nameof(Get), null, new { id = id.ToString("N") }, null); }
Notice that the input parameter isn't a separate DTO, but rather the shared Table object. Since it's shared, the Controller can pass it directly to the repository without any mapping.
The same simplicity is on display in the Get method:
[HttpGet("{id}")] public async Task<IActionResult> Get(string id) { if (!Guid.TryParseExact(id, "N", out var guid)) return new BadRequestResult(); Table? table = await repository.Read(guid).ConfigureAwait(false); if (table is null) return new NotFoundResult(); return new OkObjectResult(table); }
Once the Get method has parsed the id it goes straight to the repository, retrieves the table and returns it if it's there. No mapping is required by the Controller. What about the repository?
Data access #
The SqlTablesRepository class reads and writes data from SQL Server using Entity Framework. The Create method is as simple as this:
public async Task Create(Guid id, Table table) { ArgumentNullException.ThrowIfNull(table); table.PublicId = id; await context.Tables.AddAsync(table).ConfigureAwait(false); await context.SaveChangesAsync().ConfigureAwait(false); }
The Read method is even simpler - a one-liner:
public async Task<Table?> Read(Guid id) { return await context.Tables .SingleOrDefaultAsync(t => t.PublicId == id).ConfigureAwait(false); }
Again, no mapping. Just return the database Entity.
XML serialization #
Simple, so far, but how does this data architecture handle changing requirements?
One axis of variation is when a service needs to support multiple representations. In this example, I'll imagine that the service also needs to support XML.
Granted, you may not run into that particular requirement that often, but it's typical of a kind of change that you're likely to run into. In REST APIs, for example, you should use content negotiation for versioning, and that's the same kind of problem.
To be fair, application code also changes for a variety of other reasons, including new features, changes to business logic, etc. I can't possibly cover all, though, and many of these are much better described than changes in wire formats.
As was also the case in the previous article, it quickly turns out that it's not possible to support any of the desired XML formats described in the introduction article. Instead, for the sake of exploring what is possible, I'll compromise and support XML documents like these examples:
<table> <type>communal</type> <capacity>12</capacity> </table> <table> <type>single</type> <capacity>4</capacity> <minimal-reservation>3</minimal-reservation> </table>
This schema, it turns out, is the same as the element-biased format from the previous article. I could, instead, have chosen to support the attribute-biased format, but, because of the shared data model, not both.
Notice how using statically typed classes, attributes, and Reflection to guide serialization leads toward certain kinds of formats. You can't easily support any arbitrary JSON or XML schema, but are rather nudged into a more constrained subset of possible formats. There's nothing too bad about this. As usual, there are trade-offs involved. You concede flexibility, but gain convenience: Just slab some attributes on your DTO, and it works well enough for most purposes. I mostly point it out because this entire article series is about awareness of choice. There's always some cost to be paid.
That said, supporting that XML format is surprisingly easy:
[XmlRoot("table")] public partial class Table { [JsonIgnore, XmlIgnore] public int Id { get; set; } [JsonIgnore, XmlIgnore] public Guid PublicId { get; set; } [XmlElement("type"), NotMapped] public string? Type { get; set; } [XmlElement("capacity")] public int Capacity { get; set; } [XmlElement("minimal-reservation")] public int? MinimalReservation { get; set; } public bool ShouldSerializeMinimalReservation() => MinimalReservation.HasValue; internal void InferType() { Type = MinimalReservation.HasValue ? "single" : "communal"; } }
Most of the changes are simple additions of the XmlRoot, XmlElement, and XmlIgnore attributes. In order to serialize the <type> element, however, I also had to convert the Type property to a read/write property, which had some ripple effects.
For one, I had to add the NotMapped attribute to tell Entity Framework that it shouldn't try to save the value of that property in the database. As you can see in the above SQL schema, the Tables table has no Type column.
This also meant that I had to change the Read method in SqlTablesRepository to call the new InferType method:
public async Task<Table?> Read(Guid id) { var table = await context.Tables .SingleOrDefaultAsync(t => t.PublicId == id).ConfigureAwait(false); table?.InferType(); return table; }
I'm not happy with this kind of sequential coupling, but to be honest, this data architecture inherently has an appalling lack of encapsulation. Having to call InferType is just par for the course.
That said, despite a few stumbling blocks, adding XML support turned out to be surprisingly easy in this data architecture. Granted, I had to compromise on the schema, and could only support one XML schema, so we shouldn't really take this as an endorsement. To paraphrase Gerald Weinberg, if it doesn't have to work, it's easy to implement.
Evaluation #
There's no denying that the Shared Data Model architecture is simple. There's no mapping between different layers, and it's easy to get started. Like the DTO-based Ports and Adapters architecture, you'll find many documentation examples and getting-started guides that work like this. In a sense, you can say that it's what the ASP.NET framework, or, perhaps particularly the Entity Framework (EF), 'wants you to do'. To be fair, I find ASP.NET to be reasonably unopinionated, so what inveigling you may run into may be mostly attributable to EF.
While it may feel nice that it's easy to get started, instant gratification often comes at a cost. Consider the Table class shown here. Because of various constraints imposed by EF and the JSON and XML serializers, it has no encapsulation. One thing is that the sophisticated Visitor-encoded Table class introduced in the article Serializing restaurant tables in C# is completely out of the question, but you can't even add a required constructor like this one:
public Table(int capacity) { Capacity = capacity; }
Granted, it seems to work with both EF and the JSON serializer, which I suppose is a recent development, but it doesn't work with the XML serializer, which requires that
"A class must have a parameterless constructor to be serialized by XmlSerializer."
Even if this, too, changes in the future, DTO-based designs are at odds with encapsulation. If you doubt the veracity of that statement, I challenge you to complete the Priority Collection kata with serializable DTOs.
Another problem with the Shared Data Model architecture is that it so easily decays to a Big Ball of Mud. Even though the above architecture diagram hollowly insists that layering is still possible, a Shared Data Model is an attractor of behaviour. You'll soon find that a class like Table has methods that serve presentation concerns, others that implement business logic, and others again that address persistence issues. It has become a God Class.
From these problems it doesn't follow that the architecture doesn't have merit. If you're developing a CRUD-heavy application with a user interface (UI) that's merely a glorified table view, this could be a good choice. You would be coupling the UI to the database, so that if you need to change how the UI works, you might also have to modify the database schema, or vice versa.
This is still not an indictment, but merely an observation of consequences. If you can live with them, then choose the Shared Data Model architecture. I can easily imagine application types where that would be the case.
Conclusion #
In the Shared Data Model architecture you use a single model (here, a class) to handle all application concerns: UI, business logic, data access. While this shows a blatant disregard for the notion of separation of concerns, no law states that you must, always, separate concerns.
Sometimes it's okay to mix concerns, and then the Shared Data Model architecture is dead simple. Just make sure that you know when it's okay.
While this architecture is the ultimate in simplicity, it's also quite constrained. The third and final data architecture I'll cover, on the other hand, offers the ultimate in flexibility, at the expense (not surprisingly) of some complexity.
Next: Using only a Domain Model to persist restaurant table configurations.
