ploeh blog danish software design
Fractal hex flowers
The code behind the cover of Code That Fits in Your Head
A book needs a cover, but how do you choose a cover illustration for a programming book? Software development tends to be abstract, so how to pick a compelling picture?
Occasionally, a book manages to do everything right, such as the wonderful Mazes for Programmers, which also happens to have a cover appropriate for its contents. Most publishers, however, resort to pictures of bridges, outer space, animals, or folk costumes.
For my new book, I wanted a cover that, like Mazes for Programmers, relates to its contents. Fortunately, the book contains a few concepts that easily visualise, including a concept I call fractal architecture. You can create some compelling drawings based on hex flowers nested within the petals of other hex flowers. I chose to render some of those for the book cover:

I used Observable to host the code that renders the fractal hex flowers. This enabled me to experiment with various colour schemes and effects. Here's one example:
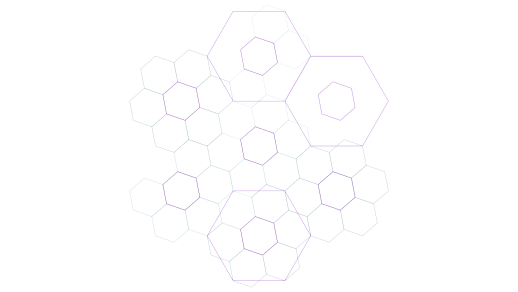
Not only did I write the program to render the figures on Observable, I turned the notebook into a comprehensive article explaining not only how to draw the figures, but also the geometry behind it.
The present blog post is really only meant as a placeholder. The real article is over at Observable. Go there to read it.
Property-based testing is not the same as partition testing
Including an example of property-based testing without much partitioning.
A tweet from Brian Marick induced me to read a paper by Dick Hamlet and Ross Taylor called Partition Testing Does Not Inspire Confidence. In general, I find the conclusion fairly intuitive, but on the other hand hardly an argument against property-based testing.
I'll later return to why I find the conclusion intuitive, but first, I'd like to address the implied connection between partition testing and property-based testing. I'll also show a detailed example.
The source code used in this article is available on GitHub.
Not the same #
The Hamlet & Taylor paper is exclusively concerned with partition testing, which makes sense, since it's from 1990. As far as I'm aware, property-based testing wasn't invented until later.
Brian Marick extends its conclusions to property-based testing:
This seems to imply that property-based testing isn't effective, because (if you accept the paper's conclusions) partition testing isn't effective."I've been a grump about property-based testing because I bought into the conclusion of Hamlet&Taylor's 1990 "Partition testing does not inspire confidence""
There's certainly overlap between partition testing and property-based testing, but it's not complete. Some property-based testing isn't partition testing, or the other way around:
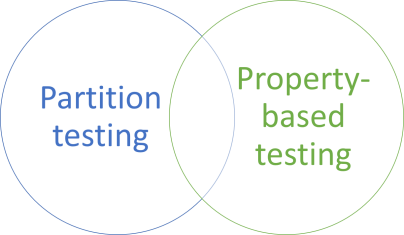
To be fair, the overlap may easily be larger than the figure implies, but you can certainly describes properties without having to partition a function's domain.
In fact, the canonical example of property-based testing (that reversing a list twice yields the original list: reverse (reverse xs) == xs) does not rely on partitioning. It works for all finite lists.
You may think that this is only because the case is so simple, but that's not the case. You can also avoid partitioning on the slightly more complex problem presented by the Diamond kata. In fact, the domain for that problem is so small that you don't need a property-based framework.
You may argue that the Diamond kata is another toy problem, but I've also solved a realistic, complex business problem with property-based testing without relying on partitioning. Granted, the property shown in that article doesn't sample uniformly from the entire domain of the System Under Test, but the property (there's only one) doesn't rely on partitioning. Instead, it relies on incremental tightening of preconditions to tease out the desired behaviour.
I'll show another example next.
FizzBuzz via partitioning #
When introducing equivalence classes and property-based testing in workshops, I sometimes use the FizzBuzz kata as an example. When I do this, I first introduce the concept of equivalence classes and then proceed to explain how instead of manually picking values from each partition, you can randomly sample from them:
[<Property(QuietOnSuccess = true)>] let ``FizzBuzz.transform returns Buzz`` (number : int) = (number % 5 = 0 && number % 3 <> 0) ==> lazy let actual = FizzBuzz.transform number let expected = "Buzz" expected = actual
(That's F# code, but the rest of the code in this article is going to be Haskell.)
While this gently introduces the concept of testing based on randomly sampling inputs, it relies heavily on partitioning. The above example filters inputs so that it only runs with numbers that are divisible by five, but not by three.
As at least one workshop attendee objected, it's getting perilously close to reproducing the implementation logic in the test. It always hurts when someone directs valid criticism at you, but he was right. That's not a problem with property-based testing, though, but rather with the way I presented it.
We can do better.
FizzBuzz with proper properties #
The trick to 'true' property-based testing is identifying proper properties for the problem being solved. Granted, this can be difficult and often requires some creative thinking (which is also why I find it so enjoyable). Fortunately, certain patterns tend to recur; for example, Scott Wlaschin has a small collection of property-based testing patterns.
As the FizzBuzz kata is described, the domain for a fizzBuzz function is only the numbers from one to 100. Let's be generous, however, and expand it to all integers, since it makes no practical difference.
In Haskell, for example, we might aim for a function with this API:
fizzBuzz :: (Integral a, Show a) => a -> String
Is it possible to test-drive the correct implementation with QuickCheck without relying on partitioning?
I must admit that I can't figure out how to entirely avoid partitioning, but it's possible to bootstrap the process using only a single partition. If you know of a way to entirely do without partitioning, leave a comment.
FizzBuzz #
In order to anchor the behaviour, we have to describe how at least a single value translates to a string, for example that all multiples of both three and five translate to "FizzBuzz". It might be enough to simply state that a small number like 0 or 15 translates to "FizzBuzz", but we might as well exercise that entire partition:
testProperty "Divisible by both 3 and 5" $ \ (seed :: Int) -> let i = seed * 3 * 5 actual = fizzBuzz i in "FizzBuzz" === actual
Here I take any integer seed and use it to produce an integer i which is guaranteed to belong to the partition that always produces the output "FizzBuzz".
Certainly, this tests only a single partition, but as Johannes Link points out, property-based testing still performs randomised testing within the partition.
The simplest implementation that passes the test is this:
fizzBuzz :: Integral a => a -> String fizzBuzz _ = "FizzBuzz"
From here, however, it's possible to describe the rest of the problem without relying on partition testing.
At least one number in three consecutive values #
How to proceed from there long eluded me. Then it dawned on me that while it's hard to test a single call to the fizzBuzz function without relying on partitioning, you can examine the output from projecting a small range of inputs to outputs.
What happens if we pick a random number, use it as an origin to enumerate three numbers in total (that is: two more numbers), and then call fizzBuzz with each of them?
Imagine what happens if we randomly pick 10. In that case, we're going to enumerate three numbers, starting with 10: 10, 11, 12. What's the expected output of applying these three numbers to fizzBuzz? It's Buzz, 11, Fizz. Let's try a few more, and make a table of it:
| i | i+1 | i+2 |
|---|---|---|
| 10 → Buzz | 11 → 11 | 12 → Fizz |
| 11 → 11 | 12 → Fizz | 13 → 13 |
| 12 → Fizz | 13 → 13 | 14 → 14 |
| 13 → 13 | 14 → 14 | 15 → FizzBuzz |
| 14 → 14 | 15 → FizzBuzz | 16 → 16 |
Do you notice a pattern?
There's more than a single pattern, but one is that there's always at least one number among the three results. Even if you have both a Fizz and a Buzz, as is the case with 10, 11, 12, at least one of the results (11) remains a number. Think about it some more to convince yourself that this should always be the case for three consecutive numbers.
That's a property of fizzBuzz, and it holds universally (also for negative integers).
You can turn it into a QuickCheck property like this:
testProperty "At least one number in 3 consecutive values" $ \ (i :: Int) -> let range = [i..i+2] actual = fizzBuzz <$> range in counterexample (show range ++ "->" ++ show actual) $ any (\x -> isJust (readMaybe x :: Maybe Int)) actual
This test doesn't rely on input partitioning. It works for all integers.
In this test I used QuickCheck's counterexample function to provide a helpful message in case of failure. Running the test suite against the above version of fizzBuzz yields a failure like this:
At least one number in 3 consecutive values: [Failed]
*** Failed! Falsified (after 1 test):
0
[0,1,2]->["FizzBuzz","FizzBuzz","FizzBuzz"]
(used seed -6204080625786338123)
Here we see that the sequence [0,1,2] produces the output ["FizzBuzz","FizzBuzz","FizzBuzz"], which is not only wrong, but is specifically incorrect in the sense that none of the values can be parsed as an integer.
Given the current implementation, that's hardly surprising.
Using the Devil's Advocate technique, I chose to pass both tests with this implementation:
fizzBuzz :: Integral a => a -> String fizzBuzz i = if i `mod` 15 == 0 then "FizzBuzz" else "2112"
The property I just added doesn't check whether the number is one of the input numbers, so the implementation can get away with returning the hard-coded string "2112".
At least one Fizz in three consecutive values #
Take a look at the above table. Do you notice any other patterns?
Of each set of three results, there's always a string that starts with Fizz. Sometimes, as we see with the input 15, the output is FizzBuzz, so it's not always just Fizz, but there's always a string that starts with Fizz.
This is another universal property of the fizzBuzz function, which we can express as a test:
testProperty "At least one Fizz in 3 consecutive values" $ \ (i :: Int) -> let range = [i..i+2] actual = fizzBuzz <$> range in counterexample (show range ++ "->" ++ show actual) $ any ("Fizz" `isPrefixOf`) actual
Again, no partitioning is required to express this property. The arbitrary parameter i is unconstrained.
To pass all tests, I implemented fizzBuzz like this:
fizzBuzz :: Integral a => a -> String fizzBuzz i = if i `mod` 3 == 0 then "FizzBuzz" else "2112"
It doesn't look as though much changed, but notice that the modulo check changed from modulo 15 to modulo 3. While incorrect, it passes all tests.
Only one Buzz in five consecutive values #
Using the same reasoning as above, another property emerges. If, instead of looking at sequences of three input arguments, you create five values, only one of them should result in a Buzz result; e.g. 8, 9, 10, 11, 12 should result in 8, Fizz, Buzz, 11, Fizz. Sometimes, however, the Buzz value is FizzBuzz, for example when the origin is 11: 11, 12, 13, 14, 15 should produce 11, Fizz, 13, 14, FizzBuzz.
Like the above property, there's only one Buzz, but sometimes it's part of a compound word. What's clear, though, is that there should be only one result that ends with Buzz.
Not only is the idea similar to the one above, so is the test:
testProperty "Only one Buzz in 5 consecutive values" $ \ (i :: Int) -> let range = [i..i+4] actual = fizzBuzz <$> range in counterexample (show range ++ "->" ++ show actual) $ 1 == length (filter ("Buzz" `isSuffixOf`) actual)
Again, no partitioning is required to express this property.
This version of fizzBuzz passes all tests:
fizzBuzz :: Integral a => a -> String fizzBuzz i | i `mod` 5 == 0 = "FizzBuzz" fizzBuzz i | i `mod` 3 == 0 = "Fizz" fizzBuzz _ = "2112"
We're not quite there yet, but we're getting closer.
At least one literal Buzz in ten consecutive values #
What's wrong with the above implementation?
It never returns Buzz. How can we express a property that forces it to do that?
We can keep going in the same vein. We know that if we sample a sufficiently large sequence of numbers, it might produce a FizzBuzz value, but even if it does, there's going to be a Buzz value five positions before and after. For example, if the input sequence contains 30 (producing FizzBuzz) then both 25 and 35 should produce Buzz.
How big a range should we sample to be certain that there's at least one Buzz?
If it's not immediately clear, try setting up a table similar to the one above:
| i | i+1 | i+2 | i+3 | i+4 | i+5 | i+6 | i+7 | i+8 | i+9 |
|---|---|---|---|---|---|---|---|---|---|
| 10 → Buzz |
11 → 11 |
12 → Fizz |
13 → 13 |
14 → 14 |
15 → FizzBuzz |
16 → 16 |
17 → 17 |
18 → Fizz |
19 → 19 |
| 11 → 11 |
12 → Fizz |
13 → 13 |
14 → 14 |
15 → FizzBuzz |
16 → 16 |
17 → 17 |
18 → Fizz |
19 → 19 |
20 → Buzz |
| 17 → 17 |
18 → Fizz |
19 → 19 |
20 → Buzz |
21 → Fizz |
22 → 22 |
23 → 23 |
24 → Fizz |
25 → Buzz |
26 → 26 |
Notice that as one Buzz drops off to the left, a new one appears to the right. Additionally, there may be more than one literal Buzz, but there's always at least one (that is, one that's exactly Buzz, and not just ending in Buzz).
That's another universal property: for any consecutive sequence of numbers of length ten, there's at least one exact Buzz. Here's how to express that as a QuickCheck property:
testProperty "At least one literal Buzz in 10 values" $ \ (i :: Int) -> let range = [i..i+9] actual = fizzBuzz <$> range in counterexample (show range ++ "->" ++ show actual) $ elem "Buzz" actual
Again, no partitioning is required to express this property.
This version of fizzBuzz passes all tests:
fizzBuzz :: Integral a => a -> String fizzBuzz i | i `mod` 15 == 0 = "FizzBuzz" fizzBuzz i | i `mod` 3 == 0 = "Fizz" fizzBuzz i | i `mod` 5 == 0 = "Buzz" fizzBuzz _ = "2112"
What's left? Only that the number is still hard-coded.
Numbers round-trip #
How to get rid of the hard-coded number?
From one of the above properties, we know that if we pick an arbitrary consecutive sequence of three numbers, at least one of the results will be a string representation of the input number.
It's not guaranteed to be the origin, though. If the origin is, say, 3, the input sequence is 3, 4, 5, which should yield the resulting sequence Fizz, 4, Buzz.
Since we don't know which number(s) will remain, how can we check that it translates correctly? We can use a variation of a common property-based testing pattern - the one that Scott Wlaschin calls There and back again.
We can take any sequence of three outputs and try to parse them back to integers. All successfully parsed numbers must belong to the input sequence.
That's another universal property. Here's how to express that as a QuickCheck property:
testProperty "Numbers round-trip" $ \ (i :: Int) -> let range = [i..i+2] actual = fizzBuzz <$> range numbers = catMaybes $ readMaybe <$> actual in counterexample (show range ++ "->" ++ show actual) $ all (`elem` range) numbers
The parsed numbers may contain one or two elements, but in both cases, all of them must be an element of range.
Again, no partitioning is required to express this property.
This version of fizzBuzz passes all tests:
fizzBuzz :: (Integral a, Show a) => a -> String fizzBuzz i | i `mod` 15 == 0 = "FizzBuzz" fizzBuzz i | i `mod` 3 == 0 = "Fizz" fizzBuzz i | i `mod` 5 == 0 = "Buzz" fizzBuzz i = show i
This looks good. Let's call it a day.
Not so fast, though.
Redundant property? #
With the new round-trip property, isn't the property titled At least one number in 3 consecutive values redundant?
You might think so, but it's not. What happens if we remove it?
If you remove the At least one number in 3 consecutive values property, the Devil's Advocate can corrupt fizzBuzz like this:
fizzBuzz :: (Integral a, Show a) => a -> String fizzBuzz i | i `mod` 15 == 0 = "FizzBuzz" fizzBuzz i | i `mod` 3 == 0 = "Fizz" fizzBuzz i | i `mod` 5 == 0 = "Buzz" fizzBuzz _ = "Pop"
This passes all tests if you remove At least one number in 3 consecutive values. Why doesn't the Numbers round-trip property fail?
It doesn't fail because with the above implementation of fizzBuzz its numbers list is always empty. This property doesn't require numbers to be non-empty. It doesn't have to, because that's the job of the At least one number in 3 consecutive values property. Thus, that property isn't redundant. Leave it in.
Intuition behind the paper #
What about the results from the Hamlet & Taylor paper? Are the conclusions in the paper wrong?
They may be, but that's not my take. Rather, the way I understand the paper, it says that partition testing isn't much more efficient at detecting errors than pure random sampling.
I've been using the rather schizophrenic version of the Devil's Advocate technique (the one that I call Gollum style) for so long that this conclusion rings true for me.
Consider a truly adversarial developer from Hell. He or she could subvert fizzBuzz like this:
fizzBuzz :: (Integral a, Show a) => a -> String fizzBuzz 18641 = "Pwnd" fizzBuzz i | i `mod` 15 == 0 = "FizzBuzz" fizzBuzz i | i `mod` 3 == 0 = "Fizz" fizzBuzz i | i `mod` 5 == 0 = "Buzz" fizzBuzz i = show i
The test suite is very unlikely to detect the error - even if you ask it to run each property a million times:
$ stack test --ta "-a 1000000" FizzBuzzHaskellPropertyBased> test (suite: FizzBuzz-test, args: -a 1000000) Divisible by both 3 and 5: [OK, passed 1000000 tests] At least one number in 3 consecutive values: [OK, passed 1000000 tests] At least one Fizz in 3 consecutive values: [OK, passed 1000000 tests] Only one Buzz in 5 consecutive values: [OK, passed 1000000 tests] At least one literal Buzz in 10 values: [OK, passed 1000000 tests] Numbers round-trip: [OK, passed 1000000 tests] Properties Total Passed 6 6 Failed 0 0 Total 6 6 FizzBuzzHaskellPropertyBased> Test suite FizzBuzz-test passed
How many times should we run these properties before we'd expect the At least one number in 3 consecutive values property to detect the error?
In Haskell, Int is an integer type with at least the range [-2^29 .. 2^29-1] - that is, from -536,870,912 to 536,870,911, for a total range of 1,073,741,823 numbers.
In order to detect the error, the At least one number in 3 consecutive values property needs to hit 18,641, which it can only do if QuickCheck supplies an i value of 18,639, 18,640, or 18,641. That's three values out of 1,073,741,823.
If we assume a uniform distribution, the chance of detecting the error is 3 / 1,073,741,823, or approximately one in 333 million.
Neither property-based testing nor randomised testing is likely to detect this kind of error. That's basically the intuition that makes sense to me when reading the Hamlet & Taylor paper. If you don't know where to look, partition testing isn't going to help you detect errors like the above.
I can live with that. After all, the value I get out of property-based testing is as a variation on test-driven development, rather than only quality assurance. It enables me to incrementally flesh out a problem in a way that example-based testing sometimes can't.
Conclusion #
There's a big overlap between partition testing and property-based testing. Often, identifying equivalence classes is the first step to expressing a property. A conspicuous example can be seen in my article series Types + Properties = Software, which shows a detailed walk-through of the Tennis kata done with FsCheck. For a hybrid approach, see Roman numerals via property-based TDD.
In my experience, it's much easier to partition a domain into equivalence classes than it is to describe universal properties of a system. Thus, many properties I write tend to be a kind of partition testing. On the other hand, it's more satisfying when you can express universal properties. I'm not sure that it's always possible, but I find that when it is, it better decouples the tests from implementation details.
Based on the FizzBuzz example shown here, you may find it unappealing that there's more test code than 'production code'. Clearly, for a problem like FizzBuzz, this is unwarranted. That, however, wasn't the point with the example. The point was to show an easily digestible example of universal properties. For a more realistic example, I'll refer you to the scheduling problem I also linked to earlier. While the production code ultimately turned out to be compact, it's far from trivial.
Agile pull requests
If it hurts, do it more often.
The agile software development movement has been instrumental in uncovering better ways of developing software. Under that umbrella term you find such seminal ideas as test-driven development, continuous delivery, responding to change, and so on. Yet, as we're entering the third decade of agile software development, most organisations still struggle to take in the ethos and adopt its practices.
Change is hard. A typical reaction from a development organisation would be:
"We tried it, but it doesn't work for us."
The usual agile response to such foot-draggery is: if it hurts, do it more often.
I'd like to suggest exactly that remedy for a perceived problem that many agile proponents seem to believe exist.
Pull request problems and solutions #
I like collaborating with other developers via pull requests, but I also admit that my personality may influence that preference. I like deep contemplation; I like doing things on my own time, to my own schedule; I like having the freedom to self-organise. Yes, I fit the description of an introvert. Pull requests do enable contemplation, they do let me self-organise.
Yet, I'm quite aware that there are plenty of problems with pull requests. First, many pull requests are poorly done. They are too big, bundle together unrelated things and introduce noise. I wrote an article titled 10 tips for better Pull Requests to help developers create better pull requests. With a little practice, you can write small, focused pull requests.
If it hurts, do it more often.
Another problem with pull requests is in the review process. The most common criticism of the pull request process with its review phase is that it takes too long. I discuss this problem, and a remedy, in my coming book Code That Fits in Your Head:
I've tried this in a small organisation, and it can work. I'm not claiming that it's easy, but it's hardly impossible."The problem with typical approaches is illustrated by [the figure below]. A developer submits a piece of work for review. Then much time passes before the review takes place.

"[Figure caption:] How not to do code reviews: let much time pass between completion of a feature and the review. (The smaller boxes to the right of the review indicates improvements based on the initial review, and a subsequent review of the improvements.)
"[The figure below] illustrates an obvious solution to the problem. Reduce the wait time. Make code reviews part of the daily rhythm of the organisation.

"[Figure caption:] Reduce the wait time between feature completion and code review. A review will typically spark some improvements, and a smaller review of those improvements. These activities are indicated by the smaller boxes to the right of the review.
"Most people already have a routine that they follow. You should make code reviews part of that routine. You can do that on an individual level, or you can structure your team around a daily rhythm. Many teams already have a daily stand-up. Such a regularly occurring event creates an anchor around which the day revolves. Typically, lunchtime is another natural break in work.
"Consider, for example, setting aside half an hour each morning, as well as half an hour after lunch, for reviews.
"Keep in mind that you should make only small sets of changes. Sets that represent less than half a day's work. If you do that, and all team members review those small changes twice a day, the maximum wait time will be around four hours."
If it hurts, do it more often.
An underlying problem is that people often feel that they don't have the time to review their colleagues' code. This is a real problem. If you are being measured (formally or informally) on your 'individual contribution', then anything you do to help your team looks like a waste of time. This is, in my opinion, an organisational problem, rather than a problem with doing reviews.
It's also a problem that pair programming doesn't solve.
Pull requests versus pair programming #
You can make the pull request process work, but should you? Isn't pair (or ensemble) programming better?
Pair programming can also be effective. I discuss that too in my new book. What works best, I believe, is a question of trade-offs. What's more important to you? Latency or throughput?
In other words, while I have a personality-based preference for the contemplative, asynchronous pull request process, I readily admit that pair or ensemble programming may be better in many situations.
I suspect, however, that many proponents of pair programming are as driven by their personality-based preference as I am, but that since they might be extroverts, they favour close personal interaction over contemplation.
In any case, use what works for you, but be wary of unequivocal claims that one way is clearly better than the other. We have scant scientific knowledge about software development. Most of what I write, and what industry luminaries write, is based on anecdotal evidence. This also applies to this discussion of pull requests versus pair programming.
Conclusion #
I have anecdotal evidence that pull requests can work in an 'agile' setting. One team had implemented continuous deployment and used pull requests because more than half the team members were working from remote (this was before the COVID-19 pandemic). Pull requests were small and reviews could typically be done in five-ten minutes. Knowing this, reviews were prompt and frequent. Turnaround-time was good.
I also have anecdotal evidence that ensemble programming works well. To me, it solves a completely different problem, but I've used it to great effect for knowledge transfer.
Programmers more extrovert than me report anecdotal evidence that pair programming is best, and I accept that this is true - for them. I do not, however, accept it as a universal truth. Neither do I claim that my personal preference for pull request is incontrovertibly best.
New book: Code That Fits in Your Head
The expanded universe.
It gives me great pleasure to announce that my new book Code That Fits in Your Head will be out in September 2021. The subtitle is Heuristics for Software Engineering.
Many regular readers have been expecting me to write a book about functional programming, and while that may also some day happen, this book is neither about object-oriented nor functional programming per se. Rather, it takes a step back and looks at various software development techniques and practices that I've found myself teaching for years. It covers both coding, troubleshooting, software design, team work, refactoring, and architecture.
The target audience is all the hard-working enterprise developers in our industry. I estimate that there's great overlap with the general readership of this blog. In other words, if you find this blog useful, I hope that you'll also find the book useful.
As the title suggests, the theme is working effectively with code in a way that acknowledges the limitations of the human brain. This is a theme I've already explored in my Humane Code video, but in the book I expand the scope.
Expanded universe #
I've structured the book around a realistic sample application. You'll see how to bootstrap a code base, but also how to work effectively with existing code. Along with the book, you'll get access to a complete Git repository with more than 500 commits and more than 6,000 lines of lovingly crafted code.
While I was developing the sample code, I solved many interesting problems. The best and most universal examples I used in the book, but many didn't make the cut. The book aims broadly at programmers comfortable with a C-based programming language: Java, C#, JavaScript, C++, and so on. Some of the problems I solved along the way were specific to .NET, so I found them a poor fit for the book. I didn't want these great lessons to go to waste, so instead I've been blogging about them.
These are the articles based on the code base from the book:
- Closing database connections during test teardown
- Using the nameof C# keyword with ASP.NET 3 IUrlHelper
- An ASP.NET Core URL Builder
- Adding REST links as a cross-cutting concern
- EnsureSuccessStatusCode as an assertion
- Fortunately, I don't squash my commits
- Monomorphic functors
- Signing URLs with ASP.NET
- Checking signed URLs with ASP.NET
- Redirect legacy URLs
- Name by role
- Branching tests
- Waiting to happen
- Parametrised test primitive obsession code smell
- Self-hosted integration tests in ASP.NET
- ASP.NET POCO Controllers: an experience report
- When properties are easier than examples
- Pendulum swing: internal by default
- Pendulum swing: sealed by default
- Consider including identity in URLs
- Leaky abstraction by omission
- Structural equality for better tests
- Simplifying code with Decorated Commands
- Unit testing private helper methods
- Keep IDs internal with REST
- The Equivalence contravariant functor
- Waiting to never happen
- Test Double clocks
- An applicative reservation validation example in C#
- ASP.NET validation revisited
- Coalescing DTOs
- Stubs and mocks break encapsulation
- An initial proof of concept of applicative assertions in C#
- Warnings-as-errors friction
- A restaurant example of refactoring from example-based to property-based testing
- Decomposing CTFiYH's sample code base
- Do ORMs reduce the need for mapping?
- The case of the mysterious comparison
- A restaurant sandwich
- Testing races with a slow Decorator
- Greyscale-box test-driven development
- Filtering as domain logic
- Code that fits in a context window
That the above list represents the outtakes from the book's example code base should give you an idea of the richness of it.
I may add to the list in the future if I write more articles that use the book's example code base.
Conclusion #
A decade after my first book, I've finally written a completely new book. Over the years, I had a few false starts. This book wasn't the book I thought that I'd be writing if you'd asked me five years ago, but when it finally dawned on me that the topic ought to be Code That Fits in Your Head: Heuristics for Software Engineering, the book almost wrote itself.
This one is for all the software developers out there who aspire to improve their practical skills.
Comments
When will the book be available for pre-purchase in Europe/Denmark? Looking forward to reading it!
Eric, thank you for writing. The book has already made its way to amazon.de and amazon.fr. On the other hand, it seems to be available neither on amazon.co.uk nor amazon.se.
Granted, it doesn't look as though you can pre-order on those two sites yet.
If you wish to buy the book directly in Denmark, I think that your best bet is to contact the book store of your preference and ask if and when they're going to carry it.
When and how to offer a book for sale is ultimately the purview of book sellers, so not something I can accurately answer. That said, you can already today pre-order the book on amazon.com, but it's probably going to cost you a little extra in shipping cost.
I'd expect that when the book is finally published, many of the above sites will also sell it. For what it's worth, the manuscript has been done for months. The book is currently 'in production', being proofed and set. As I understand it, this is a fairly predictable process, so I don't expect significant delays relative to the late September 2021 timeline.
Will it be available as an eBook? Unexpectedly, Google shows no results.
Serg, thank you for writing. Yes, the book will be available as both PDF and for Kindle.
Excellent book! I highly recommend it to new and experienced software developers.
Abstruse nomenclature
Some thoughts on programming terminology.
Functional programming has a reputation for abstruse nomenclature:
I've already discussed when x, y, and z are great variable names, and I don't intend to say more about that sort of naming here. (And to be clear, zygohistomorphic prepromorphisms are a joke.)"Functional programmer: (noun) One who names variables "x", names functions "f", and names code patterns "zygohistomorphic prepromorphism""
What I would like to talk about is the contrast to the impenetrable jargon of functional programming: the crystal-clear vocabulary of object-oriented design. Particularly, I'd like to talk about polymorphism.
Etymology #
As Wikipedia puts it (retrieved 2021-06-04), polymorphism is the provision of a single interface to entities of different types. This doesn't quite fit with the actual meaning of the word, though.
The word polymorphism is derived from Greek. Poly means many, and morphism stems from μορφή (morphḗ), which means shape. Putting all of this together, polymorphism means many-shape.
How does that fit with the idea of having a single interface? Not very well, I think.
A matter of perspective? #
I suppose that if you view the idea of object-oriented polymorphism from the implementer's perspective, talking about many shapes makes marginal sense. Consider, for example, two classes from a recent article. Imagine, for example, that we replace every character in the Advantage code with an x:
xxxxxx xxxxxx xxxxxxxxx x xxxxxx
x
xxxxxx xxxxxxxxxxxxxxxx xxxxxxx
x
xxxxxx x xxxxxxx
x
xxxxxx xxxxxx xxxxxx x xxxx xxxx x
xxxxxx xxxx xxxxxxxxxxxxx xxxxxxx xxxx xxxxx
x
xx xxxxxxx xx xxxxxxx
xxxxxxxxxx x xxx xxxxxxxxxxxxxxxxxxxxxx
xxxx
xxxxxxxxxx x xxxxxxxxxxxxxxx
x
x
This trick of replacing all characters with x to see the shape of code is one I picked up from Kevlin Henney. Try to do the same with the Deuce struct from the same article:
xxxxxx xxxxxx xxxxx x xxxxxx
x
xxxxxx xxxxxxxx xxxxxx xxxxxx xxxxxxxx x xxx xxxxxxxx
xxxxxx xxxx xxxxxxxxxxxxx xxxxxxx xxxx xxxxx
x
xxxxxxxxxx x xxx xxxxxxxxxxxxxxxxxx
x
x
Clearly, these two classes have different shapes.
You could argue that all classes have different shapes, but what unites Advantage with Deuce (and three other classes) is that they implement a common interface called IScore. In a sense you can view an IScore object as an object that can have multiple shapes; i.e. a polymorphism.
While there's some soundness to this view, as terminology goes, the most important part is only implicitly understood. Yes, all objects have different shapes (poly-morphic), but in order to be a polymorphism, they must present as one.
In practice, most of us understand what the other means if one of us says polymorphism, but this is only because we've learned what the word means in the context of object-oriented programming. It's not because the word itself is particularly communicative, even if you pick up the Greek roots.
Common interface #
The above outline doesn't present how I usually think about polymorphism. I've deliberately tried to steelman it.
When I think of polymorphism, I usually focus on what two or more classes may have in common. Instead of replacing every character with an x, try instead to reduce the Advantage and Deuce structs to their public interfaces. First, Advantage:
public struct Advantage : IScore { public Advantage(Player player) public Player Player { get; } public void BallTo(Player winner, Game game) }
Now do the same with Deuce:
public struct Deuce : IScore { public readonly static IScore Instance public void BallTo(Player winner, Game game) }
These two APIs are clearly different, yet they have something in common: the BallTo method. In fact, you can draw a Venn diagram of the public members of all five IScore classes:
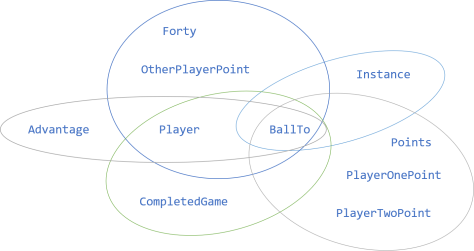
Incidentally, three of the five classes (Forty, Advantage, and CompletedGame) also share a Player property, but all five share the BallTo method. Singling out that method yields the IScore interface:
public interface IScore { void BallTo(Player winner, Game game); }
Such a (statically-typed) common API is what I usually think of when I think of polymorphism. It's the shape that all five classes have in common. When viewed through the lens of the IScore interface, all five classes have the same form!
The term polymorphism (many shapes) makes little sense in this light. Really, it ought to have been called isomorphism (equal shape), but unfortunately, that word already means something else.
Sometimes, when you discover that the Greek word for a term is already taken, you can use Latin instead. Let's see, what would one shape be in Latin? Uniform? Yeah, that's also taken.
Okay, I'm cheating by deliberately picking words that are already taken. Perhaps a better option might be idiomorphism, from Greek, ἴδιος (idios, “own, personal, distinct”).
Opacity #
The point of all of this really isn't to harp on polymorphism in particular. This term is well understood in our industry, so there's no pragmatic reason to change it.
Rather, I wish to point out the following:
- Object-oriented design also includes Greek terms
- Even if you can decipher a Greek term, the name may not be helpful
- In fact, the name may be outright misleading
This is true also in programming. Without a context, polymorphism can mean many things. In biology, for example, it means the occurrence of two or more clearly different forms within a species, for example light and black jaguars (the animal, not the car - another example that a word belongs in a context).
This type of polymorphism in biology reminds me more of role interfaces, where a single class can implement several interfaces, but perhaps that's just me.
Ultimately, industry terminology is opaque until you learn it. Some words may be easier to learn than others, but looks can be deceiving. Inheritance may sound straightforward, but in object-oriented design, inheritance doesn't entail the death of someone else. Additionally, in programming languages with single inheritance, descendants can only inherit once. As a metaphor, inheritance is mediocre at best.
Another friendly-sounding piece of terminology is encapsulation - despite the fact that it's essentially Latin, just warped by two millennia of slight linguistic drift. Even so, this most fundamental concept of object-oriented design is also the most misunderstood. The word itself doesn't much help communicating the concept.
Finally, I wish to remind my English-speaking readers that not all programmers have English as their native language. For many programmers, words like class, object, or encapsulation may be words that they only know via programming. These could be words that have no prior, intrinsic meaning to a speaker of Hungarian or Japanese.
Functional programming terminology #
Is functional programming terminology harder than object-oriented jargon? I don't think so.
A nice little word like monoid, for example, is Greek for one-like. Again, it's not self-explanatory, but once the concept of a monoid is explained, it makes sense: it's an abstraction that enables you to treat many things as though they are a single thing (with possible loss of fidelity, though). As names go, I find this more accurate than polymorphism.
Granted, there's more Greek in functional programming than in object-oriented design, but (Latin) English is still present: recursion, fold, and traversal are common terms.
And then there's the occasional nonsense word, like functor. Despite some of digging, I've only managed to learn that functor is a compaction of function and factor - that is, a function factor, but what does that tell you?
In many ways, I prefer nonsense words like functor, because at least, they aren't misleading. When you learn that word, you have no preconception that you think you already know what it means. Michael Feathers is experimenting with a similar idea, but in another context, inventing words like exot, lavin, endot, parzo, duon, and tojon.
Conclusion #
It's easy to dismiss the alien as incomprehensible. This often happens in programming. New ideas are dismissed as non-idiomatic. Alternative paradigms like functional programming are rejected because some words aren't immediately forthcoming.
This, to me, says more about the person spurning new knowledge than it says about the ideas themselves.
From State tennis to endomorphism
You can refactor the State pattern to pure functions.
In a previous article you saw how to do the Tennis kata with the State design pattern. Like most other patterns in Design Patterns, the State pattern relies on mutation. If you favour functional programming and immutable data, you may not like that. Fortunately, converting the API to immutable data and pure functions is plain sailing.
In this post I'll show you how I did it.
Return Score #
Recall from the previous article that the IScore interface defined a single method, BallTo:
public interface IScore { void BallTo(Player winner, Game game); }
With its void return type, it clearly indicate that BallTo mutates the state of something - although it's less clear whether it's the object itself, game, or both.
As a first step towards turning the method into a pure function, then, you can change the return type so that it returns an IScore object:
public interface IScore { IScore BallTo(Player winner, Game game); }
In itself, this doesn't guarantee that the function is pure. In fact, after this small step, none of the implementations are. Here, for example, is the updated Advantage implementation:
public IScore BallTo(Player winner, Game game) { if (winner == Player) game.Score = new CompletedGame(winner); else game.Score = Deuce.Instance; return game.Score; }
This implementation still modifies game.Score before returning it. All the other IScore implementations do the same.
Use the returned score #
Now that the BallTo method returns an IScore object, you can edit the Game class' BallTo method so that it uses the returned value:
public void BallTo(Player player) { Score = Score.BallTo(player, this); }
Given that all the IScore implementations currently mutate game.Score, this seems redundant, but sets you up for the next refactoring step.
Remove State mutation #
You can now remove the mutation of game.Score from all the implementations of IScore. Here's Advantage after the refactoring:
public IScore BallTo(Player winner, Game game) { if (winner == Player) return new CompletedGame(winner); else return Deuce.Instance; }
Notice that this implementation no longer uses the game parameter.
The other IScore implementations get a similar treatment.
Remove game parameter #
Since no implementations use the game parameter you can remove it from the interface:
public interface IScore { IScore BallTo(Player winner); }
and, of course, from each of the implementations:
public IScore BallTo(Player winner) { if (winner == Player) return new CompletedGame(winner); else return Deuce.Instance; }
The above method, again, is the implementation of Advantage.
Return Game #
You can now make the same sequence of changes to the Game class itself. Recall from above that its BallTo method returns void. As a the first refactoring step towards turning that method into a pure function, then, change the return type:
public Game BallTo(Player player) { Score = Score.BallTo(player); return this; }
The mutation remains a little while longer, but the method looks like something that could be a pure function.
Return new Game #
The next refactoring step is to return a new Game instance instead of the same (mutated) instance:
public Game BallTo(Player player) { Score = Score.BallTo(player); return new Game(Score); }
The first line still mutates Score, but now you're only one step away from an immutable implementation.
Remove Game mutation #
Finally, you can remove the mutation of the Game class. First, remove the internal setter from the Score property:
public IScore Score { get; }
You can now lean on the compiler, as Michael Feathers explains in Working Effectively with Legacy Code. This forces you to fix the the BallTo method:
public Game BallTo(Player player) { return new Game(Score.BallTo(player)); }
This is also the only refactoring that requires you to edit the unit tests. Here a few methods as examples:
[Theory] [InlineData(Player.One, Point.Love)] [InlineData(Player.One, Point.Fifteen)] [InlineData(Player.One, Point.Thirty)] [InlineData(Player.Two, Point.Love)] [InlineData(Player.Two, Point.Fifteen)] [InlineData(Player.Two, Point.Thirty)] public void FortyWins(Player winner, Point otherPlayerPoint) { var sut = new Game(new Forty(winner, otherPlayerPoint)); var actual = sut.BallTo(winner); Assert.Equal(new CompletedGame(winner), actual.Score); } [Theory] [InlineData(Player.One)] [InlineData(Player.Two)] public void FortyThirty(Player player) { var sut = new Game(new Forty(player, Point.Thirty)); var actual = sut.BallTo(player.Other()); Assert.Equal(Deuce.Instance, actual.Score); }
These are the same test methods as shown in the previous article. The changes are: the introduction of the actual variable, and that the assertion now compares the expected value to actual.Score rather than sut.Score.
Both variations of BallTo are now endomorphisms.
Explicit endomorphism #
If you're not convinced that the refactored IScore interface describes an endomorphism, you can make it explicit - strictly for illustrative purposes. First, introduce an explicit IEndomorphism interface:
public interface IEndomorphism<T> { T Run(T x); }
This is the same interface as already introduced in the article Builder as a monoid. To be clear, I wouldn't use such an interface in normal C# code. I only use it here to illustrate how the BallTo method describes an endomorphism.
You can turn a Player into an endomorphism with an extension method:
public static IEndomorphism<IScore> ToEndomorphism(this Player player) { return new ScoreEndomorphism(player); } private struct ScoreEndomorphism : IEndomorphism<IScore> { public ScoreEndomorphism(Player player) { Player = player; } public Player Player { get; } public IScore Run(IScore score) { return score.BallTo(Player); } }
This is equivalent to partial function application. It applies the player, and by doing that returns an IEndomorphism<IScore>.
The Game class' BallTo implementation can now Run the endomorphism:
public Game BallTo(Player player) { IEndomorphism<IScore> endo = player.ToEndomorphism(); IScore newScore = endo.Run(Score); return new Game(newScore); }
Again, I'm not recommending this style of C# programming. I'm only showing this to illustrate how the object playing the State role now describes an endomorphism.
You could subject the Game class' BallTo method to the same treatment, but if you did, you'd have to call the extension method something that would distinguish it from the above ToEndomorphism extension method, since C# doesn't allow overloading exclusively on return type.
Conclusion #
Like many of the other patterns in Design Patterns, the State pattern relies on mutation. It's straightforward, however, to refactor it to a set of pure functions. For what it's worth, these are all endomorphisms.
This article used a take on the tennis kata as an example.
Tennis kata using the State pattern
An example of using the State design pattern.
Regular readers of this blog will know that I keep coming back to the tennis kata. It's an interesting little problem to attack from various angles.
I don't think you have to do the kata that many times before you realise that you're describing a simple state machine. A few years ago I decided to use that insight to get reacquainted with the State design pattern.
In this article I'll show you what the code looks like.
Context #
As part of the exercise, I decided to stay close to the pattern description in Design Patterns. The public API should be exposed as a single class that hides all the internal state machinery. In the general pattern description, this class is called Context. The TCP example given in the book, however, calls the example class TCPConnection. This indicates that you don't have to use the word context when naming the class. I chose to simply call it Game:
public class Game { public Game() : this(new Points(Point.Love, Point.Love)) { } public Game(IScore score) { Score = score; } public IScore Score { get; internal set; } public void BallTo(Player player) { Score.BallTo(player, this); } }
Since the Game class delegates all behaviour to its Score property, it's basically redundant. This may be a degenerate example, but as an exercise of staying true to the pattern, I decided to keep it. It's the class that all tests work through.
Test #
All tests look similar. This parametrised test verifies what happens after deuce:
[Theory] [InlineData(Player.One)] [InlineData(Player.Two)] public void ScoreDeuce(Player winner) { var sut = new Game(Deuce.Instance); sut.BallTo(winner); Assert.Equal(new Advantage(winner), sut.Score); }
This is code that I wrote years ago, so it uses xUnit.net 2.3.1 and runs on .NET Framework 4.6.1, but I don't think it'd have looked different today. It follows my heuristic for formatting unit tests.
Structural equality #
The equality assertion works because Advantage has structural equality. In this exercise, I found it simpler to declare types as value types instead of overriding Equals and GetHashCode:
public struct Advantage : IScore { public Advantage(Player player) { Player = player; } public Player Player { get; set; } public void BallTo(Player winner, Game game) { if (winner == Player) game.Score = new CompletedGame(winner); else game.Score = Deuce.Instance; } }
This turned out to be possible throughout, since all types emerged as mere compositions of other value types. The above Advantage struct, for example, adapts a Player, which, unsurprisingly, is an enum:
public enum Player { One = 0, Two }
One of the states holds no data at all, so I made it a Singleton, as suggested in the book. (Contrary to popular belief, I don't consider Singleton an anti-pattern.)
public struct Deuce : IScore { public readonly static IScore Instance = new Deuce(); public void BallTo(Player winner, Game game) { game.Score = new Advantage(winner); } }
Since it's a Singleton, from an equality perspective it doesn't matter whether it's a value or reference type, but I made it a struct for consistency's sake.
State #
In the State design pattern's formal structure, the Context delegates all behaviour to an abstract State class. Since I consider inheritance harmful (as well as redundant), I instead chose to model the state as an interface:
public interface IScore { void BallTo(Player winner, Game game); }
As the pattern suggests, the State object exposes methods that take the Context as an extra parameter. This enables concrete State implementation to change the state of the Context, as both the above structs (Advantage and Deuce) demonstrate. They both implement the interface.
When I do the kata, I always seem to arrive at five distinct states. I'm not sure if this reflects the underlying properties of the problem, or if it's just because that's what worked for me years ago, and I'm now stuck in some cognitive local maximum. In any case, that's what happened here as well. Apart from the above Advantage and Deuce there's also a Forty implementation:
public struct Forty : IScore { public Forty(Player player, Point otherPlayerPoint) { Player = player; OtherPlayerPoint = otherPlayerPoint; } public Player Player { get; } public Point OtherPlayerPoint { get; } public void BallTo(Player winner, Game game) { if (Player == winner) game.Score = new CompletedGame(winner); else if (OtherPlayerPoint == Point.Thirty) game.Score = Deuce.Instance; else if (OtherPlayerPoint == Point.Fifteen) game.Score = new Forty(Player, Point.Thirty); else game.Score = new Forty(Player, Point.Fifteen); } }
Another thing that I've also noticed when doing the Tennis kata is that the state logic for advantage and deuce is simple, whereas the state transitions involving points is more complicated. If you think Forty looks complicated, then consider Points:
public struct Points : IScore { public Points(Point playerOnePoint, Point playerTwoPoint) { PlayerOnePoint = playerOnePoint; PlayerTwoPoint = playerTwoPoint; } public Point PlayerOnePoint { get; } public Point PlayerTwoPoint { get; } public void BallTo(Player winner, Game game) { var pp = PlayerPoint(winner); var opp = PlayerPoint(winner.Other()); if (pp == Point.Thirty) game.Score = new Forty(winner, opp); else if (winner == Player.One) game.Score = new Points(Increment(PlayerOnePoint), PlayerTwoPoint); else game.Score = new Points(PlayerOnePoint, Increment(PlayerTwoPoint)); } private Point PlayerPoint(Player player) { if (player == Player.One) return PlayerOnePoint; else return PlayerTwoPoint; } private static Point Increment(Point point) { if (point == Point.Love) return Point.Fifteen; else return Point.Thirty; } }
The last IScore implementation represents a completed game:
public struct CompletedGame : IScore { public CompletedGame(Player player) { Player = player; } public Player Player { get; } public void BallTo(Player winner, Game game) { } }
In a completed game, the BallTo implementation is a no-op, because Player has already won the game.
Miscellany #
Here's a few more tests, just to back up my claim that all tests look similar:
[Theory] [InlineData(Player.One, Point.Love)] [InlineData(Player.One, Point.Fifteen)] [InlineData(Player.One, Point.Thirty)] [InlineData(Player.Two, Point.Love)] [InlineData(Player.Two, Point.Fifteen)] [InlineData(Player.Two, Point.Thirty)] public void FortyWins(Player winner, Point otherPlayerPoint) { var sut = new Game(new Forty(winner, otherPlayerPoint)); sut.BallTo(winner); Assert.Equal(new CompletedGame(winner), sut.Score); } [Theory] [InlineData(Player.One)] [InlineData(Player.Two)] public void FortyThirty(Player player) { var sut = new Game(new Forty(player, Point.Thirty)); sut.BallTo(player.Other()); Assert.Equal(Deuce.Instance, sut.Score); }
The second of these test methods uses an extension method called Other:
public static class PlayerEnvy { public static Player Other(this Player player) { if (player == Player.One) return Player.Two; else return Player.One; } }
As is my custom, I named the class containing the extension method with the Envy suffix, because I often consider this kind of extension method a sign of Feature Envy. Alas, in C# you can't add methods to an enum.
Conclusion #
Implementing the tennis kata with the classic State pattern is straightforward.
After having spent the majority of the last decade with functional programming, I've come to realise that many problems are really just state machines waiting to be revealed as such. Implementing a finite state machine in a language with algebraic data types is so easy that you often reach for that kind of modelling.
Before I learned functional programming, when all I knew was procedural and object-oriented code, I rarely thought of problems in terms of finite state machines. Now I see them everywhere. It's an example of how learning a completely different thing can feed back on everyday programming.
Once you recognise that a problem can be modelled as a finite state machine, you have new options. If you're in a conservative context where colleagues aren't keen on fancy FP shenanigans, you can always reach for the State design pattern.
Comments
Do you think that perhaps you are at risk of making too many problems look like nails for your state machine hammer? :-) Actually, you just want to convert a pair of points into a tennis score. That doesn't require a state machine, I don't think:
using NUnit.Framework;
namespace TennisKata
{
public class Tests
{
private TennisGame tennisGame;
[SetUp]
public void Setup()
{
tennisGame = new TennisGame();
}
[TestCase(0, 0, ExpectedResult = "Love All")]
[TestCase(1, 1, ExpectedResult = "Fifteen All")]
[TestCase(2, 2, ExpectedResult = "Thirty All")]
[TestCase(3, 3, ExpectedResult = "Deuce")]
[TestCase(4, 4, ExpectedResult = "Deuce")]
[TestCase(1, 0, ExpectedResult = "Fifteen - Love")]
[TestCase(2, 1, ExpectedResult = "Thirty - Fifteen")]
[TestCase(3, 2, ExpectedResult = "Forty - Thirty")]
[TestCase(4, 0, ExpectedResult = "Game Server")]
[TestCase(0, 1, ExpectedResult = "Love - Fifteen")]
[TestCase(1, 2, ExpectedResult = "Fifteen - Thirty")]
[TestCase(2, 3, ExpectedResult = "Thirty - Forty")]
[TestCase(0, 4, ExpectedResult = "Game Receiver")]
[TestCase(4, 3, ExpectedResult = "Advantage Server")]
[TestCase(3, 4, ExpectedResult = "Advantage Receiver")]
[TestCase(5, 4, ExpectedResult = "Advantage Server")]
[TestCase(4, 5, ExpectedResult = "Advantage Receiver")]
[TestCase(5, 3, ExpectedResult = "Game Server")]
[TestCase(3, 5, ExpectedResult = "Game Receiver")]
[TestCase(5, 2, ExpectedResult = "Invalid score")]
[TestCase(2, 5, ExpectedResult = "Invalid score")]
public string ShouldConvertPointsToTennisStyleScore(int serverPoints, int receiverPoints)
{
SetServerPointsTo(serverPoints);
SetReceiverPointsTo(receiverPoints);
return tennisGame.Score;
}
private void SetServerPointsTo(int serverPoints)
{
for (var i = 0; i < serverPoints; i++)
{
tennisGame.PointToServer();
}
}
private void SetReceiverPointsTo(int serverPoints)
{
for (var i = 0; i < serverPoints; i++)
{
tennisGame.PointToReceiver();
}
}
}
public class TennisGame
{
private int serverPoints;
private int receiverPoints;
public string Score => serverPoints switch
{
_ when serverPoints == receiverPoints && serverPoints >= 3 => "Deuce",
_ when serverPoints == receiverPoints => $"{PointsAsWord(serverPoints)} All",
_ when serverPoints >= 4 && serverPoints > receiverPoints => GetGameOrAdvantage(serverPoints, receiverPoints, "Server"),
_ when receiverPoints >= 4 => GetGameOrAdvantage(receiverPoints, serverPoints, "Receiver"),
_ => $"{PointsAsWord(serverPoints)} - {PointsAsWord(receiverPoints)}"
};
public void PointToServer()
{
serverPoints++;
}
public void PointToReceiver()
{
receiverPoints++;
}
private static string GetGameOrAdvantage(int highScore, int lowScore, string highScorerName)
{
var scoreDifference = highScore - lowScore;
return scoreDifference switch
{
1 => $"Advantage {highScorerName}",
_ when highScore > 4 && scoreDifference > 2 => "Invalid score",
_ => $"Game {highScorerName}"
};
}
private string PointsAsWord(int points)
{
var pointNames = new [] { "Love", "Fifteen", "Thirty", "Forty"};
return pointNames[points];
}
}
}
Jim, thank you for writing. You're right: a state machine isn't required. It's a nice judo trick to keep track of the server and receiver points as two different numbers. That does simplify the code.
I tried something similar many years ago (after all, the kata description itself strongly hints at that alternative perspective), but for various reasons ended with an implementation that wasn't as nice as yours. I never published it. I've done this exercise many times, and I've only published the ones that I find can be used to highlight some interesting point.
The point of doing a coding kata is to experiment with variation. The goal isn't always to reach the fewest lines of code, or complete the exercise as fast as possible. These can be interesting exercises in their own rights, but by doing a kata with other constraints can be illuminating as well.
My goal with this variation was mainly to get reacquainted with the State pattern. Actually 'solving' the problem is a requirement, but not the goal.
Modelling the problem with the State pattern has advantages and disadvantages. A major advantage is that it offers an API that enables client code to programmatically distinguish between the various states. When I did the exercise similar to your code, asserting against a string is easy. However, basing an API on a returned string may not be an adequate design. It's okay for an exercise, but imagine that you were asked to translate the scores. For example, in Danish, advantage is instead called fordel. Another requirement might be that you report players by name. So, for example, a Danish score might instead require something like fordel Serena Williams.
Don't take this as a criticism of your code. Sometimes, you don't need more than what you've done, and in such cases, doing more would be over-engineering.
On the other hand, if you find yourself in situations where e.g. translation is required, it can be helpful to be aware that other ways to model a problem are available. That's the underlying benefit of doing katas. The more variations you do, the better prepared you become to 'choose the right tool for the job.'
All that said, though, with the tennis kata, you can make it trivially simple modelling it as a finite state automaton.
Against consistency
A one-sided argument against imposing a uniform coding style.
I want to credit Nat Pryce for planting the seed for the following line of thinking at GOTO Copenhagen 2012. I'd also like to relieve him of any responsibility for what follows. The blame is all mine.
I'd also like to point out that I'm not categorically against consistency in code. There are plenty of good arguments for having a consistent coding style, but as regular readers may have observed, I have a contrarian streak to my personality. If you're only aware of one side of an argument, I believe that you're unequipped to make informed decisions. Thus, I make the following case against imposing coding styles, not because I'm dead-set opposed to consistent code, but because I believe you should be aware of the disadvantages.
TL;DR #
In this essay, I use the term coding style to indicate a set of rules that governs how code should be formatted. This may include rules about where you put brackets, whether to use tabs or spaces, which naming conventions to use, maximum line width, in C# whether you should use the var keyword or explicit variable declaration, and so on.
As already stated, I can appreciate consistency in code as much as the next programmer. I've seen more than one code base, however, where a formal coding style contributed to ossification.
I've consulted a few development organisations with an eye to improving processes and code quality. Sometimes my suggestions are met with hesitation. When I investigate what causes developers to resist, it turns out that my advice goes against 'how things are done around here.' It might even go against the company's formal coding style guidelines.
Coding styles may impede progress.
Below, I'll discuss a few examples.
Class fields #
A typical example of a coding style regulates naming of class fields. While it seems to be on retreat now, at one time many C# developers would name class fields with a leading underscore:
private readonly string? _action; private readonly string? _controller; private readonly object? _values;
I never liked that naming convention because it meant that I always had to type an underscore and then at least one other letter before I could make good use of my IDE. For example, in order to take advantage of auto-completion when using the _action field, I'd have to type _a, instead of just a.
Yes, I know that typing isn't a bottleneck, but it still annoyed me because it seemed redundant.
A variation of this coding style is to mandate an m_ prefix, which only exacerbates the problem.
Many years ago, I came across a 'solution': Put the underscore after the field name, instead of in front of it:
private readonly string? action_; private readonly string? controller_; private readonly object? values_;
Problem solved - I thought for some years.
Then someone pointed out to me that if distinguishing a class field from a local variable is the goal, you can use the this qualifier. That made sense to me. Why invent some controversial naming rule when you can use a language keyword instead?
So, for years, I'd always interact with class fields like this.action, this.controller, and so on.
Then someone else point out to me that this ostensible need to be able to distinguish class fields from local variables, or static from instance fields, was really a symptom of either poor naming or too big classes. While that hurt a bit, I couldn't really defend against the argument.
This is all many years ago. These days, I name class fields like I name variables, and I don't qualify access.
The point of this little story is to highlight how you can institute a naming convention with the best of intentions. As experience accumulates, however, you may realise that you've become wiser. Perhaps that naming convention wasn't such a good idea after all.
When that happens, change the convention. Don't worry that this is going to make the code base inconsistent. An improvement is an improvement, while consistency might only imply that the code base is consistently bad.
Explicit variable declaration versus var #
In late 2007, more than a decade ago, C# 3 introduced the var keyword to the language. This tells the compiler to automatically infer the static type of a variable. Before that, you'd have to explicitly declare the type of all variables:
string href = new UrlBuilder() .WithAction(nameof(CalendarController.Get)) .WithController(nameof(CalendarController)) .WithValues(new { year = DateTime.Now.Year }) .BuildAbsolute(Url);
In the above example, the variable href is explicitly declared as a string. With the var keyword you can alternatively write the expression like this:
var href = new UrlBuilder() .WithAction(nameof(CalendarController.Get)) .WithController(nameof(CalendarController)) .WithValues(new { year = DateTime.Now.Year }) .BuildAbsolute(Url);
The href variable is still statically typed as a string. The compiler figures that out for you, in this case because the BuildAbsolute method returns a string:
public string BuildAbsolute(IUrlHelper url)
These two alternatives are interchangeable. They compile to the same IL code.
When C# introduced this language feature, a year-long controversy erupted. Opponents felt that using var made code less readable. This isn't an entirely unreasonable argument, but most C# programmers subsequently figured that the advantages of using var outweigh the disadvantages.
A major advantage is that using var better facilitates refactoring. Sometimes, for example, you decide to change the return type of a method. What happens if you change the return type of UrlBuilder?
public Uri BuildAbsolute(IUrlHelper url)
If you've used the var keyword, the compiler just infers a different type. If, on the other hand, you've explicitly declared href as a string, that piece of code no longer compiles.
Using the var keyword makes refactoring easier. You'll still need to edit some call sites when you make a change like this, because Uri affords a different API than string. The point, however, is that when you use var, the cost of making a change is lower. Less ceremony means that you can spend your effort where it matters.
In the context of coding styles, I still, more than a decade after the var keyword was introduced, encounter code bases that use explicit variable declaration.
When I explain the advantages of using the var keyword to the team responsible for the code base, they may agree in principle, but still oppose using it in practice. The reason? Using var would make the code base inconsistent.
Aiming for a consistent coding style is fine, but only as long as it doesn't prohibit improvements. Don't let it stand in the way of progress.
Habitability #
I don't mind consistency; in fact, I find it quite attractive. It must not, however, become a barrier to improvement.
I've met programmers who so strongly favour consistency that they feel that, in order to change coding style, they'd have to go through the entire code base and retroactively update it all to fit the new rule. This is obviously prohibitively expensive to do, so practically it prevents change.
Consistency is fine, but learn to accept inconsistency. As Nat Pryce said, we should learn to love the mess, to adopt a philosophy akin to wabi-sabi.
I think this view on inconsistent code helped me come to grips with my own desire for neatness. An inconsistent code base looks inhabited. I don't mind looking around in a code base and immediately being able to tell: oh, Anna wrote this, or Nader is the author of this method.
What's more important is that the code is comprehensible.
Conclusion #
Consistency in code isn't a bad thing. Coding styles can help encourage a degree of consistency. I think that's fine.
On the other hand, consistency shouldn't be the highest goal of a code base. If improving the code makes a code base inconsistent, I think that the improvement should trump consistency every time.
Let the old code be as it is, until you need to work with it. When you do, you can apply Robert C. Martin's boy scout rule: Always leave the code cleaner than you found it. Code perfection is like eventual consistency; it's something that you should constantly move towards, yet may never attain.
Learn to appreciate the 'lived-in' quality of an active code base.
Simplifying code with Decorated Commands
Consider modelling many side effects as a single Command.
In a previous article I discussed how an abstraction can sometimes be leaky by omission. In this article, you'll see how removing the leak enables some beneficial refactoring. I'm going to assume that you've read the previous article.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
The relative cost of the four CRUD operations #
In this article, you'll see code that implements an ASP.NET Controller action. It enables a REST client to update an existing reservation via a PUT request.
I chose to show you the Put method because it's the worst, and thereby the one where refactoring is most warranted. This seems to follow a pattern I've noticed over the years: data updates are always the worst.
Before I show you the code, I'd like to take a little detour to discuss this observation.
Consider the four CRUD operations. Which one is the easiest to implement and maintain, and which one gives you most grief?
Deletes are typically straightforward: A unique identifier is all it takes. The only small complication you may have to consider is idempotence. If you delete an entity once, it's gone. What should happen if you 'delete' it again? To be clear, I don't consider this a trick question. A delete operation should be idempotent, but sometimes, depending on the underlying storage technology, you may have to write a few lines of code to make that happen.
Reads are a little more complicated. I'm actually not sure if reads are more or less involved than create operations. The complexity is probably about the same. Reading a single document from a document database is easy, as is reading a single row from a database. Relational databases can make this a bit harder when you have to join tables, but when you get the hang of it, it's not that hard.
Create operations tend to be about as easy or difficult as reads. Adding a new document to a document database or BLOB storage is easy. Adding a complex entity with foreign key relationships in a relational database is a bit more complicated, but still doable.
Updates, though, are evil. In a document database, it may be easy enough if you can just replace the document wholesale. Often, however, updates involves delta detection. Particularly in databases, when foreign keys are involved, you may have to recursively track down all the related rows and either update those as well, or delete and recreate them.
As you'll see in the upcoming code example, an update typically also involves complicated auxiliary logic to determine what changed, and how to react to it.
For that reason, if possible, I prefer modelling data without supporting updates. Create/read/delete is fine, but if you don't support updates, you may not need deletes either. There's a reason I like Event Sourcing.
A complicated Put method #
My restaurant reservation API included this method that enabled REST clients to update reservations:
[HttpPut("restaurants/{restaurantId}/reservations/{id}")] public async Task<ActionResult> Put( int restaurantId, string id, ReservationDto dto) { if (dto is null) throw new ArgumentNullException(nameof(dto)); if (!Guid.TryParse(id, out var rid)) return new NotFoundResult(); Reservation? reservation = dto.Validate(rid); if (reservation is null) return new BadRequestResult(); var restaurant = await RestaurantDatabase .GetRestaurant(restaurantId).ConfigureAwait(false); if (restaurant is null) return new NotFoundResult(); return await TryUpdate(restaurant, reservation).ConfigureAwait(false); }
Had I written this code exclusively for myself, I'd written in a more functional style, as an impureim sandwich. (Actually, had I written this code exclusively for myself, I'd written it in F# or Haskell.) This code, however, is written for another audience, so I didn't want to assume that the reader knows about impureim sandwiches.
I still wanted to decompose the functionality into small blocks. There's still an echo of the impureim sandwich architecture in the Put method, because it handles most of the impure preparation - the top of the sandwich, so to speak.
The rest - any functional core there might be, as well as impure post-processing - it delegates to the TryUpdate method.
TryUpdate #
Here's the TryUpdate method:
private async Task<ActionResult> TryUpdate( Restaurant restaurant, Reservation reservation) { using var scope = new TransactionScope( TransactionScopeAsyncFlowOption.Enabled); var existing = await Repository.ReadReservation(reservation.Id) .ConfigureAwait(false); if (existing is null) return new NotFoundResult(); var ok = await WillAcceptUpdate(restaurant, reservation) .ConfigureAwait(false); if (!ok) return NoTables500InternalServerError(); await Update(restaurant, reservation, existing) .ConfigureAwait(false); scope.Complete(); return new OkObjectResult(reservation.ToDto()); }
To be honest, this is mostly just more impure pre-processing. The functional core is hidden away inside the (impure) WillAcceptUpdate method, but I'm not going to show you that one. It's not important in this context.
If, however, the method decides that the update is possible, it'll make one more delegation, to the Update method.
I admit it: This isn't the prettiest code I've ever written. I did warn you, though. I chose this method as an example because it could really do with some refactoring. One problem I have with it is the naming. You have a Put method, which calls a TryUpdate method, which again calls an Update method.
Even though the Try prefix is a .NET idiom, I still feel that a regular reader could be easily confused, having to choose between TryUpdate and Update.
Still, let's soldier on and review the Update method as well. It's the last one, I promise.
Update #
Here's the Update method:
private async Task Update( Restaurant restaurant, Reservation reservation, Reservation existing) { if (existing.Email != reservation.Email) await PostOffice .EmailReservationUpdating(restaurant.Id, existing) .ConfigureAwait(false); await Repository.Update(reservation).ConfigureAwait(false); await PostOffice .EmailReservationUpdated(restaurant.Id, reservation) .ConfigureAwait(false); }
The method perfectly illustrates what I meant when I wrote that you often have to do various kinds of delta analysis when implementing an update - even if delta analysis isn't required by the data store.
This method does two things:
- It sends emails
- It updates the repository
Update sends an email to the old address. This is an example of delta analysis. This only happens on a changing email address. It doesn't happen if the name or quantity changes.
The motivation is that it may serve to warn the user if someone tries to change the reservation. Only when the email address changes is it necessary to send an email to the old address.
In all cases, the method sends an email to the 'current' address.
This seems ripe for refactoring.
Plugging the leak #
The Update method is an asynchronous Command. It exclusively produces side effects, but it doesn't return anything (we'll regard Task as 'asynchronous unit').
I've known since 2011 that Commands are composable. Later, I also figured out the fundamental reason for that.
The Update method composes three other Commands - one conditional and two unconditional. This seems to call for some sort of composition: Chain of Responsibility, Decorator, or Composite. Common to these patterns, however, is that the object that they compose must share an API. In a language like C# it means that they must share a polymorphic type.
Which type might that be? Let's list the three method signatures in action, one after the other:
-
Task EmailReservationUpdating(int restaurantId, Reservation reservation) -
Task Update(Reservation reservation) -
Task EmailReservationUpdated(int restaurantId, Reservation reservation)
The commonality might be easier to spot if we X out the names (which are only skin-deep, anyway):
-
Task Xxx(int restaurantId, Reservation reservation) -
Task Xxx( Reservation reservation) -
Task Xxx(int restaurantId, Reservation reservation)
The only deviation is that the middle method (originally the Update method) lacks a restaurantId parameter.
As the previous article explained, though, this is a leaky abstraction by omission. Will plugging the leak enable a refactoring?
Let's try. Make restaurantId a parameter for all methods defined by the interface:
public interface IReservationsRepository { Task Create(int restaurantId, Reservation reservation); Task<IReadOnlyCollection<Reservation>> ReadReservations( int restaurantId, DateTime min, DateTime max); Task<Reservation?> ReadReservation(int restaurantId, Guid id); Task Update(int restaurantId, Reservation reservation); Task Delete(int restaurantId, Guid id); }
This is the suggested remedy from the previous article, so I put it here solely as a reminder.
An emailing Decorator #
There's a sequence to the actions in the Update method:
- It emails the old address about a changing address
- It updates the reservation
- It emails the current address about the update
IReservationsRepository:
public class EmailingReservationsRepository : IReservationsRepository { public EmailingReservationsRepository( IPostOffice postOffice, IReservationsRepository inner) { PostOffice = postOffice; Inner = inner; } public IPostOffice PostOffice { get; } public IReservationsRepository Inner { get; } public async Task Update(int restaurantId, Reservation reservation) { if (reservation is null) throw new ArgumentNullException(nameof(reservation)); var existing = await Inner.ReadReservation(restaurantId, reservation.Id) .ConfigureAwait(false); if (existing is { } && existing.Email != reservation.Email) await PostOffice .EmailReservationUpdating(restaurantId, existing) .ConfigureAwait(false); await Inner.Update(restaurantId, reservation) .ConfigureAwait(false); await PostOffice.EmailReservationUpdated(restaurantId, reservation) .ConfigureAwait(false); } // Other members go here... }
You may think that it seems odd to have a 'repository' that also sends emails. I think that this is mostly an artefact of unfortunate naming. Perhaps a follow-up change should be to rename both the interface and the Controller's Repository property. I'm open to suggestions, but for now, I'll leave the names as they are.
If you're still not convinced, consider an alternative architecture based on asynchronous message passing (e.g. CQRS). In such architectures, you'd put Commands on a message bus and think no more of it. A background process would then asynchronously perform all the actions, including sending emails and updating the data store. I think that people used to that kind of architecture wouldn't bat an eyelid by bus.Send(new UpdateReservation(/**/)).
This would also be close to the kind of design that Steven van Deursen and I describe in chapter 10 of our book.
Simplification #
This greatly simplifies things. The above Update method now becomes redundant and can be deleted. Instead, TryUpdate can now directly call Repository.Update:
private async Task<ActionResult> TryUpdate( Restaurant restaurant, Reservation reservation) { using var scope = new TransactionScope( TransactionScopeAsyncFlowOption.Enabled); var existing = await Repository .ReadReservation(restaurant.Id, reservation.Id) .ConfigureAwait(false); if (existing is null) return new NotFoundResult(); var ok = await WillAcceptUpdate(restaurant, reservation) .ConfigureAwait(false); if (!ok) return NoTables500InternalServerError(); await Repository.Update(restaurant.Id, reservation) .ConfigureAwait(false); scope.Complete(); return new OkObjectResult(reservation.ToDto()); }
This also means that you can remove the PostOffice dependency from the Controller. Lots of things becomes simpler by this refactoring. It better separates concerns, so tests become simpler as well.
Conclusion #
You can simplify code by composing Commands. Candidate patterns for this are Chain of Responsibility, Decorator, and Composite. These patterns, however, require a common polymorphic type. Key to refactoring to these patterns is to identify such a common interface. In this article, I used the refactored IReservationsRepository interface.
Whenever a client calls a method on the repository, a change of state now automatically also sends emails. The client doesn't have to worry about that.
Consider modelling many related side-effects as a single composed Command.
Structural equality for better tests
A Fluent Builder as a Value Object?
If you've read a bit about unit testing, test-driven development, or other kinds of developer testing, you've probably come across a phrase like this:
Test behaviour, not implementation.It's often taken to mean something like behaviour-driven development (BDD), and that's certainly one interpretation. I've no problem with that. My own Pluralsight course Outside-In Test-Driven Development shows a similar technique.
It'd be a logical fallacy, however, to thereby conclude that you can only apply that ideal in the large, but not in the small. That it's only possible to do it with coarse-grained tests at the boundary of the system, but not with unit testing.
It may be harder to do at the unit level, since when writing unit tests, you're closer to the implementation, so to speak. Writing the test before the implementation may, however, help
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
An example test #
Here's a test (using xUnit.net 2.4.1) I wrote before the implementation:
[Theory] [InlineData("Home")] [InlineData("Calendar")] [InlineData("Reservations")] public void WithControllerHandlesSuffix(string name) { var sut = new UrlBuilder(); var actual = sut.WithController(name + "Controller"); var expected = sut.WithController(name); Assert.Equal(expected, actual); }
It tests an ASP.NET Core URL Builder; particular how it deals with the Controller suffix issue I ran into last year.
Do you notice something odd about this test?
It describes an equality relation between two individual projections of an initial UrlBuilder object (sut).
First of all, with a Mutable Fluent Builder the test would produce a false negative because aliasing would make the assertion a tautological assertion. Using an Immutable Fluent Builder, however, elegantly dodges that bullet: expected and actual are two separate objects.
Yet, it's possible to compare them. How?
Assertions #
I think that most people would have written the above test like this:
[Theory] [InlineData("Home")] [InlineData("Calendar")] [InlineData("Reservations")] public void WithControllerHandlesSuffix(string name) { var sut = new UrlBuilder(); var actual = sut.WithController(name + "Controller"); var expected = sut.WithController(name); Assert.Equal(expected.Controller, actual.Controller); }
Instead of comparing two whole objects, this variation compares the Controller property values from two objects. In order for this to compile, you have to expose an implementation detail: that the class has a class field (here exposed as an automatic property) that keeps track of the Controller name.
I think that most object-oriented programmers' default habit is to write assertions that compare properties or class fields because in both C# and Java, objects by default only have reference equality. This leads to primitive obsession, this time in the context of test assertions.
Structural equality, on the other hand, makes it much easier to write concise and meaningful assertions. Just compare expected with actual.
Structural equality on a Builder? #
The UrlBuilder class has structural equality by overriding Equals and GetHashCode:
public override bool Equals(object? obj) { return obj is UrlBuilder builder && action == builder.action && controller == builder.controller && EqualityComparer<object?>.Default.Equals(values, builder.values); } public override int GetHashCode() { return HashCode.Combine(action, controller, values); }
That's why the above Assert.Equal statement works.
You may think that it's an odd choice to give a Fluent Builder structural equality, but why not? Since it's immutable, it's perfectly safe, and it makes things like testing much easier.
I rarely see people do this. Even programmers experienced with functional programming often seem to categorise structural equality as something associated exclusively with algebraic data types (ADTs). The UrlBuilder class, on the other hand, doesn't look like an ADT. After all, its public API exposes only behaviour, but no data:
public sealed class UrlBuilder { public UrlBuilder() public UrlBuilder WithAction(string newAction) public UrlBuilder WithController(string newController) public UrlBuilder WithValues(object newValues) public Uri BuildAbsolute(IUrlHelper url) public override bool Equals(object? obj) public override int GetHashCode() }
On the other hand, my threshold for when I give an immutable class structural equality is monotonically decreasing. Structural equality just makes things easier. The above test is just one example. Structural equality enables you to test behaviour instead of implementation details. In this example, the behaviour can be expressed as an equality relation between two different inputs.
UrlBuilder as an algebraic data type #
While it may seem odd or surprising to give a Fluent Builder structural equality, it's really isomorphic to a simple record type equipped with a few endomorphisms. (After all, we already know that the Builder pattern is isomorphic to the endomorphism monoid.) Let's make this explicit with F#.
Start by declaring a record type with a private definition:
type UrlBuilder = private { Action : string option; Controller : string option; Values : obj option }
While its definition is private, it's still an algebraic data type. Records in F# automatically have structural equality, and so does this one.
Since it's private, client code can't use the normal language constructs to create instances. Instead, the module that defines the type must supply an API that client code can use:
let emptyUrlBuilder = { Action = None; Controller = None; Values = None } let withAction action ub = { ub with Action = Some action } let withController (controller : string) ub = let index = controller.LastIndexOf ("controller", StringComparison.OrdinalIgnoreCase) let newController = if 0 <= index then controller.Remove(index) else controller { ub with Controller = Some newController } let withValues values ub = { ub with Values = Some values }
Without further ceremony you can port the initial test to F# as well:
[<Theory>] [<InlineData("Home")>] [<InlineData("Calendar")>] [<InlineData("Reservations")>] let ``withController handles suffix`` name = let sut = emptyUrlBuilder let actual = sut |> withController (name + "Controller") let expected = sut |> withController name expected =! actual
In addition to xUnit.net this test also uses Unquote 6.0.0.
Even though UrlBuilder has no externally visible data, it automatically has structural equality. Functional programming is, indeed, more test-friendly than object-oriented programming.
This F# implementation is equivalent to the C# UrlBuilder class.
Conclusion #
You can safely give immutable objects structural equality. Besides other advantages, it makes it easier to write tests. With structural equality, you can express a relationship between the expected and actual outcome using high-level language.
These days, I don't really care if the type in question is a 'proper' algebraic data type. If it's immutable, I don't have to think much about it before giving it structural equality.
Comments
Records in F# automatically have structural equality, and so does this one.
That is mostly true but not compeltely so. Consider the type
type MyRecord = { MyField: int -> bool }
If you try to compare two instances with F#'s = operator, then you will get this compilier error.
Error FS0001: The type 'MyRecord' does not support the 'equality' constraint because it is a record, union or struct with one or more structural element types which do not support the 'equality' constraint. Either avoid the use of equality with this type, or add the 'StructuralEquality' attribute to the type to determine which field type does not support equality.
Adding the StructuralEquality attribute results in this compiler error.
Error FS1180: The struct, record or union type 'MyRecord' has the 'StructuralEquality' attribute but the component type '(int -> bool)' does not satisfy the 'equality' constraint.
I learned all this the hard way. I had added some F# functions to some of my models in my MVU architecture. Later when I tried to test my root model for structual equality, I ran into this issue. Taking the suggestion in the compiler error, I fixed the problem by adding the StructuralEquality attribute (as well as the NoComparison attribute) to my root model and refactored the code to fix the resulting compiler errors.
During this time, I also realized that F#'s structual equality delegates to object.Equals(object) for types that extend object, which of course defaults to reference equality. For example, the following code compiles.
[<StructuralEquality>] [<NoComparison>] type MyRecord = { MyField: IDisposable }
Tyson, thank you for writing. Yes, you're right. Language is imprecise. F# records automatically have structural equality, when possible.

Comments
Hi. Thanks for this insight. And thank you for the emphasize about 'anecdotal' vs 'scientific proof'.
About this topic, do you have any information regarding Evidence-based Software Engineering (free ebook) ? If so, is it worth reading ? (Yep, I have total confidence about your knowledge and your judgment)
Timothée, thank you for writing. I haven't read or heard about Evidence-based Software Engineering. After having read both The Leprechauns of Software Engineering (wonderful book) and Making Software: What Really Works, and Why We Believe It (not so much), I don't feel like reading another one.
You mention the adage "If it hurts, do it more often", and I 100% agree. But couldn't it also apply to those personality traits you mention? If you like doing things in your own time, to your own schedule, having the freedom to self-organize, then it means that doing the opposite "hurts", as an introvert. Couldn't that mean that it would be a good idea to actually try it out, and "do it more often"? I am an introvert too, and the urge to do things on my own and in peace is strong. But over the past years I've realized that perhaps the #1 most important aspect in our work is communication. I try to go against my introvert nature and talk to others, and be involved in face-to-face instances as much as I can.
In regards to code reviews, I found that a face-to-face code review works well, and is a sensible middle point between pair programming and pull-request-based code review. You get the benefits of pair programming where you can transfer knowledge to someone else; have a face to face discussion on design decisions; it's easy to have a back and forth of ideas; it's easier to develop a shared coding standard; etc. On the other hand it's easier to apply this to every feature/development since it takes "less time" from developers than pair programming (which could be harder to apply or convince management to do, since it theoretically halves developer throughput). You can also forego the back and forths that would be done via comments in a pull request, having them occur in the moment, instead of over a span of a few days/hours. The author can answer questions and doubts from the reviewer much more quickly; the author can provide context and a "story" of the feature so the reviewer has it easier to review it. I found that is provides a lot of benefits. However, I must admit I have had more experience with this face-to-face style of code review than the pull-request style of code review. What do you think?
Gonzalo, thank you for writing. You're right, it goes both ways. For what it's worth, I've done quite a bit of ensemble programming the last few years, and I find it quite effective for knowledge transfer.
In general, there's definitely a case to be made for face-to-face communication. Earlier in my career, once or twice I've fallen into the trap of maintaining a written discussion for weeks. Then, when someone finally called a meeting, we could amiably resolve the issues within an hour.
What concerns me about face-to-face code reviews, however, is the following: When you, as a reviewer, encounter something that you don't understand, you can immediately ask about it. What happens when you receive an answer? Do you then accept the answer and move on?
If so, haven't you collectively failed to address an underlying problem with the code? If there's something you don't understand, and you have to ask the original programmer, what happens if that colleague is no longer around? Or what happens when that team member has also forgotten the answer?
The code is the only artefact that contains the truth about how the software is defined. The code is the specification. If the code is difficult to understand, aren't you relying on collective tacit knowledge?
That's my concern, but it may be misplaced. I haven't worked in a team that does code reviews as you describe, so I have no experience with it.
Hi Mark. If, in the code review, I find something I don't understand, the author responds, and I agree with his response, how is it any different than making a comment in the pull request, the author responding, and me taking that comment/change request back?
If he responds and I still find it confusing, or I still believe it should be changed, then I would ask him to change it, and the feature should not be merged until he makes those changes. I don't see what could be different from the pull-request based approach here
Gonzalo, thank you for writing. I suppose you can make it work with an oral review as well, but doesn't it require more discipline to stick to protocol?
As a reviewer, whether or not I, personally, understand the proposed code is a local concern. The broader responsibility is to ensure that the code, itself, is understandable. Kant's categorical imperative comes to mind:
A code review should be conducted in such a manner that the implied protocol can be raised to a universal rule to the benefit of all team members. As a team member, I'd like the code review process to benefit me, even when I'm taking no part in it.Assume that I'm not the person doing the review. Instead, assume that another team member performs the review. If she runs into something she doesn't understand, it doesn't help me that she receives an answer that satisfies her. If I have to maintain the code, I'm not aware of the exchange that took place during the review.
If there's an issue with the proposed code, it's a symptom. You can relieve the symptom by answering an immediate query, or you can address the underlying problem. I prefer the latter.
When doing a written pull request review, most online services (GitHub, Azure DevOps) keep track of issues and require you to actively mark ongoing discussions as resolved. When I perform a review, I usually don't consider an answer as a resolution to the issue. An answer doesn't change the code, which means that the issue remains for the next reader to struggle with.
Instead, I will request that the contributor amends the proposed code to address the problem. This may include refactoring, renaming a method, or just adding a comment to the code. In its most basic form, if I had a question, other team members may have the same question. If the contributor can satisfactorily answer the question, then the least he or she can do is to add the answer as a comment to the code base so that it's readily available to all readers of it.
This turns tacit knowledge into explicit knowledge.
In my new book Code That Fits in Your Head I propose a hierarchy of communication:
- Guide the reader by giving APIs distinct types.
- Guide the reader by giving methods helpful names.
- Guide the reader by writing good comments.
- Guide the reader by providing illustrative examples as automated tests.
- Guide the reader by writing helpful commit messages in Git.
- Guide the reader by writing good documentation
I admit that I, like everyone else, am biased by my experience. The above suggested heuristic arose in a context. Most development organisations I've worked with has a major problem with tacit knowledge. I'm biased toward combating that problem by encouraging team members to capture knowledge in writing, and put it where it's discoverable.If you don't have a problem with tacit knowledge, I suppose that most of the above doesn't apply.
What concerns me about an oral code review is that knowledge remains tacit. I suppose that with a sufficient rigorous review protocol, you could still address that problem. You could keep a log of the questions you ask, so that even if the reviewer receives a satisfactory answer, the log still states that the question was asked. The log indicates that there are unresolved issues with the proposed code. After the review, the contributor would have to take the log and address the questions by updating the pull request.
I suppose I'm not convinced that most people have the discipline to follow such a protocol, which is why I favour the nudging provided by review tools like those offered by GitHub and Azure DevOps.
Perhaps I'm painting myself into a corner here. Perhaps your concerns are completely different. Are you addressing a different problem?