ploeh blog danish software design
Pendulum swing: sealed by default
Inheritance is evil. Seal your classes.
This is an article in a small series of articles about personal pendulum swings. Here, I document another recent change of heart that's been a long way coming. In short, I now seal C# classes whenever I remember to do it.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Background #
After I discovered test-driven development (TDD) (circa 2003) I embarked on a quest for proper ways to enable testability. Automated tests should be deterministic, but real software systems rarely are. Software depends on the system clock, random number generators, the file system, the states of databases, web services, and so on. All of these may change independently of the software, making it difficult to express an automated systems test in a deterministic manner.
This is a known problem in TDD. In order to get the system under test (SUT) under control, you have to introduce what Michael Feathers calls seams. In C#, there's traditionally been two ways you could do that: extract and override, and interfaces.
The original Framework Design Guidelines explicitly recommended base classes over interfaces, and I wasn't wise to how unfortunate that recommendation was. For a long time, I'd define abstractions with (abstract) base classes. I was even envious of Java, where instance members are virtual (overridable) by default. In C# you must explicitly declare a method virtual to make it overridable.
Abstract base classes aren't too bad if you leave them completely empty, but I never had much success with non-abstract base classes and virtual members and the whole extract-and-override manoeuvre. I soon concluded that Dependency Injection with interfaces was a better alternative.
Even after I changed to exclusively relying on interfaces (instead of abstract base classes), remnants of the rule stuck with me for years: unsealed good; sealed bad. Even today, the framework design guidelines favour unsealed classes:
I can no longer agree with this guidance; I think it's poor advice."CONSIDER using unsealed classes with no added virtual or protected members as a great way to provide inexpensive yet much appreciated extensibility to a framework."
You don't need inheritance #
Base classes imply class inheritance as a reuse and extensibility mechanism. We've known since 1994, though, that inheritance probably isn't the best design principle.
In single-inheritance languages like C# and Java, inheritance is just evil. Once you decide to inherit from a base class, you exclude all other base classes. Inheritance signifies a single 'yes' and an infinity of 'noes'. This is particularly problematic if you rely on inheritance for reuse. You can only 'reuse' a single base class, which again leads to duplication or bloated base classes."Favor object composition over class inheritance."
It's been years (probably more than a decade) since I stopped relying on base classes for anything. You don't need inheritance. Haskell doesn't have it at all, and I only use it in C# when a framework forces me to derive from some base class.
There's little you can do with an abstract class that you can't do in some other way. Abstract classes are isomorphic with Dependency Injection up to accessibility.
Seal #
If I already follow a design principle of not relying on inheritance, then why keep classes unsealed? Explicit is better than implicit, so why not make that principle visible? Seal classes.
It doesn't have any immediate impact on the code, but it might make it clearer to other programmers that an explicit decision was made.
You already saw examples in the previous article: Both Month and Seating are sealed classes. They're also immutable records. I seal more than record types, too:
public sealed class HomeController
I seal Controllers, as well as services:
public sealed class SmtpPostOffice : IPostOffice
Another example is an ASP.NET filter named UrlIntegrityFilter.
A common counter-argument is that 'you may need extensibility in the future':
I agree that it'd be arrogant to claim that you've thought about all extension points. Trying to predict future need is futile."by using "sealed" and not virtual in libs dev says "I thought of all extension point" which seems arrogant"
I don't agree, however, that making everything virtual is a good idea, but it's because I disagree with the underlying premise. The presupposition is that extensibility should be enabled through inheritance. If it's not already clear, I believe that this has many undesirable consequences. There are better ways to enable extensibility than through inheritance.
Conclusion #
I've begun to routinely seal new classes. I don't always remember to do it, but I think that I ought to. As I also explained in the previous article, this is only my default. If something has to be a base class, that's still an option. Likewise, just because a class starts out sealed doesn't mean that it has to stay sealed forever. While sealing an unsealed class is a breaking change, unsealing a sealed class isn't.
I can't think of any reason why I'd do that, though.
Pendulum swing: internal by default
Declare new C# classes as internal by default, and public by choice.
This is an article in a small series of articles about personal pendulum swings. Here, I document a recent change of heart that's been a long way coming. In short, I now declare C# classes as internal unless they're driven by tests.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Background #
When you create a new class in Visual Studio, the default accessibility is internal. In fact, Visual Studio's default templates don't add an access modifier at all, but if no access modifier is present, it implies internal.
When I started out programming C#, I don't recall thinking much about accessibility modifiers. By default, then, I'd be using mostly internal classes. What little I knew about encapsulation (information hiding, anyone?) led me to believe that the more internal my code was, the better encapsulation it had.
It's possible that I make my past self more ignorant than I actually was. It's almost twenty years ago: I don't recall all the details.
Public all the things #
When I discovered test-driven development (TDD) (circa 2003) all my classes became public. They had to. When tests are interacting with code in another library, they can only exercise the system under test (SUT) if they can reach it. The tests make the SUT classes public.
Yes, it's technically possible to test internal classes in .NET, but I don't believe that you should. I've yet to change my mind about that; no imminent pendulum swing there. You're testing something you care about. If the internal code serves any, any, purpose, it must be somehow observable. If so, verify that such observable behaviour takes place; if not, delete the code. (I'm sure you can dream up some corner cases where this doesn't hold; fine: I'm painting with a broad brush, here.)
For years, I applied TDD, but I wasn't aware of the red-green-refactor cycle. I rarely changed the public API that the tests interacted with, and when I did, I made sure to adjust the tests accordingly. If a refactoring gave rise to new classes, I'd often write tests for those new classes as well.
Imagine, for example, invoking the Extract Class refactoring. The new class would be as covered by tests as before the extraction, but what happens next is typically that you need to tweak it. When that happened to me, I'd typically write completely new tests to cover it. To do that, I'd need the extracted class to be public.
In this phase of my professional life, my classes were almost exclusively public, with internal classes only making a rare appearance.
One problem this tends to cause is that it makes code bases more brittle. Every type change is a potential breaking change. When every public class is covered by tests, this makes tests brittle.
I think that it's relevant to consider the context of the code base. At this phase of my professional life, I maintained AutoFixture, a fairly popular open-source library. I wanted that library to be stable so that users could trust it. I considered the test suite a guard of the contract. As long as a change didn't break any test, I considered it likely that it wasn't a breaking change. Thus, I was already conservative when it came to editing tests. I considered test to be append-only in principle.
I still consider it prudent to be conservative when it comes to a library with a public API. This doesn't mean, however, that this line of thinking carries over to code bases without a public (language-level) API. This may include web sites and services, but could also include installed apps. As long as there's no public API, there's no contract to break.
Internal by default #
In 2020 I wrote a REST API of middling complexity. I used outside-in TDD as a major driver. In the spirit of behaviour-driven development I favour describing the observable behaviour of the system. I use self-hosted state-based integration tests for this purpose. Only when I find that these tests get too complex do I grudgingly drop down to the unit-test level.
The things that I test with unit tests have to be public. This still leaves plenty of room for behaviour described by the integration tests to have internal implementation details. The code base I mentioned has several examples of that. Some of them I've already described here on the blog.
For example, notice that the LinksFilter shown here is an internal class. Its behaviour is covered by abundant integration tests, so I'm not afraid to refactor it if need be. Those LinkToYear, LinkToMonth, and LinkToDay extension methods that it uses are internal too.
Another example is the UrlIntegrityFilter seen here. The class itself is internal and its behaviour is composed from private helper functions. Its counterpart SigningUrlHelper is also internal. (Its companion SigningUrlHelperFactory, shown in the same article, is public, but that's an oversight on my part. It can easily be internal as well.) All that URL-signing behaviour is, again, covered by tests that verify the behaviour of the REST API.
Another example from the same code base can be found in its so-called calendar feature. The system is an online restaurant reservation system. It allows clients to browse a day, a month, or even a year to see if there are any free spots for a given time slot. You can see an example here. While I test-drove the calendar feature with integration tests, it quickly dawned on me that I had three disparate cases (day, month, year) that essentially represented the same concept: a period.
A period is a closed set of heterogeneous data. A year contains only a single datum: the year itself (e.g. 2021). A month contains both a month and a year, and so on. A closed set of heterogeneous data describes a sum type, and since I know that in object-oriented programming, sum types can be encoded as Visitors, I introduced a Visitor API:
internal interface IPeriod { T Accept<T>(IPeriodVisitor<T> visitor); } internal interface IPeriodVisitor<T> { T VisitYear(int year); T VisitMonth(int year, int month); T VisitDay(int year, int month, int day); }
I decided, however, to keep this API internal, since this isn't the only possible way to model this feature. As is the case with the other examples I've shown here, the behaviour is covered by integration tests. I feel free to refactor. In fact, this Visitor-based API is actually the result of a refactoring from something more ad hoc that I didn't like.
Here's one of the three IPeriod implementation, in case you're curious:
internal sealed class Month : IPeriod { private readonly int year; private readonly int month; public Month(int year, int month) { this.year = year; this.month = month; } public T Accept<T>(IPeriodVisitor<T> visitor) { return visitor.VisitMonth(year, month); } public override bool Equals(object? obj) { return obj is Month month && year == month.year && this.month == month.month; } public override int GetHashCode() { return HashCode.Combine(year, month); } }
This class, too, is internal, as are its two companions Day and Year. I'll leave it as an exercise for the interested reader to implement these two classes, as well as IPeriodVisitor<T> implementations that return the next or previous period, or the first or last tick of the period, etcetera.
Public by choice #
This shifted emphasis of mine isn't a return to a simpler time. It's not internal all the things! It's about shifting the default for classes that are not driven by tests. Those classes that are artefacts of TDD are still public since I don't directly unit test internal classes.
Other classes may start out as internal and then get promoted to public by choice. For example, I'd introduced a Seating class in the code base to model how long a seating was supposed to take:
internal sealed class Seating { internal Seating(TimeSpan seatingDuration, Reservation reservation) { SeatingDuration = seatingDuration; Reservation = reservation; } // Members follow...
Some restaurants have second seatings (or more). They give you a predefined duration after which you're supposed to be done so that they can reuse your table for another party. I'd used the Seating class to encapsulate some logic related to that, such as the Overlaps method:
internal DateTime Start { get { return Reservation.At; } } internal DateTime End { get { return Start + SeatingDuration; } } internal bool Overlaps(Reservation other) { var otherSeating = new Seating(SeatingDuration, other); return Start < otherSeating.End && otherSeating.Start < End; }
While I considered this a well-designed little class with good encapsulation, I kept it internal simply because there was no need to make it public. It was indirectly covered by test cases, but it was a result of a refactoring and not directly test-driven.
As I started to add a new feature, I realised that I'd be able to write new unit tests in a better way if I could reuse Seating and a variation of its Overlaps method. I considered it carefully and decided to make the class and its members public:
public sealed class Seating { public Seating(TimeSpan seatingDuration, Reservation reservation) { SeatingDuration = seatingDuration; Reservation = reservation; } // Members follow...
I made this decision after explicit deliberation. It didn't take long, though, but I did shortly stop to consider whether this seemed like a good idea. This code base isn't a reusable library in the wild, so I wasn't concerned about misuse of the API. I did consider, on the other hand, how this would increase coupling between the tests and the production code base. It didn't take me long to decide that in this case, I was okay with that.
Seating had already existed as an internal class for some time and had proven useful and stable. Putting on my DDD hat, I also thought that Seating represented a proper domain concept.
Conclusion #
You can go back and forth on how you write code; which rules of thumb you apply. For many years, I favoured public classes. I think that I even, at one time, tweaked the Visual Studio templates to explicitly create new classes as public.
Now, I've changed my heuristic. Classes driven into existence by tests are public; they have to be. Other classes I now make internal by default, and public by choice.
This is going to be my rule until I change it.
Pendulum swings
The software development industry goes back and forth on how to do things, and so do I.
I've been working with something IT-related since 1994, and I've been a professional programmer since 1999. When you observe the software development industry over decades, you may start to notice some trends. One decade, service-oriented architecture (SOA) is cool; the next, consolidation sets in; then it's micro-services; and, as far as I can tell, monoliths are on the way in again, although I'm sure that we'll find something else to call them.
It's as if a pendulum swings from one extreme to the other. Sooner or later, it comes back, only to then continue its swing in the other direction. If you view it over time and assume no loss to friction, a pendulum describes a sine wave.
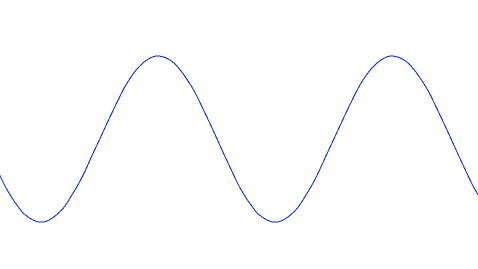
There's probably several reasons for this motion. The benign interpretation is that it's still a young industry and we're still learning. It's not uncommon to see oscillations in dynamic systems, particularly when feedback isn't immediate.
Software architecture tends to produce slow feedback. Architecture solves more than one problem, including scalability, but a major motivation to think about architecture is to pick a way to organise the source code so that you don't have to rewrite from scratch every 2-3 years. Tautologically, then, it takes years before you know whether or not you succeeded.
While waiting for feedback, you may continue doing what you believe is right: micro-services versus monoliths, unit tests versus acceptance tests, etcetera. Once you discover that a particular way to work has problems, you may overcompensate by going too far in the other direction.
Once you discover the problem with that, you may begin to pull back towards the original position. Because feedback is delayed, the pendulum once more swings too far.
If we manage to learn from our mistakes, one could hope that the oscillations we currently observe will dampen until we reach equilibrium in the future. The industry is still so young, though, that the pendulum makes wide swings. Perhaps it'll takes decades, or even centuries, before the oscillations die down.
The more cynic interpretation is that most software developers have only a few years of professional experience, and aren't taught the experiences of past generations.
In this light, the industry keeps regurgitating the same ideas over and over, never learning from past mistakes."Those who cannot remember the past are condemned to repeat it."
The truth is probably a mix of both explanations.
Personal pendulum #
I've noticed a similar tendency in myself. I work in a particular way until I run into the limitations of that way. Then, after a time of frustration, I change direction.
As an example, I'm an autodidact programmer. In the beginning of my career, I'd just throw together code until I thought it worked, then launch the software with the debugger attached only to discover that it didn't, then go back and tweak some more, and so on.
Then I discovered test-driven development (TDD) and for years, it was the only way I could conceive of working. As my experience with TDD grew, I started to notice that it wasn't the panacea that I believed when it was all new. I wrote about that as early as late 2010. Knowing myself, I'd probably started to notice problems with TDD before that. I have cognitive biases just like the next person. You can lie to yourself for years before the problems become so blatant that you can no longer ignore them.
To be clear, I never lost faith in TDD, but I began to glimpse the contours of its limitations. It's good for many circumstances, and it's still my preferred technique for developing new production code, but I use other techniques for e.g. prototyping.
In 2020 I wrote a code base of middling complexity, and I noticed that I'd started to change my position on some other long-standing practices. As I've tried to explain, it may look like pendulum swings, but I hope that they are, at least, dampened swings. I intend to observe what happens so that I can learn from these new directions.
In the following, I'll be writing about these new approaches that I'm trying on, and so far like:
- Pendulum swing: internal by default
- Pendulum swing: sealed by default
- Pendulum swing: pure by default
- Pendulum swing: no Haskell type annotation by default
Conclusion #
One year TDD is all the rage; a few years later, it's BDD. One year it's SOA, then it's ports and adapters (which implies consolidated deployment), then it's micro-services. One year, it's XML, then it's JSON, then it's YAML. One decade it's structured programming, then it's object-orientation, then it's functional programming, and so on ad nauseam.
Hopefully, this is just a symptom of growing pains. Hopefully, we'll learn from all these wild swings so that we don't have to rewrite applications when older developers leave.
The only course of action that I can see for myself here is to document how I work so that I, and others, can learn from those experiences.
When properties are easier than examples
Sometimes, describing the properties of a function is easier than coming up with examples.
Instead of the term test-driven development you may occasionally encounter the phrase example-driven development. The idea is that each test is an example of how the system under test ought to behave. As you add more tests, you add more examples.
I've noticed that beginners often find it difficult to come up with good examples. This is the reason I've developed the Devil's advocate technique. It's meant as a heuristic that may help you identify the next good example. It's particularly effective if you combine it with the Transformation Priority Premise (TPP) and equivalence partitioning.
I've noticed, however, that translating concrete examples into code is not always straightforward. In the following, I'll describe an experience I had in 2020 while developing an online restaurant reservation system.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Problem outline #
I'm going to start by explaining what it was that I was trying to do. I wanted to present the maître d' (or other restaurant staff) with a schedule of a day's reservations. It should take the form of a list of time entries, one entry for every time one or more new reservations would start. I also wanted to list, for each entry, all reservations that were currently ongoing, or would soon start. Here's a simple example, represented as JSON:
"date": "2023-08-23", "entries": [ { "time": "20:00:00", "reservations": [ { "id": "af5feb35f62f475cb02df2a281948829", "at": "2023-08-23T20:00:00.0000000", "email": "crystalmeth@example.net", "name": "Crystal Metheney", "quantity": 3 }, { "id": "eae39bc5b3a7408eb2049373b2661e32", "at": "2023-08-23T20:30:00.0000000", "email": "x.benedict@example.org", "name": "Benedict Xavier", "quantity": 4 } ] }, { "time": "20:30:00", "reservations": [ { "id": "af5feb35f62f475cb02df2a281948829", "at": "2023-08-23T20:00:00.0000000", "email": "crystalmeth@example.net", "name": "Crystal Metheney", "quantity": 3 }, { "id": "eae39bc5b3a7408eb2049373b2661e32", "at": "2023-08-23T20:30:00.0000000", "email": "x.benedict@example.org", "name": "Benedict Xavier", "quantity": 4 } ] } ]
To keep the example simple, there are only two reservations for that particular day: one for 20:00 and one for 20:30. Since something happens at both of these times, both time has an entry. My intent isn't necessarily that a user interface should show the data in this way, but I wanted to make the relevant data available so that a user interface could show it if it needed to.
The first entry for 20:00 shows both reservations. It shows the reservation for 20:00 for obvious reasons, and it shows the reservation for 20:30 to indicate that the staff can expect a party of four at 20:30. Since this restaurant runs with a single seating per evening, this effectively means that although the reservation hasn't started yet, it still reserves a table. This gives a user interface an opportunity to show the state of the restaurant at that time. The table for the 20:30 party isn't active yet, but it's effectively reserved.
For restaurants with shorter seating durations, the schedule should reflect that. If the seating duration is, say, two hours, and someone has a reservation for 20:00, you can sell that table to another party at 18:00, but not at 18:30. I wanted the functionality to take such things into account.
The other entry in the above example is for 20:30. Again, both reservations are shown because one is ongoing (and takes up a table) and the other is just starting.
Desired API #
A major benefit of test-driven development (TDD) is that you get fast feedback on the API you intent for the system under test (SUT). You write a test against the intended API, and besides a pass-or-fail result, you also learn something about the interaction between client code and the SUT. You often learn that the original design you had in mind isn't going to work well once it meets the harsh realities of an actual programming language.
In TDD, you often have to revise the design multiple times during the process.
This doesn't mean that you can't have a plan. You can't write the initial test if you have no inkling of what the API should look like. For the schedule feature, I did have a plan. It turned out to hold, more or less. I wanted the API to be a method on a class called MaitreD, which already had these four fields and the constructors to support them:
public TimeOfDay OpensAt { get; } public TimeOfDay LastSeating { get; } public TimeSpan SeatingDuration { get; } public IEnumerable<Table> Tables { get; }
I planned to implement the new feature as a new instance method on that class:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations)
This plan turned out to hold in general, although I ultimately decided to simplify the return type by getting rid of the Occurrence container. It's going to be present throughout this article, however, so I need to briefly introduce it. I meant to use it as a generic container of anything, but with an time-stamp associated with the value:
public sealed class Occurrence<T> { public Occurrence(DateTime at, T value) { At = at; Value = value; } public DateTime At { get; } public T Value { get; } public Occurrence<TResult> Select<TResult>(Func<T, TResult> selector) { if (selector is null) throw new ArgumentNullException(nameof(selector)); return new Occurrence<TResult>(At, selector(Value)); } public override bool Equals(object? obj) { return obj is Occurrence<T> occurrence && At == occurrence.At && EqualityComparer<T>.Default.Equals(Value, occurrence.Value); } public override int GetHashCode() { return HashCode.Combine(At, Value); } }
You may notice that due to the presence of the Select method this is a functor.
There's also a little extension method that we may later encounter:
public static Occurrence<T> At<T>(this T value, DateTime at) { return new Occurrence<T>(at, value); }
The plan, then, is to return a collection of occurrences, each of which may contain a collection of tables that are relevant to include at that time entry.
Examples #
When I embarked on developing this feature, I thought that it was a good fit for example-driven development. Since the input for Schedule requires a collection of Reservation objects, each of which comes with some data, I expected the test cases to become verbose. So I decided to bite the bullet right away and define test cases using xUnit.net's [ClassData] feature. I wrote this test:
[Theory, ClassData(typeof(ScheduleTestCases))] public void Schedule( MaitreD sut, IEnumerable<Reservation> reservations, IEnumerable<Occurrence<Table[]>> expected) { var actual = sut.Schedule(reservations); Assert.Equal( expected.Select(o => o.Select(ts => ts.AsEnumerable())), actual); }
This is almost as simple as it can be: Call the method and verify that expected is equal to actual. The only slightly complicated piece is the nested projection of expected from IEnumerable<Occurrence<Table[]>> to IEnumerable<Occurrence<IEnumerable<Table>>>. There are ugly reasons for this that I don't want to discuss here, since they have no bearing on the actual topic, which is coming up with tests.
I also added the ScheduleTestCases class and a single test case:
private class ScheduleTestCases : TheoryData<MaitreD, IEnumerable<Reservation>, IEnumerable<Occurrence<Table[]>>> { public ScheduleTestCases() { // No reservations, so no occurrences: Add(new MaitreD( TimeSpan.FromHours(18), TimeSpan.FromHours(21), TimeSpan.FromHours(6), Table.Communal(12)), Array.Empty<Reservation>(), Array.Empty<Occurrence<Table[]>>()); } }
The simplest implementation that passed that test was this:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { yield break; }
Okay, hardly rocket science, but this was just a test case to get started. So I added another one:
private void SingleReservationCommunalTable() { var table = Table.Communal(12); var r = Some.Reservation; Add(new MaitreD( TimeSpan.FromHours(18), TimeSpan.FromHours(21), TimeSpan.FromHours(6), table), new[] { r }, new[] { new[] { table.Reserve(r) }.At(r.At) }); }
This test case adds a single reservation to a restaurant with a single communal table. The expected result is now a single occurrence with that reservation. In true TDD fashion, this new test case caused a test failure, and I now had to adjust the Schedule method to pass all tests:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { if (reservations.Any()) { var r = reservations.First(); yield return new[] { Table.Communal(12).Reserve(r) }.AsEnumerable().At(r.At); } yield break; }
You might have wanted to jump to something prettier right away, but I wanted to proceed according to the Devil's advocate technique. I was concerned that I was going to mess up the implementation if I moved too fast.
And that was when I basically hit a wall.
Property-based testing to the rescue #
I couldn't figure out how to proceed from there. Which test case ought to be the next? I wanted to follow the spirit of the TPP and pick a test case that would cause another incremental step in the right direction. The sheer number of possible combinations overwhelmed me, though. Should I adjust the reservations? The table configuration for the MaitreD class? The SeatingDuration?
It's possible that you'd be able to conjure up the perfect next test case, but I couldn't. I actually let it stew for a couple of days before I decided to give up on the example-driven approach. While I couldn't see a clear path forward with concrete examples, I had a vivid vision of how to proceed with property-based testing.
I left the above tests in place and instead added a new test class to my code base. Its only purpose: to test the Schedule method. The test method itself is only a composition of various data definitions and the actual test code:
[Property] public Property Schedule() { return Prop.ForAll( GenReservation.ArrayOf().ToArbitrary(), ScheduleImp); }
This uses FsCheck 2.14.3, which is written in F# and composes better if you also write the tests in F#. In order to make things a little more palatable for C# developers, I decided to implement the building blocks for the property using methods and class properties.
The ScheduleImp method, for example, actually implements the test. This method runs a hundred times (FsCheck's default value) with randomly generated input values:
private static void ScheduleImp(Reservation[] reservations) { // Create a table for each reservation, to ensure that all // reservations can be allotted a table. var tables = reservations.Select(r => Table.Standard(r.Quantity)); var sut = new MaitreD( TimeSpan.FromHours(18), TimeSpan.FromHours(21), TimeSpan.FromHours(6), tables); var actual = sut.Schedule(reservations); Assert.Equal( reservations.Select(r => r.At).Distinct().Count(), actual.Count()); }
The step you see in the first line of code is an example of a trick that I find myself doing often with property-based testing: instead of trying to find some good test values for a particular set of circumstances, I create a set of circumstances that fits the randomly generated test values. As the code comment explains, given a set of Reservation values, it creates a table that fits each reservation. In that way I ensure that all the reservations can be allocated a table.
I'll soon return to how those random Reservation values are generated, but first let's discuss the rest of the test body. Given a valid MaitreD object it calls the Schedule method. In the assertion phase, it so far only verifies that there's as many time entries in actual as there are distinct At values in reservations.
That's hardly a comprehensive description of the SUT, but it's a start. The following implementation passes both the new property, as well as the two examples above.
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { return from r in reservations group Table.Communal(12).Reserve(r) by r.At into g select g.AsEnumerable().At(g.Key); }
I know that many C# programmers don't like query syntax, but I've always had a soft spot for it. I liked it, but wasn't sure that I'd be able to keep it up as I added more constraints to the property.
Generators #
Before we get to that, though, I promised to show you how the random reservations are generated. FsCheck has an API for that, and it's also query-syntax-friendly:
private static Gen<Email> GenEmail => from s in Arb.Default.NonWhiteSpaceString().Generator select new Email(s.Item); private static Gen<Name> GenName => from s in Arb.Default.StringWithoutNullChars().Generator select new Name(s.Item); private static Gen<Reservation> GenReservation => from id in Arb.Default.Guid().Generator from d in Arb.Default.DateTime().Generator from e in GenEmail from n in GenName from q in Arb.Default.PositiveInt().Generator select new Reservation(id, d, e, n, q.Item);
GenReservation is a generator of Reservation values (for a simplified explanation of how such a generator might work, see The Test Data Generator functor). It's composed from smaller generators, among these GenEmail and GenName. The rest of the generators are general-purpose generators defined by FsCheck.
If you refer back to the Schedule property above, you'll see that it uses GenReservation to produce an array generator. This is another general-purpose combinator provided by FsCheck. It turns any single-object generator into a generator of arrays containing such objects. Some of these arrays will be empty, which is often desirable, because it means that you'll automatically get coverage of that edge case.
Iterative development #
As I already discovered in 2015 some problems are just much better suited for property-based development than example-driven development. As I expected, this one turned out to be just such a problem. (Recently, Hillel Wayne identified a set of problems with no clear properties as rho problems. I wonder if we should pick another Greek letter for this type of problems that almost ooze properties. Sigma problems? Maybe we should just call them describable problems...)
For the next step, I didn't have to write a completely new property. I only had to add a new assertion, and thereby strengthening the postconditions of the Schedule method:
Assert.Equal( actual.Select(o => o.At).OrderBy(d => d), actual.Select(o => o.At));
I added the above assertion to ScheduleImp after the previous assertion. It simply states that actual should be sorted in ascending order.
To pass this new requirement I added an ordering clause to the implementation:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { return from r in reservations group Table.Communal(12).Reserve(r) by r.At into g orderby g.Key select g.AsEnumerable().At(g.Key); }
It passes all tests. Commit to Git. Next.
Table configuration #
If you consider the current implementation, there's much not to like. The worst offence, I think, is that it conjures a hard-coded communal table out of thin air. The method ought to use the table configuration passed to the MaitreD object. This seems like an obvious flaw to address. I therefore added this to the property:
Assert.All(actual, o => AssertTables(tables, o.Value)); } private static void AssertTables( IEnumerable<Table> expected, IEnumerable<Table> actual) { Assert.Equal(expected.Count(), actual.Count()); }
It's just another assertion that uses the helper assertion also shown. As a first pass, it's not enough to cheat the Devil, but it sets me up for my next move. The plan is to assert that no tables are generated out of thin air. Currently, AssertTables only verifies that the actual count of tables in each occurrence matches the expected count.
The Devil easily foils that plan by generating a table for each reservation:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { var tables = reservations.Select(r => Table.Communal(12).Reserve(r)); return from r in reservations group r by r.At into g orderby g.Key select tables.At(g.Key); }
This (unfortunately) passes all tests, so commit to Git and move on.
The next move I made was to add an assertion to AssertTables:
Assert.Equal( expected.Sum(t => t.Capacity), actual.Sum(t => t.Capacity));
This new requirement states that the total capacity of the actual tables should be equal to the total capacity of the allocated tables. It doesn't prevent the Devil from generating tables out of thin air, but it makes it harder. At least, it makes it so hard that I found it more reasonable to use the supplied table configuration:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { var tables = reservations.Zip(Tables, (r, t) => t.Reserve(r)); return from r in reservations group r by r.At into g orderby g.Key select tables.At(g.Key); }
The implementation of Schedule still cheats because it 'knows' that no tests (except for the degenerate test where there are no reservations) have surplus tables in the configuration. It takes advantage of that knowledge to zip the two collections, which is really not appropriate.
Still, it seems that things are moving in the right direction.
Generated SUT #
Until now, ScheduleImp has been using a hard-coded sut. It's time to change that.
To keep my steps as small as possible, I decided to start with the SeatingDuration since it was currently not being used by the implementation. This meant that I could start randomising it without affecting the SUT. Since this was a code change of middling complexity in the test code, I found it most prudent to move in such a way that I didn't have to change the SUT as well.
I completely extracted the initialisation of the sut to a method argument of the ScheduleImp method, and adjusted it accordingly:
private static void ScheduleImp(MaitreD sut, Reservation[] reservations) { var actual = sut.Schedule(reservations); Assert.Equal( reservations.Select(r => r.At).Distinct().Count(), actual.Count()); Assert.Equal( actual.Select(o => o.At).OrderBy(d => d), actual.Select(o => o.At)); Assert.All(actual, o => AssertTables(sut.Tables, o.Value)); }
This meant that I also had to adjust the calling property:
public Property Schedule() { return Prop.ForAll( GenReservation .ArrayOf() .SelectMany(rs => GenMaitreD(rs).Select(m => (m, rs))) .ToArbitrary(), t => ScheduleImp(t.m, t.rs)); }
You've already seen GenReservation, but GenMaitreD is new:
private static Gen<MaitreD> GenMaitreD(IEnumerable<Reservation> reservations) { // Create a table for each reservation, to ensure that all // reservations can be allotted a table. var tables = reservations.Select(r => Table.Standard(r.Quantity)); return from seatingDuration in Gen.Choose(1, 6) select new MaitreD( TimeSpan.FromHours(18), TimeSpan.FromHours(21), TimeSpan.FromHours(seatingDuration), tables); }
The only difference from before is that the new MaitreD object is now initialised from within a generator expression. The duration is randomly picked from the range of one to six hours (those numbers are my arbitrary choices).
Notice that it's possible to base one generator on values randomly generated by another generator. Here, reservations are randomly produced by GenReservation and merged to a tuple with SelectMany, as you can see above.
This in itself didn't impact the SUT, but set up the code for my next move, which was to generate more tables than reservations, so that there'd be some free tables left after the schedule allocation. I first added a more complex table generator:
/// <summary> /// Generate a table configuration that can at minimum accomodate all /// reservations. /// </summary> /// <param name="reservations">The reservations to accommodate</param> /// <returns>A generator of valid table configurations.</returns> private static Gen<IEnumerable<Table>> GenTables(IEnumerable<Reservation> reservations) { // Create a table for each reservation, to ensure that all // reservations can be allotted a table. var tables = reservations.Select(r => Table.Standard(r.Quantity)); return from moreTables in Gen.Choose(1, 12).Select(Table.Standard).ArrayOf() from allTables in Gen.Shuffle(tables.Concat(moreTables)) select allTables.AsEnumerable(); }
This function first creates standard tables that exactly accommodate each reservation. It then generates an array of moreTables, each fitting between one and twelve people. It then mixes those tables together with the ones that fit a reservation and returns the sequence. Since moreTables can be empty, it's possible that the entire sequence of tables only just accommodates the reservations.
I then modified GenMaitreD to use GenTables:
private static Gen<MaitreD> GenMaitreD(IEnumerable<Reservation> reservations) { return from seatingDuration in Gen.Choose(1, 6) from tables in GenTables(reservations) select new MaitreD( TimeSpan.FromHours(18), TimeSpan.FromHours(21), TimeSpan.FromHours(seatingDuration), tables); }
This provoked a change in the SUT:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { return from r in reservations group r by r.At into g orderby g.Key select Allocate(g).At(g.Key); }
The Schedule method now calls a private helper method called Allocate. This method already existed, since it supports the algorithm used to decide whether or not to accept a reservation request.
Rinse and repeat #
I hope that a pattern starts to emerge. I kept adding more and more randomisation to the data generators, while I also added more and more assertions to the property. Here's what it looked like after a few more iterations:
private static void ScheduleImp(MaitreD sut, Reservation[] reservations) { var actual = sut.Schedule(reservations); Assert.Equal( reservations.Select(r => r.At).Distinct().Count(), actual.Count()); Assert.Equal( actual.Select(o => o.At).OrderBy(d => d), actual.Select(o => o.At)); Assert.All(actual, o => AssertTables(sut.Tables, o.Value)); Assert.All( actual, o => AssertRelevance(reservations, sut.SeatingDuration, o)); }
While AssertTables didn't change further, I added another helper assertion called AssertRelevance. I'm not going to show it here, but it checks that each occurrence only contains reservations that overlaps that point in time, give or take the SeatingDuration.
I also made the reservation generator more sophisticated. If you consider the one defined above, one flaw is that it generates reservations at random dates. The chance that it'll generate two reservations that are actually adjacent in time is minimal. To counter this problem, I added a function that would return a generator of adjacent reservations:
/// <summary> /// Generate an adjacant reservation with a 25% chance. /// </summary> /// <param name="reservation">The candidate reservation</param> /// <returns> /// A generator of an array of reservations. The generated array is /// either a singleton or a pair. In 75% of the cases, the input /// <paramref name="reservation" /> is returned as a singleton array. /// In 25% of the cases, the array contains two reservations: the input /// reservation as well as another reservation adjacent to it. /// </returns> private static Gen<Reservation[]> GenAdjacentReservations(Reservation reservation) { return from adjacent in GenReservationAdjacentTo(reservation) from useAdjacent in Gen.Frequency( new WeightAndValue<Gen<bool>>(3, Gen.Constant(false)), new WeightAndValue<Gen<bool>>(1, Gen.Constant(true))) let rs = useAdjacent ? new[] { reservation, adjacent } : new[] { reservation } select rs; } private static Gen<Reservation> GenReservationAdjacentTo(Reservation reservation) { return from minutes in Gen.Choose(-6 * 4, 6 * 4) // 4: quarters/h from r in GenReservation select r.WithDate( reservation.At + TimeSpan.FromMinutes(minutes)); }
Now that I look at it again, I wonder whether I could have expressed this in a simpler way... It gets the job done, though.
I then defined a generator that would either create entirely random reservations, or some with some adjacent ones mixed in:
private static Gen<Reservation[]> GenReservations { get { var normalArrayGen = GenReservation.ArrayOf(); var adjacentReservationsGen = GenReservation.ArrayOf() .SelectMany(rs => Gen .Sequence(rs.Select(GenAdjacentReservations)) .SelectMany(rss => Gen.Shuffle( rss.SelectMany(rs => rs)))); return Gen.OneOf(normalArrayGen, adjacentReservationsGen); } }
I changed the property to use this generator instead:
[Property] public Property Schedule() { return Prop.ForAll( GenReservations .SelectMany(rs => GenMaitreD(rs).Select(m => (m, rs))) .ToArbitrary(), t => ScheduleImp(t.m, t.rs)); }
I could have kept at it longer, but this turned out to be good enough to bring about the change in the SUT that I was looking for.
Implementation #
These incremental changes iteratively brought me closer and closer to an implementation that I think has the correct behaviour:
public IEnumerable<Occurrence<IEnumerable<Table>>> Schedule(IEnumerable<Reservation> reservations) { return from r in reservations group r by r.At into g orderby g.Key let seating = new Seating(SeatingDuration, g.Key) let overlapping = reservations.Where(seating.Overlaps) select Allocate(overlapping).At(g.Key); }
Contrary to my initial expectations, I managed to keep the implementation to a single query expression all the way through.
Conclusion #
This was a problem that I was stuck on for a couple of days. I could describe the properties I wanted the function to have, but I had a hard time coming up with a good set of examples for unit tests.
You may think that using property-based testing looks even more complicated, and I admit that it's far from trivial. The problem itself, however, isn't easy, and while the property-based approach may look daunting, it turned an intractable problem into a manageable one. That's a win in my book.
It's also worth noting that this would all have looked more elegant in F#. There's an object-oriented tax to be paid when using FsCheck from C#.
Accountability and free speech
A most likely naive suggestion.
A few years ago, my mother (born 1940) went to Paris on vacation with her older sister. She was a little concerned if she'd be able to navigate the Métro, so she asked me to print out all sorts of maps in advance. I wasn't keen on another encounter with my nemesis, the printer, so I instead showed her how she could use Google Maps to get on-demand routes. Google Maps now include timetables and line information for many metropolitan subway lines around the world. I've successfully used it to find my way around London, Paris, New York, Tokyo, Sydney, and Melbourne.
It even works in my backwater home-town:
It's rapidly turning into indispensable digital infrastructure, and that's beginning to trouble me.
You can still get paper maps of the various rapid transit systems around the world, but for how long?
Digital infrastructure #
If you're old enough, you may remember phone books. In the days of land lines and analogue phones, you'd look up a number and then dial it. As the internet became increasingly ubiquitous, phone directories went online as well. Paper phone books were seen as waste, and ultimately disappeared from everyday life.
You can think of paper phone books as a piece of infrastructure that's now gone. I don't miss them, but it's worth reflecting on what impact their disappearing has. Today, if I need to find a phone number, Google is often the place I go. The physical infrastructure is gone, replaced by a digital infrastructure.
Google, in particular, now provides important infrastructure for modern society. Not only web search, but also maps, video sharing, translation, emails, and much more.
Other companies offer other services that verge on being infrastructure. Facebook is more than just updates to friends and families. Many organisations, including schools and universities, coordinate activities via Facebook, and the political discourse increasingly happens there and on Twitter.
We've come to rely on these 'free' services to a degree that resembles our reliance on physical infrastructure like the power grid, running water, roads, telephones, etcetera.
TANSTAAFL #
Robert A. Heinlein coined the phrase There ain't no such thing as a free lunch (TANSTAAFL) in his excellent book The Moon is a Harsh Mistress. Indeed, the digital infrastructure isn't free.
Recent events have magnified some of the cost we're paying. In January, Facebook and Twitter suspended the then-president of the United States from the platforms. I've little sympathy for Donald Trump, who strikes me as an uncouth narcissist, but since I'm a Danish citizen living in Denmark, I don't think that I ought to have much of an opinion about American politics.
I do think, on the other hand, that the suspension sets an uncomfortable precedent.
Should we let a handful of tech billionaires control essential infrastructure? This time, the victim was someone half the world was glad to see go, but who's next? Might these companies suspend the accounts of politicians who work against them?
Never in the history of the world has decision power over so many people been so concentrated. I'll remind my readers that Facebook, Twitter, Google, etcetera are in worldwide use. The decisions of a handful of majority shareholders can now affect billions of people.
If you're suspended from one of these platforms, you may lose your ability to participate in school activities, or from finding your way through a foreign city, or from taking part of the democratic discussion.
The case for regulation #
In this article, I mainly want to focus on the free-speech issue related mostly to Facebook and Twitter. These companies make money from ads. The longer you stay on the platform, the more ads they can show you, and they've discovered that nothing pulls you in like anger. These incentives are incredibly counter-productive for society.
Users are implicitly encouraged to create or spread anger, yet few are held accountable. One reason is that you can easily create new accounts without disclosing your real-world identity. This makes it difficult to hold users accountable for their utterances.
Instead of clear rules, users are suspended for inexplicable and arbitrary reasons. It seems that these are mostly the verdicts of algorithms, but as we've seen in the case of Donald Trump, it can also be the result of an undemocratic, but political decision.
Everyone can lose their opportunities for self-expression for arbitrary reasons. This is a free-speech issue.
Yes, free speech.
I'm well aware that Facebook and Twitter are private companies, and no-one has any right to an account on those platforms. That's why I started this essay by discussing how these services are turning into infrastructure.
More than a century ago, the telephone was new technology operated by private companies. I know the Danish history best, but it serves well as an example. KTAS, one of the world's first telephone companies, was a private company. Via mergers and acquisitions, it still is, but as it grew and became the backbone of the country's electronic communications network, the government introduced legislation. For decades, it and its sister companies were regional monopolies.
The government allowed the monopoly in exchange for various obligations. Even when the monopoly ended in 1996, the original monopoly companies inherited these legal obligations. For instance, every Danish citizen has the right to get a land-line installed, even if that installation by itself is a commercial loss for the company. This could be the case on certain remote islands or other rural areas. The Danish state compensates the telephone operator for this potential loss.
Many other utility companies run in a similar fashion. Some are semi-public, some are private, but common to water, electricity, garbage disposal, heating, and other operators is that they are regulated by government.
When a utility becomes important to the functioning of society, a sensible government steps in to regulate it to ensure the further smooth functioning of society.
I think that the services offered by Google, Facebook, and Twitter are fast approaching a level of significance that ought to trigger government regulation.
I don't say that lightly. I'm actually quite libertarian in my views, but I'm no anarcho-libertarian. I do acknowledge that a state offers essential services such as protection of property rights, a judicial system, and so on.
Accountability #
How should we regulate social media? I think we should start by exchanging accountability for the right to post.
Let's take another step back for a moment. For generations, it's been possible to send a letter to the editor of a regular newspaper. If the editor deems it worthy for publication, it'll be printed in the next issue. You don't have any right to get your letter published; this happens at the discretion of the editor.
Why does it work that way? It works that way because the editor is accountable for what's printed in the paper. Ultimately, he or she can go to jail for what's printed.
Freedom of speech is more complicated than it looks at first glance. For instance, censorship in Denmark was abolished with the 1849 constitution. This doesn't mean that you can freely say whatever you'd like; it only means that government has no right to prevent you from saying or writing something. You can still be prosecuted after the fact if you say or write something libellous, or if you incite violence, or if you disclose secrets that you've agreed to keep, etcetera.
This is accountability. It works when the person making the utterance is known and within reach of the law.
Notice, particularly, that an editor-in-chief is accountable for a newspaper's contents. Why isn't Facebook or Twitter accountable for content?
These companies have managed to spin a story that they're platforms rather than publishers. This argument might have had some legs ten years ago. When I started using Twitter in 2009, the algorithm was easy to understand: My feed showed the tweets from the accounts that I followed, in the order that they were published. This was easy to understand, and Twitter didn't, as far as I could tell, edit the feed. Since no editing took place, I find the platform argument applicable.
Later, the social networks began editing the feeds. No humans were directly involved, but today, some posts are amplified while others get little attention. Since this is done by 'algorithms' rather than editors, the companies have managed to convince lawmakers that they're still only platforms. Let's be real, though. Apparently, the public needs a programmer to say the following, and I'm a programmer.
Programmers, employees of those companies, wrote the algorithms. They experimented and tweaked those algorithms to maximise 'engagement'. Humans are continually involved in this process. Editing takes place.
I think it's time to stop treating social media networks as platforms, and start treating them as publishers.
Practicality #
Facebook and Twitter will protest that it's practically impossible for them to 'edit' what happens on the networks. I find this argument unconvincing, since editing already takes place.
I'd like to suggest a partial way out, though. This brings us back to regulation.
I think that each country or jurisdiction should make it possible for users to opt in to being accountable. Users should be able to verify their accounts as real, legal persons. If they do that, their activity on the platform should be governed by the jurisdiction in which they reside, instead of by the arbitrary and ill-defined 'community guidelines' offered by the networks. You'd be accountable for your utterances according to local law where you live. The advantage, though, is that this accountability buys you the right to be present on the platform. You can be sued for your posts, but you can't be kicked off.
I'm aware that not everyone lives in a benign welfare state such as Denmark. This is why I suggest this as an option. Even if you live in a state that regulates social media as outlined above, the option to stay anonymous should remain. This is how it already works, and I imagine that it should continue to work like that for this group of users. The cost of staying anonymous, though, is that you submit to the arbitrary and despotic rules of those networks. For many people, including minorities and citizens of oppressive states, this is likely to remain a better trade-off.
Problems #
This suggestion is in no way perfect. I can already identify one problem with it.
A country could grant its citizens the right to conduct infowar on an adversary; think troll armies and the like. If these citizens are verified and 'accountable' to their local government, but this government encourages rather than punishes incitement to violence in a foreign country, then how do we prevent that?
I have a few half-baked ideas, but I'd rather leave the problem here in the hope that it might inspire other people to start thinking about it, too.
Conclusion #
This is a post that I've waited for a long time for someone else to write. If someone already did, I'm not aware of it. I can think of three reasons:
- It's a really stupid idea.
- It's a common idea, but no-one talks about it because of pluralistic ignorance.
- It's an original idea that no-one else have had.
The idea is, in short, to make it optional for users to 'buy' the right to stay on a social network for the price of being held legally accountable. This requires some national as well as international regulation of the digital infrastructure.
Could it work? I don't know, but isn't it worth discussing?
ASP.NET POCO Controllers: an experience report
Controllers don't have to derive from a base class.
In most tutorials about ASP.NET web APIs you'll be told to let Controller classes derive from a base class. It may be convenient if you believe that productivity is measured by how fast you can get an initial version of the software into production. Granted, sometimes that's the case, but usually there's a price to be paid. Did you produce legacy code in the process?
One common definition of legacy code is that it's code without tests. With ASP.NET I've repeatedly found that when Controllers derive from ControllerBase they become harder to unit test. It may be convenient to have access to the Url and User properties, but this tends to make the arrange phase of a unit test much more complex. Not impossible; just more complex than I like. In short, inheriting from ControllerBase just to get access to, say, Url or User violates the Interface Segregation Principle. That ControllerBase is too big a dependency for my taste.
I already use self-hosting in integration tests so that I can interact with my REST APIs via HTTP. When I want to test how my API reacts to various HTTP-specific circumstances, I do that via integration tests. So, in a recent code base I decided to see if I could write an entire REST API in ASP.NET Core without inheriting from ControllerBase.
The short answer is that, yes, this is possible, and I'd do it again, but you have to jump through some hoops. I consider that hoop-jumping a fine price to pay for the benefits of simpler unit tests and (it turns out) better separation of concerns.
In this article, I'll share what I've learned. The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
POCO Controllers #
Just so that we're on the same page: A POCO Controller is a Controller class that doesn't inherit from any base class. In my code base, they're defined like this:
[Route("")] public sealed class HomeController
or
[Authorize(Roles = "MaitreD")] public class ScheduleController
As you can tell, they don't inherit from ControllerBase or any other base class. They are annotated with attributes, like [Route], [Authorize], or [ApiController]. Strictly speaking, that may disqualify them as true POCOs, but in practice I've found that those attributes don't impact the sustainability of the code base in a negative manner.
Dependency Injection is still possible, and in use:
[ApiController] public class ReservationsController { public ReservationsController( IClock clock, IRestaurantDatabase restaurantDatabase, IReservationsRepository repository) { Clock = clock; RestaurantDatabase = restaurantDatabase; Repository = repository; } public IClock Clock { get; } public IRestaurantDatabase RestaurantDatabase { get; } public IReservationsRepository Repository { get; } // Controller actions and other members go here...
I consider Dependency Injection nothing but an application of polymorphism, so I think that still fits the POCO label. After all, Dependency Injection is just argument-passing.
HTTP responses and status codes #
The first thing I had to figure out was how to return various HTTP status codes. If you just return some model object, the default status code is 200 OK. That's fine in many situations, but if you're implementing a proper REST API, you should be using headers and status codes to communicate with the client.
The ControllerBase class defines many helper methods to return various other types of responses, such as BadRequest or NotFound. I had to figure out how to return such responses without access to the base class.
Fortunately, ASP.NET Core is now open source, so it isn't too hard to look at the source code for those helper methods to see what they do. It turns out that they are just discoverable methods that create and return various result objects. So, instead of calling the BadRequest helper method, I can just return a BadRequestResult:
return new BadRequestResult();
Some of the responses were a little more involved, so I created my own domain-specific helper methods for them:
private static ActionResult Reservation201Created(int restaurantId, Reservation r) { return new CreatedAtActionResult( actionName: nameof(Get), controllerName: null, routeValues: new { restaurantId, id = r.Id.ToString("N") }, value: r.ToDto()); }
Apparently, the controllerName argument isn't required, so should be null. I had to experiment with various combinations to get it right, but I have self-hosted integration tests that cover this result. If it doesn't work as intended, tests will fail.
Returning this CreatedAtActionResult object produces an HTTP response like this:
HTTP/1.1 201 Created
Content-Type: application/json; charset=utf-8
Location: https://example.net:443/restaurants/2112/reservations/276d124f20cf4cc3b502f57b89433f80
{
"id": "276d124f20cf4cc3b502f57b89433f80",
"at": "2022-01-14T19:45:00.0000000",
"email": "donkeyman@example.org",
"name": "Don Keyman",
"quantity": 4
}
I've edited and coloured the response for readability. The Location URL actually also includes a digital signature, which I've removed here just to make the example look a little prettier.
In any case, returning various HTTP headers and status codes is less discoverable when you don't have a base class with all the helper methods, but once you've figured out the objects to return, it's straightforward, and the code is simple.
Generating links #
A true (level 3) REST API uses hypermedia as the engine of application state; that is, links. This means that a HTTP response will typically include a JSON or XML representation with several links. This article includes several examples.
ASP.NET provides IUrlHelper for exactly that purpose, and if you inherit from ControllerBase the above-mentioned Url property gives you convenient access to just such an object.
When a class doesn't inherit from ControllerBase, you don't have convenient access to an IUrlHelper. Then what?
It's possible to get an IUrlHelper via the framework's built-in Dependency Injection engine, but if you add such a dependency to a POCO Controller, you'll have to jump through all sorts of hoops to configure it in unit tests. That was exactly the situation I wanted to avoid, so that got me thinking about design alternatives.
That was the real, underlying reason I came up with the idea to instead add REST links as a cross-cutting concern. The Controllers are wonderfully free of that concern, which helps keeping the complexity down of the unit tests.
I still have test coverage of the links, but I prefer testing HTTP-related behaviour via the HTTP API instead of relying on implementation details:
[Theory] [InlineData("Hipgnosta")] [InlineData("Nono")] [InlineData("The Vatican Cellar")] public async Task RestaurantReturnsCorrectLinks(string name) { using var api = new SelfHostedApi(); var client = api.CreateClient(); var response = await client.GetRestaurant(name); var expected = new HashSet<string?>(new[] { "urn:reservations", "urn:year", "urn:month", "urn:day" }); var actual = await response.ParseJsonContent<RestaurantDto>(); var actualRels = actual.Links.Select(l => l.Rel).ToHashSet(); Assert.Superset(expected, actualRels); Assert.All(actual.Links, AssertHrefAbsoluteUrl); }
This test verifies that the representation returned in response contains four labelled links. Granted, this particular test only verifies that each link contains an absolute URL (which could, in theory, be http://www.example.com), but the whole point of fit URLs is that they should be opaque. I've other tests that follow links to verify that the API affords the desired behaviour.
Authorisation #
The final kind of behaviour that caused me a bit of trouble was authorisation. It's easy enough to annotate a Controller with an [Authorize] attribute, which is fine as long all you need is role-based authorisation.
I did, however, run into one situation where I needed something closer to an access control list. The system that includes all these code examples is a multi-tenant restaurant reservation system. There's one protected resource: a day's schedule, intended for use by the restaurant's staff. Here's a simplified example:
GET /restaurants/2112/schedule/2021/2/23 HTTP/1.1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInCI6IkpXVCJ9.eyJ...
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"name": "Nono",
"year": 2021,
"month": 2,
"day": 23,
"days": [
{
"date": "2021-02-23",
"entries": [
{
"time": "19:45:00",
"reservations": [
{
"id": "2c7ace4bbee94553950afd60a86c530c",
"at": "2021-02-23T19:45:00.0000000",
"email": "anarchi@example.net",
"name": "Ann Archie",
"quantity": 2
}
]
}
]
}
]
}
Since this resource contains personally identifiable information (email addresses) it's protected. You have to present a valid JSON Web Token with required claims. Role claims, however, aren't enough. A minimum bar is that the token must contain a sufficient role claim like "MaitreD" shown above, but that's not enough. This is, after all, a multi-tenant system, and we don't want one restaurant's MaitreD to be able to see another restaurant's schedule.
If ASP.NET can address that kind of problem with annotations, I haven't figured out how. The Controller needs to check an access control list against the resource being accessed. The above-mentioned User property of ControllerBase would be really convenient here.
Again, there are ways to inject an entire ClaimsPrincipal class into the Controller that needs it, but once more I felt that that would violate the Interface Segregation Principle. I didn't need an entire ClaimsPrincipal; I just needed a list of restaurant IDs that a particular JSON Web Token allows access to.
As is often my modus operandi in such situations, I started by writing the code I wished to use, and then figured out how to make it work:
[HttpGet("restaurants/{restaurantId}/schedule/{year}/{month}/{day}")] public async Task<ActionResult> Get(int restaurantId, int year, int month, int day) { if (!AccessControlList.Authorize(restaurantId)) return new ForbidResult(); // Do the real work here...
AccessControlList is a Concrete Dependency. It's just a wrapper around a collection of IDs:
public sealed class AccessControlList { private readonly IReadOnlyCollection<int> restaurantIds;
I had to create a new class in order to keep the built-in ASP.NET DI Container happy. Had I been doing Pure DI I could have just injected IReadOnlyCollection<int> directly into the Controller, but in this code base I used the built-in DI Container, which I had to configure like this:
services.AddHttpContextAccessor(); services.AddTransient(sp => AccessControlList.FromUser( sp.GetService<IHttpContextAccessor>().HttpContext.User));
Apart from having to wrap IReadOnlyCollection<int> in a new class, I found such an implementation preferable to inheriting from ControllerBase. The Controller in question only depends on the services it needs:
public ScheduleController( IRestaurantDatabase restaurantDatabase, IReservationsRepository repository, AccessControlList accessControlList)
The ScheduleController uses its restaurantDatabase dependency to look up a specific restaurant based on the restaurantId, the repository to read the schedule, and accessControlList to implement authorisation. That's what it needs, so that's its dependencies. It follows the Interface Segregation Principle.
The ScheduleController class is easy to unit test, since a test can just create a new AccessControlList object whenever it needs to:
[Fact] public async Task GetScheduleForAbsentRestaurant() { var sut = new ScheduleController( new InMemoryRestaurantDatabase(Some.Restaurant.WithId(2)), new FakeDatabase(), new AccessControlList(3)); var actual = await sut.Get(3, 2089, 12, 9); Assert.IsAssignableFrom<NotFoundResult>(actual); }
This test requests the schedule for a restaurant with the ID 3, and the access control list does include that ID. The restaurant, however, doesn't exist, so despite correct permissions, the expected result is 404 Not Found.
Conclusion #
ASP.NET has supported POCO Controllers for some time now, but it's clearly not a mainstream scenario. The documentation and Visual Studio tooling assumes that your Controllers inherit from one of the framework base classes.
You do, therefore, have to jump through a few hoops to make POCO Controllers work. The result, however, is more lightweight Controllers and better separation of concerns. I find the jumping worthwhile.
Comments
Hi Mark, as I read the part about BadRequest and NotFound being less discoverable, I wondered if you had
considered creating a ControllerHelper (terrible name
I know)
class with BadRequest, etc?
Then by adding using static Resteraunt.ControllerHelper as a little bit of boilerplate code to
the top of each POCO controller, you would be able to do return BadRequest(); again.
Dave, thank you for writing. I hadn't thought of that, but it's a useful idea. Someone would have to figure out how to write such a helper class, but once it exists, it would offer the same degree of discoverability. I'd suggest a name like Result or HttpResult, so that you could write e.g. Result.BadRequest().
Wouldn't adding a static import defy the purpose, though? As I see it, C# discoverability is enabled by 'dot-driven development'. Don't you lose that by a static import?
Self-hosted integration tests in ASP.NET
A way to self-host a REST API and test it through HTTP.
In 2020 I developed a sizeable code base for an online restaurant REST API. In the spirit of outside-in TDD, I found it best to test the HTTP behaviour of the API by actually interacting with it via HTTP.
Sometimes ASP.NET offers more than one way to achieve the same end result. For example, to return 200 OK, you can use both OkObjectResult and ObjectResult. I don't want my tests to be coupled to such implementation details, so by testing an API via HTTP instead of using the ASP.NET object model, I decouple the two.
You can easily self-host an ASP.NET web API and test it using an HttpClient. In this article, I'll show you how I went about it.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Reserving a table #
In true outside-in fashion, I'll first show you the test. Then I'll break it down to show you how it works.
[Fact] public async Task ReserveTableAtNono() { using var api = new SelfHostedApi(); var client = api.CreateClient(); var at = DateTime.Today.AddDays(434).At(20, 15); var dto = Some.Reservation.WithDate(at).WithQuantity(6).ToDto(); var response = await client.PostReservation("Nono", dto); await AssertRemainingCapacity(client, at, "Nono", 4); await AssertRemainingCapacity(client, at, "Hipgnosta", 10); }
This test uses xUnit.net 2.4.1 to make a reservation at the restaurant named Nono. The first line that creates the api variable spins up a self-hosted instance of the REST API. The next line creates an HttpClient configured to communicate with the self-hosted instance.
The test proceeds to create a Data Transfer Object that it posts to the Nono restaurant. It then asserts that the remaining capacity at the Nono and Hipgnosta restaurants are as expected.
You'll see the implementation details soon, but I first want to discuss this high-level test. As is the case with most of my code, it's far from perfect. If you're not familiar with this code base, you may have plenty of questions:
- Why does it make a reservation 434 days in the future? Why not 433, or 211, or 1?
- Is there anything significant about the quantity 6?
- Why is the expected remaining capacity at Nono 4?
- Why is the expected remaining capacity at Hipgnosta 10? Why does it even verify that?
The three other questions are all related. A bit of background is in order. I wrote this test during a process where I turned the system into a multi-tenant system. Before that change, there was only one restaurant, which was Hipgnosta. I wanted to verify that if you make a reservation at another restaurant (here, Nono) it changes the observable state of that restaurant, and not of Hipgnosta.
The way these two restaurants are configured, Hipgnosta has a single communal table that seats ten guests. This explains why the expected capacity of Hipgnosta is 10. Making a reservation at Nono shouldn't affect Hipgnosta.
Nono has a more complex table configuration. It has both standard and communal tables, but the largest table is a six-person communal table. There's only one table of that size. The next-largest tables are four-person tables. Thus, a reservation for six people reserves the largest table that day, after which only four-person and two-person tables are available. Therefore the remaining capacity ought to be 4.
The above test knows all this. You are welcome to criticise such hard-coded knowledge. There's a real risk that it might make it more difficult to maintain the test suite in the future.
Certainly, had this been a unit test, and not an integration test, I wouldn't have accepted so much implicit knowledge - particularly because I mostly apply functional architecture, and pure functions should have isolation. Functions shouldn't depend on implicit global state; they should return a value based on input arguments. That's a bit of digression, though.
These are integration tests, which I mostly use for smoke tests and to verify HTTP-specific behaviour. I have unit tests for fine-grained testing of edge cases and variations of input. While I wouldn't accept so much implicit knowledge from a unit test, I find that it so far works well with integration tests.
Self-hosting #
It only takes a WebApplicationFactory to self-host an ASP.NET API. You can use it directly, but if you want to modify the hosted service in some way, you can also inherit from it.
I want my self-hosted integration tests to run as state-based tests that use an in-memory database instead of SQL Server. I've defined SelfHostedApi for that purpose:
internal sealed class SelfHostedApi : WebApplicationFactory<Startup> { protected override void ConfigureWebHost(IWebHostBuilder builder) { builder.ConfigureServices(services => { services.RemoveAll<IReservationsRepository>(); services.AddSingleton<IReservationsRepository>(new FakeDatabase()); }); } }
The way that WebApplicationFactory works, its ConfigureWebHost method runs after the Startup class' ConfigureServices method. Thus, when ConfigureWebHost runs, the services collection is already configured to use SQL Server. As Julius H so kindly pointed out to me, the RemoveAll extension method removes all existing registrations of a service. I use it to remove the SQL Server dependency from the system, after which I replace it with a test-specific in-memory implementation.
Since the in-memory database is configured with Singleton lifetime, that instance is going to be around for the lifetime of the service. While it's only keeping track of things in memory, it'll keep state until the service shuts down, which happens when the above api variable goes out of scope.
Notice that I named the class by the role it plays rather than which base class it derives from.
Posting a reservation #
The PostReservation method is an extension method on HttpClient:
internal static async Task<HttpResponseMessage> PostReservation( this HttpClient client, string name, object reservation) { string json = JsonSerializer.Serialize(reservation); using var content = new StringContent(json); content.Headers.ContentType.MediaType = "application/json"; var resp = await client.GetRestaurant(name); resp.EnsureSuccessStatusCode(); var rest = await resp.ParseJsonContent<RestaurantDto>(); var address = rest.Links.FindAddress("urn:reservations"); return await client.PostAsync(address, content); }
It's part of a larger set of methods that enables an HttpClient to interact with the REST API. Three of those methods are visible here: GetRestaurant, ParseJsonContent, and FindAddress. These, and many other, methods form a client API for interacting with the REST API. While this is currently test code, it's ripe for being extracted to a reusable client SDK library.
I'm not going to show all of them, but here's GetRestaurant to give you a sense of what's going on:
internal static async Task<HttpResponseMessage> GetRestaurant(this HttpClient client, string name) { var homeResponse = await client.GetAsync(new Uri("", UriKind.Relative)); homeResponse.EnsureSuccessStatusCode(); var homeRepresentation = await homeResponse.ParseJsonContent<HomeDto>(); var restaurant = homeRepresentation.Restaurants.First(r => r.Name == name); var address = restaurant.Links.FindAddress("urn:restaurant"); return await client.GetAsync(address); }
The REST API has only a single documented address, which is the 'home' resource at the relative URL ""; i.e. the root of the API. In this incarnation of the API, the home resource responds with a JSON array of restaurants. The GetRestaurant method finds the restaurant with the desired name and finds its address. It then issues another GET request against that address, and returns the response.
Verifying state #
The verification phase of the above test calls a private helper method:
private static async Task AssertRemainingCapacity( HttpClient client, DateTime date, string name, int expected) { var response = await client.GetDay(name, date.Year, date.Month, date.Day); var day = await response.ParseJsonContent<CalendarDto>(); Assert.All( day.Days.Single().Entries, e => Assert.Equal(expected, e.MaximumPartySize)); }
It uses another of the above-mentioned client API extension methods, GetDay, to inspect the REST API's calendar entry for the restaurant and day in question. Each calendar contains a series of time entries that lists the largest party size the restaurant can accept at that time slot. The two restaurants in question only have single seatings, so once you've booked a six-person table, you have it for the entire evening.
Notice that verification is done by interacting with the system itself. No Back Door Manipulation is required. I favour this if at all possible, since I believe that it offers better confidence that the system behaves as it should.
Conclusion #
It's been possible to self-host .NET REST APIs for testing purposes at least since 2012, but it's only become easier over the years. All you need to get started is the WebApplicationFactory<TEntryPoint> class, although you're probably going to need a derived class to override some of the system configuration.
From there, you can interact with the self-hosted system using the standard HttpClient class.
Since I configure these tests to run on an in-memory database, the execution time is comparable to 'normal' unit tests. I admit that I haven't measured it, but that's because I haven't felt the need to do so.
Comments
Hi Mark, 2 questions from me:
- What kind of integration does this test verify? The integration between the HTTP request processing part and the service logic? If so, why fake the database only and not the whole logic?
- If you fake the database here, then would you have a separate test for testing integration with DB (e.g. some kind of "adapter test", as described in the GOOS book)?
Grzegorz, thank you for writing.
1. As I already hinted at, the motivation for this test was that I was expanding the code from a single-tenant to a multi-tenant system. I did this in small steps, using tests to drive the augmented behaviour. Before I added the above test, I'd introduced the concept of a restaurant ID to identify each restaurant, and initially added a method overload to my data access interface that required such an ID:
Task Create(int restaurantId, Reservation reservation);
I was using the Strangler pattern to be able to move in small steps. One step was to add overloads like the above. Subsequent steps would be to move existing callers from the 'legacy' overload to the new overload, and then finally delete the 'legacy' overload.
When moving from a single-tenant system to a multi-tenant system, I had to grandfather in the existing restaurant, which I arbitrarily chose to give the restaurant ID 1. During this process, I kept the existing system working so as to not break existing clients.
I gradually introduced method overloads that took a restaurant ID as a parameter (as above), and then deleted the legacy methods that didn't take a restaurant ID. In order to not break anything, I'd initially be calling the new methods with the hard-coded restaurant ID 1.
The above test was one in a series of tests that followed. Their purpose was to verify that the system had become truly multi-tenant. Before I added that test, an attempt to make a reservation at Nono would result in a call to Create(1, reservation) because there was still hard-coded restaurant IDs left in the code base.
(To be honest, the above is a simplified account of events. It was actually more complex than that, since it involved hypermedia controls. I also, for reasons that I may divulge in the future, didn't perform this work behind a feature flag, which under other circumstances would have been appropriate.)
What the above test verifies, then, is that the reservation gets associated with the correct restaurant, instead of the restaurant that was grandfathered in (Hipgnosta). An in-memory (Fake) database was sufficient to demonstrate that.
Why didn't I use the real, relational database? Read on.
2. As I've recently discussed, integration tests that involve SQL Server are certainly possible. They tend to be orders-of-magnitudes slower than unit tests that run entirely in memory, so I only add them if I deem them necessary.
I interact with databases according to the Dependency Inversion Principle. The above Create method is an example of that. The method is defined by the needs of the client code rather than on implementation details.
The actual implementation of the data access interface is, as you imply, an Adapter. It adapts the SQL Server SDK (i.e. ADO.NET) to my data access interface. As long as I can keep such Adapters Humble Objects I don't cover them by tests.
Such Adapters are often just mappings: This class field maps to that table column, that field to that other column, and so on. If there's no logic, there isn't much to test.
This doesn't mean that bugs can't appear in database Adapters. If that happens, I may introduce regression tests that involve the database. I prefer to do this in a separate test suite, however, since such tests tend to be slow, and TDD test suites should be fast.
Hi Mark, I have been a fan of "integration" style testing since I found Andrew Locks's post on the topic. In fact, I personally find that it makes sense to take that idea to one extreme.
As far as I can see, your test assumes something like "Given that no reservations have been made". Did you consider to make that "Given" explicitly recognizable in your test?
I am asking because this is a major pet topic of mine and I would love to hear your thoughts. I am not suggesting writing Gherkin instead of C# code, just if and how you would make the "Given" assumption explicit.
A more practical comment is on your use of services.RemoveAll<IReservationsRepository>(); It seems extreme to remove all, as all you want to achieve is to overwrite a few service declarations. Andrew Lock demonstrates how to keep all the ASP.NET middleware intact by keeping most of the service registrations.
I usually use ConfigureTestServices on WebApplicationFactory, something like,
factory.WithWebHostBuilder(builder => builder.ConfigureTestServices(MyTestCompositionRoot.Initialize));
Brian, thank you for writing. You're correct that one implicit assumption is that no prior reservations have been made to Nono on that date. The reality is, as you suggest, that there are no reservations at all, but the test doesn't require that. It only relies on the weaker assumption that there are prior reservations to neither Nono nor Hipgnosta on the date in question.
I often find it tricky to make 'negative' assumptions explicit. How much should one highlight? Is it also relevant to highlight that SelfHostedApi isn't going to send notification emails? That it doesn't write to a persistent log? That it doesn't have the capability to launch missiles?
I'm not saying that it's irrelevant to highlight certain assumptions, but I'm not sure that I have a clear heuristic for it. After all, it depends on what the reader cares about, and how clear the assumptions are.
If it became clear to me that the assumption of 'no prior reservations' was important to the reader, I might consider to embed that in the name of the test, or perhaps by adding a comment. Another option is to hide the initialisation of SelfHostedApi behind a required factory method so that you'd have to initialise it as using var api = SelfHostedApi.StartEmpty();
In this particular code base, though, that SelfHostedApi is used repeatedly. A programmer who regularly works with that code base will quickly internalise the assumptions embedded in that self-hosted service.
Granted, it can be a dangerous strategy to rely too much on implicit assumptions, because it can make it more difficult to change things if those assumptions change in the future. I do, after all, favour the wisdom from the Zen of Python: Explicit is better than implicit.
Making such things as we discuss here explicit does, however, tend to make the tests more verbose. Pragmatically, then, there's a balance to strike. I'm not claiming that the test shown here is perfect. In a a living code base, this would be a concern that I would keep a constant eye on. I'd fiddle with it, trying out making things more explicit, less explicit, and so on, to see what works best in context.
Your other point about services.RemoveAll<IReservationsRepository>() I don't understand. Why is that extreme? It's literally the most minimal, precise change I can make. It removes only the IReservationsRepository, of which there's exactly one Singleton instance:
var connStr = Configuration.GetConnectionString("Restaurant"); services.AddSingleton<IReservationsRepository>(sp => { var logger = sp.GetService<ILogger<LoggingReservationsRepository>>(); var postOffice = sp.GetService<IPostOffice>(); return new EmailingReservationsRepository( postOffice, new LoggingReservationsRepository( logger, new SqlReservationsRepository(connStr))); });
The integration test throws away that Singleton object graph, but nothing else.
Hi Mark, thanks for a thorough answer.
Alas, my second question was not thought through - I somehow thought you threw away all service registrations, which you obviously do not. In fact, I do exactly what you do, usually with Replace and thereby implicitly assume that there is only one registration. My Bad.
We very much agree in the importance of favouring explicit assumptions.
The solution to stating 'negative' assumptions, as long as we talk about the 'initial context' (the 'Given') is actually quite simple if your readers know that you always state assumptions explicitly. If none are stated, it's the same as saying 'the world is empty' - at least when it comes to the bounded context of whatever you are testing. I find that the process of identifying a minimal set of assumptions per test is a worthwhile exercise.
So, IMHO it boils down to consistently stating all assumptions and making the relevant bounded context clear.
Brian, thank you for writing. I agree that it's a good rule of thumb to expect the world to be empty unless explicitly stated otherwise. This is the reason that I love functional programming.
One question, however, is whether a statement is sufficiently explicit. The integration test shown here is a good example. What's actually happening is that SelfHostedApi sets up a self-hosted service configured in a certain way. It contains three restaurants, of which two are relevant in this particular test. Each restaurant comes with quite a bit of configuration: opening time, closing time, seating duration, and the configuration of tables. Just consider the configuration of Nono:
{
"Id": 2112,
"Name": "Nono",
"OpensAt": "18:00",
"LastSeating": "21:00",
"SeatingDuration": "6:00",
"Tables": [
{
"TableType": "Communal",
"Seats": 6
},
{
"TableType": "Communal",
"Seats": 4
},
{
"TableType": "Standard",
"Seats": 2
},
{
"TableType": "Standard",
"Seats": 2
},
{
"TableType": "Standard",
"Seats": 4
},
{
"TableType": "Standard",
"Seats": 4
}
]
}
The code base also enables a test writer to express the above configuration as code instead of JSON, but the point I'm trying to make is that you probably don't want that amount of detail to appear in the Arrange phase of each test, regardless of how explicit it'd be.
To work around an issue like this, you might instead define an immutable test data variable called nono. Then, in each test that uses these restaurants, you might include something like AddRestaurant(nono) or AddRestaurant(hipgnosta) in the Arrange phase (hypothetical API). That's not quite as explicit, because it hides the actual values away, but is probably still good enough.
Then you find yourself always adding the same restaurants, so you say to yourself: It'd be nice if I had a helper method like AddStandardRestaurants. So, you may add such a helper method.
But you find that for the integration tests, you always call that helper method, so ultimately, you decide to just roll it into the definition of SelfHostedApi. That's basically what's going on here.
I don't recall whether I explicitly stated the following in the article, but I use integration tests consistent with the test pyramid. The purpose of the integration tests is to verify that components integrate correctly, and that the HTTP API behaves according to contract. In my experience, I can let the 'givens' be somewhat implicit and still keep the code maintainable. For integration tests, that is.
On the unit level, I favour pure functions, which are intrinsically testable. Due to isolation, everything that affects the behaviour of a pure function must be explicitly passed as arguments, and as a bi-product, they become explicit as part of a test's Arrange phase.
But, again, let me reiterate that I agree with you. I don't claim that the code shown here is perfect. It's so implicit that it makes me uncomfortable too, but on the other hand, I think that a test like the above communicates intent well. The more explicit details one adds, the more they may drown out the intent. It's a difficult balance to strike.
Hi Mark, I'm happy that we agree. Still, this is a pet topic of mine so please allow me one additional comment.
I wish all code had at least a functional core, as that would make testing so much easier. You could say that explicitly stating initial context resembles testing pure functions.
I do believe that it is possible to state initial context without being overwhelmed by details. It can by no means be fully automated - this is where the mind of a tester must be used. Also, it will never be perfect, but at least it can be documented somewhat systematically and kept under version control, so the reasoning can be challenged.
In your example, I would not add Nono or Hipgnosta or a standard restaurant, as those names say noting about what makes my test pass.
Rather, I would add e.g. a "restaurant with a 6 and a 4 person table", as this seems to be what makes your test pass, if I understood it correctly. In another test I might have "restaurant which is open from 6 PM with last seating at 9 PM" if I want to test time aspects of booking. It may be the same Json file used in those two tests, because what's most important is that you document what makes each individual test pass.
However, if it's not too much trouble (it sometimes is) I would even try to minimize the initial context. For example, I would test timing aspects with a minimal restaurant with a single table. Unless, timing and tables interact - maybe late bookings are OK if the restaurant is starved for customers? This is where the "tester mind" comes in handy.
In your restaurant example, that would mean having quite a few restaurant definitions, but only definitions which include the needed context for each test. My experience is that minimizing the initial context will teach you a lot about the code. This is similar to unit tests which focus on a small part of code, but "minimizing initial context" allows for less fragile tests than when "minimizing code".
We started using this approach because our tests did not give sufficient confidence. Tests were flaky and it was difficult to see what was tested and why. I can safely say that this is much better now.
My examples of initial context above may appear like they could grow out of control, but our experience so far is that it is possible to find a relatively small set of equivalence classes of initial context items, even for fairly complex functionality.
Brian, I agree that in unit testing, being able to reduce test cases to minimal examples is useful. Once you have those minimal examples, being explicit about all preconditions is more attainable. This is why, when I coach teams, I try to teach them about equivalence class partitioning. If, within each equivalence class, you can impose some sort of (partial) ordering, you may be able to pick a canonical representation that constitutes the minimal example.
This is basically what the shrinking process of property-based testing frameworks attempt to do.
Thus, when my testing goal is to explore the boundaries of the system under test, I go to great lengths to ensure that the arrange phase is as explicit as possible. I recently published an example of how I use property-based testing to such an end.
The goal of the integration test in the present article, however, is not to explore boundary cases or verify the correctness of algorithms in question. I have unit tests for that. The goal is to examine whether things may be correctly 'clicked together'.
Expressing an explicit minimal context for the above test is more involved than you outline. Having two restaurants, with two differently sized tables, is only the beginning. You must also ensure that they are open at the same time, so that an attempted reservation would fit both. Furthermore, you must then pick the date and time of the reservation to fit within that time window. This is still not hopelessly difficult, and might make for a good exercise, but it could easily add 4-5 extra lines of code to the test.
And again: had this been a unit test, I'd happily added those extra lines, but for an integration test, I felt that it was less important.
Parametrised test primitive obsession code smell
Watch out for this code smell with some unit testing frameworks.
In a previous article you saw this state-based integration test:
[Theory] [InlineData(1049, 19, 00, "juliad@example.net", "Julia Domna", 5)] [InlineData(1130, 18, 15, "x@example.com", "Xenia Ng", 9)] [InlineData( 956, 16, 55, "kite@example.edu", null, 2)] [InlineData( 433, 17, 30, "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); var db = new FakeDatabase(); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), db); var dto = new ReservationDto { Id = "B50DF5B1-F484-4D99-88F9-1915087AF568", At = at.ToString("O"), Email = email, Name = name, Quantity = quantity }; await sut.Post(dto); var expected = new Reservation( Guid.Parse(dto.Id), DateTime.Parse(dto.At, CultureInfo.InvariantCulture), new Email(dto.Email), new Name(dto.Name ?? ""), dto.Quantity); Assert.Contains(expected, db.Grandfather); }
This was the test after I improved it. Still, I wasn't satisfied with it. It has several problems. Take a few moments to consider it. Can you identify any problems? Which ones?
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Size #
I know that you're not familiar with all the moving parts. You don't know how ReservationDto or Reservation are implemented. You don't know what InMemoryRestaurantDatabase is, or how ReservationsController behaves. Still, the issues I have in mind aren't specific to a particular code base.
I feel that the method is verging on being too big. Quantifiably, it doesn't fit in an 80x24 box, but that's just an arbitrary threshold anyway. Still, I think it's grown to a size that makes me uncomfortable.
If you aren't convinced, think of this code example as a stand-in for something larger. In the above test, a reservation contains five smaller values (Id, At, Email, Name, and Quantity). How would a similar test look if the object in question contains ten or twenty values?
In the decades I've been programming and consulting, I've seen plenty of code bases. Data objects made from twenty fields are hardly unusual.
What would a similar test look like if the dto and the expected object required twenty smaller values?
The test would be too big.
Primitive obsession #
A test like this one contains a mix of essential behaviour and implementation details. The behaviour that it verifies is that when you Post a valid dto, the data makes it all the way to the database.
Exactly how the dto or the expected value are constructed is less relevant for the test. Yet it's intermingled with the test of behaviour. The signal-to-noise ratio in the test isn't all that great. What can you do to improve things?
As given, it seems difficult to do much. The problem is primitive obsession. While this is a parametrised test, all the method parameters are primitives: integers and strings. The makes it hard to introduce useful abstractions.
In C# (and probably other languages as well) parametrised tests often suffer from primitive obsession. The most common data source is an attribute (AKA annotation), like xUnit.net's [InlineData] attribute. This isn't a limitation of xUnit.net, but rather of .NET attributes. You can only create attributes with primitive values and arrays.
What is a limitation of xUnit.net (and the other mainstream .NET testing frameworks, as far as I know) is that tests aren't first-class values. In Haskell, by contrast, it's easy to write parametrised tests using the normal language constructs exactly because tests are first-class values. (I hope that the next version of xUnit.net will support tests as first-class values.)
Imagine that instead of only five constituent fields, you'd have to write a parametrised test for objects with twenty primitive values. As long as you stick with attribute-based data sources, you'll be stuck with primitive values.
Granted, attributes like [InlineData] are lightweight, but over the years, my patience with them has grown shorter. They lock me into primitive obsession, and I don't appreciate that.
Essential test #
While tests as first-class values aren't an option in xUnit.net, you can provide other data sources for the [Theory] attribute than [InlineData]. It's not as lightweight, but it breaks the primitive obsession and re-enables normal code design techniques. It enables you to reduce the test itself to its essence. You no longer have to think in primitives, but can instead express the test unshackled by constraints. As a first pass, I'd like the test to look like this:
[Theory] [ClassData(typeof(PostValidReservationWhenDatabaseIsEmptyTestCases))] public async Task PostValidReservationWhenDatabaseIsEmpty( ReservationDto validDto, Reservation expected) { var db = new FakeDatabase(); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), db); await sut.Post(validDto); Assert.Contains(expected, db.Grandfather); }
This version of the test eliminates the noise. How validDto and expected are constructed is an implementation detail that has little bearing on the behaviour being tested.
For a reader of the code, it's should now be clearer what's at stake here: If you Post a validDto the expected reservation should appear in the database.
Reducing the test code to its essentials made me realise something that hitherto had escaped me: that I could name the DTO by role. Instead of just dto, I could call the parameter validDto.
Granted, I could also have done that previously, but I didn't think of it. There's was so much noise in that test that I didn't stop to consider whether dto sufficiently communicated the role of that variable.
The less code, the easier it becomes to think such things through, I find.
In any case, the test code now much more succinctly expresses the essence of the desired behaviour. Notice how I started my refactoring by writing the desired test code. I've yet to implement the data source. Now that the data source expresses test data as full objects, I'm not so concerned with whether or not that's going to be possible. Of course it's possible.
Object data source #
You can define data sources for xUnit.net as classes or methods. In C# I usually reach for the [ClassData] option, since an object (in C#, that is) gives me better options for further decomposition. For example, I can define a class and delegate the details to helper methods:
private class PostValidReservationWhenDatabaseIsEmptyTestCases : TheoryData<ReservationDto, Reservation> { public PostValidReservationWhenDatabaseIsEmptyTestCases() { AddWithName(1049, 19, 00, "juliad@example.net", "Julia Domna", 5); AddWithName(1130, 18, 15, "x@example.com", "Xenia Ng", 9); AddWithoutName(956, 16, 55, "kite@example.edu", 2); AddWithName(433, 17, 30, "shli@example.org", "Shanghai Li", 5); } // More members here...
Here, I'm taking advantage of xUnit.net's built-in TheoryData<T1, T2> base class, but that's just a convenience. All you have to do is to implement IEnumerable<object[]>.
As you can see, the constructor adds the four test cases by calling two private helper methods. Here's the first of those:
private const string id = "B50DF5B1-F484-4D99-88F9-1915087AF568"; private void AddWithName( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); Add(new ReservationDto { Id = id, At = at.ToString("O"), Email = email, Name = name, Quantity = quantity }, new Reservation( Guid.Parse(id), at, new Email(email), new Name(name), quantity)); }
The other helper method is almost identical, although it has a slight variation when it comes to the reservation name:
private void AddWithoutName( int days, int hours, int minutes, string email, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); Add(new ReservationDto { Id = id, At = at.ToString("O"), Email = email, Quantity = quantity }, new Reservation( Guid.Parse(id), at, new Email(email), new Name(""), quantity)); }
In total, this refactoring results in more code, so how is this an improvement?
The paradox of decomposition #
In object-oriented design, decomposition tends to lead to more code. If you want to isolate and make reusable a particular piece of behaviour, you'll usually introduce an interface or a base class. Even stateless functions need a static class to define them. (To be fair, functional programming isn't entirely devoid of such overhead associated with decomposition, but the cost tends to smaller.) This leads to more code, compared with the situation before decomposition.
This is a situation you may also encounter if you attempt to refactor to design patterns, or follow the SOLID principles. You'll have more code than when you started. This often leads to resistance to such 'code bloat'.
It's fine to resist code bloat. It's also fine to dislike 'complexity for complexity's sake'. Try to evaluate each potential code change based on advantages and disadvantages. I'm not insisting that the above refactoring is objectively better. I did feel, however, that I had a problem that I ought to address, and that this was a viable alternative. The result is more code, but each piece of code is smaller and simpler.
You can, conceivably, read the test method itself to get a feel for what it tests, even if you don't know all the implementation details. You can read the four statements in the PostValidReservationWhenDatabaseIsEmptyTestCases constructor without, I hope, understanding all the details about the two helper methods. And you can read AddWithName without understanding how AddWithoutName works, and vice versa, because these two methods don't depend on each other.
Conclusion #
In this article, I've described how the use of code annotations for parametrised tests tend to pull in the direction of primitive obsession. This is a force worth keeping an eye on, I think.
You saw how to refactor to class-based test data generation. This enables you to use objects instead of primitives, thus opening your design palette. You can now use all your usual object-oriented or functional design skills to factor the code in a way that's satisfactory.
Was it worth it in this case? Keep in mind that the original problem was already marginal. While the code didn't fit in a 80x24 box, it was only 33 lines of code (excluding the test data). Imagine, however, that instead of a five-field reservation, you'd be dealing with a twenty-field data class, and such a refactoring begins to look more compelling.
Is the code now perfect? It still isn't. I'm a little put off by the similarity of AddWithName and AddWithoutName. I'm also aware that there's a trace of production code duplicated in the test case, in the way that the test code duplicates how a valid ReservationDto relates to a Reservation. I'm on the fence whether I should do anything about this.
At the moment I'm inclined to heed the rule of three. The duplication is still too insubstantial to warrant refactoring, but it's worth keeping an eye on.
Comments
Hi Mark, fair point! Indeed, sometimes [InlineData] is too simple and having test data creation moved to a separate class with all its advantages is a valid approach (using f.e. [ClassData]).
I just wanted to clarify on TheoryData class, I noticed that it was added in xUnit v3. But I can't find this new version anywhere on NuGet - are you using it from some early adopter feed? Thanks!
Mateusz, thank you for writing. The code shown in this article uses xUnit.net 2.4.1, which (apparently) includes the TheoryData base classes. I must admit that I don't know exactly when they were added to the library.
Waiting to happen
A typical future test maintenance problem.
In a recent article I showed a unit test and parenthetically mentioned that it might have a future maintenance problem. Here's a more recent version of the same test. Can you tell what the future issue might be?
[Theory] [InlineData("2023-11-24 19:00", "juliad@example.net", "Julia Domna", 5)] [InlineData("2024-02-13 18:15", "x@example.com", "Xenia Ng", 9)] [InlineData("2023-08-23 16:55", "kite@example.edu", null, 2)] [InlineData("2022-03-18 17:30", "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( string at, string email, string name, int quantity) { var db = new FakeDatabase(); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), db); var dto = new ReservationDto { Id = "B50DF5B1-F484-4D99-88F9-1915087AF568", At = at, Email = email, Name = name, Quantity = quantity }; await sut.Post(dto); var expected = new Reservation( Guid.Parse(dto.Id), DateTime.Parse(dto.At, CultureInfo.InvariantCulture), new Email(dto.Email), new Name(dto.Name ?? ""), dto.Quantity); Assert.Contains(expected, db.Grandfather); }
To be honest, there's more than one problem with this test, but presently I'm going to focus on one of them.
Since you don't know the details of the implementation, you may not be able to tell what the problem might be. It's not a trick question. On the other hand, you might still be able to guess, just from the clues available in the above code listing.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Sooner or later #
Here are some clues to consider: I'm writing this article in the beginning of 2021. Consider the dates supplied via the [InlineData] attributes. Seen from 2021, they're all in the future.
Notice, as well, that the sut takes a SystemClock dependency. You don't know the SystemClock class (it's a proprietary class in this code base), but from the name I'm sure that you can imagine what it represents.
From the perspective of early 2021, all dates are going to be in the future for more than a year. What is going to happen, though, once the test runs after March 18, 2022?
That test case is going to fail.
You can't tell from the above code listing, but the system under test rejects reservations in the past. Once March 18, 2022 has come and gone, the reservation at "2022-03-18 17:30" is going to be in the past. The sut will reject the reservation, and the assertion will fail.
You have to be careful with tests that rely on the system clock.
Test Double? #
The fundamental problem is that the system clock is non-deterministic. A typical reaction to non-determinism in unit testing is to introduce a Test Double of some sort. Instead of using the system clock, you could use a Stub as a stand-in for the real time.
This is possible here as well. The ReservationsController class actually depends on an IClock interface that SystemClock implements. You could define a test-specific ConstantClock implementation that would always return a constant date and time. This would actually work, but would rely on an implementation detail.
At the moment, the ReservationsController only calls Clock.GetCurrentDateTime() a single time to get the current time. As soon as it has that value, it passes it to a pure function, which implements the business logic:
var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return NoTables500InternalServerError();
A ConstantClock would work, but only as long as the ReservationsController only calls Clock.GetCurrentDateTime() once. If it ever began to call this method multiple times to detect the passing of time, using a constant time value would mostly likely again break the test. This seems brittle, so I don't want to go that way.
Relative time #
Working with the system clock in automated tests is easier if you deal with relative time. Instead of defining the test cases as absolute dates, express them as days into the future. Here's one way to refactor the test:
[Theory] [InlineData(1049, 19, 00, "juliad@example.net", "Julia Domna", 5)] [InlineData(1130, 18, 15, "x@example.com", "Xenia Ng", 9)] [InlineData( 956, 16, 55, "kite@example.edu", null, 2)] [InlineData( 433, 17, 30, "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); var db = new FakeDatabase(); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), db); var dto = new ReservationDto { Id = "B50DF5B1-F484-4D99-88F9-1915087AF568", At = at.ToString("O"), Email = email, Name = name, Quantity = quantity }; await sut.Post(dto); var expected = new Reservation( Guid.Parse(dto.Id), DateTime.Parse(dto.At, CultureInfo.InvariantCulture), new Email(dto.Email), new Name(dto.Name ?? ""), dto.Quantity); Assert.Contains(expected, db.Grandfather); }
The absolute dates always were fairly arbitrary, so I just took the current date and converted the dates to a number of days into the future. Now, the first test case will always be a date 1,049 days (not quite three years) into the future, instead of November 24, 2023.
The test is no longer a failure waiting to happen.
Conclusion #
Treating test cases that involve time and date as relative to the current time, instead of as absolute values, is usually a good idea if the system under test depends on the system clock.
It's always a good idea to factor as much code as you can as pure functions, like the above WillAccept method. Pure functions don't depend on the system clock, so here you can safely pass absolute time and date values. Pure functions are intrinsically testable.
Still, as the test pyramid suggests, relying exclusively on unit tests isn't a good idea. The test shown in this article isn't really a unit test, but rather a state-based integration test. It relies on both the system clock and a Fake database. Expressing the test cases for this test as relative time values effectively addresses the problem introduced by the system clock.
There are plenty of other problems with the above test. One thing that bothers me is that the 'fix' made the line count grow. It didn't quite fit into a 80x24 box before, but now it's even worse! I should do something about that, but that's a topic for another article.
Dynamic test oracles for rho problems
A proof of concept of cross-branch testing for compiled languages.
Hillel Wayne recently published an article called Cross-Branch Testing. It outlines an approach to a class of problems that are hard to test. He mentions computer vision and simulations, among others. I can add that it's also difficult to write intuitive tests of convex hulls and Conway's game of life.
Hillel Wayne calls these rho problems, 'just because'. I'm totally going to run with that term.
In the article, he outlines an approach where you test an iteration of rho code against a 'last known good' snapshot. He uses git worktree to set up a snapshot of the reference implementation. He then writes a property that compares the refactored code's behaviour against the reference.
The example code is in Python, which is a language that I don't know. As far as I can tell, it works because Python is 'lightweight' enough that you can load and execute source code directly. I found that the approach makes much sense, but I wondered how it would apply for statically typed, compiled languages. I decided to create a proof of concept in F#.
Test cases from Python #
My first problem was to port Hillel Wayne's example rho problem to F#. The function f doesn't have any immediate mathematical properties; nor is its behaviour intuitive. While I think that I understand what each line of code in f means, I don't really know Python. Since one of the properties of rho problems is that bugs can be subtle, I didn't trust myself to be able to port the Python code to F# without some test cases.
To solve that problem, I first found an online Python interpreter and pasted the f function into it. I then wrote code to print the output of a function call:
print(f'1, 2, 3, { f(1, 2, 3) }')
This line of code produces this output:
1, 2, 3, True
In other words, I could produce comma-separated values of input and actual output.
Hillel Wayne wrote properties using Hypothesis, which, it seems, by default runs each property 200 times.
In F# I'm going to use FsCheck, so I first used F# Interactive with FsCheck to produce 200 Python print statements like the above:
> Arb.Default.Int32().Generator
|> Gen.three
|> Gen.map (fun (x, y, z) -> sprintf "print(f'%i, %i, %i, { f(%i, %i, %i) }')" x y z x y z)
|> Gen.sample 100 200
|> List.iter (printfn "%s");;
print(f'-77, 67, 84, { f(-77, 67, 84) }')
print(f'58, -46, 3, { f(58, -46, 3) }')
print(f'21, 13, 94, { f(21, 13, 94) }')
...
This is a throwaway data pipeline that starts with an FsCheck integer generator, creates a triple from it, turns that triple into a Python print statement, and finally writes 200 of those to the console. The above code listing only shows the first three lines of output, while the rest are indicated by an ellipsis.
I copied those 200 print statements over to the online Python interpreter and ran the code. That produced 200 comma-separated values like these:
-77, 67, 84, False 58, -46, 3, False 21, 13, 94, True ...
These can serve as test cases for porting the Python code to F#.
Port to F# #
The next step is to write a parametrised test, using a provisional implementation of f:
[<Theory; MemberData(nameof fTestCases)>]
let ``test f`` x y z expected = expected =! f x y z
This test uses xUnit.net 2.4.1 and Unquote 5.0.0. As you can tell, apart from the annotations, it's a true one-liner. It calls the f function with the three supplied arguments x, y, and z and compares the return value with the expected value.
The code uses the new nameof feature of F# 5. fTestCases is a function in the same module that holds the test:
// unit -> seq<obj []> let fTestCases () = use strm = typeof<Anchor>.Assembly.GetManifestResourceStream streamName use rdr = new StreamReader (strm) let s = rdr.ReadToEnd () s.Split Environment.NewLine |> Seq.map csvToTestCase
It reads an embedded resource stream of test cases, like the above comma-separated values. Even though the values are in a text file, it's easier to embed the file in the test assembly, because it nicely dispenses with the problem of copying a text file to the appropriate output directory when the code compiles. That would, however, be an valid alternative.
Anchor is a dummy type to support typeof, and streamName is just a string constant that identifies the name of the stream.
The csvToTestCase function converts each line of comma-separated values to test cases for the [<Theory>] attribute:
// string -> obj [] let csvToTestCase (csv : string) = let values = csv.Split ',' [| values.[0] |> Convert.ToInt32 |> box values.[1] |> Convert.ToInt32 |> box values.[2] |> Convert.ToInt32 |> box values.[3] |> Convert.ToBoolean |> box |]
It's not the safest code I could write, but this is, after all, a proof of concept.
The most direct port of the Python code I could produce is this:
// f : int -> int -> int -> bool let f (x : int) (y : int) (z : int) = let mutable mx = bigint x let mutable my = bigint y let mutable mz = bigint z let mutable out = 0I for i in [0I..9I] do out <- out * mx + abs (my * mz - i * i) let x' = mx let y' = my let z' = mz mx <- y' + 1I my <- z' mz <- x' abs out % 100I < 10I
As F# code goes, it's disagreeable, but it passes all 200 test cases, so this will serve as an initial implementation. The out variable can grow to values that overflow even 64-bit integers, so I had to convert to bigint to get all test cases to pass.
If I make the same mutation to the code that Hillel Wayne did (abs out % 100I < 9I) two test cases fail. This gives me some confidence that I have a degree of problem coverage comparable to his.
Test oracle #
Now that a reference implementation exists, we can use it as a test oracle for refactorings. You can, for example, add a little test-only utility to your program portfolio:
open Prod open FsCheck [<EntryPoint>] let main argv = Arb.Default.Int32().Generator |> Gen.three |> Gen.sample 100 200 |> List.iter (fun (x, y, z) -> printfn "%i, %i, %i, %b" x y z (f x y z)) 0 // return an integer exit code
Notice that the last step in the pipeline is to output the values of each x, y, and z, as well as the result of calling f x y z.
This is a command-line executable that uses FsCheck to produce new test cases by calling the f function. It looks similar to the above one-off script that produced Python code, but this one instead just produces comma-separated values. You can run it from the command line to produce a new sample of test cases:
$ ./foracle 29, -48, -78, false -8, -25, 13, false -74, 34, -68, true ...
As above, I've used an ellipsis to indicate that in reality, 200 lines of comma-separated values scroll by.
When you use Bash, you can even pipe the output straight to a file:
$ ./foracle > csv.txt
You can now take the new comma-separated values and update the test values that the above test f test uses.
In other words, you use version n of f as a test oracle for version n + 1. When iteration n + 1 is a function of iteration n, you have a so-called dynamic system, so I think that we can call this technique dynamic test oracles.
The above foracle program is just a proof of concept. You could make it more flexible by making it take command-line arguments that would let you control the sample size and FsCheck's size parameter (the hard-coded 100 in the above code listing).
Refactoring #
With the confidence instilled by the test cases, we can now refactor the f function:
// f : int -> int -> int -> bool let f (x : int) (y : int) (z : int) = let imp (x, y, z, out) i = let out = out * x + abs (y * z - i * i) y + 1I, z, x, out let (_, _, _, out) = List.fold imp (bigint x, bigint y, bigint z, 0I) [0I..9I] abs out % 100I < 10I
Instead of all those mutable variables, the function is, after all, just a left fold. Phew, I feel better now.
Conclusion #
This article demonstrated a proof of concept where you use a known good version (n) of the code as a test oracle for the next version (n + 1). In interpreted languages, you may be able to load two versions of the code base side by side, but that's rarely practical in a statically typed compiled language like F#. Instead, I used a utility program to generate test cases that can be used as a data source for a parametrised test.
The example rho problem takes only integers as input, and returns a simple Boolean value, so in this case it's trivial to encode each test case as a line of comma-separated values. For (real) problems that may involve more complex types, it'd be better to use another serialisation format, such as JSON or XML.
An outstanding issue is whether it's possible to implement shrinking behaviour when tests fail. Currently, the proof of concept just uses a set of serialised test cases. Normally, when a property-based testing framework like FsCheck detects a counter-example, it'll shrink the counter-example to values that are easier to understand than the original. This proof of concept doesn't do that. I'm not sure if a framework like FsCheck currently contains enough extensibility points to enable that sort of behaviour. I'll leave that question open for any reader interested in taking on that problem.
Comments
Hi Mark! Thanks for another thought provoking post.
I believe you and Hillel are writing characterization tests, which you've mentioned in the past. Namely, you're both using the behavior of existing code to verify the correctness of a refactor. The novel part to me is that Hillel is using code as the test oracle. Your solution serializes the oracle to a static file. The library I use for characterization tests (ApprovalTests) does this as well.
I believe shrinking is impossible when the oracle is a static file. However with Hillel's solution the oracle may be consulted at any time, making shrinking viable. If only there was a practical way to combine the two...
A thought provoking post indeed!
In F# I'm going to use FsCheck...
I think that is a fine choice given the use case laid out in this post. In general though, I think Hedgehog is a better property-based testing library. Its killer feature is integrated shrinking, which means that all generators can also shrink and this extra power is essentially free.
For the record (because this can be a point of confusion), Haskell has QuickCheck and (Haskell) Hedgehog while F# has ports from Haskell called FsCheck and (FSharp) Hedgehog.
Jacob Stanley gave this excellent talk at YOW! Lambda Jam 2017 that explains the key idea that allows Hedgehog to have integrated shrinking. (Spoiler: A generic type that is invariant in its only type parameter is replaced by a different generic type that is monadic in its only type parameter. API design guided by functional programming for the win!)
Normally, when a property-based testing framework like FsCheck detects a counter-example, it'll shrink the counter-example to values that are easier to understand than the original.
In my experience, property-based tests written with QuickCheck / FsCheck do not normally shrink. I think this is because of the extra work required to enable shrinking. For an anecdotal example, consider this post by Fraser Tweedale. He believed that it would be faster to add (Haskell) Hedgehog as a dependency and create a generator for it than to add shrinking to his existing generator in QuickCheck.
In other words, you use version n of f as a test oracle for version n + 1. When iteration n + 1 is a function of iteration n, you have a so-called dynamic system, so I think that we can call this technique dynamic test oracles.
I am confused by this paragraph. I interpret your word "When" at the start of the second sentence as a common-language synonym for the mathematical word "If". Here is roughly how I understand that paragraph, where A stands for "version / iteration n of f" and B stands for "version / iteration n + 1 of f". "A depends on B. If B depends on A, then we have a dynamic system. Therefore, we have a dynamic system." I feel like the paragraph assumes (because it is obvious?) that version / iteration n + 1 of f depends on version / iteration n of f. In what sense is that the case?
An outstanding issue is whether it's possible to implement shrinking behaviour when tests fail. [...] I'll leave that question open for any reader interested in taking on that problem.
I am interested!
Quoting Mark and then Alex.
Hillel Wayne [...] outlines an approach where you test an iteration of rho code against a 'last known good' snapshot. He uses
git worktreeto set up a snapshot of the reference implementation. He then writes a property that compares the refactored code's behaviour against the reference.The example code is in Python, which is a language that I don't know. As far as I can tell, it works because Python is 'lightweight' enough that you can load and execute source code directly. I found that the approach makes much sense, but I wondered how it would apply for statically typed, compiled languages. I decided to create a proof of concept in F#.
I believe shrinking is impossible when the oracle is a static file. However with Hillel's solution the oracle may be consulted at any time, making shrinking viable.
I want to start by elaborating on this to make sure we are all on the same page. I think of shrinking as involving two parts. On the one hand, we have the "shrink tree", which contains the values to test during the shrinking process. On the other hand, for each input tested, we need to know if the output should cause the test to pass or fail.
With Hedgehog, getting a shrink tree would not be too difficult. For a generator with type parameter 'a, the current generator API returns a "random" shrink tree of type 'a in which the root is an instance a of the type 'a and the tree completely depends on a. It should be easy to expose an additional function that accepts inputs of type 'a Gen and 'a and returns the tree with the given 'a as its root.
The difficult part is being able to query the test oracle. As Mark said, this seems easy to do in a dynamically-typed language like Python. In contrast, the fundamental issue with a statically-typed language like F# is that the compiled code exists in an assembly and only one assembly of a given name can be loaded in a given process at the same time.
This leads me to two ideas for workarounds. First, we could query the test oracle in a different process. I imagine an entry point could be generated that gives direct access to the test oracle. Then the test process could query the test oracle by executing this generated process. Second, we could generate a different assembly that exposes the test oracle. Then the test process could load this generated assembly to query the test oracle. The second approach seems like it would have a faster query time but be harder to implement. The first approach seems easier to implement but would probably have a slower query time. Maybe the query time would be fast enough though, especially if it was only queried when shrinking.
But given such a solution, who wants to restrict access to the test oracle only to shrinking? If the test oracle is always available, then there is no need to store input-output pairs. Instead of always checking that the system under test works correctly for a previously selected set of inputs, the property-based test can check that the system under test has the expected behavior for a unique set of inputs each time the property-based test is executed. In my experience, this is the default behavior of a property-based test.
One concern that some people might have is the idea of checking into the code repository the binary containing the test oracle. My first though is that the size of this is likely so small that it does not matter. My second thought is that the binary containing the test oracle does not have to be included in the repository. Instead, the workflow could be to (1) create the property-based test that uses the compiled test oracle, (2) refactor the system under test, (3) observe that the property-based test still passes, (4) commit the refactored code, and (5) discard the remaining changes, which will delete the property-based test and the compiled test oracle.
Instead of completely removing that property-based test, it might be better to leave it there with input-output pairs stored in a file. Then the conversion from that state of the property-based test to the one that uses the compiled test oracle will be much smaller.
Alex, thank you for writing. Yes, I think that calling this a Characterisation Test is correct. I wasn't aware of the ApprovalTests library; thank you for mentioning it.
When I originally wrote the article, I was under the impression that shrinking might still be possible. I admit, though, that I hadn't thought things through. I think that Tyson Williams argues convincingly that this isn't possible.
Tyson, thank you for writing. I'm well aware of Hedgehog, and I'm keen on the way it works. I rarely use it, however, as it so far doesn't quite seem to have the same degree of 'industrial strength' to it that FsCheck has. Additionally, I find that shrinking is less important in practice than it might seem in theory.
I'm not sure that I understand your confusion about the term dynamic. You write:
Why do you write that? I don't think, in the way you've labelled iterations, that"
Adepends onB."
A depends on B.
When it comes to shrinking, I think that you convincingly argues that it can't be done unless one is able to query the oracle. As long as all you have is a list of test cases, you can't do that... unless, perhaps, you were to also generate and run all the shrunk test cases when you capture the list of test cases... Again, I haven't thought this through, so there may be some obvious gotcha that I'm missing.
I would be wary of trying to host the previous iteration in a different process. This is technically possible, but, in .NET at least, quite cumbersome. You'll have to deal with data marshalling and lifetime management of the second process. It was difficult enough in .NET framework back when remoting was a thing; I'm not even sure how one would go about such a problem in .NET Core - particularly if you want it to work on both Windows, Linux, and Mac. HTTP?
[Hedgehog] so far doesn't quite seem to have the same degree of 'industrial strength' to it that FsCheck has.
That seems reasonable. I haven't used FsCheck, so I wouldn't know myself. Several of us are making many great improvements to F# Hedgehog right now.
When it comes to shrinking, I think that you convincingly argues that it can't be done unless one is able to query the oracle. As long as all you have is a list of test cases, you can't do that... unless, perhaps, you were to also generate and run all the shrunk test cases when you capture the list of test cases... Again, I haven't thought this through, so there may be some obvious gotcha that I'm missing.
That would be too many test cases. The shrinking process finds two values n and n+1 such that the test passes for n and fails for n+1. This can be viewed as a constraint. The objective is to minimize the value of n. The only way to ensure that some value is the minimum is to test all values smaller than it. However, doing so is not practical. Property-based tests uses randomness precisely because it is not practical to test every possible value.
Instead, the shrinking process uses binary search as a heuristic to find a value satisfying the constraint that is rather small but not necessarily the smallest.
Why do you write that? I don't think, in the way you've labelled iterations, thatAdepends onB.
Ok. I will go slower and ask smaller questions.
When iteration n + 1 is a function of iteration n [...]
Does this phrase have the same meaning if "When" is replaced by "If"?
In other words, you use version n of f as a test oracle for version n + 1. When iteration n + 1 is a function of iteration n, you have a so-called dynamic system, so I think that we can call this technique dynamic test oracles.
I understand how version n of f is being used as a test oracle for version n + 1. In this blog post, in what sense is something of iteration n + 1 is a function of iteration n?
Tyson, thank you for writing.
"Does this phrase have the same meaning if "When" is replaced by "If"?"I'm not sure that there's a big difference, but then, I don't know how you parse that. As Kevlin Henney puts it,
It seems to me that you're attempting to parse my prose as though it was an unambiguous description, which it can't be."The act of describing a program in unambiguous detail and the act of programming are one and the same."
A dynamic system is a system such that xt+1 = f(xt), where xt is the value of x at time t, and xt+1 is the value of x at time t+1. For simplicity, this is the definition of a dynamic system in discrete time. Mathematically, you can also express it in continuous time using calculus.
It seems to me that you're attempting to parse my prose as though it was an unambiguous description, which it can't be.
Oh, yes. My mistake. I meant to phrase in slightly differently thereby changing it from essentially an impossible question to one that only you can answer. Here is what I meant to ask.
Does this phrase have the same meaning to you if "When" is replaced by "If"?
No matter though. I simply misunderstood your description / defintion of a dynamical system. I understand now. Thanks for your patience and willingness to explain it to me again.

Comments
Hi Mark, I would just like to say that I like the idea :)
Thank you for writing this.