ploeh blog danish software design
Async as surrogate IO
Haskell defines IO as an explicit context for handling effects. In F#, you can experiment with using Async as a surrogate.
As a reaction to my article on the relationship between Functional architecture and Ports and Adapters, Szymon Pobiega suggested on Twitter:
random idea: in c# “IO Int” translates to “Task<int>”. By consistently using this we can make type system help you even in c#If you know Haskell, you might object to that statement, but I don't think Szymon meant it literally. It's an idea worth exploring, I think.
Async as an IO surrogate #
Functions in Haskell are, by default, pure. Whenever you need to do something impure, like querying a database or sending an email, you need to explicitly do this in an impure context: IO. Don't let the name IO mislead you: it's not only for input and output, but for all impure actions. As an example, random number generation is impure as well, because a function that returns a new value every time isn't pure. (There are ways to model random number generation with pure functions, but let's forget about that for now.)
F#, on the other hand, doesn't make the distinction between pure and impure functions in its type system, so nothing 'translates' from IO in Haskell into an equivalent type in F#. Still, it's worth looking into Szymon's suggestion.
In 2013, C# finally caught up with F#'s support for asynchronous work-flows, and since then, many IO-bound .NET APIs have gotten asynchronous versions. The underlying API for C#'s async/await support is the Task Parallel Library, which isn't particularly constrained to IO-bound operations. The use of async/await, however, makes most sense for IO-bound operations. It improves resource utilisation because it can free up threads while waiting for IO-bound operations to complete.
It seems to be a frequent observation that once you start using asynchronous operations, they tend to be 'infectious'. A common rule of thumb is async all the way. You can easily call synchronous methods from asynchronous methods, but it's harder the other way around.
This is similar to the distinction between pure and impure functions. You can call pure functions from impure functions, but not the other way around. If you call an impure function from a 'pure' function in F#, the caller also automatically becomes impure. In Haskell, it's not even possible; you can call a pure function from an IO context, but not the other way around.
In F#, Async<'a> is more idiomatic than using Task<T>. While Async<'a> doesn't translate directly to Haskell's IO either, it's worth experimenting with the analogy.
Async I/O #
In the previous Haskell example, communication with the database was implemented by functions returning IO:
getReservedSeatsFromDB :: ConnectionString -> ZonedTime -> IO Int saveReservation :: ConnectionString -> Reservation -> IO ()
By applying the analogy of IO to Async<'a>, you can implement your F# data access module to return Async work-flows:
module SqlGateway = // string -> DateTimeOffset -> Async<int> let getReservedSeats connectionString (date : DateTimeOffset) = // ... // string -> Reservation -> Async<unit> let saveReservation connectionString (reservation : Reservation) = // ...
This makes it harder to compose the desired imp function, because you need to deal with both asynchronous work-flows and the Either monad. In Haskell, the building blocks are already there in the shape of the EitherT monad transformer. F# doesn't have monad transformers, but in the spirit of the previous article, you can define a computation expression that combines Either and Async:
type AsyncEitherBuilder () = // Async<Result<'a,'c>> * ('a -> Async<Result<'b,'c>>) // -> Async<Result<'b,'c>> member this.Bind(x, f) = async { let! x' = x match x' with | Success s -> return! f s | Failure f -> return Failure f } // 'a -> 'a member this.ReturnFrom x = x let asyncEither = AsyncEitherBuilder ()
This is the minimal implementation required for the following composition. A more complete implementation would also define a Return method, as well as other useful methods.
In the Haskell example, you saw how I had to use hoistEither and liftIO to 'extract' the values within the do block. This is necessary because sometimes you need to pull a value out of an Either value, and sometimes you need to get the value inside an IO context.
In an asyncEither expression, you need similar functions:
// Async<'a> -> Async<Result<'a,'b>> let liftAsync x = async { let! x' = x return Success x' } // 'a -> Async<'a> let asyncReturn x = async { return x }
I chose to name the first one liftAsync as a counterpart to Haskell's liftIO, since I'm using Async<'a> as a surrogate for IO. The other function I named asyncReturn because it returns a pure value wrapped in an asynchronous work-flow.
You can now compose the desired imp function from the above building blocks:
let imp candidate = asyncEither { let! r = Validate.reservation candidate |> asyncReturn let! i = SqlGateway.getReservedSeats connectionString r.Date |> liftAsync let! r = Capacity.check 10 i r |> asyncReturn return! SqlGateway.saveReservation connectionString r |> liftAsync }
Notice how, in contrast with the previous example, this expression uses let! and return! throughout, but that you have to compose each line with asyncReturn or liftAsync in order to pull out the appropriate values.
As an example, the original, unmodified Validate.reservation function has the type ReservationRendition -> Result<Reservation, Error>. Inside an asyncEither expression, however, all let!-bound values must be of the type Async<Result<'a, 'b>>, so you need to wrap the return value Result<Reservation, Error> in Async. That's what asyncReturn does. Since this expression is let!-bound, the r value has the type Reservation. It's 'double-unwrapped', if you will.
Likewise, SqlGateway.getReservedSeats returns a value of the type Async<int>, so you need to pipe it into liftAsync in order to turn it into an Async<Result<int, Error>>. When that value is let!-bound, then, i has the type int.
There's one change compared to the previous examples: the type of imp changed. It's now ReservationRendition -> Async<Result<unit, Error>>. While you could write an adapter function that executes this function synchronously, it's better to recall the mantra: async all the way!
Async Controller #
Instead of coercing the imp function to be synchronous, you can change the ReservationsController that uses it to be asynchronous as well:
// ReservationRendition -> Task<IHttpActionResult> member this.Post(rendition : ReservationRendition) = async { let! res = imp rendition match res with | Failure (ValidationError msg) -> return this.BadRequest msg | Failure CapacityExceeded -> return this.StatusCode HttpStatusCode.Forbidden | Success () -> return this.Ok () } |> Async.StartAsTask
Notice that the method body uses an async computation expression, instead of the new asyncEither. This is because, when returning a result, you finally need to explicitly deal with the error cases as well as the success case. Using a standard async expression enables you to let!-bind res to the result of invoking the asynchronous imp function, and pattern match against it.
Since ASP.NET Web API support asynchronous controllers, this works when you convert the async work-flow to a Task with Async.StartAsTask. Async all the way.
In order to get this to work, I had to overload the BadRequest, StatusCode, and Ok methods, because they are protected, and you can't use protected methods from within a closure. Here's the entire code for the Controller, including the above Post method for completeness sake:
type ReservationsController(imp) = inherit ApiController() member private this.BadRequest (msg : string) = base.BadRequest msg :> IHttpActionResult member private this.StatusCode statusCode = base.StatusCode statusCode :> IHttpActionResult member private this.Ok () = base.Ok () :> IHttpActionResult // ReservationRendition -> Task<IHttpActionResult> member this.Post(rendition : ReservationRendition) = async { let! res = imp rendition match res with | Failure (ValidationError msg) -> return this.BadRequest msg | Failure CapacityExceeded -> return this.StatusCode HttpStatusCode.Forbidden | Success () -> return this.Ok () } |> Async.StartAsTask
As you can see, apart from the overloaded methods, the Post method is all there is. It uses the injected imp function to perform the actual work, asynchronously translates the result into a proper HTTP response, and returns it as a Task<IHttpActionResult>.
Summary #
The initial idea was to experiment with using Async as a surrogate for IO. If you want to derive any value from this convention, you'll need to be disciplined and make all impure functions return Async<'a> - even those not IO-bound, but impure for other reasons (like random number generators).
I'm not sure I'm entirely convinced that this would be a useful strategy to adopt, but on the other hand, I'm not deterred either. At least, the outcome of this experiment demonstrates that you can combine asynchronous work-flows with the Either monad, and that the code is still manageable, with good separation of concerns. Since it is a good idea to access IO-bound resources using asynchronous work-flows, it's nice to know that they can be combined with sane error handling.
Composition with an Either computation expression
A simple example of a composition using an F# computation expression.
In a previous article, you saw how to compose an application feature from functions:
let imp = Validate.reservation >> map (fun r -> SqlGateway.getReservedSeats connectionString r.Date, r) >> bind (fun (i, r) -> Capacity.check 10 i r) >> map (SqlGateway.saveReservation connectionString)
This is awkward because of the need to carry the result of Validate.reservation (r) on to Capacity.check, while also needing it for SqlGateway.getReservedSeats. In this article, you'll see a neater, alternative syntax.
Building blocks #
To recapitulate the context, you have this Result discriminated union from Scott Wlaschin's article about railway-oriented programming:
type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailure
A type with this structure is also sometimes known as Either, because the result can be either a success or a failure.
The above example also uses bind and map functions, which are implemented this way:
// ('a -> Result<'b,'c>) -> Result<'a,'c> -> Result<'b,'c> let bind f x = match x with | Success s -> f s | Failure f -> Failure f // ('a -> 'b) -> Result<'a,'c> -> Result<'b,'c> let map f x = match x with | Success s -> Success(f s) | Failure f -> Failure f
With these building blocks, it's trivial to implement a computation expression for the type:
type EitherBuilder () = member this.Bind(x, f) = bind f x member this.ReturnFrom x = x
You can add more members to EitherBuilder if you need support for more advanced syntax, but this is the minimal implementation required for the following example.
You also need a value of the EitherBuilder type:
let either = EitherBuilder ()
All this code is entirely generic, so you could put it (or a more comprehensive version) in a reusable library.
Composition using the Either computation expression #
Since this Either computation expression is for general-purpose use, you can also use it to compose the above imp function:
let imp candidate = either { let! r = Validate.reservation candidate let i = SqlGateway.getReservedSeats connectionString r.Date return! Capacity.check 10 i r |> map (SqlGateway.saveReservation connectionString) }
Notice how the r value can be used by both the SqlGateway.getReservedSeats and Capacity.check functions, because they are all within the same scope.
This example looks more like the Haskell composition in my previous article. It even looks cleaner in F#, but to be fair to Haskell, in F# you don't have to explicitly deal with IO as a monadic context, so that in itself makes things look simpler.
A variation using shadowing #
You may wonder why I chose to use return! with an expression using the map function. One reason was that I wanted to avoid having to bind a named value to the result of calling Capacity.check. Naming is always difficult, and while I find the names r and i acceptable because the scope is so small, I prefer composing functions without having to declare intermediary values.
Another reason was that I wanted to show you an example that resembles the previous Haskell example as closely as possible.
You may, however, find the following variation more readable. In order to use return instead of return!, you need to furnish a Return method on your computation builder:
type EitherBuilder () = member this.Bind(x, f) = bind f x member this.Return x = Success x
Nothing prevents you from adding both Return and ReturnFrom (as well as other) methods to the EitherBuilder class, but I'm showing you the minimal implementation required for the example to work.
Using this variation of EitherBuilder, you can alternatively write the imp function like this:
let imp candidate = either { let! r = Validate.reservation candidate let i = SqlGateway.getReservedSeats connectionString r.Date let! r = Capacity.check 10 i r return SqlGateway.saveReservation connectionString r }
In such an alternative, you can use a let!-bound value to capture the result of calling Capacity.check, but that obligates you to devise a name for the value. You'll often see names like r', but I always feel uneasy when I resort to such naming. Here, I circumvented the problem by shadowing the original r value with a new value also called r. This is possible, and even desirable, because once the reservation has been checked, you should use that new, checked value, and not the original value. That's what the original composition, above, does, so shadowing is both equivalent and appropriate.
Summary #
Computation expressions give you an opportunity to compose functions in a readable way. It's an alternative to using the underlying bind and map functions. Whether you prefer one over the other is partly subjective, but I tend to favour the underlying functions until they become inconvenient. The initial version of the imp function in this article is an example of map and bind becoming unwieldy, and where a computation expression affords a cleaner, more readable syntax.
The disadvantage of computation expressions is that you need to use return or return! to return a value. That forces you to write an extra line of code that isn't necessary with a simple bind or map.
Functional architecture is Ports and Adapters
Functional architecture tends to fall into a pit of success that looks a lot like Ports and Adapters.
In object-oriented architecture, we often struggle towards the ideal of the Ports and Adapters architecture, although we often call it something else: layered architecture, onion architecture, hexagonal architecture, and so on. The goal is to decouple the business logic from technical implementation details, so that we can vary each independently.
This creates value because it enables us to manoeuvre nimbly, responding to changes in business or technology.
Ports and Adapters #
The idea behind the Ports and Adapters architecture is that ports make up the boundaries of an application. A port is something that interacts with the outside world: user interfaces, message queues, databases, files, command-line prompts, etcetera. While the ports constitute the interface to the rest of the world, adapters translate between the ports and the application model.
The word adapter is aptly chosen, because the role of the Adapter design pattern is exactly to translate between two different interfaces.
You ought to arrive at some sort of variation of Ports and Adapters if you apply Dependency Injection, as I've previously attempted to explain.
The problem with this architecture, however, is that it seems to take a lot of explaining:
- My book about Dependency Injection is 500 pages long.
- Robert C. Martin's book about the SOLID principles, package and component design, and so on is 700 pages long.
- Domain-Driven Design is 500 pages long.
- and so on...

It's possible to implement a Ports and Adapters architecture with object-oriented programming, but it takes so much effort. Does it have to be that difficult?
Haskell as a learning aid #
Someone recently asked me: how do I know I'm being sufficiently Functional?
I was wondering that myself, so I decided to learn Haskell. Not that Haskell is the only Functional language out there, but it enforces purity in a way that neither F#, Clojure, nor Scala does. In Haskell, a function must be pure, unless its type indicates otherwise. This forces you to be deliberate in your design, and to separate pure functions from functions with (side) effects.
If you don't know Haskell, code with side effects can only happen inside of a particular 'context' called IO. It's a monadic type, but that's not the most important point. The point is that you can tell by a function's type whether or not it's pure. A function with the type ReservationRendition -> Either Error Reservation is pure, because IO appears nowhere in the type. On the other hand, a function with the type ConnectionString -> ZonedTime -> IO Int is impure because its return type is IO Int. This means that the return value is an integer, but that this integer originates from a context where it could change between function calls.
There's a fundamental distinction between a function that returns Int, and one that returns IO Int. Any function that returns Int is, in Haskell, referentially transparent. This means that you're guaranteed that the function will always return the same value given the same input. On the other hand, a function returning IO Int doesn't provide such a guarantee.
In Haskell programming, you should strive towards maximising the amount of pure functions you write, pushing the impure code to the edges of the system. A good Haskell program has a big core of pure functions, and a shell of IO code. Does that sound familiar?
It basically means that Haskell's type system enforces the Ports and Adapters architecture. The ports are all your IO code. The application's core is all your pure functions. The type system automatically creates a pit of success.

Haskell is a great learning aid, because it forces you to explicitly make the distinction between pure and impure functions. You can even use it as a verification step to figure out whether your F# code is 'sufficiently Functional'. F# is a Functional first language, but it also allows you to write object-oriented or imperative code. If you write your F# code in a Functional manner, though, it's easy to translate to Haskell. If your F# code is difficult to translate to Haskell, it's probably because it isn't Functional.
Here's an example.
Accepting reservations in F#, first attempt #
In my Test-Driven Development with F# Pluralsight course (a free, condensed version is also available), I demonstrate how to implement an HTTP API that accepts reservation requests for an on-line restaurant booking system. One of the steps when handling the reservation request is to check whether the restaurant has enough remaining capacity to accept the reservation. The function looks like this:
// int // -> (DateTimeOffset -> int) // -> Reservation // -> Result<Reservation,Error> let check capacity getReservedSeats reservation = let reservedSeats = getReservedSeats reservation.Date if capacity < reservation.Quantity + reservedSeats then Failure CapacityExceeded else Success reservation
As the comment suggests, the second argument, getReservedSeats, is a function of the type DateTimeOffset -> int. The check function calls this function to retrieve the number of already reserved seats on the requested date.
When unit testing, you can supply a pure function as a Stub; for example:
let getReservedSeats _ = 0 let actual = Capacity.check capacity getReservedSeats reservation
When finally composing the application, instead of using a pure function with a hard-coded return value, you can compose with an impure function that queries a database for the desired information:
let imp = Validate.reservation >> bind (Capacity.check 10 (SqlGateway.getReservedSeats connectionString)) >> map (SqlGateway.saveReservation connectionString)
Here, SqlGateway.getReservedSeats connectionString is a partially applied function, the type of which is DateTimeOffset -> int. In F#, you can't tell by its type that it's impure, but I know that this is the case because I wrote it. It queries a database, so isn't referentially transparent.
This works well in F#, where it's up to you whether a particular function is pure or impure. Since that imp function is composed in the application's Composition Root, the impure functions SqlGateway.getReservedSeats and SqlGateway.saveReservation are only pulled in at the edge of the system. The rest of the system is nicely protected against side-effects.
It feels Functional, but is it?
Feedback from Haskell #
In order to answer that question, I decided to re-implement the central parts of this application in Haskell. My first attempt to check the capacity was this direct translation:
checkCapacity :: Int
-> (ZonedTime -> Int)
-> Reservation
-> Either Error Reservation
checkCapacity capacity getReservedSeats reservation =
let reservedSeats = getReservedSeats $ date reservation
in if capacity < quantity reservation + reservedSeats
then Left CapacityExceeded
else Right reservation
This compiles, and at first glance seems promising. The type of the getReservedSeats function is ZonedTime -> Int. Since IO appears nowhere in this type, Haskell guarantees that it's pure.
On the other hand, when you need to implement the function to retrieve the number of reserved seats from a database, this function must, by its very nature, be impure, because the return value could change between two function calls. In order to enable that in Haskell, the function must have this type:
getReservedSeatsFromDB :: ConnectionString -> ZonedTime -> IO Int
While you can partially apply the first ConnectionString argument, the return value is IO Int, not Int.
A function with the type ZonedTime -> IO Int isn't the same as ZonedTime -> Int. Even when executing inside of an IO context, you can't convert ZonedTime -> IO Int to ZonedTime -> Int.
You can, on the other hand, call the impure function inside of an IO context, and extract the Int from the IO Int. That doesn't quite fit with the above checkCapacity function, so you'll need to reconsider the design. While it was 'Functional enough' for F#, it turns out that this design isn't really Functional.
If you consider the above checkCapacity function, though, you may wonder why it's necessary to pass in a function in order to determine the number of reserved seats. Why not simply pass in this number instead?
checkCapacity :: Int -> Int -> Reservation -> Either Error Reservation
checkCapacity capacity reservedSeats reservation =
if capacity < quantity reservation + reservedSeats
then Left CapacityExceeded
else Right reservation
That's much simpler. At the edge of the system, the application executes in an IO context, and that enables you to compose the pure and impure functions:
import Control.Monad.Trans (liftIO) import Control.Monad.Trans.Either (EitherT(..), hoistEither) postReservation :: ReservationRendition -> IO (HttpResult ()) postReservation candidate = fmap toHttpResult $ runEitherT $ do r <- hoistEither $ validateReservation candidate i <- liftIO $ getReservedSeatsFromDB connStr $ date r hoistEither $ checkCapacity 10 i r >>= liftIO . saveReservation connStr
(Complete source code is available here.)
Don't worry if you don't understand all the details of this composition. The highlights are these:
The postReservation function takes a ReservationRendition (think of it as a JSON document) as input, and returns an IO (HttpResult ()) as output. The use of IO informs you that this entire function is executing within the IO monad. In other words: it's impure. This shouldn't be surprising, since this is the edge of the system.
Furthermore, notice that the function liftIO is called twice. You don't have to understand exactly what it does, but it's necessary to use in order to 'pull out' a value from an IO type; for example pulling out the Int from an IO Int. This makes it clear where the pure code is, and where the impure code is: the liftIO function is applied to the functions getReservedSeatsFromDB and saveReservation. This tells you that these two functions are impure. By exclusion, the rest of the functions (validateReservation, checkCapacity, and toHttpResult) are pure.
It's interesting to observe how you can interleave pure and impure functions. If you squint, you can almost see how the data flows from the pure validateReservation function, to the impure getReservedSeatsFromDB function, and then both output values (r and i) are passed to the pure checkCapacity function, and finally to the impure saveReservation function. All of this happens within an (EitherT Error IO) () do block, so if any of these functions return Left, the function short-circuits right there and returns the resulting error. See e.g. Scott Wlaschin's excellent article on railway-oriented programming for an exceptional, lucid, clear, and visual introduction to the Either monad.
The value from this expression is composed with the built-in runEitherT function, and again with this pure function:
toHttpResult :: Either Error () -> HttpResult () toHttpResult (Left (ValidationError msg)) = BadRequest msg toHttpResult (Left CapacityExceeded) = StatusCode Forbidden toHttpResult (Right ()) = OK ()
The entire postReservation function is impure, and sits at the edge of the system, since it handles IO. The same is the case of the getReservedSeatsFromDB and saveReservation functions. I deliberately put the two database functions in the bottom of the below diagram, in order to make it look more familiar to readers used to looking at layered architecture diagrams. You can imagine that there's a cylinder-shaped figure below the circles, representing a database.
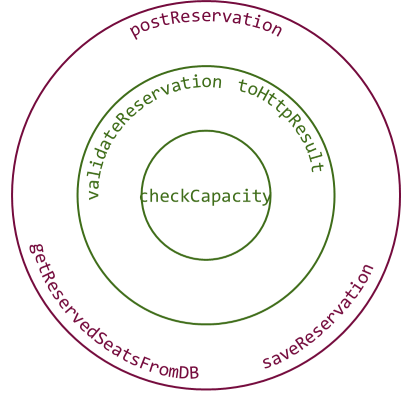
You can think of the validateReservation and toHttpResult functions as belonging to the application model. While pure functions, they translate between the external and internal representation of data. Finally, the checkCapacity function is part of the application's Domain Model, if you will.
Most of the design from my first F# attempt survived, apart from the Capacity.check function. Re-implementing the design in Haskell has taught me an important lesson that I can now go back and apply to my F# code.
Accepting reservations in F#, even more Functionally #
Since the required change is so little, it's easy to apply the lesson learned from Haskell to the F# code base. The culprit was the Capacity.check function, which ought to instead be implemented like this:
let check capacity reservedSeats reservation = if capacity < reservation.Quantity + reservedSeats then Failure CapacityExceeded else Success reservation
This simplifies the implementation, but makes the composition slightly more involved:
let imp = Validate.reservation >> map (fun r -> SqlGateway.getReservedSeats connectionString r.Date, r) >> bind (fun (i, r) -> Capacity.check 10 i r) >> map (SqlGateway.saveReservation connectionString)
This almost looks more complicated than the Haskell function. Haskell has the advantage that you can automatically use any type that implements the Monad typeclass inside of a do block, and since (EitherT Error IO) () is a Monad instance, the do syntax is available for free.
You could do something similar in F#, but then you'd have to implement a custom computation expression builder for the Result type. Perhaps I'll do this in a later blog post...
Summary #
Good Functional design is equivalent to the Ports and Adapters architecture. If you use Haskell as a yardstick for 'ideal' Functional architecture, you'll see how its explicit distinction between pure and impure functions creates a pit of success. Unless you write your entire application to execute within the IO monad, Haskell will automatically enforce the distinction, and push all communication with the external world to the edges of the system.
Some Functional languages, like F#, don't explicitly enforce this distinction. Still, in F#, it's easy to informally make the distinction and compose applications with impure functions pushed to the edges of the system. While this isn't enforced by the type system, it still feels natural.
Comments
Great post as always. However, I saw that you are using IO monad. I wonder if you shouldn't use IO action instead? To be honest, I'm not proficient in Haskell. But according to that post they are encouraging to use IO action rather than IO monad if we are not talking about monadic properties.
Arkadiusz, thank you for writing. It's the first time I see that post, but if I understand the argument correctly, it argues against the (over)use of the monad terminology when talking about IO actions that aren't intrinsically monadic in nature. As far as I can tell, it doesn't argue against the use of the IO type in Haskell.
It seems a reasonable point that it's unhelpful to newcomers to throw them straight into a discussion about monads, when all they want to see is a hello world example.
As some of the comments to that post point out, however, you'll soon need to compose IO actions in Haskell, and it's the monadic nature of the IO type that enables the use of do blocks. (..or, if you want to be more specific, it seems that sometimes, all you need is a Functor. It hardly helps to talk about the IO functor instead of the IO monad, though...)
I don't claim to be a Haskell expert, so there may be more subtle nuances in that article that simply went over my head. Still, within my current understanding, the discussion in this particular post of mine does relate to the IO monad.
When I wrote the article, I chose my words with some caution. Notice that when I introduce the IO type my article, I mostly talk about it as a 'context'.
When it comes to the discussion about the postReservation function, however, I pull out the stops and increasingly use the word monad. The reason is that this composition wouldn't be possible without the monadic properties of IO. Most of this function executes within a monadic 'stack': EitherT Error IO. EitherT is a monad transformer, and in order to be useful (e.g. composable in do blocks), the type it transforms must be a monad as well (or perhaps, as hinted above, a functor would be sufficient).
I agree with Justin Le's article that overuse of monad is likely counterproductive. On the other hand, one can also fall into the opposite side. There are some educators who seem to avoid the word at any cost. That's not my policy. I try to use as precise language as possible. That means that I'll use monad when I talk about monads, and I'll avoid it when it isn't necessary. That's my goal, but I may not have achieved it. Do you think I used it incorrectly here?
Mark, thank you for your comprehensive explanation. I was rather just asking you about opinion on this topic. I didn't try to claim that you had used it incorrectly. Now, I see that as you wrote you are first talking about IO context and then about IO monad when it comes to use monadic properties.
Hello, thanks so much for your website and pluralsight library -- it's been a tremendous help to me getting started with F# and functional programming (and TDD to a degree). I'm having some problems with the big picture question of how to structure applications, and this post is leaving me even more confused.
I can't understand how some of the original code, and especially the changes made in this post could possibly scale to a larger or more complicated application. Many real-life domain operations are going to need to query some data, make decisions based on that data, map that data into different domain objects, persist something, and so on.
It seems like the end result is that we end up copying much of the meaningful internal logic of the domain out to this boundary area in the Web API project. In this code we've extracted:
- The logic of only checking existing reservations on the same day as the day on the request
- The logic of not saving a new reservation if the request failed the capacity check
Does that logic not properly belong 'behind the wall' inside the domain? I would have expected to see a simple 'makeReserveration r' function as the public face to the domain. Suppose the restaurant also had a desktop/kiosk application in their building to manage their reservation system. Wouldn't we now be forced to duplicate this internal logic in the Composition Root of that application?
What I instinctively want to gravitate towards is something like this:
let internal makeReservation' getReservedSeats saveReservation check r = (getReservedSeats r.Date, r) |> bind (fun (i, r) -> check 10 i r) |> map saveReservation let makeReservation = makeReservation' SqlGateway.getReservedSeats SqlGateway.saveReservation Capacity.check
With this, the SqlGateway code needs be visible to the reservation code, putting it at the center of the app not on the edges. However, are there any practical disadvantages to this if the code is disciplined to only use it within this sort of dependency injection? What problems would I be likely to run into?
At least as a beginner, this seems to me to have a couple advantages:
- From the perspective of the unit tests (which test makeReservation') it is a pure function, as you noted above. Testability is no problem here.
- Code at the UI/Presentation level is nice and tight -- just make sure you can successfully transform the JSON request into a domain request, then process the command result.
But most notable to me, dependencies are 'injected' right where they were needed. Imagine a much more complicated aggregate operation like 'performOvernightCloseout' that needs to do many things like read cash register totals and send them to accounting, send timeclock info to HR, write order statistics to a reporting database, check inventory and create new orders for the following day. Of course we'd break this down into a hierarchy of functions, with top level orchestration calling down into increasingly specific functions, no function individually being too complicated.
The original demo application would have to approach this scenario by passing in a huge number of functions to the operation root, which then parcels them out level by level where they are needed. This would seem very brittle since any change in a low level function would require changes to the parameter list all the way up.
With newer code shown in this post, it would seem impossible. There might be a handful of small functions that can be in the central library, but the bulk of the logic is going to need to be extracted into a now-500-line imp method in the Web API project, or whatever service is launching this operation.
John, thank you for writing. I'm not sure I can answer everything to your satisfaction in single response, but we can always view this as a beginning of longer interchange. Some of the doubts you express are ambiguous, so I'm not sure how to interpret them, but I'll do my best to be as explicit as possible.
In the beginning of your comment, you write:
"Many real-life domain operations are going to need to query some data, make decisions based on that data, map that data into different domain objects, persist something, and so on."This is exactly the reason why I like the reservation request example so much, because it does all of that. It queries data, because it reads the number of already reserved seats from a database. It makes decisions based on that data, because it decides whether or not it can accept the reservation based on the number of remaining seats. It maps from an external JSON (or XML) data format to a Reservation record type (belonging to the Domain Model, if you will); it also maps back to an HTTP response. Finally, the example also saves the reservation to the database, if it was accepted.
When you say that we've extracted the logic, it's true, but I'm not sure what you mean by "behind the wall", but let's look at each of your bullet points in turn.
Querying existing reservations
You write that I've extracted the "logic of only checking existing reservations on the same day as the day on the request". It's a simple database query. In F#, one implementation may look like this:
// In module SqlGateway: let getReservedSeats connectionString (date : DateTimeOffset) = let min = DateTimeOffset(date.Date , date.Offset) let max = DateTimeOffset(date.Date.AddDays 1., date.Offset) let sql = " SELECT ISNULL(SUM(Quantity), 0) FROM [dbo].[Reservations] WHERE @min <= Date AND Date < @max" use conn = new SqlConnection(connectionString) use cmd = new SqlCommand(sql, conn) cmd.Parameters.AddWithValue("@min", min) |> ignore cmd.Parameters.AddWithValue("@max", max) |> ignore conn.Open() cmd.ExecuteScalar() :?> int
In my opinion, there's no logic in this function, but this is an example where terminology can be ambiguous. To me, however, logic implies that decisions are being made. That's not the case here. This getReservedSeats function has a cyclomatic complexity of 1.
This function is an Adapter: it adapts the ADO.NET SDK (the port to SQL Server) to something the Domain Model can use. In this case, the answer is a simple integer.
To save, or not to save
You also write that I've extracted out the "logic of not saving a new reservation if the request failed the capacity check". Yes, that logic is extracted out to the check function above. Since that's a pure function, it's part of the Domain Model.
The function that saves the reservation in the database, again, contains no logic (as I interpret the word logic):
// In module SqlGateway: let saveReservation connectionString (reservation : Reservation) = let sql = " INSERT INTO Reservations(Date, Name, Email, Quantity) VALUES(@Date, @Name, @Email, @Quantity)" use conn = new SqlConnection(connectionString) use cmd = new SqlCommand(sql, conn) cmd.Parameters.AddWithValue("@Date", reservation.Date) |> ignore cmd.Parameters.AddWithValue("@Name", reservation.Name) |> ignore cmd.Parameters.AddWithValue("@Email", reservation.Email) |> ignore cmd.Parameters.AddWithValue("@Quantity", reservation.Quantity) |> ignore conn.Open() cmd.ExecuteNonQuery() |> ignore
Due to the way the Either monad works, however, this function is only going to be called if all previous functions returned Success (or Right in Haskell). That logic is an entirely reusable abstraction. It's also part of the glue that composes functions together.
Reuse of composition
Further down, you ask:
"Suppose the restaurant also had a desktop/kiosk application in their building to manage their reservation system. Wouldn't we now be forced to duplicate this internal logic in the Composition Root of that application?"That's an excellent question! I'm glad you asked.
A desktop or kiosk application is noticeably different from a web application. It may have a different application flow, and it certainly exposes a different interface to the outside world. Instead of handling incoming HTTP requests, and translating results to HTTP responses, it'll need to respond to click events and transform results to on-screen UI events. This means that validation may be different, and that you don't need to map results back to HTTP response values. Again, this may be clearer in the Haskell implementation, where the toHttpResult function would obviously be superfluous. Additionally, a UI may present a native date and time picker control, which can directly produce strongly typed date and time values, negating the need for validation.
Additionally, a kiosk may need to be able to work in off-line, or occasionally connected, mode, so perhaps you'd prefer a different data store implementation. Instead of connecting directly to a database, such an application would need to write to a message queue, and read from an off-line snapshot of reservations.
That's a sufficiently different application that it warrants creating applications from fine-grained building blocks instead of course-grained building blocks. Perhaps the only part you'll end up reusing is the core business logic contained in the check[Capacity] function. Composition Roots aren't reusable.
(As an aside, you may think that if the check[Capacity] function is the only reusable part, then what's the point? This function is only a couple of lines long, so why even bother? That'd be a fair concern, if it wasn't for the context that all of this is only example code. Think of this example as a stand-in for much more complex business logic. Perhaps the restaurant will allow a certain percentage of over-booking, because some people never show up. Perhaps it will allow different over-booking percentages on different (week) days. Perhaps it'll need to handle reservations on per-table basis, instead of per-seat. Perhaps it'll need to handle multiple seatings on the same day. There are lots of variations you can throw into this business domain that will make it much more complex, and worthy of reuse.)
Brittleness of composition
Finally, you refer to a more realistic scenario, called performOvernightCloseout, and ask if a fine-grained composition wouldn't be brittle? In my experience, it wouldn't be more brittle than any alternatives I've identified. Whether you 'inject' functions into other functions, or you compose them in the Composition Root, doesn't change the underlying forces that act on your code. If you make substantial changes to the dependencies involved, it will break your code, and you'll need to address that. This is true for any manual composition, including Pure DI. The only way to avoid compilation errors when you redefine your dependency graphs is to use a DI Container, but that only makes the feedback loop worse, because it'd change a compile-time error into a run-time error.
This is a long answer, and even so, I'm not sure I've sufficiently addressed all of your concerns. If not, please write again for clarifications.
I believe there was a bit of miscommunication. When I talked about the 'logic of only checking existing reservations on the same day', I wasn't talking about the implementation of the SqlGateway. I was talking about the 'imp' function:
let imp = Validate.reservation >> map (fun r -> SqlGateway.getReservedSeats connectionString r.Date, r) >> bind (fun (i, r) -> Capacity.check 10 i r) >> map (SqlGateway.saveReservation connectionString)
This implements the logic of 'Validation comes first. If that checks out, then get the number of reserved seats from the data store. Use the date on the request for that. Feed this into the capacity check routine and only if everything checks out should we persist the reservation.
That's all internal logic that in my mind ought to be encapsulated within the domain. That's what I meant by 'behind the wall'. There should simply be a function 'makeReservation' with the signature ReservationRequest -> ReservationResponse. That's it. Clients should not be worrying themselves with these extra details. That 'imp' function just seems deeply inappropriate as something that lives externally to the reservations module, and that must be supplied individually by each client accessing the module.
I guess I'm rejecting the idea of Onion/Hexagonal architecture, or at least the idea that all I/O always belongs at the outside. To me, a reservations module must depend on a reservations data store, because if you don't persist information to the db, you haven't actually made the reservation. Of course, I still want to depend on interfaces, not implementations (perhaps naming the reference ReservationDataStore.saveReservation). The data store IS a separate layer and should have a well defined interface.
I just don't understand why anyone would find this design more desirable than the straightforward UI -> Logic -> Storage chain of dependencies. Clearly there's some sort of appeal -- lots of smart people show excitement for it. But it's a bit mystifying to me.
John, thank you for writing. It's OK to reject the concept of ports and adapters; it's not a one-size-fits-all architecture. While I often use it, I don't always use it. One of my most successful customer engagements involved building a set of REST APIs on top of an existing IT infrastructure. All the business logic was already implemented elsewhere, so I deliberately chose a simpler, more coupled architecture, because there'd be no benefit from a full ports and adapters architecture. The code bases involved still run in production four years later, even though they're constantly being changed and enhanced.
If, on the other hand, you choose to adopt the ports and adapters architecture, you'll need to do it right so that you can harvest the benefits.
A Façade function with the type ReservationRequest -> ReservationResponse only makes sense in an HTTP request/response scenario, because both the ReservationRequest and ReservationResponse types are specific to the web context. You can't reuse such a function in a different setting.
You still have such a function, because that's the function that handles the web request, but you'll need to compose it from smaller components, unless you want to write a Transaction Script within that function (which is also sometimes OK).
Granted, there's some 'logic' involved in this composition, in the sense that it might be possible to create a faulty composition, but that logic has to go somewhere.
Hi Mark, thanks for this post and the discussion.
I feel that I share some of the concerns that John is bringing up. The postReservation function is pretty simple now, but eventually we might want to make external calls based on some conditional logic from the domain model.
Let's say there is a new feature request. The restaurant has struck a deal with the local caravan dealership, allowing them to rent a caravan to park outside the restaurant in order to increase the seating capacity for one evening. Of course, sometimes there are no caravans available, so we'll need to query the caravan database to see if there is a big enough caravan available that evening:
findCaravan :: Int -> ZoneTime -> IO (Maybe Caravan)
findCaravan minimumCapacity date = ... -- database stuff
How would we integrate this? We could put a call to findCaravan inside the IO context of postReservation, but since we only want to query the caravan database if the first capacity check failed, we'll need to add branching logic to postReservation. We want to have tests for this logic, but since we are coupled to the IO context, we are in trouble.
The original issue was that the F# version of checkCapacity could be made impure by injecting the impure getReservedSeats function to it, which is something that Haskell disallows. What if we changed the Haskell version of checkCapacity to the following instead?
checkCapacity :: Monad m => Int
-> (ZonedTime -> m Int)
-> Reservation
-> EitherT Error m Reservation
checkCapacity capacity getReservedSeats reservation = EitherT $ do
reservedSeats <- getReservedSeats $ date reservation
if capacity < quantity reservation + reservedSeats
then return $ Left CapacityExceeded
else return $ Right reservation
Since we know that getReservedSeats will be effectful, we declare it so in its type signature. We change postReservation to become:
postReservation :: ReservationRendition -> IO (HttpResult ()) postReservation candidate = fmap toHttpResult $ runEitherT $ hoistEither $ validateReservation candidate >>= checkCapacity 10 (getReservedSeatsFromDB connStr) >>= liftIO . saveReservation connStr
(Or something like that. Monad transformers are the current step on my Haskell learning journey, so I'm not sure this will typecheck.)
This way, we can once more inject an IO typed function as the getReservedSeats argument of checkCapacity like we did in F#. If we want to test it, we can create a stub database call by using the monad instance of Identity, for example:
stubGetReservedSeats :: ZonedTime -> Identity Int
stubGetReservedSeats date = return 8
The new feature request also becomes easy to implement. Just pass findCaravan as a new argument to checkCapacity, and make the type of that argument to be ZonedTime -> m (Maybe Caravan). The checkCapacity function can now do the initial capacity check, and if that fails, call findCaravan to see if it is still possible to allow the booking by renting a suitable caravan. The branching logic that is needed is now inside checkCapacity and can be tested outside of the IO context.
I don't know if this would work well in practice, or if it would cause more trouble than what it's worth. What do you think?
Martin, thank you for writing. Your question prompted me to write a new article. It takes a slightly different approach to the one you suggest.
I haven't tried defining checkCapacity in the way you suggest, but that may be an exercise for another day. In general, though, I'm hesitant to introduce constraints not required by the implementation. In this case, I think it'd be a fair question to ask why the getReservedSeats argument has to have the type ZonedTime -> m Int? Nothing in its implementation seems to indicate the need for that, so it looks like a leaky abstraction to me.
I'd like to follow up my twitter comments here
Very interesting article! I'm sorry that some Haskell details are quite difficult for me at the moment and the F# code looks a bit too simplified or maybe just incomplete
So I'd prefer your approach here : it better translates Haskell to F# but I still have to study its implications. Anyway the concrete benefits of Async are evident, like the ones of F# computation expressions (to wrap exceptions etc...)
On the other hand I fail to see the benefit of purity vs other IoC patterns. Besides async and exceptions wrapping, purity seems an unnecessarily strict enforcement of Haskell (isn't it?): original F# was testable in isolation
What's missing if I only mock/stub/inject the dependency? When you say
"ability to reason is eroded"and
"it breaks encapsulation"about DI, do you mean something related to this topic?
Thank you so much for your interesting insights!
Why do you think that the only goal of pure functions is testability?My bad, actually I don't know. I assume that purity's goal is to avoid side effects. It is very clear that this can be useful when I have a hidden side effect in the function, but it is less obvious (to me) what it does mean when the side effect is as evident as an argument (?).
Anyway, I'll follow your implicit suggestion that with a pure function I can reach a more important goal than testability. Ok, practical example. Today I spent one hour to fix a bug that I introduced with a previous enhancement. My goal is to avoid this next time, by learning a better programming style from your article, but first I need to understand what went wrong. I can spot 3 problems:
- 1) I didn't see the bug when I wrote the code changes
- 2) I didn't go through that part of my app when I tested the upgrade
- 3) I needed a whole hour to fix that stupid bug, because I could not immediately find the point where it was
Now unfortunately I struggle to interpret Haskell's details and I can't find enough F# to recover the whole meaning, but the main point I get is that a part of code (that could be bugged because the ability to reason is eroded there) has been moved from a finally 'pure' function to a new 'impure' one, that is introduced by a special 'liftIO' keyword (sorry for my poor recap)
Finally my question is, but what about that all the possible bugs (often at the interface between persistence and model layers) that have simply been migrated around this critical IO land? are they going to counterbalance the above said benefits? where is exactly the net, overall improvement?
First, I should make it specific that when I discuss object-oriented code in general, and encapsulation specifically, I tend to draw heavily on the work of Bertrand Meyer in Object-Oriented Software Construction. Some people may regard Alan Kay as the original inventor of object-orientation, but C# and Java's interpretation of object-oriented programming seems closer to Meyer's than to Kay's.
To Meyer, the most important motivation for object-orientation was reuse. He wanted to be able to reuse software that other people had written, instead of, as had been the norm until then, importing other people's source code into new code bases. I'm sure you can see how that goal was important.
In order to make binary libraries reusable, Meyer wanted to establish some techniques that would enable developers to (re)use the code without having access to the source code. His vision was that every object should come with a set of invariants, pre-, and post-conditions. He even invented a programming language, Eiffel, that included the ability to define such rules as programmable and enforceable checks. Furthermore, such rules could be exported as automatic documentation. This concept, which Meyer called contracts, is what we now know as encapsulation (I have a Pluralsight course that explains this in more details).
While the idea of formal contracts seemed like a good idea, neither Java nor C# have them. In C# and Java, you can still implement invariants with guard clauses, assertions, and so on, but there's no formal, externally visible way to communicate such invariants.
In other words, in modern object-oriented languages, you can't reason about the code from its API alone. Meyer's goal was that you should be able to reuse an object that someone else had written, without reading the source code. In a nutshell: if you have to read the source code, it means that encapsulation is broken.
One of the other concepts that Meyer introduced was Command-Query Separation (CQS). To Meyer, it was important to be able to distinguish between operations that had side-effects, and operations that didn't.
In my experience, a big category of defects are caused by unintended side-effects. One developer doesn't realise that the method call (s)he invokes has a side-effect that another developer put there. Languages like C# and Java have few constraints, so any method could potentially hide a side-effect. The only way you can know is by reading the code.
What if, then, there was a programming language where you could tell, at a glance, whether an operation had a side-effect? Such programming languages exist. Haskell is one of them. In Haskell, all functions are pure by default. This means that they are deterministic and have no side-effects. If you want to write an impure function, you must explicitly declare that in the function's type (which is done with the IO type).
In Haskell, you don't have to read the source code in order to know whether a function is impure or not. You can simply look at the type!
This is one of the many benefits of pure functions: we know, by definition, that they have no side-effects. This property holds not only for the function itself, but for all functions that that pure function calls. This follows from the definition of purity. A pure function can call other pure functions, but it can't call impure functions, because, if it did, it would become impure itself. Haskell enforces this rule, so when you're looking at a pure function, you know that that entire subgraph of your code is pure. Otherwise, it wouldn't compile.
Not only does that relationship force us to push impure functions to the boundary of applications, as described in the present article. It also makes functions intrinsically testable. There are other advantages of pure functions besides these, such as easy composability, but in general, pure functions are attractive because it becomes easier to figure out what a function does without having to understand all the details. In other words, pure functions are better abstractions.
To be clear: functional programming doesn't protect you from defects, but in my experience, it helps you to avoid entire classes of bugs. I still write automated tests of my F# code, but I write fewer tests than when I wrote C# code. Despite that, I also seem to be producing fewer defects, and I rarely need to debug the functions.
What's the overall net improvement? I don't know. How would you measure that?
Consider a logic that, depending on a condition, performs one IO operation or another. In Java (I don’t know F# or Haskell):
int foo(boolean condition, IntSupplier io1, IntSupplier io2) {
if (condition) {
return io1.getAsInt();
} else {
return io2.getAsInt();
}
}
Would you recommend pre-fetching the two values prior to calling the foo function even though only one would ultimately be required?
Abel, thank you for writing. There's a discussion closely related to that question in the remarks sections of my dependency rejection article. It's the remark from 2017-02-18 19:54 UTC (I really ought to get around to add permalinks to comments...).
Additionally, there's a discussion on this page that lead to a new article that goes into some further details.
(This is rather a delayed reply, but...) @Martin Rykfors, you mentioned monad transformers as an option. A few months before your comment I recorded a livecoded session of applying MTL-style monad transformers to this code.
I'm not sure if you're interested (it's nearly an hour of me talking to myself), but just in case... 🙂
Ad-hoc Arbitraries - now with pipes
Slightly improved syntax for defining ad-hoc, in-line Arbitraries for FsCheck.Xunit.
Last year, I described how to define and use ad-hoc, in-line Arbitraries with FsCheck.Xunit. The final example code looked like this:
[<Property(QuietOnSuccess = true)>] let ``Any live cell with > 3 live neighbors dies`` (cell : int * int) = let nc = Gen.elements [4..8] |> Arb.fromGen Prop.forAll nc (fun neighborCount -> let liveNeighbors = cell |> findNeighbors |> shuffle |> Seq.take neighborCount |> Seq.toList let actual : State = calculateNextState (cell :: liveNeighbors |> shuffle |> set) cell Dead =! actual)
There's one tiny problem with this way of expressing properties using Prop.forAll: the use of brackets to demarcate the anonymous multi-line function. Notice how the opening bracket appears to the left of the fun keyword, while the closing bracket appears eleven lines down, after the end of the expression Dead =! actual.
While it isn't pretty, I haven't found it that bad for readability, either. When you're writing the property, however, this syntax is cumbersome.
Issues writing the code #
After having written Prop.forAll nc, you start writing (fun neighborCount -> ). After you've typed the closing bracket, you have to move your cursor one place to the left. When entering new lines, you have to keep diligent, making sure that the closing bracket is always to the right of your cursor.
If you ever need to use a nested level of brackets within that anonymous function, your vigilance will be tested to its utmost. When I wrote the above property, for example, when I reached the point where I wanted to call the calculateNextState function, I wrote:
let actual : State =
calculateNextState (
The editor detects that I'm writing an opening bracket, but since I have the closing bracket to the immediate right of the cursor, this is what happens:
let actual : State =
calculateNextState ()
What normally happens when you type an opening bracket is that the editor automatically inserts a closing bracket to the right of your cursor, but in this case, it doesn't do that. There's already a closing bracket immediately to the right of the cursor, and the editor assumes that this bracket belongs to the opening bracket I just typed. What it really should have done was this:
let actual : State = calculateNextState ())
The editor doesn't have a chance, though, because at this point, I'm still typing, and the code doesn't compile. None of the alternatives compile at this point. You can't really blame the editor.
To make a long story short, enclosing a multi-line anonymous function in brackets is a source of errors. If only there was a better alternative.
Backward pipe #
The solution started to dawn on me because I've been learning Haskell for the last half year, and in Haskell, you often use the $ operator to get rid of unwanted brackets. F# has an equivalent operator: <|, the backward pipe operator.
I rarely use the <| operator in F#, but in this case, it works really well:
[<Property(QuietOnSuccess = true)>] let ``Any live cell with > 3 live neighbors dies`` (cell : int * int) = let nc = Gen.elements [4..8] |> Arb.fromGen Prop.forAll nc <| fun neighborCount -> let liveNeighbors = cell |> findNeighbors |> shuffle |> Seq.take neighborCount |> Seq.toList let actual : State = calculateNextState (cell :: liveNeighbors |> shuffle |> set) cell Dead =! actual
Notice that there's no longer any need for a closing bracket after Dead =! actual.
Summary #
When the last argument passed to a function is another function, you can replace the brackets with a single application of the <| operator. I only use this operator sparingly, but in the case of in-line ad-hoc FsCheck Arbitraries, I find it useful.
Addendum 2016-05-17: You can get rid of the nc value with TIE fighter infix notation.
Types + Properties = Software: other properties
Even simple functions may have properties that can be expressed independently of the implementation.
This article is the eighth in a series of articles that demonstrate how to develop software using types and properties. In previous articles, you've seen an extensive example of how to solve the Tennis Kata with type design and Property-Based Testing. Specifically, in the third article, you saw the introduction of a function called other. In that article we didn't cover that function with automatic tests, but this article rectifies that omission.
The source code for this article series is available on GitHub.
Implementation duplication #
The other function is used to find the opponent of a player. The implementation is trivial:
let other = function PlayerOne -> PlayerTwo | PlayerTwo -> PlayerOne
Unless you're developing software where lives, or extraordinary amounts of money, are at stake, you probably need not test such a trivial function. I'm still going to show you how you could do this, mostly because it's a good example of how Property-Based Testing can sometimes help you test the behaviour of a function, instead of the implementation.
Before I show you that, however, I'll show you why example-based unit tests are inadequate for testing this function.
You could test this function using examples, and because the space of possible input is so small, you can even cover it in its entirety:
[<Fact>] let ``other than playerOne returns correct result`` () = PlayerTwo =! other PlayerOne [<Fact>] let ``other than playerTwo returns correct result`` () = PlayerOne =! other PlayerTwo
The =! operator is a custom operator defined by Unquote, an assertion library. You can read the first expression as player two must equal other than player one.
The problem with these tests, however, is that they don't state anything not already stated by the implementation itself. Basically, what these tests state is that if the input is PlayerOne, the output is PlayerTwo, and if the input is PlayerTwo, the output is PlayerOne.
That's exactly what the implementation does.
The only important difference is that the implementation of other states this relationship more succinctly than the tests.
It's as though the tests duplicate the information already in the implementation. How does that add value?
Sometimes, this can be the only way to cover functionality with tests, but in this case, there's an alternative.
Behaviour instead of implementation #
Property-Based Testing inspires you to think about the observable behaviour of a system, rather than the implementation. Which properties do the other function have?
If you call it with a Player value, you'd expect it to return a Player value that's not the input value:
[<Property>] let ``other returns a different player`` player = player <>! other player
The <>! operator is another custom operator defined by Unquote. You can read the expression as player must not equal other player.
This property alone doesn't completely define the behaviour of other, but combined with the next property, it does:
[<Property>] let ``other other returns same player`` player = player =! other (other player)
If you call other, and then you take the output of that call and use it as input to call other again, you should get the original Player value. This property is an excellent example of what Scott Wlaschin calls there and back again.
These two properties, together, describe the behaviour of the other function, without going into details about the implementation.
Summary #
You've seen a simple example of how to describe the properties of a function without resorting to duplicating the implementation in the tests. You may not always be able to do this, but it always feels right when you can.
If you're interested in learning more about Property-Based Testing, you can watch my introduction to Property-based Testing with F# Pluralsight course.
Types + Properties = Software: finite state machine
How to compose the tennis game code into a finite state machine.
This article is the seventh in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you saw how to define the initial state of a tennis game. In this article, you'll see how to define the tennis game as a finite state machine.
The source code for this article series is available on GitHub.
Scoring a sequence of balls #
Previously, you saw how to score a game in an ad-hoc fashion:
> let firstBall = score newGame PlayerTwo;;
val firstBall : Score = Points {PlayerOnePoint = Love;
PlayerTwoPoint = Fifteen;}
> let secondBall = score firstBall PlayerOne;;
val secondBall : Score = Points {PlayerOnePoint = Fifteen;
PlayerTwoPoint = Fifteen;}
You'll quickly get tired of that, so you may think that you can do something like this instead:
> newGame |> (fun s -> score s PlayerOne) |> (fun s -> score s PlayerTwo);;
val it : Score = Points {PlayerOnePoint = Fifteen;
PlayerTwoPoint = Fifteen;}
That does seem a little clumsy, though, but it's not really what you need to be able to do either. What you'd probably appreciate more is to be able to calculate the score given a sequence of wins. A sequence of wins is a list of Player values; for instance, [PlayerOne; PlayerOne; PlayerTwo] means that player one won the first two balls, and then player two won the third ball.
Since we already know the initial state of a game, and how to calculate the score for each ball, it's a one-liner to calculate the score for a sequence of balls:
let scoreSeq wins = Seq.fold score newGame wins
This function has the type Player seq -> Score. It uses newGame as the initial state of a left fold over the wins. The aggregator function is the score function.
You can use it with a sequence of wins, like this:
> scoreSeq [PlayerOne; PlayerOne; PlayerTwo];;
val it : Score = Points {PlayerOnePoint = Thirty;
PlayerTwoPoint = Fifteen;}
Since player one won the first two balls, and player two then won the third ball, the score at that point is thirty-fifteen.
Properties for the state machine #
Can you think of any properties for the scoreSeq function?
There are quite a few, it turns out. It may be a good exercise if you pause reading for a couple of minutes, and try to think of some properties.
If you have a list of properties, you can compare them with the ones I though of.
Before we start, you may find the following helper functions useful:
let isPoints = function Points _ -> true | _ -> false let isForty = function Forty _ -> true | _ -> false let isDeuce = function Deuce -> true | _ -> false let isAdvantage = function Advantage _ -> true | _ -> false let isGame = function Game _ -> true | _ -> false
These can be useful to express some properties, but I don't think that they are generally useful, so I put them together with the test code.
Limited win sequences #
If you look at short win sequences, you can already say something about them. For instance, it takes at least four balls to finish a game, so you know that if you have fewer wins than four, the game must still be on-going:
[<Property>] let ``A game with less then four balls isn't over`` (wins : Player list) = let actual : Score = wins |> Seq.truncate 3 |> scoreSeq test <@ actual |> (not << isGame) @>
The built-in function Seq.truncate returns only the n (in this case: 3) first elements of a sequence. If the sequence is shorter than that, then the entire sequence is returned. The use of Seq.truncate 3 guarantees that the sequence passed to scoreSeq is no longer than three elements long, no matter what FsCheck originally generated.
Likewise, you can't reach deuce in less than six balls:
[<Property>] let ``A game with less than six balls can't be Deuce`` (wins : Player list) = let actual = wins |> Seq.truncate 5 |> scoreSeq test <@ actual |> (not << isDeuce) @>
This is similar to the previous property. There's one more in that family:
[<Property>] let ``A game with less than seven balls can't have any player with advantage`` (wins : Player list) = let actual = wins |> Seq.truncate 6 |> scoreSeq test <@ actual |> (not << isAdvantage) @>
It takes at least seven balls before the score can reach a state where one of the players have the advantage.
Longer win sequences #
Conversely, you can also express some properties related to win sequences of a minimum size. This one is more intricate to express with FsCheck, though. You'll need a sequence of Player values, but the sequence should be guaranteed to have a minimum length. There's no built-in in function for that in FsCheck, so you need to define it yourself:
// int -> Gen<Player list> let genListLongerThan n = let playerGen = Arb.generate<Player> let nPlayers = playerGen |> Gen.listOfLength (n + 1) let morePlayers = playerGen |> Gen.listOf Gen.map2 (@) nPlayers morePlayers
This function takes an exclusive minimum size, and returns an FsCheck generator that will generate Player lists longer than n. It does that by combining two of FsCheck's built-in generators. Gen.listOfLength generates lists of the requested length, and Gen.listOf generates all sorts of lists, including the empty list.
Both nPlayers and morePlayers are values of the type Gen<Player list>. Using Gen.map2, you can concatenate these two list generators using F#'s built-in list concatenation operator @. (All operators in F# are also functions. The (@) function has the type 'a list -> 'a list -> 'a list.)
With the genListLongerThan function, you can now express properties related to longer win sequences. As an example, if the players have played more than four balls, the score can't be a Points case:
[<Property>] let ``A game with more than four balls can't be Points`` () = let moreThanFourBalls = genListLongerThan 4 |> Arb.fromGen Prop.forAll moreThanFourBalls (fun wins -> let actual = scoreSeq wins test <@ actual |> (not << isPoints) @>)
As previously explained, Prop.forAll expresses a property that must hold for all lists generated by moreThanFourBalls.
Correspondingly, if the players have played more than five balls, the score can't be a Forty case:
[<Property>] let ``A game with more than five balls can't be Forty`` () = let moreThanFiveBalls = genListLongerThan 5 |> Arb.fromGen Prop.forAll moreThanFiveBalls (fun wins -> let actual = scoreSeq wins test <@ actual |> (not << isForty) @>)
This property is, as you can see, similar to the previous example.
Shortest completed game #
Do you still have your list of tennis game properties? Let's see if you thought of this one. The shortest possible way to complete a tennis game is when one of the players wins four balls in a row. This property should hold for all (two) players:
[<Property>] let ``A game where one player wins all balls is over in four balls`` (player) = let fourWins = Seq.init 4 (fun _ -> player) let actual = scoreSeq fourWins let expected = Game player expected =! actual
This test first defines fourWins, of the type Player seq. It does that by using the player argument created by FsCheck, and repeating it four times, using Seq.init.
The =! operator is a custom operator defined by Unquote, an assertion library. You can read the expression as expected must equal actual.
Infinite games #
The tennis scoring system turns out to be a rich domain. There are still more properties. We'll look at a final one, because it showcases another way to use FsCheck's API, and then we'll call it a day.
An interesting property of the tennis scoring system is that a game isn't guaranteed to end. It may, theoretically, continue forever, if players alternate winning balls:
[<Property>] let ``A game where players alternate never ends`` firstWinner = let alternateWins = firstWinner |> Gen.constant |> Gen.map (fun p -> [p; other p]) |> Gen.listOf |> Gen.map List.concat |> Arb.fromGen Prop.forAll alternateWins (fun wins -> let actual = scoreSeq wins test <@ actual |> (not << isGame) @>)
This property starts by creating alternateWins, an Arbitrary<Player list>. It creates lists with alternating players, like [PlayerOne; PlayerTwo], or [PlayerTwo; PlayerOne; PlayerTwo; PlayerOne; PlayerTwo; PlayerOne]. It does that by using the firstWinner argument (of the type Player) as a constant starting value. It's only constant within each test, because firstWinner itself varies.
Using that initial Player value, it then proceeds to map that value to a list with two elements: the player, and the other player, using the other function. This creates a Gen<Player list>, but piped into Gen.listOf, it becomes a Gen<Player list list>. An example of the sort of list that would generate could be [[PlayerTwo; PlayerOne]; [PlayerTwo; PlayerOne]]. Obviously, you need to flatten such lists, which you can do with List.concat; you have to do it inside of a Gen, though, so it's Gen.map List.concat. That gives you a Gen<Player list>, which you can finally turn into an Arbitrary<Player list> with Arb.fromGen.
This enables you to use Prop.forAll with alternateWins to express that regardless of the size of such alternating win lists, the game never reaches a Game state.
Summary #
In this article, you saw how to implement a finite state machine for calculating tennis scores. It's a left fold over the score function, always starting in the initial state where both players are at love. You also saw how you can express various properties that hold for a game of tennis.
In this article series, you've seen an extensive example of how to design with types and properties. You may have noticed that out of the six example articles so far, only the first one was about designing with types, and the next five articles were about Property-Based Testing. It looks as though not much is gained from designing with types.
On the contrary, much is gained by designing with types, but you don't see it, exactly because it's efficient. If you don't design with types in order to make illegal states unrepresentable, you'd have to write even more automated tests in order to test what happens when input is invalid. Also, if illegal states are representable, it would have been much harder to write Property-Based Tests. Instead of trusting that FsCheck generates only valid values based exclusively on the types, you'd have to write custom Generators or Arbitraries for each type of input. That would have been even more work than you've seen in this articles series.
Designing with types makes Property-Based Testing a comfortable undertaking. Together, they enable you to develop software that you can trust.
If you're interested in learning more about Property-Based Testing, you can watch my introduction to Property-based Testing with F# Pluralsight course.
Types + Properties = Software: initial state
How to define the initial state in a tennis game, using F#.
This article is the sixth in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you saw how to compose a function that returns a new score based on a previous score, and information about which player won the ball. In this article, you'll see how to define the initial state of a tennis game.
The source code for this article series is available on GitHub.
Initial state #
You may recall from the article on designing with types that a Score is a discriminated union. One of the union cases is the Points case, which you can use to model the case where both players have either Love, Fifteen, or Thirty points.
The game starts with both players at love. You can define this as a value:
let newGame = Points { PlayerOnePoint = Love; PlayerTwoPoint = Love }
Since this is a value (that is: not a function), it would make no sense to attempt to test it. Thus, you can simply add it, and move on.
You can use this value to calculate ad-hoc scores from the beginning of a game, like this:
> let firstBall = score newGame PlayerTwo;;
val firstBall : Score = Points {PlayerOnePoint = Love;
PlayerTwoPoint = Fifteen;}
> let secondBall = score firstBall PlayerOne;;
val secondBall : Score = Points {PlayerOnePoint = Fifteen;
PlayerTwoPoint = Fifteen;}
You'll soon get tired of defining firstBall, secondBall, thirdBall, and so on, so a more general way to handle and calculate scores is warranted.
To be continued... #
In this article, you saw how to define the initial state for a tennis game. There's nothing to it, but armed with this value, you now have half of the requirements needed to turn the tennis score function into a finite state machine. You'll see how to do that in the next article.
Types + Properties = Software: composition
In which a general transition function is composed from specialised transition functions.
This article is the fifth in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you witnessed the continued walk-through of the Tennis Kata done with Property-Based Test-Driven Development. In these articles, you saw how to define small, specific functions that model the transition out of particular states. In this article, you'll see how to compose these functions to a more general function.
The source code for this article series is available on GitHub.
Composing the general function #
If you recall the second article in this series, what you need to implement is a state transition of the type Score -> Player -> Score. What you have so far are the following functions:
scoreWhenPoints : PointsData -> Player -> ScorescoreWhenForty : FortyData -> Player -> ScorescoreWhenDeuce : Player -> ScorescoreWhenAdvantage : Player -> Player -> ScorescoreWhenGame : Player -> Score
These five functions are all the building blocks you need to implement the desired function of the type Score -> Player -> Score. You may recall that Score is a discriminated union defined as:
type Score = | Points of PointsData | Forty of FortyData | Deuce | Advantage of Player | Game of Player
Notice how these cases align with the five functions above. That's not a coincidence. The driving factor behind the design of these five function was to match them with the five cases of the Score type. In another article series, I've previously shown this technique, applied to a different problem.
You can implement the desired function by clicking the pieces together:
let score current winner = match current with | Points p -> scoreWhenPoints p winner | Forty f -> scoreWhenForty f winner | Deuce -> scoreWhenDeuce winner | Advantage a -> scoreWhenAdvantage a winner | Game g -> scoreWhenGame g
There's not a lot to it, apart from matching on current. If, for example, current is a Forty value, the match is the Forty case, and f represents the FortyData value in that case. The destructured f can be passed as an argument to scoreWhenForty, together with winner. The scoreWhenForty function returns a Score value, so the score function has the type Score -> Player -> Score - exactly what you want!
Here's an example of using the function:
> score Deuce PlayerOne;; val it : Score = Advantage PlayerOne
When the score is deuce and player one wins the ball, the resulting score is advantage to player one.
Properties for the score function #
Can you express some properties for the score function? Yes and no. You can't state particularly interesting properties about the function in isolation, but you can express meaningful properties about sequences of scores. We'll return to that in a later article. For now, let's focus on the function in itself.
You can, for example, state that the function can handle all input:
[<Property>] let ``score returns a value`` (current : Score) (winner : Player) = let actual : Score = score current winner true // Didn't crash - this is mostly a boundary condition test
This property isn't particularly interesting. It's mostly a smoke test that I added because I thought that it might flush out boundary issues, if any exist. That doesn't seem to be the case.
You can also add properties that examine each case of input:
[<Property>] let ``score Points returns correct result`` points winner = let actual = score (Points points) winner let expected = scoreWhenPoints points winner expected =! actual
Such a property is unlikely to be of much use, because it mostly reproduces the implementation details of the score function. Unless you're writing high-stakes software (e.g. for medical purposes), such properties are likely to have little or negative value. After all, tests are also code; do you trust the test code more than the production code? Sometimes, you may, but if you look at the source code for the score function, it's easy to review.
You can write four other properties, similar to the one above, but I'm going to skip them here. They are in the source code repository, though, so you're welcome to look there if you want to see them.
To be continued... #
In this article, you saw how to compose the five specific state transition functions into an overall state transition function. This is only a single function that calculates a score based on another score. In order to turn this function into a finite state machine, you must define an initial state and a way to transition based on a sequence of events.
In the next article, you'll see how to define the initial state, and in the article beyond that, you'll see how to move through a sequence of transitions.
If you're interested in learning more about designing with types, you can watch my Type-Driven Development with F# Pluralsight course.
Types + Properties = Software: properties for the Forties
An example of how to constrain generated input with FsCheck.
This article is the fourth in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you saw how to express properties for a simple state transition: finding the next tennis score when the current score is advantage to a player. These properties were simple, because they had to hold for all input of the given type (Player). In this article, you'll see how to constrain the input that FsCheck generates, in order to express properties about tennis scores where one of the players have forty points.
The source code for this article series is available on GitHub.
Winning the game #
When one of the players have forty points, there are three possible outcomes of the next ball:
- If the player with forty points wins the ball, (s)he wins the game.
- If the other player has thirty points, and wins the ball, the score is deuce.
- If the other player has less than thirty points, and wins the ball, his or her points increases to the next level (from love to fifteen, or from fifteen to thirty).
You may recall that when one of the players have forty points, you express that score with the FortyData record type:
type FortyData = { Player : Player; OtherPlayerPoint : Point }
Since Point is defined as Love | Fifteen | Thirty, it's clear that the Player who has forty points has a higher score than the other player - regardless of the OtherPlayerPoint value. This means that if that player wins, (s)he wins the game. It's easy to express that property with FsCheck:
[<Property>] let ``Given player: 40 when player wins then score is correct`` (current : FortyData) = let actual = scoreWhenForty current current.Player let expected = Game current.Player expected =! actual
Notice that this test function takes a single function argument called current, of the type FortyData. Since illegal states are unrepresentable, FsCheck can only generate legal values of that type.
The scoreWhenForty function is a function that explicitly models what happens when the score is in the Forty case. The first argument is the data associated with the current score: current. The second argument is the winner of the next ball. In this test case, you want to express the case where the winner is the player who already has forty points: current.Player.
The expected outcome of this is always that current.Player wins the game.
The =! operator is a custom operator defined by Unquote, an assertion library. You can read the expression as expected must equal actual.
In order to pass this property, you must implement a scoreWhenForty function. This is the simplest implementation that could possible work:
let scoreWhenForty current winner = Game winner
While this passes all tests, it's obviously not a complete implementation.
Getting even #
Another outcome of a Forty score is that if the other player has thirty points, and wins the ball, the new score is deuce. Expressing this as a property is only slightly more involved:
[<Property>] let ``Given player: 40 - other: 30 when other wins then score is correct`` (current : FortyData) = let current = { current with OtherPlayerPoint = Thirty } let actual = scoreWhenForty current (other current.Player) Deuce =! actual
In this test case, the other player specifically has thirty points. There's no variability involved, so you can simply set OtherPlayerPoint to Thirty.
Notice that instead of creating a new FortyData value from scratch, this property takes current (which is generated by FsCheck) and uses a copy-and-update expression to explicitly bind OtherPlayerPoint to Thirty. This ensures that all other values of current can vary, but OtherPlayerPoint is fixed.
The first line of code shadows the current argument by binding the result of the copy-and-update expression to a new value, also called current. Shadowing means that the original current argument is no longer available in the rest of the scope. This is exactly what you want, because the function argument isn't guaranteed to model the test case where the other player has forty points. Instead, it can be any FortyData value. You can think of the argument provided by FsCheck as a seed used to arrange the Test Fixture.
The property proceeds to invoke the scoreWhenForty function with the current score, and indicating that the other player wins the ball. You saw the other function in the previous article, but it's so small that it can be repeated here without taking up much space:
let other = function PlayerOne -> PlayerTwo | PlayerTwo -> PlayerOne
Finally, the property asserts that deuce must equal actual. In other words, the expected result is deuce.
This property fails until you fix the implementation:
let scoreWhenForty current winner = if current.Player = winner then Game winner else Deuce
This is a step in the right direction, but still not the complete implementation. If the other player has only love or fifteen points, and wins the ball, the new score shouldn't be deuce.
Incrementing points #
The last test case is where it gets interesting. The situation you need to test is that one of the players has forty points, and the other player has either love or fifteen points. This feels like the previous case, but has more variable parts. In the previous test case (above), the other player always had thirty points, but in this test case, the other player's points can vary within a constrained range.
Perhaps you've noticed that so far, you haven't seen any examples of using FsCheck's API. Until now, we've been able to express properties from values generated by FsCheck without constraints. This is no longer possible, but fortunately, FsCheck comes with an excellent API that enables you to configure it. Here, you'll see how to configure it to create values from a proper subset of all possible values:
[<Property>] let ``Given player: 40 - other: < 30 when other wins then score is correct`` (current : FortyData) = let opp = Gen.elements [Love; Fifteen] |> Arb.fromGen Prop.forAll opp (fun otherPlayerPoint -> let current = { current with OtherPlayerPoint = otherPlayerPoint } let actual = scoreWhenForty current (other current.Player) let expected = incrementPoint current.OtherPlayerPoint |> Option.map (fun np -> { current with OtherPlayerPoint = np }) |> Option.map Forty expected =! Some actual)
That's only nine lines of code, and some of it is similar to the previous property you saw (above). Still, F# code can have a high degree of information density, so I'll walk you through it.
FsCheck's API is centred around Generators and Arbitraries. Ultimately, when you need to configure FsCheck, you'll need to define an Arbitrary<'a>, but you'll often use a Gen<'a> value to do that. In this test case, you need to tell FsCheck to use only the values Love and Fifteen when generating Point values.
This is done in the first line of code. Gen.elements creates a Generator that creates random values by drawing from a sequence of possible values. Here, we pass it a list of two values: Love and Fifteen. Because both of these values are of the type Point, the result is a value of the type Gen<Point>. This Generator is piped to Arb.fromGen, which turns it into an Arbitrary (for now, you don't have to worry about exactly what that means). Thus, opp is a value of type Arbitrary<Point>.
You can now take that Arbitrary and state that, for all values created by it, a particular property must hold. This is what Prop.forAll does. The first argument passed is opp, and the second argument is a function that expresses the property. When the test runs, FsCheck call this function 100 times (by default), each time passing a random value generated by opp.
The next couple of lines are similar to code you've seen before. As in the case where the other player had thirty points, you can shadow the current argument with a new value where the other player's points is set to a value drawn from opp; that is, Love or Fifteen.
Notice how the original current value comes from an argument to the containing test function, whereas otherPlayerPoint comes from the opp Arbitrary. FsCheck is smart enough to enable this combination, so you still get the variation implied by combining these two sources of random data.
The actual value is bound to the result of calling scoreWhenForty with the current score, and indicating that the other player wins the ball.
The expected outcome is a new Forty value that originates from current, but with the other player's points incremented. There is, however, something odd-looking going on with Option.map - and where did that incrementPoint function come from?
In the previous article, you saw how sometimes, a test triggers the creation of a new helper function. Sometimes, such a helper function is of such general utility that it makes sense to put it in the 'production code'. Previously, it was the other function. Now, it's the incrementPoint function.
Before I show you the implementation of the incrementPoint function, I would like to suggest that you reflect on it. The purpose of this function is to return the point that comes after a given point. Do you remember how, in the article on designing with types, we quickly realised that love, fifteen, thirty, and forty are mere labels; that we don't need to do arithmetic on these values?
There's one piece of 'arithmetic' you need to do with these values, after all: you must be able to 'add one' to a value, in order to get the next value. That's the purpose of the incrementPoint function: given Love, it'll return Fifteen, and so on - but with a twist!
What should it return when given Thirty as input? Forty? That's not possible. There's no Point value higher than Thirty. Forty doesn't exist.
The object-oriented answer would be to throw an exception, but in functional programming, we don't like such arbitrary jump statements in our code. GOTO is, after all, considered harmful.
Instead, we can return None, but that means that we must wrap all the other return values in Some:
let incrementPoint = function | Love -> Some Fifteen | Fifteen -> Some Thirty | Thirty -> None
This function has the type Point -> Point option, and it behaves like this:
> incrementPoint Love;; val it : Point option = Some Fifteen > incrementPoint Fifteen;; val it : Point option = Some Thirty > incrementPoint Thirty;; val it : Point option = None
Back to the property: the expected value is that the other player's points are incremented, and this new points value (np, for New Points) is bound to OtherPlayerPoint in a copy-and-update expression, using current as the original value. In other words, this expression returns the current score, with the only change that OtherPlayerPoint now has the incremented Point value.
This has to happen inside of an Option.map, though, because incrementPoint may return None. Furthermore, the new value created from current is of the type FortyData, but you need a Forty value. This can be achieved by piping the option value into another map that composes the Forty case constructor.
The expected value has the type Score option, so in order to be able to compare it to actual, which is 'only' a Score value, you need to make actual a Score option value as well. This is the reason expected is compared to Some actual.
One implementation that passes this and all previous properties is:
let scoreWhenForty current winner = if current.Player = winner then Game winner else match incrementPoint current.OtherPlayerPoint with | Some p -> Forty { current with OtherPlayerPoint = p } | None -> Deuce
Notice that the implementation also uses the incrementPoint function.
To be continued... #
In this article, you saw how, even when illegal states are unrepresentable, you may need to further constrain the input into a property in order to express a particular test case. The FsCheck combinator library can be used to do that. It's flexible and well thought-out.
While I could go on and show you how to express properties for more state transitions, you've now seen the most important techniques. If you want to see more of the tennis state transitions, you can always check out the source code accompanying this article series.
In the next article, instead, you'll see how to compose all these functions into a system that implements the tennis scoring rules.
If you're interested in learning more about Property-Based Testing, you can watch my introduction to Property-based Testing with F# Pluralsight course.
Types + Properties = Software: properties for the advantage state
An example of Property-Based Test-Driven Development.
This article is the third in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you saw how to get started with Property-Based Testing, using a Test-Driven Development tactic. In this article, you'll see the previous Tennis Kata example continued. This time, you'll see how to express properties for the state when one of the players have the advantage.
The source code for this article series is available on GitHub.
Winning the game #
When one of the players have the advantage in tennis, the result can go one of two ways: either the player with the advantage wins the ball, in which case he or she wins the game, or the other player wins, in which case the next score is deuce. This implies that you'll have to write at least two properties: one for each situation. Let's start with the case where the advantaged player wins the ball. Using FsCheck, you can express that property like this:
[<Property>] let ``Given advantage when advantaged player wins then score is correct`` (advantagedPlayer : Player) = let actual : Score = scoreWhenAdvantage advantagedPlayer advantagedPlayer let expected = Game advantagedPlayer expected =! actual
As explained in the previous article, FsCheck will interpret this function and discover that it'll need to generate arbitrary Player values for the advantagedPlayer argument. Because illegal states are unrepresentable, you're guaranteed valid values.
This property calls the scoreWhenAdvantage function (that doesn't yet exist), passing advantagedPlayer as argument twice. The first argument is an indication of the current score. The scoreWhenAdvantage function only models how to transition out of the Advantage case. The data associated with the Advantage case is the player currently having the advantage, so passing in advantagedPlayer as the first argument describes the current state to the function.
The second argument is the winner of the ball. In this test case, the same player wins again, so advantagedPlayer is passed as the second argument as well. The exact value of advantagedPlayer doesn't matter; this property holds for all (two) players.
The =! operator is a custom operator defined by Unquote, an assertion library. You can read the expression as expected must equal actual.
In order to pass this property, you can implement the function in the simplest way that could possibly work:
let scoreWhenAdvantage advantagedPlayer winner = Game advantagedPlayer
Here, I've arbitrarily chosen to return Game advantagedPlayer, but as an alternative, Game winner also passes the test.
Back to deuce #
The above implementation of scoreWhenAdvantage is obviously incorrect, because it always claims that the advantaged player wins the game, regardless of who wins the ball. You'll need to describe the other test case as well, which is slightly more involved, yet still easy:
[<Property>] let ``Given advantage when other player wins then score is correct`` (advantagedPlayer : Player) = let actual = scoreWhenAdvantage advantagedPlayer (other advantagedPlayer) Deuce =! actual
The first argument to the scoreWhenAdvantage function describes the current score. The test case is that the other player wins the ball. In order to figure out who the other player is, you can call the other function.
Which other function?
The function you only now create for this express purpose:
let other = function PlayerOne -> PlayerTwo | PlayerTwo -> PlayerOne
As the name suggests, this function returns the other player, for any given player. In the previous article, I promised to avoid point-free style, but here I broke that promise. This function is equivalent to this:
let other player = match player with | PlayerOne -> PlayerTwo | PlayerTwo -> PlayerOne
I decided to place this function in the same module as the scoreWhenGame function, because it seemed like a generally useful function, more than a test-specific function. It turns out that the tennis score module, indeed, does need this function later.
Since the other function is part of the module being tested, shouldn't you test it as well? For now, I'll leave it uncovered by directed tests, because it's so simple that I'm confident that it works, just by looking at it. Later, I can return to it in order to add some properties.
With the other function in place, the new property fails, so you need to change the implementation of scoreWhenAdvantage in order to pass all tests:
let scoreWhenAdvantage advantagedPlayer winner = if advantagedPlayer = winner then Game winner else Deuce
This implementation deals with all combinations of input.
It turned out that, in this case, two properties are all we need in order to describe which tennis score comes after advantage.
To be continued... #
In this article, you saw how to express the properties associated with the advantage state of a tennis game. These properties were each simple. You can express each of them based on any arbitrary input of the given type, as shown here.
Even when all test input values are guaranteed to be valid, sometimes you need to manipulate an arbitrary test value in order to describe a particular test case. You'll see how to do this in the next article.
If you're interested in learning more about Property-Based Testing, you can watch my introduction to Property-based Testing with F# Pluralsight course.

Comments
In my opinion, the true purpose of
IOis to allow you to write pure effectful functions. For example, Haskell'sputStrLnis referentially transparent - i.e.,[putStrLn "hello", putStrLn "hello"]has the same meaning asreplicate 2 $ putStrLn "hello". This means you can treat a function that returns an IO the same way you'd treat any other function.This is possible for two reasons: 1)
IOactions are not run until they hit the "edge of the universe" whereunsafePerformIOis called and 2) they don't memoize the result - if anIOaction is executed twice, it will calculate two possibly distinct values.The problem with
Taskis that it's not referentially transparent.new[] { Task.Run(() => WriteLine("hello")), Task.Run(() => WriteLine("hello")) }is not the same asvar t = Task.Run(() => WriteLine("hello"))+new [] { t, t }. Even if you usenew Task()instead ofTask.Runto delay its execution, you still wouldn't be able to factor out the task because it memoizes the result (in this case, void), so you'd still see "hello" only once on the screen.Since Task cannot be used to model pure functions, I don't think it's a suitable replacement for IO.
Diogo, thank you for writing. The point about Tasks not being referentially transparent is well taken. You are, indeed, correct.
F# asynchronous work-flows work differently, though. Extending the experiment outlined in this article, you can attempt to 'translate'
putStrLnto F#. Since the return type ofputStrLnisIO (), you'll need a function that returnsAsync<unit>. Here's my naive attempt:Corresponding to your two Haskell examples, consider, then, these two F# values:
Both of these values have the type
seq<Async<unit>>, and I'd expect them to be equivalent.In Haskell, I used
sequenceto run your code in GHCI, turning[IO ()]intoIO [()]. In F#, you can do something similar:Using this function, you can evaluate both expressions:
As you can see, the result is the same in both cases, like you'd expect them to be.
I'm still not claiming that
Async<'a>is a direct translation of Haskell'sIO, but there are similarities. Admittedly, I've never considered whether F# asynchronous work-flows satisfy the monad laws, but it wouldn't surprise me if they did.Ah, I see! It wasn't clear to me that async workflows were referentially transparent. That being the case, it seems like they are, indeed, a good substitute for
IO a.It seems like the F# team got async right :) The C# team should take a page from their book...
I know what functional programmers generally and Mark specially mean when they say that function is (or is not) referentially transparent. Namely, a function is referentially transparent if and only if its behavior is unchanged when memozied.
I see how caching behavior varies among Haskell's IO, F#'s Async, and C#'s Task. However, the previous comments are the only times that I have anyone say that a type is (or is not) referentially transparent. In general, what does it mean for a type to be (or not to be) referentially transparent?
Tyson, language is imprecise. I take it that we meant that the behaviour that the type (here: an object) affords helps preserve referential transparency. It's fairly clear to me that it makes sense to say that
Task<T>isn't referentially transparent, because of the behaviour shown by the above examples.In C# or F#, we can't universally state that
Asyncis always referentially transparent, because these languages allow impure actions to be passed to the type's members. Still, if we pass pure functions, the members are referentially transparent too.In object-oriented programming, we often think of a type as an object: data with behaviour. In Haskell, you often have a type and an associated type class. In F#, some containers (like
Async) have an associated computation expression builder; again, that's a set of functions.If a set of associated functions or members are all referentially transparent, it makes sense to me to talk about the type as being referentially transparent, but all this is a view I've just retconned as I'm writing. You may be able to poke holes in it, so don't take it for more than it is.