ploeh blog danish software design
Types + Properties = Software: state transition properties
Specify valid state transitions as properties.
This article is the second in a series of articles that demonstrate how to develop software using types and properties. In the previous article, you saw how to design with types so that illegal states are unrepresentable. In this article, you'll see an example of how to express properties for transitions between legal states.
The source code for this article series is available on GitHub.
This article continues the Tennis Kata example from the previous article. It uses FsCheck to generate test values, and xUnit.net as the overall test framework. It also uses Unquote for assertions.
State transitions #
While the types defined in the previous article make illegal states unrepresentable, they don't enforce any rules about how to transition from one state into another. There's yet no definition of what a state transition is, in the tennis domain. Let's make a definition, then.
A state transition should be a function that takes a current Score and the winner of a ball and returns a new Score. More formally, it should have the type Score -> Player -> Score.
(If you're thinking that all this terminology sounds like we're developing a finite state machine, you're bang on; that's exactly the case.)
For a simple domain like tennis, it'd be possible to define properties directly for such a function, but I often prefer to define a smaller function for each case, and test the properties of each of these functions. When you have all these small functions, you can easily combine them into the desired state transition function. This is the strategy you'll see in use here.
Deuce property #
The tennis types defined in the previous article guarantee that when you ask FsCheck to generate values, you will get only legal values. This makes it easy to express properties for transitions. Let's write the property first, and let's start with the simplest state transition: the transition out of deuce.
[<Property>] let ``Given deuce when player wins then score is correct`` (winner : Player) = let actual : Score = scoreWhenDeuce winner let expected = Advantage winner expected =! actual
This test exercises a transition function called scoreWhenDeuce. The case of deuce is special, because there's no further data associated with the state; when the score is deuce, it's deuce. This means that when calling scoreWhenDeuce, you don't have to supply the current state of the game; it's implied by the function itself.
You do need, however, to pass a Player argument in order to state which player won the ball. Instead of coming up with some hard-coded examples, the test simply requests Player values from FsCheck (by requiring the winner function argument).
Because the Player type makes illegal states unrepresentable, you're guaranteed that only valid Player values will be passed as the winner argument.
(In this particular example, Player can only be the values PlayerOne and PlayerTwo. FsCheck will, because of its default settings, run the property function 100 times, which means that it will generate 100 Player values. With an even distribution, that means that it will generate approximately 50 PlayerOne values, and 50 PlayerTwo values. Wouldn't it be easier, and faster, to use a [<Theory>] that deterministically generates only those two values, without duplication? Yes, in this case it would; This sometimes happens, and it's okay. In this example, though, I'm going to keep using FsCheck, because I think this entire example is a good stand-in for a more complex business problem.)
Regardless of the value of the winner argument, the property should hold that the return value of the scoreWhenDeuce function is that the winner now has the advantage.
The =! operator is a custom operator defined by Unquote. You can read it as a must equal operator: expected must equal actual.
Red phase #
When you apply Test-Driven Development, you should follow the Red/Green/Refactor cycle. In this example, we're doing just that, but at the moment the code doesn't even compile, because there's no scoreWhenDeuce function.
In the Red phase, it's important to observe that the test fails as expected before moving on to the Green phase. In order to make that happen, you can create this temporary implementation of the function:
let scoreWhenDeuce winner = Deuce
With this definition, the code compiles, and when you run the test, you get this test failure:
Test 'Ploeh.Katas.TennisProperties.Given deuce when player wins then score is correct' failed: FsCheck.Xunit.PropertyFailedException : Falsifiable, after 1 test (0 shrinks) (StdGen (427100699,296115298)): Original: PlayerOne ---- Swensen.Unquote.AssertionFailedException : Test failed: Advantage PlayerOne = Deuce false
This test failure is the expected failure, so you should now feel confident that the property is correctly expressed.
Green phase #
With the Red phase properly completed, it's time to move on to the Green phase: make the test(s) pass. For deuce, this is trivial:
let scoreWhenDeuce winner = Advantage winner
This passes 'all' tests:
Output from Ploeh.Katas.TennisProperties.Given deuce when player wins then score is correct: Ok, passed 100 tests.
The property holds.
Refactor #
When you follow the Red/Green/Refactor cycle, you should now refactor the implementation, but there's little to do at this point
You could, in fact, perform an eta reduction:
let scoreWhenDeuce = Advantage
This would be idiomatic in Haskell, but not quite so much in F#. In my experience, many people find the point-free style less readable, so I'm not going to pursue this type of refactoring for the rest of this article series.
To be continued... #
In this article, you've seen how to express the single property that when the score is deuce, the winner of the next ball will have the advantage. Because illegal states are unrepresentable, you can declaratively state the type of value(s) the property requires, and FsCheck will have no choice but to give you valid values.
In the next article, you'll see how to express properties for slightly more complex state transitions. In this article, I took care to spell out each step in the process, but in the next article, I promise to increase the pace.
If you're interested in learning more about Property-Based Testing, you can watch my introduction to Property-based Testing with F# Pluralsight course.
Types + Properties = Software: designing with types
Design types so that illegal states are unrepresentable.
This article is the first in a series of articles that demonstrate how to develop software using types and properties. In this article, you'll see an example of how to design with algebraic data types, and in future articles, you'll see how to specify properties that must hold for the system. This example uses F#, but you can design similar types in Haskell.
The source code for this article series is available on GitHub.
Tennis #
The example used in this series of articles is the Tennis Kata. Although a tennis match consists of multiple sets that again are played as several games, in the kata, you only have to implement the scoring system for a single game:
- Each player can have either of these points in one game: Love, 15, 30, 40.
- If you have 40 and you win the ball, you win the game. There are, however, special rules.
- If both have 40, the players are deuce.
- If the game is in deuce, the winner of a ball will have advantage and game ball.
- If the player with advantage wins the ball, (s)he wins the game.
- If the player without advantage wins, they are back at deuce.
You can take on this problem in many different ways, but in this article, you'll see how F#'s type system can be used to make illegal states unrepresentable. Perhaps you think this is overkill for such a simple problem, but think of the Tennis Kata as a stand-in for a more complex domain problem.
Players #
In tennis, there are two players, which we can easily model with a discriminated union:
type Player = PlayerOne | PlayerTwo
When designing with types, I often experiment with values in FSI (the F# REPL) to figure out if they make sense. For such a simple type as Player, that's not strictly necessary, but I'll show you anyway, take illustrate the point:
> PlayerOne;; val it : Player = PlayerOne > PlayerTwo;; val it : Player = PlayerTwo > PlayerZero;; PlayerZero;; ^^^^^^^^^^ error FS0039: The value or constructor 'PlayerZero' is not defined > PlayerThree;; PlayerThree;; ^^^^^^^^^^^ error FS0039: The value or constructor 'PlayerThree' is not defined
As you can see, both PlayerOne and PlayerTwo are values inferred to be of the type Player, whereas both PlayerZero and PlayerThree are illegal expressions.
Not only is it possible to represent all valid values, but illegal values are unrepresentable. Success.
Naive point attempt with a type alias #
If you're unfamiliar with designing with types, you may briefly consider using a type alias to model players' points:
type Point = int
This easily enables you to model some of the legal point values:
> let p : Point = 15;; val p : Point = 15 > let p : Point = 30;; val p : Point = 30
It looks good so far, but how do you model love? It's not really an integer.
Still, both players start with love, so it's intuitive to try to model love as 0:
> let p : Point = 0;; val p : Point = 0
It's a hack, but it works.
Are illegal values unrepresentable? Hardly:
> let p : Point = 42;; val p : Point = 42 > let p : Point = -1337;; val p : Point = -1337
With a type alias, it's possible to assign every value that the 'real' type supports. For a 32-bit integer, this means that we have four legal representations (0, 15, 30, 40), and 4,294,967,291 illegal representations of a tennis point. Clearly this doesn't meet the goal of making illegal states unrepresentable.
Second point attempt with a discriminated Union #
If you think about the problem for a while, you're likely to come to the realisation that love, 15, 30, and 40 aren't numbers, but rather labels. No arithmetic is performed on them. It's easy to constrain the domain of points with a discriminated union:
type Point = Love | Fifteen | Thirty | Forty
You can play around with values of this Point type in FSI if you will, but there should be no surprises.
A Point value isn't a score, though. A score is a representation of a state in the game, with (amongh other options) a point to each player. You can model this with a record:
type PointsData = { PlayerOnePoint : Point; PlayerTwoPoint : Point }
You can experiment with this type in FSI, like you can with the other types:
> { PlayerOnePoint = Love; PlayerTwoPoint = Love };;
val it : PointsData = {PlayerOnePoint = Love;
PlayerTwoPoint = Love;}
> { PlayerOnePoint = Love; PlayerTwoPoint = Thirty };;
val it : PointsData = {PlayerOnePoint = Love;
PlayerTwoPoint = Thirty;}
> { PlayerOnePoint = Thirty; PlayerTwoPoint = Forty };;
val it : PointsData = {PlayerOnePoint = Thirty;
PlayerTwoPoint = Forty;}
That looks promising. What happens if players are evenly matched?
> { PlayerOnePoint = Forty; PlayerTwoPoint = Forty };;
val it : PointsData = {PlayerOnePoint = Forty;
PlayerTwoPoint = Forty;}
That works as well, but it shouldn't!
Forty-forty isn't a valid tennis score; it's called deuce.
Does it matter? you may ask. Couldn't we 'just' say that forty-forty 'means' deuce and get on with it?
You could. You should try. I've tried doing this (I've done the Tennis Kata several times, in various languages), and it turns out that it's possible, but it makes the code more complicated. One of the reasons is that deuce is more than a synonym for forty-forty. The score can also be deuce after advantage to one of the players. You can, for example, have a score progression like this:
- ...
- Forty-thirty
- Deuce
- Advantage to player one
- Deuce
- Advantage to player two
- Deuce
- ...
Additionally, if you're into Domain-Driven Design, you prefer using the ubiquitous language of the domain. When the tennis domain language says that it's not called forty-forty, but deuce, the code should reflect that.
Final attempt at a point type #
Fortunately, you don't have to throw away everything you've done so far. The love-love, fifteen-love, etc. values that you can represent with the above PointsData type are all valid. Only when you approach the boundary value of forty do problems appear.
A solution is to remove the offending Forty case from Point. The updated definition of Point is this:
type Point = Love | Fifteen | Thirty
You can still represent the 'early' scores using PointsData:
> { PlayerOnePoint = Love; PlayerTwoPoint = Love };;
val it : PointsData = {PlayerOnePoint = Love;
PlayerTwoPoint = Love;}
> { PlayerOnePoint = Love; PlayerTwoPoint = Thirty };;
val it : PointsData = {PlayerOnePoint = Love;
PlayerTwoPoint = Thirty;}
Additionally, the illegal forty-forty state is now unrepresentable:
> { PlayerOnePoint = Forty; PlayerTwoPoint = Forty };;
{ PlayerOnePoint = Forty; PlayerTwoPoint = Forty };;
-------------------^^^^^
error FS0039: The value or constructor 'Forty' is not defined
This is much better, apart from the elephant in the room: you also lost the ability to model valid states where only one of the players have forty points:
> { PlayerOnePoint = Thirty; PlayerTwoPoint = Forty };;
{ PlayerOnePoint = Thirty; PlayerTwoPoint = Forty };;
--------------------------------------------^^^^^
error FS0039: The value or constructor 'Forty' is not defined
Did we just throw the baby out with the bathwater?
Not really, because we weren't close to being done anyway. While we were making progress on modelling the score as a pair of Point values, remaining work includes modelling deuce, advantage and winning the game.
Life begins at forty #
At this point, it may be helpful to recap what we have:
type Player = PlayerOne | PlayerTwo type Point = Love | Fifteen | Thirty type PointsData = { PlayerOnePoint : Point; PlayerTwoPoint : Point }
While this enables you to keep track of the score when both players have less than forty points, the following phases of a game still remain:
- One of the players have forty points.
- Deuce.
- Advantage to one of the players.
- One of the players won the game.
type FortyData = { Player : Player; OtherPlayerPoint : Point }
This is a record that specifically keeps track of the situation where one of the players have forty points. The Player element keeps track of which player has forty points, and the OtherPlayerPoint element keeps track of the other player's score. For instance, this value indicates that PlayerTwo has forty points, and PlayerOne has thirty:
> { Player = PlayerTwo; OtherPlayerPoint = Thirty };;
val it : FortyData = {Player = PlayerTwo;
OtherPlayerPoint = Thirty;}
This is a legal score. Other values of this type exist, but none of them are illegal.
Score #
Now you have two distinct types, PointsData and FortyData, that keep track of the score at two different phases of a tennis game. You still need to model the remaining three phases, and somehow turn all of these into a single type. This is an undertaking that can be surprisingly complicated in C# or Java, but is trivial to do with a discriminated union:
type Score = | Points of PointsData | Forty of FortyData | Deuce | Advantage of Player | Game of Player
This Score type states that a score is a value in one of these five cases. As an example, the game starts with both players at (not necessarily in) love:
> Points { PlayerOnePoint = Love; PlayerTwoPoint = Love };;
val it : Score = Points {PlayerOnePoint = Love;
PlayerTwoPoint = Love;}
If, for example, PlayerOne has forty points, and PlayerTwo has thirty points, you can create this value:
> Forty { Player = PlayerOne; OtherPlayerPoint = Thirty };;
val it : Score = Forty {Player = PlayerOne;
OtherPlayerPoint = Thirty;}
Notice how both values are of the same type (Score), even though they don't share the same data structure. Other example of valid values are:
> Deuce;; val it : Score = Deuce > Advantage PlayerTwo;; val it : Score = Advantage PlayerTwo > Game PlayerOne;; val it : Score = Game PlayerOne
This model of the tennis score system enables you to express all legal values, while making illegal states unrepresentable.
It's impossible to express that the score is seven-eleven:
> Points { PlayerOnePoint = Seven; PlayerTwoPoint = Eleven };;
Points { PlayerOnePoint = Seven; PlayerTwoPoint = Eleven };;
--------------------------^^^^^
error FS0039: The value or constructor 'Seven' is not defined
It's impossible to state that the score is fifteen-thirty-fifteen:
> Points { PlayerOnePoint = Fifteen; PlayerTwoPoint = Thirty; PlayerThreePoint = Fifteen };;
Points { PlayerOnePoint = Fifteen; PlayerTwoPoint = Thirty; PlayerThreePoint = Fifteen };;
------------------------------------------------------------^^^^^^^^^^^^^^^^
error FS1129: The type 'PointsData' does not contain a field 'PlayerThreePoint'
It's impossible to express that both players have forty points:
> Points { PlayerOnePoint = Forty; PlayerTwoPoint = Forty };;
Points { PlayerOnePoint = Forty; PlayerTwoPoint = Forty };;
--------------------------^^^^^
error FS0001: This expression was expected to have type
Point
but here has type
FortyData -> Score
> Forty { Player = PlayerOne; OtherPlayerPoint = Forty };;
Forty { Player = PlayerOne; OtherPlayerPoint = Forty };;
-----------------------------------------------^^^^^
error FS0001: This expression was expected to have type
Point
but here has type
FortyData -> Score
In the above example, I even attempted to express forty-forty in two different ways, but none of them work.
Summary #
You now have a model of the domain that enables you to express valid values, but that makes illegal states unrepresentable. This is half the battle won, without any moving parts. These types govern what can be stated in the domain, but they don't provide any rules for how values can transition from one state to another.
This is a task you can take on with Property-Based Testing. Since all values of these types are valid, it's easy to express the properties of a tennis game score. In the next article, you'll see how to start that work.
If you're interested in learning more about designing with types, you can watch my Type-Driven Development with F# Pluralsight course.
Types + Properties = Software
Combine a strong type system with Property-Based Testing to specify software.
When Kent Beck rediscovered Test-Driven Development (TDD) some twenty years ago, the original context was SmallTalk programming. When the concept of TDD began to catch on, it seemed to me to proliferate particularly in dynamic language communities like Python and Ruby.
It makes sense that if you can't get fast feedback from a compilation step, you seek another way to get feedback on your work. Unit testing is such a fast feedback mechanism. Watching the NodeJS community from the side, it always seemed to me that TDD is an integral way of working with that stack. This makes sense.
This also explains why e.g. C# programmers were more reluctant to adopt TDD. That your code compiles gives a smidgen of confidence.
C# and Java programmers may joke that if it compiles, it works, but also realise that that's all it is: a joke. Automated testing adds another layer of safety on top of compilation. On the other hand, you may get by with writing fewer tests than in a dynamic language, because the static type system does provide some guarantees.
What if you had a stronger type system than what C# or Java provides? Then you'd have to write even fewer tests.
Type spectrum #
It can be useful to think about typing as a spectrum.

To the left, we have dynamically typed languages like JavaScript and Ruby. Python can be compiled, and Clojure is compiled, so we can think of them as being a little closer to the middle. Purists would want to point out that whether or not a language is compiled and how statically typed it is are two independent concerns, but the point of this spectrum is to illustrate the degree of confidence the type system gives you.
Java and C# are statically typed, compiled languages, but a lot of things can still go wrong at run-time. Just consider all the null pointer exceptions you've encountered over the years.
Further to the right are languages with Hindley–Milner type systems, such as F# and Haskell. These offer more safety from static typing alone. Such types are the subject of this and future articles.
I've put Haskell a bit to the right of F# because it has higher-order types. To the right of Haskell sits dependently-typed languages like Idris. To the far right, we have a hypothetical language with such a strong type system that, indeed, if it compiles, it works. As far as I'm aware, no such language exist.
Creating software with Hindley-Milner type systems #
It turns out that when you shift from a Java/C#-style type system to the stronger type system offered by F# or Haskell, you can further shift your design emphasis towards designing with types. You still need to cover behaviour with automated tests, but fewer are necessary.
With the algebraic data types available in F# or Haskell, you can design your types so that illegal states are unrepresentable. In other words, all values of a particular type are guaranteed to be valid within the domain they model. This makes it much easier to test the behaviour of your system with Property-Based Testing, because you can declaratively state that you want your Property-Based Testing framework (FsCheck, QuickCheck, etc.) to provide random values of a given type. The framework will give you random values, but it can only give you valid values.
In this series of articles, you'll see an example of this in F#:
- Types + Properties = Software: designing with types
- Types + Properties = Software: state transition properties
- Types + Properties = Software: properties for the advantage state
- Types + Properties = Software: properties for the Forties
- Types + Properties = Software: composition
- Types + Properties = Software: initial state
- Types + Properties = Software: finite state machine
- Types + Properties = Software: other properties
Summary #
The stronger a language's type system is, the more you can use static types to model your application's problem domain. With a sufficiently strong type system, you can make illegal states unrepresentable. While states are guaranteed to be legal, transitions between states need not be. You can often use Property-Based Testing to ensure that the state transitions are correct. The combination of types and properties give you a simple, but surprisingly powerful way of specifying the behaviour of the software you create.
Are shuffled plays random?
Have you ever asked your music player to shuffle all your music, only to wonder: didn't it play that song only yesterday?
When I work, I often listen to music. Sometimes, I make a deliberate choice, but often, I just ask my music player to shuffle my entire music library.
It invariably happens that it plays a song it played only a couple of days before; I often notice when it's a song I don't like, because then it annoys me that it plays that stupid song again. Given that I have more than 16,000 tracks, and approximately 5,000 tracks on my laptop, it seems unlikely that the music player should pick the same track within only a few days.
This is a well-known phenomenon known as frequency illusion, or more colloquially as the Baader-Meinhof Phenomenon. Your brain seeks patterns, even where no patterns exist. This is a really strong feeling, it turns out.
When tracks are played in truly random fashion, it's as unlikely that it should play two tracks far apart as it should play them close together. Therefore, many media players come with shuffle algorithms that are not random, but designed to feel random.
With my thousands of tracks, I couldn't shake the feeling that my player's shuffle algorithm was one of those non-random algorithms, so I decided to analyse my plays.
Getting the data in shape #
Fortunately, I've been scrobbling my plays to Last.fm since 2007, so I had comprehensive statistics to work with.
There's a third-party service where you can download all your Last.fm scrobbles as a CSV file, so I did that; all 53,700 scrobbles.
This file contains all my scrobbles since 2007, but I had to clean it up:
- I haven't used the same music player in all those years, so I decide to only look at the entries since January 1, 2014. I know I've only used one player in that period.
- It often happens that I put on a particular artist, album, or playlist, and I had to remove those, because I wanted to look at only the entries when I was listening in shuffle mode.
Analysing with F# #
Next, I created an F# script file, and read in the file's contents:
open System open System.IO type Track = { Artist : string; Album : string; Name : string } type Scrobble = { Track : Track; Time : string } let parse (line : string) = match line.Split '|' with | [| artist; album; track; time |] -> Some { Track = { Artist = artist; Album = album; Name = track } Time = time } | _ -> None let scrobbles = File.ReadAllLines @"Last.fm_ploeh_shuffled.csv" |> Array.map parse
This script reads the file, with each line an element in an array. It then parses each line into Scrobble values. There may be parse errors, if a line contains the wrong number of elements, but this turned out to not be the case:
> let hasParseErrors = scrobbles |> Array.exists (Option.isNone);; val hasParseErrors : bool = false
The next step was to group the scrobbles into distinct tracks, with a count of each track:
let counts = scrobbles |> Array.choose id |> Array.countBy (fun s -> s.Track) |> Array.sortByDescending snd
This gave me a sorted 'hit list', showing me the songs played the most in the top of the list. Here's the top 10:
DJ Zen, Peace Therapy, Anamatha (Intro) : ....... Abakus, That Much Closer to the Sun, Igmatik : ....... Yoji Biomehanika, Technicolor Nrg Show, seduction (sleep tonight remix): ...... Mindsphere, Patience for Heaven. CD 2: Inner Cyclone, inner cyclone : ...... Massive Attack, Mezzanine, Black Milk : ...... Dimension 5, TransAddendum, Strange Phenomena : ...... Dire Straits, Brothers in Arms, Your Latest Trick : ...... Digicult, Out Of This World, Star Travel : ...... Infected Mushroom, Classical Mushroom, Bust A Move : ...... Brother Brown feat. Frank'ee, Under The Water, Under The Water (Or[...]: ......
None of these, with the exception of Under The Water, are particular favourites of mine, so I don't think these were tracks I'd definitely selected; remember: I'd made a deliberate effort to remove such tracks before starting the analysis.
This list tells me something, because I know what I like and don't like, but it doesn't tell me much about the distribution of tracks. The two most 'popular' tracks had been played 7 times over the last two years, and the remaining tracks 6 times. How about the other 5,155 entries in counts? How were they distributed?
It's easy to count how many tracks were played 7 times, how many were played 6 times, 5 times, etc.:
> let frequencyCounts = counts |> Array.countBy snd;; val frequencyCounts : (int * int) [] = [|(7, 2); (6, 9); (5, 43); (4, 159); (3, 561); (2, 1475); (1, 2916)|]
It looks as though the 'popular' tracks are rare occurrences. Most tracks (2,916) were played only once, and 1,475 only twice. This is perhaps easier to understand when visualised.
Visualisation #
While there are great visualisation packages for F#, for this ad-hoc task, I found it easier to use Excel. After all, I only had 7 observations to plot:
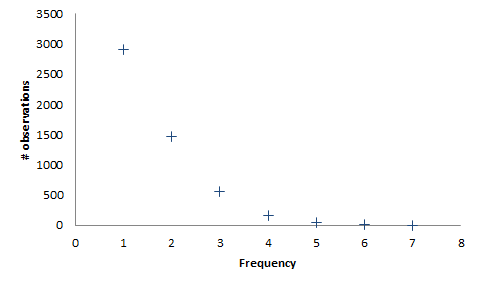
This figure shows that almost 3,000 tracks were scrobbled only once, approximately 1,500 were scrobbled twice, 500 or so were scrobbled thrice, and so on.
Even if we expect the distribution to be entirely uniform, we should expect to see duplicates. While I have more than 16,000 tracks on my home system, I only have some 5,000 tracks on my laptop, and these are the tracks for which I have data. Since I had 8,500 scrobbles to analyse, there must be duplicates, but we shouldn't expect to see two plays being more common than one, because even with an even distribution, you can't play all tracks twice when you have 5,000 tracks, but 'only' 8,500 plays.
That there are some 500 tracks that have been played three times don't seem unlikely in this light. Furthermore, outliers are to be expected as well; while they're there, the figure also shows that they promptly taper off to insignificance.
Although I took theoretical statistics in university (I had to), I never liked it, and got the lowest passing grade. In other words: don't trust any of this. I haven't formally analysed it with proper statistical tools.
Conclusion #
Still, based on this little Friday exercise, I now feel renewed confidence that my music player does, indeed, pick tracks at random when I tell it to play all songs shuffled.
Make pre-conditions explicit in Property-Based Tests
Pre-conditions are important in Property-Based Tests.
Last week, I was giving a workshop on Property-Based Testing, and we were looking at this test:
[<Property>] let ``Validate.reservation returns right result on invalid date`` (rendition : ReservationRendition) = let actual = Validate.reservation rendition let expected : Result<Reservation, Error> = Failure(ValidationError("Invalid date.")) test <@ expected = actual @>
The test case being exercised by this test is to verify what happens when the input (essentially a representation of an incoming JSON document) is invalid.
The System Under Test is this function:
module Validate = let reservation (rendition : ReservationRendition) = match rendition.Date |> DateTimeOffset.TryParse with | (true, date) -> Success { Date = date Name = rendition.Name Email = rendition.Email Quantity = rendition.Quantity } | _ -> Failure(ValidationError "Invalid date.")
The validation rule is simple: if the rendition.Date string can be parsed into a DateTimeOffset value, then the input is valid; otherwise, it's not.
If you run the test, if passes:
Output from Ploeh.Samples.BookingApi.UnitTests.ValidatorTests.Validate.reservation returns right result on invalid date: Ok, passed 100 tests.
Only, this test isn't guaranteed to pass. Can you spot the problem?
There's a tiny, but real, risk that the randomly generated rendition.Date string can be parsed as a DateTimeOffset value. While it's not particularly likely, it will happen once in a blue moon. This can lead to spurious false positives.
In order to see this, you can increase the number of test cases generated by FsCheck:
[<Property(MaxTest = 100000)>] let ``Validate.reservation returns right result on invalid date`` (rendition : ReservationRendition) = let actual = Validate.reservation rendition let expected : Result<Reservation, Error> = Failure(ValidationError("Invalid date.")) test <@ expected = actual @>
In my experience, when you ask for 100,000 test cases, the property usually fails:
Test 'Ploeh.Samples.BookingApi.UnitTests.ValidatorTests.Validate.reservation returns right result on invalid date' failed:
FsCheck.Xunit.PropertyFailedException :
Falsifiable, after 9719 tests (11 shrinks) (StdGen (1054829489,296106988)):
Original:
{Date = "7am";
Name = "6WUx;";
Email = "W";
Quantity = -5;}
Shrunk:
{Date = "7am";
Name = "";
Email = "";
Quantity = 0;}
---- Swensen.Unquote.AssertionFailedException : Test failed:
Failure (ValidationError "Invalid date.") = Success {Date = 15.01.2016 07:00:00 +00:00;
Name = "";
Email = "";
Quantity = 0;}
false
The problem is that the generated date "7am" can be parsed as a DateTimeOffset value:
> open System;; > DateTimeOffset.Now;; val it : DateTimeOffset = 15.01.2016 21:09:25 +00:00 > "7am" |> DateTimeOffset.TryParse;; val it : bool * DateTimeOffset = (true, 15.01.2016 07:00:00 +00:00)
The above test is written with the implicit assumption that the generated value for rendition.Date will always be an invalidly formatted string. As the Zen of Python reminds us, explicit is better than implicit. You should make that assumption explicit:
[<Property>] let ``Validate.reservation returns right result on invalid date`` (rendition : ReservationRendition) = not(fst(DateTimeOffset.TryParse rendition.Date)) ==> lazy let actual = Validate.reservation rendition let expected : Result<Reservation, Error> = Failure(ValidationError("Invalid date.")) test <@ expected = actual @>
This version of the test uses FsCheck's built-in custom operator ==>. This operator will only evaluate the expression on the right-hand side if the boolean expression on the left-hand side evaluates to true. In the unlikely event that the above condition evaluates to false, FsCheck is going to ignore that randomly generated value, and try with a new one.
This version of the test succeeds, even if you set MaxTest to 1,000,000.
The ==> operator effectively discards candidate values that don't match the 'guard' condition. You shouldn't always use this feature to constrain the input, as it can be wasteful. If the condition isn't satisfied, FsCheck will attempt to generate a new value that satisfies the condition. In this particular example, only in extremely rare cases will FsCheck be forced to discard a candidate value, so this use of the feature is appropriate.
In other cases, you should consider other options. Imagine that you want only even numbers. While you could write a 'guard' condition that ensures that only even numbers are used, that would cause FsCheck to throw away half of the generated candidates. In such cases, you should instead consider defining a custom Arbitrary, using FsCheck's API.
Another discussion entirely is whether the current behaviour is a good idea. If we consider tests as a feedback mechanism about software design, then perhaps we should explicitly specify the expected format. At the moment, the implementation is an extremely Tolerant Reader (because DateTimeOffset.TryParse is a Tolerant Reader). Perhaps it'd make sense to instead use TryParseExact. That's an API modelling decision, though, and might have to involve various other stakeholders than only programmers.
If you wish to learn more about Property-Based Testing with FsCheck, consider watching my Pluralsight course.
Tail Recurse
Tips on refactoring recursive functions to tail-recursive functions.
In a recent article, I described how to refactor an imperative loop to a recursive function. If you're coming from C# or Java, however, you may have learned to avoid recursion, since it leads to stack overflows when the recursion is too deep.
In some Functional languages, like F# and Haskell, such stack overflows can be prevented with tail recursion. If the last function call being made is a recursive call to the function itself, the current stack frame can be eliminated because execution is effectively completed. This allows a tail-recursive function to keep recursing without ever overflowing.
When you have a recursive function that's not tail recursive, however, it can sometimes be difficult to figure out how to refactor it so that it becomes tail recursive. In this article, I'll outline some techniques I've found to be effective.
Introduce an accumulator #
It seems as though the universal trick related to recursion is to introduce an accumulator argument. This is how you refactor an imperative loop to a recursive function, but it can also be used to make a non-tail-recursive function tail recursive. This will also require you to introduce an 'implementation function' that does the actual work.
Example: discarding candidate points when finding a convex hull #
In previous articles I've described various problems I had when implementing the Graham Scan algorithm to find the convex hull of a set of points.
One of my functions examined the three last points in a sequence of points in order to determine if the next-to-last point is in the interior of the set, or if that point could potentially be on the hull. If the point is positively known to be in the interior of the set, it should be discarded. At one stage, the function was implemented this way:
let tryDiscard points = let rec tryDiscardImp = function | [p1; p2; p3] when turn p1 p2 p3 = Direction.Right -> [p1; p3] | [p1; p2; p3] -> [p1; p2; p3] | p :: ps -> p :: tryDiscardImp ps | [] -> [] let newPoints = tryDiscardImp points if newPoints.Length <> points.Length then Some newPoints else None
This function was earlier called check, which is the name used in the article about refactoring to recursion. The tryDiscard function is actually an inner function in a more complex function that's defined with the inline keyword, so the type of tryDiscard is somewhat complicated, but think of it as having the type (int * int) list -> (int * int) list option. If a point was discarded, the new, reduced list of points is returned in a Some case; otherwise, None is returned.
The tryDiscard function already has an 'implementation function' called tryDiscardImp, but while tryDiscardImp is recursive, it isn't tail recursive. The problem is that in the p :: ps case, the recursive call to tryDiscardImp isn't the tail call. Rather, the stack frame has to wait for the recursive call tryDiscardImp ps to complete, because only then can it cons p onto its return value.
Since an 'implementation function' already exists, you can make it tail recursive by adding an accumulator argument to tryDiscardImp:
let tryDiscard points = let rec tryDiscardImp acc = function | [p1; p2; p3] when turn p1 p2 p3 = Direction.Right -> acc @ [p1; p3] | [p1; p2; p3] -> acc @ [p1; p2; p3] | p :: ps -> tryDiscardImp (acc @ [p]) ps | [] -> acc let newPoints = tryDiscardImp [] points if newPoints.Length <> points.Length then Some newPoints else None
As you can see, I added the acc argument to tryDiscardImp; it has the type (int * int) list (again: not really, but close enough). Instead of returning from each case, the tryDiscardImp function now appends points to acc until it reaches the end of the list, which is when it returns the accumulator. The p :: ps case now first appends the point in consideration to the accumulator (acc @ [p]), and only then recursively calls tryDiscardImp. This puts the call to tryDiscardImp in the tail position.
The repeated use of the append operator (@) is terribly inefficient, though, but I'll return to this issue later in this article. For now, let's take a step back.
Example: implementing map with recursion #
A common exercise for people new to Functional Programming is to implement a map function (C# developers will know it as Select) using recursion. This function already exists in the List module, but it can be enlightening to do the exercise.
An easy, but naive implementation is only two lines of code, using pattern matching:
let rec mapNaive f = function | [] -> [] | h::t -> f h :: mapNaive f t
Is mapNaive tail recursive? No, it isn't. The last operation happening is that f h is consed unto the return value of mapNaive f t. While mapNaive f t is a recursive call, it's not in the tail position. For long lists, this will create a stack overflow.
How can you create a tail-recursive map implementation?
Example: inefficient tail-recursive map implementation #
According to my introduction, adding an accumulator and an 'implementation' function should do the trick. Here's the straightforward application of that technique:
let mapTailRecursiveUsingAppend f xs = let rec mapImp f acc = function | [] -> acc | h::t -> mapImp f (acc @ [f h]) t mapImp f [] xs
The mapImp function does the actual work, and it's tail recursive. It appends the result of mapping the head of the list unto the accumulator: acc @ [f h]. Only then does it recursively call itself with the new accumulator and the tail of the list.
While this version is tail recursive, it's horribly inefficient, because appending to the tail of a (linked) list is inefficient. In theory, this implementation would never result in a stack overflow, but the question is whether anyone has the patience to wait for that to happen?
> mapTailRecursiveUsingAppend ((*) 2) [1..100000];; Real: 00:02:46.104, CPU: 00:02:44.750, GC gen0: 13068, gen1: 6380, gen2: 1 val it : int list = [2; 4; 6; 8; 10; 12; 14; 16; 18; 20; 22; 24; 26; 28; 30; 32; 34; 36; ...]
Doubling 100,000 integers this way takes nearly 3 minutes on my (admittedly mediocre) laptop. A better approach is required.
Example: efficient tail-recursive map implementation #
The problem with mapTailRecursiveUsingAppend is that appending to a list is slow when the left-hand list is long. This is because lists are linked lists, so the append operation has to traverse the entire list and copy all the element to link to the right-hand list.
Consing a single item unto an existing list, on the other hand, is efficient:
let mapTailRecursiveUsingRev f xs = let rec mapImp f acc = function | [] -> acc | h::t -> mapImp f (f h :: acc) t mapImp f [] xs |> List.rev
This function conses unto the accumulator (f h :: acc) instead of appending to the accumulator. The only problem with this is that acc is in reverse order compared to the input, so the final step must be to reverse the output of mapImp. While there's a cost to reversing a list, you pay it only once. In practice, it turns out to be efficient:
> mapTailRecursiveUsingRev ((*) 2) [1..100000];; Real: 00:00:00.017, CPU: 00:00:00.015, GC gen0: 1, gen1: 0, gen2: 0 val it : int list = [2; 4; 6; 8; 10; 12; 14; 16; 18; 20; 22; 24; 26; 28; 30; 32; 34; 36; ...]
From nearly three minutes to 17 milliseconds! That's a nice performance improvement.
The only problem, from a point of view where learning is in focus, is that it feels a bit like cheating: we've delegated an important step in the algorithm to List.rev. If we think it's OK to use the library functions, we could have directly used List.map. The whole point of this exercise, however, is to learn something about how to write tail-recursive functions.
At this point, we have two options:
- Learn how to write an efficient, tail-recursive implementation of
rev. - Consider alternatives.
Example: efficient tail-recursive map using a difference list #
The mapTailRecursiveUsingAppend function is attractive because of its simplicity. If only there was an efficient way to append a single item to the tail of a (long) list, like acc appendSingle (f h)! (appendSingle is a hypothetical function that we wish existed.)
So far, we've treated data as data, and functions as functions, but in Functional Programming, functions are data as well!
What if we could partially apply a cons operation?
Unfortunately, the cons operator (::) can't be used as a function, so you'll have to introduce a little helper function:
// 'a -> 'a list -> 'a list let cons x xs = x :: xs
This enables you to partially apply a cons operation:
> cons 1;; val it : (int list -> int list) = <fun:it@4-5>
The expression cons 1 is a function that awaits an int list argument. You can, for example, call it with the empty list, or another list:
> (cons 1) [];; val it : int list = [1] > (cons 1) [2];; val it : int list = [1; 2]
That hardly seems useful, but what happens if you start composing such partially applied functions?
> cons 1 >> cons 2;; val it : (int list -> int list) = <fun:it@7-8>
Notice that the result is another function with the same signature as cons 1. A way to read it is: cons 1 is a function that takes a list as input, appends the list after 1, and returns that new list. The return value of cons 1 is passed to cons 2, which takes that input, appends that list after 2, and returns that list. Got it? Try it out:
> (cons 1 >> cons 2) [];; val it : int list = [2; 1]
Not what you expected? Try going through the data flow again. The input is the empty list ([]), which, when applied to cons 1 produces [1]. That value is then passed to cons 2, which puts 2 at the head of [1], yielding the final result of [2; 1].
This still doesn't seem to help, because it still reverses the list. True, but you can reverse the composition:
> (cons 2 >> cons 1) [];; val it : int list = [1; 2] > (cons 1 << cons 2) [];; val it : int list = [1; 2]
Notice that in the first line, I reversed the composition by changing the order of partially applied functions. This, however, is equivalent to keeping the order, but using the reverse composition operator (<<).
You can repeat this composition:
> (cons 1 << cons 2 << cons 3 << cons 4) [];; val it : int list = [1; 2; 3; 4]
That's exactly what you need, enabling you to write acc << (cons (f h)) in order to efficiently append a single element to the tail of a list!
let mapTailRecursiveUsingDifferenceList f xs = let cons x xs = x :: xs let rec mapImp f acc = function | [] -> acc [] | h::t -> mapImp f (acc << (cons (f h))) t mapImp f id xs
This implementation of map uses this technique, introduced by John Hughes in 1985. Real World Haskell calls the technique a difference list, without explaining why.
This mapImp function's accumulator is no longer a list, but a function. For every item, it composes a new accumulator function from the old one, effectively appending the mapped item to the tail of the accumulated list. Yet, because acc isn't a list, but rather a function, the 'append' operation doesn't trigger a list traversal.
When the recursive function finally reaches the end of the list (the [] case), it invokes the acc function with the empty list ([]) as the initial input.
This implementation is also tail recursive, because the accumulator is being completely composed (acc << (cons (f h))) before mapImp is recursively invoked.
Is it efficient, then?
> mapTailRecursiveUsingDifferenceList ((*) 2) [1..100000];; Real: 00:00:00.024, CPU: 00:00:00.031, GC gen0: 1, gen1: 0, gen2: 0 val it : int list = [2; 4; 6; 8; 10; 12; 14; 16; 18; 20; 22; 24; 26; 28; 30; 32; 34; 36; ...]
24 milliseconds is decent. It's not as good as mapTailRecursiveUsingRev (17 milliseconds), but it's close.
In practice, you'll probably find that mapTailRecursiveUsingRev is not only more efficient, but also easier to understand. The advantage of using the difference list technique, however, is that now mapImp has a shape that almost screams to be refactored to a fold.
Example: implementing map with fold #
The mapImp function in mapTailRecursiveUsingDifferenceList almost has the shape required by the accumulator function in List.fold. This enables you to rewrite mapImp using fold:
let mapUsingFold f xs = let cons x xs = x :: xs let mapImp = List.fold (fun acc h -> acc << (cons (f h))) id mapImp xs []
As usual in Functional Programming, the ultimate goal seems to be to avoid writing recursive functions after all!
The mapUsingFold function is as efficient as mapTailRecursiveUsingDifferenceList:
> mapUsingFold ((*) 2) [1..100000];; Real: 00:00:00.025, CPU: 00:00:00.031, GC gen0: 2, gen1: 1, gen2: 1 val it : int list = [2; 4; 6; 8; 10; 12; 14; 16; 18; 20; 22; 24; 26; 28; 30; 32; 34; 36; ...]
Not only does 25 milliseconds seem fast, but it's also comparable with the performance of the built-in map function:
> List.map ((*) 2) [1..100000];; Real: 00:00:00.011, CPU: 00:00:00.015, GC gen0: 0, gen1: 0, gen2: 0 val it : int list = [2; 4; 6; 8; 10; 12; 14; 16; 18; 20; 22; 24; 26; 28; 30; 32; 34; 36; ...]
Granted, List.map seems to be twice as fast, but it's also been the subject of more scrutiny than the above fun exercise.
Summary #
In Functional Programming, recursive functions take the place of imperative loops. In order to be efficient, they must be tail recursive.
You can make a function tail recursive by introducing an accumulator argument to an 'implementation function'. This also tends to put you in a position where you can ultimately refactor the implementation to use a fold instead of explicit recursion.
Integration Testing composed functions
When you build a system from small functions that you subsequently compose, how do you know that the composition works? Integration testing is one option.
Despite its reputation as a niche language for scientific or finance computing, F# is a wonderful language for 'mainstream' software development. You can compose applications from small, inherently testable functions.
Composition #
Once you have your functions as building blocks, you compose them. This is best done in an application's Composition Root - no different from Dependency Injection in Object-Oriented Programming.
In my (free) Build Stuff talk on Functional TDD with F# (expanded version available on Pluralsight), I demonstrate how to compose such a function:
let imp = Validate.reservation >> bind (Capacity.check 10 (SqlGateway.getReservedSeats connectionString)) >> map (SqlGateway.saveReservation connectionString)
How can you be sure that this composition is correct?
Integration Testing #
The answer to that question isn't different from its Object-Oriented counterpart. When you implement small building blocks, you can test them. Call these small building blocks units, and it should be clear that such tests are unit tests. It doesn't matter if units are (small) classes or functions.
Unit testing ought to give you confidence that each unit behaves correctly, but unit tests don't tell you how they integrate. Are there issue that only surface when units interact? Are units correctly composed?
In my experience, you can develop entire systems based exclusively on unit tests, and the final application can be stable and sturdy without the need for further testing. This depends on circumstances, though. In other cases, you need further testing to gain confidence that the application is correctly composed from its building blocks.
You can use a small set of integration tests for that.
Example #
In my Outside-In Test-Driven Development Pluralsight course, I demonstrate how to apply the GOOS approach to an HTTP API built with ASP.NET Web API. One of the techniques I describe is how to integration test the API against its HTTP boundary.
In that course, you learn how to test an API implemented in C#, but since the tests are made against the HTTP boundary, the implementation language doesn't matter. Even so, you can also write the tests themselves in F#. Here's an example that exercises the Controller that uses the above imp function:
[<Fact; UseDatabase>] let ``Post returns success`` () = use client = createClient() let json = ReservationJson.Root("2014-10-21", "Mark Seemann", "x@example.com", 4) let response = client.PostAsJsonAsync("reservations", json).Result test <@ response.IsSuccessStatusCode @>
This test creates a new HttpClient object called client. It then creates a JSON document with some reservation data, and POSTs it to the reservations resource. Finally, it verifies that the response indicated a success.
The ReservationJson type was created from a sample JSON document using the JSON Type Provider. The createClient function is a bit more involved, but follows the same recipe I describe in my course:
let createClient () = let baseAddress = Uri "http://localhost:8765" let config = new HttpSelfHostConfiguration(baseAddress) configure connStr config config.IncludeErrorDetailPolicy <- IncludeErrorDetailPolicy.Always let server = new HttpSelfHostServer(config) let client = new HttpClient(server) client.BaseAddress <- baseAddress client
The (impure) configure function is a function defined by the application implementation. Among many other things, it creates the above imp composition. When the test passes, you can trust that imp is correctly composed.
Smoke Testing #
You may already have noticed that the ``Post returns success`` test is course-grained and vague. It doesn't attempt to make strong assertions about the posterior state of the system; if the response indicates success, the test passes.
The reason for this is that all important behaviour is already covered by unit tests.
- Is the response specifically a 201 (Created) response? Covered by unit tests.
- Does the response have a Location header indicating the address of a newly created resource? Covered by unit test.
- What happens if the input is malformed? Covered by unit tests.
- What happens if the system can't accept the request due to business rules? Covered by unit tests.
- ...and so on.
Specifically, it has been my experience that the most common integration issues are related to various configuration errors:
- Missing configuration values
- Wrong configuration values
- Network errors
- Security errors
- ... etc.
In other words: you should have a legion of unit tests covering specific behaviour, and a few integration tests covering common integration issues. You may already have recognised this principle as the Test Pyramid.
Summary #
In this article, you saw an example of an integration test against an HTTP API, written in F#. The principle is universal, though. You can compose applications from units. These units can be functions written in F#, or Haskell, or Scala, or they can be classes written in C#, Java, Python, and so on. Composition can be done on functions, or on objects using Dependency Injection.
In all of these cases, you can cover the units with unit tests. Issues with composition can be screened by a few smoke tests at the integration level.
The Rules of Attraction: Location
Widen your hiring pool to the entire world; you won't believe what happens next.
Every week in my Twitter stream, there's some enticing offer:
NoWare is looking for strong F# or Haskell developers with experience in TDD, property-based testing, object-oriented design, REST, and software architecture.For half a second I go: "Oh, man, that's so much a description of me! This sounds terrific!" But then, with small letters, it says: "Must be willing to relocate to Sauda."
Oh.
If your company is based in London, New York, Silicon Valley, Seattle, and perhaps a few other places, I can even understand that attitude. The local 'talent pool' is already big in those places, and more people are willing to move there for work.
In most other areas, I find that attitude towards hiring programmers lazy and self-centred.
As an example, consider Copenhagen, where I live. The greater metropolitan area is home to some 3.5 million people, so you'd think it was possible to find programmers to hire. Yet, every employer here whines that it's too hard to find developers.
While Copenhagen is nice enough, I can understand if the majority of the world's programmers aren't itching to move here. Apparently, this place is only attractive if you live in Afghanistan, Somalia, Nigeria, Syria, or some other horrible place.
All digital #
The outcome of programming is software, a 100% immaterial, digital product. Source code, as well, is entirely digital. Documentation, if it exists, tends to be digital. Source control systems are networked. Developers shouldn't have physical access to production servers.
Why do programmers need to be physically present?
Tacit knowledge #
I think I know why programmers need to be physically present in many organisations. It's because all the knowledge of 'how things are done' is in the heads of people.
- How do I configure my development machine? Ask Joe; he can tell you.
- What's the password to the CI server? Call Kathy in the satellite office. Maybe she knows.
- How do I find the logs related to this bug I was asked to fix? Go and talk to Jane. She can show you.
- Why did we build our own ORM, instead of using Entity Framework? Uhm, yeah, there was this lead developer, Rick... He's no longer with the company...
- Would anyone mind if I add an extra argument to the BloobedlyBloo method? Sure, go right ahead!
- How are we going to address this new feature request? I don't know. Let's have a meeting!
- What's the status of the Foo component? I don't know. Let's have a meeting!
- Is there any way to prevent the back-office developers from accessing our database directly? Probably not, but let's have a meeting!
Perhaps organisations that work that way are effective, but it doesn't scale. Every time a new team member or stakeholder joins the project, someone needs to take time bringing him or her up to speed. The more people in the organisation, the worse it becomes.
At one time I worked in an organisation that operated like that. I'd have meeting upon meeting about particular topics. The next week, I'd have the same meetings again, because a new stakeholder wanted to get involved. Nothing new happened; nothing new was decided, but it was necessary, because nothing was written down. Lots of time was wasted.
That's when I started writing documentation and meeting minutes. Not that I enjoyed doing that, but it saved me time. The next time someone came and asked me to sit in on a meeting, I'd forward the minutes and documentation and ask people to read that instead.
Conway's law #
Imagine that you could hire programmers from all over the world. Not only within driving distance of your offices, but from the entire world. Just think of the supply of developers you'd be able to choose from. You can literally select from among the world's best programmers, if you're willing to pay the price. Some companies, like Stack Overflow, GitHub, Basecamp, and Basho, already do this, with great success.
It's only going to work, though, if your organisation is set up for it. Processes must be written down. Decisions must be documented. Work must be asynchronous, in order to accommodate people in different time zones. You can't easily have meetings, so you'll need to discuss strategy, architecture, design, etc. using collaborative online tools.
If your organisation doesn't already work like that, you'll have to transform it. Software development with distributed teams can work, but only if you enable it. The good news is that there's plenty of publicly available examples on how to do this: just find your favourite open source project, and study how it's organised. Most open source is written by programmers from all over the world, at various times, and yet it still works.
As a modest example, my own experience with AutoFixture has taught me a thing or two about running a distributed project. Contributors have submitted code from Australia, South Korea, USA, Greece, England, Denmark, Sweden, Russia, and lots of other countries. Discussions happen in the open, in GitHub issues.
You'll most likely find that if you can get distributed development to work, your software architecture, too, will become more and more distributed and asynchronous in nature. This is Conway's law: organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations.
If your organisation is based on ad hoc ephemeral communication and impromptu meetings, your software will have no clear communication structures either. There's a word for that kind of software architecture.
If, on the other hand, you set yourself up for distributed development teams, you'll be forced to make the communication channels clearer - both in your organisation, and in your software. This will enable you to scale your development organisation.
Summary #
You can claim that you're a 'world-class' organisation that hires only the best of the best (within a radius of 100 km).
Or you can be a world-class organisation by literally having developers working all over the world. You still need to be able to find the best, though. Perhaps you should try to let them find you instead.
The Rules of Attraction: Language
How to attract the best developers to your organisation, with one weird trick.
In a 2009 interview, Anders Hejlsberg, the inventor of C#, Turbo Pascal, TypeScript, etc. said:
"Well, you know, platforms live maybe 10, 15 years and then they cave in under their own weight, one way or the other."C# is now 15 years old; Java: 20 years.
You don't have to believe that Anders Hejlsberg is right, though. After all, COBOL is still in use, 56 years after its invention. One of the world's most popular languages, C++, is 32 years old, and C is 43 years old. Still, it's food for thought.
When I consult and advise, I often encounter organisations that standardise on C# or Java. When I try to tell CTOs and development leads about the benefits of adopting 'new' languages like F# (10 years), Haskell (25 years), Clojure (8 years), Erlang (29 years), or Scala (11 years), the response is always the same:
"How will I find developers?"That's the easiest thing in the world!
In the early 2000s, Java was already getting close to 10 years old, and some programmers were beginning to look for the next cool technology. They found it in Python, and for a while, Python was perceived as the cutting edge.
In the late 2000s, C# 'alpha developers' migrated to Ruby en masse. It became so bad that I'm-leaving-.NET blog posts became a cliché.
In the early 2010s, the main attraction has been Node.js, and JavaScript in general.
Let's not forget those of us who have fallen in love with F#, Clojure, Haskell, Elixir, etc.
The most curious developers eventually get tired of using the same programming language year in and year out. Those first-movers that migrated to Python 10 years ago are already on to the next language. The same goes for the Rubyists.
Finding F#, Clojure, Elixir, etc. developers is the easiest thing in the world. The most important thing you can do as an organisation is to say:
"We wish to hire F# developers!", or Clojure developers, Haskell developers, etc.
You don't have to find such developers; make them find you.
Although there are few of these developers out there, they are easy to attract. This is called the Python Paradox, after the early 2000 Python migration.
Not only is it easy to attract developers for such 'new' languages, you also get the most progressive, curious, motivated, enthusiastic programmers. That's the 'talent' all companies seem to be pining for these days.
Some programmers will even accept a decrease in income, only for the chance to get to work with a technology they love.
You'll probably also get some difficult-to-work-with primadonnas who are gone again after three years... TANSTAAFL.
The crux of the matter is that the argument that you can't find developers for a particular cool language doesn't hold.
Recurse
How to refactor from a loop using mutable state to a recursive implementation.
One of the most compelling reasons to adopt Functional Programming (FP) is the emphasis on immutable values. All the dread and angst associated with state that can implicitly change while you're not looking, is gone.
One of the most frustrating aspects of FP for people coming from other paradigms is the emphasis on immutable values. You know that you ought to be able to implement a given algorithm using immutable values, but given your background in Object-Oriented Programming, you can't quite figure out how to do it.
In FP, loops are implemented with recursion, and mutable values are replaced with accumulator arguments. This article describes how to refactor from a procedural, mutable loop implementation to a pure, tail-recursive implementation.
Motivation #
You want your loop implementation to be 'Functional' instead of procedural. There can be many reasons for this. Perhaps you want to learn FP. Perhaps you want to eliminate mutable state in order to make your implementation thread-safe. Perhaps you think that getting rid of mutation will make the code more readable and maintainable. Perhaps you want to port your implementation to a language that doesn't support mutability at all (like Haskell).
Mechanics #
Start with a procedural implementation, using a mutable loop variable. This obviously only works in multi-paradigmatic languages where mutable variables are possible, even if they're not ideal. Examples include F#, Scala, and Clojure, but not Haskell, which isn't multi-paradigmatic.
- Instead of your imperative loop, introduce a recursive function.
- Replace each mutable loop variable with an argument for the recursive function.
Example: backspace characters #
Imagine that you receive a stream of characters from someone typing on a keyboard. Sometimes, the typist mistypes and uses the backspace key, which sends the character '\b'. Whenever you encounter '\b', you should remove the preceding character, as well as the backspace character itself. This example is based on this Stack Overflow question.
The original F# implementation is procedural, using a for loop and a single mutable variable:
open System open System.Collections.Generic let handleBackspaces textToProcess : string = let stack = Stack<char>() for c in textToProcess do if c = '\b' then stack.Pop() |> ignore else stack.Push c stack |> Seq.rev |> Seq.toArray |> String
While this implementation doesn't explicitly use the mutable keyword, the stack variable is mutable because Stack<T> is mutable. Since textToProcess is a string, and string implements IEnumerable<char>, you can loop over each char value, pushing the value on the stack unless it's a backspace character; in that case, the previous value is instead popped and thrown away.
According to the rules of the Recurse refactoring, you should introduce a recursive function instead of the loop, and add an argument that will replace the stack. To make it easy, call the recursive function imp, and the function argument acc. The name acc is popular; it's short for accumulator. This argument is used to accumulate the final value, just like stack in the above example.
let handleBackspaces' textToProcess : string = let rec imp acc = function | [] -> acc | '\b'::cs -> imp (acc |> List.tail) cs | c::cs -> imp (c::acc) cs textToProcess |> Seq.toList |> imp [] |> List.rev |> List.toArray |> String
The imp function is declared with the rec keyword to mark it as a recursive function. It has the type char list -> char list -> char list. acc is a char list, which is also the case for the second argument implied by the function keyword. The function returns the accumulator if the input list is empty; otherwise, it matches on the head of the list. If the head is explicitly the backspace character, the imp function calls itself recursively, but replaces acc with the tail of acc; it uses List.tail to get the tail. This effectively removes the most recent character from the accumulator. In all other cases, the function also calls itself by consing c on acc.
The imp function is tail-recursive, since all other values are already computed when a recursive call to imp takes place.
You can further refactor this implementation to use a fold instead of a recursive function.
Example: Graham Scan #
This second example is a more complex example that further illustrates how to apply the Recurse refactoring. If you already feel that you understand how to apply this refactoring, you can skip reading the following example.
Some time ago, I was attempting to implement the Graham Scan algorithm to find the convex hull for a set of points. As I've described before, this turned out to be quite difficult for me. One of my problems was that I was trying to implement the algorithm in Haskell, and while I understood the algorithm, I couldn't figure out how to implement it in a functional way - and when you can't do it the functional way, you can't do it at all in Haskell.
In F#, on the other hand, you can implement algorithms using procedural code if you must, so I decided to implement the algorithm in F# first, using a procedural approach, and then subsequently figure out how to refactor to immutable values. Once I had a pure F# implementation, I could always back-port it to Haskell.
This is one of the reasons I think F# is a better language for learning FP if you come from an Object-Oriented background: you can gradually refactor towards more Functional implementations as you become better at FP.
The part that caused me particular difficulty was the scan part, where the algorithm examines all points to identify which points to discard from the hull (because they're in the interior of the hull, and not on the hull).
After sorting all candidates according to special rules, the algorithm must consider each point in turn. If that new point is 'to the right' of the previous two points, the previous point is in the interior of the hull and should be discarded. The previous-to-previous point could also be 'to the right' of the new point, so the algorithm needs to check again, and so on.
My imperative solution looked like this:
let inline hullPoints points = let mutable ps = [] for p in points do ps <- ps @ [p] let mutable shouldCheck = true while shouldCheck do let wasDiscarded, newPoints = check ps shouldCheck <- wasDiscarded if wasDiscarded then ps <- newPoints ps
(You can see the full code base on GitHub. The start is at 5290abd3c31c162ee6c4b21b82494ce97ecf7fa5, and the end state that this post describes is at e3efd1b457a46112cff6f06b8cbb100d153f0ef1.)
Due to the inline keyword, the hullPoints function has a complex type, but for practical purposes, think of it as having the type (int * int) seq -> (int * int) list. The points argument is a sequence of coordinates: (int * int) seq.
As you can see, this implementation has a nested loop. The outer loop traverses all points and appends the point in consideration to the mutable list variable ps. At this stage, p is only a candidate. What the algorithm must now determine is whether p is in the interior or might be a hull point.
In order to do that, it calls another function called check. The check function is another inline function, but you can think about it as having the type (int * int) list -> bool * (int * int) list. The return type is peculiar, but the idea is that it returns true in the first tuple element if points were discarded from the input, and false if no points were discarded. The second tuple element contains the points (that may or may not have had points removed compared to the input points). (I later refactored this function to a function called tryDiscard with the type (int * int) list -> (int * int) list option.)
If points were discarded, the algorithm must check again, as there may be more points to discard. Only when no more points were discarded can the outer loop move on to the next candidate.
According to the Recurse refactoring, you need to define a recursive function for each loop. There are two loops here, but do the inner loop first. Each mutable variable should be replaced with a function argument, but fortunately there's only one:
let inline hullPoints points = let rec update candidates = let wasDiscarded, newCandidates = check candidates if wasDiscarded then update newCandidates else candidates let mutable candidates = [] for p in points do candidates <- candidates @ [p] candidates <- update candidates candidates
The new update function calls the check function. If wasDiscarded is true, it calls itself recursively with the new candidates; otherwise, it returns the input candidates.
The update function is now a recursive function without mutable variables, but the containing hullPoints function still has a mutable candidates variable. You'll need to apply the Recursive refactoring again:
let hullPoints points = let rec update candidates = let wasDiscarded, newCandidates = check candidates if wasDiscarded then update newCandidates else candidates let rec hpImp candidates = function | [] -> candidates | p :: tail -> let cs = candidates @ [p] let updatedCandidates = update cs hpImp updatedCandidates tail hpImp [] points
The hpImp function replaces the remaining loop, and candidates is now a function argument instead of mutable variable.
As long as candidates has contents, the head of the list p is appended to candidates, and update is invoked. Subsequently, hpImp is invoked recursively with the updated candidates and the tail of the list.
The hullPoints function returns the value of calling hpImp with empty hull candidates, and the points argument. This implementation has no mutable variables.
You can refactor this implementation to make it more readable, but that's not the point of this article. You can see what I then did in the GitHub repository.
(Now that I had a pure implementation, I could also port it to Haskell, which met my original goal.)
Summary #
For programmers used to imperative programming, it can be difficult to apply pure Functional techniques. When you have loops that update a mutable variable in each step of the loop, you can refactor to use a recursive function; the mutable variable is replaced with a function argument. When you've tried it a couple of times, you'll get the hang of it.
Once you have a recursive function with an accumulator argument, you can often further refactor it to use a fold, instead of a recursive function.
(This post is the December 1st entry in the 2015 F# Advent Calendar.)

Comments
I verified the behavior you showed for
mapTailRecursiveUsingDifferenceListandmapUsingFold: when executed in the F# Interactive window, both functions have the correct behavior. I further verified that both functions have the same correct behavior when executed as a unit test compiled inRELEASEmode. However, when executed as a unit test compiled inDEBUGmode, both tests fail (technically aborted when using XUnit) because each overflows the stack. In contrast,List.maphas the correct behavior in all three situations.I haven't tested the same in Haskell. I don't even know if Haskell has complication modes like
DEBUGandRELEASE.Do you know how to implement
mapforlistin F# so that it does not stack overflow the stack even when executed inDEBUGmode? Of course your functionmapTailRecursiveUsingRevachieves that goal. The problem that I actually want to solve is figure out how to implementmapfor the type'a -> 'bas a (covariant) functor in'bin such a way that the stack does not overflow. See this issue for more details. I am thinking that seeing such amapfunction implemented forlistwithout usingList.revwill help me figure out how to correctly implement this for the type'a -> 'bas a (covariant) functor in'b.Oh, that code partially answers my question. First, that is legacy code now. The current version is hosted in the dotnet/fsharp repository. Then
List.mapdelegates toMicrosoft.FSharp.Primitives.Basics.List.map, which, by way ofmapToFreshConsTailcalls the impure functionsetFreshConsTailthat is allowed to mutate the tail pointer of a cons cell.List.mapis "twice as fast" because it does "half as much work".mapUsingFoldcallsList.fold, which executes in linear time, to essentially compute the elements that will be in the final list. Then it callsmapImp, which also executes in linear time, to construct that final list. In contrast,List.mapdoes both of those in one pass with its ability to mutate the tail pointer of a cons cell.I wonder if I can use mutability in a similarly pure way to achieve my goal. **Goes away to think**
To avoid overflowing the stack, it is a necessary condition that all recursive calls are tail calls. However, this is not sufficient. In
mapTailRecursiveUsingDifferenceList, it is crucial (at least in F#) that the function compositionacc << (cons (f h))(which I prefer to write as(cons (f h)) >> acc) happened in that order. If John Hughes had designed the code differently so that the composition wasacc >> (cons (f h))(which, as you demonstrated, would be the correct output if only this change were made except with the order reversed), then the stack would still overflow even though all recursive fucntions only involve tail calls. See this comment for more information.I figured out how to use the difference list technique to avoid overflowing the stack when composing on the right. See this comment. I wonder if my implementation can be simplified. This problem of avoiding stack overflows when composing on the right has to be a standard problem with a well-known answer.
Thanks for being a great place for me to share this partial stream of consciousness that I have had over the last couple days.
P.S. You can simplify
mapTailRecursiveUsingDifferenceLista bit. The local functionmapImpis always given the same value off. Therefore, this arguemnt can be removed (since the samefis also in scope). The resulting code does not overflow the stack (which, again, is a stronger statement than staying that all recursive calls inmapImpare tail calls). You essentially made this simplification when you implementedmapUsingFold.Tyson, thank you for writing. I have to admit that I've now lost track... Did you manage to unravel all you wanted to know by yourself, or is there still a question left?