ploeh blog danish software design
The Rules of Attraction: Location
Widen your hiring pool to the entire world; you won't believe what happens next.
Every week in my Twitter stream, there's some enticing offer:
NoWare is looking for strong F# or Haskell developers with experience in TDD, property-based testing, object-oriented design, REST, and software architecture.For half a second I go: "Oh, man, that's so much a description of me! This sounds terrific!" But then, with small letters, it says: "Must be willing to relocate to Sauda."
Oh.
If your company is based in London, New York, Silicon Valley, Seattle, and perhaps a few other places, I can even understand that attitude. The local 'talent pool' is already big in those places, and more people are willing to move there for work.
In most other areas, I find that attitude towards hiring programmers lazy and self-centred.
As an example, consider Copenhagen, where I live. The greater metropolitan area is home to some 3.5 million people, so you'd think it was possible to find programmers to hire. Yet, every employer here whines that it's too hard to find developers.
While Copenhagen is nice enough, I can understand if the majority of the world's programmers aren't itching to move here. Apparently, this place is only attractive if you live in Afghanistan, Somalia, Nigeria, Syria, or some other horrible place.
All digital #
The outcome of programming is software, a 100% immaterial, digital product. Source code, as well, is entirely digital. Documentation, if it exists, tends to be digital. Source control systems are networked. Developers shouldn't have physical access to production servers.
Why do programmers need to be physically present?
Tacit knowledge #
I think I know why programmers need to be physically present in many organisations. It's because all the knowledge of 'how things are done' is in the heads of people.
- How do I configure my development machine? Ask Joe; he can tell you.
- What's the password to the CI server? Call Kathy in the satellite office. Maybe she knows.
- How do I find the logs related to this bug I was asked to fix? Go and talk to Jane. She can show you.
- Why did we build our own ORM, instead of using Entity Framework? Uhm, yeah, there was this lead developer, Rick... He's no longer with the company...
- Would anyone mind if I add an extra argument to the BloobedlyBloo method? Sure, go right ahead!
- How are we going to address this new feature request? I don't know. Let's have a meeting!
- What's the status of the Foo component? I don't know. Let's have a meeting!
- Is there any way to prevent the back-office developers from accessing our database directly? Probably not, but let's have a meeting!
Perhaps organisations that work that way are effective, but it doesn't scale. Every time a new team member or stakeholder joins the project, someone needs to take time bringing him or her up to speed. The more people in the organisation, the worse it becomes.
At one time I worked in an organisation that operated like that. I'd have meeting upon meeting about particular topics. The next week, I'd have the same meetings again, because a new stakeholder wanted to get involved. Nothing new happened; nothing new was decided, but it was necessary, because nothing was written down. Lots of time was wasted.
That's when I started writing documentation and meeting minutes. Not that I enjoyed doing that, but it saved me time. The next time someone came and asked me to sit in on a meeting, I'd forward the minutes and documentation and ask people to read that instead.
Conway's law #
Imagine that you could hire programmers from all over the world. Not only within driving distance of your offices, but from the entire world. Just think of the supply of developers you'd be able to choose from. You can literally select from among the world's best programmers, if you're willing to pay the price. Some companies, like Stack Overflow, GitHub, Basecamp, and Basho, already do this, with great success.
It's only going to work, though, if your organisation is set up for it. Processes must be written down. Decisions must be documented. Work must be asynchronous, in order to accommodate people in different time zones. You can't easily have meetings, so you'll need to discuss strategy, architecture, design, etc. using collaborative online tools.
If your organisation doesn't already work like that, you'll have to transform it. Software development with distributed teams can work, but only if you enable it. The good news is that there's plenty of publicly available examples on how to do this: just find your favourite open source project, and study how it's organised. Most open source is written by programmers from all over the world, at various times, and yet it still works.
As a modest example, my own experience with AutoFixture has taught me a thing or two about running a distributed project. Contributors have submitted code from Australia, South Korea, USA, Greece, England, Denmark, Sweden, Russia, and lots of other countries. Discussions happen in the open, in GitHub issues.
You'll most likely find that if you can get distributed development to work, your software architecture, too, will become more and more distributed and asynchronous in nature. This is Conway's law: organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations.
If your organisation is based on ad hoc ephemeral communication and impromptu meetings, your software will have no clear communication structures either. There's a word for that kind of software architecture.
If, on the other hand, you set yourself up for distributed development teams, you'll be forced to make the communication channels clearer - both in your organisation, and in your software. This will enable you to scale your development organisation.
Summary #
You can claim that you're a 'world-class' organisation that hires only the best of the best (within a radius of 100 km).
Or you can be a world-class organisation by literally having developers working all over the world. You still need to be able to find the best, though. Perhaps you should try to let them find you instead.
The Rules of Attraction: Language
How to attract the best developers to your organisation, with one weird trick.
In a 2009 interview, Anders Hejlsberg, the inventor of C#, Turbo Pascal, TypeScript, etc. said:
"Well, you know, platforms live maybe 10, 15 years and then they cave in under their own weight, one way or the other."C# is now 15 years old; Java: 20 years.
You don't have to believe that Anders Hejlsberg is right, though. After all, COBOL is still in use, 56 years after its invention. One of the world's most popular languages, C++, is 32 years old, and C is 43 years old. Still, it's food for thought.
When I consult and advise, I often encounter organisations that standardise on C# or Java. When I try to tell CTOs and development leads about the benefits of adopting 'new' languages like F# (10 years), Haskell (25 years), Clojure (8 years), Erlang (29 years), or Scala (11 years), the response is always the same:
"How will I find developers?"That's the easiest thing in the world!
In the early 2000s, Java was already getting close to 10 years old, and some programmers were beginning to look for the next cool technology. They found it in Python, and for a while, Python was perceived as the cutting edge.
In the late 2000s, C# 'alpha developers' migrated to Ruby en masse. It became so bad that I'm-leaving-.NET blog posts became a cliché.
In the early 2010s, the main attraction has been Node.js, and JavaScript in general.
Let's not forget those of us who have fallen in love with F#, Clojure, Haskell, Elixir, etc.
The most curious developers eventually get tired of using the same programming language year in and year out. Those first-movers that migrated to Python 10 years ago are already on to the next language. The same goes for the Rubyists.
Finding F#, Clojure, Elixir, etc. developers is the easiest thing in the world. The most important thing you can do as an organisation is to say:
"We wish to hire F# developers!", or Clojure developers, Haskell developers, etc.
You don't have to find such developers; make them find you.
Although there are few of these developers out there, they are easy to attract. This is called the Python Paradox, after the early 2000 Python migration.
Not only is it easy to attract developers for such 'new' languages, you also get the most progressive, curious, motivated, enthusiastic programmers. That's the 'talent' all companies seem to be pining for these days.
Some programmers will even accept a decrease in income, only for the chance to get to work with a technology they love.
You'll probably also get some difficult-to-work-with primadonnas who are gone again after three years... TANSTAAFL.
The crux of the matter is that the argument that you can't find developers for a particular cool language doesn't hold.
Recurse
How to refactor from a loop using mutable state to a recursive implementation.
One of the most compelling reasons to adopt Functional Programming (FP) is the emphasis on immutable values. All the dread and angst associated with state that can implicitly change while you're not looking, is gone.
One of the most frustrating aspects of FP for people coming from other paradigms is the emphasis on immutable values. You know that you ought to be able to implement a given algorithm using immutable values, but given your background in Object-Oriented Programming, you can't quite figure out how to do it.
In FP, loops are implemented with recursion, and mutable values are replaced with accumulator arguments. This article describes how to refactor from a procedural, mutable loop implementation to a pure, tail-recursive implementation.
Motivation #
You want your loop implementation to be 'Functional' instead of procedural. There can be many reasons for this. Perhaps you want to learn FP. Perhaps you want to eliminate mutable state in order to make your implementation thread-safe. Perhaps you think that getting rid of mutation will make the code more readable and maintainable. Perhaps you want to port your implementation to a language that doesn't support mutability at all (like Haskell).
Mechanics #
Start with a procedural implementation, using a mutable loop variable. This obviously only works in multi-paradigmatic languages where mutable variables are possible, even if they're not ideal. Examples include F#, Scala, and Clojure, but not Haskell, which isn't multi-paradigmatic.
- Instead of your imperative loop, introduce a recursive function.
- Replace each mutable loop variable with an argument for the recursive function.
Example: backspace characters #
Imagine that you receive a stream of characters from someone typing on a keyboard. Sometimes, the typist mistypes and uses the backspace key, which sends the character '\b'. Whenever you encounter '\b', you should remove the preceding character, as well as the backspace character itself. This example is based on this Stack Overflow question.
The original F# implementation is procedural, using a for loop and a single mutable variable:
open System open System.Collections.Generic let handleBackspaces textToProcess : string = let stack = Stack<char>() for c in textToProcess do if c = '\b' then stack.Pop() |> ignore else stack.Push c stack |> Seq.rev |> Seq.toArray |> String
While this implementation doesn't explicitly use the mutable keyword, the stack variable is mutable because Stack<T> is mutable. Since textToProcess is a string, and string implements IEnumerable<char>, you can loop over each char value, pushing the value on the stack unless it's a backspace character; in that case, the previous value is instead popped and thrown away.
According to the rules of the Recurse refactoring, you should introduce a recursive function instead of the loop, and add an argument that will replace the stack. To make it easy, call the recursive function imp, and the function argument acc. The name acc is popular; it's short for accumulator. This argument is used to accumulate the final value, just like stack in the above example.
let handleBackspaces' textToProcess : string = let rec imp acc = function | [] -> acc | '\b'::cs -> imp (acc |> List.tail) cs | c::cs -> imp (c::acc) cs textToProcess |> Seq.toList |> imp [] |> List.rev |> List.toArray |> String
The imp function is declared with the rec keyword to mark it as a recursive function. It has the type char list -> char list -> char list. acc is a char list, which is also the case for the second argument implied by the function keyword. The function returns the accumulator if the input list is empty; otherwise, it matches on the head of the list. If the head is explicitly the backspace character, the imp function calls itself recursively, but replaces acc with the tail of acc; it uses List.tail to get the tail. This effectively removes the most recent character from the accumulator. In all other cases, the function also calls itself by consing c on acc.
The imp function is tail-recursive, since all other values are already computed when a recursive call to imp takes place.
You can further refactor this implementation to use a fold instead of a recursive function.
Example: Graham Scan #
This second example is a more complex example that further illustrates how to apply the Recurse refactoring. If you already feel that you understand how to apply this refactoring, you can skip reading the following example.
Some time ago, I was attempting to implement the Graham Scan algorithm to find the convex hull for a set of points. As I've described before, this turned out to be quite difficult for me. One of my problems was that I was trying to implement the algorithm in Haskell, and while I understood the algorithm, I couldn't figure out how to implement it in a functional way - and when you can't do it the functional way, you can't do it at all in Haskell.
In F#, on the other hand, you can implement algorithms using procedural code if you must, so I decided to implement the algorithm in F# first, using a procedural approach, and then subsequently figure out how to refactor to immutable values. Once I had a pure F# implementation, I could always back-port it to Haskell.
This is one of the reasons I think F# is a better language for learning FP if you come from an Object-Oriented background: you can gradually refactor towards more Functional implementations as you become better at FP.
The part that caused me particular difficulty was the scan part, where the algorithm examines all points to identify which points to discard from the hull (because they're in the interior of the hull, and not on the hull).
After sorting all candidates according to special rules, the algorithm must consider each point in turn. If that new point is 'to the right' of the previous two points, the previous point is in the interior of the hull and should be discarded. The previous-to-previous point could also be 'to the right' of the new point, so the algorithm needs to check again, and so on.
My imperative solution looked like this:
let inline hullPoints points = let mutable ps = [] for p in points do ps <- ps @ [p] let mutable shouldCheck = true while shouldCheck do let wasDiscarded, newPoints = check ps shouldCheck <- wasDiscarded if wasDiscarded then ps <- newPoints ps
(You can see the full code base on GitHub. The start is at 5290abd3c31c162ee6c4b21b82494ce97ecf7fa5, and the end state that this post describes is at e3efd1b457a46112cff6f06b8cbb100d153f0ef1.)
Due to the inline keyword, the hullPoints function has a complex type, but for practical purposes, think of it as having the type (int * int) seq -> (int * int) list. The points argument is a sequence of coordinates: (int * int) seq.
As you can see, this implementation has a nested loop. The outer loop traverses all points and appends the point in consideration to the mutable list variable ps. At this stage, p is only a candidate. What the algorithm must now determine is whether p is in the interior or might be a hull point.
In order to do that, it calls another function called check. The check function is another inline function, but you can think about it as having the type (int * int) list -> bool * (int * int) list. The return type is peculiar, but the idea is that it returns true in the first tuple element if points were discarded from the input, and false if no points were discarded. The second tuple element contains the points (that may or may not have had points removed compared to the input points). (I later refactored this function to a function called tryDiscard with the type (int * int) list -> (int * int) list option.)
If points were discarded, the algorithm must check again, as there may be more points to discard. Only when no more points were discarded can the outer loop move on to the next candidate.
According to the Recurse refactoring, you need to define a recursive function for each loop. There are two loops here, but do the inner loop first. Each mutable variable should be replaced with a function argument, but fortunately there's only one:
let inline hullPoints points = let rec update candidates = let wasDiscarded, newCandidates = check candidates if wasDiscarded then update newCandidates else candidates let mutable candidates = [] for p in points do candidates <- candidates @ [p] candidates <- update candidates candidates
The new update function calls the check function. If wasDiscarded is true, it calls itself recursively with the new candidates; otherwise, it returns the input candidates.
The update function is now a recursive function without mutable variables, but the containing hullPoints function still has a mutable candidates variable. You'll need to apply the Recursive refactoring again:
let hullPoints points = let rec update candidates = let wasDiscarded, newCandidates = check candidates if wasDiscarded then update newCandidates else candidates let rec hpImp candidates = function | [] -> candidates | p :: tail -> let cs = candidates @ [p] let updatedCandidates = update cs hpImp updatedCandidates tail hpImp [] points
The hpImp function replaces the remaining loop, and candidates is now a function argument instead of mutable variable.
As long as candidates has contents, the head of the list p is appended to candidates, and update is invoked. Subsequently, hpImp is invoked recursively with the updated candidates and the tail of the list.
The hullPoints function returns the value of calling hpImp with empty hull candidates, and the points argument. This implementation has no mutable variables.
You can refactor this implementation to make it more readable, but that's not the point of this article. You can see what I then did in the GitHub repository.
(Now that I had a pure implementation, I could also port it to Haskell, which met my original goal.)
Summary #
For programmers used to imperative programming, it can be difficult to apply pure Functional techniques. When you have loops that update a mutable variable in each step of the loop, you can refactor to use a recursive function; the mutable variable is replaced with a function argument. When you've tried it a couple of times, you'll get the hang of it.
Once you have a recursive function with an accumulator argument, you can often further refactor it to use a fold, instead of a recursive function.
(This post is the December 1st entry in the 2015 F# Advent Calendar.)
To log or not to log
There's no reason to make logging any harder than it has to be. Here's a compositional approach in F#.
Logging seems to be one of those cross-cutting concerns on which people tend to spend a lot of effort. For programmers coming from an object-oriented language like C#, finding a sane approach to logging seems to be particularly difficult.
In my book about Dependency Injection, I made an effort to explain that logging and other cross-cutting concerns are best addressed by Decorators (or dynamic interception). You can use the same design with F# functions.
Example scenario #
Consider, as an example, an HTTP API for a restaurant booking system. This example is taken from my Test-Driven Development with F# Pluralsight course, but you can see an almost identical example for free in this recording of a BuildStuff talk.
The application is composed of small, mostly pure functions:
let imp = Validate.reservationValid >> Rop.bind (Capacity.check 10 SqlGateway.getReservedSeats) >> Rop.map SqlGateway.saveReservation
Exactly what each function does isn't important in this context, but here are the types involved:
| Function | Type |
|---|---|
| imp | ReservationRendition -> Rop.Result<unit, Error> |
| Validate.reservationValid | ReservationRendition -> Rop.Result<Reservation, Error> |
| Capacity.check | int -> (DateTimeOffset -> int) -> Reservation -> Rop.Result<Reservation, Error> |
| SqlGateway.saveReservation | Reservation -> unit |
In short, the imp function validates the input, applies some business rules if the input was valid, and saves the reservation to a database if the business rules allow it.
I strongly believe that in any well-designed code base, the core implementation should be independent of cross-cutting concerns such as logging. If the above reservation system is well-designed, it should be possible to retrofit logging onto it without changing the existing functions. Indeed, that turns out to be possible.
Adding logs #
You should use an existing logging library such as Serilog, log4net, NLog, etc. instead of rolling your own. In this example, imagine that you're using the well-known SomeExternalLoggingLibrary. In order to protect yourself against changes etc. in the external library, you first define your own, application-specific logging module:
module BookingLog = let logError = SomeExternalLoggingLibrary.logError let logInformation = SomeExternalLoggingLibrary.logInformation
Both functions have the type fileName:string -> msg:string -> unit.
As a beginning, you can start by logging the final result of executing the imp function. Since it has the type ReservationRendition -> Rop.Result<unit, Error>, if you implement a log function that both accepts and returns Rop.Result<unit, Error>, you can append that to the composition of imp. Start with the logging function itself:
module BookingLog = // ... let logReservationsPost logFile result = match result with | Failure(ValidationError msg) -> logError logFile msg | Failure CapacityExceeded -> logError logFile "Capacity exceeded." | Success () -> logInformation logFile "Reservation saved." result
This function has the type string -> Rop.Result<unit, Error> -> Rop.Result<unit, Error>. It matches on the cases of result and logs something relevant for each case; then it returns result without modifying it.
Since the logReservationsPost function both accepts and returns the same type, you can easily append it to the other functions while composing imp:
let imp = Validate.reservationValid >> Rop.bind (Capacity.check 10 SqlGateway.getReservedSeats) >> Rop.map SqlGateway.saveReservation >> BookingLog.logReservationsPost logFile
Notice how BookingLog.logReservationsPost is simply added as the last line of composition. This compiles because that function returns its input.
Running the application with various input demonstrates that logging works as intended:
Information: Reservation saved. Error: Invalid date. Information: Reservation saved. Error: Capacity exceeded.
You've seen that you can append high-level logging of the final value, but can you also add logging deeper in the guts of the implementation?
Logging business behaviour #
Imagine that you need to also log what happens before and after Capacity.check is called. One option is to add a logging function with the same type as Capacity.check, that also Decorates Capacity.check, but I think it's simpler to add two functions that log the values before and after Capacity.check.
The type of Capacity.check is int -> (DateTimeOffset -> int) -> Reservation -> Rop.Result<Reservation, Error>, but after partial application, it's only Reservation -> Rop.Result<Reservation, Error>. In order to log what happens before Capacity.check is called, you can add a function that both accepts and returns a Reservation:
let logBeforeCapacityCheck logFile reservation = logInformation logFile (sprintf "Checking capacity for %s..." (reservation.Date.ToString "d")) reservation
This function has the type string -> Reservation -> Reservation, and is placed within the BookingLog module. The logInformation function is used to log the input, which is then returned.
Likewise, you can also log what happens after Capacity.check is invoked. Since Capacity.check returns Rop.Result<Reservation, Error>, your log file must take that type as both input and output:
let logAfterCapacityCheck logFile result = match result with | Failure(ValidationError msg) -> logError logFile msg | Failure CapacityExceeded -> logError logFile (sprintf "Capacity exceeded.") | Success r -> logInformation logFile (sprintf "All is good for %s." (r.Date.ToString "d")) result
The logAfterCapacityCheck function has the type string -> Rop.Result<Reservation, Error> -> Rop.Result<Reservation, Error>, and is also placed within the BookingLog module. Like the logReservationsPost function, it matches on result and logs accordingly; then it returns result. Do you see a pattern?
Because of these types, you can compose them into imp:
let imp = Validate.reservationValid >> Rop.map (BookingLog.logBeforeCapacityCheck logFile) >> Rop.bind (Capacity.check 10 SqlGateway.getReservedSeats) >> BookingLog.logAfterCapacityCheck logFile >> Rop.map SqlGateway.saveReservation >> BookingLog.logReservationsPost logFile
Notice that BookingLog.logBeforeCapacityCheck and BookingLog.logAfterCapacityCheck are composed around Capacity.check. The final BookingLog.logReservationsPost is also still in effect. Running the application shows that logging still works:
Information: Checking capacity for 27.11.2015... Information: All is good for 27.11.2015. Information: Reservation saved.
The first two log entries are created by the logs around Capacity.check, whereas the last line is written by BookingLog.logReservationsPost.
Conditional logging #
Some programmers are concerned about the performance implications of logging. You may wish to be able to control whether or not to log.
The easiest way to do that is to make logging itself conditional:
let logError fileName msg = if log then SomeExternalLoggingLibrary.logError fileName msg else () let logInformation fileName msg = if log then SomeExternalLoggingLibrary.logInformation fileName msg else ()
where log is a boolean value. If log is false, the above two functions simply return () (unit) without doing anything. This prevents costly IO from happening, so may already be enough of a performance optimisation. As always when performance is the topic: don't assume anything; measure.
In reality, you probably want to use more granular flags than a single log flag, so that you can control informational logging independently from error logging, but I'm sure you get the overall idea.
Conditional compilation #
Even with boolean flags, you may be concerned that logging adds overhead even when the log flag is false. After all, you still have a function like logBeforeCapacityCheck above: it uses sprintf to format a string, and that may still be too much if it happens too often (again: measure).
For the sake of argument, imagine that you've measured the cost of leaving the logging functions logReservationsPost, logBeforeCapacityCheck, and logAfterCapacityCheck in place when log is false, and that you find that you'll need to turn them off in production. That's not a problem. Recall that before you added these functions, the application worked fine without logging. You compose these functions into imp in order to add logging, but you don't have to. You can even make this decision at compile time:
let imp = Validate.reservationValid #if LOG >> Rop.map (BookingLog.logBeforeCapacityCheck logFile) #endif >> Rop.bind (Capacity.check 10 SqlGateway.getReservedSeats) #if LOG >> BookingLog.logAfterCapacityCheck logFile #endif >> Rop.map SqlGateway.saveReservation #if LOG >> BookingLog.logReservationsPost logFile #endif
Notice the presence of the conditional compilation flag LOG. Only if the application is compiled with the LOG flag will the logging code be compiled into the application; otherwise, it runs without any logging overhead at all.
Personally, I've never needed to control logging at this level, so this isn't a recommendation; it's only a demonstration that it's possible. What's much more important to me is that everything you've seen here has required zero changes of the application code. The only code being modified is the Composition Root, and I regard the Composition Root as a configuration file.
Summary #
In a well-designed application, you should be able to append logging without impacting the core implementation. You can do that by taking a Decorator-like approach to logging, even in a Functional application. Due to the compositional nature of a well-designed code base, you can simply slide log functions in where you need them.
Even if you're concerned about the performance implications of logging, there are various ways by which you can easily turn off logging overhead if you don't need it. Only do this if you've measured the performance of your application and found that you need to do so. The point is that if you design the application to be composed from small functions, you can always fine-tune logging performance if you need to. You don't have to do a lot of up-front design to cater specifically to logging, though.
In my examples, I deliberately kept things crude in order to make it clear how to approach the problem, but I'm sure Scott Wlaschin could teach us how to refactor such code to a sophisticated monadic design.
It should also be noted that the approach outlined here leverages F#'s support for impure functions. All the log functions shown here return unit, which is a strong indicator of side-effects. In Haskell, logging would have to happen in an IO context, but that wouldn't impact the overall approach. The boundary of a Haskell application is an IO context, and the Composition Root belongs there.
Code coverage is a useless target measure
Aiming for a particular percentage of code coverage is counter-productive.
It's the end of 2015, and here I thought that it was common knowledge that using code coverage as a metric for code quality is useless at best. After all, Martin Fowler wrote a good article on the subject in 2012, but the fundamental realisation is much older than that. Apparently, it's one of those insights that one assumes that everyone else already knows, but in reality, that's not the case.
Let's make it clear, then: don't set goals for code coverage.
You may think that it could make your code base better, but asking developers to reach a certain code coverage goal will only make your code worse.
I'll show you some examples, but on a general level, the reason is that as with all other measurements, you get what you measure. Unfortunately, we can't measure productivity, so measuring code coverage will produce results that are entirely unrelated to software quality.
"People respond to incentives, although not necessarily in ways that are predictable or manifest. Therefore, one of the most powerful laws in the universe is the law of unintended consequences." - Super FreakonomicsIncentives with negative consequences are called perverse incentives; asking developers to reach a particular code coverage goal is clearly a perverse incentive.
It doesn't matter whether you set the target at 100% code coverage, 90%, 80%, or some other number.
Reaching 100% coverage is easy #
Here's a simple code example:
public class GoldCustomerSpecification : ICustomerSpecification { public bool IsSatisfiedBy(Customer candidate) { return candidate.TotalPurchases >= 10000; } }
Imagine that you have been asked to reach a high level of code coverage, and that this class is still not covered by tests. Not only that, but you have bugs to fix, meetings to go to, new features to implement, documentation to write, time sheets to fill out, and the project is already behind schedule, over budget, and your family is complaining that you're never home.
Fortunately, it's easy to achieve 100% code coverage of the GoldCustomerSpecification class:
[Fact] public void MeaninglessTestThatStillGivesFullCoverage() { try { var sut = new GoldCustomerSpecification(); sut.IsSatisfiedBy(new Customer()); } catch { } }
This test achieves 100% code coverage of the GoldCustomerSpecification class, but is completely useless. Because of the try/catch block and the lack of assertions, this test will never fail. This is what Martin Fowler calls Assertion-Free Testing.
If you can declare a rule that your code base must have so-and-so test coverage, however, you can also declare that all unit tests must have assertions, and must not have try/catch blocks.
Despite of this new policy, you still have lots of other things you need to attend to, so instead, you write this test:
[Fact] public void SlightlyMoreInnocuousLookingTestThatGivesFullCoverage() { var sut = new GoldCustomerSpecification(); var actual = sut.IsSatisfiedBy(new Customer()); Assert.False(actual); }
This test also reaches 100% coverage of the GoldCustomerSpecification class.
What's wrong with this test? Nothing, as such. It looks like a fine test, but in itself, it doesn't prevent regressions, or proves that the System Under Test works as intended. In fact, this alternative implementation also passes the test:
public class GoldCustomerSpecification : ICustomerSpecification { public bool IsSatisfiedBy(Customer candidate) { return false; } }
If you want your tests to demonstrate that the software works as intended, particularly at boundary values, you'll need to add more tests:
[Theory] [InlineData(100, false)] [InlineData(9999, false)] [InlineData(10000, true)] [InlineData(20000, true)] public void IsSatisfiedReturnsCorrectResult( int totalPurchases, bool expected) { var sut = new GoldCustomerSpecification(); var candidate = new Customer { TotalPurchases = totalPurchases }; var actual = sut.IsSatisfiedBy(candidate); Assert.Equal(expected, actual); }
This is a much better test, but it doesn't increase code coverage! Code coverage was already 100% with the SlightlyMoreInnocuousLookingTestThatGivesFullCoverage test, and it's still 100% with this test. There's no correlation between code coverage and the quality of the test(s).
Code coverage objectives inhibit quality improvement #
Not only is test coverage percentage a meaningless number in itself, but setting a goal that must be reached actually hinders improvement of quality. Take another look at the GoldCustomerSpecification class:
public class GoldCustomerSpecification : ICustomerSpecification { public bool IsSatisfiedBy(Customer candidate) { return candidate.TotalPurchases >= 10000; } }
Is the implementation good? Can you think of any improvements to this code?
What happens if candidate is null? In that case, a NullReferenceException will be thrown. In other words, the IsSatisfiedBy method doesn't properly check that its preconditions are satisfied (which means that encapsulation is broken).
A better implementation would be to explicitly check for null:
public class GoldCustomerSpecification : ICustomerSpecification { public bool IsSatisfiedBy(Customer candidate) { if (candidate == null) throw new ArgumentNullException(nameof(candidate)); return candidate.TotalPurchases >= 10000; } }
The problem, though, is that if you do this, coverage drops! That is, unless you write another test case...
Developers in a hurry often refrain from making the code better, because it would hurt their coverage target - and they don't feel they have time to also write the tests that go with the improvement in question.
Instituting a code coverage target - any percentage - will have that effect. Not only does the coverage number (e.g. 87%) tell you nothing, but setting it as a target will make the code base worse.
Attitude #
You may argue that I'm taking too dim a view on developers, but I've seen examples of the behaviour I describe. People mostly have good intentions, but if you put enough pressure on them, they'll act according to that pressure. This is the reason we need to be aware of perverse incentives.
You may also argue that if a team is already doing Test Driven Development, and in general prioritise code quality, then coverage will already be high. In that case, will it hurt setting a target? Perhaps not, but it's not going to help either. At best, the target will be irrelevant.
This article, however, doesn't discuss teams that already do everything right; it describes the negative consequences that code coverage targets will have on teams where managers or lead developers mistakenly believe that setting such goals is a good idea.
Code coverage is still useful #
While it's dangerous to use code coverage for target setting, collecting coverage metrics can still be useful.
Some people use it to find areas where coverage is weak. There may be good reasons that some parts of a code base are sparsely covered by tests, but doing a manual inspection once in a while is a good idea. Perhaps you find that all is good, but you may also discover that a quality effort is overdue.
In some projects, I've had some success watching the code coverage trend. When I review pull requests, I first review the changes by looking at them. If the pull request needs improvement, I work with the contributor to get the pull request to an acceptable quality. Once that is done, I've already made my decision on merging the code, and then I measure code coverage. It doesn't influence my decision to merge, but it tells me about the trend. On some projects, I've reported that trend back to the contributor while closing the pull request. I wouldn't report the exact number, but I'd remark that coverage went up, or down, or remained the same, by 'a little', 'much', etc. The point of that is to make team members aware that testing is important.
Sometimes, coverage goes down. There are many good reasons that could happen. Watching how coverage evolves over time doesn't mean that you have to pounce on developers every time it goes down, but it means that if something looks odd, it may be worth investigating.
Summary #
Don't use code coverage as an objective. Code coverage has no correlation with code quality, and setting a target can easily make the quality worse.
On the other hand, it can be useful to measure code coverage once in a while, but it shouldn't be your main source of information about the status of your source code.
Null has no type, but Maybe has
In C#, null has no type, but most variables can be null; you can't really trust the type system. A Maybe, on the other hand, always has a type, which means that Maybe is a saner approach to the question of values that may or may not be present.
A few days ago, I was looking at some C# code that, reduced to essentials, looked like this:
string foo = null; var isNullAString = foo is string;
What is the value of isNullAString after execution?
Since foo is declared as a string, I thought that the answer clearly had to be true. Much to my surprise, it turns out that it's false.
Wondering if I was exceptionally bad at predicting the type of null values, I created a Twitter poll. 235 votes later, the outcome was this:
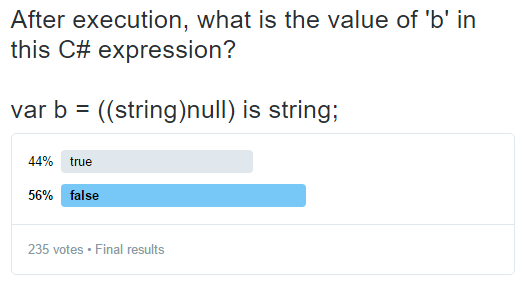
Forty-four percent of respondents (some 103 people) were as wrong as I was! At one point, while the poll was still open and some 100 people had responded, the distribution was even fifty-fifty. Ultimately, I believe that the final results are artificially skewed toward false, because people could try the code first, before answering, and there's evidence that at least one person did that.
In short, that a null string isn't a string doesn't make much sense to a lot of people.
It's not a bug, though. It's explicitly stated in section 7.10.10 of the C# language specification:
"If E is [...] the null literal, of if the type of E is a reference type or a nullable type and the value of E is null, the result is false."The specification doesn't offer much of an explanation, but Eric Lippert shares some information on the topic.
It still doesn't make any sense to me...
Apparently, the rules of C#'s type system is: a variable is guaranteed to be of a certain type, except when it isn't. Once again, null throws a wrench into any attempt to reason sanely about code.
The .NET Rocks! episode about less is more sparked a ton of comments; most of them in defence of null. People don't seem to understand just how malicious null references are. That null has no type is yet another example.
I think that the main reason that people defend null is that they have a hard time imagining other ways of modelling situations where a value may or may not be present. Even when introduced to the Maybe monad, most people remain unconvinced, because it's difficult to understand how Maybe is better than null.
The difference is clear: only values explicitly declared as Maybes can be Maybes, and Maybe values always have a type!
In F#, Maybe is called option, and it's always typed. The logical equivalent of the above type check would be this in F#:
let foo : string option = None let isNoneAStringOption = foo :? string option
Only, this doesn't even compile!
If you try this in F#, the compiler will complain:
"error FS0016: The type 'string option' does not have any proper subtypes and cannot be used as the source of a type test or runtime coercion."That expression doesn't even make sense in F#. Of course
foo is a string option, because it's the only thing it can be!
You'll have to upcast foo to obj in order to be able to perform the type check:
let foo : string option = None let isNoneAStringOption = box foo :? string option
As expected, this evaluates to true. Of course isNoneAStringOption is true, even when it's None! What else could it possibly be?
In Haskell, it doesn't even make sense to ask such a question, because there's no type hierarchy. In Haskell, you can't upcast a value to its base type, because there's no inheritance.
In short, null values invalidate all rules and guarantees that the C# type system attempts to make. It's truly a toxic language 'feature'.
Comments
null certainly is a toxic feature of C#. It was one of the key reasons behind me creating the Succinc<T> library. It brings all the wonderfulness of F#'s options to C#.
It let's one write equivalent code to your example:
var foo = Option<string>.None();
var isNoneAStringOption = foo is Option<string>;
Which gives the same true result as the F# code.
Just because a language has a feature, doesn't mean we have to use it. The same applies just as much to null as to switch and goto. Alternatives exist to these features.
Service Locator violates encapsulation
Service Locator violates encapsulation in statically typed languages because it doesn't clearly communicate preconditions.
The horse has been long dead, but some people still want to ride it, so I'll beat it yet again. Over the years, I've made various attempts to explain why Service Locator is an anti-pattern (e.g. that it violates SOLID), but recently it struck me that most of my arguments have been focused on symptoms without ever addressing the fundamental problem.
As an example of discussing symptoms, in my original article, I described how IntelliSense is hurt by the use of Service Locator. In 2010, it never occurred to me that the underlying problem is that encapsulation is violated.
Consider my original example:
public class OrderProcessor : IOrderProcessor { public void Process(Order order) { var validator = Locator.Resolve<IOrderValidator>(); if (validator.Validate(order)) { var shipper = Locator.Resolve<IOrderShipper>(); shipper.Ship(order); } } }
This is C# code, but it'd be similar in Java or another comparable statically typed language.
Pre- and postconditions #
One of the major benefits of encapsulation is abstraction: relieving you of the burden of having to understand every implementation detail of every piece of code in your code base. Well-designed encapsulation enables you to use a class without knowing all the intricate details of how it's implemented. This is done by establishing a contract for interaction.
As Object-Oriented Software Construction explains, a contract consists of a set of pre- and postconditions for interaction. If the client satisfies the preconditions, the object promises to satisfy the postconditions.
In statically typed languages like C# and Java, many preconditions can be expressed with the type system itself, as I've previously demonstrated.
If you look at the public API for the above OrderProcessor class, then what would you think its preconditions are?
public class OrderProcessor : IOrderProcessor { public void Process(Order order) }
As far as we can tell, there aren't many preconditions. The only one I can identify from the API is that there ought to be an Order object before you can call the Process method.
Yet, if you attempt to use OrderProcessor using only that precondition, it's going to fail at run-time:
var op = new OrderProcessor(); op.Process(order); // throws
The actual preconditions are:
- There ought to be an Order object (this one we already identified).
- There ought to be an IOrderValidator service in some Locator global directory.
- There ought to be an IOrderShipper service in some Locator global directory.
As you can see, Service Locator violates encapsulation because it hides the preconditions for correct use.
Passing arguments #
Several people have jokingly identified Dependency Injection as a glorified term for passing arguments, and there may be some truth to that. The easiest way to make the preconditions apparent would be to use the type system to advertise the requirements. After all, we already figured out that an Order object is required. This was evident because Order is an argument to the Process method.
Can you make the need for IOrderValidator and IOrderShipper as apparent as the need for the Order object using the same technique? Is the following a possible solution?
public void Process( Order order, IOrderValidator validator, IOrderShipper shipper)
In some circumstances, this could be all you need to do; now the three preconditions are equally apparent.
Unfortunately, often this isn't possible. In this case, OrderProcessor implements the IOrderProcessor interface:
public interface IOrderProcessor { void Process(Order order); }
Since the shape of the Process method is already defined, you can't add more arguments to it. You can still make the preconditions visible via the type system by requiring the caller to pass the required objects as arguments, but you'll need to pass them via some other member. The constructor is the safest channel:
public class OrderProcessor : IOrderProcessor { private readonly IOrderValidator validator; private readonly IOrderShipper shipper; public OrderProcessor(IOrderValidator validator, IOrderShipper shipper) { if (validator == null) throw new ArgumentNullException("validator"); if (shipper == null) throw new ArgumentNullException("shipper"); this.validator = validator; this.shipper = shipper; } public void Process(Order order) { if (this.validator.Validate(order)) this.shipper.Ship(order); } }
With this design, the public API now looks like this:
public class OrderProcessor : IOrderProcessor { public OrderProcessor(IOrderValidator validator, IOrderShipper shipper) public void Process(Order order) }
Now it's clear that all three object are required before you can call the Process method; this version of the OrderProcessor class advertises its preconditions via the type system. You can't even compile client code unless you pass arguments to constructor and method (you can pass null, but that's another discussion).
Summary #
Service Locator is an anti-pattern in statically typed, object-oriented languages because it violates encapsulation. The reason is that it hides preconditions for proper usage.
If you need an accessible introduction to encapsulation, you should consider watching my Encapsulation and SOLID Pluralsight course. If you wish to learn more about Dependency Injection, you can read my award-winning book Dependency Injection in .NET.
Comments
If we take a look at the original example, we should notice that terms from multiple domains are interleaving. Therefore, the OrderProcessor is violating context independence as described in GOOS book. To become context independent OrderProcessor should make his relationships explicit by allowing to pass them in constructor.
It is a slightly different perspective of the problem, but conclusion is the same, because context independence also concerns encapsulation.
Is it only the usage of a Service Locator within a class that's an anti-pattern? That is, as long as OrderProcessor makes its dependencies explicit via the constructor, there's nothing wrong with using a Service Locator to get those dependencies when creating a OrderProcessor instance?
Jeffrey, thank you for writing. I'm not sure I fully understand, but perhaps you are considering whether the use of a DI Container as a composition engine is also an anti-pattern?
If so, you can use a DI Container from within your Composition Root, but personally, I still prefer Pure DI.
Visual Value Verification
Sometimes, the most efficient way to verify the outcome of executing a piece of code is to visualise it.
Recently, I've been working my way through Real World Haskell, and although some of the exercises in the book are exasperating, others are stimulating and engaging. One of the good exercises is to use the Graham Scan algorithm to find the convex hull for a set of points.
This proved to be unexpectedly difficult for me, but I also found the exercise captivating, so I kept at it. My main problems turned out to be related to the algorithm itself, so during the exercise, I temporarily switched to F# in order to work out the kinks of my implementation. This enabled me to focus on the problem itself without also having to fight with an unfamiliar programming language.
Surprisingly, it turned out that one of my biggest problems was that I didn't have a good way to verify my implementation.
Return values #
Since I was approaching the problem with Functional Programming, it ought to be easy to unit test. After all, Functional design is intrinsically testable. My overall function to find the convex hull looks like this:
let inline hull points = // ...
In simplified form, the type of this function is (^a * ^d) list -> (^a * ^d) list where the ^a and ^d generic type arguments have a whole lot of constraints that I don't want to bother you with. In practice, both ^a and ^d can be integers, so that the hull function gets the type (int * int) list -> (int * int) list. In other words: you supply a list of integer points, and you get a list of integer points back.
Here's a simple example:
> hull [(3, 1); (2, 3); (2, 4); (2, 5); (3, 7); (1, 2); (1, 6)];; val it : (int * int) list = [(3, 1); (3, 7); (2, 5); (1, 6); (1, 2)]
Quick! At a glance: is this result correct or incorrect?
How about this result?
> hull [(5, -2); (5, 6); (-4, 7); (-6, 0); (-8, 0); (-2, 5); (-3, -4); (-2, -2); (-9, -7); (2, -9); (4, -2); (2, -10); (4, -10); (4, -9); (2, -10); (3, -9); (8, 2); (-8, -5); (-9, -4); (5, -6); (6, 4); (8, -10); (-5, 0); (5, 9); (-5, -4); (-6, 8); (0, -9); (7, -4); (6, 4); (-8, -5); (-7, -7); (8, -9); (7, -3); (6, 4); (-6, -8); (-4, 4); (-2, -2); (-6, -10); (0, 1); (5, -7); (-5, 4); (5, -5); (6, 4); (0, 7); (5, 5); (-1, -4); (-6, 0); (-9, 3); (5, 6); (-7, 7); (4, -10); (5, -8); (9, -1); (0, -9); (6, 6); (6, -6); (9, 8); (-10, -2); (-3, 2); (-5, -7)];; val it : (int * int) list = [(-6, -10); (2, -10); (4, -10); (8, -10); (9, -1); (9, 8); (5, 9); (-6, 8); (-7, 7); (-9, 3); (-10, -2); (-9, -7)]
(In the first example, the output is incorrect, but in the second, it's correct.)
It's easy enough to write automated unit tests once you know what the expected outcome should be. In this case, my problem was that I didn't have an easy way to calculate if a given list of points was the correct answer or not. After all, I was trying to implement a function that could be used for this purpose, but I needed to know if the function returned the correct values.
In the beginning, I tried to plot the values into Excel, in order to draw them as diagrams, but that soon turned out to be tedious and inefficient.
Then I considered Property-Based Testing, but I couldn't come up with a good set of properties that didn't involve half of the algorithm I was trying to implement.
Visual Value Verification #
The concept of a convex hull is simple, and easy to verify if you can visualise it. That's what I tried to do with Excel, but here my problem was that the process was too cumbersome.
Instead, I decided to pull in FSharp.Charting, because it enabled me to easily visualise the result of calling the hull function. This is all it takes:
open System open FSharp.Charting let inline hullChart points = let hullPoints = hull points let hullChart = let closedHull = hullPoints @ [hullPoints.Head] Chart.Line(closedHull, Name = "Hull") |> Chart.WithStyling(Color = Drawing.Color.Blue) let pointsChart = Chart.Point(points, Name = "Points") |> Chart.WithStyling(Color = Drawing.Color.Black) [hullChart; pointsChart] |> Chart.Combine |> Chart.WithYAxis(MajorGrid = ChartTypes.Grid(Enabled = false)) |> Chart.WithXAxis(MajorGrid = ChartTypes.Grid(Enabled = false))
The signature of the hullChart function is (^a * ^d) list -> FSharp.Charting.ChartTypes.GenericChart (where, again, the ^a and ^d types are generic type arguments with various type constraints; think of them as numbers). It first calls the hull function with points. Then it creates a line chart to draw the hull, and a point chart to plot in all the input points. Finally, it combines both charts into a single chart.
With the hullChart function, it's easy to do ad-hoc testing in F# Interactive and visually inspect the results of calling the hull function with various input. At one point, I had a particular problem with my interpretation of the Graham Scan algorithm, and this was easy to see using the hullChart function, which would produce this chart:
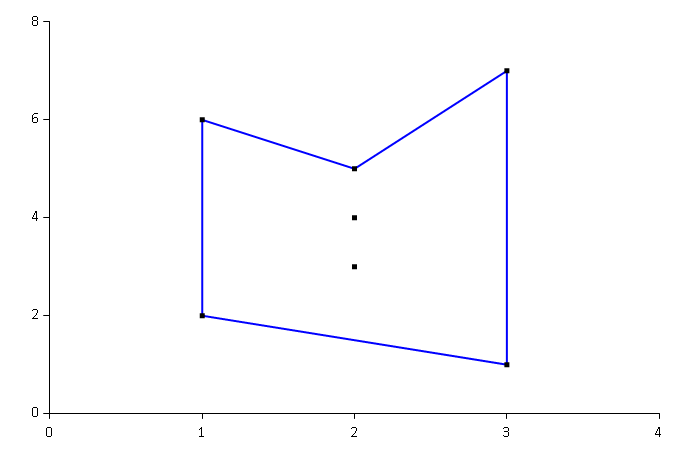
With this chart it's easy to see, at a glance, that the calculated hull is concave, and thus not a convex hull. There's an error in the implementation. (This is the first result set that I asked you to evaluate above.)
Struggling on with the exercise, I was able to solve my immediate problem and produce a convex hull from that particular input. Did that mean that I now had the correct implementation, or could there be other errors? I needed more test results before I felt that I had confidence in my implementation.
This, on the other hand, was now easy to get.
First, I could randomly generate points like this:
let randomPoints (r : Random) = [1..r.Next(1, 100)] |> List.map (fun _ -> (r.Next(-10, 10), r.Next(-10, 10)))
For ad-hoc testing, I could now create a random set of points and show the calculated hull:
> (randomPoints (Random()) |> hullChart).ShowChart();;
Immediately, a window would pop up, enabling me to visually verify the calculated hull value. Literally, verification at a glance.
From Visual Value Verification to automated tests #
You may object to this approach because such testing isn't sustainable. Ultimately, we'd like to have a suite of automated tests that can give us a succeed or failure result.
Still, the ability to visually verify the calculated hull values enabled me to produce a set of input points, as well as calculated hull points that I knew to be correct. I could, for example, use the randomPoints function to produce 100 input sets. For each of these 100 input sets, I could visually inspect the diagrams.
Here's an example of six diagrams, instead of 100, just to give you an idea about how quickly you can verify such a set:
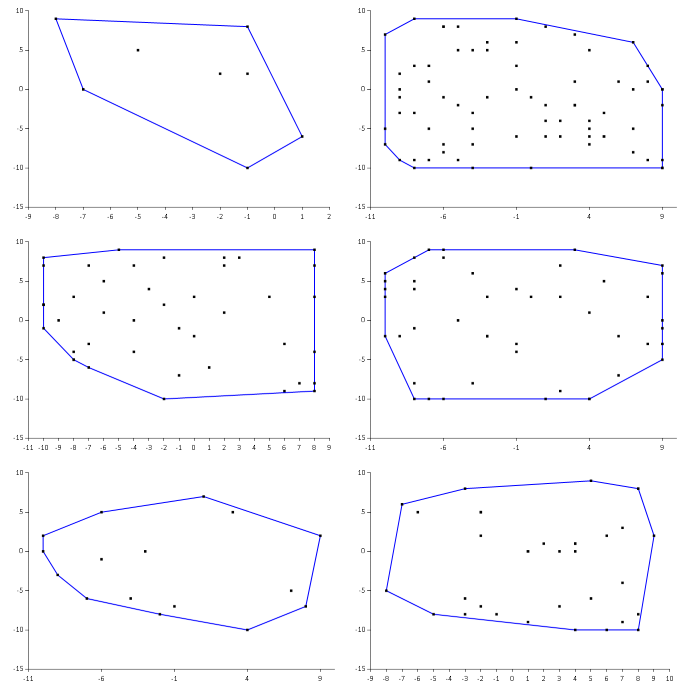
If all of the generated diagrams look okay, you know that for at least these 100 sets, the output of the hull function is correct. You can now capture those input values and the corresponding (correct) output values as a parametrised test. Here's an xUnit.net example with five test cases:
// No [<ClassData>] attribute in xUnit.net 2.0 :( type HullDataAttribute() = inherit Xunit.Sdk.DataAttribute () override this.GetData testMethod = // The following input data comes from randomly generated points. // The expected values come from a prototype of the hull function where // the output was subsequently visually inspected by drawing the input // points and the calculated hull on a coordinate system to verify that // the hull prototype function calculated the correct values. seq { yield [| // Points (input): [(3, 1); (3, 7); (2, 5); (2, 4); (1, 6); (2, 3); (1, 2)] // Expected: [(3, 1); (3, 7); (1, 6); (1, 2)] |] yield [| [(1, -4); (2, 5); (1, 3); (1, -3); (1, -2); (0, 4)] [(1, -4); (2, 5); (0, 4)] |] yield [| [(1, 1); (0, 3); (-2, 1); (-4, 3); (5, 2); (3, 2); (5, 5); (2, 5); (1, 3); (1, -3); (1, -2); (7, -4); (-1, 1); (-3, 0); (-5, -2); (1, -4); (0, 1); (0, 4); (3, -3); (6, 1)] [(1, -4); (7, -4); (6, 1); (5, 5); (2, 5); (-4, 3); (-5, -2)] |] yield [| [(-7, -7); (4, -7); (2, 3); (4, 4); (3, 1); (2, -1); (-3, -5); (4, -2); (-1, -7); (-6, 9); (4, 4); (-8, -2); (9, 4); (3, 0); (7, 0); (-7, 3); (0, 9); (4, -7); (-7, -6); (-1, 7); (6, 5); (7, -3); (-8, -8); (-6, -2); (3, 5); (-5, 7); (8, 1); (3, -2); (-9, -4); (-7, 8)] [(-8, -8); (4, -7); (7, -3); (9, 4); (0, 9); (-6, 9); (-7, 8); (-9, -4)] |] yield [| [(3, -3); (-9, -3); (0, 7); (3, 8); (3, -9); (1, 3); (-9, 5); (-4, 9); (-2, -10); (8, -2); (-4, 2); (-7, -9); (-5, -10); (0, 2); (9, -7); (6, -4); (4, 7); (-9, -7); (2, 1); (-3, -5); (-5, -1); (9, 6); (-3, 1); (6, -6); (-5, -4); (-6, 5); (0, 9); (-2, -9); (-6, -10); (-8, -1); (-4, -9); (8, -1); (-5, -5); (9, -6); (4, -8); (-3, 7); (2, 3); (-8, 6); (3, -4); (3, 4); (-6, -5); (-4, 3); (9, -10); (5, 4); (-1, 9); (9, 1); (-1, 7); (8, -7); (1, -1); (0, -9); (2, 1); (0, -8); (8, -3); (-8, 7); (7, 1); (-2, 8); (-4, -2); (-5, -10); (4, -6); (0, -5); (-1, -6); (5, 4); (-7, 6); (-3, 4); (4, 8); (-6, -7); (5, 2); (-9, 2); (5, -6); (4, 2); (7, 8); (7, 7)] [(-6, -10); (-5, -10); (-2, -10); (9, -10); (9, -7); (9, -6); (9, 1); (9, 6); (7, 8); (0, 9); (-1, 9); (-4, 9); (-8, 7); (-9, 5); (-9, 2); (-9, -3); (-9, -7)] |] } [<Theory; HullData>] let ``hull returns correct result`` (points : (int * int) list) (expected : (int * int) list) = let actual = hull points expected =! actual
(The =! operator is an assertion operator from Unquote; read it as should equal - i.e. expected should equal actual.)
This gives you a deterministic test suite you can run repeatedly to protect the hull function against regressions.
Summary #
Sometimes, the nature of the problem is such that the easiest way to verify that the System Under Test (SUT) produces the correct results, is to visually verify the resulting value of exercising the SUT. We can call this Visual Value Verification (VVV).
In this article, I used the problem of finding the convex hull for a set of points as an example, but I've encountered other problems where this technique has proven useful. The most prominent that comes to mind is when implementing Conway's Game of Life; that's another problem where, just by looking at lists of numbers, you can't easily verify that your implementation is correct.
Once you've visually verified that output looks correct, you can capture the known input and output into a test case that you can run repeatedly.
Command Query Separation when Queries should have side-effects
How can you adhere to Command Query Separation if your Domain Model requires Queries to have side-effects?
Command Query Separation (CQS) can be difficult until you get the hang of it; then it's not so difficult - just like most other things in life :)
In a previous article, I covered how to retrieve server-generated IDs after Create operations. That article discussed how to prevent Commands from turning into Queries. In the present article, you'll see some examples of how to prevent Queries from turning into Commands.
Context #
This article was triggered by a viewer's question related to my Encapsulation and SOLID Pluralsight course. As I interpret it, the hypothetical scenario is some school or university exam taking software:
"If a student has not submitted a solution to an exercise yet, when and if they look at the exercise hint for the first time, flag that hint as viewed. The points granted to a student's solution will be subtracted by 5 points, if the related hint is flagged as viewed."As stated here, it sounds like a Query (reading the exercise hint) must have a side-effect. This time, we can't easily wave it away by saying that the side-effect is one that the client isn't responsible for, so it'll be OK. If the side-effect had been an audit log, we could have gotten away with that, but here the side-effect is within the Domain Model itself.
How can you implement this business requirement while still adhering to CQS? Perhaps you'd like to pause reading for a moment to reflect on this question; then you can compare your notes to mine.
Is it even worth applying CQS to this problem, or should we simply give up? After all, the Domain Model seems to inherently associate certain Queries with side-effects.
In my opinion, it's exactly in such scenarios that CQS really shines. Otherwise, you're looking at the code as a team developer, and you go: Why did the score just go down? I didn't change anything! You can waste hours when side-effects are implicit. Applying CQS makes side-effects explicit, and as the Zen of Python goes:
Explicit is better than implicit.There are various ways to address this apparently impossible problem. You don't have to use any of them, but the first key to choosing your tools is to have something to choose from.
Contextual types #
With the requirements given above, we don't know what we're building. Is it a web-based application? An app? A desktop application? Let's, for a while, imagine that we're developing an app or desktop application. In my fevered imagination, this sort of application may have all the questions and hints preloaded in memory, or in files, and continually displays the current score on the screen. There may not be further persistent storage, or perhaps the application publishes the final scores for the exam to a central server once the exam is over. Think occasionally connected clients.
In this type of scenario, the most important point is to keep the score up-to-date in memory. This can easily be done with a contextual or 'amplified' type. In this case, we can call it Scored<T>:
public sealed class Scored<T> { public readonly T Item; public readonly int Score; public Scored(T item, int score) { if (item == null) throw new ArgumentNullException(nameof(item)); this.Item = item; this.Score = score; } public Scored<T> Add(int scoreDelta) { return new Scored<T>(this.Item, this.Score + scoreDelta); } public override bool Equals(object obj) { var other = obj as Scored<T>; if (other == null) return base.Equals(obj); return object.Equals(this.Item, other.Item) && object.Equals(this.Score, other.Score); } public override int GetHashCode() { return this.Item.GetHashCode() ^ this.Score.GetHashCode(); } }
The Scored<T> class enables you to carry a score value around within a computation. In order to keep the example as simple as possible, I modelled the score as an integer, but perhaps you should consider refactoring from Primitive Obsession to Domain Modelling; that's a different story, though.
This means you can model your API in such a way that a client must supply the current score in order to retrieve a hint, and the new score is returned together with the hint:
public interface IHintQuery { Scored<Hint> Read(int hintId, int currentScore); }
The Read method is a Query, and there's no implied side-effect by calling it. Since the return type is Scored<Hint>, it should be clear to the client that the score may have changed.
An implementation could look like this:
public class HintQuery : IHintQuery { private readonly IHints hints; public HintQuery(IHints hints) { if (hints == null) throw new ArgumentNullException(nameof(hints)); this.hints = hints; } public Scored<Hint> Read(int hintId, int currentScore) { var valFromInner = this.hints.FirstById(hintId); return new Scored<Hint>(valFromInner, currentScore).Add(-5); } }
The Read method uses an injected (lower-level) Query interface to read the answer hint, packages the result in a Scored<Hint> value, and subtracts 5 points from the score.
Both the score type (int) and Scored<T> are immutable. No side-effects occur while the client reads the answer hint, but the score is nonetheless adjusted.
In this scenario, the score travels around in the memory of the application. Perhaps, after the exam is over, the final score can be sent to a central repository for record-keeping. This architecture could work well in client-side implementations, but may be less suitable in stateless web scenarios.
Pessimistic locking #
If you're developing a web-based exam-taking system, you may want to be able to use stateless web servers for scalability or redundancy reasons. In such cases, perhaps keeping the score in memory isn't a good idea.
You could still use the above model, but the client must remember to save the updated score before returning an HTTP response to the browser. Perhaps you find this unsatisfactorily fail-safe, so here's an alternative: use pessimistic locking.
Essentially, you can expose an interface like this:
public interface IHintRepository { void UnlockHint(int hintId); Hint Read(int hintId); }
If a client attempts to call the Read method without first unlocking the hint, the method will throw an exception. First, you'll have to unlock the hint using the UnlockHint method, which is clearly a Command.
This is less discoverable, because you can't tell by the type signature of the Read method that it may fail for that particular reason, but it safely protects the system from accidentally reading the hint without impacting the score.
(In type systems with Sum types, you can make the design clearer by statically modelling the return type to be one of several mutually exclusive cases: hint, no hint (hintId doesn't refer to an existing hint), or hint is still locked.)
This sort of interface might in fact align well with a good User Experience, because you might want to ask the user if he or she is sure that (s)he wants to see the hint, given the cost. Such a user interface warning would be followed by a call to UnlockHint if the user agrees to the score deduction.
An implementation of UnlockHint would leave behind a permanent record that the answer hint was unlocked by a particular user, and that record can then subsequently be used when calculating the final score.
Summary #
Sometimes, it can be difficult to see how to both follow CQS and implement the desired business logic. In my experience, it's always possible to recast the problem in such a way that this is possible, but it may take some deliberation before it clicks.
Must you always follow CQS? Not necessarily, but if you understand what your options are, then you know what you're saying no to if you decide not to do it. That's quite a different situation from not having any idea about how to apply the principle.
In this article, I showed two options for reconciling CQS with a Domain Model where a Query seems to have side-effects.
Comments
Philippe, thank you for writing. That's a great observation, and one that I must admit that I hadn't considered myself!
At least, in this case encapsulation is still intact because pre- and post-conditions are preserved. You can't leave the system in an incorrect state.
The reason I described the option using Scored<T> before the pessimistic locking alternative is that I like the first option best. Among other benefits, it doesn't suffer from temporal coupling.
Hi Mark, those are all nice solutions!
I think there are also other options, for example sending a "Excercice hint viewed" notification which could then be handled by a subscriber calling a command.
But this is at the cost of some indirection, so it's nice to have other choices.
Loïc, thank you for writing. I'm sure there are other alternatives than the ones I've outlined. The purpose of the article wasn't to provide an exhaustive list of options, but rather explain that it is possible to adhere to the CQS, even though sometimes it seems difficult.
Specifically, are you suggesting to send a notification when the Query is made? Isn't that a side-effect?
There are some alternatives way in which I would consider handling this if I'm being honest. We always want to retrieve the hint. We singularly want to reduce the person's score by 5 points if they have not seen this hint before. This depreciation in points is idempotent and should only be executed if the hint hasn't been viewed before. Contextual information associated to the returned hint, such as last time viewed by current user, would inform the triggering of the command.
I think this is OK, because we care whether a user has viewed a hint. A hint having been viewed by a user means something, so returning it from the query feels valid. Acting up on this accordingly also feels valid, but the command itself becomes nicely idempotent as it understand the single-hit decrease in the points.
Applications and their side effects
All applications have side-effects, but you can isolate those side-effects at the boundaries.
In my Encapsulation and SOLID Pluralsight course, I introduce Command-Query Separation (CQS) as a fundamental tool that will help you think about encapsulation. (I didn't come up with this myself, but rather picked it up from Bertrand Meyer's Object-Oriented Software Construction.)
Despite the age of the CQS principle, it's still news to many people, and I get lots of questions about it; I attempt to answer them as well as I can. Most questions are about specific situations where the inquirer can't see a way out of issuing a Query and at the same time producing a side-effect.
Perhaps the most common situation comes up when auditing comes into play. In some domains, auditing is a legal requirement. Asking any question must produce the side-effect that an audit record is created.
How can you reconcile such requirements with CQS?
Definition #
It may be helpful to first take a step back and attempt to answer the question: what's a side-effect, anyway?
Perhaps we can learn from Functional Programming (gee, who'd have thunk!?), because Functional Programming is all about taming side-effects. Apparently, Simon Peyton-Jones once said during an introduction to Haskell, that if your program has no side-effects, it cannot print a result, it cannot ask for input, it cannot interact with the network or the file system. All it does is heat up the CPU, after which someone from the audience interjected that heating up the CPU is also a side-effect, so, technically speaking, if you want your program to have no side-effects, you cannot even run it. (I only have this story on second hand, but it makes an important point.)
Clearly, there's no such thing as a truly side-effect free program, so how do we define what a side-effect is?
In strictly Functional languages, a side-effect occurs whenever a function isn't referentially transparent. This fancy term means that you can replace a function call with its return value. If a function call isn't equivalent to its return value, it's either because the function call also has a side-effect, or because some side-effect caused the return value to change.
This is closely related to the popular definition of a Query in CQS: Asking the question mustn't change the answer. This is, though, a weaker statement, because it allows a change in global state (e.g. another process updating a database record) to change the answer between two identical queries.
In a completely different context, in REST it's often helpful to distinguish between safe and idempotent requests. The term safe is closely related to a side-effect free Query. As REST in Practice states (p. 38): "By safe, we mean a GET request generates no server-side effects for which the client can be held responsible" (my emphasis). That can often be a useful distinction when thinking about CQS. A Query may cause a side-effect to happen (such as an audit record being written), but that side-effect doesn't concern the client.
Applications are never side-effect free #
All of the above is useful because there's a large set of side-effects we can ignore in practice. We can ignore that the CPU heats up. We can ignore that web servers log HTTP requests. We can (probably) ignore that audit records are written. Such side-effects don't change the answer of a Query.
There may still be cases where you need to deal explicitly with side-effects. You may wish to acknowledge to a user that a file was written. You may want to return a receipt to a client that your service received a document.
It's important to realise that at the application level, applications are all about side-effects.
- Applications may have GUIs; every time the application updates the screen, that's a side-effect.
- An application may be a REST service; it handles HTTP, which is modelled on the Request-Response pattern. Even POST requests have responses. Everything in HTTP looks like Queries, because responses are return values.
- Applications may write to a database; clearly, side-effects are involved.
Applications, on the other hand, are compositions of all relevant concerns. As I've previously described, at the boundaries, applications aren't Object-Oriented. Neither are they Functional. All applications must have a boundary where Encapsulation, or FP, or CQS, doesn't apply. The trick is to keep that boundary as thin as possible.
Thus, if you must violate CQS, do it in the boundary of the application. As an example, perhaps you're creating a REST service that enables clients to create new resources with POST requests. As a response, you want to return the address of the new resource. That violates CQS, but if you keep that violation at the entry point of the request, you've isolated the violation to the boundary of the application.
Summary #
It can be difficult to follow CQS, until you get your head around it, but it's always possible to apply it - except at the application boundary.
How do we know that we can always apply CQS? We know this from Functional Programming. Strict Functional languages like Haskell model everything as Queries (except at the boundaries), and Haskell is a Turing-complete language. If you can model everything as Queries, it should be clear that you can also separate Commands and Queries: if in doubt, eliminate the Command; FP shows how to do that.
Even if you're working in an Object-Oriented language, learn some Functional Programming. It'll teach you how to apply CQS, which is a cornerstone of Encapsulation.
Comments

Comments
It's implicit in these strategies that "application-specific logging module" will be a singleton, right? Otherwise, it would be necessary to pass a logger instance into every method.
In a multi-threaded context, this will result in all logs going to the same destination, with potential for jumbles if multiple threads are executing simultaneously, relatively unpredictable results if execution flows through multiple threads, etc.
I've never been able to come up with a way around the "jumble" problem other than passing a logger in every function call (or, when using OOP, giving every class a Logger property). But having every function take a "logger" parameter is not ideal either, for obvious reasons.
Do you have any thoughts on how to allow logging to be specific to each flow of execution, other than generating a logger at the entry point and passing it as a parameter to everything?
Ben, thank you for writing. It's not at all implicit that Singletons are involved. This article discusses a semi-functional design where there's no objects, just functions. It seems, however, that some of your concerns relate to object-oriented design.
In object-oriented design, I recommend modelling logging and other cross-cutting concerns as applications of the Decorator or Chain of Responsibility design patterns. As mentioned in this article, I discuss this in my book, but this blog also contains an example of this, although it's about instrumentation instead of logging. These two cross-cutting concerns are closely related in structure, though, so I hope you still find it informative. Such an approach to design eliminates the need for passing
logdependencies around in business logic and other places where it doesn't belong.The way I've seen people address the problem with multi-threaded logging is to have a logger object per thread (or, safer this day, per HTTP request, or similar). This object simply collects all log data in memory until flushed. Some designs require client developers to explicitly call a
Flushmethod, but typically you can automate this so that it happens automatically when the thread or HTTP context is disposed of.When
Flushis called, the infrastructure writes the entire log message to a queue. This can happen concurrently, but then you have a single-threaded subscriber on that queue that handles each message one at a time. This serialises the log messages, and you avoid interleaving of data.