ploeh blog danish software design
A simpler Arbitrary for the Diamond kata
There's a simple way to make FsCheck generate letters in a particular range.
In my post about the Diamond kata with FsCheck, I changed the way FsCheck generates char values, using this custom Arbitrary (essentially a random value generator):
type Letters = static member Char() = Arb.Default.Char() |> Arb.filter (fun c -> 'A' <= c && c <= 'Z')
This uses the default, built-in Arbitrary for char values, but filters its values so that most of them are thrown away, and only the letters 'A'-'Z' are left. This works, but isn't particularly efficient. Why generate a lot of values only to throw them away?
It's also possible to instruct FsCheck to generate values from a particular set of valid values, which seems like an appropriate action to take here:
type Letters = static member Char() = Gen.elements ['A' .. 'Z'] |> Arb.fromGen
Instead of using Arb.Default.Char() and filtering the values generated by it, this implementation uses Gen.elements to create a Generator of the values 'A'-'Z', and then an Arbitrary from that Generator.
Much simpler, but now it's also clear that this custom Arbitrary will be used to generate 100 test cases (for each property) from a set of 26 values; that doesn't seem right...
Library Bundle Facade
Some people want to define a Facade for a bundle of libraries. Is that a good idea?
My recent article on Composition Root reuse generated some comments:
These comments are from two different people, but they provide a decent summary of the concerns being voiced."What do you think about pushing these factories and builders to a library so that they can be reused by different composition roots?"
"We want to share the composition root, because otherwise when a component needs a new dependency and a constructor parameter is added, we'd have to change the same code in two different places."
Is it a good idea to provide one or more Facades, for example in the form of Factories or Builders, for the libraries making up a Composition Root? More specifically, is it a good idea to provide a Factory or Builder that can compose a complete object graph spanning multiple libraries?
In this article, I will attempt to answer that question for various cases of library bundles. To make the terminology a bit more streamlined, I'll refer to any Factory or Builder that composes object graphs as a Composer.
Single library #
In the case of a single library, I think I've already answered the question in the affirmative. There's nothing wrong with including a Facade in the form of a Factory or Builder in order to make that single library easier to use.
Two libraries #
When you introduce a second library, things start becoming interesting. If we consider the case of two libraries, for example a Domain Model and a Data Access Library, the Composition Root will need to compose an object graph where some of the objects in the graph are from the Domain Model, and some of the objects are from the Data Access Library.

In the spirit of Agile Principles, Patterns, and Practices (APPP), it turns out that simply drawing dependency diagrams can be helpful. From the Dependency Inversion Principle (DIP) we know that the "clients [...] own the abstract interfaces" (APPP, chapter 11), which means that for our two example libraries, the dependency graph must look like this:
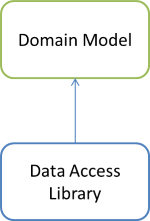
At least, if you follow the most common architectures for loosely couple code, the Domain Model is the 'client', so it gets to define the interfaces it needs. Thus, it follows that the Data Access Library, in order to implement those interfaces, must have a compile-time dependency on the Domain Model. That's what the arrow means.
From this diagram, it should be clear that you can't put a Factory or Builder in the Domain Model library. If the Composer should compose object graphs from both libraries, it would need to reference both of those libraries, and the Domain Model can't reference the Data Access Library, since that would result in a circular reference.
You could put the Composer in the Data Access Library, but that somehow doesn't feel right, and in any case, as we shall see later, this solution can't be generalised to n libraries.
A solution that many people reach for, then, is to pull the interfaces out into a separate library, like this:
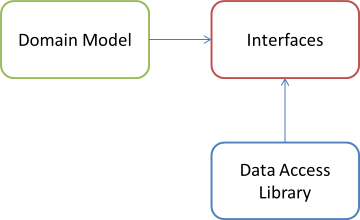
It's a bit like cheating, according to the DIP, but it's as decoupled as before. In this diagram, the Domain Model depends on the interfaces because it uses them, while the Data Access Library depends on the interface library because it implements the interfaces. Unfortunately, this doesn't solve the problem at all, because there's still no place to place a Composer without getting into a problem with either the DIP, or circular references (exercise: try it!).
A possible option is to keep the libraries as the DIP dictates, and then add a third Composer library:
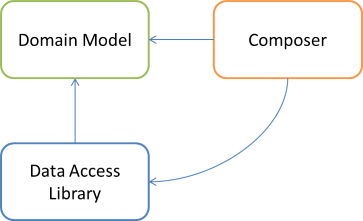
The Composer library references both the Domain Model and the Data Access Library, so it's possible for it to compose object graphs with objects from both libraries. The only purpose of this library, then, is to compose those object graphs, so it'll likely only contain a single class.
Multiple libraries #
Does the above conclusions change if you have more than two libraries? Only in the sense that it further restricts your options. As the analysis of the special case with two libraries demonstrated, you only have two options for adding a Composer to your bundle of libraries:
- Put the Composer in the Data Access Library
- Put the Composer in a new dedicated library
Imagine that you have two Data Access Libraries instead of one:
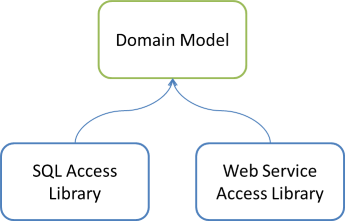
For instance, the SQL Access Library may implement various interfaces defined by the Domain Model, based on a SQL Server database; and the Web Service Access Library may implement some other interfaces by calling out to some web service.
If the Composer must be able to compose object graphs with object from all three libraries, it must reside in a library that references all of the relevant libraries. The Domain Model is still out of the question because you can't have circular references. That leaves one of the two Data Access libraries. It'd be technically possible to e.g. add a reference from the SQL Access Library to the Web Service Access Library, and put the Composer in the SQL Access Library:
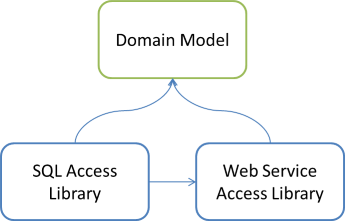
However, why would you ever do that? It's clearly wrong to let one Data Access library depend on another, and it doesn't help if you reverse the arrow.
Thus, the only option left is to add a new Composer library:
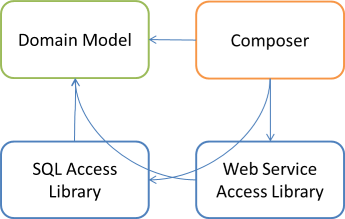
As before, the Composer library has references to all other libraries, and contains a single class that composes object graphs.
Over-engineering #
The point of this analysis is to arrive at the conclusion that no matter how you twist and turn, you'll have to add a completely new library with the only purpose of composing object graphs. Is it warranted?
If the only motivation for doing this is to avoid duplicated code, I would argue that this looks like over-engineering. In the questions quoted above, it sounds as if the Rule of Three isn't even satisfied. It's always important to question your motivations for avoiding duplication. In this case, I'd be wary of introducing so much extra complexity only in order to avoid writing the same lines of code twice - particularly when it's likely that the duplication is accidental.
TL;DR #
Attempting to provide a reusable Facade to compose object graphs across multiple libraries is hardly worth the trouble. Think twice before you do it.
From Primitive Obsession to Domain Modelling
A string is sometimes not a string. Model it accordingly.
Recently, I was reviewing some code that looked like this:
public IHttpActionResult Get(string userName) { if (string.IsNullOrWhiteSpace(userName)) return this.BadRequest("Invalid user name."); var user = this.repository.FindUser(userName.ToUpper()); return this.Ok(user); }
There was a few things with this that struck me as a bit odd; most notably the use of IsNullOrWhiteSpace. When I review code, IsNullOrWhiteSpace is one of the many things I look for, because most people use it incorrectly.
This made me ask the author of the code why he had chosen to use IsNullOrWhiteSpace, or, more specifically, what was wrong with a string with white space in it?
The answer wasn't what I expected, though. The answer was that it was a business rule that the user name can't be all white space.
You can't really argue about business logic.
In this case, the rule even seems quite reasonable, but I was just so ready to have a discussion about invariants (pre- and postconditions) that I didn't see that one coming. It got me thinking, though.
Where should business rules go? #
It seems like a reasonable business rule that a user name can't consist entirely of white space, but is it reasonable to put that business rule in a Controller? Does that mean that everywhere you have a user name string, you must remember to add the business rule to that code, in order to validate it? That sounds like the kind of duplication that actually hurts.
Shouldn't business rules go in a proper Domain Model?
This is where many programmers would start to write extension methods for strings, but that's just putting lipstick on a pig. What if you forget to call the appropriate extension method? What if a new developer on the team doesn't know about the appropriate extension method to use?
The root problem here is Primitive Obsession. Just because you can represent a value as a string, it doesn't mean that you always should.
The string data type literally can represent any text. A user name (in the example domain above) can not be any text - we've already established that.
Make it a type #
Instead of string, you can (and should) make user name a type. That type can encapsulate all the business rules in a single place, without violating DRY. This is what is meant by a Domain Model. In Domain-Driven Design terminology, a primitive like a string or a number can be turned into a Value Object. Jimmy Bogard already covered that ground years ago, but here's how I would define a UserName class:
public class UserName { private readonly string value; public UserName(string value) { if (value == null) throw new ArgumentNullException("value"); if (!UserName.IsValid(value)) throw new ArgumentException("Invalid value.", "value"); this.value = value; } public static bool IsValid(string candidate) { if (string.IsNullOrEmpty(candidate)) return false; return candidate.Trim().ToUpper() == candidate; } public static bool TryParse(string candidate, out UserName userName) { userName = null; if (string.IsNullOrWhiteSpace(candidate)) return false; userName = new UserName(candidate.Trim().ToUpper()); return true; } public static implicit operator string(UserName userName) { return userName.value; } public override string ToString() { return this.value.ToString(); } public override bool Equals(object obj) { var other = obj as UserName; if (other == null) return base.Equals(obj); return object.Equals(this.value, other.value); } public override int GetHashCode() { return this.value.GetHashCode(); } }
As you can tell, this class protects its invariants. In case you were wondering about the use of ToUpper, it turns out that there's also another business rule that states that user names are case-insensitive, and one of the ways you can implement that is by converting the value to upper case letters. All business rules pertaining to user names are now nicely encapsulated in this single class, so you don't need to remember where to apply them to strings.
If you want to know the underlying string, you can either invoke ToString, or take advantage of the implicit conversion from UserName to string. You can also compare two UserName instances, because the class overrides Equals. If you have a string, and want to convert it to a UserName, you can use TryParse.
The original code example above can be refactored to use the UserName class instead:
public IHttpActionResult Get(string candidate) { UserName userName; if (!UserName.TryParse(candidate, out userName)) return this.BadRequest("Invalid user name."); var user = this.repository.FindUser(userName); return this.Ok(user); }
This code has the same complexity as the original example, but now it's much clearer what's going on. You don't have to wonder about what looks like arbitrary rules; they're all nicely encapsulated in the UserName class.
Furthermore, as soon as you've left the not Object-Oriented boundary of your system, you can express the rest of your code in terms of the Domain Model; in this case, the UserName class. Here's the IUserRepository interface's Find method:
User FindUser(UserName userName);
As you can tell, it's expressed in terms of the Domain Model, so you can't accidentally pass it a string. From that point, since you're receiving a UserName instance, you know that it conforms to all business rules encapsulated in the UserName class.
Not only for OOP #
While I've used the term encapsulation once or twice here, this way of thinking is in no way limited to Object-Oriented Programming. Scott Wlaschin describes how to wrap primitives in meaningful types in F#. The motivation and the advantages you gain are the same in Functional F# as what I've described here.
Over-engineering? #
Isn't this over-engineering? A 56 lines of code class instead of a string? Really? The answer to such a question is always context-dependent, but I rarely find that it is (over-engineering). You can create a Value Object like the above UserName class in less than half an hour - even if you use Test-Driven Development. When I created this example, I wrote 27 test cases distributed over five test methods in order to make sure that I hadn't done something stupid. It took me 15 minutes.
You may argue that 15 minutes is a lot, compared to the 0 minutes it would take you if you'd 'just' use a string. On the surface, that seems like a valid counter-argument, but perhaps you're forgetting that with a primitive string, you still need to write validation and business logic 'around' the string, and you have to remember to apply that logic consistently across your entire code base. My guess is that you'll spend more than 15 minutes on doing this, and troubleshooting defects that occur when someone forgets to apply one of those rules to a string in some other part of the code base.
Summary #
Primitive values such as strings, integers, decimal numbers, etc. often represent concepts that are constrained in some ways; they're not just any string, any integer, or any decimal number. Ask yourself if extreme values (like the entire APPP manuscript, Int32.MinValue, and so on) are suitable for such variables. If that's not the case, consider introducing a Value Object instead.
If you want to learn more about Encapsulation, you can watch my Encapsulation and SOLID Pluralsight course.
Comments
Mark, I enjoyed your article. I feel that this is the way to go. Too often have I seen people using arrays if bytes for images and strings for email addresses.
An important aspect of DDD is within the language and when there are people talking about user names all the time, that usually indicates that usernames are an important aspect of what is going on and should be modeled explicitly and not use primitives.
The solution doesn't look overengineered to me, although I had to defend similar code before for the same reason. Not only is it now a good place to put further validation, but also allows further distinction using other types and a polymorphism (if carefully used, they can be a delight), each of which covers different invariants.
A UserName can be moved around and used to retrieve objects. But maybe you can't do that with a class of the type InvalidUsername. In another example, maybe there are functions that deal with email eddresses - which I have often seen modeled as strings. Some accept InvalidEmailAddress objects, others accept ValidEmail addresses. While it doesn't reduce the amount of boilerplate null checks, a SendEmail function wouldn't have to do
... SendEmail(EmailAddress email)
{
if(email.IsValid()) {
email.Send()
}
}
One could simply make it to only accept valid email addresses. Their mere existence would guarantee, that the email address is valid. One could then write functions dealing with valid email addresses and some dealing with invalid ones. You can log and analyze bad account creation requests with the invalid ones, but not send email to them and prevent everyone else from doing so, depending on what kind of email address is being passed around.
Johannes, thank you for writing. You are right, it's possible to take the idea further in the way you describe. Again, such techniques aren't even limited to OOP; for instance, Scott Wlaschin explains how to make illegal states unrepresentable in F#.
In fact, the Functional approach using Sum Types (Discriminated Unions) is nicer, because it doesn't rely on inheritance :)
Interesting article. I have no qualms about creating domain types around primitives per se, but IMHO there should be a bit more complexity in the invariants than a single condition before resorting to that. In this case, I would think that the username constraint should be implemented in the User class. If other entities shared the constraint (e.g. Company.AccountName), the logic might be refactored into a NameValidator, and then referenced concretely by the entities.
A string holding a strong password would be a good candidate for promoting to something smarter.
Mark,
This is exactly right. I honestly have no comment on the concept because I have changed primitives to value objects a number of times and use something similar.
Quick side-note, and this may just be a preference: In the TryParse, a Trim()'d value is being passed into the constructor. So if I want to create two usernames " Suamere " and "Suamere", the second will fail since, unbeknownst to me, the first had been successfully created with Trim(). It seems to me that "Do not allow pre/post white-space" is a business rule. Therefore, if there is white-space, I consider that to be breaking a business rule.
My main motivation for this comment is that this UserName Object shows a perfect example of a pattern I've seen when using the TryParse pattern (or Monads). That is: The logic in the TryParse is frequently an exact duplicate of logic in another method such as the constructor. Though instead of throwing exceptions, TryParse gracefully informs the consumer of success/failure.
So business logic is duplicated in the CTOR(), IsValid(), and the TryParse(). Instead, I consider this pattern:
public UserName(string value) { CheckIsValid(value, true); this.value = value; } public static bool TryParse(string candidate, out UserName userName) { userName = null; if (!CheckIsValid(candidate, false)) return false; userName = new UserName(candidate); return true; } public static bool IsValid(string candidate) { return CheckIsValid(candidate, false); } private static bool CheckIsValid(string candidate, bool throwExceptions) { //Brevity follows, but can be split up into more granular rules and exceptions if (string.IsNullOrWhiteSpace(candidate)) { if (throwExceptions) throw new ArgumentNullException("candidate"); return false; } if (!string.Equals(candidate, candidate.Trim(), StringComparison.OrdinalIgnoreCase)) { if (throwExceptions) throw new ArgumentException("Invalid value.", "candidate"); return false; } return true; }
Let me know what you think!
~Suamere, Steven Fletcher
Mike, thank you for writing. A business rule doesn't have to be complex in order to be important. The point isn't only to encapsulate complex logic, but to make sure that (any) business logic is applied consistently.
In my experience, things often start simple, but evolve (or do they devolve?) into something more complex; when do you draw the line?
Steven, thank you for writing. You exhibit traits of critical thinking, which is always good when dealing with business logic :) In the end, it all boils down to what exactly the business rule is. As you interpret the business rule, you rephrase it as "Do not allow pre/post white-space", but that's not the business rule I had in mind.
Since I'm the author of the blog post, I have the luxury of coming up with the example, and thus, in this case, defining the business rule. The business rule I had in mind is that user names are case-insensitive, and they're also insensitive to leading and trailing white space. Thus, " Suamere " and "Suamere" are considered to be two representations of the same user name, just as "FOO" and "foo" represent the same user name. The canonicalised representation of these two user names are "SUAMERE" and "FOO", respectively.
That's also the reason I chose the name TryParse; it's equivalent to DateTime.TryParse, which should be a well-known .NET idiom. If I parse the two strings "2015-01-21" and " 21. januar 2015 " on my machine (which is running with the da-DK locale), I get the exact same value from both strings. Notice that DateTime.TryParse also blissfully ignores leading and trailing white space. This is all correct according to Postel's law.
If all I'd wanted to do was to convert an already valid string into a UserName instance, I'd have implemented an explicit conversion, which is what Jimmy Bogard did in his article. In fact, such an explicit conversion doesn't conflict with the current TryParse method, so I'd find it quite reasonable to add that as well, if any client had the need for it.
This question might be slightly besides the point, but I'm having trouble with the bit about UserName values being case-insensitive. I take that to mean that you can create a UserName with all uppercase, all lowercase, or any combination thereof, and they'll all be treated equally.
To me, that doesn't mean that you have to pass in an uppercase-only value to the constructor (or TryParse() method, for that matter) in order to successfully instantiate a UserName. Was that your intent?
I created a Gist with some tests to illustrate what I'm talking about: I can instantiate with "JEFF", but not with "jeff", using either the constructor directly or the TryParse method.
Jeff, I attempted to run your unit tests, and the only one that fails is, as expected, if you attempt to use the constructor with "jeff"; TryParse with "jeff" works.
Would it have helped if the constructor was private?
I stand corrected regarding the failing tests; I worked with the tests again, and indeed, only the constructor method failed passing in "jeff" in lowercase.
Making the constructor private would clarify things in that there would only be one way for a client to instantiate UserName, which happens to ensure anything passed into the private constructor is all upper-case.
That seems to better match the stated business rule, that UserName values are case-insensitive, rather than a rule that prohibits anything but upper-case values. In any case, it's not quite central to the point of your article, so I thank you for taking the time to reply anyway.
Jeff, I think we fundamentally agree, and I do understand why you'd find it surprising that the constructor accepts "JEFF", but not "jeff". FWIW, I follow (a lot) of rules (of thumb) when I design APIs, and one of them is that the purpose of constructors is to initialise objects. A constructor may perform validation, but must not perform work in the sense of transforming the input or producing side-effects. In other words, constructors are used to initialise objects with valid values.
Whenever I need to transform data as part of initialisation, I often create some sort of factory method for that explicit purpose. A static TryParse method is one of many options available when such a need arises. The point is exactly that the input may not start out being 'valid', but it can be transformed into a valid representation. Going from "jeff" to UserName("JEFF") is a conversion.
This idea of constructors only accepting valid values may seem a bit foreign at first, but if you follow it as a general principle, you get a code base that's easier to reason about, because it's consistent. It's probably because I'm so used to this principle that I just left the constructor public, following another principle of mine, which is that there's no reason to make anything internal or private if the class or member can properly protect its invariants.
Sorry to rant; you just inspired me to explain some of my underlying design thoughts that caused me to arrive at this particular solution.
Thanks for your post, very informative as usual. I would add a few insights.
As much as it can feel Over engineering, I would totally agree and say it doesn't. I deal with GPU resource creation (Direct3D11) on a daily basis and this has helped me so much and saved me headaches (for example a Buffer size must have more than 0 elements, failing to do so gives you a cryptic runtime error than you can only catch error message by enabling Debug Device and looking at Debug output window!
Using a simple BufferElementCount in that case enforces the fact that I provide a correct value, and throw a meaningful exception early in the process. By passing a BufferElementCount I can (almost) safely expect that my buffer gets created.
On the lines of code, I would expect that the initial 50 lines would largely be overtaken by rewriting the same logic, but scattered across the whole code (plus likely adding try/catch blocks in many places on top of it), so I'm pretty sure doing the 0 lines version would lead to more code at the end. Plus 50 lines of code to save be a deep debug session on half million lines code base is a trade-off I'll happily take!
Also as a little bonus, for simple cases I wrote a little snippet so I guess I would share it here Domain Primitive. Now it takes even less than 2 minutes in most simple cases.
Your Equals is fragile. Because the class is not sealed, one could descend from it and break the equality contract.
Example of how to break through descending:
public class DomainUserName : UserName{
private string domain;
//Equals written to compare both username and domain
}
UserName u1 = new DomainUserName("BOB", "GITHUB");
UserName u2 = new UserName("BOB");
u1.Equals(u2) //will use DomainUserName's Equals and return false
u2.Equals(u1) //will use UserName's Equals and return true
But equality contract must be symmetrical. So either seal the class or else compare GetTypes() as example here: msdn.microsoft.com/en-us/library/vstudio/336aedhh%28v=vs.100%29.aspx
Alan, thank you for writing. You're right; I'd never considered this - most likely because I never use inheritance. Therefore, my default coping strategy would most likely be to make the class sealed by default, but otherwise, explicitly comparing GetType() return values would have to do.
Thank you for teaching me something today!
Great article and completely agree on having primitive types wrapped up into its own class. I had few questions around how this would be applied to provide a good validation feedback to consuming clients. If we want to provide more details on why the 'user name is invalid', like say 'User name should not be small letters' and 'User name should not have trailing spaces' how would we handle this in the class. How would the class communicate out the details of the rules that it is abstracting to its consuming clients.
When accepting multiple such 'classes' in a endpoint, what would be a suggested validation approach. For instance if we are to look at a similar endpoint, which takes in 'Name' and 'Phone' number(or even more in the case of POST endpoint where we are creating a new user), wouldnt the controller soon be overladed with a lot of such TryParse calls.
From the above comment of constructor only accepting valid values, where would it make sense to use the constructor as opposed to TryParse. Is it at the persistence boundary of the application?
Rahul, thank you for writing. As a general rule, at the boundary of an application, all input must be considered evil until proven otherwise. That means that if you try to pass unvalidated input values into constructors, you should expect exceptions to be thrown on a regular basis. Since exceptions are for exceptional cases, that's most likely not the best way to go forward.
Instead, domain objects could offer Validate methods. These would be a bit like TryParse methods, but instead of returning a primitive boolean value, they'd have to return a list of messages. If there are no messages, the input is good. If there are messages, the input is bad. You can encapsulate such a validation result in an object if you think the rule about messages/no messages is too implicit. Such Validate methods could still take out parameters like TryParse methods if you want to validate and potentially convert into a domain object in one go.
This isn't particularly elegant in languages like C# or Java, but due to the lack of sum types in these languages, that's the best we can do.
In languages with sum types, you can use the Either monad and applicative composition to address this type of problem much more elegantly. A good place to start would be Scott Wlaschin's article on Railway Oriented Programming.
Mark, implicit conversion operator should never throw exception. In the example, it can throw NullReferenceException when UserName is null. What would you recommend to fix that issue?
Eugene, thank you for writing. That's probably a good rule, but I admit I hadn't thought about it. One option is to convert it to an explicit conversion instead. Another option is to forgo the conversion operators all together. The conversion ability isn't the important point in this article.
A third option is to leave it as is. In the code bases I control, null is never an appropriate value, so if null appears anywhere, I'd consider it a bug somewhere else.
To be realistic, though, I think I'd prefer one of the two first options, as I tend to agree with the Zen of Python: Explicit is better than implicit.
Insightful post Mark!
I have a question, if we are implementing a class that implements Parse and TryParse menthods and this class requires
dependency, how should that be passed?
Consider following example - MobileNumber requires a list of valid area codes, I am passing this dependency in the
constructor and Parse and TryParse method:
public class MobileNumber
{
public MobileNumber(IEnumerable<string> areaCodes, string countryCode, string phoneNumber)
{
/* Something */
}
public static MobileNumber Parse(IEnumerable<string> areaCodes, string countryCode, string phoneNumber)
{
/* Something */
}
public static bool TryParse(IEnumerable<string> areaCodes, string countryCode, string phoneNumber, out MobileNumber mobileNumber)
{
/* Something */
}
}
Is it a right design?
Moiz, thank you for writing. Is it the right design? As usual, It Depends™. Which problem are you trying to solve? What does the input look like? What should the result be of attempting to parse various examples?
It can often be illuminating to write a couple of parametrised tests. What would such tests look like?
A benefit of this technique is that it doesn't prescribe where the business logic should be; only where
- access to it
10 tips for better Pull Requests
Making a good Pull Request involves more than writing good code.
The Pull Request model has turned out to be a great way to build software in teams - particularly for distributed teams; not only for open source development, but also in enterprises. Since some time around 2010, I've been reviewing Pull Requests both for my open source projects, but also as a team member for some of my customers, doing closed-source software, but still using the Pull Request work flow internally.
During all of that time, I've seen many great Pull Requests, and some that needed some work.
A good Pull Request involves more than just some code. In most cases, there's one or more reviewer(s) involved, who will have to review your Pull Request in order to evaluate whether it's a good fit for inclusion in the code base. Not only must you produce good code, but you must also cater to the person(s) doing the review.
Here's a list of tips to make your Pull Request better. It isn't exhaustive, but I think it addresses some of the more important aspects of creating a good Pull Request.
1. Make it small #
A small, focused Pull Request gives you the best chance of having it accepted.
The first thing I do when I get a notification about a Pull Request is that I look it over to get an idea about its size. It takes time to properly review a Pull Request, and in my experience, the time it takes is exponential to the size; the relationship certainly isn't linear.
If I get a big Pull Request for an open source project, I do realize that the submitter has most likely already put in substantial work in his or her spare time, so I do go to some lengths to review a big Pull Request, even if I think it's too big - particularly when it looks like it's a first-time contributor. Still, if the Pull Request is big, I'll need to schedule time to review it: I can't review a big chunk of code using five minutes here and five minutes there; I need contiguous time to do that. This already introduces a delay into the review process.
If I get a big Pull Request in a professional setting (i.e. where the submitter is being paid to write the code), I often reject the Pull Request simply because of the size of it.
How small is small enough? Obviously, it depends on what the Pull Request is about, but a Pull Request that touches less than a dozen files isn't too bad.
2. Do only one thing #
Just as the Single Responsibility Principle states that a class should have only one responsibility, so should a Pull Request address only a single concern.
Imagine, as a counter-example, that you submit a Pull Request that addresses three independent, separate concerns (let's call them A, B, and C). The reviewer may immediately agree with you that A and C are valid concerns, and that your solution is correct. However, the reviewer has issues with your B concern. Perhaps he or she thinks it's not a concern at all, or she disagrees with the way you've addressed it.
This becomes the start of a lengthy discussion about concern B, and how it's being addressed. This discussion can go on for days (particularly if you're in different time zones), while you attempt to come to agreement; perhaps you'll need to make changes to your Pull Request to address the reviewer's concerns. This all takes time.
It may, in fact, take so much time that other commits have been merged into master in the meantime, and your Pull Request has fallen so much behind that it no longer can be automatically merged. Welcome to Merge Hell.
All that time, your perfectly acceptable solutions to the A and C concerns are sitting idly in your Pull Request, adding absolutely no value to the overall code base.
Instead, submit three independent Pull Requests that address respectively A, B, and C. If you do that, the reviewer who agrees with A and C will immediately accept two of those three Pull Requests. In this way, your non-controversial contributions can immediately add value to the code base.
The more concerns you address in a single Pull Request, the bigger the risk that at least one of them will block acceptance of your contribution. Do only one thing per Pull Request. It also helps you make each Pull Request smaller.
3. Watch your line width #
The reviewer of your Pull Request will most likely be reviewing your contribution using a diff tool. Both GitHub and Stash provide browser-based diff views for reviewing. A reviewer can even configure the diff view to be side-by-side; it makes it much easier to understand what changes are included in the contribution, but it also means that the code must be readable on half a screen.
If you have wide lines, you force the reviewer to scroll horizontally.
There are many reasons to keep line width below 80 characters; making your code easy to review just adds another reason to that list.
4. Avoid re-formatting #
You may feel the urge to change the formatting of the existing code to fit 'your' style. Please abstain.
Every byte you change in the source code shows up in the diff views. Some diff viewers have options to ignore changes of white space, but even with this option on, there are limits to what those diff viewers can ignore. Particularly, they can't ignore if you move code around, so please don't do that.
If you really need to address white space issues, move code around within files, change formatting, or do other stylistic changes to the code, please do so in an isolated pull request that does only that, and state so in your Pull Request comment.
5. Make sure the code builds #
Before submitting a Pull Request, build it on your own machine. True, works on my machine isn't particularly useful, but it's a minimum bar. If it doesn't work on your machine, it's unlikely to work on other machines as well.
Watch out for compiler warnings. They may not prevent you from compiling, so you may not notice them if you don't explicitly look for them. However, if your Pull Request causes (more) compiler warnings, a reviewer may reject it; I do.
If the project has a build script, try to run that, and only submit your pull request if the build succeeds. In many of my open source projects, I have a build script that (among other things) treats warnings as errors. Such a build script may automate or implement various rules for that particular code base. Use it before submitting, because the reviewer most likely will use it before merging your branch.
6. Make sure all tests pass #
Assuming that the code base in question has automated tests, make sure all tests pass before submitting a Pull Request.
This should go without saying, but I regularly receive Pull Requests where one or more tests are failing.
7. Add tests #
Again, assuming that the code in question already has automated (unit) tests, do add tests for the code you submit.
It doesn't often happen that I receive a Pull Request without tests, but when I do, I often reject it.
This isn't a hard rule. There are various cases where you may need to add code without test coverage (e.g. when adding a Humble Object), but if it can be tested, it should be tested.
You'll need to follow the testing strategy already established for the code base in question.
8. Document your reasoning #
Self-documenting code rarely is.
Yes, code comments are apologies, and I definitely prefer well-named operations, types, and values over comments. Still, when writing code, you often have to make decisions that aren't self-evident (particularly when dealing with Business 'Logic').
Document why you wrote the code in the way you did; not what it does.
My preferred priority is this:
- Self-documenting code: You can make some decisions about the code self-documenting. Clean Code is literally a book on how to do that.
- Code comments: If you can't make the code sufficiently self-documenting, add a code comment. At least, the comment is co-located with the code, so even in the unlikely event that you decide to change version control system, the comment is still preserved. Here's an example where I found a comment more appropriate than attempting to design my way out of the problem.
- Commit messages: Most version control systems give you the opportunity to write a commit message. Most people don't bother putting anything other than a bare minimum into these, but you can document your reasoning here as well. Sometimes, you'll need to explain why you're doing things in a certain order. This doesn't fit well in code comments, but is a good fit for a commit message. As long as you keep using the same version control system, you preserve these commit messages, but they're once removed from the actual source code, and you may loose the messages if you change to another source control system. Here's an example where I felt the need to write an extensive commit message, but I don't always do that.
- Pull Request comments: Rarely, you may find yourself in a situation where none of the above options are appropriate. In Pull Request management systems such as GitHub or Stash, you can also add custom messages to the Pull Request itself. This message is twice removed from the actual source code, and will only persist as long as you keep using the same host. If you move from e.g. CodePlex to GitHub, you'll loose those Pull Request messages. Still, occasionally, I find that I need to explain myself to the reviewer, but the explanation involves something external to the source code anyway. Here's an example where I found that a reasonable approach.
9. Write well #
Write good code, but also write good prose. This is partly subjective, but there are rules for both code and prose. Code has correctness rules: if you break them, it doesn't compile (or, for interpreted languages, it fails at run-time).
The same goes for the prose you may add: Code comments. Commit messages. Pull Request messages.
Please use correct spelling, grammar, and punctuation. If you don't, your prose is harder to understand, and your reviewer is a human being.
10. Avoid thrashing #
Sometimes, a reviewer will point out various issues with your Pull Request, and you'll agree to address them.
This may cause you to add more commits to your Pull Request branch. There's nothing wrong with that per se. However, this can lead to unwarranted thrashing.
As an example, your pull request may contain five commits: A, B, C, D, and E. The reviewer doesn't like what you did in commits B and C, so she asks you to remove that code. Most people do that by checking out their pull request branch and deleting the offending code, adding yet another commit (F) to the commit list: [A, B, C, D, E, F]
Why should we have to merge a series of commits that first adds unwanted code, and then removes it again? It's just thrashing; it doesn't add any value.
Instead, remove the offending commits, and force push your modified branch: [A, D, E]. While under review, you're the sole owner of that branch, so you can modify and force push it all you want.
Another example of thrashing that I see a lot is when a Pull Request is becoming old (often due to lengthy discussions): in these cases, the author regularly merges his or her branch with master to keep the Pull Request branch up to date.
Again: why do I have to look at all those merge commits? You are the sole owner of that branch. Just rebase your Pull Request branch and force push it. The resulting commit history will be cleaner.
Summary #
One or more persons will review your Pull Request. Don't make your reviewer work.
The more you make your reviewer work, the greater the risk is that your Pull Request will be rejected.
Comments
How do you balance the advice to write small, focused Pull Requests with the practical necessity of sometimes bundling refactoring in with features? Especially given the fact that most workplaces inevitably prioritise merging features.
Sam, thank you for writing. Even without refactoring, it's common that a feature is so large that you can't implement it as a single, focused pull request. The best way to address that issue is to hide the work in progress behind a feature flag. You can do the same with refactoring.
As Kent Beck puts it:
You may need to first refactor to 'make room' for the new feature. I'd often put that in an isolated pull request and send that first. If anyone complains that I'm doing refactoring work instead of feature work, I'd truthfully respond that I'm doing the refactoring in order to be able to implement the feature."for each desired change, make the change easy (warning: this may be hard), then make the easy change"
I consider this to be part of being professional. It's how software should be developed, and I think that non-technical stakeholders should have little to say about how things are done. You don't have to tell them every little detail about how you write code. You shouldn't have to ask for permission to do this, and you shouldn't have to inform them that that's what you're doing.
My new book contains a realistic and practical example of a feature developed behind a feature flag.
Diamond kata with FsCheck
This post is a walk-through of doing the Diamond kata with FsCheck.
Recently, Nat Pryce tweeted:
The diamond kata, TDD'd only with property-based tests. https://github.com/npryce/property-driven-diamond-kata One commit for each step: add test/make test pass/refactorThis made me curious. First, I'd never heard about the Diamond kata, and second, I find Property-Based Testing quite interesting these days.
Digging a bit lead me to a blog post by Seb Rose; the Diamond kata is extremely easy to explain:
After having thought about it a little, I couldn't even begin to see how one could approach this problem using Property-Based Testing. It struck me as a problem inherently suited for Example-Driven Development, so I decided to do that first.Given a letter, print a diamond starting with ‘A’ with the supplied letter at the widest point.
For example: print-diamond ‘C’ prints
A B B C C B B A
Example-Driven Development #
The no-brain approach to Example-Driven Development is to start with 'A', then 'B', and so on. Exactly as Seb Rose predicts, when you approach the problem like this, when you reach 'C', it no longer seems reasonable to hard-code the responses, but then the entire complexity of the problem hits you all at once. It's quite hard to do incremental development by going through the 'A', 'B', 'C' progression.
This annoyed me, but I was curious about the implementation, so I spent an hours or so toying with making the 'C' case pass. After this, on the other hand, I had an implementation that works for all letters A-Z.
Property-Driven Development #
On my commute it subsequently struck me that solving the Diamond kata with Example-Driven Development taught me a lot about the problem itsef, and I could easily come up with the first 10 properties about it.
Therefore, I decided to give the kata another try, this time with FsCheck. I also wanted to see if it would be possible to make the development more incremental; while I didn't follow the Transformation Priority Premise (TPP) to the letter, I was inspired by it. My third 'rule' was to use Devil's Advocate to force me to write properties that completely describe the problem.
Ice Breaker #
To get started, it can be a good idea to write a simple (ice breaker) test, because there's always a little work involved in getting everything up and running. To meet that goal, I wrote this almost useless property:
[<Property(QuietOnSuccess = true)>] let ``Diamond is non-empty`` (letter : char) = let actual = Diamond.make letter not (String.IsNullOrWhiteSpace actual)
It only states that the string returned from the Diamond.make function isn't an empty string. Using Devil's Advocate, I created this implementation:
let make letter = "Devil's advocate."
This hard-coded result satisfies the single property. However, the only reason it works is because it ignores the input.
Constraining the input #
The kata only states what should happen for the inputs A-Z, but as currently written, FsCheck will serve all sorts of char values, including white space and funny characters like '<', ']', '?', etc. While I could write a run-time check in the make function, and return None upon invalid input, I am, after all, only doing a kata, so I'd rather want to tell FsCheck to give me only the letters A-Z. Here's one way to do that:
type Letters = static member Char() = Arb.Default.Char() |> Arb.filter (fun c -> 'A' <= c && c <= 'Z') type DiamondPropertyAttribute() = inherit PropertyAttribute( Arbitrary = [| typeof<Letters> |], QuietOnSuccess = true) [<DiamondProperty>] let ``Diamond is non-empty`` (letter : char) = let actual = Diamond.make letter not (String.IsNullOrWhiteSpace actual)
The Letters type redefines how char values are generated, using the default generator of char, but then filtering the values so that they only fall in the range [A-Z].
To save myself from a bit of typing, I also defined the custom DiamondPropertyAttribute that uses the Letters type, and used it to adorn the test function instead of FsCheck's built-in PropertyAttribute.
Top and bottom #
Considering the TPP, I wondered which property I should write next, since I wanted to define a property that would force me to change my current implementation in the right direction, but only by a small step.
A good candidate seemed to state something about the top and bottom of the diamond: the first and the last line of the diamond must always contain a single 'A'. Here's how I expressed that in code:
let split (x : string) = x.Split([| Environment.NewLine |], StringSplitOptions.None) let trim (x : string) = x.Trim() [<DiamondProperty>] let ``First row contains A`` (letter : char) = let actual = Diamond.make letter let rows = split actual rows |> Seq.head |> trim = "A" [<DiamondProperty>] let ``Last row contains A`` (letter : char) = let actual = Diamond.make letter let rows = split actual rows |> Seq.last |> trim = "A"
Notice that I wrote the test-specific helper functions split and trim in order to make the code a bit more readable, and that I also decided to define the property for the top of the diamond separately from the property for the bottom.
In the degenerate case where the input is 'A', the first and the last rows are identical, but the properties still hold.
Using the Devil's Advocate, this implementation passes all properties defined so far:
let make letter = " A "
This is slightly better, but I purposely placed the 'A' slightly off-centre. In fact, the entire hard-coded string is 16 characters wide, so it can never have a single, centred letter. The next property should address this problem.
Vertical symmetry #
A fairly important property of the diamond is that it must be symmetric. Here's how I defined symmetry over the vertical axis:
let leadingSpaces (x : string) = let indexOfNonSpace = x.IndexOfAny [| 'A' .. 'Z' |] x.Substring(0, indexOfNonSpace) let trailingSpaces (x : string) = let lastIndexOfNonSpace = x.LastIndexOfAny [| 'A' .. 'Z' |] x.Substring(lastIndexOfNonSpace + 1) [<DiamondProperty>] let ``All rows must have a symmetric contour`` (letter : char) = let actual = Diamond.make letter let rows = split actual rows |> Array.forall (fun r -> (leadingSpaces r) = (trailingSpaces r))
Using the two new helper functions, this property states that the diamond should have a symmetric contour; that is, that it's external shape should be symmetric. The property doesn't define what's inside of the diamond.
Again, using the Devil's Advocate technique, this implementations passes all tests:
let make letter = " A "
At least the string is now symmetric, but it feels like we aren't getting anywhere, so it's time to define a property that will force me to use the input letter.
Letters, in correct order #
When considering the shape of the required diamond, we know that the first line should contain an 'A', the next line should contain a 'B', the third line a 'C', and so on, until the input letter is reached, after which the order is reversed. Here's my way of stating that:
[<DiamondProperty>] let ``Rows must contain the correct letters, in the correct order`` (letter : char) = let actual = Diamond.make letter let letters = ['A' .. letter] let expectedLetters = letters @ (letters |> List.rev |> List.tail) |> List.toArray let rows = split actual expectedLetters = (rows |> Array.map trim |> Array.map Seq.head)
The expression let letters = ['A' .. letter] produces a list of letters up to, and including, the input letter. As an example, if letter is 'D', then letters will be ['A'; 'B'; 'C'; 'D']. That's only the top and middle parts of the diamond, but we can use letters again: we just have to reverse it (['D'; 'C'; 'B'; 'A']) and throw away the first element ('D') in order to remove the duplicate in the middle.
This property is still quite loosely stated, because it only states that each row's first non-white space character should be the expected letter, but it doesn't say anything about subsequent letters. The reason I defined this property so loosely was that I didn't want to force too many changes on the implementation at once. The simplest implementation I could think of was this:
let make letter = let letters = ['A' .. letter] let letters = letters @ (letters |> List.rev |> List.tail) letters |> List.map string |> List.reduce (fun x y -> sprintf "%s%s%s" x System.Environment.NewLine y)
It duplicates the test code a bit, because it reuse the algorithm that generates the desired sequence of letters. However, I'm not too concerned about the occasional DRY violation.
For the input 'D', this implementation produces this output:
A B C D C B A
All properties still hold. Obviously this isn't correct yet, but I was happy that I was able to define a property that led me down a path where I could take a small, controlled step towards a more correct solution.
As wide as it's high #
While I already have various properties that examine the white space around the letters, I've now temporarily arrived at an implementation entirely without white space. This made me consider how I could take advantage of those, and combine them with a new property, to re-introduce the second dimension to the figure.
It's fairly clear that the figure must be as wide as it's high, if we count both width and height in number of letters. This property is easy to define:
[<DiamondProperty>] let ``Diamond is as wide as it's high`` (letter : char) = let actual = Diamond.make letter let rows = split actual let expected = rows.Length rows |> Array.forall (fun x -> x.Length = expected)
It simply verifies that each row has exactly the same number of letters as there are rows in the figure. My implementation then became this:
let make letter = let makeLine width letter = match letter with | 'A' -> let padding = String(' ', (width - 1) / 2) sprintf "%s%c%s" padding letter padding | _ -> String(letter, width) let letters = ['A' .. letter] let letters = letters @ (letters |> List.rev |> List.tail) let width = letters.Length letters |> List.map (makeLine width) |> List.reduce (fun x y -> sprintf "%s%s%s" x Environment.NewLine y)
This prompted me to introduce a private makeLine function, which produces the line for a single letter. It has a special case to handle the 'A', since this value is the only value where there's only a single letter on a line. For all other letters, there will be two letters - eventually with spaces between them.
This seemed a reasonable rationale for introducing a branch in the code, but after having completed the kata, I can see that Nat Pryce has a more elegant solution.
If the input is 'D' the output now looks like this:
A BBBBBBB CCCCCCC DDDDDDD CCCCCCC BBBBBBB A
There's still not much white space in the implementation, but at least we regained the second dimension of the figure.
Inner space #
The next incremental change I wanted to introduce was the space between two letters. It seemed reasonable that this would be a small step for the makeLine function.
[<DiamondProperty>] let ``All rows except top and bottom have two identical letters`` (letter : char) = let actual = Diamond.make letter let isTwoIdenticalLetters x = let hasIdenticalLetters = x |> Seq.distinct |> Seq.length = 1 let hasTwoLetters = x |> Seq.length = 2 hasIdenticalLetters && hasTwoLetters let rows = split actual rows |> Array.filter (fun x -> not (x.Contains("A"))) |> Array.map (fun x -> x.Replace(" ", "")) |> Array.forall isTwoIdenticalLetters
The property itself simply states that each row must consist of exactly two identical letters, and then white space to fill out the shape. The way to verify this is to first replace all spaces with the empty string, and then examine the remaining string. Each remaining string must contain exactly two letters, so its length must be 2, and if you perform a distinct operation on its constituent char values, the resulting sequence of chars should have a length of 1.
This property only applies to the 'internal' rows, but not the top and bottom rows that contain a single 'A', so these rows are filtered out.
The new property itself only states that apart from the 'A' rows, each row must have exactly two identical letters. Because the tests for the 'A' rows, together with the tests for symmetric contours, already imply that each row must have a width of an uneven number, and again because of the symmetric contour requirement, I had to introduce at least a single space between the two characters.
let make letter = let makeLine width letter = match letter with | 'A' -> let padding = String(' ', (width - 1) / 2) sprintf "%s%c%s" padding letter padding | _ -> let innerSpace = String(' ', width - 2) sprintf "%c%s%c" letter innerSpace letter let letters = ['A' .. letter] let letters = letters @ (letters |> List.rev |> List.tail) let width = letters.Length letters |> List.map (makeLine width) |> List.reduce (fun x y -> sprintf "%s%s%s" x Environment.NewLine y)
Using the Devil's Advocate technique, it seems that the simplest way of passing all tests is to fill out the inner space completely. Here's an example of calling Diamond.make 'D' with the current implementation:
A B B C C D D C C B B A
Again, I like how this new property enabled me to do an incremental change to the implementation. Visually, we can see that the figure looks 'more correct' than it previously did.
Bottom triangle #
At this point I thought that it was appropriate to begin to address the diamond shape of the figure. After having spent some time considering how to express that without repeating the implementation code, I decided that the easiest step would be to verify that the lower left space forms a triangle.
[<DiamondProperty>] let ``Lower left space is a triangle`` (letter : char) = let actual = Diamond.make letter let rows = split actual let lowerLeftSpace = rows |> Seq.skipWhile (fun x -> not (x.Contains(string letter))) |> Seq.map leadingSpaces let spaceCounts = lowerLeftSpace |> Seq.map (fun x -> x.Length) let expected = Seq.initInfinite id spaceCounts |> Seq.zip expected |> Seq.forall (fun (x, y) -> x = y)
This one is a bit tricky. It examines the shape of the lower left white space. Getting that shape itself is easy enough, using the previously defined leadingSpaces helper function. For each row, spaceCounts contains the number of leading spaces.
The expected value contains an infinite sequence of numbers, {0; 1; 2; 3; 4; ...} because, due to the random nature of Property-Based Testing, I don't know exactly how many numbers to expect.
Zipping an infinite sequence with a finite sequence matches elements in each sequence, until the shortest sequence (that would be the finite sequence) ends. Each resulting element is a tuple, and if the lower left space forms a triangle, the sequence of tuples should look like this: {(0, 0); (1, 1); (2, 2); ...}. The final step in the property is therefore to verify that all of those tuples have identical elements.
The implementation uses Devil's Advocate, and goes quite a bit out of its way to make the top of the figure wrong. As you'll see shortly, it will actually be a simpler implementation to keep the figure symmetric around the horizontal axis as well, but we should have that as an explicit property.
let make letter = let makeLine width (letter, letterIndex) = match letter with | 'A' -> let padding = String(' ', (width - 1) / 2) sprintf "%s%c%s" padding letter padding | _ -> let innerSpaceWidth = letterIndex * 2 - 1 let padding = String(' ', (width - 2 - innerSpaceWidth) / 2) let innerSpace = String(' ', innerSpaceWidth) sprintf "%s%c%s%c%s" padding letter innerSpace letter padding let indexedLetters = ['A' .. letter] |> Seq.mapi (fun i l -> l, i) |> Seq.toList let indexedLetters = ( indexedLetters |> List.map (fun (l, _) -> l, 1) |> List.rev |> List.tail |> List.rev) @ (indexedLetters |> List.rev) let width = indexedLetters.Length indexedLetters |> List.map (makeLine width) |> List.reduce (fun x y -> sprintf "%s%s%s" x Environment.NewLine y)
The main change here is that now each letter is being indexed, but then I deliberately throw away the indexes for the top part, in order to force myself to add yet another property later. While I could have skipped this step, and gone straight for the correct solution at this point, I was, after all, doing a kata, so I also wanted to write one last property.
The current implementation produces the figure below when Diamond.make is called with 'D':
A B B C C D D C C B B A
The shape is almost there, but obviously, the top is wrong, because I deliberately made it so.
Horizontal symmetry #
Just as the figure must be symmetric over its vertical axis, it must also be symmetric over its horizontal axis:
[<DiamondProperty>] let ``Figure is symmetric around the horizontal axis`` (letter : char) = let actual = Diamond.make letter let rows = split actual let topRows = rows |> Seq.takeWhile (fun x -> not (x.Contains(string letter))) |> Seq.toList let bottomRows = rows |> Seq.skipWhile (fun x -> not (x.Contains(string letter))) |> Seq.skip 1 |> Seq.toList |> List.rev topRows = bottomRows
This property finally 'allows' me to simplify my implementation:
let make letter = let makeLine width (letter, letterIndex) = match letter with | 'A' -> let padding = String(' ', (width - 1) / 2) sprintf "%s%c%s" padding letter padding | _ -> let innerSpaceWidth = letterIndex * 2 - 1 let padding = String(' ', (width - 2 - innerSpaceWidth) / 2) let innerSpace = String(' ', innerSpaceWidth) sprintf "%s%c%s%c%s" padding letter innerSpace letter padding let indexedLetters = ['A' .. letter] |> Seq.mapi (fun i l -> l, i) |> Seq.toList let indexedLetters = indexedLetters @ (indexedLetters |> List.rev |> List.tail) let width = indexedLetters.Length indexedLetters |> List.map (makeLine width) |> List.reduce (fun x y -> sprintf "%s%s%s" x Environment.NewLine y)
Calling Diamond.make with 'D' now produces:
A B B C C D D C C B B A
It works with other letters, too.
Summary #
It turned out to be an interesting exercise to do this kata with Property-Based Testing. To me, the most surprising part was that it was much easier to approach the problem in an incremental fashion than it was with Example-Driven Development.
If you're interested in perusing the source code, including my detailed, step-by-step commit remarks, it's on GitHub. If you want to learn more about Property-Based Testing, you can watch my Introduction to Property-based Testing with F# Pluralsight course. There are more examples in some of my other F# Pluralsight courses - particularly Type-Driven Development with F#.
Composition Root Reuse
A Composition Root is application-specific. It makes no sense to reuse it across code bases.
At regular intervals, I get questions about how to reuse Composition Roots. The short answer is: you don't.
Since it appears to be a Frequently Asked Question, it seems that a more detailed answer is warranted.
Composition Roots define applications #
A Composition Root is application-specific; it's what defines a single application. After having written nice, decoupled code throughout your code base, the Composition Root is where you finally couple everything, from data access to (user) interfaces.
Here's a simplified example:
public class CompositionRoot : IHttpControllerActivator { public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { if(controllerType == typeof(ReservationsController)) { var ctx = new ReservationsContext(); var repository = new SqlReservationRepository(ctx); request.RegisterForDispose(ctx); request.RegisterForDispose(repository); return new ReservationsController( new ApiValidator(), repository, new MaîtreD(10), new ReservationMapper()); } // Handle more controller types here... throw new ArgumentException( "Unknown Controller type: " + controllerType, "controllerType"); } }
This is an excerpt of a Composition Root for an ASP.NET Web API service, but the hosting framework isn't particularly important. What's important is that this piece of code pulls in objects from all over an application's code base in order to compose the application.
The ReservationsContext class derives from DbContext; an instance of it is injected into a SqlReservationRepository object. From this, it's clear that this application uses SQL Server for it data persistence. This decision is hard-coded into the Composition Root. You can't change this unless you recompile the Composition Root.
At another boundary of this hexagonal/onion/whatever architecture is a ReservationsController, which derives from ApiController. From this, it's clear that this application is a REST API that uses ASP.NET Web API for its implementation. This decision, too, is hard-coded into the Composition Root.
From this, it should be clear that the Composition Root is what defines the application. It combines all the loosely coupled components into an application: software that can be executed in an OS process.
It makes no more sense to attempt to reuse a Composition Root than it does attempting to 'reuse' an application.
Container-based Composition Roots #
The above example uses Pure DI in order to explain how a Composition Root is equivalent to an application definition. What about DI Container-based Composition Roots, then?
It's essentially the same story, but with a twist. Imagine that you want to use Castle Windsor to compose your Web API; I've already previously explained how to do that, but here's the IHttpControllerActivator implementation repeated:
public class WindsorCompositionRoot : IHttpControllerActivator { private readonly IWindsorContainer container; public WindsorCompositionRoot(IWindsorContainer container) { this.container = container; } public IHttpController Create( HttpRequestMessage request, HttpControllerDescriptor controllerDescriptor, Type controllerType) { var controller = (IHttpController)this.container.Resolve(controllerType); request.RegisterForDispose( new Release( () => this.container.Release(controller))); return controller; } private class Release : IDisposable { private readonly Action release; public Release(Action release) { this.release = release; } public void Dispose() { this.release(); } } }
Indeed, there's no application-specific code there; this class is completely reusable. However, this reusability is accomplished because the container is injected into the object. The container itself must be configured in order to work, and configuration code is just as application-specific as the above Pure DI example.
Thus, with a DI Container, you may be able to decouple and reuse the part of the Composition Root that performs the run-time composition. However, the design-time composition is where you put the configuration code that select which concrete types should be used in which cases. This is the part that specifies the application, and that's not reusable.
Summary #
Composition Roots aren't reusable.
Sometimes, you might be building a suite of applications that share a substantial subset of dependencies. Imagine, for example, that you're building a REST API and a batch job that together solve a business problem. The Domain Model and the Data Access Layer may be shared between these two applications, but the boundary isn't. The batch job isn't going to need any Controllers, and the REST API isn't going to need whatever is going to kick off the batch job (e.g. a scheduler). These two applications may have a lot in common, but they're still different. Thus, they can't share a Composition Root.
What about the DRY principle, then?
Different applications have differing Composition Roots. Even if they start with substantial amounts of duplicated Composition Root code, in my experience, the 'common' code tends to diverge the more the applications are allowed to evolve. That duplication may be accidental, and attempting to eliminate it may increase coupling. It's better to understand why you want to avoid duplication in the first place.
When it comes to Composition Roots, duplication tends to be accidental. Composition Roots aren't reusable.
Comments
In the example where the domain layer and the data access layer are shared between applications, it really depends whether they will have a future need to be wired differently according to the application.
If that's not the case, you could argue that there's no need for two components either.
One solution would be to use a Facade which internally wires them up and exposes it as a single interface. This allows for reuse of the domain and the DAL as a single component, opaque to the client.
Kenneth, thank you for writing. If you create a Facade that internally wires up a Domain Model and DAL, you've created a tightly coupled bundle. What if you later discover that you need to instrument your DAL? You can't do that if you prematurely compose object graphs.
Clearly, there are disadvantages to doing such a thing. What are the advantages?
Dear Mark,
Thank you for another excellent post.
Some of the composition roots I wrote became really large, too, especially the more complex the application got. In these cases I often introduced factories and builders that created parts of the final object graph and the imperative statements in the composition root just wired these subgraphs together. And this leads me to my actual question:
What do you think about pushing these factories and builders to a library so that they can be reused by different composition roots? This would result in much less code that wires the object graph. I know that abstract factories belong to the client, but one could provide Simple Factories / Factory Methods or, even better I think, the Builder Pattern is predestined for these situations, because it provides default dependencies that can be exchanged before the Build method is called.
If I think about automated tests, I can see that the concept I just described is already in use: every test has an arrange phase which in my opinion is the composition root for the test. To share arrange code between tests, one can use e.g. builders or fixture objects (or of course AutoFixture ;-) ). This reduces the code needed for the arrange phase and improves readability.
What is your opinion on pushing Simple Factories / Builders to a reusable library?
With regards,
Kenny
In the production environment, the service is deployed as a Windows Service, but for easier testing and development, we also have a console application that hosts the same service. Both entry points are basically the same composition root and should use the same components. We want to share the composition root, because otherwise when a component needs a new dependency and a constructor parameter is added, we'd have to change the same code in two different places.
Kenny, Daniel, thank you for writing. In an attempt to answer your questions, I wrote a completely new blog post on the subject; I hope it answers some of your questions, although I suppose you aren't going to like the answer.
If you truly have a big Composition Root, it may be one of the cases where you should consider adopting a DI Container with a convention-based configuration.
Another option is to make your 'boundary library' (e.g. your UI, or your RESTful endpoints) a library in itself, and host that library in various contexts. The Composition Root resides in that boundary library, so various hosts can 'reuse' it, as they reuse the entire application. You can see an example of this in my Outside-In Test-Driven Development Pluralsight course.
Dear Mark, thank you for writing the other blog post. Now I finally have time to answer.
I think in our specific situation there is a subtle but important difference: Rather than reusing a composition root between two libraries, we essentially have two different ways of hosting the same library (and thus composition root). One is used primarily during development, while the other is used in production, but essentially they are (and always will be) the same thing. So in my opinion it would even be dangerous to not use the same composition root here, as it would just add a source of errors if you change the dependency graph setup in one project but forget to do so in the other.
But I guess this is what you meant with creating a boundary library, isn't it?
Daniel, if I understand you correctly, that's indeed the same technique that I demonstrate in my Outside-In Test-Driven Development Pluralsight course. Although it may only be me splitting hairs, I don't consider that as reusing the Composition Root as much as it's deploying the same application to two different hosts; one of the hosts just happens to be a test harnes :)
Placement of Abstract Factories
Where should you define an Abstract Factory? Where should you implement it? Not where you'd think.
An Abstract Factory is one of the workhorses of Dependency Injection, although it's a somewhat blunt instrument. As I've described in chapter 6 of my book, whenever you need to map a run-time value to an abstraction, you can use an Abstract Factory. However, often there are more sophisticated options available.
Still, it can be a useful pattern, but you have to understand where to define it, and where to implement it. One of my readers ask:
These are good question that deserve a more thorough treatment than a tweet in reply.
Situation #
Based on the above questions, I imagine that the situation can be depicted like this:
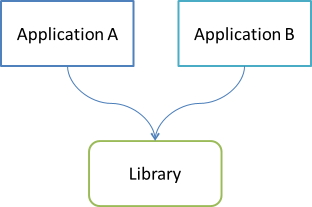
Two or more applications share a common library. These applications may be a web service and a batch job, a web site and a mobile app, or any other combination that makes sense to you.
Defining the Abstract Factory #
Where should an Abstract Factory be defined? In order to answer this question, first you must understand what an Abstract Factory is. Essentially, it's an interface (or Abstract Base Class - it's not important) that looks like this:
public interface IFactory<T> { T Create(object context); }
Sometimes, the Abstract Factory is a non-generic interface; sometimes it takes more than a single parameter; often, the parameter(s) have stronger types than object.
Where do interfaces go?
From Agile Principles, Patterns, and Practices, chapter 11, we know that the Dependency Inversion Principle means that "clients [...] own the abstract interfaces". This makes sense, if you think about it.
Imagine that the (shared) library defines a concrete class Foo that takes three values in its constructor:
public Foo(Guid bar, int baz, string qux)
Why would the library ever need to define an interface like the following?
public interface IFooFactory { Foo Create(Guid bar, int baz, string qux); }
It could, but what would be the purpose? The library itself doesn't need the interface, because the Foo class has a nice constructor it can use.
Often, the Abstract Factory pattern is most useful if you have some of the values available at composition time, but can't fully compose the object because you're waiting for one of the values to materialize at run-time. If you think this sounds abstract, my article series on Role Hints contains some realistic examples - particularly the articles Metadata Role Hint, Role Interface Role Hint, and Partial Type Name Role Hint.
A client may, for example, wait for the bar value before it can fully compose an instance of Foo. Thus, the client can define an interface like this:
public interface IFooFactory { Foo Create(Guid bar); }
This makes sense to the client, but not to the library. From the library's perspective, what's so special about bar? Why should the library define the above Abstract Factory, but not the following?
public partial interface IFooFactory { Foo Create(int baz); }
Such Abstract Factories make no sense to the library; they are meaningful only to their clients. Since the client owns the interfaces, they should be defined together with their clients. A more detailed diagram illustrates these relationships:
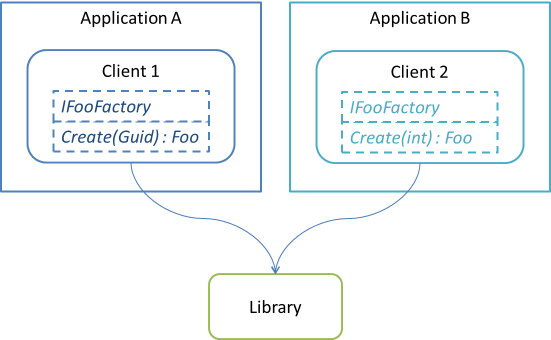
As you can see, although both definitions of IFooFactory depend on the shared library (since they both return instances of Foo), they are two different interfaces. In Client 1, apparently, the run-time value to be mapped to Foo is bar (a Guid), whereas in Client 2, the run-time value to be mapped to Foo is baz (an int).
The bottom line is: by default, libraries shouldn't define Abstract Factories for their own concrete types. Clients should define the Abstract Factories they need (if any).
Implementing the Abstract Factory #
While I've previously described how to implement an Abstract Factory, I may then have given short shrift to the topic of where to put the implementation.
Perhaps a bit surprising, this (at least partially) depends on the return type of the Abstract Factory's Create method. In the case of both IFooFactory definitions above, the return type of the Create methods is the concrete Foo class, defined in the shared library. This means that both Client 1 and Client 2 already depends on the shared library. In such situations, they can each implement their Abstract Factories as Manually Coded Factories. They don't have to do this, but at least it's an option.
On the other hand, if the return type of an Abstract Factory is another interface defined by the client itself, it's a different story. Imagine, as an alternative scenario, that a client depends on an IPloeh interface that it has defined by itself. It may also define an Abstract Factory like this:
public interface IPloehFactory { IPloeh Create(Guid bar); }
This has nothing to do with the library that defines the Foo class. However, another library, somewhere else, may implement an Adapter of IPloeh over Foo. If this is the case, that implementing third party could also implement IPloehFactory. In such cases, the library that defines IPloeh and IPloehFactory must not implement either interface, because that creates the coupling it works so hard to avoid.
The third party that ultimately implements these interfaces is often the Composition Root. If this is the case, other implementation options are Container-based Factories or Dynamic Proxies.
Summary #
In order to answer the initial question: my default approach would be to implement the Abstract Factory multiple times, favouring decoupling over DRY. These days I prefer Pure DI, so I'd tend to go with the Manually Coded Factory.
Still, this answer of mine presupposes that Abstract Factory is the correct answer to a design problem. Often, it's not. It can lead to horrible interfaces like IFooManagerFactoryStrategyFactoryFactory, so I consider Abstract Factory as a last resort. Often, the Metadata, Role Interface, or Partial Type Name Role Hints are better options. In the degenerate case where there's no argument to the Abstract Factory's Create method, a Decoraptor is worth considering.
This article explains the matter in terms of relatively simple dependency graphs. In general, dependency graphs should be shallow, but if you want to learn about principles for composing more complex dependency graphs, Agile Principles, Patterns, and Practices contains a chapter on Principles of Package and Component Design (chapter 28) that I recommend.
Exception messages are for programmers
Exception messages should be aimed at other developers, not end users.
Once in a while, I come across fellow programmers with uncertain understanding of the purpose of exception messages. In my experience, when it comes to writing exception messages, most developers approach the job with one of these mindsets:
- Write the shortest possible exception message; if possible, ignore good grammar, punctuation, and proper spelling.
- Write lovingly crafted error messages for the end users.
Damn the torpedoes #
As far as I can tell, the most common approach to writing error messages is to get it over with as quickly as possible. Apparently, writing a good exception message is such tedious work that a developer can't possibly be bothered with it. Here are some examples:
throw new Exception("Unknown FaileType");
or:
throw new Exception("Unecpected workingDirectory");
These aren't particularly helpful. At the very least, is it too much to ask that they apply correct spelling and punctuation? Would it have been a horrible experience for the developer to write "Unknown FailureType.", or "Unexpected workingDirectory."?
Even if spelling, grammar, and punctuation are corrected, these exception messages aren't particularly helpful to anyone. Fair enough that the FailureType or workingDirectory values were unknown or unexpected, but what were they, then?
If you're seeing such exceptions while working with the code in your IDE, you may be able to attach a debugger and figure out what was the wrong value, but if you're looking at an error log from a production system, you'd really like to know the exact value that was unexpected.
Unfortunately, most developers apparently can't be bothered with supplying even such rudimentary information.
Exception messages for end users? #
Developers who do care about exception messages often seem to have end users in mind. They may spell exception messages correctly, but shy away from providing technical information in the messages, because they are considering the user experience for the end users. They would argue that the "Unknown FailureType" shouldn't be included in the exception message, because it's too technical.
It is, indeed, too technical for end users, but the misconception here is that exception messages should be exposed to end users at all. These developers seems to have a plan for exception handling, which essentially involves catching all exceptions at the boundary of the application, and simply show the exception message to the end user.
That's unlikely to provide a good user experience.
It should be clear that "Unknown FailureType." isn't particularly helpful to a fellow programmer, but it's even more useless to a non-technical end user. Thus, in an effort to shield end users from the technical failure modes of our program, we make exception messages useless to end users and fellow programmers alike.
Security #
Another argument I often encounter is one of security - in this case Information Disclosure. According to the argument, exception messages shouldn't include run-time values, because that may leak information about how the system works. Again, this argument seems to hinge on the implied usage of exception messages shown to end users.
Language #
Exception messages aren't for end users. End users don't speak your language. They don't speak 'Technical'. They may not even speak English. What if your target demographic is all Dutch? Are you going to write all of your exception messages in Dutch? Even if you do, what about exceptions thrown by your Base Class Library or third-party libraries? These are likely to be in English, so if you catch and display all exceptions, you may occasionally display an English message to your Dutch users.
What if your application is designed for a Swiss audience? In which language are you going to write your exception messages? German? French? Italian? Romansh?
Conceptual coupling #
All of the above arguments even implicitly assume that you're writing exception messages for a known system. What if you're writing a reusable library? If you're writing a reusable library, you don't know the context in which it's going to be used. If you don't know the context, then how can you write an appropriate message for an end user?
It should be clear that when writing a reusable library, you're unlikely to know the language of the end user, but it's worse than that: you don't know anything about the end user. You don't even know if there's going to be an end user at all; your library may as well be running inside a batch job.
The converse is true as well. Even if you aren't writing a reusable library, end user-targeted exception messages increases the coupling in the system, because exception messages would be coupled to a particular user interface. This sort of coupling doesn't occur in the type system, but is conceptual. Exactly because it's not tied to any type system, an automated tool can't detect it, so it's much harder to notice, and more insidious as a result.
Exception messages are not for end users. Applications can catch known exception types and translate them to context-aware error messages, but this is a user interface concern - not a technical concern.
Exception messages for client developers #
Now that you understand that exception messages shouldn't be aimed at end users, who's left? Your fellow programmers, including your future self. As I explain in my encapsulation course, exception messages can be used as documentation of the system.
Imagine that you're using a new library that you don't yet know well. Which exception message would you, as a programmer, prefer to encounter?
"Unecpected workingDirectory"or this:
How do those two messages make you feel?"You tried to provide a working directory string that doesn't represent a working directory. It's not your fault, because it wasn't possible to design the FileStore class in such a way that this is a statically typed pre-condition, but please supply a valid path to an existing directory.
"The invalid value was: "fllobdedy"."
The first type of exception message often make me feel that I suck. The second is mostly an annoyance that my program doesn't work, followed by delight that the object I'm using makes it easy for me to solve my problem.
If you encounter the first exception message, you'll often need to attach a debugger to figure out what was wrong, or at least open the offending code to understand what made it fail. In the second example, the object you're using does its best to provide you with all the information you need in order to solve the problem.
Call to action #
Do write useful exception messages aimed at other developers. Use correct grammar, spelling, and punctuation. Try to phrase the message in a non-blaming way. Supply information about the context or the offending value. If possible, suggest how to resolve the error.
It will take you an extra five minutes to write such an exception message, but will save your colleagues, your clients, and your future self hours of troubleshooting and debugging.
Comments
Exceptions with exceptionally great error messages is a pet peeve of mine, and I've always had the personal philosophy that exceptions should not be a slap in the face; they should be a step forward. Therefore, I usually follow the rule that exceptions must provide both a) details about the error (including, of course, the wrong value and information about the expected domain), and b) one or more suggestions for a way forward (which may have been done implicitly already by elaborating on the domain, but may sometimes require extra effort like e.g. helping with coming up with a proper value).
I have a question for you though, regarding exceptions: I usually introduce a special exception when I'm building software for clients: a DomainException! As you might have guessed, it's a special exception that is meant to be consumed by humanoids, i.e. the end user. This means that it is crafted to be displayed without a stack trace, providing all the necessary context through its Message alone. This is the exception that the domain model may throw from deep down, telling the user intimate details about a failed validation that could only be checked at that time and place.
As far as I can see, there's two problems with my DomainException: 1) It's not that exceptional since it's used as a fallback validation that can be used when the UI is too lazy to provide the validation (or has higher prioritized work to do), and 2) I wouldn't know how to introduce a second language in my application with this approach.
The 1st "problem" isn't really a problem in my book - I get that it's silly to use exceptions for control flow, but I bet there's no way you can provide a clearer and more succinct way of guarding the domain model's integrity AND provide an excellent error message at the same time than you can by throwing an appropriate DomainException.
The 2nd problem could be a problem though - luckily, I haven't yet tried building something that didn't use either Danish or English as its only language, but I guess I could make the DomainException localizable somehow...
I'm curious, though, as to how other people solve the problem of deep-domain validation, and now - since you wrote this blog post - I'm asking you: how do you do it? :)
I wholeheartedly agree with you, Mark. Users shouldn't see technical error messages and they really don't care about them. They just want it to work and when it doesn't, they want to feel sure that somebody is looking into it.
Exceptions and error handling are, obviously, tightly connected and I have written about this. Its a long piece, but the gist of it is that there are three general classes of errors:
- Unrecoverable errors - the computers and the users involved cannot do anything about.
- Recoverable errors requiring user intervention - e.g. spelling mistakes.
- Recoverable errors not requiring user intervention - e.g. time outs, which can be automatically retried.
What is important for an exception is for it to contain enough information for the UI-layer (be it web, desktop, whatever), to ensure the user that somebody is actually on the go to solve the problem. It could be something as simple as a link to where the user can be updated about progress. This of course means that exceptions should be logged and meticulously followed up upon, which takes time and resources.
This leads on to the general concept of application logging, which I have not written about, yet ;)
To Mogens: I think your DomainException should not contain any text, per say, just the data. The text should then be stored
in resources, the same way as any other localizable text should be.
I sympathize with Mogens. I, too, have found situations where an exception wants to be able to provide a user-facing message. However, I think I've found a better pattern for this that avoids a lot of problems. I posted about it here.
It's a good article which mostly forgotten by developers. The points are well delivered. I also have some of those badly-formed exceptions. Which I just fixed after reading this article.
As for Mogens, I kinda agree with Torben. The DomainException may contain text or raw data, and let the
top-level exception handler at your application handle the message format for you. It can decrease coupling as you can
handle the message to different UI (batch, web, desktop, mobile). It also provide more properly formatted text.
Mogens, thank you for writing. I know that you have a passion for well-written exception messages; in fact, you are one of the many people who inspired me to make exception messages more and more helpful.
How do I deal with 'deep' exceptions? First of all, I try hard to avoid them in the first place. One of the ways to do that is to validate input as close to the application boundary as possible, and transform it into something that properly protects its invariants; I recently wrote an article with a simple example of doing that (you may also want to read the comments, which contain a few gems).
Even if you can eliminate many 'deep' exceptions, you can't get rid of all of them. Particularly if you integrate with legacy systems, it can be difficult to validate everything up front, because the 'rules' of the legacy system may not be clear or public. In such cases, I prefer to throw custom exceptions. In each place where I need to throw an exception, I create a new Exception class and throw that. This means that any client can catch that particular exception type, and convert it to a friendly user message. If you need to provide additional information to the user, the custom Exception class can have extra properties with the required information.
Typically, if you start with the approach of validating input, and protecting invariants of objects, you aren't going to need a ton of custom Exception classes, so I find this approach manageable, although still not 'nice'.
The solution described by James Jensen above is one that I've never seen before, but it sounds like a good alternative.
As an overall comment, it's true that we shouldn't use exceptions for control flow, but unfortunately, most object-oriented languages give us no nice alternatives. However, in languages with Sum Types (Discriminated Unions in F#), there are much better options for error handling. That's what I use when I write F# code, which is my preferred language these days.
I agree with this post at a basic level. Starting out this is the right way to handle exceptions. The thing is, you haven't really addressed the problems this restriction leads on to.
Internally caught exceptions are for the programmer to handle and write code for. You may want different types to indicate the handling. For example, I have a piece of code that has to communicate over an unreliable network connection. When this fails, it tends to be more efficient to catch to exception and make certain decisions about retrying than to have the error bounce all the way back up the chain of commands where all that will happen in most circumstances anyway is that a retry attempt will be made.
What happens when the programmer doesn't catch the exception? Why can't it be for the user? What if there is something more you can do to help the user beyond "computer said no"? There might be a reason that meme exists. Something unexpected can happen in the code and IO, the user is one of those components. Why can't it be handled there or in another system the exception propagates to? This is a weird one if you think about it. For any other IO fault I can just throw an exception saying what is wrong but when it comes to the user, I can't use exceptions for this?
I believe that in any large multiple interface project that exceptions can and potentially should be for everyone. However I do not believe this should be ambiguous.
I solve this by creating special "UserDoneBadExceptions" so to speak (not literally called that). A few other names and approaches come to mind such as safe exception and friendly exception (hi *wave*). I'll stick to safe exception from now on. Different languages or frameworks will influence which approach for this is best. Personally I've found myself having to monkey patch some nasty kludges for this.
If something reaches the top level without being caught, then it will be forwarded to the next system if it is a safe exception otherwise the current exception will be consumed (such a to the log) and a safe exception will be sent. A safe exception is no different really to those special exceptions that help tell the programmer how to handle them or what to do (retry, fallback, log and ignore, abort, reopen, reconnect, clean up in a certain way, etc). I tend to describe exceptions that need to be converted as give up, complain to support, prey, retry, figure out a workaround, do what you want or shrug exceptions. Basically they're an ouch, the error has been logged, the developer *may* look at the logs and fix it at some date but if it's really important, workaround, go to support, etc.
Establishing that it might be a good idea for an exception system to indicate action at every level raises the question of what to indicate for an exception exiting the system to another system. You always assume at some point it will reach a user so the default is typically that a safe exception triggered by any other exception should explain to the user that an error has occured, not much can be done, perhaps a link to support, definitely some means of linking to the error log (at least a timestamp) and in extreme cases the error log encrypted so they can copy and paste it to support.
There is a repeat ambiguity with safe exceptions because the receiving system may be able to handle the exception. In fact it may be handled both in how it deals with the user and through automation. It is common to extend safe exceptions so that they contain action for the user in the sense of providing them with feedback about what they can do as well as sufficient data for the system so that if it is capable it can take action. I've found the two most common cases for this is to either be able to provide auxilery updated data if the front end is out of date or to indicate a redirect (which can double as a refresh, be careful, very careful). A simple way to look at it is if you cared for using HTTP status codes then which codes and messages should you exceptions indicate the use of?
What this really comes down to is that you need to define separate domains for your exceptions. Are they internal or external? Are they some combination of both (if you are poking your own RPC service then it's technically internal external but really just internal, you can propagate it as-is)? The concept could be called intersystem exceptions. The benefit I find for this is better code reuse and generally less coded needed. I can use all of my permissions systems for RPC for anything with sometimes a thin layer of conversion for different output types and it works pretty well as a one size fits all. Whether my exceptions are poking out into AJAX, websocket XML RPC, JSON RPC, HTML full page load, etc in each case a thin layer of conversion, handling, etc manages it all.
With that it is important to make special safe exceptions reasonably abstract avoiding specifics unless specifics are needed or work better. It's something to think about. Should a login required safe exception simply be a redirect exception to the login page or should it be down to the system to interpret the error type/code and to then be self aware about where the login prompt should be and where to display it? I would personally opt for the latter in a lot of cases but it really depends on what systems you're deailing with. This approach wont be for everyone. Not that many projects become large enough to justify architecting a complex inter system exception system.
Good times with F#
Some operations take time to perform, and you may want to capture that information. This post describes one way to do it.
Occasionally, you may find yourself in the situation where your software must make a decision based on how much time it has left. Is there time to handle one more message before shutting down? How much time did the last operation take? What was the time when it started?
It can be tempting to simply use DateTime.Now or DateTimeOffset.Now, but the problem is that it couples your code to the machine clock. It also tends to interleave timing logic with other logic, so that it becomes difficult to vary these independently. Incidentally, it also tends to make it difficult to unit test the time-dependent code.
Timed<'a> #
One alternative to DateTimeOffset.Now that I've recently found useful is to define a Timed<'a> generic type, like this:
type Timed<'a> = { Started : DateTimeOffset Stopped : DateTimeOffset Result : 'a } member this.Duration = this.Stopped - this.Started
A value of Timed<'a> not only carries with it the result of some computation, but also information about when it started and stopped. It also has a calculated property called Duration, which you can use to examine how long the operation took.
Untimed transformations #
Timed<'a> looks like a standard monadic type, and you can also implement standard Bind and Map functions for it:
module Untimed = let bind f x = let t = f x.Result { t with Started = x.Started } let map f x = { Started = x.Started; Stopped = x.Stopped; Result = f x.Result }
Notice, though, that these functions only transforms the Result (and, in the case of Bind, Stopped), but no actual time measurement is taking place; that's the reason I put both functions in a module called Untimed.
In the case of the Bind function, the time measurement is implicitly taking place when the f function is executed, because it returns a Timed<'b>. In the Map function, on the other hand, no time measurement takes place at all. The function simply maps Result from one value to another using the f function.
So far, I've found no use for the Bind function, and only occasional use for the Untimed.map function. What really matters, after all, is to measure time.
Timing functions #
Ultimately, Timed<'a> is only interesting if you measure the time computations take. Here are a few functions I've found useful to do that:
module Timed = let capture clock x = let now = clock() { Started = now; Stopped = now; Result = x } let map clock f x = let result = f x.Result let stopped = clock () { Started = x.Started; Stopped = stopped; Result = result }
Notice that both functions take a clock argument. This is a function with the signature unit -> DateTimeOffset, enabling the capture and map functions to get the time. As the name indicates, the capture function is used to capture a value and 'promote' it to a Timed<'a> value. This value can subsequently be used with the map function to measure the time it took to exectute the f function.
Clocks #
Using the computer's clock is easy:
let machineClock () = DateTimeOffset.Now
As you can tell, this function returns the value of DateTimeOffset.Now every time it's invoked.
You can also implement other clocks, e.g. for unit testing purposes. Here's one (not particularly Functional) way of doing it:
let qlock (q : System.Collections.Generic.Queue<DateTimeOffset>) () = q.Dequeue()
Obviously, since this clock is based on a Queue, I decided to call it qlock. Using that, you can define an easier-to-use function based on a sequence of DateTimeOffset values:
let seqlock (l : DateTimeOffset seq) = qlock (System.Collections.Generic.Queue<DateTimeOffset>(l))
Here's a fake clock that counts up all the days before Christmas in December (so obviously, I had to name it xlock):
let xlock = [1 .. 24] |> List.map (fun d -> DateTimeOffset(DateTime(2014, 12, d))) |> seqlock
The first time you execute xlock:
(xlock ()).ToString("d")
you get "01.12.2014", the next time you get "02.12.2014", the third time "03.12.2014", and so on.
Such fake clocks are mostly useful for testing, but you could also use them to perform simulations in accelerated time - or perhaps even move time backwards! (Last time I used it, WorldWide Telescope enabled you to look at the solar system in accelerated time. I don't know how that feature is implemented, but it sounds like a good case for a custom clock. The point of this digression is that depending on your application's need, being able to manipulate time may not be as exotic as it first sounds.)
Measuring the time of execution #
These are all the building blocks you need to measure the time it takes to perform an operation. There are various ways to do it, but given a clock of the type unit -> DateTimeOffset, you can close over the clock like this:
let time f x = x |> Timed.capture clock |> Timed.map clock f
The time function has the type ('a -> 'b) -> 'a -> Timed<'b>, so, if for example you have a function called readCustomerFromDb of the type int -> Customer option, you can time it like this:
let c = time readCustomerFromDb 42
This might give you a result like this:
{Started = 17.12.2014 11:24:38 +01:00;
Stopped = 17.12.2014 11:24:39 +01:00;
Result = Some {Id = 42; Name = "Foo";};}
As you can tell, the result of querying the database for customer 42 is the customer data, as well as information about when the operation started and stopped.
Concluding remarks #
The nice quality of Timed<'a> is that it decouples timing of operations from the result of those operations. This enables you to compose functions without explicitly having to consider how to measure their execution times.
It also helps with unit testing, because if you want to test what happens in a function if a previous function ran on a Sunday, or if it took more than three seconds to run, you can simply create a value of Timed<'a> that captures that information:
let c' = { Started = DateTimeOffset(DateTime(2014, 12, 14, 11, 43, 11)) Stopped = DateTimeOffset(DateTime(2014, 12, 14, 11, 43, 15)) Result = Some { Id = 1337; Name = "Ploeh" } }
This value can now be used in a unit test to verify the behaviour in that particular case.
In a future post, I will demonstrate how to compose more complex time-sensitive behaviour using Timed<'a> and the associated modules.
This post is number 17 in the 2014 F# Advent Calendar.
Update 2017-05-25: A more recent treatment, including a more realistic usage scenario, is available in the article Type Driven Development.
Name this operation
A type of operation seems to be repeatedly appearing in my code, but I can't figure out what to call it; can you help me?
Across various code bases that I work with, it seems like operations (methods or functions) like these keep appearing:
public IDictionary<string, string> Foo( IDictionary<string, string> bar, Baz baz)
In order to keep the example general, I've renamed the method to Foo, and the arguments to bar and baz; in this article throughout, I'll make heavy use of metasyntactic variables. The types involved aren't particularly important; in this example they are IDictionary<string, string> and Baz, but they could be anything. The crux of the matter is that the output type is the same as one of the inputs (in this case, IDictionary<string, string> is both input and output).
Another C# example could be:
public int Qux(int corge, string grault)
Notice that the types involved don't have to be interfaces or complex types. The only recurring motif seems to be that the type of one of the arguments is identical to the return type.
Although the return value shares its type with one of the input arguments, the implementation doesn't have to echo the value as output. In fact, this is often not the case.
At this point, there's also no implicit assumption that the operation is referentially transparent. Thus, we may have implementation where some database is queried. Another possibility is that the operation is a closure over additional values. Here's an F# example:
let sign calculateSignature issuer (expiry : DateTimeOffset) claims = claims |> List.append [ { Type = "signature"; Value = calculateSignature claims } { Type = "issuer"; Value = issuer } { Type = "expiry"; Value = expiry.ToString "o" }]
You could imagine that the purpose of this function is to sign a set of security claims, by calculating a signature and add this and other issuer claims to the input list of claims. The signature of this particular function is (Claim list -> string) -> string -> DateTimeOffset -> Claim list -> Claim list. However, the leftmost arguments aren't going to vary much, so it would make sense to partially apply the function. Imagine that you have a correctly implemented signature function called calculateHMacSha, and that the name of the issuer should be "Ploeh":
let sign' = sign calculateHMacSha "Ploeh"
The type of the sign' function is DateTimeOffset -> Claim list -> Claim list, which is equivalent to the above Foo and Qux methods.
The question is: What should we call such an operation?
Why care?
In its general form, such an operation would have the shape
public interface IGrault<T1, T2> { T1 Garply(T1 waldo, T2 fred); }
in C# syntax, or 'a -> 'b -> 'b type in F# syntax.
Why should you care about operations like these?
It turns out that they are rather composable. For instance, it's trivial to implement the Null Object pattern, because you can always simply return the matching argument. Often, it also makes sense to make Composites out of them, or chain them in various ways.
In Functional Programming, you may just do this by composing functions together (while not particularly considering the terminology of what you're doing), but in Object-Oriented languages like C#, we have to name the abstraction before we can use it (because we have to define the type).
If T2 or 'a is a predicate, the operation might be a filter, but as illustrated with the above sign' function, the operation may also enrich the input. In some cases, it may even replace the original input and return a completely different value (of the same type). Thus, such an operation could be a 'filter', an 'expansion', or a 'replacement'; those are quite vague properties, so any name for such operations are likely to be vague or broad as well.
My question to you is: what do we call this type of operation?
While I do have a short-list of candidate names, I encounter these constructs so often that I'd be surprised if such operations don't already have a conceptual name. If so, what is it? If not, what should we call them?
(I'd hoped that this type of operation was already a 'thing' in functional programming, so I asked on Twitter, but the context is often lost on Twitter, so therefore this blog post.)
Comments
Hey Mark,
In a mathematical sense, I would say that this operation is an accumulation: you take a (complex or simple) value and according to the second parameter (and possible other contextual information), this value is transformed, which could mean that either subvalues are changed on the (mutable) target or a new value (which is probably immutable) is created from the given information. This whole process could imply that information is added or stripped from the first parameter.
What I found interesting is that there is always exactly one other parameter (not two or more), and it feels like the information from two is incorporated into parameter one.
Thus I would call this operation a Junction or Consolidation because information of parameter 2 is joined with parameter 1.
Kenny, thank you for your suggestions. Others have pointed out the similarities with accumulation, so that looks like the most popular candidate. Junction and Consolidation are new to me, but I've added both to my list.
When it comes to the second argument, I decided to present the problem with only a second argument in order to keep it simple. You could also have variations with two or three arguments, but since you can rephrase any parameter list to a Parameter Object, it's not particularly important.
Dear Mark,
I choose Junction over accumulation because it is a word that (almost) everybody is familiar with: a junction of rivers. When two or more rivers meet, they form a new river or the tributary rivers flow into the main river. I think this natural phenomenon is a reasonable metaphor for the operation your describing in your post.
Accumulation in contrast is specific to mathematics and IMHO I don't think everybody would understand the concept immediately (especially when lacking academic math education). Thus I think the name Junction can be grasped more easily - especially if you think of other OOP patterns like Factory, Command, Memento or Decorator: the pattern name provides a metaphor to a thing or phenomena (almost) everybody knows, which make them easy to learn and remember.
It was never my intention to imply that I necessarily considered Accumulation the best option, but it has been mentioned independently multiple times.
At first, I didn't make the connection to river junctions, but now that you've explained the metaphor, I really like it. It's like a tributary joining a major river. The Danube is still the Danube after the Inn has joined it. Thank you.
Sorry, I didn't want to sound like a teacher :-)
Not sure if you came to a conclusion here. Here are some relevant terms I've witnessed other places.
- In f#, these kinds of functions are often composed by piping (|>), so maybe IPipeable
- Clojure has the threading macro. Unfortunately, thread has interference with scheduling threads
- The clojure library pedestal operates around a pattern that is effectively lists of strategies. They call it interceptor, but that has interference with the more AOP concept of interceptor
I'm curious, did you experiment with this pattern in a language without partial application? It seems like shepherding operations into the shared type would be verbose.
Spencer, thank you for writing. You're certainly reaching back into the past!
Identifying a name for this kind of API was something that I struggled with at least as far back as 2010, where, for lack of better terms at the time I labelled them Closure of Operations and Reduction of Input. As I learned much later, these are essentially endomorphisms.
I've learned a lot from your content! I decided to start at the beginning to experience your evolution of thought over time. I love how deeply you think and your clear explanations of complex ideas. Thank you for sharing your experience!
Endomorphism makes sense. I got too focused on my notion of piping and forgot the key highlighted value was closure.

Comments
Dear Mark,
Thanks again for another wonderful post. I'm one of the guys you mentioned at the beginning of this text and I totally agree with you on this subject.
Maybe I wasn't specific enough in my comment that I didn't mean to introduce factories and builders handling dependencies from two or more assemblies, but only from a single one. The composition root wires the independent subgraphs from the different assemblies together.
However, I want to reemphasize the Builder Pattern in this context: it provides default dependencies for the object graph to be created and (usually) a fluent API (i.e. some sort of method chaining) to exchange these dependencies. This has the following consequences for the client programmer using the builder(s): he or she can easily create a default object graph by calling new Builder().Build() and still exchange dependencies he or she cares about. This can keep the composition root clean (at least for Arrange phases of tests this is true).
Why I'm so excited about this? Because I use this all the time in my automated tests, but haven't really used it in my production composition roots (or seen it in others). After reading this post and Composition Root Reuse, I will try to incorporate builders more often in my production code.
Mark - thank you for making me think about this.
Kenny, thank you for writing. The Builder pattern is indeed a good way to implement Facades for a single library.