ploeh blog danish software design
Easy ASP.NET Web API DTOs with F# CLIMutable records
With F#, it's easy to create DTOs for use with the ASP.NET Web API, using record types.
When writing HTTP (or RESTful) web services with the ASP.NET Web API, the most normal approach is to define Data Transfer Objects (DTOs), which represents the data structures that go on the wire in the form of JSON or XML. While I usually call these boundary objects for renditions (a bit punny), a more normal terminology is, indeed, DTOs.
To enable the default .NET serializers (and particularly, deserializers) to do their magic, these DTOs must be mutable and have a default constructor. Not particularly something that seems to fit nicely with F#.
Until recently, I've been declaring such DTOs like this in F#:
type HomeRendition() = [<DefaultValue>] val mutable Message : string [<DefaultValue>] val mutable Time : string
However, then I discovered the [<CLIMutable>] attribute. This effectively turn a standard F# record type into something that can be serialized with the normal .NET serializers. This means that it's possible to redefine the above HomeRendition like this:
[<CLIMutable>]
type HomeRendition = {
Message : string
Time : string }
This is much better, because this looks like a proper immutable record type from the perspective of the F# compiler. However, from a CLI perspective, the HomeRendition class has a default constructor, and mutable properties.
A DTO defined like this still works with the ASP.NET Web API, although by default, the serialization looks a bit strange:
<HomeRendition> <Message_x0040_> This message is served by a pure F# ASP.NET Web API implementation. </Message_x0040_> <Time_x0040_>2013-10-15T23:32:42.6725088+02:00</Time_x0040_> </HomeRendition>
The reason for that is that the [<CLIMutable>] attribute causes the record type to be compile with auto-generated internal mutable fields, and these are named by appending an @ character - in this case, the field names become Message@ and Time@. Since the unicode value for the @ character is x0040, these field names become Message_x0040_ and Time_x0040_.
Wait a minute! Did I say internal fields? Yes, I did. Then why are the internal fields being serialized instead of the public properties? Well, what can I say, other than the DataContractSerializer once again proves to be a rather poor choice of default serializer. Yet another reason to use a sane XML serializer.
No doubt, one of my readers can come up with a good solution for the DataContractSerializer too, but since I always switch my Web API services to use a proper XML serializer, I don't really care:
GlobalConfiguration.Configuration.Formatters.XmlFormatter.UseXmlSerializer <- true
Now all is well again:
<HomeRendition> <Message> This message is served by a pure F# ASP.NET Web API implementation. </Message> <Time>2013-10-15T23:50:06.9025322+02:00</Time> </HomeRendition>
That's it: much easier, and more robust, Web API DTOs with F# record types. Just apply the [<CLIMutable>] attribute.
Verifying every single commit in a Git branch
You can run a validation task for every commit in a Git branch in order to verify the integrity of a Git branch's history.
Just like the Soviet Union, I occasionally prefer to rewrite history... although I limit myself to rewriting the history of one or more Git branches. When I do that, I'd like to verify that I didn't break anything after an interactive rebase. It actually turns out that this can easily happen. Some commits are left in a state where they either don't compile, or tests fail. Git is happy, but the code isn't. To deal with such situations, I wanted a tool that could verify each and every commit in a branch like this:
- Check out a commit.
- Compile the code.
- Run all tests.
- Repeat for the next commit, or stop if there's a failure.
Motivation #
If you don't care about my motivation for doing this, you can skip this section and move on to the solution. However, some people might like to point out to me that I shouldn't rewrite the history of my Git repositories - and particularly not of the master branch. I agree, for all repositories where I actually collaborate with other programmers.
However, I also use Git locally to produce teaching materials. As an example, if you download the example code for my Pluralsight courses, you'll see that it's all available as Git repositories. I think that's an added benefit for the student, because not only can you see the final result, but you can also see all the steps that lead me there. I even occasionally write commit messages longer than a single line, explaining my thinking as I check in code.
Like everyone else, I'm fallible, so often, when I prepare such materials, I end up taking some detours that I feel will confuse students more than it will help. Thus, I have a need to be able to edit my Git repositories. Right now, as an example, I'm working with a repository with 120 commits on the master branch, and I need to make some changes in the beginning of the history.
Solution #
With much help from Darrell Hamilton, who ended up providing this gist, I was able to piece together this bash script:
#!/bin/sh
COMMITS=$(git --git-dir=BookingApi/.git --work-tree=BookingApi log --oneline --reverse | cut -d " " -f 1)
CODE=0
git --git-dir=BookingApi/.git --work-tree=BookingApi reset --hard
git --git-dir=BookingApi/.git --work-tree=BookingApi clean -xdf
for COMMIT in $COMMITS
do
git --git-dir=BookingApi/.git --work-tree=BookingApi checkout $COMMIT
# run-tests
./build.sh
if [ $? -eq 0 ]
then
echo $COMMIT - passed
else
echo $COMMIT - failed
exit
fi
git --git-dir=BookingApi/.git --work-tree=BookingApi reset --hard
git --git-dir=BookingApi/.git --work-tree=BookingApi clean -xdf
done
git --git-dir=BookingApi/.git --work-tree=BookingApi checkout master
As you can tell, it follows the algorithm outlined above. First, it does a git log to get all the commits in the branch, and then it loops through all of them, one by one. For each commit, it compiles and runs all tests by calling out to a separate build.sh script. If the build and test step succeeds, it cleans up the working directory and moves on to the next step. If the verification step fails, it stops, so that I can examine the problem.
(The reason for the use of --git-dir and --work-tree is that I need to run the script from outside the Git repository itself; otherwise, the git clean -xdf step would delete the script files!)
This has turned out to work beautifully, and has already caught quite a number of commits that Git could happily rebase, but afterwards either couldn't compile, or had failing tests.
Running those tests in a tight loop has also finally provided some work for my multi-core processor:
Each run through those 120 commits takes about 20 minutes, so, even though today we have fast compilers, once again, we have an excuse for slacking off.
Comments
A talk on some of Git's lesser known features that I recently saw suggested that there is a built-in mechanism for what you are trying to achieve. The
git bisect command
allows you to run a script for each of a number of commits. The exact details on how to perform
this are provided in Pro Git,
so I won't repeat them here.Thanks,
Steven
Hi Steven
Thank you for writing. As far as I can tell from the documentation, git bisect doesn't quite do what I'd like to do. The bisect feature basically performs a search through the repository to figure out which commit introduces a particular error. The search algorithm is attempting to be as efficient as possible, so it keeps bisecting the list of commits to figure out on which side the error occurs - hence the name. Thus, it very explicitly doesn't check each and every commit.
My scenario is different. While I'm not looking for any particular error, I just want to verify that every commit is OK.
As of Git 1.7.12, the interactive rebase command can take an --exec <cmd> option, which will make it execute <cmd> after each commit. If the command fails, the interactive rebase will stop so you can fix the problem.
I didn't know about the --exec option, but I'll try it out the next time I perform a rebase. Thank you for the tip.
DI in .NET receives a Jolt Productivity Award
My book Dependency Injection in .NET has received a Jolt Productivity Award!
It turns out that my book Dependency Injection in .NET has received a Jolt Productivity Award 2013 in the Best Books category. This is a completely unexpected (but obviously very pleasant) surprise :D

The motivation for giving the award states that it:
"provide[s] a brilliant and remarkably readable explanation of DI"
and concludes that
"It's the definitive guide to DI and the first place architects and implementers should turn for a truly deep and complete understanding of the pattern — regardless of whether .NET is part of their toolkit.""
Although it's already been selling well, the book is still available either directly from Manning, or via Amazon.com - and, in case you didn't know, every time you buy a Manning book, you automatically also get the electronic version, which (in the case of my book), includes a Kindle version, as well as a PDF. You can also skip the physical copy and buy only the electronic version, but this option is (AFAIK) only available from Manning.
What an honor!
Karma from bash on Windows
Note to future self: how I got Karma running from bash in Windows.
Yesterday, I spent quite a bit of time getting Karma to run from bash on my Windows 7 (x64) laptop. Since, a month from now, I'll have absolutely no recollection of how I achieved this, I'm writing it down here for the benefit of my future self, as well as any other people who may find this valuable.
Add karma to PATH #
My first problem was that 'karma' wasn't a recognized command. Although I'd used Chocolatey to install node.js, used npm to install Karma, and 'karma' was a recognized command from PowerShell, bash didn't recognize it. While I don't yet know if the following is the 100 % correct solution, I managed to make bash recognize karma by adding my karma directory to my bash path:
PATH=$PATH:~/appdata/roaming/npm/node_modules/karma/bin
This works in the session itself, but will be forgotten by bash unless you add it to ~/.bash_profile. BTW, that file doesn't exist by default in a new Git Bash installation on Windows, so you'll have to add it yourself.
Chrome path #
My next problem was that, while karma could be found, I got the error message that it couldn't find Chrome, and that I should set the CHROME_BIN environment variable. After much experimentation, I managed to make it work by setting:
CHROME_BIN=/c/Program\ Files\ \(x86\)/Google/Chrome/Application/chrome.exe export CHROME_BIN
That looks really simple, so why did I waste so much time shaving that yak? Well, setting the environment variable was one thing, but it didn't work before I also figured out to export it.
Once again, I added these lines to my .bash_profile file. Now I can run Karma from bash on Windows.
DI and events: Composition
With Reactive Extensions, and a bit of composition, you can publish and subscribe to events in a structurally safe way.
Previously, in my series about Dependency Injection and events, you learned how to connect a publisher and a subscriber via a third party (often the Composition Root).
The problem with that approach is that while it's loosely coupled, it's too easy to forget to connect the publisher and the subscriber. It's also possible to forget to unsubscribe. In neither case can the compiler help you.
However, the advantage of using Reactive Extensions over .NET events is that IObserver<T> is composable. That turns out to be quite an important distinction!
The problem with IObservable<T> #
While I consider IObserver<T> to be an extremely versatile interface, I consider IObservable<T> to be of limited usefulness. Consider its definition:
public interface IObservable<out T> { IDisposable Subscribe(IObserver<T> observer); }
The idea is that the publisher (the Observable) receives a subscriber (the Observer) via Method Injection. When the method completes, the subscriber is considered subscribed to the publisher's events, until the subscriber disposes of the returned subscription reference.
There's a couple of problems with this design:
- It's too easy to forget to invoke the Subscribe method. This is not a problem if you're writing a system in which publishers dynamically subscribe to event streams, but it's problematic if your system relies on certain publishers and subscribers to be connected.
- It implies mutation in the publisher, because the publisher must somehow keep a list of all its subscribers.
- It breaks Command Query Separation (CQS).
- Since it implies mutation, it's not thread-safe by default.
From Method Injection to Constructor Injection #
As you learned in the last couple of articles, the subscriber should not require any dependency in order to react to events. Yet, if Method Injection via IObservable<T> isn't a good approach either, then what's left?
Good old Constructor Injection.
The important realization is that it's not the subscriber (NeedyClass, in previous examples) that requires a dependency - it's the publisher!
Imagine that until now, you've had a publisher implementing IObservable<T>. In keeping with the running example throughout this series, this was the publisher that originally implemented IDependency. Thus, it's still called RealDependency. For simplicity's sake, assume that its implementation is as simple as this:
public class RealDependency : IObservable<Unit> { private readonly Subject<Unit> subject; public RealDependency() { this.subject = new Subject<Unit>(); } public void MakeItHappen() { this.subject.OnNext(Unit.Default); } public IDisposable Subscribe(IObserver<Unit> observer) { return this.subject.Subscribe(observer); } }
What if, instead of implementing IObservable<Unit>, this class would use Constructor Injection to request an IObserver<Unit>? Then it would look like this:
public class RealDependency { private readonly IObserver<Unit> observer; public RealDependency(IObserver<Unit> observer) { this.observer = observer; } public void MakeItHappen() { this.observer.OnNext(Unit.Default); } }
That's much simpler, and you just got rid of an entire type (IObservable<Unit>)! Even better, you've also eliminated all use of IDisposable. Oh, and it also conforms to CQS, and is thread-safe.
Connection #
The names of the concrete classes are completely off by now, but you can connect publisher (RealDependency) with its subscriber (NeedyClass) from a third party (Composition Root):
var subscriber = new NeedyClass(); var publisher = new RealDependency(subscriber);
Not only is this easy, the statically typed structure of both classes helps you do the right thing: the compiler will issue an error if you don't supply a subscriber to the publisher.
But wait, you say: now the publisher is forced to have a single observer. Isn't the whole idea about publish/subscribe that you can have an arbitrary number of subscribers for a given publisher? Yes, it is, and that's still possible.
Composition #
More than a single subscriber is easy if you introduce a Composite:
public class CompositeObserver<T> : IObserver<T> { private readonly IEnumerable<IObserver<T>> observers; public CompositeObserver(IEnumerable<IObserver<T>> observers) { this.observers = observers; } public void OnCompleted() { foreach (var observer in this.observers) observer.OnCompleted(); } public void OnError(Exception error) { foreach (var observer in this.observers) observer.OnError(error); } public void OnNext(T value) { foreach (var observer in this.observers) observer.OnNext(value); } }
While it looks like a bit of work, this class is so reusable that I wonder why it's not included in the Rx library itself... It enables you to subscribe any number of subscribers to the publisher, e.g. two:
var sub1 = new NeedyClass(); var sub2 = new AnotherObserver(); var publisher = new RealDependency( new CompositeObserver<Unit>( new IObserver<Unit>[] { sub1, sub2 }));
I'll leave it as an exercise to the reader to figure out how to implement the scenario with no subscribers :)
Conclusion #
Sticking to IObserver<T> and simply injecting it into the publishers is much simpler than any other alternative I've described so far. Nonetheless, keep in mind that the reason this simplification works so well is because it assumes that you know all subscribers when you compose your object graph.
There's a reason the IObservable<T> interface exists, and that's to support scenarios where publishers and subscribers come and go during the lifetime of an application. The simplification described here doesn't handle that scenario, but if you don't need that flexibility, you can greatly simplify your eventing infrastructure by disposing of IObservable<T> ;)
Comments
Tony, thank you for writing. That's a good observation, and you're right: if you need to make substantial transformation, filtering, aggregation, and so on, on your event streams, then it would be valuable to be able to leverage Reactive Extensions. Not being able to do that would be a loss.
Using IObserver, as I suggest here, does come with that disadvantage, so as always, it's important to weigh the advantages and disadvantages against each other. If you're doing lots of event stream processing, then it would most likely be best to go with idiomatic Reactive Extensions (and not the solution proposed in this article). If, on the other hand, you mostly need to make sure that some Command is executed once and only once (or at least once, depending on your delivery guarantees), then my proposed solution may be more appropriate.
At its heart, the choice is between pub/sub systems on one side, and point-to-point systems on the other side. If it's important that exactly one destination system receives the messages, it's a point-to-point channel in action. If, on the other hand, zero to any arbitrary number of subscribers are welcome to consume the messages, it's a pub/sub system.
I have briefly experimenting with this idea over the last couple of days.
In my experiemnt I found that rather than implement the IObserver interface on my subscribers it was easier to use Observer.Create and pass in an the Action I wanted to call to that.
This has left me wondering wether I could dispense with the whole IObserver interfacea and simply pass the Action that I wanted to call into the publisher.
Spencer, thank you for writing. Indeed, delegates are equivalent to single-method interfaces. Once you realise that, functional programming begins to look more and more attractive.
Actions, with their void return type, don't seem particularly functional, however, but you can build up an entire architecture on that concept.
Personally, in C#, I prefer to stick with interfaces for dependency injection, since I find it more idiomatic, but other people have different opinions on that.
DI and events: Reactive Extensions
With Reactive Extensions, you can convert event subscription to something that looks more object-oriented, but all is still not quite as it should be...
In my series about Dependency Injection and events, you previously saw how to let a third party connect publisher and subscriber. I think that approach is valuable in all those cases where you connect publishers and subscribers in a narrow and well-defined area of your application, such as in the Composition Root. However, it's not a good fit if you need to connect and disconnect publishers and subscribers throughout your application's code base.
This article examines alternatives based on Reactive Extensions.
Re-design #
For the rest of this article, I'm going to assume that you're in a position where you can change the design - particularly the design of the IDependency interface. If not, you can always convert a standard .NET event into the appropriate IObservable<T>.
Using small iterations, you can first make IDependency implement IObservable<Unit>:
public interface IDependency : IObservable<Unit> { event EventHandler ItHappened; }
This enables you to change the implementation of NeedyClass to subscribe to IObservable<Unit> instead of the ItHappened event:
public class NeedyClass : IObserver<Unit>, IDisposable { private readonly IDisposable subscription; public NeedyClass(IDependency dependency) { if (dependency == null) throw new ArgumentNullException("dependency"); this.subscription = dependency.Subscribe(this); } public void OnCompleted() { } public void OnError(Exception error) { } public void OnNext(Unit value) { // Handle event here } public void Dispose() { this.subscription.Dispose(); } }
Because IObservable<T>.Subscribe returns an IDisposable, NeedyClass still needs to store that object in a field and dipose of it when it's done, which also means that it must implement IDisposable itself. Thus, you seem to be no better off than with Constructor Subscription. Actually, you're slightly worse off, because now NeedyClass gained three new public methods (OnCompleted, OnError, and OnNext), compared to a single public method with Constructor Subscription.
What's even worse is that you're still violating Nikola Malovic's 4th law of IoC: Injection Constructors should perform no work.
This doesn't seem promising.
Simplification #
While you seem to have gained little from introducing Reactive Extensions, at least you can simplify IDependency a bit. No classes should have to subscribe to the old-fashioned .NET event, so you can remove that from IDependency:
public interface IDependency : IObservable<Unit> { }
That leaves IDependency degenerate, so you might as well dispense entirely with it and let NeedyClass subscribe directly to IObservable<Unit>:
public class NeedyClass : IObserver<Unit>, IDisposable { private readonly IDisposable subscription; public NeedyClass(IObservable<Unit> dependency) { if (dependency == null) throw new ArgumentNullException("dependency"); this.subscription = dependency.Subscribe(this); } public void OnCompleted() { } public void OnError(Exception error) { } public void OnNext(Unit value) { // Handle event here } public void Dispose() { this.subscription.Dispose(); } }
At least you got rid of a custom type in favor of a well-known abstraction, so that will have to count for something.
Injection disconnect #
If you refer back to the discussion about Constructor Subscription, you may recall an inkling that NeedyClass requests the wrong type of dependency via the constructor. If it's saving an IDisposable as its class field, then why is it requesting an IObservable<Unit>? Shouldn't it simply request an IDisposable?
This sounds promising, but in the end turns out to be a false lead. Still, this actually compiles:
public class NeedyClass : IObserver<Unit>, IDisposable { private readonly IDisposable subscription; public NeedyClass(IDisposable subscription) { if (subscription == null) throw new ArgumentNullException("subscription"); this.subscription = subscription; } public void OnCompleted() { } public void OnError(Exception error) { } public void OnNext(Unit value) { // Handle event here } public void Dispose() { this.subscription.Dispose(); } }
The problem with this is that while it compiles, it doesn't work. Considering the implementation, you should also be suspicious: it's basically a degenerate Decorator of IDisposable. That subscription field doesn't seem to add anything to NeedyClass...
Examining why it doesn't work should be enlightening, though. A third party can attempt to connect NeedyClass with the observable. One attempt might look like this:
var observable = new FakyDependency(); var nc = new NeedyClass(observable.Subscribe());
However, this doesn't work, because that overload of the Subscribe method only exists to evaluate an event stream for side effects. The overload you'd need is the Subscribe(IObserver<T>) overload. However, the IObserver<Unit> you'd like to supply is an instance of NeedyClass, but you can't supply an instance of NeedyClass before you've supplied an IDisposable to it (a Catch-22)!
Third-party Connect #
Once more, this suggests that NeedyClass really shouldn't have a dependency in order to react to events. You can simply let it be a stand-alone implementation of IObserver<Unit>:
public class NeedyClass : IObserver<Unit> { public void OnCompleted() { } public void OnError(Exception error) { } public void OnNext(Unit value) { // Handle event here } }
Once again, you have a nice, stand-alone class you can connect to a publisher:
var nc = new NeedyClass(); var subscription = observable.Subscribe(nc);
That pretty much puts you back at the Third-party Connect solution, so that didn't seem to buy you much.
(Preliminary) conclusion #
So far, using Reactive Extensions instead of .NET events seems to have provided little value. You're able to replace a custom IDependency interface with a BCL interface, and that's always good. Apart from that, there seems to be little value to be gained from Reactive Extensions in this scenario.
The greatest advantage gained so far is that, hopefully you've learned something. You've learned (through two refactoring attempts) that NeedyClass isn't needy at all, and should not have a dependency in order to react to events.
The last advantage gained by using Reactive Extensions may seem like a small thing, but actually turns out to the most important of them all: by using IObservable<T>/IObserver<T> instead of .NET events, you've converted your code to work with objects. You know, .NET events are not real objects, so they can't be passed around, but IObservable<T> and IObserver<T> instances are real objects. This means that now that you know that NeedyClass shouldn't have a dependency, perhaps some other class should. Remember what I originally said about Inversion of Inversion of Control? In the next article in the series, I'll address that issue, and arrive at a more idiomatic DI solution.
DI and events: Third-party Connect
Instead of using Constructor Injection to subscribe to events on a dependency, you can let a third party connect the subscriber to the publisher.
In the previous article in my series about Dependency Injection and events, you saw an example of how injecting a dependency that raises events violates Nikola Malovic's 4th law of IoC: Injection Constructors should perform no work.
In this article, you'll see the first of several alternatives.
Third-party Connect #
Take a step back and recall why you're using Dependency Injection in the first place. Hopefully, you use Dependency Injection because it provides the decoupling necessary to make your code more maintainable (and thus, you and your colleagues more productive). However, events are already a mechanism for decoupling. In .NET, events are simply a (limited) baked-in implementation of the Observer pattern.
Perhaps it's helpful if we consider alternative names for Dependency Injection. Nat Pryce prefers the term Third-party Connect, and I think that there's much sense in that name. Instead of focusing on the injection part, or even Inversion of Control, the term Third-party Connect focuses on the fact that when you decouple two objects, you need a third party to connect them with each other. In a well-designed application, this third party will often be the Composition Root.
If you already have a third party connecting NeedyClass with IDependency, must you use Constructor Injection?
Further decoupling #
Apparently, if you consider the code in the previous article, NeedyClass is required to do something whenever a particular IDependency instance raises its ItHappened event. What if, instead of injecting IDependency and subscribing a private event handler, you were to expose a public method that implements the same logic as that private event handler?
public class NeedyClass { public void DoSomethingInteresting() { // Handle event here } }
Notice how much simpler this implementation is, compared with the previous version. Nothing is injected, there are no interfaces in play. Such a class is very easy to unit test as well, so I think this looks very promising.
Doesn't this design break encapsulation? Not more than before. Remember, in the previous implementation, you could always inject an implementation of IDependency that enabled you to raise the ItHappened event, and thereby invoke the private event handler in NeedyClass. This new design just makes it a bit easier to invoke the method. Keep in mind that encapsulation isn't about public versus private members; encapsulation is about invariants.
This version of NeedyClass doesn't actually expose a public 'event handler', since the DoSomethingInteresting method doesn't match the event handler signature. Thus, if you use a static code analysis tool, it's not going to complain about a public event handler. The DoSomethingInteresting method is a method just like any other method. This design is much more decoupled than before, because NeedyClass knows nothing about IDependency. Hopefully, it makes sense as a stand-alone class with its own API. This makes it more reusable.
At this point, NeedyClass is no longer an appropriate name, but let's keep it for now.
Subscription #
In order to connect NeedyClass with IDependency, the third party (e.g. the Composition Root) can subscribe the DoSomethingInteresting method to the ItHappened event:
var nc = new NeedyClass(); dependency.ItHappened += (s, e) => nc.DoSomethingInteresting();
The advantage of this design is that it's much more decoupled than before. NeedyClass knows nothing about IDependency, and IDependency knows nothing about NeedyClass. However, one disadvantage is that it's easy to forget to connect these two objects with each other; the compiler no longer offers any help.
If both objects are long-lived objects (i.e. have the Singleton lifetime style), you probably only need to write and invoke that connection code once, in the Composition Root. In this case, one or two Smoke Tests should prevent any regressions.
However, if one or both of these objects have shorter lifetimes, you may want to encapsulate the creation of NeedyClass in some sort of Factory. Still, unless you make the NeedyClass constructor internal or private, programmers may forget to use the Factory, so this can still be a fragile solution.
Unsubscription #
Another problem that this Third-party Connect solution shares with Constructor Subscription is that you still need to think about disconnecting the two objects, once you're done with them. This isn't hard to do.
EventHandler handler = (s, e) => nc.DoSomethingInteresting(); dependency.ItHappened += handler; // Do something interesting here dependency.ItHappened -= handler;
While not particularly difficult, it does require you to take the extra step of assigning the event handler to a variable you can later use to unsubscribe. Still, the worst part of this attempt at a solution is probably that, just like you'll need to remember to subscribe NeedyClass to the event, you must also remember to unsubscribe it. At least, in this case, there's a better symmetry, because you must remember to both subscribe and unsubscribe, whereas with Constructor Subscription, you only needed to remember to unsubscribe (or dispose, as it were).
Conclusion #
Using Third-party Connect leads to a simpler, but more Fragile design. Still, I often find that the extreme simplicity of the involved classes trumps the fragility of the design; if I had to choose between Third-party Connect and Constructor Subscription, I'd select Third-party Connect. Fortunately, these aren't the only options available to you; in future articles, I'll approach a better alternative.
DI and events: Constructor Subscription
Using Constructor Injection, you can subscribe to an event within the constructor, but should you?
This post is the first in a series of articles about Dependency Injection and events.
Imagine that you have an interface that defines an event:
public interface IDependency { event EventHandler ItHappened; }
In order to keep the example simple, the ItHappened event carries no information; it just raises an event with an EventArgs instance. Thus, subscribers can react to the fact that this particular event happened, but there's no data contained in the event. However, the following discussion doesn't change if the event carries information.
A class must react to the events raised by IDependency implementations. A common approach is to subscribe to the event in the constructor. We can call this pattern Constructor Subscription:
public class NeedyClass { private readonly IDependency dependency; public NeedyClass(IDependency dependency) { if (dependency == null) throw new ArgumentNullException("dependency"); this.dependency = dependency; this.dependency.ItHappened += this.OnItHappened; } private void OnItHappened(object sender, EventArgs e) { // Handle event here } }
The concern is that, by subscribing to an event, the constructor violates Nikola Malovic's 4th law of IoC: Injection Constructors should perform no work.
This rule about Dependency Injection explains why you can compose big object graphs with confidence. Still, the most compelling reason for conforming strictly to the rule is most likely performance considerations. So, what if you subscribe to a single event or two during construction? Will it adversely (and noticeably) affect performance of your overall system?
As always, the answer to such questions is: measure. However, I'd be quite surprised if it turns out that a single event subscription has a huge impact on performance...
Smell #
Consider the implementation of NeedyClass: it contains a design smell. Can you spot it?
Given the definition of the IDependency interface, the ItHappened event is the only member defined by the interface. If this is the case, then why is NeedyClass holding on to a reference of the interface?
You can remove the dependency field from NeedyClass, and nothing is going to break:
public class NeedyClass { public NeedyClass(IDependency dependency) { if (dependency == null) throw new ArgumentNullException("dependency"); dependency.ItHappened += this.OnItHappened; } private void OnItHappened(object sender, EventArgs e) { // Handle event here } }
From the perspective of an outside observer, that's really strange. Why are we required to pass in an object that's not going to be used as is? Just like in a previous discussion about the implications of injecting IEnumerable<T>, if you're injecting an abstraction, and the constructor then starts querying, modifying, examining, or otherwise fidget with the injected object, then you're probably injecting the wrong object.
Keep in mind that Constructor Injection is a declaration of requirements. It's the declaring class that advertises to the world: these are (some of) my invariants. If the class can't use the injected dependency as is, it suggests that it requested the wrong object from its clients. The class with the Injection Constructor should declare what it really needs. In this case, it needs to react to events.
In the next post, I'll show you a better (i.e. simpler) design for reacting to events.
Unsubscription (Update, September 9, 2013, 11:48 UTC) #
Some readers have commented that NeedyClass must keep the reference to IDependency in order to unsubscribe from the event. This is true, and something I overlooked when I originally banged together the sample code yesterday evening. Apparently, three unit tests were at least a test too few... :$
From a perspective of basic correctness, NeedyClass works appropriately, but as Geert van Horrik and Claus Nielsen point out, this could easily lead to resource leaks (although in practice, that depends on the effective lifetime of NeedyClass).
What happens when we start taking resource management into account?
Well, NeedyClass must be sure to unsubscribe from the event when it goes out of scope. The most correct way of making sure this happens is to implement IDisposable:
public class NeedyClass : IDisposable { private readonly IDependency dependency; public NeedyClass(IDependency dependency) { if (dependency == null) throw new ArgumentNullException("dependency"); this.dependency = dependency; this.dependency.ItHappened += this.OnItHappened; } private void OnItHappened(object sender, EventArgs e) { // Handle event here } public void Dispose() { this.dependency.ItHappened -= this.OnItHappened; } }
While this weakens the argument that NeedyClass is requesting the wrong kind of dependency, this is a lot of work just to consume an event. Furthermore, it isn't particularly safe, because you'll have to remember to dispose of all of your NeedyClass instances.
Thus, a better approach is still warranted.
Comments
Or if you want to be explicit about the dependencies, then go for something like NeedyClass : IHandle<ItHappened>. Nevertheless, dependency on ItHappened within NeedyClass would still easily be found with static analysis. A few lines of CQLinq with NDepend.
Dependency Injection and events
Overview of articles about Dependency Injection and events.
One of my readers, Kenny Pflug, asks me about subscribing to events in the constructor of a class using Constructor Injection:
I want to register to a plain old .NET event of a dependency that is supplied via constructor injection. I read your book "DI in .NET" and in it you mention that injection constructors should be simple and not perform any other work than guarding for null values and assigning the dependencies to (read-only) fields. I also read on your blog that this is only a pattern and might be broken gently if the need would arise.
[...] do you know and prefer any patterns to solve this "registering to events of dependencies in a constructor" problem?
In short, I think that it's a code smell if a design requires you to subscribe to an event in the constructor; it's a smell that the dependency chain is slightly inverted. Inversion of Inversion of Control - how about that?
In the next series of posts, I'll attempt to provide various perspectives on this situation, starting with the original context.
- DI and events: Constructor Subscription.
- DI and events: Third-party Connect.
- DI and events: Reactive Extensions.
- DI and events: Composition.
In summary, it's probably not going to be a big problem if you subscribe to an event in a constructor, but it's a code smell, because it betrays a design issue.
Running a pure F# Web API on Azure Web Sites
This post explains how to make a pure F# implementation of an ASP.NET Web API run in an Azure Web Site.
In my previous post, I explained how to create an ASP.NET Web API project entirely in F#, without relying on a C# or VB host project. At the end of that article, I had a service which can be launched from Visual Studio 2012 and run in IIS Express, but it didn't run in Azure Web Sites. In this post, I'll explain how to make this possible.
Deploying to Azure #
The first problem to solve is how to even deploy the Web Project to Azure in the first place. Because the project is a 'real' Visual Studio Web Project, it's possible to right-click on the project and select "Publish..." This brings up the dialog for publishing a Web Project to Azure, so that seems promising.
However, actually attempting to do so soon produces this error message:
Exception in executing publishing : The method or operation is not implemented.Apparently, someone in Microsoft chose to violate the Liskov Substitution Principle...
Another, and, as it turns out, ultimately more productive, deployment options is to deploy via Git. Fortunately, I already kept a Git repository for the code, in order to make it easier for me to back out, if my experiments took me in wrong directions (which did happen a couple of times). Thus, I created the Web Site on the Azure portal, and configured it with a Git repository to which I can push.
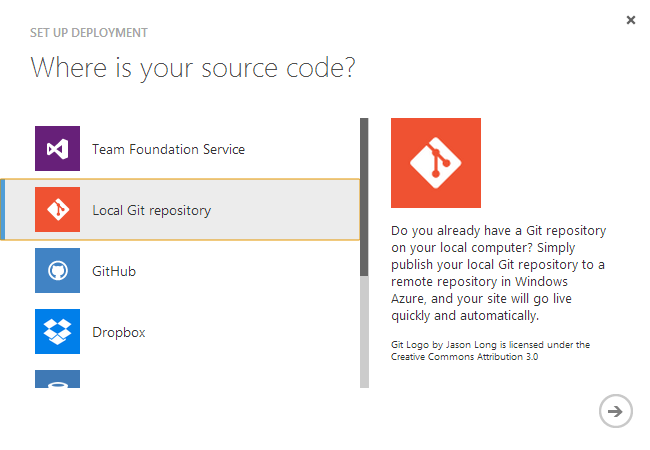
This should enable me to simply go
$ git push azure master
in order to deploy to my new Azure Web Site. Unfortunately, it didn't quite work:
$ git push azure master Counting objects: 113, done. Delta compression using up to 4 threads. Compressing objects: 100% (101/101), done. Writing objects: 100% (113/113), 1.41 MiB | 22.00 KiB/s, done. Total 113 (delta 34), reused 0 (delta 0) remote: Updating branch 'master'. remote: Updating submodules. remote: Preparing deployment for commit id 'dd501baeaa'. remote: Generating deployment script. remote: . remote: info: Executing command site deploymentscript remote: info: Project file path: .\FebApi\FebApi.fsproj remote: info: Solution file path: .\FebApi.sln remote: info: Generating deployment script for .NET Web Application remote: info: Generated deployment script files remote: info: site deploymentscript command OK remote: Running deployment command... remote: Handling .NET Web Application deployment. remote: ..... remote: FebApi -> C:\DWASFiles\Sites\FebApi\VirtualDirectory0\site\repository\FebApi\bin\Release\FebApi.dll remote: C:\DWASFiles\Sites\FebApi\VirtualDirectory0\site\repository\FebApi\FebApi.fsproj : error MSB4057: The target "pipelinePreDeployCopyAllFilesToOneFolder" does not exist in the project. remote: An error has occurred during web site deployment. remote: remote: Error - Changes committed to remote repository but your website not updated. To https://******@febapi.scm.azurewebsites.net:443/FebApi.git * [new branch] master -> master
More work apparently remained.
Import MSBuild projects #
As you can tell from the error message, the "target "pipelinePreDeployCopyAllFilesToOneFolder" does not exist in the project." Knowing that Visual Studio project files are actually MSBuild files with another extension, this sounds like an MSBuild issue. To figure out what to do, I opened a C# Web Project and began looking for various Import elements.
After copying a couple of Import elements from a C# Web Project, and a bit of experimentation, I ended up with this in my .fsproj file:
<Import Project="$(VSToolsPath)\WebApplications\Microsoft.WebApplication.targets" Condition="'$(VSToolsPath)' != ''" /> <Import Project="$(MSBuildExtensionsPath32)\Microsoft\VisualStudio\v11.0\WebApplications\Microsoft.WebApplication.targets" Condition="true" />
My .fsproj file already had an existing Import element, so I added these two just below the existing element. I haven't experimented with removing one of these elements, so it may be possible to simplify this, or somehow make it more robust. What mattered to me was that this enabled me to move on:
$ git push azure master Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (4/4), done. Writing objects: 100% (4/4), 404 bytes | 0 bytes/s, done. Total 4 (delta 3), reused 0 (delta 0) remote: Updating branch 'master'. remote: Updating submodules. remote: Preparing deployment for commit id 'd3625cfef0'. remote: Generating deployment script. remote: Running deployment command... remote: Handling .NET Web Application deployment. remote: .... remote: FebApi -> C:\DWASFiles\Sites\FebApi\VirtualDirectory0\site\repository\FebApi\bin\Release\FebApi.dll remote: Copying all files to temporary location below for package/publish: remote: C:\DWASFiles\Sites\FebApi\Temp\7a1a548e-d5fe-48d6-94ec-99146f20676a. remote: KuduSync.NET from: 'C:\DWASFiles\Sites\FebApi\Temp\7a1a548e-d5fe-48d6-94ec-99146f20676a' to: 'C:\DWASFiles\Sites\FebApi\VirtualDirectory0\site\wwwroot' remote: Deleting file: 'hostingstart.html' remote: Copying file: 'bin\FebApi.dll' remote: Copying file: 'bin\FebApi.XML' remote: Copying file: 'bin\FSharp.Core.dll' remote: Copying file: 'bin\Microsoft.Web.Infrastructure.dll' remote: Copying file: 'bin\Newtonsoft.Json.dll' remote: Copying file: 'bin\System.Net.Http.Formatting.dll' remote: Copying file: 'bin\System.Web.Http.dll' remote: Copying file: 'bin\System.Web.Http.WebHost.dll' remote: Finished successfully. remote: Deployment successful. To https://ploeh@febapi.scm.azurewebsites.net:443/FebApi.git 658e859..d3625cf master -> master
Alas, while deployment succeeded, I wasn't out of the woods yet.
Build actions #
Browsing to the (successfully deployed) site gave me this (rather disappointing) message:
You do not have permission to view this directory or page.
After digging around for a while, I discovered that neither Global.asax nor web.config were deployed to the actual site. The way to resolve that is to change the Build Action for these files to Content.
This was the last hurdle. Pushing those changes to the remote Git repository updated the API, which now works! For the time being, you can see it running here, although I will not promise to keep it around forever.

Comments
Hi Mark, thanks for this, I blogged about serialization of record types last year. the only way I could get XML serialization to work nicely with the DataContractSerializer was to put a DataMember attribute on each field of the record and a DataContract attribute on the record itself.
JSON serialization can be handled nicely by default in WEP API however by annotating the class with JsonObject(MemberSerialization=MemberSerialization.OptOut). I have checked and by combining our 2 methods the WEB API can serialize nicely as both JSON and XML.
Hi Patrick, thank you for writing. For JSON serialization, I usually just add this configuration:
This not only gives the JSON idiomatic casing, but also renders CLIMutable F# records nicely.
Any thoughts on trying to return a Discriminated Union with an F# WebAPI controller? I notice that asp.net throws a runtime InvalidOperationException when you try to do this. Furthermore, the CLIMutable Attribute isn't even allowed on a DU. I find this counter intuitve, however, as you can work with F# DUs in C# code and determine the type using the Tag propery that is visible only in C#/VB.net. Why can't this Tag property be serialized and returned as part of a DU DTO?
Nick, I haven't tried returning a Discriminated Union from a Web API Controller. Why would I want to do that? As I've previously described, at the boundaries, applications aren't object-oriented, and similarly, they aren't functional either. What would it mean to return a Discriminated Union? How would it render as JSON or XML?
Apart from that, I have no idea how a Discriminated Union compiles to IL...
Hey Mark, It's interesting that Json serialization works even without `CLIMutable`, both when reading or writing data.
For example this works properly:
type HomeRecord = { Message : string Time : string } type InputModel = { Message : string } type HomeController() = inherit ApiController() member this.Get() = this.Ok({ Message = "Hello from F#!"; Time = DateTime.Now.ToString() }) member this.Post(input : InputModel) = this.Ok(input.Message)But only for the Json serializer, the XML one does not work without `CLIMutable`. Do you know what makes the Json serialization work? Is there special support implemented in the Json serializer for the immutable F# record types?
Thanks, Mark
Mark, thank you for writing. ASP.NET Web API uses JSON.NET for JSON serialization, and, as far as know, it has built-in F# support. It can also serialize discriminated unions.
The .NET XML serializer doesn't have built-in F# support.