ploeh blog danish software design
An ASP.NET Core URL Builder
A use case for the Immutable Fluent Builder design pattern variant.
The Fluent Builder design pattern is popular in object-oriented programming. Most programmers use the mutable variant, while I favour the immutable alternative. The advantages of Immutable Fluent Builders, however, may not be immediately clear.
It inspires me when I encounter a differing perspective. Could I be wrong? Or did I fail to produce a compelling example?"I never thought of someone reusing a configured builder (soulds like too big class/SRP violation)."
It's possible that I'm wrong, but in my my recent article on Builder isomorphisms I focused on the pattern variations themselves, to the point where a convincing example wasn't my top priority.
I recently encountered a good use case for an Immutable Fluent Builder.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Build links #
I was developing a REST API and wanted to generate some links like these:
{
"links": [
{
"rel": "urn:reservations",
"href": "http://localhost:53568/reservations"
},
{
"rel": "urn:year",
"href": "http://localhost:53568/calendar/2020"
},
{
"rel": "urn:month",
"href": "http://localhost:53568/calendar/2020/7"
},
{
"rel": "urn:day",
"href": "http://localhost:53568/calendar/2020/7/7"
}
]
}
As I recently described, the ASP.NET Core Action API is tricky, and since there was some repetition, I was looking for a way to reduce the code duplication. At first I just thought I'd make a few private helper methods, but then it occurred to me that an Immutable Fluent Builder as an Adapter to the Action API might offer a fertile alternative.
UrlBuilder class #
The various Action overloads all accept null arguments, so there's effectively no clear invariants to enforce on that dimension. While I wanted an Immutable Fluent Builder, I made all the fields nullable.
public sealed class UrlBuilder { private readonly string? action; private readonly string? controller; private readonly object? values; public UrlBuilder() { } private UrlBuilder(string? action, string? controller, object? values) { this.action = action; this.controller = controller; this.values = values; } // ...
I also gave the UrlBuilder class a public constructor and a private copy constructor. That's the standard way I implement that pattern.
Most of the modification methods are straightforward:
public UrlBuilder WithAction(string newAction) { return new UrlBuilder(newAction, controller, values); } public UrlBuilder WithValues(object newValues) { return new UrlBuilder(action, controller, newValues); }
I wanted to encapsulate the suffix-handling behaviour I recently described in the appropriate method:
public UrlBuilder WithController(string newController) { if (newController is null) throw new ArgumentNullException(nameof(newController)); const string controllerSuffix = "controller"; var index = newController.LastIndexOf( controllerSuffix, StringComparison.OrdinalIgnoreCase); if (0 <= index) newController = newController.Remove(index); return new UrlBuilder(action, newController, values); }
The WithController method handles both the case where newController is suffixed by "Controller" and the case where it isn't. I also wrote unit tests to verify that the implementation works as intended.
Finally, a Builder should have a method to build the desired object:
public Uri BuildAbsolute(IUrlHelper url) { if (url is null) throw new ArgumentNullException(nameof(url)); var actionUrl = url.Action( action, controller, values, url.ActionContext.HttpContext.Request.Scheme, url.ActionContext.HttpContext.Request.Host.ToUriComponent()); return new Uri(actionUrl); }
One could imagine also defining a BuildRelative method, but I didn't need it.
Generating links #
Each of the objects shown above are represented by a simple Data Transfer Object:
public class LinkDto { public string? Rel { get; set; } public string? Href { get; set; } }
My next step was to define an extension method on Uri, so that I could turn a URL into a link:
internal static LinkDto Link(this Uri uri, string rel) { return new LinkDto { Rel = rel, Href = uri.ToString() }; }
With that function I could now write code like this:
private LinkDto CreateYearLink() { return new UrlBuilder() .WithAction(nameof(CalendarController.Get)) .WithController(nameof(CalendarController)) .WithValues(new { year = DateTime.Now.Year }) .BuildAbsolute(Url) .Link("urn:year"); }
It's acceptable, but verbose. This only creates the urn:year link; to create the urn:month and urn:day links, I needed similar code. Only the WithValues method calls differed. The calls to WithAction and WithController were identical.
Shared Immutable Builder #
Since UrlBuilder is immutable, I can trivially define a shared instance:
private readonly static UrlBuilder calendar = new UrlBuilder() .WithAction(nameof(CalendarController.Get)) .WithController(nameof(CalendarController));
This enabled me to write more succinct methods for each of the relationship types:
internal static LinkDto LinkToYear(this IUrlHelper url, int year) { return calendar.WithValues(new { year }).BuildAbsolute(url).Link("urn:year"); } internal static LinkDto LinkToMonth(this IUrlHelper url, int year, int month) { return calendar.WithValues(new { year, month }).BuildAbsolute(url).Link("urn:month"); } internal static LinkDto LinkToDay(this IUrlHelper url, int year, int month, int day) { return calendar.WithValues(new { year, month, day }).BuildAbsolute(url).Link("urn:day"); }
This is possible exactly because UrlBuilder is immutable. Had the Builder been mutable, such sharing would have created an aliasing bug, as I previously described. Immutability enables reuse.
Conclusion #
I got my first taste of functional programming around 2010. Since then, when I'm not programming in F# or Haskell, I've steadily worked on identifying good ways to enjoy the benefits of functional programming in C#.
Immutability is a fairly low-hanging fruit. It requires more boilerplate code, but apart from that, it's easy to make classes immutable in C#, and Visual Studio has plenty of refactorings that make it easier.
Immutability is one of those features you're unlikely to realise that you're missing. When it's not there, you work around it, but when it's there, it simplifies many tasks.
The example you've seen in this article relates to the Fluent Builder pattern. At first glance, it seems as though a mutable Fluent Builder has the same capabilities as a corresponding Immutable Fluent Builder. You can, however, build upon shared Immutable Fluent Builders, which you can't with mutable Fluent Builders.
Using the nameof C# keyword with ASP.NET 3 IUrlHelper
How to generate links to other resources in a refactoring-friendly way.
I recently spent a couple of hours yak-shaving, and despite much Googling couldn't find any help on the internet. I'm surprised that the following problem turned out to be so difficult to figure out, so it may just be that I'm ignorant or that my web search skills failed me that day. On the other hand, if this really is as difficult as I found it, perhaps this article can save some other poor soul an hour or two.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
I was developing a REST API and wanted to generate some links like these:
{
"links": [
{
"rel": "urn:reservations",
"href": "http://localhost:53568/reservations"
},
{
"rel": "urn:year",
"href": "http://localhost:53568/calendar/2020"
},
{
"rel": "urn:month",
"href": "http://localhost:53568/calendar/2020/7"
},
{
"rel": "urn:day",
"href": "http://localhost:53568/calendar/2020/7/7"
}
]
}
Like previous incarnations of the framework, ASP.NET Core 3 has an API for generating links to a method on a Controller. I just couldn't get it to work.
Using nameof #
I wanted to generate a URL like http://localhost:53568/calendar/2020 in a refactoring-friendly way. While ASP.NET wants you to define HTTP resources as methods (actions) on Controllers, the various Action overloads want you to identify these actions and Controllers as strings. What happens if someone renames one of those methods or Controller classes?
That's what the C# nameof keyword is for.
I naively called the Action method like this:
var href = Url.Action( nameof(CalendarController.Get), nameof(CalendarController), new { year = DateTime.Now.Year }, Url.ActionContext.HttpContext.Request.Scheme, Url.ActionContext.HttpContext.Request.Host.ToUriComponent());
Looks good, doesn't it?
I thought so, but it didn't work. In the time-honoured tradition of mainstream programming languages, the method just silently fails to return a value and instead returns null. That's not helpful. What might be the problem? No clue is provided. It just doesn't work.
Strip off the suffix #
It turns out that the Action method expects the controller argument to not contain the Controller suffix. Not surprisingly, nameof(CalendarController) becomes the string "CalendarController", which doesn't work.
It took me some time to figure out that I was supposed to pass a string like "Calendar". That works!
As a first pass at the problem, then, I changed my code to this:
var controllerName = nameof(CalendarController); var controller = controllerName.Remove( controllerName.LastIndexOf( "Controller", StringComparison.Ordinal)); var href = Url.Action( nameof(CalendarController.Get), controller, new { year = DateTime.Now.Year }, Url.ActionContext.HttpContext.Request.Scheme, Url.ActionContext.HttpContext.Request.Host.ToUriComponent());
That also works, and is more refactoring-friendly. You can rename both the Controller class and the method, and the link should still work.
Conclusion #
The UrlHelperExtensions.Action methods expect the controller to be the 'semantic' name of the Controller, if you will - not the actual class name. If you're calling it with values produced with the nameof keyword, you'll have to strip the Controller suffix away.
Task asynchronous programming as an IO surrogate
Is task asynchronous programming a substitute for the IO container? An article for C# programmers.
This article is part of an article series about the IO container in C#. In the previous articles, you've seen how a type like IO<T> can be used to distinguish between pure functions and impure actions. While it's an effective and elegant solution to the problem, it depends on a convention: that all impure actions return IO objects, which are opaque to pure functions.
In reality, .NET base class library methods don't do that, and it's unrealistic that this is ever going to happen. It'd require a breaking reset of the entire .NET ecosystem to introduce this design.
A comparable reset did, however, happen a few years ago.
TAP reset #
Microsoft introduced the task asynchronous programming (TAP) model some years ago. Operations that involve I/O got a new return type. Not IO<T>, but Task<T>.
The .NET framework team began a long process of adding asynchronous alternatives to existing APIs that involve I/O. Not as breaking changes, but by adding new, asynchronous methods side-by-side with older methods. ExecuteReaderAsync as an alternative to ExecuteReader, ReadAllLinesAsync side by side with ReadAllLines, and so on.
Modern APIs exclusively with asynchronous methods appeared. For example, the HttpClient class only affords asynchronous I/O-based operations.
The TAP reset was further strengthened by the move from .NET to .NET Core. Some frameworks, most notably ASP.NET, were redesigned on a fundamentally asynchronous core.
In 2020, most I/O operations in .NET are easily recognisable, because they return Task<T>.
Task as a surrogate IO #
I/O operations are impure. Either you're receiving input from outside the running process, which is consistently non-deterministic, or you're writing to an external resource, which implies a side effect. It might seem natural to think of Task<T> as a replacement for IO<T>. Szymon Pobiega had a similar idea in 2016, and I investigated his idea in an article. This was based on F#'s Async<'a> container, which is equivalent to Task<T> - except when it comes to referential transparency.
Unfortunately, Task<T> is far from a perfect replacement of IO<T>, because the .NET base class library (BCL) still contains plenty of impure actions that 'look' pure. Examples include Console.WriteLine, the parameterless Random constructor, Guid.NewGuid, and DateTime.Now (arguably a candidate for the worst-designed API in the BCL). None of those methods return tasks, which they ought to if tasks should serve as easily recognisable signifiers of impurity.
Still, you could write asynchronous Adapters over such APIs. Your Console Adapter might present this API:
public static class Console { public static Task<string> ReadLine(); public static Task WriteLine(string value); }
Moreover, the Clock API might look like this:
public static class Clock { public static Task<DateTime> GetLocalTime(); }
Modern versions of C# enable you to write asynchronous entry points, so the hello world example shown in this article series becomes:
static async Task Main(string[] args) { await Console.WriteLine("What's your name?"); var name = await Console.ReadLine(); var now = await Clock.GetLocalTime(); var greeting = Greeter.Greet(now, name); await Console.WriteLine(greeting); }
That's nice idiomatic C# code, so what's not to like?
No referential transparency #
The above Main example is probably as good as it's going to get in C#. I've nothing against that style of C# programming, but you shouldn't believe that this gives you compile-time checking of referential transparency. It doesn't.
Consider a simple function like this, written using the IO container shown in previous articles:
public static string AmIEvil() { Console.WriteLine("Side effect!"); return "No, I'm not."; }
Is this method referentially transparent? Surprisingly, despite the apparent side effect, it is. The reason becomes clearer if you write the code so that it explicitly ignores the return value:
public static string AmIEvil() { IO<Unit> _ = Console.WriteLine("Side effect!"); return "No, I'm not."; }
The Console.WriteLine method returns an object that represents a computation that might take place. This IO<Unit> object, however, never escapes the method, and thus never runs. The side effect never takes place, which means that the method is referentially transparent. You can replace AmIEvil() with its return value "No, I'm not.", and your program would behave exactly the same.
Consider what happens when you replace IO with Task:
public static string AmIEvil() { Task _ = Console.WriteLine("Side effect!"); return "Yes, I am."; }
Is this method a pure function? No, it's not. The problem is that the most common way that .NET libraries return tasks is that the task is already running when it's returned. This is also the case here. As soon as you call this version of Console.WriteLine, the task starts running on a background thread. Even though you ignore the task and return a plain string, the side effect sooner or later takes place. You can't replace a call to AmIEvil() with its return value. If you did, the side effect wouldn't happen, and that would change the behaviour of your program.
Contrary to IO, tasks don't guarantee referential transparency.
Conclusion #
While it'd be technically possible to make C# distinguish between pure and impure code at compile time, it'd require such a breaking reset to the entire .NET ecosystem that it's unrealistic to hope for. It seems, though, that there's enough overlap with the design of IO<T> and task asynchronous programming that the latter might fill that role.
Unfortunately it doesn't, because it fails to guarantee referential transparency. It's better than nothing, though. Most C# programmers have now learned that while Task objects come with a Result property, you shouldn't use it. Instead, you should write your entire program using async and await. That, at least, takes you halfway towards where you want to be.
The compiler, on the other hand, doesn't help you when it comes to those impure actions that look pure. Neither does it protect you against asynchronous side effects. Diligence, code reviews, and programming discipline are still required if you want to separate pure functions from impure actions.
Closing database connections during test teardown
How to close database connections to SQL Server during integration testing teardown.
Whenever I need to run integration tests that involve SQL Server, I have a standard approach that I've evolved since 2007. It involves
- setting up a SQL Server Express database before each test
- running the test
- tearing down the database
One problem with that approach is that SQL Server doesn't allow you to delete a database if it has existing connections.
Turn off connection pooling #
I usually solve the problem by turning off connection pooling. For an integration test suite, this is fine. I usually use integration testing to verify functionality - not performance.
Turning off connection pooling is easily done by setting the flag to false in the connection string:
Server=(LocalDB)\MSSQLLocalDB;Database=Booking;Integrated Security=true;Pooling=false
This means that when you get to the teardown phase of the test, you can issue a DDL statement to the master database:
IF EXISTS (SELECT name
FROM master.dbo.sysdatabases
WHERE name = N'Booking')
DROP DATABASE [Booking]
When connection pooling is turned off, no other connections are open when you attempt to do that, and the database (here named Booking) is deleted.
Forcibly close other connections #
Recently, however, I ran into a testing scenario where connection pooling had to be turned on. When you turn on connection pooling, however, the above DROP DATABASE statement fails because at least one connection from the pool is still connected to the database.
To solve that issue, I forcibly close other connections during teardown:
IF EXISTS (SELECT name
FROM master.dbo.sysdatabases
WHERE name = N'Booking')
BEGIN
-- This closes existing connections:
ALTER DATABASE [Booking]
SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [Booking]
END
Surprisingly, turning on connection pooling like this makes the integration tests slower. I suppose it's because throwing other connections off the database involves a bit of negotiation between the server and the clients, and that takes some time.
While slower, it does enable you to run the integration tests with connection pooling turned on. When you need it, you need it.
Summary #
You can run integration tests against a SQL Server Express database. People do it in various ways, but I've found that setting up and tearing down a pristine database for each test case is a robust and maintainable solution to the problem.
SQL Server will not, however, allow you to delete a database if other connections exist. The easiest and fastest solution to that problem is to turn off connection pooling.
Sometimes, you can't do that, so instead, you can expand your database teardown script so that it closes existing connections before it deletes the database.
Comments
This sounds like a great approach. I have been on projects with tests that involved the database, but none of them were designed as well as this. I will be sure to come back to this post when we add a database to my current project.
My understanding is that SQL Server Express and LocalDB are not the same thing. Are you using SQL Server Express or LocalDB? Do you prefer one over the other for this database testing approach of yours?
Tyson, thank you for writing. It's not really my area of expertise. I use the one bundled with Visual Studio, so I suppose that's actually LocalDB, and not SQL Server Express.
Implementation of the C# IO container
Implementation details of the C# IO container.
This article is part of an article series about the IO container in C#. In the previous articles, you've seen how a type like IO<T> can be used to distinguish between pure functions and impure actions.
The point of the article series is to illustrate the concept that Haskell uses to impose the functional interaction law at compile time. The implementation details really aren't important. Still, I believe that I know my readership well enough that a substantial fraction would be left unsatisfied if I didn't share the implementation details.
I consider this an appendix to the article series. It's not really what this is all about, but here it is, nonetheless.
Constructor #
Based on the public API already published, the constructor implementation hardly comes as a surprise.
private readonly Func<T> item; public IO(Func<T> item) { this.item = item; }
The IO<T> class is little more than a wrapper around a lazily evaluated function, with the restriction that while you can put a Func<T> object into an IO object, you can never get it out again. Thus, the item is a private class field instead of a public property.
SelectMany #
The SelectMany method is a little more tricky:
public IO<TResult> SelectMany<TResult>(Func<T, IO<TResult>> selector) { return new IO<TResult>(() => selector(item()).item()); }
To guarantee referential transparency, we don't want the method to trigger evaluation of the lazy value, so the selector has to run inside a new lazy computation. This produces a lazy IO value that the method then has to unwrap inside another lazy computation. Such a translation from Func<IO<TResult>> to a new IO object with a Func<TResult> inside it is reminiscent of what in Haskell is known as a traversal.
UnsafePerformIO #
Finally, the UnsafePerformIO method isn't part of the API, but as explained in the previous article, this is the special method that the hypothetical parallel-world framework calls on the IO<Unit> returned by Main methods.
internal T UnsafePerformIO() { return item(); }
Since only the framework is supposed to call this method, it's internal by design. The only thing it does is to force evaluation of the lazy item.
Conclusion #
Most of the implementation of IO<T> is straightforward, with the single exception of SelectMany, which has to jump through a few hoops to keep the behaviour lazy until it's activated.
Once more I want to point out that the purpose of this article series is to explain how a type system like Haskell's guarantees referential transparency. C# could do the same, but it'd require that all impure actions in all libraries in the entire .NET ecosystem were to return IO values. That's not going to happen, but something similar already has happened. Read on in the next article.
Comments
In your previous post, you said
Haskell is a lazily evaluated language. That's an important piece of the puzzle, so I've modelled theIO<T>example so that it only wrapsLazyvalues. That emulates Haskell's behaviour in C#.
After several days, I finally feel like I fully understand this.
The concept of lazy has serveral slightly different definitions depending on the context. Haskell is a lazily evaluated language in the sense that its evaluation strategy is call by need. In C#, both Lazy<T> and Func<T> are lazy in the sense that neither actually contains a T, but both could produce a T if asked to do so. The difference is the presence or absence of caching. I remember all this by saying that Lazy<T> is lazy with caching and Func<T> is lazy without caching. So Lazy<T> is to call by need as Func<T> is to call by name.
Therefore, Lazy<T> is the correct choice if we want to model or emulate the evaluation strategy of Haskell in C#. What about Haskell's IO<T>? Is it lazy with caching or lazy without caching? My guess was lazy without caching, but I finally installed the ghc Haskell compiler and compiled Haskell on my machine for the first time in order to test this. I think this example shows that Haskell's IO<T> is lazy without caching.
-- output: xx
main =
let io = putStr "x"
in do { io ; io }
I think this would be equivalent C# code in this parallel world that you have created.
// output: x
static IO<Unit> MainIO(string[] args) {
var io = Console.Write("x");
return from _1 in io
from _2 in io
select Unit.Instance;
}
What makes me think that I fully understand this now is that I think I see where you are going. I think you already knew all this and decided to model Haskell's IO<T> using Lazy<T> anyway because Task<T> is also lazy with caching just like Lazy<T>, and your next post will discuss using Task<T> as a surrogate for Haskell's IO<T>. I think you want your C# implementation of IO<T> to be more like C#'s Task<T> than Haskell's IO<T>.
Thank you for including such a gem for me to think about...and enough motivation to finally put Haskell on my machine!
Tyson, thank you for writing. You've almost turned my blog into a peer-reviewed journal, and you've just pointed out a major blunder of mine 👍
I think I was mislead by the name Lazy, my attention was elsewhere, and I completely forgot about the memoisation that both Lazy<T> and Task<T> employ. It does turn out to be problematic in this context. Take the following example:
static IO<Unit> Main(string[] args) { IO<DateTime> getTime = Clock.GetLocalTime(); return getTime.SelectMany(t1 => Console.WriteLine(t1.Ticks.ToString()).Select(u1 => { Thread.Sleep(2); return Unit.Instance; }).SelectMany(u2 => getTime).SelectMany(t2 => Console.WriteLine(t2.Ticks.ToString()))); }
Notice that this example reuses getTime twice. We'd like any IO<T> value to represent an impure computation, so evaluating it twice with a 2 millisecond delay in between ought to yield two different results.
Due to the memoisation built into Lazy<T>, the first value is reused. That's not the behaviour we'd like to see.
While this is a rather big error on my part, it's fortunately only of a technical nature (I think). As you imply, the correct implementation is to use Func<T> rather than Lazy<T>:
public sealed class IO<T> { private readonly Func<T> item; public IO(Func<T> item) { this.item = item; } public IO<TResult> SelectMany<TResult>(Func<T, IO<TResult>> selector) { return new IO<TResult>(() => selector(item()).item()); } internal T UnsafePerformIO() { return item(); } }
This addresses the above reuse bug. With this implementation, the above Main method prints two different values, even though it reuses getTime.
Haskell IO doesn't memoise values, so this Func-based implementation better emulates the Haskell behaviour, which is actually what I wanted to do all along.
This mistake of mine is potentially so confusing that I think that it's best if I go back and edit the other posts in this articles series. Before I do that, though, I'd like to get your feedback.
Does this look better to you, or do you see other problems with it?
Tyson, thank you for writing. You've almost turned my blog into a peer-reviewed journal, and you've just pointed out a major blunder of mine 👍
You're welcome. I am certainly a peer, and I benefit greatly from closly reviewing your posts. They always give me so much to think about. I am happy that we both benefit from this :)
While this is a rather big error on my part, it's fortunately only of a technical nature (I think). ...
Haskell
IOdoesn't memoise values, so thisFunc-based implementation better emulates the Haskell behaviour, which is actually what I wanted to do all along.This mistake of mine is potentially so confusing that I think that it's best if I go back and edit the other posts in this articles series. Before I do that, though, I'd like to get your feedback.
Does this look better to you, or do you see other problems with it?
Yes, your Func<T>-based implementation better emulates Haskell's IO<T>. My guess was that you had used Lazy<T> with its caching behavior in mind. I do think it is a minor issue. I can't think of any code that I would write on purpose that would depend on this difference.
I think editing the previous posts depends on exactly how you want to suggesst Task<T> as an IO<T> surrogate.
From a purely teaching perspective, I think I prefer to first implement Haskell's IO<T> in C# using Func<T>, then suggest this implemention is essentialy the same as Task<T>, then point out the caching difference for those that are still reading. It would be a shame to lose some readers eariler by pointing out the difference too soon. I wouldn't expect you lost any readres in your current presentation that includes the caching difference but without mentioning it.
Func<T>, Lazy<T>, and Task<T> are all lazy (in the sense that none contain a T but all could produce one if requested. Here are their differences:
Func<T>is synchronous without caching,Lazy<T>is synchronous with caching, andTask<T>is asynchronous with caching.
Func<T> and Task<T>. The nested type Func<Task<T>> can asynchronously produce a T without caching. Maybe this would be helpful in this article series.
Overall though, I don't know of any other potential changes to consider.
For any reader following the discussion after today (July 24, 2020), it may be slightly confusing. Based on Tyson Williams' feedback, I've edited the article series with the above implementation. The previous incarnation of the article series had this implementation of IO<T>:
public sealed class IO<T> { private readonly Lazy<T> item; public IO(Lazy<T> item) { this.item = item; } public IO<TResult> SelectMany<TResult>(Func<T, IO<TResult>> selector) { var res = new Lazy<IO<TResult>>(() => selector(item.Value)); return new IO<TResult>( new Lazy<TResult>(() => res.Value.item.Value)); } internal T UnsafePerformIO() { return item.Value; } }
As this discussion reveals, the memoisation performed by Lazy<T> causes problems. After thinking it through, I've decided to retroactively change the articles in the series. This is something that I rarely do, but in this case I think is the best way forward, as the Lazy-based implementation could be confusing to new readers.
Readers interested in the history of these articles can peruse the Git log.
Referential transparency of IO
How the IO container guarantees referential integrity. An article for object-oriented programmers.
This article is part of an article series about the IO container in C#. In a previous article you got a basic introduction to the IO<T> container I use to explain how a type system like Haskell's distinguishes between pure functions and impure actions.
The whole point of the IO container is to effectuate the functional interaction law: a pure function mustn't be able to invoke an impure activity. This rule follows from referential transparency.
The practical way to think about it is to consider the two rules of pure functions:
- Pure functions must be deterministic
- Pure functions may have no side effects
IO<T> imposes those rules.
Determinism #
Like in the previous articles in this series, you must imagine that you're living in a parallel universe where all impure library functions return IO<T> objects. By elimination, then, methods that return naked values must be pure functions.
Consider the Greet function from the previous article. Since it returns a plain string, you can infer that it must be a pure function. What prevents it from doing something impure?
What if you thought that passing now as an argument is a silly design. Couldn't you just call Clock.GetLocalTime from the method?
Well, yes, in fact you can:
public static string Greet(DateTime now, string name) { IO<DateTime> now1 = Clock.GetLocalTime(); var greeting = "Hello"; if (IsMorning(now)) greeting = "Good morning"; if (IsAfternoon(now)) greeting = "Good afternoon"; if (IsEvening(now)) greeting = "Good evening"; if (string.IsNullOrWhiteSpace(name)) return $"{greeting}."; return $"{greeting}, {name.Trim()}."; }
This compiles, but is only the first refactoring step you have in mind. Next, you want to extract the DateTime from now1 so that you can get rid of the now parameter. Alas, you now run into an insuperable barrier. How do you get the DateTime out of the IO?
You can't. By design.
While you can call the GetLocalTime method, you can't use the return value. The only way you can use it is by composing it with SelectMany, but that still accomplishes nothing unless you return the resulting IO object. If you do that, though, you've now turned the entire Greet method into an impure action.
You can't perform any non-deterministic behaviour inside a pure function.
Side effects #
How does IO<T> protect against side effects? In the Greet method, couldn't you just write to the console, like the following?
public static string Greet(DateTime now, string name) { Console.WriteLine("Side effect!"); var greeting = "Hello"; if (IsMorning(now)) greeting = "Good morning"; if (IsAfternoon(now)) greeting = "Good afternoon"; if (IsEvening(now)) greeting = "Good evening"; if (string.IsNullOrWhiteSpace(name)) return $"{greeting}."; return $"{greeting}, {name.Trim()}."; }
This also compiles, despite our best efforts. That's unfortunate, but, as you'll see in a moment, it doesn't violate referential transparency.
In Haskell or F# equivalent code would make the compiler complain. Those compilers don't have special knowledge about IO, but they can see that an action returns a value. F# generates a compiler warning if you ignore a return value. In Haskell the story is a bit different, but the result is the same. Those compilers complain because you try to ignore the return value.
You can get around the issue using the language's wildcard pattern. This tells the compiler that you're actively ignoring the result of the action. You can do the same in C#:
public static string Greet(DateTime now, string name) { IO<Unit> _ = Console.WriteLine("Side effect!"); var greeting = "Hello"; if (IsMorning(now)) greeting = "Good morning"; if (IsAfternoon(now)) greeting = "Good afternoon"; if (IsEvening(now)) greeting = "Good evening"; if (string.IsNullOrWhiteSpace(name)) return $"{greeting}."; return $"{greeting}, {name.Trim()}."; }
The situation is now similar to the above treatment of non-determinism. While there's no value of interest in an IO<Unit>, the fact that there's an object at all is a hint. Like Lazy<T>, that value isn't a result. It's a placeholder for a computation.
If there's a way to make the C# compiler complain about ignored return values, I'm not aware of it, so I don't know if we can get closer to how Haskell works than this. Regardless, keep in mind that I'm not trying to encourage you to write C# like this; I'm only trying to explain how Haskell enforces referential transparency at the type level.
Referential transparency #
While the above examples compile without warnings in C#, both are still referentially transparent!
This may surprise you. Particularly the second example that includes Console.WriteLine looks like it has a side effect, and thus violates referential transparency.
Keep in mind, though, what referential transparency means. It means that you can replace a particular function call with its value. For example, you should be able to replace the function call Greeter.Greet(new DateTime(2020, 6, 4, 12, 10, 0), "Nearth") with its return value "Hello, Nearth.", or the function call Greeter.Greet(new DateTime(2020, 6, 4, 7, 30, 0), "Bru") with "Good morning, Bru.", without changing the behaviour of the software. This property still holds.
Even when the Greet method includes the Console.WriteLine call, that side effect never happens.
The reason is that an IO object represents a potential computation that may take place (also known as a thunk). Notice that the IO<T> constructor takes a Func as argument. It's basically just a lazily evaluated function wrapped in such a way that you can't force evaluation.
Instead, you should imagine that after Main returns its IO<Unit> object, the parallel-universe .NET framework executes it.
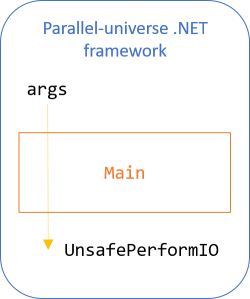
The framework supplies command-line arguments to the Main method. Once the method returns an IO<Unit> object, the framework executes it with a special method that only the framework can invoke. Any other IO values that may have been created (e.g. the above Console.WriteLine) never gets executed, because they're not included in the return value.
Conclusion #
The IO container makes sure that pure functions maintain referential transparency. The underlying assumption that makes all of this work is that all impure actions return IO objects. That's not how the .NET framework works, but that's how Haskell works. Since the IO container is opaque, pure functions can't see the contents of IO boxes.
Program entry points are all impure. The return value of the entry point must be IO<Unit>. The hypothetical parallel-universe framework executes the IO value returned by Main.
Haskell is a lazily evaluated language. That's an important piece of the puzzle, so I've modelled the IO<T> example so that it only wraps lazily evaluated Func values. That emulates Haskell's behaviour in C#. In the next article, you'll see how I wrote the C# code that supports these articles.
Comments
In a previous post, you said
...a pure function has to obey two rules:
- The same input always produces the same output.
- Calling it causes no side effects.
In this post, you said
...the two rules of pure functions:
- Pure functions must be deterministic
- Pure functions may have no side effects
The first two items are not the same. Is this difference intentional?
Tyson, thank you for writing. Indeed, the words er verbatim not the same, but I do intend them to carry the same meaning.
If one wants to define purity in a way that leaves little ambiguity, one has to use more words. Just look at the linked Wikipedia article. I link to Wikipedia for the benefit of those readers who'd like to get a more rigorous definition of the term, while at the same time I enumerate the two rules as a summary for the benefit of those readers who just need a reminder.
Does that answer your question?
...I do intend them to carry the same meaning.
I don't think they don't mean the same thing. That is part of the discussion we are having on this previous post. I think the simplest example to see the difference is randomzied quicksort. For each input, the output is always the same. However, randomized quicksort is not deterministic because it uses randomness.
Do you still think they mean the same thing?
You can get around the issue using the language's wildcard pattern. This tells the compiler that you're actively ignoring the result of the action.
You made a standard variable declaration and I believe you meant to use a stand-alone discard rather than a wildcard pattern? Like below?
public static string Greet(DateTime now, string name) { _ = Console.WriteLine("Side effect!"); var greeting = "Hello"; if (IsMorning(now)) greeting = "Good morning"; if (IsAfternoon(now)) greeting = "Good afternoon"; if (IsEvening(now)) greeting = "Good evening"; if (string.IsNullOrWhiteSpace(name)) return $"{greeting}."; return $"{greeting}, {name.Trim()}."; }
Tyson, I apologise in advance for my use of weasel words, but 'in the literature', a function that always returns the same output when given the same input is called 'deterministic'. I can't give you a comprehensive list of 'the literature' right now, but here's at least one example.
I'm well aware that this might be confusing. One could argue that querying a database is deterministic, because the output is completely determined by the state of the database. The same goes for reading the contents of a file. Such operations, however, may return different outputs for the same inputs, as the state of the resource changes. There's no stochastic process involved in such state changes, but we still consider such actions non-deterministic.
In the same vein, in this jargon, 'deterministic' doesn't imply the absence of internal randomness, as you have so convincingly argued. In the present context, 'deterministic' is defined as the property that a given input value always produces the same output value.
That's the reason I tend to use those phrases interchangeably. In this context, they literally mean the same. I can see how this might be confusing, though.
Atif, thank you for writing. I didn't know about that language construct. Thank you for pointing it out to me!
[Wikipedia says that] a function that always returns the same output when given the same input is called 'deterministic'.
In the same vein, in this jargon, 'deterministic' doesn't imply the absence of internal randomness, as you have so convincingly argued. In the present context, 'deterministic' is defined as the property that a given input value always produces the same output value.
That's the reason I tend to use those phrases interchangeably. In this context, they literally mean the same. I can see how this might be confusing, though.
I am certainly still confused. I can't tell if you are purposefully providing your own definition for determinism, if you are accidentally misunderstanding the actual definition of determinism, if you think the definition of determinism is equivalent to the definition you gave due to being in some context or operating with an additional assumption (of which I am unsure), or maybe something else.
If I had to guess, then I think you do see the difference between the two definitions but are claiming that are equivalent due to being in some context or operating with an additional assumption. If this guess is correct, then what is the additional assumption you are making?
To ensure that you do understand determinism, I will interpret your statements as literally as possible and then respond to them. I apologize in advance if this is not the correct interpretation and for any harshness in the tone of my response.
You misquoted the Wikipedia article. Here is the exact text (after replacing "algorithm" with "function" since the difference between these is not important to us now).
a deterministic function is a function which, given a particular input, will always produce the same output, with the underlying machine always passing through the same sequence of states.
Your quotation essentially excludes the phrase "with the underlying machine always passing through the same sequence of states". Let's put these two definitions next to each other.
Let f be a function. Consider the following two statements about f that might or might not be true (depending on the exact value of f).
- Given a particular input,
fwill always produce the same output. - Given a particular input,
fwill always produce the same output, with the underlying machine always passing through the same sequence of states.
Suppose some f satisfies statement 2. Then f clearly satisfies statement 1 as well. These two sentences together are equivalent to saying that statement 2 implies statement 1. The contrapositive then says that not satisfying statement 1 implies not satisfying statement 2. Also, Wikipedia says that such an f is said to be deterministic.
Now suppose some f satisfies statement 1. Then f need not also satisfy statement 2. An example that proves this is randomized quicksort (as I pointed out in this comment). This means that statement 1 does not imply statement 2.
"Wikipedia gave" a name to functions that satisfy statement 2. I do not recall ever seeing anyone give a name to functions that satisfy statement 1. In this comment, you asked me about what I meant by "weak determinism". I am trying to give a name to functions that satisfy statement 1. I am suggesting that we call them weakly deterministic. This name allows us to say that a deterministic function is also weakly deterministic, but a weakly deterministic function might not be deterministic. Furthermore, not being a weakly deterministic implies not being deterministic.
One could argue that querying a database is deterministic, because the output is completely determined by the state of the database. The same goes for reading the contents of a file. Such operations, however, may return different outputs for the same inputs, as the state of the resource changes. There's no stochastic process involved in such state changes, but we still consider such actions non-deterministic.
Indeed. I agree. If we distinguish determinism from weak determinism, then we can say that such a function is not weakly deterministic, which implies that it is not deterministic.
Tyson, I'm sorry, I picked a bad example. It's possible that my brain is playing a trick with me. I'm not purposefully providing my own definition of determinism.
I've learned all of this from diverse sources, and I don't recall all of them. Some of them are books, some were conference talks I attended, some may have been conversations, and some online resources. All of that becomes an amalgam of knowledge. Somewhere I've picked up the shorthand that 'deterministic' is the same as 'the same input produces the same output'; I can't tell you the exact source of that habit, and it may, indeed, be confusing.
It seems that I'm not the only person with that habit, though:
I'm not saying that John A De Goes is an authority you should unquestionably accept; I'm only pointing to that tweet to illustrate that I'm not the only person who occasionally use 'deterministic' in that way. And I don't think that John A De Goes picked up the habit from me."Deterministic: They return the same output for the same input."
The key to all of this is referential transparency. In an ideal world, I wouldn't need to use the terms 'pure function' or 'deterministic'. I can't, however, write these articles and only refer to referential transparency. The articles are my attempt to share what I have learned with readers who would also like to learn. The problem with referential transparency is that it's an abstract concept: can I replace a function call with its output? This may be a tractable notion to pick up, but how do you evaluate that in practice?
I believe that it's easier for readers to learn that they have to look for two properties:
- Does the same input always produce the same output?
- Are there no side effects?
As all programmers know: language is imprecise. Even the above two bullets are vague. What's a side effect? Does the rule about input and output apply to all values in the function's domain?
I don't think that it's possible to write perfectly precise and unambiguous prose. Mathematical notation was developed as an attempt to be more precise and unambiguous. Source code has the same quality.
I'm not writing mathematical treatises, but I use C#, F#, and Haskell source code to demonstrate concepts as precisely as I can. The surrounding prose is my attempt at explaining what the code does, and why it's written the way it is. The prose will be ambiguous; I can't help it.
Sometimes, I need a shorthand to remind the reader about referential transparency in a way that (hopefully) assists him or her. Sometimes, this is best done by using a few adjectives, such as "a deterministic and side-effect-free function". It's not a definition, it's a reading aid.
Mark, I am also sorry. As I reread my comment, I think I was too critical. I admire your great compassion and humility, especially in your writing. I have been trying to write more like you, but my previous comment shows that I still have room for improvement. Your blog is still my favorite place to read and learn about software development and functional programming. It is almost scary how much I agree with you. I hope posting questions about my confusion or comments about our differences don't overshadow all the ways in which we agree and sour our relationship.
Tyson, don't worry about it. Questions teach me where there's room for improvement. You also sometimes point out genuine mistakes that I make. If you didn't do that, I might never realise my mistakes, and then I wouldn't be able to correct them.
I appreciate the feedback because it improves the content and teaches me things that I didn't know. On the other hand, as the cliché goes, all errors are my own.
Syntactic sugar for IO
How to make use of the C# IO container less ugly.
This article is part of an article series about the IO container in C#. In the previous article you saw a basic C# hello world program using IO<T> to explicitly distinguish between pure functions and impure actions. The code wasn't as pretty as you could hope for. In this article, you'll see how to improve the aesthetics a bit.
The code isn't going to be perfect, but I think it'll be better.
Sugared version #
The IO<T> container is an imitation of the Haskell IO type. In Haskell, IO is a monad. This isn't a monad tutorial, and I hope that you're able to read the article without a deep understanding of monads. I only mention this because when you compose monadic values with each other, you'll sometimes have to write some 'noisy' code - even in Haskell. To alleviate that pain, Haskell offers syntactic sugar in the form of so-called do notation.
Likewise, F# comes with computation expressions, which also gives you syntactic sugar over monads.
C#, too, comes with syntactic sugar over monads. This is query syntax, but it's not as powerful as Haskell do notation or F# computation expressions. It's powerful enough, though, to enable you to improve the Main method from the previous article:
static IO<Unit> Main(string[] args) { return from _ in Console.WriteLine("What's your name?") from name in Console.ReadLine() from now in Clock.GetLocalTime() let greeting = Greeter.Greet(now, name) from res in Console.WriteLine(greeting) select res; }
If you use C# query syntax at all, you may think of it as exclusively the realm of object-relational mapping, but in fact it works for any monad. There's no data access going on here - just the interleaving of pure and impure code (in an impureim sandwich, even).
Infrastructure #
For the above code to compile, you must add a pair of methods to the IO<T> API. You can write them as extension methods if you like, but here I've written them as instance methods on IO<T>.
When you have multiple from keywords in the same query expression, you must supply a particular overload of SelectMany. This is an oddity of the implementation of the query syntax language feature in C#. You don't have to do anything similar to that in F# or Haskell.
public IO<TResult> SelectMany<U, TResult>(Func<T, IO<U>> k, Func<T, U, TResult> s) { return SelectMany(x => k(x).SelectMany(y => new IO<TResult>(() => s(x, y)))); }
Once you've implemented such overloads a couple of times, they're more tedious than challenging to write. They always follow the same template. First use SelectMany with k, and then SelectMany again with s. The only marginally stimulating part of the implementation is figuring out how to wrap the return value from s.
You're also going to need Select as shown in the article about IO as a functor.
Conclusion #
C#'s query syntax offers limited syntactic sugar over functors and monads. Compared with F# and Haskell, the syntax is odd and its functionality limited. The most galling lacuna is that you can't branch (e.g. use if or switch) inside query expressions.
The point of these articles is (still) not to endorse this style of programming. While the code I show in this article series is working C# code that runs and passes its tests, I'm pretending that all impure actions in C# return IO results. To be clear, the Console class this code interacts with isn't the Console class from the base class library. It's a class that pretends to be such a class from a parallel universe.
So far in these articles, you've seen how to compose impure actions with pure functions. What I haven't covered yet is the motivation for it all. We want the compiler to enforce the functional interaction law: a pure function shouldn't be able to invoke an impure action. That's the topic for the next article.
The IO functor
The IO container forms a functor. An article for object-oriented programmers.
This article is an instalment in an article series about functors. Previous articles have covered Maybe, Lazy, and other functors. This article provides another example.
Functor #
In a recent article, I gave an example of what IO might look like in C#. The IO<T> container already has sufficient API to make it a functor. All it needs is a Select method:
public IO<TResult> Select<TResult>(Func<T, TResult> selector) { return SelectMany(x => new IO<TResult>(() => selector(x))); }
This is an instance method on IO<T>, but you can also write it as an extension method, if that's more to your liking.
When you call selector(x), the return value is an object of the type TResult. The SelectMany method, however, wants you to return an object of the type IO<TResult>, so you use the IO constructor to wrap that return value.
Haskell #
The C# IO<T> container is an illustration of how Haskell's IO type works. It should come as no surprise to Haskellers that IO is a functor. In fact, it's a monad, and all monads are also functors.
The C# IO<T> API is based around a constructor and the SelectMany method. The constructor wraps a plain T value in IO<T>, so that corresponds to Haskell's return method. The SelectMany method corresponds to Haskell's monadic bind operator >>=. When you have lawful return and >>= implementations, you can have a Monad instance. When you have a Monad instance, you not only can have Functor and Applicative instances, you must have them.
Conclusion #
IO forms a functor, among other abstractions. In C#, this manifests as a proper implementation of a Select method.
Next: Monomorphic functors.
Comments
The constructor wraps a plainTvalue inIO<T>
Did you mean to say that the constructor wraps a Lazy<T> value in IO<T>?
Tyson, thank you for writing. Well, yes, that's technically what happens... I'm deliberately being imprecise with the language because I'm trying to draw a parallel to Haskell. In Haskell, return takes a value and wraps it in IO (the type is effectively a -> IO a). In Haskell, however, computation is lazy by default. This means that the value you wrap in IO is already lazy. This turns out to be important, as I'll explain in a future article, so in C# we have to first make sure that the value is lazy.
The concept, however, involves taking a 'bare' value and wrapping it in a container, and that's the reason I chose my words as I did.
IO container in a parallel C# universe
A C# model of IO at the type level.
This article is part of an article series about the IO container in C#. The previous article provided a conceptual overview. In this article you'll see C# code examples.
In a world... #
Imagine a parallel universe where a C# entry point is supposed to look like this:
static IO<Unit> Main(string[] args)
Like another Neo, you notice that something in your reality is odd, so you decide to follow the white rabbit. Unit? What's that? Navigating to its definition, you see this:
public sealed class Unit { public static readonly Unit Instance; }
There's not much to see here. Unit is a type that serves the same role as the void keyword. They're isomorphic, but Unit has the advantage that it's a proper type. This means that it can be a type parameter in a generically typed container like IO.
So what's IO? When you view its definition, this is what you see:
public sealed class IO<T> { public IO(Func<T> item) public IO<TResult> SelectMany<TResult>(Func<T, IO<TResult>> selector) }
There's a constructor you can initialise with a lazily evaluated value, and a SelectMany method that looks strikingly like something out of LINQ.
You'll probably notice right away that while you can put a value into the IO container, you can't get it back. As the introductory article explained, this is by design. Still, you may think: What's the point? Why would I ever want to use this class?
You get part of the answer when you try to implement your program's entry point. In order for it to compile, the Main method must return an IO<Unit> object. Thus, the simplest Main method that compiles is this:
static IO<Unit> Main(string[] args) { return new IO<Unit>(() => Unit.Instance); };
That's only a roundabout no-op. What if you want write real code? Like hello world?
Impure actions #
You'd like to write a program that asks the user about his or her name. Based on the answer, and the time of day, it'll write Hello, Nearth, or Good evening, Kate. You'd like to know how to take user input and write to the standard output stream. In this parallel world, the Console API looks like this:
public static class Console { public static IO<string> ReadLine(); public static IO<Unit> WriteLine(string value); // More members here... }
You notice that both methods return IO values. This immediately tells you that they're impure. This is hardly surprising, since ReadLine is non-deterministic and WriteLine has a side effect.
You'll also need the current time of day. How do you get that?
public static class Clock { public static IO<DateTime> GetLocalTime(); }
Again, IO signifies that the returned DateTime value is impure; it's non-deterministic.
Pure logic #
A major benefit of functional programming is the natural separation of concerns; separation of business logic from implementation details (a.k.a. the Dependency Inversion Principle).
Write the logic of the program as a pure function:
public static string Greet(DateTime now, string name) { var greeting = "Hello"; if (IsMorning(now)) greeting = "Good morning"; if (IsAfternoon(now)) greeting = "Good afternoon"; if (IsEvening(now)) greeting = "Good evening"; if (string.IsNullOrWhiteSpace(name)) return $"{greeting}."; return $"{greeting}, {name.Trim()}."; }
You can tell that this is a pure function from its return type. In this parallel universe, all impure library methods look like the above Console and Clock methods. Thus, by elimination, a method that doesn't return IO is pure.
Composition #
You have impure actions you can invoke, and a pure piece of logic. You can use ReadLine to get the user's name, and GetLocalTime to get the local time. When you have those two pieces of data, you can call the Greet method.
This is where most people run aground. "Yes, but Greet needs a string, but I have an IO<string>. How do I get the string out of the IO?
If you've been following the plot so far, you know the answer: mu. You don't. You compose all the things with SelectMany:
static IO<Unit> Main(string[] args) { return Console.WriteLine("What's your name?").SelectMany(_ => Console.ReadLine().SelectMany(name => Clock.GetLocalTime().SelectMany(now => { var greeting = Greeter.Greet(now, name); return Console.WriteLine(greeting); }))); }
I'm not going to walk through all the details of how this works. There's plenty of monad tutorials out there, but take a moment to contemplate the SelectMany method's selector argument. It takes a plain T value as input, but must return an IO<TResult> object. That's what each of the above lambda expressions do, but that means that name and now are unwrapped values; i.e. string and DateTime.
That means that you can call Greet with name and now, which is exactly what happens.
Notice that the above lambda expressions are nested. With idiomatic formatting, they'd exhibit the dreaded arrow shape, but with this formatting, it looks more like the sequential composition that it actually is.
Conclusion #
The code you've seen here all works. The only difference between this hypothetical C# and the real C# is that your Main method can't look like that, and impure library methods don't return IO values.
The point of the article isn't to recommend this style of programming. You can't, really, since it relies on the counter-factual assumption that all impure library methods return IO. The point of the article is to explain how a language like Haskell uses the type system to distinguish between pure functions and impure actions.
Perhaps the code in that Main method isn't the prettiest code you've ever seen, but we can make it a little nicer. That's the topic of the next article in the series.
Next: Syntactic sugar for IO.
Comments
Why is the input of the IO constructor of type Lazy<T> instead of just type T?
Tyson, thank you for writing. A future article in this article series will answer that question 😀
FWIW, the promised article is now available.
Ah, sure. I was thinking that IO<T> is a monad (in T), so there should be a constructor with argument T. However, the function doens't need to be a constructor. The lambda expression t => new IO<T>(new Lazy<T>(() => t)) satisifies the requirement.
Yes 👍
The IO Container
How a type system can distinguish between pure and impure code.
Referential transparency is the foundation of functional architecture. If you categorise all operations into pure functions and impure actions, then most other traits associated with functional programming follow.
Unfortunately, mainstream programming languages don't distinguish between pure functions and impure actions. Identifying pure functions is tricky, and the knowledge is fleeting. What was a pure function today may become impure next time someone changes the code.
Separating pure and impure code is important. It'd be nice if you could automate the process. Perhaps you could run some tests, or, even better, make the compiler do the work. That's what Haskell and a few other languages do.
In Haskell, the distinction is made with a container called IO. This static type enforces the functional interaction law at compile time: pure functions can't invoke impure actions.
Opaque container #
Regular readers of this blog know that I often use Haskell to demonstrate principles of functional programming. If you don't know Haskell, however, its ability to guarantee the functional interaction law at compile time may seem magical. It's not.
Fortunately, the design is so simple that it's easy to explain the fundamental concept: Results of impure actions are always enclosed in an opaque container called IO. You can think of it as a box with a label.

The label only tells you about the static type of the value inside the box. It could be an int, a DateTime, or your own custom type, say Reservation. While you know what type of value is inside the box, you can't see what's in it, and you can't open it.
Name #
The container itself is called IO, but don't take the word too literally. While all I/O (input/output) is inherently impure, other operations that you don't typically think of as I/O is impure as well. Generation of random numbers (including GUIDs) is the most prominent example. Random number generators rely on the system clock, which you can think of as an input device, although I think many programmers don't.
I could have called the container Impure instead, but I chose to go with IO, since this is the word used in Haskell. It also has the advantage of being short.
What's in the boooox? #
A question frequently comes up: How do I get the value out of my IO? As always, the answer is mu. You don't. You inject the desired behaviour into the container. This goes for all monads, including IO.
But naturally you wonder: If you can't see the value inside the IO box then what's the point?
The point is to enforce the functional interaction law at the type level. A pure function that calls an impure action will receive a sealed, opaque IO box. There's no API that enables a pure function to extract the contents of the container, so this effectively enforces the rule that pure functions can't call impure actions.
The other three types of interactions are still possible.
- Pure functions should be able to call pure functions. Pure functions return 'normal' values (i.e. values not hidden in IO boxes), so they can call each other as usual.
- Impure actions should be able to call pure functions. This becomes possible because you can inject pure behaviour into any monad. You'll see example of that in later articles in this series.
- Impure actions should be able to call other impure actions. Likewise, you can compose many IO actions into one IO action via the IO API.
On the other hand, if you're already inside the box, you can see the contents. And there's one additional rule: If you're already inside an IO box, you can open other IO boxes and see their contents!
In subsequent articles in this article series, you'll see how all of this manifests as C# code. This article gives a high-level view of the concept. I suggest that you go back and re-read it once you've seen the code.
The many-worlds interpretation #
If you're looking for metaphors or other ways to understand what's going on, there's two perspectives I find useful. None of them offer the full picture, but together, I find that they help.
A common interpretation of IO is that it's like the box in which you put Schrödinger's cat. IO<Cat> can be viewed as the superposition of the two states of cat (assuming that Cat is basically a sum type with the cases Alive and Dead). Likewise, IO<int> represents the superposition of all 4,294,967,296 32-bit integers, IO<string> the superposition of infinitely many strings, etcetera.
Only when you observe the contents of the box does the superposition collapse to a single value.
But... you can't observe the contents of an IO box, can you?
The black hole interpretation #
The IO container represents an impenetrable barrier between the outside and the inside. It's like a black hole. Matter can fall into a black hole, but no information can escape its event horizon.
In high school I took cosmology, among many other things. I don't know if the following is still current, but we learned a formula for calculating the density of a black hole, based on its mass. When you input the estimated mass of the universe, the formula suggests a density near vacuum. Wait, what?! Are we actually living inside a black hole? Perhaps. Could there be other universes 'inside' black holes?
The analogy to the IO container seems apt. You can't see into a black hole from the outside, but once beyond the blue event horizon, you can observe everything that goes on in that interior universe. You can't escape to the original universe, though.
As with all metaphors, this one breaks down if you think too much about it. Code running in IO can unpack other IO boxes, even nested boxes. There's no reason to believe that if you're inside a black hole that you can then gaze beyond the event horizon of nested black holes.
Code examples #
In the next articles in this series, you'll see C# code examples that illustrate how this concept might be implemented. The purpose of these code examples is to give you a sense for how IO works in Haskell, but with more familiar syntax.
- IO container in a parallel C# universe
- Syntactic sugar for IO
- Referential transparency of IO
- Implementation of the C# IO container
- Task asynchronous programming as an IO surrogate
Conclusion #
When you saw the title, did you think that this would be an article about IoC Containers? It's not. The title isn't a typo, and I never use the term IoC Container. As Steven and I explain in our book, Inversion of Control (IoC) is a broader concept than Dependency Injection (DI). It's called a DI Container.
IO, on the other hand, is a container of impure values. Its API enables you to 'build' bigger structures (programs) from smaller IO boxes. You can compose IO actions together and inject pure functions into them. The boxes, however, are opaque. Pure functions can't see their contents. This effectively enforces the functional interaction law at the type level.
Comments
Come on, you know there is a perfect metaphor. Monads are like burritos.
Christer, I appreciate that this is all in good fun 🤓
For the benefit of readers who may still be trying to learn these concepts, I'll point out that just as this isn't an article about IoC containers, it's not a monad tutorial. It's an explanation of a particular API called IO, which, among other traits, also forms a monad. I'm trying to downplay that aspect here, because I hope that you can understand most of this and the next articles without knowing what a monad is.
"While you know what type of value is inside the box, you can't see what's in it, and you can't open it."
Well you technically can, with unsafePerformIO ;) although it defeats the whole purpose.

Comments
This is a great idea. It seems like the only Problem with Tasks is that they are usually already started, either on the current or a Worker Thread. If we return Tasks that are not started yet, then Side-Effects don't happen until we await them. And we have to await them to get their Result or use them in other Tasks. I experimented with a modified GetTime() Method returning a new Task that is not run yet:
Using a SelectMany Method that ensures that Tasks have been run, the Time is not evaluated until the resulting Task is awaited or another SelectMany is built using the Task from the first SelectMany. The Time of one such Task is also evaluated only once. On repeating Calls the same Result is returned:
public static async Task<TResult> SelectMany<T, TResult>(this Task<T> source , Func<T, Task<TResult>> project) { T t = await source.GetResultAsync(); Task<TResult>? ret = project(t); return await ret.GetResultAsync(); } /// <summary> Asynchronously runs the <paramref name="task"/> to Completion </summary> /// <returns><see cref="Task{T}.Result"/></returns> public static async Task<T> GetResultAsync<T>(this Task<T> task) { switch (task.Status) { case TaskStatus.Created: await Task.Run(task.RunSynchronously); return task.Result; case TaskStatus.WaitingForActivation: case TaskStatus.WaitingToRun: case TaskStatus.Running: case TaskStatus.WaitingForChildrenToComplete: return await task; case TaskStatus.Canceled: case TaskStatus.Faulted: case TaskStatus.RanToCompletion: return task.Result; //let the Exceptions fly... default: throw new ArgumentOutOfRangeException(); } }Since I/O Operations with side-effects are usually asynchronous anyway, Tasks and I/O are a good match.
Consistenly not starting Tasks and using this SelectMany Method either ensures Method purity or enforces to return the Task. To avoid ambiguity with started Tasks a Wrapper-IO-Class could be constructed, that always takes and creates unstarted Tasks. Am I missing something or do you think this would not be worth the effort? Are there more idiomatic ways to start enforcing purity in C#, except e.g. using the [Pure] Attribute and StyleCop-Warnings for unused Return Values?
Matt, thank you for writing. That's essentially how F# asynchronous workflows work.