ploeh blog danish software design
Monomorphic functors
Non-generic mappable containers, with a realistic example.
This article is an instalment in an article series about functors. Previous articles have covered Maybe, Lazy, and other functors. This article looks at what happens when you weaken one of the conditions that the article series so far has implied.
In the introductory article, I wrote:
As a rule of thumb, if you have a type with a generic type argument, it's a candidate to be a functor.That still holds, but then Tyson Williams asks if that's a required condition. It turns out that it isn't. In this article, you'll learn about the implications of weakening this condition.
As is my habit with many of the articles in this article series, I'll start by uncovering the structure of the concept, and only later show a more realistic example.
Mapping strings #
So far in this article series, you've seen examples of containers with a generic type argument: Tree<T>, Task<T>, and so on. Furthermore, you've seen how a functor is a container with a structure-preserving map. This function has various names in different languages: Select, fmap, map, etcetera.
Until now, you've only seen examples where this mapping enables you to translate from one type argument to another. You can, for example, translate the characters in a string to Boolean values, like this:
> "Safe From Harm".Select(c => c.IsVowel()) Enumerable.WhereSelectEnumerableIterator<char, bool> { false, true, false, true, false, false, false, true, false, false, false, true, false, false }
This works because in C#, the String class implements various interfaces, among these IEnumerable<char>. By treating a string as an IEnumerable<char>, you can map each element. That's the standard IEnumerable functor (AKA the list functor).
What if you'd like to map the characters in a string to other characters? Perhaps you'd like to map vowels to upper case, and all other characters to lower case. You could try this:
> "Safe From Harm".Select(c => c.IsVowel() ? char.ToUpper(c) : char.ToLower(c)) Enumerable.WhereSelectEnumerableIterator<char, char> { 's', 'A', 'f', 'E', ' ', 'f', 'r', 'O', 'm', ' ', 'h', 'A', 'r', 'm' }
That sort of works, but as you can tell, the result isn't a string, it's an IEnumerable<char>.
This isn't a big problem, because one of the string constructor overloads take a char array as input, so you can do this:
> new string ("Safe From Harm".Select(c => c.IsVowel() ? char.ToUpper(c) : char.ToLower(c)).ToArray()) "sAfE frOm hArm"
It isn't the prettiest, but it gets the job done.
Monomorphic functor in C# #
If you contemplate the last example, you may arrive at the conclusion that you could package some of that boilerplate code in a reusable function. Since we're already talking about functors, why not call it Select?
public static string Select(this string source, Func<char, char> selector) { return new string(source.AsEnumerable().Select(selector).ToArray()); }
It somewhat simplifies things:
> "Safe From Harm".Select(c => c.IsVowel() ? char.ToUpper(c) : char.ToLower(c)) "sAfE frOm hArm"
Since I deliberately wrote the Select method in the style of other Select methods (apart from the generics), you may wonder if C# query syntax also works?
> from c in "Army of Me" . select c.IsVowel() ? char.ToUpper(c) : char.ToLower(c) "ArmY Of mE"
It compiles and works! The C# compiler understands monomorphic containers!
I admit that I was quite surprised when I first tried this out.
Monomorphic functor in Haskell #
Surprisingly, in this particular instance, C# comes out looking more flexible than Haskell. This is mainly because in C#, functors are implemented as a special compiler feature, whereas in Haskell, Functor is defined using the general-purpose type class language feature.
There's a package that defines a MonoFunctor type class, as well as some instances. With it, you can write code like this:
ftg :: Text ftg = omap (\c -> if isVowel c then toUpper c else toLower c) "Fade to Grey"
Even though Text isn't a Functor instance, it is a MonoFunctor instance. The value of ftg is "fAdE tO grEY".
All the normal functors ([], Maybe, etc.) are also MonoFunctor instances, since the normal Functor instance is more capable than a MonoFunctor.
Restaurant example #
While I've introduced the concept of a monomorphic functor with a trivial string example, I actually discovered the C# feature when I was working on some more realistic code. As I often do, I was working on a variation of an online restaurant reservation system. The code shown in the following is part of the sample code base that accompanies my book Code That Fits in Your Head.
The code base contained a rather complex variation of an implementation of the Maître d' kata. The MaitreD constructor looked like this:
public MaitreD( TimeOfDay opensAt, TimeOfDay lastSeating, TimeSpan seatingDuration, IEnumerable<Table> tables)
This had worked well when the system only dealt with a single restaurant, but I was now expanding it to a multi-tenant system and I needed to keep track of some more information about each restaurant, such as its name and ID. While I could have added such information to the MaitreD class, I didn't want to pollute that class with data it didn't need. While the restaurant's opening time and seating duration are necessary for the decision algorithm, the name isn't.
So I introduced a wrapper class:
public sealed class Restaurant { public Restaurant(int id, string name, MaitreD maitreD) { Id = id; Name = name; MaitreD = maitreD; } public int Id { get; } public string Name { get; } public MaitreD MaitreD { get; } // More code follows...
I also added copy-and-update methods (AKA 'withers'):
public Restaurant WithId(int newId) { return new Restaurant(newId, Name, MaitreD); } public Restaurant WithName(string newName) { return new Restaurant(Id, newName, MaitreD); } public Restaurant WithMaitreD(MaitreD newMaitreD) { return new Restaurant(Id, Name, newMaitreD); }
Still, if you need to modify the MaitreD within a given Restaurant object, you first have to have a reference to the Restaurant so that you can read its MaitreD property, then you can edit the MaitreD, and finally call WithMaitreD. Doable, but awkward:
restaurant.WithMaitreD(restaurant.MaitreD.WithSeatingDuration(TimeSpan.FromHours(.5)))
So I got the idea that I might try to add a structure-preserving map to Restaurant, which I did:
public Restaurant Select(Func<MaitreD, MaitreD> selector) { if (selector is null) throw new ArgumentNullException(nameof(selector)); return WithMaitreD(selector(MaitreD)); }
The first time around, it enabled me to rewrite the above expression as:
restaurant.Select(m => m.WithSeatingDuration(TimeSpan.FromHours(.5)))
That's already a little nicer. It also handles the situation where you may not have a named Restaurant variable you can query; e.g. if you have a method that returns a Restaurant object, and you just want to continue calling into a Fluent API.
Then I thought, I wonder if query syntax works, too...
from m in restaurant select m.WithSeatingDuration(TimeSpan.FromHours(.5))
And it does work!
I know that a lot of people don't like query syntax, but I think it has certain advantages. In this case, it actually isn't shorter, but it's a nice alternative. I particularly find that if I try to fit my code into a tight box, query syntax sometimes gives me an opportunity to format code over multiple lines in a way that's more natural than with method-call syntax.
Conclusion #
A monomorphic functor is still a functor, only it constrains the type of mapping you can perform. It can be useful to map monomorphic containers like strings, or immutable nested data structures like the above Restaurant class.
Next: Set is not a functor.
Subjectivity
A subjective experience can be sublime, but it isn't an argument.
I once wrote a book. One of the most common adjectives people used about it was opinionated. That's okay. It is, I think, a ramification of the way I write. I prioritise writing so that you understand what I mean, and why I mean it. You can call that opinionated if you like.
This means that I frequently run into online arguments, mostly on Twitter. This particularly happens when I write something that readers don't like.
The sublime #
Whether or not you like something is a subjective experience. I have nothing against subjective experiences.
Subjective experiences fuel art. Before I became a programmer, I wanted to be an artist. I've loved French-Belgian comics for as long as I remember (my favourites have always been Hermann and Jean Giraud), and until I gave up in my mid-twenties, I wanted to become a graphic novelist.

This interest in drawing also fuelled a similar interest in paintings and art in general. I've had many sublime experiences in front of a work of art in various museums around the world. These were all subjective experiences that were precious to me.
For as long as I've been interested in graphic arts, I've also loved music. I've worn LPs thin in the 1970s and '80s. I've played guitar and wanted to be a rock star. I regularly get goosebumps from listing to outstanding music. These are all subjective experiences.
Having an experience is part of the human condition.
How you feel about something, however, isn't an argument.
Arguing about subjective experience #
I rarely read music reviews. How you experience music is such a personal experience that I find it futile to argue about it. Maybe you share my feelings that Army of Me is a sublime track, or maybe it leaves you cold. If you don't like that kind of music, I can't argue that you should.
Such a discussion generally takes place at the kindergarten level: "Army of Me is a great song!, "No it isn't," "Yes it is," and so on.
This doesn't mean that we can't talk about music (or, by extension, other subjective experiences). Talking about music can be exhilarating, particularly when you meet someone who shares your taste. Finding common ground, exploring and inspiring each other, learning about artists you didn't know about, is wonderful. It forges bonds between people. I suppose it's the same mechanism in which sports fans find common ground.
Sharing subjective experience may not be entirely futile. You can't use your feelings as an argument, but explaining why you feel a certain way can be illuminating. This is the realm of much art criticism. A good, popular and easily digestible example is the Strong Songs podcast. The host, Kirk Hamilton, likes plenty of music that I don't. I must admit, though, that his exigesis of Satisfied from Hamilton left me with more appreciation for that song than I normally have for that genre.
This is why, in a technical argument, when people say, "I don't like it", I ask why?
Your preference doesn't convince me to change my mind, but if you can explain your perspective, it may make me consider a point of which I wasn't aware.
It Depends™ #
Among other roles, I consult. Consultants are infamous for saying it depends, and obviously, if that's all we say, it'd be useless.
Most advice is given in a context. When a consultant starts a sentence with it depends, he or she must continue by explaining on what it depends. Done right, this can be tremendously valuable, because it gives the customer a framework they can use to make decisions.
In the same family as it depends, I often run into arguments like nothing is black or white, it's a trade-off, or other platitudes. Okay, it probably is a trade-off, but between what?
If it's a trade-off between my reasoned argument on the one hand, and someone's preference on the other hand, my reasoned argument wins.
Why? Because I can always trump with my preference as well.
Conclusion #
Our subjective experiences are important pieces of our lives. I hope that my detour around my love of art highlighted that I consider subjective experiences vital.
When we discuss how to do things, however, a preference isn't an argument. You may prefer to do things in one way, and I another. Such assertions, alone, don't move the discussion anywhere.
What we can do is to attempt to uncover the underlying causes for our preferences. There's no guarantee that we'll reach enlightenment, but it's certain that we'll get nowhere if we don't.
That's the reason that, when someone states "I prefer", I often ask why?
Comments
Consultants are infamous for saying it depends, and obviously, if that's all we say, it'd be useless.
Most advice is given in a context. When a consultant starts a sentence with it depends, he or she must continue by explaining on what it depends. Done right, this can be tremendously valuable, because it gives the customer a framework they can use to make decisions.
I have a vague memory of learning this through some smoothly worded saying. As I recall, it went something like this.
Anyone can say "It depends", but an expert can say on what it depends.
I don't think that is the exact phrase, because I don't think it sounds very smooth. Does anyone know of a succinct and smooth mnemonic phrase that captures this idea?
Fortunately, I don't squash my commits
The story of a bug, and how I addressed it.
Okay, I admit it: I could have given this article all sorts of alternative titles, each of which would have made as much sense as the one I chose. I didn't want to go with some of the other titles I had in mind, because they would give it all away up front. I didn't want to spoil the surprise.
I recently ran into this bug, it took me hours to troubleshoot it, and I was appalled when I realised what the problem was.
This is the story of that bug.
There are several insights from this story, and I admit that I picked the most click-baity one for the title.
Yak shaving #
I was working on the umpteenth variation of an online restaurant reservations system, and one of the features I'd added was a schedule only visible to the maître d'. The schedule includes a list of all reservations for a day, including guests' email addresses and so on. For that reason, I'd protected that resource by requiring a valid JSON Web Token (JWT) with an appropriate role.
The code discussed here is part of the sample code base that accompanies my book Code That Fits in Your Head.
I'd deployed a new version of the API and went for an ad-hoc test. To my surprise, that particular resource didn't work. When I tried to request it, I got a 403 Forbidden response.
"That's odd," I though, "it worked the last time I tried this."
The system is set up with continuous deployment. I push master to a remote repository, and a build pipeline takes over from there. It only deploys the new version if all tests pass, so my first reaction was that I might have made a mistake with the JWT.
I wasted significant time decoding the JWT and comparing its contents to what it was supposed to be. I couldn't find any problems.
I also meticulously compared the encryption key I'd used to sign the JWT with the key on the server. They were identical.
Incredulous, and running out of ideas, I tried running all tests on my development machine. Indeed, all 170 tests passed.
Finally, I gave up and ran the API on my development machine. It takes all of a 30 seconds to configure the code to run in that environment, so you're excused if you wonder why I didn't already do that. What can I say? I've almost two decades of experience with automated test suites. Usually, if all tests pass, the problem is environmental: a network topology issue, a bad or missing connection string, a misconfigured encryption key, an invalid JWT, things like that.
To my surprise, the problem also manifested on my machine.
Not my code #
Okay, even with hundreds of tests, perhaps some edge case went unnoticed. The only problem with that hypothesis was that this was hardly an edge case. I was only making a GET request with a Bearer token. I wasn't going through some convoluted sequence of steps.
GET /restaurants/1/schedule/2020/9/30 HTTP/1.1 Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5c[...]
I expected a successful response containing some JSON, but the result was 403 Forbidden. That was the same behaviour I saw in the production environment.
Now, to be clear, this is indeed a protected resource. If you present an invalid JWT, 403 Forbidden is the expected response. That's why I wasted a few hours looking for problems with the the JWT.
I finally, hesitatingly, concluded that the problem might be somewhere else. The JWT looked okay. So, hours into my troubleshooting I reluctantly set a breakpoint in my code and started the debugger. It isn't rational, but I tend to see it as a small personal defeat if I have to use the debugger. Even so, if used judiciously, it can be an effective way to identify problems.
The debugger never hit my breakpoint.
To be clear, the beginning of my Controller method looked like this:
[Authorize(Roles = "MaitreD")] [HttpGet("restaurants/{restaurantId}/schedule/{year}/{month}/{day}")] public async Task<ActionResult> Get( int restaurantId, int year, int month, int day) { if (!AccessControlList.Authorize(restaurantId)) return new ForbidResult();
My breakpoint was on the first line (the if conditional), but the debugger didn't break into it. When I issued my GET request, I immediately got the 403 Forbidden response. The breakpoint just sat there in the debugger, mocking me.
When that happens, it's natural to conclude that the problem occurs somewhere in the framework; in this case, ASP.NET. To test that hypothesis, I commented out the [Authorize] attribute and reissued the GET request. My hypothesis was that I'd get a 200 OK response, since the attribute is what tells ASP.NET to check authorisation.
The hypothesis held. The response was 200 OK.
Test interdependency #
I hate when that happens. It's up there with fixing other people's printers. The problem is in the framework, not in my code. I didn't have any authorisation callbacks registered, so I was fairly certain that the problem wasn't in my code.
I rarely jump to the conclusion that there's a bug in the framework. In my experience, select is rarely broken. My new hypothesis had to be that I'd somehow managed to misconfigure the framework.
But where? There were automated tests that verified that a client could request that resource with a valid JWT. There were other automated tests that verified what happened if you presented an invalid JWT, or none at all. And all tests were passing.
While I was fiddling with the tests, I eventually ran a parametrised test by itself, instead of the entire test suite:
[Theory] [InlineData( "Hipgnosta", 2024, 11, 2)] [InlineData( "Nono", 2018, 9, 9)] [InlineData("The Vatican Cellar", 2021, 10, 10)] public async Task GetRestaurantScheduleWhileAuthorized( string name, int year, int month, int day)
This parametrised test has three test cases. When I ran just that test method, two of the test cases passed, but one failed: the Nono case, for some reason I haven't yet figured out.
I didn't understand why that test case ought to fail while the others succeeded, but I had an inkling. I commented out the Nono test case and ran the test method again.
One passed and one failing test.
Now The Vatican Cellar test case was failing. I commented that out and ran the test method again. The remaining test case failed.
This reeks of some sort of test interdependency. Apparently, something happens during the first test run that makes succeeding tests pass, but it happens too late for the first one. But what?
Bisect #
Then something occurred to me that I should have thought of sooner. This feature used to work. Not only had the tests been passing, but I'd actually interacted with the deployed service, presenting a valid JWT and received a 200 OK response.
Once than dawned on me, I realised that it was just a manner of performing a binary search. Since, of course, I use version control, I had a version I knew worked, and a version that didn't work. The task, then, was to find the commit that introduced the defect.
As I've already implied, the system in question is an example code base. While I have a cloud-based production environment, none but I use it. It had been four or five days since I'd actually interacted with the real service, and I'd been busy making changes, trusting exclusively in my test suite. I tend to make frequent, small commits instead of big, infrequent commits, so I had accumulated about a hundred and fifty commits since the 'last known good' deployment.
Searching through hundreds of commits sounds overwhelming, but using binary search, it's actually not that bad. Pick the commit halfway between the 'last known good' commit and the most recent commit, and check it out. See if the defect is present there. If it is, you know that it was introduced somewhere between the commit you're looking at, and the 'last known good' commit. If it isn't present, it was introduced later. Regardless of the outcome, you know in which half to look. You now pick a new commit in the middle of that set and repeat the exercise. Even with, say, a hundred commits, the first bisection reduces the candidate set to 50, the next bisection to 25, then 13, then 7, 4, 2, and then you have it. If you do this systematically, you should find the exact commit in less than eight iterations.
This is, as far as I understand it, the algorithm used by Git bisect. You don't have to use the bisect command - the algorithm is easy enough to do by hand - but let's see how it works.
You start a bisect session with:
mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((93c6c35...)) $ git bisect start mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((93c6c35...)|BISECTING)
This starts an interactive session, which you can tell from the Git integration in Git Bash (it says BISECTING). You now mark a commit as being bad:
$ git bisect bad mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((93c6c35...)|BISECTING)
If you don't provide a commit ID at that point, Git is going to assume that you meant that the current commit (in this case 93c6c35) is bad. That's what I had in mind, so that's fine.
You now tell it about a commit ID that you know is good:
$ git bisect good 7dfdab2 Bisecting: 75 revisions left to test after this (roughly 6 steps) [1f78c9a90c2088423ab4fc145b7b2ec3859d6a9a] Use InMemoryRestaurantDatabase in a test mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((1f78c9a...)|BISECTING)
Notice that Git is already telling us how many iterations we should expect. You can also see that it checked out a new commit (1f78c9a) for you. That's the half-way commit.
At this point, I manually ran the test method with the three test cases. All three passed, so I marked that commit as good:
$ git bisect good Bisecting: 37 revisions left to test after this (roughly 5 steps) [5abf65a72628efabbf05fccd1b79340bac4490bc] Delete Either API mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((5abf65a...)|BISECTING)
Again, Git estimates how many more steps are left and checks out a new commit (5abf65a).
I repeated the process for each step, marking the commit as either good or bad, depending on whether or not the test passed:
$ git bisect bad Bisecting: 18 revisions left to test after this (roughly 4 steps) [fc48292b0d654f4f20522710c14d7726e6eefa70] Delete redundant Test Data Builders mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((fc48292...)|BISECTING) $ git bisect good Bisecting: 9 revisions left to test after this (roughly 3 steps) [b0cb1f5c1e9e40b1dabe035c41bfb4babfbe4585] Extract WillAcceptUpdate helper method mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((b0cb1f5...)|BISECTING) $ git bisect good Bisecting: 4 revisions left to test after this (roughly 2 steps) [d160c57288455377f8b0ad05985b029146228445] Extract ConfigureClock helper method mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((d160c57...)|BISECTING) $ git bisect good Bisecting: 2 revisions left to test after this (roughly 1 step) [4cb73c219565d8377aa67d79024d6836f9000935] Compact code mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((4cb73c2...)|BISECTING) $ git bisect good Bisecting: 0 revisions left to test after this (roughly 1 step) [34238c7d2606e9007b96b54b43e678589723520c] Extract CreateTokenValidationParameters method mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((34238c7...)|BISECTING) $ git bisect bad Bisecting: 0 revisions left to test after this (roughly 0 steps) [7d6583a97ff45fbd85878cecb5af11d93213a25d] Move Configure method up mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((7d6583a...)|BISECTING) $ git bisect good 34238c7d2606e9007b96b54b43e678589723520c is the first bad commit commit 34238c7d2606e9007b96b54b43e678589723520c Author: Mark Seemann <mark@example.com> Date: Wed Sep 16 07:15:12 2020 +0200 Extract CreateTokenValidationParameters method Restaurant.RestApi/Startup.cs | 32 +++++++++++++++++++------------- 1 file changed, 19 insertions(+), 13 deletions(-) mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((7d6583a...)|BISECTING)
Notice that the last step finds the culprit. It tells you which commit is the bad one, but surprisingly doesn't check it out for you. You can do that using a label Git has created for you:
$ git checkout refs/bisect/bad Previous HEAD position was 7d6583a Move Configure method up HEAD is now at 34238c7 Extract CreateTokenValidationParameters method mark@Vindemiatrix MINGW64 ~/Documents/Redacted/Restaurant ((34238c7...)|BISECTING)
You've now found and checked out the offending commit. Hopefully, the changes in that commit should give you a clue about the problem.
The culprit #
What's in that commit? Take a gander:
$ git show commit 34238c7d2606e9007b96b54b43e678589723520c (HEAD, refs/bisect/bad) Author: Mark Seemann <mark@example.com> Date: Wed Sep 16 07:15:12 2020 +0200 Extract CreateTokenValidationParameters method diff --git a/Restaurant.RestApi/Startup.cs b/Restaurant.RestApi/Startup.cs index 6c161b5..bcde861 100644 --- a/Restaurant.RestApi/Startup.cs +++ b/Restaurant.RestApi/Startup.cs @@ -79,10 +79,6 @@ namespace Ploeh.Samples.Restaurants.RestApi private void ConfigureAuthorization(IServiceCollection services) { - JwtSecurityTokenHandler.DefaultMapInboundClaims = false; - - var secret = Configuration["JwtIssuerSigningKey"]; - services.AddAuthentication(opts => { opts.DefaultAuthenticateScheme = @@ -91,15 +87,8 @@ namespace Ploeh.Samples.Restaurants.RestApi JwtBearerDefaults.AuthenticationScheme; }).AddJwtBearer(opts => { - opts.TokenValidationParameters = new TokenValidationParameters - { - ValidateIssuerSigningKey = true, - IssuerSigningKey = new SymmetricSecurityKey( - Encoding.ASCII.GetBytes(secret)), - ValidateIssuer = false, - ValidateAudience = false, - RoleClaimType = "role" - }; + opts.TokenValidationParameters = + CreateTokenValidationParameters(); opts.RequireHttpsMetadata = false; }); @@ -108,6 +97,23 @@ namespace Ploeh.Samples.Restaurants.RestApi sp.GetService<IHttpContextAccessor>().HttpContext.User)); } + private TokenValidationParameters CreateTokenValidationParameters() + { + JwtSecurityTokenHandler.DefaultMapInboundClaims = false; + + var secret = Configuration["JwtIssuerSigningKey"]; + + return new TokenValidationParameters + { + ValidateIssuerSigningKey = true, + IssuerSigningKey = new SymmetricSecurityKey( + Encoding.ASCII.GetBytes(secret)), + ValidateIssuer = false, + ValidateAudience = false, + RoleClaimType = "role" + }; + } + private void ConfigureRepository(IServiceCollection services) {
Can you spot the problem?
As soon as I saw that diff, the problem almost jumped out at me. I'm so happy that I make small commits. What you see here is, I promise, the entire diff of that commit.
Clearly, you're not familiar with this code base, but even so, you might be able to intuit the problem from the above diff. You don't need domain-specific knowledge for it, or knowledge of the rest of the code base.
I'll give you a hint: I moved a line of code into a lambda expression.
Deferred execution #
In the above commit, I extracted a helper method that I called CreateTokenValidationParameters. As the name communicates, it creates JWT validation parameters. In other words, it supplies the configuration values that determine how ASP.NET figures out how to authorise an HTTP request.
Among other things, it sets the RoleClaimType property to "role". By default, the [Authorize] attribute is looking for a role claim with a rather complicated identifier. Setting the RoleClaimType enables you to change the identifier. By setting it to "role", I'm telling the ASP.NET framework that it should look for claims named role in the JWT, and these should be translated to role claims.
Except that it doesn't work.
Ostensibly, this is for backwards compatibility reasons. You have to set JwtSecurityTokenHandler.DefaultMapInboundClaims to false. Notice that this is a global variable.
I thought that the line of code that does that conceptually belongs together with the other code that configures the JWT validation parameters, so I moved it in there. I didn't think much about it, and all my tests were still passing.
What happened, though, was that I moved mutation of a global variable into a helper method that was called from a lambda expression. Keep in mind that lambda expressions represent code that may run later; that execution is deferred.
By moving that mutation statement into the helper method, I inadvertently deferred its execution. When the application's Startup code runs, it configures the service. All the code that runs inside of AddJwtBearer, however, doesn't run immediately; it runs when needed.
This explains why all tests were passing. My test suite has plenty of self-hosted integration tests in the style of outside-in test-driven development. When I ran all the tests, the deferred code block would run in some other test context, flipping that global bit as a side effect. When the test suite reaches the test that fails when run in isolation, the bit is already flipped, and then it works.
It took me hours to figure out what the problem was, and it turned out that the root cause was a global variable.
Global variables are evil. Who knew?
Can't reproduce #
Once you figure out what the problem is, you should reproduce it with an automated test.
Yes, and how do I do that here? I already had tests that verify that you can GET the desired resource if you present a valid JWT. And that test passes!
The only way I can think of to reproduce the issue with an automated test is to create a completely new, independent test library with only one test. I considered doing that, weighed the advantages against the disadvantages and decided, given the context, that it wasn't worth the effort.
That means, though, that I had to accept that within the confines of my existing testing strategy, I can't reproduce the defect. This doesn't happen to me often. In fact, I can't recall that it's ever happened to me before, like this.
Resolution #
It took me hours to find the bug, and ten seconds to fix it. I just moved the mutation of JwtSecurityTokenHandler.DefaultMapInboundClaims back to the ConfigureAuthorization method:
diff --git a/Restaurant.RestApi/Startup.cs b/Restaurant.RestApi/Startup.cs index d4917f5..e40032f 100644 --- a/Restaurant.RestApi/Startup.cs +++ b/Restaurant.RestApi/Startup.cs @@ -79,6 +79,7 @@ namespace Ploeh.Samples.Restaurants.RestApi private void ConfigureAuthorization(IServiceCollection services) { + JwtSecurityTokenHandler.DefaultMapInboundClaims = false; services.AddAuthentication(opts => { opts.DefaultAuthenticateScheme = @@ -99,8 +100,6 @@ namespace Ploeh.Samples.Restaurants.RestApi private TokenValidationParameters CreateTokenValidationParameters() { - JwtSecurityTokenHandler.DefaultMapInboundClaims = false; - var secret = Configuration["JwtIssuerSigningKey"]; return new TokenValidationParameters
An ad-hoc smoke test verified that this solved the problem.
Conclusion #
There are multiple insights to be had from this experience:
- Global variables are evil
- Binary search, or bisection, is useful when troubleshooting
- Not all bugs can be reproduced by an automated test
- Small commits make it easy to detect problems
EnsureSuccessStatusCode as an assertion
It finally dawned on me that EnsureSuccessStatusCode is a fine test assertion.
Okay, I admit that sometimes I can be too literal and rigid in my thinking. At least as far back as 2012 I've been doing outside-in TDD against self-hosted HTTP APIs. When you do that, you'll regularly need to verify that an HTTP response is successful.
Assert equality #
You can, of course, write an assertion like this:
Assert.Equal(HttpStatusCode.OK, response.StatusCode);
If the assertion fails, it'll produce a comprehensible message like this:
Assert.Equal() Failure Expected: OK Actual: BadRequest
What's not to like?
Assert success #
The problem with testing strict equality in this context is that it's often too narrow a definition of success.
You may start by returning 200 OK as response to a POST request, but then later evolve the API to return 201 Created or 202 Accepted. Those status codes still indicate success, and are typically accompanied by more information (e.g. a Location header). Thus, evolving a REST API from returning 200 OK to 201 Created or 202 Accepted isn't a breaking change.
It does, however, break the above assertion, which may now fail like this:
Assert.Equal() Failure Expected: OK Actual: Created
You could attempt to fix this issue by instead verifying IsSuccessStatusCode:
Assert.True(response.IsSuccessStatusCode);
That permits the API to evolve, but introduces another problem.
Legibility #
What happens when an assertion against IsSuccessStatusCode fails?
Assert.True() Failure Expected: True Actual: False
That's not helpful. At least, you'd like to know which other status code was returned instead. You can address that concern by using an overload to Assert.True (most unit testing frameworks come with such an overload):
Assert.True( response.IsSuccessStatusCode, $"Actual status code: {response.StatusCode}.");
This produces more helpful error messages:
Actual status code: BadRequest. Expected: True Actual: False
Granted, the Expected: True, Actual: False lines are redundant, but at least the information you care about is there; in this example, the status code was 400 Bad Request.
Conciseness #
That's not bad. You can use that Assert.True overload everywhere you want to assert success. You can even copy and paste the code, because it's an idiom that doesn't change. Still, since I like to stay within 80 characters line width, this little phrase takes up three lines of code.
Surely, a helper method can address that problem:
internal static void AssertSuccess(this HttpResponseMessage response) { Assert.True( response.IsSuccessStatusCode, $"Actual status code: {response.StatusCode}."); }
I can now write a one-liner as an assertion:
response.AssertSuccess();
What's not to like?
Carrying coals to Newcastle #
If you're already familiar with the HttpResponseMessage class, you may have been reading this far with some frustration. It already comes with a method called EnsureSuccessStatusCode. Why not just use that instead?
response.EnsureSuccessStatusCode();
As long as the response status code is in the 200 range, this method call succeeds, but if not, it throws an exception:
Response status code does not indicate success: 400 (Bad Request).
That's exactly the information you need.
I admit that I can sometimes be too rigid in my thinking. I've known about this method for years, but I never thought of it as a unit testing assertion. It's as if there's a category in my programming brain that's labelled unit testing assertions, and it only contains methods that originate from unit testing.
I even knew about Debug.Assert, so I knew that assertions also exist outside of unit testing. That assertion isn't suitable for unit testing, however, so I never included it in my category of unit testing assertions.
The EnsureSuccessStatusCode method doesn't have assert in its name, but it behaves just like a unit testing assertion: it throws an exception with a useful error message if a criterion is not fulfilled. I just never thought of it as useful for unit testing purposes because it's part of 'production code'.
Conclusion #
The built-in EnsureSuccessStatusCode method is fine for unit testing purposes. Who knows, perhaps other class libraries contain similar assertion methods, although they may be hiding behind names that don't include assert. Perhaps your own production code contains such methods. If so, they can double as unit testing assertions.
I've been doing test-driven development for close to two decades now, and one of many consistent experiences is this:
- In the beginning of a project, the unit tests I write are verbose. This is natural, because I'm still getting to know the domain.
- After some time, I begin to notice patterns in my tests, so I refactor them. I introduce helper APIs in the test code.
- Finally, I realise that some of those unit testing APIs might actually be useful in the production code too, so I move them over there.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Comments
Unfortunately, I can't agree that it's fine to use EnsureSuccessStatusCode or other similar methods for assertions. An exception of a kind different from assertion (XunitException for XUnit, AssertionException for NUnit) is handled in a bit different way by the testing framework. EnsureSuccessStatusCode method throws HttpRequestException. Basically, a test that fails with such exception is considered as "Failed by error".
For example, the test result message in case of 404 status produced by the EnsureSuccessStatusCode method is:
System.Net.Http.HttpRequestException : Response status code does not indicate success: 404 (Not Found).
Where "System.Net.Http.HttpRequestException :" text looks redundant, as we do assertion. This also may make other people think that the reason for this failure is not an assertion, but an unexpected exception. In case of regular assertion exception type, that text is missing.
Other points are related to NUnit:
-
There are 2 different failure test outcome kinds in NUnit:
- Failure: a test assertion failed. (Status=Failed, Label=empty)
- Error: an unexpected exception occurred. (Status=Failed, Label=Error)
- You can't use methods like
EnsureSuccessStatusCodeas assertion inside multiple asserts. - NUnit tracks the count of assertions for each test.
"assertions"property gets into the test results XML file and might be useful. This property increments on assertion methods,EnsureSuccessStatusCode- obviously doesn't increment it.
Yevgeniy, thank you for writing. This shows, I think, that all advice is contextual. It's been more than a decade since I regularly used NUnit, but I vaguely recall that it gives special treatment to its own assertion exceptions.
I also grant that the "System.Net.Http.HttpRequestException" part of the message is redundant. To make matters worse, even without that 'prologue' the information that we care about (the actual status code) is all the way to the right. It'll often require horizontal scrolling to see it.
That doesn't much bother me, though. I think that one should optimise for the most frequent scenario. For example, I favour taking a bit of extra time to write readable code, because the bottleneck in programming isn't typing. In the same vein, I find it a good trade-off being able to avoid adding more code against an occasional need to scroll horizontally. The cost of code isn't the time it takes to write it, but the maintenance burden it imposes, as well as the cognitive load it adds.
The point here is that while horizontal scrolling is inconvenient, the most frequent scenario is that tests don't fail. The inconvenience only manifests in the rare circumstance that a test fails.
I want to thank you, however, for pointing out the issues with NUnit. It reinforces the impression I already had of it, as a framework to stay away from. That design seems to me to impose a lock-in that prevents you from mixing NUnit with improved APIs.
In contrast, the xunit.core library doesn't include xunit.assert. I often take advantage of that when I write unit tests in F#. While the xUnit.net assertion library is adequate, Unquote is much better for F#. I appreciate that xUnit.net enables me to combine the tools that work best in a given situation.
I see your point, Mark. Thanks for your reply.
I would like to add a few words in defense of the NUnit.
First of all, there is no problem to use an extra library for NUnit assertions too. For example, I like FluentAssertions that works great for both XUnit and NUnit.
NUnit 3 also has a set of useful features that are missing in XUnit like:
- Multiple asserts - quite useful for UI testing, for example.
- Warnings.
- TestContext.
- File attachments - useful for UI tests or tests that verify files. For example, when the UI test fails, you can take a screenshot, save it and add to NUnit as an attachment. Or when you test PDF file, you can attach the file that doesn't pass the test.
I can recommend to reconsider the view of NUnit, as the library progressed well during its 3rd version. XUnit and NUnit seem interchangeable for unit testing. But NUnit, from my point of view, provides the features that are helpful in integration and UI testing.
Yevgeniy, I haven't done UI testing since sometime in 2005, I think, so I wasn't aware of that. It's good to know that NUnit may excel at that, and the other scenarios you point out.
To be clear, while I still think I may prefer xUnit.net, I don't consider it perfect.
I would like to mention FluentAssertions.Web, a library I wrote with the purpose to solve exact this problem I had while maintaining API tests. It's frustrating not to tell in two seconds why a test failed. Yeah, it is a Bad Request, but why. Maybe the response is in the respons content?
Wouldn't be an idea to see the response content? This FluentAssertions extension outputs everything starting from the request to the response, when the test fails.
Adrian, thank you for writing. Your comment inspired me to write an article on when tests fail. This article is now in the publication queue. I'll try to remember to come back here and add a link once it's published.
(Placeholder)
An XPath query for long methods
A filter for Visual Studio code metrics.
I consider it a good idea to limit the size of code blocks. Small methods are easier to troubleshoot and in general fit better in your head. When it comes to vertical size, however, the editors I use don't come with visual indicators like they do for horizontal size.
When you're in the midst of developing a feature, you don't want to be prevented from doing so by a tool that refuses to compile your code if methods get too long. On the other hand, it might be a good idea to regularly run a tool over your code base to identify which methods are getting too long.
With Visual Studio you can calculate code metrics, which include a measure of the number of lines of code for each method. One option produces an XML file, but if you have a large code base, those XML files are big.
The XML files typically look like this:
<?xml version="1.0" encoding="utf-8"?> <CodeMetricsReport Version="1.0"> <Targets> <Target Name="Restaurant.RestApi.csproj"> <Assembly Name="Ploeh.Samples.Restaurants.RestApi, ..."> <Metrics> <Metric Name="MaintainabilityIndex" Value="87" /> <Metric Name="CyclomaticComplexity" Value="537" /> <Metric Name="ClassCoupling" Value="208" /> <Metric Name="DepthOfInheritance" Value="1" /> <Metric Name="SourceLines" Value="3188" /> <Metric Name="ExecutableLines" Value="711" /> </Metrics> <Namespaces> <Namespace Name="Ploeh.Samples.Restaurants.RestApi"> <Metrics> <Metric Name="MaintainabilityIndex" Value="87" /> <Metric Name="CyclomaticComplexity" Value="499" /> <Metric Name="ClassCoupling" Value="204" /> <Metric Name="DepthOfInheritance" Value="1" /> <Metric Name="SourceLines" Value="3100" /> <Metric Name="ExecutableLines" Value="701" /> </Metrics> <Types> <NamedType Name="CalendarController"> <Metrics> <Metric Name="MaintainabilityIndex" Value="73" /> <Metric Name="CyclomaticComplexity" Value="14" /> <Metric Name="ClassCoupling" Value="34" /> <Metric Name="DepthOfInheritance" Value="1" /> <Metric Name="SourceLines" Value="190" /> <Metric Name="ExecutableLines" Value="42" /> </Metrics> <Members> <Method Name="Task<ActionResult> CalendarController.Get(..."> <Metrics> <Metric Name="MaintainabilityIndex" Value="64" /> <Metric Name="CyclomaticComplexity" Value="2" /> <Metric Name="ClassCoupling" Value="12" /> <Metric Name="SourceLines" Value="28" /> <Metric Name="ExecutableLines" Value="7" /> </Metrics> </Method> <!--Much more data goes here--> </Members> </NamedType> </Types> </Namespace> </Namespaces> </Assembly> </Target> </Targets> </CodeMetricsReport>
How can you filter such a file to find only those methods that are too long?
That sounds like a job for XPath. I admit, though, that I use XPath only rarely. While the general idea of the syntax is easy to grasp, it has enough subtle pitfalls that it's not that easy to use, either.
Partly for my own benefit, and partly for anyone else who might need it, here's an XPath query that looks for long methods:
//Members/child::*[Metrics/Metric[@Value > 24 and @Name = "SourceLines"]]
This query looks for methods longer that 24 lines of code. If you don't agree with that threshold you can always change it to another value. You can also change @Name to look for CyclomaticComplexity or one of the other metrics.
Given the above XML metrics report, the XPath filter would select (among other members) the CalendarController.Get method, because it has 28 lines of source code. It turns out, though, that the filter produces some false positives. The method in question is actually fine:
/* This method loads a year's worth of reservations in order to segment * them all. In a realistic system, this could be quite stressful for * both the database and the web server. Some of that concern can be * addressed with an appropriate HTTP cache header and a reverse proxy, * but a better solution would be a CQRS-style architecture where the * calendars get re-rendered as materialised views in a background * process. That's beyond the scope of this example code base, though. */ [ResponseCache(Duration = 60)] [HttpGet("restaurants/{restaurantId}/calendar/{year}")] public async Task<ActionResult> Get(int restaurantId, int year) { var restaurant = await RestaurantDatabase .GetRestaurant(restaurantId).ConfigureAwait(false); if (restaurant is null) return new NotFoundResult(); var period = Period.Year(year); var days = await MakeDays(restaurant, period) .ConfigureAwait(false); return new OkObjectResult( new CalendarDto { Name = restaurant.Name, Year = year, Days = days }); }
That method only has 18 lines of actual source code, from the beginning of the method declaration to the closing bracket. Visual Studio's metrics calculator, however, also counts the attributes and the comments.
In general, I only add comments when I want to communicate something that I can't express as a type or a method name, so in this particular code base, it's not much of an issue. If you consistently adorn every method with doc comments, on the other hand, you may need to perform some pre-processing on the source code before you calculate the metrics.
We need young programmers; we need old programmers
The software industry loves young people, but old-timers serve an important purpose, too.
Our culture idolises youth. There's several reasons for this, I believe. Youth seems synonymous with vigour, strength, beauty, and many other desirable qualities. The cynical perspective is that young people, while rebellious, also tend to be easy to manipulate, if you know which buttons to push. A middle-aged man like me isn't susceptible to the argument that I should buy a particular pair of Nike shoes because they're named after Michael Jordan, but for a while, one pair wasn't enough for my teenage daughter.
In intellectual pursuits (like software development), youth is often extolled as the source of innovation. You're often confronted with examples like that of Évariste Galois, who made all his discoveries before turning 21. Ada Lovelace was around 28 years when she produced what is considered the 'first computer program'. Alan Turing was 24 when he wrote On Computable Numbers, with an Application to the Entscheidungsproblem.
Clearly, young age is no detriment to making ground-breaking contributions. It has even become folklore that everyone past the age of 35 is a has-been whose only chance at academic influence is to write a textbook.
The story of the five monkeys #
You may have seen a story called the five monkeys experiment. It's most likely a fabrication, but it goes like this:
A group of scientists placed five monkeys in a cage, and in the middle, a ladder with bananas on the top. Every time a monkey went up the ladder, the scientists soaked the rest of the monkeys with cold water. After a while, every time a monkey went up the ladder, the others would beat it up.
After some time, none of the monkeys dared go up the ladder regardless of the temptation. The scientists then substituted one of the monkeys with a new one, who'd immediately go for the bananas, only to be beaten up by the others. After several beatings, the new member learned not to climb the ladder even though it never knew why.
A second monkey was substituted and the same occurred. The first monkey participated in beating the second. A third monkey was exchanged and the story repeated. The fourth was substituted and the beating was repeated. Finally the fifth monkey was replaced.
Left was a group of five monkeys who, even though they never received a cold shower, continued to beat up any monkey who attempted to climb the ladder. If it was possible to ask the monkeys why they would beat up all who attempted to go up the ladder, the answer would probably be:
"That's how we do things here."
While the story is probably just that: a story, it tells us something about the drag induced by age and experience. If you've been in the business for decades, you've seen numerous failed attempts at something you yourself tried when you were young. You know that it can't be done.
Young people don't know that a thing can't be done. If they can avoid the monkey-beating, they'll attempt the impossible.
Changing circumstances #
Is attempting the impossible a good idea?
In general, no, because it's... impossible. There's a reason older people tell young people that a thing can't be done. It's not just because they're stodgy conservatives who abhor change. It's because they see the effort as wasteful. Perhaps they're even trying to be kind, guiding young people off a path where only toil and disappointment is to be found.
What old people don't realise is that sometimes, circumstances change.
What was impossible twenty years ago may not be impossible today. We see this happening in many fields. Producing a commercially viable electric car was impossible for decades, until, with the advances made in battery technology, it became possible.
Technology changes rapidly in software development. People trying something previously impossible may find that it's possible today. Once, if you had lots of data, you had to store it in fully normalised form, because storage was expensive. For a decade, relational databases were the only game in town. Then circumstances changed. Storage became cheaper, and a new movement of NoSQL storage emerged. What was before impossible became possible.
Older people often don't see the new opportunities, because they 'know' that some things are impossible. Young people push the envelope driven by a combination of zest and ignorance. Most fail, but a few succeed.
Lottery of the impossible #
I think of this process as a lottery. Imagine that every impossible thing is a red ball in an urn. Every young person who tries the impossible draws a random ball from the urn.
The urn contains millions of red balls, but every now and then, one of them turns green. You don't know which one, but if you draw it, it represents something that was previously impossible which has now become possible.
This process produces growth, because once discovered, the new and better way of doing things can improve society in general. Occasionally, the young discoverer may even gain some fame and fortune.
It seems wasteful, though. Most people who attempt the impossible will reach the predictable conclusion. What was deemed impossible was, indeed, impossible.
When I'm in a cynical mood, I don't think that it's youth in itself that is the source of progress. It's just the law of large numbers applied. If there's a one in million chance that something will succeed, but ten million people attempt it, it's only a matter of time before one succeeds.
Society at large can benefit from the success of the few, but ten million people still wasted their efforts.
We need the old, too #
If you accept the argument that young people are more likely to try the impossible, we need the young people. Do we need the old people?
I'm turning fifty in 2020. You may consider that old, but I expect to work for many more years. I don't know if the software industry needs fifty-year-olds, but that's not the kind of old I have in mind. I'm thinking of people who have retired, or are close to retirement.
In our youth-glorifying culture, we tend to dismiss the opinion and experiences of old people. Oh, well, it's just a codgy old man (or woman), we'll say.
We ignore the experience of the old, because we believe that they haven't been keeping up with times. Their experiences don't apply to us, because we live under new circumstance. Well, see above.
I'm not advocating that we turn into a gerontocracy that venerates our elders solely because of their age. Again, according to the law of large numbers, some people live to old age. There need not be any correlation between survivors and wisdom.
We need the old to tell us the truth, because they have little to lose.
Nothing to lose #
In the last couple of years, I've noticed a trend. A book comes out, exposing the sad state of affairs in some organisation. This has happened regularly in Denmark, where I live. One book may expose the deplorable conditions of the Danish tax authorities, one may describe the situation in the ministry of defence, one criticises the groupthink associated with the climate crisis, and so on.
Invariably, it turns out that the book is written by a professor emeritus or a retired department head.
I don't think that these people, all of a sudden, had an epiphany after they retired. They knew all about the rot in the system they were part of, while they were part of it, but they've had too much to lose. You could argue that they should have said something before they retired, but that requires a moral backbone we can't expect most people to have.
When people retire, the threat of getting fired disappears. Old people can speak freely to a degree most other people can't.
Granted, many may simply use that freedom to spew bile or shout Get off my lawn!, but many are in the unique position to reveal truths no-one else dare speak. Many are, perhaps, just bitter, but some may possess knowledge that they are in a unique position to reveal.
When that grumpy old guy on Twitter writes something that makes you uncomfortable, consider this: he may still be right.
Being unreasonable #
In a way, you could say that we need young and old people for the same fundamental reason. Not all of them, but enough of them, are in a position to be unreasonable.
Young people and old people are unreasonable in each their own way, and we need both."The reasonable man adapts himself to the world: the unreasonable one persists in trying to adapt the world to himself. Therefore all progress depends on the unreasonable man."
Conclusion #
We need young people in the software development industry. Because of their vigour and inexperience, they'll push the envelope. Most will fail to do the impossible, but a few succeed.
This may seem like a cynical view, but we've all been young, and most of us have been through such a phase. It's like a rite of passage, and even if you fail to make your mark on the world, you're still likely to have learned a lot.
We need old people because they're in a position to speak truth to the world. Notice that I didn't make my argument about the experience of old-timers. Actually, I find that valuable as well, but that's the ordinary argument: Listen to old people, because they have experience and wisdom.
Some of them do, at least.
I didn't make much out of that argument, because you already know it. There'd be no reason to write this essay if that was all I had to say. Old people have less on the line, so they can speak more freely. If someone you used to admire retires and all of a sudden starts saying or writing unpleasant and surprising things, there might be a good explanation, and it might be a good idea to pay attention.
Or maybe he or she is just bitter or going senile...
Add null check without brackets in Visual Studio
A Visual Studio tweak.
The most recent versions of Visual Studio have included many new Quick Actions, accessible with Ctrl + . or Alt + Enter. The overall feature has been around for some years, but the product group has been adding features at a good pace recently, it seems to me.
One feature has been around for at least a year: Add null check. In a default installation of Visual Studio, it looks like this:
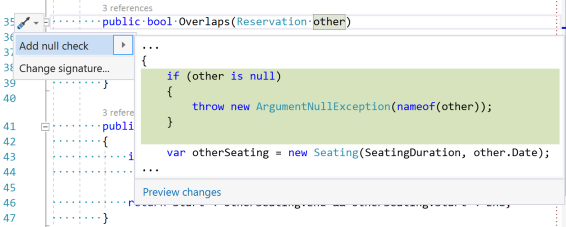
As the screen shot shows, it'll auto-generate a Guard Clause like this:
public bool Overlaps(Reservation other) { if (other is null) { throw new ArgumentNullException(nameof(other)); } var otherSeating = new Seating(SeatingDuration, other.Date); return Overlaps(otherSeating); }
Part of my personal coding style is that I don't use brackets for one-liners. This is partially motivated by the desire to save vertical space, since I try to keep methods as small as possible. Some people worry that not using brackets for one-liners makes the code more vulnerable to defects, but I typically have automated regressions tests to keep an eye on correctness.
The above default behaviour of the Add null check Quick Action annoyed me because I had to manually remove the brackets. It's one of those things that annoy you a little, but not enough that you throw aside what you're doing to figure out if you can change the situation.
Until it annoyed me enough to investigate whether there was something I could do about it. It turns out to be easy to tweak the behaviour.
In Visual Studio 2019, go to Tools, Options, Text Editor, C#, Code Style, General and change the Prefer braces option to No:
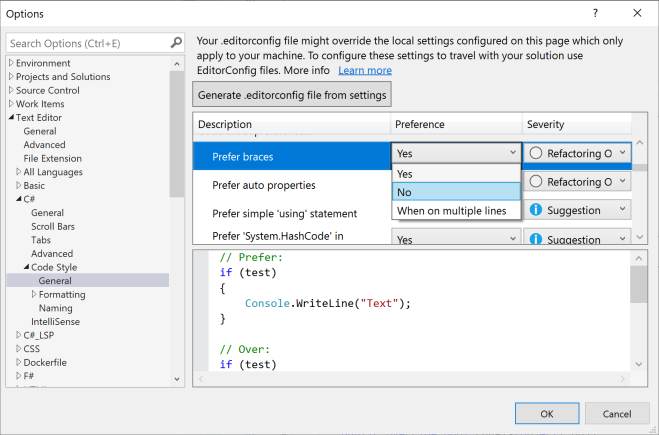
This changes the behaviour of the Add null check Quick Action:
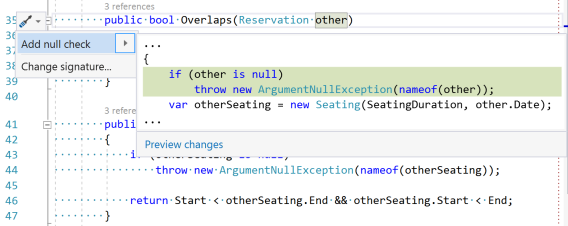
After applying the Quick Action, my code now looks like this:
public bool Overlaps(Reservation other) { if (other is null) throw new ArgumentNullException(nameof(other)); var otherSeating = new Seating(SeatingDuration, other.Date); return Overlaps(otherSeating); }
This better fits my preference.
Comments
The same should go for if's, switch's, try/catch and perhaps a few other things. While we are at it, spacing is also a good source for changing layout in code, e.g: decimal.Round( amount * 1.0000m, provider.Getdecimals( currency ) ) ).
When assigning parameters to fields, I like this one-line option for a null check:
_thing = thing ?? throw new ArgumentNullException(nameof(thing));.
How do you feel about it? You could even use a disard in your example:
_ = thing ?? throw new ArgumentNullException(nameof(thing));
James, thank you for writing. I'm aware of that option, but rarely use it in my examples. I try to write my example code in a way that they may also be helpful to Java developers, or programmers that use other C-based languages. Obviously, that concern doesn't apply if I discuss something specific to C#, but when I try to explain design patterns or low-level architecture, I try to stay away from language features exclusive to C#.
In other contexts, I might or might not use that language feature, but I admit that it jars me. I find that it's a 'clever' solution to something that's not much of a problem. The ?? operator is intended as a short-circuiting operator one can use to simplify variable assignment. Throwing on the right-hand side never assigns a value.
It's as though you would use the coalescing monoid to pick the left-hand side, but let the program fail on the right-hand side. In Haskell it would look like this:
x = thing <> undefined
The compiler infers that x has the same type as thing, e.g. Semigroup a => Maybe a. If thing, however, is Nothing, the expression crashes when evaluated.
While this compiles in Haskell, I consider it unidiomatic. It too blatantly advertises the existence of the so-called bottom value (⊥). We know it's there, but we prefer to pretend that it's not.
That line of reasoning is subjective, and if I find myself in a code base that uses ?? like you've shown, I'd try to fit in with that style. It doesn't annoy me that much, after all.
It's also shorter, I must admit that.
The above default behaviour of the Add null check Quick Action annoyed me because I had to manually remove the brackets. It's one of those things that annoy you a little, but not enough that you throw aside what you're doing to figure out if you can change the situation.
Until it annoyed me enough to investigate whether there was something I could do about it. It turns out to be easy to tweak the behaviour.
In Visual Studio 2019, go to Tools, Options, Text Editor, C#, Code Style, General and change the Prefer braces option to No:
You can do more than that. As suggested by Visual Studio in your second screenshot, you can (after making the change to not prefer braces) generate an .editorconfig file containing your coding style settings. Visual Studio will prompt you to save the file alongside your solution. If you do so, then any developer that opens these files with Visual Studio with also have your setting to not prefer braces. I wrote a short post about EditorConfig that contains more information.
Properties for all
Writing test cases for all possible input values.
I've noticed that programmers new to automated testing struggle with a fundamental task: how to come up with good test input?
There's plenty of design patterns that address that issue, including Test Data Builders. Still, test-driven development, when done right, gives you good feedback on the design of your API. I don't consider having to resort to Test Data Builder as much of a compromise, but still, it's even better if you can model the API in question so that it requires no redundant data.
Most business processes can be modelled as finite state machines. Once you've understood the problem well enough to enumerate the possible states, you can reverse-engineer an algebraic data type from that enumeration.
While the data carried around in the state machine may be unconstrained, the number of state and state transitions is usually limited. Model the states as enumerable values, and you can cover all input values with simple combinatorics.
Tennis states #
The Tennis kata is one of my favourite exercises. Just like a business process, it turns out that you can model the rules as a finite state machine. There's a state where both players have love, 15, 30, or 40 points (although both can't have 40 points; that state is called deuce); there's a state where a player has the advantage; and so on.
I've previously written about how to design the states of the Tennis kata with types, so here, I'll just limit myself to the few types that turn out to matter as test input: players and points.
Here are both types defined as Haskell sum types:
data Player = PlayerOne | PlayerTwo deriving (Eq, Show, Read, Enum, Bounded) data Point = Love | Fifteen | Thirty deriving (Eq, Show, Read, Enum, Bounded)
Notice that both are instances of the Enum and Bounded type classes. This means that it's possible to enumerate all values that inhabit each type. You can use that to your advantage when writing unit tests.
Properties for every value #
Most people think of property-based testing as something that involves a special framework such as QuickCheck, Hedgehog, or FsCheck. I often use such frameworks, but as I've written about before, sometimes enumerating all possible input values is simpler and faster than relying on randomly generated values. There's no reason to generate 100 random values of a type inhabited by only three values.
Instead, write properties for the entire domain of the function in question.
In Haskell, you can define a generic enumeration like this:
every :: (Enum a, Bounded a) => [a] every = [minBound .. maxBound]
I don't know why this function doesn't already exist in the standard library, but I suppose that most people just rely on the list comprehension syntax [minBound .. maxBound]...
With it you can write simple properties of the Tennis game. For example:
"Given deuce, when player wins, then that player has advantage" ~: do player <- every let actual = score Deuce player return $ Advantage player ~=? actual
Here I'm using inlined HUnit test lists. With the Tennis kata, it's easiest to start with the deuce case, because regardless of player, the new state is that the winning player has advantage. That's what that property asserts. Because of the do notation, the property produces a list of test cases, one for every player. There's only two Player values, so it's only two test cases.
The beauty of do notation (or the list monad in general) is that you can combine enumerations, for example like this:
"Given forty, when player wins ball, then that player wins the game" ~: do player <- every opp <- every let actual = score (Forty $ FortyData player opp) player return $ Game player ~=? actual
While player is a Player value, opp (Other Player's Point) is a Point value. Since there's two possible Player values and three possible Point values, the combination yields six test cases.
I've been doing the Tennis kata a couple of times using this approach. I've also done it in C# with xUnit.net, where the first test of the deuce state looks like this:
[Theory, MemberData(nameof(Player))] public void TransitionFromDeuce(IPlayer player) { var sut = new Deuce(); var actual = sut.BallTo(player); var expected = new Advantage(player); Assert.Equal(expected, actual); }
C# takes more ceremony than Haskell, but the idea is the same. The Player data source for the [Theory] is defined as an enumeration of the possible values:
public static IEnumerable<object[]> Player { get { yield return new object[] { new PlayerOne() }; yield return new object[] { new PlayerTwo() }; } }
All the times I've done the Tennis kata by fully exhausting the domain of the transition functions in question, I've arrived at 40 test cases. I wonder if that's the number of possible state transitions of the game, or if it's just an artefact of the way I've modelled it. I suspect the latter...
Conclusion #
You can sometimes enumerate all possible inputs to an API. Even if a function takes a Boolean value and a byte as input, the enumeration of all possible combinations is only 2 * 256 = 512 values. You computer will tear through all of those combinations faster than you can say random selection. Consider writing APIs that take algebraic data types as input, and writing properties that exhaust the domain of the functions in question.
Adding REST links as a cross-cutting concern
Use a piece of middleware to enrich a Data Transfer Object. An ASP.NET Core example.
When developing true REST APIs, you should use hypermedia controls (i.e. links) to guide clients to the resources they need. I've always felt that the code that generates these links tends to make otherwise readable Controller methods unreadable.
I'm currently experimenting with generating links as a cross-cutting concern. So far, I like it very much.
The code shown here is part of the sample code base that accompanies my book Code That Fits in Your Head.
Links from home #
Consider an online restaurant reservation system. When you make a GET request against the home resource (which is the only published URL for the API), you should receive a representation like this:
{
"links": [
{
"rel": "urn:reservations",
"href": "http://localhost:53568/reservations"
},
{
"rel": "urn:year",
"href": "http://localhost:53568/calendar/2020"
},
{
"rel": "urn:month",
"href": "http://localhost:53568/calendar/2020/8"
},
{
"rel": "urn:day",
"href": "http://localhost:53568/calendar/2020/8/13"
}
]
}
As you can tell, my example just runs on my local development machine, but I'm sure that you can see past that. There's three calendar links that clients can use to GET the restaurant's calendar for the current day, month, or year. Clients can use these resources to present a user with a date picker or a similar user interface so that it's possible to pick a date for a reservation.
When a client wants to make a reservation, it can use the URL identified by the rel (relationship type) "urn:reservations" to make a POST request.
Link generation as a Controller responsibility #
I first wrote the code that generates these links directly in the Controller class that serves the home resource. It looked like this:
public IActionResult Get() { var links = new List<LinkDto>(); links.Add(Url.LinkToReservations()); if (enableCalendar) { var now = DateTime.Now; links.Add(Url.LinkToYear(now.Year)); links.Add(Url.LinkToMonth(now.Year, now.Month)); links.Add(Url.LinkToDay(now.Year, now.Month, now.Day)); } return Ok(new HomeDto { Links = links.ToArray() }); }
That doesn't look too bad, but 90% of the code is exclusively concerned with generating links. (enableCalendar, by the way, is a feature flag.) That seems acceptable in this special case, because there's really nothing else the home resource has to do. For other resources, the Controller code might contain some composition code as well, and then all the link code starts to look like noise that makes it harder to understand the actual purpose of the Controller method. You'll see an example of a non-trivial Controller method later in this article.
It seemed to me that enriching a Data Transfer Object (DTO) with links ought to be a cross-cutting concern.
LinksFilter #
In ASP.NET Core, you can implement cross-cutting concerns with a type of middleware called IAsyncActionFilter. I added one called LinksFilter:
internal class LinksFilter : IAsyncActionFilter { private readonly bool enableCalendar; public IUrlHelperFactory UrlHelperFactory { get; } public LinksFilter( IUrlHelperFactory urlHelperFactory, CalendarFlag calendarFlag) { UrlHelperFactory = urlHelperFactory; enableCalendar = calendarFlag.Enabled; } public async Task OnActionExecutionAsync( ActionExecutingContext context, ActionExecutionDelegate next) { var ctxAfter = await next().ConfigureAwait(false); if (!(ctxAfter.Result is OkObjectResult ok)) return; var url = UrlHelperFactory.GetUrlHelper(ctxAfter); switch (ok.Value) { case HomeDto homeDto: AddLinks(homeDto, url); break; case CalendarDto calendarDto: AddLinks(calendarDto, url); break; default: break; } } // ...
There's only one method to implement. If you want to run some code after the Controllers have had their chance, you invoke the next delegate to get the resulting context. It should contain the response to be returned. If Result isn't an OkObjectResult there's no content to enrich with links, so the method just returns.
Otherwise, it switches on the type of the ok.Value and passes the DTO to an appropriate helper method. Here's the AddLinks overload for HomeDto:
private void AddLinks(HomeDto dto, IUrlHelper url) { if (enableCalendar) { var now = DateTime.Now; dto.Links = new[] { url.LinkToReservations(), url.LinkToYear(now.Year), url.LinkToMonth(now.Year, now.Month), url.LinkToDay(now.Year, now.Month, now.Day) }; } else { dto.Links = new[] { url.LinkToReservations() }; } }
You can probably recognise the implemented behaviour from before, where it was implemented in the Get method. That method now looks like this:
public ActionResult Get() { return new OkObjectResult(new HomeDto()); }
That's clearly much simpler, but you probably think that little has been achieved. After all, doesn't this just move some code from one place to another?
Yes, that's the case in this particular example, but I wanted to start with an example that was so simple that it highlights how to move the code to a filter. Consider, then, the following example.
A calendar resource #
The online reservation system enables clients to navigate its calendar to look up dates and time slots. A representation might look like this:
{
"links": [
{
"rel": "previous",
"href": "http://localhost:53568/calendar/2020/8/12"
},
{
"rel": "next",
"href": "http://localhost:53568/calendar/2020/8/14"
}
],
"year": 2020,
"month": 8,
"day": 13,
"days": [
{
"links": [
{
"rel": "urn:year",
"href": "http://localhost:53568/calendar/2020"
},
{
"rel": "urn:month",
"href": "http://localhost:53568/calendar/2020/8"
},
{
"rel": "urn:day",
"href": "http://localhost:53568/calendar/2020/8/13"
}
],
"date": "2020-08-13",
"entries": [
{
"time": "18:00:00",
"maximumPartySize": 10
},
{
"time": "18:15:00",
"maximumPartySize": 10
},
{
"time": "18:30:00",
"maximumPartySize": 10
},
{
"time": "18:45:00",
"maximumPartySize": 10
},
{
"time": "19:00:00",
"maximumPartySize": 10
},
{
"time": "19:15:00",
"maximumPartySize": 10
},
{
"time": "19:30:00",
"maximumPartySize": 10
},
{
"time": "19:45:00",
"maximumPartySize": 10
},
{
"time": "20:00:00",
"maximumPartySize": 10
},
{
"time": "20:15:00",
"maximumPartySize": 10
},
{
"time": "20:30:00",
"maximumPartySize": 10
},
{
"time": "20:45:00",
"maximumPartySize": 10
},
{
"time": "21:00:00",
"maximumPartySize": 10
}
]
}
]
}
This is a JSON representation of the calendar for August 13, 2020. The data it contains is the identification of the date, as well as a series of entries that lists the largest reservation the restaurant can accept for each time slot.
Apart from the data, the representation also contains links. There's a general collection of links that currently holds only next and previous. In addition to that, each day has its own array of links. In the above example, only a single day is represented, so the days array contains only a single object. For a month calendar (navigatable via the urn:month link), there'd be between 28 and 31 days, each with its own links array.
Generating all these links is a complex undertaking all by itself, so separation of concerns is a boon.
Calendar links #
As you can see in the above LinksFilter, it branches on the type of value wrapped in an OkObjectResult. If the type is CalendarDto, it calls the appropriate AddLinks overload:
private static void AddLinks(CalendarDto dto, IUrlHelper url) { var period = dto.ToPeriod(); var previous = period.Accept(new PreviousPeriodVisitor()); var next = period.Accept(new NextPeriodVisitor()); dto.Links = new[] { url.LinkToPeriod(previous, "previous"), url.LinkToPeriod(next, "next") }; if (dto.Days is { }) foreach (var day in dto.Days) AddLinks(day, url); }
It both generates the previous and next links on the dto, as well as the links for each day. While I'm not going to bore you with more of that code, you can tell, I hope, that the AddLinks method calls other helper methods and classes. The point is that link generation involves more than just a few lines of code.
You already saw that in the first example (related to HomeDto). The question is whether there's still some significant code left in the Controller class?
Calendar resource #
The CalendarController class defines three overloads of Get - one for a single day, one for a month, and one for an entire year. Each of them looks like this:
public async Task<ActionResult> Get(int year, int month) { var period = Period.Month(year, month); var days = await MakeDays(period).ConfigureAwait(false); return new OkObjectResult( new CalendarDto { Year = year, Month = month, Days = days }); }
It doesn't look as though much is going on, but at least you can see that it returns a CalendarDto object.
While the method looks simple, it's not. Significant work happens in the MakeDays helper method:
private async Task<DayDto[]> MakeDays(IPeriod period) { var firstTick = period.Accept(new FirstTickVisitor()); var lastTick = period.Accept(new LastTickVisitor()); var reservations = await Repository .ReadReservations(firstTick, lastTick).ConfigureAwait(false); var days = period.Accept(new DaysVisitor()) .Select(d => MakeDay(d, reservations)) .ToArray(); return days; }
After having read relevant reservations from the database, it applies complex business logic to allocate them and thereby being able to report on remaining capacity for each time slot.
Not having to worry about link generation while doing all that work seems like a benefit.
Filter registration #
You must tell the ASP.NET Core framework about any filters that you add. You can do that in the Startup class' ConfigureServices method:
public void ConfigureServices(IServiceCollection services) { services.AddControllers(opts => opts.Filters.Add<LinksFilter>()); // ...
When registered, the filter executes for each HTTP request. When the object represents a 200 OK result, the filter populates the DTOs with links.
Conclusion #
By treating RESTful link generation as a cross-cutting concern, you can separate if from the logic of generating the data structure that represents the resource. That's not the only way to do it. You could also write a simple function that populates DTOs, and call it directly from each Controller action.
What I like about using a filter is that I don't have to remember to do that. Once the filter is registered, it'll populate all the DTOs it knows about, regardless of which Controller generated them.
Comments
Thanks for your good and insightful posts.
Separation of REST concerns from MVC controller's concerns is a great idea, But in my opinion this solution has two problems:
Distance between related REST implementations #
When implementing REST by MVC pattern often REST archetypes are the reasons for a MVC Controller class to be created. As long as the MVC Controller class describes the archetype, And links of a resource is a part of the response when implementing hypermedia controls, having the archetype and its related links in the place where the resource described is a big advantage in easiness and readability of the design. pulling out link implementations and putting them in separate classes causes higher readability and uniformity of the code abstranction levels in the action method at the expense of making a distance between related REST implementation.
Implementation scalability #
There is a switch statement on the ActionExecutingContext's result in the LinksFilter to decide what links must be represented to the client in the response.The DTOs thre are the results of the clients's requests for URIs. If this solution generalised for every resources the API must represent there will be several cases for the switch statement to handle. Beside that every resources may have different implemetations for generating their links. Putting all this in one place leads the LinksFilter to be coupled with too many helper classes and this coupling process never stops.
Solution #
LinkDescriptor and LinkSubscriber for resources links definition
public class LinkDescriptor { public string Rel { get; set; } public string Href { get; set; } public string Resource { get; set; } }
Letting the MVC controller classes have their resource's links definitions but not in action methods.
public ActionResult Get() { return new OkObjectResult(new HomeDto()); } public static void RegisterLinks(LinkSubscriber subscriber) { subscriber .Add( resource: "/Home", rel: "urn:reservations", href: "/reservations") .Add( resource: "/Home", rel: "urn:year", href: "/calendar/2020") .Add( resource: "/Home", rel: "urn:month", href: "/calendar/2020/8") .Add( resource: "/Home", rel: "urn:day", href: "/calendar/2020/8/13"); }
Registering resources links by convention
public static class MvcBuilderExtensions { public static IMvcBuilder AddRestLinks(this IMvcBuilder mvcBuilder) { var subscriber = new LinkSubscriber(); var linkRegistrationMethods = GetLinkRegistrationMethods(mvcBuilder.Services); PopulateLinks(subscriber, linkRegistrationMethods); mvcBuilder.Services.AddSingleton<IEnumerable<LinkDescriptor>>(subscriber.LinkDescriptors); return mvcBuilder; } private static List<MethodInfo> GetLinkRegistrationMethods(IServiceCollection services) { return typeof(MvcBuilderExtensions).Assembly.ExportedTypes .Where(tp => typeof(ControllerBase).IsAssignableFrom(tp)) .Select(tp => tp.GetMethod("RegisterLinks", new[] { typeof(LinkSubscriber) })) .Where(mi => mi != null) .ToList(); } private static void PopulateLinks(LinkSubscriber subscriber, List<MethodInfo> linkRegistrationMethods) { foreach (var method in linkRegistrationMethods) { method.Invoke(null, new[] { subscriber }); } } }
Add dependencies and execute procedures for adding links to responses
public void ConfigureServices(IServiceCollection services) { services.AddControllers(conf => conf.Filters.Add<LinksFilter>()) .AddRestLinks(); }
And Last letting the LinksFilter to dynamicaly add resources links by utilizing ExpandoObject
public class LinksFilter : IAsyncActionFilter { private readonly IEnumerable<LinkDescriptor> links; public LinksFilter(IEnumerable<LinkDescriptor> links) { this.links = links; } public async Task OnActionExecutionAsync(ActionExecutingContext context, ActionExecutionDelegate next) { var relatedLinks = links .Where(lk => context.HttpContext.Request.Path.Value.ToLower() == lk.Resource); if (relatedLinks.Any()) await ManipulateResponseAsync(context, next, relatedLinks); } private async Task ManipulateResponseAsync(ActionExecutingContext context, ActionExecutionDelegate next, IEnumerable<LinkDescriptor> relatedLinks) { var ctxAfter = await next().ConfigureAwait(false); if (!(ctxAfter.Result is ObjectResult objRes)) return; var expandoResult = new ExpandoObject(); FillExpandoWithResultProperties(expandoResult, objRes.Value); FillExpandoWithLinks(expandoResult, relatedLinks); objRes.Value = expandoResult; } private void FillExpandoWithResultProperties(ExpandoObject resultExpando, object value) { var properties = value.GetType().GetProperties(); foreach (var property in properties) { resultExpando.TryAdd(property.Name, property.GetValue(value)); } } private void FillExpandoWithLinks(ExpandoObject resultExpando, IEnumerable<LinkDescriptor> relatedLinks) { var linksToAdd = relatedLinks.Select(lk => new { Rel = lk.Rel, Href = lk.Href }); resultExpando.TryAdd("Links", linksToAdd); } }
If absoulute URI in href field is prefered, IUriHelper can be injected in LinksFilter to create URI paths.
Mark, thanks for figuring out the tricky parts so we don't have to. :-)
I did not see a link to a repo with the completed code from this article, and a cursory look around your Github profile didn't give away any obvious clues. Is the example code in the article part of a repo we can clone? If so, could you please provide a link?
Jes, it's part of a larger project that I'm currently working on. Eventually, I hope to publish it, but it's not yet in a state where I wish to do that.
Did I leave out essential details that makes it hard to reproduce the idea?
No, your presentation was fine. Looking forward to see the completed project!
Mehdi, thank you for writing. It's true that the LinksFilter implementation code contains a switch statement, and that this is one of multiple possible designs. I do believe that this is a trade-off rather than a problem per se.
That switch statement is an implementation detail of the filter, and something I might decide to change in the future. I did choose that implementation, though, because I it was the simplest design that came to my mind. As presented, the switch statement just calls some private helper methods (all called AddLinks), but if one wanted that code close to the rest of the Controller code, one could just move those helper methods to the relevant Controller classes.
While you wouldn't need to resort to Reflection to do that, it's true that this would leave that switch statement as a central place where developers would have to go if they add a new resource. It's true that your proposed solution addresses that problem, but doesn't it just shift the burden somewhere else? Now, developers will have to know that they ought to add a RegisterLinks method with a specific signature to their Controller classes. This replaces a design with compile-time checking with something that may fail at run time. How is that an improvement?
I think that I understand your other point about the distance of code, but it assumes a particular notion of REST that I find parochial. Most (.NET) developers I've met design REST APIs in a code-centric (if not a database-centric) way. They tend to conflate representations with resources and translate both to Controller classes.
The idea behind Representational State Transfer, however, is to decouple state from representation. Resources have state, but can have multiple representations. Vice versa, many resources may share the same representation. In the code base I used for this article, not only do I have three overloaded Get methods on CalendarController that produce CalendarDto representations, I also have a ScheduleController class that does the same.
Granted, not all REST API code bases are designed like this. I admit that what actually motivated me to do things like this was to avoid having to inherit from ControllerBase. Moving all the code that relies heavily on the ASP.NET infrastructure keeps the Controller classes lighter, and thus easier to test. I should probably write an article about that...
Unit testing is fine
Unit testing considered harmful? I think not.
Once in a while, some article, video, or podcast makes the rounds on social media, arguing that unit testing is bad, overrated, harmful, or the like. I'm not going to link to any specific resources, because this post isn't an attack on any particular piece of work. Many of these are sophisticated, thoughtful, and make good points, but still arrive at the wrong conclusion.
The line of reasoning tends to be to show examples of bad unit tests and conclude that, based on the examples, unit tests are bad.
The power of examples is great, but clearly, this is a logical fallacy.
Symbolisation #
In case it isn't clear that the argument is invalid, I'll demonstrate it using the techniques I've learned from Howard Pospesel's introduction to predicate logic.
We can begin by symbolising the natural-language arguments into well-formed formulas. I'll keep this as simple as possible:
∃xBx ⊢ ∀xBx (Domain: unit tests; Bx = x is bad)
Basically, Bx states that x is bad, where x is a unit test. ∃xBx is a statement that there exists a unit test x for which x is bad; i.e. bad unit tests exist. The statement ∀xBx claims that for all unit tests x, x is bad; i.e. all unit tests are bad. The turnstile symbol ⊢ in the middle indicates that the antecedent on the left proves the consequent to the right.
Translated back to natural language, the claim is this: Because bad unit tests exist, all unit tests are bad.
You can trivially prove this sequent invalid.
Logical fallacy #
One way to prove the sequent invalid is to use a truth tree:
Briefly, the way this works is that the statements on the left-hand side represent truth, while the ones to the right are false. By placing the antecedent on the left, but the consequent on the right, you're basically assuming the sequent to be wrong. This is is also the way you prove correct sequents true; if the conclusion is assumed false, a logical truth should lead to a contradiction. If it doesn't, the sequent is invalid. That's what happens here.
The tree remains open, which means that the original sequent is invalid. It's a logical fallacy.
Counter examples #
You probably already knew that. All it takes to counter a universal assertion such as all unit tests are bad is to produce a counter example. One is sufficient, because if just a single good unit test exists, it can't be true that all are bad.
Most of the think pieces that argue that unit testing is bad do so by showing examples of bad unit tests. These tests typically involve lots of mocks and stubs; they tend to test the interaction between internal components instead of the components themselves, or the system as a whole. I agree that this often leads to fragile tests.
While I still spend my testing energy according to the Test Pyramid, I don't write unit tests like that. I rarely use dynamic mock libraries. Instead, I push impure actions to the boundary of the system and write most of the application code as pure functions, which are intrinsically testable. No test-induced damage there.
I follow up with boundary tests that demonstrate that the functions are integrated into a working system. That's just another layer in the Test Pyramid, but smaller. You don't need that many integration tests when you have a foundation of good unit tests.
While I'm currently working on a larger body of work that showcases this approach, this blog already has examples of this.
Conclusion #
You often hear or see the claim that unit tests are bad. The supporting argument is that a particular (popular, I admit) style of unit testing is bad.
If the person making this claim only knows of that single style of unit testing, it's natural to jump to the conclusion that all unit testing must be bad.
That's not the case. I write most of my unit tests in a style dissimilar from the interaction-heavy, mocks-and-stubs-based style that most people use. These test have a low maintenance burden and don't cause test-induced damage.
Unit testing is fine.

Comments
Excellent article! I was planning to eventually write a blog post on this topic, but now there is no need.
Said another way, one objective measure that is better in this case when using query syntax is that the maximum line width is smaller. It is objective primarily in the sense that maximum line width is objective and secondarily in the sense that we generally agree that code with a lower maximum line width is typically easier to understand.
Another such objective measure of quality that I value is the maximum number of matching pairs of parentheses that are nested. This measure improves to two in your query syntax code from three in your previous code. The reason it was three before is because there are four levels of detail and your code decreases the level of detail three times:
RestauranttoMaitreD,MaitreDtoTimeSpan, andTimeSpantodouble. Query syntax is one way to decrease the level of detail without having to introduce a pair of matching parentheses.I find more success minimizing this measure of quality when taking a bottom-up approach. Using the
Applyextension method fromlanguage-ext, which is like the forward pipe operator in F#, we can rewrite this code without any nested pairs of matching parentheses as.5.Apply(TimeSpan.FromHours).Apply(m => m.WithSeatingDuration).Apply(restaurant.Select)(I did not check if this code compiles. If it does not, it would be because the C# compiler is unsure how to implicitly convert some method group to its intended
Func<,>delegate.) This code also has natural line-breaking points before each dot operator, which leads to a comfortable value for the maximum line width.Another advantage of this code that I value is that the execution happens in the same order in which I (as an English speaker) read it: left to right. Your code before using the query syntax executed from right to left as dictated by the matching parentheses. In fact, since the dot operator is left associative, the degree to which execution occurs from left to right is inversely correlated to the number of nested pairs of parentheses. (One confusing thing here is the myriad of different semantic meanings in C# to the syntactic use of a pair of parentheses.)
Tyson, thank you for writing. I've never thought about measuring complexity by nested parentheses, but I like it! It makes intuitive sense.
I'm not sure it applies to LISP-like languages, but perhaps some reader comes by some day who can enlighten us.
While reading your articles about contravairant functors, a better name occured to me for what you called a monomorphic functor in this article.
For a covariant functor, its mapping function accepts a function with types that vary (i.e. differ). The order in which they vary matches the order that the types vary in the corresponding elevated function. For a contravariant functor, its mapping function also accepts a function with types that vary. However, the order in which they vary is reversed compared to the order that the types vary in the corresponding elevated function. For the functor in this article that you called a monomorphic functor, its mapping function accepts a function with types that do not vary. As such, we should call such a functor an invariant functor.
Tyson, thank you for writing. That's a great suggestion that makes a lot of sense.
The term invariant functor seems, however, to be taken by a wider definition.
This seems, at first glance, to fit your description quite well, but when we try to encode this in a programming language, something surprising happens. We'd typically say that the types
aandbare isomorphic if and only if there exists two functionsa -> bandb -> a. Thus, we can encode this in a Haskell type class like this one:I've taken the name of both type class and method from Thinking with Types, but we find the same naming in Data.Functor.Invariant. The first version of the invariant package is from 2012, so assume that Sandy Maguire has taken the name from there (and not the other way around).
There's a similar-looking definition in Cats (although I generally don't read Scala), and in C# we might define a method like this:
This seems, at first glance, to describe monomorphic functors quite well, but it turns out that it's not quite the same. Consider mapping of
String, as discussed in this article. TheMonoFunctorinstance ofString(or, generally,[a]) lifts aChar -> Charfunction toString -> String.In Haskell,
Stringis really a type alias for[Char], but what happens if we attempt to describeStringas anInvariantinstance? We can't, becauseStringhas no type argument.We can, however, see what happens if we try to make
[a]anInvariantinstance. If we can do that, we can try to experiment withChar's underlying implementation as a number:ordandchrenable us to treatCharandIntas isomorphic:Since we have both
Char -> IntandInt -> Char, we should be able to useinvmap ord chr, and indeed, it works:When, however, we look at the
Invariant []instance, we may be in for a surprise:The instance uses only the
a -> bfunction, while it completely ignores theb -> afunction! Since the instance usesfmap, rather thanmap, it also strongly suggests that all (covariant)Functorinstances are alsoInvariantinstances. That's also the conclusion reached by the invariant package. Not only that, but every Contravariant functor is also an Invariant functor.That seems to completely counter the idea that
aandbshould be isomorphic. I can't say that I've entirely grokked this disconnect yet, but it seems to me to be an artefact of instances' ability to ignore either of the functions passed toinvmap. At least we can say that client code can't callinvmapunless it supplies both functions (here I pretend thatundefineddoesn't exist).If we go with the Haskell definition of things, an invariant functor is a much wider concept than a monomorphic functor.
Invariantdescribes a superset that contains both (covariant)FunctorandContravariantfunctor. This superset is more than just the union of those two sets, since it also includes containers that are neitherFunctornorContravariant, for example Endo:For example, toUpper is an endomorphism, so we can apply it to
invmapand evaluate it like this:This example takes the
Int102and converts it to aStringwithchr:It then applies
'f'totoUpper:Finally, it converts
'F'withord:Endomorphisms are neither covariant nor contravariant functors - they are invariant functors. They may also be monomorphic functors. The mono-traversable package doesn't define a
MonoFunctorinstance forEndo, but that may just be an omission. It'd be an interesting exercise to see if such an instance is possible. I don't know yet, but I think that it is...For now, though, I'm going to leave that as an exercise. Readers who manage to implement a lawful instance of
MonoFunctorforEndoshould send a pull request to the mono-traversable package.Finally, a note on words. I agree that invariant functor would also have been a good description of monomorphic functors. It seems to me that in both mathematics and programming, there's sometimes a 'land-grab' of terms. The first person to think of a concept gets to pick the word. If the concept is compelling, the word may stick.
This strikes me as an unavoidable consequence of how knowledge progresses. Ideas rarely spring forth fully formed. Often, someone gets a half-baked idea and names it before fully understanding it. When later, more complete understanding emerges, it may be too late to change the terminology.
This has happened to me in this very article series, which I titled From design patterns to category theory before fully understanding where it'd lead me. I've later come to realise that we need only abstract algebra to describe monoids, semigroups, et cetera. Thus, the article series turned out to have little to do with category theory, but I couldn't (wouldn't) change the title and the URL of the original article, since it was already published.
The same may be the case with the terms invariant functors and monomorphic functors. Perhaps invariant functors should instead have been called isomorphic functors...
I've started a small article series on invariant functors.