ploeh blog danish software design
Uncurry isomorphisms
Curried functions are isomorphic to tupled functions.
This article is part of a series of articles about software design isomorphisms. Nota bene: it's not about Curry–Howard isomorphism. In order to prevent too much confusion, I chose the title Uncurry isomorphism over Curry isomorphism.
The Haskell base library includes two functions called curry and uncurry, and for anyone aware of them, it should be no surprise that they are each others' inverses. This is another important software design isomorphism, because in the previous article, you saw that all methods can be represented in tupled form. The current isomorphism then extends that result because tupled and curried forms are isomorphic.
An F# introduction to curry and uncurry #
While Haskell programmers are likely to be familiar with curry and uncurry, developers more familiar with other languages may not know them well. In this section follows an introduction in F#. Haskellers can skip it if they like.
In F#, you often have to interoperate with code written in C#, and as the previous article explained, all such methods look to F# like functions taking a single tuple as input. Sometimes, however, you'd wish they were curried.
This little function can help with that:
// ('a * 'b -> 'c) -> 'a -> 'b -> 'c let curry f x y = f (x, y)
You'll probably have to look at it for a while, and perhaps play with it, before it clicks, but it does this: it takes a function (f) that takes a tuple ('a * 'b) as input, and returns a new function that does the same, but instead takes the arguments in curried form: 'a -> 'b -> 'c.
It can be useful in interoperability scenarios. Imagine, as a toy example, that you have to list the powers of two from 0 to 10. You can use Math.Pow, but since it was designed with C# in mind, its argument is a single tuple. curry to the rescue:
> List.map (curry Math.Pow 2.) [0.0..10.0];; val it : float list = [1.0; 2.0; 4.0; 8.0; 16.0; 32.0; 64.0; 128.0; 256.0; 512.0; 1024.0]
While Math.Pow has the type float * float -> float, curry Math.Pow turns it into a function with the type float -> float -> float. Since that function is curried, it can be partially applied with the value 2., which returns a function of the type float -> float. That's a function you can use with List.map.
You'd hardly be surprised that you can also uncurry a function:
// ('a -> 'b -> 'c) -> 'a * 'b -> 'c let uncurry f (x, y) = f x y
This function takes a curried function f, and returns a new function that does the same, but instead takes a tuple as input.
Pair isomorphism #
Haskell comes with curry and uncurry as part of its standard library. It hardly comes as a surprise that they form an isomorphism. You can demonstrate this with some QuickCheck properties.
If you have a curried function, you should be able to first uncurry it, then curry that function, and that function should be the same as the original function. In order to demonstrate that, I chose the (<>) operator from Data.Semigroup. Recall that Haskell operators are curried functions. This property function demonstrates the round-trip property of uncurry and curry:
semigroup2RoundTrips :: (Semigroup a, Eq a) => a -> a -> Bool semigroup2RoundTrips x y = x <> y == curry (uncurry (<>)) x y
This property states that the result of combining two semigroup values is the same as first uncurrying (<>), and then 'recurry' it. It passes for various Semigroup instances:
testProperty "All round-trips" (semigroup2RoundTrips :: All -> All -> Bool), testProperty "Any round-trips" (semigroup2RoundTrips :: Any -> Any -> Bool), testProperty "First round-trips" (semigroup2RoundTrips :: First Int -> First Int -> Bool), testProperty "Last round-trips" (semigroup2RoundTrips :: Last Int -> Last Int -> Bool), testProperty "Sum round-trips" (semigroup2RoundTrips :: Sum Int -> Sum Int -> Bool), testProperty "Product round-trips" (semigroup2RoundTrips :: Product Int -> Product Int -> Bool)
It's not a formal proof that all of these properties pass, but it does demonstrate the isomorphic nature of these two functions. In order to be truly isomorphic, however, you must also be able to start with a tupled function. In order to have a similar tupled function, I defined this:
t2sg :: Semigroup a => (a, a) -> a t2sg (x, y) = x <> y
The t2 in the name stands for tuple-2, and sg means semigroup. It really only exposes (<>) in tupled form. With it, though, you can write another property that demonstrates that the mapping starting with a tupled form is also an isomorphism:
pairedRoundTrips :: (Semigroup a, Eq a) => a -> a -> Bool pairedRoundTrips x y = t2sg (x, y) == uncurry (curry t2sg) (x, y)
You can create properties for the same instances of Semigroup as the above list for semigroup2RoundTrips, and they all pass as well.
Triplet isomorphism #
curry and uncurry only works for pairs (two-tuples) and functions that take exactly two curried arguments. What if you have a function that takes three curried arguments, or a function that takes a triplet (three-tuple) as an argument?
First of all, while they aren't built-in, you can easily define corresponding mappings for those as well:
curry3 :: ((a, b, c) -> d) -> a -> b -> c -> d curry3 f x y z = f (x, y, z) uncurry3 :: (a -> b -> c -> d) -> (a, b, c) -> d uncurry3 f (x, y, z) = f x y z
These form an isomorphism as well.
More generally, though, you can represent a triplet (a, b, c) as a nested pair: (a, (b, c)). These two representations are also isomorphic, as is (a, b, c, d) with (a, (b, (c, d))). In other words, you can represent any n-tuple as a nested pair, and you already know that a function taking a pair as input is isomorphic to a curried function.
Summary #
From abstract algebra, and particularly its application to a language like Haskell, we have mathematical abstractions over computation - semigroups, for example! In Haskell, these abstractions are often represented in curried form. If we wish to learn about such abstractions, and see if we can use them in object-oriented programming as well, we need to translate the curried representations into something more closely related to object-oriented programming, such as C# or Java.
The present article describes how functions in curried form are equivalent to functions that take a single tuple as argument, and in a previous article, you saw how such functions are isomorphic to C# or Java methods. These equivalences provide a bridge that enables us to take what we've learned about abstract algebra and category theory, and bring them to object-oriented programming.
Next: Object isomorphisms.
Argument list isomorphisms
There are many ways to represent an argument list. An overview for object-oriented programmers.
This article is part of a series of articles about software design isomorphisms.
Most programming languages enable you to pass arguments to operations. In C# and Java, you declare methods with a list of arguments:
public Foo Bar(Baz baz, Qux qux)
Here, baz and qux are arguments to the Bar method. Together, the arguments for a method is called an argument list. To be clear, this isn't universally adopted terminology, but is what I'll be using in this article. Sometimes, people (including me) say parameter instead of argument, and I'm not aware of any formal specification to differentiate the two.
While you can pass arguments as a flat list, you can also model them as parameter objects or tuples. These representations are equivalent, because lossless translations between them exist. We say that they are isomorphic.
Isomorphisms #
In theory, you can declare a method that takes thousands of arguments. In practice, you should constrain your design to as few arguments as possible. As Refactoring demonstrates, one way to do that is to Introduce Parameter Object. That, already, teaches us that there's a mapping from a flat argument list to a Parameter Object. Is there an inverse mapping? Do other representations exist?
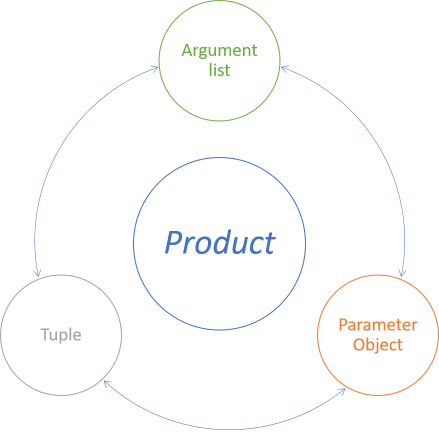
There's at least three alternative representations of a group of arguments:
- Argument list
- Parameter Object
- Tuple
Argument list/Parameter Object isomorphism #
Perhaps the best-known mapping from an argument list is the Introduce Parameter Object refactoring described in Refactoring.
Since the refactoring is described in detail in the book, I don't want to repeat it all here, but in short, assume that you have a method like this:
public Bar Baz(Qux qux, Corge corge)
In this case, the method only has two arguments, so the refactoring may not be necessary, but that's not the point. The point is that it's possible to refactor the code to this:
public Bar Baz(BazParameter arg)
where BazParameter looks like this:
public class BazParameter { public Qux Qux { get; set; } public Corge Corge { get; set; } }
In Refactoring, the recipe states that you should make the class immutable, and while that's a good idea (I recommend it!), it's technically not necessary in order to perform the translation, so I omitted it here in order to make the code simpler.
You're probably able to figure out how to translate back again. We could call this refactoring Dissolve Parameter Object:
- For each field or property in the Parameter Object, add a new method argument to the target method.
- At all call sites, pass the Parameter Object's field or property value as each of those new arguments.
- Change the method body so that it uses each new argument, instead of the Parameter Object.
- Remove the Parameter Object argument, and update call sites accordingly.
As an example, consider the Roster example from a previous article. The Combine method on the Roster class is implemented like this:
public Roster Combine(Roster other) { return new Roster( this.Girls + other.Girls, this.Boys + other.Boys, this.Exemptions.Concat(other.Exemptions).ToArray()); }
This method takes an object as a single argument. You can think of this Roster object as a Parameter Object.
If you like, you can add a method overload that dissolves the Roster object to its constituent values:
public Roster Combine( int otherGirls, int otherBoys, params string[] otherExemptions) { return this.Combine( new Roster(otherGirls, otherBoys, otherExemptions)); }
In this incarnation, the dissolved method overload creates a new Roster from its argument list and delegates to the other overload. This is, however, an arbitrary implementation detail. You could just as well implement the two methods the other way around:
public Roster Combine(Roster other) { return this.Combine( other.Girls, other.Boys, other.Exemptions.ToArray()); } public Roster Combine( int otherGirls, int otherBoys, params string[] otherExemptions) { return new Roster( this.Girls + otherGirls, this.Boys + otherBoys, this.Exemptions.Concat(otherExemptions).ToArray()); }
In this variation, the overload that takes three arguments contains the implementation, whereas the Combine(Roster) overload simply delegates to the Combine(int, int, string[]) overload.
In order to illustrate the idea that both APIs are equivalent, in this example I show two method overloads side by side. The overall point, however, is that you can translate between such two representations without changing the behaviour of the system. You don't have to keep both method overloads in place together.
Argument list/tuple isomorphism #
In relationship to statically typed functional programming, the term argument list is confounding. In the functional programming languages I've so far dabbled with (F#, Haskell, PureScript, Clojure, Erlang), the word list is used synonymously with linked list.
As a data type, a linked list can hold an arbitrary number of elements. (In Haskell, it can even be infinite, because Haskell is lazily evaluated.) Statically typed languages like F# and Haskell add the constraint that all elements must have the same type.
An argument list like (Qux qux, Corge corge) isn't at all a statically typed linked list. Neither does it have an arbitrary size nor does it contain elements of the same type. On the contrary, it has a fixed length (two), and elements of different types. The first element must be a Qux value, and the second element must be a Corge value.
That's not a list; that's a tuple.
Surprisingly, Haskell may provide the most digestible illustration of that, even if you don't know how to read Haskell syntax. Suppose you have the values qux and corge, of similarly named types. Consider a C# method call Baz(qux, corge). What's the type of the 'argument list'?
λ> :type (qux, corge) (qux, corge) :: (Qux, Corge)
:type is a GHCi command that displays the type of an expression. By coincidence (or is it?), the C# argument list (qux, corge) is also valid Haskell syntax, but it is syntax for a tuple. In this example, the tuple is a pair where the first element has the type Qux, and the second element has the type Corge, but (foo, qux, corge) would be a triple, (foo, qux, corge, grault) would be a quadruple, and so on.
We know that the argument list/tuple isomorphism exists, because that's how the F# compiler works. F# is a multi-paradigmatic language, and it can interact with C# code. It does that by treating all C# argument lists as tuples. Consider this example of calling Math.Pow:
let i = Math.Pow(2., 4.)
Programmers who still write more C# than F# often write it like that, because it looks like a method call, but I prefer to insert a space between the method and the arguments:
let i = Math.Pow (2., 4.)
The reason is that in F#, function calls are delimited with space. The brackets are there in order to override the normal operator precedence, just like you'd write (1 + 2) * 3 in order to get 9 instead of 7. This is better illustrated by introducing an intermediate value:
let t = (2., 4.) let i = Math.Pow t
or even
let t = 2., 4. let i = Math.Pow t
because the brackets are now redundant. In the last two examples, t is a tuple of two floating-point numbers. All four code examples are equivalent and compile, thereby demonstrating that a translation exist from F# tuples to C# argument lists.
The inverse translation exists as well. You can see a demonstration of this in the (dormant) Numsense code base, which includes an object-oriented Façade, which defines (among other things) an interface where the TryParse method takes a tuple argument. Here's the declaration of that method:
abstract TryParse : s : string * [<Out>]result : int byref -> bool
That looks cryptic, but if you remove the [<Out>] annotation and the argument names, the method is declared as taking single input value of the type string * int byref. It's a single value, but it's a tuple (a pair).
Perhaps it's easier to understand if you see an implementation of this interface method, so here's the English implementation:
member this.TryParse (s, result) = Helper.tryParse Numeral.tryParseEnglish (s, &result)
You can see that, as I've described above, I've inserted a space between this.TryParse and (s, result), in order to highlight that this is an F# function that takes a single tuple as input.
In C#, however, you can use the method as though it had a standard C# argument list:
int i; var success = Numeral.English.TryParse( "one-thousand-three-hundred-thirty-seven", out i);
You'll note that this is an advanced example that involves an out parameter, but even in this edge case, the translation is possible.
C# argument lists and F# tuples are isomorphic. I'd be surprised if this result doesn't extend to other languages.
Parameter Object/tuple isomorphism #
The third isomorphism that I claim exists is the one between Parameter Objects and tuples. If, however, we assume that the two above isomorphisms hold, then this third isomorphism exists as well. I know from my copy of Conceptual Mathematics that isomorphisms are transitive. If you can translate from Parameter Object to argument list, and from argument list to tuple, then you can translate from Parameter Object to tuple; and vice versa.
Thus, I'm not going to use more words on this isomorphism.
Summary #
Argument lists, Parameter Objects, and tuples are isomorphic. This has a few interesting implications, first of which is that because all these refactorings exist, you can employ them. If a method's argument list is inconvenient, consider introducing a Parameter Object. If your Parameter Object starts to look so generic that you have a hard time coming up with good names for its elements, perhaps a tuple is more appropriate. On the other hand, if you have a tuple, but it's unclear what role each unnamed element plays, consider refactoring to an argument list or Parameter Object.
Another important result is that since these three ways to model arguments are isomorphic, we can treat them as interchangeable in analysis. For instance, from category theory we can learn about the properties of tuples. These properties, then, also apply to C# and Java argument lists.
Next: Uncurry isomorphisms.
Function isomorphisms
Instance methods are isomorphic to functions.
This article is part of a series of articles about software design isomorphisms.
While I have already, in an earlier article, quoted the following parable about Anton, Qc Na, objects, and closures, it's too good a fit to the current topic to pass up, so please pardon the duplication.
The venerable master Qc Na was walking with his student, Anton. Hoping to prompt the master into a discussion, Anton said "Master, I have heard that objects are a very good thing - is this true?" Qc Na looked pityingly at his student and replied, "Foolish pupil - objects are merely a poor man's closures."
Chastised, Anton took his leave from his master and returned to his cell, intent on studying closures. He carefully read the entire "Lambda: The Ultimate..." series of papers and its cousins, and implemented a small Scheme interpreter with a closure-based object system. He learned much, and looked forward to informing his master of his progress.
On his next walk with Qc Na, Anton attempted to impress his master by saying "Master, I have diligently studied the matter, and now understand that objects are truly a poor man's closures." Qc Na responded by hitting Anton with his stick, saying "When will you learn? Closures are a poor man's object." At that moment, Anton became enlightened.
The point is that objects and closures are two ways of looking at a thing. In a nutshell, objects are data with behaviour, whereas closures are behaviour with data. I've already shown an elaborate C# example of this, so in this article, you'll get a slightly more formal treatment of the subject.
Isomorphism #
In object-oriented design, you often bundle operations as methods that belong to objects. These are isomorphic to static methods, because a lossless translation exists. We can call such static methods functions, although they aren't guaranteed to be pure.
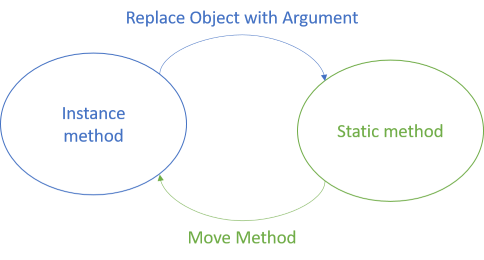
In the spirit of Refactoring, we can describe each translation as a refactoring, because that's what it is. I don't think the book contains a specific refactoring that describes how to translate from an instance method to a static method, but we could call it Replace Object with Argument.
Going the other way is, on the other hand, already described, so we can use Refactoring's Move Method.
Replace Object with Argument #
While the concept of refactoring ought to be neutral across paradigms, the original book is about object-oriented programming. In object-oriented programming, objects are the design ideal, so it didn't make much sense to include, in the book, a refactoring that turns an instance method into a static method.
Nevertheless, it's straightforward:
- Add an argument to the instance method. Declare the argument as the type of the hosting class.
- In the method body, change all calls to
thisandbaseto the new argument. - Make the method static.
Baz method:
public class Foo { public Bar Baz(Qux qux, Corge corge) { // Do stuff, return bar } // Other members... }
You'll first introduce a new Foo foo argument to Baz, change the method body to use foo instead of this, and then make the method static. The result is this:
public class Foo { public static Bar Baz(Foo foo, Qux qux, Corge corge) { // Do stuff, return bar } // Other members... }
Once you have a static method, you can always move it to another class, if you'd like. This can, however, cause some problems with accessibility. In C#, for example, you'd no longer be able to access private or protected members from a method outside the class. You can choose to leave the static method reside on the original class, or you can make the member in question available to more clients (make it internal or public).
Move Method #
The book Refactoring doesn't contain a recipe like the above, because the goal of that book is better object-oriented design. It would consider a static method, like the second variation of Baz above, a code smell named Feature Envy. You have this code smell when it looks as if a method is more interested in one of its arguments than in its host object. In that case, the book suggests using the Move Method refactoring.
The book already describes this refactoring, so I'm not going to repeat it here. Also, there's no sense in showing you the code example, because it's literally the same two code examples as above, only in the opposite order. You start with the static method and end with the instance method.
C# developers are most likely already aware of this relationship between static methods and objects, because you can use the this keyword in a static method to make it look like an instance method:
public static Bar Baz(this Foo foo, Qux qux, Corge corge)
The addition of this in front of the Foo foo argument enables the C# compiler to treat the Baz method as though it's an instance method on a Fooobject:
var bar = foo.Baz(qux, corge);
This is only syntactic sugar. The method is still compiled as a static method, and if you, as a client developer, wish to use it as a static method, that's still possible.
Functions #
A static method like public static Bar Baz(Foo foo, Qux qux, Corge corge) looks a lot like a function. If refactored from object-oriented design, that function is likely to be impure, but its shape is function-like.
In C#, for example, you could model it as a variable of a delegate type:
Func<Foo, Qux, Corge, Bar> baz = (foo, qux, corge) => { // Do stuff, return bar };
Here, baz is a function with the same signature as the above static Baz method.
Have you ever noticed something odd about the various Func delegates in C#?
They take the return type as the last type argument, which is contrary to C# syntax, where you have to declare the return type before the method name and argument list. Since C# is the dominant .NET language, that's surprising, and even counter-intuitive.
It does, however, nicely align with an ML language like F#. As we'll see in a future article, the above baz function translates to an F# function with the type Foo * Qux * Corge -> Bar, and to Haskell as a function with the type (Foo, Qux, Corge) -> Bar. Notice that the return type comes last, just like in the C# Func.
Closures #
...but, you may say, what about data with behaviour? One of the advantages, after all, of objects is that you can associate a particular collection of data with some behaviour. The above Foo class could have data members, and you may sometimes have a need for passing both data and behaviour around as a single... well... object.
That seems to be much harder with a static Baz method.
Don't worry, write a closure:
var foo = new Foo { /* initialize members here */ }; Func<Qux, Corge, Bar> baz = (qux, corge) => { // Do stuff with foo, qux, and corge; return bar };
In this variation, baz closes over foo. Inside the function body, you can use foo like you can use qux and corge. As I've already covered in an earlier article, the C# compiler compiles this to an IL class, making it even more obvious that objects and closures are two sides of the same coin.
Summary #
Object-oriented instance methods are isomorphic to both static methods and function values. The translations that transforms your code from one to the other are refactorings. Since you can move in both directions without loss of information, these refactorings constitute an isomorphism.
This is another important result about the relationship between object-oriented design and functional programming, because this enables us to reduce any method to a canonical form, in the shape of a function. From a language like Haskell, we know a lot about the relationship between category theory and functional programming. With isomorphisms like the present, we can begin to extend that knowledge to object-oriented design.
Next: Argument list isomorphisms.
Unit isomorphisms
The C# and Java keyword 'void' is isomorphic to a data type called 'unit'.
This article is part of a series of articles about software design isomorphisms.
Many programming languages, such as C# and Java, distinguish between methods that return something, and methods that don't return anything. In C# and Java, a method must be declared with a return type, but if it doesn't return anything, you can use the special keyword void to indicate that this is the case:
public void Foo(int bar)
This is a C# example, but it would look similar (isomorphic?) in Java.
Two kinds of methods #
In C# and Java, void isn't a type, but a keyword. This means that there are two distinct types of methods:
- Methods that return something
- Methods that return nothing
public Foo Bar(Baz baz, Qux qux)
On the other hand, methods that return nothing must use the special void keyword:
public void Bar(Baz baz, Qux qux)
If you want to generalise, you can use generics like this:
public T Foo<T, T1, T2>(T1 x, T2 y)
Such a method could return anything, but, surprisingly, not nothing. In C# and Java, nothing is special. You can't generalise all methods to a common set. Even with generics, you must model methods that return nothing in a different way:
public void Foo<T1, T2>(T1 x, T2 y)
In C#, for example, this leads to the distinction between Func and Action. You can't reconcile these two fundamentally distinct types of methods into one.
Visual Basic .NET makes the same distinction, but uses the keywords Sub and Function instead of void.
Sometimes, particularly when writing code with generics, this dichotomy is really annoying. Wouldn't it be nice to be able to generalise all methods?
Unit #
While I don't recall the source, I've read somewhere the suggestion that the keyword void was chosen to go with null, because null and void is an English (legal) idiom. That choice is, however, unfortunate.
In category theory, the term void denotes a type or set with no inhabitants (e.g. an empty set). That sounds like the same concept. The problem, from a programming perspective, is that if you have a (static) type with no inhabitants, you can't create an instance of it. See Bartosz Milewski's article Types and Functions for a great explanation and more details.
Functional programming languages like F# and Haskell instead model nothing by a type called unit (often rendered as empty brackets: ()). This type is a type with exactly one inhabitant, a bit like a Singleton, but with the extra restriction that the inhabitant carries no information. It simply is.
It may sound strange and counter-intuitive that a singleton value represents nothing, but it turns out that this is, indeed, isomorphic to C# or Java's void.
This is admirably illustrated by F#, which consistently uses unit instead of void. F# is a multi-paradigmatic language, so you can write classes with methods as well as functions:
member this.Bar (x : int) = ()
This Bar method has the return type unit. When you compile F# code, it becomes Intermediate Language, which you can decompile into C#. If you do that, the above F# code becomes:
public void Bar(int x)
The inverse translation works as well. When you use F#'s interoperability features to interact with objects written in C# or Visual Basic, the F# compiler interprets void methods as if they return unit. For example, calling GC.Collect returns unit in F#, although C# sees it as 'returning' void:
> GC.Collect 0;; val it : unit = ()
F#'s unit is isomorphic to C#'s void keyword, but apart from that, there's nothing special about it. It's a value like any other, and can be used in generically typed functions, like the built-in id function:
> id 42;; val it : int = 42 > id "foo";; val it : string = "foo" > id ();; val it : unit = ()
The built-in function id simply returns its input argument. It has the type 'a -> 'a, and as the above F# Interactive session demonstrates, you can call it with unit as well as with int, string, and so on.
Monoid #
Unit, by the way, forms a monoid. This is most evident in Haskell, where this is encoded into the type. In general, a monoid is a binary operation, and not a type, but what could the combination of two () (unit) values be, other than ()?
λ> mempty :: () () λ> mappend () () ()
In fact, the above (rhetorical) question is imprecise, since there aren't two unit values. There's only one, but used twice.
Since only a single unit value exists, any binary operation is automatically associative, because, after all, it can only return unit. Likewise, unit is the identity (mempty) for the operation, because it doesn't change the output. Thus, the monoid laws hold, and unit forms a monoid.
This result is interesting when you start to think about composition, because a monoid can always be used to reduce (aggregate) multiple values to a single value. With this result, and unit isomorphism, we've already explained why Commands are composable.
Summary #
Since unit is a type only inhabited by a single value, people (including me) often use the word unit about both the type and its only value. Normally, the context surrounding such use is enough to dispel any ambiguity.
Unit is isomorphic to C# or Java void. This is an important result, because if we're to study software design and code structure, we don't have to deal with two distinct cases (methods that return nothing, and methods that return something). Instead, we can ignore methods that return nothing, because they can instead be modelled as methods that return unit.
The reason I've titled this article in the plural is that you could view the isomorphism between F# unit and C# void as a different isomorphism than the one between C# and Java void. Add Haskell's () (unit) type and Visual Basic's Sub keyword to the mix, and it should be clear that there are many translations to the category theory concept of Unit.
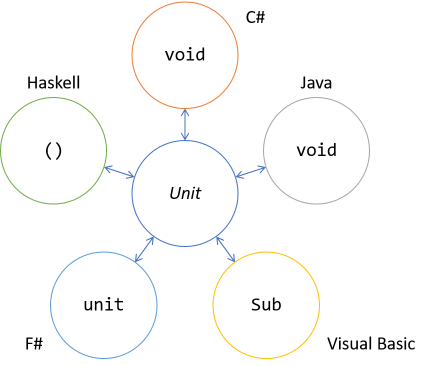
Unit isomorphism is an example of an interlingual isomorphism, in the sense that C# void maps to F# unit, and vice versa. In the next example, you'll see an isomorphism that mostly stays within a single language, although a translation between languages is also pertinent.
Next: Function isomorphisms.
Software design isomorphisms
When programming, you can often express the same concept in multiple ways. If you can losslessly translate between two alternatives, it's an isomorphism. An introduction for object-oriented programmers.
This article series is part of an even larger series of articles about the relationship between design patterns and category theory.
There's a school of functional programming that looks to category theory for inspiration, verification, abstraction, and cross-pollination of ideas. Perhaps you're put off by terms like zygohistomorphic prepromorphism (a joke), but you shouldn't be. There are often good reasons for using abstract naming. In any case, one term from category theory that occasionally makes the rounds is isomorphism.
Equivalence #
Don't let the terminology daunt you. An isomorphism is an easy enough concept to grasp. In essence, two things are isomorphic if you can translate losslessly back and forth between them. It's a formalisation of equivalence.
Many programming languages, like C# and Java, offer a multitude of alternative ways to do things. Just consider this C# example from my Humane Code video:
public bool IsSatisfiedBy(Customer candidate) { bool retVal; if (candidate.TotalPurchases >= 10000) retVal = true; else retVal = false; return retVal; }
which is equivalent to this:
public bool IsSatisfiedBy(Customer candidate) { return candidate.TotalPurchases >= 10000; }
An outside observer can't tell the difference between these two implementations, because they have exactly the same externally visible behaviour. You can always refactor from one implementation to the other without loss of information. Thus, we could claim that they're isomorphic.
Terminology #
If you're an object-oriented programmer, then you already know the word polymorphism, which sounds similar to isomorphism. Perhaps you've also heard the word xenomorph. It's all Greek. Morph means form or shape, and while poly means many, iso means equal. So isomorphism means 'being of equal shape'.
This is most likely the explanation for the term Isomorphic JavaScript. The people who came up with that term knew (enough) Greek, but apparently not mathematics. In mathematics, and particularly category theory, an isomorphism is a translation with an inverse. That's still not a formal definition, but just my attempt at presenting it without too much jargon.
Category theory uses the word object to describe a member of a category. I'm going to use that terminology here as well, but you should be aware that object doesn't imply object-oriented programming. It just means 'thing', 'item', 'element', 'entity', etcetera.
In category theory, a morphism is a mapping or translation of an object to another object. If, for all objects, there's an inverse morphism that leads back to the origin, then it's an isomorphism.
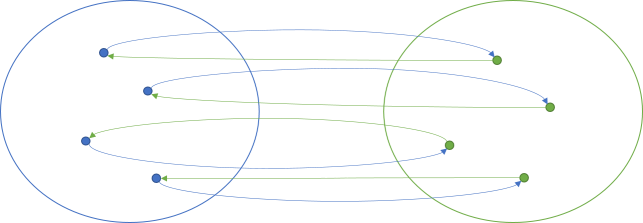
In this illustration, the blue arrows going from left to right indicate a single morphism. It's a mapping of objects on the blue left side to objects on the green right side. The green arrows going from right to left is another morphism. In this case, the green right-to-left morphism is an inverse of the blue left-to-right morphism, because by applying both morphisms, you end where you started. It doesn't matter if you start at the blue left side or the green right side.
Another way to view this is to say that a lossless translation exists. When a translation is lossless, it means that you don't lose information by performing the translation. Since all information is still present after a translation, you can go back to the original representation.
Software design isomorphisms #
When programming, you can often solve the same problem in different ways. Sometimes, the alternatives are isomorphic: you can go back and forth between two alternatives without loss of information.
Martin Fowler's book Refactoring contains several examples. For instance, you can apply Extract Method followed by Inline Method and be back where you started.
There are many other isomorphisms in programming. Some are morphisms in the same language, as is the case with the above C# example. This is also the case with the isomorphisms in Refactoring, because a refactoring, by definition, is a change applied to a particular code base, be it C#, Java, Ruby, or Python.
Other programming isomorphisms go between languages, where a concept can be modelled in one way in, say, C++, but in another way in Clojure. The present blog, for instance, contains several examples of translating between C# and F#, and between F# and Haskell.
Being aware of software design isomorphisms can make you a better programmer. It'll enable you to select the best alternative for solving a particular problem. Identifying programming isomorphisms is also important because it'll enable us to formally think about code structure by reducing many alternative representations to a canonical representation. For these reasons, this article presents a catalogue of software design isomorphisms:
- Unit isomorphisms
- Function isomorphisms
- Argument list isomorphisms
- Uncurry isomorphisms
- Object isomorphisms
- Abstract class isomorphism
- Inheritance-composition isomorphism
- Tester-Doer isomorphisms
- Builder isomorphisms
Many more software design isomorphisms exist, so if you revisit this article in the future, I may have added more items to this catalogue. In no way should you consider this catalogue exhaustive.
Summary #
An isomorphism is a mapping for which an inverse mapping also exists. It's a way to describe equivalence.
In programming, you often have the choice to implement a particular feature in more than one way. These alternatives may be equivalent, in which case they're isomorphic. That's one of the reasons that many code bases come with a style guide.
Understanding how code is isomorphic to other code enables us to reduce many alternatives to a canonical representation. This makes analysis easier, because we can narrow our analysis to the canonical form, and generalise from there.
Next: Unit isomorphisms.
Comments
Sergey, thank you for writing. Good point, you're right that viewed as a general-purpose translation, Inline Method is indeed lossy. When you look at the purpose of refactoring code, the motivation is mostly (if not always) to make the code better in some way. Particularly when the purpose is make the code more readable, a refactoring introduces clarity. Thus, going the opposite way would remove that clarity, so I think it's fair to argue that such a change would be lossy.
It's perfectly reasonable to view a refactoring like Inline Method as a general-purpose algorithm, in which case you're right that it's lossy. I don't dispute that.
My agenda with this article series, however, is different. I'm not trying to make multiple angels dance on a pinhead; it's not my intent to try to redefine the word refactoring. The purpose with this series of articles is to describe how the same behaviour can be implemented in many different ways. The book Refactoring is one source of such equivalent representations.
One quality of morphisms is that there can be several translations between two objects. One such translation could be the general-purpose refactoring that you so rightly point out is lossy. Another translation could be one that 'remembers' the name of the original method.
Take, as an example, the isomorphism described under the heading Roster isomorphism in my article Tuple monoids. When you consider the method ToTriple, you could, indeed, argue that it's lossy, because it 'forgets' that the label associated with the first integer is Girls, that the label associated with the second integer is Boys, and so on. The reverse translation, however, 'remembers' that information, as you can see in the implementation of FromTriple.
This isn't necessarily a 'safe' translation. You could easily write a method like this:
public static Roster FromTriple(Tuple<int, int, string[]> triple) { return new Roster(triple.Item2, triple.Item1, triple.Item3); }
This compiles, but it translates triples created by ToTriple the wrong way.
On the other hand, the pair of translations that I do show in the article is an isomorphism. The point is that an isomorphism exists; not that it's the only possible set of morphisms.
The same argument can be applied to specific pairs of Extract Method and Inline Method. As a general-purpose algorithm, I still agree that Inline Method is lossy. That doesn't preclude that specific pairs of translations exist. For instance, in an article, I discuss how some people refactor Guard Clauses like this:
if (subject == null) throw new ArgumentNullException("subject");
to something like this:
Guard.AgainstNull(subject, "subject");
Again, an isomorphism exists: a translation from a Null Guard to Guard.AgainstNull, and another from Guard.AgainstNull to a Null Guard. Those are specific incarnations of Extract Method and Inline Method.
This may not be particularly useful as a refactoring, I admit, but that's also not the agenda of these articles. The programme is to show how particular software behaviour can be expressed in various different ways that are equivalent to each other.
Colour-mixing magma
Mixing RGB colours forms a magma. An example for object-oriented programmers.
This article is part of a larger series about monoids, semigroups, and other group-like algebraic structures. In this article, you'll see an example of a magma, which is a binary operation without additional constraints.
RGB colours #
The opening article about monoids, semigroups, and their friends emphasised Eric Evans' pigment mixing example from Domain-Driven Design. The following article series then promptly proceeded to ignore that example. The reason is that while the example has Closure of Operations, it exhibits precious few other properties. It's neither monoid, semigroup, quasigroup, nor any other named binary operation, apart from being a magma.
Instead of pigments, consider a more primitive, but well-understood colour model: that of RGB colours. In C#, you can model RGB colours using a struct that holds three byte fields. In my final code base, I ended up implementing ==, !=, Equals, and so on, but I'm not going to bore you with all of those details. Here's the RgbColor constructor, so that you can get a sense of the type:
private readonly byte red; private readonly byte green; private readonly byte blue; public RgbColor(byte red, byte green, byte blue) { this.red = red; this.green = green; this.blue = blue; }
As you can see, RgbColor holds three byte fields, one for red, green, and blue. If you want to mix two colours, you can use the MixWith instance method:
public RgbColor MixWith(RgbColor other) { var newRed = ((int)this.red + (int)other.red) / 2m; var newGreen = ((int)this.green + (int)other.green) / 2m; var newBlue = ((int)this.blue + (int)other.blue) / 2m; return new RgbColor( (byte)Math.Round(newRed), (byte)Math.Round(newGreen), (byte)Math.Round(newBlue)); }
This is a binary operation, because it's an instance method on RgbColor, taking another RgbColor as input, and returning RgbColor. Since it's a binary operation, it's a magma, but could it be another, stricter category of operation?
Lack of associativity #
Could MixWith, for instance, be a semigroup? In order to be a semigroup, the binary operation must be associative, and while it can be demanding to prove that an operation is always associative, it only takes a single counter-example to prove that it's not:
[Fact] public void MixWithIsNotAssociative() { // Counter-example var x = new RgbColor( 67, 108, 13); var y = new RgbColor( 33, 114, 130); var z = new RgbColor( 38, 104, 245); Assert.NotEqual( x.MixWith(y).MixWith(z), x.MixWith(y.MixWith(z))); }
This xUnit.net unit test passes, thereby demonstrating that MixWith is not associative. When you mix x with y, you get #326F48, and when you mix that with z you get #2C6C9E. On the other hand, when you mix y with z you get #246DBC, which, combined with x, gives #346C64. #2C6C9E is not equal to #346C64, so the NotEqual assertion passes.
Because of this counter-example, MixWith isn't associative, and therefore not a semigroup. Since monoid requires associativity as well, we can also rule out that MixWith is a monoid.
Lack of invertibility #
While MixWith isn't a semigroup, could it be a quasigroup? In order to be a quasigroup, a binary operation must be invertible. This means that for any two elements a and b, there must exist two other elements x and y that turns a into b.
This property must hold for all values involved in the binary operation, so again, a single counter-example suffices to demonstrate that MixWith isn't invertible, either:
[Fact] public void MixWithIsNotInvertible() { // Counter-example var a = new RgbColor( 94, 35, 172); var b = new RgbColor(151, 185, 7); Assert.False(RgbColor.All.Any(x => a.MixWith(x) == b)); Assert.False(RgbColor.All.Any(y => y.MixWith(a) == b)); }
This xUnit.net-based test also passes. It uses brute force to demonstrate that for all RgbColor values, there's no x and y that satisfy the invertibility property. The test actually takes a while to execute, because All returns all 16,777,216 possible RgbColor values:
private static RgbColor[] all; private readonly static object syncLock = new object(); public static IReadOnlyCollection<RgbColor> All { get { if (all == null) lock (syncLock) if (all == null) { var max = 256 * 256 * 256; all = new RgbColor[max]; foreach (var i in Enumerable.Range(0, max)) all[i] = (RgbColor)i; } return all; } }
For performance reasons, the All property uses lazy initialisation with double-checked locking. It simply counts from 0 to 256 * 256 * 256 (16,777,216) and converts each integer to an RgbColor value using this explicit conversion:
public static explicit operator RgbColor(int i) { var red = (i & 0xFF0000) / 0x10000; var green = (i & 0xFF00) / 0x100; var blue = i & 0xFF; return new RgbColor((byte)red, (byte)green, (byte)blue); }
The bottom line, though, is that the test passes, thereby demonstrating that for the chosen counter-example, no x and y satisfies the invertibility property. Therefore, MixWith isn't a quasigroup.
Lack of identity #
Since MixWith is neither associative nor invertible, it's not really any named algebraic construct, other than a magma. It's neither group, semigroup, quasigroup, monoid, loop, groupoid, etc. Does it have any properties at all, apart from being a binary operation?
It doesn't have identity either, which you can illustrate with another counter-example:
[Fact] public void MixWithHasNoIdentity() { var nearBlack = new RgbColor(1, 1, 1); var identityCandidates = from e in RgbColor.All where nearBlack.MixWith(e) == nearBlack select e; // Verify that there's only a single candidate: var identityCandidate = Assert.Single(identityCandidates); // Demonstrate that the candidate does behave like identity for // nearBlack: Assert.Equal(nearBlack, nearBlack.MixWith(identityCandidate)); Assert.Equal(nearBlack, identityCandidate.MixWith(nearBlack)); // Counter-example var counterExample = new RgbColor(3, 3, 3); Assert.NotEqual( counterExample, counterExample.MixWith(identityCandidate)); }
The counter-example starts with a near-black colour. The reason I didn't pick absolute black (new RgbColor(0, 0, 0)) is that, due to rounding when mixing, there are eight candidates for absolute black, but only one for nearBlack. This is demonstrated by the Assert.Single assertion. identityCandidate, by the way, is also new RgbColor(1, 1, 1), and further Guard Assertions demonstrate that identityCandidate behaves like the identity for nearBlack.
You can now pick another colour, such as new RgbColor(3, 3, 3) and demonstrate that identityCandidate does not behave like the identity for the counter-example. Notice that the assertion is Assert.NotEqual.
If an identity exists for a magma, it must behave as the identity for all possible values. That's demonstrably not the case for MixWith, so it doesn't have identity.
Commutativity #
While MixWith is neither associative, invertible, nor has identity, it does have at least one property: it's commutative. This means that the order of the input values doesn't matter. In other words, for any two RgbColor values x and y, this assertion always passes:
Assert.Equal(
x.MixWith(y),
y.MixWith(x));
Since x.MixWith(y) is equal to y.MixWith(x), MixWith is commutative.
Summary #
The MixWith operation is a commutative magma, but while, for example, we call an associative magma a semigroup, there's no fancy word for a commutative magma.
In this article, you got another, fairly realistic, example of a binary operation. Throughout the overall article series on monoids, semigroup, and other group-like algebraic structures, you've seen many examples, and you've learned how to analyse binary operations for the presence or absence of various properties. The present article concludes the series. You can, however, continue reading the even more overall article series.
Comments
At first, the lack of associativity felt counterintuitive: If I take equals parts of three colors, it shouldn't matter in which order I mix them. Then I realized this function doesn't take equal parts of all three. Basically the first mixture mixes one unit of each of two colors, resulting in two units of mixture. Then the second mixture takes one unit of the first mixture and one unit of the third color. That's why it's not associative!
Mark, thank you for writing. I never gave that question that much attention when I wrote the article, but that makes total sense. Thank you for explaining it.
Rock Paper Scissors magma
The Rock Paper Scissors game forms a magma. An example for object-oriented programmers.
This article is part of a larger series about monoids, semigroups, and other group-like algebraic structures. In this article, you'll see an example of a magma, which is a binary operation without additional constraints.
Rock Paper Scissors #
When my first child was born, my wife and I quickly settled on a first name, but we couldn't agree on the surname, since we don't share the same surname. She wanted our daughter to have her surname, and I wanted her to have mine. We couldn't think of any rational arguments for one or the other, so we decided to settle the matter with a game of Rock Paper Scissors. I lost, so my daughter has my wife's surname.
Despite that outcome, I still find that Rock Paper Scissors is a great way to pick between two equally valid alternatives. You could also flip a coin, or throw a die, but most people have their hands handy, so to speak.
In C#, you can model the three shapes of rock, paper, and scissors like this:
public abstract class Rps { public readonly static Rps Rock = new R(); public readonly static Rps Paper = new P(); public readonly static Rps Scissors = new S(); private Rps() { } private class R : Rps { } private class P : Rps { } private class S : Rps { } // More members... }
I've seen more than one example where people use an enum to model the three shapes, but I believe that this is wrong, because enums have an order to them, including a maximum and a minimum value (by default, enum is implemented with a 32-bit integer). That's not how Rock Paper Scissors work, so instead, I chose a different model where Rock, Paper, and Scissors are Singletons.
This design works for the example, although I'm not entirely happy with it. The problem is that Rock, Paper, and Scissors should be a finite set, but by making Rps abstract, another developer could, conceivably, create additional derived classes. A finite sum type would have been better, but this isn't easily done in C#. In a language with algebraic data types, you can make a prettier implementation, like this Haskell example. F# would be another good language option.
Binary operation #
When playing the game of Rock Paper Scissors, each round is a throw that compares two shapes. You can model a throw as a binary operation that returns the winning shape:
public static Rps Throw(Rps x, Rps y) { if (x == Rock && y == Rock) return Rock; if (x == Rock && y == Paper) return Paper; if (x == Rock && y == Scissors) return Rock; if (x == Paper && y == Paper) return Paper; if (x == Paper && y == Scissors) return Scissors; if (x == Paper && y == Rock) return Paper; if (x == Scissors && y == Scissors) return Scissors; if (x == Scissors && y == Rock) return Rock; return Scissors; }
To a C# programmer, perhaps the method name Throw is bewildering, because you might expect the method to throw an exception, but I chose to use the domain language of the game.
Because this method takes two Rps values as input and returns an Rps value as output, it's a binary operation. Thus, you already know it's a magma, but could it, also, be another, stricter binary operations, such as a semigroup or quasigroup?
Lack of associativity #
In order to be a semigroup, the binary operation must be associative. You can easily demonstrate that Throw isn't associative by use of a counter-example:
[Fact] public void ThrowIsNotAssociative() { // Counter-example Assert.NotEqual( Rps.Throw(Rps.Throw(Rps.Paper, Rps.Rock), Rps.Scissors), Rps.Throw(Rps.Paper, Rps.Throw(Rps.Rock, Rps.Scissors))); }
This xUnit.net unit test passes, thereby demonstrating that Throw is not associative. The result of paper versus rock is paper, which, pitted against scissors yields scissors. On the other hand, paper versus the result of rock versus scissors is paper, because rock versus scissors is rock, and rock versus paper is paper.
Since Throw isn't associative, it's not a semigroup (and, by extension, not a monoid). Could it be a quasigroup?
Lack of invertibility #
A binary operation must be invertible in order to be a quasigroup. This means that for any two elements a and b, there must exist two other elements x and y that turns a into b.
This property must hold for all values involved in the binary operation - in this case Rock, Paper, and Scissors. A single counter-example is enough to show that Throw is not invertible:
[Fact] public void ThrowIsNotInvertible() { // Counter-example var a = Rps.Rock; var b = Rps.Scissors; Assert.False(Rps.All.Any(x => Rps.Throw(a, x) == b)); Assert.False(Rps.All.Any(y => Rps.Throw(y, a) == b)); }
This (passing) unit test utilises an All property on Rps:
public static IReadOnlyCollection<Rps> All { get { return new[] { Rock, Paper, Scissors }; } }
For a counter-example, pick Rock as a and Scissors as b. There's no value in All that satisfies the invertibility property. Therefore, Throw is not a quasigroup, either.
Lack of identity #
Since Throw is neither associative nor invertible, it's not really any named algebraic construct, other than a magma. It's neither group, semigroup, quasigroup, monoid, loop, groupoid, etc. Does it have any properties at all, apart from being a binary operation?
It doesn't have identity either, which you can illustrate with another counter-example:
[Fact] public void ThrowHasNoIdentity() { // Find all identity candidates for Rock var rockIdentities = from e in Rps.All where Rps.Throw(e, Rps.Rock) == Rps.Rock && Rps.Throw(Rps.Rock, e) == Rps.Rock select e; // Narrow for Paper var paperIdentities = from e in rockIdentities where Rps.Throw(e, Rps.Paper) == Rps.Paper && Rps.Throw(Rps.Paper, e) == Rps.Paper select e; // None of those candidates are the identity for Scissors var scissorIdentities = from e in paperIdentities where Rps.Throw(e, Rps.Scissors) == Rps.Scissors && Rps.Throw(Rps.Scissors, e) == Rps.Scissors select e; Assert.Empty(scissorIdentities); }
First, you use Rps.All to find all the values that behave as an identity element for Rps.Rock. Recall that the identity is an element that doesn't change the input. In other words it's a value that when combined with Rps.Rock in Throw still returns Rps.Rock. There are two values that fulfil that property: Rps.Rock and Rps.Scissors. Those are the two values contained in rockIdentities.
In order to be an identity, the value must behave as a neutral element for all possible values, so next, filter rockIdentities to find those elements that also behave as identities for Rps.Paper. Between Rps.Rock and Rps.Scissors, only Rps.Rock behaves like an identity for Rps.Paper, so paperIdentities is a collection containing only the single value Rps.Rock.
Is Rps.Rock an identity for Rps.Scissors, then? It's not. scissorIdentities is empty. There's no element in Rps.All that acts an identity for all values in Rps.All. Therefore, by brute force, the test ThrowHasNoIdentity demonstrates (as it says on the tin) that throw has no identity.
Commutativity #
While Throw is neither associative, invertible, nor has identity, it does have at least one property: it's commutative. This means that the order of the input values doesn't matter. In other words, for any two Rps values x and y, this assertion always passes:
Assert.Equal( Rps.Throw(x, y), Rps.Throw(y, x));
Since Rps.Throw(x, y) is equal to Rps.Throw(y, x), Throw is commutative.
Summary #
The Rock Paper Scissors Throw operation is a commutative magma, but while, for example, we call an associative magma a semigroup, there's no fancy word for a commutative magma.
Next: Colour-mixing magma.
Magmas
A binary operation with no constraints on its behaviour is called a magma. An introduction for object-oriented programmers.
In the overall article series about group-like algebraic structures, you've so far seen examples of monoids, semigroups, and quasigroups. Common to all of these structures is that they are binary operations governed by at least one law. The laws are different for the different categories, but there are rules.
What if you have a binary operation that follows none of those rules?
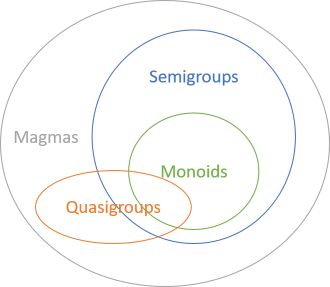
All binary operations are magmas. If they have additional properties, we may call them quasigroups, or monoids, or some such, depending on the specific properties, but they're still all magmas. This is the most inclusive category.
You've already seen examples of monoids and semigroups, but what about magma examples? In a sense, you've already seen those as well, because all the examples you've seen so far have also been magma examples. After all, since all monoids are magmas, all the monoid examples you've seen have also been magma examples.
Still, it's not that hard to come up with some programming examples of magmas that aren't semi- or quasigroups. In the next articles, you'll see some examples.
Particularly the second example is fairly realistic, which demonstrates that as programmers, we can benefit from having vocabulary that enables us to describe any binary operation that doesn't obey any particular laws. In fact, establishing a vocabulary has been my primary motivation for writing this article series.Quasigroups
A brief introduction to quasigroups for object-oriented programmers.
This article is part of a larger series about monoids, semigroups, and other group-like algebraic structures. In this article, you'll get acquainted with the concept of a quasigroup. I don't think it plays that big of a role in software design, but it is a thing, and I thought that I'd cover it briefly with a well known-example.
During all this talk of monoids and semigroups, you've seen that normal arithmetic operations like addition and multiplication form monoids. Perhaps you've been wondering where subtraction fits in.
Subtraction forms a quasigroup.
What's a quasigroup? It's an invertible binary operation.
Inversion #
What does it mean for a binary operation to be invertible? It means that for any two elements a and b, there must exist two other elements x and y that turns a into b.
This is true for subtraction, as this FsCheck-based test demonstrates:
[Property(QuietOnSuccess = true)] public void SubtractionIsInvertible(int a, int b) { var x = a - b; var y = a + b; Assert.True(a - x == b); Assert.True(y - a == b); }
This example uses the FsCheck.Xunit glue library for xUnit.net. Notice that although FsCheck is written in F#, you can also use it from C#. This test (as well as all other tests in this article) passes.
For any a and b generated by FsCheck, we can calculate unique x and y that satisfy a - x == b and y - a == b.
Subtraction isn't the only invertible binary operation. In fact, addition is also invertible:
[Property(QuietOnSuccess = true)] public void AdditionIsInvertible(int a, int b) { var x = b - a; var y = b - a; Assert.True(a + x == b); Assert.True(y + a == b); Assert.Equal(x, y); }
Here I added a third assertion that demonstrates that for addition, the inversion is symmetric; x and y are equal.
Not only is integer addition a monoid - it's also a quasigroup. In fact, it's a group. Being associative or having identity doesn't preclude a binary operation from being a quasigroup, but these properties aren't required.
No identity #
No identity element exists for integer subtraction. For instance, 3 - 0 is 3, but 0 - 3 is not 3. Therefore, subtraction can't be a monoid.
No associativity #
Likewise, subtraction is not an associative operation. You can easily convince yourself of that by coming up with a counter-example, such as (3 - 2) - 1, which is 0, but different from 3 - (2 - 1), which is 2. Therefore, it can't be a semigroup either.
Summary #
A quasigroup is an invertible binary operation. Invertibility is the only required property of a quasigroup (apart from being a binary operation), but if it has other properties (like associativity), it's still a quasigroup.
I haven't had much utility from thinking about software design in terms of quasigroups, but I wanted to include it in case you were wondering how subtraction fits into all of this.
What if, however, you have a binary operation with no other properties?
Next: Magmas.
Comments
Is division over real numbers also a quasigroup? I think so, for any number a and b we have x and y such that:
a / x = b
y / a = b
I think division over integers is not a quasigroup since for 5 and 10 there is no x such that 5 / x = 10 since 0.5 is not an integer.
Onur, thank you for writing. In general, when pondering pure mathematics rather than their programming aspects, I'm no authority. You'd be better off researching somewhere else. The Wikipedia article on quasigroups isn't too bad for that purpose, I find.
According to that article, division of non-zero rational or real numbers is an invertible binary operation.
As far as I can tell (I'm not a mathematician) you're correct that integer division doesn't form a quasigroup. When, as you suggestion, you pick a = 5 and b = 10, there's no integer x for which 5 / x = 10.
Semigroups accumulate
You can accumulate an arbitrary, non-zero number of semigroup values to a single value. An article for object-oriented programmers.
This article is part of a series about semigroups. In short, a semigroup is an associative binary operation.
As you've learned in a previous article, you can accumulate an arbitrary number of monoidal values to a single value. A corresponding property holds for semigroups.
Monoid accumulation #
When an instance method Op forms a monoid, you can easily write a function that accumulates an arbitrary number of Foo values:
public static Foo Accumulate(IReadOnlyCollection<Foo> foos) { var acc = Identity; foreach (var f in foos) acc = acc.Op(f); return acc; }
Notice how this generally applicable algorithm starts with the Identity value. One implication of this is that when foos is empty, the return value will be Identity. When Op is a semigroup, however, there's no identity, so this doesn't quite work. You need a value to start the accumulation; something you can return if the collection is empty.
Semigroup accumulation #
From Haskell you can learn that if you have a semigroup, you can accumulate any non-empty collection:
sconcat :: Semigroup a => NonEmpty a -> a
You can read this as: for any generic type a, when a forms a Semigroup, the sconcat function takes a non-empty list of a values, and reduces them to a single a value. NonEmpty a is a list with at least one element.
NotEmptyCollection #
You can also define a NotEmptyCollection<T> class in C#:
public class NotEmptyCollection<T> : IReadOnlyCollection<T> { public NotEmptyCollection(T head, params T[] tail) { if (head == null) throw new ArgumentNullException(nameof(head)); this.Head = head; this.Tail = tail; } public T Head { get; } public IReadOnlyCollection<T> Tail { get; } public int Count { get => this.Tail.Count + 1; } public IEnumerator<T> GetEnumerator() { yield return this.Head; foreach (var item in this.Tail) yield return item; } IEnumerator IEnumerable.GetEnumerator() { return this.GetEnumerator(); } }
Because of the way the constructor is defined, you must supply at least one element in order to create an instance. You can provide any number of extra elements via the tail array, but one is minimum.
The Count property returns the number of elements in Tail, plus one, because there's always a Head value.
The GetEnumerator method returns an iterator that always starts with the Head value, and proceeds with all the Tail values, if there are any.
Finding the maximum of a non-empty collection #
As you've already learned, Math.Max is a semigroup. Although the .NET Base Class Library has built-in methods for this, you can use a generally applicable algorithm to find the maximum value in a non-empty list of integers.
private static int Accumulate(NotEmptyCollection<int> numbers) { var acc = numbers.Head; foreach (var n in numbers.Tail) acc = Math.Max(acc, n); return acc; }
Notice how similar this algorithm is to monoid accumulation! The only difference is that instead of using Identity to get started, you can use Head, and then loop over all elements of Tail.
You can use it like this:
var nec = new NotEmptyCollection<int>(42, 1337, 123); var max = Accumulate(nec);
Here, max is obviously 1337.
As usual, however, this is much nicer, and more succinct in Haskell:
Prelude Data.Semigroup Data.List.NonEmpty> getMax $ sconcat $ fmap Max $ 42 :| [1337, 123] 1337
That's hardly the idiomatic way of getting a maximum element in Haskell, but it does show how you can 'click together' concepts in order to achieve a goal.
Aggregate #
Perhaps the observant reader will, at this point, have recalled to him- or herself that the .NET Base Class Library already includes an Aggregate extension method, with an overload that takes a seed. In general, the simpliest Aggregate method doesn't gracefully handle empty collections, but using the overload that takes a seed is more robust. You can rewrite the above Accumulate method using Aggregate:
private static int Accumulate(NotEmptyCollection<int> numbers) { return numbers.Tail.Aggregate( numbers.Head, (x, y) => Math.Max(x, y)); }
Notice how you can pass Head as the seed, and accumulate the Tail using that starting point. The Aggregate method is more like Haskell's sconcat for semigroups than mconcat for monoids.
Summary #
A semigroup operation can be used to reduce values to a single value, just like a monoid can. The only difference is that a semigroup operation can't reduce an empty collection, whereas a monoid can.
Next: Quasigroups

Comments
This Isomorphism applies to non-polymorphic Methods. Polymorphic Functions need to be mapped to a Set is static Methods with the same Signature. Is there a functional Construct for this?
Matt, thank you for writing. What makes you write that this isomorphism applies (only, I take it) to non-polymorphic methods. The view here is on the implementation. In C# (and all other statically typed languages that I know that support functions), functions are polymorphic based on signature.
A consumer that depends on a function with the type
Func<Foo, Qux, Corge, Bar>can interact with any function with that type.