ploeh blog danish software design
From Test Data Builders to the identity functor
The Test Data Builder unit testing design pattern is closely related to the identity functor.
The Test Data Builder design pattern is a valuable technique for managing data for unit testing. It enables you to express test cases in such a way that the important parts of the test case stands out in your code, while the unimportant parts disappear. It perfectly fits Robert C. Martin's definition of an abstraction:
"Abstraction is the elimination of the irrelevant and the amplification of the essential"Not only are Test Data Builders great abstractions, but they're also eminently composable. You can use fine-grained Test Data Builders as building blocks for more complex Test Data Builders. This turns out to be more than a coincidence. In this series of articles, you'll learn how Test Data Builders are closely related to the identity functor. If you don't know what a functor is, then keep reading; you'll learn about functors as well.
- Test Data Builders in C#
- Generalised Test Data Builder
- The Builder functor
- Builder as Identity
- Test data without Builders
- (The Test Data Generator functor)
- How to make your code easier to use in unit tests.
- What a functor is.
- How Test Data Builders generalise.
- Why Test Data Builders are composable.
For readers wondering if this is 'yet another monad tutorial', it's not; it's a functor tutorial.
Next: Test Data Builders in C#.
F# free monad recipe
How to create free monads in F#.
This is not a design pattern, but it's something related. Let's call it a recipe. A design pattern should, in my opinion, be fairly language-agnostic (although hardly universally applicable). This article, on the contrary, specifically addresses a problem in F#:
How do you create a free monad in F#?
By following the present recipe.
The recipe here is a step-by-step process, but be sure to first read the sections on motivation and when to use it. A free monads isn't a goal in itself.
This article doesn't attempt to explain the details of free monads, but instead serve as a reference. For an introduction to free monads, I think my article Pure times is a good place to start. See also the Motivating examples section, below.
Motivation #
A frequently asked question about F# is: what's the F# equivalent to an interface? There's no single answer to this question, because, as always, It Depends™. Why do you need an interface in the first place? What is its intended use?
Sometimes, in OOP, an interface can be used for a Strategy. This enables you to dynamically replace or select between different (sub)algorithms at run-time. If the algorithm is pure, then an idiomatic F# equivalent would be a function.
At other times, though, the person asking the question has Dependency Injection in mind. In OOP, dependencies are often modelled as interfaces with several members. Such dependencies are systematically impure, and thereby not part of functional design. If at all possible, prefer impure/pure/impure sandwiches over interactions. Sometimes, however, you'll need something that works like an interface or abstract base class. Free monads can address such situations.
In general, a free monad allows you to build a monad from any functor, but why would you want to do that? The most common reason I've encountered is exactly in order to model impure interactions in a pure manner; in other words: Dependency Injection.
Refactor interface to functor #
This recipe comes in three parts:
- A recipe for refactoring interfaces to a functor.
- The core recipe for creating a monad from any functor.
- A recipe for adding an interpreter.
Imagine that you have an interface that you'd like to refactor. In C# it might look like this:
public interface IFace { Out1 Member1(In1 input); Out2 Member2(In2 input); }
In F#, it'd look like this:
type IFace = abstract member Member1 : input:In1 -> Out1 abstract member Member2 : input:In2 -> Out2
I've deliberately kept the interface vague and abstract in order to showcase the recipe instead of a particular example. For realistic examples, refer to the examples section, further down.
To refactor such an interface to a functor, do the following:
- Create a discriminated union. Name it after the interface name, but append the word instruction as a suffix.
- Make the union type generic.
-
For each member in the interface, add a case.
- Name the case after the name of the member.
- Declare the type of data contained in the case as a pair (a two-element tuple).
- Declare the type of the first element in that tuple as the type of the input argument(s) to the interface member. If the member has more than one input argument, declare it as a (nested) tuple.
- Declare the type of the second element in the tuple as a function. The input type of that function should be the output type of the original interface member, and the output type of the function should be the generic type argument for the union type.
- Add a map function for the union type. I'd recommend making this function private and avoid naming it
mapin order to prevent naming conflicts. I usually name this functionmapI, where the I stands for instruction. - The map function should take a function of the type
'a -> 'bas its first (curried) argument, and a value of the union type as its second argument. It should return a value of the union type, but with the generic type argument changed from'ato'b. - For each case in the union type, map it to a value of the same case. Copy the (non-generic) first element of the pair over without modification, but compose the function in the second element with the input function to the map function.
type FaceInstruction<'a> = | Member1 of (In1 * (Out1 -> 'a)) | Member2 of (In2 * (Out2 -> 'a))
The map function becomes:
// ('a -> 'b) -> FaceInstruction<'a> -> FaceInstruction<'b> let private mapI f = function | Member1 (x, next) -> Member1 (x, next >> f) | Member2 (x, next) -> Member2 (x, next >> f)
Such a combination of union type and map function satisfies the functor laws, so that's how you refactor an interface to a functor.
Free monad recipe #
Given any functor, you can create a monad. The monad will be a new type that contains the functor; you will not be turning the functor itself into a monad. (Some functors can be turned into monads themselves, but if that's the case, you don't need to create a free monad.)
The recipe for turning any functor into a monad is as follows:
- Create a generic discriminated union. You can name it after the underlying functor, but append a suffix such as Program. In the following, this is called the 'program' union type.
- Add two cases to the union:
FreeandPure. - The
Freecase should contain a single value of the contained functor, generically typed to the 'program' union type itself. This is a recursive type definition. - The
Purecase should contain a single value of the union's generic type. - Add a
bindfunction for the new union type. The function should take two arguments: - The first argument to the
bindfunction should be a function that takes the generic type argument as input, and returns a value of the 'program' union type as output. In the rest of this recipe, this function is calledf. - The second argument to the
bindfunction should be a 'program' union type value. - The return type of the
bindfunction should be a 'program' union type value, with the same generic type as the return type of the first argument (f). - Declare the
bindfunction as recursive by adding thereckeyword. - Implement the
bindfunction by pattern-matching on theFreeandPurecases: - In the
Freecase, pipe the contained functor value to the functor's map function, usingbind fas the mapper function; then pipe the result of that toFree. - In the
Purecase, returnf x, wherexis the value contained in thePurecase. - Add a computation expression builder, using
bindforBindandPureforReturn.
type FaceProgram<'a> = | Free of FaceInstruction<FaceProgram<'a>> | Pure of 'a
It's worth noting that the Pure case always looks like that. While it doesn't take much effort to write it, you could copy and paste it from another free monad, and no changes would be required.
According to the recipe, the bind function should be implemented like this:
// ('a -> FaceProgram<'b>) -> FaceProgram<'a> -> FaceProgram<'b> let rec bind f = function | Free x -> x |> mapI (bind f) |> Free | Pure x -> f x
Apart from one small detail, the bind function always looks like that, so you can often copy and paste it from here and use it in your code, if you will. The only variation is that the underlying functor's map function isn't guaranteed to be called mapI - but if it is, you can use the above bind function as is. No modifications will be necessary.
In F#, a monad is rarely a goal in itself, but once you have a monad, you can add a computation expression builder:
type FaceBuilder () = member this.Bind (x, f) = bind f x member this.Return x = Pure x member this.ReturnFrom x = x member this.Zero () = Pure ()
While you could add more members (such as Combine, For, TryFinally, and so on), I find that usually, those four methods are all I need.
Create an instance of the builder object, and you can start writing computation expressions:
let face = FaceBuilder ()
Finally, as an optional step, if you've refactored an interface to an instruction set, you can add convenience functions that lift each instruction case to the free monad type:
- For each case, add a function of the same name, but camelCased instead of PascalCased.
- Each function should have input arguments that correspond to the first element of the case's contained tuple (i.e. the input argument for the original interface). I usually prefer the arguments in curried form, but that's not a requirement.
- Each function should return the corresponding instruction union case inside of the
Freecase. The case constructor must be invoked with the pair of data it requires. Populate the first element with values from the input arguments to the convenience function. The second element should be thePurecase constructor, passed as a function.
FaceInstruction<'a>:
// In1 -> FaceProgram<Out1> let member1 in1 = Free (Member1 (in1, Pure)) // In2 -> FaceProgram<Out2> let member2 in2 = Free (Member2 (in2, Pure))
Such functions are conveniences that make it easier to express what the underlying functor expresses, but in the context of the free monad.
Interpreters #
A free monad is a recursive type, and values are trees. The leafs are the Pure values. Often (if not always), the point of a free monad is to evaluate the tree in order to pull the leaf values out of it. In order to do that, you must add an interpreter. This is a function that recursively pattern-matches over the free monad value until it encounters a Pure case.
At least in the case where you've refactored an interface to a functor, writing an interpreter also follows a recipe. This is equivalent to writing a concrete class that implements an interface.
- For each case in the instruction-set functor, write an implementation function that takes the case's 'input' tuple element type as input, and returns a value of the type used in the case's second tuple element. Recall that the second element in the pair is a function; the output type of the implementation function should be the input type for that function.
- Add a function to implement the interpreter; I often call it
interpret. Make it recursive by adding thereckeyword. - Pattern-match on
Pureand each case contained inFree. - In the
Purecase, simply return the value contained in the case. - In the
Freecase, pattern-match the underlying pair out if each of the instruction-set functor's cases. The first element of that tuple is the 'input value'. Pipe that value to the corresponding implementation function, pipe the return value of that to the function contained in the second element of the tuple, and pipe the result of that recursively to the interpreter function.
imp1 and imp2 exist. According to the recipe, imp1 has the type In1 -> Out1, and imp2 has the type In2 -> Out2. Given these functions, the running example becomes:
// FaceProgram<'a> -> 'a let rec interpret = function | Pure x -> x | Free (Member1 (x, next)) -> x |> imp1 |> next |> interpret | Free (Member2 (x, next)) -> x |> imp2 |> next |> interpret
The Pure case always looks like that. Each of the Free cases use a different implementation function, but apart from that, they are, as you can tell, the spitting image of each other.
Interpreters like this are often impure because the implementation functions are impure. Nothing prevents you from defining pure interpreters, although they often have limited use. They do have their place in unit testing, though.
// Out1 -> Out2 -> FaceProgram<'a> -> 'a let rec interpretStub out1 out2 = function | Pure x -> x | Free (Member1 (_, next)) -> out1 |> next |> interpretStub out1 out2 | Free (Member2 (_, next)) -> out2 |> next |> interpretStub out1 out2
This interpreter effectively ignores the input value contained within each Free case, and instead uses the pure values out1 and out2. This is essentially a Stub - an 'implementation' that always returns pre-defined values.
The point is that you can have more than a single interpreter, pure or impure, just like you can have more than one implementation of an interface.
When to use it #
Free monads are often used instead of Dependency Injection. Note, however, that while the free monad values themselves are pure, they imply impure behaviour. In my opinion, the main benefit of pure code is that, as a code reader and maintainer, I don't have to worry about side-effects if I know that the code is pure. With a free monad, I do have to worry about side-effects, because, although the ASTs are pure, an impure interpreter will cause side-effects to happen. At least, however, the side-effects are known; they're restricted to a small subset of operations. Haskell enforces this distinction, but F# doesn't. The question, then, is how valuable you find this sort of design.
I think it still has some value, because a free monad explicitly communicates an intent of doing something impure. This intent becomes encoded in the types in your code base, there for all to see. Just as I prefer that functions return 'a option values if they may fail to produce a value, I like that I can tell from a function's return type that a delimited set of impure operations may result.
Clearly, creating free monads in F# requires some boilerplate code. I hope that this article has demonstrated that writing that boilerplate code isn't difficult - just follow the recipe. You almost don't have to think. Since a monad is a universal abstraction, once you've written the code, it's unlikely that you'll need to deal with it much in the future. After all, mathematical abstractions don't change.
Perhaps a more significant concern is how familiar free monads are to developers of a particular code base. Depending on your position, you could argue that free monads come with high cognitive overhead, or that they specifically lower the cognitive overhead.
Insights are obscure until you grasp them; after that, they become clear.
This applies to free monads as well. You have to put effort into understanding them, but once you do, you realise that they are more than a pattern. They are universal abstractions, governed by laws. Once you grok free monads, their cognitive load wane.
Consider, then, the developers who will be interacting with the free monad. If they already know free monads, or have enough of a grasp of monads that this might be their next step, then using free monads could be beneficial. On the other hand, if most developers are new to F# or functional programming, free monads should probably be avoided for the time being.
This flowchart summarises the above reflections:
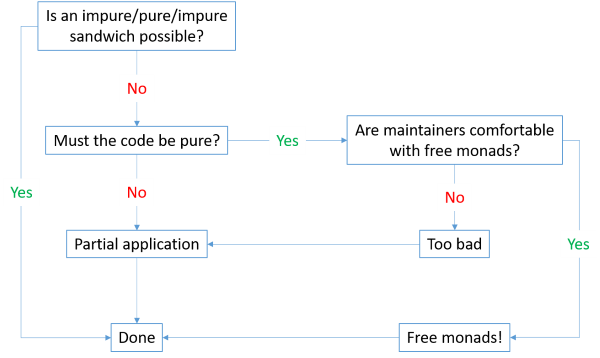
Your first consideration should be whether your context enables an impure/pure/impure sandwich. If so, there's no reason to make things more complicated than they have to be. To use Fred Brooks' terminology, this should go a long way to avoid accidental complexity.
If you can't avoid long-running, impure interactions, then consider whether purity, or strictly functional design, is important to you. F# is a multi-paradigmatic language, and it's perfectly possible to write code that's impure, yet still well-structured. You can use partial application as an idiomatic alternative to Dependency Injection.
If you prefer to keep your code functional and explicit, you may consider using free monads. In this case, I still think you should consider the maintainers of the code base in question. If everyone involved are comfortable with free monads, or willing to learn, then I believe it's a viable option. Otherwise, I'd recommend falling back to partial application, even though Dependency Injection makes everything impure.
Motivating examples #
The strongest motivation, I believe, for introducing free monads into a code base is to model long-running, impure interactions in a functional style.
Like most other software design considerations, the overall purpose of application architecture is to deal with (essential) complexity. Thus, any example must be complex enough to warrant the design. There's little point in a Dependency Injection hello world example in C#. Likewise, a hello world example using free monads hardly seems justified. For that reason, examples are provided in separate articles.
A good place to start, I believe, is with the small Pure times article series. These articles show how to address a particular, authentic problem using strictly functional programming. The focus of these articles is on problem-solving, so they sometimes omit detailed explanations in order to keep the narrative moving.
If you need detailed explanations about all elements of free monads in F#, the present article series offers just that, particularly the Hello, pure command-line interaction article.
Variations #
The above recipes describe the regular scenario. Variations are possible. Obviously, you can choose different naming strategies and so on, but I'm not going to cover this in greater detail.
There are, however, various degenerate cases that deserve a few words. An interaction may return no data, or take no input. In F#, you can always model the lack of data as unit (()), so it's definitely possible to define an instruction case like Foo of (unit * Out1 -> 'a), or Bar of (In2 * unit -> 'a), but since unit doesn't contain any data, you can remove it without changing the abstraction.
The Hello, pure command-line interaction article contains a single type that exemplifies both degenerate cases. It defines this instruction set:
type CommandLineInstruction<'a> = | ReadLine of (string -> 'a) | WriteLine of string * 'a
The ReadLine case takes no input, so instead of containing a pair of input and continuation, this case contains only the continuation function. Likewise, the WriteLine case is also degenerate, but here, there's no output. This case does contain a pair, but the second element isn't a function, but a value.
This has some superficial consequences for the implementation of functor and monad functions. For example, the mapI function becomes:
// ('a -> 'b) -> CommandLineInstruction<'a> -> CommandLineInstruction<'b> let private mapI f = function | ReadLine next -> ReadLine (next >> f) | WriteLine (x, next) -> WriteLine (x, next |> f)
Notice that in the ReadLine case, there's no tuple on which to pattern-match. Instead, you can directly access next.
In the WriteLine case, the return value changes from function composition (next >> f) to a regular function call (next |> f, which is equivalent to f next).
The lift functions also change:
// CommandLineProgram<string> let readLine = Free (ReadLine Pure) // string -> CommandLineProgram<unit> let writeLine s = Free (WriteLine (s, Pure ()))
Since there's no input, readLine degenerates to a value, instead of a function. On the other hand, while writeLine remains a function, you'll have to pass a value (Pure ()) as the second element of the pair, instead of the regular function (Pure).
Apart from such minor changes, the omission of unit values for input or output has little significance.
Another variation from the above recipe that you may see relates to interpreters. In the above recipe, I described how, for each instruction, you should create an implementation function. Sometimes, however, that function is only a few lines of code. When that happens, I occasionally inline the function directly in the interpreter. Once more, the CommandLineProgram API provides an example:
// CommandLineProgram<'a> -> 'a let rec interpret = function | Pure x -> x | Free (ReadLine next) -> Console.ReadLine () |> next |> interpret | Free (WriteLine (s, next)) -> Console.WriteLine s next |> interpret
Here, no custom implementation functions are required, because Console.ReadLine and Console.WriteLine already exist and serve the desired purpose.
Summary #
This article describes a repeatable, and automatable, process for refactoring an interface to a free monad. I've done this enough times now that I believe that this process is always possible, but I have no formal proof for this.
I also strongly suspect that the reverse process is possible. For any instruction set elevated to a free monad, I think you should be able to define an object-oriented interface. If this is true, then object-oriented interfaces and AST-based free monads are isomorphic.
Combining free monads in F#
An example of how to compose free monads in F#.
This article is an instalment in a series of articles about modelling long-running interactions with pure, functional code. In the previous article, you saw how to combine a pure command-line API with an HTTP-client API in Haskell. In this article, you'll see how to translate the Haskell proof of concept to F#.
HTTP API client module #
You've already seen how to model command-line interactions as pure code in a previous article. You can define interactions with the online restaurant reservation HTTP API in the same way. First, define some types required for input and output to the API:
type Slot = { Date : DateTimeOffset; SeatsLeft : int } type Reservation = { Date : DateTimeOffset Name : string Email : string Quantity : int }
The Slot type contains information about how many available seats are left on a particular date. The Reservation type contains the information required in order to make a reservation. It's the same Reservation F# record type you saw in a previous article, but now it's moved here.
The online restaurant reservation HTTP API may afford more functionality than you need, but there's no reason to model more instructions than required:
type ReservationsApiInstruction<'a> = | GetSlots of (DateTimeOffset * (Slot list -> 'a)) | PostReservation of Reservation * 'a
This instruction set models two interactions. The GetSlots case models an instruction to request, from the HTTP API, the slots for a particular date. The PostReservation case models an instruction to make a POST HTTP request with a Reservation, thereby making a reservation.
While Haskell can automatically make this type a Functor, in F# you have to write the code yourself:
// ('a -> 'b) -> ReservationsApiInstruction<'a> // -> ReservationsApiInstruction<'b> let private mapI f = function | GetSlots (x, next) -> GetSlots (x, next >> f) | PostReservation (x, next) -> PostReservation (x, next |> f)
This turns ReservationsApiInstruction<'a> into a functor, which is, however, not the ultimate goal. The final objective is to enable syntactic sugar, so that you can write pure ReservationsApiInstruction<'a> Abstract Syntax Trees (ASTs) in standard F# syntax. In order to fulfil that ambition, you need a computation expression builder, and to create one of those, you need a monad.
You can turn ReservationsApiInstruction<'a> into a monad using the free monad recipe that you've already seen. Creating a free monad, however, involves adding another type that will become both monad and functor, so I deliberately make mapI private in order to prevent confusion. This is also the reason I didn't name the function map: you'll need that name for a different type. The I in mapI stands for instruction.
The mapI function pattern-matches on the (implicit) ReservationsApiInstruction argument. In the GetSlots case, it returns a new GetSlots value, but composes the next continuation with f. In the PostReservation case, it returns a new PostReservation value, but pipes next to f. The reason for the difference is that PostReservation is degenerate: next isn't a function, but a value.
Now that ReservationsApiInstruction<'a> is a functor, you can create a free monad from it. The first step is to introduce a new type for the monad:
type ReservationsApiProgram<'a> = | Free of ReservationsApiInstruction<ReservationsApiProgram<'a>> | Pure of 'a
This is a recursive type that enables you to assemble ASTs that ultimately can return a value. The Pure case enables you to return a value, while the Free case lets you describe what should happen next.
Using mapI, you can make a monad out of ReservationsApiProgram<'a> by adding a bind function:
// ('a -> ReservationsApiProgram<'b>) -> ReservationsApiProgram<'a> // -> ReservationsApiProgram<'b> let rec bind f = function | Free instruction -> instruction |> mapI (bind f) |> Free | Pure x -> f x
If you refer back to the bind implementation for CommandLineProgram<'a>, you'll see that it's the exact same code. In Haskell, creating a free monad from a functor is automatic. In F#, it's boilerplate.
Likewise, you can make ReservationsApiProgram<'a> a functor:
// ('a -> 'b) -> ReservationsApiProgram<'a> -> ReservationsApiProgram<'b> let map f = bind (f >> Pure)
Again, this is the same code as in the CommandLine module. You can copy and paste it. It is, however, not the same function, because the types are different.
Finally, to round off the reservations HTTP client API, you can supply functions that lift instructions to programs:
// DateTimeOffset -> ReservationsApiProgram<Slot list> let getSlots date = Free (GetSlots (date, Pure)) // Reservation -> ReservationsApiProgram<unit> let postReservation r = Free (PostReservation (r, Pure ()))
That's everything you need to create a small computation expression builder:
type ReservationsApiBuilder () = member this.Bind (x, f) = ReservationsApi.bind f x member this.Return x = Pure x member this.ReturnFrom x = x member this.Zero () = Pure ()
Create an instance of the ReservationsApiBuilder class in order to use reservationsApi computation expressions:
let reservationsApi = ReservationsApiBuilder ()
This, in total, defines a pure API for interacting with the online restaurant reservation system, including all the syntactic sugar you'll need to stay sane. As usual, some boilerplate code is required, but I'm not too worried about its maintenance overhead, as it's unlikely to change much, once you've added it. If you've followed the recipe, the API obeys the category, functor, and monad laws, so it's not something you've invented; it's an instance of a universal abstraction.
Monad stack #
The addition of the above ReservationsApi module is only a step towards the overall goal, which is to write a command-line wizard you can use to make reservations against the online API. In order to do so, you must combine the two monads CommandLineProgram<'a> and ReservationsApiProgram<'a>. In Haskell, you get that combination for free via the built-in generic FreeT type, which enables you to stack monads. In F#, you have to explicitly declare the type:
type CommandLineReservationsApiT<'a> = | Run of CommandLineProgram<ReservationsApiProgram<'a>>
This is a single-case discriminated union that stacks ReservationsApiProgram and CommandLineProgram. In this incarnation, it defines a single case called Run. The reason for this is that it enables you to follow the free monad recipe without having to do much thinking. Later, you'll see that it's possible to simplify the type.
The naming is inspired by Haskell. This type is a piece of the puzzle corresponding to Haskell's FreeT type. The T in FreeT stands for transformer, because FreeT is actually something called a monad transformer. That's not terribly important in an F# context, but that's the reason I also tagged on the T in CommandLineReservationsApiT<'a>.
FreeT is actually only a 'wrapper' around another monad. In order to extract the contained monad, you can use a function called runFreeT. That's the reason I called the F# case Run.
You can easily make your stack of monads a functor:
// ('a -> 'b) -> CommandLineProgram<ReservationsApiProgram<'a>> // -> CommandLineProgram<ReservationsApiProgram<'b>> let private mapStack f x = commandLine { let! x' = x return ReservationsApi.map f x' }
The mapStack function uses the commandLine computation expression to access the ReservationsApiProgram contained within the CommandLineProgram. Thanks to the let! binding, x' is a ReservationsApiProgram<'a> value. You can use ReservationsApi.map to map x' with f.
It's now trivial to make CommandLineReservationsApiT<'a> a functor as well:
// ('a -> 'b) -> CommandLineReservationsApiT<'a> // -> CommandLineReservationsApiT<'b> let private mapT f (Run p) = mapStack f p |> Run
The mapT function simply pattern-matches the monad stack out of the Run case, calls mapStack, and pipes the return value into another Run case.
By now, it's should be fairly clear that we're following the same recipe as before. You have a functor; make a monad out of it. First, define a type for the monad:
type CommandLineReservationsApiProgram<'a> = | Free of CommandLineReservationsApiT<CommandLineReservationsApiProgram<'a>> | Pure of 'a
Then add a bind function:
// ('a -> CommandLineReservationsApiProgram<'b>) // -> CommandLineReservationsApiProgram<'a> // -> CommandLineReservationsApiProgram<'b> let rec bind f = function | Free instruction -> instruction |> mapT (bind f) |> Free | Pure x -> f x
This is almost the same code as the above bind function for ReservationsApi. The only difference is that the underlying map function is named mapT instead of mapI. The types involved, however, are different.
You can also add a map function:
// ('a -> 'b) -> (CommandLineReservationsApiProgram<'a> // -> CommandLineReservationsApiProgram<'b>) let map f = bind (f >> Pure)
This is another copy-and-paste job. Such repeatable. Wow.
When you create a monad stack, you need a way to lift values from each of the constituent monads up to the combined monad. In Haskell, this is done with the lift and liftF functions, but in F#, you must explicitly add such functions:
// CommandLineProgram<ReservationsApiProgram<'a>> // -> CommandLineReservationsApiProgram<'a> let private wrap x = x |> Run |> mapT Pure |> Free // CommandLineProgram<'a> -> CommandLineReservationsApiProgram<'a> let liftCL x = wrap <| CommandLine.map ReservationsApiProgram.Pure x // ReservationsApiProgram<'a> -> CommandLineReservationsApiProgram<'a> let liftRA x = wrap <| CommandLineProgram.Pure x
The private wrap function takes the underlying 'naked' monad stack (CommandLineProgram<ReservationsApiProgram<'a>>) and turns it into a CommandLineReservationsApiProgram<'a> value. It first wraps x in Run, which turns x into a CommandLineReservationsApiT<'a> value. By piping that value into mapT Pure, you get a CommandLineReservationsApiT<CommandLineReservationsApiProgram<'a>> value that you can finally pipe into Free in order to produce a CommandLineReservationsApiProgram<'a> value. Phew!
The liftCL function lifts a CommandLineProgram (CL) to CommandLineReservationsApiProgram by first using CommandLine.map to lift x to a CommandLineProgram<ReservationsApiProgram<'a>> value. It then pipes that value to wrap.
Likewise, the liftRA function lifts a ReservationsApiProgram (RA) to CommandLineReservationsApiProgram. It simply elevates x to a CommandLineProgram value by using CommandLineProgram.Pure. Subsequently, it pipes that value to wrap.
In both of these functions, I used the slightly unusual backwards pipe operator <|. The reason for that is that it emphasises the similarity between liftCL and liftRA. This is easier to see if you remove the type comments:
let liftCL x = wrap <| CommandLine.map ReservationsApiProgram.Pure x let liftRA x = wrap <| CommandLineProgram.Pure x
This is how I normally write my F# code. I only add the type comments for the benefit of you, dear reader. Normally, when you have an IDE, you can always inspect the types using the built-in tools.
Using the backwards pipe operator makes it immediately clear that both functions depend in the wrap function. This would have been muddied by use of the normal forward pipe operator:
let liftCL x = CommandLine.map ReservationsApiProgram.Pure x |> wrap let liftRA x = CommandLineProgram.Pure x |> wrap
The behaviour is the same, but now wrap doesn't align, making it harder to discover the kinship between the two functions. My use of the backward pipe operator is motivated by readability concerns.
Following the free monad recipe, now create a computation expression builder:
type CommandLineReservationsApiBuilder () = member this.Bind (x, f) = CommandLineReservationsApi.bind f x member this.Return x = Pure x member this.ReturnFrom x = x member this.Zero () = Pure ()
Finally, create an instance of the class:
let commandLineReservationsApi = CommandLineReservationsApiBuilder ()
Putting the commandLineReservationsApi value in a module will enable you to use it for computation expressions whenever you open that module. I normally put it in a module with the [<AutoOpen>] attribute so that it automatically becomes available as soon as I open the containing namespace.
Simplification #
While there can be good reasons to introduce single-case discriminated unions in your F# code, they're isomorphic with their contained type. (This means that there's a lossless conversion between the union type and the contained type, in both directions.) Following the free monad recipe, I introduced CommandLineReservationsApiT as a discriminated union, but since it's a single-case union, you can refactor it to its contained type.
If you delete the CommandLineReservationsApiT type, you'll first have to change the definition of the program type to this:
type CommandLineReservationsApiProgram<'a> = | Free of CommandLineProgram<ReservationsApiProgram<CommandLineReservationsApiProgram<'a>>> | Pure of 'a
You simply replace CommandLineReservationsApiT<_> with CommandLineProgram<ReservationsApiProgram<_>>, effectively promoting the type contained in the Run case to be the container in the Free case.
Once CommandLineReservationsApiT is gone, you'll also need to delete the mapT function, and amend bind:
// ('a -> CommandLineReservationsApiProgram<'b>) // -> CommandLineReservationsApiProgram<'a> // -> CommandLineReservationsApiProgram<'b> let rec bind f = function | Free instruction -> instruction |> mapStack (bind f) |> Free | Pure x -> f x
Likewise, you must also adjust the wrap function:
let private wrap x = x |> mapStack Pure |> Free
The rest of the above code stays the same.
Wizard #
In Haskell, you get combinations of monads for free via the FreeT type, whereas in F#, you have to work for it. Once you have the combination in monadic form as well, you can write programs with that combination. Here's the wizard that collects your data and attempts to make a restaurant reservation on your behalf:
// CommandLineReservationsApiProgram<unit> let tryReserve = commandLineReservationsApi { let! count = liftCL readQuantity let! date = liftCL readDate let! availableSeats = ReservationsApi.getSlots date |> ReservationsApi.map (List.sumBy (fun slot -> slot.SeatsLeft)) |> liftRA if availableSeats < count then do! sprintf "Only %i remaining seats." availableSeats |> CommandLine.writeLine |> liftCL else let! name = liftCL readName let! email = liftCL readEmail do! { Date = date; Name = name; Email = email; Quantity = count } |> ReservationsApi.postReservation |> liftRA }
Notice that tryReserve is a value, and not a function. It's a pure value that contains an AST - a small program that describes the impure interactions that you'd like to take place. It's defined entirely within a commandLineReservationsApi computation expression.
It starts by using the readQuantity and readDate program values you saw in the previous F# article. Both of these values are CommandLineProgram values, so you have to use liftCL to lift them to CommandLineReservationsApiProgram values - only then can you let! bind them to an int and a DateTimeOffset, respectively. This is just like the use of lift in the previous article's Haskell example.
Once the program has collected the desired date from the user, it calls ReservationsApi.getSlots and calculates the sum over all the returned SeatsLeft labels. The ReservationsApi.getSlots function returns a ReservationsApiProgram<Slot list>, the ReservationsApi.map turns it into a ReservationsApiProgram<int> value that you must liftRA in order to be able to let! bind it to an int value. Let me stress once again: the program actually doesn't do any of that; it constructs an AST with instructions to that effect.
If it turns out that there's too few seats left, the program writes that on the command line and exits. Otherwise, it continues to collect the user's name and email address. That's all the data required to create a Reservation record and pipe it to ReservationsApi.postReservation.
Interpreters #
The tryReserve wizard is a pure value. It contains an AST that can be interpreted in such a way that impure operations happen. You've already seen the CommandLineProgram interpreter in a previous article, so I'm not going to repeat it here. I'll only note that I renamed it to interpretCommandLine because I want to use the name interpret for the combined interpreter.
The interpreter for ReservationsApiProgram values is similar to the CommandLineProgram interpreter:
// ReservationsApiProgram<'a> -> 'a let rec interpretReservationsApi = function | ReservationsApiProgram.Pure x -> x | ReservationsApiProgram.Free (GetSlots (d, next)) -> ReservationHttpClient.getSlots d |> Async.RunSynchronously |> next |> interpretReservationsApi | ReservationsApiProgram.Free (PostReservation (r, next)) -> ReservationHttpClient.postReservation r |> Async.RunSynchronously next |> interpretReservationsApi
The interpretReservationsApi function pattern-matches on its (implicit) ReservationsApiProgram argument, and performs the appropriate actions according to each instruction. In all Free cases, it delegates to implementations defined in a ReservationHttpClient module. The code in that module isn't shown here, but you can see it in the GitHub repository that accompanies this article.
You can combine the two 'leaf' interpreters in an interpreter of CommandLineReservationsApiProgram values:
// CommandLineReservationsApiProgram<'a> -> 'a let rec interpret = function | CommandLineReservationsApiProgram.Pure x -> x | CommandLineReservationsApiProgram.Free p -> p |> interpretCommandLine |> interpretReservationsApi |> interpret
As usual, in the Pure case, it simply returns the contained value. In the Free case, p is a CommandLineProgram<ReservationsApiProgram<CommandLineReservationsApiProgram<'a>>>. Since it's a CommandLineProgram value, you can interpret it with interpretCommandLine, which returns a ReservationsApiProgram<CommandLineReservationsApiProgram<'a>>. Since that's a ReservationsApiProgram, you can pipe it to interpretReservationsApi, which then returns a CommandLineReservationsApiProgram<'a>. An interpreter exists for that type as well, namely the interpret function itself, so recursively invoke it again. In other words, interpret will keep recursing until it hits a Pure case.
Execution #
Everything is now in place so that you can execute your program. This is the program's entry point:
[<EntryPoint>] let main _ = interpret Wizard.tryReserve 0 // return an integer exit code
When you run it, you'll be able to have an interaction like this:
Please enter number of diners: 4 Please enter your desired date: 2017-11-25 Please enter your name: Mark Seemann Please enter your email address: mark@example.net OK
If you want to run this code sample yourself, you're going to need an appropriate HTTP API with which you can interact. I hosted the API on my local machine, and afterwards verified that the record was, indeed, written in the reservations database.
Summary #
As expected, you can combine free monads in F#, although it requires more boilerplate code than in Haskell.
Next: F# free monad recipe.
Combining free monads in Haskell
An example on how to compose free monads in Haskell.
In the previous article in this series on pure interactions, you saw how to write a command-line wizard in F#, using a free monad to build an Abstract Syntax Tree (AST). The example collects information about a potential restaurant reservations you'd like to make. That example, however, didn't do more than that.
For a more complete experience, you'd like your command-line interface (CLI) to not only collect data about a reservation, but actually make the reservation, using the available HTTP API. This means that you'll also need to model interaction with the HTTP API as an AST, but a different AST. Then, you'll have to figure out how to compose these two APIs into a combined API.
In order to figure out how to do this in F#, I first had to do it in Haskell. In this article, you'll see how to do it in Haskell, and in the next article, you'll see how to translate this Haskell prototype to F#. This should ensure that you get a functional F# code base as well.
Command line API #
Let's make an easy start of it. In a previous article, you saw how to model command-line interactions as ASTs, complete with syntactic sugar provided by a computation expression. That took a fair amount of boilerplate code in F#, but in Haskell, it's declarative:
import Control.Monad.Trans.Free (Free, liftF) data CommandLineInstruction next = ReadLine (String -> next) | WriteLine String next deriving (Functor) type CommandLineProgram = Free CommandLineInstruction readLine :: CommandLineProgram String readLine = liftF (ReadLine id) writeLine :: String -> CommandLineProgram () writeLine s = liftF (WriteLine s ())
This is all the code required to define your AST and make it a monad in Haskell. Contrast that with all the code you have to write in F#!
The CommandLineInstruction type defines the instruction set, and makes use of a language extension called DeriveFunctor, which enables Haskell to automatically create a Functor instance from the type.
The type alias type CommandLineProgram = Free CommandLineInstruction creates a monad from CommandLineInstruction, since Free is a Monad when the underlying type is a Functor.
The readLine value and writeLine function are conveniences that lift the instructions from CommandLineInstruction into CommandLineProgram values. These were also one-liners in F#.
HTTP client API #
You can write a small wizard to collect restaurant reservation data with the CommandLineProgram API, but the new requirement is to make HTTP calls so that the CLI program actually makes the reservation against the back-end system. You could extend CommandLineProgram with more instructions, but that would be to mix concerns. It'd be more appropriate to define a new instruction set for making the required HTTP requests.
This API will send and receive more complex values than simple String values, so you can start by defining their types:
data Slot = Slot { slotDate :: ZonedTime, seatsLeft :: Int } deriving (Show) data Reservation = Reservation { reservationDate :: ZonedTime , reservationName :: String , reservationEmail :: String , reservationQuantity :: Int } deriving (Show)
The Slot type contains information about how many available seats are left on a particular date. The Reservation type contains the information required in order to make a reservation. It's similar to the Reservation F# record type you saw in the previous article.
The online restaurant reservation HTTP API may afford more functionality than you need, but there's no reason to model more instructions than required:
data ReservationsApiInstruction next = GetSlots ZonedTime ([Slot] -> next) | PostReservation Reservation next deriving (Functor)
This instruction set models two interactions. The GetSlots case models an instruction to request, from the HTTP API, the slots for a particular date. The PostReservation case models an instruction to make a POST HTTP request with a Reservation, thereby making a reservation.
Like the above CommandLineInstruction, this type is (automatically) a Functor, which means that we can create a Monad from it:
type ReservationsApiProgram = Free ReservationsApiInstruction
Once again, the monad is nothing but a type alias.
Finally, you're going to need the usual lifts:
getSlots :: ZonedTime -> ReservationsApiProgram [Slot] getSlots d = liftF (GetSlots d id) postReservation :: Reservation -> ReservationsApiProgram () postReservation r = liftF (PostReservation r ())
This is all you need to write a wizard that interleaves CommandLineProgram and ReservationsApiProgram instructions in order to create a more complex AST.
Wizard #
The wizard should do the following:
- Collect the number of diners, and the date for the reservation.
- Query the HTTP API about availability for the requested date. If insufficient seats are available, it should exit.
- If sufficient capacity remains, collect name and email.
- Make the reservation against the HTTP API.
readParse :: Read a => String -> String -> CommandLineProgram a readParse prompt errorMessage = do writeLine prompt l <- readLine case readMaybe l of Just dt -> return dt Nothing -> do writeLine errorMessage readParse prompt errorMessage
It first uses writeLine to write prompt to the command line - or rather, it creates an instruction to do so. The instruction is a pure value. No side-effects are involved until an interpreter evaluates the AST.
The next line uses readLine to read the user's input. While readLine is a CommandLineProgram String value, due to Haskell's do notation, l is a String value. You can now attempt to parse that String value with readMaybe, which returns a Maybe a value that you can handle with pattern matching. If readMaybe returns a Just value, then return the contained value; otherwise, write errorMessage and recursively call readParse again.
Like in the previous F# example, the only way to continue is to write something that readMaybe can parse. There's no other way to exit; there probably should be an option to quit, but it's not important for this demo purpose.
You may also have noticed that, contrary to the previous F# example, I here succumbed to the temptation to break the rule of three. It's easier to define a reusable function in Haskell, because you can leave it generic, with the proviso that the generic value must be an instance of the Read typeclass.
The readParse function returns a CommandLineProgram a value. It doesn't combine CommandLineProgram with ReservationsApiProgram. That's going to happen in another function, but before we look at that, you're also going to need another little helper:
readAnything :: String -> CommandLineProgram String readAnything prompt = do writeLine prompt readLine
The readAnything function simply writes a prompt, reads the user's input, and unconditionally returns it. You could also have written it as a one-liner like readAnything prompt = writeLine prompt >> readLine, but I find the above code more readable, even though it's slightly more verbose.
That's all you need to write the wizard:
tryReserve :: FreeT ReservationsApiProgram CommandLineProgram () tryReserve = do q <- lift $ readParse "Please enter number of diners:" "Not an Integer." d <- lift $ readParse "Please enter your desired date:" "Not a date." availableSeats <- liftF $ (sum . fmap seatsLeft) <$> getSlots d if availableSeats < q then lift $ writeLine $ "Only " ++ show availableSeats ++ " remaining seats." else do n <- lift $ readAnything "Please enter your name:" e <- lift $ readAnything "Please enter your email address:" liftF $ postReservation Reservation { reservationDate = d , reservationName = n , reservationEmail = e , reservationQuantity = q }
The tryReserve program first prompt the user for a number of diners and a date. Once it has the date d, it calls getSlots and calculates the sum of the remaining seats. availableSeats is an Int value like q, so you can compare those two values with each other. If the number of available seats is less than the desired quantity, the program writes that and exits.
This interaction demonstrates how to interleave CommandLineProgram and ReservationsApiProgram instructions. It would be a bad user experience if the program would ask the user to input all information, and only then discover that there's insufficient capacity.
If, on the other hand, there's enough remaining capacity, the program continues collecting information from the user, by prompting for the user's name and email address. Once all data is collected, it creates a new Reservation value and invokes postReservation.
Consider the type of tryReserve. It's a combination of CommandLineProgram and ReservationsApiProgram, contained within a type called FreeT. This type is also a Monad, which is the reason the do notation still works. This also begins to explain the various lift and liftF calls sprinkled over the code.
Whenever you use a <- arrow to 'pull the value out of the monad' within a do block, the right-hand side of the arrow must have the same type as the return type of the overall function (or value). In this case, the return type is FreeT ReservationsApiProgram CommandLineProgram (), whereas readParse returns a CommandLineProgram a value. As an example, lift turns CommandLineProgram Int into FreeT ReservationsApiProgram CommandLineProgram Int.
The way the type of tryReserve is declared, when you have a CommandLineProgram a value, you use lift, but when you have a ReservationsApiProgram a, you use liftF. This depends on the order of the monads contained within FreeT. If you swap CommandLineProgram and ReservationsApiProgram, you'll also need to use lift instead of liftF, and vice versa.
Interpreters #
tryReserve is a pure value. It's an Abstract Syntax Tree that combines two separate instruction sets to describe a complex interaction between user, command line, and an HTTP client. The program doesn't do anything until interpreted.
You can write an impure interpreter for each of the APIs, and a third one that uses the other two to interpret tryReserve.
Interpreting CommandLineProgram values is similar to the previous F# example:
interpretCommandLine :: CommandLineProgram a -> IO a interpretCommandLine program = case runFree program of Pure r -> return r Free (ReadLine next) -> do line <- getLine interpretCommandLine $ next line Free (WriteLine line next) -> do putStrLn line interpretCommandLine next
This interpreter is a recursive function that pattern-matches all the cases in any CommandLineProgram a. When it encounters a Pure case, it simply returns the contained value.
When it encounters a ReadLine value, it calls getLine, which returns an IO String value read from the command line, but thanks to the do block, line is a String value. The interpreter then calls next with line, and passes the return value of that recursively to itself.
A similar treatment is given to the WriteLine case. putStrLn line writes line to the command line, where after next is used as an input argument to interpretCommandLine.
Thanks to Haskell's type system, you can easily tell that interpretCommandLine is impure, because for every CommandLineProgram a it returns IO a. That was the intent all along.
Likewise, you can write an interpreter for ReservationsApiProgram values:
interpretReservationsApi :: ReservationsApiProgram a -> IO a interpretReservationsApi program = case runFree program of Pure x -> return x Free (GetSlots zt next) -> do slots <- HttpClient.getSlots zt interpretReservationsApi $ next slots Free (PostReservation r next) -> do HttpClient.postReservation r interpretReservationsApi next
The structure of interpretReservationsApi is similar to interpretCommandLine. It delegates its implementation to an HttpClient module that contains the impure interactions with the HTTP API. This module isn't shown in this article, but you can see it in the GitHub repository that accompanies this article.
From these two interpreters, you can create a combined interpreter:
interpret :: FreeT ReservationsApiProgram CommandLineProgram a -> IO a interpret program = do r <- interpretCommandLine $ runFreeT program case r of Pure x -> return x Free p -> do y <- interpretReservationsApi p interpret y
This function has the required type: it evaluates any FreeT ReservationsApiProgram CommandLineProgram a and returns an IO a. runFreeT returns the CommandLineProgram part of the combined program. Passing this value to interpretCommandLine, you get the underlying type - the a in CommandLineProgram a, if you will. In this case, however, the a is quite a complex type that I'm not going to write out here. Suffice it to say that, at the container level, it's a FreeF value, which can be either a Pure or a Free case that you can use for pattern matching.
In the Pure case, you're done, so you can simply return the underlying value.
In the Free case, the p contained inside is a ReservationsApiProgram value, which you can interpret with interpretReservationsApi. That returns an IO a value, and due to the do block, y is the a. In this case, however, a is FreeT ReservationsApiProgram CommandLineProgram a, but that means that the function can now recursively call itself with y in order to interpret the next instruction.
Execution #
Armed with both an AST and an interpreter, executing the program is trivial:
main :: IO () main = interpret tryReserve
When you run the program, you could produce an interaction like this:
Please enter number of diners:
4
Please enter your desired date:
2017-11-25 18-30-00Z
Not a date.
Please enter your desired date:
2017-11-25 18:30:00Z
Please enter your name:
Mark Seemann
Please enter your email address:
mark@example.org
Status {statusCode = 200, statusMessage = "OK"}
You'll notice that I initially made a mistake on the date format, which caused readParse to prompt me again.
If you want to run this code sample yourself, you're going to need an appropriate HTTP API with which you can interact. I hosted the API on my local machine, and afterwards verified that the record was, indeed, written in the reservations database.
Summary #
This proof of concept proves that it's possible to combine separate free monads. Now that we know that it works, and the overall outline of it, it should be possible to translate this to F#. You should, however, expect more boilerplate code.
Next: Combining free monads in F#.
Comments
Here's an additional simplification. Rather than writing FreeT ReservationsApiProgram CommandLineProgram which requires you to lift, you can instead form the sum (coproduct) of both functors:
import Data.Functor.Sum type Program = Free (Sum CommandLineInstruction ReservationsApiInstruction) liftCommandLine :: CommandLineInstruction a -> Program a liftCommandLine = liftF . InL liftReservation :: ReservationsApiInstruction a -> Program a liftReservation = liftF . InR
Now you can lift the helpers directly to Program, like so:
readLine :: Program String readLine = liftCommandLine (ReadLine id) writeLine :: String -> Program () writeLine s = liftCommandLine (WriteLine s ()) getSlots :: ZonedTime -> Program [Slot] getSlots d = liftReservation (GetSlots d id) postReservation :: Reservation -> Program () postReservation r = liftReservation (PostReservation r ())
Then (after you change the types of the read* helpers), you can drop all lifts from tryReserve:
tryReserve :: Program ()
tryReserve = do
q <- readParse "Please enter number of diners:" "Not an Integer."
d <- readParse "Please enter your desired date:" "Not a date."
availableSeats <- (sum . fmap seatsLeft) <$> getSlots d
if availableSeats < q
then writeLine $ "Only " ++ show availableSeats ++ " remaining seats."
else do
n <- readAnything "Please enter your name:"
e <- readAnything "Please enter your email address:"
postReservation Reservation
{ reservationDate = d
, reservationName = n
, reservationEmail = e
, reservationQuantity = q }
And finally your interpreter needs to dispatch over InL/InR (this is using functions from Control.Monad.Free, you can actually drop the Trans import at this point):
interpretCommandLine :: CommandLineInstruction (IO a) -> IO a
interpretCommandLine (ReadLine next) = getLine >>= next
interpretCommandLine (WriteLine line next) = putStrLn line >> next
interpretReservationsApi :: ReservationsApiInstruction (IO a) -> IO a
interpretReservationsApi (GetSlots zt next) = HttpClient.getSlots zt >>= next
interpretReservationsApi (PostReservation r next) = HttpClient.postReservation r >> next
interpret :: Program a -> IO a
interpret program =
iterM go program
where
go (InL cmd) = interpretCommandLine cmd
go (InR res) = interpretReservationsApi res
I find this to be quite clean!
George, thank you for writing. That alternative does, indeed, look simpler and cleaner than mine. Thank you for sharing.
FWIW, one reason I write articles on this blog is to learn and become better. I publish what I know and have learned so far, and sometimes, people tell me that there's a better way. That's great, because it makes me a better programmer, and hopefully, it may make other readers better as well.
In case you'll be puzzling over my next blog post, however, I'm going to share a little secret (which is not a secret if you look at the blog's commit history): I wrote this article series more than a month ago, which means that all the remaining articles are already written. While I agree that using the sum of functors instead of FreeT simplifies the Haskell code, I don't think it makes that much of a difference when translating to F#. I may be wrong, but I haven't tried yet. My point, though, is that the next article in the series is going to ignore this better alternative, because, when it was written, I didn't know about it. I invite any interested reader to post, as a comment to that future article, their better alternatives :)
Hi Mark,
I think you'll enjoy Data Types a la Carte. It's the definitive introduction to the style that George Pollard demonstrates above. Swierstra covers how to build datatypes with initial algebras over coproducts, compose them abstracting over the concrete functor, and tear them down generically. It's well written, too 😉
Benjamin
A pure command-line wizard
An example of a small Abstract Syntax Tree written with F# syntactic sugar.
In the previous article, you got an introduction to a functional command-line API in F#. The example in that article, however, was too simple to highlight its composability. In this article, you'll see a fuller example.
Command-line wizard for on-line restaurant reservations #
In previous articles, you can see variations on an HTTP-based back-end for an on-line restaurant reservation system. In this article, on the other hand, you're going to see a first attempt at a command-line client for the API.
Normally, an on-line restaurant reservation system would have GUIs hosted in web pages or mobile apps, but with an open HTTP API, a self-respecting geek would prefer a command-line interface (CLI)... right?!
Please enter number of diners:
four
Not an integer.
Please enter number of diners:
4
Please enter your desired date:
My next birthday
Not a date.
Please enter your desired date:
2017-11-25
Please enter your name:
Mark Seemann
Please enter your email address:
mark@example.com
{Date = 25.11.2017 00:00:00 +01:00;
Name = "Mark Seemann";
Email = "mark@example.com";
Quantity = 4;}
In this incarnation, the CLI only collects information in order to dump a rendition of an F# record on the command-line. In a future article, you'll see how to combine this with an HTTP client in order to make a reservation with the back-end system.
Notice that the CLI is a wizard. It leads you through a series of questions. You have to give an appropriate answer to each question before you can move on to the next question. For instance, you must type an integer for the number of guests; if you don't, the wizard will repeatedly ask you for an integer until you do.
You can develop such an interface with the commandLine computation expression from the previous article.
Reading quantities #
There are four steps in the wizard. The first is to read the desired quantity from the command line:
// CommandLineProgram<int> let rec readQuantity = commandLine { do! CommandLine.writeLine "Please enter number of diners:" let! l = CommandLine.readLine match Int32.TryParse l with | true, dinerCount -> return dinerCount | _ -> do! CommandLine.writeLine "Not an integer." return! readQuantity }
This small piece of interaction is defined entirely within a commandLine expression. This enables you to use do! expressions and let! bindings to compose smaller CommandLineProgram values, such as CommandLine.writeLine and CommandLine.readLine (both shown in the previous article).
After prompting the user to enter a number, the program reads the user's input from the command line. While CommandLine.readLine is a CommandLineProgram<string> value, the let! binding turns l into a string value. If you can parse l as an integer, you return the integer; otherwise, you recursively return readQuantity.
The readQuantity program will continue to prompt the user for an integer. It gives you no option to cancel the wizard. This is a deliberate simplification I did in order to keep the example as simple as possible, but a real program should offer an option to abort the wizard.
The function returns a CommandLineProgram<int> value. This is a pure value containing an Abstract Syntax Tree (AST) that describes the interactions to perform. It doesn't do anything until interpreted. Contrary to designing with Dependency Injection and interfaces, however, you can immediately tell, from the type, that explicitly delimited impure interactions may take place within that part of your code base.
Reading dates #
When you've entered a proper number of diners, you proceed to enter a date. The program for that looks similar to readQuantity:
// CommandLineProgram<DateTimeOffset> let rec readDate = commandLine { do! CommandLine.writeLine "Please enter your desired date:" let! l = CommandLine.readLine match DateTimeOffset.TryParse l with | true, dt -> return dt | _ -> do! CommandLine.writeLine "Not a date." return! readDate }
The readDate value is so similar to readQuantity that you might be tempted to refactor both into a single, reusable function. In this case, however, I chose to stick to the rule of three.
Reading strings #
Reading the customer's name and email address from the command line is easy, as no parsing is required:
// CommandLineProgram<string> let readName = commandLine { do! CommandLine.writeLine "Please enter your name:" return! CommandLine.readLine } // CommandLineProgram<string> let readEmail = commandLine { do! CommandLine.writeLine "Please enter your email address:" return! CommandLine.readLine }
Both of these values unconditionally accept whatever you write when prompted. From a security standpoint, all input is evil, so in a production code base, you should still perform some validation. This, on the other hand, is demo code, so with that caveat, it accepts all strings you might type.
These values are similar to each other, but once again I invoke the rule of three and keep them as separate values.
Composing the wizard #
Together with the general-purpose command line API, the above values are all you need to compose the wizard. In this incarnation, the wizard should collect the information you type, and create a single record with those values. This is the type of record it must create:
type Reservation = { Date : DateTimeOffset Name : string Email : string Quantity : int }
You can easily compose the wizard like this:
// CommandLineProgram<Reservation> let readReservationRequest = commandLine { let! count = readQuantity let! date = readDate let! name = readName let! email = readEmail return { Date = date; Name = name; Email = email; Quantity = count } }
There's really nothing to it. As all the previous code examples in this article, you compose the readReservationRequest value entirely inside a commandLine expression. You use let! bindings to collect the four data elements you need, and once you have all four, you can return a Reservation value.
Running the program #
You may have noticed that no code so far shown define functions; they are all values. They are small program fragments, expressed as ASTs, composed into slightly larger programs that are still ASTs. So far, all the code is pure.
In order to run the program, you need an interpreter. You can reuse the interpreter from the previous article when composing your main function:
[<EntryPoint>] let main _ = Wizard.readReservationRequest |> CommandLine.bind (CommandLine.writeLine << (sprintf "%A")) |> interpret 0 // return an integer exit code
Notice that most of the behaviour is defined by the above Wizard.readReservationRequest value. That program, however, returns a Reservation value that you should also print to the command line, using the CommandLine module. You can achieve that behaviour by composing Wizard.readReservationRequest with CommandLine.writeLine using CommandLine.bind. Another way to write the same composition would be by using a commandLine computation expression, but in this case, I find the small pipeline of functions easier to read.
When you bind two CommandLineProgram values to each other, the result is a third CommandLineProgram. You can pipe that to interpret in order to run the program. The result is an interaction like the one shown in the beginning of this article.
Summary #
In this article, you've seen how you can create larger ASTs from smaller ASTs, using the syntactic sugar that F# computation expressions afford. The point, so far, is that you can make side-effects and non-deterministic behaviour explicit, while retaining the 'normal' F# development experience.
In Haskell, impure code can execute within an IO context, but inside IO, any sort of side-effect or non-deterministic behaviour could take place. For that reason, even in Haskell, it often makes sense to define an explicitly delimited set of impure operations. In the previous article, you can see a small Haskell code snippet that defines a command-line instruction AST type using Free. When you, as a code reader, encounter a value of the type CommandLineProgram String, you know more about the potential impurities than if you encounter a value of the type IO String. The same argument applies, with qualifications, in F#.
When you encounter a value of the type CommandLineProgram<Reservation>, you know what sort of impurities to expect: the program will only write to the command line, or read from the command line. What if, however, you'd like to combine those particular interactions with other types of interactions?
Read on.
Hello, pure command-line interaction
A gentle introduction to modelling impure interactions with pure code.
Dependency Injection is a well-described concept in object-oriented programming, but as I've explained earlier, its not functional, because it makes everything impure. In general, you should reject the notion of dependencies by instead designing your application on the concept of an impure/pure/impure sandwich. This is possible more often than you'd think, but there's still a large group of applications where this will not work. If your application needs to interact with the impure world for an extended time, you need a way to model such interactions in a pure way.
This article introduces a way to do that.
Command line API #
Imagine that you have to write a command-line program that can ask a series of questions and print appropriate responses. In the general case, this is a (potentially) long-running series of interactions between the user and the program. To keep it simple, though, in this article we'll start by looking at a degenerate example:
Please enter your name. Mark Hello, Mark!
The program is simply going to request that you enter your name. Once you've done that, it prints the greeting. In object-oriented programming, using Dependency Injection, you might introduce an interface. Keeping it simple, you can restrict such an interface to two methods:
public interface ICommandLine { string ReadLine(); void WriteLine(string text); }
Please note that this is clearly a toy example. In later articles, you'll see how to expand the example to cover some more complex interactions, but you could also read a more realistic example already. Initially, the example is degenerate, because there's only a single interaction. In this case, an impure/pure/impure sandwich is still possible, but such a design wouldn't scale to more complex interactions.
The problem with defining and injecting an interface is that it isn't functional. What's the functional equivalent, then?
Instruction set #
Instead of defining an interface, you can define a discriminated union that describes a limited instruction set for command-line interactions:
type CommandLineInstruction<'a> = | ReadLine of (string -> 'a) | WriteLine of string * 'a
You may notice that it looks a bit like the above C# interface. Instead of defining two methods, it defines two cases, but the names are similar.
The ReadLine case is an instruction that an interpreter can evaluate. The data contained in the case is a continuation function. After evaluating the instruction, an interpreter must invoke this function with a string. It's up to the interpreter to figure out which string to use, but it could, for example, come from reading an input string from the command line. The continuation function is the next step in whatever program you're writing.
The WriteLine case is another instruction for interpreters. The data contained in this case is a tuple. The first element of the tuple is input for the interpreter, which can choose to e.g. print the value on the command line, or ignore it, and so on. The second element of the tuple is a value used to continue whatever program this case is a part of.
This enables you to write a small, specialised Abstract Syntax Tree (AST), but there's currently no way to return from it. One way to do that is to add a third 'stop' case. If you're interested in that option, Scott Wlaschin covers this as one iteration in his excellent explanation of the AST design.
Instead of adding a third 'stop' case to CommandLineInstruction<'a>, another option is to add a new wrapper type around it:
type CommandLineProgram<'a> = | Free of CommandLineInstruction<CommandLineProgram<'a>> | Pure of 'a
The Free case contains a CommandLineInstruction that always continues to a new CommandLineProgram value. The only way you can escape the AST is via the Pure case, which simply contains the 'return' value.
Abstract Syntax Trees #
With these two types you can write specialised programs that contain instructions for an interpreter. Notice that the types are pure by intent, although in F# we can't really tell. You can, however, repeat this exercise in Haskell, where the instruction set looks like this:
data CommandLineInstruction next = ReadLine (String -> next) | WriteLine String next deriving (Functor) type CommandLineProgram = Free CommandLineInstruction
Both of these types are pure, because IO is nowhere in sight. In Haskell, functions are pure by default. This also applies to the String -> next function contained in the ReadLine case.
Back in F# land, you can write an AST that implements the command-line interaction shown in the beginning of the article:
// CommandLineProgram<unit> let program = Free (WriteLine ( "Please enter your name.", Free (ReadLine ( fun s -> Free (WriteLine ( sprintf "Hello, %s!" s, Pure ()))))))
This AST defines a little program. The first step is a WriteLine instruction with the input value "Please enter your name.". The WriteLine case constructor takes a tuple as input argument. The first tuple element is that prompt, and the second element is the continuation, which has to be a new CommandLineInstruction<CommandLineProgram<'a>> value.
In this example, the continuation value is a ReadLine case, which takes a continuation function as input. This function should return a new program value, which it does by returning a WriteLine.
This second WriteLine value creates a string from the outer value s. The second tuple element for the WriteLine case must, again, be a new program value, but now the program is done, so you can use the 'stop' value Pure ().
You probably think that I should quit the mushrooms. No one in their right mind will want to write code like this. Neither would I. Fortunately, you can make the coding experience much better, but you'll see how to do that later.
Interpretation #
The above program value is a small CommandLineProgram<unit>. It's a pure value. In itself, it doesn't do anything.
Clearly, we'd like it to do something. In order to make that happen, you can write an interpreter:
// CommandLineProgram<'a> -> 'a let rec interpret = function | Pure x -> x | Free (ReadLine next) -> Console.ReadLine () |> next |> interpret | Free (WriteLine (s, next)) -> Console.WriteLine s next |> interpret
This interpreter is a recursive function that pattern-matches all the cases in any CommandLineProgram<'a>. When it encounters a Pure case, it simply returns the contained value.
When it encounters a ReadLine value, it calls Console.ReadLine (), which returns a string value read from the command line. It then pipes that input value to its next continuation function, which produces a new CommandLineInstruction<CommandLineProgram<'a>> value. Finally, it pipes that continuation value recursively to itself.
A similar treatment is given to the WriteLine case. Console.WriteLine s writes s to the command line, where after next is recursively piped to interpret.
When you run interpret program, you get an interaction like this:
Please enter your name. ploeh Hello, ploeh!
The program is pure; the interpret function is impure.
Syntactic sugar #
Clearly, you don't want to write programs as ASTs like the above. Fortunately, you don't have to. You can add syntactic sugar in the form of computation expressions. The way to do that is to turn your AST types into a monad. In Haskell, you'd already be done, because Free is a monad. In F#, some code is required.
Source functor #
The first step is to define a map function for the underlying instruction set union type. Conceptually, when you can define a map function for a type, you've created a functor (if it obeys the functor laws, that is). Functors are common, so it often pays off being aware of them.
// ('a -> 'b) -> CommandLineInstruction<'a> -> CommandLineInstruction<'b> let private mapI f = function | ReadLine next -> ReadLine (next >> f) | WriteLine (x, next) -> WriteLine (x, next |> f)
The mapI function takes a CommandLineInstruction<'a> value and maps it to a new value by mapping the 'underlying value'. I decided to make the function private because later, I'm also going to define a map function for CommandLineProgram<'a>, and I don't want to confuse users of the API with two different map functions. This is also the reason that the name of the function isn't simply map, but rather mapI, where the I stands for instruction.
mapI pattern-matches on the (implicit) input argument. If it's a ReadLine case, it returns a new ReadLine value, but it uses the mapper function f to translate the next function. Recall that next is a function of the type string -> 'a. When you compose it with f (which is a function of the type 'a -> 'b), you get (string -> 'a) >> ('a -> 'b), or string -> 'b. You've transformed the 'a to a 'b for the ReadLine case. If you can do the same for the WriteLine case, you'll have a functor.
Fortunately, the WriteLine case is similar, although a small tweak is required. This case contains a tuple of data. The first element (x) isn't a generic type (it's a string), so there's nothing to map. You can use it as-is in the new WriteLine value that you'll return. The WriteLine case is degenerate because next isn't a function, but rather a value. It has a type of 'a, and f is a function of the type 'a -> 'b, so piping next to f returns a 'b.
That's it: now you have a functor.
(In order to keep the category theorists happy, I should point out that such functors are really a sub-type of functors called endo-functors. Additionally, functors must obey some simple and intuitive laws in order to be functors, but that's all I'll say about that here.)
Free monad #
There's a reason I spend so much time talking about functors. The goal is syntactic sugar. You can get that with computation expressions. In order to create a computation expression builder, you need a monad.
You need a recipe for creating a monad. Fortunately, there's a type of monad called a free monad. It has the virtue that it enables you to create a monad from any functor.
Just what you need.
In Haskell, this happens automatically when you declare type CommandLineProgram = Free CommandLineInstruction. Thanks to Haskell's type system, Free is automatically a Monad when the underlying type is a Functor. In F#, you have to work for your monads, but the fact that Haskell can automate this means that there's a recipe that you can follow.
Earlier in this article, I mentioned in passing that there are alternative ways in which you can define a 'stop' case for your instruction set. The reason I chose to separate the API into two types (an 'instruction set', and a 'program') is that the instruction set is the underlying functor. The 'program' is part of the free monad. The other part is a bind function (that obeys the monad laws).
// ('a -> CommandLineProgram<'b>) -> CommandLineProgram<'a> // -> CommandLineProgram<'b> let rec bind f = function | Free instruction -> instruction |> mapI (bind f) |> Free | Pure x -> f x
This recursive function pattern-matches on the (implicit) CommandLineProgram<'a> argument. In the Pure case, the 'return' value x has the type 'a, which fits as input for the f function. The result is a value of type CommandLineProgram<'b>.
In the Free case, the instruction is a functor with the map function mapI. The first argument to the mapI function must be a function with the type 'a -> 'b. How can you compose such a function?
If you partially apply the recursive bind function with f (that is: bind f), you get a function of the type CommandLineProgram<'a> -> CommandLineProgram<'b>. This fits with mapI, because instruction has the type CommandLineInstruction<CommandLineProgram<'a>> (refer back to the definition of the Free case if need to convince yourself of that). The result of calling mapI with instruction is a CommandLineInstruction<CommandLineProgram<'b>> value. In order to turn it into a CommandLineProgram<'b> value, you wrap it in a new Free case.
Although this required a bit of explanation, defining a bind function for a free monad is a repeatable process. After all, in Haskell it's automated. In F#, you have to explicitly write the code, but it follows a recipe. Once you get the hang of it, there's not much to it.
Functor #
You'll occasionally need to explicitly use the bind function, but often it'll 'disappear' into a computation expression. There are other building blocks to an API than a bind function, though. You may, for example, need a map function:
// ('a -> 'b) -> CommandLineProgram<'a> -> CommandLineProgram<'b> let map f = bind (f >> Pure)
This makes CommandLineProgram<'a> a functor as well. This is the reason I made mapI private, because mapI makes the instruction set a functor, but the API is expressed in terms of AST programs, and it should be consistent. Within the same module, map should work on the same data type as bind.
Notice that map can be defined as a composition of bind and Pure. This is part of the recipe. For a free monad, the map function always looks like that. The f function is a function with the type 'a -> 'b, and Pure is a case constructor with the type 'b -> CommandLineProgram<'b>. Notice that I've used 'b for the generic type argument instead of the usual 'a. Hopefully, this makes it clear that when you compose these two functions together (f >> Pure), you get a function of the type ('a -> 'b) >> ('b -> CommandLineProgram<'b>), or 'a -> CommandLineProgram<'b>. That's just the type of function needed for the bind function, so the whole composition turns out to type-check and work as intended.
API #
In order to work with an API, you need the ability to create values of the API's type(s). In this case, you must be able to create CommandLineProgram<'a> values. While you can create them explicitly using the ReadLine, WriteLine, Free, and Pure case constructors, it'll be more convenient if you have some predefined functions and values for that.
// CommandLineProgram<string> let readLine = Free (ReadLine Pure) // string -> CommandLineProgram<unit> let writeLine s = Free (WriteLine (s, Pure ()))
In the ReadLine case, there's no input to the instruction, so you can define readLine as a predefined CommandLineProgram<string> value.
The WriteLine case, on the other hand, takes as an input argument a string to write, so you can define writeLine as a function that returns a CommandLineProgram<unit> value.
Computation expression #
The addition of map and supporting API is, to be honest, a bit of digression. You're going to use these functions later, but they aren't required in order to create a computation expression builder. All you need is a bind function and a way to lift a raw value into the monad. All of these are in place, so the builder is a matter of delegation:
type CommandLineBuilder () = member this.Bind (x, f) = CommandLine.bind f x member this.Return x = Pure x member this.ReturnFrom x = x member this.Zero () = Pure ()
This is a fairly minimal builder, but in my experience, most of times, this is all you need.
Create an instance of the CommandLineBuilder class, and you can write computation expressions:
let commandLine = CommandLineBuilder ()
I usually put such an object in a module with an [<AutoOpen>] attribute, so that it's available as a global object.
Producing ASTs with pretty code #
Using the commandLine computation expression is like using the built-in async or seq expressions. You can use it to rewrite the above AST as readable code:
// CommandLineProgram<unit> let program = commandLine { do! CommandLine.writeLine "Please enter your name." let! name = CommandLine.readLine do! sprintf "Hello, %s!" name |> CommandLine.writeLine }
This produces the same AST as before, but with much more readable syntax. The AST is the same, and you can use the above interpret function to run it. The interaction is the same as before:
Please enter your name. Free Hello, Free!
This is, obviously, a toy example, but in coming articles, you'll see how to gradually enhance the code to perform some more complex interactions.
Summary #
Functional programming emphasises pure functions, and a separation of pure and impure code. The simplest way to achieve such a separation is to design your code as an impure/pure/impure sandwich, but sometimes this isn't possible. When it's not possible, an alternative is to define an instruction set for an AST, and turn it into a free monad in order to enable enough syntactic sugar to keep the code readable.
While this may seem complicated, it has the benefit of making impurities explicit in the code. Whenever you see a CommandLineProgram value, you know that, at run-time, something impure is likely to happen. It's not uncontrolled impurity, though. Inside a CommandLineProgram, only reading from, and writing to, the command line will happen. It's not going to generate random values, change global variables, send an email, or any other unpredictable operation - that is, unless the interpreter does that...
Next: A pure command-line wizard.
Pure interactions
Long-running, non-deterministic interactions can be modelled in a pure, functional way.
In a previous article, you can read why Dependency Injection and (strict) functional programming are mutually exclusive. Dependency Injection makes everything impure, and if nothing is pure, then it's hardly functional. In Dependency rejection, you can see how you can often separate impure and pure code into an impure/pure/impure sandwich.
Micro-operation-based architectures #
The impure/pure/impure sandwich architecture works well in scenarios with limited interaction. Some data arrives at the boundary of the system, the system responds, and that's it. That, however, describes a significant fraction of all software running in the world today.
Any HTTP-based application (web site, REST API, most SOAP services) fits the description: an HTTP request arrives, and the server responds with an HTTP response. In a well-designed and well-running system, you should return the response within seconds, if not faster. Everything the software needs in order to run to completion is either part of the request, or part of the application state. You may need to query a database to gather more data based on the incoming request, but you can still gather most data from impure sources, pass it all to your pure core implementation, get the pure values back and return the response.
Likewise, asynchronous message-based systems, such as pub/sub, Pipes and Filters, Actor-based systems, 'SOA done right', CQRS/Event Sourcing, and so on, are based on short-lived, stateless interactions. Similar to HTTP-based applications, there's often (persisted) application state, but once a message arrives at a message handler, the software should process it as quickly as possible. Again, it can read extra (impure) data from a database, pass everything to a pure function, and finally do something impure with the return value.
Common for all such systems is that while they can handle large volumes of data, they do so as the result of a multitude of parallel, distinct, and isolated micro-operations.
Interactive software #
There is, however, another category of software. We could call it 'interactive software'. As the name implies, this includes everything with a user interface, but can also be a long-running batch job, or, as you've already seen, time-sensitive software.
For such software, the impure/pure/impure sandwich architecture is no longer possible. Just think of a UI-based program, like an email client. You compose and send an email, receive a response, then compose a reply, and so on. Every send and receive is impure, as is all the user interface rendering. What happens next depends on what happened before, and everything that happens in the real world is impure.
Have we finally identified the limitations of functional programming?
Hardly. In this series of articles, I'm going to show you how to model pure interactions:
- Hello, pure command-line interaction
- A pure command-line wizard
- Combining free monads in Haskell
- Combining free monads in F#
- F# free monad recipe
This series of articles gives you a comprehensive walkthrough of pure interactions and free monads in F#. For a motivating example, see Pure times, which presents a more realistic example that, on the other hand, doesn't go to the same level of detail.
Summary #
The solution to the problem of continuous impure interactions is to model them as a instructions in a (domain-specific) Abstract Syntax Tree (AST), and then using an impure interpreter for the pure AST. You can model the AST as a (free) monad in order to make the required syntax nice.
Pure times in F#
A Polling Consumer implementation written in F#.
Previously, you saw how to implement a Polling Consumer in Haskell. This proves that it's possible to write pure functional code modelling long-running interactions with the (impure) world. In this article, you'll see how to port the Haskell code to F#.
For reference, I'll repeat the state transition diagram here:
For a complete description of the goals and constraints of this particular Polling Consumer implementation, see my earlier Type Driven Development article, or, even better, watch my Pluralsight course Type-Driven Development with F#.
State data types #
The program has to keep track of various durations. You can model these as naked TimeSpan values, but in order to add extra type safety, you can, instead, define them as separate types:
type PollDuration = PollDuration of TimeSpan type IdleDuration = IdleDuration of TimeSpan type HandleDuration = HandleDuration of TimeSpan type CycleDuration = { PollDuration : PollDuration HandleDuration : HandleDuration }
This is a straightforward port of the Haskell code. See the previous article for more details about the motivation for doing this.
You can now define the states of the finite state machine:
type State<'msg> = | ReadyState of CycleDuration list | ReceivedMessageState of (CycleDuration list * PollDuration * 'msg) | NoMessageState of (CycleDuration list * PollDuration) | StoppedState of CycleDuration list
Again, this is a straight port of the Haskell code.
From instruction set to syntactic sugar #
The Polling Consumer must interact with its environment in various ways:
- Query the system clock
- Poll for messages
- Handle messages
- Idle
type PollingInstruction<'msg, 'next> = | CurrentTime of (DateTimeOffset -> 'next) | Poll of (('msg option * PollDuration) -> 'next) | Handle of ('msg * (HandleDuration -> 'next)) | Idle of (IdleDuration * (IdleDuration -> 'next))
Once more, this is a direct translation of the Haskell code, but from here, this is where your F# code will have to deviate from Haskell. In Haskell, you can, with a single line of code, declare that such a type is a functor. This isn't possible in F#. Instead, you have to explicitly write a map function. This isn't difficult, though. There's a reason that the Haskell compiler can automate this:
// ('a -> 'b) -> PollingInstruction<'c,'a> -> PollingInstruction<'c,'b> let private mapI f = function | CurrentTime next -> CurrentTime (next >> f) | Poll next -> Poll (next >> f) | Handle (x, next) -> Handle (x, next >> f) | Idle (x, next) -> Idle (x, next >> f)
The function is named mapI, where the I stands for instruction. It's private because the next step is to package the functor in a monad. From that monad, you can define a new functor, so in order to prevent any confusion, I decided to hide the underlying functor from any consumers of the API.
Defining a map function for a generic type like PollingInstruction<'msg, 'next> is well-defined. Pattern-match each union case and return the same case, but with the next function composed with the input function argument f: next >> f. In later articles, you'll see more examples, and you'll see how this recipe is entirely repeatable and automatable.
While a functor isn't an explicit concept in F#, this is how PollingInstruction msg next is a Functor in Haskell. Given a functor, you can produce a free monad. The reason you'd want to do this is that once you have a monad, you can get syntactic sugar. Currently, PollingInstruction<'msg, 'next> only enables you to create Abstract Syntax Trees (ASTs), but the programming experience would be cumbersome and alien. Monads give you automatic do notation in Haskell; in F#, it enables you to write a computation expression builder.
Haskell's type system enables you to make a monad from a functor with a one-liner: type PollingProgram msg = Free (PollingInstruction msg). In F#, you'll have to write some boilerplate code. First, you have to define the monadic type:
type PollingProgram<'msg, 'next> = | Free of PollingInstruction<'msg, PollingProgram<'msg, 'next>> | Pure of 'next
You already saw a hint of such a type in the previous article. The PollingProgram<'msg, 'next> discriminated union defines two cases: Free and Pure. The Free case is a PollingInstruction that produces a new PollingProgram as its next step. In essence, this enables you to build an AST, but you also need a signal to stop and return a value from the AST. That's the purpose of the Pure case.
Such a type is only a monad if it defines a bind function (that obey the monad laws):
// ('a -> PollingProgram<'b,'c>) -> PollingProgram<'b,'a> // -> PollingProgram<'b,'c> let rec bind f = function | Free instruction -> instruction |> mapI (bind f) |> Free | Pure x -> f x
This bind function pattern-matches on Free and Pure, respectively. In the Pure case, it simply uses the underlying result value x as an input argument to f. In the Free case, it composes the underlying functor (mapI) with itself recursively. If you find this step obscure, I will not blame you. Just like the implementation of mapI is a bit of boilerplate code, then so is this. It always seems to work this way. If you want to dig deeper into the inner workings of this, then Scott Wlaschin has a detailed explanation.
With the addition of bind PollingProgram<'msg, 'next> becomes a monad (I'm not going to show that the monad laws hold, but they do). Making it a functor is trivial:
// ('a -> 'b) -> PollingProgram<'c,'a> -> PollingProgram<'c,'b> let map f = bind (f >> Pure)
The underlying PollingInstruction type was already a functor. This function makes PollingProgram a functor as well.
It'll be convenient with some functions that lifts each PollingInstruction case to a corresponding PollingProgram value. In Haskell, you can use the liftF function for this, but in F# you'll have to be slightly more explicit:
// PollingProgram<'a,DateTimeOffset> let currentTime = Free (CurrentTime Pure) // PollingProgram<'a,('a option * PollDuration)> let poll = Free (Poll Pure) // 'a -> PollingProgram<'a,HandleDuration> let handle msg = Free (Handle (msg, Pure)) // IdleDuration -> PollingProgram<'a,IdleDuration> let idle duration = Free (Idle (duration, Pure))
currentTime and poll aren't even functions, but values. They are, however, small PollingProgram values, so while they look like values (as contrasted to functions), they represent singular executable instructions.
handle and idle are both functions that return PollingProgram values.
You can now implement a small computation expression builder:
type PollingBuilder () = member this.Bind (x, f) = Polling.bind f x member this.Return x = Pure x member this.ReturnFrom x = x member this.Zero () = this.Return ()
As you can tell, not much is going on here. The Bind method simply delegates to the above bind function, and the rest are trivial one-liners.
You can create an instance of the PollingBuilder class so that you can write PollingPrograms with syntactic sugar:
let polling = PollingBuilder ()
This enables you to write polling computation expressions. You'll see examples of this shortly.
Most of the code you've seen here is automated in Haskell. This means that while you'll have to explicitly write it in F#, it follows a recipe. Once you get the hang of it, it doesn't take much time. The maintenance overhead of the code is also minimal, because you're essentially implementing a universal abstraction. It's not going to change.
Support functions #
Continuing the port of the previous article's Haskell code, you can write a pair of support functions. These are small PollingProgram values:
// IdleDuration -> DateTimeOffset -> PollingProgram<'a,bool> let private shouldIdle (IdleDuration d) stopBefore = polling { let! now = Polling.currentTime return now + d < stopBefore }
This shouldIdle function uses the polling computation expression defined above. It first uses the above Polling.currentTime value to get the current time. While Polling.currentTime is a value of the type PollingProgram<'b,DateTimeOffset>, the let! binding makes now a simple DateTimeOffset value. Computation expressions give you the same sort of syntactic sugar that do notation does in Haskell.
If you add now to d, you get a new DateTimeOffset value that represents the time that the program will resume, if it decides to suspend itself for the idle duration. If this time is before stopBefore, the return value is true; otherwise, it's false. Similar to the Haskell example, the return value of shouldIdle isn't just bool, but rather PollingProgram<'a,bool>, because it all takes place inside the polling computation expression.
The function looks impure, but it is pure.
In the same vein, you can implement a shouldPoll function:
// CycleDuration -> TimeSpan let toTotalCycleTimeSpan x = let (PollDuration pd) = x.PollDuration let (HandleDuration hd) = x.HandleDuration pd + hd // TimeSpan -> DateTimeOffset -> CycleDuration list -> PollingProgram<'a,bool> let private shouldPoll estimatedDuration stopBefore statistics = polling { let expectedHandleDuration = statistics |> List.map toTotalCycleTimeSpan |> Statistics.calculateExpectedDuration estimatedDuration let! now = Polling.currentTime return now + expectedHandleDuration < stopBefore }
This function uses two helper functions: toTotalCycleTimeSpan and Statistics.calculateExpectedDuration. I've included toTotalCycleTimeSpan in the code shown here, while I'm skipping Statistics.calculateExpectedDuration, because it hasn't changed since the code I show in my Pluralsight course. You can also see the function in the GitHub repository accompanying this article.
Compared to shouldIdle, the shouldPoll function needs an extra (pure) step in order to figure out the expectedHandleDuration, but from there, the two functions are similar.
Transitions #
All building blocks are now ready for the finite state machine. In order to break the problem into manageable pieces, you can write a function for each state. Such a function should take as input the data associated with a particular state, and return the next state, based on the input.
The simplest transition is when the program reaches the end state, because there's no way out of that state:
// CycleDuration list -> PollingProgram<'a,State<'b>> let transitionFromStopped s = polling { return StoppedState s }
The data contained in a StoppedState case has the type CycleDuration list, so the transitionFromStopped function simply lifts such a list to a PollingProgram value by returning a StoppedState value from within a polling computation expression.
Slightly more complex, but still simple, is the transition out of the received state. There's no branching logic involved. You just have to handle the message, measure how much time it takes, append the measurements to previous statistics, and return to the ready state:
// CycleDuration list * PollDuration * 'a -> PollingProgram<'a,State<'b>> let transitionFromReceived (statistics, pd, msg) = polling { let! hd = Polling.handle msg return { PollDuration = pd; HandleDuration = hd } :: statistics |> ReadyState }
This function uses the Polling.handle convenience function to handle the input message. Although the handle function returns a PollingProgram<'a,HandleDuration> value, the let! binding inside of a polling computation expression makes hd a HandleDuration value.
The data contained within a ReceivedMessageState case is a CycleDuration list * PollDuration * 'msg tuple. That's the input argument to the transitionFromReceived function, which immediately pattern-matches the tuple's three elements into statistics, pd, and msg.
The pd element is the PollDuration - i.e. the time it took to reach the received state. The hd value returned by Polling.handle gives you the time it took to handle the message. From those two values you can create a new CycleDuration value, and cons (::) it onto the previous statistics. This returns an updated list of statistics that you can pipe to the ReadyState case constructor.
ReadyState in itself creates a new State<'msg> value, but since all of this takes place inside a polling computation expression, the return type of the function becomes PollingProgram<'a,State<'b>>.
The transitionFromReceived function handles the state when the program has received a message, but you also need to handle the state when no message was received:
// IdleDuration -> DateTimeOffset -> CycleDuration list * 'a // -> PollingProgram<'b,State<'c>> let transitionFromNoMessage d stopBefore (statistics, _) = polling { let! b = shouldIdle d stopBefore if b then do! Polling.idle d |> Polling.map ignore return ReadyState statistics else return StoppedState statistics }
This function first calls the shouldIdle support function. Similar to Haskell, you can see how you can compose larger PollingPrograms from smaller PollingProgram values - just like you can compose 'normal' functions from smaller functions.
With the syntactic sugar in place, b is simply a bool value that you can use in a standard if/then/else expression. If b is false, then return a StoppedState value; otherwise, continue with the next steps.
Polling.idle returns the duration of the suspension, but you don't actually need this data, so you can ignore it. When Polling.idle returns, you can return a ReadyState value.
It may look as though that do! expression is a blocking call, but it really isn't. The transitionFromNoMessage function only builds an Abstract Syntax Tree, where one of the instructions suggests that an interpreter could block. Unless evaluated by an impure interpreter, transitionFromNoMessage is pure.
The final transition is the most complex, because there are three possible outcomes:
// TimeSpan -> DateTimeOffset -> CycleDuration list // -> PollingProgram<'a,State<'a>> let transitionFromReady estimatedDuration stopBefore statistics = polling { let! b = shouldPoll estimatedDuration stopBefore statistics if b then let! pollResult = Polling.poll match pollResult with | Some msg, pd -> return ReceivedMessageState (statistics, pd, msg) | None, pd -> return NoMessageState (statistics, pd) else return StoppedState statistics }
In the same way that transitionFromNoMessage uses shouldIdle, the transitionFromReady function uses the shouldPoll support function to decide whether or not to keep going. If b is false, it returns a StoppedState value.
Otherwise, it goes on to poll. Thanks to all the syntactic sugar, pollResult is an 'a option * PollDuration value. As always, when you have a discriminated union, you can handle all cases with pattern matching (and the compiler will help you keep track of whether or not you've handled all of them).
In the Some case, you have a message, and the duration it took to poll for that message. This is all the data you need to return a ReceivedMessageState value.
In the None case, you also have the poll duration pd; return a NoMessageState value.
That's four transition functions that you can combine in a single function that, for any state, returns a new state:
// TimeSpan -> IdleDuration -> DateTimeOffset -> State<'a> // -> PollingProgram<'a,State<'a>> let transition estimatedDuration idleDuration stopBefore = function | ReadyState s -> transitionFromReady estimatedDuration stopBefore s | ReceivedMessageState s -> transitionFromReceived s | NoMessageState s -> transitionFromNoMessage idleDuration stopBefore s | StoppedState s -> transitionFromStopped s
You simply pattern-match the (implicit) input argument with the four state cases, and call the appropriate transition function for each case.
Interpretation #
The transition function is pure. It returns a PollingProgram value. How do you turn it into something that performs real work?
You write an interpreter:
// PollingProgram<Msg,'a> -> 'a let rec interpret = function | Pure x -> x | Free (CurrentTime next) -> DateTimeOffset.Now |> next |> interpret | Free (Poll next) -> Imp.poll () |> next |> interpret | Free (Handle (msg, next)) -> Imp.handle msg |> next |> interpret | Free (Idle (d, next)) -> Imp.idle d |> next |> interpret
A PollingProgram is either a Pure or a Free case. In the Free case, the contained data is a PollingInstruction value, which can be one of four separate cases. With pattern matching, the interpreter handles all five cases.
In the Pure case, it returns the value, but in all the Free cases, it recursively calls itself after having first followed the instruction in each PollingInstruction case. For instance, when the instruction is CurrentTime, it invokes DateTimeOffset.Now, passes the return value (a DateTimeOffset value) to the next continuation, and then recursively calls interpret. The next instruction, then, could be another Free case, or it could be Pure.
The other three instruction cases delegate to implementation functions defined in an Imp module. I'm not going to show them here. They're normal, although impure, F# functions.
Execution #
You're almost done. You have a function that returns a new state for any given input state, as well as an interpreter. You need a function that can repeat this in a loop until it reaches StoppedState:
// TimeSpan -> IdleDuration -> DateTimeOffset -> State<Msg> -> State<Msg> let rec run estimatedDuration idleDuration stopBefore s = let ns = PollingConsumer.transition estimatedDuration idleDuration stopBefore s |> interpret match ns with | PollingConsumer.StoppedState _ -> ns | _ -> run estimatedDuration idleDuration stopBefore ns
This function calls PollingConsumer.transition with the input state s, which returns a new PollingProgram<Msg,PollingConsumer.State<Msg>> value that you can pipe to the interpret function. That gives you the new state ns. If ns is a StoppedState, you return; otherwise, you recurse into run for another round.
Finally, you can write the entry point for the application:
[<EntryPoint>] let main _ = let timeAtEntry = DateTimeOffset.Now printOnEntry timeAtEntry let stopBefore = timeAtEntry + limit let estimatedDuration = TimeSpan.FromSeconds 2. let idleDuration = TimeSpan.FromSeconds 5. |> IdleDuration let durations = PollingConsumer.ReadyState [] |> run estimatedDuration idleDuration stopBefore |> PollingConsumer.durations |> List.map PollingConsumer.toTotalCycleTimeSpan printOnExit timeAtEntry durations // Return 0. This indicates success. 0
This defines an estimated duration of 2 seconds, an idle duration of 5 seconds, and a maximum run time of 60 seconds (limit). The initial state is ReadyState with no prior statistics. Pass all these arguments to the run function, and you have a running program.
This function also uses a few printout functions that I'm not going to show here. When you run the program, you should see output like this:
Started polling at 11:18:28. Polling Handling Polling Handling Polling Sleeping Polling Sleeping Polling Handling Polling Handling Polling Sleeping Polling Sleeping Polling Sleeping Polling Handling Polling Sleeping Polling Sleeping Polling Sleeping Polling Sleeping Polling Handling Stopped polling at 11:19:26. Elapsed time: 00:00:58.4428980. Handled 6 message(s). Average duration: 00:00:01.0550346 Standard deviation: 00:00:00.3970599
It does, indeed, exit before 60 seconds have elapsed.
Summary #
You can model long-running interactions with an Abstract Syntax Tree. Without computation expressions, writing programs as 'raw' ASTs would be cumbersome, but turning the AST into a (free) monad makes it all quite palatable.
Haskell code with a free monad can be ported to F#, although some boilerplate code is required. That code, however, is unlikely to be much of a burden, because it follows a well-known recipe that implements a universal abstraction.
For more details on how to write free monads in F#, see Pure interactions.
Pure times in Haskell
A Polling Consumer implementation written in Haskell.
As you can read in the introductory article, I've come to realise that the Polling Consumer that I originally wrote in F# isn't particularly functional. Being the friendly and productive language that it is, F# doesn't protect you from mixing pure and impure code, but Haskell does. For that reason, you can develop a prototype in Haskell, and later port it to F#, if you want to learn how to solve the problem in a strictly functional way.
To recapitulate, the task is to implement a Polling Consumer that runs for a predefined duration, after which it exits (so that it can be restarted by a scheduler).
The program is a finite state machine that moves between four states. From the ready state, it'll need to decide whether to poll for a new message or exit. Polling and handling takes time (and at compile-time we don't know how long), and the program ought to stop at a pre-defined time. If it gets too close to that time, it should exit, but otherwise, it should attempt to handle a message (and keep track of how long this takes). You can read a more elaborate description of the problem in the original article.
State data types #
The premise in that initial article was that F#'s type system is so powerful that it can aid you in designing a good solution. Haskell's type system is even more powerful, so it can give you even better help.
The Polling Consumer program must measure and keep track of how long it takes to poll, handle a message, or idle. All of these are durations. In Haskell, we can represent them as NominalDiffTime values. I'm a bit concerned, though, that if I represent all of these durations as NominalDiffTime values, I may accidentally use a poll duration where I really need a handle duration, and so on. Perhaps I'm being overly cautious, but I like to get help from the type system. In the words of Igal Tabachnik, types prevent typos:
newtype PollDuration = PollDuration NominalDiffTime deriving (Eq, Show) newtype IdleDuration = IdleDuration NominalDiffTime deriving (Eq, Show) newtype HandleDuration = HandleDuration NominalDiffTime deriving (Eq, Show) data CycleDuration = CycleDuration { pollDuration :: PollDuration, handleDuration :: HandleDuration } deriving (Eq, Show)
This simply declares that PollDuration, IdleDuration, and HandleDuration are all NominalDiffTime values, but you can't mistakenly use a PollDuration where a HandleDuration is required, and so on.
In addition to those three types of duration, I also define a CycleDuration. This is the data that I actually need to keep track of: how long does it take to handle a single message? I'm assuming that polling for a message is an I/O-bound operation, so it may take significant time. Likewise, handling a message may take time. When deciding whether to exit or handle a new message, both durations count. Instead of defining CycleDuration as a newtype alias for NominalDiffTime, I decided to define it as a record type comprised of a PollDuration and a HandleDuration. It's not that I'm really interested in keeping track of these two values individually, but it protects me from making stupid mistakes. I can only create a CycleDuration value if I have both a PollDuration and a HandleDuration value.
In short, I'm trying to combat primitive obsession.
With these duration types in place, you can define the states of the finite state machine:
data PollingState msg = Ready [CycleDuration] | ReceivedMessage [CycleDuration] PollDuration msg | NoMessage [CycleDuration] PollDuration | Stopped [CycleDuration] deriving (Show)
Like the original F# code, state data can be represented as a sum type, with a case for each state. In all four cases, a CycleDuration list keeps track of the observed message-handling statistics. This is the way the program should attempt to calculate whether it's safe to handle another message, or exit. Two of the cases (ReceivedMessage and NoMessage) also contain a PollDuration, which informs the program about the duration of the poll operation that caused it to reach that state. Additionally, the ReceivedMessage case contains a message of the generic type msg. This makes the entire PollingState type generic. A message can be of any type: a string, a number, or a complex data structure. The Polling Consumer program doesn't care, because it doesn't handle messages; it only schedules the polling.
This is reminiscent of the previous F# attempt, with the most notable difference that it doesn't attempt to capture durations as Timed<'a> values. It does capture durations, but not when the operations started and stopped. So how will it know what time it is?
Interactions as pure values #
This is the heart of the matter. The Polling Consumer must constantly look at the clock. It's under a deadline, and it must also measure durations of poll, handle, and idle operations. All of this is non-deterministic, so not pure. The program has to interact with impure operations during its entire lifetime. In fact, its ultimate decision to exit will be based on impure data. How can you model this in a pure fashion?
You can model long-running (impure) interactions by defining a small instruction set for an Abstract Syntax Tree (AST). That sounds intimidating, but once you get the hang of it, it becomes routine. In later articles, I'll expand on this, but for now I'll refer you to an excellent article by Scott Wlaschin, who explains the approach in F#.
data PollingInstruction msg next = CurrentTime (UTCTime -> next) | Poll ((Maybe msg, PollDuration) -> next) | Handle msg (HandleDuration -> next) | Idle IdleDuration (IdleDuration -> next) deriving (Functor)
This PollingInstruction sum type defines four cases of interaction. Each case is
- named after the interaction
- defines the type of data used as input arguments for the interaction
- and also defines a continuation; that is: a function that will be executed with the return value of the interaction
Handle case contains all three elements: the interaction is named Handle, the input to the interaction is of the generic type msg, and the continuation is a function that takes a HandleDuration value as input, and returns a value of the generic type next. In other words, the interaction takes a msg value as input, and returns a HandleDuration value as output. That duration is the time it took to handle the input message. (The intent is that the operation that 'implements' this interaction also actually handles the message, whatever that means.)
Likewise, the Idle interaction takes an IdleDuration as input, and also returns an IdleDuration. The intent here is that the 'implementation' of the interaction suspends itself for the duration of the input value, and returns the time it actually spent in suspension (which is likely to be slightly longer than the requested duration).
Both CurrentTime and Poll, on the other hand, are degenerate, because they take no input. You don't need to supply any input argument to read the current time. You could model that interaction as taking () ('unit') as an input argument (CurrentTime () (UTCTime -> next)), but the () is redundant and can be omitted. The same is the case for the Poll case, which returns a Maybe msg and how long the poll took.
(The PollingInstruction sum type defines four cases, which is also the number of cases defined by PollingState. This is a coincidence; don't read anything into it.)
The PollingInstruction type is generic in a way that you can make it a Functor. Haskell can do this for you automatically, using the DeriveFunctor language extension; that's what deriving (Functor) does. If you'd like to see how to explicitly make such a data structure a functor, please refer to the F# example; F# can't automatically derive functors, so you'll have to do it manually.
Since PollingInstruction is a Functor, we can make a Monad out of it. You use a free monad, which allows you to build a monad from any functor:
type PollingProgram msg = Free (PollingInstruction msg)
In Haskell, it's literally a one-liner, but in F# you'll have to write the code yourself. Thus, if you're interested in learning how this magic happens, I'm going to dissect this step in the next article.
The motivation for defining a Monad is that we get automatic syntactic sugar for our PollingProgram ASTs, via Haskell's do notation. In F#, we're going to write a computation expression builder to achieve the same effect.
The final building blocks for the specialised PollingProgram API is a convenience function for each case:
currentTime :: PollingProgram msg UTCTime currentTime = liftF (CurrentTime id) poll :: PollingProgram msg (Maybe msg, PollDuration) poll = liftF (Poll id) handle :: msg -> PollingProgram msg HandleDuration handle msg = liftF (Handle msg id) idle :: IdleDuration -> PollingProgram msg IdleDuration idle d = liftF (Idle d id)
More one-liners, as you can tell. These all use liftF to turn PollingInstruction cases into PollingProgram values. The degenerate cases CurrentTime and Poll simply become values, whereas the complete cases become (pure) functions.
Support functions #
You may have noticed that until now, I haven't written much 'code' in the sense that most people think of it. It's mostly been type declarations and a few one-liners. A strong and sophisticated type system like Haskell's enable you to shift some of the programming burden from 'real programming' to type definitions, but you'll still have to write some code.
Before we get to the state transitions proper, we'll look at some support functions. These will, I hope, serve as a good introduction to how to use the PollingProgram API.
One decision the Polling Consumer program has to make is to decide whether it should suspend itself for a short time. That's easy to express using the API:
shouldIdle :: IdleDuration -> UTCTime -> PollingProgram msg Bool shouldIdle (IdleDuration d) stopBefore = do now <- currentTime return $ d `addUTCTime` now < stopBefore
The shouldIdle function returns a small program that, when evaluated, will decide whether or not to suspend itself. It first reads the current time using the above currentTime value. While currentTime has the type PollingProgram msg UTCTime, due to Haskell's do notation, the now value simply has the type UTCTime. This enables you to use the built-in addUTCTime function (here written using infix notation) to add now to d (a NominalDiffTime value, due to pattern matching into IdleDuration).
Adding the idle duration d to the current time now gives you the time the program would resume, were it to suspend itself. The shouldIdle function compares that time to the stopBefore argument (another UTCTime value). If the time the program would resume is before the time it ought to stop, the return value is True; otherwise, it's False.
Since the entire function is defined within a do block, the return type isn't just Bool, but rather PollingProgram msg Bool. It's a little PollingProgram AST, but it looks like imperative code.
You sometimes hear the bon mot that Haskell is the world's greatest imperative language. The combination of free monads and do notation certainly makes it easy to define small grammars (dare I say DSLs?) that look like imperative code, while still being strictly functional.
The crux is that shouldIdle is pure. It looks impure, but it's not. It's an Abstract Syntax Tree, and it only becomes non-deterministic if interpreted by an impure interpreter (more on that later).
The purpose of shouldIdle is to decide whether or not to idle or exit. If the program decides to idle, it should return to the ready state, as per the above state diagram. In this state, it needs to decide whether or not to poll for a message. If there's a message, it should be handled, and all of that takes time. In the ready state, then, the program must figure out how much time it thinks that handling a message will take.
One way to do that is to consider the observed durations so far. This helper function calculates the expected duration based on the average and standard deviation of the previous durations:
calculateExpectedDuration :: NominalDiffTime -> [CycleDuration] -> NominalDiffTime calculateExpectedDuration estimatedDuration [] = estimatedDuration calculateExpectedDuration _ statistics = toEnum $ fromEnum $ avg + stdDev * 3 where fromCycleDuration :: CycleDuration -> Float fromCycleDuration (CycleDuration (PollDuration pd) (HandleDuration hd)) = toEnum $ fromEnum $ pd + hd durations = fmap fromCycleDuration statistics l = toEnum $ length durations avg = sum durations / l stdDev = sqrt (sum (fmap (\x -> (x - avg) ** 2) durations) / l)
I'm not going to dwell much on this function, as it's a normal, pure, mathematical function. The only feature I'll emphasise is that in order to call it, you must pass an estimatedDuration that will be used when statistics is empty. This is because you can't calculate the average of an empty list. This estimated duration is simply your wild guess at how long you think it'll take to handle a message.
With this helper function, you can now write a small PollingProgram that decides whether or not to poll:
shouldPoll :: NominalDiffTime -> UTCTime -> [CycleDuration] -> PollingProgram msg Bool shouldPoll estimatedDuration stopBefore statistics = do let expectedHandleDuration = calculateExpectedDuration estimatedDuration statistics now <- currentTime return $ expectedHandleDuration `addUTCTime` now < stopBefore
Notice that the shouldPoll function looks similar to shouldIdle. As an extra initial step, it first calculates expectedHandleDuration using the above calculateExpectedDuration function. With that, it follows the same two steps as shouldIdle.
This function is also pure, because it returns an AST. While it looks impure, it's not, because it doesn't actually do anything.
Transitions #
Those are all the building blocks required to write the state transitions. In order to break down the problem in manageable chunks, you can write a transition function for each state. Such a function would return the next state, given a particular input state.
While it'd be intuitive to begin with the ready state, let's instead start with the simplest transition. In the end state, nothing should happen, so the transition is a one-liner:
transitionFromStopped :: Monad m => [CycleDuration] -> m (PollingState msg) transitionFromStopped statistics = return $ Stopped statistics
Once stopped, the program stays in the Stopped state. This function simply takes a list of CycleDuration values and elevates them to a monad type. Notice that the return value isn't specifically a PollingProgram, but any monad. Since PollingProgram is a monad, that'll work too, though.
Slightly more complicated than transitionFromStopped is the transition from the received state. There's no branching in that case; simply handle the message, measure how long it took, add the observed duration to the statistics, and transition back to ready:
transitionFromReceived :: [CycleDuration] -> PollDuration -> msg -> PollingProgram msg (PollingState msg) transitionFromReceived statistics pd msg = do hd <- handle msg return $ Ready (CycleDuration pd hd : statistics)
Again, this looks impure, but the return type is PollingProgram msg (PollingState msg), indicating that the return value is an AST. As is not uncommon in Haskell, the type declaration is larger than the implementation.
Things get slightly more interesting in the no message state. Here you get to use the above shouldIdle support function:
transitionFromNoMessage :: IdleDuration -> UTCTime -> [CycleDuration] -> PollingProgram msg (PollingState msg) transitionFromNoMessage d stopBefore statistics = do b <- shouldIdle d stopBefore if b then idle d >> return (Ready statistics) else return $ Stopped statistics
The first step in transitionFromNoMessage is calling shouldIdle. Thanks to Haskell's do notation, the b value is a simple Bool value that you can use to branch. If b is True, then first call idle and then return to the Ready state; otherwise, exit to the Stopped state.
Notice how PollingProgram values are composable. For instance, shouldIdle defines a small PollingProgram that can be (re)used in a bigger program, such as in transitionFromNoMessage.
Finally, from the ready state, the program can transition to three other states, so this is the most complex transition:
transitionFromReady :: NominalDiffTime -> UTCTime -> [CycleDuration] -> PollingProgram msg (PollingState msg) transitionFromReady estimatedDuration stopBefore statistics = do b <- shouldPoll estimatedDuration stopBefore statistics if b then do pollResult <- poll case pollResult of (Just msg, pd) -> return $ ReceivedMessage statistics pd msg (Nothing , pd) -> return $ NoMessage statistics pd else return $ Stopped statistics
Like transitionFromNoMessage, the transitionFromReady function first calls a supporting function (this time shouldPoll) in order to make a decision. If b is False, the next state is Stopped; otherwise, the program moves on to the next step.
The program polls for a message using the poll helper function defined above. While poll is a PollingProgram msg (Maybe msg, PollDuration) value, thanks to do notation, pollResult is a Maybe msg, PollDuration value. Matching on that value requires you to handle two separate cases: If a message was received (Just msg), then return a ReceivedMessage state with the message. Otherwise (Nothing), return a NoMessage state.
With those four functions you can now define a function that can transition from any input state:
transition :: NominalDiffTime -> IdleDuration -> UTCTime -> PollingState msg -> PollingProgram msg (PollingState msg) transition estimatedDuration idleDuration stopBefore state = case state of Ready stats -> transitionFromReady estimatedDuration stopBefore stats ReceivedMessage stats pd msg -> transitionFromReceived stats pd msg NoMessage stats _ -> transitionFromNoMessage idleDuration stopBefore stats Stopped stats -> transitionFromStopped stats
The transition function simply pattern-matches on the input state and delegates to each of the four above transition functions.
A short philosophical interlude #
All code so far has been pure, although it may not look that way. At this stage, it may be reasonable to pause and consider: what's the point, even?
After all, when interpreted, a PollingProgram can (and, in reality, almost certainly will) have impure behaviour. If we create an entire executable upon this abstraction, then we've essentially developed a big program with impure behaviour...
Indeed we have, but the alternative would have been to write it all in the context of IO. If you'd done that, then you'd allow any non-deterministic, side-effecty behaviour anywhere in your program. At least with a PollingProgram, any reader will quickly learn that only a maximum of four impure operations can happen. In other words, you've managed to control and restrict the impurity to exactly those interactions you want to model.
Not only that, but the type of impurity is immediately visible as part of a value's type. In a later article, you'll see how different impure interaction APIs can be composed.
Interpretation #
At this point, you have a program in the form of an AST. How do you execute it?
You write an interpreter:
interpret :: PollingProgram Message a -> IO a interpret program = case runFree program of Pure r -> return r Free (CurrentTime next) -> getCurrentTime >>= interpret . next Free (Poll next) -> pollImp >>= interpret . next Free (Handle msg next) -> handleImp msg >>= interpret . next Free (Idle d next) -> idleImp d >>= interpret . next
When you turn a functor into a monad using the Free constructor (see above), your functor is wrapped in a general-purpose sum type with two cases: Pure and Free. Your functor is always contained in the Free case, whereas Pure is the escape hatch. This is where you return the value of the entire computation.
An interpreter must match both Pure and Free. Pure is easy, because you simply return the result value.
In the Free case, you'll need to match each of the four cases of PollingInstruction. In all four cases, you invoke an impure implementation function, pass its return value to next, and finally recursively invoke interpret with the value returned by next.
Three of the implementations are details that aren't of importance here, but if you want to review them, the entire source code for this article is available as a gist. The fourth implementation is the built-in getCurrentTime function. They are all impure; all return IO values. This also implies that the return type of the entire interpret function is IO a.
This particular interpreter is impure, but nothing prevents you from writing a pure interpreter, for example for use in unit testing.
Execution #
You're almost done. You have a function that returns a new state for any given input state, as well as an interpreter. You need a function that can repeat this in a loop until it reaches the Stopped state:
run :: NominalDiffTime -> IdleDuration -> UTCTime -> PollingState Message -> IO (PollingState Message) run estimatedDuration idleDuration stopBefore state = do ns <- interpret $ transition estimatedDuration idleDuration stopBefore state case ns of Stopped _ -> return ns _ -> run estimatedDuration idleDuration stopBefore ns
This recursive function calls transition with the input state. You may recall that transition returns a PollingProgram msg (PollingState msg) value. Passing this value to interpret returns an IO (PollingState Message) value, and because of the do notation, the new state (ns) is a PollingState Message value.
You can now pattern match on ns. If it's a Stopped value, you return the value. Otherwise, you recursively call run once more.
The run function keeps doing this until it reaches the Stopped state.
Finally, then, you can write the entry point for the program:
main :: IO () main = do timeAtEntry <- getCurrentTime let estimatedDuration = 2 let idleDuration = IdleDuration 5 let stopBefore = addUTCTime 60 timeAtEntry s <- run estimatedDuration idleDuration stopBefore $ Ready [] timeAtExit <- getCurrentTime putStrLn $ "Elapsed time: " ++ show (diffUTCTime timeAtExit timeAtEntry) putStrLn $ printf "%d message(s) handled." $ report s
It defines the initial input parameters:
- My wild guess about the handle duration is 2 seconds
- I'd like the idle duration to be 5 seconds
- The program should run for 60 seconds
Ready []. These are all the arguments you need to call run.
Once run returns, you can print the number of messages handled using a (trivial) report function that I haven't shown (but which is available in the gist).
If you run the program, it'll produce output similar to this:
Polling Handling Polling Handling Polling Handling Polling Sleeping Polling Handling Polling Sleeping Polling Handling Polling Handling Polling Sleeping Polling Sleeping Polling Sleeping Polling Sleeping Polling Sleeping Polling Handling Polling Handling Polling Handling Polling Handling Polling Sleeping Polling Elapsed time: 56.6835022s 10 message(s) handled.
It does, indeed, exit before 60 seconds have elapsed.
Summary #
You can model long-running interactions with an Abstract Syntax Tree. Without do notation, writing programs as 'raw' ASTs would be cumbersome, but turning the AST into a (free) monad makes it all quite palatable.
Haskell's sophisticated type system makes this a fairly low-hanging fruit, once you understand how to do it. You can also port this type of design to F#, although, as you shall see next, more boilerplate is required.
Next: Pure times in F#.
Comments
Good introduction to the notion of programs-as-embedded-languages here, thanks for writing it!
In my experience a majority of Free interpreters fit into the foldFree pattern. Saves you the repetitous bits of your interpret function:
interpret = foldFree eta
where eta (CurrentTime k) = k <$> getCurrentTime
eta (Poll k) = k <$> pollImp
eta (Handle msg k) = k <$> handleImp msg
eta (Idle d k) = k <$> idleImp d
Anyway, I just wanted to give an alternative viewpoint on the topic of Free which will hopefully be some food for thought. I'm generally not an advocate of the Free approach to modelling effectful computation. I don't think it has much of an advantage over the old fashioned mtl style, especially since you have only one effect and only one interpreter. I'd have written your interface like this:
class Monad m => MonadPoll msg m | m -> msg where
currentTime :: m UTCTime
poll :: m (Maybe msg, PollDuration)
handle :: msg -> m HandleDuration
idle :: m IdleDuration
transitionFromNoMessage :: MonadPoll msg m => IdleDuration -> UTCTime -> [CycleDuration] -> m (PollingState msg)
transitionFromNoMessage d stopBefore statistics = do
b <- shouldIdle d stopBefore
if b
then idle d >> return (Ready statistics)
else return $ Stopped statistics
It's a clearer, more direct expression of the monadic interface, in my opinion, and it admits simpler implementations (and it's faster because GHC can specialise and inline everything). Computations with access to only a MonadPoll context can only perform polling actions, so it's still pure, and you can swap out different implementations of MonadPoll (eg, for testing) by writing types with different instances. You can do eg this if you need "decorator"-style interpreters. The main downside of the mtl style is the "n^2 instances problem" (though GeneralizedNewtypeDeriving does somewhat ease the pain).
Kiselyov has some good lecture notes about using the mtl style to model abstract syntax trees and compositional interpreters. I probably wouldn't go that far if I were building a compiler! Type classes are good at effect systems and algebraic data types are good at syntax trees, and while each job can be done by either it pays to pick your tools carefully.
Having said all that, the Free approach is probably more attractive in F#, because it doesn't feature type classes or higher kinds. And Free has other uses outside of the world of effect systems.
Hope all the above is interesting to you!
Benjamin
Benjamin, thank you for writing. It is, indeed, interesting to me, and I appreciate that you took the time to write such a helpful and concise comment.
I wasn't aware of foldFree, but I can see that I'll have to look into it.
One day (soon), I'll have to try writing a small Haskell program using the mtl style instead. It looks as though the code would be quite similar, although the types are different. Are these approaches isomorphic?
In any case, I hope that I'm not coming off as being too authoritative. In some sense, this blog often serves as my own elaborate journal documenting what I've been learning recently. I hope that what I write is mostly correct, but I don't presume that what I write is the one and only truth; it's bound by my knowledge at the time of writing. I still have much to learn, and I'm always happy when people help me expand my horizon.
I think that you hit the nail concerning F#. One of my motivations for exploring this space was to figure out what can be done in F#. As far as I can tell, the mtl style doesn't translate well to F#. You can debate whether or not free monads translate well to F#, but at least the concept does carry over.
Yep, they're isomorphic, in that you can round-trip in either direction between the two representations - to . from = from . to = id:
instance MonadPoll msg (Free (PollingInstruction msg)) where
currentTime = liftF (CurrentTime id)
poll = liftF (Poll id)
handle msg = liftF (Handle msg id)
idle d = liftF (Idle d id)
to :: (forall m. MonadPoll msg m => m a) -> Free (PollingInstruction msg) a
to x = x
from :: MonadPoll msg m => Free (PollingInstruction msg) a -> m a
from x = foldFree eta
where eta (CurrentTime k) = k <$> currentTime
eta (Poll k) = k <$> poll
eta (Handle msg k) = k <$> handle msg
eta (Idle d k) = k <$> idle d
But the representations being isomorphic doesn't mean they're equally convenient. (Another example of this would be lenses: van Laarhoven lenses (à la lens) are isomorphic to "costate comonad coalgebra" (ie get/set) lenses, but they're much more composable.)
Benjamin
Benjamin, thank you once again for writing. It's amazing that not only are they isomorphic, but you can actually prove it with code. I have to admit, though, that I haven't tried compiling or running your code yet. First, I need to digest this.
I was never under the impression that I knew most of what there was to know, but by Jove!, poking at Haskell unearths fathomless depths of knowledge of which I still only glance the surface. It's occasionally frustrating, but mostly exhilarating.
Pure times
How to interact with the system clock using strict functional programming.
A couple of years ago, I published an article called Good times with F#. Unfortunately, that article never lived up to my expectations. Not that I don't have a good time with F# (I do), but the article introduced an attempt to model execution durations of operations in a functional manner. The article introduced a Timed<'a> generic type that I had high hopes for.
Later, I published a Pluralsight course called Type-Driven Development with F#, in which I used Timed<'a> to implement a Polling Consumer. It's a good course that teaches you how to let F#'s type system give you rapid feedback. You can read a few articles that highlight the important parts of the course.
There's a problem with the implementation, though. It's not functional.
It's nice F# code, but F# is this friendly, forgiving, multi-paradigmatic language that enables you to get real work done. If you want to do this using partial application as a replacement for Dependency Injection, it'll let you. It is, however, not functional.
Consider, as an example, this function:
// (Timed<TimeSpan list> -> bool) -> (unit -> Timed<'a>) -> Timed<TimeSpan list> // -> State let transitionFromNoMessage shouldIdle idle nm = if shouldIdle nm then idle () |> Untimed.withResult nm.Result |> ReadyState else StoppedState nm.Result
The idle function has the type unit -> Timed<'a>. This can't possibly be a pure function, since a deterministic function can't produce a value from nothing when it doesn't know the type of the value. (In F#, this is technically not true, since we could return null for all reference types, and 'zero' for all value types, but even so, it should be clear that we can't produce any useful return value in a deterministic manner.)
The same argument applies, in weaker form, to the shouldIdle function. While it is possible to write more than one pure function with the type Timed<TimeSpan list> -> bool, the intent is that it should look at the time statistics and the current time, and decide whether or not it's 'safe' to poll again. Getting the current time from the system clock is a non-deterministic operation.
Ever since I discovered that Dependency Injection is impossible in functional programming, I knew that I had to return to the Polling Consumer example and show how to implement it in a truly functional style. In order to be sure that I don't accidentally call an impure function from a 'pure' function, I'll first rewrite the Polling Consumer in Haskell, and afterwards translate the Haskell code to F#. When reading, you can skip the Haskell article and go directly to the F# article, or vice versa, if you like.
Next: Pure times in Haskell.

Comments
Hello Mark. I am trying to understand what is going on.
So basically the Free Moand allows us to separate pure code from impure code even when the impure/pure/impure sandwish idea is not possible to implement. Right?
We want to separate pure and impure code for these reasons: (1) Easier testing (2) Reasoning about pure code is easier than impure code (3) making impure code explicit makes it easier to understand programs. Is this correct?
What I am still trying to figure out is why we can't simply do this with Dependency Injection?
We can separate all units of behavior into pure ones and impure ones (e.g. functions), and then compose them all in the Composition Root. Pure units take no dependencies, they take in "direct input" and give back "direct output" as you describe in one of your blog posts.
To make the impure code explicit and clear, we can make the root method in the Composition Root construct all impure units of behavior first (e.g. adapters to the external world) and then inject them into a method that bakes these dependencies with the rest of pure code. E.g.:
public static IApplication CreateApplication(IImpureDependency1 dependency1, IImpureDependency2 dependency2) => { //compose graph here}If you have sub methods that the CreateApplication method uses for modularizing the Composition Root, they will also take any impurities they need as parameters.
So in summary, only the Composition Root knows about the impure parts of the application and they are explicitly stated as parameters in the Composition Root methods.
Doesn't this solve the impure/pure separation issue?
For example, to test, you can easilly call the CreateApplication method and pass the fake (pure) dependencies. This will make the whole graph pure in the test.
Also, the Composition Root would make it clear which impure dependencies each component in the system depends on.
Am I missing something?
Hello Yacoub, thank you for writing. Your summary of the motivations covers most of them. The reason that purity interests me is that it forces me (and everyone else) to consider decoupling. One day, I should write a more explicit article about this, but I believe that the general problem with programming today has little to do with writing code, but with reading it. Until I get such an article written, I can only refer to my Humane Code video, and perhaps my recent appearance on .NET Rocks!. What fundamentally interests me is how to break down code into small enough chunks that they fit in our brains at all levels of abstraction. Purity, and functional programming in general, attracts me because it offers a principled way of doing that.
If we forget about functional programming and free monads for a while, we could ask a question similar to yours about Dependency Injection (DI). Why should we use Dependency Injection? Can't we just, say, call a database when we need some data? Technically, we can, but we deliberately invert the control of our code so that it becomes easier to break apart into smaller chunks. You may find this observation trivial, but it wasn't ten years ago, and I made much effort in my book to explain the benefits of DI.
The problem with DI is that at detailed levels of abstractions, DI-based code may fit in our brains, but at higher levels of abstraction the complexity still increases. Put another way, understanding a single class that receives a few dependencies is easy. Getting a high-level, big-picture understanding of a DI-based code base can still be quite the challenge. At a high level of abstraction, the moving parts in underlying components are still too visible, you could say.
Strictly functional programming interests me because, by pushing impure behaviours to the boundaries of the application, the pure core of an application becomes easier to treat as a hierarchy of abstractions. (I really need to write an article with diagrams about this some day.)
What's strictly functional programming? It's code that obeys the rule that pure code can't call impure code. The reason I find Haskell so interesting is that the compiler enforces that rule. Code isn't pure if it calls impure functions, and in Haskell, the code simply will not compile if you attempt to do that.
F#, on the other hand, doesn't work like that. There's no compile-time check of whether the code is pure or impure. Thus, when you pass functions to other functions, your higher-order function could look pure, but since you don't know what an 'injected' function does, you really don't know if it's pure or not. In F#, all it takes is a single call to, say,
DateTime.Now,Guid.NewGuid(), or similar, deep in your system, and that makes the entire code base impure!The only way to prevent that in F# is by diligence.
That's a roundabout answer to your question. The gist of it, though, is that in F#, you rarely need free monads. If you find yourself in the situation where a free monad would be required in Haskell, you could just as well use DI, or rather, partial application. My article on that approach explains how this works in F#, but also why it doesn't work in Haskell. When you inject impure behaviour into an 'otherwise' pure function, then everything becomes impure.
This is where F# differs from Haskell. In Haskell, such an attempt simply doesn't compile. In F#, an otherwise pure function suddenly becomes impure. If you mostly care about that distinction because of, say, testability, then that's not a problem, because when you 'inject' pure behaviour, then the composed function is still pure, and thus trivial to unit test.
The entire system is still impure with that design, though, and that can make it difficult to fit the entire application behaviour in our brains.
I'm afraid this answer doesn't help. I'll have to write a more coherent article on this some day, but I wanted to leave this here because, realistically, a more coherent article isn't part of my immediate plans.
Hello Mark. Thanks for the reply and for providing the links. I have already watched your Humane Code videos at clean coders before. Will listen to the podcast too.
I understand that with the free monad, you can maintain the rule that pure code will never call impure code.
This is one goal.
However, as you describe, this by itself is not the final goal. We want to achieve this goal as a mean to achieve other goals. For example, we want our code to be easier to reason about.
As you describe, we cannot achieve the first goal using DI (or partial application). And in Haskell, the compiler will prevent us from even trying.
However, I think you agree with me that there is still some great value in separating "pure" and impure code in different functions or classes, and then combining them in the Composition Root. This is basically Command Query Separation + DI. Although the graph as a whole is impure, some benefit (e.g. easier to reason about code) is still there as a result of the separation.
What I am trying to argue (or let me say think about and discuss) is that if one does the following:
- Separate impure and pure behavior at the level of individual units of behavior (e.g. functions or classes).
- Compose these units at the Composition Root (only the Composition Root knows about the impure units).
- In the Composition Root, first all impure units are created/prepared, and then injected into "pure" (now not pure) units.
- Make impure dependencies explicit as parameters in the "Create" methods of the Composition Root. (Basically "Create" methods are a way to modularize the Composition Root. I describe what I mean in more details here
then there is not much value in moving from what I just described to using Free monads just to make the Haskell compiler happy :).Or is there something that I am missing?
Basically, if we forget for a moment about the first goal (since it is only a mean to other goals), what goals will we be not achieving?
In your reply, I can find the following that might answer these questions:
"Getting a high-level, big-picture understanding of a DI-based code base can still be quite the challenge. At a high level of abstraction, the moving parts in underlying components are still too visible"
But I can't understand what you mean here. What is the problem here? and how does the Free monad fix it?
I hope I was able to explain my ideas correctly.
Reading my comment again, I would like to add/update a few things.
Regarding CQS, this is not exactly the same as separating impure and pure code. Still, a query can be impure (like one that reads from the database). Such query can be separated into a set of pure and impure queries. Also, a command can have some pure logic in it that can be extracted into a separate pure query (or queries). But, CQS is a step in the right direction towards this and it is a good example of how separation at some level has benefits of its own.
I would like to explain also that the steps I describe in my comment aim basically to delay the composition of pure and impure code to the last possible moment. So basically, all pure logic is composed first (parameterized with functions/delegates/interfaces representing possibly impure code). After that, impure code will be injected into such pure graph rendering it impure of course.
So basically, imagine an imaginary version of Haskell that would allow the root method of an application to allow “pure” code to call impure code.
Here is a concrete example. Imagine these three pure functions:
(A, Func<C,D> dep1, Func<E,F> dep2) => B (1)
(C, Func<G,H> dep3) => D (2)
(G, Func<I,J> dep4) => H (3)
Now, in the Composition Root, we "compose" these together to get the following:
(A, Func<I,J> dep4, Func<E,F> dep2) =>B
So far, this is a pure function, we havn't injected any impurities in it. Thinking about this, this might be a special case of dependency injection. We might call it dependency replacing or something like that.
What I have done is "inject" function #2 as dep1 in function #1. But this is not fully injected. I replaced "dep1" with "dep3".
Then, I "inject" function #3 as dep3. Again, this is not full injection as I replace it with "dep4".
Now, after all "pure" functions have been baked together, I inject the impure "dep4" and "dep2" to get this:
A => B
I hope the code gets displayed correctly in the comment.
Yacoub, thank you for the pseudo-code. That makes it easier to discuss things.
Your premise is that functions 1, 2, and 3 are pure. The rest of the argument rests on whether or not they are. Just to be sure that we share the same terminology, I take pure to mean referentially transparent. Nothing you've written gives me any indication that this isn't your interpretation as well, so I mostly include this as an explicit definition for the benefit of other readers who may happen upon this discussion in the future.
It's clear that a function (or method) that adds two numbers together is pure. This also applies to any other first-order function with isolation. I use the word isolation as described by Jessica Kerr: A function has the property of isolation when the only information it has about the external word is passed into it via arguments.
You can write arbitrarily complex isolated functions in, say, C#:
To be clear, this
Foomethod makes no sense, but it is, as far as I can tell, pure; it operates entirely on its input.Consider, however, this variation:
Notice that
DateTime.DaysInMonth(year, imonth)replaces the hard-coded value28. Is this variation pure?I don't know. In order to figure that out, we'd need to understand if
DateTime.DaysInMonthis pure. Does it use a hard-coded table or algorithm of leap years, or does it use a call to the operating system (OS)? If the latter, does the OS base its functionality on a pure implementation, or does it look up the information in some resource (like the Windows Registry)?With leap years, and for the Gregorian calendar, a pure algorithm exists, but imagine that we create a similar nonsense function that creates
DateTimeOffsetvalues, including time and time-zone offsets. In this case, figuring out if a value is valid relies on external data, since rules about daylight saving time are political and subject to change.My point is that without a machine tool (such as a type system) to guide us, it's practically impossible to reason about the purity of code.
To make matters worse, as soon as you pass a function as an argument to another function, all bets are off. Even if you've diligently reviewed functions like 1, 2, and 3 above for purity, they're only pure if
dep2anddep4are pure as well.Haskell takes away all that angst related to purity by enforcing it via its type system. This liberates us to worry about other things, because the compiler has our backs regarding purity.
In C#, F#, Java, and most other languages, we get no such guarantees. As I've tried to demonstrate above, I'd regard all non-trivial code to be impure. All it takes is one system call,
Guid.NewGuid(),random.Next(),DateTime.Now,log.Warning("foo"), etc. to make all code transitively calling such a statement impure. This is, realistically, impossible to prevent.Do we care, then? What if the functions 1, 2, and 3 are 'pure enough'?
In an analogy to this discussion, in RESTful design,
GETrequests should be side-effect free. Almost all web servers, however, log HTTP requests, soGETrequests are never side-effect free. The interpretation used in that context, therefore, is thatGETrequests should be free of side effects for which the client is responsible.You can have a similar discussion about functional programming. What if a function logs debug information? Does that change the observable state of the system?
In any case, before even beginning to discuss whether dependency injection or partial application is functional, we need to make it clear why we care about purity.
I care about purity because it eliminates entire classes of bugs. It also means that I don't have to log what happens inside my pure code; as long as I log what happens at the impure boundary, I can always reproduce the result of a pure computation. All this makes the overall code simpler. Logging, caching, instrumentation. Many cross-cutting concerns either disappear or greatly simplify.
Returning to the overall discussion related to this article, free monads are one way to separate pure code from impure code. What you suggest, though, isn't pure, because all it takes to make the entire composition impure is that
dep2ordep4are impure (or one of the 'pure' functions turning out to be impure after all). It's Dependency Injection, only you replace interfaces with delegates.Does it matter? Probably not. Trying to keep things 'as pure as possible' in C# and similar languages could still provide benefits. That's how I approach F#. Ultimately, the goal is to make the code sustainable. If you can do that with Dependency Injection or partial application, then the mission is accomplished.
In Haskell, free monads are sometimes required, but in F#, it's a specialised design I'd only reach for in niche situations.
Hello! I just want to add my humble optinion to Mark and Yacoub disscussion. There is something that you could not achieve with partial application.
Imagine that you have pipeline that process some entity. And if some conditions are met you need another one. Id of second entity is the field of first.
So you can not just pass second entity as parameter. Because you do not sure if it is needed. You can pass function that give you an entity.
But what is return type of this function? SecondEntetyType or Async<SecondEntetyType> or Task<SecondEntetyType>? What if you use library with callback interface to load this entity?
Should you care about it to declare relations between first and second entities?
Without free monad answer is yes !!!
It is main achievement from free monads for me.
Hi, I had the same questions as Yacoub i.e. how is Free any better than raw Dependency Injection?
After some research I can see at least couple of advantages. Even if code is messy and pure/impure parts interleaved chaotically, and function doesn't reduce to a simple tree and therefore can't serve as a convincing test case without being further interpreted etc. - there are still at least two advantages over DI:
1. No need to pass extra parameters representing the abstraction of impure code all over the place
2. Async aspect doesn't leak: e.g. WriteLine case from the article's example could have been interpreted as Console.Out.WriteLineAsync() - why not? but the "pure" core would still be decopuled from async aspect.
Thank you Mark for these high quality articles. I was wondering if it wouldn't be more relevant to talk about Operations rather than Members in the interface:
Indeed, a dependency is needed in order to perform some (impure?) operations to be delegated to another object, in another layer or to follow the Single Responsibility Principle. Also it makes more sense to have operations rather than "members" in an instruction:
On the other hand, being extreme in the application of another SOLID principle, the Segragation Principle Interface, each operation may be splitted in as many different interfaces to be injected into the object. I think it doesn't change your recipe: putting all operations in the same instruction set / union type. What do you think of about it?
Romain, thank you for writing. In addition to members, we could call them operations, or actions. I chose member because it's established C# terminology when you're talking about the united set of methods, properties, and events defined by a type such as an interface.
If you approach free monads from functional programming, we wouldn't call them members, but rather functions.
I chose to start with the term member because I surmised that this would be the term with which most readers would be familiar. Since the article starts with those names, I chose to keep the same terms all the way through so that the reader would be able to follow the various steps in the recipe.
With regards to the SOLID principles, the logical conclusion is to have lots of one-method interfaces. You can have one-function free monads as well, but combining them involves much plumbing work in F#. This is much easier in Haskell.