ploeh blog danish software design
Unit testing internals
FAQ: How should you unit test internals? A: Through the public API.
This question seems to come up repeatedly: I have some internal (package-private in Java) code. How do I unit test it?
The short answer is: you unit test it as you unit test all other code: through the public API of the System Under Test (SUT).
Purpose of automated testing #
Details can be interesting, but don't lose sight of the big picture. Why do you test your software with automated tests?
Automated testing (as opposed to manual testing) only serves a single purpose: it prevents regressions. Some would say that it demonstrates that the software works correctly, but that's inaccurate. Automated tests can only demonstrate that the software works correctly if the tests are written correctly, but that's a different discussion.
Assuming that all automated tests are correct, then yes: automated tests also demonstrate that the software works, but it's still regression testing. The tests were written to demonstrate that the software worked correctly once. Running the tests repeatedly only demonstrates that it still works correctly.
What does it mean that the software works correctly? When it comes to automated testing, the verification is only as good as the tests. If the tests are good, the verification is strong. If the tests are weak, the verification is weak.
Consider the purpose of writing the software you're currently being paid to produce. Is the purpose of the software to pass all tests? Hardly. The purpose of the software is to solve some problem, to make it easier to perform some task, or (if you're writing games) to entertain. The tests are proxies of the actual purpose.
It ought to be evident, then, that automated tests should be aligned with the purpose of the software. There's nothing new in this: Dan North introduced Behaviour Driven Development (BDD) in order to emphasise that testing should be done with the purpose of the software in mind. You should test the behaviour of the software, not its implementation.
Various software can have different purposes. The software typically emphasised by BDD tends to be business software that solves a business problem. Often, these are full applications. Other types of software include reusable libraries. These exist to be reusable. Common to all is that they have a reason to exist: they have externally visible behaviour that some consumer cares about.
If you want to test a piece of software to prevent regressions, you should make sure that you're testing the externally visible behaviour of the software.
Combinatorics #
In an ideal world, then, all automated testing should be done against the public interface of the SUT. If the application is a web application, testing should be done against the HTML and JavaScript. If the application is a mobile app, testing should be done somehow by automating user interaction against its GUI. In reality, these approaches to testing tend to be brittle, so instead, you can resort to subcutaneous testing.
Even if you're developing a reusable library, or a command-line executable, if you're doing something even moderately complex, you run into another problem: a combinatorial explosion of possible paths through the code. As J.B. Rainsberger explains much better than I can do, if you combine software modules (e.g. validation, business logic, data access, authentication and authorisation, caching, logging, etc) you can easily have tens of thousands distinct paths through a particular part of your software - all via a single entry point.
This isn't related to BDD, or business problems, or agile... It's a mathematical result. There's a reason the Test Pyramid looks like it does.
When you combine a procedure with four distinct paths with another with five paths, the number of possible paths isn't (4 + 5 =) nine; it's (4 * 5 =) twenty. As you combine units together, you easily reach tens of thousands distinct paths through your software. (This is basic combinatorics).
You aren't going to write tens of thousands of automated tests.
In the ideal world, we would like to only test the behaviour of software against its public interface. In the real world, we have to separate any moderately complex software into modules, and instead test the behaviour of those modules in isolation. This prevents the combinatorial explosion.
If you cut up your software in an appropriate manner, you'll get modules that are independent of each other. Many books and articles have been written about how to do this. You've probably heard about Layered Application Architecture, Hexagonal Architecture, or Ports and Adapters. The recent interest related to microservices is another (promising) attempt at factoring code into smaller units.
You still need to care about the behaviour of those modules. Splitting up your software doesn't change the overall purpose of the software (whatever that is).
Internals #
When I do code reviews, often the code is already factored into separate concerns, but internal classes are everywhere. What could be the reason for that?
When I ask, answers always fall into one of two categories:
- Members (or entire classes) are poorly encapsulated, so the developers don't want to expose these internals for fear of destabilising the system.
- Types or members are kept hidden in order to protect the code base from backwards compatibility issues.
private void CalculateAverage() { this.average = TimeSpan.FromTicks( (long)this.durations.Average(ts => ts.Ticks)); }
This CalculateAverage method is marked private because it's unsafe to call it. this.durations can be null, in which case the method would throw an exception. It may feel like a solution to lock down the method with an access modifier, but really it only smells of poor encapsulation. Instead, refactor the code to a proper, robust design.
There are valid use cases for the private and internal access modifiers, but the majority of the time I see private and internal code, it merely smells of poor design. If you change the design, you could make types and members public, and feel good about it.
The other issue, concerns about compatibility, can be addressed as well. In any case, for most developers, this is essentially a theoretical issue, because most code written isn't for public consumption anyway. If you also control all consumers of your API, you may not need to worry about compatibility. If you need to change the name of a class, just let your favourite refactoring tool do this for you, and all is still good. (I'd still recommend that you should adopt a Ranger approach to your Zoo software, but that's a different topic.)
The bottom line: you don't have to hide most of your code behind access modifiers. There are good alternatives that lead to better designs.
Testing internals #
That was a long detour around reasons for testing, as well as software design in general. How, then, do you test internal code?
Through the public API. Remember: the reason for testing is to verify that the observable behaviour of the SUT is correct. If a class or member is internal, it isn't visible; it's not observable. It may exist in order to support the public API, but if you explicitly chose to not make it visible, you also stated that it can't be directly observable. You can't have it both ways. (Yes, I know that .NET developers will point the [InternalsVisibleTo] attribute out to me, but this attribute isn't a solution; it's part of the problem.)
Why would you test something that has no 'official' existence?
I think I know the answer to that question. It's because of the combinatorial explosion problem. You want the software to solve a particular problem, and to keep everything else 'below the surface'. Unfortunately, as the complexity of the software grows, you realise (explicitly or implicitly) that you can't cover the entire code base with high-level BDD-style tests. You want to unit test the internals.
The problem with doing this is that it's just as brittle as testing through a GUI. Every time you change the internals, you'll have to change your tests.
A well-designed system tends to be more stable when it comes to unit testing. A poorly designed system is often characterised by tests that are too coupled to implementation details. As soon as you decide to change something in such a system, you'll need to change the tests as well.
Recall that automated testing is regression testing. The only information we get from running tests is whether or not existing tests passed or failed. We don't learn if the tests are correct. How do we know that tests are correct? Essentially, we know because we review them, see them fail, and never touch them again. If you constantly have to fiddle with your tests, how do you know they still test the right behaviour?
Design your sub-modules well, on the other hand, and test maintenance tends to be much lower. If you have well-designed sub-modules, though, you don't have to make all types internal. Make them public. They are part of your solution.
Summary #
A system's public API should enable you to exercise and verify its observable behaviour. That's what you should care about, because that's the SUT's reason to exist. It may have internal types and members, but these are implementation details. They exist to support the system's observable behaviour, so test them through the public API.
If you can't get good test coverage of the internal parts through the public API, then why do these internal parts exist? If they exhibit no observable behaviour, couldn't you delete them?
If they do exist for a reason, but you somehow can't reach them through the public API, it's a design smell. Address that smell instead of trying to test internals.
Public types hidden in plain sight
Instead of making types internal to a package, you can hide them in plain sight as public types.
When I review object-oriented code, I often see lots of internal (package-private in Java) classes and members. Sometimes, most of a code base is written at that access level.
When I ask for the reasoning behind this, the answer is invariably: encapsulation.
Encapsulation is one of the most misunderstood concepts in programming. If you think it's about making everything inaccessible, then there's only one logical conclusion: all your code must have this API:
public class Program { public static int Main(string[] args) { // Everything else goes here! } }
If you've seen my Pluralsight course about encapsulation, you'll know that I prefer Bertrand Meyer's view, as outlined in Object-Oriented Software Construction. Essentially, it's about design by contract (pre- and post-conditions).
Once I start to ask more pointed questions about enthusiastic use of internal-only access, it turns out that often, the underlying reason is that the developers want to be able to change the design of their internal types and members, without breaking existing clients. A noble goal.
Imagine that such a code base has existing clients. While the maintainers can't change the public types without breaking these clients, they can change all internal types as much as they want.
Unfortunately, there are disadvantages to this design strategy. You can't easily unit test such code bases. There are ways, but none of them are good.
What if, instead of making types internal, you made them public? Are there ways to prevent clients from relying on such types? Yes, plenty of ways.
Public, append-only #
My preferred approach to this problem is to make types public anyway. If my overall feeling about a type is that "it seems okay", I make it public, even if I know that there's a risk involved with this.
Consider, as an example, the private DurationStatistics class I extracted in a recent article. In that article, I kept the class private, because I wanted to discuss visibility in a separate article.
You can easily promote the DurationStatistics class to a public class:
public class DurationStatistics
Here you only see the declaration of the class, because the implementation is exactly the same as in the other article. The code is moved out of the Estimator class and put into its own file, though.
How can you be sure that DurationStatistics is 'done'? How can you be sure that you're not going to need to change it later?
You can't.
You can, however, deal with that when it occurs. You can still add new members to the class, but you can't remove members or change the type's name.
If you need to change something (thereby breaking compatibility), then don't change it. Instead, add the new type or member, but leave the old artefact in place and deprecate it. In .NET, you can do this by adorning the member or type with the [Obsolete] attribute. You can even add a message that points clients to the new, preferred way of doing things:
[Obsolete("DurationStatistics is being retired (our fault). Use Foo instead.")] public class DurationStatistics
This will cause a compiler warning in all client code using the DurationStatistics class. You should make the message as helpful and friendly as possible.
This may leave your code with compiler warnings. This is good, because you should work to remove these warnings from your own code base. The only place you should leave them in place is in your unit tests. As long as you have a deprecated type in your published code base, you should also keep it covered by unit tests. This will cause compiler warnings in your unit tests, but you can suppress such warnings explicitly there:
[Theory] [InlineData(new[] { 1, 1, 1 }, 1)] [InlineData(new[] { 2, 3, 4 }, 3)] public void AverageIsCorrect(int[] seconds, int expectedSeconds) { #pragma warning disable 618 var sut = new DurationStatistics( seconds.Select(s => TimeSpan.FromSeconds(s)).ToArray()); #pragma warning restore 618 var actual = sut.Average; Assert.Equal(expectedSeconds, actual.TotalSeconds); }
Keep the 'disable scope' as small as possible, and always remember to restore the warning after disabling it.
Perhaps you think that this approach of just making everything public and dealing with the consequences later is an unprofessional, unhygienic, and ugly way to evolve code, but it's really the logical way to produce and publish SOLID code.
Obsolete by default #
A variant of the above technique is that instead of making a type or member internal, you can deprecate it right away. This will immediately warn clients that they're doing something they aren't supposed to do.
If you ever decide to 'promote' that type to a bona fide member of your API, you can simply remove the [Obsolete] attribute.
Separate namespaces #
You can also hide public types in separate namespaces. If you don't document the types in those 'hidden' namespaces, clients will again have to do something explicit to use them.
This is a softer way of hiding public types in plain sight, because clients get no compiler warnings if they use those 'hidden' types. Still, it can be quite effective.
My experience with maintaining public software (e.g. the now-more-than-six-year-old AutoFixture project) is that the most common problem is that users don't even find the public types I want them to find! If you knew how many times I've seen people reinvent a feature already available in the API... And that's even when all the interesting stuff is in the same namespace.
Putting types in separate namespaces is, in my experience, quite an effective way of hiding them.
Separate libraries #
Ultimately, you can put your volatile types in a separate library. In the Estimation example, you can ship the Estimator class (your 'real' public API) in one library, but put DurationStatistics in another library:
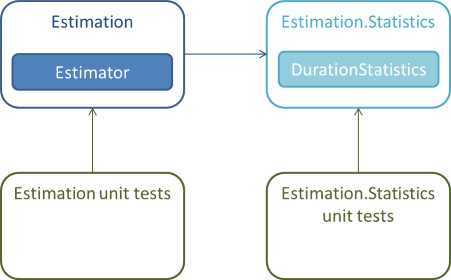
The Estimation library references the Estimation.Statistics library, so it can use all the public types in that library. You can unit test the public types in the Estimation library, but you can also unit test the public types in the Estimation.Statistics library.
When you publish your API, you give clients a reference to Estimation, but not to Estimation.Statistics. You still ship Estimation.Statistics as a dependency of your API, but clients shouldn't reference it.
Specifically, if you wish to publish your API as a NuGet package, you can use the <references> element to ensure that only the 'official' library is added to a project:
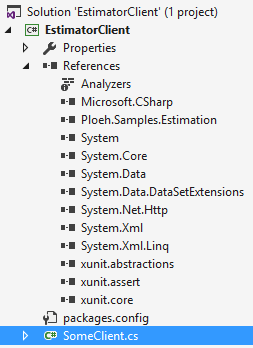
In this library, I installed the (local) Estimation NuGet package, and as you can see, only Ploeh.Samples.Estimation is referenced, whereas Ploeh.Samples.Estimation.Statistics isn't. This means that the client can easily use the official API, e.g. to create a new instance of the Estimator class:
this.estimator = new Estimator(TimeSpan.FromMinutes(1));
On the other hand, if a client developer attempts to use the public DurationStatistics class, that's not possible:

Not only is DurationStatistics not available, all Visual Studio can suggest is to create it; it can't suggest pulling in the appropriate assembly reference, which is a good thing.
The library is still there, it's just not referenced, so Estimator still works at run-time.
The trick to set up a NuGet package in this way is to use the <references> element in the .nuspec file:
<?xml version="1.0"?> <package > <metadata> <id>Estimation</id> <version>1.0.0</version> <authors>Mark Seemann</authors> <owners>Mark Seemann</owners> <requireLicenseAcceptance>false</requireLicenseAcceptance> <description> This is an example that demonstrates how dependent libraries can hide public types in plain sight. </description> <copyright>Copyright Mark Seemann 2015</copyright> <references> <reference file="Ploeh.Samples.Estimation.dll" /> </references> </metadata> <files> <file src="..\Estimation\bin\Debug\Ploeh.Samples.Estimation.dll" target="lib\net45" /> <file src="..\Estimation\bin\Debug\Ploeh.Samples.Estimation.Statistics.dll" target="lib\net45" /> </files> </package>
Notice that both Ploeh.Samples.Estimation.dll and Ploeh.Samples.Estimation.Statistics.dll are included in the NuGet package, but that only Ploeh.Samples.Estimation.dll should be referenced when the NuGet package is added.
For good measure I should point out that in order to create these demo files, I only installed the Estimation NuGet package from my local disk (using the -Source switch), so don't go and look for it on nuget.org.
Summary #
There are plenty of ways to hide public types in plain sight. Often, one or more of these options are better than misusing the internal/package-private access modifier. This doesn't mean that you must never make a class internal, but it means that you should consider the advantages and disadvantages of all options before making such a decision.
The main disadvantage of using the internal access modifier is that you can't easily unit test such a class. The options provided here should give you plenty of alternatives that will enable you to easily unit test classes while still hiding them from client developers.
Comments
The problem with the [InternalsVisibleTo] attribute is exactly that it enables you to unit test internals, which you shouldn't.
Dear Mark,
Thanks for another great article. I totally agree with your point of view, but I can also see why Børge might be somewhat unsatisfied with the answer to not use the InternalsVisibleTo attribute in the context of automated testing.
I think that using internal to hide certain types of a reusable code base is a violation of the Open/Closed Principle, because there is no easy way to extend the internal types without touching the source code (you can use reflection to call internal methods, but that's annoying, and you simply cannot derive from an internal class or implement an internal interface.)
What are your thoughts on this argument?
With regards,
Kenny
Kenny, thank you for writing. Overall, I like that additional argument. In order to keep this discussion balanced, I think it's worth pointing out that your argument certainly applies to reusable software, but that lots of software isn't (or rather, shouldn't be) reusable. Udi Dahan has pointed out that reuse may be overrated, or even have negative consequences, and while I've been disagreeing with certain parts of that claim, in general I think there's much wisdom in that observation.
Some software is written to be reusable, but much software shouldn't be. This is the sort of software I call Zoo software. Your argument about violation of the OCP certainly applies to Wildlife Software, but only indirectly to Zoo software.
Temporary Field code smell
Temporary Field is a well-known code smell. Here's an example and remedy.
The Temporary Field code smell was described more than a decade ago, but I keep encountering it when doing code reviews. Despite its vintage, I couldn't find a good example, so I decided to provide one.
The code smell is described in Refactoring:
"Sometimes you see an object in which an instance variable is set only in certain circumstances. Such code is difficult to understand, because you expect an object to need all of its variables. [...]
"A common case of temporary field occurs when a complicated algorithm needs several variables. Because the programmer didn't want to pass around a huge parameter list (who does?), he put them in fields."
- Refactoring, Martin Fowler et al., Addison-Wesley 1999. p. 84
Unfortunately, Refactoring doesn't provide an example, and I couldn't find a good, self-contained example on the web either.
Example: estimate a duration #
In this example, a developer was asked to provide an estimate of a duration, based on a collection of previously observed durations. The requirements are these:
- There's a collection of previously observed durations. These must be used as statistics upon which to base the estimate.
- It's better to estimate too high than too low.
- Durations are assumed to be normal distributed.
- The estimate should be higher than the actual duration in more than 99% of the times.
- If there are no previous observations, a default estimate must be used as a fall-back mechanism.
It's not that bad, actually. Because the distribution is assumed to be normal, you can find a good estimate by calculating the average, and add three times the standard deviation.
Here's how our developer attempted to solve the problem:
public class Estimator { private readonly TimeSpan defaultEstimate; private IReadOnlyCollection<TimeSpan> durations; private TimeSpan average; private TimeSpan standardDeviation; public Estimator(TimeSpan defaultEstimate) { this.defaultEstimate = defaultEstimate; } public TimeSpan CalculateEstimate( IReadOnlyCollection<TimeSpan> durations) { if (durations == null) throw new ArgumentNullException(nameof(durations)); if (durations.Count == 0) return this.defaultEstimate; this.durations = durations; this.CalculateAverage(); this.CalculateStandardDeviation(); var margin = TimeSpan.FromTicks(this.standardDeviation.Ticks * 3); return this.average + margin; } private void CalculateAverage() { this.average = TimeSpan.FromTicks( (long)this.durations.Average(ts => ts.Ticks)); } private void CalculateStandardDeviation() { var variance = this.durations.Average(ts => Math.Pow( (ts - this.average).Ticks, 2)); this.standardDeviation = TimeSpan.FromTicks((long)Math.Sqrt(variance)); } }
The CalculateEstimate method directly uses the temporary field durations, as well as implicitly the fields average and standardDeviation. The reason for this is to avoid passing parameters around. Both the average and the standard deviation depend on the durations, but the standard deviation also depends on the average.
These dependencies are difficult to see in this code snippet:
this.durations = durations; this.CalculateAverage(); this.CalculateStandardDeviation();
What if I wanted to switch the order around?
this.durations = durations; this.CalculateStandardDeviation(); this.CalculateAverage();
This compiles! It also produces a result if you invoke the CalculateEstimate method. No exception is thrown, but the result returned is incorrect!
Not only is this code difficult to understand, it's also brittle. Furthermore, it's not thread-safe.
This was most likely done with the best of intentions. After all, in Clean Code you learn that methods with zero arguments are better than methods with one argument (which are better than methods with two arguments, and so on).
There are better ways to factor the code, though.
Extract Class #
In Refactoring, the suggested cure is to extract a class that contains only the temporary fields. This refactoring is called Extract Class. Your first step can be to introduce a private, nested class within the containing class. In the case of the example, you might call this class DurationStatistics. It can be used from CalculateEstimate in this way:
public TimeSpan CalculateEstimate( IReadOnlyCollection<TimeSpan> durations) { if (durations == null) throw new ArgumentNullException(nameof(durations)); if (durations.Count == 0) return this.defaultEstimate; var stats = new DurationStatistics(durations); var margin = TimeSpan.FromTicks(stats.StandardDeviation.Ticks * 3); return stats.Average + margin; }
It's now much clearer what's going on. You have some statistics based on the durations, and those contain both the average and the standard deviation. The flow of data is also clear: you need the stats to get the average and the standard deviation, and you need stats.StandardDeviation in order to calculate the margin, and the margin before you can calculate the return value. If you attempt to move those lines of code around, it's no longer going to compile.
This solution is also thread-safe.
Here's the full code of the Estimator class, after the Extract Class refactoring:
public class Estimator { private readonly TimeSpan defaultEstimate; public Estimator(TimeSpan defaultEstimate) { this.defaultEstimate = defaultEstimate; } public TimeSpan CalculateEstimate( IReadOnlyCollection<TimeSpan> durations) { if (durations == null) throw new ArgumentNullException(nameof(durations)); if (durations.Count == 0) return this.defaultEstimate; var stats = new DurationStatistics(durations); var margin = TimeSpan.FromTicks(stats.StandardDeviation.Ticks * 3); return stats.Average + margin; } private class DurationStatistics { private readonly IReadOnlyCollection<TimeSpan> durations; private readonly Lazy<TimeSpan> average; private readonly Lazy<TimeSpan> standardDeviation; public DurationStatistics(IReadOnlyCollection<TimeSpan> durations) { if (durations == null) throw new ArgumentNullException(nameof(durations)); if (durations.Count == 0) throw new ArgumentException( "Empty collection not allowed.", nameof(durations)); this.durations = durations; this.average = new Lazy<TimeSpan>(this.CalculateAverage); this.standardDeviation = new Lazy<TimeSpan>(this.CalculateStandardDeviation); } public TimeSpan Average { get { return this.average.Value; } } public TimeSpan StandardDeviation { get { return this.standardDeviation.Value; } } private TimeSpan CalculateAverage() { return TimeSpan.FromTicks( (long)this.durations.Average(ts => ts.Ticks)); } private TimeSpan CalculateStandardDeviation() { var variance = this.durations.Average(ts => Math.Pow( (ts - this.average.Value).Ticks, 2)); return TimeSpan.FromTicks((long)Math.Sqrt(variance)); } } }
As you can see, the Estimator class now only has a single read-only field, which ensures that it isn't temporary.
The original intent of not passing parameters around is still preserved, so this solution still adheres to that Clean Code principle.
The DurationStatistics class lazily calculates the average and standard deviation, and memoizes their results (or rather, that's what Lazy<T> does).
Instances of DurationStatistics have a shorter lifetime than the containing Estimator object.
The DurationStatistics class is a private, nested class, but a next step might be to pull it out to a public class in its own right. You don't have to do this. Sometimes I leave such classes as private classes, because they only exist to organise the code better; their purpose and behaviour are still narrow in scope, and associated with the containing class. In other cases, such a refactoring may uncover a great way to model a particular type of problem. If that's the case, making it a public class could make the entire code base better, because you've now introduced a reusable concept.
Summary #
Class fields are intended to be used by the class. They constitute the data part of data with behaviour. If you have temporary values, either pass them around as arguments, or extract a new class to contain them.
Comments
How about passing everything as parameters and returning the calculated value as result, would this be considered dirty code?
Just trying to get the most out of this example.
Tom, thank you for writing. Great observation about passing arguments around instead! In this case, passing the necessary arguments around would also be a good solution. It would look like this:
public class Estimator { private readonly TimeSpan defaultEstimate; public Estimator(TimeSpan defaultEstimate) { this.defaultEstimate = defaultEstimate; } public TimeSpan CalculateEstimate( IReadOnlyCollection<TimeSpan> durations) { if (durations == null) throw new ArgumentNullException(nameof(durations)); if (durations.Count == 0) return this.defaultEstimate; var average = CalculateAverage(durations); var standardDeviation = CalculateStandardDeviation(durations, average); var margin = TimeSpan.FromTicks(standardDeviation.Ticks * 3); return average + margin; } private static TimeSpan CalculateAverage( IReadOnlyCollection<TimeSpan> durations) { return TimeSpan.FromTicks((long)durations.Average(ts => ts.Ticks)); } private static TimeSpan CalculateStandardDeviation( IReadOnlyCollection<TimeSpan> durations, TimeSpan average) { var variance = durations.Average(ts => Math.Pow( (ts - average).Ticks, 2)); return TimeSpan.FromTicks((long)Math.Sqrt(variance)); } }
This refactoring also eliminates the temporary fields, and is probably even easier to understand.
To be quite honest, that's what I would have done with this particular example if it had been production code. The reason I wanted to show the Extract Class refactoring instead is that passing arguments doesn't scale well when you add more intermediate values. In this example, the maximum number of arguments you have to pass is two, which is easily within acceptable limits, but what if you have 15 intermediate values?
Passing 15 method arguments around is well beyond most people's threshold, so instead they sometimes resort to temporary fields. The point here is that this isn't necessary, because you have the alternative of extracting classes.
Why didn't I show an example with 15 intermediate values, then? Well, first, I couldn't think of a realistic example, and even if I could, it would be so complicated that no one would read the article :)
Sounds reasonable - Passing one or two around is okay but at a certain point an Extract Class would make more sense.
No, it's a good example otherwise it would be too confusing as you mentioned. Interesting post, thanks!
Ad hoc Arbitraries with FsCheck.Xunit
When using FsCheck with xUnit.net, you can define ad hoc Arbitraries in-line in your test functions.
Writing properties with FsCheck and using xUnit.net as a test host is a nice combination. Properties are written as normal functions annotated with the Property attribute:
[<Property>] let ``findNeighbors returns 8 cells`` (cell : int * int) = let actual : Set<int * int> = findNeighbors cell 8 =! actual.Count
FsCheck takes care of generating values for the cell argument. This works well in many cases, but sometimes you need a bit more control over the range of values being generated by FsCheck.
Motivating example #
You may already have guessed it from the above code snippet, but the example for this article is a property-based approach to Conway's Game of Life. One of the properties of the game is that any live cell with more than three live neighbours dies.
This means that you have to write a property where one of the values is the number of live neighbours. That number must be a (randomly generated) number between 4 and 8 (including both ends), because the maximum number of neighbours in a cell grid is eight. How do you get FsCheck to give you a number between 4 and 8?
Crude solution: conditional property #
There are various solutions to the problem of getting fine control over certain values generated by FsCheck, but the ones I first learned turn out to be problematic.
One attempt is to use conditional properties, where you supply a boolean expression, and FsCheck will throw away all properties that fail the boolean test:
[<Property>] let ``Any live cell with more than three live neighbors dies`` (cell : int * int) (neighborCount : int) = (3 < neighborCount && neighborCount <= 8) ==> lazy let neighborCells = findNeighbors cell |> pickRandom neighborCount let actual = calculateNextState (cell :: neighborCells) cell Dead =! actual
The ==> operator is an FsCheck-specific operator that indicates that FsCheck should disregard all properties where the input arguments don't satisfy the boolean condition on the left side. The use of lazy ensures that FsCheck will only attempt to evaluate the property when the condition is true.
That's simple and tidy, but unfortunately doesn't work. If you attempt to run this property, you'll get a result like this:
Test 'Ploeh.Katas.GameOfLifeProperties.Any live cell with more than three live neighbors dies' failed: Arguments exhausted after 34 tests.
The reason is that FsCheck generates random integers for neighborCount, and most of these values (statistically) fall outside of the range 4-8. After a (default) maximum of 1000 attempts, FsCheck gives up, because at that time, it's only managed to find 34 values that satisfy the condition, but it wants to find 100.
What a disappointment.
Crude solution: custom Arbitrary #
Another apparent solution is to define a custom Arbitrary for FsCheck.Xunit. The mechanism is to define a static class with your custom rule, and register that with the Property attribute. The class must have a static method that returns an Arbitrary<'a>.
In this particular example, you'll need to define a custom Arbitrary that only picks random numbers between 4 and 8. That's easy, but there's a catch: if you change the way int values are generated, you're also going to impact the generated cell values, because a cell here is an int * int tuple.
Since you only need a small number, you can cheat and customize byte values instead:
type ByteBetween1and8 = static member Byte () = Gen.elements [1uy .. 8uy] |> Arb.fromGen [<Property(Arbitrary = [| typeof<ByteBetween1and8> |])>] let ``Any live cell with more than three live neighbors dies`` (cell : int * int) (neighborCount : byte) = neighborCount > 3uy ==> lazy let neighborCells = findNeighbors cell |> pickRandom (int neighborCount) let actual = calculateNextState (cell :: neighborCells) cell Dead =! actual
The ByteBetween1and8 type is a static class with a single static member that returns Arbitrary<byte>. By using the Arbitrary property of the Property attribute (!), you can register this custom Arbitrary with the Property.
This 'solution' side-steps the issue by using a substitute data type instead of the desired data type. There are several problems with this:
- You have to convert the byte value back to an integer in order to use it with the System Under Test:
int neighborCount. 3uyis less readable than3.- A newcomer will wonder why
neighborCountis a byte instead of an int. - You can't generalise this solution. It works because F# has more than one number type, but if you need to generate strings, you're out of luck: there's only one (normal) type of string in .NET.
This way works, but is hardly elegant or safe.
Ad hoc, in-line Arbitraries #
There's a safe way to define ad hoc, in-line Arbitraries with FsCheck.Xunit:
[<Property>] let ``Any live cell with > 3 live neighbors dies`` (cell : int * int) = let nc = Gen.elements [4..8] |> Arb.fromGen Prop.forAll nc (fun neighborCount -> let liveNeighbors = cell |> findNeighbors |> shuffle |> Seq.take neighborCount |> Seq.toList let actual : State = calculateNextState (cell :: liveNeighbors |> shuffle |> set) cell Dead =! actual)
Using Prop.forAll enables you to execute your property with a custom Arbitrary, but mixed with the 'normally' generated values that the function receives via its arguments. In this example, nc is an Arbitrary<int>. Notice how it's explicitly used to populate the neighborCount value of the property, whereas the cell value arrives via normal means.
This is type-safe, because nc is an Arbitrary<int>, which means that neighborCount is statically inferred to be an int.
If you need more than a single ad hoc Arbitrary, you can always create Arbitraries for each of them, and then use Gen.map2, Gen.map3, and so on, to turn those individual Arbitraries into a single Arbitrary of a tuple. You can then use that tuple with Prop.forAll.
Summary #
FsCheck is a well-designed library that you can combine in lots of interesting ways. In this article you learned how to use Prop.forAll to evaluate a property with a mix of normal, arbitrarily generated values, and an ad hoc, in-line Arbitrary.
Addendum 2016-03-01: You can write such properties slightly better using the backward pipe operator.
When x, y, and z are great variable names
A common complaint against Functional Programming is the terse naming: x and y for variables, and f for functions. There are good reasons behind these names, though. Learn to love them here.
One of the facets of Function Programming that bothered my when I first started to look into it, is that often in examples, variables and functions have terribly terse names like x, y, f, and so on. I wasn't alone, feeling like that, either:
"Functional programmer: (noun) One who names variables "x", names functions "f", and names code patterns "zygohistomorphic prepromorphism"" - James IryIn this article, I'm not going to discuss zygohistomorphic prepromorphism, but I am going to discuss names like
x and f.
Descriptive names #
When I started my Functional Programming journey, I came from a SOLID Object-Oriented background, and I had read and internalised Clean Code - or so I thought.
Readable code should have descriptive names, and f and x hardly seem descriptive.
For a while, I thought that the underlying reason for those 'poor' names was that the people writing all that Functional example code were academics with little practical experience in software development. It seems I'm not the only person who had that thought.
It may be true that Functional Programming has a root in mathematics, and that it has grown out of academia rather than industry, but there are good reasons that some names seem rather generic.
Generics #
In statically typed Functional languages like F# or Haskell, you rarely declare the types of functions and arguments. Instead, types are inferred, based on usage or implementation. It often turns out that functions are more generic than you first thought when you started writing it.
Here's a simple example. When I did the Diamond kata with Property-Based Testing, I created this little helper function along the way:
let isTwoIdenticalLetters x = let hasIdenticalLetters = x |> Seq.distinct |> Seq.length = 1 let hasTwoLetters = x |> Seq.length = 2 hasIdenticalLetters && hasTwoLetters
As the name of the function suggests, it tells us if x is a string of two identical letters. It returns true for strings such as "ff", "AA", and "11", but false for values like "ab", "aA", and "TTT".
Okay, so there's already an x there, but this function works on any string, so what else should I have called it? In C#, I'd probably called it text, but that's at best negligibly better than x.
Would you say that, based on the nice, descriptive name isTwoIdenticalLetters, you understand what the function does?
That may not be the case.
Consider the function's type: seq<'a> -> bool when 'a : equality. What!? That's not what we expected! Where's the string?
This function is more generic than I had in mind when I wrote it. System.String implements seq<char>, but this function can accept any seq<'a> (IEnumerable<T>), as long as the type argument 'a supports equality comparison.
So it turns out that text would have been a bad argument name after all. Perhaps xs would have been better than x, in order to indicate the plural nature of the argument, but that's about as much meaning as we can put into it. After all, this all works as well:
> isTwoIdenticalLetters [1; 1];; val it : bool = true > isTwoIdenticalLetters [TimeSpan.FromMinutes 1.; TimeSpan.FromMinutes 1.];; val it : bool = true > isTwoIdenticalLetters [true; true; true];; val it : bool = false
That function name is misleading, so you'd want to rename it:
let isTwoIdenticalElements x = let hasIdenticalLetters = x |> Seq.distinct |> Seq.length = 1 let hasTwoLetters = x |> Seq.length = 2 hasIdenticalLetters && hasTwoLetters
That's better, but now the names of the values hasIdenticalLetters and hasTwoLetters are misleading as well. Both are boolean values, but they're not particularly about letters.
This may be more honest:
let isTwoIdenticalElements x = let hasIdenticalElements = x |> Seq.distinct |> Seq.length = 1 let hasTwoElements = x |> Seq.length = 2 hasIdenticalElements && hasTwoElements
This is better, but now I'm beginning to realize that I've been thinking too much about strings and letters, and not about the more general question this function apparently answers. A more straightforward (depending on your perspective) implementation may be this:
let isTwoIdenticalElements x = match x |> Seq.truncate 3 |> Seq.toList with | [y; z] -> y = z | _ -> false
This may be slightly more efficient, because it doesn't have to traverse the sequence twice, but most importantly, I think it looks more idiomatic.
Notice the return of 'Functional' names like y and z. Although terse, these are appropriate names. Both y and z are values of the generic type argument 'a. If not y and z, then what would you call them? element1 and element2? How would those names be better?
Because of F#'s strong type inference, you'll frequently experience that if you use as few type annotations as possible, the functions often turn out to be generic, both in the technical sense of the word, but also in the English interpretation of it.
Likewise, when you create higher-order functions, functions passed in as arguments are often generic as well. Such a function could sometimes be any function that matches the required type, which means that f is often the most appropriate name for it.
Scope #
Another problem I had with the Functional naming style when I started writing F# code was that names were often short. Having done Object-Oriented Programming for years, I'd learned that names should be sufficiently long to be descriptive. As Code Complete explains, teamMemberCount is better than tmc.
Using that argument, you'd think that element1 and element2 are better names than y and z. Let's try:
let isTwoIdenticalElements x = match x |> Seq.truncate 3 |> Seq.toList with | [element1; element2] -> element1 = element2 | _ -> false
At this point, the discussion becomes subjective, but I don't think this change is helpful. Quite contrary, these longer names only seem to add more noise to the code. Originally, the distance between where y and z are introduced and where they're used was only a few characters. In the case of z, that distance was 9 characters. After the rename, the distance between where element2 is introduced and used is now 16 characters.
There's nothing new about this. Remarkably, I can find support for my dislike of long names in small scopes in Clean Code (which isn't about Functional Programming at all). In the last chapter about smells and heuristics, Robert C. Martin has this to say about scope and naming:
"The length of a name should be related to the length of the scope. You can use very short variable names for tiny scopes, but for big scopes you should use longer names.
"Variable names like
iandjare just fine if their scope is five lines long."
Do you use variable names like i in for loops in C# or Java? I do, so I find it appropriate to also use short names in small functions in F# and Haskell.
Well-factored Functional code consists of small, concise functions, just as well-factored SOLID code consists of small classes with clear responsibilities. When functions are small, scopes are small, so it's only natural that we encounter many tersely named variables like x, y, and f.
It's more readable that way.
Summary #
There are at least two good reasons for naming values and functions with short names like f, x, and y.
- Functions are sometimes so generic that we can't say anything more meaningful about such values.
- Scopes are small, so short names are more readable than long names.
Comments
Dave, thank you for writing. FWIW, I don't think there's anything wrong with longer camel-cased names when a function or a value is more explicit. As an example, I still kept the name of the example function fairly long and explicit: isTwoIdenticalElements.
When I started with F#, I had many years of experience with writing C# code, and in the beginning, my F# code was more verbose than it is today. What I'm trying to explain with this article isn't that the short names are terse for the sake of being terse, but rather because sometimes, the functions and values are so generic that they could be anything. When that happens, f and x are good names. When functions and values are less generic, the names still ought to be more descriptive.
Type Driven Development: composition
When you develop a system with an outside-in technique like Type Driven Development, you'll eventually have all the required building blocks. Now you need to compose them into an application. This post shows an example.
In my article about Type Driven Development, I demonstrated how to approach a problem in an iterative fashion, using the F# type system to do outside-in development, and in a follow-up article, I showed you how to implement one of the inferred methods. In this article, you'll see how to compose all the resulting building blocks into an application.
Building blocks #
In the first article, you learned that apart from the functions defined in that article itself, you'd need four other functions:
- ReadyData -> bool
- unit -> Timed<MessageHandler option>
- NoMessageData -> bool
- unit -> Timed<'a>
As you can see in my Type-Driven Development with F# Pluralsight course, some of the other implementations turn out to have function arguments themselves. It's not quite enough with only those four functions. Still, the final number of implementation functions is only 9.
Here are all the building blocks (excluding the types and functions related to Timed<'a>):
- run : (PollingConsumer -> PollingConsumer) -> PollingConsumer -> PollingConsumer
- transition : (ReadyData -> bool) -> (unit -> Timed<MessageHandler option>) -> (NoMessageData -> bool) -> (unit -> Timed<'a>) -> PollingConsumer -> PollingConsumer
- shouldIdle : TimeSpan -> DateTimeOffset -> NoMessageData -> bool
- idle : TimeSpan -> unit -> Timed<unit>
- shouldPoll : (TimeSpan list -> TimeSpan) -> DateTimeOffset -> ReadyData -> bool
- poll : (unit -> 'a option) -> ('a -> 'b) -> (unit -> DateTimeOffset) -> unit -> Timed<MessageHandler option>
- calculateExpectedDuration : TimeSpan -> TimeSpan list -> TimeSpan
- simulatedPollForMessage : Random -> unit -> unit option
- simulatedHandle : Random -> unit -> unit
Composition #
When the Polling Consumer starts, it can start by figuring out the current time, and calculate some derived values from that and some configuration values, as previously explained.
let now' = DateTimeOffset.Now let stopBefore' = now' + TimeSpan.FromMinutes 1. let estimatedDuration' = TimeSpan.FromSeconds 2. let idleDuration' = TimeSpan.FromSeconds 5.
The estimatedDuration' value is a TimeSpan containing a (conservative) estimate of how long time it takes to handle a single message. It's only used if there are no already observed message handling durations, as the algorithm then has no statistics about the average execution time for each message. This value could come from a configuration system, or a command-line argument. In a recent system, I just arbitrarily set it to 2 seconds.
Given these initial values, we can compose all other required functions:
let shouldPoll' = shouldPoll (calculateExpectedDuration estimatedDuration') stopBefore' let r' = Random() let handle' = simulatedHandle r' let pollForMessage' = simulatedPollForMessage r' let poll' = poll pollForMessage' handle' Clocks.machineClock let shouldIdle' = shouldIdle idleDuration' stopBefore' let idle' = idle idleDuration' let transition' = transition shouldPoll' poll' shouldIdle' idle' let run' = run transition'
The composed run' function has the type PollingConsumer -> PollingConsumer. The input PollingConsumer value is the start state, and the function will return another PollingConsumer when it's done. Due to the way the run function is implemented, this return value is always going to be StoppedState.
Execution #
All that's left to do is to execute the run' function with a ReadyState as the initial state:
let result' = run'(ReadyState([] |> Timed.capture Clocks.machineClock))
A ReadyState value is required as input, and the ReadyState case constructor takes a ReadyData value as input. ReadyData is an alias for Timed<TimeSpan list>. An the beginning, the Polling Consumer hasn't observed any messages, so the TimeSpan list should be empty.
The empty TimeSpan list must be converted to Timed<TimeSpan list>, which can be done by piping it into Timed.capture, using the machine clock.
When you execute the run' function, it may produce output like this:
Polling Sleeping Polling Sleeping Polling Handling Polling Sleeping Polling Sleeping Polling Sleeping Polling Handling Polling Sleeping Polling Sleeping Polling Sleeping Polling Sleeping Polling Handling Polling Handling Polling Sleeping Real: 00:00:59.392, CPU: 00:00:00.031, GC gen0: 0, gen1: 0, gen2: 0
This is because I set up some of the functions to print to the console so that we can see what's going on.
Notice that the state machine ran for 59 seconds and 392 milliseconds, exiting just before the minute was up.
Summary #
Once you have all the appropriate building blocks, you can compose your desired system and run it. Notice how much this resembles the Composition Root pattern, only with functions instead of objects.
If you want to see more details about this example, or get access to the full source code, you can watch my Type-Driven Development with F# Pluralsight course. Please be aware that only certain subscription levels will give you source code access.
Type Driven Development: implementing shouldIdle
Type Driven Development is an outside-in technique. Once you have the overall behaviour defined, you need to implement the details. Here's an example.
In my article about Type Driven Development, I demonstrated how to approach a problem in an iterative fashion, using the F# type system to do outside-in development. With the overall behaviour in place, there's still work to be done.
From type inference of the higher-order functions' arguments, we know that we still need to implement functions with these signatures:
- ReadyData -> bool
- unit -> Timed<MessageHandler option>
- NoMessageData -> bool
- unit -> Timed<'a>
NoMessageData -> bool function. If you want to see how to implement the other three functions, you can watch my Type-Driven Development with F# Pluralsight course.
The NoMessageData -> bool function is defined as the shouldIdle argument to the transitionFromNoMessage higher-order function. The purpose of the shouldIdle function is to determine whether there's enough remaining time to idle.
Development #
Since we know the signature of the function, we can start by declaring it like this:
let shouldIdle (nm : NoMessageData) : bool =
Although it doesn't have to be called shouldIdle, in this case, I think the name is appropriate.
In order to determine if there's enough time left to idle, the function must know what time it is right now. Recall that, by design, PollingConsumer states are instantaneous, while transitions take time. The time a transition starts and stops is captured by a Timed<'a> value.
The nm argument has the type NoMessageData, which is an alias for Timed<TimeSpan list>. The Timed part contains information about when the transition into the No message state started and stopped. Since being in a state has no duration, nm.Stopped represents the time when shouldIdle executes. That's part of the solution, so we can start typing:
let shouldIdle (nm : NoMessageData) : bool = nm.Stopped
This doesn't yet compile, because nm.Stopped is a DateTimeOffset value, but the function is declared as returning bool.
If we imagine that we add the idle duration to the current time, it should gives us the time it'd be when idling is done. That time should be less than the time the Polling Consumer must exit:
let shouldIdle (nm : NoMessageData) : bool = nm.Stopped + idleDuration < stopBefore
This still doesn't compile because idleDuration and stopBefore are undefined, but this is easy to fix: promote them to arguments:
let shouldIdle idleDuration stopBefore (nm : NoMessageData) : bool = nm.Stopped + idleDuration < stopBefore
If you paid attention to the previous article, you'll notice that this is exactly the same technique I used for the transitionFromNoMessage function. Apparently, we're not done with outside-in development yet.
Type inference #
The function now compiles, and has the type TimeSpan -> DateTimeOffset -> NoMessageData -> bool.
Once again, I've used the trick of promoting an undefined value to a function argument, and let type inference take care of the rest. This also works here. Since nm.Stopped is a DateTimeOffset value, and we're adding something to it with the + operator, idleDuration has to be of a type that supports adding to DateTimeOffset. The only thing you can add to DateTimeOffset is a TimeSpan, so idleDuration is inferred to be a TimeSpan value.
When you add a TimeSpan value to a DateTimeOffset value, you get another DateTimeOffset value back, so the type of the expression nm.Stopped + idleDuration is DateTimeOffset. The entire return expression compares that DateTimeOffset value with the < operator, which requires that both the left-hand and the right-hand expressions have the same type. Ergo must stopBefore also be a DateTimeOffset value.
While we set out to implement a function with the type NoMessageData -> bool, we eventually created a function with the type TimeSpan -> DateTimeOffset -> NoMessageData -> bool, which isn't quite what we need.
Partial application #
The extra arguments can be removed again with partial function application. When the Polling Consumer application starts, it can easily calculate when it ought to stop:
let now' = DateTimeOffset.Now let stopBefore' = now' + TimeSpan.FromMinutes 1.
This assumes that the Polling Consumer should run for a maximum of 1 minute.
Likewise, we can create an idle duration value:
let idleDuration' = TimeSpan.FromSeconds 5.
Here, the value is hard-coded, but it could have gone in a configuration file instead, or be passed in as a command-line argument.
Given these values, we can now partially apply the function:
let shouldIdle' = shouldIdle idleDuration' stopBefore'
Since we're not supplying the third NoMessageData argument for the function, the return value of this partial application is a new function with the type NoMessageData -> bool - exactly what we need.
Summary #
In this article, you saw how to approach the implementation of one of the functions identified with the outside-in Type Driven Development technique. If you want to see the other three functions implemented, a much more detailed discussion of the technique, as well as the entire code base with commit messages, you can watch my Type-Driven Development with F# Pluralsight course.
Type Driven Development
A strong type system can not only prevent errors, but also guide you and provide feedback in your design process.
Have you ever worked in a statically typed language (e.g. C# or Java), only to wish that you'd be allowed to focus on what you're doing, instead of having to declare types of arguments and create new classes all the time?
Have you, on the other hand, ever worked in a dynamic language (e.g. Javascript) and wished you could get static type checking to prevent a myriad of small, but preventable errors?
You can have the best of both worlds, and more! F#'s type system is strong, but non-obtrusive. It enables you to focus on the behaviour of the code you're writing, while still being statically typed.
Not only can it prevent syntax and usage errors, but it can even provide guidance on how to proceed with a given problem.
This is best explained with an example.
Example problem: simulate a continuously running process as a series of discrete processes #
A couple of years ago I had a very particular problem: I needed to simulate a continuously running task using a sequence of discrete processes.
In short, I needed to start a process (in reality a simple .exe file) that would act as a Polling Consumer, but with the twist that it would keep track of time. It would need to run for one minute, and then shut down so that an overall scheduler could start the process again. This was to guarantee that the process would be running on at most one server in a farm.
The Polling Consumer should pull a message off a queue and hand it to some dispatcher, which would then make sure that the message was handled by an appropriate handler. This takes time, so makes the whole process more complex.
If the Polling Consumer estimates that receiving and handling a message takes 200 milliseconds, and it's 100 milliseconds from shutting down, it shouldn't poll for a message. It would take too long, and it wouldn't be able to shut down in time.
My problem was that I didn't know how long it took to handle a message, so the Polling Consumer would have to measure that as well, constantly updating its estimates of how long it takes to handle a message.
This wasn't a harder problem that I could originally solve it in a highly coupled imperative fashion. I wasn't happy with that implementation, though, so I'm happy that there's a much more incremental approach to the problem.
A Finite State Machine #
The first breakthrough came when I realised that I could model the problem as a finite state machine:
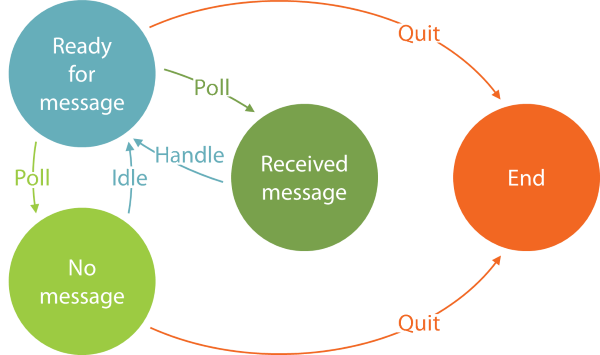
The implicit start state is always the Ready state, because when the Polling Consumer starts, it has no message, but plenty of time, so therefore ready for a new message.
From the Ready state, the Polling Consumer may decide to poll for a message; if one is received, the new state is the Received state.
From the Received state, the only legal transition is back into the Ready state by handling the message.
From the Ready state, it may also turn out that there's currently no message in the queue, in which case the new state is the No message state.
In the No message state, the Polling Consumer may decide to idle for perhaps five seconds before transitioning back into the Ready state.
When in the Ready or No message states, the Polling Consumer may also realise that time is running out, and so decide to quit, in which case the (final) state is the End state.
This means that the Polling Consumer needs to measure what it does, and those measurements influence what it decides to do.
Separation of concerns #
It sounds like we have a time concern (do I dare say dimension?), and a concern related to doing something. Given multiple concerns, we should separate them
The first thing I did was to introduce a Timed<'a> generic record type. This represents the result of performing a computation, as well as the times the computation started and stopped. I changed it slightly from the linked article, so here's the updated code for that:
type Timed<'a> = { Started : DateTimeOffset Stopped : DateTimeOffset Result : 'a } member this.Duration = this.Stopped - this.Started module Untimed = let map f x = { Started = x.Started; Stopped = x.Stopped; Result = f x.Result } let withResult newResult x = map (fun _ -> newResult) x module Timed = let capture clock x = let now = clock() { Started = now; Stopped = now; Result = x } let map clock f x = let result = f x.Result let stopped = clock () { Started = x.Started; Stopped = stopped; Result = result } let timeOn clock f x = x |> capture clock |> map clock f
This enables me to capture timing information about any operation, including the transitions between various states in a finite state machine.
The way I modelled the finite state machine for the Polling Consumer explicitly models all states as being instantaneous, while transitioning between states takes time. This means that we can model all transitions as functions that return Timed<'something>.
State data types #
The first step is to model the data associated with each state in the finite state machine. This is an iterative process, but here I'll just show you the final result. If you're interested in seeing this design process in more details, you can watch my Pluralsight course Type-Driven Development with F#.
// Auxiliary types type MessageHandler = unit -> Timed<unit> // State data type ReadyData = Timed<TimeSpan list> type ReceivedMessageData = Timed<TimeSpan list * MessageHandler> type NoMessageData = Timed<TimeSpan list>
All of these types are simply type aliases, so in fact they aren't strictly necessary. It's just helpful to give things a name from time to time.
The auxiliary MessageHandler type is a function that takes nothing (unit) as input, and returns 'timed nothing' as output. You may wonder how that handles a message. The intent is that any MessageHandler function is going to close over a real message: when a client calls it, it handles the message it closes over, and returns the time it took. The reason for this design is that the Polling Consumer doesn't need to 'see' the message; it only needs to know that it was handled, and how long it took. This design keeps the Polling Consumer decoupled from any particular message types.
There are three state data types: one for each state.
Hey! What about the End state?
It turns out that the End state doesn't need any associated data, because once the End state is reached, no more decisions should be made.
As promised, the three other states all contain a Timed<'something>. The timing information tells us when the transition into the given state started and stopped.
The data for the Ready and No message states are the same: Timed<TimeSpan list>, but notice that the TimeSpan list also appears in the Received state. This list of durations contains the statistics that the Polling Consumer measures. Every time it handles a message, it needs to measure how long it took. All such measurements are collected in this TimeSpan list, which must be passed around in all states so that the data isn't lost.
The data for the Received message state is different, because it also contains a MessageHandler. Every time the Polling Consumer receives a message, this message must be composed into a MessageHandler, and the MessageHandler passed as the second element of the state's tuple of data.
With all four states defined, we can now define a discriminated union that models a snapshot of the state machine:
type PollingConsumer = | ReadyState of ReadyData | ReceivedMessageState of ReceivedMessageData | NoMessageState of NoMessageData | StoppedState
That is, a PollingConsumer value represents a state of the Polling Consumer state machine.
Already at this stage, it should be apparent that F#'s type system is a great thinking tool, because it enables you to define type aliases declaratively, with only a single line of code here and there. Still, the advantage of the type system becomes much more apparent once you start to use these types.
Transitions #
With data types defined for each state, the next step of implementing a finite state machine is to define a function for each state. These functions are called transitions, and they should take a concrete state as input, and return a new PollingConsumer value as output. Since there are four concrete states in this example, there must be four transitions. Each should have the type 'concreteData -> PollingConsumer, e.g. ReadyData -> PollingConsumer, ReceivedMessageData -> PollingConsumer, etc.
As you can see, we're already getting guidance from the type system, because we now know the types of the four transitions we must implement.
Let's begin with the simplest one. When the Polling Consumer is Stopped, it should stay Stopped. That's easy. The transition should have the type unit -> PollingConsumer, because there's no data associated with the StoppedState.
Your first attempt might look like this:
let transitionFromStopped () : PollingConsumer = ??
This obviously doesn't compile because of the question marks (which aren't proper F# syntax). Knowing that you must return a PollingConsumer value, which one (of ReadyState, ReceivedMessageState, NoMessageState, or StoppedState) should you return?
Once the Polling Consumer is in the Stopped state, it should stay in the Stopped state, so the answer is easy: this transition should always return the Stopped state:
let transitionFromStopped () : PollingConsumer = StoppedState
It's as easy as that.
Since the (unit) input into the function doesn't do anything, we can remove it, effectively turning this particular function into a value:
let transitionFromStopped : PollingConsumer = StoppedState
This is a degenerate case, and not something that always happens.
Another transition #
Let's do another transition!
Another good example is the transition out of the No message state. This transition must have the type NoMessageData -> PollingConsumer, so you can start typing:
let transitionFromNoMessage (nm : NoMessageData) : PollingConsumer =
This function takes NoMessageData as input, and returns a PollingConsumer value as output. Now you only need to figure out how to implement it. What should it do?
If you look at the state transition diagram, you can see that from the No message state, the Polling Consumer should either decide to quit, or transition back to the Ready state after idling. That's the high-level behaviour we're aiming for, so let's try to put it into code:
let transitionFromNoMessage (nm : NoMessageData) : PollingConsumer = if shouldIdle nm then idle () |> ReadyState else StoppedState
This doesn't compile, because neither shouldIdle nor idle are defined, but this is the overall behaviour we're aiming for.
Let's keep it high-level, so we'll simply promote the undefined values to arguments:
let transitionFromNoMessage shouldIdle idle (nm : NoMessageData) : PollingConsumer = if shouldIdle nm then idle () |> ReadyState else StoppedState
This compiles! Notice how type inference enables you to easily introduce new arguments without breaking your flow. In statically typed languages like C# or Java, you'd have to stop and declare the type of the arguments. If the types you need for those arguments doesn't exist, you'd have to go and create them first. That'd often mean creating new interfaces or classes in new files. That breaks your flow when you're actually trying to figure out how to model the high-level behaviour of a system.
Often, figuring out how to model the behaviour of a system is an exploratory process, so perhaps you don't get it right in the first attempt. Again, with languages like C# or Java, you'd have to waste a lot of time fiddling with the argument declarations, and perhaps the types you'd have to define in order to declare those arguments.
In F#, you can stay focused on the high-level behaviour, and take advantage of type inference to subsequently contemplate if all looks good.
In the transitionFromNoMessage function, the shouldIdle argument is inferred to be of the type NoMessageData -> bool. That seems reasonable. It's a function that determines whether or not to idle, based on a NoMessageData value. Recall that NoMessageData is an alias for Timed<TimeSpan list>, and that all transition functions take time and return Timed<'something> in order to capture the time spent in transition. This means that the time data in NoMessageData contains information about when the transition into the No message state started and stopped. That should be plenty of information necessary to make the decision on whether there's time to idle or not. In a future article, you'll see how to implement a shouldIdle function.
What about the idle argument, then? As the transitionFromNoMessage function is currently written, this argument is inferred to be of the type unit -> ReadyData. Recall that ReadyData is an alias for Timed<TimeSpan list>; what we're really looking at here, is a function of the type unit -> Timed<TimeSpan list>. In other words, a function that produces a Timed<TimeSpan list> out of thin air! That doesn't sound right. Which TimeSpan list should such a function return? Recall that this list contains the statistics for all the previously handled messages. How can a function produce these statistics given nothing (unit) as input?
This seems extra strange, because the statistics are already there, contained in the nm argument, which is a NoMessageData (that is: a Timed<TimeSpan list>) value. The inferred signature of idle suggests that the statistics contained in nm are being ignored.
Notice how the type inference gives us an opportunity to contemplate the current implementation. In this case, just by looking at inferred types, we realise that something is wrong.
Instead, let's change the transitionFromNoMessage function:
let transitionFromNoMessage shouldIdle idle (nm : NoMessageData) = if shouldIdle nm then idle () |> Untimed.withResult nm.Result |> ReadyState else StoppedState
This seems more reasonable: the function idles, but then takes the timing information from idling, but replaces it with the statistics from nm. The inferred type of idle is now unit -> Timed<'a>. That seems more reasonable. It's any function that returns Timed<'a>, where the timing information indicates when idling started and stopped.
This still doesn't look like a pure function, because it relies on the side effect that time passes, but it turns out to be good enough for this purpose.
Higher-order functions #
Perhaps one thing is bothering you: I said that the transition out of the No message state should have the type NoMessageData -> PollingConsumer, but the final version of transitionFromNoMessage has the type (NoMessageData -> bool) -> (unit -> Timed<'a>) -> NoMessageData -> PollingConsumer!
The transitionFromNoMessage function has turned out to be a higher-order function, because it takes other functions as arguments.
Even though it doesn't exactly have the desired type, it can be partially applied. Imagine that you have two functions named shouldIdle' and idle', with the appropriate types, you can use them to partially apply the transitionFromNoMessage function:
let transitionFromNoMessage' = transitionFromNoMessage shouldIdle' idle'
The transitionFromNoMessage' function has the type NoMessageData -> PollingConsumer - exactly what we need!
All transitions #
In this article, you've seen two of the four transitions necessary for defining the behaviour of the Polling Consumer. In total, all four are required:
- ReadyData -> PollingConsumer
- ReceivedMessageData -> PollingConsumer
- NoMessageData -> PollingConsumer
- (StoppedData) -> PollingConsumer
In this article, I will leave it as an exercise to you to implement ReadyData -> PollingConsumer and ReceivedMessageData -> PollingConsumer. If you want to see full implementations of these, as well as a more detailed discussion of this general topic, please watch my Type-Driven Development with F# Pluralsight course.
Imagine that we now have all four transitions. This makes it easy to implement the overall state machine.
State machine #
Here's one way to execute the state machine:
let rec run trans state = let nextState = trans state match nextState with | StoppedState -> StoppedState | _ -> run trans nextState
This run function has the inferred type (PollingConsumer -> PollingConsumer) -> PollingConsumer -> PollingConsumer. It takes a trans function that turns one PollingConsumer into another, as well as an initial PollingConsumer value. It then proceeds to recursively call the trans function and itself, until it reaches a StoppedState value.
How can we implement a PollingConsumer -> PollingConsumer function?
That's easy, because we have all four transition functions, so we can use them:
let transition shouldPoll poll shouldIdle idle state = match state with | ReadyState r -> transitionFromReady shouldPoll poll r | ReceivedMessageState rm -> transitionFromReceived rm | NoMessageState nm -> transitionFromNoMessage shouldIdle idle nm | StoppedState -> transitionFromStopped
The transition function has the type (ReadyData -> bool) -> (unit -> Timed<messagehandler option>) -> (NoMessageData -> bool) -> (unit -> Timed<'a>) -> PollingConsumer -> PollingConsumer. That looks positively horrendous, but it's not so bad; you can partially apply it in order to get a function with the desired type PollingConsumer -> PollingConsumer.
Implicit to-do list #
Even though we now have the run and transition functions, we only have the high-level behaviour in place. We still have a lot of implementation details left.
This is, in my opinion, one of the benefits of this approach to using the low-friction type system: First, you can focus on the desired behaviour of the system. Then, you address various implementation concerns. It's outside-in development.
Another advantage is that at this point, it's quite clear what to do next.
The transitionFromNoMessage function clearly states that it needs the functions shouldIdle and idle as arguments. You can't call the function without these arguments, so it's clear that you must supply them.
Not only did the type system allow us to introduce these function arguments with low friction, but it also tells us the types they should have.
In my Pluralsight course you can see how the transition out of the Ready state also turns out to be a higher-order function that takes two other functions as arguments.
In all, that's four functions we still need to implement before we can use the state machine. It's not going to be possible to partially apply the transition function before these four functions are available.
The type system thereby tells us that we still need to implement these four functions:
- ReadyData -> bool
- unit -> Timed<MessageHandler option>
- NoMessageData -> bool
- unit -> Timed<'a>
run function. Once we can compile a composition of the run function, there are no implementation details left.
Summary #
Although this turned out to be quite a lengthy article, it only provides a sketch of the technique. You can see more code details, and a more in-depth discussion of the approach, in my Type-Driven Development with F# Pluralsight course.
The F# type system can be used in ways that C# and Java's type systems cant:
- Dependencies can be introduced just-in-time as function arguments.
- You can contemplate the inferred types to evaluate the soundness of the design.
- The type system implicitly keeps a to-do list for you.
Update 2017-07-10: See Pure times for a more functional design.
Idiomatic or idiosyncratic?
A strange programming construct may just be a friendly construct you haven't yet met.
Take a look at this fragment of JavaScript, and reflect on how you feel about it.
var nerdCapsToKebabCase = function (text) { var result = ""; for (var i = 0; i < text.length; i++) { var c = text.charAt(i); if (i > 0 && c == c.toUpperCase()) { result = result + "-"; } result = result + c.toLowerCase(); } return result; };
Do you understand what it does? Does it feel appropriate for the language? Does it communicate its purpose?
Most likely, you answered yes to all three questions - at least if you know what NerdCaps and kebab-case means.
Would your father, or your 12-year old daughter, or your English teacher, also answer yes to all of these questions? Probably not, assuming they don't know programming.
Everything is easy once you know how to do it; everything is hard if you don't.
Beauty is in the eye of the beholder #
Writing software is hard. Writing maintainable software - code that you and your team can keep working on year after year - is extraordinarily hard. The most prominent sources of problems seem to be accidental complexity and coupling.
During my career, I've advised thousands of people on how to write maintainable code: how to reduce coupling, how to simplify, how to express code that a human can easily reason about.
The most common reaction to my suggestions?
"But, that's even more unreadable than the code we already had!"What that really means is usually: "I don't understand this, and I feel very uncomfortable about that."
That's perfectly natural, but it doesn't mean that my suggestions are really unreadable. It just means that you may have to work a little before it becomes readable, but once that happens, you will understand why it's not only readable, but also better.
Let's take a step back and examine what it means when source code is readable.
Imperative code for beginners #
Imagine that you're a beginner programmer, and that you have to implement the nerd caps to kebab case converter from the introduction.
This converter should take as input a string in NerdCaps, and convert it to kebab-case. Here's some sample data:
| Input | Expected output |
|---|---|
| Foo | foo |
| Bar | bar |
| FooBar | foo-bar |
| barBaz | bar-baz |
| barBazQuux | bar-baz-quux |
| garplyGorgeFoo | garply-gorge-foo |
Since (in this imaginary example) you're a beginner, you should choose to use a beginner's language, so perhaps you select Visual Basic .NET. That seems appropriate, as BASIC was originally an acronym for Beginner's All-purpose Symbolic Instruction Code.
Perhaps you write the function like this:
Function Convert(text As String) As String Dim result = "" For index = 0 To text.Length - 1 Dim c = text(index) If index > 0 And Char.IsUpper(c) Then result = result + "-" End If result = result + c.ToString().ToLower() Next Return result End Function
Is this appropriate Visual Basic code? Yes, it is.
Is it readable? That completely depends on who's doing the reading. You may find it readable, but does your father, or your 12-year old daughter?
I asked my 12-year old daughter if she understood, and she didn't. However, she understands this:
Funktionen omformer en stump tekst ved at først at dele den op i stumper hver gang der optræder et stort bogstav. Derefter sætter den bindestreg mellem hver tekststump, og laver hele teksten om til små bogstaver - altså nu med bindestreger mellem hver tekststump.
Did you understand that? If you understand Danish (or another Scandinavian language), you probably did; otherwise, you probably didn't.
Readability is evaluated based on what you already know. However, what you know isn't constant.
Imperative code for seasoned programmers #
Once you've gained some experience, you may find Visual Basic's syntax too verbose. For instance, once you understand the idea about scope, you may find End If, End Function etc. to be noisy rather than helpful.
Perhaps you're ready to replace those keywords with curly braces. Here's the same function in C#:
public string Convert(string text) { var result = ""; for (int i = 0; i < text.Length; i++) { var c = text[i]; if (i > 0 && Char.IsUpper(c)) result = result + "-"; result = result + c.ToString().ToLower(); } return result; }
Is this proper C# code? Yes. Is it readable? Again, it really depends on what you already know, but most programmers familiar with the C language family would probably find it fairly approachable. Notice how close it is to the original JavaScript example.
Imperative code for experts #
Once you've gained lots of experience, you will have learned that although the curly braces formally delimit scopes, in order to make the code readable, you have to make sure to indent each scope appropriately. That seems to violate the DRY principle. Why not let the indentation make the code readable, as well as indicate the scope?
Various languages have so-called significant whitespace. The most widely known may be Python, but since we've already looked at two .NET languages, why not look at a third?
Here's the above function in F#:
let nerdCapsToKebabCase (text : string) = let mutable result = "" for i = 0 to text.Length - 1 do let c = text.Chars i if (i > 0 && Char.IsUpper c) then result <- result + "-" result <- result + c.ToString().ToLower() result
Is this appropriate F# code?
Not really. While it compiles and works, it goes against the grain of the language. F# is a Functional First language, but the above implementation is as imperative as all the previous examples.
Functional refactoring #
A more Functional approach in F# could be this:
let nerdCapsToKebabCase (text : string) = let addSkewer index c = let s = c.ToString().ToLower() match index, Char.IsUpper c with | 0, _ -> s | _, true -> "-" + s | _, false -> s text |> Seq.mapi addSkewer |> String.concat ""
This implementation uses a private, inner function called addSkewer to convert each character to a string, based on the value of the character, as well as the position it appears. This conversion is applied to each character, and the resulting sequence of strings is finally concatenated and returned.
Is this good F#? Yes, I would say that it is. There are lots of different ways you could have approached this problem. This is only one of them, but I find it quite passable.
Is it readable? Again, if you don't know F#, you probably don't think that it is. However, the F# programmers I asked found it readable.
This solution has the advantage that it doesn't rely on mutation. Since the conversion problem in this article is a bit of a toy problem, the use of imperative code with heavy use of mutation probably isn't a problem, but as the size of your procedures grow, mutation makes it harder to understand what happens in the code.
Another improvement over the imperative version is that this implementation uses a higher level of abstraction. Instead of stating how to arrive at the desired result, it states what to do. This means that it becomes easier to change the composition of it in order to change other characteristics. As an example, this implementation is what is known as embarrassingly parallel, although it probably wouldn't pay to parallelise this implementation (it depends on how big you expect the input to be).
Back-porting the functional approach #
While F# is a multi-paradigmatic language with an emphasis on Functional Programming, C# and Visual Basic are multi-paradigmatic languages with emphasis on Object-Oriented Programming. However, they still have some Functional capabilities, so you can back-port the F# approach. Here's one way to do it in C# using LINQ:
public string Convert(string text) { return String.Concat(text.Select(AddSkewer)); } private static string AddSkewer(char c, int index) { var s = c.ToString().ToLower(); if (index == 0) return s; if (Char.IsUpper(c)) return "-" + s; return s; }
The LINQ Select method is equivalent to F#'s mapi function, and the AddSkewer function must rely on individual conditionals instead of pattern matching, but apart from that, it's structurally the same implementation.
You can do the same in Visual Basic:
Function Convert(text As String) As String Return String.Concat(text.Select(AddressOf AddSkewer)) End Function Private Function AddSkewer(c As Char, index As Integer) Dim s = c.ToString().ToLower() If index = 0 Then Return s End If If Char.IsUpper(c) Then Return "-" + s End If Return s End Function
Are these back-ported implementations examples of appropriate C# or Visual Basic code? This is where the issue becomes more controversial.
Idiomatic or idiosyncratic #
Apart from reactions such as "that's unreadable," one of the most common reactions I get to such suggestions is:
"That's not idiomatic C#" (or Visual Basic).
Perhaps, but could it become idiomatic?
Think about what an idiom is. In language, it just means a figure of speech, like "jumping the shark". Once upon a time, no-one said "jump the shark". Then Jon Hein came up with it, other people adopted it, and it became an idiom.
It's a bit like that with idiomatic C#, idiomatic Visual Basic, idiomatic Ruby, idiomatic JavaScript, etc. Idioms are adopted because they're deemed beneficial. It doesn't mean that the set of idioms for any language is finite or complete.
That something isn't idiomatic C# may only mean that it isn't idiomatic yet.
Or perhaps it is idiomatic, but it's just an idiom you haven't seen yet. We all have idiosyncrasies, but we should try to see past them. If a language construct is strange, it may be a friendly construct you just haven't met.
Constant learning #
One of my friends once told me that he'd been giving a week-long programming course to a group of professional software developers, and as the week was winding down, one of the participants asked my friend how he knew so much.
My friend answered that he constantly studied and practised programming, mostly in his spare time.
The course participant incredulously replied: "You mean that there's more to learn?"
As my friend told me, he really wanted to reply: “If that's a problem for you, then you've picked the wrong profession." However, he found something more bland, but polite, to answer.
There's no way around it: if you want to be (and stay) a programmer, you'll have to keep learning - not only new languages and technologies, but also new ways to use the subjects you already think you know.
If you ask me about advice about a particular problem, I will often suggest something that seems foreign to you. That doesn't make it bad, or unreadable. Give it a chance even if it makes you uncomfortable right now. Being uncomfortable often means that you're learning.
Luckily, in these days of internet, finding materials that will help you learn is easier and more accessible than ever before in history. There are tutorials, blog posts, books, and video services like Pluralsight.
Comments
I would have done this...
Regex.Replace(s, "(?<=.)[A-Z]", _ => "-" + _.Value).ToLower();
Craig, fair enough :)
In addition to Craig's proposal (which I immediately though of too hehe), think of this one:
const string MATCH_UPPERCASE_LETTERS = "(?<=.)[A-Z]";
// ...
Regex.Replace(s, MATCH_UPPERCASE_LETTERS, letterFound => "-" + letterFound.Value).ToLower();
It probably does not follow the whole conventions of the language, but the great thing about it is that it can be easily understood without knowledge of the language. This brings it to another complete level of maintainability.
Of course, the meta-information that you convey through the code is subject to another complete analysis and discussion, since there are way too many options on how to approach that, and while most of us will lean on "readable code", it all comes down to what the code itself is telling you about itself.
Finally, as a side note, something that I found quite interesting is that most of the introductory guides to Ruby as a language will talk about how Ruby was design to read like english.
door.close unless door.is_closed?
(based on Why's Poignant Guide to Ruby.)
While I found that pretty appealing when learning Ruby, some other constructs will take it far away from how English works, pretty much what happened to your example with F#. Not that they cannot be made to read easier, but that extra effort is not always performed.
My conclusion is: readability is not about the code or the algorithm (which definitely can help), but about the information that the code itself gives you about what it does. Prefer to use pre-built language functions rather than implementing them yourself.
In under than 30 seconds of seeing the code blocks, I can't follow any of the process. But I know what the operation is doing thanks to the operation name, nerdCapsToKebabCase. Surely that the terms nerdCaps and KebabCase is uncommon, but I only need some minutes to know what are those using internet.
So for me, no matter how good you write your code, you can't make it commonly readable by using the code itself. Won't the readability can be enhanced by using comments / documentation? Ex: /* convert thisKindOfPhrase to this-kind-of-phrase */. I've also used unit tests to improve the readability to some extent too.
To end the loop it may be fair to give a JavaScript function sample which became more idiomatic since 2015 :)
ES5 syntax to be consistent with the first example.
var nerdCapsToKebabCase = function (text) {
return text.split('')
.map( function(c){
return (c === c.toUpperCase()) ? '-' + c.toLowerCase() : c ;
})
.join('');
};
I know you can use String.prototype.replace with a regex in this case but it don't illustrate well the idiom from Imperative to functional (even it's a High-Order Function).
Type Driven Development with F# Pluralsight course
The F# type system can do much more than C# or Java's type system. Learn how to use it as a design feedback technique in my new Pluralsight course.
Not only can the F# type system help you catch basic errors in your code, but it can also help you by providing rapid feedback, and make suggestions on how to proceed. All you have to do is learn to listen.
My new Pluralsight course, Type-Driven Development with F#, first walks you through three modules of exploration of a real problem, showing various ways you can take advantage of the type system in an Outside-in fashion. As you can tell, it involves some celebration related to Finite State Machines:

It then shows you how to stabilize the prototype using Property-based Testing with FsCheck.

Comments
Dear Mark,
Thank you for this excellent article. I got one question: in the "Internals" section, you state that there are valid use cases for the internal access modifier - can you name some of them for me?
I'm also a proponent of keeping nearly all types public in reusable code bases even if most of them are not considered to be part of the API that a client usually consumes - therefore I would only think about marking a class internal if it cannot protect it's invariants properly and fail fast when it's used in the wrong way. But you also mentioned that in this article, too.
When I did a Google search on the topic, I couldn't find any useful answers either. The best one is probably from Eric Lippert on a Stack Overflow question, stating that big important classes that are hard to verify in the development process should be marked internal. But one can easily counter that by not designing code in such a way.
Anyways, it would be very kind of you if you could provide some beneficial use cases for the use of internal.
Sincerely,
Kenny
Kenny, thank you for writing. The answer given by Eric Lippert does, in my opinion, still paint an appropriate picture. There's always a cost to making types or members public, and I don't always wish to pay that cost. The point that I'm trying to make in the present article is that while this cost exists, it's not so high that it justifies unit testing internals via mechanisms like Reflections or [InternalsVisibleTo]. The cost of doing that is higher than making types or members public.
Still, there are many cases where it's possible to cover internal or private code though a public API. Sometimes, I may be in doubt that the way I've modelled the internal code is the best way to do so, and then I'd rather avoid the cost of making it public. After all, making code public means that you're making a promise that it'll be around without breaking changes for a long time.
Much of my code has plenty of private or internal code. An example is Hyprlinkr, which has private helper methods for one of its central features. These private helpers only exist in order to make the feature implementation more readable, but are not meant for public consumption. They're all covered by tests that exercise the various public members of the class.
Likewise, you can consider the private DurationStatistics class from my Temporary Field code smell article. At first, you may want to keep this class private, because you're not sure that it's stable (i.e. that it isn't going to change). Later, you may realise that you'll need that code in other parts of your code base, so you move it to an internal class. If you're still not convinced that it's stable, you may feel better keeping it internal rather than making it public. Ultimately, you may realise that it is, indeed, stable, in which case you may decide to make it public - or you may decide that no one has had the need for it, so it doesn't really matter, after all.
My goal with this article wasn't to advise against internal code, but only to advise against trying to directly call such code for unit testing purposes. In my experience, when people ask how to unit test internal code, it's a problem they have because they haven't used Test-Driven Development (TDD). If you do TDD, you'll have sufficient coverage, and then it doesn't matter how you choose to organise the internals of your code base.