ploeh blog danish software design
How to create a pure F# ASP.NET Web API project
How to create a single F# project for an ASP.NET Web API, without using an auxiliary C# or VB host project.
Implementing an ASP.NET Web API service in F# is a relatively well-described process, but everywhere I look, it seems that people are relying on a (Humble) C# Web Project to act as a host for a library written in F#. You can use an online Visual Studio template, or you can do this by hand - it's not particularly difficult. Where's the challenge in that?
Partly in a quest to demonstrate that F# is a general-purpose language, and partly just to see if it can be done, I wanted to create a pure F# ASP.NET Web API project, without relying on a C# host project. Most people on Twitter advised against it because there's no F# support for Razor, *.aspx, or *.cshtml. However, that's not a concern for a Web API, since it's not going to generate HTML anyway.
As @dotnetnerd puts it:
"not trivial but doable"That turns out to be quite an accurate description. Here's how.
Create an F# library project #
The first thing I did was to create a normal F# library project.
As you can see, there's nothing in that project yet.
Turn the project into a Web Project #
In contrast to C# and VB, there's no built-in F# Web Project template. However, in order to work with a web project in Visual Studio 2012, it helps if the project is a 'real' Web Project, because it means that you can launch it in IIS Express, and such things.
Because there's no built-in Web Project template for F#, I'm not aware of a nice way to do this through the Visual Studio UI, but you can open your .fsproj file in an text editor and hand-edit it. In order to turn my project into a Web Project, I added this line of code to my .fsproj file (just below the Project/PropertyGroup/ProjectGuid element):
<ProjectTypeGuids>{349c5851-65df-11da-9384-00065b846f21};{F2A71F9B-5D33-465A-A702-920D77279786}</ProjectTypeGuids>
The 349c5851-65df-11da-9384-00065b846f21 GUID tells Visual Studio that this is a Web Project, while F2A71F9B-5D33-465A-A702-920D77279786 indicates an F# project.
This isn't entirely without drawbacks (that I'll get to in a minute), but you can now reload the project in Visual Studio, and you actually have an F# Web Project.
Turn on IIS Express #
One of the things you can do with a Web Project is to right-click in Solution Explorer and select "Use IIS Express...", so I did that.
Add Web API dependencies #
In order to use the ASP.NET Web API, you'll need to add the appropriate dependencies. I did that by adding the Microsoft.AspNet.WebApi.WebHost NuGet package.
Add a code file #
One of the disadvantages of creating an F# Web Project is that it's an unknown combination, so you can't add anything to the project:
In order to work around this problem, I again hand-edited the .fsproj file, temporarily commenting out the ProjectTypeGuids element I previously added. Then I added an F# code file, and finally added the ProjectTypeGuids element again.
Change the output folder #
The default output folder for the debug build is "bin\Debug". Although I'm not sure whether this is strictly necessary, I changed it to "bin" because that's how C# Web Projects work...
Reference System.Web #
In order to be able to derive a Global class from System.Web.HttpApplication, I added a reference to System.Web. This is a BCL library, so I added it by using the old-fashioned Add reference menu item (instead of using NuGet).
Add Global.asax #
Next, I added a Global.asax file with this content:
<%@ Application Inherits="Ploeh.Samples.FebApi.Global" %>
The class Ploeh.Samples.FebApi.Global doesn't exist yet, so if you try to run the site at this stage, it's going to fail.
Add a Global class #
In order to add the Ploeh.Samples.FebApi.Global class, I wrote the first F# code in the project:
namespace Ploeh.Samples.FebApi open System type Global() = inherit System.Web.HttpApplication() member this.Application_Start (sender : obj) (e : EventArgs) = ()
The site still can't run, but at least now it doesn't complain about a missing Global class.
Add a Route #
The next step was to add a default Web API route:
namespace Ploeh.Samples.FebApi open System open System.Web.Http type HttpRouteDefaults = { Controller : string; Id : obj } type Global() = inherit System.Web.HttpApplication() member this.Application_Start (sender : obj) (e : EventArgs) = GlobalConfiguration.Configuration.Routes.MapHttpRoute( "DefaultAPI", "{controller}/{id}", { Controller = "Home"; Id = RouteParameter.Optional }) |> ignore
At this point, you actually have an ASP.NET Web API site, because now, when you attempt to run the site, you get this error message:
No HTTP resource was found that matches the request URI 'http://localhost:64176/'. No type was found that matches the controller named 'Home'.Which is great, because this is known territory.
Add HomeController #
Adding the missing HomeController class is easy:
type HomeController() = inherit ApiController()
Of course, it doesn't do anything yet, so when you browse to the API, you get this (entirely expected) error message:
The requested resource does not support http method 'GET'.This problem is easy to solve:
type HomeRendition() = [<DefaultValue>] val mutable Message : string [<DefaultValue>] val mutable Time : string type HomeController() = inherit ApiController() member this.Get() = this.Request.CreateResponse( HttpStatusCode.OK, HomeRendition( Message = "Hello from F#", Time = DateTimeOffset.Now.ToString("o")))
Now, when browsing to the API, you get something like this:
<HomeRendition xmlns="http://schemas.datacontract.org/2004/07/Ploeh.Samples.FebApi"> <Message>Hello from F#</Message> <Time>2013-08-23T10:26:40.8490741+02:00</Time> </HomeRendition>
Success, of a sort!
This Web API now runs in IIS Express on my local machine. However, at this point, it still doesn't run in an Azure Web Site (which is something I also wanted to enable), but I'll cover how to do that in a future post.
Update 2013.19.12: It turns out that it's possible to hack the registry to make it possible to add standard F# project items to the project.
Update 2014.02.17: Since I wrote this article, new F# templates are now available for Visual Studio, including a template for F# ASP.NET MVC 5 and Web API 2 projects.
Checking math homework with F#
Teaching my daughter F# while checking her math homework.
My daughter Linea is 10 years old, and I've been looking for ways to make programming relevant to her. Last year, I discovered that her math homework was beginning to include simple functions, although they weren't called that. Instead, they were verbal assignments like: "for each of the following numbers, multiply the number by 3, and subtract 2." Still, it got me thinking whether Functional Programming would be a relevant introduction to programming.
In vacations, we've been doing a bit of F# programming, and I actually got so far as to help her implement FizzBuzz in F#. Still, I was struggling with coming up with a continuing set of small problems that would enable us to progress.
Until yesterday, that is. Linea actually likes doing her math homework, but she always wants me to check it for her. This is something I'm already using some time at, but suddenly I realized that we could do it together - in F#! She would have to check her results by typing in each question, and learn F# as we go along.
This makes F# relevant to her, and being the lazy programmer that I am, I'm at the same time trying to teach her a few shortcuts we can take here and there. Here's a scan of a small part of her homework:
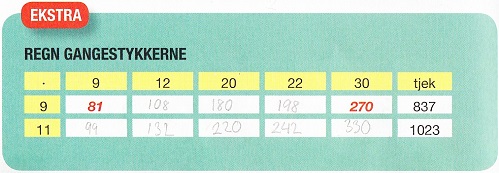
The Danish text basically says: multiply the numbers. As you can tell, Linea first did her homework the old-fashioned way, filling the numbers into the table. Then we sat down to check her work with F#. Here's a copy of the part of tonight's F# Interactive (FSI, a REPL for F#) session related to that table:
> let m9 x = 9 * x;; val m9 : x:int -> int > m9 12;; val it : int = 108 > m9 20;; val it : int = 180 > m9 22;; val it : int = 198 > let m11 x = 11 * x;; val m11 : x:int -> int > let input = [9;12;20;22;30];; val input : int list = [9; 12; 20; 22; 30] > Seq.map m11 input;; val it : seq<int> = seq [99; 132; 220; 242; ...] > List.map m11 input;; val it : int list = [99; 132; 220; 242; 330] > input |> List.map m11;; val it : int list = [99; 132; 220; 242; 330] > input |> List.map m11 |> List.sum;; val it : int = 1023 > List.map m9 input;; val it : int list = [81; 108; 180; 198; 270] > input |> List.map m9;; val it : int list = [81; 108; 180; 198; 270] > input |> List.map m9 |> List.sum;; val it : int = 837 >
As you can tell, Linea first created a function (m9) in order to multiply a number with 9. This is the function form I've taught her back when we were doing FizzBuzz. You could write it more succinctly as let m9 = (*) 9, but I didn't want to confuse her :)
She evaluated the first row in the table using the m9 function one cell at a time, but when it came to the next row, I decided to teach her about List.map. First, I had her create a list (input) of all the column head numbers from the table. Then I taught her to invoke the map function with the input and her m11 function. As you can see, first I had her use the imperative function call style she already knew, and then I had her use the pipe operator. That gave us a list with all the results for the last row of the table, and we could now compare the list with her homework to confirm that her results were correct.
If you look at the table, you'll see that the last column is called tjek (check), and contains a pre-populated sum the pupil can use to check whether her homework is correct. I wanted Linea to use F# to calculate the sum to confirm that everything indeed adds up correctly, so I introduced her to List.sum, and how she could further pipe her result list into the sum function, to get the sum. As you can see from the FSI session, she did that for both rows.
Obviously, I helped her here and there, but she picked up some of the concepts quite easily, and was altogether happy about our session. She felt that she learned a bit of F#, and she could relate to the work we did because she likes math already.
My purpose of posting this was to share the idea of using F# (or another programming language) to teach kids programming. While you could use other languages, I find F# a good fit because its syntax is close to the math syntax Linea learns in school, and she doesn't have to relate to a lot of curly brackets and parentheses. Additionally, the FSI makes this kind of ad hoc work easily approachable.
LINQ versus the LSP
This post examines the conflict between Iterators, LINQ, and the Liskov Substitution Principle.
As a reaction to my my previous post on Defensive Coding, one of my readers sent me this question:
"[One] very prominent scenario of defensive coding is used when the input argument is IEnumerable<T>
public class Publisher { public Publisher(IEnumerable<Subscriber> subscribers) { // defensive copy -> good or bad? this.subscribers = subscribers.ToArray(); } // … }"You could argue: when the intention is to use IEnumerable<T>, the receiver shall not to believe this sequence is immutable. You could indicate an immutable sequence with ICollection for instance. In the example above, the caller might add a new subscriber silently to its own list and have it automatically injected into the 'publisher' (maybe that's the intention from the perspective of the caller). However, a defensive copy breaks this behavior because the injected sequence is now no longer under control of the caller. This shows how simple an implementation detail can change the behavior on the client.
"The reason you often see code like this is because we like immutable objects and second because of the unknown performance impact of IEnumerable. Once you take a copy of the input you can predict the performance of your class otherwise you can't.
"I tend to say it's 'bad' to take defensive copy (after reading many of your blog posts), but would be happy to hear your opinion on that."
This question warrants an in-depth answer.
Encapsulation #
IEnumerable<T> is one of the most misunderstood interfaces in .NET. It carries very few guarantees, and many method calls on it may actually break the Liskov Substitution Principle (LSP). ToArray is one of them, because it assumes that the sequence produced by the Iterator is finite, which it may not be. Thus, if you invoke ToArray on an infinite Iterator, you will eventually get an exception.
It doesn't really matter whether you call ToArray in the constructor, or in the class method(s) where you use the injected IEnumerable<T>. However, from a Fail First perspective, and in order to protect the class' invariant, if the class requires the sequence to be finite, you could argue that you should invoke ToArray (or ToList) in the constructor. However, this breaks Nikola Malovic's 4th law of IoC: constructors should do no work. This should make you stop and ponder: if you require an array, you should state that requirement up front:
public class Publisher { public Publisher(Subscriber[] subscribers) { this.subscribers = subscribers; } // … }
Notice that instead of requesting IEnumerable<T>, this version requests an array and simply assigns the array to a private field.
However, the problem is that an array isn't quite the same as an Iterator; the most profound difference is that the Publisher class is actually able to mutate the array by replacing elements within the array. This could be a problem if the array is shared with other clients.
Another problem is that if the Publisher doesn't need the ability to mutate the array, it now breaks the Robustness Principle, because a finite Iterator would have been good enough for its needs, but still, it puts an unwarranted demand on its clients.
Asking for ICollection<T>, as my reader suggests, is an even greater violation of the Robustness Principle, because that interface adds seven new methods on top of IEnumerable<T> - three of which are only about mutation. The rest of the methods have been made redundant by LINQ.
LINQ and the LSP #
In a previous post, I've talked about the conflict between IQueryable and the LSP, but even constraining the discussion to LINQ to Objects, it turns out that LINQ has lots of built-in LSP violations.
Recall the essence of the LSP: you should be able to pass any implementation of an interface to a client without changing the correctness of the system. While 'correctness' is application-specific, the lowest common denominator must be that if a method works for one implementation, it mustn't throw exceptions for another implementation. However, consider these two implementations of IEnumerable<string>:
new[] { "foo", "bar", "baz" };
and this one:
public class InfiniteStrings : IEnumerable<string> { public IEnumerator<string> GetEnumerator() { while (true) yield return "foo"; } System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator() { return this.GetEnumerator(); } }
As I've already discussed, invoking ToArray (or ToList) on these two implementations changes the correctness of the system, because the second implementation (the infinite Iterator) will cause an exception to be thrown. In fact, as far as I can tell, the only LSP-compliant LINQ methods are:
- Any()
- AsEnumerable()
- Concat(IEnumerable<T>)
- DefaultIfEmpty()
- DefaultIfEmpty(T)
- Distinct (maybe...)
- Distinct(IEqualityComparer<T>) (maybe...)
- ElementAt(int)
- ElementAtOrDefault(int)
- First()
- FirstOrDefault()
- OfType<TResult>()
- Select(Func<TSource, TResult>)
- Select(Func<TSource, int, TResult>)
- SelectMany(Func<TSource, IEnumerable<TResult>>)
- SelectMany(Func<TSource, int, IEnumerable<TResult>>)
- SelectMany(Func<TSource, IEnumerable<TCollection>>, Func<TSource, TCollection, TResult>)
- SelectMany(Func<TSource, int, IEnumerable<TCollection>>, Func<TSource, TCollection, TResult>)
- Single()
- SingleOrDefault()
- Skip(int)
- Take(int)
- Where(Func<TSource, bool>)
- Where(Func<TSource, int, bool>)
- Zip(IEnumerable<TSecond>, Func<TFirst, TSecond, TResult>)
This actually demonstrates a need for a 'Finite Iterator' interface, and I have to admit that, before researching for this article, I'd never heard about IReadOnlyCollection<T>, but there it is; it's seems to be a new interface in .NET 4.5. I think I'll begin to use this interface some more!
Summary #
The bottom line is that defensive copying of IEnumerable<T> into arrays should be avoided. If you can get by with the LSP-compliant subset of LINQ, then all is good (but consider writing a couple of unit tests that involve infinite Iterators). If you require a finite sequence and you're on .NET 4.5, require IReadOnlyCollection<T> as an argument instead of IEnumerable<T>. If you require a finite sequence and you're not on .NET 4.5, ask for an array as an argument (and consider adding some unit tests that verify that your implementation doesn't mutate the array).
Defensive coding
This post examines the advantages and disadvantages of defensive coding.
One of my readers, Barry Giles, recently wrote me and asked a question that I think is interesting enough to warrant a discussion:
"Recently I came up against an interesting situation at work: I was getting a review and I had put defensive checks in – one for a null argument check against a constructor parameter, one for a null check on a property return value. I also had some assertions for private methods which I tend to use to state my assumptions.
"It seems the prevailing mood in my team is to not have any of the checks and just let it fail. To be honest I’m struggling with this concept as I am so used to developing in this way and thought it was good practice. I’m pretty sure it’s in most tutorials and blog posts.
"Can you advise on why it’s better to code defensively like this instead of just letting it fail and checking the stack trace please?"
Actually, I don't think defensive coding necessarily is better; I also don't think it's worse. As usual, there are different forces in play, so the short answer is the usual: it depends.
That answer is obviously useless unless you can answer the question: on what does it depend? In this article, I'll examine some of the forces at play. However, I'm not going to claim that this will be an exhaustive treatment of the subject.
Letting it fail #
What is the value of defensive coding, if all you're going to do is to immediately throw an exception? Wouldn't it be just as good to let the code fail? Let's look at some code.
public class ProductDetailsController { private readonly IUserRepository userRepository; private readonly IProductRepository productRepository; private readonly ICurrencyExchange exchange; public ProductDetailsController( IUserRepository userRepository, IProductRepository productRepository, ICurrencyExchange exchange) { this.userRepository = userRepository; this.productRepository = productRepository; this.exchange = exchange; } public ProductDetailsViewModel GetProductDetails( string userId, string productId) { var user = this.userRepository.Get(userId); var targetCurrency = user.PreferredCurrency; var product = this.productRepository.Get(productId); var convertedPrice = this.exchange.Convert(product.UnitPrice, targetCurrency); return new ProductDetailsViewModel { Name = product.Name, Price = convertedPrice.ToString() }; } }
In this simple ProductDetailsController, the GetProductDetails method produces a ProductDetailsViewModel instance by getting user and product information from injected Repositories, converting the product unit price to the user's desired currency, and returning data about the product for display purposes. For the sake of argument, let's focus only on null issues. How many things could go wrong in the GetProductDetails method? How many objects can be null?
Quite a few, it turns out. Even decoupled from its dependencies, this small piece of code can throw a NullReferenceException in at least six different ways. Imagine that you receive an error report from your production system. The stack trace points to the ProductDetailsViewModel method, and the exception is a NullReferenceException. Which of the six possible nulls caused the error?
By just letting the system fail, it's hard to answer that question. Keep in mind that this is even a demo example. Most production code I've seen has more than five to six lines of code, so looking for the cause of an error report can quickly become like looking for a needle in a haystack.
Just letting the code fail isn't particularly helpful. Obviously, if you write very short methods (a practice I highly recommend), the problem is less pronounced, but the longer your methods are, the less professional I think 'just letting it fail' sounds.
Defensive coding to the rescue? #
By adding explicit guards against null, you can throw more descriptive exception messages:
public class ProductDetailsController { private readonly IUserRepository userRepository; private readonly IProductRepository productRepository; private readonly ICurrencyExchange exchange; public ProductDetailsController( IUserRepository userRepository, IProductRepository productRepository, ICurrencyExchange exchange) { if (userRepository == null) throw new ArgumentNullException("userRepository"); if (productRepository == null) throw new ArgumentNullException("productRepository"); if (exchange == null) throw new ArgumentNullException("exchange"); this.userRepository = userRepository; this.productRepository = productRepository; this.exchange = exchange; } public ProductDetailsViewModel GetProductDetails( string userId, string productId) { var user = this.userRepository.Get(userId); if (user == null) throw new InvalidOperationException("User was null."); var targetCurrency = user.PreferredCurrency; var product = this.productRepository.Get(productId); if (product == null) throw new InvalidOperationException("Product was null."); var convertedPrice = this.exchange.Convert(product.UnitPrice, targetCurrency); if (convertedPrice == null) throw new InvalidOperationException("Converted price was null."); return new ProductDetailsViewModel { Name = product.Name, Price = convertedPrice.ToString() }; } }
Is this better? From a troubleshooting perspective it is, because with this version of the code, if you get an error message from your production system, the exception message will tell you exactly which of the six null situations your program encountered. If I were in maintenance mode, I know which of the two versions I'd like to support.
However, from a readability perspective, you're much worse off. The GetProductDetails method grew from five to eleven lines of code. Defensive coding more than doubled the line count! The flow through the method drowns in guard clauses, so it's less readable now. If you're a typical programmer, you read code much more than you write it, so a practice that makes it harder to read code should trigger your code smell sense. No wonder that many programmers consider defensive coding a bad practice.
Robustness #
Is it possible to balance the forces at play here? Yes it is, but in order to understand how, you need to understand the root cause of the problem. The original code example isn't particularly complicated, but even so, there are so many ways it can fail. When it comes to null references, the cause is a language design mistake, but in general, the question is whether or not you can trust input. The return values from invoking IUserRepository.Get is (indirect) input too.
Depending on the environment in which your program is running, you may or may not be able to trust input. Consider, for a moment, the situation where your software is running in the wild. It may be a reusable library or framework. In this case, you can't trust input at all. If fact, you may want to apply the robustness principle and make sure that, not only are you going to be very defensive about input, but you're also going to be careful and nice about the output of your program. In other words, you don't want to pass null (or other evil values) to your collaborators.
The sample code presented here may pass null to its dependencies, e.g. if userId is null, or (more subtly) if user.PreferredCurrency is null. Thus, to apply the robustness principle, you'd have to add even more defensive coding:
public class ProductDetailsController { private readonly IUserRepository userRepository; private readonly IProductRepository productRepository; private readonly ICurrencyExchange exchange; public ProductDetailsController( IUserRepository userRepository, IProductRepository productRepository, ICurrencyExchange exchange) { if (userRepository == null) throw new ArgumentNullException("userRepository"); if (productRepository == null) throw new ArgumentNullException("productRepository"); if (exchange == null) throw new ArgumentNullException("exchange"); this.userRepository = userRepository; this.productRepository = productRepository; this.exchange = exchange; } public ProductDetailsViewModel GetProductDetails( string userId, string productId) { if (userId == null) throw new ArgumentNullException("userId"); if (productId == null) throw new ArgumentNullException("productId"); var user = this.userRepository.Get(userId); if (user == null) throw new InvalidOperationException("User was null."); if (user.PreferredCurrency == null) throw new InvalidOperationException("Preferred currency was null."); var targetCurrency = user.PreferredCurrency; var product = this.productRepository.Get(productId); if (product == null) throw new InvalidOperationException("Product was null."); if (product.Name == null) throw new InvalidOperationException("Product name was null."); if (product.UnitPrice == null) throw new InvalidOperationException("Unit price was null."); var convertedPrice = this.exchange.Convert(product.UnitPrice, targetCurrency); if (convertedPrice == null) throw new InvalidOperationException("Converted price was null."); return new ProductDetailsViewModel { Name = product.Name, Price = convertedPrice.ToString() }; } }
This is clearly even more horrendous than the previous defensive programming example. Now you're not only defending yourself, but also standing up for your collaborators. Noble, but unreadable.
Still, when I write wildlife code, this is basically what I do, although I'd tend to refactor my code so that first I'd collect and check all the input, and then I'd pass on that input to another class that performs the logic.
Protected enclosures #
What if your code is a zoo animal? What if your code is running in an environment, where all the collaborators are other classes also part of the same code base, written by you and your colleagues? If you can trust each other to follow some consistent rules, you could skip much of the defensive coding.
In most of the teams I work with, I always suggest that we adopt the robustness principle. In practice, that means that null is never an acceptable return value. If a class member returns null, the bug is in that class, not in the consumer. Following that team rule, the code example can be reduced to this:
public class ProductDetailsController { private readonly IUserRepository userRepository; private readonly IProductRepository productRepository; private readonly ICurrencyExchange exchange; public ProductDetailsController( IUserRepository userRepository, IProductRepository productRepository, ICurrencyExchange exchange) { if (userRepository == null) throw new ArgumentNullException("userRepository"); if (productRepository == null) throw new ArgumentNullException("productRepository"); if (exchange == null) throw new ArgumentNullException("exchange"); this.userRepository = userRepository; this.productRepository = productRepository; this.exchange = exchange; } public ProductDetailsViewModel GetProductDetails( string userId, string productId) { if (userId == null) throw new ArgumentNullException("userId"); if (productId == null) throw new ArgumentNullException("productId"); var user = this.userRepository.Get(userId); if (user.PreferredCurrency == null) throw new InvalidOperationException("Preferred currency was null."); var targetCurrency = user.PreferredCurrency; var product = this.productRepository.Get(productId); if (product.Name == null) throw new InvalidOperationException("Product name was null."); if (product.UnitPrice == null) throw new InvalidOperationException("Unit price was null."); var convertedPrice = this.exchange.Convert(product.UnitPrice, targetCurrency); return new ProductDetailsViewModel { Name = product.Name, Price = convertedPrice.ToString() }; } }
That's better, but not quite good enough yet... but wait: readable properties are return values too, so you shouldn't have to check for those either:
public class ProductDetailsController { private readonly IUserRepository userRepository; private readonly IProductRepository productRepository; private readonly ICurrencyExchange exchange; public ProductDetailsController( IUserRepository userRepository, IProductRepository productRepository, ICurrencyExchange exchange) { if (userRepository == null) throw new ArgumentNullException("userRepository"); if (productRepository == null) throw new ArgumentNullException("productRepository"); if (exchange == null) throw new ArgumentNullException("exchange"); this.userRepository = userRepository; this.productRepository = productRepository; this.exchange = exchange; } public ProductDetailsViewModel GetProductDetails( string userId, string productId) { if (userId == null) throw new ArgumentNullException("userId"); if (productId == null) throw new ArgumentNullException("productId"); var user = this.userRepository.Get(userId); var targetCurrency = user.PreferredCurrency; var product = this.productRepository.Get(productId); var convertedPrice = this.exchange.Convert(product.UnitPrice, targetCurrency); return new ProductDetailsViewModel { Name = product.Name, Price = convertedPrice.ToString() }; } }
This is pretty good, because now you're almost back where you started. The only difference is the Guard Clauses at the beginning of each member. When following the robustness principle, most members tend to look like that. After a while, you get used to that, and you don't really see them any longer. I consider them a sort of preamble for each member. As a code reader, you can skip the Guard Clauses and concentrate on the program flow, without any interrupting defense checks interfering with the readability of the code.
Encapsulation #
If it's an error to return null, then how does the User class, or the Product class, adhere to the robustness principle? In exactly the same way:
public class User { private string preferredCurrency; public User() { this.preferredCurrency = "DKK"; } public string PreferredCurrency { get { return this.preferredCurrency; } set { if (value == null) throw new ArgumentNullException("value"); this.preferredCurrency = value; } } }
Notice how the User class protects its invariants. The PreferredCurrency property can never be null. This principle is also known by another name: it's called encapsulation.
Summary #
As always, it helps to understand the forces working on your code base. You have to be much more defensive if your code is running in the wild, than if it's running in a protected environment. Still, I generally think that it's a fallacy if you believe that you can get by with writing sloppy code; we should all be Ranger programmers.
Unstructured defensive coding hurts readability; it's just another excuse for writing Spaghetti Code. Conversely, structured defensive coding is encapsulation. I know what I prefer.
NDC 2013 session recordings
NDC 2013 session recordings are now available, including mine.
The NDC 2013 conference is over, and most (if not all) of the session recordings are now available. Specifically, both of the talks I gave were recorded and are now available for general viewing.
As a bonus, Jimmy Bogard gave a talk on Holistic testing with quite a bit of AutoFixture content.A heuristic for formatting code according to the AAA pattern
This article describes a rule of thumb for formatting unit tests.
The Arrange Act Assert (AAA) pattern is one of the most fundamental and important patterns for writing maintainable unit tests. It states that you should separate each test into three phases (Arrange, Act, and Assert).
Like most other code, unit tests are read more than they are written, so it's important to make the tests readable. This article presents one way to make it easy for a test reader easily to distinguish the three AAA phases of a test method.
The way of AAA #
The technique is simple:
- As long as there are less than three lines of code in a test, they appear without any special formatting or white space.
- When a test contains more than three lines of code, you separate the three phases with a blank line.
- When a single phase contains so many lines of code that you'll need to divide it into subsections to make it readable, you should explicitly mark the beginning of each phase with a code comment.
Motivating example #
Many programmers use the AAA pattern by explicitly demarking each phase with a code comment:
[Fact] public void UseBasketPipelineOnExpensiveBasket() { // Arrange var basket = new Basket( new BasketItem("Chocolate", 50, 3), new BasketItem("Gruyère", 45.5m, 1), new BasketItem("Barolo", 250, 2)); CompositePipe<Basket> pipeline = new BasketPipeline(); // Act var actual = pipeline.Pipe(basket); // Assert var expected = new Basket( new BasketItem("Chocolate", 50, 3), new BasketItem("Gruyère", 45.5m, 1), new BasketItem("Barolo", 250, 2), new Discount(34.775m), new Vat(165.18125m), new BasketTotal(825.90625m)); Assert.Equal(expected, actual); }
Notice the use of code comments to indicate the beginning of each of the three phases.
Given an example like the above, this seems like a benign approach, but mandatory use of code comments starts to fall apart when tests are very simple.
Consider this Structural Inspection test:
[Fact] public void SutIsBasketElement() { // Arrange // Act? var sut = new Vat(); // Assert Assert.IsAssignableFrom<IBasketElement>(sut); }
Notice the question mark after the // Act comment. It seems that the writer of the test was unsure if the act of creating an instance of the System Under Test (SUT) constitutes the Act phase.
You could just as well argue that creating the SUT is part of the Arrange phase:
[Fact] public void SutIsBasketElement() { // Arrange var sut = new Vat(); // Act // Assert Assert.IsAssignableFrom<IBasketElement>(sut); }
However, now the Act phase is empty. Clearly, using code comments to split two lines of code into three phases is not helpful to the reader.
Three lines of code and less #
Here's a simpler alternative:
[Fact] public void SutIsBasketElement() { var sut = new Vat(); Assert.IsAssignableFrom<IBasketElement>(sut); }
When there's only two lines of code, the test is so simple that you don't need help from code comments. If you wanted, you could even reduce that test to a single line of code, by inlining the sut variable:
[Fact] public void SutIsBasketElement() { Assert.IsAssignableFrom<IBasketElement>(new Vat()); }
Such a test is either a degenerate case of AAA where one or more phase is empty, or else it doesn't really fit into the AAA pattern at all. In these cases, code comments are only in the way, so it's better to omit them.
Even if you have a test that you can properly divide into the three distinct AAA phases, you don't need comments or formatting if it's only three lines of code:
[Theory] [InlineData("", "", 1, 1, 1, 1, true)] [InlineData("foo", "", 1, 1, 1, 1, false)] [InlineData("", "bar", 1, 1, 1, 1, false)] [InlineData("foo", "foo", 1, 1, 1, 1, true)] [InlineData("foo", "foo", 2, 1, 1, 1, false)] [InlineData("foo", "foo", 2, 2, 1, 1, true)] [InlineData("foo", "foo", 2, 2, 2, 1, false)] [InlineData("foo", "foo", 2, 2, 2, 2, true)] public void EqualsReturnsCorrectResult( string sutName, string otherName, int sutUnitPrice, int otherUnitPrice, int sutQuantity, int otherQuantity, bool expected) { var sut = new BasketItem(sutName, sutUnitPrice, sutQuantity); var actual = sut.Equals( new BasketItem(otherName, otherUnitPrice, otherQuantity)); Assert.Equal(expected, actual); }
Three lines of code, and three phases of AAA; I think it's obvious what goes where - even if this single test method captures eight different test cases.
Simple tests with more than three lines of code #
When you have more than three lines of code, you'll need to help the reader identify what goes where. As long as you can keep it simple, I think that you accomplish this best with simple whitespace:
[Fact] public void UseBasketPipelineOnExpensiveBasket() { var basket = new Basket( new BasketItem("Chocolate", 50, 3), new BasketItem("Gruyère", 45.5m, 1), new BasketItem("Barolo", 250, 2)); CompositePipe<Basket> pipeline = new BasketPipeline(); var actual = pipeline.Pipe(basket); var expected = new Basket( new BasketItem("Chocolate", 50, 3), new BasketItem("Gruyère", 45.5m, 1), new BasketItem("Barolo", 250, 2), new Discount(34.775m), new Vat(165.18125m), new BasketTotal(825.90625m)); Assert.Equal(expected, actual); }
This is the same test as in the motivating example, only with the comments removed. The use of whitespace makes it easy for you to identify three phases in the method, so comments are redundant.
As long as you can express each phase without using whitespace within each phase, you can omit the comments. The only whitespace in the test marks the boundaries between each phase.
Complex tests requiring more whitespace #
If your tests grow in complexity, you may need to divide the code into various sub-phases in order to keep it readable. When this happens, you'll have to resort to using code comments to demark the phases, because use of only whitespace would be ambiguous:
[Fact] public void PipeReturnsCorrectResult() { // Arrange var r = new MockRepository(MockBehavior.Default) { DefaultValue = DefaultValue.Mock }; var v1Stub = r.Create<IBasketVisitor>(); var v2Stub = r.Create<IBasketVisitor>(); var v3Stub = r.Create<IBasketVisitor>(); var e1Stub = r.Create<IBasketElement>(); var e2Stub = r.Create<IBasketElement>(); e1Stub.Setup(e => e.Accept(v1Stub.Object)).Returns(v2Stub.Object); e2Stub.Setup(e => e.Accept(v2Stub.Object)).Returns(v3Stub.Object); var newElements = new[] { r.Create<IBasketElement>().Object, r.Create<IBasketElement>().Object, r.Create<IBasketElement>().Object, }; v3Stub .Setup(v => v.GetEnumerator()) .Returns(newElements.AsEnumerable().GetEnumerator()); var sut = new BasketVisitorPipe(v1Stub.Object); // Act var basket = new Basket(e1Stub.Object, e2Stub.Object); Basket actual = sut.Pipe(basket); // Assert Assert.True(basket.Concat(newElements).SequenceEqual(actual)); }
In this example, the Arrange phase is so complicated that I've had to divide it into various sections in order to make it just a bit more readable. Since I've had to use whitespace to indicate the various sections, I need another mechanism to indicate the three AAA phases. Code comments is an easy way to do this.
As Tim Ottinger described back in 2006, code comments are apologies for not making the code clear enough. A code comment is a code smell, because it means that the code itself isn't sufficiently self-documenting. This is also true in this case.
Whenever I need to add code comments to indicate the three AAA phases, an alarm goes off in my head. Something is wrong; the test is too complex. It would be better if I could refactor either the test or the SUT to become simpler.
When TDD’ing, I tend to accept the occasional complicated unit test method, but if I seem to be writing too many complicated unit tests, it's time to stop and think.
Summary #
In Growing Object-Oriented Software, Guided by Tests, one of the most consistent pieces of advice is that you should listen to your tests. If your tests are too hard to write; if your tests are too complicated, it's time to consider alternatives.
How do you know when a test has become too complicated? If you need to added code comments to it, it probably is.
This article first appeared in the The Developer No 2/2013. It's reprinted here with kind permission.
Comments
Currently reading your last book Code That Fits in Your Head (Lucky draw, thank you for writing!!) and find this section. I used several techniques to refactor those unbalanced structure. A recent one is to leverage local function to gather noise, top structure acting like TOC when bottom one provides insight for those interested. More or less like template method but keeping stuff internally. I find it particularly useful when such noise is one-shot. Extracting it into private method or fixture does not smell good to me.
[Theory]
[InlineData(194, 107, 37, "#C26B25")]
[InlineData(66, 138, 245, "#428AF5")]
public void Mapper(int r, int g, int b, string hex)
{
var (sut, source, expected) = Arrange();
var res = sut.Convert(source);
Assert.Equal(expected, source);
(Sut sut, Color1 color, Color2 color) Arrange()
{
// Do complex or verbose stuff eg:
// Create C1 from hex
// Create c2 from {r,g,b}
// Create SUT
return (s, c1, c2);
}
}
I am used to apply the same pattern to process impure method: I provide a local pure function that I leverage above using instance filed, I/O, ... It is a good first step instead of right away create a private helper or equivalent. Then , if it apperas it can be reused, you only have to promote the local function.
Romain, thank you for writing. Local functions can indeed be useful (also) in unit tests. The main use, as you imply, is as a cheaper alternative to the Template Method pattern. The main benefit, compared to private helper methods, is that you limit the scope of the method.
On the other hand, a local function still involves more ceremony than a lambda expression, which is often a better alternative.
With regards to your particular example, do you gain anything from moving the Arrange phase down?
Indeed, the three AAA phases may be more apparent. You're also following the principle of leading with the big overview, and then leaving the implementation details for later. I can never remember who originally described this principle for organising code, but I find it useful. (It's one the main challenges with F#, because of its single-pass compiler. That language feature, however, provides some other great benefits.)
Still, isn't this mostly symptomatic relief? I wouldn't mind doing something like this if I could think of nothing better, but I'd still view the need for a complex Arrange phase as being a code smell. Not a test smell, but as feedback that the System Under Test is too complicated.
Where to put unit tests
This article provides arguments for (and against) putting unit tests in libraries different from the production code.
One of my readers ask me "whether unit tests should be done in separate assemblies or if they should be done in [...] the production assemblies?" As he puts it, he "always took for granted that the test should go into separate assemblies," but is this really true, and if it is: what are the arguments?
Despite the fundamental nature of this question, I haven't seen much explicit treatment of it, and to answer it, I had to pause and think. The key to the answer, I think, is to first understand why you write automated tests at all. (This way of thinking about questions and answers is closely related to the (Lean) technique of 5 whys.)
As always, the short answer is that it depends, but that's not very helpful, so here are some common reasons.
Regression testing #
In my experience, most people focus on the quality control aspect of automated testing. If your only purpose of having automated tests is to have a good regression test suite, then it seems that it doesn't really matter where the tests go.
Still, even if that's your only reason for unit testing, I think putting the unit tests in a separate library is the best choice:
- It gives you a clearer separation of concerns. If you put unit tests in your production library, it will blur the distinction between production code and test code. How do you know which code to test? How do you know what not to test? There are different ways to address these concerns (namespaces, TDD), but I think the simplest way to deal with such issues is to put the tests in a separate library. (This argument reminds me a little of Occam's razor.)
- Putting unit tests in your production code will make your compiled libraries bigger. It will take (slightly) more time to load the libraries into memory, and they will take up more memory. This probably doesn't matter at all on a big server, but may be important if your production code runs on a (small) mobile device. Once again, it depends.
- The more code you put in your production software, the larger the potential attack surface becomes. Have you performed a security analysis of your unit tests? It's much easier to put the tests in a separate library that you never deploy to production, because it means that you don't have to waste valuable time and resources doing a security analysis of your test code.
In short, if you put unit tests in the same library as your production code, all that unit test must adhere to the same standards as your production code. Obviously, if you have no standards for your production code, this doesn't apply, but then you probably have bigger problems.
API design feedback #
While I find regression testing useful in itself, I find Test-Driven Development (TDD) particularly valuable because it provides feedback about the API I'm building. In the spirit of GOOS, if the test is difficult to write, it's probably because the API is difficult to use. You'll only get this feedback if you test against the public API of your code; the unit test is the first client of your API.
However, if your unit tests reside in the same library as your production code, you can easily invoke internal classes and members from your unit tests. You simply lose the opportunity to get valuable feedback about the usability of your code. (Note that this argument also applies to the use of the [InternalsVisibleTo] attribute, which means that you should never use it.)
For me, this reason alone is enough that I always prefer putting unit tests in separate libraries.
Shipping production code with tests #
Although I think that there are strong arguments against putting unit tests in production code, there may also be reasons in favor. As one answer on Stack Overflow describes, shipping your production code with a test suite can be valuable as a self-diagnostics tool. This might be particularly valuable if you deploy your production code to heterogeneous environments, and you're unable to predict and test the configuration of all environments before you ship your code.
Summary #
In the end, the answer depends on your context. If you understand why you (want to) have unit tests, you'll be able to answer the initial question: should unit tests go in a separate library, or can they go in the same library as the production code? In mainstream scenarios I will strongly recommend putting tests in a separate library, but you may have special circumstances where it makes sense to put the tests together with the production code. As long as you understand the pros and cons, you can make your own informed decision.
Comments
Another big issue with having tests in your production code is that you will drag along depencencies to test libraries. You mention this in the second issue above but I think it would be a good idea to state it more explicitly.
Could you share your opinion on bundling test projects with their target projects in source control repositories? I use Git, but I would imagine this is applicable in many source control implementations.
I currently keep my tests in their own projects, as you generally recommend here, and also track them in their own Git repository, separately from the tested project. However, I'm finding that when I create a new branch to add a new feature in the project, I create the same branch in the test project. This is critical especially in situations where the new behavior necessarily causes existing tests to fail. If I forget to create a new branch in the test project to match the new branch in the project under test, it can sometimes lead to annoying clean-up work that was preventable.
I am beginning to question why I'm not combining the test project and the tested project in the same Git repository, so that when I branch out on a new idea, I only need to do it once, and my tests are forever in sync with my tested code. I haven't come across a scenario where that would cause problems - can you think of any compelling reason not to keep the projects in the same source control repository?
Jeff, thank you for writing.
If I were to exaggerate a bit, I would claim that I've used Test-Driven Development (TDD) longer than I've used source control systems, so it has never occurred to me to keep tests in a separate repository. It sounds really... inconvenient, but I've never tried it, so I don't know if it's a good or bad idea. Yet, in all that time, I've never had any problems keeping tests and production code in the same version control repository.
With TDD, the tests are such an integral part of the code base that I wouldn't like to experiment with keeping them in a different repository. Additionally, when you use a test suite as a regression test suite, it's important that you version tests and production code together. This also means tagging them together.
If you take a look at the various code bases I maintain on GitHub, you will also see that all of them include unit tests as part of each repository.
REST lesson learned: Consider a self link on all resources
Add a self-link on RESTful resource.
This suggestion is part of my REST lessons learned series of blog posts. Contrary to previous posts, this advice doesn't originate from a lesson learned the hard way, but is more of a gentle suggestion.
One of the many advantages of a well-designed REST API is that it's 'web-scale'. The reason it's 'web-scale' is because it can leverage HTTP caching.
HTTP caching is based on URLs. If two URLs are different, they represent different resources, and can't be cached as one. However, conceivably, a client could arrive at the same resource via a number of different URLs:
- If a client follows redirect, it may not arrive at the URL it originally requested.
- If a client builds URLs from templates, it may order query string parameters in various ways.
Consider, as courtesy, adding a self-link to all resources. Adding a self link is as easy as this:
<product xmlns="http://fnaah.ploeh.dk/productcatalog/2013/05"
xmlns:atom="http://www.w3.org/2005/Atom">
<atom:link href="http://catalog.api.ploeh.dk/products/1337"
rel="self" />
<atom:link href="http://catalog.api.ploeh.dk"
rel="http://catalog.api.ploeh.dk/docs/rels/home" />
<atom:link href="http://catalog.api.ploeh.dk/categories/chocolate"
rel="http://catalog.api.ploeh.dk/docs/rels/category" />
<atom:link href="http://catalog.api.ploeh.dk/categories/gourmet"
rel="http://catalog.api.ploeh.dk/docs/rels/category" />
<name>Fine Criollo dark chocolate</name>
<price>50 DKK</price>
<weight>100 g</weight>
</product>
Notice the link with the rel value of "self"; from its href value you now know that the canonical URL of that product resource is http://catalog.api.ploeh.dk/products/1337.
Particularly when there are (technically) more than one URL that will serve the same content, do inform the client about the canonical URL. There's no way a client can tell which URL variation is the canonical URL. Only the API knows that.
Redirected clients #
A level 3 RESTful API can evolve over time. As I previously described, you may start with URLs like http://foo.ploeh.dk/orders/1234 only to realize that in a later version of the API, you'd rather want it to be http://foo.ploeh.dk/customers/1234/orders.
As the RESTful Web Services Cookbook explains, you should keep URLs cool. In practice, that means that if you change the URLs of your API, you should at least leave a 301 (Moved Permanently) at the old URL.
If you imagine a mature API, this may have happened more than once, which means that a client arriving at one of the original URLs may be redirected several times.
In your browser, you know that if redirects happen, the address bar will (normally) display the final URL at which you arrived. However, consider that REST clients are applications. It will be implementation-specific whether or not the client realizes that the value of the final address isn't the URL originally requested.
As a courtesy to clients, do consider informing them of the final address at which they arrived.
URL variations #
While the following scenario isn't applicable for level 3 RESTful APIs, level 1 and 2 services require clients to construct URLs from templates. As an example, such services may define a product search resource as /products/search?q={query}&p={page}. To search for chocolate (and see the third (zero-indexed) page) you could construct the URL as /products/search?q=chocolate&p=2. However, most platforms (e.g. the ASP.NET Web API) would handle /products/search?p=2&q=chocolate in exactly the same way. The more query parameters you allow, the more permutations are possible.
This is a well-known problem in search (and computer science); it's called Canonicalization. Only the API knows the canonical value of a given URL: do consider informing the client about this value.
Summary #
Adding a self-link to each resource isn't much of a burden for the service, but could provide advantages for both the service and its clients. In most cases I'd expect the ROI to be high, simply because the investment is low.
Comments
The primary reason I didn't mention the Content-Location header here was that, frankly, I wasn't aware of it. Now that I've read the specification, I'll have to take your word for it :) You may be right, in which case there's no particular reason to prefer a self-link over a Content-Location header.
When it comes following links, it's true that a protocol-near client would know the location after each redirect. The question is, if you're using an HTTP library, do you ever become aware of this?
Consider a client, using a hypothetical HTTP client library:
client.FollowRedirects = true;
var response = client.Get("/foo");
The response may actually be the result of various redirects, so that the final response is from "/bar", but unless the client is very careful, it may never notice this.
REST lesson learned: Consider a home link on all resources
Add home links on RESTful resources.
This suggestion is part of my REST lessons learned series of blog posts. Contrary to the previous posts, this advice doesn't originate from a lesson learned the hard way, but is more of a gentle suggestion.
When designing a level 3 RESTful API, I've found that it's often helpful to think about design issues in terms of: how would you design it if it was a web site? On web sites, we don't ask users to construct URLs and enter them into the browser's address bar. On web sites, users follow links (and fill out forms). Many well-designed web sites are actually HATEOAS services, so it makes sense to learn from them when designing RESTful APIs.
One almost universal principle for well-designed web sites is that they always have a 'home' link (usually in the top left corner). It makes sense to transfer this principle to RESTful APIs.
All the RESTful APIs that I've helped design so far have had a single 'home' resource, which acts as a starting point for all clients. This is the only published URL for the entire API. From that starting page, clients must follow (semantic) links in order to accomplish their goals.
As an example, here's a 'home' resource on a hypothetical product catalog API:
<home xmlns="http://fnaah.ploeh.dk/productcatalog/2013/05"
xmlns:atom="http://www.w3.org/2005/Atom">
<atom:link href="http://catalog.api.ploeh.dk/products/1234"
rel="http://catalog.api.ploeh.dk/docs/rels/products/discounted" />
<atom:link href="http://catalog.api.ploeh.dk/products/5678"
rel="http://catalog.api.ploeh.dk/docs/rels/products/discounted" />
<atom:link href="http://catalog.api.ploeh.dk/products/1337"
rel="http://catalog.api.ploeh.dk/docs/rels/products/discounted" />
<atom:link href="http://catalog.api.ploeh.dk/categories"
rel="http://catalog.api.ploeh.dk/docs/rels/product/categories" />
</home>
From this (rather sparse) 'home' resource, you can view each discounted product by following the discounted link, or you can browse the catalog by following the categories link.
If you follow one of the discounted links, you get a new resource:
<product xmlns="http://fnaah.ploeh.dk/productcatalog/2013/05"
xmlns:atom="http://www.w3.org/2005/Atom">
<atom:link href="http://catalog.api.ploeh.dk"
rel="http://catalog.api.ploeh.dk/docs/rels/home" />
<atom:link href="http://catalog.api.ploeh.dk/categories/chocolate"
rel="http://catalog.api.ploeh.dk/docs/rels/category" />
<atom:link href="http://catalog.api.ploeh.dk/categories/gourmet"
rel="http://catalog.api.ploeh.dk/docs/rels/category" />
<name>Fine Criollo dark chocolate</name>
<price>50 DKK</price>
<weight>100 g</weight>
</product>
Notice that in addition to the two category links, the resource representation also contains a home link, enabling the client to go back to the 'home' resource.
Having a home link on all resources is another courtesy to the client, just like avoiding 204 responses - in fact, if you can't think of anything else to return instead of 204 (No Content), at the very least, you could return a home link.
In the above examples, I didn't obfuscate the URLs, but I would do that for a real REST API. The reason I didn't obfuscate the URLs here is to make the example easier to understand.
REST lesson learned: Avoid hackable URLs
Avoid hackable URLs if you are building a REST API.
This is a lesson about REST API design that I learned while building non-trivial REST APIs. If you provide a full-on level 3 REST API, consider avoiding hackable URLs.
Hackable URLs #
A hackable URL is a URL where there's a clear pattern or template for constructing the URL. As an example, if I present to you the URL http://foo.ploeh.dk/products/1234, it's easy to guess that this is a resource representing a product with the SKU of 1234. If you know the SKU of another product, it's easy to 'hack' the URL to produce e.g. http://foo.ploeh.dk/products/5678.
That's a really nice feature of your API if you are doing a level 1 or 2 API, but for a HATEOAS API, this defies the purpose.
The great divide #
Please notice that the shift from level 2 to level 3 RESTful APIs mark a fundamental shift in the way you should approach URL design.
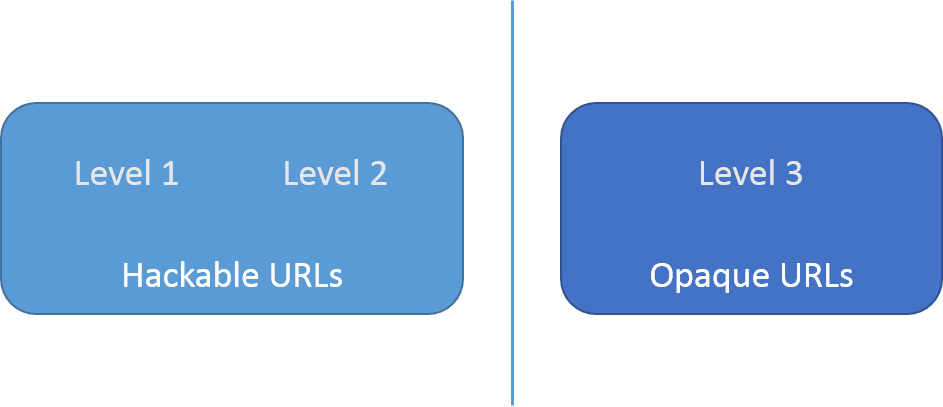
Hackable URLs are great for level 1 and 2 APIs because the way you (as a client) are told to construct URLs is by assembling them from templates. As an example, the Windows Azure REST APIs explicitly instruct you to construct the URL in a particular way: the URL to get BLOB container properties is https://myaccount.blob.core.windows.net/mycontainer?restype=container, where you should replace myaccount with your account name, and mycontainer with your container name. While code aesthetics are subjective, it's not even a particularly clean URL, but it's easy enough to produce. The URL template is part of the contract, which puts the Windows Azure API solidly at level 2 of the Richardson Maturity Model. If I were designing a level 1 or 2 API, I'd make sure to make URLs hackable, too.
However, if you're building a level 3 API, hypermedia is king. Clients are expected to follow links. The addresses of resources are not published as having a particular template; instead, clients must follow semantic links in order to arrive at the desired resource(s). When hypermedia is the engine of application state, it's no good if the client can short-circuit the application flow by 'hacking' URLs. It may leave the application in an inconsistent state if it tries to do that.
Hackable URLs are great for level 1 and 2 APIs, but counter-productive for level 3 APIs.
Evolving URLs #
One of the main attractions of building a level 3 RESTful API is that it's easier to evolve. Exactly because URL templates are not part of the contract, you can decide to change the URL structure when evolving your API.
Imagine that the first version of your API has an (internal) URL template like /orders/{customerId}, so that the example URL http://foo.ploeh.dk/orders/1234 is the address of the order history for customer 1234. However, in version 2 of your API, you realize that this way of thinking is still too RPC-like, and you'd rather prefer /customers/{customerId}/orders, e.g. http://foo.ploeh.dk/customers/1234/orders.
With a level 3 RESTful API, you can change your internal URL templates, and as long as you keep providing links, clients following links will not notice the difference. However, if clients are 'hacking' your URLs, their applications may stop working if you change URL templates.
Keep clients safe #
In the end, HATEOAS is about encapsulation: make it easy for the client to do the right thing, and make it hard for the client to do the wrong thing. Following links will make clients more robust, because they will be able to handle changes in the API. Making it easy for clients to follow links is one side of designing a good API, but the other side is important too: make it difficult for clients to not follow links: make it difficult for clients to 'hack' URLs.
The services I've helped design so far are level 3 APIs, but they still used hackable URLs. One reason for that was that this is the default in the implementation platform we used (ASP.NET Web API); another reason was that I thought it would be easier for me and the rest of the development team if the URLs were human-readable. Today, I think this decision was a mistake.
What's the harm of supplying human-readable URLs for a level 3 RESTful API? After all, if a client only follows links, the values of the URLs shouldn't matter.
Indeed, if the client only follows links. However, clients are created by human developers, and humans often take the road of least resistance. While there are long-time benefits (robustness) from following links, it is more work in the short term. The API team and I repeatedly experienced that the developers consuming our APIs had 'hacked' our URLs; when we changed our URL templates, their clients broke and they complained. Even though we had tried to explicitly tell them that they must follow links, they didn't. While we never documented our URL templates, they were simply too easy to guess from pure extrapolation.
Opaque URLs #
In the future, I plan to make URLs opaque when building level 3 APIs. Instead of http://foo.ploeh.dk/customers/1234/orders, I'm going to make it http://foo.ploeh.dk/DC884298C70C41798ABE9052DC69CAEE, and instead of http://foo.ploeh.dk/products/2345, I'm going to make it http://foo.ploeh.dk/598CB0CAC30646E1BB768596BFE91F2C, and so on.
Obviously, that means that my API will have to maintain some sort of two-way lookup table that can map DC884298C70C41798ABE9052DC69CAEE to a request for customer 1234's orders, 598CB0CAC30646E1BB768596BFE91F2C to request for product 2345, but that's trivial to implement.
It puts a small burden on the server(s), but effectively stops client developers from shooting themselves in their feet.
Summary #
Hackable URLs are a good idea if you are building a web site, or a level 1 or 2 REST API, but unless you know that all client developers are enthusiastic RESTafarians, consider producing opaque URLs for level 3 REST APIs.
Comments
I understand the benefits of the idea that clients must follow links, I just can't see how it would work in reality. Say you are building a website to display products and you are consuming a rest API, how do you support deep linking to individual products? OK, you can either use the same URL as the underlying API or encode it in, but what are you expected to do if the API changes it's links? Redirect the user to your home page? What if you want to display information from 2 or more resources on the same webpage?
First of all, keep in mind that while it can be helpful to think about REST design principles in terms of "how would I design this if it was a web site", a REST API is not a web site.
You can do deep linking in your web site, but why would you want to do 'deep linking' for an API? These are two different concerns.
It's very common to create a web site where each page calls many individual services. This can be done either from the web server (e.g. from ASP.NET or similar), or from the browser as AJAX calls. This is commonly known as mash-up architecture, because the GUI is really just a mash-up of service data. Amazon.com works that way. You can still deep link to a web page; it's the web page's responsibility to figure out which services to call with what parameters.
That said, as described in the RESTful Web Services Cookbook, you should serve cool URLs, so if you ever decide to change your internal URI template, you should leave a 301 (Moved Permanently) behind at the old URL. This would enable a client that once bookmarked a resource to follow the redirect to the new address.
When you say "it's the web page's responsibility to figure out which services to call", that's what I'm getting at, how would the client do that?
I'm guessing one way would be to cache links followed and update them on 301s or "re-follow" on 404s. So, say you wanted a web page displaying "product/24", you might:
- GET the REST endpoint
- GET product catalogue URL from response
- GET product URL from response
- Cache the product URL against the website product URL
- Subsequent requests hit the cached URL
Then if the product URL changes, if the response is 301, you simply update the cache. If the response is 404 then you'd redo the above steps.
I'm just thinking this through, is the above a "standard" approach for creating rest clients?
That sounds like one way of doing it. I don't think there's a 'standard' way for creating RESTful clients.
The sketch you paint sounds like a lot of work, and it seems that it would be easier if the client could simply assemble appropriate URLs from templates. That would indicate level 1 and 2 REST APIs, which might be perfectly fine if the only purpose of building the service is to support a GUI. However, what you get in exchange for the extra effort it takes to consume a level 3 API, is better decoupling. It's always going to be a trade-off.
It's definitely going to be more work to build and consume a truly HATEOAS-based API, so you should only do it if it's going to provide a good return on investment. When would that be? One general scenario I can think of is when you're building a service, which is going to be consumed by multiple (unknown) clients. If you control the service, but not the clients, I'd say a level 3 API is very beneficial, because it enables you to evolve the API independently of the clients. Conversely, if the only purpose of building a service is to support a single client, it's probably going to be overkill.
The way I see it is that being HATEOAS compliant does not impose non-hackable URLs, but that URLs - even if they might look hackable (/1, /2...etc) - are not guaranteed to work, are not part of the contract and thus should not be relied uppon. In other words, a link is only guaranteed to work if you, the client, got it from a previous reponse, be it "hackable-looking" or not.
So I think opaque URLs are just a way to inforce that contract. But don't we always here that "a good REST client should be well behaved" ?
Reda, thank you for writing. You're right, and if we could rely on all clients to be well-behaved, there'd be no problems. However, in my experience, client developers often don't read the documentation particularly thoroughly. Instead, they look at the returned data and start inferring the URL scheme from examples. I already wrote about this in this post:
"The API team and I repeatedly experienced that the developers consuming our APIs had 'hacked' our URLs; when we changed our URL templates, their clients broke and they complained. Even though we had tried to explicitly tell them that they must follow links, they didn't."So, in this imperfect world, non-hackable URLs start to look attractive, because then the client developers have no choice but to follow the links.
I'd like to propose an alternate strategy to achieve the desired result while maintaining the ability to easily debug production issues at the client: only use the non-hackable urls for the "dev sandbox".
Another inducement to better client behvior might be to have the getting started documentation use existing libraries for the chosen hypermedia media type.
Finally, have the clients send a "developer [org] identifier". Find a way to probe clients for correctness. For instance, occasionally alter hrefs, but also support the "hackable" form.
With this data, be proactive about informing the user that "we're planning a release and your app will probably break because you're not following links as expected".
In the end, some people will still fail and be angry. With opaque urls, I would worry that users would have a hard time communicating production issues when looking at logs /fiddler / browser tools / etc.
Kijana, thank you for writing. You suggest various good ideas that I'll have to keep in mind. Not all of them are universally applicable, but then I also don't think that my suggestion should be applied indiscriminately.
Your first suggestion assumes that there is a dev sandbox; this may or may not be the case. The APIs with which I currently work have no dev sandboxes.
The idea about using existing client libraries for the chosen hypermedia type is only possible if such libraries exist. The APIs I currently design use vendor media types, so client libraries only exist if we develop them ourselves. However, one of the important goals of RESTful services is to ensure interoperability, so we can't assume that clients are going to run on .NET, or Java, or Ruby, or whatever. For vendor media types, I don't think this is a viable option.
Using a client identifier is an option, but in order to work well, there must be some way to correlate that identifier to a contact in the client's organisation. That's an option if you already have a mechanism in place where you only allow known clients to access your API. On the other hand, if you publish a truly scalable public API, you may not want to do that, as registration requirements tend to hurt adoption. The APIs I currently work with is a mix of both of those; some are publicly accessible, while others require a 'client key'.
These are all interesting ideas, but ultimately, I'm not sure I understand your concern. Let's first establish that 'users' are other programmers. Why would a URL like http://foo.ploeh.dk/DC884298C70C41798ABE9052DC69CAEE be harder to communicate than http://foo.ploeh.dk/customers/1234/orders? Isn't it copy and paste in both cases?
To be clear: I don't claim that obfuscated URLs don't make client developers' work more difficult; it does, compared to 'cheating' by hacking the URL schemes, instead of following links. Even for well-behaved client developers, another level of abstraction always makes things harder. On the other hand, this should also make clients more robust, so as always, it's a trade-off.
“The API team and I repeatedly experienced that the developers consuming our APIs had 'hacked' our URLs; when we changed our URL templates, their clients broke and they complained. Even though we had tried to explicitly tell them that they must follow links, they didn't.”
I recently worked on an API for an iOS app and we ran into the same problem. It didn't matter how often I said "these URLs are probably going to change, don't hard-code them into the app" we still ran into issues. This was an internal team, I can only imagine how much more difficult it would be with an external team.
Instead of hashing the URLs, we changed the server-side URL generation to HMAC the URL and append the signature onto the query string. Requests without a valid signature would return a 403 Forbidden response. The root of the domain is the only URL that doesn't require a signature, and it returns a json response with signed URLs for each of the "base" resources.
We enabled this on a staging server and since all dev was happening on it, all the hard-coded URLs stopped functioning and were quickly removed from the application. It forced both us and the iOS developers to think more about navigation between resources, since it was impossible to get from one resource to another without valid URLs included in the json responses. I think it was probably also nicer for debugging than hashed URLs would be.
Dan, thank you for sharing that great idea! That looks like a much better solution than my original suggestion of obscuring the URL, because the URL is still human-readable, and thus probably still easier to troubleshoot for developers.
Your suggestion also doesn't require a lookup table. My suggested solution would require a lookup table in order to understand what each obscured URL actually means, and if you're running on multiple servers, that lookup table would have to be kept consistent across all servers, which can be hard to do in itself (you can use a database, but then you'd have a single point of failure). Your solution doesn't need any of that; it only requires that the HMAC key is the same on all servers.
The only disadvantage that I can think of is that you may need to keep that HMAC key secret, particularly in internal projects, in order to prevent clients from (literally) hacking the URLs.
Still, it sounds like your solution has more advantages, so I'm going to try that approach next time. Thank you for sharing!
“The only disadvantage that I can think of is that you may need to keep that HMAC key secret, particularly in internal projects, in order to prevent clients from (literally) hacking the URLs.”
That was one concern of ours too. One approach we considered was including the git commit SHA as part of the HMAC secret so that every commit would invalidate existing URLs. We decided against it because we were doing Continous Delivery, so multiple times a day we were deploying to the server, and we didn't want the communication overhead of having to notify everyone on each commit. We wanted to be able to merge feature branches into master and just know the CI server was going to handle deployment; and that unless we got alerts from CI, Pingdom or New Relic, everything is working as expected. The last thing we wanted to do was babysit the build so we could tell everyone "ok, the new build has deployed to staging, URLs will break so restart any clients you are in the middle of testing". Also part of the reason we use REST (and json-api) was to decouple front and backend development, it seemed counterproductive to introduce coupling back into the process.
An internal team could still re-implement this whole mechanism and sign their own URLs. We could either generate random secrets every day or have a simple tool that we can use to change the secret at-will (probably both).
Even though it doesn't completely stop URL hard coding, another idea we had was to include an expiration timestamp in the query string and then HMAC the URL with the timestamp included. We would use the responses' Cache-Control max-age to calculate the time, which would allow the client to use any URLs from cached responses. If the client didn't implement proper cache invalidation the URLs would inexplicably break, thus having a nice side-effect of forcing the client to handle Cache-Control max-age properly.
Dan, there are lots of interesting ideas there. What I assumed from your first comment is that you'd calculate the HMAC using asymmetric encryption, which would mean that unless clients have the server's encryption key, they wouldn't be able to recalculate the HMAC, and that would effectively prevent them from attempting to 'guess' URLs instead of following links.
If an external client has the server's encryption key, you have a different sort of problem.
However, for internal clients, developers may actually be able to find the key in your source control repository, build server, or wherever else you keep it (depending on the size of your organisation). You can solve this with security measures, like ACL-based security on the crypto key itself. It not hard, but it's something you may explicitly have to do.
When it comes to tying the URL to cache invalidation, that makes me a bit uneasy. While RESTful clients should follow links, they are allowed to bookmark links. It's a fundamental tenet of proper web design (not only REST) that cool URIs don't change. A client should be allowed to keep a particular URL around forever, and a service following Postel's law should keep honouring requests for that URL. As the RESTful Web Services Cookbook explains, if you move the resource, you should at least return a 301 (Moved Permanently) "or, in rare cases," issue a 410 (Gone) response.
As Dan said, you can use an HMAC to protect certain parameters in a URL from tampering. I actually formalized this approach in a .NET library I call Clavis, and which I first discussed in detail here.
Clavis just provides a simple framework for declaring a resources parameter interface. Given that interface, Clavis provides a way to generate URLs when given a valid set of parameters, and also provides a way to safely parse values given a constructed URL. Arbitrary types can be specified as resource parameters, and there's very little boilerplate to convert to/from strings.
Parameters are protected from tampering by default, but you can declare that some are unprotected, meaning the client can change them without triggering a server validation error. You want this in some cases, for instance to support GET forms, like a search.
Late to the party, but I wonder how you will create a hypermedia form that generates http://foo.ploeh.dk/598CB0CAC30646E1BB768596BFE91F2C rather than http://foo.ploeh.dk/products/2345.
In the case of hyperlinks, I fully agree: linking to a product should not require an specifically structured identifier. However, hypermedia is more than links alone: what if the client wants to navigate to product with a given tracking number, or a list of people with a given first name?
“Hackable URIs” are not a necessity for REST, but they are a potential/likely consequence of hypermedia forms. Such forms can be described with less expressive power if only simple string replacements are required instead of more complex transformations.
Ruben, thank you for writing. This is a commonly occuring requirement, particularly when searching for particular resources, and I usually solve it with URI templates, as outlined in the RESTful Web Services Cookbook. Essentially, it involves providing URI templates like http://foo.ploeh.dk/0D89C19343DA4ED985A492DA1A8CDC53/{term}, and making sure that each template is served like a link, with a particular relationship type. For example:
<home xmlns="http://fnaah.ploeh.dk/productcatalog/2013/05"> <link-template href="http://foo.ploeh.dk/0D89C19343DA4ED985A492DA1A8CDC53/{term}" rel="http://catalog.api.ploeh.dk/docs/rels/product/search" /> </home>
It isn't perfect, but the best I've been able to come up with, and it works fairly well in practice.
Sure, URI templates are a means for creating hypermedia controls. But the point is that what they generate are hackable URIs.
You still have a (semi-)hackable URI with http://foo.ploeh.dk/0D89C19343DA4ED985A492DA1A8CDC53/{term}. Even though the /0D89C19343DA4ED985A492DA1A8CDC53/ part is non-manipulable, terms can still be changed at the end. This shows that hackable URIs cannot entirely be avoided if we want to keep hypermedia controls simple. What else are hackable URIs but underspecified, out-of-band hypermedia controls?
An in-band IRI template makes the message follow the REST style by putting the control inside of the message, but it results in a hackable IRI. So, apparently, an HTTP REST API without hackable URIs is hard when there's more than just links.
Ruben, it's not that you can't avoid hackable URLs. URI templates are an optimisation that you can opt to apply, but you don't have to use them. As with so many other architecture decisions, it's a trade-off.
When considering RESTful API design, it often helps to ask yourself: how would a web site running in a browser work? You don't have to copy web site mechanics one-to-one (for one, browsers utilise only GET and POST), but you can often get inspiration.
A feature like search is, in my experience, one of the clearest cases for URI templates, so let's consider other designs. How does search work on a web site? It works by asking the user to type the search term into a form, and then submitting this form to the server.
You can do the same with a RESTful design. When a client wishes to search, it'll have to perform an HTTP POST request with a well-formed request body containing the search term(s):
POST /108B618F06644379879B9F2FEA1CAE92 HTTP/1.1
Content-Type: application/json
Accept: application/json
{ "term": "chocolate" }
The response can either contain the search hits, or a link to a resource containing the hits.
Both options have potential drawbacks. If you return the search results in the response to the POST request, the client immediately receives the results, but you've lost the ability to cache them.
HTTP/1.1 200 OK
Content-Type: application/json
{
"term": "chocolate",
"results": [{
"name": "Valrhona",
"link": {
"href": "http://example.com/B69AD9193F6E472AB75D8EBD97331E22",
"rel": "product"
}
}, {
"name": "Friis-Holm",
"link": {
"href": "http://example.com/3C4BEC72BFB54E1B8FADB16CCB3E7A67",
"rel": "product"
}
}]
}
On the other hand, if the POST response only replies with a link to the search result, the search results themselves are cacheable, but now the client has to perform an extra request.
HTTP/1.1 303 See Other Location: http://example.com/0D25692DE79B4AF9A73F128554A9119E
In both cases, though, you'll need to document the valid representations that a client can POST to the search resource, which means that you need to consider backwards compatibility if you want to change things, and so on. In other words, you can 'protect' the URL schema of the search resource, but not the payload schema.
If you're already exposing an API over HTTPS, caching is of marginal relevance anyway, so you may decide to use the first POST option outlined above. Sometimes, however, performance is more important than transport security. As an example, I once wrote (for a client) a publicly available music catalogue API. This API isn't protected, because the data isn't secret, and it has to be fast. Resources are cached for 6 hours, so if you're searching for something popular (say, Rihanna), odds are that you're going to get a response from an intermediary cache. URI templates work well in this scenario, but it's a deliberate performance optimisation.
One can always avoid hackable URLs with trickery, but would you say that leads to a cleaner solution? I agree that search is “one of the clearest cases for URI templates”, so why bother putting in an unneeded POST request just to avoid hackable URIs? I fail to see why this would be a better REST design, given that you loose the beneficial properties of the uniform interface constraints by overloading the POST method for what is essentially a read-only operation. The trade-off here is entirely non-technical: you trade the performance of the interface for the aesthetics of its URLs.
Here's how a website would do it: it would have an HTML form for a GET request, which would naturally lead to a hackable URL. Because that's how HTML forms work: like URI templates, they result in hackable URLs. It's unavoidable. Hackable URLs are a direct consequence of common hypermedia controls, which are a necessity to realize the hypermedia constraint. You can swim against the current and make more difficult hypermedia controls, but to whose benefit? It's much easier to just accept that hackability is a side-effect of HTML forms and URI templates.
Therefore, your thesis that one should avoid hackable URIs breaks down at this point. APIs with non-hackable URIs are inherently incompatible with URI templates—and why throw away this excellent means of affordance? After all, the most straightforward way to realize search functionality is with an in-band URI template. And URI templates lead to hackable URIs. Hence, hackable URIs occur in REST APIs. You can work around this, but it's quite artificial to do so. In essence, you're using the POST request to obfuscate the URI; having such a translation step for purely aesthetic motives complicates the API and sacrifices caching for no good reason. Hackable URIs are definitely the lesser evil of the two.
So, would you avoid hackable URIs at any cost? Or can you agree that they indeed have a place if we like to keep using the hypermedia controls that have been standardized?
Ruben, my intent with this post was to highlight a problem I've experienced when publishing REST APIs, and that I've attempted to explain in the section titled Keep clients safe. I wish that problem didn't exist, but in my experience, it does. It most likely depends on a lot of factors, so if you don't have that problem, you can disregard the entire article.
The issue isn't that I want to make URLs opaque. The real issue at stake is that I want clients to follow links, because it gives me options to evolve the API. Consider the example in this article. If a client wants to see a user's messages, it should follow links. If, however, a client developer writes the code in such a way that it'll explicitly look for a root > users > user details > user messages route, little is gained.
A client looking for user messages should be implemented with a prioritised rule set:
- Look for a
user-messageslink. If found, follow it. Done. - Look for a
user-detailslink. If found, follow it, and apply this rule list again from the top. - Look for a
userlink. If found, follow it, and apply this rule list again from the top.
If client developers can guess, and thereby 'hack', my service's URLs, I can't restructure my API. It's not really a question of aesthetics; it's not that I want to be able to rename URLs. The real issue is that sometimes, when developing software, you discover that you've modelled a concept the wrong way. Perhaps you've conflated two concepts that ought to be treated as separate resources. Perhaps you've create a false distinction, but now you realise that two concepts that you thought were separate, is really the same. Therefore, sometimes you want to split one type of resource into two, or more, or you want to combine two or more different types of resources into one.
If clients follow links, you have a chance to pull off such radical restructuring. If clients have hard-coded URLs, you're out of luck.
Thank you for an interesting post and discussion. I am no expert wrt REST but I have a comment (posed as a question) and a question.
If client developers abuse transparent URLs (that are provided in a level 3 api) isn't the fact that the client stops working when the URLs change their problem? And sure, they can guess other URLs, just like in the browser we can guess other pages. Doesn't mean the application stage should let them access those pages etc.
And now the question. Are there any libraries or tools that allow REST client applications to easily get a list of the links and "follow the links" (i.e. do an API call)? I can see a client having slots for possible / expected links, filling those that exist, and calling them. Is there any library to help this?
Ashley, thank you for writing. In the end, as you point out, it's the client's problem if they don't adhere to the contract. In some scenarios, that's the end of the story. In other scenarios (e.g. the ones I often find myself in), there's a major client that has a lot of clout, and if those developers find that you've moved their cheese, their default reaction is that it's your fault - not theirs. In such cases, it can be political to ensure that there's no doubt about the contract.
I'm not aware of any libraries apart from HttpClient. It doesn't do any of the things you ask about, because it's too low-level, but at least it enables you to build a sensible client API on top of it.

Comments
This is so awesome!
One note: For adding a new file, I simply used Ctrl+N (i.e. File>New) to create a file in the Miscellaneous Files meta solution folder. I saved the file in the physical project folder, then in Solution Explorer I dragged it's icon from the Miscellaneous Files folder onto the F# Project node. Voila! New code file. Not as easy as it should be, but easier than unloading the project to edit the fsproj file.
Mike, that's a great tip! Thank you.
Another option is to create the file in the file system (with Windows Explorer, or your preferred shell), and then add the existing file to the project.