ploeh blog danish software design
Functor compositions
A functor nested within another functor forms a functor. With examples in C# and another language.
This article is part of a series of articles about functor relationships. In this one you'll learn about a universal composition of functors. In short, if you have one functor nested within another functor, then this composition itself gives rise to a functor.
Together with other articles in this series, this result can help you answer questions such as: Does this data structure form a functor?
Since functors tend to be quite common, and since they're useful enough that many programming languages have special support or syntax for them, the ability to recognize a potential functor can be useful. Given a type like Foo<T> (C# syntax) or Bar<T1, T2>, being able to recognize it as a functor can come in handy. One scenario is if you yourself have just defined this data type. Recognizing that it's a functor strongly suggests that you should give it a Select method in C#, a map function in F#, and so on.
Not all generic types give rise to a (covariant) functor. Some are rather contravariant functors, and some are invariant.
If, on the other hand, you have a data type where one functor is nested within another functor, then the data type itself gives rise to a functor. You'll see some examples in this article.
Abstract shape #
Before we look at some examples found in other code, it helps if we know what we're looking for. Imagine that you have two functors F and G, and you're now considering a data structure that contains a value where G is nested inside of F.
public sealed class GInF<T> { private readonly F<G<T>> ginf; public GInF(F<G<T>> ginf) { this.ginf = ginf; } // Methods go here...
The GInF<T> class has a single class field. The type of this field is an F container, but 'inside' F there's a G functor.
This kind of data structure gives rise to a functor. Knowing that, you can give it a Select method:
public GInF<TResult> Select<TResult>(Func<T, TResult> selector) { return new GInF<TResult>(ginf.Select(g => g.Select(selector))); }
The composed Select method calls Select on the F functor, passing it a lambda expression that calls Select on the G functor. That nested Select call produces an F<G<TResult>> that the composed Select method finally wraps in a new GInF<TResult> object that it returns.
I'll have more to say about how this generalizes to a nested composition of more than two functors, but first, let's consider some examples.
Priority list #
A common configuration is when the 'outer' functor is a collection, and the 'inner' functor is some other kind of container. The article An immutable priority collection shows a straightforward example. The PriorityCollection<T> class composes a single class field:
private readonly Prioritized<T>[] priorities;
The priorities field is an array (a collection) of Prioritized<T> objects. That type is a simple record type:
public sealed record Prioritized<T>(T Item, byte Priority);
If we squint a little and consider only the parameter list, we may realize that this is fundamentally an 'embellished' tuple: (T Item, byte Priority). A pair forms a bifunctor, but in the Haskell Prelude a tuple is also a Functor instance over its rightmost element. In other words, if we'd swapped the Prioritized<T> constructor parameters, it might have naturally looked like something we could fmap:
ghci> fmap (elem 'r') (55, "foo") (55,False)
Here we have a tuple of an integer and a string. Imagine that the number 55 is the priority that we give to the label "foo". This little ad-hoc example demonstrates how to map that tuple to another tuple with a priority, but now it instead holds a Boolean value indicating whether or not the string contained the character 'r' (which it didn't).
You can easily swap the elements:
ghci> import Data.Tuple
ghci> swap (55, "foo")
("foo",55)
This looks just like the Prioritized<T> parameter list. This also implies that if you originally have the parameter list in that order, you could swap it, map it, and swap it again:
ghci> swap $ fmap (elem 'r') $ swap ("foo", 55)
(False,55)
My point is only that Prioritized<T> is isomorphic to a known functor. In reality you rarely need to analyze things that thoroughly to come to that realization, but the bottom line is that you can give Prioritized<T> a lawful Select method:
public sealed record Prioritized<T>(T Item, byte Priority) { public Prioritized<TResult> Select<TResult>(Func<T, TResult> selector) { return new(selector(Item), Priority); } }
Hardly surprising, but since this article postulates that a functor of a functor is a functor, and since we already know that collections give rise to a functor, we should deduce that we can give PriorityCollection<T> a Select method. And we can:
public PriorityCollection<TResult> Select<TResult>(Func<T, TResult> selector) { return new PriorityCollection<TResult>( priorities.Select(p => p.Select(selector)).ToArray()); }
Notice how much this implementation looks like the above GInF<T> 'shape' implementation.
Tree #
An example only marginally more complicated than the above is shown in A Tree functor. The Tree<T> class shown in that article contains two constituents:
private readonly IReadOnlyCollection<Tree<T>> children; public T Item { get; }
Just like PriorityCollection<T> there's a collection, as well as a 'naked' T value. The main difference is that here, the collection is of the same type as the object itself: Tree<T>.
You've seen a similar example in the previous article, which also had a recursive data structure. If you assume, however, that Tree<T> gives rise to a functor, then so does the nested composition of putting it in a collection. This means, from the 'theorem' put forth in this article, that IReadOnlyCollection<Tree<T>> composes as a functor. Finally you have a product of a T (which is isomorphic to the Identity functor) and that composed functor. From Functor products it follows that that's a functor too, which explains why Tree<T> forms a functor. The article shows the Select implementation.
Binary tree Zipper #
In both previous articles you've seen pieces of the puzzle explaining why the binary tree Zipper gives rise to functor. There's one missing piece, however, that we can now finally address.
Recall that BinaryTreeZipper<T> composes these two objects:
public BinaryTree<T> Tree { get; } public IEnumerable<Crumb<T>> Breadcrumbs { get; }
We've already established that both BinaryTree<T> and Crumb<T> form functors. In this article you've learned that a functor in a functor is a functor, which applies to IEnumerable<Crumb<T>>. Both of the above read-only properties are functors, then, which means that the entire class is a product of functors. The Select method follows:
public BinaryTreeZipper<TResult> Select<TResult>(Func<T, TResult> selector) { return new BinaryTreeZipper<TResult>( Tree.Select(selector), Breadcrumbs.Select(c => c.Select(selector))); }
Notice that this Select implementation calls Select on the 'outer' Breadcrumbs by calling Select on each Crumb<T>. This is similar to the previous examples in this article.
Other nested containers #
There are plenty of other examples of functors that contains other functor values. Asynchronous programming supplies its own family of examples.
The way that C# and many other languages model asynchronous or I/O-bound actions is to wrap them in a Task container. If the value inside the Task<T> container is itself a functor, you can make that a functor, too. Examples include Task<IEnumerable<T>>, Task<Maybe<T>> (or its close cousin Task<T?>; notice the question mark), Task<Result<T1, T2>>, etc. You'll run into such types every time you have an I/O-bound or concurrent operation that returns IEnumerable<T>, Maybe<T> etc. as an asynchronous result.
While you can make such nested task functors a functor in its own right, you rarely need that in languages with native async and await features, since those languages nudge you in other directions.
You can, however, run into other issues with task-based programming, but you'll see examples and solutions in a future article.
You'll run into other examples of nested containers with many property-based testing libraries. They typically define Test Data Generators, often called Gen<T>. For .NET, both FsCheck, Hedgehog, and CsCheck does this. For Haskell, QuickCheck, too, defines Gen a.
You often need to generate random collections, in which case you'd work with Gen<IEnumerable<T>> or a similar collection type. If you need random Maybe values, you'll work with Gen<Maybe<T>>, and so on.
On the other hand, sometimes you need to work with a collection of generators, such as seq<Gen<'a>>.
These are all examples of functors within functors. It's not a given that you must treat such a combination as a functor in its own right. To be honest, typically, you don't. On the other hand, if you find yourself writing Select within Select, or map within map, depending on your language, it might make your code more succinct and readable if you give that combination a specialized functor affordance.
Higher arities #
Like the previous two articles, the 'theorem' presented here generalizes to more than two functors. If you have a third H functor, then F<G<H<T>>> also gives rise to a functor. You can easily prove this by simple induction. We may first consider the base case. With a single functor (n = 1) any functor (say, F) is trivially a functor.
In the induction step (n > 1), you then assume that the n - 1 'stack' of functors already gives rise to a functor, and then proceed to prove that the configuration where all those nested functors are wrapped by yet another functor also forms a functor. Since the 'inner stack' of functors forms a functor (by assumption), you only need to prove that a configuration of the outer functor, and that 'inner stack', gives rise to a functor. You've seen how this works in this article, but I admit that a few examples constitute no proof. I'll leave you with only a sketch of this step, but you may consider using equational reasoning as demonstrated by Bartosz Milewski and then prove the functor laws for such a composition.
The Haskell Data.Functor.Compose module defines a general-purpose data type to compose functors. You may, for example, compose a tuple inside a Maybe inside a list:
thriceNested :: Compose [] (Compose Maybe ((,) Integer)) String thriceNested = Compose [Compose (Just (42, "foo")), Compose Nothing, Compose (Just (89, "ba"))]
You can easily fmap that data structure, for example by evaluating whether the number of characters in each string is an odd number (if it's there at all):
ghci> fmap (odd . length) thriceNested Compose [Compose (Just (42,True)),Compose Nothing,Compose (Just (89,False))]
The first element now has True as the second tuple element, since "foo" has an odd number of characters (3). The next element is Nothing, because Nothing maps to Nothing. The third element has False in the rightmost tuple element, since "ba" doesn't have an odd number of characters (it has 2).
Relations to monads #
A nested 'stack' of functors may remind you of the way that I prefer to teach monads: A monad is a functor your can flatten. In short, the definition is the ability to 'flatten' F<F<T>> to F<T>. A function that can do that is often called join or Flatten.
So far in this article, we've been looking at stacks of different functors, abstractly denoted F<G<T>>. There's no rule, however, that says that F and G may not be the same. If F = G then F<G<T>> is really F<F<T>>. This starts to look like the antecedent of the monad definition.
While the starting point may be the same, these notions are not equivalent. Yes, F<F<T>> may form a monad (if you can flatten it), but it does, universally, give rise to a functor. On the other hand, we can hardly talk about flattening F<G<T>>, because that would imply that you'd have to somehow 'throw away' either F or G. There may be specific functors (e.g. Identity) for which this is possible, but there's no universal law to that effect.
Not all 'stacks' of functors are monads. All monads, on the other hand, are functors.
Conclusion #
A data structure that configures one type of functor inside of another functor itself forms a functor. The examples shown in this article are mostly constrained to two functors, but if you have a 'stack' of three, four, or more functors, that arrangement still gives rise to a functor.
This is useful to know, particularly if you're working in a language with only partial support for functors. Mainstream languages aren't going to automatically turn such stacks into functors, in the way that Haskell's Compose container almost does. Thus, knowing when you can safely give your generic types a Select method or map function may come in handy.
To be honest, though, this result is hardly the most important 'theorem' concerning stacks of functors. In reality, you often run into situations where you do have a stack of functors, but they're in the wrong order. You may have a collection of asynchronous tasks, but you really need an asynchronous task that contains a collection of values. The next article addresses that problem.
Next: Traversals.
Legacy Security Manager in Haskell
A translation of the kata, and my first attempt at it.
In early 2013 Richard Dalton published an article about legacy code katas. The idea is to present a piece of 'legacy code' that you have to somehow refactor or improve. Of course, in order to make the exercise manageable, it's necessary to reduce it to some essence of what we might regard as legacy code. It'll only be one aspect of true legacy code. For the legacy Security Manager exercise, the main problem is that the code is difficult to unit test.
The original kata presents the 'legacy code' in C#, which may exclude programmers who aren't familiar with that language and platform. Since I find the exercise useful, I've previous published a port to Python. In this article, I'll port the exercise to Haskell, as well as walk through one attempt at achieving the goals of the kata.
The legacy code #
The original C# code is a static procedure that uses the Console API to ask a user a few simple questions, do some basic input validation, and print a message to the standard output stream. That's easy enough to port to Haskell:
module SecurityManager (createUser) where import Text.Printf (printf) createUser :: IO () createUser = do putStrLn "Enter a username" username <- getLine putStrLn "Enter your full name" fullName <- getLine putStrLn "Enter your password" password <- getLine putStrLn "Re-enter your password" confirmPassword <- getLine if password /= confirmPassword then putStrLn "The passwords don't match" else if length password < 8 then putStrLn "Password must be at least 8 characters in length" else do -- Encrypt the password (just reverse it, should be secure) let array = reverse password putStrLn $ printf "Saving Details for User (%s, %s, %s)" username fullName array
Notice how the Haskell code seems to suffer slightly from the Arrow code smell, which is a problem that the C# code actually doesn't exhibit. The reason is that when using Haskell in an 'imperative style' (which you can, after a fashion, with do notation), you can't 'exit early' from a an if check. The problem is that you can't have if-then without else.
Haskell has other language features that enable you to get rid of Arrow code, but in the spirit of the exercise, this would take us too far away from the original C# code. Making the code prettier should be a task for the refactoring exercise, rather than the starting point.
I've published the code to GitHub, if you want a leg up.
Combined with Richard Dalton's original article, that's all you need to try your hand at the exercise. In the rest of this article, I'll go through my own attempt at the exercise. That said, while this was my first attempt at the Haskell version of it, I've done it multiple times in C#, and once in Python. In other words, this isn't my first rodeo.
Break the dependency on the Console #
As warned, the rest of the article is a walkthrough of the exercise, so if you'd like to try it yourself, stop reading now. On the other hand, if you want to read on, but follow along in the GitHub repository, I've pushed the rest of the code to a branch called first-pass.
The first part of the exercise is to break the dependency on the console. In a language like Haskell where functions are first-class citizens, this part is trivial. I removed the type declaration, moved putStrLn and getLine to parameters and renamed them. Finally, I asked the compiler what the new type is, and added the new type signature.
import Text.Printf (printf, IsChar) createUser :: (Monad m, Eq a, IsChar a) => (String -> m ()) -> m [a] -> m () createUser writeLine readLine = do writeLine "Enter a username" username <- readLine writeLine "Enter your full name" fullName <- readLine writeLine "Enter your password" password <- readLine writeLine "Re-enter your password" confirmPassword <- readLine if password /= confirmPassword then writeLine "The passwords don't match" else if length password < 8 then writeLine "Password must be at least 8 characters in length" else do -- Encrypt the password (just reverse it, should be secure) let array = reverse password writeLine $ printf "Saving Details for User (%s, %s, %s)" username fullName array
I also changed the main action of the program to pass putStrLn and getLine as arguments:
import SecurityManager (createUser) main :: IO () main = createUser putStrLn getLine
Manual testing indicates that I didn't break any functionality.
Get the password comparison feature under test #
The next task is to get the password comparison feature under test. Over a small series of Git commits, I added these inlined, parametrized HUnit tests:
"Matching passwords" ~: do pw <- ["password", "12345678", "abcdefgh"] let actual = comparePasswords pw pw return $ Right pw ~=? actual , "Non-matching passwords" ~: do (pw1, pw2) <- [ ("password", "PASSWORD"), ("12345678", "12345677"), ("abcdefgh", "bacdefgh"), ("aaa", "bbb") ] let actual = comparePasswords pw1 pw2 return $ Left "The passwords don't match" ~=? actual
The resulting implementation is this comparePasswords function:
comparePasswords :: String -> String -> Either String String comparePasswords pw1 pw2 = if pw1 == pw2 then Right pw1 else Left "The passwords don't match"
You'll notice that I chose to implement it as an Either-valued function. While I consider validation a solved problem, the usual solution involves some applicative validation container. In this exercise, validation is already short-circuiting, which means that we can use the standard monadic composition that Either affords.
At this point in the exercise, I just left the comparePasswords function there, without trying to use it within createUser. The reason for that is that Either-based composition is sufficiently different from if-then-else code that I wanted to get the entire system under test before I attempted that.
Get the password validation feature under test #
The third task of the exercise is to get the password validation feature under test. That's similar to the previous task. Once more, I'll show the tests first, and then the function driven by those tests, but I want to point out that both code artefacts came iteratively into existence through the usual red-green-refactor cycle.
"Validate short password" ~: do pw <- ["", "1", "12", "abc", "1234", "gtrex", "123456", "1234567"] let actual = validatePassword pw return $ Left "Password must be at least 8 characters in length" ~=? actual , "Validate long password" ~: do pw <- ["12345678", "123456789", "abcdefghij", "elevenchars"] let actual = validatePassword pw return $ Right pw ~=? actual
The resulting function is hardly surprising.
validatePassword :: String -> Either String String validatePassword pw = if length pw < 8 then Left "Password must be at least 8 characters in length" else Right pw
As in the previous step, I chose to postpone using this function from within createUser until I had a set of characterization tests. That may not be entirely in the spirit of the four subtasks of the exercise, but on the other hand, I intended to do more than just those four activities. The code here is actually simple enough that I could easily refactor without full test coverage, but recalling that this is a legacy code exercise, I find it warranted to pretend that it's complicated.
To be fair to the exercise, there'd also be a valuable exercise in attempting to extract each feature piecemeal, because it's not alway possible to add complete characterization test coverage to a piece of gnarly legacy code. Be that as it may, I've already done that kind of exercise in C# a few times, and I had a different agenda for the Haskell exercise. In short, I was curious about what sort of inferred type createUser would have, once I'd gone through all four subtasks. I'll return to that topic in a moment. First, I want to address the fourth subtask.
Allow different encryption algorithms to be used #
The final part of the exercise is to add a feature to allow different encryption algorithms to be used. Once again, when you're working in a language where functions are first-class citizens, and higher-order functions are idiomatic, one solution is easily at hand:
createUser :: (Monad m, Foldable t, Eq (t a), PrintfArg (t a), PrintfArg b) => (String -> m ()) -> m (t a) -> (t a -> b) -> m () createUser writeLine readLine encrypt = do writeLine "Enter a username" username <- readLine writeLine "Enter your full name" fullName <- readLine writeLine "Enter your password" password <- readLine writeLine "Re-enter your password" confirmPassword <- readLine if password /= confirmPassword then writeLine "The passwords don't match" else if length password < 8 then writeLine "Password must be at least 8 characters in length" else do let array = encrypt password writeLine $ printf "Saving Details for User (%s, %s, %s)" username fullName array
The only change I've made is to promote encrypt to a parameter. This, of course, ripples through the code that calls the action, but currently, that's only the main action, where I had to add reverse as a third argument:
main :: IO () main = createUser putStrLn getLine reverse
Before I made the change, I removed the type annotation from createUser, because adding a parameter causes the type to change. Keeping the type annotation would have caused a compilation error. Eschewing type annotations makes it easier to make changes. Once I'd made the change, I added the new annotation, inferred by the Haskell Visual Studio Code extension.
I was curious what kind of abstraction would arise. Would it be testable in some way?
Testability #
Consider the inferred type of createUser above. It's quite abstract, and I was curious if it was flexible enough to allow testability without adding test-induced damage. In short, in object-oriented programming, you often need to add Dependency Injection to make code testable, and the valid criticism is that this makes code more complicated than it would otherwise have been. I consider such reproval justified, although I disagree with the conclusion. It's not the desire for testability that causes the damage, but rather that object-oriented design is at odds with testability.
That's my conjecture, anyway, so I'm always curious when working with other paradigms like functional programming. Is idiomatic code already testable, or do you need to 'do damage to it' in order to make it testable?
As a Haskell action goes, I would consider its type fairly idiomatic. The code, too, is straightforward, although perhaps rather naive. It looks like beginner Haskell, and as we'll see later, we can rewrite it to be more elegant.
Before I started the exercise, I wondered whether it'd be necessary to use free monads to model pure command-line interactions. Since createUser returns m (), where m is any Monad instance, using a free monad would be possible, but turns out to be overkill. After having thought about it a bit, I recalled that in many languages and platforms, you can redirect standard in and standard out for testing purposes. The way you do that is typically by replacing each with some kind of text stream. Based on that knowledge, I thought I could use the State monad for characterization testing, with a list of strings for each text stream.
In other words, the code is already testable as it is. No test-induced damage here.
Characterization tests #
To use the State monad, I started by importing Control.Monad.Trans.State.Lazy into my test code. This enabled me to write the first characterization test:
"Happy path" ~: flip evalState (["just.inhale", "Justin Hale", "12345678", "12345678"], []) $ do let writeLine x = modify (second (++ [x])) let readLine = state (\(i, o) -> (head i, (tail i, o))) let encrypt = reverse createUser writeLine readLine encrypt actual <- gets snd let expected = [ "Enter a username", "Enter your full name", "Enter your password", "Re-enter your password", "Saving Details for User (just.inhale, Justin Hale, 87654321)"] return $ expected ~=? actual
I consulted my earlier code from An example of state-based testing in Haskell instead of reinventing the wheel, so if you want a more detailed walkthrough, you may want to consult that article as well as this one.
The type of the state that the test makes use of is ([String], [String]). As the lambda expression suggests by naming the elements i and o, the two string lists are used for respectively input and output. The test starts with an 'input stream' populated by 'user input' values, corresponding to each of the four answers a user might give to the questions asked.
The readLine function works by pulling the head off the input list i, while on the other hand not touching the output list o. Its type is State ([a], b) a, compatible with createUser, which requires its readLine parameter to have the type m (t a), where m is a Monad instance, and t a Foldable instance. The effective type turns out to be t a ~ [Char] = String, so that readLine effectively has the type State ([String], b) String. Since State ([String], b) is a Monad instance, it fits the m type argument of the requirement.
The same kind of reasoning applies to writeLine, which appends the input value to the 'output stream', which is the second list in the I/O tuple.
The test runs the createUser action and then checks that the output list contains the expected values.
A similar test verifies the behaviour when the passwords don't match:
"Mismatched passwords" ~: flip evalState (["i.lean.right", "Ilene Wright", "password", "Password"], []) $ do let writeLine x = modify (second (++ [x])) let readLine = state (\(i, o) -> (head i, (tail i, o))) let encrypt = reverse createUser writeLine readLine encrypt actual <- gets snd let expected = [ "Enter a username", "Enter your full name", "Enter your password", "Re-enter your password", "The passwords don't match"] return $ expected ~=? actual
You can see the third and final characterization test in the GitHub repository.
Refactored action #
With full test coverage I could proceed to refactor the createUser action, pulling in the two functions I'd test-driven into existence earlier:
createUser :: (Monad m, PrintfArg a) => (String -> m ()) -> m String -> (String -> a) -> m () createUser writeLine readLine encrypt = do writeLine "Enter a username" username <- readLine writeLine "Enter your full name" fullName <- readLine writeLine "Enter your password" password <- readLine writeLine "Re-enter your password" confirmPassword <- readLine writeLine $ either id (printf "Saving Details for User (%s, %s, %s)" username fullName . encrypt) (validatePassword =<< comparePasswords password confirmPassword)
Because createUser now calls comparePasswords and validatePassword, the type of the overall composition is also more concrete. That's really just an artefact of my (misguided?) decision to give each of the two helper functions types that are more concrete than necessary.
As you can see, I left the initial call-and-response sequence intact, since I didn't feel that it needed improvement.
Conclusion #
I ported the Legacy Security Manager kata to Haskell because I thought it'd be easy enough to port the code itself, and I also found the exercise compelling enough in its own right.
The most interesting point, I think, is that the createUser action remains testable without making any other concession to testability than turning it into a higher-order function. For pure functions, we would expect this to be the case, since pure functions are intrinsically testable, but for impure actions like createUser, this isn't a given. Interacting exclusively with the command-line API is, however, sufficiently simple that we can get by with the State monad. No free monad is needed, and so test-induced damage is kept at a minimum.
Functor sums
A choice of two or more functors gives rise to a functor. An article for object-oriented programmers.
This article is part of a series of articles about functor relationships. In this one you'll learn about a universal composition of functors. In short, if you have a sum type of functors, that data structure itself gives rise to a functor.
Together with other articles in this series, this result can help you answer questions such as: Does this data structure form a functor?
Since functors tend to be quite common, and since they're useful enough that many programming languages have special support or syntax for them, the ability to recognize a potential functor can be useful. Given a type like Foo<T> (C# syntax) or Bar<T1, T2>, being able to recognize it as a functor can come in handy. One scenario is if you yourself have just defined this data type. Recognizing that it's a functor strongly suggests that you should give it a Select method in C#, a map function in F#, and so on.
Not all generic types give rise to a (covariant) functor. Some are rather contravariant functors, and some are invariant.
If, on the other hand, you have a data type which is a sum of two or more (covariant) functors with the same type parameter, then the data type itself gives rise to a functor. You'll see some examples in this article.
Abstract shape in F# #
Before we look at some examples found in other code, it helps if we know what we're looking for. You'll see a C# example in a minute, but since sum types require so much ceremony in C#, we'll make a brief detour around F#.
Imagine that you have two lawful functors, F and G. Also imagine that you have a data structure that holds either an F<'a> value or a G<'a> value:
type FOrG<'a> = FOrGF of F<'a> | FOrGG of G<'a>
The name of the type is FOrG. In the FOrGF case, it holds an F<'a> value, and in the FOrGG case it holds a G<'a> value.
The point of this article is that since both F and G are (lawful) functors, then FOrG also gives rise to a functor. The composed map function can pattern-match on each case and call the respective map function that belongs to each of the two functors.
let map f forg = match forg with | FOrGF fa -> FOrGF (F.map f fa) | FOrGG ga -> FOrGG (G.map f ga)
For clarity I've named the values fa indicating f of a and ga indicating g of a.
Notice that it's an essential requirement that the individual functors (here F and G) are parametrized by the same type parameter (here 'a). If your data structure contains F<'a> and G<'b>, the 'theorem' doesn't apply.
Abstract shape in C# #
The same kind of abstract shape requires much more boilerplate in C#. When defining a sum type in a language that doesn't support them, we may instead either turn to the Visitor design pattern or alternatively use Church encoding. While the two are isomorphic, Church encoding is a bit simpler while the Visitor pattern seems more object-oriented. In this example I've chosen the simplicity of Church encoding.
Like in the above F# code, I've named the data structure the same, but it's now a class:
public sealed class FOrG<T>
Two constructors enable you to initialize it with either an F<T> or a G<T> value.
public FOrG(F<T> f) public FOrG(G<T> g)
Notice that F<T> and G<T> share the same type parameter T. If a class had, instead, composed either F<T1> or G<T2>, the 'theorem' doesn't apply.
Finally, a Match method completes the Church encoding.
public TResult Match<TResult>( Func<F<T>, TResult> whenF, Func<G<T>, TResult> whenG)
Regardless of exactly what F and G are, you can add a Select method to FOrG<T> like this:
public FOrG<TResult> Select<TResult>(Func<T, TResult> selector) { return Match( whenF: f => new FOrG<TResult>(f.Select(selector)), whenG: g => new FOrG<TResult>(g.Select(selector))); }
Since we assume that F and G are functors, which in C# idiomatically have a Select method, we pass the selector to their respective Select methods. f.Select returns a new F value, while g.Select returns a new G value, but there's a constructor for each case, so the composed Select method repackages those return values in new FOrG<TResult> objects.
I'll have more to say about how this generalizes to a sum of more than two alternatives, but first, let's consider some examples.
Open or closed endpoints #
The simplest example that I can think of is that of range endpoints. A range may be open, closed, or a mix thereof. Some mathematical notations use (1, 6] to indicate the range between 1 and 6, where 1 is excluded from the range, but 6 is included. An alternative notation is ]1, 6].
A given endpoint (1 and 6, above) is either open or closed, which implies a sum type. In F# I defined it like this:
type Endpoint<'a> = Open of 'a | Closed of 'a
If you're at all familiar with F#, this is clearly a discriminated union, which is just what the F# documentation calls sum types.
The article Range as a functor goes through examples in both Haskell, F#, and C#, demonstrating, among other points, how an endpoint sum type forms a functor.
Binary tree #
The next example we'll consider is the binary tree from A Binary Tree Zipper in C#. In the original Haskell Zippers article, the data type is defined like this:
data Tree a = Empty | Node a (Tree a) (Tree a) deriving (Show)
Even if you're not familiar with Haskell syntax, the vertical bar (|) indicates a choice between the left-hand side and the right-hand side. Many programming languages use the | character for Boolean disjunction (or), so the syntax should be intuitive. In this definition, a binary tree is either empty or a node with a value and two subtrees. What interests us here is that it's a sum type.
One way this manifests in C# is in the choice of two alternative constructors:
public BinaryTree() : this(Empty.Instance) { } public BinaryTree(T value, BinaryTree<T> left, BinaryTree<T> right) : this(new Node(value, left.root, right.root)) { }
BinaryTree<T> clearly has a generic type parameter. Does the class give rise to a functor?
It does if it's composed from a sum of two functors. Is that the case?
On the 'left' side, it seems that we have nothing. In the Haskell code, it's called Empty. In the C# code, this case is represented by the parameterless constructor (also known as the default constructor). There's no T there, so that doesn't look much like a functor.
All is, however, not lost. We may view this lack of data as a particular value ('nothing') wrapped in the Const functor. In Haskell and F# a value without data is called unit and written (). In C# or Java you may think of it as void, although unit is a value that you can pass around, which isn't the case for void.
In Haskell, we could instead represent Empty as Const (), which is a bona-fide Functor instance that you can fmap:
ghci> emptyNode = Const () ghci> fmap (+1) emptyNode Const ()
This examples pretends to 'increment' a number that isn't there. Not that you'd need to do this. I'm only showing you this to make the argument that the empty node forms a functor.
The 'right' side of the sum type is most succinctly summarized by the Haskell code:
Node a (Tree a) (Tree a)
It's a 'naked' generic value and two generic trees. In C# it's the parameter list
(T value, BinaryTree<T> left, BinaryTree<T> right)
Does that make a functor? Yes, it's a triple of a 'naked' generic value and two recursive subtrees, all sharing the same T. Just like in the previous article we can view a 'naked' generic value as equivalent to the Identity functor, so that parameter is a functor. The other ones are recursive types: They are of the same type as the type we're trying to evaluate, BinaryTree<T>. If we assume that that forms a functor, that triple is a product type of functors. From the previous article, we know that that gives rise to a functor.
This means that in C#, for example, you can add the idiomatic Select method:
public BinaryTree<TResult> Select<TResult>(Func<T, TResult> selector) { return Aggregate( whenEmpty: () => new BinaryTree<TResult>(), whenNode: (value, left, right) => new BinaryTree<TResult>(selector(value), left, right)); }
In languages that support pattern-matching on sum types (such as F#), you'd have to match on each case and explicitly deal with the recursive mapping. Notice, however, that here I've used the Aggregate method to implement Select. The Aggregate method is the BinaryTree<T> class' catamorphism, and it already handles the recursion for us. In other words, left and right are already BinaryTree<TResult> objects.
What remains is only to tell Aggregate what to do when the tree is empty, and how to transform the 'naked' node value. The Select implementation handles the former by returning a new empty tree, and the latter by invoking selector(value).
Not only does the binary tree form a functor, but it turns out that the Zipper does as well, because the breadcrumbs also give rise to a functor.
Breadcrumbs #
The original Haskell Zippers article defines a breadcrumb for the binary tree Zipper like this:
data Crumb a = LeftCrumb a (Tree a) | RightCrumb a (Tree a) deriving (Show)
That's another sum type with generics on the left as well as the right. In C# the two options may be best illustrated by these two creation methods:
public static Crumb<T> Left<T>(T value, BinaryTree<T> right) { return Crumb<T>.Left(value, right); } public static Crumb<T> Right<T>(T value, BinaryTree<T> left) { return Crumb<T>.Right(value, left); }
Notice that the Left and Right choices have the same structure: A 'naked' generic T value, and a BinaryTree<T> object. Only the names differ. This suggests that we only need to think about one of them, and then we can reuse our conclusion for the other.
As we've already done once, we consider a T value equivalent with Identity<T>, which is a functor. We've also, just above, established that BinaryTree<T> forms a functor. We have a product (argument list, or tuple) of functors, so that combination forms a functor.
Since this is true for both alternatives, this sum type, too, gives rise to a functor. This enables you to implement a Select method:
public Crumb<TResult> Select<TResult>(Func<T, TResult> selector) { return Match( (v, r) => Crumb.Left(selector(v), r.Select(selector)), (v, l) => Crumb.Right(selector(v), l.Select(selector))); }
By now the pattern should be familiar. Call selector(v) directly on the 'naked' values, and pass selector to any other functors' Select method.
That's almost all the building blocks we have to declare BinaryTreeZipper<T> a functor as well, but we need one last theorem before we can do that. We'll conclude this work in the next article.
Higher arities #
Although we finally saw a 'real' triple product, all the sum types have involved binary choices between a 'left side' and a 'right side'. As was the case with functor products, the result generalizes to higher arities. A sum type with any number of cases forms a functor if all the cases give rise to a functor.
We can, again, use canonicalized forms to argue the case. (See Thinking with Types for a clear explanation of canonicalization of types.) A two-way choice is isomorphic to Either, and a three-way choice is isomorphic to Either a (Either b c). Just like it's possible to build triples, quadruples, etc. by nesting pairs, we can construct n-ary choices by nesting Eithers. It's the same kind of inductive reasoning.
This is relevant because just as Haskell's base library provides Data.Functor.Product for composing two (and thereby any number of) functors, it also provides Data.Functor.Sum for composing functor sums.
The Sum type defines two case constructors: InL and InR, but it's isomorphic with Either:
canonizeSum :: Sum f g a -> Either (f a) (g a) canonizeSum (InL x) = Left x canonizeSum (InR y) = Right y summarizeEither :: Either (f a) (g a) -> Sum f g a summarizeEither (Left x) = InL x summarizeEither (Right y) = InR y
The point is that we can compose not only a choice of two, but of any number of functors, to a single functor type. A simple example is this choice between Maybe, list, or Tree:
maybeOrListOrTree :: Sum (Sum Maybe []) Tree String maybeOrListOrTree = InL (InL (Just "foo"))
If we rather wanted to embed a list in that type, we can do that as well:
maybeOrListOrTree' :: Sum (Sum Maybe []) Tree String maybeOrListOrTree' = InL (InR ["bar", "baz"])
Both values have the same type, and since it's a Functor instance, you can fmap over it:
ghci> fmap (elem 'r') maybeOrListOrTree InL (InL (Just False)) ghci> fmap (elem 'r') maybeOrListOrTree' InL (InR [True,False])
These queries examine each String to determine whether or not they contain the letter 'r', which only "bar" does.
The point, anyway, is that sum types of any arity form a functor if all the cases do.
Conclusion #
In the previous article, you learned that a functor product gives rise to a functor. In this article, you learned that a functor sum does, too. If a data structure contains a choice of two or more functors, then that data type itself forms a functor.
As the previous article argues, this is useful to know, particularly if you're working in a language with only partial support for functors. Mainstream languages aren't going to automatically turn such sums into functors, in the way that Haskell's Sum container almost does. Thus, knowing when you can safely give your generic types a Select method or map function may come in handy.
There's one more rule like this one.
Next: Functor compositions.
The Const functor
Package a constant value, but make it look like a functor. An article for object-oriented programmers.
This article is an instalment in an article series about functors. In previous articles, you've learned about useful functors such as Maybe and Either. You've also seen at least one less-than useful functor: The Identity functor. In this article, you'll learn about another (practically) useless functor called Const. You can skip this article if you want.
Like Identity, the Const functor may not be that useful, but it nonetheless exists. You'll probably not need it for actual programming tasks, but knowing that it exists, like Identity, can be a useful as an analysis tool. It may help you quickly evaluate whether a particular data structure affords various compositions. For example, it may enable you to quickly identify whether, say, a constant type and a list may compose to a functor.
This article starts with C#, then proceeds over F# to finally discuss Haskell's built-in Const functor. You can just skip the languages you don't care about.
C# Const class #
While C# supports records, and you can implement Const as one, I here present it as a full-fledged class. For readers who may not be that familiar with modern C#, a normal class may be more recognizable.
public sealed class Const<T1, T2> { public T1 Value { get; } public Const(T1 value) { Value = value; } public Const<T1, TResult> Select<TResult>(Func<T2, TResult> selector) { return new Const<T1, TResult>(Value); } public override bool Equals(object obj) { return obj is Const<T1, T2> @const && EqualityComparer<T1>.Default.Equals(Value, @const.Value); } public override int GetHashCode() { return -1584136870 + EqualityComparer<T1>.Default.GetHashCode(Value); } }
The point of the Const functor is to make a constant value look like a functor; that is, a container that you can map from one type to another. The difference from the Identity functor is that Const doesn't allow you to map the constant. Rather, it cheats and pretends having a mappable type that, however, has no value associated with it; a phantom type.
In Const<T1, T2>, the T2 type parameter is the 'pretend' type. While the class contains a T1 value, it contains no T2 value. The Select method, on the other hand, maps T2 to TResult. The operation is close to being a no-op, but still not quite. While it doesn't do anything particularly practical, it does change the type of the returned value.
Here's a simple example of using the Select method:
Const<string, double> c = new Const<string, int>("foo").Select(i => Math.Sqrt(i));
The new c value also contains "foo". Only its type has changed.
If you find this peculiar, think of it as similar to mapping an empty list, or an empty Maybe value. In those cases, too, no values change; only the type changes. The difference between empty Maybe objects or empty lists, and the Const functor is that Const isn't empty. There is a value; it's just not the value being mapped.
Functor laws #
Although the Const functor doesn't really do anything, it still obeys the functor laws. To illustrate it (but not to prove it), here's an FsCheck property that exercises the first functor law:
[Property(QuietOnSuccess = true)] public void ConstObeysFirstFunctorLaw(int i) { var left = new Const<int, string>(i); var right = new Const<int, string>(i).Select(x => x); Assert.Equal(left, right); }
If you think it over for a minute, this makes sense. The test creates a Const<int, string> that contains the integer i, and then proceeds to map the string that isn't there to 'itself'. Clearly, this doesn't change the i value contained in the Const<int, string> container.
In the same spirit, a property demonstrates the second functor law:
[Property(QuietOnSuccess = true)] public void ConstObeysSecondFunctorLaw( Func<string, byte> f, Func<int, string> g, short s) { Const<short, byte> left = new Const<short, int>(s).Select(g).Select(f); Const<short, byte> right = new Const<short, int>(s).Select(x => f(g(x))); Assert.Equal(left, right); }
Again, the same kind of almost-no-op takes place. The g function first changes the int type to string, and then f changes the string type to byte, but no value ever changes; only the second type parameter. Thus, left and right remain equal, since they both contain the same value s.
F# Const #
In F# we may idiomatically express Const as a single-case union:
type Const<'v, 'a> = Const of 'v
Here I've chosen to name the first type parameter 'v (for value) in order to keep the 'functor type parameter' name 'a. This enables me to meaningfully annotate the functor mapping function with the type 'a -> 'b:
module Const = let get (Const x) = x let map (f : 'a -> 'b) (Const x : Const<'v, 'a>) : Const<'v, 'b> = Const x
Usually, you don't need to annotate F# functions like map, but in this case I added explicit types in order to make it a recognizable functor map.
I could also have defined map like this:
// 'a -> Const<'b,'c> -> Const<'b,'d> let map f (Const x) = Const x
This still works, but is less recognizable as a functor map, since f may be any 'a. Notice that if type inference is left to its own devices, it names the input type Const<'b,'c> and the return type Const<'b,'d>. This also means that if you want to supply f as a mapping function, this is legal, because we may consider 'a ~ 'c -> 'd. It's still a functor map, but a less familiar representation.
Similar to the above C# code, two FsCheck properties demonstrate that the Const type obeys the functor laws.
[<Property(QuietOnSuccess = true)>] let ``Const obeys first functor law`` (i : int) = let left = Const i let right = Const i |> Const.map id left =! right [<Property(QuietOnSuccess = true)>] let ``Const obeys second functor law`` (f : string -> byte) (g : int -> string) (s : int16) = let left = Const s |> Const.map g |> Const.map f let right = Const s |> Const.map (g >> f) left =! right
The assertions use Unquote's =! operator, which I usually read as should equal or must equal.
Haskell Const #
The Haskell base library already comes with a Const newtype.
You can easily create a new Const value:
ghci> Const "foo" Const "foo"
If you inquire about its type, GHCi will tell you in a rather verbose way that the first type parameter is String, but the second may be any type b:
ghci> :t Const "foo"
Const "foo" :: forall {k} {b :: k}. Const String b
You can also map by 'incrementing' its non-existent second value:
ghci> (+1) <$> Const "foo" Const "foo" ghci> :t (+1) <$> Const "foo" (+1) <$> Const "foo" :: Num b => Const String b
While the value remains Const "foo", the type of b is now constrained to a Num instance, which follows from the use of the + operator.
Functor law proofs #
If you look at the source code for the Functor instance, it looks much like its F# equivalent:
instance Functor (Const m) where
fmap _ (Const v) = Const v
We can use equational reasoning with the notation that Bartosz Milewski uses to prove that both functor laws hold, starting with the first:
fmap id (Const x)
= { definition of fmap }
Const x
Clearly, there's not much to that part. What about the second functor law?
fmap (g . f) (Const x)
= { definition of fmap }
Const x
= { definition of fmap }
fmap g (Const x)
= { definition of fmap }
fmap g (fmap f (Const x))
= { definition of composition }
(fmap g . fmap f) (Const x)
While that proof takes a few more steps, most are as trivial as the first proof.
Conclusion #
The Const functor is hardly a programming construct you'll use in your day-to-day work, but the fact that it exists can be used to generalize some results that involve functors. Now, whenever you have a result that involves a functor, you know that it also generalizes to constant values, just like the Identity functor teaches us that 'naked' type parameters can be thought of as functors.
To give a few examples, we may already know that Tree<T> (C# syntax) is a functor, but a 'naked' generic type parameter T also gives rise to a functor (Identity), as does a non-generic type (such as int or MyCustomClass).
Thus, if you have a function that operates on any functor, it may also, conceivably, operate on data structures that have non-generic types. This may for example be interesting when we begin to consider how functors compose.
Next: The State functor.
Das verflixte Hunde-Spiel
A puzzle kata, and a possible solution.
When I was a boy I had a nine-piece puzzle that I'd been gifted by the Swizz branch of my family. It's called Das verflixte Hunde-Spiel, which means something like the confounded dog game in English. And while a puzzle with nine pieces doesn't sound like much, it is, in fact, incredibly difficult.
It's just a specific incarnation of a kind of game that you've almost certainly encountered, too.

There are nine tiles, each with two dog heads and two dog ends. A dog may be coloured in one of four different patterns. The object of the game is to lay out the nine tiles in a 3x3 square so that all dog halves line up.
Game details #
The game is from 1979. Two of the tiles are identical, and, according to the information on the back of the box, two possible solutions exist. Described from top clockwise, the tiles are the following:
- Brown head, grey head, umber tail, spotted tail
- Brown head, spotted head, brown tail, umber tail
- Brown head, spotted head, grey tail, umber tail
- Brown head, spotted head, grey tail, umber tail
- Brown head, umber head, spotted tail, grey tail
- Grey head, brown head, spotted tail, umber tail
- Grey head, spotted head, brown tail, umber tail
- Grey head, umber head, brown tail, spotted tail
- Grey head, umber head, grey tail, spotted tail
I've taken the liberty of using a shorthand for the patterns. The grey dogs are actually also spotted, but since there's only one grey pattern, the grey label is unambiguous. The dogs I've named umber are actually rather burnt umber, but that's too verbose for my tastes, so I just named them umber. Finally, the label spotted indicates dogs that are actually burnt umber with brown blotches.
Notice that there are two tiles with a brown head, a spotted head, a grey tail, and an umber tail.
The object of the game is to lay down the tiles in a 3x3 square so that all dogs fit. For further reference, I've numbered each position from one to nine like this:

What makes the game hard? There are nine cards, so if you start with the upper left corner, you have nine choices. If you just randomly put down the tiles, you now have eight left for the top middle position, and so on. Standard combinatorics indicate that there are at least 9! = 362,880 permutations.
That's not the whole story, however, since you can rotate each tile in four different ways. You can rotate the first tile four ways, the second tile four ways, etc. for a total of 49 = 262,144 ways. Multiply these two numbers together, and you get 499! = 95,126,814,720 combinations. No wonder this puzzle is hard if there's only two solutions.
When analysed this way, however, there are actually 16 solutions, but that still makes it incredibly unlikely to arrive at a solution by chance. I'll get back to why there are 16 solutions later. For now, you should have enough information to try your hand with this game, if you'd like.
I found that the game made for an interesting kata: Write a program that finds all possible solutions to the puzzle.
If you'd like to try your hand at this exercise, I suggest that you pause reading here.
In the rest of the article, I'll outline my first attempt. Spoiler alert: I'll also show one of the solutions.
Types #
When you program in Haskell, it's natural to start by defining some types.
data Half = Head | Tail deriving (Show, Eq) data Pattern = Brown | Grey | Spotted | Umber deriving (Show, Eq) data Tile = Tile { top :: (Pattern, Half), right :: (Pattern, Half), bottom :: (Pattern, Half), left :: (Pattern, Half) } deriving (Show, Eq)
Each tile describes what you find on its top, right side, bottom, and left side.
We're also going to need a function to evaluate whether two halves match:
matches :: (Pattern, Half) -> (Pattern, Half) -> Bool matches (p1, h1) (p2, h2) = p1 == p2 && h1 /= h2
This function demands that the patterns match, but that the halves are opposites.
You can use the Tile type and its constituents to define the nine tiles of the game:
tiles :: [Tile] tiles = [ Tile (Brown, Head) (Grey, Head) (Umber, Tail) (Spotted, Tail), Tile (Brown, Head) (Spotted, Head) (Brown, Tail) (Umber, Tail), Tile (Brown, Head) (Spotted, Head) (Grey, Tail) (Umber, Tail), Tile (Brown, Head) (Spotted, Head) (Grey, Tail) (Umber, Tail), Tile (Brown, Head) (Umber, Head) (Spotted, Tail) (Grey, Tail), Tile (Grey, Head) (Brown, Head) (Spotted, Tail) (Umber, Tail), Tile (Grey, Head) (Spotted, Head) (Brown, Tail) (Umber, Tail), Tile (Grey, Head) (Umber, Head) (Brown, Tail) (Spotted, Tail), Tile (Grey, Head) (Umber, Head) (Grey, Tail) (Spotted, Tail) ]
Because I'm the neatnik that I am, I've sorted the tiles in lexicographic order, but the solution below doesn't rely on that.
Brute force doesn't work #
Before I started, I cast around the internet to see if there was an appropriate algorithm for the problem. While I found a few answers on Stack Overflow, none of them gave me indication that any sophisticated algorithm was available. (Even so, there may be, and I just didn't find it.)
It seems clear, however, that you can implement some kind of recursive search-tree algorithm that cuts a branch off as soon as it realizes that it doesn't work. I'll get back to that later, so let's leave that for now.
Since I'd planned on writing the code in Haskell, I decided to first try something that might look like brute force. Because Haskell is lazily evaluated, you can sometimes get away with techniques that look wasteful when you're used to strict/eager evaluation. In this case, it turned out to not work, but it's often quicker to just make the attempt than trying to analyze the problem.
As already outlined, I first attempted a purely brute-force solution, betting that Haskell's lazy evaluation would be enough to skip over the unnecessary calculations:
allRotationsOf9 = replicateM 9 [0..3] allRotations :: [Tile] -> [[Tile]] allRotations ts = fmap (\rs -> (\(r, t) -> rotations t !! r) <$> zip rs ts) allRotationsOf9 allConfigurations :: [[Tile]] allConfigurations = permutations tiles >>= allRotations solutions = filter isSolution allConfigurations
My idea with the allConfigurations value was that it's supposed to enumerate all 95 billion combinations. Whether it actually does that, I was never able to verify, because if I try to run that code, my poor laptop runs for a couple of hours before it eventually runs out of memory. In other words, the GHCi process crashes.
I haven't shown isSolution or rotations, because I consider the implementations irrelevant. This attempt doesn't work anyway.
Now that I look at it, it's quite clear why this isn't a good strategy. There's little to be gained from lazy evaluation when the final attempt just attempts to filter a list. Even with lazy evaluation, the code still has to run through all 95 billion combinations.
Things might have been different if I just had to find one solution. With a little luck, it might be that the first solution appears after, say, a hundred million iterations, and lazy evaluation would then had meant that the remaining combinations would never run. Not so here, but hindsight is 20-20.
Search tree #
Back to the search tree idea. It goes like this: Start from the top left position and pick a random tile and rotation. Now pick an arbitrary tile that fits and place it to the right of it, and so on. As far as I can tell, you can always place the first four cards, but from there, you can easily encounter a combination that allows no further tiles. Here's an example:

None of the remaining five tiles fit in the fifth position. This means that we don't have to do any permutations that involve these four tiles in that combination. While the algorithm has to search through all five remaining tiles and rotations to discover that none fit in position 5, once it knows that, it doesn't have to go through the remaining four positions. That's 444! = 6,144 combinations that it can skip every time it discovers an impossible beginning. That doesn't sound like that much, but if we assume that this happens more often than not, it's still an improvement by orders of magnitude.
We may think of this algorithm as constructing a search tree, but immediately pruning all branches that aren't viable, as close to the root as possible.
Matches #
Before we get to the algorithm proper we need a few simple helper functions. One kind of function is a predicate that determines if a particular tile can occupy a given position. Since we may place any tile in any rotation in the first position, we don't need to write a predicate for that, but if we wanted to generalize, const True would do.
Whether or not we can place a given tile in the second position depends exclusively on the tile in the first position:
tile2Matches :: Tile -> Tile -> Bool tile2Matches t1 t2 = right t1 `matches` left t2
If the right dog part of the first tile matches the left part of the second tile, the return value is True; otherwise, it's False. Note that I'm using infix notation for matches. I could also have written the function as
tile2Matches :: Tile -> Tile -> Bool tile2Matches t1 t2 = matches (right t1) (left t2)
but it doesn't read as well.
In any case, the corresponding matching functions for the third and forth tile look similar:
tile3Matches :: Tile -> Tile -> Bool tile3Matches t2 t3 = right t2 `matches` left t3 tile4Matches :: Tile -> Tile -> Bool tile4Matches t1 t4 = bottom t1 `matches` top t4
Notice that tile4Matches compares the fourth tile with the first tile rather than the third tile, because position 4 is directly beneath position 1, rather than to the right of position 3 (cf. the grid above). For that reason it also compares the bottom of tile 1 to the top of the fourth tile.
The matcher for the fifth tile is different:
tile5Matches :: Tile -> Tile -> Tile -> Bool tile5Matches t2 t4 t5 = bottom t2 `matches` top t5 && right t4 `matches` left t5
This is the first predicate that depends on two, rather than one, previous tiles. In position 5 we need to examine both the tile in position 2 and the one in position 4.
The same is true for position 6:
tile6Matches :: Tile -> Tile -> Tile -> Bool tile6Matches t3 t5 t6 = bottom t3 `matches` top t6 && right t5 `matches` left t6
but then the matcher for position 7 looks like the predicate for position 4:
tile7Matches :: Tile -> Tile -> Bool tile7Matches t4 t7 = bottom t4 `matches` top t7
This is, of course, because the tile in position 7 only has to consider the tile in position 4. Finally, not surprising, the two remaining predicates look like something we've already seen:
tile8Matches :: Tile -> Tile -> Tile -> Bool tile8Matches t5 t7 t8 = bottom t5 `matches` top t8 && right t7 `matches` left t8 tile9Matches :: Tile -> Tile -> Tile -> Bool tile9Matches t6 t8 t9 = bottom t6 `matches` top t9 && right t8 `matches` left t9
You may suggest that it'd be possible to reduce the number of predicates. After all, there's effectively only three different predicates: One that only looks at the tile to the left, one that only looks at the tile above, and one that looks both to the left and above.
Indeed, I could have boiled it down to just three functions:
matchesHorizontally :: Tile -> Tile -> Bool matchesHorizontally x y = right x `matches` left y matchesVertically :: Tile -> Tile -> Bool matchesVertically x y = bottom x `matches` top y matchesBoth :: Tile -> Tile -> Tile -> Bool matchesBoth x y z = matchesVertically x z && matchesHorizontally y z
but I now run the risk of calling the wrong predicate from my implementation of the algorithm. As you'll see, I'll call each predicate by name at each appropriate step, but if I had only these three functions, there's a risk that I might mistakenly use matchesHorizontally when I should have used matchesVertically, or vice versa. Reducing eight one-liners to three one-liners doesn't really seem to warrant the risk.
Rotations #
In addition to examining whether a given tile fits in a given position, we also need to be able to rotate any tile:
rotateClockwise :: Tile -> Tile rotateClockwise (Tile t r b l) = Tile l t r b rotateCounterClockwise :: Tile -> Tile rotateCounterClockwise (Tile t r b l) = Tile r b l t upend :: Tile -> Tile upend (Tile t r b l) = Tile b l t r
What is really needed, it turns out, is to enumerate all four rotations of a tile:
rotations :: Tile -> [Tile] rotations t = [t, rotateClockwise t, upend t, rotateCounterClockwise t]
Since this, like everything else here, is a pure function, I experimented with defining a 'memoized tile' type that embedded all four rotations upon creation, so that the algorithm doesn't need to call the rotations function millions of times, but I couldn't measure any discernable performance improvement from it. There's no reason to make things more complicated than they need to be, so I didn't keep that change. (Since I do, however, use Git tactically i did, of course, stash the experiment.)
Permutations #
While I couldn't make things work by enumerating all 95 billion combinations, enumerating all 362,880 permutations of non-rotated tiles is well within the realm of the possible:
allPermutations :: [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] allPermutations = (\[t1, t2, t3, t4, t5, t6, t7, t8, t9] -> (t1, t2, t3, t4, t5, t6, t7, t8, t9)) <$> permutations tiles
Doing this in GHCi on my old laptop takes 300 milliseconds, which is good enough compared to what comes next.
This list value uses permutations to enumerate all the permutations. You may already have noticed that it converts the result into a nine-tuple. The reason for that is that this enables the algorithm to pattern-match into specific positions without having to resort to the index operator, which is both partial and requires iteration of the list to reach the indexed element. Granted, the list is only nine elements long, and often the algorithm will only need to index to the fourth or fifth element. On the other hand, it's going to do it a lot. Perhaps it's a premature optimization, but if it is, it's at least one that makes the code more, rather than less, readable.
Algorithm #
I found it easiest to begin at the 'bottom' of what is effectively a recursive algorithm, even though I didn't implement it that way. At the 'bottom', I imagine that I'm almost done: That I've found eight tiles that match, and now I only need to examine if I can rotate the final tile so that it matches:
solve9th :: (a, b, c, d, e, Tile, g, Tile, Tile) -> [(a, b, c, d, e, Tile, g, Tile, Tile)] solve9th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile9Matches t6 t8) $ rotations t9 return (t1, t2, t3, t4, t5, t6, t7, t8, match)
Recalling that Haskell functions compose from right to left, the function starts by enumerating the four rotations of the ninth and final tile t9. It then filters those four rotations by the tile9Matches predicate.
The match value is a rotation of t9 that matches t6 and t8. Whenever solve9th finds such a match, it returns the entire nine-tuple, because the assumption is that the eight first tiles are already valid.
Notice that the function uses do notation in the list monad, so it's quite possible that the first filter expression produces no match. In that case, the second line of code never runs, and instead, the function returns the empty list.
How do we find a tuple where the first eight elements are valid? Well, if we have seven valid tiles, we may consider the eighth and subsequently call solve9th:
solve8th :: (a, b, c, d, Tile, Tile, Tile, Tile, Tile) -> [(a, b, c, d, Tile, Tile, Tile, Tile, Tile)] solve8th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile8Matches t5 t7) $ rotations t8 solve9th (t1, t2, t3, t4, t5, t6, t7, match, t9)
This function looks a lot like solve9th, but it instead enumerates the four rotations of the eighth tile t8 and filters with the tile8Matches predicate. Due to the do notation, it'll only call solve9th if it finds a match.
Once more, this function assumes that the first seven tiles are already in a legal constellation. How do we find seven valid tiles? The same way we find eight: By assuming that we have six valid tiles, and then finding the seventh, and so on:
solve7th :: (a, b, c, Tile, Tile, Tile, Tile, Tile, Tile) -> [(a, b, c, Tile, Tile, Tile, Tile, Tile, Tile)] solve7th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile7Matches t4) $ rotations t7 solve8th (t1, t2, t3, t4, t5, t6, match, t8, t9) solve6th :: (a, b, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(a, b, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve6th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile6Matches t3 t5) $ rotations t6 solve7th (t1, t2, t3, t4, t5, match, t7, t8, t9) solve5th :: (a, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(a, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve5th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile5Matches t2 t4) $ rotations t5 solve6th (t1, t2, t3, t4, match, t6, t7, t8, t9) solve4th :: (Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve4th (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile4Matches t1) $ rotations t4 solve5th (t1, t2, t3, match, t5, t6, t7, t8, t9) solve3rd :: (Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve3rd (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile3Matches t2) $ rotations t3 solve4th (t1, t2, match, t4, t5, t6, t7, t8, t9) solve2nd :: (Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve2nd (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- filter (tile2Matches t1) $ rotations t2 solve3rd (t1, match, t3, t4, t5, t6, t7, t8, t9)
You'll observe that solve7th down to solve2nd are very similar. The only things that really vary are the predicates, and the positions of the tile being examined, as well as its neighbours. Clearly I can generalize this code, but I'm not sure it's worth it. I wrote a few of these in the order I've presented them here, because it helped me think the problem through, and to be honest, once I had two or three of them, GitHub Copilot picked up on the pattern and wrote the remaining functions for me.
Granted, typing isn't a programming bottleneck, so we should rather ask if this kind of duplication looks like a maintenance problem. Given that this is a one-time exercise, I'll just leave it be and move on.
Particularly, if you're struggling to understand how this implements the 'truncated search tree', keep in mind that e..g solve5th is likely to produce no valid match, in which case it'll never call solve6th. The same may happen in solve6th, etc.
The 'top' function is a bit different because it doesn't need to filter anything:
solve1st :: (Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile) -> [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solve1st (t1, t2, t3, t4, t5, t6, t7, t8, t9) = do match <- rotations t1 solve2nd (match, t2, t3, t4, t5, t6, t7, t8, t9)
In the first position, any tile in any rotation is legal, so solve1st only enumerates all four rotations of t1 and calls solve2nd for each.
The final step is to compose allPermutations with solve1st:
solutions :: [(Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile, Tile)] solutions = allPermutations >>= solve1st
Running this in GHCi on my 4½-year old laptop produces all 16 solutions in approximately 22 seconds.
Evaluation #
Is that good performance? Well, it turns out that it's possible to substantially improve on the situation. As I've mentioned a couple of times, so far I've been running the program from GHCi, the Haskell REPL. Most of the 22 seconds are spent interpreting or compiling the code.
If I compile the code with some optimizations turned on, the executable runs in approximately 300 ms. That seems quite decent, if I may say so.
I can think of a few tweaks to the code that might conceivably improve things even more, but when I test, there's no discernable difference. Thus, I'll keep the code as shown here.
Here's one of the solutions:

The information on the box claims that there's two solutions. Why does the code shown here produce 16 solutions?
There's a good explanation for that. Recall that two of the tiles are identical. In the above solution picture, it's tile 1 and 3, although they're rotated 90° in relation to each other. This implies that you could take tile 1, rotate it counter-clockwise and put it in position 3, while simultaneously taking tile 3, rotating it clockwise, and putting it in position 1. Visually, you can't tell the difference, so they don't count as two distinct solutions. The algorithm, however, doesn't make that distinction, so it enumerates what is effectively the same solution twice.
Not surprising, it turns out that all 16 solutions are doublets in that way. We can confirm that by evaluating length $ nub solutions, which returns 8.
Eight solutions are, however, still four times more than two. Can you figure out what's going on?
The algorithm also enumerates four rotations of each solution. Once we take this into account, there's only two visually distinct solutions left. One of them is shown above. I also have a picture of the other one, but I'm not going to totally spoil things for you.
Conclusion #
When I was eight, I might have had the time and the patience to actually lay the puzzle. Despite the incredibly bad odds, I vaguely remember finally solving it. There must be some more holistic processing going on in the brain, if even a kid can solve the puzzle, because it seems inconceivable that it should be done as described here.
Today, I don't care for that kind of puzzle in analog form, but I did, on the other hand, find it an interesting programming exercise.
The code could be smaller, but I like it as it is. While a bit on the verbose side, I think that it communicates well what's going on.
I was pleasantly surprised that I managed to get execution time down to 300 ms. I'd honestly not expected that when I started.
FSZipper in C#
Another functional model of a file system, with code examples in C#.
This article is part of a series about Zippers. In this one, I port the FSZipper data structure from the Learn You a Haskell for Great Good! article Zippers.
A word of warning: I'm assuming that you're familiar with the contents of that article, so I'll skip the pedagogical explanations; I can hardly do it better that it's done there. Additionally, I'll make heavy use of certain standard constructs to port Haskell code, most notably Church encoding to model sum types in languages that don't natively have them. Such as C#. In some cases, I'll implement the Church encoding using the data structure's catamorphism. Since the cyclomatic complexity of the resulting code is quite low, you may be able to follow what's going on even if you don't know what Church encoding or catamorphisms are, but if you want to understand the background and motivation for that style of programming, you can consult the cited resources.
The code shown in this article is available on GitHub.
File system item initialization and structure #
If you haven't already noticed, Haskell (and other statically typed functional programming languages like F#) makes heavy use of sum types, and the FSZipper example is no exception. It starts with a one-liner to define a file system item, which may be either a file or a folder. In C# we must instead use a class:
public sealed class FSItem
Contrary to the two previous examples, the FSItem class has no generic type parameter. This is because I'm following the Haskell example code as closely as possible, but as I've previously shown, you can model a file hierarchy with a general-purpose rose tree.
Staying consistent with the two previous articles, I'll use Church encoding to model a sum type, and as discussed in the previous article I use a private implementation for that.
private readonly IFSItem imp; private FSItem(IFSItem imp) { this.imp = imp; } public static FSItem CreateFile(string name, string data) { return new(new File(name, data)); } public static FSItem CreateFolder(string name, IReadOnlyCollection<FSItem> items) { return new(new Folder(name, items)); }
Two static creation methods enable client developers to create a single FSItem object, or an entire tree, like the example from the Haskell code, here ported to C#:
private static readonly FSItem myDisk = FSItem.CreateFolder("root", [ FSItem.CreateFile("goat_yelling_like_man.wmv", "baaaaaa"), FSItem.CreateFile("pope_time.avi", "god bless"), FSItem.CreateFolder("pics", [ FSItem.CreateFile("ape_throwing_up.jpg", "bleargh"), FSItem.CreateFile("watermelon_smash.gif", "smash!!"), FSItem.CreateFile("skull_man(scary).bmp", "Yikes!") ]), FSItem.CreateFile("dijon_poupon.doc", "best mustard"), FSItem.CreateFolder("programs", [ FSItem.CreateFile("fartwizard.exe", "10gotofart"), FSItem.CreateFile("owl_bandit.dmg", "mov eax, h00t"), FSItem.CreateFile("not_a_virus.exe", "really not a virus"), FSItem.CreateFolder("source code", [ FSItem.CreateFile("best_hs_prog.hs", "main = print (fix error)"), FSItem.CreateFile("random.hs", "main = print 4") ]) ]) ]);
Since the imp class field is just a private implementation detail, a client developer needs a way to query an FSItem object about its contents.
File system item catamorphism #
Just like the previous article, I'll start with the catamorphism. This is essentially the rose tree catamorphism, just less generic, since FSItem doesn't have a generic type parameter.
public TResult Aggregate<TResult>( Func<string, string, TResult> whenFile, Func<string, IReadOnlyCollection<TResult>, TResult> whenFolder) { return imp.Aggregate(whenFile, whenFolder); }
The Aggregate method delegates to its internal implementation class field, which is defined as the private nested interface IFSItem:
private interface IFSItem { TResult Aggregate<TResult>( Func<string, string, TResult> whenFile, Func<string, IReadOnlyCollection<TResult>, TResult> whenFolder); }
As discussed in the previous article, the interface is hidden away because it's only a vehicle for polymorphism. It's not intended for client developers to be used (although that would be benign) or implemented (which could break encapsulation). There are only, and should ever only be, two implementations. The one that represents a file is the simplest:
private sealed record File(string Name, string Data) : IFSItem { public TResult Aggregate<TResult>( Func<string, string, TResult> whenFile, Func<string, IReadOnlyCollection<TResult>, TResult> whenFolder) { return whenFile(Name, Data); } }
The File record's Aggregate method unconditionally calls the supplied whenFile function argument with the Name and Data that was originally supplied via its constructor.
The Folder implementation is a bit trickier, mostly due to its recursive nature, but also because I wanted it to have structural equality.
private sealed class Folder : IFSItem { private readonly string name; private readonly IReadOnlyCollection<FSItem> items; public Folder(string Name, IReadOnlyCollection<FSItem> Items) { name = Name; items = Items; } public TResult Aggregate<TResult>( Func<string, string, TResult> whenFile, Func<string, IReadOnlyCollection<TResult>, TResult> whenFolder) { return whenFolder( name, items.Select(i => i.Aggregate(whenFile, whenFolder)).ToList()); } public override bool Equals(object? obj) { return obj is Folder folder && name == folder.name && items.SequenceEqual(folder.items); } public override int GetHashCode() { return HashCode.Combine(name, items); } }
It, too, unconditionally calls one of the two functions passed to its Aggregate method, but this time whenFolder. It does that, however, by first recursively calling Aggregate within a Select expression. It needs to do that because the whenFolder function expects the subtree to have been already converted to values of the TResult return type. This is a common pattern with catamorphisms, and takes a bit of time getting used to. You can see similar examples in the articles Tree catamorphism, Rose tree catamorphism, Full binary tree catamorphism, as well as the previous one in this series.
I also had to make Folder a class rather than a record, because I wanted the type to have structural equality, and you can't override Equals on records (and if the base class library has any collection type with structural equality, I'm not aware of it).
File system item Church encoding #
True to the structure of the previous article, the catamorphism doesn't look quite like a Church encoding, but it's possible to define the latter from the former.
public TResult Match<TResult>( Func<string, string, TResult> whenFile, Func<string, IReadOnlyCollection<FSItem>, TResult> whenFolder) { return Aggregate( whenFile: (name, data) => (item: CreateFile(name, data), result: whenFile(name, data)), whenFolder: (name, pairs) => { var items = pairs.Select(i => i.item).ToList(); return (CreateFolder(name, items), whenFolder(name, items)); }).result; }
The trick is the same as in the previous article: Build up an intermediate tuple that contains both the current item as well as the result being accumulated. Once the Aggregate method returns, the Match method returns only the result part of the resulting tuple.
I implemented the whenFolder expression as a code block, because both tuple elements needed the items collection. You can inline the Select expression, but that would cause it to run twice. That's probably a premature optimization, but it also made the code a bit shorter, and, one may hope, a bit more readable.
Fily system breadcrumb #
Finally, things seem to be becoming a little easier. The port of FSCrumb is straightforward.
public sealed class FSCrumb { public FSCrumb( string name, IReadOnlyCollection<FSItem> left, IReadOnlyCollection<FSItem> right) { Name = name; Left = left; Right = right; } public string Name { get; } public IReadOnlyCollection<FSItem> Left { get; } public IReadOnlyCollection<FSItem> Right { get; } public override bool Equals(object? obj) { return obj is FSCrumb crumb && Name == crumb.Name && Left.SequenceEqual(crumb.Left) && Right.SequenceEqual(crumb.Right); } public override int GetHashCode() { return HashCode.Combine(Name, Left, Right); } }
The only reason this isn't a record is, once again, that I want to override Equals so that the type can have structural equality. Visual Studio wants me to convert to a primary constructor. That would simplify the code a bit, but actually not that much.
(I'm still somewhat conservative in my choice of new C# language features. Not that I have anything against primary constructors which, after all, F# has had forever. The reason I'm holding back is for didactic reasons. Not every reader is on the latest language version, and some readers may be using another programming language entirely. On the other hand, primary constructors seem natural and intuitive, so I may start using them here on the blog as well. I don't think that they're going to be much of a barrier to understanding.)
Now that we have both the data type we want to zip, as well as the breadcrumb type we need, we can proceed to add the Zipper.
File system Zipper #
The FSZipper C# class fills the position of the eponymous Haskell type alias. Data structure and initialization is straightforward.
public sealed class FSZipper { private FSZipper(FSItem fSItem, IReadOnlyCollection<FSCrumb> breadcrumbs) { FSItem = fSItem; Breadcrumbs = breadcrumbs; } public FSZipper(FSItem fSItem) : this(fSItem, []) { } public FSItem FSItem { get; } public IReadOnlyCollection<FSCrumb> Breadcrumbs { get; } // Methods follow here...
True to the style I've already established, I've made the master constructor private in order to highlight that the Breadcrumbs are the responsibility of the FSZipper class itself. It's not something client code need worry about.
Going down #
The Haskell Zippers article introduces fsUp before fsTo, but if we want to see some example code, we need to navigate to somewhere before we can navigate up. Thus, I'll instead start with the function that navigates to a child node.
public FSZipper? GoTo(string name) { return FSItem.Match( (_, _) => null, (folderName, items) => { FSItem? item = null; var ls = new List<FSItem>(); var rs = new List<FSItem>(); foreach (var i in items) { if (item is null && i.IsNamed(name)) item = i; else if (item is null) ls.Add(i); else rs.Add(i); } if (item is null) return null; return new FSZipper( item, Breadcrumbs.Prepend(new FSCrumb(folderName, ls, rs)).ToList()); }); }
This is by far the most complicated navigation we've seen so far, and I've even taken the liberty of writing an imperative implementation. It's not that I don't know how I could implement it in a purely functional fashion, but I've chosen this implementation for a couple of reasons. The first of which is that, frankly, it was easier this way.
This stems from the second reason: That the .NET base class library, as far as I know, offers no functionality like Haskell's break function. I could have written such a function myself, but felt that it was too much of a digression, even for me. Maybe I'll do that another day. It might make for a nice little exercise.
The third reason is that C# doesn't afford pattern matching on sequences, in the shape of destructuring the head and the tail of a list. (Not that I know of, anyway, but that language changes rapidly at the moment, and it does have some pattern-matching features now.) This means that I have to check item for null anyway.
In any case, while the implementation is imperative, an external caller can't tell. The GoTo method is still referentially transparent. Which means that it fits in your head.
You may have noticed that the implementation calls IsNamed, which is also new.
public bool IsNamed(string name) { return Match((n, _) => n == name, (n, _) => n == name); }
This is an instance method I added to FSItem.
In summary, the GoTo method enables client code to navigate down in the file hierarchy, as this unit test demonstrates:
[Fact] public void GoToSkullMan() { var sut = new FSZipper(myDisk); var actual = sut.GoTo("pics")?.GoTo("skull_man(scary).bmp"); Assert.NotNull(actual); Assert.Equal( FSItem.CreateFile("skull_man(scary).bmp", "Yikes!"), actual.FSItem); }
The example is elementary. First go to the pics folder, and from there to the skull_man(scary).bmp.
Going up #
Going back up the hierarchy isn't as complicated.
public FSZipper? GoUp() { if (Breadcrumbs.Count == 0) return null; var head = Breadcrumbs.First(); var tail = Breadcrumbs.Skip(1); return new FSZipper( FSItem.CreateFolder(head.Name, [.. head.Left, FSItem, .. head.Right]), tail.ToList()); }
If the Breadcrumbs collection is empty, we're already at the root, in which case we can't go further up. In that case, the GoUp method returns null, as does the GoTo method if it can't find an item with the desired name. This possibility is explicitly indicated by the FSZipper? return type; notice the question mark, which indicates that the value may be null. If you're working in a context or language where that feature isn't available, you may instead consider taking advantage of the Maybe monad (which is also what you'd idiomatically do in Haskell).
If Breadcrumbs is not empty, it means that there's a place to go up to. It also implies that the previous operation navigated down, and the only way that's possible is if the previous node was a folder. Thus, the GoUp method knows that it needs to reconstitute a folder, and from the head breadcrumb, it knows that folder's name, and what was originally to the Left and Right of the Zipper's FSItem property.
This unit test demonstrates how client code may use the GoUp method:
[Fact] public void GoUpFromSkullMan() { var sut = new FSZipper(myDisk); // This is the same as the GoToSkullMan test var newFocus = sut.GoTo("pics")?.GoTo("skull_man(scary).bmp"); var actual = newFocus?.GoUp()?.GoTo("watermelon_smash.gif"); Assert.NotNull(actual); Assert.Equal( FSItem.CreateFile("watermelon_smash.gif", "smash!!"), actual.FSItem); }
This test first repeats the navigation also performed by the other test, then uses GoUp to go one level up, which finally enables it to navigate to the watermelon_smash.gif file.
Renaming a file or folder #
A Zipper enables you to navigate a data structure, but you can also use it to modify the element in focus. One option is to rename a file or folder.
public FSZipper Rename(string newName) { return new FSZipper( FSItem.Match( (_, dat) => FSItem.CreateFile(newName, dat), (_, items) => FSItem.CreateFolder(newName, items)), Breadcrumbs); }
The Rename method 'pattern-matches' on the 'current' FSItem and in both cases creates a new file or folder with the new name. Since it doesn't need the old name for anything, it uses the wildcard pattern to ignore that value. This operation is always possible, so the return type is FSZipper, without a question mark, indicating that the method never returns null.
The following unit test replicates the Haskell article's example by renaming the pics folder to cspi.
[Fact] public void RenamePics() { var sut = new FSZipper(myDisk); var actual = sut.GoTo("pics")?.Rename("cspi").GoUp(); Assert.NotNull(actual); Assert.Empty(actual.Breadcrumbs); Assert.Equal( FSItem.CreateFolder("root", [ FSItem.CreateFile("goat_yelling_like_man.wmv", "baaaaaa"), FSItem.CreateFile("pope_time.avi", "god bless"), FSItem.CreateFolder("cspi", [ FSItem.CreateFile("ape_throwing_up.jpg", "bleargh"), FSItem.CreateFile("watermelon_smash.gif", "smash!!"), FSItem.CreateFile("skull_man(scary).bmp", "Yikes!") ]), FSItem.CreateFile("dijon_poupon.doc", "best mustard"), FSItem.CreateFolder("programs", [ FSItem.CreateFile("fartwizard.exe", "10gotofart"), FSItem.CreateFile("owl_bandit.dmg", "mov eax, h00t"), FSItem.CreateFile("not_a_virus.exe", "really not a virus"), FSItem.CreateFolder("source code", [ FSItem.CreateFile("best_hs_prog.hs", "main = print (fix error)"), FSItem.CreateFile("random.hs", "main = print 4") ]) ]) ]), actual.FSItem); }
Since the test uses GoUp after Rename, the actual value contains the entire tree, while the Breadcrumbs collection is empty.
Adding a new file #
Finally, we can add a new file to a folder.
public FSZipper? Add(FSItem item) { return FSItem.Match<FSZipper?>( whenFile: (_, _) => null, whenFolder: (name, items) => new FSZipper( FSItem.CreateFolder(name, items.Prepend(item).ToList()), Breadcrumbs)); }
This operation may fail, since we can't add a file to a file. This is, again, clearly indicated by the return type, which allows null.
This implementation adds the file to the start of the folder, but it would also be possible to add it at the end. I would consider that slightly more idiomatic in C#, but here I've followed the Haskell example code, which conses the new item to the beginning of the list. As is idiomatic in Haskell.
The following unit test reproduces the Haskell article's example.
[Fact] public void AddPic() { var sut = new FSZipper(myDisk); var actual = sut.GoTo("pics")?.Add(FSItem.CreateFile("heh.jpg", "lol"))?.GoUp(); Assert.NotNull(actual); Assert.Equal( FSItem.CreateFolder("root", [ FSItem.CreateFile("goat_yelling_like_man.wmv", "baaaaaa"), FSItem.CreateFile("pope_time.avi", "god bless"), FSItem.CreateFolder("pics", [ FSItem.CreateFile("heh.jpg", "lol"), FSItem.CreateFile("ape_throwing_up.jpg", "bleargh"), FSItem.CreateFile("watermelon_smash.gif", "smash!!"), FSItem.CreateFile("skull_man(scary).bmp", "Yikes!") ]), FSItem.CreateFile("dijon_poupon.doc", "best mustard"), FSItem.CreateFolder("programs", [ FSItem.CreateFile("fartwizard.exe", "10gotofart"), FSItem.CreateFile("owl_bandit.dmg", "mov eax, h00t"), FSItem.CreateFile("not_a_virus.exe", "really not a virus"), FSItem.CreateFolder("source code", [ FSItem.CreateFile("best_hs_prog.hs", "main = print (fix error)"), FSItem.CreateFile("random.hs", "main = print 4") ]) ]) ]), actual.FSItem); Assert.Empty(actual.Breadcrumbs); }
This example also follows the edit with a GoUp call, with the effect that the Zipper is once more focused on the entire tree. The assertion verifies that the new heh.jpg file is the first file in the pics folder.
Conclusion #
The code for FSZipper is actually a bit simpler than for the binary tree. This, I think, is mostly attributable to the FSZipper having fewer constituent sum types. While sum types are trivial, and extraordinarily useful in languages that natively support them, they require a lot of boilerplate in a language like C#.
Do you need something like FSZipper in C#? Probably not. As I've already discussed, this article series mostly exists as a programming exercise.
Functor products
A tuple or class of functors is also a functor. An article for object-oriented developers.
This article is part of a series of articles about functor relationships. In this one you'll learn about a universal composition of functors. In short, if you have a product type of functors, that data structure itself gives rise to a functor.
Together with other articles in this series, this result can help you answer questions such as: Does this data structure form a functor?
Since functors tend to be quite common, and since they're useful enough that many programming languages have special support or syntax for them, the ability to recognize a potential functor can be useful. Given a type like Foo<T> (C# syntax) or Bar<T1, T2>, being able to recognize it as a functor can come in handy. One scenario is if you yourself have just defined such a data type. Recognizing that it's a functor strongly suggests that you should give it a Select method in C#, a map function in F#, and so on.
Not all generic types give rise to a (covariant) functor. Some are rather contravariant functors, and some are invariant.
If, on the other hand, you have a data type which is a product of two or more (covariant) functors with the same type parameter, then the data type itself gives rise to a functor. You'll see some examples in this article.
Abstract shape #
Before we look at some examples found in other code, it helps if we know what we're looking for. Most (if not all?) languages support product types. In canonical form, they're just tuples of values, but in an object-oriented language like C#, such types are typically classes.
Imagine that you have two functors F and G, and you're now considering a data structure that contains a value of both types.
public sealed class FAndG<T> { public FAndG(F<T> f, G<T> g) { F = f; G = g; } public F<T> F { get; } public G<T> G { get; } // Methods go here...
The name of the type is FAndG<T> because it contains both an F<T> object and a G<T> object.
Notice that it's an essential requirement that the individual functors (here F and G) are parametrized by the same type parameter (here T). If your data structure contains F<T1> and G<T2>, the following 'theorem' doesn't apply.
The point of this article is that such an FAndG<T> data structure forms a functor. The Select implementation is quite unsurprising:
public FAndG<TResult> Select<TResult>(Func<T, TResult> selector) { return new FAndG<TResult>(F.Select(selector), G.Select(selector)); }
Since we've assumed that both F and G already are functors, they must come with some projection function. In C# it's idiomatically called Select, while in F# it'd typically be called map:
// ('a -> 'b) -> FAndG<'a> -> FAndG<'b> let map f fandg = { F = F.map f fandg.F; G = G.map f fandg.G }
assuming a record type like
type FAndG<'a> = { F : F<'a>; G : G<'a> }
In both the C# Select example and the F# map function, the composed functor passes the function argument (selector or f) to both F and G and uses it to map both constituents. It then composes a new product from these individual results.
I'll have more to say about how this generalizes to a product of more than two functors, but first, let's consider some examples.
List Zipper #
One of the simplest example I can think of is a List Zipper, which in Haskell is nothing but a type alias of a tuple of lists:
type ListZipper a = ([a],[a])
In the article A List Zipper in C# you saw how the ListZipper<T> class composes two IEnumerable<T> objects.
private readonly IEnumerable<T> values; public IEnumerable<T> Breadcrumbs { get; } private ListZipper(IEnumerable<T> values, IEnumerable<T> breadcrumbs) { this.values = values; Breadcrumbs = breadcrumbs; }
Since we already know that sequences like IEnumerable<T> form functors, we now know that so must ListZipper<T>. And indeed, the Select implementation looks similar to the above 'shape outline'.
public ListZipper<TResult> Select<TResult>(Func<T, TResult> selector) { return new ListZipper<TResult>(values.Select(selector), Breadcrumbs.Select(selector)); }
It passes the selector function to the Select method of both values and Breadcrumbs, and composes the results into a new ListZipper<TResult>.
While this example is straightforward, it may not be the most compelling, because ListZipper<T> composes two identical functors: IEnumerable<T>. The knowledge that functors compose is more general than that.
Non-empty collection #
Next after the above List Zipper, the simplest example I can think of is a non-empty list. On this blog I originally introduced it in the article Semigroups accumulate, but here I'll use the variant from NonEmpty catamorphism. It composes a single value of the type T with an IReadOnlyCollection<T>.
public NonEmptyCollection(T head, params T[] tail) { if (head == null) throw new ArgumentNullException(nameof(head)); this.Head = head; this.Tail = tail; } public T Head { get; } public IReadOnlyCollection<T> Tail { get; }
The Tail, being an IReadOnlyCollection<T>, easily forms a functor, since it's a kind of list. But what about Head, which is a 'naked' T value? Does that form a functor? If so, which one?
Indeed, a 'naked' T value is isomorphic to the Identity functor. This situation is an example of how knowing about the Identity functor is useful, even if you never actually write code that uses it. Once you realize that T is equivalent with a functor, you've now established that NonEmptyCollection<T> composes two functors. Therefore, it must itself form a functor, and you realize that you can give it a Select method.
public NonEmptyCollection<TResult> Select<TResult>(Func<T, TResult> selector) { return new NonEmptyCollection<TResult>(selector(Head), Tail.Select(selector).ToArray()); }
Notice that even though we understand that T is equivalent to the Identity functor, there's no reason to actually wrap Head in an Identity<T> container just to call Select on it and unwrap the result. Rather, the above Select implementation directly invokes selector with Head. It is, after all, a function that takes a T value as input and returns a TResult object as output.
Ranges #
It's hard to come up with an example that's both somewhat compelling and realistic, and at the same time prototypically pure. Stripped of all 'noise' functor products are just tuples, but that hardly makes for a compelling example. On the other hand, most other examples I can think of combine results about functors where they compose in more than one way. Not only as products, but also as sums of functors, as well as nested compositions. You'll be able to read about these in future articles, but for the next examples, you'll have to accept some claims about functors at face value.
In Range as a functor you saw how both Endpoint<T> and Range<T> are functors. The article shows functor implementations for each, in both C#, F#, and Haskell. For now we'll ignore the deeper underlying reason why Endpoint<T> forms a functor, and instead focus on Range<T>.
In Haskell I never defined an explicit Range type, but rather just treated ranges as tuples. As stated repeatedly already, tuples are the essential products, so if you accept that Endpoint gives rise to a functor, then a 'range tuple' does, too.
In F# Range is defined like this:
type Range<'a> = { LowerBound : Endpoint<'a>; UpperBound : Endpoint<'a> }
Such a record type is also easily identified as a product type. In a sense, we can think of a record type as a 'tuple with metadata', where the metadata contains names of elements.
In C# Range<T> is a class with two Endpoint<T> fields.
private readonly Endpoint<T> min; private readonly Endpoint<T> max; public Range(Endpoint<T> min, Endpoint<T> max) { this.min = min; this.max = max; }
In a sense, you can think of such an immutable class as equivalent to a record type, only requiring substantial ceremony. The point is that because a range is a product of two functors, it itself gives rise to a functor. You can see all the implementations in Range as a functor.
Binary tree Zipper #
In A Binary Tree Zipper in C# you saw that the BinaryTreeZipper<T> class has two class fields:
public BinaryTree<T> Tree { get; } public IEnumerable<Crumb<T>> Breadcrumbs { get; }
Both have the same generic type parameter T, so the question is whether BinaryTreeZipper<T> may form a functor? We now know that the answer is affirmative if BinaryTree<T> and IEnumerable<Crumb<T>> are both functors.
For now, believe me when I claim that this is the case. This means that you can add a Select method to the class:
public BinaryTreeZipper<TResult> Select<TResult>(Func<T, TResult> selector) { return new BinaryTreeZipper<TResult>( Tree.Select(selector), Breadcrumbs.Select(c => c.Select(selector))); }
By now, this should hardly be surprising: Call Select on each constituent functor and create a proper return value from the results.
Higher arities #
All examples have involved products of only two functors, but the result generalizes to higher arities. To gain an understanding of why, consider that it's always possible to rewrite tuples of higher arities as nested pairs. As an example, a triple like (42, "foo", True) can be rewritten as (42, ("foo", True)) without loss of information. The latter representation is a pair (a two-tuple) where the first element is 42, but the second element is another pair. These two representations are isomorphic, meaning that we can go back and forth without losing data.
By induction you can generalize this result to any arity. The point is that the only data type you need to describe a product is a pair.
Haskell's base library defines a specialized container called Product for this very purpose: If you have two Functor instances, you can Pair them up, and they become a single Functor.
Let's start with a Pair of Maybe and a list:
ghci> Pair (Just "foo") ["bar", "baz", "qux"] Pair (Just "foo") ["bar","baz","qux"]
This is a single 'object', if you will, that composes those two Functor instances. This means that you can map over it:
ghci> elem 'b' <$> Pair (Just "foo") ["bar", "baz", "qux"] Pair (Just False) [True,True,False]
Here I've used the infix <$> operator as an alternative to fmap. By composing with elem 'b', I'm asking every value inside the container whether or not it contains the character b. The Maybe value doesn't, while the first two list elements do.
If you want to compose three, rather than two, Functor instances, you just nest the Pairs, just like you can nest tuples:
ghci> elem 'b' <$> Pair (Identity "quux") (Pair (Just "foo") ["bar", "baz", "qux"]) Pair (Identity False) (Pair (Just False) [True,True,False])
This example now introduces the Identity container as a third Functor instance. I could have used any other Functor instance instead of Identity, but some of them are more awkward to create or display. For example, the Reader or State functors have no Show instances in Haskell, meaning that GHCi doesn't know how to print them as values. Other Functor instances didn't work as well for the example, since they tend to be more awkward to create. As an example, any non-trivial Tree requires substantial editor space to express.
Conclusion #
A product of functors may itself be made a functor. The examples shown in this article are all constrained to two functors, but if you have a product of three, four, or more functors, that product still gives rise to a functor.
This is useful to know, particularly if you're working in a language with only partial support for functors. Mainstream languages aren't going to automatically turn such products into functors, in the way that Haskell's Product container almost does. Thus, knowing when you can safely give your generic types a Select method or map function may come in handy.
There are more rules like this one. The next article examines another.
Next: Functor sums.
A Binary Tree Zipper in C#
A port of another Haskell example, still just because.
This article is part of a series about Zippers. In this one, I port the Zipper data structure from the Learn You a Haskell for Great Good! article also called Zippers.
A word of warning: I'm assuming that you're familiar with the contents of that article, so I'll skip the pedagogical explanations; I can hardly do it better that it's done there. Additionally, I'll make heavy use of certain standard constructs to port Haskell code, most notably Church encoding to model sum types in languages that don't natively have them. Such as C#. In some cases, I'll implement the Church encoding using the data structure's catamorphism. Since the cyclomatic complexity of the resulting code is quite low, you may be able to follow what's going on even if you don't know what Church encoding or catamorphisms are, but if you want to understand the background and motivation for that style of programming, you can consult the cited resources.
The code shown in this article is available on GitHub.
Binary tree initialization and structure #
In the Haskell code, the binary Tree type is a recursive sum type, defined on a single line of code. C#, on the other hand, has no built-in language construct that supports sum types, so a more elaborate solution is required. At least two options are available to us. One is to model a sum type as a Visitor. Another is to use Church encoding. In this article, I'll do the latter.
I find the type name (Tree) used in the Zippers article a bit too vague, and since I consider explicit better than implicit, I'll use a more precise class name:
public sealed class BinaryTree<T>
Even so, there are different kinds of binary trees. In a previous article I've shown a catamorphism for a full binary tree. This variation is not as strict, since it allows a node to have zero, one, or two children. Or, strictly speaking, a node always has exactly two children, but both, or one of them, may be empty. BinaryTree<T> uses Church encoding to distinguish between the two, but we'll return to that in a moment.
First, we'll examine how the class allows initialization:
private readonly IBinaryTree root; private BinaryTree(IBinaryTree root) { this.root = root; } public BinaryTree() : this(Empty.Instance) { } public BinaryTree(T value, BinaryTree<T> left, BinaryTree<T> right) : this(new Node(value, left.root, right.root)) { }
The class uses a private root object to implement behaviour, and constructor chaining for initialization. The master constructor is private, since the IBinaryTree interface is private. The parameterless constructor implicitly indicates an empty node, whereas the other public constructor indicates a node with a value and two children. Yes, I know that I just wrote that explicit is better than implicit, but it turns out that with the target-typed new operator feature in C#, constructing trees in code becomes easier with this design choice:
BinaryTree<int> sut = new( 42, new(), new(2, new(), new()));
As the variable name suggests, I've taken this code example from a unit test.
Private interface #
The class delegates method calls to the root field, which is an instance of the private, nested IBinaryTree interface:
private interface IBinaryTree { TResult Aggregate<TResult>( Func<TResult> whenEmpty, Func<T, TResult, TResult, TResult> whenNode); }
Why is IBinaryTree a private interface? Why does that interface even exist?
To be frank, I could have chosen another implementation strategy. Since there's only two mutually exclusive alternatives (node or empty), I could also have indicated which is which with a Boolean flag. You can see an example of that implementation tactic in the Table class in the sample code that accompanies Code That Fits in Your Head.
Using a Boolean flag, however, only works when there are exactly two choices. If you have three or more, things because more complicated. You could try to use an enum, but in most languages, these tend to be nothing but glorified integers, and are typically not type-safe. If you define a three-way enum, there's no guarantee that a value of that type takes only one of these three values, and a good compiler will typically insist that you check for any other value as well. The C# compiler certainly does.
Church encoding offers a better alternative, but since it makes use of polymorphism, the most idiomatic choice in C# is either an interface or a base class. Since I favour interfaces over base classes, that's what I've chosen here, but for the purposes of this little digression, it makes no difference: The following argument applies to base classes as well.
An interface (or base class) suggests to users of an API that they can implement it in order to extend behaviour. That's an impression I don't wish to give client developers. The purpose of the interface is exclusively to enable double dispatch to work. There's only two implementations of the IBinaryTree interface, and under no circumstances should there be more.
The interface is an implementation detail, which is why both it, and its implementations, are private.
Binary tree catamorphism #
The IBinaryTree interface defines a catamorphism for the BinaryTree<T> class. Since we may often view a catamorphism as a sort of 'generalized fold', and since these kinds of operations in C# are typically called Aggregate, that's what I've called the method.
An aggregate function affords a way to traverse a data structure and collect information into a single value, here of type TResult. The return type may, however, be a complex type, including another BinaryTree<T>. You'll see examples of complex return values later in this article.
As already discussed, there are exactly two implementations of IBinaryTree. The one representing an empty node is the simplest:
private sealed class Empty : IBinaryTree { public readonly static Empty Instance = new(); private Empty() { } public TResult Aggregate<TResult>( Func<TResult> whenEmpty, Func<T, TResult, TResult, TResult> whenNode) { return whenEmpty(); } }
The Aggregate implementation unconditionally calls the supplied whenEmpty function, which returns some TResult value unknown to the Empty class.
Although not strictly necessary, I've made the class a Singleton. Since I like to take advantage of structural equality to write better tests, it was either that, or overriding Equals and GetHashCode.
The other implementation gets around that problem by being a record:
private sealed record Node(T Value, IBinaryTree Left, IBinaryTree Right) : IBinaryTree { public TResult Aggregate<TResult>( Func<TResult> whenEmpty, Func<T, TResult, TResult, TResult> whenNode) { return whenNode( Value, Left.Aggregate(whenEmpty, whenNode), Right.Aggregate(whenEmpty, whenNode)); } }
It, too, unconditionally calls one of the two functions passed to its Aggregate method, but this time whenNode. It does that, however, by first recursively calling Aggregate on both Left and Right. It needs to do that because the whenNode function expects the subtrees to have been already converted to values of the TResult return type. This is a common pattern with catamorphisms, and takes a bit of time getting used to. You can see similar examples in the articles Tree catamorphism, Rose tree catamorphism, and Full binary tree catamorphism.
The BinaryTree<T> class defines a public Aggregate method that delegates to its root field:
public TResult Aggregate<TResult>( Func<TResult> whenEmpty, Func<T, TResult, TResult, TResult> whenNode) { return root.Aggregate(whenEmpty, whenNode); }
The astute reader may now remark that the Aggregate method doesn't look like a Church encoding.
Binary tree Church encoding #
A Church encoding will typically have a Match method that enables client code to match on all the alternative cases in the sum type, without those confusing already-converted TResult values. It turns out that you can implement the desired Match method with the Aggregate method.
One of the advantages of doing meaningless coding exercises like this one is that you can pursue various ideas that interest you. One idea that interests me is the potential universality of catamorphisms. I conjecture that a catamorphism is an algebraic data type's universal API, and that you can implement all other methods or functions with it. I admit that I haven't done much research in the form of perusing existing literature, but at least it seems to be the case conspicuously often.
As it is here.
public TResult Match<TResult>( Func<TResult> whenEmpty, Func<T, BinaryTree<T>, BinaryTree<T>, TResult> whenNode) { return root .Aggregate( () => (tree: new BinaryTree<T>(), result: whenEmpty()), (x, l, r) => ( new BinaryTree<T>(x, l.tree, r.tree), whenNode(x, l.tree, r.tree))) .result; }
Now, I readily admit that it took me a couple of hours tossing and turning in my bed before this solution came to me. I don't find it intuitive at all, but it works.
The Aggregate method requires that the whenNode function's left and right values are of the same TResult type as the return type. How do we consolidate that requirement with the Match method's variation, where its whenNode function requires the left and right values to be BinaryTree<T> values, but the return type still TResult?
The way out of this conundrum, it turns out, is to combine both in a tuple. Thus, when Match calls Aggregate, the implied TResult type is not the TResult visible in the Match method declaration. Rather, it's inferred to be of the type (BinaryTree<T>, TResult). That is, a tuple where the first element is a BinaryTree<T> value, and the second element is a TResult value. The C# compiler's type inference engine then figures out that (BinaryTree<T>, TResult) must also be the return type of the Aggregate method call.
That's not what Match should return, but the second tuple element contains a value of the correct type, so it returns that. Since I've given the tuple elements names, the Match implementation accomplishes that by returning the result tuple field.
Breadcrumbs #
That's just the tree that we want to zip. So far, we can only move from root to branches, but not the other way. Before we can define a Zipper for the tree, we need a data structure to store breadcrumbs (the navigation log, if you will).
In Haskell it's just another one-liner, but in C# this requires another full-fledged class:
public sealed class Crumb<T>
It's another sum type, so once more, I make the constructor private and use a private class field for the implementation:
private readonly ICrumb imp; private Crumb(ICrumb imp) { this.imp = imp; } internal static Crumb<T> Left(T value, BinaryTree<T> right) { return new(new LeftCrumb(value, right)); } internal static Crumb<T> Right(T value, BinaryTree<T> left) { return new(new RightCrumb(value, left)); }
To stay consistent throughout the code base, I also use Church encoding to distinguish between a Left and Right breadcrumb, and the technique is similar. First, define a private interface:
private interface ICrumb { TResult Match<TResult>( Func<T, BinaryTree<T>, TResult> whenLeft, Func<T, BinaryTree<T>, TResult> whenRight); }
Then, use private nested types to implement the interface.
private sealed record LeftCrumb(T Value, BinaryTree<T> Right) : ICrumb { public TResult Match<TResult>( Func<T, BinaryTree<T>, TResult> whenLeft, Func<T, BinaryTree<T>, TResult> whenRight) { return whenLeft(Value, Right); } }
The RightCrumb record is essentially just the 'mirror image' of the LeftCrumb record, and just as was the case with BinaryTree<T>, the Crumb<T> class exposes an externally accessible Match method that just delegates to the private class field:
public TResult Match<TResult>( Func<T, BinaryTree<T>, TResult> whenLeft, Func<T, BinaryTree<T>, TResult> whenRight) { return imp.Match(whenLeft, whenRight); }
Finally, all the building blocks are ready for the actual Zipper.
Zipper data structure and initialization #
In the Haskell code, the Zipper is another one-liner, and really just a type alias. In C#, once more, we're going to need a full class.
public sealed class BinaryTreeZipper<T>
The Haskell article simply calls this type alias Zipper, but I find that name too general, since there's more than one kind of Zipper. I think I understand that the article chooses that name for didactic reasons, but here I've chosen a more consistent disambiguation scheme, so I've named the class BinaryTreeZipper<T>.
The Haskell example is just a type alias for a tuple, and the C# class is similar, although with significantly more ceremony:
public BinaryTree<T> Tree { get; } public IEnumerable<Crumb<T>> Breadcrumbs { get; } private BinaryTreeZipper( BinaryTree<T> tree, IEnumerable<Crumb<T>> breadcrumbs) { Tree = tree; Breadcrumbs = breadcrumbs; } public BinaryTreeZipper(BinaryTree<T> tree) : this(tree, []) { }
I've here chosen to add an extra bit of encapsulation by making the master constructor private. This prevents client code from creating an arbitrary object with breadcrumbs without having navigated through the tree. To be honest, I don't think it violates any contract even if we allow this, but it at least highlights that the Breadcrumbs role is to keep a log of what previously happened to the object.
Navigation #
We can now reproduce the navigation functions from the Haskell article.
public BinaryTreeZipper<T>? GoLeft() { return Tree.Match<BinaryTreeZipper<T>?>( whenEmpty: () => null, whenNode: (x, l, r) => new BinaryTreeZipper<T>( l, Breadcrumbs.Prepend(Crumb.Left(x, r)))); }
Going left 'pattern-matches' on the Tree and, if not empty, constructs a new BinaryTreeZipper object with the left tree, and a Left breadcrumb that stores the 'current' node value and the right subtree. If the 'current' node is empty, on the other hand, the method returns null. This possibility is explicitly indicated by the BinaryTreeZipper<T>? return type; notice the question mark, which indicates that the value may be null. If you're working in a context or language where that feature isn't available, you may instead consider taking advantage of the Maybe monad (which is also what you'd idiomatically do in Haskell).
The GoRight method is similar to GoLeft.
We may also attempt to navigate up in the tree, undoing our last downward move:
public BinaryTreeZipper<T>? GoUp() { if (!Breadcrumbs.Any()) return null; var head = Breadcrumbs.First(); var tail = Breadcrumbs.Skip(1); return head.Match( whenLeft: (x, r) => new BinaryTreeZipper<T>( new BinaryTree<T>(x, Tree, r), tail), whenRight: (x, l) => new BinaryTreeZipper<T>( new BinaryTree<T>(x, l, Tree), tail)); }
This is another operation that may fail. If we're already at the root of the tree, there are no Breadcrumbs, in which case the only option is to return a value indicating that the operation failed; here, null, but in other languages perhaps None or Nothing.
If, on the other hand, there's at least one breadcrumb, the GoUp method uses the most recent one (head) to construct a new BinaryTreeZipper<T> object that reconstitutes the opposite (sibling) subtree and the parent node. It does that by 'pattern-matching' on the head breadcrumb, which enables it to distinguish a left breadcrumb from a right breadcrumb.
Finally, we may keep trying to GoUp until we reach the root:
public BinaryTreeZipper<T> TopMost() { return GoUp()?.TopMost() ?? this; }
You'll see an example of that a little later.
Modifications #
Continuing the port of the Haskell code, we can Modify the current node with a function:
public BinaryTreeZipper<T> Modify(Func<T, T> f) { return new BinaryTreeZipper<T>( Tree.Match( whenEmpty: () => new BinaryTree<T>(), whenNode: (x, l, r) => new BinaryTree<T>(f(x), l, r)), Breadcrumbs); }
This operation always succeeds, since it chooses to ignore the change if the tree is empty. Thus, there's no question mark on the return type, indicating that the method never returns null.
Finally, we may replace a node with a new subtree:
public BinaryTreeZipper<T> Attach(BinaryTree<T> tree) { return new BinaryTreeZipper<T>(tree, Breadcrumbs); }
The following unit test demonstrates a combination of several of the methods shown above:
[Fact] public void AttachAndGoTopMost() { var sut = new BinaryTreeZipper<char>(freeTree); var farLeft = sut.GoLeft()?.GoLeft()?.GoLeft()?.GoLeft(); var actual = farLeft?.Attach(new('Z', new(), new())).TopMost(); Assert.NotNull(actual); Assert.Equal( new('P', new('O', new('L', new('N', new('Z', new(), new()), new()), new('T', new(), new())), new('Y', new('S', new(), new()), new('A', new(), new()))), new('L', new('W', new('C', new(), new()), new('R', new(), new())), new('A', new('A', new(), new()), new('C', new(), new())))), actual.Tree); Assert.Empty(actual.Breadcrumbs); }
The test starts with freeTree (not shown) and first navigates to the leftmost empty node. Here it uses Attach to add a new 'singleton' subtree with the value 'Z'. Finally, it uses TopMost to return to the root node.
In the Assert phase, the test verifies that the actual object contains the expected values.
Conclusion #
The Tree Zipper shown here is a port of the example given in the Haskell Zippers article. As I've already discussed in the introduction article, this data structure doesn't make much sense in C#, where you can easily implement a navigable tree with two-way links. Even if this requires state mutation, you can package such a data structure in a proper object with good encapsulation, so that operations don't leave any dangling pointers or the like.
As far as I can tell, the code shown in this article isn't useful in production code, but I hope that, at least, you still learned something from it. I always learn a new thing or two from doing programming exercises and writing about them, and this was no exception.
In the next article, I continue with the final of the Haskell article's three examples.
Next: FSZipper in C#.
Keeping cross-cutting concerns out of application code
Don't inject third-party dependencies. Use Decorators.
I recently came across a Stack Overflow question that reminded me of a topic I've been meaning to write about for a long time: Cross-cutting concerns.
When it comes to the usual suspects, logging, fault tolerance, caching, the best solution is usually to apply the Decorator pattern.
I often see code that uses Dependency Injection (DI) to inject, say, a logging interface into application code. You can see an example of that in Repeatable execution, as well as a suggestion for a better design. Not surprisingly, the better design involves logging Decorators.
The Stack Overflow question isn't about logging, but rather about fault tolerance; Circuit Breaker, retry policies, timeouts, etc.
Injected concern #
The question does a good job of presenting a minimal, reproducible example. At the outset, the code looks like this:
public class MyApi { private readonly ResiliencePipeline pipeline; private readonly IOrganizationService service; public MyApi(ResiliencePipelineProvider<string> provider, IOrganizationService service) { this.pipeline = provider.GetPipeline("retry-pipeline"); this.service = service; } public List<string> GetSomething(QueryByAttribute query) { var result = this.pipeline.Execute(() => service.RetrieveMultiple(query)); return result.Entities.Cast<string>().ToList(); } }
The Stack Overflow question asks how to test this implementation, but I'd rather take the example as an opportunity to discuss design alternatives. Not surprisingly, it turns out that with a more decoupled design, testing becomes easier, too.
Before we proceed, a few words about this example code. I assume that this isn't Andy Cooke's actual production code. Rather, I interpret it as a reduced example that highlights the actual question. This is important because you might ask: Why bother testing two lines of code?
Indeed, as presented, the GetSomething method is so simple that you may consider not testing it. Thus, I interpret the second line of code as a stand-in for more complicated production code. Hold on to that thought, because once I'm done, that's all that's going to be left, and you may then think that it's so simple that it really doesn't warrant all this hoo-ha.
Coupling #
As shown, the MyApi class is coupled to Polly, because ResiliencePipeline is defined by that library. To be clear, all I've heard is that Polly is a fine library. I've used it for a few projects myself, but I also admit that I haven't that much experience with it. I'd probably use it again the next time I need a Circuit Breaker or similar, so the following discussion isn't a denouncement of Polly. Rather, it applies to all third-party dependencies, or perhaps even dependencies that are part of your language's base library.
Coupling is a major cause of spaghetti code and code rot in general. To write sustainable code, you should be cognizant of coupling. The most decoupled code is code that you can easily delete.
This doesn't mean that you shouldn't use high-quality third-party libraries like Polly. Among myriads of software engineering heuristics, we know that we should be aware of the not-invented-here syndrome.
When it comes to classic cross-cutting concerns, the Decorator pattern is usually a better design than injecting the concern into application code. The above example clearly looks innocuous, but imagine injecting both a ResiliencePipeline, a logger, and perhaps a caching service, and your real application code eventually disappears in 'infrastructure code'.
It's not that we don't want to have these third-party dependencies, but rather that we want to move them somewhere else.
Resilient Decorator #
The concern in the above example is the desire to make the IOrganizationService dependency more resilient. The MyApi class only becomes more resilient as a transitive effect. The first refactoring step, then, is to introduce a resilient Decorator.
public sealed class ResilientOrganizationService( ResiliencePipeline pipeline, IOrganizationService inner) : IOrganizationService { public QueryResult RetrieveMultiple(QueryByAttribute query) { return pipeline.Execute(() => inner.RetrieveMultiple(query)); } }
As Decorators must, this class composes another IOrganizationService while also implementing that interface itself. It does so by being an Adapter over the Polly API.
I've applied Nikola Malovic's 4th law of DI:
"Every constructor of a class being resolved should not have any implementation other then accepting a set of its own dependencies."
Instead of injecting a ResiliencePipelineProvider<string> only to call GetPipeline on it, it just receives a ResiliencePipeline and saves the object for use in the RetrieveMultiple method. It does that via a primary constructor, which is a recent C# language addition. It's just syntactic sugar for Constructor Injection, and as usual F# developers should feel right at home.
Simplifying MyApi #
Now that you have a resilient version of IOrganizationService you don't need to have any Polly code in MyApi. Remove it and simplify:
public class MyApi { private readonly IOrganizationService service; public MyApi(IOrganizationService service) { this.service = service; } public List<string> GetSomething(QueryByAttribute query) { var result = service.RetrieveMultiple(query); return result.Entities.Cast<string>().ToList(); } }
As promised, there's almost nothing left of it now, but I'll remind you that I consider the second line of GetSomething as a stand-in for something more complicated that you might need to test. As it is now, though, testing it is trivial:
[Theory] [InlineData("foo", "bar", "baz")] [InlineData("qux", "quux", "corge")] [InlineData("grault", "garply", "waldo")] public void GetSomething(params string[] expected) { var service = new Mock<IOrganizationService>(); service .Setup(s => s.RetrieveMultiple(new QueryByAttribute())) .Returns(new QueryResult(expected)); var sut = new MyApi(service.Object); var actual = sut.GetSomething(new QueryByAttribute()); Assert.Equal(expected, actual); }
The larger point, however, is that not only have you now managed to keep third-party dependencies out of your application code, you've also simplified it and made it easier to test.
Composition #
You can still create a resilient MyApi object in your Composition Root:
var service = new ResilientOrganizationService(pipeline, inner); var myApi = new MyApi(service);
Decomposing the problem in this way, you decouple your application code from third-party dependencies. You can define ResilientOrganizationService in the application's Composition Root, which also keeps the Polly dependency there. Even so, you can implement MyApi as part of your application layer.
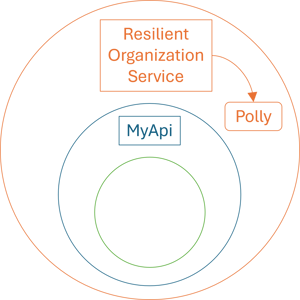
I usually illustrate Ports and Adapters, or, if you will, Clean Architecture as concentric circles, but in this diagram I've skewed the circles to make space for the boxes. In other words, the diagram is 'not to scale'. Ideally, the outermost layer is much smaller and thinner than any of the the other layers. I've also included an inner green layer which indicates the architecture's Domain Model, but since I assume that MyApi is part of some application layer, I've left the Domain Model empty.
Reasons to decouple #
Why is it important to decouple application code from Polly? First, keep in mind that in this discussion Polly is just a stand-in for any third-party dependency. It's up to you as a software architect to decide how you'll structure your code, but third-party dependencies are one of the first things I look for. A third-party component changes with time, and often independently of your base platform. You may have to deal with breaking changes or security patches at inopportune times. The organization that maintains the component may cease to operate. This happens to commercial entities and open-source contributors alike, although for different reasons.
Second, even a top-tier library like Polly will undergo changes. If your time horizon is five to ten years, you'll be surprised how much things change. You may protest that no-one designs software systems with such a long view, but I think that if you ask the business people involved with your software, they most certainly expect your system to last a long time.
I believe that I heard on a podcast that some Microsoft teams had taken a dependency on Polly. Assuming, for the sake of argument, that this is true, while we may not wish to depend on some random open-source component, depending on Polly is safe, right? In the long run, it isn't. Five years ago, you had the same situation with Json.NET, but then Microsoft hired James Newton-King and had him make a JSON API as part of the .NET base library. While Json.NET isn't dead by any means, now you have two competing JSON libraries, and Microsoft uses their own in the frameworks and libraries that they release.
Deciding to decouple your application code from a third-party component is ultimately a question of risk management. It's up to you to make the bet. Do you pay the up-front cost of decoupling, or do you postpone it, hoping it'll never be necessary?
I usually do the former, because the cost is low, and there are other benefits as well. As I've already touched on, unit testing becomes easier.
Configuration #
Since Polly only lives in the Composition Root, you'll also need to define the ResiliencePipeline there. You can write the code that creates that pieline wherever you like, but it might be natural to make it a creation function on the ResilientOrganizationService class:
public static ResiliencePipeline CreatePipeline() { return new ResiliencePipelineBuilder() .AddRetry(new RetryStrategyOptions { MaxRetryAttempts = 4 }) .AddTimeout(TimeSpan.FromSeconds(1)) .Build(); }
That's just an example, and perhaps not what you'd like to do. Perhaps you rather want some of these values to be defined in a configuration file. Thus, this isn't what you have to do, but rather what you could do.
If you use this option, however, you could take the return value of this method and inject it into the ResilientOrganizationService constructor.
Conclusion #
Cross-cutting concerns, like caching, logging, security, or, in this case, fault tolerance, are usually best addressed with the Decorator pattern. In this article, you saw an example of using the Decorator pattern to decouple the concern of fault tolerance from the consumer of the service that you need to handle in a fault-tolerant manner.
The specific example dealt with the Polly library, but the point isn't that Polly is a particularly nasty third-party component that you need to protect yourself against. Rather, it just so happened that I came across a Stack Overflow question that used Polly, and I though it was a a nice example.
As far as I can tell, Polly is actually one of the top .NET open-source packages, so this article is not a denouncement of Polly. It's just a sketch of how to move useful dependencies around in your code base to make sure that they impact your application code as little as possible.
A List Zipper in C#
A port of a Haskell example, just because.
This article is part of a series about Zippers. In this one, I port the ListZipper data structure from the Learn You a Haskell for Great Good! article also called Zippers.
A word of warning: I'm assuming that you're familiar with the contents of that article, so I'll skip the pedagogical explanations; I can hardly do it better that it's done there.
The code shown in this article is available on GitHub.
Initialization and structure #
In the Haskell code, ListZipper is just a type alias, but C# doesn't have that, so instead, we'll have to introduce a class.
public sealed class ListZipper<T> : IEnumerable<T>
Since it implements IEnumerable<T>, it may be used like any other sequence, but it also comes with some special operations that enable client code to move forward and backward, as well as inserting and removing values.
The class has the following fields, properties, and constructors:
private readonly IEnumerable<T> values; public IEnumerable<T> Breadcrumbs { get; } private ListZipper(IEnumerable<T> values, IEnumerable<T> breadcrumbs) { this.values = values; Breadcrumbs = breadcrumbs; } public ListZipper(IEnumerable<T> values) : this(values, []) { } public ListZipper(params T[] values) : this(values.AsEnumerable()) { }
It uses constructor chaining to initialize a ListZipper object with proper encapsulation. Notice that the master constructor is private. This prevents client code from initializing an object with arbitrary Breadcrumbs. Rather, the Breadcrumbs (the log, if you will) is going to be the result of various operations performed by client code, and only the ListZipper class itself can use this constructor.
You may consider the constructor that takes a single IEnumerable<T> as the 'main' public constructor, and the other one as a convenience that enables a client developer to write code like new ListZipper<string>("foo", "bar", "baz").
The class' IEnumerable<T> implementation only enumerates the values:
public IEnumerator<T> GetEnumerator() { return values.GetEnumerator(); }
In other words, when enumerating a ListZipper, you only get the 'forward' values. Client code may still examine the Breadcrumbs, since this is a public property, but it should have little need for that.
(I admit that making Breadcrumbs public is a concession to testability, since it enabled me to write assertions against this property. It's a form of structural inspection, which is a technique that I use much less than I did a decade ago. Still, in this case, while you may argue that it violates information hiding, it at least doesn't allow client code to put an object in an invalid state. Had the ListZipper class been a part of a reusable library, I would probably have hidden that data, too, but since this is exercise code, I found this an acceptable compromise. Notice, too, that in the original Haskell code, the breadcrumbs are available to client code.)
Regular readers of this blog may be aware that I usually favour IReadOnlyCollection<T> over IEnumerable<T>. Here, on the other hand, I've allowed values to be any IEnumerable<T>, which includes infinite sequences. I decided to do that because Haskell lists, too, may be infinite, and as far as I can tell, ListZipper actually does work with infinite sequences. I have, at least, written a few tests with infinite sequences, and they pass. (I may still have missed an edge case or two. I can't rule that out.)
Movement #
It's not much fun just being able to initialize an object. You also want to be able to do something with it, such as moving forward:
public ListZipper<T>? GoForward() { var head = values.Take(1); if (!head.Any()) return null; var tail = values.Skip(1); return new ListZipper<T>(tail, head.Concat(Breadcrumbs)); }
You can move forward through any IEnumerable, so why make things so complicated? The benefit of this GoForward method (function, really) is that it records where it came from, which means that moving backwards becomes an option:
public ListZipper<T>? GoBack() { var head = Breadcrumbs.Take(1); if (!head.Any()) return null; var tail = Breadcrumbs.Skip(1); return new ListZipper<T>(head.Concat(values), tail); }
This test may serve as an example of client code that makes use of those two operations:
[Fact] public void GoBack1() { var sut = new ListZipper<int>(1, 2, 3, 4); var actual = sut.GoForward()?.GoForward()?.GoForward()?.GoBack(); Assert.Equal([3, 4], actual); Assert.Equal([2, 1], actual?.Breadcrumbs); }
Going forward takes the first element off values and adds it to the front of Breadcrumbs. Going backwards is nearly symmetrical: It takes the first element off the Breadcrumbs and adds it back to the front of the values. Used in this way, Breadcrumbs works as a stack.
Notice that both GoForward and GoBack admit the possibility of failure. If values is empty, you can't go forward. If Breadcrumbs is empty, you can't go back. In both cases, the functions return null, which are also indicated by the ListZipper<T>? return types; notice the question mark, which indicates that the value may be null. If you're working in a context or language where that feature isn't available, you may instead consider taking advantage of the Maybe monad (which is also what you'd idiomatically do in Haskell).
To be clear, the Zippers article does discuss handling failures using Maybe, but only applies it to its binary tree example. Thus, the error handling shown here is my own addition.
Modifications #
In addition to moving back and forth in the list, we can also modify it. The following operations are also not in the Zippers article, but are rather my own contributions. Adding a new element is easy:
public ListZipper<T> Insert(T value) { return new ListZipper<T>(values.Prepend(value), Breadcrumbs); }
Notice that this operation is always possible. Even if the list is empty, we can Insert a value. In that case, it just becomes the list's first and only element.
A simple test demonstrates usage:
[Fact] public void InsertAtFocus() { var sut = new ListZipper<string>("foo", "bar"); var actual = sut.GoForward()?.Insert("ploeh").GoBack(); Assert.NotNull(actual); Assert.Equal(["foo", "ploeh", "bar"], actual); Assert.Empty(actual.Breadcrumbs); }
Likewise, we may attempt to remove an element from the list:
public ListZipper<T>? Remove() { if (!values.Any()) return null; return new ListZipper<T>(values.Skip(1), Breadcrumbs); }
Contrary to Insert, the Remove operation will fail if values is empty. Notice that this doesn't necessarily imply that the list as such is empty, but only that the focus is at the end of the list (which, of course, never happens if values is infinite):
[Fact] public void RemoveAtEnd() { var sut = new ListZipper<string>("foo", "bar").GoForward()?.GoForward(); var actual = sut?.Remove(); Assert.Null(actual); Assert.NotNull(sut); Assert.Empty(sut); Assert.Equal(["bar", "foo"], sut.Breadcrumbs); }
In this example, the focus is at the end of the list, so there's nothing to remove. The list, however, is not empty, but all the data currently reside in the Breadcrumbs.
Finally, we can combine insertion and removal to implement a replacement operation:
public ListZipper<T>? Replace(T newValue) { return Remove()?.Insert(newValue); }
As the name implies, this operation replaces the value currently in focus with a completely different value. Here's an example:
[Fact] public void ReplaceAtFocus() { var sut = new ListZipper<string>("foo", "bar", "baz"); var actual = sut.GoForward()?.Replace("qux")?.GoBack(); Assert.NotNull(actual); Assert.Equal(["foo", "qux", "baz"], actual); Assert.Empty(actual.Breadcrumbs); }
Once more, this may fail if the current focus is empty, so Replace also returns a nullable value.
Conclusion #
For a C# developer, the ListZipper<T> class looks odd. Why would you ever want to use this data structure? Why not just use List<T>?
As I hope I've made clear in the introduction article, I can't, indeed, think of a good reason.
I've gone through this exercise to hone my skills, and to prepare myself for the more intimidating exercise it is to implement a binary tree Zipper.
Next: A Binary Tree Zipper in C#.

Comments
Thanks for a nice blog post! I found the challange interesting, so I have written my own version of the code that both tries to be faster and also remove the redundant solutions, so it only generates two solutions in total. The code is available here. It executes in roughly 8 milliseconds both in ghci and compiled (and takes a second to compile and run using runghc) on my laptop.
In order to improve the performance, I start with a blank grid and one-by-one add tiles until it is no longer possible to do so, and then bactrack, kind of like how you would do it by hand. As a tiny bonus, that I haven't actually measured if it makes any practical difference, I also selected the order of filling in the grid so that they can constrain each other as much as possible, by filling 2-by-2 squares as early as possible. I have however calculated the number of boards explored in each of the two variations. With a spiral order, 6852 boards are explored, while with a linear order, 9332 boards are explored.
In order to eliminate rotational symmetry, I start by filling the center square and fixing its rotation, rather than trying all rotations for it, since we could view any initial rotation of the center square as equivalent to rotating the whole board. In order to eliminate the identical solutions from the two identical tiles, I changed the encoding to use a number next to the tile to say how many copies are left of it, so when we choose a tile, there is only a single way to choose each tile, even if there are multiple copies of it. Both of these would also in theory make the code slightly faster if the time wasn't already dominated by general IO and other unrelated things.
I also added various pretty printing and tracing utilites to the code, so you can see exactly how it executes and which partial solutions it explores.
Thank you for writing. I did try filling the two-by-two square first, as you suggest, but in isolation it makes no discernable difference.
I haven't tried your two other optimizations. The one to eliminate rotations should, I guess, reduce the search space to a fourth of mine, unless I'm mistaken. That would reduce my 300 ms to approximately 75 ms.
I can't easily guess how much time the other optimization shaves off, but it could be the one that makes the bigger difference.